Cube sql: ROLLUP, CUBE и GROUPING SETS операторы Transact-SQL для подведения итогов и промежуточных итогов | Info-Comp.ru
Содержание
ROLLUP, CUBE и GROUPING SETS операторы Transact-SQL для подведения итогов и промежуточных итогов | Info-Comp.ru
В статье мы рассмотрим возможность Transact-SQL формировать отчеты, как со строкой общего итога, так и со строками промежуточных итогов, для этих целей в MS SQL Server существуют такие операторы как ROLLUP, CUBE и GROUPING SETS, именно о них мы сегодня и поговорим.
Возможность построения отчетов на Transact-SQL очень полезная, мы с Вами уже об этом говорили, когда рассматривали оператор PIVOT, который может транспонировать набор данных, теперь давайте научимся писать запросы, в которых будут выделяться промежуточные итоги и итоги в целом. В Transact-SQL сделать это можно с помощью операторов ROLLUP, CUBE и GROUPING SETS.
Как Вы, наверное, догадываетесь, для того чтобы подсчитать итог или подытог, необходимо прибегнуть к агрегатным функциям и, соответственно, к группировке данных, поэтому операторы ROLLUP, CUBE и GROUPING SETS относятся к конструкции GROUP BY, т. е. являются расширением GROUP BY.
е. являются расширением GROUP BY.
Эти операторы естественно отличаются друг от друга, поэтому в процессе рассмотрения мы будем их сравнивать, но для начала давайте определимся с тестовыми данными для примеров.
Содержание
- Исходные данные для примеров
- ROLLUP
- CUBE
- GROUPING SETS
Исходные данные для примеров
В качестве SQL сервера у нас будет выступать Microsoft SQL Server Express 2014, а запросы будем писать в Management Studio Express.
Мы как всегда будем использовать выдуманные данные, и в этот раз я предлагаю вот такие, таблицу, которая будет содержать список сотрудников с указанием отдела, в котором они работают, а также сумму их заработка по годам.
Таблица
CREATE TABLE [dbo].[test_table](
[id] [INT] IDENTITY(1,1) NOT NULL,
[manager] [VARCHAR](50) NULL,
[otdel] [VARCHAR](50) NULL,
[god] [INT] NULL,
[summa] [MONEY] NULL
) ON [PRIMARY]
GO
А данные вот такие
Заметка! Если Вы не знаете, что делает вышеуказанная инструкция, рекомендую посмотреть мой видеокурс «T-SQL.
Путь программиста от новичка к профессионалу. Уровень 1 – Новичок», который предназначен для начинающих. В нем подробно рассмотрены все базовые конструкции языка T-SQL.
 Путь программиста от новичка к профессионалу. Уровень 1 – Новичок», который предназначен для начинающих. В нем подробно рассмотрены все базовые конструкции языка T-SQL.
Путь программиста от новичка к профессионалу. Уровень 1 – Новичок», который предназначен для начинающих. В нем подробно рассмотрены все базовые конструкции языка T-SQL.ROLLUP
ROLLUP – оператор Transact-SQL, который формирует промежуточные итоги для каждого указанного элемента и общий итог.
Для того чтобы понять, как работает данный оператор, предлагаю сразу перейти к примерам, и допустим, что нам необходимо получить сумму расхода на оплату труда по отделам и по годам, и сначала давайте попробуем написать запрос с группировкой без использования оператора ROLLUP.
SELECT otdel, god, SUM(summa) AS itog FROM dbo.test_table GROUP BY otdel, god ORDER BY otdel, god
Как видите, группировка у нас получилась и в принципе мы видим что, например, в бухгалтерии в 2014 был такой расход, а 2015 такой, но иногда руководство хочет видеть и общую информацию, например, общий расход по каждому отделу. Для этих целей мы можем использовать оператор ROLLUP.
Для этих целей мы можем использовать оператор ROLLUP.
Текст запроса
SELECT otdel, god, SUM(summa) AS itog FROM dbo.test_table GROUP BY ROLLUP (otdel,god)
Строки со значением NULL и есть промежуточные итоги по отделам, а самая последняя строка общий итог. Согласитесь, что это уже более наглядно.
Можно также использовать rollup и с группировкой по одному полю, например:
Группировка по отделам с общим итогом
Группировка по годам с общим итогом
CUBE
CUBE — оператор Transact-SQL, который формирует результаты для всех возможных перекрестных вычислений.
Давайте напишем практически такой же SQL запрос, только вместо rollup укажем cube и посмотрим на полученный результат.
Текст запроса
SELECT otdel, god, SUM(summa) AS itog FROM dbo.test_table GROUP BY CUBE (otdel,god)
В данном случае отличие от rollup заключается в том, что группировка и промежуточные итоги выполнены как для otdel, так и для god.
GROUPING SETS
GROUPING SETS – оператор Transact-SQL, который формирует результаты нескольких группировок в один набор данных, другими словами, он эквивалентен конструкции UNION ALL к указанным группам.
Пример GROUPING SETS
Текст запроса
SELECT otdel, god, SUM(summa) AS itog FROM dbo.test_table GROUP BY GROUPING SETS (otdel,god)
тот же результат, но с использованием UNION ALL
Текст запроса
SELECT null AS otdel, god, SUM(summa) AS itog FROM dbo.test_table GROUP BY god UNION ALL SELECT otdel, null AS god, SUM(summa) AS itog FROM dbo.test_table GROUP BY otdel
А сейчас предлагаю поговорить еще об одной полезной возможности, которая напрямую относится к перечисленным выше операторам, а именно о функции GROUPING.
GROUPING – функция Transact-SQL, которая возвращает истину, если указанное выражение является статистическим, и ложь, если выражение нестатистическое.
Данная функция создана для того, чтобы отличить статистические строки, которые добавил SQL сервер, от строк, которые и есть сами данные, так как когда используешь много группировок, запутаться в строках очень легко.
Пример GROUPING
Текст запроса
SELECT otdel,
ISNULL(CAST(god AS VARCHAR(30)),
CASE WHEN GROUPING(god)=1 ANS GROUPING(otdel)=0
THEN 'Промежуточный итог'
ELSE 'Общий итог' END) AS god,
SUM(summa) AS itog,
GROUPING(otdel) AS grouping_otdel,
GROUPING(god) AS grouping_god
FROM dbo.test_table
GROUP BY
ROLLUP (otdel,god)
На этом все, надеюсь, что возможность формировать итоги и промежуточные итоги в Microsoft SQL Server Вам будет полезна. Также рекомендую Вам почитать мою книгу «SQL код», в ней язык SQL рассматривается как стандарт, чтобы после прочтения данной книги можно было работать с языком SQL в любой системе управления базами данных. Удачи!
Удачи!
MS SQL Server и T-SQL
Последнее обновление: 19.07.2017
Дополнительно к стандартным операторам GROUP BY и HAVING SQL Server поддерживает еще четыре специальных расширения для группировки данных:
ROLLUP, CUBE, GROUPING SETS и OVER.
ROLLUP
Оператор ROLLUP добавляет суммирующую строку в результирующий набор:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products GROUP BY Manufacturer WITH ROLLUP
Как видно из скриншота, в конце таблицы была добавлена дополнительная строка, которая суммирует значение столбцов.
Альтернативный синтаксис запроса, который можно использовать, начиная с версии MS SQL Server 2008:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products GROUP BY ROLLUP(Manufacturer)
При группировке по нескольким критериям ROLLUP будет создавать суммирующую строку для каждой из подгрупп:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products GROUP BY Manufacturer, ProductCount WITH ROLLUP
При сортировке с помощью ORDER BY следует учитывать, что она применяется уже после добавления суммирующей строки.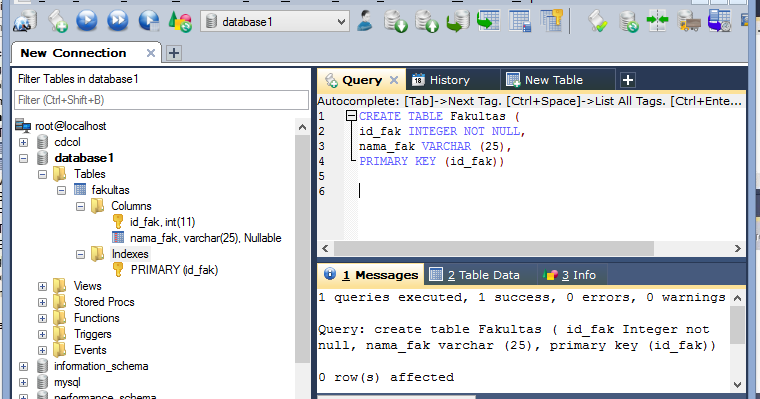
CUBE
CUBE похож на ROLLUP за тем исключением, что CUBE добавляет суммирующие строки для каждой комбинации групп.
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products GROUP BY Manufacturer, ProductCount WITH CUBE
GROUPING SETS
Оператор GROUPING SETS аналогично ROLLUP и CUBE добавляет суммирующую строку для групп. Но при этом он не включает сами группам:
SELECT Manufacturer, COUNT(*) AS Models, ProductCount FROM Products GROUP BY GROUPING SETS(Manufacturer, ProductCount)
При этом его можно комбинировать с ROLLUP или CUBE. Например, кроме суммирующих строк по каждой из групп добавим суммирующую строку для всех групп:
SELECT Manufacturer, COUNT(*) AS Models, ProductCount, SUM(ProductCount) AS Units FROM Products GROUP BY GROUPING SETS(ROLLUP(Manufacturer), ProductCount)
С помощью скобок можно определить более сложные сценарии группировки:
SELECT Manufacturer, COUNT(*) AS Models, ProductCount, SUM(ProductCount) AS Units FROM Products GROUP BY GROUPING SETS((Manufacturer, ProductCount), ProductCount)
OVER
Выражение OVER позволяет суммировать данные, при этому возвращая те строки, которые использовались для
получения суммированных данных. Например, найдем количество моделей и общее количество товаров этих моделей по производителю:
Например, найдем количество моделей и общее количество товаров этих моделей по производителю:
SELECT ProductName, Manufacturer, ProductCount, COUNT(*) OVER (PARTITION BY Manufacturer) AS Models, SUM(ProductCount) OVER (PARTITION BY Manufacturer) AS Units FROM Products
Выражение OVER ставится после агрегатной функции, затем в скобках идет выражение PARTITION BY и столбец,
по которому выполняется группировка.
То есть в данном случае мы выбираем название модели, производителя, количество единиц модели и добавляем к этому количество моделей для данного производителя и
общее количество единиц всех моделей производителя:
НазадСодержаниеВперед
Полнофункциональная и высокопроизводительная система управления реляционными базами данных, построенная на основе ядра базы данных sqlite.
Полнофункциональный и высокопроизводительный сервер на основе sqlite.
Загрузить Купить
С 2013 года cubeSQL был развернут более 117 миллионов раз.
Текущая версия: 5.9.0, выпущенная 28 июня 2022 года.
Обзор
Цены
Часто задаваемые вопросы
Технические примечания
Отзывы
Запросить ключ
cubeSQL — это полнофункциональная и высокопроизводительная система управления реляционными базами данных, построенная на основе механизма базы данных sqlite. Мы разработали первую СУБД коммерческого уровня на основе sqlite еще в 2005 году и на протяжении многих лет продолжали улучшать наш сервер, чтобы лучше соответствовать всем потребностям наших клиентов. cubeSQL — конечный результат всех наших усилий.
Это идеальный сервер базы данных как для разработчиков, которые хотят преобразовать однопользовательскую базу данных в многопользовательский проект, так и для компаний, которым нужна доступная, простая в использовании и обслуживании система управления базами данных.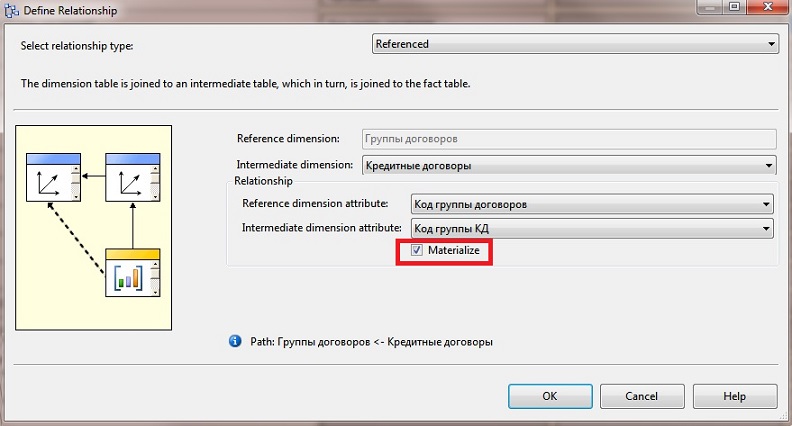
CubeSQL невероятно быстр, занимает мало места, очень надежен и работает на Windows, Mac и Linux (32-разрядные и 64-разрядные версии для всех платформ). Доступ к cubeSQL можно получить с помощью PHP, JSON, Xojo и собственного C SDK. cubeSQL написан на низкоуровневом языке ANSI C, поэтому его можно легко портировать на любые операционные системы.
ХАРАКТЕРИСТИКИ
на основе SQLite
cubeSQL основан на SQLite, самой популярной встроенной базе данных, используемой Google, Mozilla, Adobe, DropBox, Apple и многими другими.
Совместное использование за один шаг
Чтобы поделиться своим файлом базы данных sqlite с одним пользователем с тысячами клиентов, просто перетащите файл базы данных sqlite в папку баз данных сервера. Это все!
Надежный и быстрый
Поскольку CubaSQL основан на SQLite, он отличается высокой надежностью и быстротой. Вы можете легко превратить любое однопользовательское приложение базы данных в многопользовательское приложение.
Вы можете легко превратить любое однопользовательское приложение базы данных в многопользовательское приложение.
Простота использования и администрирования
Установка cubeSQL невероятно проста. Вы запустите его менее чем за пять минут. Кроме того, обслуживание cubeSQL так же просто с помощью графического инструмента администрирования.
Экономьте время на административных задачах
Приложение cubeSQL Admin имеет простой в использовании и интуитивно понятный интерфейс с гораздо более широкими функциональными возможностями, чем когда-либо прежде. Планируйте и восстанавливайте резервные копии, изучайте статистику производительности и многое другое.
Расширения SQLite
cubeSQL поддерживает все расширения SQLite, что позволяет вам использовать все виды новых функций, которые другие добавили в SQLite, ядро базы данных cubeSQL.
Более отзывчивый
В cubeSQL используются самые современные технологии для максимальной производительности. Благодаря своей мощной архитектуре cubeSQL может выполнять все операции одновременно, предотвращая замедление работы других пользователей при выполнении крупных и трудоемких операций. CubaSQL успешно решил проблему C10K много лет назад.
Благодаря своей мощной архитектуре cubeSQL может выполнять все операции одновременно, предотвращая замедление работы других пользователей при выполнении крупных и трудоемких операций. CubaSQL успешно решил проблему C10K много лет назад.
Точки восстановления
В маловероятном случае аварии ваша база данных будет в хорошем состоянии ровно настолько, насколько хороша ваша последняя резервная копия. Но как насчет операций, которые произошли ПОСЛЕ резервного копирования? Без проблем. С помощью точек восстановления cubeSQL теперь может регистрировать каждую операцию и позволяет вам восстанавливать базу данных вплоть до конкретной операции по вашему выбору.
Ваши данные в безопасности
AES, также известный как Rijndael, представляет собой блочный шифр, принятый правительством США в качестве стандарта шифрования. Он был тщательно проанализирован и в настоящее время используется во всем мире. cubeSQL поддерживает шифрование AES для записи данных в базу данных и для всей сетевой связи между сервером и всеми подключенными клиентами.
Простая файловая структура упрощает управление вашей базой данных.
Серверы баз данных, как правило, хранят данные в виде большого набора файлов, и часто эти файлы находятся в месте, к которому может получить доступ только сам механизм базы данных. Это затрудняет доступ к данным и управление ими. Некоторые механизмы баз данных SQL предоставляют возможность записи непосредственно на диск в обход файловой системы. Это значительно усложняет настройку и обслуживание. В Cubase все просто: база данных — это обычный файл на диске, который может располагаться в любом месте иерархии каталогов.
Вы можете оставаться гибкими, потому что cubeSQL является кросс-платформенным.
CubaSQL доступен для Mac OS X (x86 и PowerPC), Windows и Linux (x86). Все базы данных, создаваемые сервером, являются кроссплатформенными. Файл базы данных, написанный на одном компьютере, можно скопировать и использовать на другом компьютере с другой архитектурой; прямой или прямой, 32-битный или 64-битный не имеет значения. Все машины используют один и тот же формат файла. Кроме того, мы обязались поддерживать стабильность и обратную совместимость формата файлов, чтобы новые выпуски cubeSQL могли читать и записывать старые файлы баз данных.
Все машины используют один и тот же формат файла. Кроме того, мы обязались поддерживать стабильность и обратную совместимость формата файлов, чтобы новые выпуски cubeSQL могли читать и записывать старые файлы баз данных.
Ваши данные в безопасности
cubeSQL полностью совместим с ACID. ACID означает атомарный, последовательный, изолированный и устойчивый и связан с надежностью транзакций базы данных. Это важно, потому что это означает, что вам не нужно беспокоиться о пользователях, обращающихся к базе данных в незавершенном состоянии. Пользователи не могут видеть изменения, которые вносятся, но не зафиксированы. Если сервер теряет питание или выходит из строя во время транзакции, сервер автоматически восстанавливается до нетронутого состояния. Соответствие ACID имеет решающее значение для любой базы данных, от которой вы зависите.
Полнотекстовый поиск
CubeSQL поддерживает полнотекстовый поиск, что позволяет создавать новый класс приложений баз данных, недоступный в предыдущих версиях. Теперь вы можете хранить огромное количество текстовых данных и выполнять поиск по ним за считанные секунды.
Теперь вы можете хранить огромное количество текстовых данных и выполнять поиск по ним за считанные секунды.
JSON
cubeSQL поддерживает настраиваемый упрощенный протокол, но чтобы быть максимально открытым для сторонних клиентов, мы добавили поддержку широко используемого протокола JSON, поэтому вы можете получить доступ к серверу с помощью любого клиента, поддерживающего JSON.
Более быстрый доступ благодаря автоматическому сжатию данных
CubeSQL автоматически сжимает все данные между сервером и клиентом, чтобы значительно сократить время отклика. Большие запросы также можно разделить на настраиваемые фрагменты, чтобы повысить скорость отклика.
Сервер, который будет расти по мере вашего роста
CubeSQL может обрабатывать до 10 000 одновременных подключений с одной установки сервера! Нет необходимости устанавливать несколько серверов и настраивать их для параллелизма и балансировки нагрузки. cubeSQL остается таким же простым в установке и управлении, как и прежде, обеспечивая исключительную масштабируемость. Наконец, cubeSQL полностью поддерживает многоядерность, поэтому он будет использовать всю вычислительную мощность, которую вы ему предоставляете.
Наконец, cubeSQL полностью поддерживает многоядерность, поэтому он будет использовать всю вычислительную мощность, которую вы ему предоставляете.
Поддержка подключаемых модулей
CubaSQL имеет модульную архитектуру подключаемых модулей, и вы можете использовать ее для расширения языка SQL, изменения способа сортировки результатов или даже для создания собственных серверных команд. Архитектура подключаемых модулей дает вам возможность расширить возможности cubeSQL способами, ограниченными только вашим воображением. Собственный подключаемый модуль SDK включен в установку каждого сервера. Программное обеспечение MonkeyBread предлагает несколько полезных плагинов.
Триггеры помогают сохранить целостность ваших данных
Триггеры базы данных позволяют DBSA (администраторам баз данных) создавать дополнительные отношения между отдельными таблицами. Например, изменение записи в одной таблице может вызвать изменение записи во второй таблице. cubeSQL поддерживает создание триггеров, которые могут выполняться при вставке, обновлении или удалении строк в таблице за таблицей.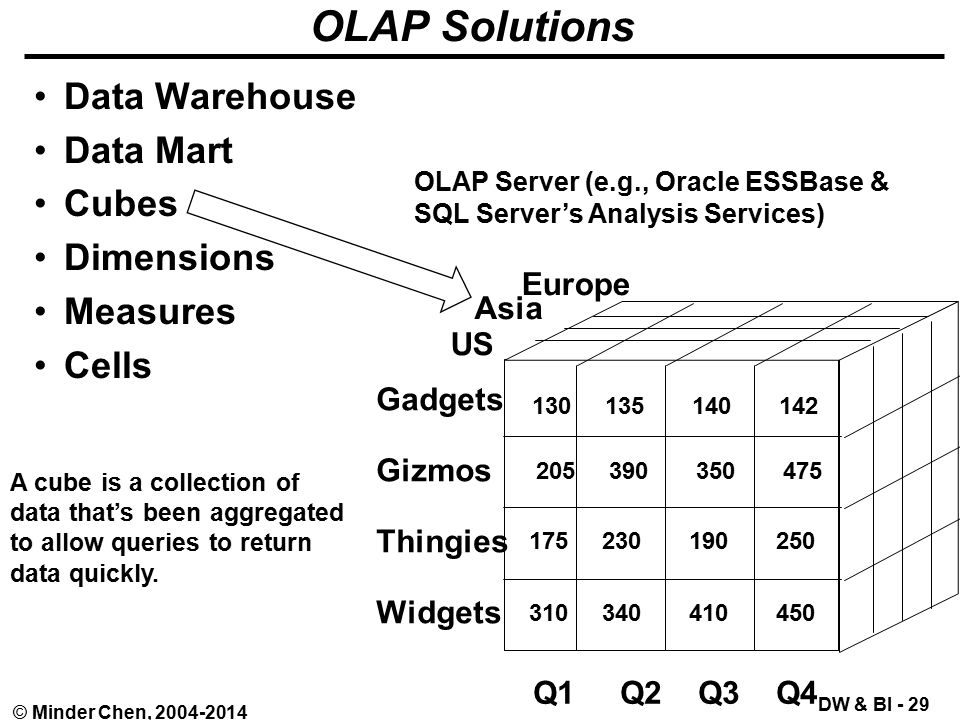
Полнофункциональная и высокопроизводительная система управления реляционными базами данных, построенная на основе ядра базы данных sqlite.
С 2013 года cubeSQL был развернут более 117 миллионов раз.
купить сейчас
CubaSQL с двумя одновременными подключениями теперь является бесплатным. Запросите бесплатный ключ сегодня!
Требования
- MacOS 10.7 или выше
- Windows VISTA/7sp1/8/10 или выше
- Ядро Linux версии 2.6.2 или выше
Сопутствующее
- Обзор
- Цены
- Часто задаваемые вопросы
- Технические примечания
- Отзывы
- Запросить ключ
- Лицензия
- История версий
- Скачать старые версии
Пример T-SQL WITH CUBE в SQL Server
SQL/OLAP предоставляет методы и инструменты для анализа данных с использованием SQL.
Усовершенствования SQL/OLAP в решениях T-SQL для бизнес-аналитики с SQL Server 2005 можно перечислить следующим образом:
— Функции ранжирования ,
— TOP n ,
— Pivot и UnPivot и
— Оператор CUBE и ROLLUP .
Давайте начнем это руководство с команды sql WITH CUBE T-SQL OLAP в SQL Server 2005 и более поздних версиях T-SQL.
Оператор T-SQL CUBE
Оператор SQL OLAP, который мы приведем здесь в этом учебнике по SQL, — это оператор куба в SQL Server 2005
. Оператор куба T-SQL очень похож на оператор SQL Group By с той лишь разницей, что в нем есть дополнительные сводные строки.
Разработчики T-SQL знают, что оператор Group By sql принимает список столбцов sql, определяющих группы, для которых будут вычисляться функции агрегирования, такие как SUM().
Столбцы, перечисленные в предложении Group By, занимают место в результирующем наборе оператора SQL Select рядом со столбцами агрегирования.
Оператор SQL Cube добавляет несколько дополнительных строк в этот набор результатов.
И выбранный набор результатов превращается в куб OLAP, где разработчики SQL также могут найти результаты агрегирования в столбцах Group By.
Это похоже на агрегирование агрегированных результатов.
Пример T-SQL CUBE
В компании, занимающейся разработкой программного обеспечения, менеджер проекта сообщил об использовании ресурсов, содержащем подробную информацию о том, какой разработчик сколько работал над какими задачами.
Чтобы визуализировать этот пример куба T-SQL , давайте сначала создадим приведенную ниже таблицу sql для вставки демонстрационных данных.
Затем выполните оператор sql Insert, чтобы заполнить таблицу sql образцами данных для t-sql WITH Cube example .
Внимательные глаза увидят, что команда вставки sql — это новый синтаксис, появившийся благодаря усовершенствованиям T-SQL в SQL Server 2008.
Создать таблицу ProjectWorks
(
[Год] int,
[Месяц] tinyint,
[Ресурс проекта] varchar(20),
[Задача проекта] varchar(20),
[Работы в человеко-часах] int
)
Вставить в Значения ProjectWorks
(2010, 10, «Разработчик 1», «T-SQL», 80),
(2010, 10, «Разработчик 1», «ASP. NET», 30),
NET», 30),
(2010, 10, «Разработчик 1", "модульный тест", 90),
(2010, 10, "Разработчик 2", "T-SQL", 30),
(2010, 10, "Разработчик 2", "ASP.NET", 60) ,
(2010, 10, «Разработчик 2», «Модульный тест», 90),
(2010, 10, «Разработчик 3», «T-SQL», 50),
(2010, 10, «Разработчик 3», «ASP.NET», 70),
(2010, 10, ' Разработчик 3», «Модульное тестирование», 60),
(2010, 11, «Разработчик 1», «T-SQL», 90),
(2010, 11, «Разработчик 1», «ASP.NET», 40 ),
(2010, 11, «Разработчик 1», «Модульное тестирование», 60),
(2010, 11, «Разработчик 2», «T-SQL», 20),
(2010, 11, «Разработчик 2 ', 'ASP.NET', 80),
(2010, 11, 'Разработчик 2', 'Модульное тестирование', 80),
(2010, 11, 'Разработчик 3', 'T-SQL', 60),
(2010, 11, «Разработчик 3», «ASP.NET», 60),
(2010, 11, «Разработчик 3», «Модульный тест», 70)
Код
Ниже разработчики t-sql могут найти базовый запрос sql WITH CUBE, который также помогает разработчикам разобраться в синтаксисе tsql WITH CUBE .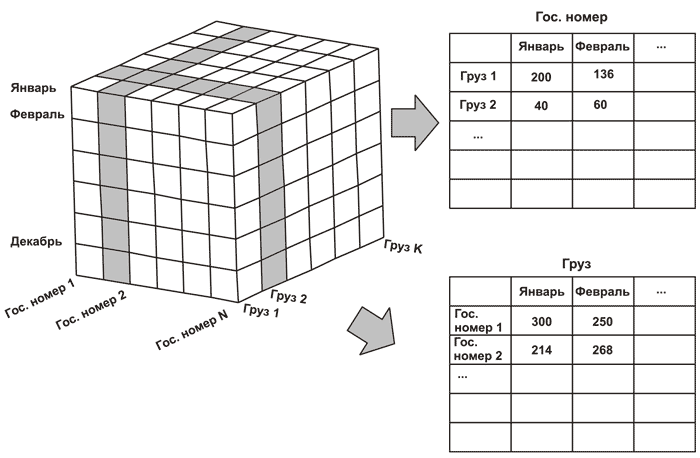
Обратите внимание, что оператор WITH CUBE используется сразу после списка столбцов GROUP BY в запросах sql.
ВЫБЕРИТЕ
[Ресурс проекта], [Задача проекта], SUM([Человек-час работы]) КАК Работа
ИЗ ProjectWorks
СГРУППИРОВАТЬ ПО
[Ресурс проекта], [Задача проекта]
С КУБОМ
Код
Вывод вышеуказанного запроса T-SQL SELECT с использованием WITH CUBE выглядит следующим образом:
.
Используя приведенный выше пример данных sql, разработчики t-sql и разработчики бизнес-аналитики могут создавать более подробные данные отчета OLAP с помощью приведенной ниже команды t-sql CUBE.
Этот запрос SELECT с использованием оператора WITH CUBE также вернет сводные данные для измерения времени.
ВЫБЕРИТЕ
[Год], [Месяц],
[Ресурс проекта], [Задача проекта],
СУММА([Работа в человеко-часах]) AS Work
ИЗ ProjectWorks
ГРУППА ПО
[Год], [Месяц], [Ресурс проекта], [Задача проекта]
С КУБОМ
Код
Подводя итог, Microsoft SQL Server представил With Cube , With Rollup и аналогичные команды SQL OLAP для использования структур Business Intelligence и SQL Cube в T-SQL и в запросах SQL разработчиками sql.