Index sql server create: CREATE INDEX (Transact-SQL) — SQL Server
Содержание
Пять главных соображений по дизайну индекса SQL Server
В этой статье мы обсудим наиболее важные моменты, которые следует учитывать при проектировании оптимального SQL-индекса. Прежде чем перейти к процедуре проектирования индекса, давайте пересмотрим концепцию индекса SQL Server.
Примечание . Дополнительные сведения об индексах SQL Server см. в статье Индексы SQL Server: основные требования, влияние на производительность и рекомендации.
Обзор индекса SQL Server
Индекс SQL считается одним из наиболее важных факторов в области настройки производительности SQL Server. Это помогает ускорить запросы, предоставляя быстрый доступ к запрошенным данным, что называется операцией поиска по индексу, вместо сканирования всей таблицы для извлечения нескольких записей. Он работает аналогично указателю книги, который помогает определить местонахождение каждого уникального слова, предоставляя страницу, на которой вы можете найти это слово, вместо того, чтобы тратить целые будние дни на чтение книги, чтобы проверить конкретную тему или определить это слово. Другими словами, наличие этого индекса сэкономит время и ресурсы.
Другими словами, наличие этого индекса сэкономит время и ресурсы.
SQL Server предоставляет нам два основных типа индексов. Кластерный индекс, который используется для хранения всех данных таблицы на основе ключа индекса выбора, состоит из одного или нескольких столбцов с возможностью создания только одного кластеризованного индекса для каждой таблицы. Существование кластеризованного индекса превращает таблицу из несортированной таблицы кучи в отсортированную кластеризованную таблицу.
- Дополнительные сведения о кластерном индексе см. в разделе Разработка эффективных кластерных индексов SQL Server.
Второй основной тип индексов SQL Server — это некластеризованный индекс, в котором конечные узлы этого индекса хранят только значения ключа индекса с указателем на место хранения этих строк в основной таблице кучи или кластеризованный индекс с возможность создания до 99 некластеризованных индексов для каждой таблицы.
- Дополнительные сведения о некластеризованном индексе см.
 в разделе Проектирование эффективных некластеризованных индексов SQL Server.
в разделе Проектирование эффективных некластеризованных индексов SQL Server.
 в разделе Проектирование эффективных некластеризованных индексов SQL Server.
в разделе Проектирование эффективных некластеризованных индексов SQL Server. SQL Server также предоставляет нам другие SQL-индексы специального назначения, полученные из кластеризованных и некластеризованных типов, которые могут помочь в повышении производительности запросов T-SQL. Эти индексы включают уникальный индекс, отфильтрованный индекс, пространственный индекс, XML-индекс, индекс Clomunstore, полнотекстовый индекс и хэш-индекс.
- Более подробные сведения об этих типах см. в разделе Работа с различными типами индексов SQL Server.
После создания индекса нам также необходимо отслеживать его использование, чтобы убедиться, что он по-прежнему эффективен и полезен для нас. Это можно сделать, собрав статистическую информацию об индексах и их использовании, а затем выполнив надлежащую операцию обслуживания этих индексов, чтобы поддерживать их в работоспособном состоянии.
Рекомендации по проектированию указателей
Целью задачи разработки индекса SQL Server является создание индекса, который оптимизатор запросов SQL Server выберет для повышения производительности отправленных запросов. Во всех своих статьях и сессиях я описывал индекс как обоюдоострый меч. Таким образом, я позабочусь о том, чтобы мы не обвиняли индекс в наших ошибках. Индекс будет нашим супергероем и улучшит производительность наших запросов, если мы правильно его спроектируем. Но если этот индекс плохо спроектирован, это приведет к снижению производительности наших запросов и замедлит процесс извлечения данных. Другими словами, отсутствие плохо разработанных индексов лучше, чем их наличие.
Во всех своих статьях и сессиях я описывал индекс как обоюдоострый меч. Таким образом, я позабочусь о том, чтобы мы не обвиняли индекс в наших ошибках. Индекс будет нашим супергероем и улучшит производительность наших запросов, если мы правильно его спроектируем. Но если этот индекс плохо спроектирован, это приведет к снижению производительности наших запросов и замедлит процесс извлечения данных. Другими словами, отсутствие плохо разработанных индексов лучше, чем их наличие.
Процесс выбора правильного индекса SQL Server, соответствующего требованиям вашей базы данных и рабочей нагрузки, — задача не из легких, но и не невыполнимая. В этом процессе вам необходимо сбалансировать выигрыш индекса в форме ускорения операции извлечения данных и накладные расходы индекса на операции вставки и изменения данных.
Чтобы помочь вам в разработке правильного индекса, который оптимизатор запросов SQL Server будет использовать для повышения производительности ваших запросов, мы обсудим здесь пять основных моментов, которые необходимо учитывать при планировании создания индекса.
Дизайн базы данных
Чтобы спроектировать правильный индекс, вам необходимо изучить характеристики базы данных, на которой будет создан индекс SQL Server. Если база данных создается для обработки рабочей нагрузки оперативной обработки транзакций (OLTP) с большим количеством запросов на вставку и изменение данных, рекомендуется не перегружать базу данных большим количеством индексов. Это связано с тем, что вставка, обновление или удаление любой строки в базовой таблице также потребует отражения тех же изменений во всех связанных индексах в этой таблице. Итак, вы должны создать минимально возможное количество индексов в OLTP-таблицах с наименьшим возможным количеством столбцов, участвующих в ключе индекса. Таким образом, мы можем воспользоваться преимуществами созданных индексов SQL для ускорения процесса извлечения данных с минимальными затратами на операции модификации данных.
Если база данных создается для обработки рабочей нагрузки оперативной аналитической обработки (OLAP), которая используется в хранилище данных как часть структуры бизнес-аналитики, большая часть рабочей нагрузки будет в форме запросов SELECT для извлечения большого объема аналитических данных. для целей анализа или отчетности, а также небольшое количество запросов на изменение данных. В этом случае вы можете создать большое количество индексов SQL Server, добавив все необходимые столбцы в качестве ключевых или неключевых столбцов индекса, чтобы повысить производительность запросов SELECT и быстрее получить запрошенные данные.
для целей анализа или отчетности, а также небольшое количество запросов на изменение данных. В этом случае вы можете создать большое количество индексов SQL Server, добавив все необходимые столбцы в качестве ключевых или неключевых столбцов индекса, чтобы повысить производительность запросов SELECT и быстрее получить запрошенные данные.
Еще одна вещь, которую следует учитывать при индексировании таблицы базы данных, — это размер таблицы. Если таблица небольшая и содержит менее 1000 страниц, индексирование этой таблицы не даст повышения производительности, поскольку оптимизатор запросов SQL Server предпочтет сканирование всей таблицы, а не изучение индекса SQL, и попытается создать наилучший возможный план. Другими словами, этот индекс в маленькой таблице не будет использоваться и будет иметь накладные расходы на таблицу, поскольку он должен поддерживаться при изменении таблицы.
Вам также необходимо взглянуть на представления базы данных и проверить те, которые содержат несколько объединений и агрегаций, и создать индексы для этих представлений, чтобы повысить производительность чтения из них.
- Дополнительные сведения о представлениях индекса см. в разделе Индексированные представления SQL Server.
Запрос T-SQL
Изучение запросов, которые очень часто обращаются к таблицам базы данных, путем проверки с разработчиком системы или использования инструментов профилирования, таких как SQL Profiler или расширенные события, поможет в разработке индекса SQL Server, который еще больше поможет повысить общую производительность системы.
Получив статистику о часто выполняемых запросах, мы должны проверить столбцы, которые используются в предикатах и условиях соединения в этих запросах, и создать правильный индекс, добавив в индекс все необходимые столбцы, чтобы охватить часто выполняемый запрос и избежать любых ненужных столбец, чтобы ускорить операцию извлечения данных.
Разработчикам SQL Server рекомендуется писать запросы на вставку и изменение данных, чтобы вставлять, обновлять или удалять как можно больше строк в одном запросе, а не писать несколько запросов. Это поможет сократить накладные расходы индекса на оператор изменения данных, где все эти изменения, выполненные в таблице, будут реплицированы в индекс SQL как одноразовый при выполнении в виде одного запроса.
Это поможет сократить накладные расходы индекса на оператор изменения данных, где все эти изменения, выполненные в таблице, будут реплицированы в индекс SQL как одноразовый при выполнении в виде одного запроса.
Столбцы
Изучив характеристику часто выполняемого запроса, которую нам нужно улучшить, и имея список столбцов для участия в ключе индекса, нам нужно учитывать некоторые моменты при выборе того, какой столбец мы должны добавить в индекс.
Первый пункт – это характеристика столбца. Не все типы данных рекомендуется использовать в качестве ключа индекса. Например, наилучшим типом данных-кандидатом для индекса SQL Server является целочисленный столбец из-за его небольшого размера. С другой стороны, столбцы с типами данных text, ntext, image, varchar(max), nvarchar(max) и varbinary(max) не могут участвовать в ключе индекса. Однако большую его часть все же можно добавить в некластеризованные неключевые столбцы. Столбец с типом данных XML можно добавить только в индекс XML.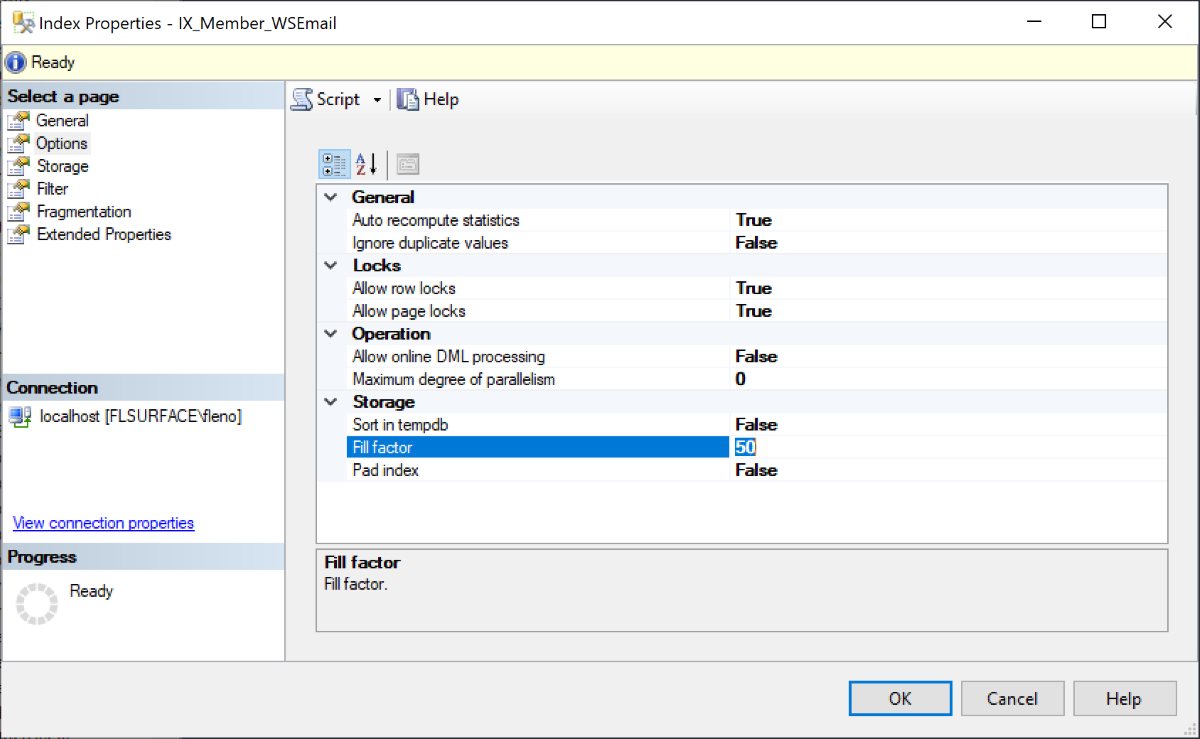 Кроме того, столбец со значениями UNIQUE и NOT NULL будет хорошим кандидатом из-за его высокого уровня селективности в качестве ключевого столбца индекса, что делает индекс более полезным.
Кроме того, столбец со значениями UNIQUE и NOT NULL будет хорошим кандидатом из-за его высокого уровня селективности в качестве ключевого столбца индекса, что делает индекс более полезным.
Второй момент — расположение столбца в запросе. Например, столбцы, используемые в предложении WHERE, предсказании JOIN, LIKE и предложении ORDER BY, являются лучшими столбцами-кандидатами для индексации. Кроме того, индексирование вычисляемых столбцов и столбцов внешнего ключа повысит производительность запросов, считывающих данные из этих столбцов.
Важным моментом, который следует учитывать после выбора правильных столбцов, которые будут задействованы в ключе индекса, является порядок столбцов в ключе индекса, особенно когда ключ состоит из нескольких столбцов. Попробуйте разместить столбцы, которые используются в условиях запроса, сначала в ключе индекса SQL Server. Кроме того, попробуйте определить критерии сортировки столбцов по возрастанию или по убыванию таким образом, чтобы они соответствовали порядку, используемому в предложении ORDER BY в вашем запросе. Таким образом, вы преодолеете высокие накладные расходы оператора SORT, повысив производительность запроса.
Таким образом, вы преодолеете высокие накладные расходы оператора SORT, повысив производительность запроса.
Типы индексов
На этом шаге мы приняли решение, что нам нужно создать индекс в конкретной таблице базы данных, чтобы охватить конкретный запрос, который вызывается очень часто, и нам нужно добавить столбцы-кандидаты в ключ индекса. Теперь нам нужно решить, какой тип индекса SQL соответствует требованиям запроса. Другими словами, нам нужно указать, должны ли мы создавать кластеризованный или некластеризованный индекс, уникальный или неуникальный индекс, индекс columnstore или rowstore. Все эти решения будут приниматься на основе покрытия запросов и требований к улучшениям.
Как упоминалось ранее, SQL Server предоставляет нам различные типы индексов специального назначения, которые мы можем использовать для повышения производительности запросов. Например, попробуйте использовать отфильтрованный индекс для столбцов с четко определенными подмножествами данных, таких как разреженные столбцы, в основном содержащие значения NULL.
- Дополнительные сведения о различных типах индексов SQL см. в разделе Работа с различными типами индексов SQL Server.
Рекомендуется начать индексирование таблицы с создания кластеризованного индекса, который охватывает столбцы, вызываемые очень часто, что преобразует их из таблицы кучи в отсортированную кластеризованную таблицу, а затем создает необходимые некластеризованные индексы, которые охватывают столбцы. оставшиеся запросы в системе. Таким образом, некластеризованные индексы будут построены на основе кластеризованного индекса SQL Server, а указатели на конечных узлах некластеризованных индексов также будут указывать на расположение строки в отсортированном кластеризованном индексе.
Если кластеризованный индекс создается для таблицы с уже существующими кластеризованными индексами, все некластеризованные индексы будут удалены и созданы снова, чтобы изменить указатели в узлах листового уровня, которые указывали на таблицу кучи, чтобы они указывали на вновь созданную таблицу. кластерный индекс. Таким образом, создание его в правильном порядке позволит преодолеть накладные расходы на повторное воссоздание некластеризованного индекса.
кластерный индекс. Таким образом, создание его в правильном порядке позволит преодолеть накладные расходы на повторное воссоздание некластеризованного индекса.
Хранение индексов
При создании индекса SQL Server он будет храниться в той же файловой группе, где создается основная таблица. Разделенный кластеризованный индекс и некластеризованный индекс могут храниться в той же файловой группе, что и основная таблица, или в другой файловой группе.
Выбор правильных критериев хранения для индекса на этапе проектирования поможет повысить производительность запросов за счет увеличения производительности ввода-вывода. Например, создание некластеризованного индекса для файловой группы, расположенной на другом диске, отличном от диска, на котором создается основная таблица, повысит производительность запросов, использующих этот некластеризованный индекс, поскольку на него не повлияют одновременное чтение данных и страниц индекса SQL, распределенных по разным дискам, которые будут выполняться на разных дисках.
Кроме того, кластеризованные и некластеризованные индексы, созданные для больших таблиц, могут быть разделены на несколько файловых групп, при этом каждая файловая группа хранится на отдельном диске, что улучшает одновременный доступ к данным и операции извлечения благодаря тому, что данные распределяются по разным дискам в индексе SQL, и оптимизатор запросов будет обрабатывать только те разделы, к которым будет обращаться запрос, исключая все остальные разделы.
Другой важной концепцией хранения, которую следует учитывать, является параметр FILLFACTOR, который можно определить при создании или перестроении индекса со значением от 0 до 100, указывающим процент пространства, которое будет заполнено на каждом листе. -страница данных уровня в созданном индексе. Например, установка значения FILLFACTOR на 80% оставит 20% каждой страницы пустой во время процесса создания или перестроения индекса SQL Server, и эти 20% процента помогут, когда вставляются новые данные или существующие данные изменяются, но не помещается в текущее пространство, где данные будут вставлены в это свободное пространство вместо разделения текущей страницы на несколько страниц, вызывающих проблему фрагментации индекса, которая со временем ухудшит производительность индекса.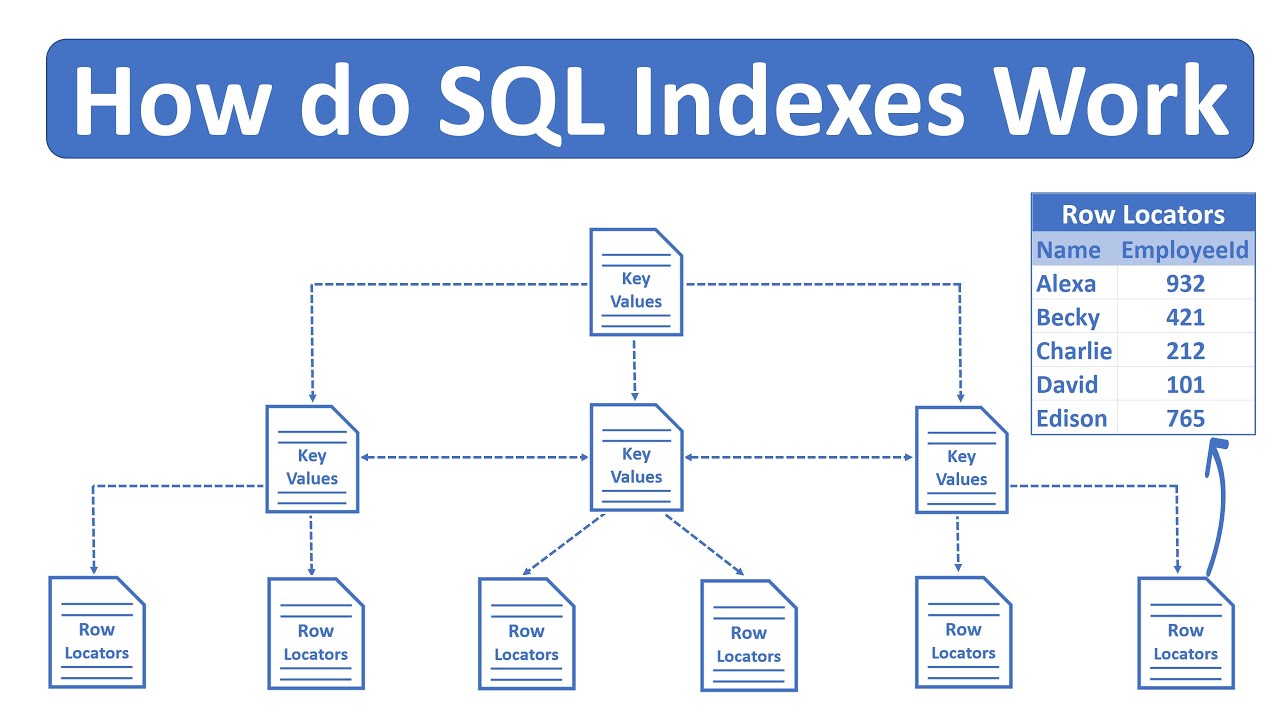 Коэффициент заполнения поможет повысить производительность запросов T-SQL и свести к минимуму объем хранилища индексов и накладные расходы на обслуживание индексов.
Коэффициент заполнения поможет повысить производительность запросов T-SQL и свести к минимуму объем хранилища индексов и накладные расходы на обслуживание индексов.
Также рекомендуется создавать узкие индексы с наименьшим возможным количеством полезных столбцов, а не создавать широкие индексы с большим количеством ненужных столбцов, поскольку это требует меньше места на диске и снижает затраты на обслуживание индекса SQL Server.
Все ранее упомянутые пункты помогут в разработке наиболее оптимального индекса, повышающего производительность запросов T-SQL, но очень важно сначала протестировать индекс в среде разработки, прежде чем создавать его в производственной среде, и убедиться, что он полезен для вашей рабочей нагрузки, и продолжайте следить за ним и мариновать его после создания в производственной среде.
- Автор
- Последние сообщения
Ахмад Ясин
Ахмад Ясин — инженер Microsoft по работе с большими данными, обладающий глубокими знаниями и опытом в области SQL BI, администрирования баз данных SQL Server и разработки.
Он является сертифицированным экспертом Microsoft по решениям в области управления данными и аналитики, сертифицированным специалистом по решениям Microsoft в области администрирования и разработки баз данных SQL, специалистом по разработке Azure и сертифицированным тренером Microsoft.
Кроме того, он публикует свои советы по SQL во многих блогах.
Просмотреть все сообщения Ахмада Ясина
Последние сообщения Ахмада Ясина (посмотреть все)
sql server — Сгенерировать сценарий всех индексов в базе данных
Я знаю, что эта ветка очень старая и это не самая красивая вещь в мире, но мне нужен был хранимый процесс, который генерировал бы индексы для указанной базы данных, и я не мог найти его в Интернете, поэтому это то, что я создал.
Эта хранимая процедура принимает имя базы данных в качестве параметра, а затем создает tsql для создания всех индексов в базе данных. Он учитывает параметры индекса, схему, владельца и столбцы INCLUDE.
```
использовать инструменты базы данных
идти
создать процедуру usp_script_index @dbname sysname
как
объявить @SchemaName varchar (100)
объявить @TableName varchar (256)
объявить @IndexName varchar (256)
объявить @ColumnName varchar (100)
объявить @is_unique varchar (100)
объявить @IndexTypeDesc varchar (100)
объявить @FileGroupName varchar (100)
объявить @is_disabled varchar (100)
объявить @IndexOptions varchar (макс.
объявить @IndexColumnId int
объявить @IsDescendingKey int
объявить @IsIncludedColumn int
объявить @TSQLScripCreationIndex varchar(max)
объявить @TSQLScripDisableIndex varchar(max)
IF DB_ID(@dbname) IS NULL /*Проверка существования имени базы данных*/
НАЧИНАТЬ
RAISERROR('Передано неверное имя базы данных',16,1)
ВОЗВРАЩАТЬСЯ
КОНЕЦ
установить нулевой счет на
создать таблицу #tbls (
sch_name системное имя,
имя_таблицы системное имя,
имя_индекса имя_системы,
уникальный_флаг varchar(20),
type_desc varchar(20),
параметры индекса varchar (500),
is_disabled целое,
fileGroupName системное имя
)
ОБЪЯВИТЬ @dynsql nvarchar(max)
объявить @dynsql2 nvarchar(max)
/*Используйте QUOTENAME, чтобы правильно экранировать любые специальные символы*/
SET @dynsql = N'insert #tbls select
имя_схемы(t.schema_id) [имя_схемы],
t.name как tbl_name,
ix.name как index_name,
случай, когда ix.is_unique = 1, тогда ''UNIQUE'' else '''' END as unique_flag
, ix.type_desc,
случай, когда ix.is_padded=1, тогда ''PAD_INDEX = ON,'' иначе ''PAD_INDEX = OFF, '' end
+ случай, когда ix.
+ случай, когда ix.allow_row_locks=1, тогда ''ALLOW_ROW_LOCKS = ON,'' иначе ''ALLOW_ROW_LOCKS = OFF,'' end
+ случай, когда INDEXPROPERTY(t.object_id, ix.name, ''IsStatistics'') = 1, тогда ''STATISTICS_NORECOMPUTE = ON,''
иначе ''STATISTICS_NORECOMPUTE = OFF,'' конец
+ случай, когда ix.ignore_dup_key=1, тогда ''IGNORE_DUP_KEY = ON,'' иначе ''IGNORE_DUP_KEY = OFF,'' end
+ ''SORT_IN_TEMPDB = OFF, FILLFACTOR ='' + CAST(ix.fill_factor AS VARCHAR(3)) AS IndexOptions
, ix.is_disabled , FILEGROUP_NAME(ix.data_space_id) FileGroupName
из ' + @dbname +'.sys.tables t
внутреннее соединение ' + @dbname +'.sys.indexes ix на t.object_id=ix.object_id
где ix.type>0 и ix.is_primary_key=0 и ix.is_unique_constraint=0
и t.is_ms_shipped=0 и t.name<>''системные диаграммы''
порядок по schema_name(t.schema_id), t.name, ix.name'
exec sp_executesql @dynsql
print 'use' + @dbname + char(10) +'go' +char(10)
объявить курсор CursorIndex для выбора sch_name, tbl_name, index_name,unique_flag, type_desc, indexoptions,is_disabled,fileGroupName из #tbls
открыть CursorIndex
выбрать следующий из CursorIndex в @SchemaName, @TableName, @IndexName, @is_unique, @IndexTypeDesc, @IndexOptions, @is_disabled, @FileGroupName
пока (@@fetch_status=0)
начинать
объявить @IndexColumns varchar(max)
объявить @IncludedColumns varchar(max)
установить @IndexColumns=''
установить @IncludedColumns=''
создать таблицу #cols
(
имя_столбца системное имя,
is_descending_key целое,
is_included_column целое
)
SET @dynsql2 = N 'вставить #cols
выберите col.
from '+ @dbname + '.sys.tables tb
внутреннее соединение ' +@dbname +'.sys.indexes ix на tb.object_id=ix.object_id
внутреннее соединение ' +@dbname +'.sys.index_columns ixc на ix.object_id=ixc.object_id и ix.index_id= ixc.index_id
внутреннее соединение ' +@dbname +'.sys.columns col на ixc.object_id =col.object_id и ixc.column_id=col.column_id
где ix.type>0 и (ix.is_primary_key=0 или ix.is_unique_constraint=0)
и schema_name(tb.schema_id)=''' + @SchemaName + ''' и tb.name= ''' + @TableName + ''' и ix.name=''' + @IndexName + ''' в порядке ixc.index_column_id '
--print @dynsql2
exec sp_executesql @dynsql2
объявить курсор CursorIndexColumn для выбора column_name, is_descending_key, is_included_column из #cols
открыть CursorIndexColumn
выбрать следующий из CursorIndexColumn в @ColumnName, @IsDescendingKey, @IsIncludedColumn
пока (@@fetch_status=0)
начинать
если @IsIncludedColumn=0
установить @IndexColumns=@IndexColumns + @ColumnName + случай, когда @IsDescendingKey=1 затем ' DESC, ' иначе ' ASC, ' конец
еще
установить @IncludedColumns=@IncludedColumns + @ColumnName +', '
выбрать следующий из CursorIndexColumn в @ColumnName, @IsDescendingKey, @IsIncludedColumn
конец
отбросить таблицу #cols
закрыть CursorIndexColumn
освободить CursorIndexColumn
установить @IndexColumns = substring(@IndexColumns, 1, len(@IndexColumns)-1)
set @IncludedColumns = случай, когда len(@IncludedColumns) >0, затем подстрока(@IncludedColumns, 1, len(@IncludedColumns)-1) else '' end
-- распечатать @IndexColumns
-- распечатать @IncludedColumns
установить @TSQLScripCreationIndex = ''
установить @TSQLScripDisableIndex = ''
set @TSQLScripCreationIndex='CREATE '+ @is_unique +@IndexTypeDesc + ' INDEX ' +QUOTENAME(@IndexName)+' ON ' + QUOTENAME(@SchemaName) +'.
 )
) allow_page_locks=1, тогда ''ALLOW_PAGE_LOCKS = ON,'' иначе ''ALLOW_PAGE_LOCKS = OFF, '' end
allow_page_locks=1, тогда ''ALLOW_PAGE_LOCKS = ON,'' иначе ''ALLOW_PAGE_LOCKS = OFF, '' end name как имя_столбца, ixc.is_descending_key, ixc.is_included_column
name как имя_столбца, ixc.is_descending_key, ixc.is_included_column