Group by sql примеры: Команда ORDER BY — сортировка записей
Содержание
Команда ORDER BY — сортировка записей
Команда ORDER BY позволяет сортировать записи по определенному полю
при выборе из базы данных.
См. также команду LIMIT,
которая ограничивает количество выбираемых записей.
Синтаксис
Сортировка по одному полю:
SELECT * FROM имя_таблицы WHERE условие ORDER BY поле_для_сортировки
Можно сортировать не по одному, а по многим полям сразу:
SELECT * FROM имя_таблицы WHERE условие ORDER BY поле1, поле2...
По умолчанию записи сортируются по возрастанию,
чтобы отсортировать по убыванию — поставьте DESC:
SELECT * FROM имя_таблицы WHERE условие ORDER BY поле DESC
По умолчанию будет сортировка, будто поставлено ASC:
SELECT * FROM имя_таблицы WHERE условие ORDER BY поле ASC
Условие WHERE не обязательно —
если его не поставить, будут выбраны все записи:
SELECT * FROM имя_таблицы ORDER BY поле
Примеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
Пример
Давайте получим все записи из таблицы и отсортируем
их по возрастанию возраста:
SELECT * FROM workers WHERE id>0 ORDER BY age
SQL запрос выберет строки в следующем порядке:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 3 | Вася | 23 | 500 |
| 2 | Петя | 25 | 500 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
| 4 | Коля | 30 | 1000 |
Так как выбираются все записи, то блок WHERE можно не указывать:
SELECT * FROM workers ORDER BY age
Можно также указать тип сортировки в явном виде — ASC —
результат от этого не изменится:
SELECT * FROM workers ORDER BY age ASC
Пример
Давайте теперь отсортируем
записи по убыванию возраста:
SELECT * FROM workers ORDER BY age DESC
SQL запрос выберет строки в следующем порядке:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 4 | Коля | 30 | 1000 |
| 6 | Кирилл | 28 | 1000 |
| 5 | Иван | 27 | 500 |
| 2 | Петя | 25 | 500 |
| 1 | Дима | 23 | 400 |
| 3 | Вася | 23 | 500 |
Пример
Давайте теперь отсортируем записи
одновременно по возрастанию возраста и по убыванию зарплаты.
При этом записи сначала будут сортироваться по возрасту,
а те записи, в которых возраст одинаковый (в нашем случае — 23),
будут располагаться по убыванию зарплаты:
SELECT * FROM workers WHERE id>0 ORDER BY age ASC, salary DESC
SQL запрос выберет строки в следующем порядке:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 3 | Вася | 23 | 500 |
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
| 4 | Коля | 30 | 1000 |
Пример
Давайте при тех же условиях (т.е. сначала сортировка по возрасту) отсортируем по возрастанию зарплаты.
Теперь первая и вторая запись поменяются местами так, чтобы сначала
шла меньшая зарплата, а потом — большая:
SELECT * FROM workers WHERE id>0 ORDER BY age ASC, salary DESC
SQL запрос выберет строки в следующем порядке:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 3 | Вася | 23 | 500 |
| 2 | Петя | 25 | 500 |
| 5 | Иван | 27 | 500 |
| 6 | Кирилл | 28 | 1000 |
| 4 | Коля | 30 | 1000 |
← Предыдущая страница
Следующая страница →
SQL GROUP BY — группировка в запросах
Навигация по уроку
- Группировка по одному столбцу без агрегатных функций
- Группировка по нескольким столбцам без агрегатных функций
- Группировка с агрегатными функциями
- Особенности применения группировки в MS SQL Server
Связанные темы
- Оператор SELECT
- Агрегатные функции
| Назад | Содержание | Вперёд>>> |
Оператор SQL GROUP BY служит для распределения строк — результата запроса — по группам, в которых
значения некоторого столбца, по которому происходит группировка, являются одинаковыми. Группировку можно
Группировку можно
производить как по одному столбцу, так и по нескольким.
Часто оператор SQL GROUP BY применяется вместе с агрегатными функциями (COUNT, SUM, AVG, MAX, MIN).
В этих случаях агрегатные функции служат для вычисления соответствующего агрегатного значения ко всему
набору строк, для которых некоторый столбец — общий.
Оператор GROUP BY имеет следующий синтаксис:
SELECT ИМЕНА_СТОЛБЦОВ
FROM ИМЯ_ТАБЛИЦЫ
[WHERE УСЛОВИЕ]
GROUP BY ИМЕНА_СТОЛБЦОВ
Если в результате запроса требуется вывести один столбец и по этому же столбцу производится группировка,
то оператор GROUP BY просто выбирает уникальные значения и убирает дубликаты, то есть выполняет те же задачи, что и ключевое слово DISTINCT.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Скрипт для создания базы данных библиотеки, её таблиц и заполения таблиц данными —
в файле по этой ссылке.
В примерах работаем с базой данных библиотеки и ее таблицей «Книга в пользовании» (Bookinuse). Отметим, что
оператор GROUP BY ведёт себя несколько по-разному в MySQL и в MS SQL Server. Эти различия будут показаны на
примерах.
| Author | Title | Pubyear | Inv_No | Customer_ID |
| Толстой | Война и мир | 2005 | 28 | 65 |
| Чехов | Вишневый сад | 2000 | 17 | 31 |
| Чехов | Избранные рассказы | 2011 | 19 | 120 |
| Чехов | Вишневый сад | 1991 | 5 | 65 |
| Ильф и Петров | Двенадцать стульев | 1985 | 3 | 31 |
| Маяковский | Поэмы | 1983 | 2 | 120 |
| Пастернак | Доктор Живаго | 2006 | 69 | 120 |
| Толстой | Воскресенье | 2006 | 77 | 47 |
| Толстой | Анна Каренина | 1989 | 7 | 205 |
| Пушкин | Капитанская дочка | 2004 | 25 | 47 |
| Гоголь | Пьесы | 2007 | 81 | 47 |
| Чехов | Избранные рассказы | 1987 | 4 | 205 |
| Пушкин | Сочинения, т. 1 1 | 1984 | 6 | 47 |
| Пастернак | Избранное | 2000 | 137 | 18 |
| Пушкин | Сочинения, т.2 | 1984 | 8 | 205 |
| NULL | Наука и жизнь 9 2018 | 2019 | 127 | 18 |
| Чехов | Ранние рассказы | 2001 | 171 | 31 |
Пример 1. Вывести авторов выданных книг, сгруппировав их. Пишем
следующий запрос:
SELECT Author
FROM BOOKINUSE
GROUP BY Author
Этот запрос вернёт следующий результат:
| Author |
| NULL |
| Гоголь |
| Ильф и Петров |
| Маяковский |
| Пастернак |
| Пушкин |
| Толстой |
| Чехов |
Как видим, в таблице стало меньше строк, так как фамилии
авторов остались каждая по одной.
В следующем примере увидим, что оператор GROUP BY не следует путать
с оператором ORDER BY и поймём, чем эти операторы отличаются друг от друга.
Пример 2. Вывести авторов и названия выданных книг,
сгруппировав по авторам. Пишем
следующий запрос, который допустим в MySQL:
SELECT Author, Title
FROM Bookinuse
GROUP BY Author
Этот запрос вернёт следующий результат:
| Author | Title |
| NULL | Наука и жизнь 9 2018 |
| Гоголь | Пьесы |
| Ильф и Петров | Двенадцать стульев |
| Маяковский | Поэмы |
| Пастернак | Доктор Живаго |
| Пушкин | Капитанская дочка |
| Толстой | Война и мир |
| Чехов | Вишнёвый сад |
Как видим, в таблице каждому автору соответствует лишь одна книга, причём та,
которая в таблице BOOKINUSE является первой по порядку записей.
Если бы нам требовалось вывести все книги, причём авторы должны были бы следовать
не «вразброс», а по порядку: сначала Гоголь и все его книги, затем другие авторы и все их книги,
то мы применили бы не оператор GROUP BY, а оператор ORDER BY.
По-другому ведёт себя оператор GROUP BY в MS SQL Server.
И всё же вывести все записи, соответствующие значению столбца, по которому происходит
группировка, можно. Но в этом случае в результирующей таблице должен появиться ещё один столбец. Такой
случай проиллюстирован в следующем примере.
Пример 3. Вывести авторов, названия выданных книг, ID пользователя и
инвентарный номер выданной книги.
Сгруппировать по авторам, ID пользователя и инвентарному номеру. На MySQL запрос будет следующим:
SELECT Author, Title, Customer_ID, Inv_no
FROM Bookinuse
GROUP BY Author, Customer_ID, Inv_no
Этот запрос вернёт следующий результат:
| Author | Title | Customer_ID | Inv_no |
| Гоголь | Пьесы | 47 | 81 |
| Ильф и Петров | Двенадцать стульев | 31 | 3 |
| Маяковский | Поэмы | 120 | 2 |
| Пастернак | Избранное | 18 | 137 |
| Пастернак | Доктор Живаго | 120 | 69 |
| Пушкин | Капитанская дочка | 47 | 25 |
| Пушкин | Сочинения, т. 1 1 | 47 | 6 |
| Пушкин | Сочинения, т.2 | 205 | 8 |
| Толстой | Воскресенье | 47 | 77 |
| Толстой | Война и мир | 65 | 28 |
| Толстой | Анна Каренина | 205 | 7 |
| Чехов | Вишневый сад | 31 | 19 |
| Чехов | Ранние рассказы | 31 | 171 |
| Чехов | Вишневый сад | 65 | 5 |
| Чехов | Избранные рассказы | 120 | 19 |
| Чехов | Избранные рассказы | 205 | 4 |
Как видим, в результирующей таблице присутствуют все книги всех авторов, причём авторы
следуют по порядку, как если бы мы применили оператор ORDER BY. Кроме того, видно, что записи сгруппированы
и по второму указанному столбцу — Customer_ID. Так, у автора Пушкина сначала перечисляются книги, выданные
пользователю с Customer_ID 47, а затем — 205. У автора Чехова сначала перечисляются книги, выданные
У автора Чехова сначала перечисляются книги, выданные
пользователю с Customer_ID 31, а затем — с другими номерами. Третий столбец, по которому происходит группировка — Inv_no —
добавлен только для того, чтобы в результирующей таблице выводились все строки, соответствующие значениям
ранее перечисленных столбцов для группировки, а не только уникальные.
По-другому ведёт себя
оператор GROUP BY в MS SQL Server
и в случае этого запроса.
Агрегатные функции COUNT, SUM, AVG, MAX, MIN служат для вычисления соответствующего агрегатного значения ко всему
набору строк, для которых некоторый столбец — общий.
Пример 4. Вывести количество выданных книг каждого автора. Запрос будет следующим:
SELECT Author, COUNT(*) AS InUse
FROM Bookinuse
GROUP BY Author
Результатом выполнения запроса будет следующая таблица:
| Author | InUse |
| NULL | 1 |
| Гоголь | 1 |
| Ильф и Петров | 1 |
| Маяковский | 1 |
| Пастернак | 2 |
| Пушкин | 3 |
| Толстой | 3 |
| Чехов | 5 |
Пример 5. Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
Вывести количество книг, выданных каждому пользователю. Запрос будет следующим:
SELECT Customer_ID, COUNT(*) AS InUse
FROM Bookinuse
GROUP BY Customer_ID
Результатом выполнения запроса будет следующая таблица:
| User_ID | InUse |
| 18 | 1 |
| 31 | 3 |
| 47 | 4 |
| 65 | 2 |
| 120 | 3 |
| 205 | 3 |
Примеры запросов к базе данных «Библиотека» есть также в уроках по оператору IN,
предикату EXISTS и функциям
CONCAT, COALESCE.
На сайте есть более подробный материал об агрегатных функциях и их совместном
использовании с оператором GROUP BY.
- Страница 2
Поделиться с друзьями
| Назад | Содержание | Вперёд>>> |
SQL GROUP BY Пункт
Предложение GROUP BY используется для получения сводных данных на основе одной или нескольких групп.
Группы могут быть сформированы на одной или нескольких колонках.
Например, запрос GROUP BY будет использоваться для подсчета количества сотрудников в каждом отделе или для получения общей заработной платы по отделам.
Вы должны использовать агрегатные функции, такие как COUNT() , MAX() , MIN() , SUM() , AVG() и т. д. в запросе SELECT.
Результат предложения GROUP BY возвращает одну строку для каждого значения столбца GROUP BY.
Синтаксис:
ВЫБЕРИТЕ столбец1, столбец2,... столбецN ИЗ имя_таблицы [КУДА] [ГРУППИРОВАТЬ ПО столбцу1, столбцу2...столбцуN] [ИМЕЮЩИЙ] [СОРТИРОВАТЬ ПО]
Предложение SELECT может включать столбцы, которые используются с предложением GROUP BY. Таким образом, чтобы включить другие столбцы в предложение SELECT, используйте агрегатные функции, такие как 9.0005 COUNT() , MAX() , MIN() , SUM() , AVG() с этими столбцами.
- Предложение GROUP BY используется для формирования групп записей.
- Предложение GROUP BY должно стоять после предложения WHERE, если оно присутствует, и перед предложением HAVING.
- Предложение GROUP BY может включать один или несколько столбцов для формирования одной или нескольких групп на основе этих столбцов.
- В предложение SELECT можно включать только столбцы GROUP BY. Чтобы использовать другие столбцы в предложении SELECT, используйте с ними агрегатные функции.
Для демонстрационных целей мы будем использовать следующие таблицы Employee и Department во всех примерах.
Таблица сотрудников
| Эмпид | Имя | Фамилия | Электронная почта | Зарплата | ИД отдела |
|---|---|---|---|---|---|
| 1 | ‘Джон’ | ‘Король’ | ‘[электронная почта защищена]’ | 33000 | 1 |
| 2 | ‘Джеймс’ | ‘Бонд’ | 1 | ||
| 3 | ‘Нина’ | ‘Кочхар’ | ‘[электронная почта защищена]’ | 17000 | 2 |
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘[электронная почта защищена]’ | 15000 | 1 |
| 5 | ‘Амит’ | ‘Патель’ | 18000 | 1 | |
| 6 | ‘Абдул’ | ‘Калам’ | ‘[электронная почта защищена]’ | 25000 | 2 |
Таблица отдела
| ИД отдела | Имя |
|---|---|
| 1 | «Финансы» |
| 2 | «HR» |
Рассмотрим следующий запрос GROUP BY.
ВЫБРАТЬ DeptId, COUNT(EmpId) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId; --следующий запрос вернет те же данные, что и выше ВЫБЕРИТЕ DeptId, COUNT (*) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId;
Приведенный выше запрос включает предложение GROUP BY DeptId , поэтому в предложение SELECT можно включить только DeptId . Вам нужно использовать агрегатные функции для включения других столбцов в предложение SELECT, поэтому COUNT(EmpId) включено, потому что мы хотим подсчитать количество сотрудников в том же DeptId .
«Количество сотрудников» является псевдонимом столбца COUNT(EmpId) . Запрос отобразит следующий результат.
| ИД отдела | Количество сотрудников |
|---|---|
| 1 | 4 |
| 2 | 2 |
Следующий запрос получает название отдела вместо DeptId в результате.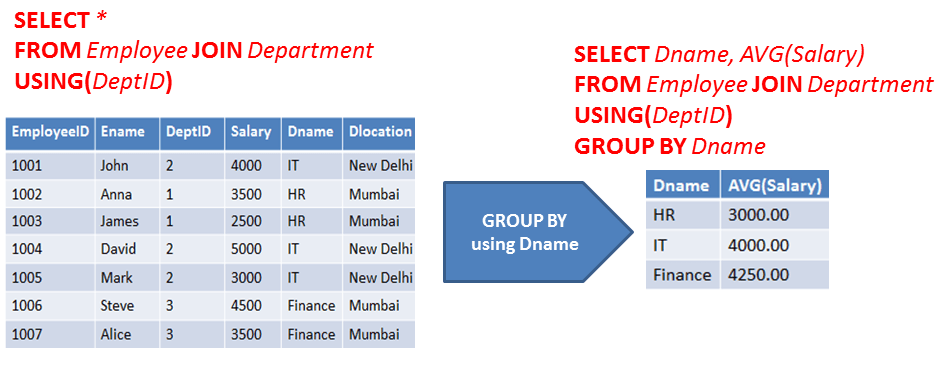
SELECT dept.Name как «Отдел», count(emp.empid) как «Число сотрудников» ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по названию отдела
| Отдел | Количество сотрудников |
|---|---|
| Финансы | 4 |
| ЧАС | 2 |
Таким же образом следующий запрос получает общую зарплату по отделам.
SELECT dept.Name, sum(emp.salary) as 'Общая зарплата' ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по названию отдела
| Отдел | Общая заработная плата |
|---|---|
| Финансы | 66000 |
| ЧАС | 42000 |
Следующий запрос вызовет ошибку, поскольку имя_отдела не включено в предложение GROUP BY или не используется агрегатная функция.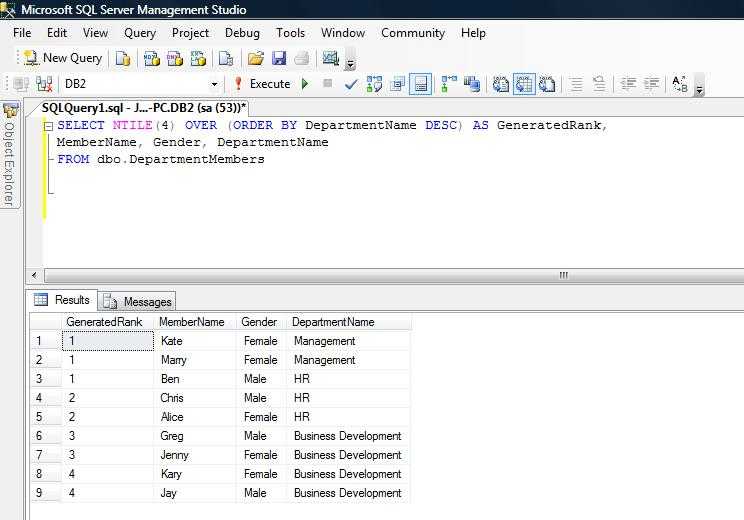
SELECT dept.Name, sum(emp.salary) as 'Общая зарплата' ОТ Сотрудник ип, отдел отдела ГДЕ emp.deptid = dept.DeptId ГРУППА по dept.DeptId
SQL GROUP BY
Резюме : в этом руководстве вы узнаете, как использовать предложение SQL GROUP BY для группировки строк на основе одного или нескольких столбцов.
Введение в предложение SQL GROUP BY
GROUP BY является необязательным предложением SELECT 9Заявление 0006. Предложение GROUP BY позволяет группировать строки на основе значений одного или нескольких столбцов. Он возвращает одну строку для каждой группы.
Ниже показан основной синтаксис предложения GROUP BY :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT столбец1, столбец2, агрегатная_функция (столбец 3) ИЗ имя_таблицы ГРУППА ПО столбец1, столбец2;
На следующем рисунке показано, как GROUP BY пункт работает:
Таблица с левой стороны имеет два столбца id и фрукты .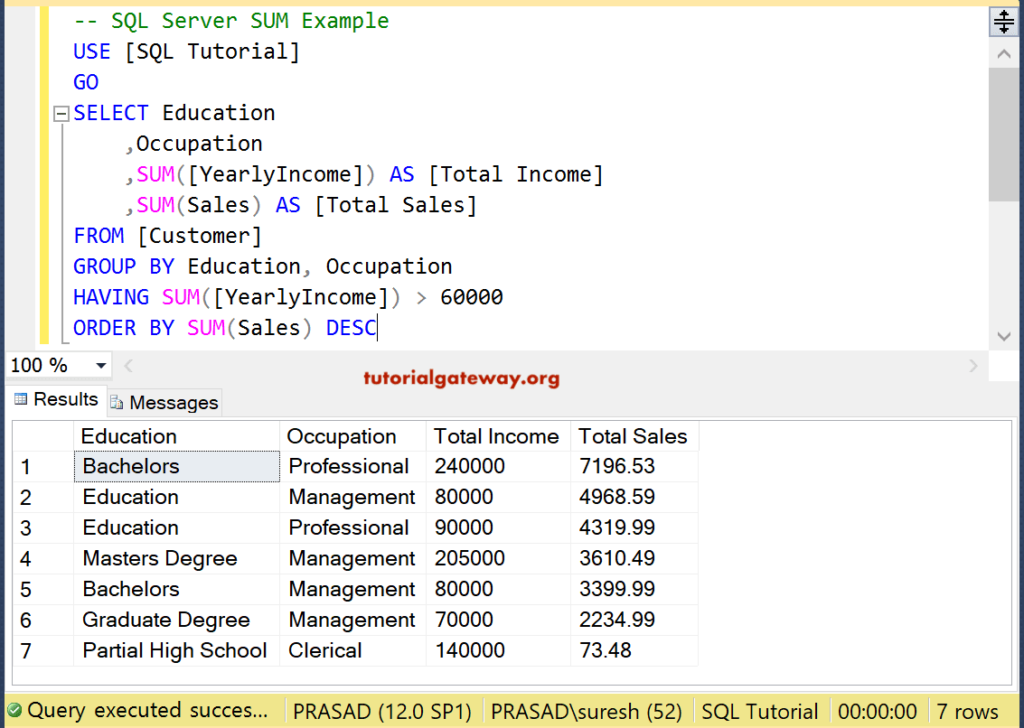 Когда вы применяете предложение
Когда вы применяете предложение GROUP BY к столбцу фруктов , он возвращает набор результатов, который включает уникальные значения из столбца фруктов :
SELECT фрукты ИЗ sample_table ГРУППА ПО фрукты;
На практике часто используется предложение GROUP BY с агрегатной функцией, такой как MIN, MAX, AVG, SUM или COUNT, для вычисления меры, предоставляющей информацию для каждой группы.
Например, ниже показано, как предложение GROUP BY работает с агрегатной функцией COUNT :
В этом примере мы группируем строки по значениям столбца fruit и применяем функцию COUNT в столбец id . Набор результатов включает уникальные значения столбцов фруктов и количество соответствующих строк.
ВЫБЕРИТЕ фрукты, COUNT(id) ИЗ sample_table ГРУППА ПО фрукты;
Столбцы, которые появляются в предложении GROUP BY , называются группирующими столбцами . Если столбец группировки содержит значения NULL, все значения NULL суммируются в одну группу, поскольку предложение
Если столбец группировки содержит значения NULL, все значения NULL суммируются в одну группу, поскольку предложение GROUP BY считает все значения NULL равными.
Примеры SQL GROUP BY
Мы будем использовать таблицы сотрудников и отделов в образце базы данных, чтобы продемонстрировать, как работает предложение GROUP BY .
В следующем примере используется предложение GROUP BY для группировки значений в столбце Department_id таблицы сотрудников :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT id_отдела ИЗ сотрудники ГРУППА ПО ИД_отдела;
Вывод:
Попробуйте
Язык кода: JavaScript (javascript)
+---------------+ | id_отдела | +---------------+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9| | 10 | | 11 | +---------------+ 11 строк в наборе (0,00 с)
В этом примере:
- Во-первых, предложение
SELECTвозвращает все значения из столбца Department_id таблицысотрудников.
- Во-вторых, предложение
GROUP BYгруппирует все значения в группы.
Столбец Department_id таблицы сотрудников содержит 40 строк, включая 9 дубликатов.0005 id_отдела значений. Однако GROUP BY группирует эти значения в группы.
Без агрегатной функции GROUP BY ведет себя как ключевое слово DISTINCT :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT DISTINCT_идентификатор_отдела ИЗ сотрудники СОРТИРОВАТЬ ПО ИД_отдела;
Попробуйте
Предложение GROUP BY будет более полезным при использовании его с агрегатной функцией.
Например, следующий оператор использует предложение GROUP BY с функцией COUNT для подсчета количества сотрудников по отделам:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT id_отдела, COUNT(employee_id) численность персонала ИЗ сотрудники ГРУППА ПО ИД_отдела;
Попробуйте
Вывод:
Язык кода: JavaScript (javascript)
+---------------+----- ------+ | id_отдела | численность персонала | +---------------+-----------+ | 1 | 1 | | 2 | 2 | | 3 | 6 | | 4 | 1 | | 5 | 7 | | 6 | 5 | | 7 | 1 | | 8 | 6 | | 9| 3 | | 10 | 6 | | 11 | 2 | +---------------+-----------+ 11 строк в наборе (0,00 сек)
Как это работает.
- Во-первых, предложение
GROUP BYгруппирует строки в таблицесотрудниковпо идентификатору отдела. - Во-вторых, функция
COUNT(employee_id)возвращает число значений идентификаторов сотрудников в каждой группе.
SQL GROUP BY с INNER JOIN пример
В следующем примере возвращается количество сотрудников по отделам. И он использует предложение INNER JOIN , чтобы включить название отдела в результат:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT название отдела, COUNT(employee_id) численность персонала ИЗ сотрудники е INNER JOIN отделы d ON d.department_id = e.department_id ГРУППА ПО название отдела;
Попробуйте
Вывод:
Язык кода: JavaScript (javascript)
+-----------------+------------+ | имя_отдела | численность персонала | +------------------+------------+ | Бухгалтерский учет | 2 | | Администрация | 1 | | Исполнительный | 3 | | Финансы | 6 | | Человеческие ресурсы | 1 | | ИТ | 5 | | Маркетинг | 2 | | Связи с общественностью | 1 | | Закупки | 6 | | Продажи | 6 | | Доставка | 7 | +------------------+------------+ 11 рядов в сете (0,01 сек)
Пример SQL GROUP BY с ORDER BY
В следующем примере используется предложение ORDER BY для сортировки отделов по численности персонала:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT название отдела, COUNT(employee_id) численность персонала ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы d ON d.
Попробуйте
Вывод:
Язык кода: JavaScript (javascript)
+------------------+------------+ | имя_отдела | численность персонала | +------------------+------------+ | Доставка | 7 | | Продажи | 6 | | Финансы | 6 | | Закупки | 6 | | ИТ | 5 | | Исполнительный | 3 | | Маркетинг | 2 | | Бухгалтерский учет | 2 | | Человеческие ресурсы | 1 | | Администрация | 1 | | Связи с общественностью | 1 | +------------------+------------+ 11 рядов в сете (0,00 сек)
Обратите внимание, что вы можете использовать псевдоним headcount или COUNT(employee_id) в предложении ORDER BY .
SQL GROUP BY с HAVING пример
В следующем примере используется предложение HAVING для поиска отделов с числом сотрудников больше 5:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT название отдела, COUNT(employee_id) численность персонала ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы d ON d.department_id = e.department_id СГРУППИРОВАТЬ ПО имя_отдела СЧИСЛЕННОСТЬ > 5 ЗАКАЗАТЬ ПО ЧИСЛЕННОСТИ DESC;
Попробуйте
Вывод:
Язык кода: JavaScript (javascript)
+-----------------+--- --------+ | имя_отдела | численность персонала | +-----------------+------------+ | Доставка | 7 | | Продажи | 6 | | Финансы | 6 | | Закупки | 6 | +-----------------+------------+ 4 строки в наборе (0,00 сек)
SQL GROUP BY с MIN, MAX и AVG пример
Следующий запрос возвращает минимальную, максимальную и среднюю зарплату сотрудников в каждом отделе.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ название отдела, MIN(зарплата) min_salary, MAX(зарплата) max_salary, ОКРУГЛ(СРЕДНЯЯ(зарплата), 2) средняя_зарплата ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы d ON d.department_id = e.department_id ГРУППА ПО название отдела;
Попробуйте
Вывод:
Язык кода: JavaScript (javascript)
+------------------+------------+---- ----------------------+--+ | имя_отдела | мин_зарплата | макс_зарплата | средняя_зарплата | +------------------+------------+-------------+---- ------------+ | Бухгалтерский учет | 8300,00 | 12000,00 | 10150,00 | | Администрация | 4400,00 | 4400,00 | 4400,00 | | Исполнительный | 17000,00 | 24000,00 | 19333,33 | | Финансы | 6900,00 | 12000,00 | 8600,00 | | Человеческие ресурсы | 6500.
Пример SQL GROUP BY с функцией SUM
Чтобы получить общую зарплату по отделам, вы применяете функцию SUM к столбцу зарплата и группируете сотрудников по столбцу Department_id следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT название отдела, СУММ(зарплата) total_salary ИЗ сотрудники е ВНУТРЕННЕЕ СОЕДИНЕНИЕ отделы d ON d.
Попробуйте
Вывод:
Язык кода: JavaScript (javascript)
+------------------+---------------+ | имя_отдела | общая_зарплата | +------------------+---------------+ | Бухгалтерский учет | 20300.00 | | Администрация | 4400,00 | | Исполнительный | 58000,00 | | Финансы | 51600,00 | | Человеческие ресурсы | 6500.00 | | ИТ | 28800,00 | | Маркетинг | 19000,00 | | Связи с общественностью | 10000,00 | | Закупки | 24900,00 | | Продажи | 57700,00 | | Доставка | 41200,00 | +------------------+---------------+ 11 рядов в сете (0,01 сек)
SQL ГРУППИРОВАТЬ ПО нескольким столбцам
До сих пор вы видели, что мы сгруппировали всех сотрудников по одному столбцу. Например, следующее предложение помещает все строки с одинаковыми значениями в столбце Department_id в одну группу.
Язык кода: SQL (язык структурированных запросов) (sql)
ГРУППИРОВАТЬ ПО Department_id
Как насчет группировки сотрудников по значениям в обоих 9Столбцы 0005 Department_id и job_id ?
Язык кода: SQL (язык структурированных запросов) (sql)
GROUP BY Department_id, job_id
Это предложение сгруппирует всех сотрудников с одинаковыми значениями в столбцах Department_id и job6id в один столбец group_id и job6id
_id .