Как посмотреть процессы базы 1с под ms sql: Производительность 1С в клиент-серверном варианте – Ваш петербургский программист 1С
Содержание
Чек-лист по настройке инфраструктуры для повышения скорости работы 1С с MS SQL (особенно важно в облаках) / Хабр
При размещении 1С в облачной инфраструктуре и среде виртуализации наиболее важными и непростыми задачами являются повышение скорости работы платформы «1С» и настройка СУБД. Для достижения максимальной производительности инфраструктуры 1С рекомендуется правильно выбирать архитектуру инфраструктуры, режимы работы, проверить и выполнить ряд важных настроек.
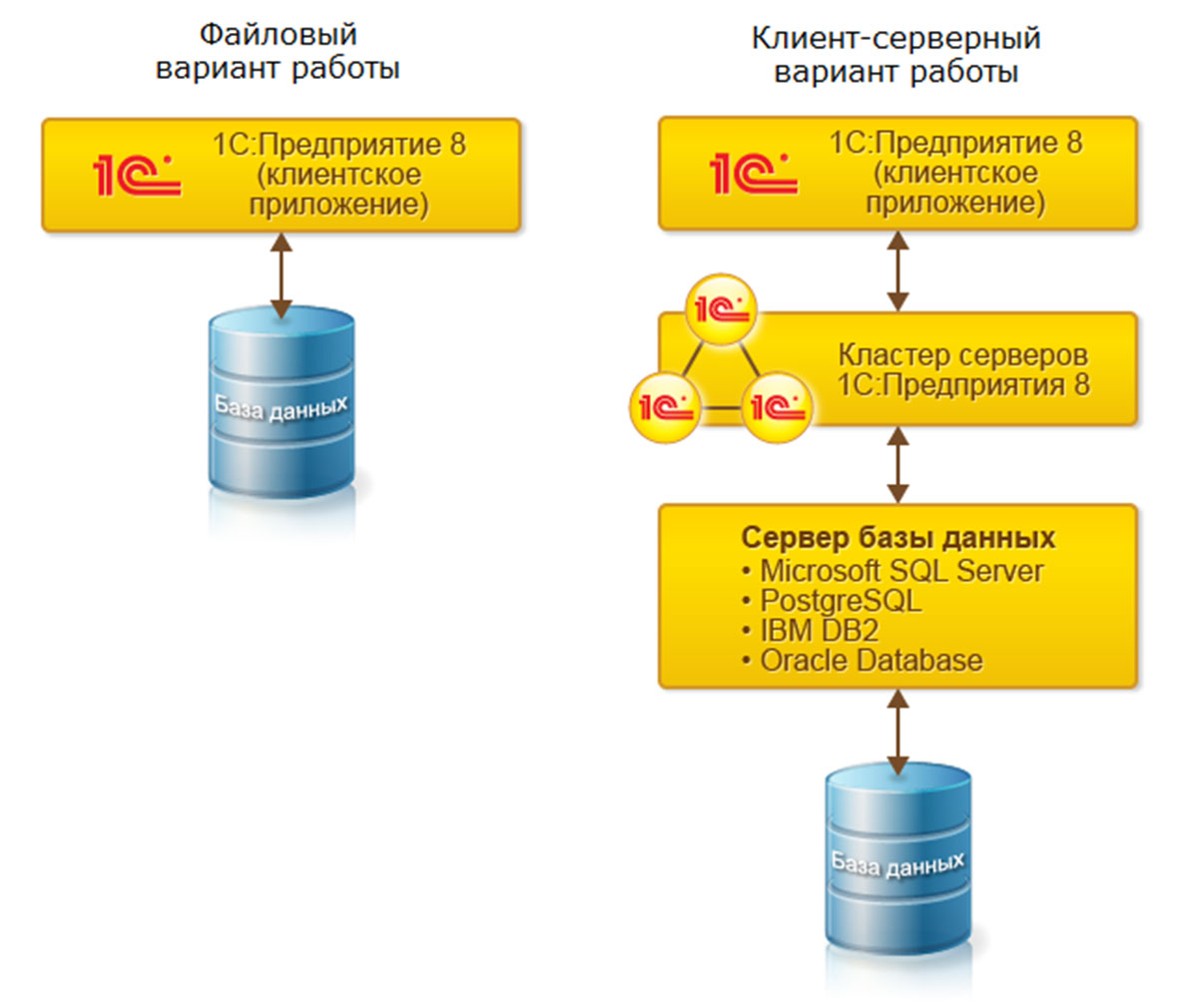
В зависимости от количества пользователей, размера баз данных и ограничений бюджета (с учетом стоимости дополнительных лицензий на сервер «1С:Предприятие 8» и лицензий на СУБД) платформа «1С» может работать в файловом и клиент-серверном вариантах (на основе трехуровневой архитектуры «клиент-сервер» (рис. 1): клиентское приложение, кластер серверов «1С:Предприятия 8», СУБД).
Рис. 1
Как правильно выбрать вариант/режим работы 1С: файловый или SQL?
Обычно для 1-10 пользователей выбирается файловый режим
От 10 и более пользователей выбирается режим работы с использованием SQL
В файловом варианте все пользователи могут работать на одной виртуальной машине в облаке, например на терминальном сервере.
Для клиент-серверного варианта лучше выбрать не менее двух виртуальных машин:
Сервер с клиентским приложением, например терминальный сервер с клиентской частью «1С» (толстый клиент)
Сервер «1С» и СУБД (MS SQL или PostgreSQL)
Как рассчитать мощности сервера для 1С в файловом режиме работы?
В обоих вариантах: файловом и SQL, для работы с пользовательским приложением 1С в классическом режиме, например, «удаленного рабочего стола» (так называемый «толстый клиент»), необходимы следующие минимальные ресурсы виртуального сервера:
Количество виртуальных ядер CPU = 1 или 2 для ОС + 0,25 * количество пользователей
Объем памяти RAM = 1 или 2 ГБ для ОС + 0,5 ГБ * количество пользователей
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (0,1-10) ГБ * количество пользователей. Для ОС и 1С рекомендуется использовать самые быстрые диски
Как рассчитать мощности сервера для 1С в варианте работы с SQL?
В клиент-серверном варианте работы 1С, в котором используется СУБД SQL, рекомендуется разместить 1С Сервер и сервер SQL на отдельном виртуальном сервере в общей с клиентским сервером локальной подсети.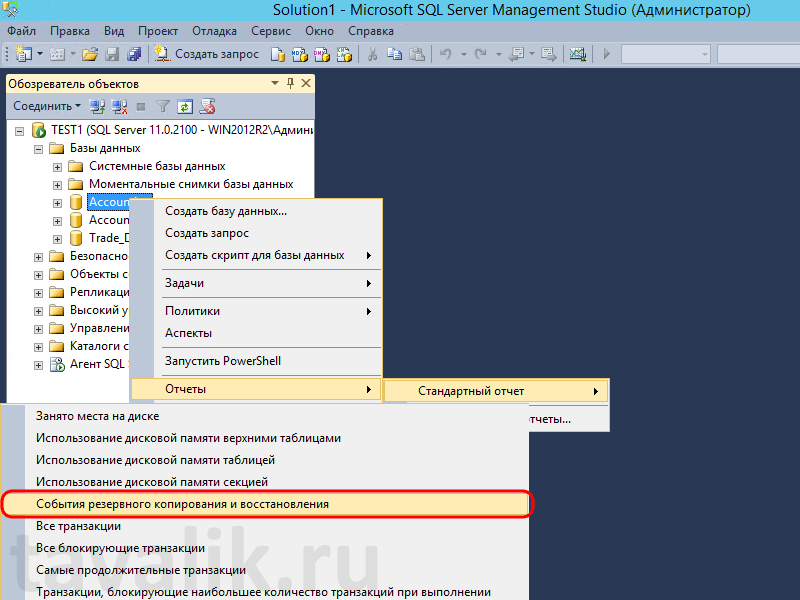 Необходимы следующие минимальные мощности для этого виртуального сервера:
Необходимы следующие минимальные мощности для этого виртуального сервера:
Количество виртуальных ядер CPU = 1 или 2 для ОС + (2-4) для Cервера 1С + (2-8-16…) для СУБД SQL в зависимости от объема и количества баз данных
Объем памяти RAM = 1 или 2 ГБ для ОС + (2-4) ГБ для Cервера 1С + (2-4-8-16-32…) ГБ для СУБД SQL в зависимости от объема и количества баз данных
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (10-1000) ГБ в зависимости от объема и количества баз данных. Для ОС и СУБД рекомендуется использовать самые быстрые диски
————
ОС — операционная система, например, Windows Server
Здесь Сервер 1С — ПО «сервер «1С:Предприятия 8»
Наиболее важными и непростыми задачами являются повышение продуктивности использования платформы «1С» в облаке и настройка СУБД. Типичные проблемы при развертывании и эксплуатации облачной инфраструктуры для «1С» следующие:
Неправильный выбор мощностей
Неквалифицированная настройка сервисов виртуальной инфраструктуры
Недостаточное внимание к тестированию производительности платформы «1С»
Для достижения максимальной производительности рекомендуется проверить и выполнить ряд настроек. Прежде всего необходимо исключить свопинг, для чего с помощью системы мониторинга следует обязательно удостовериться в том, что объем оперативной памяти достаточен для работы ВМ. Кроме того, файл подкачки ОС, профили пользователей, файлы баз данных, файлы логов транзакций (SQL) и tempDB (SQL) лучше разместить на дополнительных SSD-дисках, а для файла подкачки установить фиксированный размер.
Прежде всего необходимо исключить свопинг, для чего с помощью системы мониторинга следует обязательно удостовериться в том, что объем оперативной памяти достаточен для работы ВМ. Кроме того, файл подкачки ОС, профили пользователей, файлы баз данных, файлы логов транзакций (SQL) и tempDB (SQL) лучше разместить на дополнительных SSD-дисках, а для файла подкачки установить фиксированный размер.
На SQL-сервере необходимо выключить все ненужные службы, например FullText Search и Integration Services, установить максимально возможный объем оперативной памяти, максимальное количество потоков (Maximum Worker Threads) и повышенный приоритет сервера (Boost Priority), задать ежедневную дефрагментацию индексов и обновление статистики, настроить автоматическое увеличение файла базы данных (не менее 200 Мбайт) и файла лога (не менее 50 Мбайт), а также полную реиндексацию не реже одного раза в неделю. При размещении серверов SQL и «1С:Предприятие» на одной ВМ следует включить протокол Shared Memory.
При расчете требуемых мощностей в облаке лучше выбрать минимальные первоначальные значения без запаса, поскольку биллинг почасовой, а мощности в любой момент можно увеличить или уменьшить. Такой подход позволяет существенно экономить ресурсы и средства. Вместе с тем надо обязательно протестировать и оценить быстродействие системы, для чего можно использовать, например, бесплатные нагрузочные тесты Гилева и «1С:Корпоративный инструментальный пакет» (https://its.1c.ru/db/kip или http://v8.1c.ru/expert/etp.htm).
С помощью тестов Гилева можно быстро и достаточно легко понять, насколько эффективно работает платформа «1С», как влияют на ее производительность те или иные настройки, а также найти и устранить узкие места инфраструктуры. Для более детального анализа нагрузки и поиска узких мест рекомендуется использовать утилиту Process Explorer Марка Русиновича (https://technet.microsoft.com/en-us/sysinternals/processexplorer).
Следуя перечисленным выше рекомендациям, можно добиться увеличения быстродействия платформы «1С» в облаке в 1,5–2 раза.
Квалифицированное размещение ИТ-сервисов, в том числе «1С», на облачной платформе позволяет:
Существенно сократить расходы
Повысить уровни безопасности (доступ к данным, резервное копирование, антивирусная защита и др.) и технического обслуживания
Обеспечить централизованное администрирование и мониторинг
Организовать эффективную и безопасную удаленную работу
Воспользоваться гибкими возможностями масштабирования, лицензирования и оперативного перехода на необходимые версии конфигураций «1С»
ЧЕК-ЛИСТ ПО ОПТИМИЗАЦИИ ИНФРАСТРУКТУРЫ 1С С MS SQL
1. Включить возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
Создание базы данных
Добавление файлов, журналов или данных в существующую базу данных
Увеличение размера существующего файла (включая операции автоувеличения)
Восстановление базы данных или файловой группы
Подробности здесь
Для включения настройки:
На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.
 msc)
msc)Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей
На правой панели дважды кликните Выполнение задач по обслуживанию томов
Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server
Нажмите кнопку Применить
 msc)
msc)2. Включить параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Подробности здесь
Для включения настройки:
В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc
В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows
Разверните узлы Настройки безопасности и Локальные политики
Выберите папку Назначение прав пользователя
Политики будут показаны на панели подробностей
На этой панели дважды кликните параметр Блокировка страниц в памяти
В диалоговом окне Параметр локальной безопасности — блокировка страниц в памяти выберите «Добавить» пользователя или группу
В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server
Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server
3.
 Включить каталоги с файлами базы данных в правила исключения для антивируса.
Включить каталоги с файлами базы данных в правила исключения для антивируса.
Если антивирус будет сканировать файлы базы, это может сильно замедлить работу СУБД.
Для опытных администраторов: антивирус на сервер СУБД лучше не устанавливать.
4. Включить каталоги с файлами базы данных в список исключений для системы автоматического копирования.
Если на сервере установлена система автоматического копирования файлов, то, когда она будет копировать файлы базы, это может привести к замедлению работы. Копии базы необходимо делать средствами самой СУБД.
5. Отключить механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С.
Чтобы отключить его только для дисков, нужно:
6. Отключить сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
Открыть свойства каталога
На закладке Общие нажать кнопку Другие
Снять флаг «Сжимать» содержимое для экономии места на диске
7. Установить параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Дополнительно
Установить значение параметра равное единице
8. Ограничить максимальный объем памяти сервера MS SQL Server.

Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей.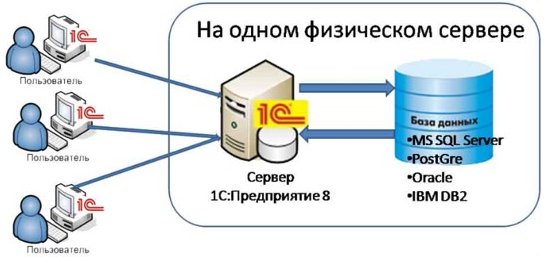 Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Память
Указать значение параметра Максимальный размер памяти сервера
9. Включить флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Процессоры
Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок
10.
 Установить размер авто увеличения файлов базы данных.
Установить размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
Для установки размера авторасширения необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
11. Разнести файлы данных mdf и файлы логов ldf на разные физические диски.

В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Запомнить имена и расположение файлов
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
Поставить флаг Удалить соединения и нажать Ок
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
Нажать кнопку Добавить и указать файл mdf с нового диска
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
12. Вынести файлы базы TempDB на отдельный диск.

Служебная база данных TempDB используется всеми базами сервера для хранения, промежуточных расчетов, временных таблиц, версий строк при использовании RCSI и многих других вещей. Обычно обращений к этой базе очень много, и если она будет лежать на медленных дисках, это может замедлить работу системы.
Рекомендуется хранить базу TempDB на отдельном диске для повышения производительности работы системы.
Для переноса базы TempDB на отдельный диск необходимо:
USE master GO ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = ‘Новый_Диск:\Новый_Каталог\tempdb.mdf’) GO ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = ‘Новый_Диск:\Новый_Каталог\templog.ldf’) GO |
13. Включить Shared Memory, если сервер 1С расположен на том же компьютере, что и сервер СУБД.
Протокол Shared Memory позволит общаться приложениям через оперативную память, а не через протокол TCP/IP.
Для включения Shared Memory необходимо:
Запустить диспетчер конфигурации SQL Server
Зайти в пункт SQL Native Client – Клиентские протоколы – Общая память – Включено
Поставить значение Да и нажать Ок
Протокол Именованные каналы нужно выключить аналогичным образом
14. Перезапустить службу MS SQL Server
Внимание! Когда все настройки выполнены, необходимо перезапустить службу MS SQL Server
Частые вопросы по миграции базы данных 1С с MS SQL на PostgreSQL / Хабр
Миграция базы данных 1С с MS SQL на PostgreSQL – по-прежнему насущная тема, особенно в контексте импортозамещения. На наших вебинарах и в беседах с клиентами мы получаем много вопросов по нюансам миграции. Решили собрать основные рекомендации в одну статью.
1. С чего начать подготовку к миграции?
Первая задача – это тюнинг параметров потребляемой памяти в Postgres.
Postgres активно взаимодействует с ОС и если не находит в своем кеше требуемой страницы, то обращается к кешу операционной системы.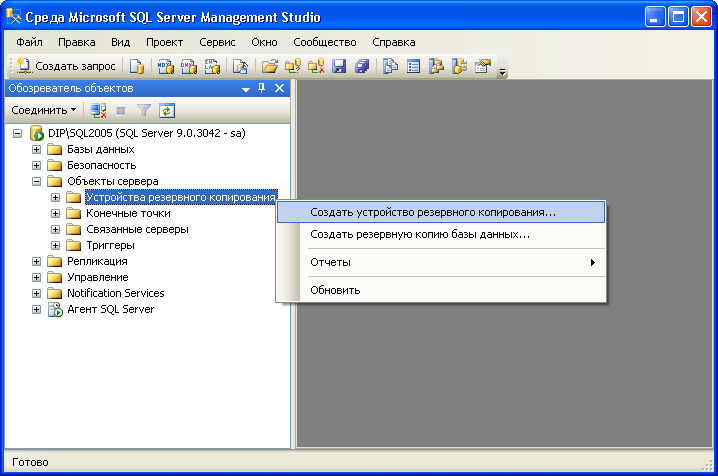 Поэтому параметр shared_buffers выставляется от 25 до 50% от общего объема памяти. Shared_buffers не должен равняться общему объему памяти, выделенному на сервер (~= ¼ от общего объема памяти, но не более 50%).
Поэтому параметр shared_buffers выставляется от 25 до 50% от общего объема памяти. Shared_buffers не должен равняться общему объему памяти, выделенному на сервер (~= ¼ от общего объема памяти, но не более 50%).
Параметр work_mem отвечает за объем памяти для операций сортировки и хеш-таблицы. Этот параметр индивидуален для каждой сессии, поэтому его не надо сильно увеличивать. Тестируйте свое решение в диапазоне от 32 до 128 Мб.
Если запросу не хватает текущего объема, work_mem обратится к временным таблицам, и здесь включится в игру следующий параметр – temp_buffers. Он отвечает за количество буферов для временных таблиц. По дефолту его значение составляет 8 Мб. Здесь тоже советуем его изменить и поставить от 128 до 256 Мб, в зависимости от конфигурации.
Так выглядит наш конфиг с выставленными настройками.
В современных ОС используется страничный способ организации виртуальной памяти. По умолчанию размер страницы составляет 4 Кб. Чем больше у вас памяти, тем больше накладных расходов потребуется на обработку ее объема.
По умолчанию размер страницы составляет 4 Кб. Чем больше у вас памяти, тем больше накладных расходов потребуется на обработку ее объема.
Каждая страница памяти сопоставлена с таблицей в адресном пространстве, которое преобразует виртуальную адресацию в физическую. C увеличением размера страницы, мы сокращаем ее. Соответственно, если таблица умещается в буфер ассоциативной памяти, то ускорение и увеличение производительности нагруженных систем с точки зрения памяти будет ощутимо. ОС трансформирует физическую трансляцию в виртуальную и кеш – в TLB.
Схема использования TLB.
Параметр Huge pages позволяет заметно сократить потребление общей памяти Postgres, его фоновых процессов и повысить производительность. По умолчанию параметр составляет 4 Кб, как размер страницы в ОС. Для процессов с большими объемами мы рекомендуем выставить его значение не менее 2 Мб. Но жесткой рекомендации нет: надо тестировать в своей системе. VmPeak /proc/1854/status
VmPeak /proc/1854/status
VmPeak: 17480728 kB
[root@pg01 ~]# echo $((17480728 / 2048 + 1))
8536
[root@pg01 ~]# echo ‘vm.nr_hugepages = 8536’ >> /etc/sysctl.d/00-postgresql.conf
[root@pg01 ~]# sysctl -p —system
2. Что нужно учесть при настройке ОС?
PostgreSQL, как и большинство приложений, зависит от параметров операционной системы. Для СУБД это особенно критично: производительность может ощутимо снизиться при некорректной настройке параметров.
Ключевыми являются следующие настройки:
1.
vm.swappines:
sysctl -w vm.swappines=2
Так регулируется процент памяти, при котором система начинает использовать swap-файл – область на диске, которая может быть использована системой как очень медленная оперативная память.
2.
vm.overcommit_memory / vm.overcommit_ratio
sysctl -w vm.overcommit_memory=2
Убираем перевыделение памяти по умолчанию: в значении vm.overcommit_memory=0 происходит эвристический анализ для определения выделяемой процессу памяти. Это дополнительная трата ресурсов, а острая нехватка памяти и большая конкуренция запустит процесс OOM Killer, при этом вы получите сообщения: “Out of Memory: Killed process 12345 (postgres)”.
Это дополнительная трата ресурсов, а острая нехватка памяти и большая конкуренция запустит процесс OOM Killer, при этом вы получите сообщения: “Out of Memory: Killed process 12345 (postgres)”.
Избежать этого поможет контроль перевыделения. Рекомендуем установить значение vm.overcommit_memory=2. Имейте в виду, что после установки этого параметра большую роль начнет играть значение vm.overcommit_ratio (число будет определять процент памяти, доступный для перевыделения, например, 50 для 4 Гб = 6 Гб) и наличие SWAP-файла. Для vm.overcommit_ratio универсальных значений нет: его обычно вычисляют исходя из доступной памяти и объема SWAP: overcommit_ratio < (RAM — swap) / RAM * 100.
3. Как повысить производительность PostgreSQL?
1С не делит данные на “горячие” и “холодные” (архивные) и все содержит в одной базе. Со временем объем данных увеличивается до многомиллионных значений. И небольшое изменение в процентном соотношении с общим объемом данных приводит к тому, что воркеры “не заходят” в эти таблицы и не пересчитывают статистику. А иметь правильную статистику очень важно, так как она используется оптимизатором при построении запроса.
А иметь правильную статистику очень важно, так как она используется оптимизатором при построении запроса.
Для ускорения и улучшения производительности стоит настроить процесс автовакуума.
Параметр autovacuum_max_workers отвечает за количество воркеров. Его можно определить по простой формуле: общее кол-во ядер делите пополам (~ кол-во vCPU / 2). Можно варьировать, но формула рабочая.
Само по себе увеличение количества воркеров не даст нам кратное увеличение производительности, поскольку на поведение воркеров влияют еще такие характеристики, как Autovacuum_vacuum_scale_factor и autovacuum_analyze_scale_factor. Они отвечают за пороги, при которых автовакуум будет заходить в таблицы/индексы, очищать и пересчитывать статистику.
Значения по умолчанию для scale_factor равны 0,2 (20%). Чем больше объем данных, тем больше влияют эти 10–20% на то, как будут заходить воркеры в таблицы и индексы: в многомиллиардных таблицах небольшие изменения будут незаметны для воркеров автовакуума. Поэтому рекомендуем уменьшить значения, выставленные по умолчанию, например:
Поэтому рекомендуем уменьшить значения, выставленные по умолчанию, например:
Таким образом мы повлияем на два важных фактора: у нас будет происходить очистка, и воркеры будут знать, что произошли изменения данных и надо обновить статистику.
Но важно помнить, что все же эти настройки индивидуальны.
Autovacuum_vacuum_cost_limit следит за суммарным порогом стоимости всех воркеров автовакуума. Если увеличиваете количество воркеров автовакуума, увеличивайте значение autovacuum_vacuum_cost_limit примерно во столько же раз.
4. Реально ли сделать перенос, если мало опыта в 1С?
Существует два способа миграции стандартными средствами 1С. У каждого есть свои плюсы и минусы.
Миграция при помощи планов обмена. Этот способ дает возможность гибкой настройки, например: отфильтровывать данные, которые вы не хотите переносить, или переключаться на новую СУБД постепенно. Однако это трудозатратно, вы не сможете обойтись без квалифицированного программиста 1С.

Выгрузка-загрузка дампа базы в .dt-файл.
Более простой метод миграции:
— вам не потребуется разработчик 1С;
— но нужна пауза в работе на время переноса базы
Сравнили два способа миграции, зеленым выделили преимущества.
Соответственно, если опыта мало, мы рекомендуем второй способ. Ниже разберем его подробнее.
5. Можно ли сотрудникам продолжать работу во время миграции?
Во время выгрузки база должна быть открыта в монопольном режиме. Работа пользователей или фоновые задания будут мешать процессу и завершат выгрузку дампа ошибкой. При многопоточной загрузке дампа в Postgres конфликт блокировок также даст ошибку загрузки. Подробно об этом можно прочитать здесь.
НО! Эти ограничения можно обойти при помощи штатной консольной утилиты ibcmd, которая создана для автономного управления сервером. Утилита существует как для Windows, так и для Linux, работает с СУБД напрямую, что значительно ускоряет процесс выгрузки и загрузки дампов.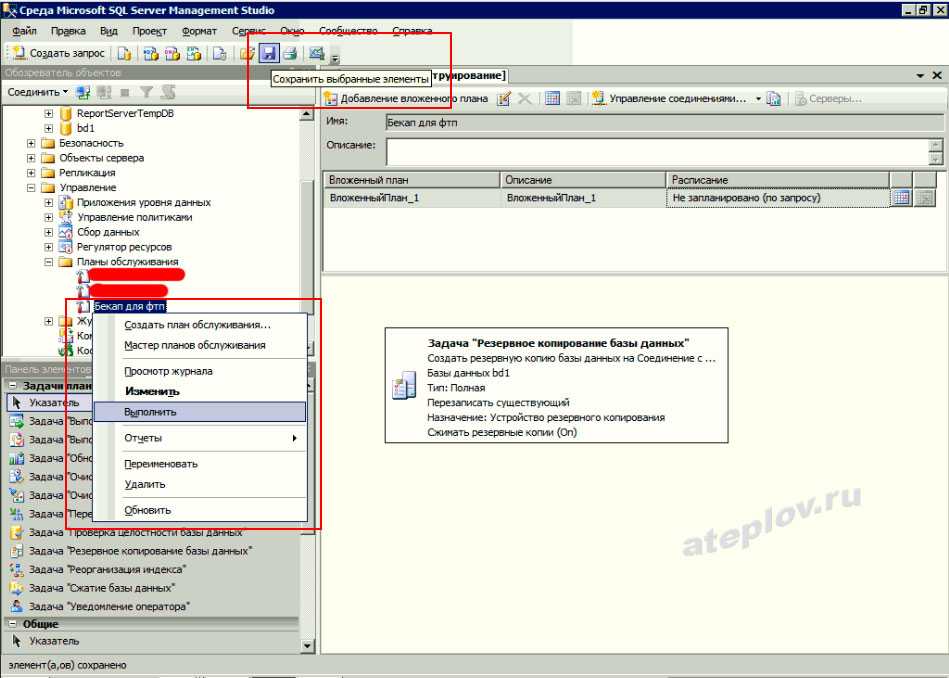 Дамп можно выгружать даже при работающих пользователях. Поэтому утилиту также используют для создания тестовых копий базы или для какой-нибудь отладки.
Дамп можно выгружать даже при работающих пользователях. Поэтому утилиту также используют для создания тестовых копий базы или для какой-нибудь отладки.
При использовании утилиты для миграции лучше отключать базу от сервера приложений, чтобы сохранить консистентность данных. Утилита устанавливается в папку \bin вместе c сервером 1С:Предприятие.
Подробные инструкции для ibcmd мы повторять не будем, их можно прочитать в этом руководстве.
6. Расскажите про миграцию БД по шагам
В нашем случае мы говорим про версию 1С:Предприятие 8.3.18.1334. Это важный момент, поскольку следующие версии имеют другой синтаксис.
Для начала вам понадобятся:
Установленный сервер 1С:Предприятие 8.3.18.1334. Службу сервера запускать не нужно, нам нужна только утилита. Чем ближе к утилите вы расположите СУБД, тем быстрее будет происходить выгрузка и загрузка.
Учетная запись к базе на сервере MS SQL.
Учетная запись к серверу Postgres c правами SuperUser.

Шаг 1. Отключаем базу от сервера приложения, чтобы исключить изменения в базе во время выгрузки дампа.
Для этого удаляем регистрацию базы на кластере 1С. Важно: удаляем только запись на кластере, саму базу оставляем на месте.
Альтернативным решением можно запретить на стороне СУБД подключение к базе пользователя, под которым сервер приложения цепляется к базе.
Шаг 2. Переходим непосредственно к выгрузке базы в dt.
Запускаем ibcmd в режиме infobase и указываем:
тип СУБД – в нашем случае это MS SQL;
сетевое имя сервера и IP-адрес;
имя базы на SQL;
логин и пароль на SQL;
команду для выгрузки dump;
путь, куда будет выгружаться база.
Все вместе:
Ibcmd.exe infobase —dbms=MSSQLServer —db-Server=ИмяСервераSQL —db-name=ИмяБазыНаSQL —db-user=ПользовательSQL —db-pwd=ПарольSQL dump \\ПапкаДляВыгрузки\ИмяФайла.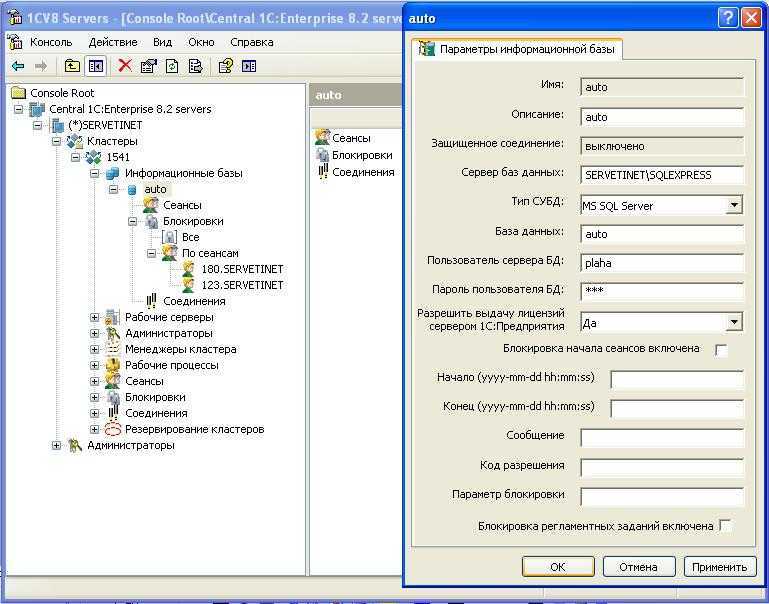 dt
dt
Шаг 3. Теперь загружаем.
Создаем базу на сервере Postgres и загружаем в нее дамп. Запускаем ibcmd в режиме infobase create. Указываем:
тип СУБД – теперь это PostgreSQL;
сетевое имя сервера;
имя базы – как она будет называться на сервере;
логин, пароль;
команду create-database, которая создает СУБД, если ее нет;
команду restore – указывает на файл дампа, который надо развернуть.
Ibcmd infobase create —dbms=PostgreSQL —db-server=ИмяСервераPostgres —db-name=ИмяБазыНаPostgres —db-user=ПользовательPostgres —db-pwd=ПарольPostgres —create-database —restore=\\ПапкаДляВыгрузки\ИмяФайла.dt
Шаг 4. По окончании загрузки регистрируем на кластере 1С развернутую базу.
Базу можно зарегистрировать под старым именем, чтобы не переписывать список клиентов.
Теперь можно считать нашу базу смигрированной.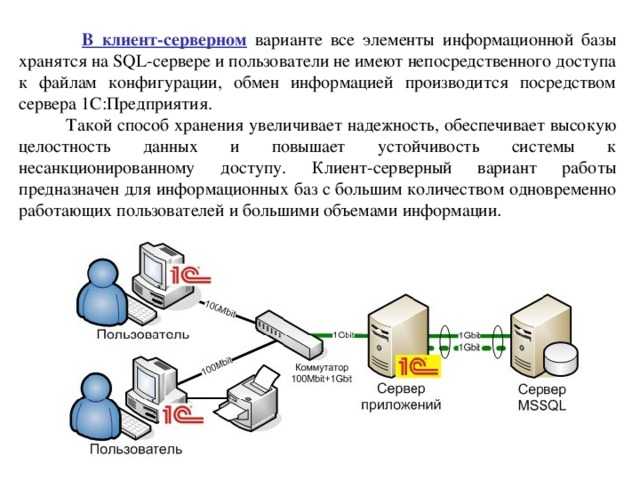
7. А можно этот процесс упаковать в скрипт?
Поскольку утилита ibcmd является консольной, все шаги выгрузки и загрузки дампа можно собрать в один скрипт. Ниже на скриншоте вы видите работу такого скрипта для загрузки базы 30 Гб.
Как видим, на процедуру ушло 17 минут.
Если вы используете для управления сервером 1С Remote admin server, то шаги с удалением и регистрацией базы на кластере можно также упаковать в скрипт.
8. Как сравнить производительность MS SQL и PostgreSQL после миграции?
На слайде ниже показана конфигурация нашего стенда: RDP, кластер 1С из двух нод и сервер СУБД. Сервер MS SQL и PostgreSQL имеют одинаковые характеристики.
У нас был классический стенд из трех звеньев
Для сравнения использовали два теста.
1. Синтетический многопоточный тест производительности Fragster. Он создает множество фоновых сеансов и выполняет с их помощью операции с различными объектами базы.
Как видно из результатов, PostgreSQL проигрывает в работе с временными таблицами, однако показывает лучшую производительность при работе с объектами, что суммарно дает одинаковую производительность с MS SQL.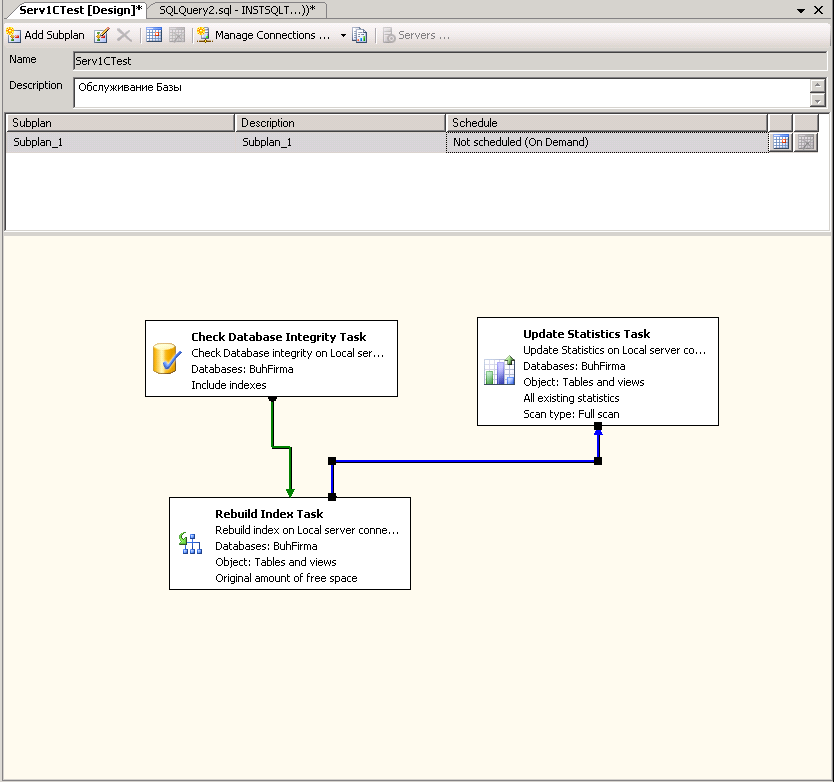
2. Тест по методике APDEX – симулирует работу пользователей 1С:Бухгалтерия типовой конфигурации. Здесь мы запускали одновременно 70 клиентов в тестовой базе, и каждый клиент проводил 500 операций, выбираемых из списка рандомно.
9. Какие инструменты администрирования в PostgreSQL аналогичны инструментам MS SQL?
Резервное копирование. Аналогом встроенного средства MS SQL в Postgres является pg_basebackup + WAL archiving или pg_probackup. Централизованные решения РК, например, Commvault или Veeam B&R, поддерживают как MS SQL, так и Postgres. Из OpenSource решений используется Bareos.
Репликация. В Postgres также есть встроенные средства. Для управления отказоустойчивостью можно использовать Patroni. Он позволит управлять кластером, добавлять новые реплики, производить автоматические контролируемые и аварийные переключения.
Мониторинг.
Здесь ничего не меняется: для алертинга и сбора также продолжаем использовать Zabbix, Nagios, Prometheus, VictoriaMetrics.Анализ. Используются встроенные средства, такие как log_statements и System View, и дополнительно можно использовать расширение pg_profile.
 Здесь ничего не меняется: для алертинга и сбора также продолжаем использовать Zabbix, Nagios, Prometheus, VictoriaMetrics.
Здесь ничего не меняется: для алертинга и сбора также продолжаем использовать Zabbix, Nagios, Prometheus, VictoriaMetrics.10. А как обстоят дела с HA? Раньше мы использовали MS SQL AlwaysOn
В PostgreSQL есть встроенная поддержка потоковой репликации. Архитектура этого процесса схожа с реализацией в MS SQL. В обеих СУБД репликация использует журналы транзакций, которые накатываются отдельными фоновыми процессами. В случае с Postgres для этого используются WAL sender, отправляющий изменения на реплику, и процесс WAL receiver, получающий данные.
Ключевым отличием от технологии AlwaysON в MS SQL является встроенная поддержка виртуального адреса (VIP) – listener в терминологии MS SQL AlwaysON. Она дает возможность “бегать” за главной репликой и тем самым позволяет клиентским приложениям быть подключенными к одному IP-адресу. В MS SQL это реализовано благодаря тесной интеграции со встроенной в Windows Server реализацией Failover Clustering (WSFC) – ставится как отдельный feature. Именно WSFC управляет сетевым стеком в данном случае и отвечает за переключение реплики с одного узла кластера на другой.
В MS SQL это реализовано благодаря тесной интеграции со встроенной в Windows Server реализацией Failover Clustering (WSFC) – ставится как отдельный feature. Именно WSFC управляет сетевым стеком в данном случае и отвечает за переключение реплики с одного узла кластера на другой.
В случае Postgres VIP реализуется сторонними инструментами и решениями, например, pacemaker. Он, как и в случае с WSFC в Windows Server, управляет VIP и контролирует его по некоторым базовым метрикам.
Кроме того, упомянутый ранее Patroni также облегчает управление отказоустойчивым решением.
11. Как изменятся механизмы бэкапа и репликации после переезда с MS SQL на PostgreSQL?
Особенности резервного копирования и восстановления для PostgreSQL продиктованы его архитектурой. Что важно понимать?
Есть несколько вариантов реализации РК:
Дамп не позволяет восстановиться к конкретному времени, поэтому для бизнес-систем, с точки зрения RTO/RPO, не применим.
Встроенные средства Postgres позволяют создавать полный бэкап и бэкап WAL.
Таким образом, восстановиться можно на заданную точку (Point-in-time-Recovery – PITR). Дифференциальные копии отсутствуют.В Postgres выполняется бэкап всей директории с данными. Нет возможности указать конкретную базу для бэкапа. Это же касается и папки с WAL-файлами: она одна на весь кластер/инстанс. Таким образом, процедура и восстановление выполняется для всей инсталляции целиком.
 Таким образом, восстановиться можно на заданную точку (Point-in-time-Recovery – PITR). Дифференциальные копии отсутствуют.
Таким образом, восстановиться можно на заданную точку (Point-in-time-Recovery – PITR). Дифференциальные копии отсутствуют.12. Стоит разносить WAL и файлы базы на отдельные дисковые группы, если они на SSD?
Все зависит от многих факторов, например:
это локальные диски на сервере или выделенная СХД, на которой запущены другие ресурсоемкие процессы;
какая нагрузка ожидается в части Read/Write? Возможно, речь идет о постоянном чтении, при котором использование WAL минимально, и будет нелогичным выделение отдельного дискового пула для WAL.
Мы поделились ответами лишь на самые основные вопросы, возникающие при подготовке к переносу 1С на PostgreSQL.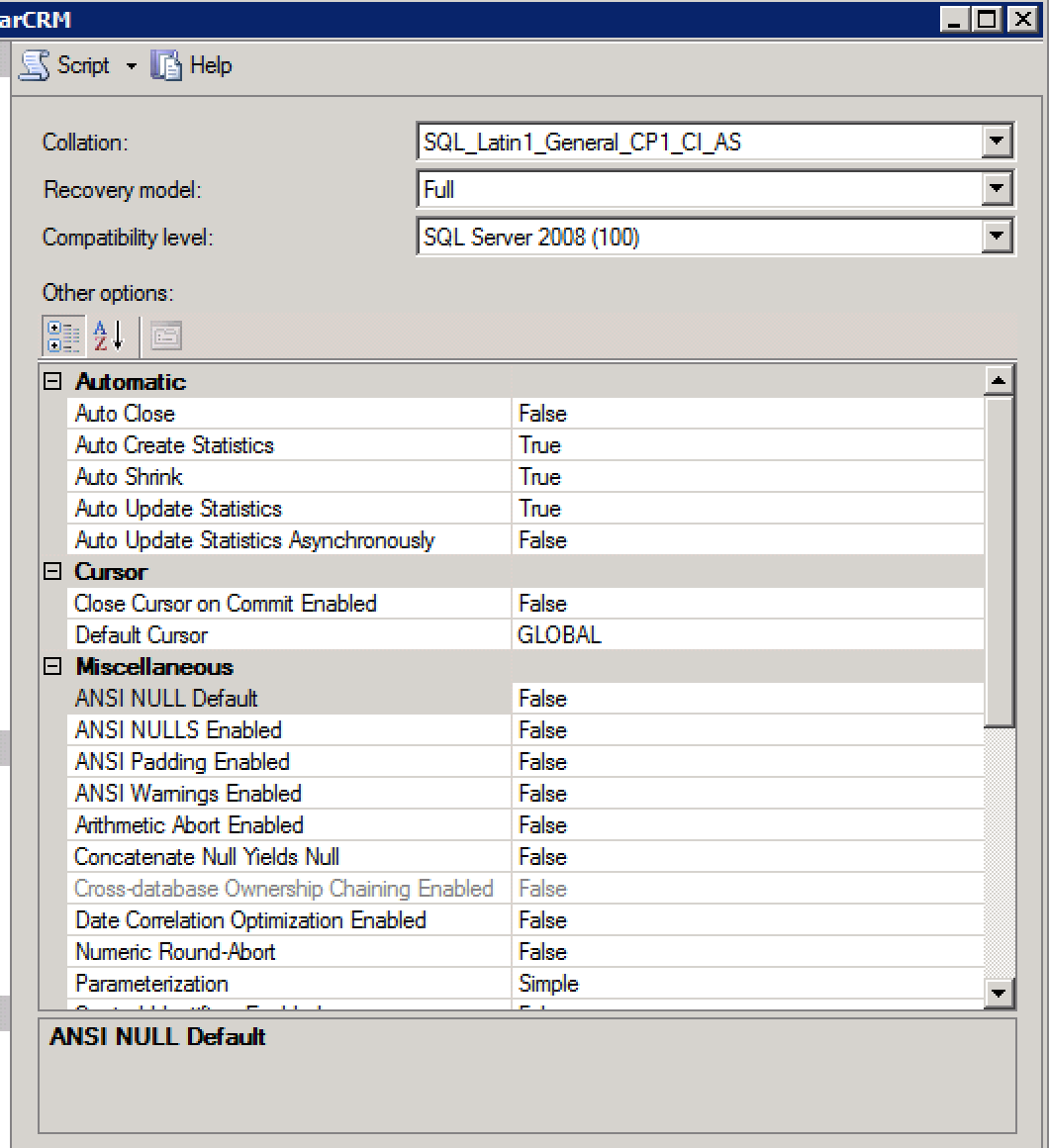 Если у вас есть другие вопросы или проблемы, обращайтесь! Расскажем-покажем, чем сможем – поможем. Удачи!
Если у вас есть другие вопросы или проблемы, обращайтесь! Расскажем-покажем, чем сможем – поможем. Удачи!
1С:Предприятие
Методом проб и ошибок, тестированием на 200+ живых пользователях, консультациями с десятками Гуру и поиском по сотням официальных и не очень сайтов был выработан оптимальный вариант настроек MS SQL для дневной и ночной работы более 200 пользователей одновременно.
1. Настройка сервера
Во-первых, нам нужен только сервер, другие сервисы, которые к нему относятся и возможно кто-то их использует, мы только мешаем работе. Остановить и отключить такие службы, как Полнотекстовый поиск (у 1С есть свой полнотекстовый поиск), Службы интеграции и иже с ними.
Только резерв:
SQL Server (SQLServr.exe)
SQL Server Agent (SQLagent.exe)
SQL Writer (SQLWRITER.EXE)
Далее, серверы через студию управления сервером:
.
Максимальный объем выделяемой памяти из расчета на сервер:
[Общая память сервера] — [система под 4Гб (2Гб если Win2003)] — [1,5Гб * rphost число процессов (. 1С и если SQL сервер на той же раскрутке)] Например, если у нас на сервере только 36 Гб памяти, работает Windows 2008 и 8 rphost, то процесс расчета будет следующим: 36 — 4 — 1,5 * 8 = 20 Гб лимит установлен для SQL.
1С и если SQL сервер на той же раскрутке)] Например, если у нас на сервере только 36 Гб памяти, работает Windows 2008 и 8 rphost, то процесс расчета будет следующим: 36 — 4 — 1,5 * 8 = 20 Гб лимит установлен для SQL.
Это нужно для того, чтобы sql сервер подсчитывал объем памяти и очищал заранее, т.к. если поставить неограниченный объем, и сервер попытается получить память, которой нет, то он начинает усиленно думать о своих поведения и очень медленно реагируют на просьбы.
Далее:
Максимальное количество потоков (Maximum worker threads) установлено 2048, по умолчанию 0 и соответственно значение сервера не создает более 255 потоков, а его не хватает (установлено опытным путем, что при большое количество одновременных транзакций сервер действительно начинает работать быстрее). Также выставляем галку высокий приоритет сервера (Boost priority).
Собственно со всеми глобальными настройками. Теперь перейдите к настройкам производственной базы данных (или нескольких баз данных, если это имеет место).
2. Настройка вашей базы данных
Заходим в свойства необходимой нам базы:
Если база еще не развернута из .dt файла, и вы знаете ее примерный размер, размер первичную инициализацию файла лучше указать >= размера базы, но это дело вкуса, она все равно будет расти размахом. А вот размер автоувеличения надо указать примерно 200 Мб на базу, а на лог 50 Мб, т.к. по умолчанию — 1Мб прирост и 10% сильно тормозят работу сервера, когда ему каждую третью транзакцию приходится увеличивать файл. Кроме того, если вы не используете RAID-массив, то хранилище файла базы данных и файла журнала лучше всего указать на разных физических дисках. Ну и ограничьте лог 2-4 гб, чтоб не много пуха.
Другие настройки как полный скриншот:
Со всеми базовыми настройками. Вы настроили запланированные задания.
3. Настройка запланированных заданий
При первом создании Плана обслуживания в разделе Управление:
Дефрагментация индексов и сбор статистики должны выполняться ежедневно, т. к. производительность сервера. Дефрагментация и обновление статистики выполняются быстро и не требуют отключения пользователей. Насколько раздроблены ваши индексы видно очень хорошее и многофункциональное обращение Гилева Вячаслава, под названием Lock1C.epf, и которое он убрал с сайта из-за коллизии ников-1С за нарушение лицензии с баллами., но хороший админ гугл всегда в Help J. Также желательно делать полную переиндексацию, блокировку базы данных, не реже одного раза в неделю, естественно, после полной переиндексации делается сразу дефрагментация индексов и обновление статистики.
к. производительность сервера. Дефрагментация и обновление статистики выполняются быстро и не требуют отключения пользователей. Насколько раздроблены ваши индексы видно очень хорошее и многофункциональное обращение Гилева Вячаслава, под названием Lock1C.epf, и которое он убрал с сайта из-за коллизии ников-1С за нарушение лицензии с баллами., но хороший админ гугл всегда в Help J. Также желательно делать полную переиндексацию, блокировку базы данных, не реже одного раза в неделю, естественно, после полной переиндексации делается сразу дефрагментация индексов и обновление статистики.
Настройка средств резервного копирования SQL.
Ту простую, добавить 2 новых задания Agent’у:
Полный BackUp, с периодичностью 1 раз в сутки и 2мя шагами T-SQL скрипта:
1. BACKUP DATABASE [
GO
2. USE [< имя_базы>]
USE [< имя_базы>]
GO
DBCC SHRINKFILE (N ‘
GO
И второе задание с периодичностью 1 раз в 1-2 часа Дифференциальное резервное копирование и один скрипт T-SQL:
НАЗАД ВВЕРХ DATABASE [
GO
Такой бэкап делается, даже когда работают люди, за 4-6 минут и практически не влияет на производительность сервера.
Да, и добавить процедурную очистку после переиндексации (раз в неделю), в задаче которая точно так же появилась в агенте после сохранения Плана обслуживания добавить еще один шаг:
DBCC FREEPROCCACHE
GO
Не забудьте изменить настройки на первом шаге, после завершения не заходите, а переходите к следующему. Спс гилв за чаевые.
На этом все О резервном копировании 1С:. http://infostart.ru/public/65849/ — Полного Бэкапа 1С и выгрузки можно делать одновременно.
http://infostart.ru/public/65849/ — Полного Бэкапа 1С и выгрузки можно делать одновременно.
MSSQL | 1С:Предприятие
Тема сжатия баз данных 1С в настоящее время достаточно часто обсуждается. Преимущества сжатия известны — уменьшение размера базы данных, снижение нагрузки на дисковую подсистему и некоторое ускорение жестких операций чтения/записи. Из недостатков – незначительное увеличение нагрузки на процессоры серверов СУБД из-за расхода ресурсов на сжатие/распаковку данных. Но при использовании в качестве СУБД MSSQL и DB2 (про Oracle и PostgreSQL не скажу, ибо не знаю) есть один «подводный камень» — при реструктуризации новые таблицы и индексы распаковываются. Это может произойти как при обновлении конфигурации с изменением структуры метаданных, так и при тестировании и исправлении ИБ (переиндексация пересоздает только индексы, а реструктуризация – и таблицы, и индексы). «Проблема» заключается в том, что знак сжатия устанавливается индивидуально для каждой таблицы и индекса.
Решение проблемы для MS SQL Server (только для Enterprise-версий 2008/2008R2).
Можно отловить момент создания новой таблицы или индекса с помощью DDL-триггера, который вызывается сразу после выполнения CREATE TABLE/INDEX, но до передачи данных платформой 1С. Триггер этого типа может быть создан как для конкретного ИБ, так и для всего сервера. Создание триггера для ИБ не входит в лицензионное соглашение 1С, поэтому лучше всего создать для всего сервера, тем более это позволит обслуживать сразу все базы на этом сервере.
Создание DDL-триггера для операции создания таблицы:
CREATE TRIGGER data_compression НА ВСЕХ СЕРВЕРАХ ПОСЛЕ CREATE_TABLE КАК --Trigger text
Создание DDL-триггера для операции создания индекса:
CREATE TRIGGER index_compression НА ВСЕХ СЕРВЕРАХ ПОСЛЕ CREATE_INDEX КАК -- Триггерный текст
Для установки знака сжатия страниц для таблицы необходимо выполнить код:
ALTER TABLE базовое имя.имя схемы.
 имя таблицы REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE)
имя таблицы REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE) Для установки признака сжатия страниц для индекса необходимо выполнить код:
ALTER INDEX имя индекса ON базовое имя.имя схемы.имя таблицы REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE)
В общем , уже достаточно создать работоспособный механизм, который не позволит платформе 1С создать новую таблицу или индекс без сжатия, а хотелось большей гибкости в настройках :).
Ниже представлено решение в том виде, в котором мы его используем. Это позволяло автоматически применять сжатие ко всем базам данных на сервере.
Сервисная база CompressionSetting создается с двумя таблицами:
1) Базы данных – для хранения списка баз, которые НЕ требуется сжимать.
СОЗДАТЬ ТАБЛИЦУ dbo.Databases(
имя nvarchar(100) NULL,
активный интервал NULL
) НА ОСНОВНОЙ Из ~200 баз на сервере я ввел в эту таблицу только одну — tempdb:
2) Trace — для мониторинга DDL-триггеров
CREATE TABLE dbo.
 trace(
текст nvarchar(max) NULL,
Имя базы данных nvarchar(max) NULL,
Дата и время NULL
) НА ОСНОВНОЙ
trace(
текст nvarchar(max) NULL,
Имя базы данных nvarchar(max) NULL,
Дата и время NULL
) НА ОСНОВНОЙ Далее я создал 2 DDL-триггера:
1) Для таблиц
CREATE TRIGGER data_compression
НА ВСЕХ СЕРВЕРАХ
ПОСЛЕ CREATE_TABLE
КАК
DECLARE @SchemaName nvarchar(150),
@ObjectName nvarchar(150),
@DatabaseName nvarchar(150),
@cmd nvarchar(150)
--Получить имя схемы из исполняемой команды CREATE TABLE
SET @SchemaName = EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)1','nvarchar(150)')
--Получить имя таблицы
SET @ObjectName = EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)1','nvarchar(150)')
--Получить базовое имя
SET @DatabaseName = EVENTDATA().value('(/EVENT_INSTANCE/DatabaseName)1','nvarchar(150)')
--Сформировать из полученных данных требуемую команду для установки знака сжатия для таблицы
set @cmd = 'ИЗМЕНИТЬ ТАБЛИЦУ' + @DatabaseName + '.' + @SchemaName + '.' + @ObjectName + 'ВОССТАНОВИТЬ РАЗДЕЛ = ВСЕ С (DATA_COMPRESSION = PAGE)'
--Теперь проверьте настройки – если в таблице CompressionSetting. dbo.Databases нет базы с признаком Active=1, то выполнить команду, иначе игнорировать
ЕСЛИ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 КАК Expr1
ИЗ CompressionSetting.dbo.Databases AS T
ГДЕ (имя = @DatabaseName) И Активный = 1)
НАЧИНАТЬ
ВСТАВЬТЕ В CompressionSetting.dbo.trace (текст, DatabaseName, DateTime) SELECT @cmd, @DatabaseName, GETDATE()
ВЫПОЛНИТЬ (@cmd)
КОНЕЦ
ЕЩЕ
НАЧИНАТЬ
ПЕЧАТЬ 'ТЕСТ'
КОНЕЦ  dbo.Databases нет базы с признаком Active=1, то выполнить команду, иначе игнорировать
ЕСЛИ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 КАК Expr1
ИЗ CompressionSetting.dbo.Databases AS T
ГДЕ (имя = @DatabaseName) И Активный = 1)
НАЧИНАТЬ
ВСТАВЬТЕ В CompressionSetting.dbo.trace (текст, DatabaseName, DateTime) SELECT @cmd, @DatabaseName, GETDATE()
ВЫПОЛНИТЬ (@cmd)
КОНЕЦ
ЕЩЕ
НАЧИНАТЬ
ПЕЧАТЬ 'ТЕСТ'
КОНЕЦ
dbo.Databases нет базы с признаком Active=1, то выполнить команду, иначе игнорировать
ЕСЛИ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 КАК Expr1
ИЗ CompressionSetting.dbo.Databases AS T
ГДЕ (имя = @DatabaseName) И Активный = 1)
НАЧИНАТЬ
ВСТАВЬТЕ В CompressionSetting.dbo.trace (текст, DatabaseName, DateTime) SELECT @cmd, @DatabaseName, GETDATE()
ВЫПОЛНИТЬ (@cmd)
КОНЕЦ
ЕЩЕ
НАЧИНАТЬ
ПЕЧАТЬ 'ТЕСТ'
КОНЕЦ 2) Для индексов
CREATE TRIGGER index_compression
НА ВСЕХ СЕРВЕРАХ
ПОСЛЕ CREATE_INDEX
КАК
DECLARE @SchemaName nvarchar(150),
@ObjectName nvarchar(150),
@TargetObjectName nvarchar(150),
@DatabaseName nvarchar(150),
@cmd nvarchar(150)
--Получить имя схемы исполняемой команды CREATE INDEX
SET @SchemaName = EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)1','nvarchar(150)')
--Получить имя индекса
SET @ObjectName = EVENTDATA().value('(/EVENT_INSTANCE/ObjectName)1','nvarchar(150)')
--Получить имя таблицы
SET @TargetObjectName = EVENTDATA().value('(/EVENT_INSTANCE/TargetObjectName)1','nvarchar(150)')
--Получить базовое имя
SET @DatabaseName = EVENTDATA(). value('(/EVENT_INSTANCE/DatabaseName)1','nvarchar(150)')
-- Сформировать из полученных данных требуемую команду для установки знака сжатия для индекса
set @cmd = 'ALTER INDEX' + @ObjectName + 'ON' + @DatabaseName + '.' + @SchemaName + '.' + @TargetObjectName + 'ВОССТАНОВИТЬ РАЗДЕЛ = ВСЕ С (DATA_COMPRESSION = PAGE)'
--Теперь проверьте настройки – если в таблице CompressionSetting.dbo.Databases нет базы с признаком Active=1, то выполнить команду, иначе игнорировать
ЕСЛИ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 КАК Expr1
ИЗ CompressionSetting.dbo.Databases AS T
ГДЕ (имя = @DatabaseName) И Активный = 1)
НАЧИНАТЬ
ВСТАВЬТЕ В CompressionSetting.dbo.trace (текст, DatabaseName, DateTime) SELECT @cmd, @DatabaseName, GETDATE()
ВЫПОЛНИТЬ (@cmd)
КОНЕЦ
ЕЩЕ
НАЧИНАТЬ
ПЕЧАТЬ 'ТЕСТ'
КОНЕЦ  value('(/EVENT_INSTANCE/DatabaseName)1','nvarchar(150)')
-- Сформировать из полученных данных требуемую команду для установки знака сжатия для индекса
set @cmd = 'ALTER INDEX' + @ObjectName + 'ON' + @DatabaseName + '.' + @SchemaName + '.' + @TargetObjectName + 'ВОССТАНОВИТЬ РАЗДЕЛ = ВСЕ С (DATA_COMPRESSION = PAGE)'
--Теперь проверьте настройки – если в таблице CompressionSetting.dbo.Databases нет базы с признаком Active=1, то выполнить команду, иначе игнорировать
ЕСЛИ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 КАК Expr1
ИЗ CompressionSetting.dbo.Databases AS T
ГДЕ (имя = @DatabaseName) И Активный = 1)
НАЧИНАТЬ
ВСТАВЬТЕ В CompressionSetting.dbo.trace (текст, DatabaseName, DateTime) SELECT @cmd, @DatabaseName, GETDATE()
ВЫПОЛНИТЬ (@cmd)
КОНЕЦ
ЕЩЕ
НАЧИНАТЬ
ПЕЧАТЬ 'ТЕСТ'
КОНЕЦ
value('(/EVENT_INSTANCE/DatabaseName)1','nvarchar(150)')
-- Сформировать из полученных данных требуемую команду для установки знака сжатия для индекса
set @cmd = 'ALTER INDEX' + @ObjectName + 'ON' + @DatabaseName + '.' + @SchemaName + '.' + @TargetObjectName + 'ВОССТАНОВИТЬ РАЗДЕЛ = ВСЕ С (DATA_COMPRESSION = PAGE)'
--Теперь проверьте настройки – если в таблице CompressionSetting.dbo.Databases нет базы с признаком Active=1, то выполнить команду, иначе игнорировать
ЕСЛИ НЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 КАК Expr1
ИЗ CompressionSetting.dbo.Databases AS T
ГДЕ (имя = @DatabaseName) И Активный = 1)
НАЧИНАТЬ
ВСТАВЬТЕ В CompressionSetting.dbo.trace (текст, DatabaseName, DateTime) SELECT @cmd, @DatabaseName, GETDATE()
ВЫПОЛНИТЬ (@cmd)
КОНЕЦ
ЕЩЕ
НАЧИНАТЬ
ПЕЧАТЬ 'ТЕСТ'
КОНЕЦ Сразу после создания триггеров никаких изменений в размерах баз, естественно, не произойдет. Для сжатия существующих баз можно использовать следующие методы:
- Написать скрипт для поочередного поиска таблиц и индексов и установки для них признака сжатия. Мне этот вариант не понравился, т.к. для сжатия больших таблиц требуется много времени, база в этом случае раздувается, а потом очень долго уменьшается через SHRINK DATABASE.
- Выполнить полную реструктуризацию через «Проверка и ремонт». По времени быстрее, но база тоже раздувается и тогда ее придется уменьшать через SHRINK DATABASE.
- Самый оптимальный вариант, на мой взгляд, — пересоздать базу через dt-файл. В этом случае готовая база будет изначально минимального размера и время загрузки базы со сжатием мало чем отличается от загрузки в обычном режиме.
 Мне этот вариант не понравился, т.к. для сжатия больших таблиц требуется много времени, база в этом случае раздувается, а потом очень долго уменьшается через SHRINK DATABASE.
Мне этот вариант не понравился, т.к. для сжатия больших таблиц требуется много времени, база в этом случае раздувается, а потом очень долго уменьшается через SHRINK DATABASE.О допустимости применения такого метода сжатия я задал вопрос в партнерской конференции, на что был получен следующий комментарий Сергея Нуралиева:
«…Можно исходить из того, что мы считаем, что использование этих возможностей должно быть запрещено или разрешено, но с соответствующим обеспечением (методическим и программным). Вариант их использования без надлежащей поддержки мы считаем некорректным, так как это приводит к проблемам с администрированием.
