Join sql on: JOIN (SQL) — что это за оператор, примеры использования
Содержание
select — Помогите в SQL получить при join только максимальную дату из таблицы
Вопрос задан
Изменён
10 месяцев назад
Просмотрен
104 раза
Помогите, пожалуйста, как можно приджоинить к таблице User таблицу UserLoginHistory так чтобы получить из нее страну по самой новой записи этого пользователя.
MySQL
User:
| id | username | |
|---|---|---|
| 1 | mailmail | Ivan |
| 2 | mail2mail | Irina |
| 3 | mail3mail | Pavel |
UserLoginHistory:
| id | country | datatime | userId |
|---|---|---|---|
| 1 | RU | 2020-03-01 15:36:44 | 1 |
| 2 | DE | 2022-03-01 15:36:44 | 1 |
| 3 | EN | 2019-03-01 15:36:44 | 2 |
Ожидаемый результат:
| userId | lastLoginCountry | |
|---|---|---|
| 1 | DE | mailmail |
| 2 | EN | mail2mail |
Пробую через PARTITION но что то работает не так, так как на MIN() или MAX() не реагирует.
SELECT u.id, ulh.datatime, MIN(ulh.country) over(PARTITION BY ulh.createdAt) as country FROM User u LEFT JOIN UserLoginHistory ulh ON u.id = ulh.playerId GROUP BY u.id
- sql
- select
- join
12
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Руководство по SQL.
 FULL JOIN. – PROSELYTE
FULL JOIN. – PROSELYTE
Элемент FULL JOIN комбинирует результаты элементов LEFT JOIN и RIGHT JOIN. Результатом такого запроса станет таблица, которые содержит все записи левой и правой таблицы, а колонки записей без совпадений будут иметь значение NULL.
Запрос с использованием FULL JOIN имеет следующий вид:
SELECT таблица1.колонка1, таблица2.колонка2... FROM таблица1 FULL JOIN таблицы2 ON таблицы1.общее_поле = таблица2.общее_поле;
Пример:
Предположим, что у нас есть две таблицы:
developers:
+----+-------------------+------------+------------+--------+ | ID | NAME | SPECIALTY | EXPERIENCE | SALARY | +----+-------------------+------------+------------+--------+ | 1 | Eugene Suleimanov | Java | 2 | 2500 | | 2 | Peter Romanenko | Java | 3 | 3500 | | 3 | Andrei Komarov | JavaScript | 3 | 2500 | | 4 | Konstantin Geiko | C# | 2 | 2000 | | 5 | Asya Suleimanova | UI/UX | 2 | 1800 | | 6 | Kolya Nikolaev | Javascript | 5 | 3400 | | 7 | Ivan Ivanov | C# | 1 | 900 | | 8 | Ludmila Geiko | UI/UX | 2 | 1800 | +----+-------------------+------------+------------+--------+
tasks:
+---------+-------------+------------------+------------+--------------+ | TASK_ID | TASK_NAME | DESCRIPTION | DEADLINE | DEVELOPER_ID | +---------+-------------+------------------+------------+--------------+ | 1 | Bug#123 | Fix company list | 2016-06-03 | 1 | | 2 | Bug#321 | Fix registration | 2016-06-06 | 2 | | 3 | Feature#777 | Latest actions | 2016-06-25 | 3 | +---------+-------------+------------------+------------+--------------+
Стоит отметить, что MySQL не поддерживает FULL JOIN, поэтому запрос для получения аналогичного результата для этой RDBMS будет иметь следующий вид:
mysql> SELECT ID, NAME, TASK_NAME, DEADLINE FROM developers LEFT JOIN tasks ON developers.ID = tasks.DEVELOPER_ID UNION ALL SELECT ID, NAME, TASK_NAME, DEADLINE FROM developers RIGHT JOIN tasks ON developers.ID = tasks.DEVELOPER_ID ;
 ID = tasks.DEVELOPER_ID
UNION ALL
SELECT ID, NAME, TASK_NAME, DEADLINE
FROM developers
RIGHT JOIN tasks
ON developers.ID = tasks.DEVELOPER_ID ;
ID = tasks.DEVELOPER_ID
UNION ALL
SELECT ID, NAME, TASK_NAME, DEADLINE
FROM developers
RIGHT JOIN tasks
ON developers.ID = tasks.DEVELOPER_ID ;
В результате мы получим следующую таблицу:
+------+-------------------+-------------+------------+ | ID | NAME | TASK_NAME | DEADLINE | +------+-------------------+-------------+------------+ | 1 | Eugene Suleimanov | Bug#123 | 2016-06-03 | | 2 | Peter Romanenko | Bug#321 | 2016-06-06 | | 3 | Andrei Komarov | Feature#777 | 2016-06-25 | | 4 | Konstantin Geiko | NULL | NULL | | 5 | Asya Suleimanova | NULL | NULL | | 6 | Kolya Nikolaev | NULL | NULL | | 7 | Ivan Ivanov | NULL | NULL | | 8 | Ludmila Geiko | NULL | NULL | | 1 | Eugene Suleimanov | Bug#123 | 2016-06-03 | | 2 | Peter Romanenko | Bug#321 | 2016-06-06 | | 3 | Andrei Komarov | Feature#777 | 2016-06-25 | | NULL | NULL | Feature#3 | 2016-06-15 | +------+-------------------+-------------+------------+
Как видите, мы получили все записи из обеих таблиц, соответствующие колонки записей, без совпадений имеют значение NULL.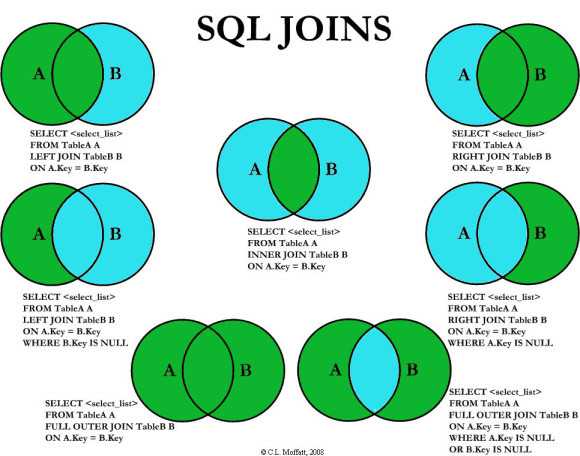
На этом мы заканчиваем изучение FULL JOIN.
Разница между WHERE и ON в SQL для JOIN данных
Последнее изменение: 09 августа 2021 г.
Есть ли разница между предложениями WHERE и ON?
Да. ON следует использовать для определения условия соединения, а WHERE — для фильтрации данных. Я использовал слово «должен», потому что это не жесткое правило. Разделение этих целей с соответствующими предложениями делает запрос наиболее читабельным, а также предотвращает получение неверных данных при использовании типов JOIN, отличных от INNER JOIN.
Чтобы углубиться, мы рассмотрим два варианта использования, которые могут поддерживаться WHERE или ON:
- Соединение данных
- Фильтрация данных
Соединение данных
Способ, которым оба этих предложения могут использоваться для облегчения объединения данных, заключается в определении условия, при котором две таблицы соединяются.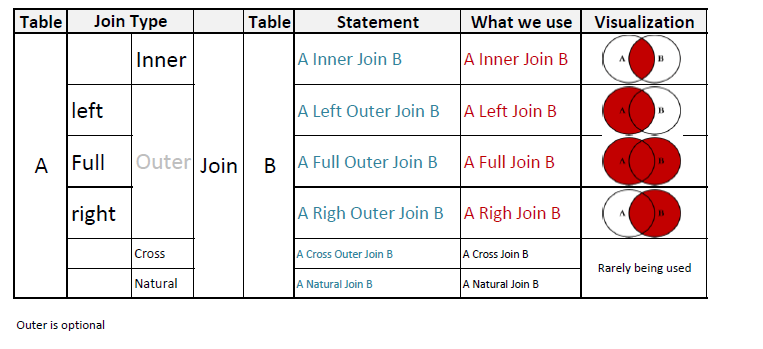 Чтобы продемонстрировать это, давайте воспользуемся примером набора данных о друзьях в Facebook и связях по LinkedIn.
Чтобы продемонстрировать это, давайте воспользуемся примером набора данных о друзьях в Facebook и связях по LinkedIn.
Мы хотим видеть людей, которые являются и нашими друзьями, и нашей связью. Так что в данном случае это будет только Мэтт. Давайте теперь запросим, используя различные определения условия JOIN.
Все три этих запроса дают одинаковый правильный результат:
ВЫБЕРИТЕ * ИЗ фейсбука ПРИСОЕДИНЯЙТЕСЬ НА facebook.name = linkedin.name ВЫБРАТЬ * ИЗ фейсбука ПРИСОЕДИНЯЙТЕСЬ ГДЕ facebook.name = linkedin.name ВЫБРАТЬ * ИЗ фейсбука, ссылка ГДЕ facebook.name = linkedin.name
Первые два являются типами явных соединений, а последнее — неявным соединением. Явное СОЕДИНЕНИЕ явно указывает, как СОЕДИНИТЬ данные, указав тип СОЕДИНЕНИЯ и условие соединения в предложении ON. Неявное СОЕДИНЕНИЕ не указывает тип СОЕДИНЕНИЯ и использует предложение WHERE для определения условия соединения.
Читаемость
Основное различие между этими запросами заключается в том, насколько легко понять, что происходит.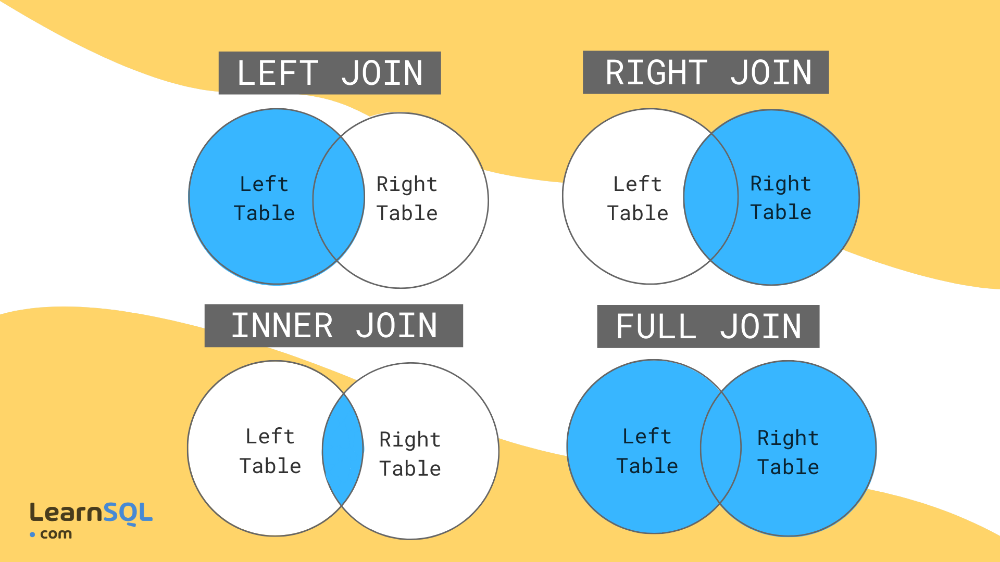 В первом запросе мы можем легко увидеть, что таблицы объединяются в предложении FROM и JOIN. Мы также можем ясно видеть условие соединения в предложении ON. Во втором запросе это кажется столь же ясным, однако мы можем сделать двойное рассмотрение предложения WHERE, поскольку оно обычно используется для фильтрации данных, а не для ПРИСОЕДИНЕНИЯ к ним. В последнем запросе мы должны внимательно следить за тем, чтобы установить, к какой таблице выполняется СОЕДИНЕНИЕ и как они СОЕДИНЯЮТСЯ.
В первом запросе мы можем легко увидеть, что таблицы объединяются в предложении FROM и JOIN. Мы также можем ясно видеть условие соединения в предложении ON. Во втором запросе это кажется столь же ясным, однако мы можем сделать двойное рассмотрение предложения WHERE, поскольку оно обычно используется для фильтрации данных, а не для ПРИСОЕДИНЕНИЯ к ним. В последнем запросе мы должны внимательно следить за тем, чтобы установить, к какой таблице выполняется СОЕДИНЕНИЕ и как они СОЕДИНЯЮТСЯ.
В последнем запросе используется так называемое неявное СОЕДИНЕНИЕ (СОЕДИНЕНИЕ, которое явно не указано в запросе. В большинстве случаев неявное СОЕДИНЕНИЕ будет действовать как ВНУТРЕННЕЕ СОЕДИНЕНИЕ. Если вы хотите использовать СОЕДИНЕНИЕ, отличное от ВНУТРЕННЕГО СОЕДИНЕНИЯ, указав его явно дает понять, что происходит.
JOIN в предложении WHERE может привести к путанице, поскольку это не является его обычной целью. Чаще всего используется для фильтрации данных. Поэтому, когда к предложению WHERE добавляются дополнительные условия фильтрации в дополнение к его использованию для определения того, как СОЕДИНЯТЬ данные, становится труднее понять.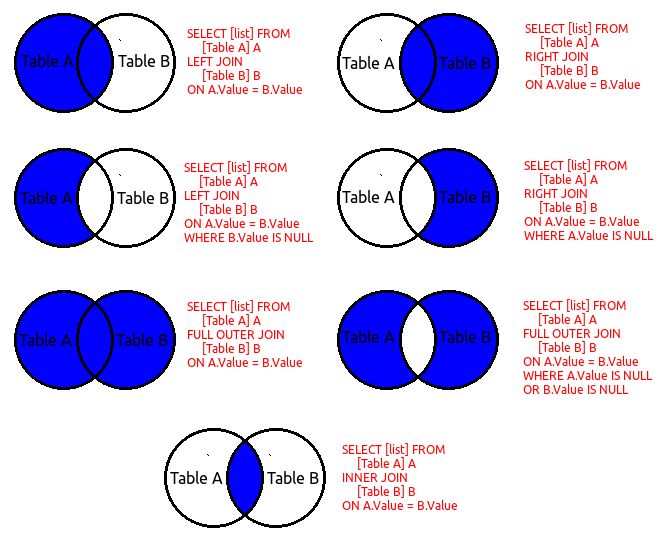
ВЫБЕРИТЕ * ИЗ фейсбука, ссылка ГДЕ facebook.name = linkedin.name И (facebook.name = Matt ИЛИ linkedin.city = "SF") ВЫБРАТЬ * ИЗ фейсбука ПРИСОЕДИНЯЙТЕСЬ НА facebook.name = linkedin.name ГДЕ facebook.name = Matt ИЛИ linkedin.city = "SF"
Несмотря на то, что в первом запросе меньше символов, чем во втором, его не так легко понять.
Оптимизация
Иногда запись запроса другим способом может привести к увеличению скорости. Однако в этом случае не должно быть преимуществ в скорости из-за того, что называется планом запроса. План запроса — это код, который SQL предлагает для выполнения запроса. Он принимает запрос, а затем создает оптимизированный способ поиска данных. Использование WHERE или ON для JOIN данных должно привести к тому же плану запроса.
Однако способ создания планов запросов может различаться в зависимости от языка и версии SQL, опять же, в этом случае все должно быть одинаковым, но вы можете протестировать его в своей базе данных, чтобы увидеть, повысится ли производительность. Будьте осторожны, так как кэширование может повлиять на результаты ваших запросов.
Будьте осторожны, так как кэширование может повлиять на результаты ваших запросов.
Фильтрация данных
Предложение ON и WHERE можно использовать для фильтрации данных в запросе. Существуют проблемы с читабельностью и точностью, которые необходимо решить с помощью фильтрации в предложении ON. Давайте используем немного больший набор данных, чтобы продемонстрировать это.
На этот раз мы ищем, какие люди являются нашими друзьями и связями, но мы хотим видеть только тех, кто также живет в Сан-Франциско.
Читаемость
Давайте оценим, насколько удобочитаем каждый вариант, эти два запроса дадут один и тот же результат:
ВЫБЕРИТЕ * ПРИСОЕДИНЯЙТЕСЬ НА facebook.name = linkedin.name ГДЕ facebook.city = 'SF' ВЫБРАТЬ * ИЗ фейсбука ПРИСОЕДИНЯЙТЕСЬ НА facebook.name = linkedin.name И facebook.city = 'SF'
Первый запрос ясен, каждое предложение имеет свою цель. Второй запрос сложнее понять, потому что предложение ON используется как для JOIN данных, так и для их фильтрации.
Точность
Фильтрация в предложении ON может привести к неожиданным результатам при использовании LEFT, RIGHT или OUTER JOIN. Эти два запроса не дадут одинаковых результатов:
.
ВЫБЕРИТЕ * ИЗ фейсбука ЛЕВОЕ ПРИСОЕДИНЯЙСЯ НА facebook.name = linkedin.name ГДЕ facebook.city = 'SF'
В ЛЕВОМ СОЕДИНЕНИИ он вводит каждую строку из первой таблицы «facebook» и объединяется везде, где выполняется условие соединения (facebook.name = linkedin.name), это верно как для Мэтта, так и для Дэйва. Таким образом, промежуточная таблица была бы.
Затем предложение WHERE отфильтровывает эти результаты по строкам, где facebook.city = ‘SF’, оставляя одну строку.
ВЫБЕРИТЕ * ИЗ фейсбука ЛЕВОЕ ПРИСОЕДИНЯЙСЯ НА facebook.name = linkedin.name И facebook.city = 'SF'
В этом запросе другое условие соединения. ЛЕВОЕ СОЕДИНЕНИЕ вводит каждую строку, а данные, которые СОЕДИНЯЮТСЯ из linkedin, появляются только тогда, когда facebook. name = linkedin.name AND facebook.city = ‘SF’. Он не отфильтровывает все строки, в которых нет facebook.city = ‘SF’
name = linkedin.name AND facebook.city = ‘SF’. Он не отфильтровывает все строки, в которых нет facebook.city = ‘SF’
.
Оптимизация
Существует потенциальная вариация в том, как построен план запроса, поэтому может быть полезно попробовать фильтрацию в ON. Некоторые языки SQL могут выполнять фильтрацию при объединении, а другие могут ждать, пока не будет построена полная таблица перед фильтрацией. Первый план был бы быстрее.
Резюме
Сохраняйте отдельный контекст между объединением таблиц и фильтрацией объединенной таблицы. Он наиболее удобочитаем, менее всего неточен и не должен быть менее производительным.
- СОЕДИНИТЬ данные в ПО
- Фильтровать данные в WHERE
- Напишите явные JOIN, чтобы сделать ваш запрос более читабельным
- Отфильтровать данные в предложении WHERE вместо JOIN, чтобы убедиться, что они правильные и удобочитаемые
- Различные языки SQL могут иметь разные планы запросов на основе фильтрации в предложении ON и предложении WHERE, поэтому проверьте производительность в своей базе данных
Написано:
Мэтт Дэвид
Отзыв:
Все, что нужно знать о ВНУТРЕННИХ СОЕДИНЕНИЯХ SQL
В продолжение моего введения в соединения SQL Server в этом руководстве по T-SQL я собираюсь более подробно рассмотреть наиболее часто используемые типы соединений в SQL Server.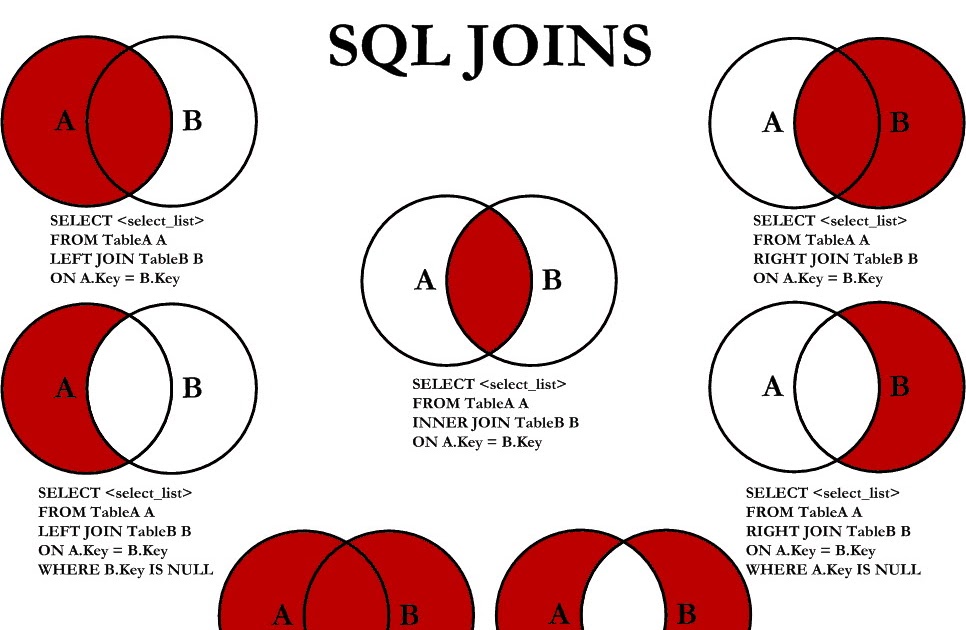 – ВНУТРЕННЕЕ СОЕДИНЕНИЕ.
– ВНУТРЕННЕЕ СОЕДИНЕНИЕ.
Что такое ВНУТРЕННЕЕ СОЕДИНЕНИЕ?
ВНУТРЕННЕЕ СОЕДИНЕНИЕ — это тип соединения, используемый для возврата строк из двух входных данных (таблиц или представлений), где обычно имеется точное совпадение в одном или нескольких столбцах между двумя входными данными. Этот тип наиболее распространен из-за того, как устроены реляционные базы данных. Процесс нормализации моделирует бизнес-сущности в группы связанных таблиц, поэтому возврат связанных данных между этими таблицами является чрезвычайно важным аспектом разработки приложений, и это делается с помощью INNER JOIN.
Как написать простое предложение INNER JOIN
Начнем с двух разных способов написания предложения INNER JOIN. Один из них представляет собой более старый синтаксис ANSI SQL-89, а другой — более новый синтаксис ANSI SQL-92. Я предпочитаю новый синтаксис, потому что он выглядит лучше и приводит к меньшему количеству ошибок при написании оператора соединения (подробнее об этом позже).
Для начала я создам две временные таблицы и буду хранить в них числовые значения. Таблица #Numbers1 будет содержать значения от 1 до 10, а #Numbers2 будет содержать значение 1, а затем все четные числа от 2 до 10.
Сначала давайте посмотрим на старый синтаксис ANSI SQL-89, и в этом синтаксисе нужно отметить две вещи. Во-первых, имена и псевдонимы таблиц перечисляются в предложении FROM через запятую. Если бы вы забыли добавить предложение WHERE, это все равно был бы вполне корректный синтаксис, но он вызвал бы CROSS JOIN, а не INNER JOIN, что привело бы к дорогостоящему декартовому продукту. Другими словами, отсутствие предложения WHERE приведет к тому, что каждая строка в таблице #Numbers1 будет умножена на каждую строку в таблице #Numbers2, что не входит в наши намерения. Этот синтаксис, несмотря на то, что он идеально подходит для ВНУТРЕННИХ СОЕДИНЕНИЙ (не разрешен для ВНЕШНИХ СОЕДИНЕНИЙ), может привести к случайным проблемам. Вы можете узнать больше о различиях между INNER JOIN и OUTER JOIN здесь.
Далее следует синтаксис ANSI SQL-92. В этом синтаксисе вы используете ключевое слово JOIN между таблицами, которые вы хотите соединить, а ключевое слово INNER не требуется в SQL Server. Предложение ON требуется с синтаксисом INNER JOIN, и именно здесь вы указываете столбцы для сравнения для объединения.
Здесь я хочу отметить одну вещь: как оцениваются сравнения для операторов JOIN. В стандартном синтаксисе SQL предложение FROM оценивается перед предложением WHERE. Это означает, что фильтр, установленный в предложении FROM, оценивается перед предложением WHERE — важное, но тонкое отличие, когда фильтры применяются для возврата данных в наших запросах.
4 Примеры распространенных проблем, которых следует избегать при использовании ВНУТРЕННЕГО СОЕДИНЕНИЯ
Одной из наиболее распространенных проблем, с которыми я сталкиваюсь, является то, как часто клиенты чрезмерно нормализуют структуру своей базы данных. Нормализация к третьей нормальной форме — отличная теория с точки зрения дизайна. Тем не менее выигрыш от уменьшения избыточности данных часто сильно перевешивается стоимостью дополнительных необходимых объединений для возврата данных.
Оптимизатор SQL Server обычно надежен в принятии правильных решений с точки зрения порядка соединения, но иногда ошибается. Включение слишком большого количества таблиц в операторы SQL часто может привести к снижению производительности, особенно если оператору SQL не требуются все таблицы, перечисленные в предложении соединения (что встречается чаще, чем вы думаете!)
Ниже я расскажу о некоторых других проблемах с ВНУТРЕННИМ СОЕДИНЕНИЕМ и предоставлю рекомендации и советы, которые помогут вам оптимизировать производительность.
1. Соединения многих таблиц
Очень часто я вижу пользовательский код с операторами SQL, которые включают шесть или более внутренних соединений между таблицами. Это связано с тем, что дизайн базы данных настолько нормализован, что необходимо иметь такое количество объединений, ИЛИ клиент просто пытается сделать слишком много с помощью одного запроса. В любом случае, чем больше таблиц вы ВНУТРЕННИМ СОЕДИНЕНИЕМ в одном операторе SQL, тем больше вероятность того, что оптимизатор запросов не выберет оптимальный путь соединения. Как правило, я склоняюсь к тому, чтобы клиенты начали задумываться о рефакторинге внутренних соединений, когда оператор select включает шесть или более внутренних соединений.
При столкновении с очень сложным оператором SQL, включающим несколько внутренних соединений между таблицами, у оптимизатора запросов есть умный способ справиться с такими ситуациями. Чтобы обеспечить своевременное выполнение запроса, оптимизатор устанавливает ограничение по времени на то, сколько оптимизации он будет выполнять. Как только он достигнет этого предела, он выполнит лучший план, который он нашел на тот момент времени. Рассмотрим следующий пример INNER JOIN, который включает 6 внутренних объединенных таблиц в образце базы данных AdventureWorks:
В плане выполнения я могу посмотреть свойство плана «Причина досрочного завершения оптимизации оператора», которое в данном случае имеет значение «Время ожидания»:
Это означает, что во время оптимизации запроса было так много вариантов плана, что лимит времени для оптимизации был достигнут, и в качестве плана выполнения был выбран «лучший» план из изученных альтернатив плана. Это происходит довольно часто, и если у вас есть сложные операторы T-SQL и вы не получаете желаемого плана выполнения, возможно, пришло время реорганизовать эти операторы T-SQL, чтобы они включали меньше объединений, или разбить операторы на отдельные заявления.
2. Исключение таблиц INNER JOIN
В некоторых случаях оптимизатор запросов SQL Server может исключить таблицы, включенные в операторы INNER JOIN, если таблицы действительно не нужны. Рассмотрим этот оператор соединения между таблицами Sales.SalesOrderHeader, Sales.SalesOrderDetail и Production.Product:
Глядя на план выполнения этого оператора, мы видим, что есть ссылка на таблицу Sales.SalesOrderDetail и таблицу Production.Product, но нет ссылки в таблицу Sales.SalesOrderHeader:
Причина в том, что существует связь внешнего ключа между таблицами Sales.SalesOrderHeader и Sales.SalesOrderDetail. В предложении WHERE нет фильтра для таблицы Sales.SalesOrderHeader, и столбцы из этой таблицы не упоминаются в списке SELECT. Доверенный внешний ключ сообщает SQL Server, что для каждой записи в таблице Sales.SalesOrderDetail должна быть связанная запись (с тем же самым SalesOrderID) в таблице Sales.SalesOrderHeader. Это отношение «один ко многим» между этими двумя таблицами. Это ограничение внешнего ключа в сочетании с отсутствием ссылок на таблицу Sales.SalesOrderHeader позволяет SQL Server решить, что нет причин включать таблицу Sales.SalesOrderHeader в запрос.
Отсутствует связь по внешнему ключу между таблицами Sales.SalesOrderDetail и таблицей Production.Product. Из-за этого требуется соединение этих двух таблиц, хотя в запросе не требуется никакой информации из таблицы Production.Product. Если я добавлю внешний ключ и повторно запущу запрос, мы увидим, что физическое соединение между двумя таблицами устранено:
Давайте удалим это ограничение для остальных демонстраций.
3. Соединения неравенства
Операторы неравенства (любое сравнение, кроме оператора сравнения равенства (=)) могут использоваться для сравнения значений столбцов для операторов INNER JOIN, но часто сравнение не имеет большого смысла, если условие соединения по неравенству является единственным сравнением. Выполнено. Рассмотрим следующий пример INNER JOIN:
Результатом этого запроса является 29 строк. Как таблица с 10 строками, соединенная с таблицей с 6 строками, может вернуть набор результатов с 29 строками? Что происходит, так это то, что сначала вычисляется декартово произведение между двумя таблицами, а затем происходит сравнение. Итак, каждое значение из #Numbers1 сравнивается с каждым значением из #Numbers2, и когда значение из #Numbers1 больше, чем значение из #Numbers2, оно возвращается. Более разумный запрос будет включать сравнение на равенство и сравнение на неравенство. Например, следующий запрос на соединение возвращает те продажи из Sales.SalesOrderDetail, где цена для данного ProductID меньше, чем ListPrice для этого продукта из таблицы Production.Product:
4. Подсказки для присоединения
Одна из областей, где я вижу, что клиенты действительно делают неправильный выбор, — это когда дело доходит до использования подсказок запросов в своем коде. Это почти всегда делается из лучших побуждений — обычно потому, что оптимизатор запросов делает определенный выбор, который не работает для определенного момента времени. Несколько причин для этого: устаревшие статистические данные, неправильная оценка количества элементов локальных переменных и чувствительность параметров. Не поймите меня неправильно — безусловно, бывают случаи, когда подсказка МОЖЕТ помочь в выполнении запроса. Тем не менее, я всегда призываю клиентов использовать их с осторожностью, поскольку они всегда пользуются уважением, и мы часто не замечаем побочных эффектов их использования.
Рассмотрим еще раз вариант запроса, который мы использовали в этой статье. Соединение между таблицей Sales.SalesOrderDetail и таблицей Production.Product создает физическое соединение Hash Match:
HASH JOIN обычно отлично подходит для работы с большими объемами данных. Сначала он строит в памяти структуру данных, хешируя ключи, участвующие в операции соединения. Это называется этапом «сборки» и является этапом блокировки (блокировка в смысле приостановки выполнения запроса, а не блокировки других операций с помощью блокировок), поскольку часто требуется запрашивать дополнительную память рабочей области. В идеале эта «внешняя» таблица должна быть меньшей из двух таблиц. Затем строки для других входных данных сканируются, хэшируются и сравниваются со значениями на этапе построения. Это отличный выбор для соединения двух больших входов.
Может возникнуть соблазн использовать подсказку, чтобы всегда использовать HASH JOIN. Однако это может вызвать некоторые непредвиденные проблемы, если сделать это без тестирования. Причина этого в том, что когда в запросе используется подсказка физического соединения, применяется порядок написания таблиц в операторе. Простое добавление ключевого слова HASH в оператор INNER JOIN всегда будет вызывать HASH JOIN, как показано ниже: общее выполнение запроса будет намного медленнее, чем исходный запрос без подсказки.
Выполняя два запроса в одном пакете, мы видим, что запрос без подсказки в два раза быстрее (по затратам в плане запроса — и процессорному времени выполнения), чем запрос с подсказкой и принудительным порядком :
Важно знать, когда использовать INNER JOIN в SQL
Понимание того, как работает INNER JOIN, является важным навыком для любого разработчика баз данных. Используйте это соединение, если вы хотите вернуть только те строки, в которых есть соответствие между таблицами. Однако есть несколько предостережений, которые следует помнить при написании этих операторов SQL. Во-первых, вы должны быть осторожны при написании предложений INNER JOIN и убедиться, что вы не слишком усложняете их — включение слишком большого количества таблиц в соединение, вероятно, приведет к далекой от идеальной производительности из-за сложности, связанной с тем, что оптимизатор запросов обеспечивает хорошее выполнение. строить планы. Во-вторых, будьте осторожны при использовании подсказок в ваших операторах SQL — эти операторы строго соблюдаются и могут иметь непредвиденные побочные эффекты.
Вы тратите слишком много времени на устранение неполадок с производительностью базы данных и исправляете одну вещь только для того, чтобы сломаться еще две? SolarWinds® SQL Sentry создан для того, чтобы дать вам всеобъемлющее представление о производительности SQL Server, ОС, уровня виртуализации и служб SQL Server Analysis Services (SSAS). Узнайте больше о том, как SQL Sentry разработан с учетом разочарований администратора баз данных.
Пол С. Рэндал — генеральный директор SQLskills.com, которым он управляет вместе со своей женой Кимберли Л. Трипп. И Пол, и Кимберли являются широко известными и уважаемыми экспертами в мире SQL Server, и оба являются давними MVP SQL Server. Пол был редактором журнала TechNet Magazine, где он два раза в месяц писал колонку вопросов и ответов по SQL и тематические статьи. Он также провел лучшие семинары и сессии на PASS Summit и TechEd. Пол активно участвует в сообществе SQL Server, от групп пользователей до онлайн-форумов и помощи в Твиттере (@PaulRandal — проверьте тег #sqlhelp).