Index sql: SQL CREATE INDEX Statement
Содержание
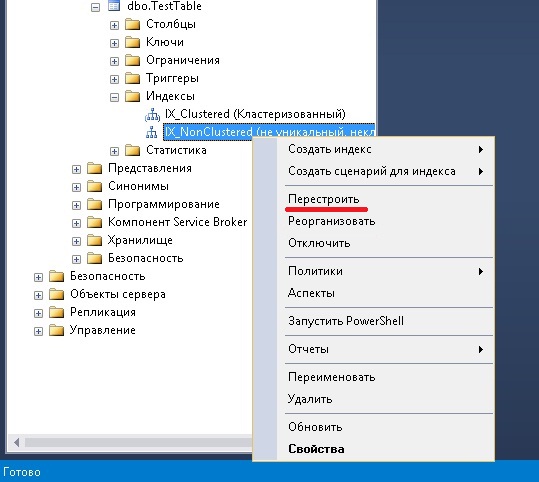
SQL Index Manager — бесплатный тул для обслуживания индексов на SQL Server и Azure
В рубрике DOU Проектор специалисты рассказывают о том, как создавали свой продукт (как стартап, так и ламповый pet-проект).
Всем доброго дня. Меня зовут Сыроватченко Сергей. Более 8 лет работаю SQL Server DBA, занимаясь администрированием серверов и оптимизацией производительности. В свободное время захотелось сделать что-то полезное для Вселенной и коллег по цеху. Так в итоге получился опенсорс тул по обслуживанию индексов для SQL Server и Azure.
Идея
Порой люди при работе над своими приоритетами могут напоминать пальчиковую батарейку — мотивационного заряда хватает лишь на одну вспышку, и потом все. И до недавнего времени я не был исключением из этого жизненного наблюдения. Часто меня посещали идеи создать что-то свое, но менялись приоритеты и ничего не доводилось до конца.
Достаточно сильное влияние на мою мотивацию и профессиональное развитие оказала работа в харьковской компании Devart, которая занималась созданием софта для разработки и администрирования баз данных SQL Server, MySQL и Oracle.
До того как прийти к ним, я мало представлял себе специфику создания собственного продукта, но уже в процессе работы почерпнул много знаний о внутреннем устройстве SQL Server. Больше года занимаясь оптимизацией запросов к метаданным в их продуктовых линейках, я постепенно стал понимать, какой функционал больше другого востребован на рынке.
На определенном этапе возникла идея сделать новый нишевый продукт, но в силу обстоятельств эта задумка не взлетела. На тот момент для нового проекта банально не нашлось достаточного количества свободных ресурсов внутри компании без ущерба для основной деятельности.
Уже когда работал на новом месте и пытался делать проект своими силами, приходилось постоянно идти на какие-то компромиссы. Первоначальная задумка сделать большой и напичканный фичами продукт быстро сошла на нет и постепенно трансформировалась в иное русло — разбить запланированный функционал на отдельные мини-тулы и реализовывать их независимо друг от друга.
В итоге так на свет появился SQL Index Manager — бесплатный тул по обслуживанию индексов для SQL Server и Azure. Главной идеей было взять за основу коммерческие альтернативы от компаний RedGate и Devart и постараться улучшить их функционал. Предоставить, как для начинающих, так и опытных пользователей, возможность удобно анализировать и обслуживать индексы.
Главной идеей было взять за основу коммерческие альтернативы от компаний RedGate и Devart и постараться улучшить их функционал. Предоставить, как для начинающих, так и опытных пользователей, возможность удобно анализировать и обслуживать индексы.
Реализация
На словах все всегда звучит просто… такой взял посмотрел пару мотивирующих видосиков, встал в стоечку и начал делать крутой продукт. Но на практике не все так радужно, поскольку существует много подводных камней при работе с системной табличной функцией sys.dm_db_index_physical_stats и по совместительству единственным местом, откуда можно получить актуальную информацию о фрагментации индексов.
С первых дней разработки была отличная возможность проложить себе тоскливый путь среди стандартных схем и скопировать уже отлаженную логику работы приложений-конкурентов, добавив при этом немного отсебятины. Но после анализа запросов к метаданным захотелось сделать что-то более оптимизированное, что в силу бюрократии больших компаний никогда бы не появилось в их продуктах.
При анализе RedGate SQL Index Manager (1.1.9.1378 — 155$) можно увидеть, что приложение использует весьма простой подход: одним запросом получаем список пользовательских таблиц и представлений, а после вторым запросом возвращается список всех индексов в рамках выбранной базы данных.
SELECT objects.name AS tableOrViewName , objects.object_id AS tableOrViewId , schemas.name AS schemaName , CAST(ISNULL(lobs.NumLobs, 0) AS BIT) AS ContainsLobs , o.is_memory_optimized FROM sys.objects AS objects JOIN sys.schemas AS schemas ON schemas.schema_id = objects.schema_id LEFT JOIN ( SELECT object_id , COUNT(*) AS NumLobs FROM sys.columns WITH (NOLOCK) WHERE system_type_id IN (34, 35, 99) OR max_length = -1 GROUP BY object_id ) AS lobs ON objects.object_id = lobs.object_id LEFT JOIN sys.tables AS o ON o.object_id = objects.object_id WHERE objects.type = 'U' OR objects.type = 'V' SELECT i.object_id AS tableOrViewId , i.name AS indexName , i.index_id AS indexId , i.allow_page_locks AS allowPageLocks , p.partition_number AS partitionNumber , CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex FROM sys.indexes AS i JOIN sys.partitions AS p ON p.index_id = i.index_id AND p.object_id = i.object_id JOIN ( SELECT COUNT(*) AS numPartitions , object_id , index_id FROM sys.partitions GROUP BY object_id , index_id ) AS c ON c.index_id = i.index_id AND c.object_id = i.object_id WHERE i.index_id > 0 -- ignore heaps AND i.is_disabled = 0 AND i.is_hypothetical = 0
 index_id AS indexId
, i.allow_page_locks AS allowPageLocks
, p.partition_number AS partitionNumber
, CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex
FROM sys.indexes AS i
JOIN sys.partitions AS p ON p.index_id = i.index_id
AND p.object_id = i.object_id
JOIN (
SELECT COUNT(*) AS numPartitions
, object_id
, index_id
FROM sys.partitions
GROUP BY object_id
, index_id
) AS c ON c.index_id = i.index_id
AND c.object_id = i.object_id
WHERE i.index_id > 0 -- ignore heaps
AND i.is_disabled = 0
AND i.is_hypothetical = 0
index_id AS indexId
, i.allow_page_locks AS allowPageLocks
, p.partition_number AS partitionNumber
, CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex
FROM sys.indexes AS i
JOIN sys.partitions AS p ON p.index_id = i.index_id
AND p.object_id = i.object_id
JOIN (
SELECT COUNT(*) AS numPartitions
, object_id
, index_id
FROM sys.partitions
GROUP BY object_id
, index_id
) AS c ON c.index_id = i.index_id
AND c.object_id = i.object_id
WHERE i.index_id > 0 -- ignore heaps
AND i.is_disabled = 0
AND i.is_hypothetical = 0
Далее в цикле для каждой секции индекса отправляется запрос по определению ее размера и уровня фрагментации. В конце сканирования индексы, которые весят меньше порога вхождения, отбрасываются на клиенте.
EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)' , N'@databaseId int,@objectId int,@indexId int,@partitionNr int' , @databaseId = 7, @objectId = 2133582639, @indexId = 1, @partitionNr = 1 EXEC sp_executesql N' SELECT index_id, avg_fragmentation_in_percent, page_count FROM sys.
 dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 2, @partitionNr = 1
EXEC sp_executesql N'
SELECT index_id, avg_fragmentation_in_percent, page_count
FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 3, @partitionNr = 1
dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 2, @partitionNr = 1
EXEC sp_executesql N'
SELECT index_id, avg_fragmentation_in_percent, page_count
FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 3, @partitionNr = 1
При анализе логики работы данного приложения можно найти много недочетов. Например, если придираться по мелочи, то до отправления запроса не делается никаких проверок о том, содержит ли текущая секция строки, чтобы исключить из сканирования пустые секции.
Но наиболее остро проблема проявляется в другом аспекте: количество запросов к серверу будет примерно равно общему числу строк из sys.partitions. С учетом того, что реальные базы могут содержать десятки тысяч секций, то этот нюанс может привести к огромному числу однотипных запросов к серверу.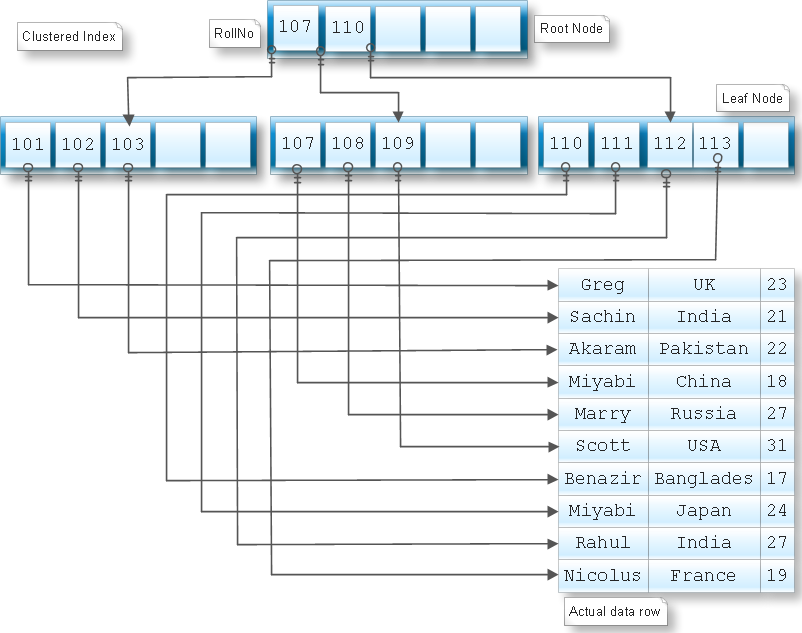 В ситуации, если база удаленная, то время сканирования станет еще длительнее за счет возросших сетевых задержек на выполнение каждого, пусть даже и самого простого запроса.
В ситуации, если база удаленная, то время сканирования станет еще длительнее за счет возросших сетевых задержек на выполнение каждого, пусть даже и самого простого запроса.
В отличие от RedGate, аналогичный продукт разработанный в Devart — dbForge Index Manager for SQL Server (1.10.38 — 99$) получает информацию одним большим запросом и затем отображает все на клиенте:
SELECT SCHEMA_NAME(o.[schema_id]) AS [schema_name] , o.name AS parent_name , o.[type] AS parent_type , i.name , i.type_desc , s.avg_fragmentation_in_percent , s.page_count , p.partition_number , p.[rows] , ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy , ISNULL(lob.is_lob, 0) AS is_lob , CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s JOIN sys.partitions p ON s.[object_id] = p.[object_id] AND s.index_id = p.index_id AND s.partition_number = p.
 partition_number
JOIN sys.indexes i ON i.[object_id] = s.[object_id]
AND i.index_id = s.index_id
LEFT JOIN (
SELECT c.[object_id]
, index_id = ISNULL(i.index_id, 1)
, is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END)
, is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END)
FROM sys.columns c
LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id]
AND c.column_id = i.column_id
AND i.index_id > 0
WHERE c.system_type_id IN (34, 35, 99)
OR c.max_length = -1
GROUP BY c.[object_id], i.index_id
) lob ON lob.[object_id] = i.[object_id]
AND lob.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = i.[object_id]
JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
WHERE i.[type] IN (1, 2)
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND s.index_level = 0
AND s.alloc_unit_type_desc = 'IN_ROW_DATA'
AND o.
partition_number
JOIN sys.indexes i ON i.[object_id] = s.[object_id]
AND i.index_id = s.index_id
LEFT JOIN (
SELECT c.[object_id]
, index_id = ISNULL(i.index_id, 1)
, is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END)
, is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END)
FROM sys.columns c
LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id]
AND c.column_id = i.column_id
AND i.index_id > 0
WHERE c.system_type_id IN (34, 35, 99)
OR c.max_length = -1
GROUP BY c.[object_id], i.index_id
) lob ON lob.[object_id] = i.[object_id]
AND lob.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = i.[object_id]
JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
WHERE i.[type] IN (1, 2)
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND s.index_level = 0
AND s.alloc_unit_type_desc = 'IN_ROW_DATA'
AND o. [type] IN ('U', 'V')
[type] IN ('U', 'V')
От основной проблемы с пеленой однотипных запросов в конкурирующем продукте удалось избавиться, но недостатки данной реализации в том, что в функцию sys.dm_db_index_physical_stats не передается никаких дополнительных параметров, которые могут ограничить сканирование заведомо ненужных индексов. По факту это приводит к получению информации по всем индексам в системе и лишним дисковым нагрузкам на этапе сканирования.
Важно отметить, что данные, получаемые из sys.dm_db_index_physical_stats, не кешируется на постоянной основе в buffer pool, поэтому минимизирование физических чтений при получении информации о фрагментации индексов было одной из приоритетных задач при разработке.
После нескольких экспериментов получилось скомбинировать оба подхода, разделив сканирование на две части. Вначале одним большим запросом определяется размер секций, заранее отфильтровывая при этом те, которые не входят в диапазон фильтрации:
INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages) SELECT [container_id] , SUM([total_pages]) , SUM([used_pages]) FROM sys.
 allocation_units WITH(NOLOCK)
GROUP BY [container_id]
HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize
allocation_units WITH(NOLOCK)
GROUP BY [container_id]
HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize
Далее мы получаем только те секции, которые содержат данные, чтобы избежать ненужных операций чтения из пустых индексов.
SELECT [object_id] , [index_id] , [partition_id] , [partition_number] , [rows] , [data_compression] INTO #Partitions FROM sys.partitions WITH(NOLOCK) WHERE [object_id] > 255 AND [rows] > 0 AND [object_id] NOT IN (SELECT * FROM #ExcludeList)
В зависимости от настроек получаются только те типы индексов, которые пользователь хочет проанализировать (поддерживается работа с кучами, кластерными/некластерными индексами и колумнсторами).
INSERT INTO #Indexes SELECT ObjectID = i.[object_id] , IndexID = i.index_id , IndexName = i.[name] , PagesCount = a.ReservedPages , UnusedPagesCount = a.ReservedPages - a.UsedPages , PartitionNumber = p.
 [partition_number]
, RowsCount = ISNULL(p.[rows], 0)
, IndexType = i.[type]
, IsAllowPageLocks = i.[allow_page_locks]
, DataSpaceID = i.[data_space_id]
, DataCompression = p.[data_compression]
, IsUnique = i.[is_unique]
, IsPK = i.[is_primary_key]
, FillFactorValue = i.[fill_factor]
, IsFiltered = i.[has_filter]
FROM #AllocationUnits a
JOIN #Partitions p ON a.ContainerID = p.[partition_id]
JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id]
AND p.[index_id] = i.[index_id]
WHERE i.[type] IN (0, 1, 2, 5, 6)
AND i.[object_id] > 255
[partition_number]
, RowsCount = ISNULL(p.[rows], 0)
, IndexType = i.[type]
, IsAllowPageLocks = i.[allow_page_locks]
, DataSpaceID = i.[data_space_id]
, DataCompression = p.[data_compression]
, IsUnique = i.[is_unique]
, IsPK = i.[is_primary_key]
, FillFactorValue = i.[fill_factor]
, IsFiltered = i.[has_filter]
FROM #AllocationUnits a
JOIN #Partitions p ON a.ContainerID = p.[partition_id]
JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id]
AND p.[index_id] = i.[index_id]
WHERE i.[type] IN (0, 1, 2, 5, 6)
AND i.[object_id] > 255
После этого начинается небольшая магия: для всех маленьких индексов мы определяем уровень фрагментации за счет многократного вызова функции sys.dm_db_index_physical_stats с полным указанием всех параметров.
INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation) SELECT i.ObjectID , i.
 IndexID
, i.PartitionNumber
, r.[avg_fragmentation_in_percent]
FROM #Indexes i
CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r
WHERE i.PagesCount <= @PreDescribeSize
AND r.[index_level] = 0
AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA'
AND i.IndexType IN (0, 1, 2)
IndexID
, i.PartitionNumber
, r.[avg_fragmentation_in_percent]
FROM #Indexes i
CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r
WHERE i.PagesCount <= @PreDescribeSize
AND r.[index_level] = 0
AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA'
AND i.IndexType IN (0, 1, 2)
Далее мы возвращаем всю возможную информацию на клиент, отфильтровывая лишние данные:
SELECT i.ObjectID , i.IndexID , i.IndexName , ObjectName = o.[name] , SchemaName = s.[name] , i.PagesCount , i.UnusedPagesCount , i.PartitionNumber , i.RowsCount , i.IndexType , i.IsAllowPageLocks , u.TotalWrites , u.TotalReads , u.TotalSeeks , u.TotalScans , u.TotalLookups , u.LastUsage , i.DataCompression , f.Fragmentation , IndexStats = STATS_DATE(i.ObjectID, i.IndexID) , IsLobLegacy = ISNULL(lob.IsLobLegacy, 0) , IsLob = ISNULL(lob.
 IsLob, 0)
, IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT)
, IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT)
, FileGroupName = fg.[name]
, i.IsUnique
, i.IsPK
, i.FillFactorValue
, i.IsFiltered
, a.IndexColumns
, a.IncludedColumns
FROM #Indexes i
JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID
JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id]
LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID
AND a.IndexID = i.IndexID
LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID
LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID
AND f.IndexID = i.IndexID
AND f.PartitionNumber = i.PartitionNumber
LEFT JOIN (
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, TotalWrites = NULLIF([user_updates], 0)
, TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0)
, TotalSeeks = NULLIF([user_seeks], 0)
, TotalScans = NULLIF([user_scans], 0)
, TotalLookups = NULLIF([user_lookups], 0)
, LastUsage = (
SELECT MAX(dt)
FROM (
VALUES ([last_user_seek])
, ([last_user_scan])
, ([last_user_lookup])
, ([last_user_update])
) t(dt)
)
FROM sys.
IsLob, 0)
, IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT)
, IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT)
, FileGroupName = fg.[name]
, i.IsUnique
, i.IsPK
, i.FillFactorValue
, i.IsFiltered
, a.IndexColumns
, a.IncludedColumns
FROM #Indexes i
JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID
JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id]
LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID
AND a.IndexID = i.IndexID
LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID
LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID
AND f.IndexID = i.IndexID
AND f.PartitionNumber = i.PartitionNumber
LEFT JOIN (
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, TotalWrites = NULLIF([user_updates], 0)
, TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0)
, TotalSeeks = NULLIF([user_seeks], 0)
, TotalScans = NULLIF([user_scans], 0)
, TotalLookups = NULLIF([user_lookups], 0)
, LastUsage = (
SELECT MAX(dt)
FROM (
VALUES ([last_user_seek])
, ([last_user_scan])
, ([last_user_lookup])
, ([last_user_update])
) t(dt)
)
FROM sys. dm_db_index_usage_stats WITH(NOLOCK)
WHERE [database_id] = @DBID
) u ON i.ObjectID = u.ObjectID
AND i.IndexID = u.IndexID
LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID
AND lob.IndexID = i.IndexID
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id]
AND i.PartitionNumber = dds.[destination_id]
JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id]
WHERE o.[type] IN ('V', 'U')
AND (
f.Fragmentation >= @Fragmentation
OR
i.PagesCount > @PreDescribeSize
OR
i.IndexType IN (5, 6)
)
dm_db_index_usage_stats WITH(NOLOCK)
WHERE [database_id] = @DBID
) u ON i.ObjectID = u.ObjectID
AND i.IndexID = u.IndexID
LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID
AND lob.IndexID = i.IndexID
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id]
AND i.PartitionNumber = dds.[destination_id]
JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id]
WHERE o.[type] IN ('V', 'U')
AND (
f.Fragmentation >= @Fragmentation
OR
i.PagesCount > @PreDescribeSize
OR
i.IndexType IN (5, 6)
)
После этого точечными запросами определяем уровень фрагментации для больших индексов.
EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'') WHERE [index_level] = 0 AND [alloc_unit_type_desc] = ''IN_ROW_DATA''' , N'@ObjectID int,@IndexID int,@PartitionNumber int' , @ObjectId = 1044198770, @IndexId = 1, @PartitionNumber = 1 EXEC sp_executesql N' DECLARE @DBID INT = DB_ID() SELECT [avg_fragmentation_in_percent] FROM sys.
 dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'')
WHERE [index_level] = 0
AND [alloc_unit_type_desc] = ''IN_ROW_DATA'''
, N'@ObjectID int,@IndexID int,@PartitionNumber int'
, @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1
dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'')
WHERE [index_level] = 0
AND [alloc_unit_type_desc] = ''IN_ROW_DATA'''
, N'@ObjectID int,@IndexID int,@PartitionNumber int'
, @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1
За счет такого подхода при генерации запросов получилось решить проблемы с производительностью сканирования, которые встречались в приложениях конкурентов. На этом можно было бы закончить, но в процессе разработки постепенно появлялись новые идеи, которые позволяли расширять область применения своего продукта.
Вначале была реализована поддержка работы с WAIT_AT_LOW_PRIORITY, потом стало возможным использовать DATA_COMPRESSION и FILL_FACTOR при ребилде индексов. Приложение по чуть-чуть обрастало незапланированным ранее функционалом вроде обслуживания колумнсторов:
SELECT * FROM ( SELECT IndexID = [index_id] , PartitionNumber = [partition_number] , PagesCount = SUM([size_in_bytes]) / 8192 , UnusedPagesCount = ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) / 8192 , Fragmentation = CAST(ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) * 100.
 / SUM([size_in_bytes]) AS FLOAT)
FROM sys.fn_column_store_row_groups(@ObjectID)
GROUP BY [index_id]
, [partition_number]
) t
WHERE Fragmentation >= @Fragmentation
AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize
/ SUM([size_in_bytes]) AS FLOAT)
FROM sys.fn_column_store_row_groups(@ObjectID)
GROUP BY [index_id]
, [partition_number]
) t
WHERE Fragmentation >= @Fragmentation
AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize
Или возможности создавать некластерные индексы на основе информации из dm_db_missing_index:
SELECT ObjectID = d.[object_id] , UserImpact = gs.[avg_user_impact] , TotalReads = gs.[user_seeks] + gs.[user_scans] , TotalSeeks = gs.[user_seeks] , TotalScans = gs.[user_scans] , LastUsage = ISNULL(gs.[last_user_scan], gs.[last_user_seek]) , IndexColumns = CASE WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NOT NULL THEN d.[equality_columns] + ', ' + d.[inequality_columns] WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NULL THEN d.[equality_columns] ELSE d.
 [inequality_columns]
END
, IncludedColumns = d.[included_columns]
FROM sys.dm_db_missing_index_groups g WITH(NOLOCK)
JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle]
JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle]
WHERE d.[database_id] = DB_ID()
[inequality_columns]
END
, IncludedColumns = d.[included_columns]
FROM sys.dm_db_missing_index_groups g WITH(NOLOCK)
JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle]
JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle]
WHERE d.[database_id] = DB_ID()Результаты и планы
После шести месяцев активной фазы разработки радует, что на этом планы не заканчиваются, поскольку хочется и дальше развивать этот продукт. На очереди планируется добавить функционал по поиску дублирующих или неиспользуемых индексов, а также реализовать полноценную поддержку по обслуживанию статистики в рамках SQL Server.
Исходя из того, что на рынке сейчас много платных решений, хочется верить, что за счет бесплатного позиционирования, более оптимизированного дескрайба метаданных и наличия разного рода полезных мелочей для кого-то этот продукт точно станет полезным в повседневных задачах.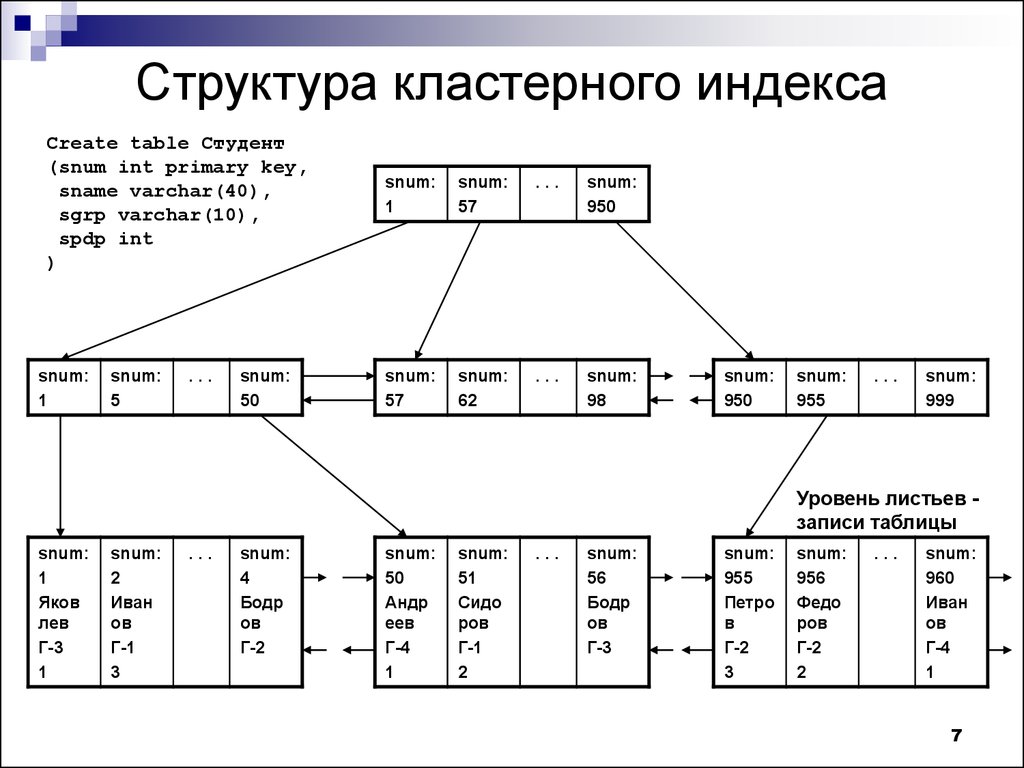
Последнюю версия приложения можно скачать на GitHub. Исходники лежат там же. Очень буду рад критике и фидбекам.
Также хотелось бы отдельно сказать спасибо:
- Евгению Васильеву — за помощь в разработке и ценные замечания по функционалу.
- Елизавете Рудаковой — за мотивацию и практические советы при разработке.
- Олегу Родионову и Денису Резнику — за мотивацию и правильные жизненные советы.
- Кириллу Черных и Дмитрию Скрипке — за помощь в тестировании.
Все про українське ІТ в Телеграмі — підписуйтеся на канал редакції DOU
Теми:
DOU Проектор, SQL Server
Установить подсказку SQL, чтобы дать оптимизатору Oracle указание выбрать план выполнения
Back to results
Print
Share
Be The First To Get Support Updates
Want to know about the latest technical content and software updates?
Get Notifications
Back to top
Summary
Подсказка Oracle предоставляет оптимизатору директиву по выбору плана выполнения для выполняемого оператора SQL.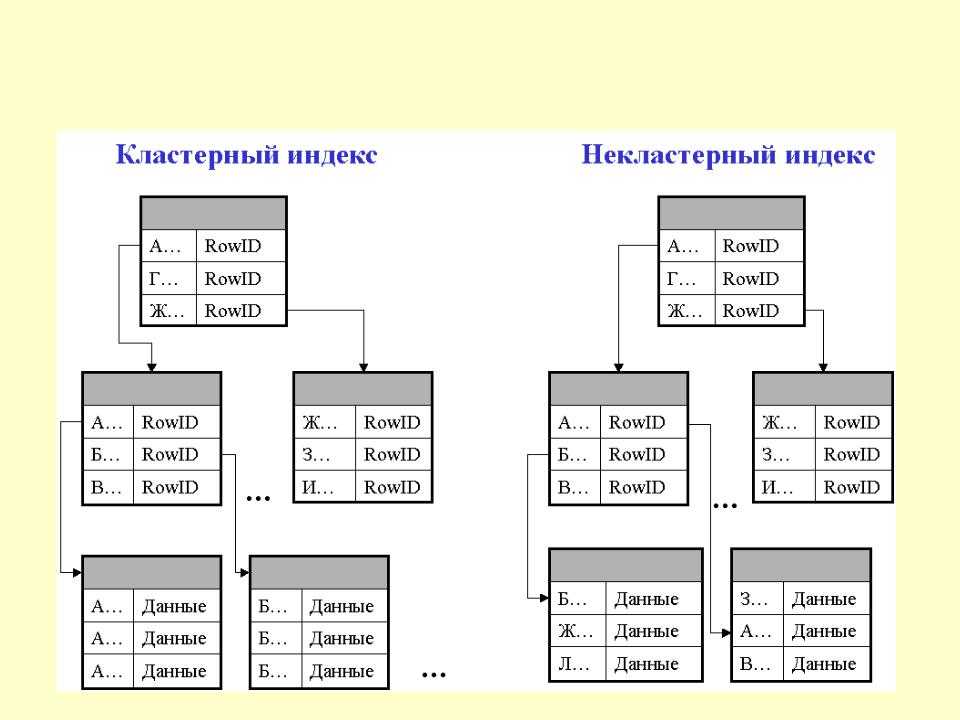
Подсказка Oracle INDEX указывает оптимизатору использовать сканирование индекса для указанной таблицы. Используйте подсказку INDEX на основе функций, домена, B-дерева, bitmap и bitmap индекса соединения.
При работе с таблицами, содержащими атрибуты ST_Geometry и st_spatial_index, укажите подсказку Oracle INDEX и имя st_spatial_index, чтобы оптимизатор получил доступ к данным через индекс.
Как указано в справочной документации Oracle SQL, (‘Если подсказка INDEX указывает единственный доступный индекс, то база данных выполняет сканирование этого индекса. Оптимизатор не рассматривает полное сканирование таблицы или сканирование другого индекса в таблице.’), когда указана подсказка INDEX, оптимизатор использует индекс в качестве основного пути доступа.
Примечание: Оптимизатор в Oracle 12c может игнорировать этот тип подсказки.
Procedure
В следующем примере демонстрируется оператор SQL, который запрашивает таблицу участков с двумя фильтрами предикатов, где владелец равен ‘ARATA’ и где конверт пересекает определенную область.
В таблице участков есть индекс формы и атрибутов владельца. Включив подсказку INDEX hint «/*+ INDEX (parcels shape_idx) */»
в операторе SQL он указывает оптимизатору использовать индекс формы в качестве пути доступа (даже если селективность и стоимость индекса владельца меньше, чем стоимость использования индекса формы).
SQL> SELECT /*+ INDEX (parcels shape_idx) */ 2 FROM parcels 3 WHERE owner = 'ARATA' 4 AND st_envintersects(shape, 10, 12, 12, 14) = 1;
Дополнительную информацию о настройке подсказок Oracle и других подсказок см. в документации Oracle.
Related Information
- Документация Oracle
Last Published: 5/6/2021
Article ID: 000009658
Software: ArcSDE 9.3.1, 9.3, 9.2
Download the Esri Support App on your phone to receive notifications when new content is available for Esri products you use
Download the Esri Support App on your phone to receive notifications when new content is available for Esri products you use
Is This Content Helpful?
Yes
No
How can we make this better? Please provide as much detail as possible.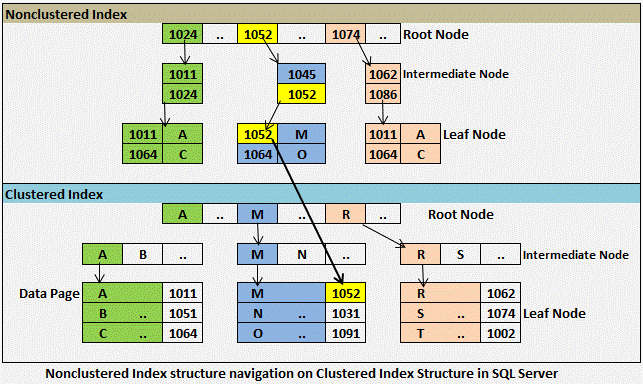
Translation Feedback
How can we make this translation better?
Get notified about latest updates to this technical article?
Do you want to Unsubscribe?
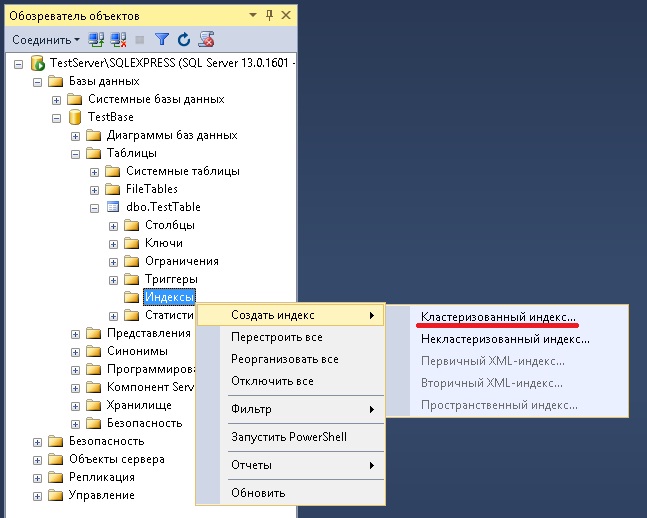
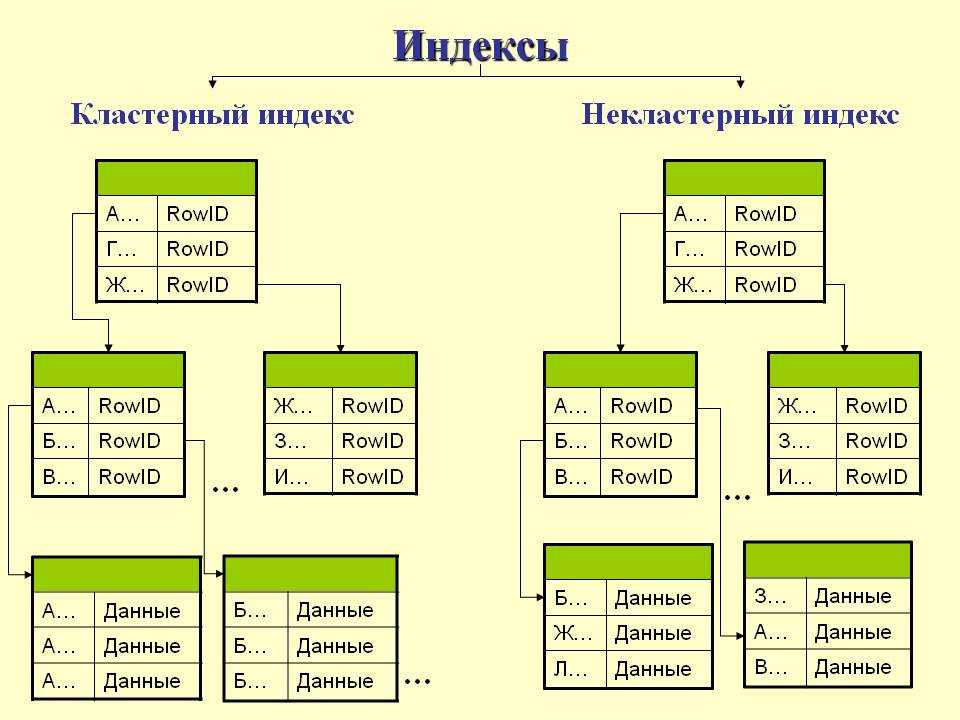
Описаны кластеризованные и некластеризованные индексы — SQL Server
Обратная связь
Редактировать
Твиттер
Фейсбук
Эл. адрес
- Статья
- 4 минуты на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
База данных SQL Azure
Управляемый экземпляр Azure SQL
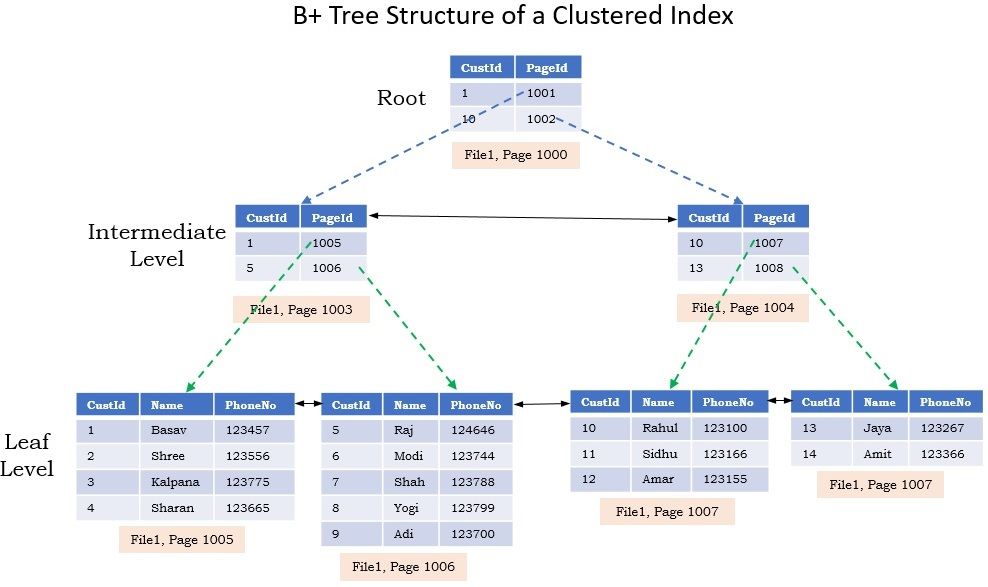
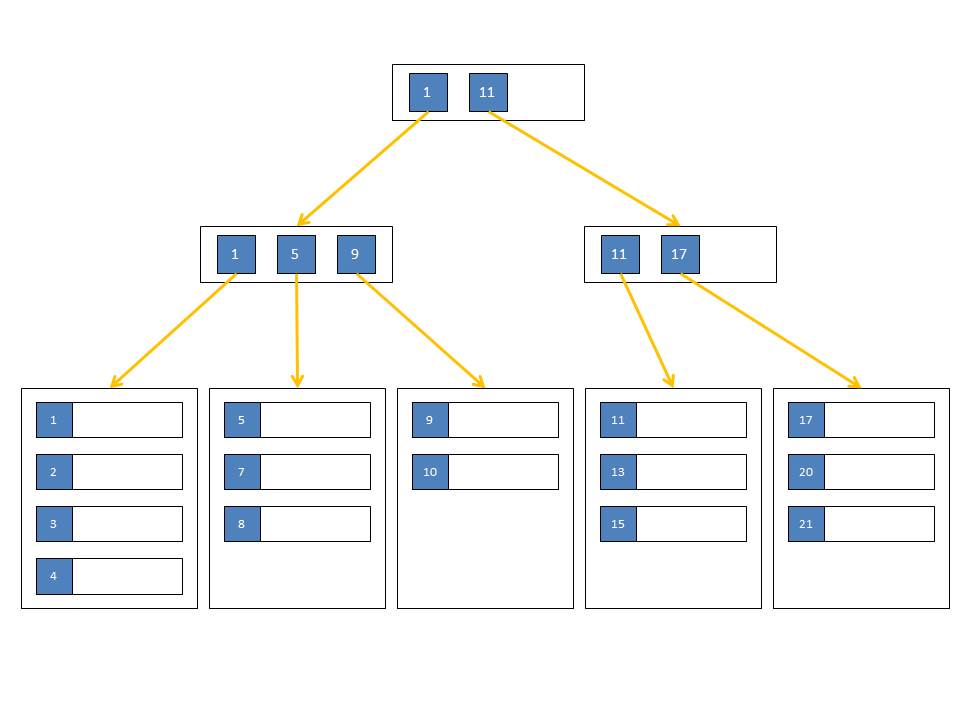
Индекс — это структура на диске, связанная с таблицей или представлением, которая ускоряет извлечение строк из таблицы или представления. Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Эти ключи хранятся в структуре (B-дереве), которая позволяет SQL Server быстро и эффективно находить строку или строки, связанные со значениями ключа.
Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Эти ключи хранятся в структуре (B-дереве), которая позволяет SQL Server быстро и эффективно находить строку или строки, связанные со значениями ключа.
Примечание
В документации SQL Server термин B-дерево обычно используется в отношении индексов. В индексах rowstore SQL Server реализует дерево B+. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в Руководстве по архитектуре и дизайну индекса SQL Server.
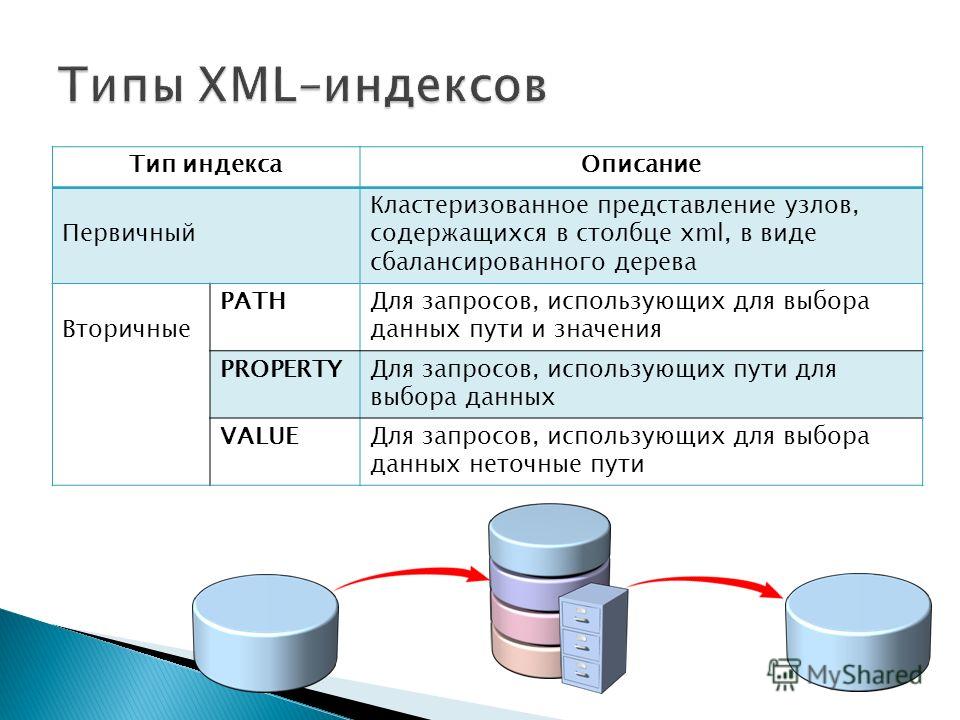
Таблица или представление могут содержать следующие типы индексов:
И кластеризованные, и некластеризованные индексы могут быть уникальными. Это означает, что никакие две строки не могут иметь одинаковое значение ключа индекса. В противном случае индекс не уникален, и несколько строк могут иметь одно и то же значение ключа. Дополнительные сведения см. в разделе Создание уникальных индексов.
Индексы автоматически поддерживаются для таблицы или представления при каждом изменении данных таблицы.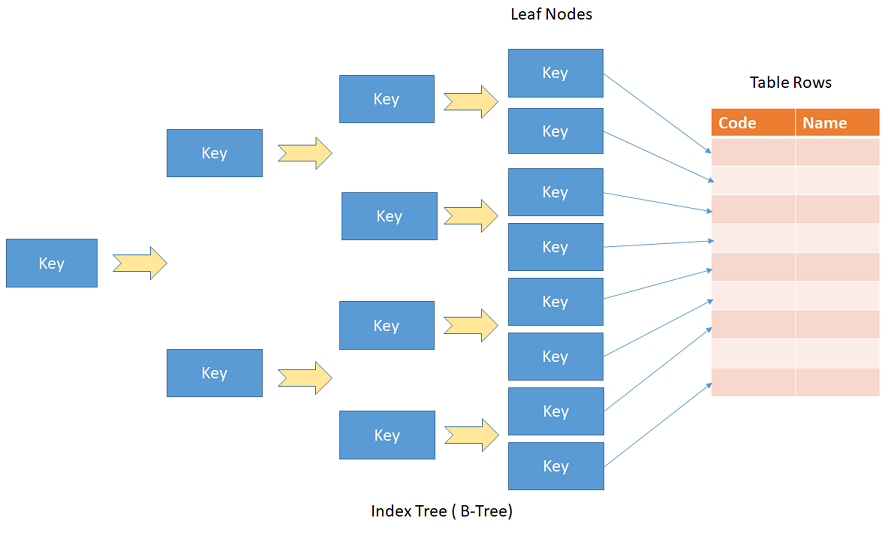
Дополнительные типы индексов специального назначения см. в разделе Индексы.
Индексы и ограничения
Индексы создаются автоматически, когда для столбцов таблицы определены ограничения PRIMARY KEY и UNIQUE. Например, когда вы создаете таблицу с ограничением UNIQUE, компонент Database Engine автоматически создает некластеризованный индекс. Если вы настроите PRIMARY KEY, компонент Database Engine автоматически создаст кластеризованный индекс, если кластеризованный индекс еще не существует. Когда вы пытаетесь применить ограничение PRIMARY KEY к существующей таблице, а для этой таблицы уже существует кластеризованный индекс, SQL Server применяет первичный ключ, используя некластеризованный индекс.
Дополнительные сведения см. в разделах Создание первичных ключей и Создание уникальных ограничений.
Как оптимизатор запросов использует индексы
Хорошо спроектированные индексы могут сократить количество дисковых операций ввода-вывода и потреблять меньше системных ресурсов, тем самым повышая производительность запросов. Индексы могут быть полезны для различных запросов, содержащих операторы SELECT, UPDATE, DELETE или MERGE. Рассмотрим запрос
Индексы могут быть полезны для различных запросов, содержащих операторы SELECT, UPDATE, DELETE или MERGE. Рассмотрим запрос SELECT Title, HireDate FROM HumanResources.Employee WHERE EmployeeID = 250 в 9База данных 0045 AdventureWorks2019 . При выполнении этого запроса оптимизатор запросов оценивает каждый доступный метод извлечения данных и выбирает наиболее эффективный метод. Этот метод может представлять собой сканирование таблицы или сканирование одного или нескольких индексов, если они существуют.
При сканировании таблицы оптимизатор запросов считывает все строки в таблице и извлекает строки, соответствующие критериям запроса. Сканирование таблицы создает множество операций дискового ввода-вывода и может требовать значительных ресурсов. Однако сканирование таблицы может быть наиболее эффективным методом, если, например, результирующий набор запроса представляет собой высокий процент строк из таблицы.
Когда оптимизатор запросов использует индекс, он ищет ключевые столбцы индекса, находит место хранения строк, необходимых для запроса, и извлекает соответствующие строки из этого местоположения.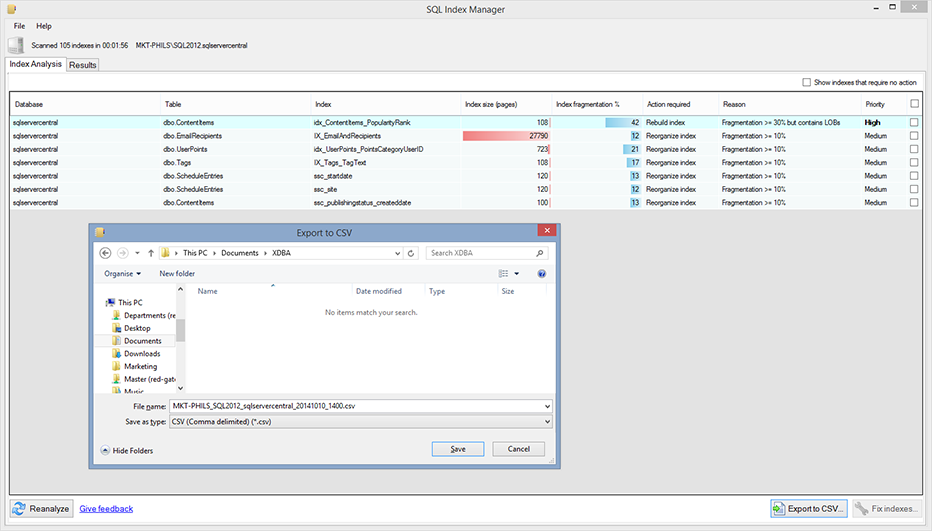 Как правило, поиск в индексе выполняется намного быстрее, чем поиск в таблице, потому что, в отличие от таблицы, индекс часто содержит очень мало столбцов в строке, а строки отсортированы.
Как правило, поиск в индексе выполняется намного быстрее, чем поиск в таблице, потому что, в отличие от таблицы, индекс часто содержит очень мало столбцов в строке, а строки отсортированы.
Оптимизатор запросов обычно выбирает наиболее эффективный метод при выполнении запросов. Однако если индексы недоступны, оптимизатор запросов должен использовать сканирование таблицы. Ваша задача — спроектировать и создать индексы, которые лучше всего подходят для вашей среды, чтобы у оптимизатора запросов был набор эффективных индексов, из которых можно было бы выбирать. SQL Server предоставляет помощника по настройке ядра базы данных, помогающего в анализе среды вашей базы данных и выборе подходящих индексов.
Important
Дополнительные сведения о рекомендациях по проектированию индексов и внутренних компонентах см. в Руководстве по проектированию индексов SQL Server.
Следующие шаги
- Руководство по проектированию индекса SQL Server
- Создание кластеризованных индексов
- Создание некластеризованных индексов
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт
Эта страница
Просмотреть все отзывы о странице
sql server — SQL INDEX WITH ONLINE = ON
Я создал индекс в SQL Azure, где запрос работает отлично, и индекс создается успешно, но с исключением ONLINE = OFF
Мой запрос на создание индекса:
CREATE НЕКЛАСТЕРНЫЙ ИНДЕКС [nci_wi_tbl_transactions] ON [dbo].
 [tbl_transactions] (
[bank_account_id]) ВКЛЮЧИТЬ ([bankcode]) WITH (ONLINE = ON)
[tbl_transactions] (
[bank_account_id]) ВКЛЮЧИТЬ ([bankcode]) WITH (ONLINE = ON)
При просмотре индекса в таблице это выглядит так:
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС nci_wi_tbl_transactions ON dbo.tbl_transactions (bank_account_id ASC)
ВКЛЮЧИТЬ (код банка)
WITH (PAD_INDEX = OFF, FILLFACTOR = 100, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, STATISTICS_NORECOMPUTE = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
НА [ПЕРВИЧНОМ]
Если вы заметили, что вышеуказанный индекс создан с ONLINE = OFF
Я пытаюсь понять, почему он создает индекс с ONLINE = OFF вместо ONLINE = ON . Возможно ли создать некластеризованный индекс с ONLINE = ON . Если да, то как я могу создать индекс с ONLINE = ON
Я что-то здесь упустил.
- sql
- sql-сервер
- tsql
- база данных azure-sql
2
С (ОНЛАЙН = ВКЛ) — это свойство оператора CREATE INDEX , а не создаваемого индекса.
Гипотетически два оператора CREATE INDEX , идентичных, за исключением того, что один содержит WITH (ONLINE = ON) , а другой — WITH (ONLINE = OFF) , приведут к созданию точно такого же индекса .
Метаданные просто не отслеживают способ их создания , потому что это операционный атрибут/атрибут времени выполнения, который не становится постоянным свойством индекса. Это было бы похоже на строку, содержащую информацию о том, в какой модели восстановления находилась база данных, когда строка была добавлена.
Не могли бы вы объяснить это немного подробнее, чтобы я мог найти решение этой проблемы.
Я имею в виду, что когда вы создаете индекс, SQL Server не помнит, делали ли вы это с помощью ONLINE = ON или ONLINE = OFF . Поэтому, когда вы просматриваете свойства или создаете новый скрипт из SSMS, он всегда будет отключен. Люди использовали другие обходные пути, такие как ручное создание сценариев для индексов, включая проверку возможности построения индекса в режиме онлайн (путем ручного добавления ONLINE = ON ), и так всегда, если это возможно.