
|
|
|
|
 Far Far |
| WinNavigator |
| Frigate |
| Norton
Commander |
| WinNC |
| Dos
Navigator |
| Servant
Salamander |
| Turbo
Browser |
|
|
| Winamp,
Skins, Plugins |
| Необходимые
Утилиты |
| Текстовые
редакторы |
| Юмор |
|
|

|
File managers and best utilites |
синтезаторы речи с русскими голосами. Синтезатор речи для яндекс браузера
Интерактивное голосовое редактирование текста с помощью новых речевых технологий от Яндекса
Пара слов, чтобы вы понимали, о чём пойдёт речь. Яндекс уже давно предоставляет бесплатное мобильное API, которое можно использовать, например, для распознавания адресов и голосовых запросов к поиску. За этот год мы смогли довести его качество почти до того же уровня, на котором такие запросы и реплики понимают сами люди. И теперь мы делаем следующий шаг — модель для распознавания свободной речи на любую тему.
Кроме этого, наш синтез речи поддерживает эмоции в голосе. И, насколько нам известно, это пока первый коммерчески доступный синтез речи с такой возможностью.
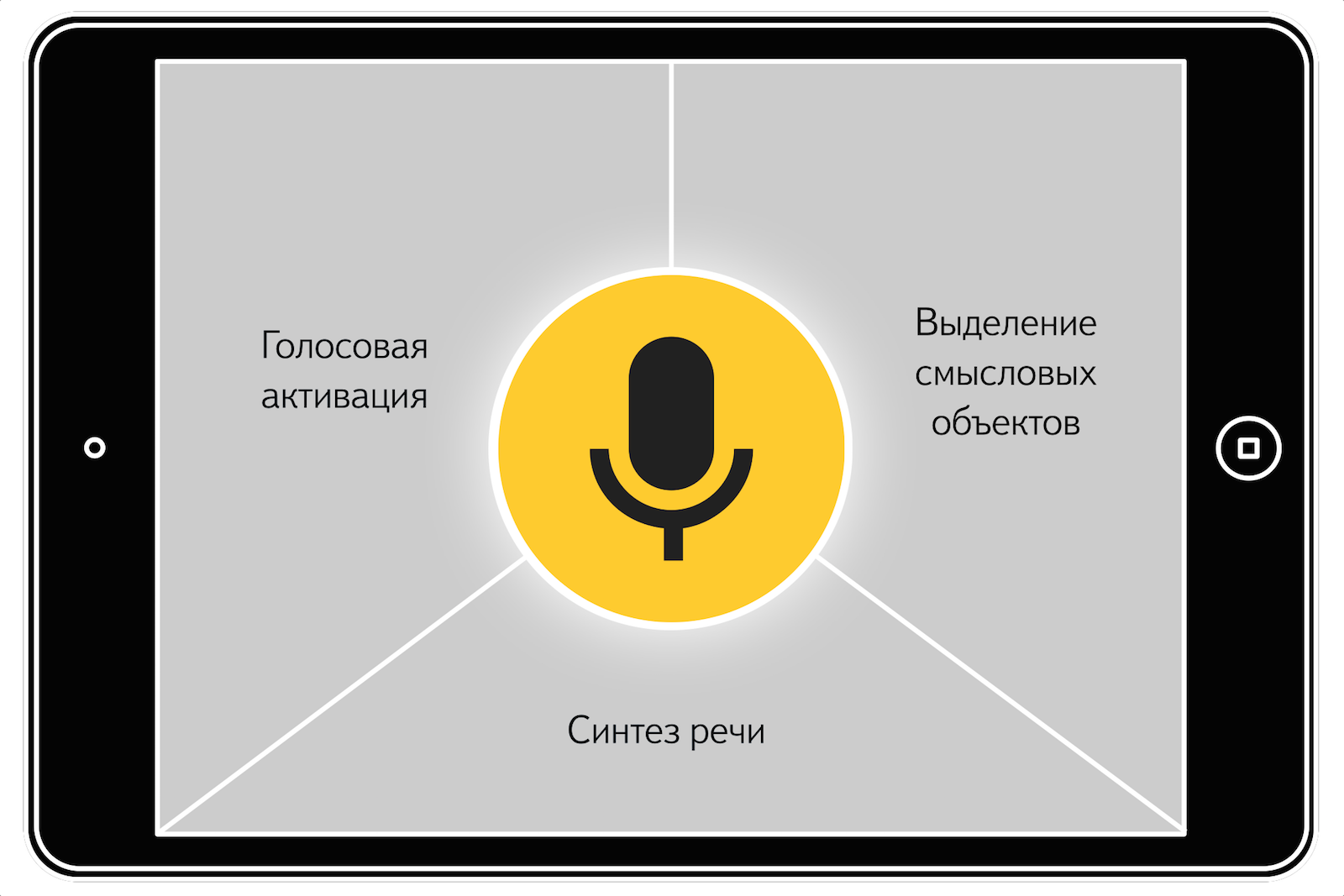
Обо всём этом, а также о некоторых других возможностях SpeechKit: об активации голосом, автоматической расстановке пунктуационных знаков и распознавании смысловых объектов в тексте — читайте ниже.
Всеядное ASR и качество распознавания
Система распознавания речи в SpeechKit работает с разными видами текста, и последний год мы работали над расширением сферы её применения. Для этого мы создали новую языковую модель, пока самую большую, для распознания коротких текстов на любую тему.За прошедший год относительная доля ошибочно распознанных слов (Word Error Rate) понизилась на 30%. Например, сегодня SpeechKit правильно распознаёт 95% адресов и географических объектов, вплотную приблизившись к человеку, который понимает 96–98% услышанных слов. Полнота распознавания новой модели для диктовки разных текстов сейчас составляет 82%. С таким уровнем можно создать полноценное решение для конечных пользователей, что мы и хотели показать на примере Диктовки.
Изначально SpeechKit работал только для поисковых запросов: общей тематики и геонавигационных. Хотя уже тогда мы задумывали сделать не просто дополнительный инструмент ввода, «голосовую» клавиатуру, а универсальный интерфейс, который полностью заменит любое взаимодействие с системой живым разговором.
Для этого нужно было научиться распознавать любую речь, тексты на произвольную тему. И мы начали работать над отдельной языковой моделью для этого, которая была в несколько раз крупнее имеющихся геонавигационной и общепоисковой моделей.
Такой размер модели ставил новые условия с точки зрения вычислительных ресурсов. Для каждого фрейма рассматриваются несколько тысяч вариантов распознавания — и чем больше мы успеваем, тем выше качество. А работать система должна в потоке, в режиме реального времени, поэтому все расчёты нужно оптимизировать динамически. Экспериментировали, пробовали, искали подход: ускорения добились, например, сменой библиотеки линейной алгебры.
Но важнее и сложнее всего было собрать достаточно правильных данных, пригодных для обучения потоковой речи. Сейчас для тренировки акустической модели используются около 500 часов вручную транскрибированной речи. Это не такая уж большая база — для сравнения, популярный научный корпус Switchboard, который часто используют в исследовательских целях, содержит примерно 300 часов живых, спонтанных разговоров. Безусловно, увеличение базы способствует росту качества обучаемой модели, но мы делаем упор на правильную подготовку данных и аккуратнее моделируем транскрипции, что позволяет с приемлемым качеством обучаться на относительно небольшой базе.
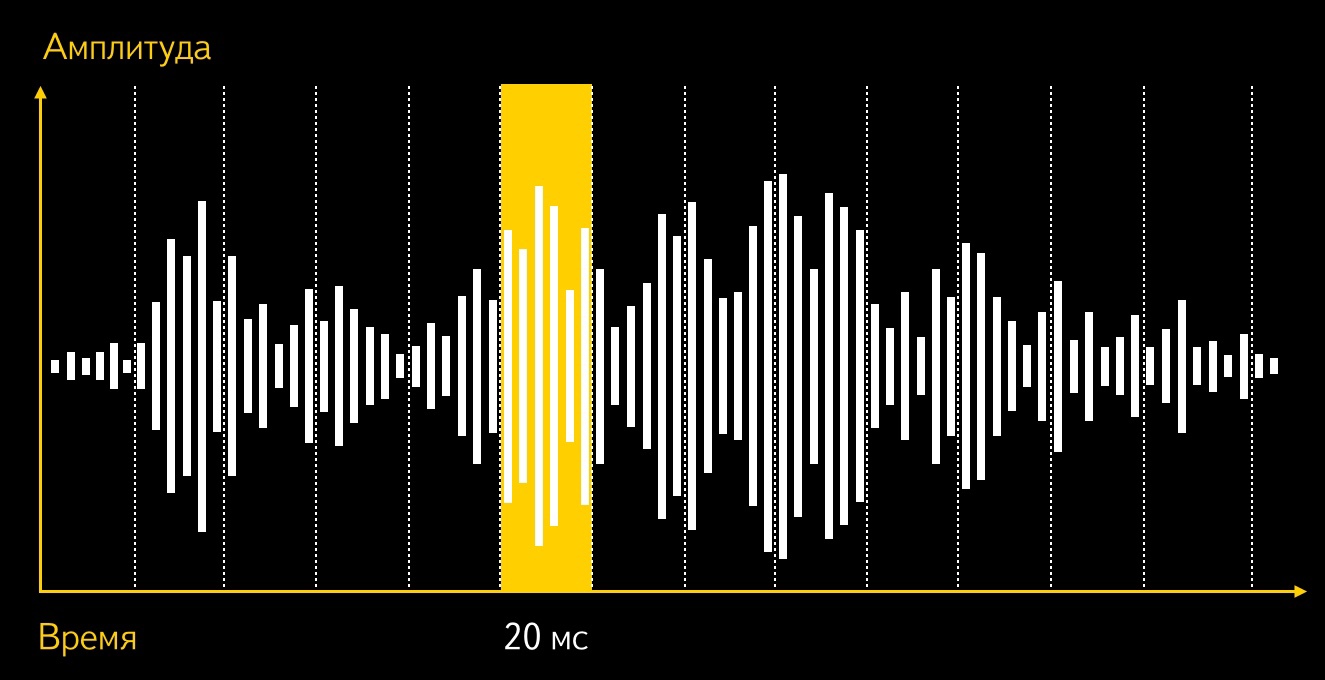
Пара слов о том, как устроен модуль распознавания (подробно мы об этом рассказывали некоторое время назад). Поток записанной речи нарезается на фреймы по 20 мс, спектр сигнала масштабируется и после ряда преобразований для каждого фрейма получаются MFCC.
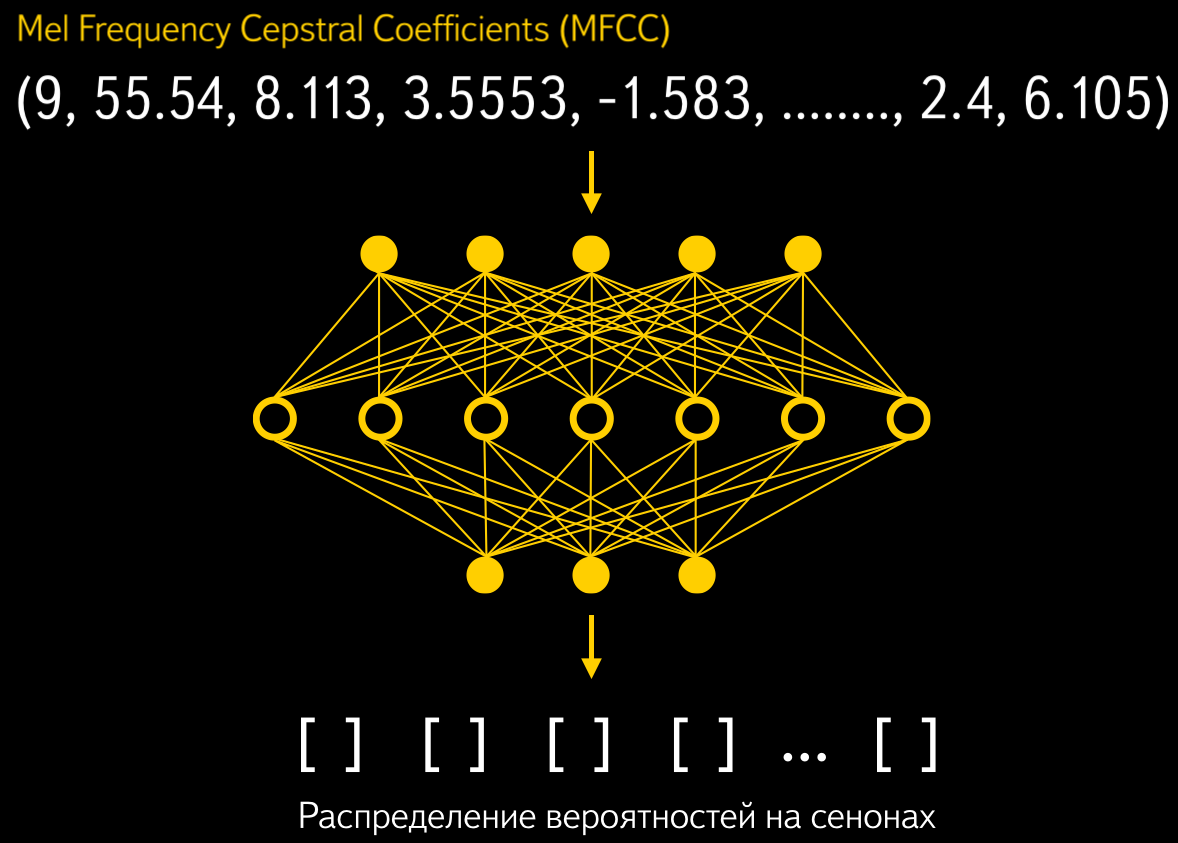
Коэффициенты поступают на вход акустической модели, которая вычисляет распределение вероятностей для примерно 4000 сенонов в каждом фрейме. Сенон — это начало, середина или конец фонемы.
Акустическая модель SpeechKit построена на комбинации скрытых Марковских моделей и глубокой нейронной сети прямого распространения (feedforward DNN). Это уже проверенное решение, и в прошлой статье мы рассказывали, как отказ от гауссовых смесей в пользу DNN дал почти двукратный скачок в качестве.
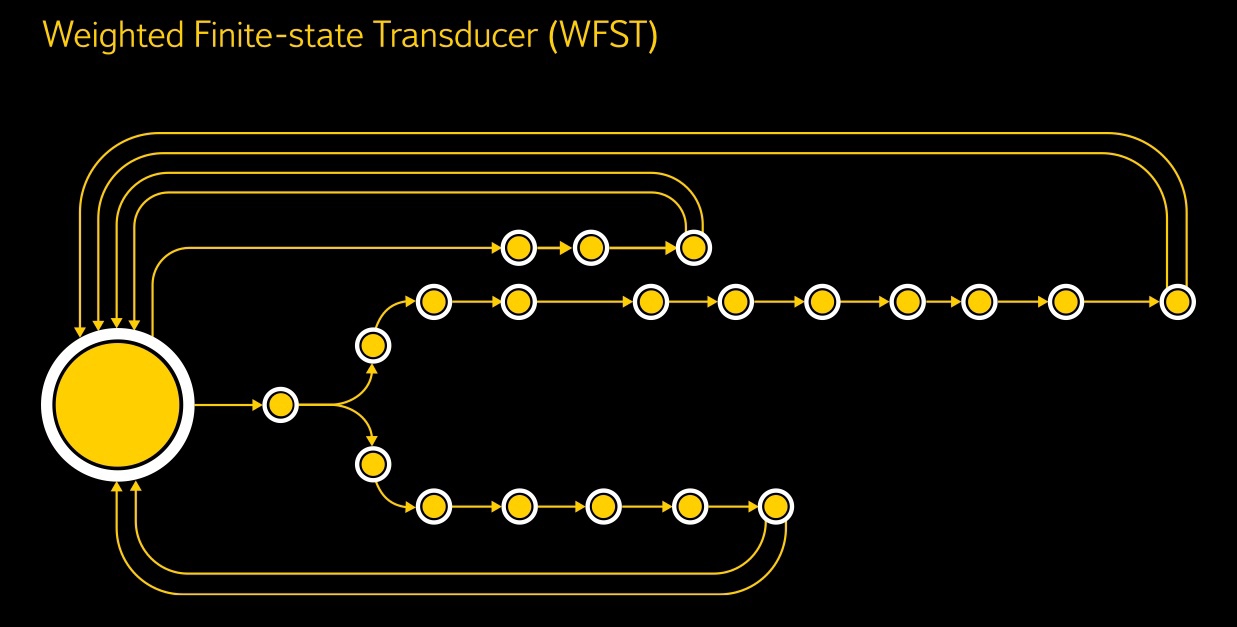
Затем вступает первая языковая модель: несколько WFST — взвешенных конечных трансдьюсеров — превращают сеноны в контекстно-зависимые фонемы, а из них уже с помощью словаря произношений строятся целые слова, причём для каждого слова получаются сотни гипотез.
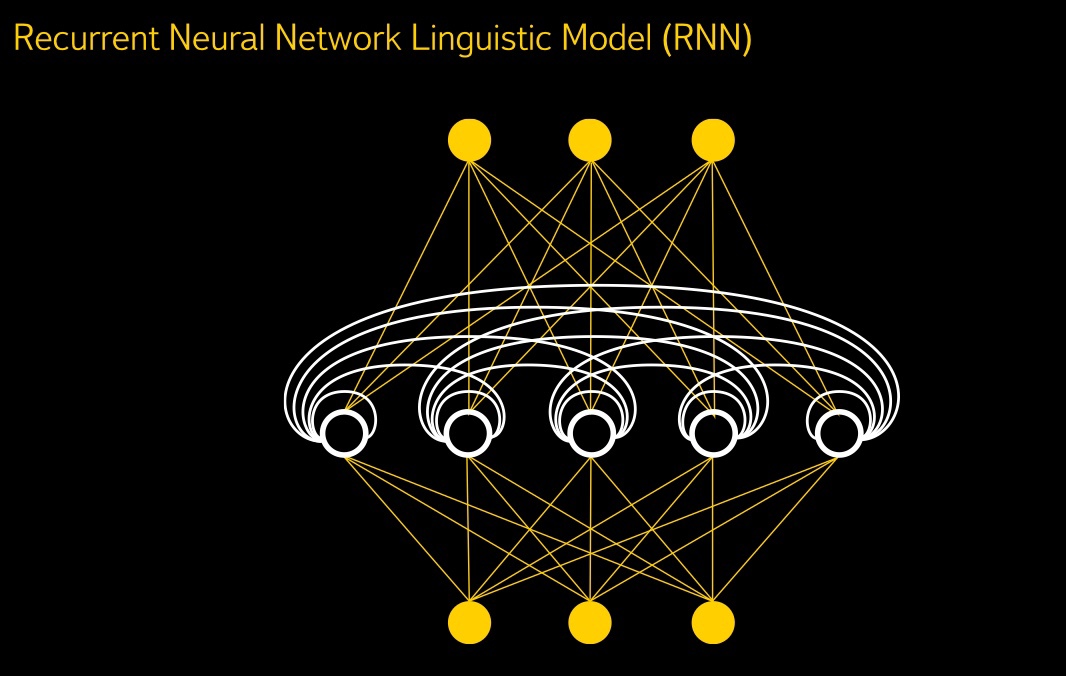
Финальная обработка происходит во второй языковой модели. К ней подключена RNN, рекуррентная нейронная сеть, и эта модель ранжирует полученные гипотезы, помогая выбрать самый правдоподобный вариант. Сеть рекуррентного типа особенно эффективна для языковой модели. Определяя контекст каждого слова, она может учитывать влияние не только ближайших слов, как в нейронной сети прямого распространения (скажем, для триграммной модели — это два предшествующих слова), но и дальше отстоящих, как бы «запоминая» их.
Распознавание длинных связных текстов доступно в SpeechKit Cloud и SpeechKit Mobile SDK — для использования новой языковой модели в параметрах запроса нужно выбрать тему «notes».
Голосовая активация
Вторая ключевая составляющая голосового интерфейса — это система активации голосом, которая запускает нужное действие в ответ на ключевую фразу. Без неё не получится в полной мере «развязать руки» пользователю. Для SpeechKit мы разработали свой модуль голосовой активации. Технология очень гибкая — разработчик, использующий библиотеку SpeechKit, может сам выбрать любую ключевую фразу для своего приложения.В отличие от, например, решения Google — их разработчики используют для распознавания коронной фразы «Окей, Google» глубокую нейронную сеть. DNN даёт высокое качество, но система активации при этом ограничена единственной командой, и для обучения нужно огромное количество данных. Скажем, модель для распознавания всем знакомой фразы обучалась на примере более чем 40 тысяч пользовательских голосов, которые обращались к своим смартфонам с Google Now.
При нашем подходе модуль голосовой активации — это, по сути, система распознавания в миниатюре. Только работает она в более жёстких условиях. Во-первых, распознавание команды должно происходить на самом устройстве, без обращения к серверу. А вычислительные мощности смартфона сильно ограничены. Критично и энергопотребление — если обычный модуль распознавания включается только на определённое время для обработки конкретного запроса, то модуль активации работает постоянно, в режиме ожидания. И при этом не должен сажать батарею.
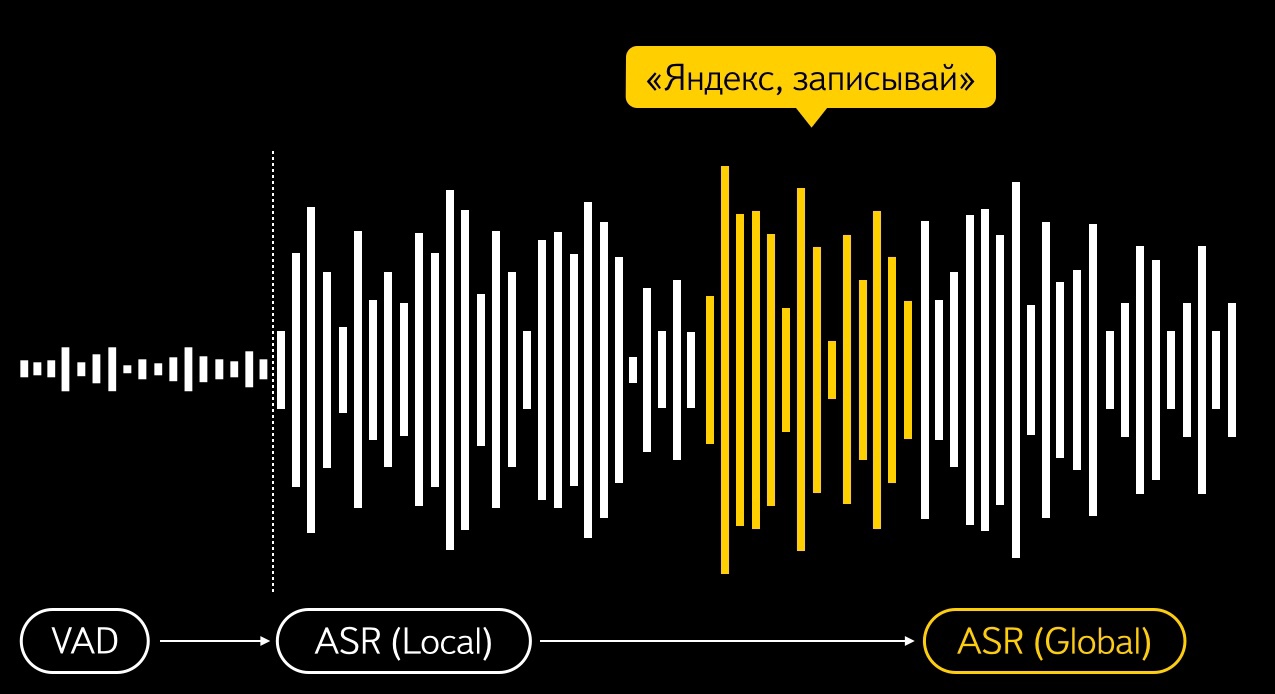
Впрочем, есть и послабление — для системы активации нужен совсем небольшой словарь, ведь ей достаточно понимать несколько ключевых фраз, а всю остальную речь можно просто игнорировать. Поэтому языковая модель активации гораздо компактнее. Большинство состояний WFST соответствуют определённой части нашей команды — например, «началу четвёртой фонемы». Есть также «мусорные» состояния, описывающие тишину, посторонний шум и всю остальную речь, отличную от ключевой фразы. Если полноценная модель распознавания в SpeechKit имеет десятки миллионов состояний и занимает до 10 гигабайт, то для голосовой активации она ограничена сотнями состояний и умещается в несколько десятков килобайт.
Поэтому модель для распознавания новой ключевой фразы строится без труда, позволяя быстро масштабировать систему. Есть одно условие — команда должна быть достаточно длинной (желательно — более одного слова) и нечасто встречаться в повседневной речи, чтобы исключить ложные срабатывания. «Пожалуйста» плохо подойдёт для голосовой активации, а «слушай мою команду» — вполне.
Вместе с ограниченной языковой моделью и «лёгкой» акустической, распознавание команд по силам любому смартфону. Остаётся разобраться с энергопотреблением. В систему встроен детектор голосовой активности, который следит за появлением во входящем звуковом потоке человеческого голоса. Остальные звуки игнорируются, поэтому в фоновом режиме энергопотребление модуля активации ограничено только микрофоном.
Синтез речи
Третий основной компонент речевой технологии — это синтез речи (text-to-speech). TTS-решение SpeechKit позволяет озвучить любой текст мужским или женским голосом, да ещё и задав нужную эмоцию. Ни у одного из известных нам голосовых движков на рынке нет такой возможности.В SpeechKit мы решили использовать статистический (параметрический) синтез речи на базе скрытых Марковских моделей. Процесс, по сути, аналогичен распознаванию, только происходит в обратном направлении. Исходный текст передаётся в модуль G2P (grapheme-to-phoneme), где преобразуется в последовательность фонем.

Затем они попадают в акустическую модель, которая генерирует векторы, описывающие спектральные характеристики каждой фонемы. Эти числа передаются вокодеру, который и синтезирует звук.

Тембр такого голоса несколько «компьютерный», зато у него естественные и плавные интонации. При этом гладкость речи не зависит от объёма и длины читаемого текста, а голос легко настраивать. Достаточно указать в параметрах запроса один ключ, и модуль синтеза выдаст голос с соответствующей эмоциональной окраской. Разумеется, никакая система unit selection на такое не способна.
Чтобы модель голоса смогла построить алгоритмы, соответствующие различным эмоциям, потребовалось правильным образом обучить её. Поэтому во время записи наша коллега Евгения, чей голос и можно услышать в SpeechKit, произносила свои реплики по очереди нейтральным голосом, радостным и, наоборот, раздражённым. В ходе обучения система выделила и описала параметры и характеристики голоса, соответствующие каждому из этих состояний.
Не все модификации голоса построены на обучении. Например, SpeechKit позволяет также окрасить синтезированный голос параметрами «drunk» и «ill». Наши разработчики пожалели Женю, и ей не пришлось напиваться перед записью или бегать на морозе, чтобы хорошенько простудиться.
Для пьяного голоса специальным образом замедляется речь — каждая фонема звучит примерно в два раза медленнее, что и даёт характерный эффект. А для больного повышается порог озвученности — фактически моделируется то, что происходит с голосовыми связками человека при ларингите. Озвученность разных фонем зависит от того, проходит ли воздух через голосовой тракт человека свободно или же на пути его оказываются вибрирующие голосовые связки. В режиме «болезни» каждая фонема озвучивается с меньшей вероятностью, что и делает голос сиплым, посаженным.
Статистический метод также позволяет быстро расширять систему. В модели unit selection для добавления нового голоса нужно создать отдельную речевую базу. Диктор должен записать много часов речи, при этом безупречно выдерживая одинаковую интонацию. В SpeechKit для создания нового голоса достаточно записать хотя бы два часа речи — примерно 1800 специальных, фонетически-сбалансированных предложений.
Выделение смысловых объектов
Слова, которые произносит человек, важно не только перевести в буквы, но и наполнить смыслом. Четвёртая технология, которая в ограниченном виде доступна в SpeechKit Cloud, не касается напрямую работы с голосом — она начинает работать уже после того, как произнесённые слова распознаны. Но без неё полный стек речевых технологий не сделать — это выделение смысловых объектов в естественной речи, которое на выходе даёт не просто распознанный, а уже размеченный текст.Сейчас в SpeechKit реализовано выделение дат и времени, ФИО, адресов. В гибридной системе сочетаются контекстно-свободные грамматики, словари ключевых слов и статистические данные поиска и разных сервисов Яндекса, а также алгоритмы машинного обучения. Например, во фразе «поехали на улицу Льва Толстого» слово «улица» помогает системе определить контекст, после чего в базе данных Яндекс.Карт находится соответствующий объект.

В Диктовке мы построили на этой технологии функцию редактирования текста голосом. Подход к выделению сущностей принципиально новый, и упор сделан на простоту конфигурации — чтобы настроить систему, не нужно владеть программированием.
На вход системы подаётся список разных типов объектов и примеры фраз из живой речи, их описывающих. Далее из этих примеров методом Pattern Mining формируются паттерны. В них учитываются начальная форма, корни, морфологические вариации слов. Следующим шагом даются примеры употребления выбранных объектов в разных сочетаниях, которые помогут системе понимать контекст. На основе этих примеров строится скрытая Марковская модель, где наблюдаемыми состояниями становятся выделенные в реплике пользователя объекты, а скрытыми — соответствующие им объекты из предметного поля с уже известным значением.
Например, есть две фразы: «вставить „привет, друг“ в начало» и «вставить из буфера». Система определяет, что в первом случае после «вставить» (действие редактирования) идёт произвольный текст, а во втором — известный ей объект («буфер обмена»), и по-разному реагирует на эти команды. В традиционной системе это потребовало бы написания правил или грамматик вручную, а в новой технологии Яндекса анализ контекста происходит автоматически.
Автопунктуация
Диктуя что-либо, в получившемся тексте ожидаешь увидеть знаки препинания. И появляться они должны автоматически, чтобы не приходилось разговаривать с интерфейсом в телеграфном стиле: «Дорогой друг — запятая — как поживаешь — вопросительный знак». Поэтому дополняет SpeechKit система автоматической расстановки знаков препинания.Роль пунктуационных знаков в речи играют интонационные паузы. Поэтому изначально мы пытались построить полноценную акустическую и языковую модель для их распознавания. Каждому знаку пунктуации назначили фонему, и с точки зрения системы в распознаваемой речи появлялись новые «слова», полностью состоящие из таких «пунктуационных» фонем — там, где возникали паузы или определённым образом менялась интонация.
Большая сложность возникла с данными для обучения — в большинстве корпусов уже нормализованные тексты, в которых знаки препинания опущены. Также почти нет пунктуации и в текстах поисковых запросов. Мы обратились к «Эху Москвы», которые вручную расшифровывают все свои эфиры, и они разрешили нам использовать свой архив. Быстро выяснилось, что для наших целей эти транскрипции непригодны — они сделаны близко к тексту, но не дословно, а поэтому для машинного обучения не годятся. Следующая попытка была сделана с аудиокнигами, но в их случае, наоборот, качество оказалось слишком высоким. Хорошо поставленные голоса, с выражением декламирующие текст, слишком далеки от реальной жизни, и результаты обучения на таких данных никак не удавалось применить в спонтанной диктовке.
Вторая проблема заключалась в том, что выбранный подход отрицательно сказывался на общем качестве распознавания. Для каждого слова языковая модель рассматривает несколько соседних, чтобы правильно определить контекст, и дополнительные «пунктуационные» слова его неизбежно сужали. Несколько месяцев экспериментов не привели ни к чему.
Начать пришлось с чистого листа — мы решили расставлять знаки препинания уже на этапе пост-обработки. Начали с одного из простейших методов, который, как ни странно, показал в итоге вполне приемлемый результат. Паузы между словами получают одну из меток: пробел, точка, запятая, вопросительный знак, восклицательный знак, двоеточие. Чтобы предсказать, какая метка соответствует конкретной паузе, используется метод условных случайных полей (CRF — conditional random fields). Для определения контекста учитываются три предшествующих и два последующих слова, и эти нехитрые правила позволяют с достаточно высокой точностью расставлять знаки. Но мы продолжаем экспериментировать и с полноценными моделями, которые смогут ещё на этапе распознавания голоса правильно интерпретировать интонации человека с точки зрения пунктуации.
Планы на будущее
Сегодня SpeechKit активно используется для решения «боевых» задач в массовых сервисах для конечных пользователей. Следующая веха — научиться распознавать спонтанную речь в живом потоке, чтобы можно было прямо в реальном времени расшифровать интервью или автоматически конспектировать лекцию, получая на выходе уже размеченный текст, с выделенными тезисами и ключевыми фактами. Это огромная и очень наукоёмкая задача, которую пока не удалось решить никому в мире — а других мы и не любим!Для развития SpeechKit очень важна обратная связь. Поставьте Яндекс.Диктовку, разговаривайте с ней почаще — чем больше данных мы получаем, тем быстрее растёт качество распознавания в доступной всем вам библиотеке. Не стесняйтесь исправлять ошибки распознавания с помощью кнопки «Корректор» — это помогает разметить данные. И обязательно пишите в форму обратной связи в приложении.
habrahabr.ru
Синтезатор речи онлайн
Программы-синтезаторы речи с каждым годом всё больше входят в нашу жизнь. Они позволяют нам более досконально учить иностранные языки, переводят тексты в удобный аудиоформат, используются в функционале различных служебных программ и многое другое. И когда у некоторых из нас возникает потребность воспроизвести онлайн какой-либо текст в аудиформате, тогда многие из нас обращаются к различным сервисам и программам по синтезу речи, способным помочь нам в трансформации нужного там текста. В этой статье я расскажу о сетевых версиях подобных продуктов, опишу, что такое синтезатор речи онлайн, какие сервисы синтеза речи online существуют, и как их использовать.

Используем синтезаторы речи
Содержание статьи:
Лучшие онлайн синтезаторы речи
Изначально, синтезаторы речи разрабатывались для людей с дефектами зрения для воспроизведения текста с помощью компьютерного голоса. Но постепенно их преимущества оценила массовая аудитория, и ныне практически любой желающий может скачать себе синтезатор речи на ПК, или воспользоваться альтернативами, которые присутствуют в некоторых версиях операционных систем.
Так какой же синтезатор речи онлайн можно выбрать? Ниже я перечислю ряд сервисов, которые позволяют воспроизвести текст в речь онлайн.
Ivona — отличный синтезатор
Голосовые движки данного онлайн сервиса отличаются очень высоким качеством, хорошей фонетической основой, звучат достаточно естественно и «металлический» компьютерный голос здесь чувствуется гораздо реже, нежели у сервисов-конкурентов.
Сервис Ivona имеет поддержку множества языков, в русском варианте присутствуют мужской голос (Maxim) и женский (Tatyana).

Синтезатор Ивона на русском языке
- Чтобы использовать синтезатор речи выполните вход на данный ресурс, слева будет окно, в который необходимо будет вставить текст для прочтения.
- Вставьте текст, кликните на кнопочку с обозначением человека, выберите язык (Russian) и вариант произношения (женский или мужской) и нажмите на кнопку «Play».
К сожалению, бесплатный функционал сайта ограничен предложением с 250 символами, и предназначен скорее для демонстрации возможностей сервиса, нежели для серьёзной работы с текстом. Большие возможности можно получить лишь платно.
Acapela — сервис распознавания речи
Компания, торгующая своими голосовыми движками для различных технических решений, предлагает вам использовать синтезатор речи Acapela в режиме онлайн. Хотя просодия этого сервиса не на такой высоте, как у Ivona, тем не менее, качество произношения здесь тоже весьма добротное. Ресурс Acapela поддерживает около 100 голосов на 34 языках.

Сервис Акапела
- Чтобы воспользоваться функционалом ресурса откройте указанный сервис, слева в окне выберите русский язык (Select a language – Russian).
- Вставьте внизу нужный текст и нажмите на кнопку «Listen» (слушать).
Максимальный размер текста для аудиопрочтения — 300 символов.
Fromtexttospeech — онлайн сервис
Чтобы перевести текст в речь онлайн можно также воспользоваться сервисом fromtexttospeech. Он работает по принципу конвертации текста в аудиофайл формата mp3, который затем можно скачать себе на компьютер. Сервис поддерживает конвертацию текста величиной в 50 тыс. символов, что является достаточно значительным объёмом.

Конвертирование текста в спич
- Для работы с сервисом fromtexttospeech перейдите на него, в опции «Select Language» выберите «Russian» (голос тут только один – Валентина).
- В большом окне введите (вставьте) нужный для озвучки текст, затем нажмите на кнопку «Create Audio File».
- Текст будет обработан, затем вы сможете послушать полученный результат, а потом и скачать его себе на ПК.
- Для этого нажмите правой клавишей мыши на «Download audio file» и выберите в появившемся меню «Сохранить объект как».
Google Переводчик также можно использовать
Всем нам известный Гугл переводчик онлайн имеет встроенную функцию воспроизведение текста в речь, причём количество прочитанного текста тут может быть весьма объёмным.

Гугл переводчик
- Для работы с ним выполните вход на данный сервис (вот здесь).
- Выберите в окне слева русский язык, и нажмите на кнопочку с динамиком снизу «Прослушать».
Качество воспроизведения на довольно сносном уровне, но не более.
Text-to-speech — синтезатор речи онлайн
Ещё один ресурс, осуществляющий синтез речи нормального качества. Бесплатный функционал ограничен набором текста длиной 1000 символов.

Тексттуспич
- Для работы с сервисом перейдите на данный сайт, в окне справа рядом с опцией «Language» (язык) выберите Russian.
- В окне наберите (или скопируйте с внешнего источника) требуемый текст, а затем нажмите на кнопку справа «Say It».
- Линк на произношение указанного текста можно также разместить в вашем е-мейле или веб-странице, кликнув на кнопку «Yes» чуть ниже.
Альтернативные программы для ПК для перевода текста в речь
Также существует программы для синтеза речи, такие как TextSpeechPro AudioBookMaker, ESpeak, Voice Reader 15, ГОЛОС и ряд других, способные конвертируют текст в речь. Их необходимо скачать и установить на свой компьютер, а функционал и возможности данных продуктов обычно чуть превышает возможности рассмотренных онлайн-сервисов. Детальная же их характеристика заслуживает отдельного обширного материала.
Заключение
Так какой же синтезатор речи онлайн выбрать? В большинстве из них бесплатные возможности существенно ограничены, а по качеству звучания сервис Ivona оставит позади своих конкурентов. Если же вас интересует возможность быстрого перевода вашего текста в аудиофайл, тогда воспользуйтесь ресурсом «fromtexttospeech» — он даёт результат хорошего качества и за достаточно короткое время.
Вконтакте
Google+
Одноклассники
sdelaicomp.ru
Балаболка и голоса | Бесплатные программы для Windows
 Внизу данной страницы представлена возможность бесплатно скачать Балаболку и русские голоса, умеющие читать вслух тексты по-русски из колонок компьютера. Стандартный инсталлятор и Balabolka Portable загружаются с сайта разработчика Ильи Морозова (Ilya Morozov). Аналогично с сайтов разработчиков легально загружаются голосовые движки. Кросплатформенность Балаболки ограничивается поддержкой OS Windows XP, Vista, 7, 8, 8.1, 10 (32-bit и 64-bit). Положительные оценки в отзывах и комментах в социальных сетях VK, Ok, Facebook, Google+, на форумах и популярных Интернет-ресурсах приветствуется. Рекомендации, как лучше всего скачать программу Балаболка и беспроблемный голосовой движок RHVoice с programmywindows.com, поощряются. Постоянный адрес: programmywindows.com/ru/readers/balabolka
Внизу данной страницы представлена возможность бесплатно скачать Балаболку и русские голоса, умеющие читать вслух тексты по-русски из колонок компьютера. Стандартный инсталлятор и Balabolka Portable загружаются с сайта разработчика Ильи Морозова (Ilya Morozov). Аналогично с сайтов разработчиков легально загружаются голосовые движки. Кросплатформенность Балаболки ограничивается поддержкой OS Windows XP, Vista, 7, 8, 8.1, 10 (32-bit и 64-bit). Положительные оценки в отзывах и комментах в социальных сетях VK, Ok, Facebook, Google+, на форумах и популярных Интернет-ресурсах приветствуется. Рекомендации, как лучше всего скачать программу Балаболка и беспроблемный голосовой движок RHVoice с programmywindows.com, поощряются. Постоянный адрес: programmywindows.com/ru/readers/balabolka
О преобразовании текстов в звук
Люди давно практикуют прослушивание текстов вместо их чтения. Причиной тому - и природная лень, и нежелание напрягаться, и забота о сохранении зрения, и русские романтические традиции, воспетые еще А. С. Пушкиным в своих детских воспоминаниях о няне из стихотворения Сон:
И шепотом рассказывать мне станетО мертвецах, о подвигах Бовы...
Как и во многих отраслях современной промышленности, информационные технологии в деле чтения пришли на помощь продолжателям дела пушкинской няни. Сегодня с переводом текста в речь, кроме приложения Balabolka, справляются аналогичная по возможностям Govorilka, текстовый редактор Демагог, ридеры Tom, Cool и Ice Book.
Самым ленивым и требовательным к качеству воспроизведения речи читателям, точнее слушателям, лучше других бесплатных программ подойдет русская версия Balabolka. Эта программа не без недостатков, но все-таки самостоятельно почитает вслух как простой текст, так и более продвинутые форматы оцифрованных книг. Попробуйте последнюю версию Балаболки скачать с голосовыми движками, говорящими на русском языке, записать из программы MP3 и послушать на любом совместимом устройстве любимые произведения классиков или современную прозу по пути в офис, в спортзале, в очереди или перед сном. На мамину или нянину сказку на ночь это, конечно, похоже не будет, но воспринимается такая машинная декламация компьютерным голосом вполне нормально.
Интерфейс Балаболки
Balabolka имеет простой и интуитивно понятный интерфейс на русском и нескольких европейских и азиатских языках. Те, кто смог скачать Балаболку бесплатно, установил Balabolka и голосовой движок, чтобы программа смогла читать русскими голосами, сразу могут прослушать тексты. Процесс воспроизведения речи запускается кнопкой Воспроизведение. Кнопкой Пауза виртуальный рассказчик приостанавливается. Прекращается воспроизведение кнопкой Стоп. Такой же интерфейс управления присутствует в любом компьютерном аудио-видео плеере. Настроить программу для работы сможет даже малоопытный пользователь.


Возможность изменения дизайна программы на любой вкус реализована с помощью нескольких сменных скинов, или тем оформления интерфейса. Также существует возможность дополнительно бесплатно скачать темы для программы Балаболка с официального сайта. Мультиязычный интерфейс с превосходным русским языком и объемный раздел справки и помощи от автора программы Ильи Морозова вдвойне упрощает задачу изучения функционала, которого немного больше, чем может показаться на первый взгляд.
Функциональные возможности
Balabolka бойко и громко прочитает текстовку из буфера обмена, а также из файлов: TXT, BXT, AZW, MOBI, PRC, CHM, DJVU, DJV, DOC, DOCX, EPUB, FB2, HTM, HTML, MHT, LIT, ODT, PDB, PDF, RAR, RTF, TCR, WPD, ZIP. Прослушивать можно не только русскоязычные произведения. Кроме уже установленного английского голосового модуля, можно установить немецкий, французский, итальянский, испанский и множество прочих голосовых движков.
Balabolka умеет разделять большие тексты на маленькие файлы для удобства, удалить символы переноса строк для предотвращения запинания во время проговаривания, декламировать набираемые слова и предложения. Программа позволяет легко изменить цвет, шрифт, откорректировать произношение, проверить текст на орфографические ошибки, находить омографы. Работу можно запускать, приостанавливать и останавливать, применяя хоткей.
Необходимо отметить следующие достоинства Балаболки:
- комфортная процедура прослушивания текстов,- продвинутая многоязычность,- управление сочетаниями горячих клавиш,- помощь людям с проблемами зрения,- эффективный метод обучения и подготовки к экзаменам,- настройка отображаемого шрифта,- демонстрация текста параллельно с прослушиванием, по принципу караоке,- изменяемые шкурки тем оформления интерфейса,- выбор голосового движка, тембра, громкости и быстроты воспроизведения,- проверка орфографии перед прочтением,- поддержка перетаскивания,- работа с закладками,- чтение электронных книг и офисных документов,- чтение из архивов без распаковки,- работа более чем с двадцатью форматами,- преобразование текста в аудио файл.
Результат работы Balabolka может сохранить в аудиофайл: MP3, MP4, WAV, WMA, M4A, M4B, AWB, OGG для последующего воспроизведения на MP3/MP4 плеере, iPhone, iPad, iPod, смартфоне на Андроид, сотовом телефоне или другом оборудовании. При сохранении в MP3 доступна опция LRC-текста или ID3-тегов для синхронного отображения бегущей строки текста параллельно со звуком, по принципу караоке.
Типы голосовых движков для Балаболки
Бесплатная программа Балаболка на русском языке работает лучше себе подобных аналогов, конечно же, при использовании качественного голосового движка, который, желательно, должен быть еще и бесплатным. Поэтому мало программу Балаболка скачать бесплатно, нужно еще скачать голосовые движки для Балаболки с русскими голосами для Windows 7, 8, 8.1, 10, и Vista, и XP SP 3 (32-bit и 64-bit) c Microsoft Speech API (SAPI 4 и 5) или Microsoft Speech Platform. Бесплатно скачать русскую Балаболку для Виндовс XP, Vista, 7, 8, 8.1, 10 (32-бит и 64-бит) проблемы не составит. В поиске Яндекса или Гугла легко найти и Balabolka торрент, и Balabolka Portable, есть даже говорилки онлайн. Труднее найти хороший свободно распространяемый голосовой движок, да еще такой, чтобы голоса для Балаболки звучали не только правильно, но и мило.
Платные голосовые синтезаторы
Balabolka работает с популярными голосами IVONA Maxim и Tatyana, Acapela Alyona, Loquendo Olga, ScanSoft (RealSpeak) Katerina, Digalo Russian Nicolai, Nuance Vocalizer TTS Milena Rus и иными компьютерными синтезаторами человеческой речи. По мнению большинства пользователей в социальных сетях вКонтакте, Одноклассники, Фейсбук, Гугл плюс, лидерами в этой подборке являются русский голос Николая для Балаболки и голосовой движок Максим от ИВОНА. Все эти русские голоса переводят текст в речь и разговаривают относительно нормально, нюанс состоит в другом. В перечне нет бесплатной полнофункциональной версии. Эти программные продукты найти можно, но работать они будут недолго. Любой из этих вариантов - это или триальная демонстрационная версия, или онлайн усеченная, или пиратка с вирусами, червями, кейлогерами, дозвонщиками, руткитами, троянцами, кейлоггерами и прочим шпионским, рекламным и вредоносным программным обеспечением. Загружая файлы из приведенного выше списка, используя сомнительные источники, следует быть предельно осторожным. Правильное легальное решение этой проблемы существует.
Устаревший голосовой движок для Балаболки L&H
Особого внимания заслуживают речевые продукты обанкротившейся в 2001 году компании Lernout&Hauspie. Сразу после ареста основателей Jo Lernout и Pol Hauspie и последующего банкротства L&H компания Nuance Communications (известная как ScanSoft) приобрела все принадлежащие L&H речевые технологии. До сих пор в Интернете можно найти и скачать русские голоса для Балаболки Boris и Svetlana Russian (L&H), а то и скачать Балаболку с русским голосом L&H в портейбл версии. Русские голоса Boris и Svetlana Russian, основанные на устаревшем стандарте SAPI 4, читают тексты на русском языке вполне прилично, но по критериям конца прошлого века. Сегодня технологии распознавания и синтеза человеческой речи ушли далеко вперед.
Голосовой движок для Балаболки от Майкрософт с голосом Елена
У Майкрософта, кроме речевого стандарта Microsoft Speech API 4 и 5 версий, а также Microsoft Speech Platform, есть еще и синтезатор речи. Этот голосовой движок называется MS Server Speech TTS Voise RU Elena и соответствует стандарту речевых функций Microsoft Speech Platform. Русский голос Elena от Microsoft можно загрузить с оф. сайта компании Майкрософт внизу данной страницы https://programmywindows.com/ru/readers/balabolka без регистрирования и SMS. Дополнительно потребуется загрузить и установить Microsoft Speech Platform (MSP x86 или x64). После установки MSP и MS Server Speech TTS Voise RU Elena для нормальной работы этих компонентов с программой Balabolka необходимо обязательно перезагрузить компьютер.
Голоса RHVoice Aleksandr и Elena
В отличие от продукта Microsoft, безопасную легально бесплатную версию голосового движка RHVoice для уже работающего Microsoft Speech API не составит труда добавить без перезагрузки компьютера. По ссылке с programmywindows.com внизу есть возможность скачать русский голосовой движок для Балаболки RHVoice с голосами Aleksandr и Elena Русский (Россия) без вирусов, регистраций и SMS, из надежного источника по прямой ссылке с официального сайта. Как правило, устанавливать MS SAPI 5 необходимости нет, в отличие от Microsoft Speech Platform.
Голосовые движки и удобства Balabolka Portable
Таким образом, на сегодня мы имеем следующий выбор из свободно распространяемых русских полнофункциональных голосов для Балаболки:
1. RHVoice Aleksandr Русский (Россия) стандарта речевых функций SAPI 5.2. RHVoice Elena Русский (Россия) стандарта речевых функций SAPI 5.3. MS Server Speech TTS Voise RU Elena стандарта речевых функций Microsoft Speech Platform.
Если Балаболка работает для двух и более пользователей с отличающимися предпочтениями в отношении скорости воспроизведения, понятности и приятности синтезированных голосов, обнаруживается один нюанс. Каждый пользователь изменяет настройки и голоса на свой вкус. Ситуация похожа на ту, когда каждый водитель автомобиля вынужден настраивать под себя кресло и автомобильные зеркала после предыдущего водителя. В такой ситуации гораздо удобнее один раз Balabolka Portable скачать бесплатно, и установить необходимое количество версий с предпочитаемыми голосовыми движками, словарями, настройками и скинами. Под каждую задачу можно выбирать конкретную портабельную Балаболку со встроенным голосовым модулем, словарями, темой оформления интерфейса и настройками, согласно предпочтениям конкретного пользователя. Кроме того, естественно, портабл Balabolka имеет все достоинства обычного автономного переносимого приложения.
Бесплатно скачать Балаболку и на выбор русские голосовые движки
programmywindows.com
5 лучших синтезаторов речи с русскими голосами
Все чаще в повседневной жизни стали использовать синтезаторы речи. Синтезаторы речи, как становится видно уже по одному названию, осуществляют синтез речи, то есть форматируют письменный текст в устный.
Благодаря этому можно учить новые иностранные слова с правильным произношением, читать книги не отвлекаясь от своих дел или, например, находясь в транспорте. Изначально разработкой таких программ занимались организации, специализирующиеся на технике для людей с проблемами зрения.
Сейчас же, любой пользователь может скачать одну из программ, установить ее на свой компьютер или телефон и синтезировать речь, в том числе и русскую.
Для этого было разработано множество различных программ, приложенный и даже целых систем. К сожалению, не все из них предназначены для русскоязычной аудитории.
Список синтезаторов речи:
1. Acapela
Acapela — один из самых распространенных речевых синтезаторов во всем мире. Программа распознает и озвучивает тексты более, чем на тридцати языках. Русский язык поддерживается двумя голосами: мужской голос — Николай, женский — Алена.Женский голос появился значительно позднее мужского и является более усовершенствованным.
Прослушать, как звучат голоса, можно на официальном сайте программы. Достаточно лишь выбрать язык и голос, и набрать свой небольшой текст.
Кстати, для мужского голоса был разработан отдельный словарь ударений, что позволяет достичь еще большей четкости произношения.
Установка программы проходит без проблем. Разработаны версии для операционных систем Windows, Linux, Mac, а также для мобильных ОС Android u IOS.
Программа платная, скачать ее можно с официального сайта Acapela.
2. Vokalizer
Вторым в нашем списке, но не по популярности является движок Милена от разработчика программы Vocalizer компании Nuance.Голос звучит очень естественно, речь чистая. Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно.Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений. Прекрасно подходит для чтения книг.
Скачать все версии Vokalizer и русскоязычный движок Милена можно на официальном сайте производителя программы.
3. RHVoice
Синтезатор речи RHVoice был разработан Ольгой Яковлевой. Программа озвучивает русские тексты тремя голосами: Елена, Ирина и Александр. Подробнее об установке и применении, а также прослушать голоса Вы сможете в прошлой статье
Код синтезатора открыт для всех, программы же абсолютно бесплатны.RHVoice выпущена в двух вариантах: как отдельная программа, так и как приложение к NVDA.Все версии можно скачать с официального сайта разработчика.
4. ESpeak
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в конце весны две тысячи тринадцатого года.
eSpeak можно установить под следующие операционные системы:
- Microsoft Windows,
- Mac OS X,
- Linux,
- RISC OS
Возможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно.А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Для разработчиков будет интересно узнать, что C++ код программы доступен в сети. Скачать программу, а также посмотреть ее код можно на официальном сайте.
5. Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете.Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальном сайте университета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений.К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
P.S.
Стоит отметить, что любой из вышеприведённых синтезаторов отлично исполнен, но выбор программы индивидуален. Всё объясняется различным произношением голосов. Смею посоветовать второй вариант с голосом Милена. ОЧень выразительный голос, насыщенное звучание и приятная во всех смыслах интонация голоса!
поделиться с друзьями:
wd-x.ru
[Linkset] Синтез речи: беглый обзор
Тем кто ищет как автоматически произносить текст несколько ссылок с кратким описанием. Системы прозношения текста называются термином Text-to-speech (TTS) или Diphone Speech Synthesis и по этим терминам проще гуглить.
Матчасть:
Синтез речи на ВикипедииSpeech Synthesis on Wikipedia
Стандарты
Speech Synthesis Markup Language (SSML) вкратце на Википедии.VoiceXMLMedia Resource Control Protocol (MRCP)Folstein Mini Mental Status Exam (MMSE) какой-то там тест по которому проверяют качество TTS.Web Speech API Specification
Java
Есть стандарт Java Speech API (JSAPI) и JSR 113: JavaTM Speech API 2.0 но с его реализацией похоже туго.No reference implementation exists for JSAPI. Вот мне всегда было непонятно зачем тогда создавать стандарт.Насколько я понял, синтезатор голоса был изначально во первой версии Java от Sun, но потом его вырезали в FreeTTS, и у IBM тоже была какая-то своя приблуда для этого IBM Speech.Вот их FAQ можно найти ответы на другие вопросы и посмотреть древний список реализаций этого апи.
jsapi.sourceforge.net
Java Speech APIWrapper for vendors to simplify usage of the Java Speech API (JSR 113). Note that the spec is an untested early access and that there may be changes in the API. Demo implementations support FreeTTS, Sphinx 4, Microsoft Speech API 5.4 and the Mac OSX speech synthesizer.Т.е. это просто биндинг к другим сервисам.
FreeTTS
FreeTTS выглядит заброшенным но вполне рабочий. Я его уже использовал для озвучивания логов как Log4J Appender где он справлялся хорошо.Изначально разрабатывался в лаборатории компании Sun. Поддерживает JSAPI 1.0 (а уже есть 2.0) но только по синтезу (javax.speech.synthesis), не по распознаванию.Поддерживает три голоса английского, но вроде как можно импортировать MBROLA голоса но русского и украинского там нет.Вообщем рекомендую для базового синтеза простых текстов.
FreeTTS is a speech synthesis system written entirely in the JavaTM programming language. It is based upon Flite: a small run-time speech synthesis engine developed at Carnegie Mellon University. Flite is derived from the Festival Speech Synthesis System from the University of Edinburgh and the FestVox project from Carnegie Mellon University.Т.е. корнями FreeTTS уходит в плюсовые программы описанные тут ниже.
Как я уже говорил, проект заброшенный, но есть форк на Гитхабе который делается одним пацаном для софта для больных Афазией.
Вот пример кода с использованием: FreeTTS Hello World Java Maven.
MARY Text-to-Speech System (MaryTTS)
Более серьёзный синтезатор разработанный в немецком университете и имеющий коммерческое применение. Разработка поддерживается, последний комит был пять дней назад.Поддерживаются американский и британский английский, мужской русский, немецкий, итальянский, шведский, турецкий, французский, телугу (язык юго-восточноо штата в Индии) и была попытка сделать тибетский и арабский (статья). Украинского нету.Список языков и голосов и если что можно сделать самому поддержку языка.
MARY is an open-source, multilingual Text-to-Speech Synthesis platform written in Java. It was originally developed as a collaborative project of DFKI’s Language Technology lab and the Institute of Phonetics at Saarland University and is now being maintained by DFKI. As of version 4.3, MARY TTS supports German, British and American English, Telugu, Turkish, and Russian; more languages are in preparation. MARY TTS comes with toolkits for quickly adding support for new languages and for building unit selection and HMM-based synthesis voices.
Я не пробовал в работе, но мне кажется что его вполне можно использовать в продакшене.
Облачные сервисы —
Послыешь запрос, получаешь
Yandex.SpeechKit
«распознавание и синтез речи, голосовую активацию и выделение смысловых объектов в произносимом тексте.»Есть в виде облачного сервиса и HTTP API к нему и в виде Mobile SDK для iOS, Android и WindowsPhone которые шлют поток с микрофона на сервер для распознавания.Платный для коммерческого использования, до 10000 запросов бесплатен, но нужно запросить API ключ и я его уже четвёртый день жду.Можно попробовать установив приложение Яндекс.Диктовка и оно распознаёт практически идеально.
Работает на своём движке. Вот тут Яндекс рассказали как Распознавание речи от Яндекса. Под капотом у Yandex.SpeechKitПоддерживает распознавание и синтез русского языка и только распознавание турецкого, разрабатывается поддержка английского, но есть возможность говорить с разными эмоциями (добрый, злой, нейтральный) что довольно прикольно как по мне. Ещё интересно что может учитывать гео координаты для более точного распознавания названий улиц.
Железки начали понимать. А мы их всё равно считаем глупымиПочему роботы разговаривают с нами только в кино
Для Cloud API можно сгенерировать звук по GET запросу например такhttp://tts.voicetech.yandex.net/generate?text=»Какой%20ровный%20и%20пра%27вильный%20голос»&speaker=zahar
Очень интересная фишка: Выделение смысловых объектов из текста с помощью которого можно распознавать например даты (что самое интересное поддерживается украинский язык), имена и адреса, что очень полезно для голосового управления.
Центр речевых технологий
«Центр речевых технологий» российская компания делающая синтезаторы текста и другой софт например для голосовой аутентификации и распознавалки для спецслужб.Семь голосов, один женский голос на казахском языке. Украинского нету.Дают облачный API для синтеза VoiceFabric, вроде не дорого.
VoiceFabric: технология синтеза речи из облака
Ребята очень крутые и даже умудрились сгенерировать голос умершего человека:
Google Speech API
У гугла есть закрытое АПИ для синтеза и распознавания речи, но они могут в любой момент закрыть к нему доступ, так что не стоит его использовать в продакшене.Для синтеза речи достаточно просто отправить GET запрос на адрес http://translate.google.com/translate_tts, например:
http://translate.google.com/translate_tts?ie=UTF-8&q=%D0%BF%D1%80%D0%B8%D0%B2%D0%B5%D1%82&tl=ru&prev=input
Голос неприятный и ограничение на длину текста примерно в сто букв, но зато есть все языки которые поддерживаются гугловым онлайн переводчиком, включая украинский, белорусский и казахский.Говорят что внутри переводчик использует движок eSpeak о котором ниже.
Также есть возможность распозновать текст но там уже нужно иметь апи ключ и лимит на 50 запросов в суткиhttps://github.com/gillesdemey/google-speech-v2
J.A.R.V.I.S. — Java биндинг (врапер) к Google Speech API
Microsoft Bing translator (Microsoft Translator API)
У поисковика Бинг тоже есть свой переводчик.И у него похоже адекватное АПИ с доступом через AJAX, HTTP и SOAP с методом SpeakКоторый также шлёт GET запрос на адресhttp://api.microsofttranslator.com/V2/Http.svc/Speak
Доступен всем через Azure и до двух миллионов символов в месяц бесплатен, если выше смотрите цены.Русский и Украинский есть, всего 45 языков.Выглядит солидно, но не пробовал в деле. Поскольку это Майкрософт то где-то подвох будет точно.
SpokenText
SpokenText lets you easily convert text in to speech. Record (English, French, Spanish or German) PDF, Word, plain text, PowerPoint files, and web pages, and convert them to speech automatically. Create .mp3 or .m4b (Audio Book) recordings (in English, French, Spanish and German) of any text content on your computer or mobile phone.
YAKiToMe!
http://www.yakitome.com/Free text to speech. Uses the world’s best text to speech (TTS) software. Upload documents, cut and paste text or link to feeds. Text reader converts text to speech automatically. Download audio and podcasts. It’s fast and easy to use. Get started right away! No software to download or install.Просто дофигища голосов английского, женский и мужской голос русского. Украинского нет.
Другие синтезаторы требующие установки на комп
Правда некоторые предоставляются облачный сервис.
Cравнение
The MBROLA Project
The aim of the MBROLA project, initiated by the TCTS Lab of the Faculté Polytechnique de Mons (Belgium), is to obtain a set of speech synthesizers for as many languages as possible, and provide them free for non-commercial applications.Проект выглядит заброшенным. Но вот тут есть список рилейтед проектов Non-commercial TTS systems and components compatible with MBROLA где тоже можно порыться.
eSpeak
C++, open sourceeSpeak uses a “formant synthesis” method. This allows many languages to be provided in a small size. The speech is clear, and can be used at high speeds, but is not as natural or smooth as larger synthesizers which are based on human speech recordings. Google has integrated eSpeak, an open source software speech synthesizer for English and other languages, in its online translation service Google Translate. The move allow users of Google Translate to hear translations spoken out loud (text-to-speech) by clicking the speaker icon beside some translations.
Первая версия бесплатного синтезатора речи eSpeak была выпущена в 2006 году. С тех пор компания-разработчик постоянно выпускает все более усовершенствованные версии. Последняя версия была представлена в весной 2013.
eSpeak можно установить под следующие операционные системы: Microsoft Windows, Mac OS X, Linux, RISC OSВозможна также компиляция кода для Windows Mobile, но делать ее придется самостоятельно.А вот с мобильной ОС Android программа работает без проблем, хотя русские словари еще не до конца разработаны. Русскоязычных голосов много, можно выбрать на свой вкус.
Festival
Festival — это целая система распознавания и синтеза речи, которая была разработана в эдинбургском университете.Программы и все модули абсолютно бесплатно и распространяются по системе open source. Скачать их и ознакомиться с демо-версиями можно на официальном сайте университета Эдинбурга.
Русский голос представлен в одном варианте, но звучание довольно хорошее и ясное, без акцента и с правильной расстановкой ударений.К сожалению, программа пока может быть установлена только в среде API, Linux. Также есть модуль для работы в Mac OS, но русский язык пока поддерживается не очень хорошо.
festvox
The Festvox project aims to make the building of new synthetic voices more systemic and better documented, making it possible for anyone to build a new voice.
Flite: a small, fast run time synthesis engine
Flite (festival-lite) is a small, fast run-time synthesis engine developed at CMU and primarily designed for small embedded machines and/or large servers. Flite is designed as an alternative synthesis engine to Festival for voices built using the FestVox suite of voice building tools.
Вообще, у них там в университете ещё много всякого софта для синтеза Speech Software at CMU, есть смысл поковыряться.
RHVoice
RHVoice синтезатор русской речи с тремя голосами и открытым кодом. Среди исходников видел биндинги к андроиду. Ещё интересно что есть язык эсперанто.Я так понял что разработчица одна, так что даже не смотрел. Там есть модуль для программы NVDA для слепых, наверное автор программы хотел сделать их мир лучше.«Наверное, лучшее, что можно найти под линукс. Под виндой тоже работает. Голоса есть.Речь, на мой взгляд, получается очень естественная, если не учитывать часто неправильные ударения.»
Praat
Praat is a free scientific software program for the analysis of speech in phonetics. It has been designed and continuously developed by Paul Boersma and David Weenink of the University of Amsterdam. It can run on a wide range of operating systems, including various Unix versions, Mac and Microsoft Windows (95, 98, NT4, ME, 2000, XP, Vista). The program also supports speech synthesis, including articulatory synthesis.Написан на С++, несмотря на то что сайт Web 1.0 последние исходники помечены датой 18 December 2014. Имеет какой-то свой встроенный скриптовый язык.
Epos
http://sourceforge.net/projects/epos/License: GNULast Update: 2013-04-23Writen in C++Epos is a language independent rule-driven Text-to-Speech (TTS) system primarily designed to serve as a research tool. Epos is (or tries to be) independent of the language processed, linguistic description method, and computing environment.Разрабатывался в каком-то чешском университете, сайт уже не работает. Кроме английского и немецкого поддерживает чешский и словацкий, что редкость и кому-то может быть принципиально.
Acapela TTS
Хороший синтезатор с множеством языков. Разработан шведами, так что шведский поддерживается лучше всего причём аж в трёх вариантах. Русский поддерживает.Есть Cloud API, но не интересовался ценой. В интернете хвалили.
Nuance Vocalizer
Вот здесь можно опробовать движки Ольга, Дмитрий, Милена:http://www.oddcast.com/home/demos/tts/tts_example.php
Обратите внимание на движок Милена, это премиум голос. Его можно взять тут:rutracker.org/forum/viewtopic.php?t=4606928Ещё послушать тутhttp://www.Nuance.Com/vocalizer5/flash/index.Html«Голос звучит очень естественно, речь чистая. Есть возможность установить различные словари, а также подкорректировать громкость, скорость и ударение, что не маловажно.Как и в случае с Акапелой, программа имеет различные версии для мобильных, автомобильных и компьютерных приложений. Прекрасно подходит для чтения книг.»
Loquendo TTS
Loquendo TTS платный, но есть на торентах.
Встроенные в Windows
Это будет работать не для всех звуковых картахhttp://wiki.audacityteam.org/wiki/Mixer_Toolbar_Issues#cphttp://www.pcadvisor.co.uk/how-to/windows/3400328/how-record-windows-audio-on-your-pc-or-laptop/
Microsoft Speech API и прикольная программка CoolSpeech которая его использует.Microsoft Speech API (SAPI) 5.4 на MSDNНужно попробовать.
Apple’s Speech Synthesizer (VoiceOver)
https://www.apple.com/accessibility/osx/voiceover/http://www.tuaw.com/2012/07/28/mountain-lion-101-updated-high-quality-voice-synthesis/https://developer.apple.com/library/mac/documentation/UserExperience/Conceptual/SpeechSynthesisProgrammingGuide/SpeechOverview/SpeechOverview.htmlВыглядит достойно. Нет мака под рукой чтобы попробовать.
Android
Я так и не понял, андроид сам может синтезировать голос или шлёт запросы на сервер гугла.http://www.geoffsimons.com/2012/06/7-best-android-text-to-speech-engines.htmlhttp://www.greenbot.com/article/2105862/how-to-get-started-with-google-text-to-speech.htmlhttps://play.google.com/store/apps/details?id=com.google.android.marvin.talkbackhttp://developer.android.com/reference/android/speech/package-summary.htmlhttps://play.google.com/store/apps/details?id=com.google.android.ttshttps://support.google.com/googleplay/answer/1062965?hl=enhttp://habrahabr.ru/post/224685/
AT&T Natural Voices
AT&T Natural Voices® Text-to-Speech Demo
I’ve used AT&T Natural Voices which provides JSAPI and MS SAPI hooks. It provides excellent quality voices, a good «general» speech dictionary, many controls over pronunciation, and multiple languages. It’s a little pricey, but works very well.
I used it to read important sensor telemetry to drivers in a mobile sensor application. We had no complaints about the voice quality. It had about 75% out-of-the-box accuracy with scientific terms and a much higher (maybe 90%+) with normal dialogue. We got it up to about 99+% accuracy by using markups (most errors were on scientific terms with unusual phoneme combinations).
It was a bit hard on the processor (we were running on a Pentium-III equivalent machine and it was pushing 50%-75% peak CPU). This uses a native speech engine (Windows, Linux, and Mac compatible) with a Java interface.There’s a huge variety of voices and languages…
Web Speech API — распознавание и озвучивание текста сразу из броузера
Вообщем вместо тысячи слов смотрите демоchrome.tts API для броузераПрезентацияWeb Speech API Specification — стандарт W3C.
UPD«С кофеваркой надо разговаривать» Интервью Дениса Филиппова, главного по речевым технологиям в «Яндексе»
Поделиться ссылкой:
Понравилось это:
Нравится Загрузка...
Похожее
stokito.wordpress.com

|
|
..:::Счетчики:::.. |
|
|
|
|
|
|
|
|