Database compare 2018 что это: ‘Compare Database’ для Windows скачать бесплатно…
Содержание
использовать сравнение схем для сопоставления различных определений баз данных — SQL Server Data Tools (SSDT)
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
-
В SQL Server Data Tools (SSDT) входит программа сравнения схем, которая позволяет сравнивать два определения базы данных. Источником и целью сравнения может быть любое сочетание подключенной базы данных, проекта базы данных SQL Server, файла моментального снимка и файла DACPAC. Результаты сравнения выводятся в виде набора действий, которые необходимо выполнить с целевой базой, чтобы сделать ее идентичной исходной базе. После завершения сравнения вы можете обновить целевую базу непосредственно (если это проект или база данных) или создать скрипт обновления, выполняющий те же действия.
Источником и целью сравнения может быть любое сочетание подключенной базы данных, проекта базы данных SQL Server, файла моментального снимка и файла DACPAC. Результаты сравнения выводятся в виде набора действий, которые необходимо выполнить с целевой базой, чтобы сделать ее идентичной исходной базе. После завершения сравнения вы можете обновить целевую базу непосредственно (если это проект или база данных) или создать скрипт обновления, выполняющий те же действия.
Различия между источником и целью представляются в виде сетки для удобства просмотра. Для каждого различия поддерживается детализация в сетке результатов или в форме скрипта. Затем вы можете выборочно исключить отдельные различия.
Результаты сравнения вы можете сохранять в составе проекта базы данных SQL Server или в отдельном файле. Также вы можете задать параметры, управляющие областью сравнения и аспектами обновления. Затем вы можете сохранить сравнение, чтобы проще было повторить его с теми же параметрами или использовать в качестве отправной точки для нового сравнения.
В следующей процедуре схема проекта базы данных сравнивается со схемой подключенной базы данных.
Предупреждение
Если проект указан как целевой для сравнения, то максимальная поддерживаемая длина пути (не считая буквы диска, двоеточия и обратной косой черты) для проекта составляет 256 символов. Если путь к проекту превышает 256 символов, то все-таки есть возможность сравнить его схему со схемой базы данных или другого проекта. Однако в таком случае нельзя обновить его схему.
Предупреждение
В следующих процедурах используются сущности, созданные с помощью процедур, которые описывались ранее в разделах Connected Database Development (Разработка подключенной базы данных) и Project-Oriented Offline Database Development (Разработка базы данных вне сети с учетом проекта).
Сравнение определений баз данных
В меню Сервис последовательно выберите SQL Server и Создать сравнение схем.
Также можно щелкнуть правой кнопкой мыши проект TradeDev в обозревателе решений и выбрать пункт Сравнение схем.

Откроется окно Сравнение схем, и Visual Studio автоматически назначит сравнению имя, например
SqlSchemaCompare1.Под панелью инструментов в окне Сравнение схем выводятся два раскрывающихся меню, разделенные зеленой стрелкой. Эти меню позволяют выбрать определения базы данных в качестве источника и цели сравнения.
В раскрывающемся списке Выбор источника выберите команду Выбрать источник. Откроется диалоговое окно выбора исходной схемы.
Обратите внимание, что если вы открыли окно Сравнение схем , щелкнув правой кнопкой мыши имя проекта, исходная схема уже заполнена, и вы можете перейти к шагу 4.
Выберите вариант Проект, а затем выберите проект базы данных TradeDev, созданный в предыдущей процедуре.
В раскрывающемся списке Выбор цели в окне Сравнение схем выберите команду Select Target (Выбрать цель).
Откроется диалоговое окно выбора целевой схемы. В разделе Схема выберите вариант База данных и нажмите кнопку Создать соединение.В диалоговом окне Свойства соединения введите имя сервера, на котором размещается база данных
TradeDev, и проверьте правильность введенных учетных данных для аутентификации. Затем выберите базу TradeDev в разделе Соединение с базой данных и нажмите кнопку ОК.Также вы можете нажать кнопку Параметры на панели инструментов в окне Сравнение схем, чтобы указать объекты для сравнения, пропускаемые типы различий и другие параметры.
Нажмите кнопку Сравнить на панели инструментов в окне Сравнение схем, чтобы запустить процесс сравнения.
Когда сравнение будет завершено, структурные различия между проектом и базой данных отобразятся на панели Результаты в верхней части окна.
По умолчанию в результатах сравнения все различия группируются по действию (удалить, изменить или добавить). На панели Результаты отображается строка для каждого объекта базы данных, который различается в двух определениях базы данных. Каждая строка определяет объект в исходной или целевой схеме и действие, которое нужно выполнить в целевой схеме, чтобы целевой объект стал идентичным исходному объекту. Если объект в ходе рефакторинга был переименован или перемещен в новую схему, то исходное и целевое имя будут различны и исходное имя будет выделено полужирным шрифтом.По умолчанию в списке результатов остаются скрытыми объекты, которые совпадают в обеих схемах или не поддерживаются для обновления (например, встроенные объекты). Чтобы показать эти объекты, вы можете выбрать соответствующие кнопки фильтров на панели инструментов.
Чтобы изменить порядок группирования, выберите раскрывающийся список Группировать результаты на панели инструментов.
Выберите пункт Тип, чтобы сгруппировать результаты по типу объекта (например, по таблицам, представлениям или хранимым процедурам).Найдите таблицу
Productsв группеTables. Выберите строку и обратите внимание, что исходное и целевое определения таблицы выводятся на панели Определения объектов с выделением различий. Также можно развернуть строку таблицыProductsна панели Результаты, чтобы проверить отдельные различающиеся элементы таблицы.По умолчанию все различия включаются в область действия «Обновить целевую схему». Вы можете исключить любые различия, которые не нужно синхронизировать. Для этого снимите флажок в столбце Действие в центре каждой строки. Кроме того, можно щелкнуть правой кнопкой мыши строку на панели «Схема» и выбрать пункт Исключить. Обратите внимание, что эта строка сразу станет неактивной. Когда придет время обновления целевой базы данных, эта строка не будет учитываться среди отложенных изменений.
Также вы можете щелкнуть правой кнопкой мыши строку группы и выбрать пункт Исключить все или Включить все, что равносильно снятию или установке флажков для всех различий в данной группе. Если результаты сгруппированы по схеме, это действие позволяет быстро включить или исключить все изменения, относящиеся к определенной схеме.
Предупреждение
Если у исключаемой строки есть зависимые объекты (например, строка Таблица, на которую ссылается строка Представление), то исключаемая строка будет отключена, но ее флажок не будет снят. После того как будут сняты флажки у всех зависимых строк, флажок отключенной строки будет снят. Кроме того, если строка прошла рефакторинг (переименована или перемещена в другую схему), то флажок будет недоступен и для этой строки, и для всех зависимых дочерних строк.
Обратите внимание, что, если обновить сравнение, то различия, которые были отмечены как пропускаемые, не будут обрабатываться.

 Откроется диалоговое окно выбора целевой схемы. В разделе Схема выберите вариант База данных и нажмите кнопку Создать соединение.
Откроется диалоговое окно выбора целевой схемы. В разделе Схема выберите вариант База данных и нажмите кнопку Создать соединение. По умолчанию в результатах сравнения все различия группируются по действию (удалить, изменить или добавить). На панели Результаты отображается строка для каждого объекта базы данных, который различается в двух определениях базы данных. Каждая строка определяет объект в исходной или целевой схеме и действие, которое нужно выполнить в целевой схеме, чтобы целевой объект стал идентичным исходному объекту. Если объект в ходе рефакторинга был переименован или перемещен в новую схему, то исходное и целевое имя будут различны и исходное имя будет выделено полужирным шрифтом.
По умолчанию в результатах сравнения все различия группируются по действию (удалить, изменить или добавить). На панели Результаты отображается строка для каждого объекта базы данных, который различается в двух определениях базы данных. Каждая строка определяет объект в исходной или целевой схеме и действие, которое нужно выполнить в целевой схеме, чтобы целевой объект стал идентичным исходному объекту. Если объект в ходе рефакторинга был переименован или перемещен в новую схему, то исходное и целевое имя будут различны и исходное имя будет выделено полужирным шрифтом. Выберите пункт Тип, чтобы сгруппировать результаты по типу объекта (например, по таблицам, представлениям или хранимым процедурам).
Выберите пункт Тип, чтобы сгруппировать результаты по типу объекта (например, по таблицам, представлениям или хранимым процедурам).

Существует два способа обновления схемы целевой базы данных. Вы можете непосредственно обновить целевую схему в окне Сравнение схем, если целью является база данных или проект, или создать скрипт обновления, если целью является база данных или файл базы данных. Созданный скрипт появляется в редакторе Transact-SQL, где можно проверить выполнение скрипта в базе данных. В следующих процедурах эти возможности описаны подробно.
Предупреждение
Обновление завершится ошибкой, поскольку изменение подразумевает изменение типа столбца с NOT NULL на NULL, что приводит к потере данных. Чтобы продолжить обновление, нажмите кнопку Параметры (пятая слева) на панели инструментов в окне «Сравнение схем» и снимите флажок Блокировать добавочное развертывание при потере данных.
Прямое обновление в окне «Сравнение схем»
Нажмите кнопку Обновить на панели инструментов в окне «Сравнение схем».
Проверьте созданный скрипт изменений. Этот скрипт вы можете сохранить с помощью меню «Файл/создать». Это может быть удобно в ситуациях, когда недостаточно полномочий для обновления производственной базы данных. В этом случае вы можете передать скрипт администратору баз данных для последующего развертывания.
При наличии необходимого разрешения на обновление базы данных нажмите кнопку Выполнить запрос на панели инструментов в области редактирования, чтобы выполнить скрипт.

Обновление с помощью скрипта
Нажмите кнопку Создать скрипт (четвертую слева) на панели инструментов в окне «Сравнение схем».
Созданный скрипт откроется в новом окне редактора Transact-SQL.
Предупреждение
Этот режим поддерживается только для DACPAC-файлов, созданных в процессе создания моментальных снимков SSDT. В этой версии нельзя выбрать DACPAC-файл, созданный платформой или средствами приложения уровня данных (DAC) SQL.
Проверьте созданный скрипт изменений. Скрипт вы можете сохранить с помощью команды «Сохранить» или «Сохранить как» в меню Файл.
Сохраненный скрипт может быть удобен в ситуациях, когда недостаточно полномочий для обновления рабочей базы данных. В этом случае вы можете передать скрипт администратору базы данных для последующего развертывания.
Также вы можете подключить редактор Transact-SQL к нужному серверу и непосредственно выполнить скрипт. Перед выполнением этой процедуры необходимо получить необходимое разрешение на создание или обновление базы данных. При наличии необходимого разрешения на обновление базы данных нажмите кнопку Выполнить запрос на панели инструментов в области редактирования, чтобы выполнить скрипт.
Нажмите кнопку Подключить. Это действие устанавливает соединение с текущим сервером либо предлагает ввести новый сервер или выбрать сервер в диалоговом окне «Соединение с сервером».
Обратите внимание, что имя базы данных определяется в скрипте как переменная команды.Проверьте скрипт и в случае необходимости измените переменные команды, которые определяют имя целевой базы данных, соответствующий префикс и пути к файлам.
Нажмите кнопку Выполнить на панели инструментов в области редактирования, чтобы выполнить скрипт.

 Обратите внимание, что имя базы данных определяется в скрипте как переменная команды.
Обратите внимание, что имя базы данных определяется в скрипте как переменная команды.
Введение в Data classes / Хабр
Одна из новых возможностей, появившихся в Python 3.7 — классы данных (Data classes). Они призваны автоматизировать генерацию кода классов, которые используются для хранения данных. Не смотря на то, что они используют другие механизмы работы, их можно сравнить с «изменяемыми именованными кортежами со значениями по умолчанию».
- PEP 557 — Data classes
- Официальная документация
Введение
Все приведенные примеры требуют для своей работы Python 3.
 7 или выше
7 или вышеБольшинству python-разработчикам приходится регулярно писать такие классы:
class RegularBook:
def __init__(self, title, author):
self.title = title
self.author = authorУже на этом примере видна избыточность. Идентификаторы title и author используются несколько раз. Реальный класс же будет ещё содержать переопределенные методы __eq__ и __repr__.
Модуль dataclasses содержит декоратор @dataclass. С его использованием аналогичный код будет выглядеть так:
from dataclasses import dataclass
@dataclass
class Book:
title: str
author: strВажно отметить, что аннотации типов обязательны. Все поля, которые не имеют отметок о типе будут проигнорированы. Конечно, если вы не хотите использовать конкретный тип, вы можете указать Any из модуля typing.
Что же вы получаете в результате? Вы автоматически получаете класс, с реализованными методами __init__, __repr__, __str__ и __eq__.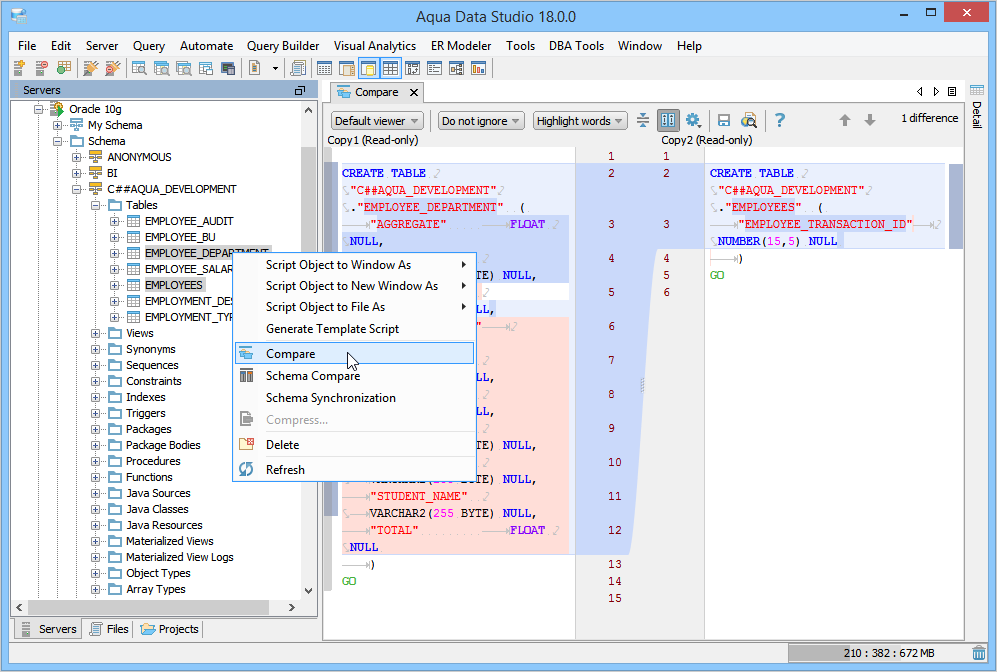 Кроме того, это будет обычный класс и вы можете наследоваться от него или добавлять произвольные методы.
Кроме того, это будет обычный класс и вы можете наследоваться от него или добавлять произвольные методы.
>>> book = Book(title="Fahrenheit 451", author="Bradbury")
>>> book
Book(title='Fahrenheit 451', author='Bradbury')
>>> book.author
'Bradbury'
>>> other = Book("Fahrenheit 451", "Bradbury")
>>> book == other
TrueАльтернативы
Кортеж или словарь
Конечно, если структура довольна простая, можно сохранить данные в словарь или кортеж:
book = ("Fahrenheit 451", "Bradbury")
other = {'title': 'Fahrenheit 451', 'author': 'Bradbury'}Однако у такого подхода есть недостатки:
- Необходимо помнить, что переменная содержит данные, относящиеся к данной структуре.
- В случае словаря, вы должны следить за названиями ключей. Такая инициализация словаря
{'name': 'Fahrenheit 451', 'author': 'Bradbury'}тоже будет формально корректной. - В случае кортежа вы должны следить за порядком значений, так как они не имеют имен.

Есть вариант получше:
Namedtuple
from collections import namedtuple
NamedTupleBook = namedtuple("NamedTupleBook", ["title", "author"])Если мы воспользуемся классом, созданным таким образом, мы получим фактически то же самое, что и использованием с data class.
>>> book = NamedTupleBook("Fahrenheit 451", "Bradbury")
>>> book.author
'Bradbury'
>>> book
NamedTupleBook(title='Fahrenheit 451', author='Bradbury')
>>> book == NamedTupleBook("Fahrenheit 451", "Bradbury"))
TrueНо несмотря на общую схожесть, именованные кортежи имеют свои ограничения. Они происходят из того, что именованные кортежи все ещё являются кортежами.
Во-первых, вы все ещё можете сравнивать экземпляры разных классов.
>>> Car = namedtuple("Car", ["model", "owner"])
>>> book = NamedTupleBook("Fahrenheit 451", "Bradbury"))
>>> book == Car("Fahrenheit 451", "Bradbury")
TrueВо-вторых, именованные кортежи неизменяемы. В некоторых ситуациях это бывает полезно, но хотелось бы большей гибкости.
В некоторых ситуациях это бывает полезно, но хотелось бы большей гибкости.
И наконец, вы можете оперировать именованным кортежем так же как обычным. Например, итерироваться.
Другие проекты
Если не ограничиваться стандартной библиотекой, можно найти другие решения данной задачи. В частности, проект attrs. Он умеет даже больше чем dataclass и работает на более старых версиях python таких как 2.7 и 3.4. И тем не менее, то, что он не является частью стандартной библиотеки, может быть неудобно
Создание
Для создания класса данных можно воспользоваться декоратором @dataclass. В этом случае, все поля класса, определенные с аннотацией типов будут использоваться в соответствующих методах результирующего класса.
В качестве альтернативы есть функция make_dataclass, которая работает аналогично созданию именованных кортежей.
from dataclasses import make_dataclass
Book = make_dataclass("Book", ["title", "author"])
book = Book("Fahrenheit 451", "Bradbury")Значения по умолчанию
Одна из полезных особенностей — легкость добавления к полям значений по умолчанию.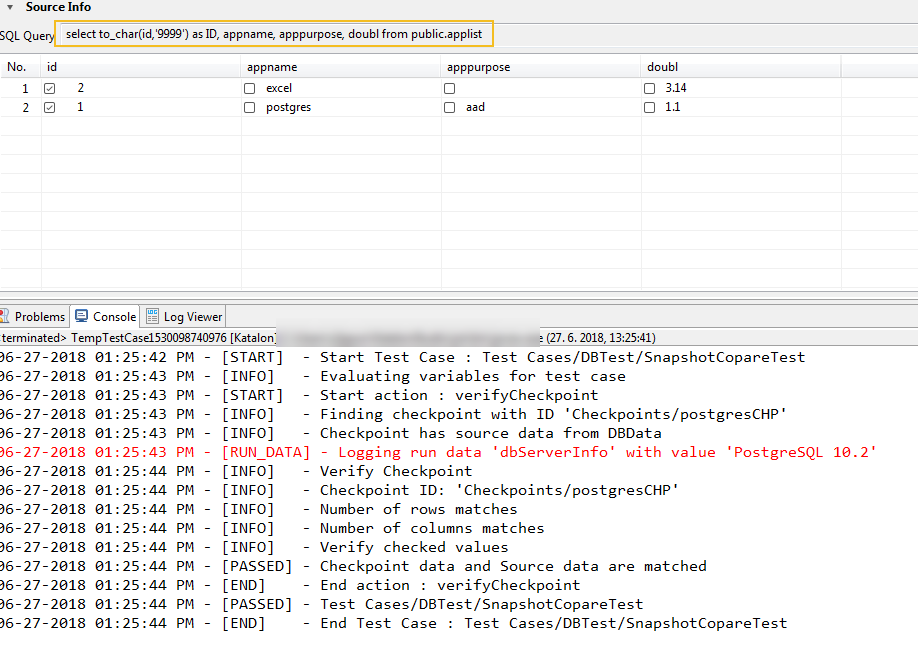 Все ещё не требуется переопределять метод
Все ещё не требуется переопределять метод __init__, достаточно указать значения прямо в классе.
@dataclass
class Book:
title: str = "Unknown"
author: str = "Unknown author"Они будут учтены в сгенерированном методе __init__
>>> Book()
Book(title='Unknown', author='Unknown author')
>>> Book("Farenheit 451")
Book(title='Farenheit 451', author='Unknown author')Но как и в случае с обычными классами и методами надо быть аккуратным с использованием изменяемых значений по умолчанию. Если вам, например, необходимо использовать список в качестве значения по умолчанию, есть другой способ, но об этом ниже.
Кроме того, важно следить за порядком определения полей, имеющих значения по умолчанию, так как он в точности соответствует их порядку в методе __init__
Иммутабельные классы данных
Экземпляры именованных кортежей неизменяемые. Во многих ситуациях, это хорошая идея. Для классов данных вы тоже можете сделать это. Просто укажите параметр
Просто укажите параметр frozen=True при создании класса и если вы попытаетесь изменять его поля, выбросится исключение FrozenInstanceError
@dataclass(frozen=True)
class Book:
title: str
author: str>>> book = Book("Fahrenheit 451", "Bradbury")
>>> book.title = "1984"
dataclasses.FrozenInstanceError: cannot assign to field 'title'Настройка класса данных
Кроме параметра frozen, декоратор @dataclass обладает другими параметрами:
init: если он равенTrue(по умолчанию), генерируется метод__init__. Если у класса уже определен метод__init__, параметр игнорируется.repr: включает (по умолчанию) создание метода__repr__. Сгенерированная строка содержит имя класса и название и представление всех полей, определенных в классе. При этом можно исключить отдельные поля (см. ниже)eq: включает (по умолчанию) создание метода__eq__. Объекты сравниваются так же, как если бы это были кортежи, содержащие соответствующие значения полей. Дополнительно проверяется совпадение типов.orderвключает (по умолчанию выключен) создание методов__lt__,__le__,__gt__и__ge__. Объекты сравниваются так же, как соответствующие кортежи из значений полей. При этом так же проверяется тип объектов. Еслиorderзадан, аeq— нет, будет сгенерировано исключениеValueError. Так же, класс не должен содержать уже определенных методов сравнения.unsafe_hashвлияет на генерацию метода__hash__. Поведение так же зависит от значений параметровeqиfrozen
 Объекты сравниваются так же, как если бы это были кортежи, содержащие соответствующие значения полей. Дополнительно проверяется совпадение типов.
Объекты сравниваются так же, как если бы это были кортежи, содержащие соответствующие значения полей. Дополнительно проверяется совпадение типов.
Настройка отдельных полей
В большинстве стандартных ситуаций это не потребуется, однако есть возможность настроить поведение класса данных вплоть до отдельных полей с использованием функции field.
Изменяемые значения по умолчанию
Типичная ситуация, о которой говорилось выше — использование списков или других изменяемых значений по умолчанию. Мы можете захотеть класс «книжная полка», содержащий список книг. Если вы запустите следующий код:
@dataclass
class Bookshelf:
books: List[Book] = []интерпретатор сообщит об ошибке:
ValueError: mutable default <class 'list'> for field books is not allowed: use default_factory
Однако для других изменяемых значений это предупреждение не сработает и приведет к некорректному поведению программы.
Чтобы избежать проблем, предлагается использовать параметр default_factory функции field. В качестве его значения может быть любой вызываемый объект или функция без параметров.
Корректная версия класса выглядит так:
@dataclass
class Bookshelf:
books: List[Book] = field(default_factory=list)Другие параметры
Кроме указанного default_factory функция field имеет следующие параметры:
default: значение по умолчанию. Этот параметр необходим, так как вызов fieldзаменяет задание значения поля по умолчаниюinit: включает (задан по умолчанию) использование поля в методе__init__repr: включает (задан по умолчанию) использование поля в методе__repr__compareвключает (задан по умолчанию) использование поля в методах сравнения (__eq__,__le__и других)hash: может быть булевое значение илиNone. Если он равенTrue, поле используется при вычислении хэша. Если указаноNone(по умолчанию) — используется значение параметраcompare.
Одной из причин указатьhash=Falseпри заданномcompare=Trueможет быть сложность вычисления хэша поля при том, что оно необходимо для сравнения.metadata: произвольный словарь илиNone. Значение оборачивается в MappingProxyType, чтобы оно стало неизменяемым. Этот параметр не используется самими классами данных и предназначено для работы сторонних расширений.
 Этот параметр необходим, так как вызов
Этот параметр необходим, так как вызов
 Значение оборачивается в
Значение оборачивается в
Обработка после инициализации
Автосгенерированный метод __init__ вызывает метод __post_init__, если он определен в классе. Как правило он вызывается в форме self.__post_init__(), однако если в классе определены переменные типа InitVar, они будут переданы в качестве параметров метода.
Если метод __init__ не был сгенерирован, то он __post_init__ не будет вызываться.
Например, добавим сгенерированное описание книги
@dataclass
class Book:
title: str
author: str
desc: str = None
def __post_init__(self):
self.desc = self.desc or "`%s` by %s" % (self.title, self.author)>>> Book("Fareneheit 481", "Bradbury")
Book(title='Fareneheit 481', author='Bradbury', desc='`Fareneheit 481` by Bradbury')Параметры только для инициализации
Одна из возможностей, связанных с методом __post_init__ — параметры, используемые только для инициализации. Если при объявления поля указать в качестве его типа
Если при объявления поля указать в качестве его типа InitVar, его значение будет передано как параметр метода __post_init__. Никак по-другому такие поля не используются в классе данных.
@dataclass
class Book:
title: str
author: str
gen_desc: InitVar[bool] = True
desc: str = None
def __post_init__(self, gen_desc: str):
if gen_desc and self.desc is None:
self.desc = "`%s` by %s" % (self.title, self.author)>>> Book("Fareneheit 481", "Bradbury")
Book(title='Fareneheit 481', author='Bradbury', desc='`Fareneheit 481` by Bradbury')
>>> Book("Fareneheit 481", "Bradbury", gen_desc=False)
Book(title='Fareneheit 481', author='Bradbury', desc=None)Наследование
Когда вы используете декоратор @dataclass, он проходит по всем родительским классам начиная с object и для каждого найденного класса данных сохраняет поля в упорядоченный словарь (ordered mapping), затем добавляя свойства обрабатываемого класса. Все сгенерированные методы используют поля из полученного упорядоченного словаря.
Все сгенерированные методы используют поля из полученного упорядоченного словаря.
Как следствие, если родительский класс определяет значения по умолчанию, вы должны будете поля определять со значениями по умолчанию.
Так как упорядоченный словарь хранит значения в порядке вставки, то для следующих классов
@dataclass
class BaseBook:
title: Any = None
author: str = None
@dataclass
class Book(BaseBook):
desc: str = None
title: str = "Unknown"будет сгенерирован __init__ метод с такой сигнатурой:
def __init__(self, title: str="Unknown", author: str=None, desc: str=None)
Сравнить две версии базы данных (Database Compare)
Access 2019 Access 2016 Access 2013 Database Compare 2013 Database Compare 2016 Database Compare 2019 Database Compare 2021 Больше…Меньше
Предположим, структура вашей настольной базы данных Microsoft Access изменилась (новые или измененные таблицы, запросы, свойства полей, формы или отчеты), и вы хотите просмотреть историю этих изменений. Вы можете использовать функцию сравнения баз данных, чтобы сравнить одну версию базы данных Access для настольных ПК с другой. Вы увидите различия, такие как новые или измененные таблицы, запросы, поля, свойства полей и т. д., в отчете служб отчетов SQL Server, который можно экспортировать в Excel или сохранить в формате PDF.
Вы можете использовать функцию сравнения баз данных, чтобы сравнить одну версию базы данных Access для настольных ПК с другой. Вы увидите различия, такие как новые или измененные таблицы, запросы, поля, свойства полей и т. д., в отчете служб отчетов SQL Server, который можно экспортировать в Excel или сохранить в формате PDF.
Примечание. Вы не можете использовать сравнение баз данных с веб-приложениями Access.
В этой статье
Сравните две базы данных Access
Создавайте резервные версии вашей базы данных
Вы получили сообщение об ошибке «Невозможно открыть базу данных Access»?
Вы получили сообщение об ошибке «Необработанное исключение»?
Примечание.
Ошибка возникает при выборе База данных Сравнить , если зависимости и предварительные требования не установлены.Сравните две базы данных Access
 Ошибка возникает при выборе База данных Сравнить , если зависимости и предварительные требования не установлены.
Ошибка возникает при выборе База данных Сравнить , если зависимости и предварительные требования не установлены.Открыть сравнение баз данных. Вы увидите простое диалоговое окно с двумя вкладками: Настройка и Результаты .
На вкладке Настройка рядом с полем Сравнить используйте кнопку Обзор , чтобы найти базу данных, которую вы хотите использовать в качестве «базовой» (или более ранней версии). Найдя нужный файл, выберите Открыть .
В разделе Параметры отчета выберите объекты базы данных (таблицы, запросы, макросы, модули, отчеты, формы или страницы), которые вы хотите сравнить, установив флажки рядом с ними.
В разделе Report Values выберите Full или Brief , чтобы указать, насколько подробными должны быть результаты.
Выберите Сравнить , чтобы запустить сравнение.
 org/ListItem»>
org/ListItem»>Рядом с полем – нажмите кнопку Обзор , чтобы найти «измененную» базу данных (или самую последнюю версию).
После завершения сравнения на экране откроется отчет служб отчетов SQL Server. Вы можете экспортировать этот отчет в Excel или сохранить отчет в формате PDF.
Вы можете экспортировать этот отчет в Excel или сохранить отчет в формате PDF.
Верх страницы
Создайте резервные версии вашей базы данных
Лучший способ отслеживать изменения структуры базы данных рабочего стола — сохранять одну или несколько версий резервной копии. Резервное копирование вашей базы данных — это другой процесс, чем просто сохранение копии.
Выберите Файл > Сохранить как .
В разделе Сохранить базу данных как > Дополнительно выберите Резервное копирование базы данных .
Ваша резервная копия сохраняется с годом, месяцем и датой, добавленными к имени файла. Если вы сохраняете несколько резервных копий в один и тот же день, после даты добавляется символ подчеркивания и число в круглых скобках. Несколько резервных копий базы данных с именем Inventory.accdb за один день (13 марта 2012 г.) могут выглядеть следующим образом:
Если вы сохраняете несколько резервных копий в один и тот же день, после даты добавляется символ подчеркивания и число в круглых скобках. Несколько резервных копий базы данных с именем Inventory.accdb за один день (13 марта 2012 г.) могут выглядеть следующим образом:
Инвентаризация _2012_03_13.accdb
Инвентаризация _2012_03_13_(1).accdb
Инвентаризация _2012_03_13_(2).accdb
Чтобы найти команду Backup Database в более ранних версиях Access:
В Access 2010 нажмите Файл > Сохранить и опубликовать > Дополнительно > Резервное копирование базы данных .
В Access 2007 нажмите кнопку Office > Управление > Резервное копирование базы данных .
В Access 2003 и более ранних версиях щелкните Файл > Резервное копирование базы данных .

Верх страницы
Вы получили сообщение об ошибке «Невозможно открыть базу данных Access»?
Если вы получаете сообщение об ошибке «Невозможно открыть базу данных Access», скорее всего, по крайней мере одна из настольных баз данных защищена паролем. Нажмите OK в диалоговом окне и введите пароль. В противном случае сравнение не может быть выполнено.
Дополнительные сведения о том, как хранить пароли в Database Compare, см. в разделе Управление паролями, используемыми для открытия файлов для сравнения.
в разделе Управление паролями, используемыми для открытия файлов для сравнения.
Верх страницы
Вы получили сообщение об ошибке «Необработанное исключение»?
Если вы получаете сообщение об ошибке «Необработанное исключение» при попытке использовать функцию сравнения баз данных, скорее всего, на вашем компьютере не установлены некоторые необходимые компоненты. Хотя средство сравнения баз данных включено в Access, некоторые предварительные компоненты, необходимые для правильной работы средства сравнения баз данных, не устанавливаются автоматически. Сделайте следующее:
Войдите на компьютер пользователя как администратор.
Загрузите и установите SQLSysClrTypes (64-разрядная версия) или SQLSysClrTypes (32-разрядная версия).
Загрузите и установите среду выполнения Microsoft Report Viewer 2015.
Перезагрузите компьютер пользователя.
 org/ListItem»>
org/ListItem»>Загрузите и установите Загрузите .NET Framework 4.0.
Верх страницы
О базе данных сравнения – База данных сравнения
The COM хватательный P rotein A llergen 9022 1 RE источник представляет собой базу данных, состоящую из белковых последовательностей известных аллергенов. COMPARE был создан на основе основного списка последовательностей, разработанного FARRP Allergen Online database v.16, в который ежегодно добавляются новые последовательности, идентифицированные в процессе COMPARE. Аллергены идентифицируются с помощью алгоритмов сортировки текста, основанных на правилах, которые сканируют общедоступные репозитории последовательностей и литературы. Независимая экспертная группа экспертов по аллергии из государственного сектора рассматривает последовательности-кандидаты из автоматизированного выбора и принимает окончательное решение по содержанию базы данных. Последовательность выбирают только в том случае, если для нее имеются литературные данные, подтверждающие связывание IgE. Эти строгие и хорошо задокументированные процессы были тщательно разработаны, чтобы соответствовать требованиям регулирующих органов по оценке безопасности аллергии.
COMPARE был создан на основе основного списка последовательностей, разработанного FARRP Allergen Online database v.16, в который ежегодно добавляются новые последовательности, идентифицированные в процессе COMPARE. Аллергены идентифицируются с помощью алгоритмов сортировки текста, основанных на правилах, которые сканируют общедоступные репозитории последовательностей и литературы. Независимая экспертная группа экспертов по аллергии из государственного сектора рассматривает последовательности-кандидаты из автоматизированного выбора и принимает окончательное решение по содержанию базы данных. Последовательность выбирают только в том случае, если для нее имеются литературные данные, подтверждающие связывание IgE. Эти строгие и хорошо задокументированные процессы были тщательно разработаны, чтобы соответствовать требованиям регулирующих органов по оценке безопасности аллергии.
COMPARE оснащен инструментом сравнительного поиска последовательностей под названием COMPASS (COMPare Analysis of Sequences with Software). Пользователи могут запросить в базе данных COMPARE свою целевую последовательность, чтобы произвести выравнивание аминокислотной последовательности с известными аллергенами. Инструмент ориентирован на нормативную проверку безопасности новых пищевых продуктов и кормов, а также на внедрение критериев, помогающих установить, имели ли место соответствующие согласования.
Пользователи могут запросить в базе данных COMPARE свою целевую последовательность, чтобы произвести выравнивание аминокислотной последовательности с известными аллергенами. Инструмент ориентирован на нормативную проверку безопасности новых пищевых продуктов и кормов, а также на внедрение критериев, помогающих установить, имели ли место соответствующие согласования.
Структура программы
Программа базы данных COMPARE является результатом совместной работы Комитета по белковым аллергенам, токсинам и биоинформатике HESI ( Институт наук о здоровье и окружающей среде, ) Белковые аллергены, токсины и биоинформатика ( PATB ) (ранее «Технический комитет по белковой аллергенности» или PATC 9025). 2 ) . PATB — это общественно-частное сотрудничество ученых, объединенных интересом к повышению достоверности оценки аллергенности в контексте оценки безопасности новых пищевых и кормовых белков.
Руководящая группа сочетает значительную поддержку в натуральной форме со стороны нескольких академических, государственных и отраслевых ученых с опытом в области аллергенности белков. Эта совместная группа HESI, состоящая из государственного и частного секторов, внесла свой вклад в разработку базы данных, решений по поисковым алгоритмам и документации на этом веб-сайте.
Эта совместная группа HESI, состоящая из государственного и частного секторов, внесла свой вклад в разработку базы данных, решений по поисковым алгоритмам и документации на этом веб-сайте.
Экспертная комиссия состоит из внешних экспертов из государственного сектора, которые ежегодно собираются для рассмотрения белковых последовательностей, идентифицированных с помощью автоматизированного отбора, и оценивают соответствующие рецензируемые публикации, чтобы определить, соответствуют ли кандидаты-аллергены критериям для включения в базу данных. Группа экспертов полностью прозрачно документирует вспомогательные данные для каждого проверенного аллергена каждого цикла PRP в файле прозрачности, доступ к которому можно получить на странице документации базы данных. Одобренные аллергены включены в базу данных COMPARE вместе со вспомогательной литературой, содержащей доказательства аллергенности. Полный процесс рецензирования и критерии включения задокументированы здесь: https://comparedatabase. org/process-development/
org/process-development/
Члены руководящей группы
- Лоран Бёф, Vilmorin & Cie
- Супратим Чоудхури, US FDA
- Ева Гитл, KWS
- Род Герман, Кортева
- Саураб Джоши, Syngenta
- Лийза Коски, HESI
- Эрик Ма, Syngenta
- Люсилия Муриес, HESI
- Клэр Наррод, Мэрилендский университет/JIFSAN
- Эсмеральда Посада Кампос, BASF
- Андре Сильванович, Байер
- Пинг Сонг, Corteva Agriscience™
- Рональд ван Ри, Академический медицинский центр Амстердамского университета
- Вибке Стригал, Агентство по охране окружающей среды США
- Гао Чжуншань, Чжэцзянский университет, Китай
Экспертная комиссия
- Габриэле Гадермайер, доктор философии, Парижско-Лондонский университет Зальцбурга, Австрия
- Карин Хоффман-Зоммергрубер, доктор медицинских наук, Венский медицинский университет, Австрия
- Ларс Поулсен, доктор философии, Университетская больница Копенгагена, Дания
- Сюзанна Тойбер, доктор медицинских наук, Калифорнийский университет, Дэвис
- Рональд ван Ри, доктор философии, Академический медицинский центр Амстердамского университета
Прошлый эксперт экспертной комиссии
- Сесилия Берин, доктор медицинских наук, Медицинская школа Икана на горе Синай, штат Нью-Йорк, США (для версий COMPARE 2017 и COMPARE 2018)
Бывшие члены руководящей группы
- Жан-Батист Раскл, Bayer
- Кевин Гленн, Monsanto
- Джон Вичини, Байер
- Ракеш Ранджан, BASF
- Грег Лэдикс, DuPont
- Скотт МакКлейн, Syngenta
- Кайл МакКиллоп, Мэрилендский университет / JIFSAN
- Афуа Тетте, БАСФ
- Генри Мирский, Corteva
- Пол Гевара, Мэрилендский университет / JIFSAN
- Эмир Исламович, BASF
- Джон Каф, Агентство по охране окружающей среды США
- Декстер Сапитер Баллерда, Мэрилендский университет / JIFSAN
- Джастин Макдональд, Syngenta
О HESI
HESI , Институт наук о здоровье и окружающей среде, является некоммерческой глобальной научной организацией, занимающейся развитием науки для более безопасного и устойчивого мира.