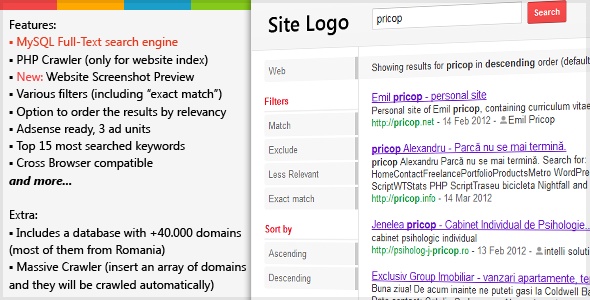
Full search text: Full-Text Search — SQL Server
Содержание
Microsoft SQL Server. Основы полнотекстового поиска (Full-Text Search)
Автор: Вячеслав
Не буду описывать, что такое полнотекстовый индекс, хотя немного можно цитатой из BOL:
“Полнотекстовые запросы выполняют лингвистический поиск в текстовых данных в полнотекстовых индексах путем обработки слов и фраз в соответствии с правилами данного языка, например английского или японского. Полнотекстовые запросы могут включать простые слова и фразы или несколько форм слова или фразы.”
Для работы полнотекстового поиска необходимо, чтобы работала служба MSSQLFDLauncher (fdhost.exe), которая необходима для фильтрации, разбиения по словам данных из таблиц.
В отличие, от MS SQL 2005, задачи которые выполнялись службой MSFTESQL , теперь выполняются процессом sql server.
Создание полнотекстового индекса выполняется по следующим шагам:
- Создание полнотекстового каталога
- Создание полнотекстового индекса
- Заполнение полнотекстового индекса
- Итак, создадим полнотекстовый каталог:
Его можно создать либо из графического интерфейса(БД->Storage ->Full Text Catalogs), либо командой t-sql:
Transact-SQL
CREATE FULLTEXT CATALOG [test_catalog]WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
AUTHORIZATION [dbo]
|
| CREATE FULLTEXT CATALOG [test_catalog]WITH ACCENT_SENSITIVITY = ON
AS DEFAULT
AUTHORIZATION [dbo] |
- Создание полнотекстового индекса:
Transact-SQL
CREATE FULLTEXT INDEX ON [Production]. [ProductDescription]
[ProductDescription]
(Description language 1033)KEY INDEX [AK_ProductDescription_rowguid] ON([test_catalog])
WITH (CHANGE_TRACKING MANUAL)
GO
|
1 2 3 4 5 6 7
| CREATE FULLTEXT INDEX ON [Production].[ProductDescription]
(Description language 1033)KEY INDEX [AK_ProductDescription_rowguid] ON([test_catalog])
WITH (CHANGE_TRACKING MANUAL)
GO |
Где Description language 1033 язык данных ключа уникального индексе AK_ProductDescription_rowguid , который будет проиндексирован. Список поддерживаемых языков для полнотекстового индексирования можно получить из представления sys.fulltext_languages.
CHANGE_TRACKING MANUAL –устанавливаем, что обновление индекса будет
Индекс создан, сами полнотекстовые индексы модно получить из представления sys.fulltext_indexes.
- После этого можно наш индекс заполнять данными.
При создание индекса, индекс заполняется автоматически, так же при создание мы указываем тип обновления индекса, в примере:
WITH (CHANGE_TRACKING MANUAL) – обновление вручную
Еще варианты AUTO и OFF.
Рекомендуется запускать настраивать индекс с параметром “Manual”, но если таблица, на которую настроен полнотекстовый индекс, обновляется мало, можно и “AUTO”. Дело в том , что обновление полнотекстового индекса происходит немного по другому, в отличие от кластерных \не кластерных индексов.
Заполнение индекса новыми данными или обновление информации , выполняется командой:
Transact-SQL
alter fulltext index on Production.ProductDescription START FULL POPULATION
|
| alter fulltext index on Production.ProductDescription START FULL POPULATION |
Запросы с полнотекстовым индексом:
Самый простой способ – это использование freetext и CONTAINS
Transact-SQL
select * from Production. ProductDescription
ProductDescription
where freetext(Description,’bike’)
go
select * from Production.ProductDescription
where CONTAINS (Description,’bike’)
|
1 2 3 4 5 6 7 8 9
| select * from Production.ProductDescription
where freetext(Description,’bike’)
go
select * from Production.ProductDescription
where CONTAINS (Description,’bike’) |
Разница, что например для второго запроса не выдадут результаты со словом , например, “bikes”.
Еще одно замечание, по умолчанию при создание индекса, если явно не указано, индекс сопоставляется с системным стоп-листом “system”, п о этому стоп-листу не будут находиться , например, числовые значение(раз, два и т.д.)
Указать стоп лист можно либо при создание полнотекстового индекса, либо если уже индекс командой:
Transact-SQL
alter fulltext index on Production.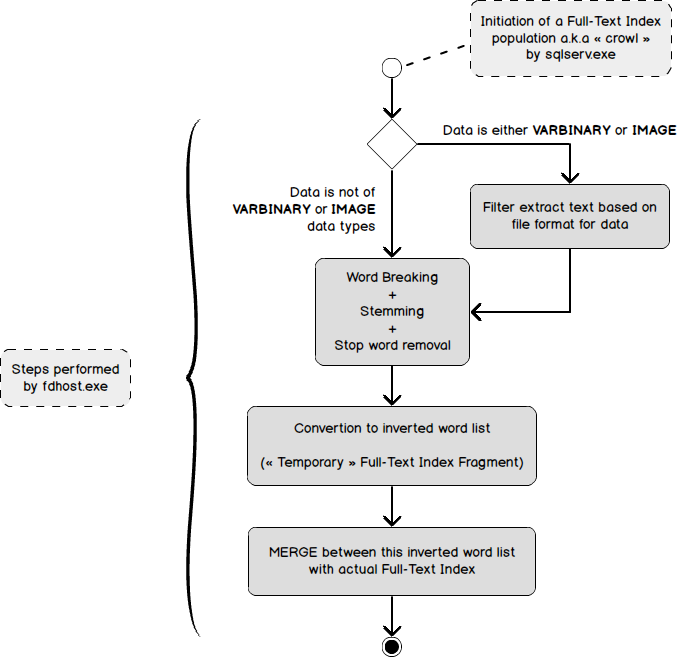 ProductDescription set stoplist=test_stlist
ProductDescription set stoplist=test_stlist
|
| alter fulltext index on Production.ProductDescription set stoplist=test_stlist |
Еще несколько примеров по запросам к полнотекстовым каталогам:
есть таблица со следующими данными:
id val
1 раз
2 Раз
3 Раз два
4 Раз, два
5 Разовый, два
6 Разовый, двоичный
7 тРи
8 раз два три четеры
9 Раз, два, три, четыре
10 Раз, два, три, четыре, пять
11 Первый второй третий
12 стоп
13 стоп два раза
14 стоппп
15 стоп — стоять
16 стоп снова
17 два, раз, ноль
18 два, раз
19 два, ноль, раз
1-й запрос к данной таблице:
Transact-SQL
SELECT
[id],[val]
FROM [test_db].[dbo].[tbl_rusful]
where CONTAINS(val,’Раз’)
|
| SELECT [id],[val] FROM [test_db].
where CONTAINS(val,’Раз’) |
 [dbo].[tbl_rusful]
[dbo].[tbl_rusful]Результат:
id val
1 раз
2 Раз
3 Раз два
4 Раз, два
8 раз два три четеры
9 Раз, два, три, четыре
10 Раз, два, три, четыре, пять
17 два, раз, ноль
18 два, раз
19 два, ноль, раз
2-ой запрос:
Transact-SQL
SELECT [id],[val]
FROM [test_db].[dbo].[tbl_rusful]
where CONTAINS(val,'»Раз» and «Два»‘)
|
| SELECT [id],[val]
FROM [test_db].[dbo].[tbl_rusful]
where CONTAINS(val,'»Раз» and «Два»‘) |
Результат:
id val
3 Раз два
4 Раз, два
8 раз два три четеры
9 Раз, два, три, четыре
10 Раз, два, три, четыре, пять
17 два, раз, ноль
18 два, раз
19 два, ноль, раз
3 -й запрос:
Transact-SQL
SELECT [id],[val]
FROM [test_db]. [dbo].[tbl_rusful]
[dbo].[tbl_rusful]
where CONTAINS(val,'»Раз*» near «Два»‘)
|
| SELECT [id],[val]
FROM [test_db].[dbo].[tbl_rusful]
where CONTAINS(val,'»Раз*» near «Два»‘) |
Результат:
id val
3 Раз два
4 Раз, два
5 Разовый, два
8 раз два три четеры
9 Раз, два, три, четыре
10 Раз, два, три, четыре, пять
13 стоп два раза
17 два, раз, ноль
18 два, раз
19 два, ноль, раз
По базовым параметрам службы полнотекстового поиска пока все.
P.S. Всё тестирование проводилось на SQL Server 2008
Запись опубликована в рубрике Полезно и интересно с метками full-text. Добавьте в закладки постоянную ссылку.
Full text searching — определение термина
метод поиска в текстовых материалах, в котором поисковые термины сопоставляются с содержанием всего текста.
Научные статьи на тему «Full text searching»
В статье рассматривается полнотекстовый поиск в MySQL для обнаружения похожих статей из поступающего новостного потока. В ходе работы была разработана система, которая периодически извлекает статьи с серверов средств массовой информации и позволяет осуществлять поиск похожих статей.
В ходе работы была разработана система, которая периодически извлекает статьи с серверов средств массовой информации и позволяет осуществлять поиск похожих статей.
Creative Commons
Научный журнал
On selection of content for modern TV news broadcasting N. Iskandarova Key words: News broadcasting, selection of news content, selfof public opinion, information occasion, efficiency The article gives a general idea on the methodology of selection of the content for news on federal channels. Thanks to the news the audience becomes knowledgeable for what is going in the world, thus рublic opinion is formed. The information produced allows not only to choose the occasion, but also actually to make news. The following is required for a qualitative news: [The news should be] brief/laconic, technological, operative, understandable, fresh, actual and urgent, important, full of content, verified for being true, objective, interesting, and standard. Besides operative work of news service, aimed at a maximal distribution of the news, the latter should be as more visitable and browsed (on the Internet) as possible. Therefore, a pricipally new approach to the text should be applied; the text …
Besides operative work of news service, aimed at a maximal distribution of the news, the latter should be as more visitable and browsed (on the Internet) as possible. Therefore, a pricipally new approach to the text should be applied; the text …
Creative Commons
Научный журнал
Еще термины по предмету «Информатика»
Алгоритм результативен
если его выполнение завершается определенными результатами.
Алгоритмизация процесса обучения
описание процесса на языке математических символов с целью составления алгоритма; это описание отображает элементарные акты процесса, их последовательность и взаимосвязь. Для осуществления алгоритмизации процесса обучения необходимо: 1) расчленить процесс обучения на элементарные акты, применительно к которым можно дать математическое описание; 2) выявить соотношения, описывающие элементарные акты процесса обучения, которые объединяются в систему; 3) описать взаимосвязь между этими актами.
Двоичные данные
[binary data] — данные, представленные в двоичном коде.
Boolean searching
Full pallet
Full House
RTF (Rich Text Format)
TREC (Text Retrieval Conferences)
Text editor ( Текстовый редактор )
Full Board (F&B)
Выпрямитель двухполупериодный (Full-wave rectifier)
Полное внешнее соединение (full outer join)
Полностью управляемая схема (Full controllable connection)
Абстрактная информационно-поисковая система
Абстракция
Адаптер
Аналоговое представление
Аппаратные средства
Визуальная модальность
Двоичные данные
Сведения, факты, данные
Тезаурус
Windows
Смотреть больше терминов
Повышай знания с онлайн-тренажером от Автор24!
- Напиши термин
- Выбери определение из предложенных или загрузи свое
- Тренажер от Автор24 поможет тебе выучить термины с помощью удобных и приятных
карточек
Возможность создать свои термины в разработке
Еще чуть-чуть и ты сможешь писать определения на платформе Автор24.
Укажи почту и мы пришлем уведомление с обновлением ☺️
Включи камеру на своем телефоне и наведи на Qr-код.
Кампус Хаб бот откроется на устройстве
Привет! Рады, что термин оказался полезен 🤩
Для копирования текста подпишись на Telegram bot.
Удобный поиск по учебным материалам в твоем телефоне
Подписаться и скачать
термин
Включи камеру на своем телефоне и наведи на Qr-код.
Кампус Хаб бот откроется на устройстве
Привет! Рады, что термин оказался полезен 🤩
Подписчики нашего Кампус Хаб бота получают
определение
прямо в телеграмм!
Просто перейди по ссылке ниже
Скачать
термин
Включи камеру на своем телефоне и наведи на Qr-код.
Кампус Хаб бот откроется на устройстве
Обновление полнотекстового поиска — SQL Server
- Статья
Применяется к: SQL Server Azure SQL Database
SQL Server обновляет полнотекстовый поиск во время установки или при присоединении, восстановлении или копировании файлов базы данных и полнотекстовых каталогов из более ранней версии SQL Server.
Обновление экземпляра сервера
При обновлении на месте экземпляр SQL Server устанавливается рядом со старой версией SQL Server, и данные переносятся. Если в старой версии SQL Server был установлен полнотекстовый поиск, автоматически устанавливается новая версия полнотекстового поиска. Параллельная установка означает, что каждый из следующих компонентов существует на уровне экземпляра SQL Server.
Средства разбиения слов, парадигматические модули и фильтры
Каждый экземпляр теперь использует свой собственный набор средств разбиения слов, парадигматических модулей и фильтров, а не зависит от версии этих компонентов операционной системы. Эти компоненты также проще зарегистрировать и настроить на уровне экземпляра. Дополнительные сведения см. в разделах Настройка и управление средствами разбиения слов и стеммеров для поиска и Настройка фильтров для поиска и управление ими.
Хост демона фильтрации
Хосты демона полнотекстовой фильтрации — это процессы, которые безопасно загружают и управляют расширяемыми внешними компонентами, используемыми для индексирования и запросов, такими как средства разбиения слов, парадигматические модули и фильтры, без нарушения целостности полнотекстового механизма. Экземпляр сервера использует многопоточный процесс для всех многопоточных фильтров и однопоточный процесс для всех однопоточных фильтров.
Примечание
В SQL Server 2008 (10. 0.x) появилась учетная запись службы для службы запуска FDHOST (MSSQLFDLauncher). Эта служба распространяет информацию об учетной записи службы на хост-процессы демона фильтрации определенного экземпляра SQL Server. Сведения о настройке учетной записи службы см. в разделе Установка учетной записи службы для средства запуска демона полнотекстовой фильтрации.
0.x) появилась учетная запись службы для службы запуска FDHOST (MSSQLFDLauncher). Эта служба распространяет информацию об учетной записи службы на хост-процессы демона фильтрации определенного экземпляра SQL Server. Сведения о настройке учетной записи службы см. в разделе Установка учетной записи службы для средства запуска демона полнотекстовой фильтрации.
В SQL Server 2005 (9.x) каждый полнотекстовый индекс находится в полнотекстовом каталоге, принадлежащем файловой группе, имеет физический путь и рассматривается как файл базы данных. В SQL Server 2008 (10.0.x) и более поздних версиях полнотекстовый каталог — это логический или виртуальный объект, содержащий группу полнотекстовых индексов. Поэтому новый полнотекстовый каталог не рассматривается как файл базы данных с физическим путем. Однако при обновлении любого полнотекстового каталога, содержащего файлы данных, на том же диске создается новая файловая группа. Это сохраняет старое поведение дискового ввода-вывода после обновления. Любой полнотекстовый индекс из этого каталога помещается в новую файловую группу, если существует корневой путь. Если старый путь к полнотекстовому каталогу недействителен, обновление сохраняет полнотекстовый индекс в той же файловой группе, что и базовая таблица, или, для многораздельной таблицы, в первичной файловой группе.
Любой полнотекстовый индекс из этого каталога помещается в новую файловую группу, если существует корневой путь. Если старый путь к полнотекстовому каталогу недействителен, обновление сохраняет полнотекстовый индекс в той же файловой группе, что и базовая таблица, или, для многораздельной таблицы, в первичной файловой группе.
Варианты полнотекстового обновления
При обновлении экземпляра SQL Server пользовательский интерфейс позволяет выбрать один из следующих вариантов полнотекстового обновления.
Импорт
Импортируются полнотекстовые каталоги. Как правило, импорт выполняется значительно быстрее, чем перестроение. Например, при использовании только одного ЦП импорт выполняется примерно в 10 раз быстрее, чем перестроение. Однако импортированный полнотекстовый каталог не использует новые средства разбиения слов, установленные в последней версии SQL Server. Чтобы обеспечить согласованность результатов запроса, необходимо перестроить полнотекстовые каталоги.
Примечание
Перестроение может выполняться в многопоточном режиме, и если доступно более 10 ЦП, перестроение может выполняться быстрее, чем импорт, если разрешить перестроение использовать все ЦП.
Если полнотекстовый каталог недоступен, соответствующие полнотекстовые индексы перестраиваются. Этот параметр доступен только для баз данных SQL Server 2005 (9.x).
Сведения о влиянии импорта полнотекстового индекса см. в разделе «Соображения по выбору варианта полнотекстового обновления» далее в этом разделе.
Восстановить
Полнотекстовые каталоги перестроены с использованием новых и усовершенствованных средств разбиения по словам. Перестроение индексов может занять некоторое время, и после обновления может потребоваться значительный объем ЦП и памяти.
Сброс
Полнотекстовые каталоги сбрасываются. При обновлении с SQL Server 2005 (9.x) файлы полнотекстовых каталогов удаляются, но метаданные для полнотекстовых каталогов и полнотекстовых индексов сохраняются. После обновления все полнотекстовые индексы отключаются для отслеживания изменений, а сканирование не запускается автоматически. Каталог останется пустым до тех пор, пока вы не заполните его вручную после завершения обновления.
После обновления все полнотекстовые индексы отключаются для отслеживания изменений, а сканирование не запускается автоматически. Каталог останется пустым до тех пор, пока вы не заполните его вручную после завершения обновления.
Рекомендации по выбору варианта полнотекстового обновления
При выборе варианта обновления для вашего обновления учитывайте следующее:
Требуется ли согласованность результатов запроса?
SQL Server устанавливает новые средства разбиения слов для использования полнотекстовым и семантическим поиском. Разбиители слов используются как во время индексации, так и во время запроса. Если вы не перестроите полнотекстовые каталоги, результаты поиска могут быть противоречивыми. Если вы выполняете полнотекстовый запрос, который ищет фразу, которая разбивается по-разному с помощью средства разбиения по словам в предыдущей версии SQL Server и текущей версии средства разбиения по словам, документ или строка, содержащая фразу, могут быть не получены.
 Это связано с тем, что проиндексированные фразы были разбиты с использованием другой логики, чем использует запрос. Решение состоит в повторном заполнении (перестроении) полнотекстовых каталогов новыми средствами разбиения по словам, чтобы поведение времени индексирования и времени запроса было идентичным. Для этого можно выбрать параметр «Перестроить» или выполнить перестроение вручную после выбора параметра «Импорт».
Это связано с тем, что проиндексированные фразы были разбиты с использованием другой логики, чем использует запрос. Решение состоит в повторном заполнении (перестроении) полнотекстовых каталогов новыми средствами разбиения по словам, чтобы поведение времени индексирования и времени запроса было идентичным. Для этого можно выбрать параметр «Перестроить» или выполнить перестроение вручную после выбора параметра «Импорт».Были ли полнотекстовые индексы построены на столбцах целочисленных полнотекстовых ключей?
При перестроении выполняется внутренняя оптимизация, которая в некоторых случаях повышает производительность запросов обновленного полнотекстового индекса. В частности, если у вас есть полнотекстовые каталоги, содержащие полнотекстовые индексы, для которых столбец полнотекстового ключа базовой таблицы является целочисленным типом данных, перестроение обеспечивает идеальную производительность полнотекстовых запросов после обновления. В этом случае мы настоятельно рекомендуем вам использовать Перестроить вариант .
Примечание
Для полнотекстовых индексов рекомендуется, чтобы столбец, служащий полнотекстовым ключом, имел целочисленный тип данных. Дополнительные сведения см. в разделе Повышение производительности полнотекстовых индексов.
Каков приоритет подключения вашего экземпляра сервера к сети?
Импорт или перестроение во время обновления требуют много ресурсов ЦП, что задерживает обновление остальной части экземпляра сервера и подключение к сети. Если важно как можно скорее перевести экземпляр сервера в оперативный режим и если вы хотите запустить ручное заполнение после обновления, Сброс подходит.
 Это связано с тем, что проиндексированные фразы были разбиты с использованием другой логики, чем использует запрос. Решение состоит в повторном заполнении (перестроении) полнотекстовых каталогов новыми средствами разбиения по словам, чтобы поведение времени индексирования и времени запроса было идентичным. Для этого можно выбрать параметр «Перестроить» или выполнить перестроение вручную после выбора параметра «Импорт».
Это связано с тем, что проиндексированные фразы были разбиты с использованием другой логики, чем использует запрос. Решение состоит в повторном заполнении (перестроении) полнотекстовых каталогов новыми средствами разбиения по словам, чтобы поведение времени индексирования и времени запроса было идентичным. Для этого можно выбрать параметр «Перестроить» или выполнить перестроение вручную после выбора параметра «Импорт».
Обеспечение согласованности результатов запроса после импорта полнотекстового индекса
Если полнотекстовый каталог был импортирован при обновлении базы данных SQL Server 2005 (9.x), несоответствия между запросом и содержимым полнотекстового индекса могут возникнуть из-за различий в поведении старых и новых средств разбиения слов. В этом случае, чтобы гарантировать полное соответствие между запросами и содержимым полнотекстового индекса, выберите один из следующих вариантов:
В этом случае, чтобы гарантировать полное соответствие между запросами и содержимым полнотекстового индекса, выберите один из следующих вариантов:
Перестроить полнотекстовый каталог, содержащий полнотекстовый индекс (ALTER FULLTEXT CATALOG имя_каталога REBUILD)
Выдать ПОЛНОЕ НАПОЛНЕНИЕ для полнотекстового индекса (ИЗМЕНИТЬ ПОЛНОТЕКСТНЫЙ ИНДЕКС НА имя_таблицы НАЧАТЬ ПОЛНОЕ НАПОЛНЕНИЕ).
Дополнительные сведения о средствах разбиения слов см. в разделе Настройка и управление средствами разбиения слов и Stemmers для поиска.
Обновление файлов пропускаемых слов до списков стоп-слов
При обновлении базы данных с SQL Server 2005 (9.x), файлы шумовых слов больше не используются. Однако старые файлы пропускаемых слов хранятся в папке FTDATA\FTNoiseThesaurusBak , и их можно использовать позже при обновлении или построении соответствующих списков стоп-слов SQL Server.
После обновления с SQL Server 2005 (9. x):
x):
Если вы никогда не добавляли, не изменяли и не удаляли файлы с пропускаемыми словами при установке SQL Server 2005 (9.x), системный стоп-лист должен соответствовать твои нужды.
Если ваши файлы пропускаемых слов были изменены в SQL Server 2005 (9.x), эти изменения будут потеряны при обновлении. Чтобы воссоздать эти обновления, вы должны вручную воссоздать эти изменения в соответствующем стоп-листе. Дополнительные сведения см. в разделе ALTER FULLTEXT STOPLIST (Transact-SQL).
Если вы не хотите применять какие-либо стоп-слова к вашим полнотекстовым индексам (например, если вы удалили или стерли файлы с пропускаемыми словами в своей установке SQL Server 2005 (9.x)), вы должны отключить стоп-лист для каждого обновленного полнотекстового индекса. Выполните следующую инструкцию Transact-SQL (заменив база данных с именем обновленной базы данных и таблица с именем таблицы ):
Использовать базу данных; ИЗМЕНИТЬ ПОЛНОТЕКСТОВЫЙ ИНДЕКС В таблице ВЫКЛЮЧИТЬ СТОП-СПИСОК; ИДТИ
Предложение STOPLIST OFF удаляет фильтрацию стоп-слов и инициирует заполнение таблицы без фильтрации слов, считающихся шумом.

Резервное копирование и импортирование полнотекстовых каталогов
Для полнотекстовых каталогов, которые перестраиваются или сбрасываются во время обновления (и для новых полнотекстовых каталогов), полнотекстовый каталог представляет собой логическую концепцию и не находится в файловой группе. Поэтому для резервного копирования полнотекстового каталога необходимо определить каждую файловую группу, содержащую полнотекстовый индекс каталога, и выполнить резервное копирование каждой из них по очереди. Дополнительные сведения см. в разделе Резервное копирование и восстановление полнотекстовых каталогов и индексов.
Для полнотекстовых каталогов, импортированных из SQL Server 2005 (9.x), полнотекстовый каталог по-прежнему является файлом базы данных в собственной файловой группе. Процесс резервного копирования SQL Server 2005 (9.x) для полнотекстовых каталогов по-прежнему применяется, за исключением того, что служба MSFTESQL не существует в SQL Server. Сведения о процессе SQL Server 2005 (9. x) см. в разделе Резервное копирование и восстановление полнотекстовых каталогов в электронной документации по SQL Server 2005.
x) см. в разделе Резервное копирование и восстановление полнотекстовых каталогов в электронной документации по SQL Server 2005.
Миграция полнотекстовых индексов при обновлении базы данных
Файлы базы данных и полнотекстовые каталоги из предыдущей версии SQL Server можно обновить до существующего экземпляра с помощью подключения, восстановления или мастера копирования базы данных. Полнотекстовые индексы SQL Server 2005 (9.x), если таковые имеются, либо импортируются, либо сбрасываются, либо перестраиваются. Свойство сервера upgrade_option определяет, какую опцию полнотекстового обновления использует экземпляр сервера во время этих обновлений базы данных.
После присоединения, восстановления или копирования любой базы данных SQL Server 2005 (9.x) в более новый экземпляр база данных становится доступной немедленно, а затем автоматически обновляется. В зависимости от объема индексируемых данных импорт может занять несколько часов, а восстановление может занять до десяти раз больше времени. Обратите также внимание на то, что если параметр обновления установлен на импорт, если полнотекстовый каталог недоступен, соответствующие полнотекстовые индексы перестраиваются.
Обратите также внимание на то, что если параметр обновления установлен на импорт, если полнотекстовый каталог недоступен, соответствующие полнотекстовые индексы перестраиваются.
Чтобы изменить поведение полнотекстового обновления на экземпляре сервера
Transact-SQL: используйте действие upgrade_option процедуры sp_fulltext_service
SQL Server Management Studio : Используйте параметр полнотекстового обновления диалогового окна Свойства сервера . Дополнительные сведения см. в разделе Управление и мониторинг полнотекстового поиска для экземпляра сервера.
Рекомендации по восстановлению SQL Server 2005 (9.x) Полнотекстовый каталог
Одним из способов обновления полнотекстовых данных из базы данных SQL Server 2005 (9.x) является восстановление полной резервной копии базы данных на более новый экземпляр SQL Server.
При импорте полнотекстового каталога SQL Server 2005 (9. x) можно создать резервную копию и восстановить базу данных и файл каталога. Поведение такое же, как и в SQL Server 2005 (9.x):
x) можно создать резервную копию и восстановить базу данных и файл каталога. Поведение такое же, как и в SQL Server 2005 (9.x):
Полная резервная копия базы данных будет включать полнотекстовый каталог. Для обращения к полнотекстовому каталогу используйте его SQL Server 2005 (9.x) имя файла, sysft_+ имя-каталога .
Если полнотекстовый каталог отключен, резервное копирование завершится ошибкой.
Дополнительные сведения о резервном копировании и восстановлении полнотекстовых каталогов SQL Server 2005 (9.x) см. в разделах Резервное копирование и восстановление полнотекстовых каталогов и Резервное копирование и восстановление файлов и полнотекстовых каталогов в SQL Server 2005 (9.x) Книги онлайн.
При восстановлении базы данных на новом экземпляре SQL Server будет создан новый файл базы данных для полнотекстового каталога. Имя этого файла по умолчанию — ftrow_ 9.0100 каталожное имя .ndf. Например, если имя-каталога равно cat1 , имя файла базы данных SQL Server по умолчанию будет ftrow_cat1. . Но если имя по умолчанию уже используется в целевом каталоге, новый файл базы данных будет называться  ndf
ndf ftrow_ имя-каталога { GUID }.ndf , где GUID — это глобальный уникальный идентификатор. фильтр нового файла.
После импорта каталогов sys.database_files и sys.master_file s обновлены для удаления записей каталога, а столбец path в sys.fulltext_catalogs имеет значение NULL.
Для резервного копирования базы данных
Полное резервное копирование базы данных (SQL Server)
Резервные копии журнала транзакций (SQL Server) (только модель полного восстановления)
Для восстановления резервной копии базы данных
Полное восстановление базы данных (простая модель восстановления)
Полное восстановление базы данных (модель полного восстановления)
Пример
В следующем примере используется предложение MOVE в инструкции RESTORE для восстановления базы данных SQL Server 2005 (9. x) с именем
x) с именем ftdb1 . Файлы базы данных, журнала и каталога SQL Server 2005 (9.x) перемещаются в новые места на экземпляре сервера SQL Server следующим образом:
Файл базы данных
ftdb1.mdfперемещается вC :\Program Files\Microsoft SQL Server\MSSQL.1MSSQL13.MSSQLSERVER\MSSQL\DATA\ftdb1.mdf.Файл журнала,
ftdb1_log.ldf, перемещается в каталог журнала на вашем дисковом дисков, log_drive: \log_directory\ ftdb1_log.ldf.Файлы каталога, соответствующие каталогу
sysft_cat90, перемещены вC:\temp. После импорта полнотекстовых индексов они будут автоматически помещены в файл базы данных C:\ftrow_sysft_cat90.ndf, а C:\temp будет удален.
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [ftdb1] С ДИСКА = N'C:\temp\ftdb1.bak' С ФАЙЛОМ = 1, ПЕРЕМЕСТИТЕ N'ftdb1' В N'C:\Program Files\Microsoft SQL Server\MSSQL12.
 MSSQLSERVER\MSSQL\DATA\ftdb1.mdf',
ПЕРЕМЕСТИТЕ N'ftdb1_log' НА N'log_drive:\log_directory\ftdb1_log.ldf',
ПЕРЕМЕСТИТЕ N'sysft_cat90' В N'C:\temp';
MSSQLSERVER\MSSQL\DATA\ftdb1.mdf',
ПЕРЕМЕСТИТЕ N'ftdb1_log' НА N'log_drive:\log_directory\ftdb1_log.ldf',
ПЕРЕМЕСТИТЕ N'sysft_cat90' В N'C:\temp';
Присоединение базы данных SQL Server 2005
В SQL Server 2008 (10.0.x) и более поздних версиях полнотекстовый каталог — это логическое понятие, относящееся к группе полнотекстовых индексов. Полнотекстовый каталог — это виртуальный объект, не принадлежащий ни к одной файловой группе. Однако при подключении SQL Server 2005 (9.x), которая содержит файлы полнотекстового каталога, на более новый экземпляр сервера SQL Server, файлы каталога присоединяются из своего предыдущего местоположения вместе с другими файлами базы данных, как и в SQL Server 2005 (9.x).
Состояние каждого присоединенного полнотекстового каталога на SQL Server такое же, как и при отсоединении базы данных от SQL Server 2005 (9.x). Если какое-либо заполнение полнотекстового индекса было приостановлено операцией отсоединения, заполнение возобновляется на SQL Server, и полнотекстовый индекс становится доступным для полнотекстового поиска.
Если SQL Server не может найти файл полнотекстового каталога или если полнотекстовый файл был перемещен во время операции присоединения без указания нового местоположения, поведение зависит от выбранного параметра полнотекстового обновления. Если опция полнотекстового обновления — Import или Rebuild , прикрепленный полнотекстовый каталог перестраивается. Если для параметра полнотекстового обновления задано значение Сбросить , приложенный полнотекстовый каталог сбрасывается.
Дополнительные сведения об отсоединении и присоединении базы данных см. в разделах Отсоединение и присоединение базы данных (SQL Server), CREATE DATABASE (SQL Server Transact-SQL), sp_attach_db и sp_detach_db (Transact-SQL).
См. также
Начало работы с полнотекстовым поиском
Настройка и управление средствами разбиения слов и стеммеров для поиска
Настройка и управление фильтрами для поиска
Объяснение полнотекстового поиска
Джош Грэм
• 4 мин чтения
Поиск в Интернете произвел революцию в том, как мы пользуемся Интернетом. Google может выполнять поиск по всему Интернету и предоставлять отличные возможности пользователям, которые пытаются найти контент. Почему же тогда поиск отсутствует или не оптимален во многих приложениях, которые мы используем сегодня? У большинства приложений гораздо меньше данных для поиска, чем у Google, но они обычно плохо справляются со своей задачей. В этой статье вы познакомитесь с «Полнотекстовым поиском» — мощным способом индексации данных, который может значительно улучшить взаимодействие с пользователем в приложениях.
Механизм полнотекстового поиска — это механизм извлечения данных, оптимизированный для эффективного поиска данных, когда пользователь знает только часть искомых данных.
Примечание
Эта статья предназначена для тех, кто только начинает осваивать полнотекстовый поиск. Я не намерен в совершенстве описывать каждую деталь полнотекстового поиска, а дать достаточно простое объяснение его внутренностей, чтобы новички могли иметь концептуальную модель того, как работает поиск, а не относиться к нему как к черному ящику.
Изображение предоставлено: brewbooks
Если ваше приложение было книгой
Чтобы лучше понять полнотекстовый поиск, полезно провести аналогию. Представьте, что ваше приложение — это книга. Механизмом базы данных будет оглавление. заказанный список того, на какой странице находится некоторый идентифицируемый контент. Например, если вы хотите найти главу 7, оглавление — очень эффективный способ найти ее. Вы просто смотрите в оглавление, переходите прямо к номеру 7 и находите нужный контент.
Теперь представьте, что вы хотите вспомнить прекрасную цитату, которую вы прочитали в книге. Вы не знаете, в какой главе она находится, вы только помните, что в ней было слово «лиса». Оглавление бесполезно для вас, потому что оно содержит только номера глав и заголовки. Итак, вы застряли, просматривая всю книгу, чтобы найти цитату. Если не указано , у вашей книги есть индекс.
Книжный указатель — это упорядоченный список слов, встречающихся в книге. Каждая запись в указателе будет содержать список номеров страниц, на которых встречается это слово. Это позволяет читателю быстро найти любую информацию в книге, относящуюся, например, к слову «лиса».
Каждая запись в указателе будет содержать список номеров страниц, на которых встречается это слово. Это позволяет читателю быстро найти любую информацию в книге, относящуюся, например, к слову «лиса».
Пример
Итак, чтобы объяснить полнотекстовый поиск с точки зрения вычислений, а не публикации. Представьте, что у вас есть следующие данные в хранилище данных документа:
[
{
"идентификатор": 1,
"имя": "Джон Смит",
"description": "Архитектор, Семья"
},
{
"идентификатор": 2,
"name": "Фрэнк Джонс",
"description": "Семья, Баскетбол"
},
{
"идентификатор": 3,
"name": "Джон Фрэнк Уитакер",
"description": "Баскетбол, Архитектор"
},
]
Если вы хотите найти информацию в записи с идентификатором 2, то любой механизм базы данных может эффективно получить эту запись для вас, потому что у них будет индекс, который выглядит примерно так:
1 => [Расположение на диске: 987654] 2 => [Расположение на диске: 549877] 3 => [Расположение на диске: 654722]
Однако, если вам нужно найти все записи, содержащие слово «Джон», механизм базы данных не будет эффективен при выполнении этого запроса, поскольку ему придется сканировать каждую запись, просматривая все поле имени и все описание . ищет слово «Джон». Поле
Поле
С другой стороны, индекс полнотекстового поиска будет выглядеть примерно так:
«Архитектор» 1 => [Расположение на диске: 987654] 3 => [Расположение на диске: 654722] "Баскетбол" 2 => [Расположение на диске: 549877] 3 => [Расположение на диске: 654722] "Семья" 1 => [Расположение на диске: 987654] 2 => [Расположение на диске: 549877] "Откровенный" 2 => [Расположение на диске: 549877] 3 => [Расположение на диске: 654722] "Джон" 1 => [Расположение на диске: 987654] 3 => [Расположение на диске: 654722] "Джонс" 2 => [Расположение на диске: 549877] "Смит" 1 => [Место на диске: 987654] "Уитакер" 3 => [Расположение на диске: 654722]
Здесь вы можете быстро увидеть, что записи 1 и 3 содержат текст «Джон», и вы можете эффективно загрузить эти записи с диска.
Подсчет очков
Движок только что искал «Джон» и получил две записи. Он вернет оба вызывающему абоненту, а также присвоит баллов каждой записи. Оценка показывает, насколько запись была близка к искомому тексту по сравнению с другими записями в наборе результатов. В нашем примере запись 1 «Джон Смит» может иметь более высокий балл, чем запись 3 «Джон Фрэнк Уитакер», потому что в записи «Джон Фрэнк Уитакер» больше текста, не совпадающего с «Джон», чем в «Джон Смит».
Оценка показывает, насколько запись была близка к искомому тексту по сравнению с другими записями в наборе результатов. В нашем примере запись 1 «Джон Смит» может иметь более высокий балл, чем запись 3 «Джон Фрэнк Уитакер», потому что в записи «Джон Фрэнк Уитакер» больше текста, не совпадающего с «Джон», чем в «Джон Смит».
Токены
Как видите, во время индексации (время построения индекса полнотекстового поиска) движок разбил строковые поля на границах слов. Полученные подстроки называются токенами . Токены — это то, что движок будет использовать для поиска результатов. В нашем примере строки были размечены на границах слов, но можно размечать и другими способами.
Токенизаторы
NGram можно использовать для дальнейшего разделения слов. Это часто бывает полезно при выполнении сценариев «поиск по мере ввода» или автозаполнения. Пример токенизации ngram будет таким:
"Фрэнк" => [ «ф», «фр», «фра», «фран», «откровенный», «р», «ра», «ран», «чин», «а», «ан», «анк», "н", "нк", "к" ]
Как вы можете догадаться, это увеличит размер поискового индекса, но позволит пользователю получить в результате «Фрэнк», набрав, например, только «fr».