Индексы в базе данных: 14 вопросов об индексах в SQL Server, которые вы стеснялись задать / Хабр
Содержание
Как устроено индексирование баз данных / Хабр
Индексирование баз данных — это техника, повышающая скорость и эффективность запросов к базе данных. Она создаёт отдельную структуру данных, сопоставляющую значения в одном или нескольких столбцах таблицы с соответствующими местоположениями на физическом накопителе, что позволяет базе данных быстро находить строки по конкретному запросу без необходимости сканирования всей таблицы. Применяются разные типы индексов, однако они занимают пространство и должны обновляться при изменении данных. Важно тщательно продумывать стратегию индексирования базы данных и регулярно её оптимизировать.
Как базы данных создают индексы
Неиндексированная и индексированная базы данных
Индексирование базы данных обычно выполняется при помощи алгоритма, определяющего, как должен создаваться и храниться индекс. Конкретный процесс создания индекса может варьироваться в зависимости от типа используемой системы базы данных, однако в целом общие этапы выглядят так:
- Определение столбца или столбцов в таблице базы данных, которые нужно индексировать.
 Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках.
Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках. - Выбор алгоритма индексирования, подходящего для типа индексируемых данных. Например, индексы в виде B-деревьев обычно используются для индексирования строковых или числовых данных, а полнотекстовые индексы — для индексирования текстовых данных.
- Применение алгоритма индексирования к выбранным столбцам, что создаёт структуру данных, сопоставляющую значения в столбцах с местоположениями соответствующих записей таблицы.
- Сохранение индекса в отдельной структуре данных, обычно в другой части диска или в памяти, чтобы доступ к ней был более эффективным, чем к соответствующим табличным данным.
- Обновление индекса в случае добавления новых записей, удаления или изменения записей в таблице.
 Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках.
Обычно они определяются по тому, какие столбцы чаще всего используются в запросах или поисках.
Создание индекса может существенно улучшить производительность запросов к базе данных и операций поиска, поскольку оно позволяет системе базы данных находить соответствующие записи быстрее и эффективнее. Однако индексирование также может обладать и недостатками, например, увеличение требований к объёму хранилища и замедление выполнения операций вставки и обновления, поэтому перед созданием индекса следует взвесить плюсы и минусы.
Однако индексирование также может обладать и недостатками, например, увеличение требований к объёму хранилища и замедление выполнения операций вставки и обновления, поэтому перед созданием индекса следует взвесить плюсы и минусы.
Алгоритмы индексирования
Как говорилось выше, существует множество алгоритмов индексирования, используемых для оптимизации скорости операций получения данных при помощи создания индексов столбцов таблиц. Вот некоторые из самых популярных алгоритмов индексирования баз данных:
- B-дерево
- Bitmap-индекс
- Хэш-индекс
- GiST (Generalized Search Tree, обобщённое поисковое дерево)
- Полнотекстовый индекс
Каждый алгоритм индексирования имеет свои сильные и слабые стороны; давайте рассмотрим их по порядку.
B-дерево
▍ Определение
B-дерево — это структура данных самобалансирующегося дерева, которая часто используется в качестве алгоритма индексирования в базах данных. Каждый узел дерева состоит из набора ключей и указателей на дочерние узлы; хранение данных осуществляется в иерархической структуре. Деревья B-узлов упорядочены таким образом, что позволяют быстро выполнять поиск, вставку и удаление данных.
Каждый узел дерева состоит из набора ключей и указателей на дочерние узлы; хранение данных осуществляется в иерархической структуре. Деревья B-узлов упорядочены таким образом, что позволяют быстро выполнять поиск, вставку и удаление данных.
Самое большое преимущество алгоритма B-дерева заключается в минимизации количества дисковых операций ввода-вывода, необходимых для доступа к данным, потому что в B-дереве все узлы-листья находятся на одном уровне, а каждый узел может хранить множество ключей и указателей. Количество ключей и указателей, которое может храниться в узле, определяется параметром, называемым «порядок» дерева.
▍ Как это работает
Алгоритм B-дерева работает следующим образом:
- Инициализация: при создании B-дерева создаётся пустой корневой узел. Параметр, задающий максимальное количество ключей («порядок»), которые могут храниться в каждом узле, управляет B-порядком дерева.
- Вставка: при добавлении нового узла в B-дерево алгоритм сначала подыскивает подходящий узел-лист, в который нужно вставить ключ. B-дерево разделяет заполненный узел-лист на два новых узла и перемещает медианный ключ в родительский узел. Пока не достигнут корневой узел, процесс разделения может распространяться по дереву. Благодаря этой процедуре дерево остаётся сбалансированным, а узлы-листья находятся на одинаковой высоте.
- Удаление: когда ключ удаляется из B-дерева, алгоритм ищет узел, который изначально хранил ключ. Если узел-лист хранил ключ, то ключ извлекается и узел может нуждаться в перебалансировке. Алгоритм удаляет предшествующий или последующий лист после листа-узла, удалив ключ с ним, если ключ обнаружен не в узле-листе.
- Поиск: в процессе поиска ключа в B-дереве алгоритм начинает с корневого узла и рекурсивно движется к веткам, пока не найдёт нужный узел-лист. Метод поиска сравнивает искомый ключ с ключами, содержащимися в каждом узле, а затем использует соответствующий указатель для перехода к дочернему узлу, в котором может находиться ключ. Этот процесс продолжается, пока не будет найден искомый ключ или пока не будет определено, что он отсутствует в дереве.
 B-дерево разделяет заполненный узел-лист на два новых узла и перемещает медианный ключ в родительский узел. Пока не достигнут корневой узел, процесс разделения может распространяться по дереву. Благодаря этой процедуре дерево остаётся сбалансированным, а узлы-листья находятся на одинаковой высоте.
B-дерево разделяет заполненный узел-лист на два новых узла и перемещает медианный ключ в родительский узел. Пока не достигнут корневой узел, процесс разделения может распространяться по дереву. Благодаря этой процедуре дерево остаётся сбалансированным, а узлы-листья находятся на одинаковой высоте.
 Этот процесс продолжается, пока не будет найден искомый ключ или пока не будет определено, что он отсутствует в дереве.
Этот процесс продолжается, пока не будет найден искомый ключ или пока не будет определено, что он отсутствует в дереве.
Однако B-деревья обладают некоторыми недостатками:
- Излишняя трата ресурсов: B-деревья задействуют большой объём излишнего пространства, поскольку каждый узел в B-дереве содержит указатель на родительский и дочерний узлы.
- Сложность: алгоритмы, используемые для вставки, удаления и поиска данных в B-дереве, сложнее по сравнению с другими структурами данных. Это усложняет реализацию и поддержку B-деревьев.
- Медленные обновления: обновление данных в B-дереве может быть относительно медленным по сравнению с другими структурами данных. Каждая операция обновления требует множества операций доступа к диску, и этот процесс может быть медленным для больших B-деревьев.
▍ Bitmap-индексирование
▍ Определение
Bitmap-индексирование — это методика индексирования данных, использующая битовые карты (bitmap) для обозначения наличия или отсутствия значения в таблице. Это успешная техника индексирования для таблиц с низкой кардинальностью, где количество уникальных значений в столбце довольно мало по сравнению с общим количеством строк.
Это успешная техника индексирования для таблиц с низкой кардинальностью, где количество уникальных значений в столбце довольно мало по сравнению с общим количеством строк.
Bitmap-индексирование может быть очень эффективным для столбцов с низкой кардинальностью, поскольку битовые карты крайне компактны и их можно быстро сканировать для извлечения данных. Bitmap-индексы очень удобны для применения в хранилищах данных, где необходимо быстро сканировать огромные объёмы данных. Кроме того, они полезны для баз данных, в которых много операций чтения, но мало обновлений или вставок.
▍ Как это работает
- Для создания bitmap-индекса столбца для каждого уникального значения столбца создаётся отдельный bitmap. Каждый bitmap имеет длину, равную количеству строк в таблице.
- Если значение присутствует в строке, соответствующему биту в bitmap присваивается значение 1, а если оно отсутствует, то присваивается значение 0. (Представьте таблицу, где столбец «Gender» имеет два уникальных значения, например, «Male» и «Female». Если этот столбец имеет bitmap-индекс, можно создать два bitmap, длина каждого из которых равна количеству строк в таблице. Когда в строке встречается «Male» или «Female», соответствующий бит в bitmap «Male» или «Female» получает значение 1, и наоборот. В случае отсутствия значения «Male» или «Female» соответствующему биту присваивается значение 0.)
- Чтобы выполнить запрос при помощи bitmap-индекса, соответствующие в запросе значения bitmap комбинируются при помощи побитовых операторов AND, OR и NOT. (например, если мы хотим найти все строки, где «Gender» равно «Male» И «Age» больше 30, нам сначала нужно получить bitmap «Male» и bitmap «Age > 30» из соответствующих индексов. Затем мы комбинируем эти два bitmap при помощи побитового оператора AND и получаем окончательный bitmap только с единицами в тех позициях, где оба условия истинны. Затем окончательный bitmap используется для получения из таблицы строк, удовлетворяющих запросу.)
 Если этот столбец имеет bitmap-индекс, можно создать два bitmap, длина каждого из которых равна количеству строк в таблице. Когда в строке встречается «Male» или «Female», соответствующий бит в bitmap «Male» или «Female» получает значение 1, и наоборот. В случае отсутствия значения «Male» или «Female» соответствующему биту присваивается значение 0.)
Если этот столбец имеет bitmap-индекс, можно создать два bitmap, длина каждого из которых равна количеству строк в таблице. Когда в строке встречается «Male» или «Female», соответствующий бит в bitmap «Male» или «Female» получает значение 1, и наоборот. В случае отсутствия значения «Male» или «Female» соответствующему биту присваивается значение 0.)
Bitmap-индексы имеют множество недостатков, и в том числе:
- Большой размер: Bitmap-индексы могут быть большими, особенно при работе с крупными датасетами. Из-за этого они могут оказаться менее эффективными, чем другие методики индексирования.
- Столбцы с высокой кардинальностью: Bitmap-индексы неэффективны для столбцов с высокой кардинальностью, где количество уникальных значений очень высоко. В таких случаях bitmap-индексы могут становиться очень большими и не помещаться в памяти.
- Смещённое распределение данных: если данные смещены, у нескольких значений может быть гораздо более высокая частота, чем у других, и bitmap-индексы окажутся неэффективными. Это вызвано тем, что bitmap для наиболее частых значений становятся очень большими и могут доминировать в индексе.
 Из-за этого они могут оказаться менее эффективными, чем другие методики индексирования.
Из-за этого они могут оказаться менее эффективными, чем другие методики индексирования.
Хэш-индекс
▍ Определение
Хэш-индекс — это разновидность методики индексирования баз данных, использующая хэш-функцию для сопоставления ключей индекса с местоположениями соответствующих записей данных. Это быстрый метод индексирования для запросов точного соответствия в одном столбце.
Сопоставление ключей индекса с местоположениями соответствующих записей данных позволяет выполнять быстрый поиск и вставки за постоянное время O(1). Однако этот метод плохо работает с запросами диапазонов или частичными совпадениями и может страдать от коллизий, с которыми можно справляться при помощи различных техник разрешения коллизий.
▍ Как это работает
Чтобы объяснить, как работает хэш-индекс, давайте рассмотрим пример. Допустим, у нас есть таблица базы данных, содержащая информацию о сотрудниках, в том числе, номера их пользовательских ID. Мы хотим создать хэш-индекс столбца пользовательских ID, чтобы получить возможность быстрого поиска данных пользователей на основании номера их ID.
- Мы создадим хэш-функцию, получающую на входе пользовательский ID и генерирующую на выходе уникальный хэш-код. Хэш-функция должна быть спроектирована таким образом, чтобы генерировать равномерно распределённое множество хэш-кодов для равномерного распределения записей по корзинам в файле индекса. На практике хэш-функция может использовать для генерации хэш-кода различные методики, например, модульную арифметику или побитовые операции.
- Мы создаём файл хэш-индекса, содержащий набор корзин (bucket), каждая из которых соответствует уникальному хэш-коду сгенерированному хэш-функцией. Каждая корзина содержит указатель на файл базы данных, содержащий записи для этого хэш-кода.
- При выполнении запроса к значению запроса применяется хэш-функция для генерации хэш-кода. Затем хэш-код используется для нахождения соответствующей корзины в файле хэш-индекса. Записи с одинаковым хэш-кодом хранятся в одной корзине, поэтому мы можем просто просканировать записи в этой корзине и найти совпадающую запись/записи. Если присутствуют коллизии (то есть несколько записей с одинаковым хэш-кодом), то для их разрешения можно использовать техники наподобие создания цепочек или открытой адресации.
- Чтобы вставить новую запись в хэш-индекс, мы применяем к значению ключа записи хэш-функцию, чтобы сгенерировать его хэш-код, а затем вставляем запись в соответствующую корзину в файле хэш-индекса. Если коллизии отсутствуют, вставку можно выполнить за постоянное время O(1), так как нам нужно всего лишь вычислить хэш-код и вставить запись в корзину. Если коллизии есть, нам может потребоваться проделать дополнительные операции, например, вставку записи в связанный список в корзине или проверку других корзин, пока не будет найден свободный слот.
 На практике хэш-функция может использовать для генерации хэш-кода различные методики, например, модульную арифметику или побитовые операции.
На практике хэш-функция может использовать для генерации хэш-кода различные методики, например, модульную арифметику или побитовые операции.
 Если коллизии отсутствуют, вставку можно выполнить за постоянное время O(1), так как нам нужно всего лишь вычислить хэш-код и вставить запись в корзину. Если коллизии есть, нам может потребоваться проделать дополнительные операции, например, вставку записи в связанный список в корзине или проверку других корзин, пока не будет найден свободный слот.
Если коллизии отсутствуют, вставку можно выполнить за постоянное время O(1), так как нам нужно всего лишь вычислить хэш-код и вставить запись в корзину. Если коллизии есть, нам может потребоваться проделать дополнительные операции, например, вставку записи в связанный список в корзине или проверку других корзин, пока не будет найден свободный слот.
Хэш-индексы также имеют множество недостатков, в том числе:
- Ограниченные возможности поиска: хэш-индексы предназначены для обработки только поисков равенства (например, «найти все записи, где столбец A равен значению»). Они плохо подходят для запросов диапазонов или сортировки.
- Коллизии: хэш-индексы могут иметь коллизии, при которых несколько ключей соответствуют одному хэш-значению. Это может привести к снижению производительности, поскольку базе данных нужно будет выполнять дополнительные операции для разрешения коллизий.
- Непредсказуемые требования к размеру хранилища: размер хэш-индекса невозможно предугадать, так как он зависит от количества уникальных значений в индексируемом столбце. Это усложняет планирование требований к размеру хранилища.
 Это усложняет планирование требований к размеру хранилища.
Это усложняет планирование требований к размеру хранилища.
▍ GiST
▍ Определение
GiST (Generalized Search Tree, обобщённое поисковое дерево) — это техника индексирования баз данных, которая может использоваться для индексирования сложных типов данных, например, геометрических объектов, текста или массивов. Это сбалансированная древовидная структура, состоящая из узлов с множественными дочерними узлами. Каждый узел описывает диапазон или множество значений и связан с предикативной функцией, проверяющей, принадлежит ли значение диапазону или множеству. Предикативная функция зависит от типа индексируемых данных и может быть подстроена под разные типы данных.
▍ Как это работает
Чтобы проиллюстрировать принцип работы индекса GiST, рассмотрим пример индексирования пространственных данных. Допустим, у нас есть таблица базы данных, содержащая информацию о городах, в том числе их названия и координаты в формате широты и долготы.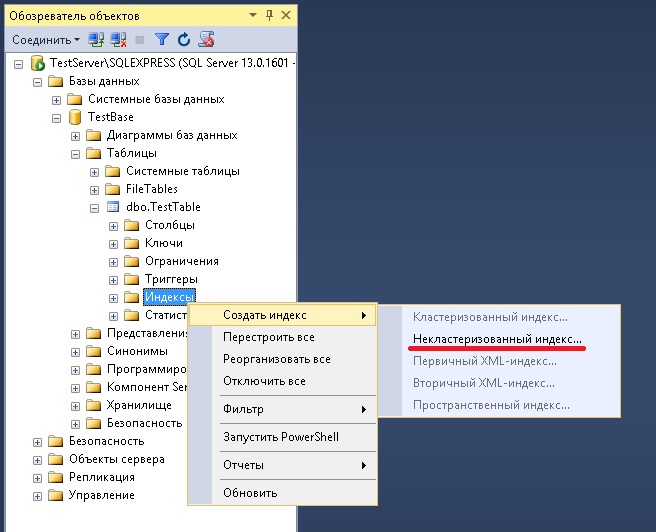
- Зададим множество предикатов и функций преобразования, специфичных для индексируемого типа пространственных данных. В данном случае мы должны задать предикат, проверяющий, находится ли заданная точка в ограничивающем прямоугольнике, описанном узлом в индексе, и функцию преобразования, преобразующую точку в набор ключей на основании её позиции в ограничивающем прямоугольнике.
- Создаём файл индекса GiST, состоящий из множества узлов, каждый из которых описывает ограничивающий прямоугольник, охватывающий диапазон координат.
Корневой узел описывает весь диапазон координат в таблице базы данных, а каждый дочерний узел описывает подмножество этого диапазона.
Каждый узел связывается с предикативной функцией и функцией преобразования, специфичными для индексируемого типа пространственных данных.
- При выполнении запроса значение в запросе преобразуется при помощи функции преобразования в набор ключей.
Затем ключи сравниваются с предикатами, связанными с каждым узлом индекса, начиная с корневого узла.
Поиск продолжается вниз по дереву и выбирает дочерний узел, содержащий значение из запроса.
Процесс повторяется, пока не будет достигнут узел-лист, содержащий элементы индекса, соответствующие значению в запросе.
- Для вставки в индекс нового города координаты города сначала при помощи функции преобразования преобразуются в набор ключей.
Затем ключи вставляются в соответствующие узлы индекса, начиная с корневого узла.
Если узел заполнен, выполняется операция разделения для создания двух новых узлов и ключи распределяются между узлами.
GiST имеет несколько недостатков, которые нужно учитывать:
- Сниженная скорость вставок и обновлений: структуры индексирования GiST могут быть сложнее, чем традиционные структуры индексирования, что может привести к снижению скорости операций вставки и обновления.
- Больше дискового пространства: структуры индексирования GiST могут требовать больше дискового пространства, чем другие методики индексирования, поскольку хранят дополнительную информацию для поддержки различных типов поиска.
- Подходит не для всех типов данных: GiST оптимизирован под индексирование сложных типов данных, например, пространственных данных, однако может быть не лучшим выбором для индексирования более простых типов данных, например, целочисленных значений или строк.
- Повышенные затраты на поддержку: из-за сложности реализации индексы GiST требуют больше обслуживания по сравнению с традиционными индексами.

▍ Полнотекстовый индекс
▍ Определение
Полнотекстовое индексирование — это методика индексирования баз данных, используемая для повышения эффективности поиска текстовых запросов. Это особый вид индекса, спроектированный для работы с текстовыми данными. В отличие от традиционных индексов, хранящих значения отдельных столбцов, полнотекстовый индекс хранит текстовое содержимое одного или нескольких столбцов как множества слов или токенов. Эти слова или токены используются при выполнении поискового запроса для быстрого нахождения релевантных строк.
Полнотекстовое индексирование способно существенно улучшить производительность текстовых поисковых запросов, особенно при работе с большими объёмами текстовых данных. Однако оно требует дополнительного дискового пространства и вычислительных ресурсов, а также тщательной настройки параметров индексирования для обеспечения оптимальной производительности.
▍ Как это работает
Процесс полнотекстового индексирования состоит из нескольких этапов:
- Токенизация: текстовое содержимое индексируемого столбца разбивается на отдельные слова или токены, которые затем сохраняются в индекс. При создании полнотекстового индекса система базы данных сначала анализирует текстовое содержимое индексируемых столбцов, а затем разбивает его на отдельные слова или токены. Этот процесс называется токенизацией, он может включать в себя фильтрацию игнорируемых слов (например, «the», «and», «or») и выделение корней (редуцирование слов до их базовой формы).
- Индексирование: затем токены индексируются при помощи специальной структуры данных, например, B-дерева или инвертированного индекса. Структура индекса обеспечивает возможность эффективного поиска и извлечения строк, содержащих указанные токены.
- Построение и выполнение запросов: система базы данных использует полнотекстовый индекс для поиска строк, содержащих релевантные токены. В процессе поиска токены запроса сопоставляются с индексированными токенами и извлекаются строки, соответствующие запросу. Результаты поиска можно ранжировать на основании их релевантности запросу, который вычисляется при помощи алгоритмов наподобие TF-IDF (term frequency-inverse document frequency).
 Структура индекса обеспечивает возможность эффективного поиска и извлечения строк, содержащих указанные токены.
Структура индекса обеспечивает возможность эффективного поиска и извлечения строк, содержащих указанные токены.
Полнотекстовое индексирование имеет некоторые недостатки:
- Сниженная скорость индексирования и поиска: полнотекстовое индексирование может быть более сложным, чем другие техники индексирования, что может приводить к снижению скорости индексирования и поиска, особенно в больших базах данных со множеством текстовых полей.
- Подходит не для всех типов данных: полнотекстовое индексирование лучше всего подходит для баз данных, содержащих большие объёмы текстовых данных. Оно может и не быть наиболее эффективной техникой для баз данных, по большей мере, для содержащих числовую или другую нетекстовую информацию.
- Зависимость от языка: полнотекстовое индексирование может быть не очень эффективно для многоязычных баз данных, поскольку требует отдельных индексов для каждого языка и может оказаться неспособным справиться с нюансами различных языков и систем письменности.
 Оно может и не быть наиболее эффективной техникой для баз данных, по большей мере, для содержащих числовую или другую нетекстовую информацию.
Оно может и не быть наиболее эффективной техникой для баз данных, по большей мере, для содержащих числовую или другую нетекстовую информацию.
Заключение
Индексирование баз данных — критически важная технология, повышающая эффективность запросов к базам данных. Оно заключается в создании специальных структур данных, обеспечивающих эффективный поиск и извлечение данных на основании одного или нескольких столбцов таблицы. Для оптимизации запросов под различные типы данных и сценарии использования применяются разные типы алгоритмов индексирования, например, B-деревья, bitmap-индексы, хэш-индексы и GiST-индексы.
Подробнее об индексировании баз данных можно узнать из следующих ресурсов:
- “Use The Index, Luke!”, Markus Winand — это подробное руководство по индексированию баз данных SQL, в котором освещаются как основы, так и расширенные возможности.
- “Database Indexing Explained”, DigitalOcean — в этом туториале представлено понятное для новичков введение в концепции и методики индексирования с примерами на PostgreSQL.
- “Indexing Strategies for MySQL and MariaDB”, Severalnines — в этом посте представлены практические советы по проектированию и оптимизации индексов в MySQL и MariaDB.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх 🕹️
НОУ ИНТУИТ | Лекция | Создание базы данных и проектирование таблиц
Аннотация: Определяется процесс создания базы данных. Описываются операторы
создания, изменения базы данных. Рассматривается возможность указания
имени файла или нескольких файлов для хранения данных, размеров и
местоположения файлов. Анализируются операторы создания, изменения,
удаления пользовательских таблиц. Приводится описание параметров для
объявления столбцов таблицы. Дается понятие и характеристика
индексов. Рассматриваются операторы создания и изменения индексов.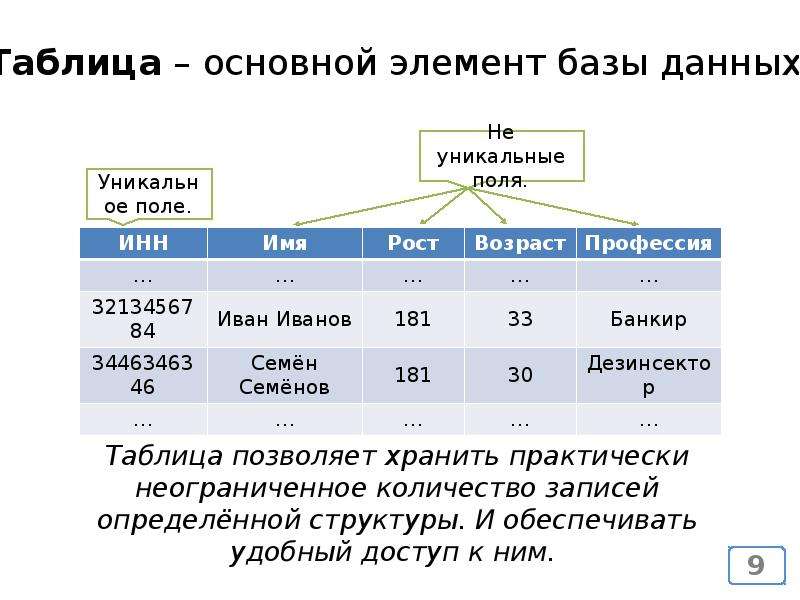
Определяется роль индексов в повышении эффективности выполнения
операторов SQL.
Ключевые слова: база данных, таблица, каталог, схема, журнал транзакций, индекс, вторичный файл, первичный файл, логическое имя файла, физическое имя файла, размер шага, создание таблицы, строка, столбец, имя таблицы, изменение таблицы, тип данных столбца, удаление таблицы, создание индекса, ключ индекса, уникальный индекс, кластерный индекс, некластерный индекс, удаление индекса
База данных
Создание базы данных
В различных СУБД процедура создания баз данных обычно закрепляется
только за администратором баз данных. В однопользовательских системах
принимаемая по умолчанию база данных может быть сформирована
непосредственно в процессе установки и настройки самой СУБД. Стандарт
SQL не определяет, как должны создаваться базы данных, поэтому в
каждом из диалектов языка SQL обычно используется свой подход. В
соответствии со стандартом SQL, таблицы и другие объекты базы данных
существуют в некоторой среде. Помимо всего прочего, каждая среда
Помимо всего прочего, каждая среда
состоит из одного или более каталогов, а каждый каталог – из набора схем. Схема представляет собой поименованную коллекцию объектов базы
данных, некоторым образом связанных друг с другом (все объекты в базе
данных должны быть описаны в той или иной схеме ). Объектами схемы
могут быть таблицы, представления, домены, утверждения,
сопоставления, толкования и наборы символов. Все они имеют одного и
того же владельца и множество общих значений, принимаемых по
умолчанию.
Стандарт SQL оставляет за разработчиками СУБД право выбора
конкретного механизма создания и уничтожения каталогов, однако
механизм создания и удаления схем регламентируется посредством
операторов CREATE SCHEMA и DROP SCHEMA. В стандарте также указано,
что в рамках оператора создания схемы должна существовать возможность
определения диапазона привилегий, доступных пользователям создаваемой схемы. Однако конкретные способы определения подобных привилегий в
разных СУБД различаются.
В настоящее время операторы CREATE SCHEMA и DROP SCHEMA реализованы в
очень немногих СУБД. В других реализациях, например, в СУБД MS SQL
Server, используется оператор CREATE DATABASE.
Создание базы данных в среде MS SQL Server
Процесс создания базы данных в системе SQL-сервера состоит из двух
этапов: сначала организуется сама база данных, а затем принадлежащий
ей журнал транзакций. Информация размещается в соответствующих
файлах, имеющих расширения *.mdf (для базы данных ) и *.ldf. (для журнала транзакций ). В файле базы данных записываются сведения об
основных объектах ( таблицах, индексах, представлениях и т.д.), а в файле журнала транзакций – о процессе работы с транзакциями (контроль
целостности данных, состояния базы данных до и после выполнения
транзакций).
Создание базы данных в системе SQL-сервер осуществляется командой CREATE DATABASE.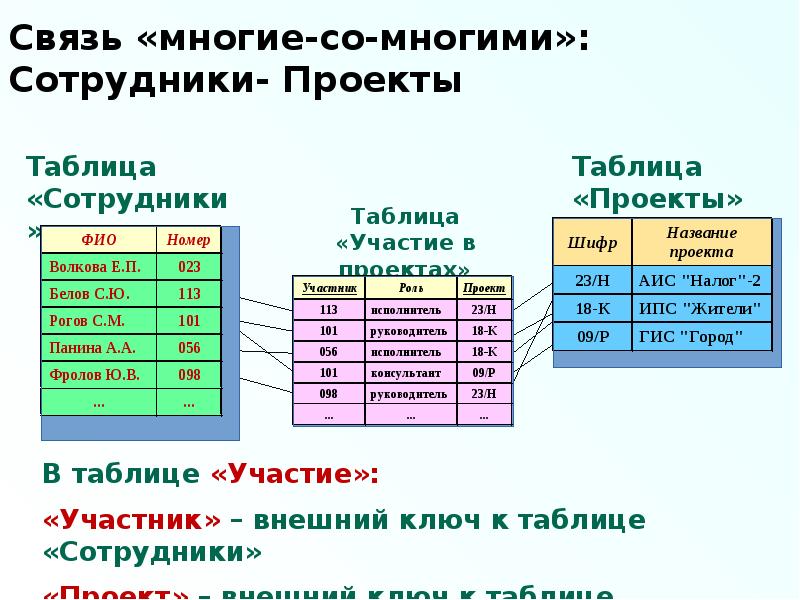 Следует отметить, что процедура создания базы данных
Следует отметить, что процедура создания базы данных
в SQL-сервере требует наличия прав администратора сервера.
<определение_базы_данных> ::=
CREATE DATABASE имя_базы_данных
[ON [PRIMARY]
[ <определение_файла> [,...n] ]
[,<определение_группы> [,...n] ] ]
[ LOG ON {<определение_файла>[,...n] } ]
[ FOR LOAD | FOR ATTACH ]Рассмотрим основные параметры представленного оператора.
При выборе имени базы данных следует руководствоваться общими
правилами именования объектов. Если имя базы данных содержит пробелы
или любые другие недопустимые символы, оно заключается в ограничители
(двойные кавычки или квадратные скобки). Имя базы данных должно быть
уникальным в пределах сервера и не может превышать 128 символов.
При создании и изменении базы данных можно указать имя файла, который
будет для нее создан, изменить имя, путь и исходный размер этого
файла.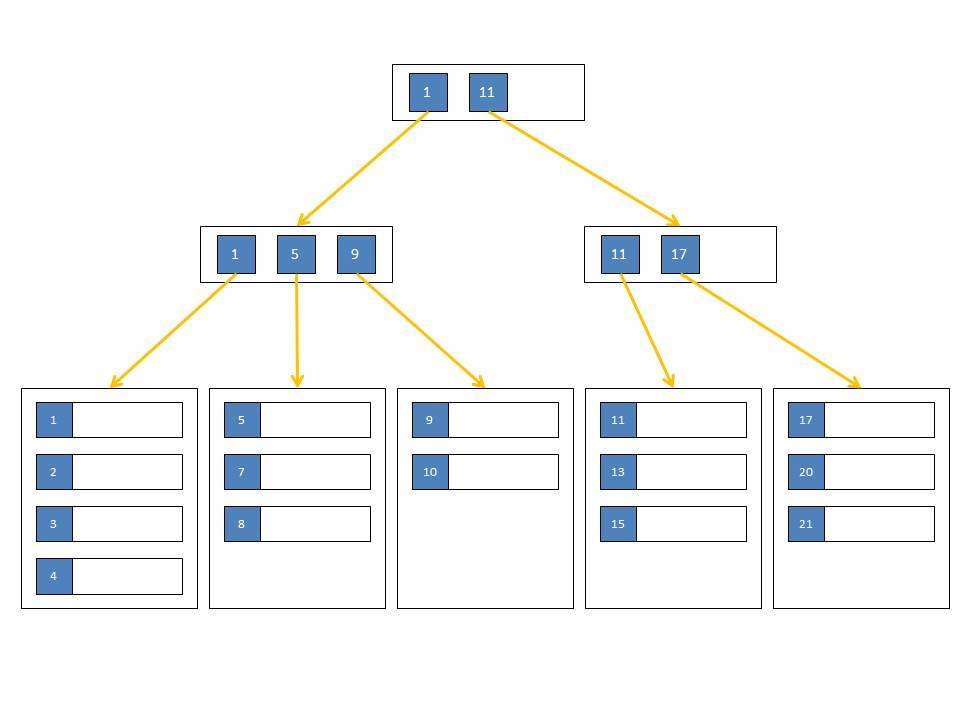 Если в процессе использования базы данных планируется ее
Если в процессе использования базы данных планируется ее
размещение на нескольких дисках, то можно создать так называемые вторичные файлы базы данных с расширением *.ndf. В этом случае
основная информация о базе данных располагается в первичном ( PRIMARY )
файле, а при нехватке для него свободного места добавляемая
информация будет размещаться во вторичном файле. Подход, используемый
в SQL-сервере, позволяет распределять содержимое базы данных по
нескольким дисковым томам.
Параметр ON определяет список файлов на диске для размещения
информации, хранящейся в базе данных.
Параметр PRIMARY определяет первичный файл. Если он опущен, то первичным является первый файл в списке.
Параметр LOG ON определяет список файлов на диске для размещения журнала транзакций. Имя файла для журнала транзакций генерируется на
основе имени базы данных, и в конце к нему добавляются символы _log.
При создании базы данных можно определить набор файлов, из которых
она будет состоять. Файл определяется с помощью следующей
конструкции:
<определение_файла>::=
([ NAME=логическое_имя_файла,]
FILENAME='физическое_имя_файла'
[,SIZE=размер_файла ]
[,MAXSIZE={max_размер_файла |UNLIMITED } ]
[, FILEGROWTH=величина_прироста ] )[,...n]Здесь логическое имя файла – это имя файла, под которым он будет
опознаваться при выполнении различных SQL-команд.
Физическое имя файла предназначено для указания полного пути и
названия соответствующего физического файла, который будет создан на
жестком диске. Это имя останется за файлом на уровне операционной
системы.
Параметр SIZE определяет первоначальный размер файла; минимальный
размер параметра – 512 Кб, если он не указан, по умолчанию
принимается 1 Мб.
Параметр MAXSIZE определяет максимальный размер файла базы данных.
При значении параметра UNLIMITED максимальный размер базы данных
ограничивается свободным местом на диске.
При создании базы данных можно разрешить или запретить автоматический
рост ее размера (это определяется параметром FILEGROWTH ) и указать
приращение с помощью абсолютной величины в Мб или процентным
соотношением. Значение может быть указано в килобайтах, мегабайтах, гигабайтах, терабайтах или процентах (%). Если указано число без суффикса МБ, КБ или %, то по умолчанию используется значение MБ. Если размер шага роста указан в процентах (%), размер увеличивается на заданную часть в процентах от размера файла. Указанный размер округляется до ближайших 64 КБ.
Дополнительные файлы могут быть включены в группу:
<определение_группы>::=FILEGROUP имя_группы_файлов
<определение_файла>[,. ..n] ..n]
..n]Пример 3.1. Создать базу данных, причем для данных определить три
файла на диске C, для журнала транзакций – два файла на диске C.
CREATE DATABASE Archive
ON PRIMARY ( NAME=Arch2,
FILENAME=’c:\user\data\archdat1.mdf’,
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),
(NAME=Arch3,
FILENAME=’c:\user\data\archdat2.mdf’,
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),
(NAME=Arch4,
FILENAME=’c:\user\data\archdat3.mdf’,
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20)
LOG ON
(NAME=Archlog1,
FILENAME=’c:\user\data\archlog1.ldf’,
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20),
(NAME=Archlog2,
FILENAME=’c:\user\data\archlog2.ldf’,
SIZE=100MB, MAXSIZE=200, FILEGROWTH=20) Пример
3.1.
Создание базы данных.
Изменение базы данных
Большинство действий по изменению конфигурации базы данных
выполняется с помощью следующей конструкции:
<изменение_базы_данных> ::=
ALTER DATABASE имя_базы_данных
{ ADD FILE <определение_файла>[,. ..n]
[TO FILEGROUP имя_группы_файлов ]
| ADD LOG FILE <определение_файла>[,...n]
| REMOVE FILE логическое_имя_файла
| ADD FILEGROUP имя_группы_файлов
| REMOVE FILEGROUP имя_группы_файлов
| MODIFY FILE <определение_файла>
| MODIFY FILEGROUP имя_группы_файлов
<свойства_группы_файлов>} ..n]
[TO FILEGROUP имя_группы_файлов ]
| ADD LOG FILE <определение_файла>[,...n]
| REMOVE FILE логическое_имя_файла
| ADD FILEGROUP имя_группы_файлов
| REMOVE FILEGROUP имя_группы_файлов
| MODIFY FILE <определение_файла>
| MODIFY FILEGROUP имя_группы_файлов
<свойства_группы_файлов>}
..n]
[TO FILEGROUP имя_группы_файлов ]
| ADD LOG FILE <определение_файла>[,...n]
| REMOVE FILE логическое_имя_файла
| ADD FILEGROUP имя_группы_файлов
| REMOVE FILEGROUP имя_группы_файлов
| MODIFY FILE <определение_файла>
| MODIFY FILEGROUP имя_группы_файлов
<свойства_группы_файлов>}Как видно из синтаксиса, за один вызов команды может быть изменено не
более одного параметра конфигурации базы данных. Если необходимо
выполнить несколько изменений, придется разбить процесс на ряд
отдельных шагов.
В базу данных можно добавить ( ADD ) новые файлы данных (в указанную
группу файлов или в группу, принятую по умолчанию) или файлы журнала
транзакций.
Параметры файлов и групп файлов можно изменять ( MODIFY ).
Для удаления из базы данных файлов или групп файлов используется
параметр REMOVE. Однако удаление файла возможно лишь при условии его
Однако удаление файла возможно лишь при условии его
освобождения от данных. В противном случае сервер не разрешит
удаление.
В качестве свойств группы файлов используются следующие:
READONLY – группа файлов используется только для чтения; READWRITE –
в группе файлов разрешаются изменения; DEFAULT – указанная группа
файлов принимается по умолчанию.
Удаление базы данных
Удаление базы данных осуществляется командой:
DROP DATABASE имя_базы_данных [,...n]
Удаляются все содержащиеся в базе данных объекты, а также файлы, в
которых она размещается. Для исполнения операции удаления базы данных
пользователь должен обладать соответствующими правами.
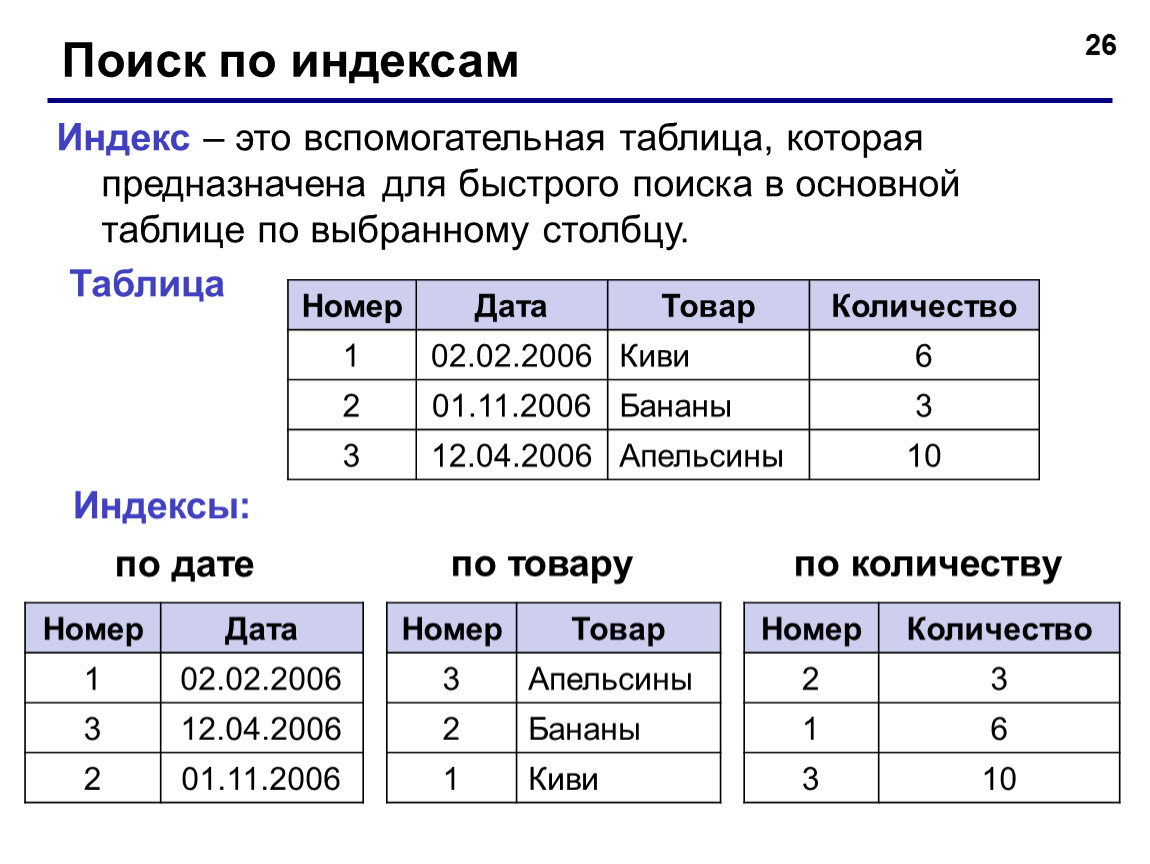
Что такое индекс базы данных? — Глоссарий ИТ
Определение индекса базы данных
Индекс базы данных Определение
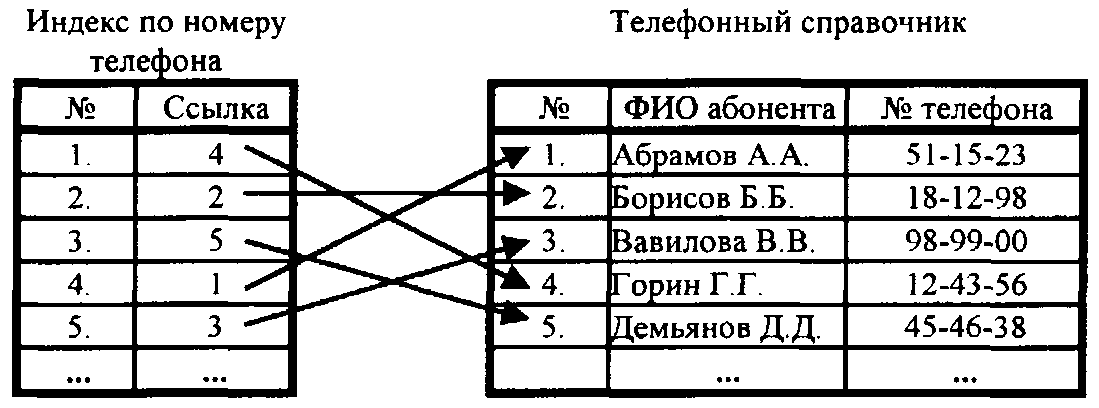
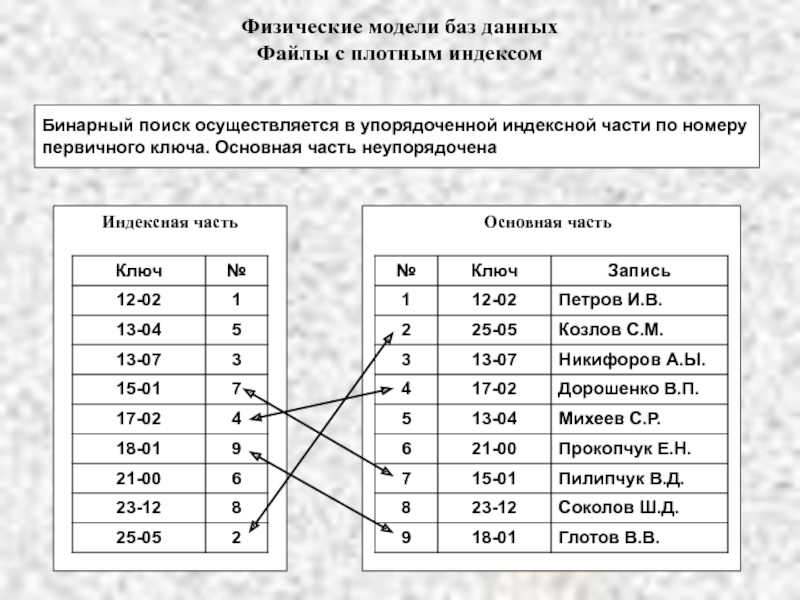
Индекс предлагает эффективный способ быстрого доступа к записям из файлов базы данных, хранящихся на диске.
Он оптимизирует скорость запросов к базе данных, выступая в качестве организованной таблицы поиска с указателями на расположение запрошенных данных.Почему индексирование используется в базе данных?
Почему в базе данных используется индексация?
Достижения в области технологий баз данных позволяют компаниям эффективно хранить терабайты информации в больших базах данных. Однако быстрый доступ к данным из больших баз данных сегодня имеет решающее значение для успеха бизнеса. Организации могут быстро извлекать нужную информацию из больших объемов данных с помощью индексации базы данных.
Большинство баз данных хранят данные в виде записи (также известной как кортеж) в разных таблицах. Каждый должен иметь определенный ключ или атрибут для уникальной идентификации, известный как первичный ключ. Например, первичным ключом в таблице сотрудников в базе данных может быть идентификатор сотрудника, который будет уникальным в каждой записи.
Индекс идентификатора сотрудника систематически хранит эти специальные ключи вместе с указателем, показывающим место на диске, где хранится фактическая запись. Всякий раз, когда вы выполняете запрос с определенным значением ключа, таким как идентификатор сотрудника, база данных быстро просматривает индекс, чтобы найти записи, связанные с ключом, вместо того, чтобы проверять каждую запись в таблице.Поскольку индексирование оптимизирует производительность запросов, большинство систем управления базами данных поддерживают встроенные и определяемые пользователем индексы. Столбцы таблицы, помеченные ограничениями уникальности или первичного ключа, могут иметь неявные индексы в большинстве баз данных. Напротив, определяемые пользователем индексы полезны, когда большинство запросов к базе данных содержат столбцы, не являющиеся первичными ключами.
Индексация также имеет определенные недостатки. Если это сделать неправильно, это может негативно повлиять на скорость операций обновления и удаления в больших базах данных, поскольку транзакции должны поддерживать как таблицы, так и индексы.
Кроме того, индексные таблицы требуют дополнительного места в базовых физических структурах хранения баз данных, а также регулярного планового профилактического обслуживания.Архитектура индекса и методы индексирования
Архитектура индекса и методы индексирования
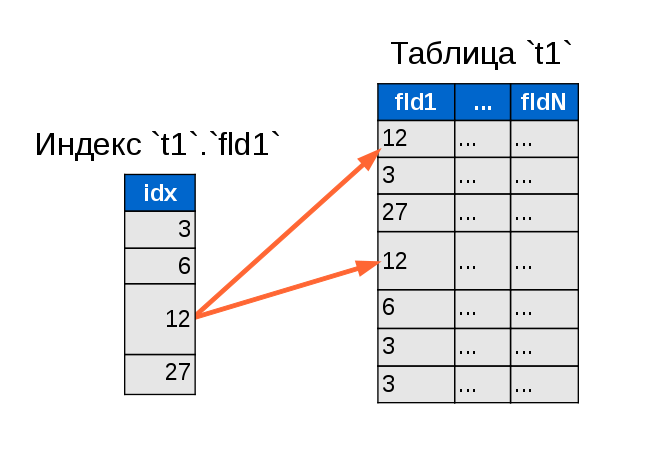
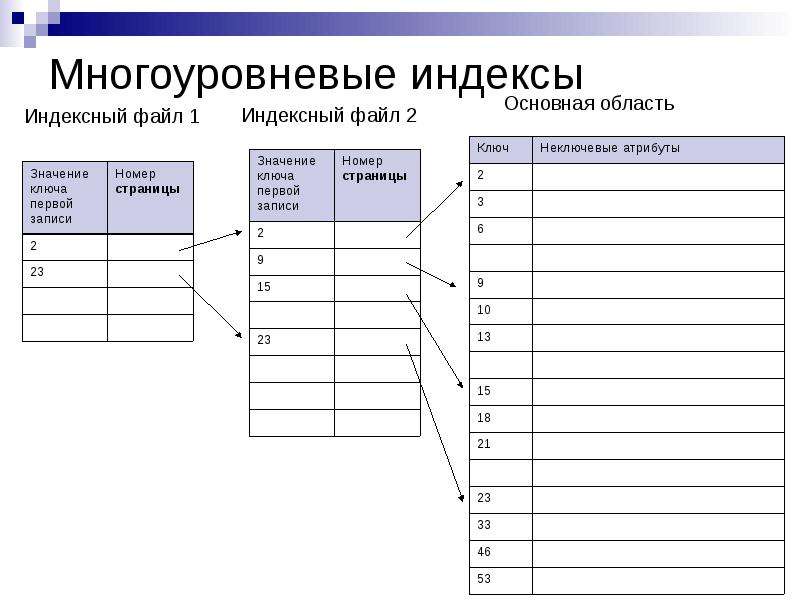
Индексы обычно используют структуру сбалансированного дерева (т. е. B-дерева) для хранения данных в отсортированном виде. (Возможны и другие структуры индексов, такие как хеш-индекс Oracle, но они встречаются редко). Использование B-tree также увеличивает скорость поиска данных и операций доступа в базе данных. Структура данных, связанная с индексом, имеет два поля. В первом поле хранятся значения столбца базы данных, который сортирует индекс. В другом поле хранится группа указателей, помогающих определить расположение на диске значений столбца.
Ниже приведены некоторые из ключевых аспектов индексов баз данных:
Кардинальность: — один из важных аспектов, который следует учитывать при создании индексов базы данных.
Столбец таблицы содержит как уникальные, так и неуникальные значения. Мощность индекса — это общее количество неповторяющихся значений, которые он содержит. Кардинальность выражается с высокой и низкой точки зрения. В случае высокой кардинальности большинство значений в проиндексированном столбце различаются. И наоборот, большинство значений в проиндексированном столбце повторяются с низкой кардинальностью.Например, предположим таблицу сотрудников с тремя столбцами: идентификатор сотрудника, возраст и отдел. Количество элементов столбца идентификатора сотрудника с ограничением первичного ключа будет высоким, поскольку каждая запись будет иметь отдельное значение для этого поля. Напротив, мощность столбцов отдела и возраста будет низкой, поскольку они могут содержать несколько повторяющихся значений. Создание индекса для столбца с низкой кардинальностью нежелательно, поскольку при запросе он возвращает несколько записей, что увеличивает общее время выполнения запроса и снижает производительность базы данных.
Селективность: мощность индекса, деленная на общее количество кортежей в индексе, представляет селективность. Например, представьте, что таблица сотрудников имеет 100 строк, а один из ее индексированных столбцов имеет 50 уникальных значений, что также является кардинальностью столбца. Тогда селективность индексированного столбца будет 50/100 = 0,5. Селективность «1» считается лучшей, поскольку она указывает, что все значения в индексе уникальны. Избирательность столбца с ограничением первичного ключа всегда высока, поскольку он не содержит похожих значений.
Напротив, столбец, имеющий несколько неуникальных значений, имеет низкую селективность. Например, столбец «Пол» в таблице сотрудников с 10 000 записей будет иметь низкую избирательность, поскольку он содержит повторяющиеся значения, такие как «мужской» и «женский». Селективность столбца пола будет 2/10000 = 0,0002.
Поскольку большинство баз данных ориентируются на показатели селективности для создания идеального плана(ов) выполнения запросов, предпочтительнее создавать индексы для столбцов с высокой селективностью.
Например, создание индекса для столбца имени сотрудника будет намного лучше, чем для столбца пола, поскольку большинство значений в столбце имени сотрудника будут отличаться от столбца пола. Любой запрос, использующий значения столбца имени сотрудника в предложении WHERE, будет возвращать ограниченное количество записей по сравнению со столбцом пола. Это также сокращает время ответа на запрос, поскольку базе данных необходимо сканировать ограниченное количество записей, чтобы найти нужные данные.Плотность: помогает оценить количество повторяющихся значений в столбце таблицы. Его можно получить с помощью следующего уравнения: 1/количество уникальных значений в столбце. Это также означает, что индекс по столбцу с высокой плотностью будет возвращать больше записей для любого конкретного запроса, поскольку он содержит больше повторяющихся значений. Поэтому индексы с высокой плотностью отрицательно сказываются на времени выполнения запроса. Плотность также обратно пропорциональна селективности, поскольку более высокое значение селективности индекса приводит к меньшему количеству строк в выходных данных запроса.
Например, предположим таблицу сотрудников с тремя столбцами: идентификатор сотрудника, отдел и имя. Многие сотрудники могут принадлежать к одному и тому же отделу в этой таблице, но каждый сотрудник может иметь только один идентификатор. Следовательно, индекс столбца идентификатора сотрудника будет более «избирательным», чем столбец отдела, поскольку он имеет низкую плотность или нулевые повторяющиеся значения по сравнению со столбцом отдела. Оптимизаторы запросов в базах данных, таких как SQL Server, используют данные плотности для определения ожидаемого количества записей, которые столбец может вернуть при запросе к нему.
Метрики плотности, кардинальности и селективности, связанные с индексом, жизненно важны для оптимизаторов запросов к базе данных для создания эффективных планов выполнения запросов. Эти показатели позволяют базе данных определить, лучше ли использовать индексы для извлечения записей из базы данных. Например, если индекс имеет низкое значение селективности, часто лучше получить конкретную запись, просканировав всю таблицу, чем индекс.
Сканирование таблицы с помощью индекса требует больше времени и ресурсов базы данных, таких как память сервера и дисковый ввод-вывод. Следовательно, лучше избегать использования индексов, если это не дает значительных преимуществ в производительности.
 Он оптимизирует скорость запросов к базе данных, выступая в качестве организованной таблицы поиска с указателями на расположение запрошенных данных.
Он оптимизирует скорость запросов к базе данных, выступая в качестве организованной таблицы поиска с указателями на расположение запрошенных данных. Индекс идентификатора сотрудника систематически хранит эти специальные ключи вместе с указателем, показывающим место на диске, где хранится фактическая запись. Всякий раз, когда вы выполняете запрос с определенным значением ключа, таким как идентификатор сотрудника, база данных быстро просматривает индекс, чтобы найти записи, связанные с ключом, вместо того, чтобы проверять каждую запись в таблице.
Индекс идентификатора сотрудника систематически хранит эти специальные ключи вместе с указателем, показывающим место на диске, где хранится фактическая запись. Всякий раз, когда вы выполняете запрос с определенным значением ключа, таким как идентификатор сотрудника, база данных быстро просматривает индекс, чтобы найти записи, связанные с ключом, вместо того, чтобы проверять каждую запись в таблице. Кроме того, индексные таблицы требуют дополнительного места в базовых физических структурах хранения баз данных, а также регулярного планового профилактического обслуживания.
Кроме того, индексные таблицы требуют дополнительного места в базовых физических структурах хранения баз данных, а также регулярного планового профилактического обслуживания. Столбец таблицы содержит как уникальные, так и неуникальные значения. Мощность индекса — это общее количество неповторяющихся значений, которые он содержит. Кардинальность выражается с высокой и низкой точки зрения. В случае высокой кардинальности большинство значений в проиндексированном столбце различаются. И наоборот, большинство значений в проиндексированном столбце повторяются с низкой кардинальностью.
Столбец таблицы содержит как уникальные, так и неуникальные значения. Мощность индекса — это общее количество неповторяющихся значений, которые он содержит. Кардинальность выражается с высокой и низкой точки зрения. В случае высокой кардинальности большинство значений в проиндексированном столбце различаются. И наоборот, большинство значений в проиндексированном столбце повторяются с низкой кардинальностью.
 Например, создание индекса для столбца имени сотрудника будет намного лучше, чем для столбца пола, поскольку большинство значений в столбце имени сотрудника будут отличаться от столбца пола. Любой запрос, использующий значения столбца имени сотрудника в предложении WHERE, будет возвращать ограниченное количество записей по сравнению со столбцом пола. Это также сокращает время ответа на запрос, поскольку базе данных необходимо сканировать ограниченное количество записей, чтобы найти нужные данные.
Например, создание индекса для столбца имени сотрудника будет намного лучше, чем для столбца пола, поскольку большинство значений в столбце имени сотрудника будут отличаться от столбца пола. Любой запрос, использующий значения столбца имени сотрудника в предложении WHERE, будет возвращать ограниченное количество записей по сравнению со столбцом пола. Это также сокращает время ответа на запрос, поскольку базе данных необходимо сканировать ограниченное количество записей, чтобы найти нужные данные.
 Сканирование таблицы с помощью индекса требует больше времени и ресурсов базы данных, таких как память сервера и дисковый ввод-вывод. Следовательно, лучше избегать использования индексов, если это не дает значительных преимуществ в производительности.
Сканирование таблицы с помощью индекса требует больше времени и ресурсов базы данных, таких как память сервера и дисковый ввод-вывод. Следовательно, лучше избегать использования индексов, если это не дает значительных преимуществ в производительности.Индексы | Документация IntelliJ IDEA
Индекс базы данных — это структура, используемая для ускорения поиска и доступа к операциям в таблице базы данных. Используя индексы, вы уменьшаете количество обращений к диску, необходимых при обработке запроса. Вы можете создавать индексы для одного или нескольких столбцов таблицы базы данных.
Индексы можно увидеть в окне инструментов базы данных. Справку по значкам узлов и объектов можно найти в главе Значки для источников данных и их элементов раздела Окно инструмента базы данных.
Значки столбцов таблицы см. в разделе Возможные комбинации значков для столбцов.
Создать индекс
В окне инструментов База данных (Вид | Окна инструментов | База данных) разверните дерево источника данных до узла столбца.
Щелкните правой кнопкой мыши таблицу или столбец и выберите Создать | Индекс.
На панели «Столбцы» нажмите кнопку «Добавить» ().
В поле Имя столбца укажите имя столбца, который вы хотите добавить в индекс.
Нажмите OK.

Изменение шаблонов для сгенерированных имен индексов и ключей
При создании индексов и ограничений первичных и внешних ключей их имена по умолчанию генерируются в соответствии с соответствующими шаблонами. Например, для первичного ключа используется шаблон {table}_{columns}_pk .
Чтобы просмотреть и изменить эти шаблоны, откройте настройки Ctrl+Alt+S и перейдите к Editor | стиль кода | SQL | Общий.