Manager ms sql: MS SQL Server и T-SQL
Содержание
Запуск программы SQL Server Enterprise Manager. Обработка баз данных на Visual Basic®.NET
Запуск программы SQL Server Enterprise Manager. Обработка баз данных на Visual Basic®.NET
ВикиЧтение
Обработка баз данных на Visual Basic®.NET
Мак-Манус Джеффри П
Содержание
Запуск программы SQL Server Enterprise Manager
Большинство действий по конфигурированию базы данных выполняются с помощью программы SQL Server Enterprise Manager. Эта программа благодаря своей простоте и мощности является одним из основных инструментов SQL Server 2000. Она предоставляет администратору простой и понятный интерфейс для выполнения необходимых действий, которые прежде требовали использования сложных команд SQL.
Для запуска программы SQL Server Enterprise Manager щелкните на кнопке Start (Пуск) и выберите команду Programs?Microsoft SQL Server?Enterprise Manager (Прогpaммы?Microsoft SQL Server?EnterpriseManager). После ее запуска можно получить доступ ко всем серверам баз данных SQL Server в доступной области сети. В следующих разделах главы описываются некоторые наиболее распространенные задачи, выполняемые с помощью Enterprise Manager в рабочем приложении.
После ее запуска можно получить доступ ко всем серверам баз данных SQL Server в доступной области сети. В следующих разделах главы описываются некоторые наиболее распространенные задачи, выполняемые с помощью Enterprise Manager в рабочем приложении.
НА ЗАМЕТКУ
После установки SQL Server создается только одна учетная запись с пустым паролем. Очевидно, что этот пароль нужно изменить, так как учетная запись с пустым паролем напоминает банковский сейф без замка. Более подробные сведения об учетных записях и системе безопасности SQL Server можно найти далее в главе.
При первом запуске программы SQL Server Enterprise Manager нужно зарегистрировать установленный SQL Server. Это позволяет программе SQL Server Enterprise Manager определить тот сервер баз данных SQL Server, с которым предстоит работать. Она также позволяет администрировать несколько установленных серверов SQL Server. Для регистрации SQL Server используется диалоговое окно Registered SQL Server Properties (Свойства зарегистрированных серверов SQL Server) программы SQL Server Enterprise Manager (рис. 3.5).
3.5).
Рис. З.5. Диалоговое окно Registered SQL Servеr Properties программы SQL Server Enterprise Manager
Для регистрации SQL Server, который установлен на данном компьютере, в поле Server (Сервер) используется строка (local). Для подключения SQL Server по локальной сети нужно щелкнуть на кнопке с многоточием возле этого поля для просмотра всех имеющихся серверов в локальной сети.
СОВЕТ
Диалоговое окно Registered SQL Server Properties содержит важный параметр Show system databases and system objects (Показать системные базы данных и системные объекты). При снятии этого флажка системные базы данных и системные объекты остаются скрытыми в разных окнах программы SQL Server Enterprise Manager. Это позволяет сократить объем ненужной информации при работе с таблицами и файлами приложения. Однако для просмотра системных объектов нужно вернуться в это диалоговое окно и установить указанный флажок.
После регистрации нужного сервера щелкните на кнопке OK в диалоговом окне Registered SQL Server Properties. (Это нужно сделать только один раз. Программа SQL Server Enterprise Manager запоминает способ соединения с указанным сервером SQL Server.) Имя зарегистрированного сервера появится в окне серверов Microsoft SQL Servers вместе с другими зарегистрированными серверами. На компьютере с подключением к локальному серверу SQL Server окно Microsoft SQL Servers будет иметь такой вид, как на рис. 3.6.
(Это нужно сделать только один раз. Программа SQL Server Enterprise Manager запоминает способ соединения с указанным сервером SQL Server.) Имя зарегистрированного сервера появится в окне серверов Microsoft SQL Servers вместе с другими зарегистрированными серверами. На компьютере с подключением к локальному серверу SQL Server окно Microsoft SQL Servers будет иметь такой вид, как на рис. 3.6.
РИС. 3.6. Окно Microsoft SQL Servers с локальным сервером баз данных SQL Server в программе SQL Server Enterprise Manager
Запуск программы
Запуск программы
Мы запустили эхо-сервер SCTP без аргументов командной строки на компьютере, работающем под управлением FreeBSD. Клиенту при запуске необходимо указать IP-адрес сервера.freebsd4% sctpclient01 10.1.1.5[0]Hello Отправка сообщения по потоку
Запуск программы
Запуск программы
Мы запустили клиент и сервер на разных компьютерах с FreeBSD, между которыми был установлен настраиваемый маршрутизатор (рис. 10.4). Маршрутизатор может создавать задержку и сбрасывать часть пакетов. Сначала мы запускаем программу без сброса пакетов на
10.4). Маршрутизатор может создавать задержку и сбрасывать часть пакетов. Сначала мы запускаем программу без сброса пакетов на
Запуск программы
Запуск программы
Мы запускаем клиент и отправляем одно сообщение.FreeBSD-lap: ./sctpclient01 10.1.1.5[0]HelloFrom str:1 seq:0 (assoc:c99e15a0):[0]HelloControl-DFreeBSD-lap:Сервер отображает сообщения обо всех происходящих событиях (приеме входящего соединения, получении сообщения, завершении
4.3 Запуск программы разметки
4.3 Запуск программы разметки
Вообще говоря, вы можете использовать любую программу разметки, например, Partition Magic или Acronis Disk Director Suite, однако я буду рассказывать про входящую в состав Ubuntu утилиту Gparted.Надеюсь, вы ещё не вышли из запущенной с LiveCD Ubuntu. Если это не так, то снова
Запуск программы mmc.
 exe
exe
Запуск программы mmc.exe
На уровне файловой системы, как оказывается, ничего интересного не происходит — по умолчанию консоль управления Microsoft не ведет журнал и не записывает события ни в один из журналов системы. Единственное, что можно отметить, так это запуск библиотеки
Установка и запуск Microsoft SQL Server
Установка и запуск Microsoft SQL Server
Работа с сервером баз данных значительно отличается от совместного использования файла базы данных Microsoft Jet. Для успешной работы с SQL Server нужно познакомиться с новыми понятиями и дополнительными возможностями. Однако установка и
Запуск и остановка SQL Server
Запуск и остановка SQL Server
Для запуска и остановки SQL Server можно использовать программу SQL Server Service Manager. В некоторых случаях необходимо остановить SQL Server, например для выполнения каких-то задач или запуска сервера баз данных SQL Server на другом (рабочем) компьютере. В обычных
В обычных
Создание базы данных с помощью программы SQL Server Enterprise Manager
Создание базы данных с помощью программы SQL Server Enterprise Manager
После регистрации сервера можно приступить к созданию рабочей базы данных и ее объектов: таблиц, представлений и хранимых процедур.Это можно выполнить с помощью команд SQL, но лучше воспользоваться программой SQL
Использование программы SQLServer Enterprise Manager для создания таблиц базы данных SQL Server
Использование программы SQLServer Enterprise Manager для создания таблиц базы данных SQL Server
После создания базы данных необходимо создать в ней таблицы. Для этого с помощью программы SQL Server Enterprise Manager выполните ряд действий.1. В окне Microsoft SQL Servers программы SQL Server Enterprise Manager щелкните на
Управление пользователями и средства безопасности с помощью программы SQL Server Enterprise Manager
Управление пользователями и средства безопасности с помощью программы SQL Server Enterprise Manager
Одной из наиболее важных причин использования сервера SQL Server является управление несколькими пользователями, которые пытаются осуществить доступ к одним и тем же данным
Управление ролями с помощью программы SQL Server Enterprise Manager
Управление ролями с помощью программы SQL Server Enterprise Manager
В SQL Server 2000 роли используются для группирования пользователей с одинаковыми разрешениями. Любой пользователь отдельной роли наследует все разрешения данной роли, а изменения разрешений роли изменяют разрешения
Любой пользователь отдельной роли наследует все разрешения данной роли, а изменения разрешений роли изменяют разрешения
Урок № 3. Запуск программы
Урок № 3. Запуск программы
После того как программа установлена, в меню Пуск будет создана ее программная группа. Для запуска программы предназначена команда 1С Предприятие. Рекомендуется для удобства работы вывести ярлык запуска на рабочий стол, используя для этого
Запуск программы
Запуск программы
Как и любое приложение, разработанное для операционной системы Windows, программу AutoCAD можно запустить несколькими способами. Давайте рассмотрим наиболее распространенные из них.• Использование меню Пуск. Для запуска программы нужно выполнить команду
Установка и запуск программы
Установка и запуск программы
Перед первым подключением телефона запустим программу установки Setup. exe. При этом последовательно появятся обычные для любых программ установки окна с предложением прочитать и принять пользовательское соглашение, а затем выбрать папку для
exe. При этом последовательно появятся обычные для любых программ установки окна с предложением прочитать и принять пользовательское соглашение, а затем выбрать папку для
SQL Index Manager — бесплатный тул для дефрагментации и обслуживания индексов / Хабр
Много лет работая SQL Server DBA и занимаясь то администрированием серверов, то оптимизацией производительности. В общем, захотелось в свободное время сделать что-то полезное для Вселенной и коллег по цеху. Так в итоге получился небольшой опенсорс тул по обслуживанию индексов для SQL Server и Azure.
Идея
Порой люди при работе над своими приоритетами могут напоминать пальчиковую батарейку — мотивационного заряда хватает лишь на одну вспышку, и потом все. И до недавнего времени я не был исключением из этого жизненного наблюдения. Часто меня посещали идеи создать что-то свое, но менялись приоритеты и ничего не доводилось до конца.
Достаточно сильное влияние на мою мотивацию и профессиональное развитие оказала работа в харьковской компании Devart, которая занималась созданием софта для разработки и администрирования баз данных SQL Server, MySQL и Oracle.
До того как прийти к ним, я мало представлял себе специфику создания собственного продукта, но уже в процессе работы почерпнул много знаний о внутреннем устройстве SQL Server. Больше года занимаясь оптимизацией запросов к метаданным в их продуктовых линейках, я постепенно стал понимать, какой функционал больше другого востребован на рынке.
На определенном этапе возникла идея сделать новый нишевый продукт, но в силу обстоятельств эта задумка не взлетела. На тот момент для нового проекта банально не нашлось достаточного количества свободных ресурсов внутри компании без ущерба для основной деятельности.
Уже когда работал на новом месте и пытался делать проект своими силами, приходилось постоянно идти на какие-то компромиссы. Первоначальная задумка сделать большой и напичканный фичами продукт быстро сошла на нет и постепенно трансформировалась в иное русло — разбить запланированный функционал на отдельные мини-тулы и реализовывать их независимо друг от друга.
В итоге так на свет появился SQL Index Manager — бесплатный тул по обслуживанию индексов для SQL Server и Azure. Главной идеей было взять за основу коммерческие альтернативы от компаний RedGate и Devart и постараться улучшить их функционал. Предоставить, как для начинающих, так и опытных пользователей, возможность удобно анализировать и обслуживать индексы.
Реализация
На словах все всегда звучит просто… такой взял посмотрел пару мотивирующих видосиков, встал в стоечку и начал делать крутой продукт. Но на практике не все так радужно, поскольку существует много подводных камней при работе с системной табличной функцией sys.dm_db_index_physical_stats и по совместительству единственным местом, откуда можно получить актуальную информацию о фрагментации индексов.
С первых дней разработки была отличная возможность проложить себе тоскливый путь среди стандартных схем и скопировать уже отлаженную логику работы приложений-конкурентов, добавив при этом немного отсебятины. Но после анализа запросов к метаданным захотелось сделать что-то более оптимизированное, что в силу бюрократии больших компаний никогда бы не появилось в их продуктах.
Но после анализа запросов к метаданным захотелось сделать что-то более оптимизированное, что в силу бюрократии больших компаний никогда бы не появилось в их продуктах.
При анализе RedGate SQL Index Manager (1.1.9.1378 — 155$) можно увидеть, что приложение использует весьма простой подход: одним запросом получаем список пользовательских таблиц и представлений, а после вторым запросом возвращается список всех индексов в рамках выбранной базы данных.
SELECT objects.name AS tableOrViewName
, objects.object_id AS tableOrViewId
, schemas.name AS schemaName
, CAST(ISNULL(lobs.NumLobs, 0) AS BIT) AS ContainsLobs
, o.is_memory_optimized
FROM sys.objects AS objects
JOIN sys.schemas AS schemas ON schemas.schema_id = objects.schema_id
LEFT JOIN (
SELECT object_id
, COUNT(*) AS NumLobs
FROM sys.columns WITH (NOLOCK)
WHERE system_type_id IN (34, 35, 99)
OR max_length = -1
GROUP BY object_id
) AS lobs ON objects.object_id = lobs.object_id
LEFT JOIN sys. tables AS o ON o.object_id = objects.object_id
WHERE objects.type = 'U'
OR objects.type = 'V'
SELECT i.object_id AS tableOrViewId
, i.name AS indexName
, i.index_id AS indexId
, i.allow_page_locks AS allowPageLocks
, p.partition_number AS partitionNumber
, CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex
FROM sys.indexes AS i
JOIN sys.partitions AS p ON p.index_id = i.index_id
AND p.object_id = i.object_id
JOIN (
SELECT COUNT(*) AS numPartitions
, object_id
, index_id
FROM sys.partitions
GROUP BY object_id
, index_id
) AS c ON c.index_id = i.index_id
AND c.object_id = i.object_id
WHERE i.index_id > 0 -- ignore heaps
AND i.is_disabled = 0
AND i.is_hypothetical = 0
tables AS o ON o.object_id = objects.object_id
WHERE objects.type = 'U'
OR objects.type = 'V'
SELECT i.object_id AS tableOrViewId
, i.name AS indexName
, i.index_id AS indexId
, i.allow_page_locks AS allowPageLocks
, p.partition_number AS partitionNumber
, CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex
FROM sys.indexes AS i
JOIN sys.partitions AS p ON p.index_id = i.index_id
AND p.object_id = i.object_id
JOIN (
SELECT COUNT(*) AS numPartitions
, object_id
, index_id
FROM sys.partitions
GROUP BY object_id
, index_id
) AS c ON c.index_id = i.index_id
AND c.object_id = i.object_id
WHERE i.index_id > 0 -- ignore heaps
AND i.is_disabled = 0
AND i.is_hypothetical = 0 tables AS o ON o.object_id = objects.object_id
WHERE objects.type = 'U'
OR objects.type = 'V'
SELECT i.object_id AS tableOrViewId
, i.name AS indexName
, i.index_id AS indexId
, i.allow_page_locks AS allowPageLocks
, p.partition_number AS partitionNumber
, CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex
FROM sys.indexes AS i
JOIN sys.partitions AS p ON p.index_id = i.index_id
AND p.object_id = i.object_id
JOIN (
SELECT COUNT(*) AS numPartitions
, object_id
, index_id
FROM sys.partitions
GROUP BY object_id
, index_id
) AS c ON c.index_id = i.index_id
AND c.object_id = i.object_id
WHERE i.index_id > 0 -- ignore heaps
AND i.is_disabled = 0
AND i.is_hypothetical = 0
tables AS o ON o.object_id = objects.object_id
WHERE objects.type = 'U'
OR objects.type = 'V'
SELECT i.object_id AS tableOrViewId
, i.name AS indexName
, i.index_id AS indexId
, i.allow_page_locks AS allowPageLocks
, p.partition_number AS partitionNumber
, CAST((c.numPartitions - 1) AS BIT) AS belongsToPartitionedIndex
FROM sys.indexes AS i
JOIN sys.partitions AS p ON p.index_id = i.index_id
AND p.object_id = i.object_id
JOIN (
SELECT COUNT(*) AS numPartitions
, object_id
, index_id
FROM sys.partitions
GROUP BY object_id
, index_id
) AS c ON c.index_id = i.index_id
AND c.object_id = i.object_id
WHERE i.index_id > 0 -- ignore heaps
AND i.is_disabled = 0
AND i.is_hypothetical = 0
Далее в цикле для каждой секции индекса отправляется запрос по определению ее размера и уровня фрагментации. В конце сканирования индексы, которые весят меньше порога вхождения, отбрасываются на клиенте.
EXEC sp_executesql N'
SELECT index_id, avg_fragmentation_in_percent, page_count
FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 1, @partitionNr = 1
EXEC sp_executesql N'
SELECT index_id, avg_fragmentation_in_percent, page_count
FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 2, @partitionNr = 1
EXEC sp_executesql N'
SELECT index_id, avg_fragmentation_in_percent, page_count
FROM sys.dm_db_index_physical_stats(@databaseId, @objectId, @indexId, @partitionNr, NULL)'
, N'@databaseId int,@objectId int,@indexId int,@partitionNr int'
, @databaseId = 7, @objectId = 2133582639, @indexId = 3, @partitionNr = 1
При анализе логики работы данного приложения можно найти много недочетов. Например, если придираться по мелочи, то до отправления запроса не делается никаких проверок о том, содержит ли текущая секция строки, чтобы исключить из сканирования пустые секции.
Например, если придираться по мелочи, то до отправления запроса не делается никаких проверок о том, содержит ли текущая секция строки, чтобы исключить из сканирования пустые секции.
Но наиболее остро проблема проявляется в другом аспекте: количество запросов к серверу будет примерно равно общему числу строк из sys.partitions. С учетом того, что реальные базы могут содержать десятки тысяч секций, то этот нюанс может привести к огромному числу однотипных запросов к серверу. В ситуации, если база удаленная, то время сканирования станет еще длительнее за счет возросших сетевых задержек на выполнение каждого, пусть даже и самого простого запроса.
В отличие от RedGate, аналогичный продукт разработанный в Devart — dbForge Index Manager for SQL Server (1.10.38 — 99$) получает информацию одним большим запросом и затем отображает все на клиенте:
SELECT SCHEMA_NAME(o.[schema_id]) AS [schema_name]
, o.name AS parent_name
, o.[type] AS parent_type
, i.name
, i. type_desc
, s.avg_fragmentation_in_percent
, s.page_count
, p.partition_number
, p.[rows]
, ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy
, ISNULL(lob.is_lob, 0) AS is_lob
, CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s
JOIN sys.partitions p ON s.[object_id] = p.[object_id]
AND s.index_id = p.index_id
AND s.partition_number = p.partition_number
JOIN sys.indexes i ON i.[object_id] = s.[object_id]
AND i.index_id = s.index_id
LEFT JOIN (
SELECT c.[object_id]
, index_id = ISNULL(i.index_id, 1)
, is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END)
, is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END)
FROM sys.columns c
LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id]
AND c.column_id = i.column_id
AND i. index_id > 0
WHERE c.system_type_id IN (34, 35, 99)
OR c.max_length = -1
GROUP BY c.[object_id], i.index_id
) lob ON lob.[object_id] = i.[object_id]
AND lob.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = i.[object_id]
JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
WHERE i.[type] IN (1, 2)
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND s.index_level = 0
AND s.alloc_unit_type_desc = 'IN_ROW_DATA'
AND o.[type] IN ('U', 'V') type_desc
, s.avg_fragmentation_in_percent
, s.page_count
, p.partition_number
, p.[rows]
, ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy
, ISNULL(lob.is_lob, 0) AS is_lob
, CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s
JOIN sys.partitions p ON s.[object_id] = p.[object_id]
AND s.index_id = p.index_id
AND s.partition_number = p.partition_number
JOIN sys.indexes i ON i.[object_id] = s.[object_id]
AND i.index_id = s.index_id
LEFT JOIN (
SELECT c.[object_id]
, index_id = ISNULL(i.index_id, 1)
, is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END)
, is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END)
FROM sys.columns c
LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id]
AND c.column_id = i.column_id
AND i.
type_desc
, s.avg_fragmentation_in_percent
, s.page_count
, p.partition_number
, p.[rows]
, ISNULL(lob.is_lob_legacy, 0) AS is_lob_legacy
, ISNULL(lob.is_lob, 0) AS is_lob
, CASE WHEN ds.[type] = 'PS' THEN 1 ELSE 0 END AS is_partitioned
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) s
JOIN sys.partitions p ON s.[object_id] = p.[object_id]
AND s.index_id = p.index_id
AND s.partition_number = p.partition_number
JOIN sys.indexes i ON i.[object_id] = s.[object_id]
AND i.index_id = s.index_id
LEFT JOIN (
SELECT c.[object_id]
, index_id = ISNULL(i.index_id, 1)
, is_lob_legacy = MAX(CASE WHEN c.system_type_id IN (34, 35, 99) THEN 1 END)
, is_lob = MAX(CASE WHEN c.max_length = -1 THEN 1 END)
FROM sys.columns c
LEFT JOIN sys.index_columns i ON c.[object_id] = i.[object_id]
AND c.column_id = i.column_id
AND i. index_id > 0
WHERE c.system_type_id IN (34, 35, 99)
OR c.max_length = -1
GROUP BY c.[object_id], i.index_id
) lob ON lob.[object_id] = i.[object_id]
AND lob.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = i.[object_id]
JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
WHERE i.[type] IN (1, 2)
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND s.index_level = 0
AND s.alloc_unit_type_desc = 'IN_ROW_DATA'
AND o.[type] IN ('U', 'V')
index_id > 0
WHERE c.system_type_id IN (34, 35, 99)
OR c.max_length = -1
GROUP BY c.[object_id], i.index_id
) lob ON lob.[object_id] = i.[object_id]
AND lob.index_id = i.index_id
JOIN sys.objects o ON o.[object_id] = i.[object_id]
JOIN sys.data_spaces ds ON i.data_space_id = ds.data_space_id
WHERE i.[type] IN (1, 2)
AND i.is_disabled = 0
AND i.is_hypothetical = 0
AND s.index_level = 0
AND s.alloc_unit_type_desc = 'IN_ROW_DATA'
AND o.[type] IN ('U', 'V')
От основной проблемы с пеленой однотипных запросов в конкурирующем продукте удалось избавиться, но недостатки данной реализации в том, что в функцию sys.dm_db_index_physical_stats не передается никаких дополнительных параметров, которые могут ограничить сканирование заведомо ненужных индексов. По факту это приводит к получению информации по всем индексам в системе и лишним дисковым нагрузкам на этапе сканирования.
Важно отметить, что данные, получаемые из sys.dm_db_index_physical_stats, не кешируется на постоянной основе в buffer pool, поэтому минимизирование физических чтений при получении информации о фрагментации индексов было одной из приоритетных задач при разработке.
После нескольких экспериментов получилось скомбинировать оба подхода, разделив сканирование на две части. Вначале одним большим запросом определяется размер секций, заранее отфильтровывая при этом те, которые не входят в диапазон фильтрации:
INSERT INTO #AllocationUnits (ContainerID, ReservedPages, UsedPages)
SELECT [container_id]
, SUM([total_pages])
, SUM([used_pages])
FROM sys.allocation_units WITH(NOLOCK)
GROUP BY [container_id]
HAVING SUM([total_pages]) BETWEEN @MinIndexSize AND @MaxIndexSize
Далее мы получаем только те секции, которые содержат данные, чтобы избежать ненужных операций чтения из пустых индексов.
SELECT [object_id]
, [index_id]
, [partition_id]
, [partition_number]
, [rows]
, [data_compression]
INTO #Partitions
FROM sys.partitions WITH(NOLOCK)
WHERE [object_id] > 255
AND [rows] > 0
AND [object_id] NOT IN (SELECT * FROM #ExcludeList)
В зависимости от настроек получаются только те типы индексов, которые пользователь хочет проанализировать (поддерживается работа с кучами, кластерными/некластерными индексами и колумнсторами).
INSERT INTO #Indexes
SELECT ObjectID = i.[object_id]
, IndexID = i.index_id
, IndexName = i.[name]
, PagesCount = a.ReservedPages
, UnusedPagesCount = a.ReservedPages - a.UsedPages
, PartitionNumber = p.[partition_number]
, RowsCount = ISNULL(p.[rows], 0)
, IndexType = i.[type]
, IsAllowPageLocks = i.[allow_page_locks]
, DataSpaceID = i.[data_space_id]
, DataCompression = p.[data_compression]
, IsUnique = i.[is_unique]
, IsPK = i.[is_primary_key]
, FillFactorValue = i.[fill_factor]
, IsFiltered = i.[has_filter]
FROM #AllocationUnits a
JOIN #Partitions p ON a.ContainerID = p.[partition_id]
JOIN sys.indexes i WITH(NOLOCK) ON i.[object_id] = p.[object_id]
AND p.[index_id] = i.[index_id]
WHERE i.[type] IN (0, 1, 2, 5, 6)
AND i.[object_id] > 255
После этого начинается небольшая магия: для всех маленьких индексов мы определяем уровень фрагментации за счет многократного вызова функции sys. dm_db_index_physical_stats с полным указанием всех параметров.
dm_db_index_physical_stats с полным указанием всех параметров.
INSERT INTO #Fragmentation (ObjectID, IndexID, PartitionNumber, Fragmentation)
SELECT i.ObjectID
, i.IndexID
, i.PartitionNumber
, r.[avg_fragmentation_in_percent]
FROM #Indexes i
CROSS APPLY sys.dm_db_index_physical_stats(@DBID, i.ObjectID, i.IndexID, i.PartitionNumber, 'LIMITED') r
WHERE i.PagesCount <= @PreDescribeSize
AND r.[index_level] = 0
AND r.[alloc_unit_type_desc] = 'IN_ROW_DATA'
AND i.IndexType IN (0, 1, 2)
Далее мы возвращаем всю возможную информацию на клиент, отфильтровывая лишние данные:
SELECT i.ObjectID
, i.IndexID
, i.IndexName
, ObjectName = o.[name]
, SchemaName = s.[name]
, i.PagesCount
, i.UnusedPagesCount
, i.PartitionNumber
, i.RowsCount
, i.IndexType
, i.IsAllowPageLocks
, u.TotalWrites
, u.TotalReads
, u.TotalSeeks
, u.TotalScans
, u.TotalLookups
, u.LastUsage
, i. DataCompression
, f.Fragmentation
, IndexStats = STATS_DATE(i.ObjectID, i.IndexID)
, IsLobLegacy = ISNULL(lob.IsLobLegacy, 0)
, IsLob = ISNULL(lob.IsLob, 0)
, IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT)
, IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT)
, FileGroupName = fg.[name]
, i.IsUnique
, i.IsPK
, i.FillFactorValue
, i.IsFiltered
, a.IndexColumns
, a.IncludedColumns
FROM #Indexes i
JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID
JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id]
LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID
AND a.IndexID = i.IndexID
LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID
LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID
AND f.IndexID = i.IndexID
AND f.PartitionNumber = i.PartitionNumber
LEFT JOIN (
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, TotalWrites = NULLIF([user_updates], 0)
, TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0)
, TotalSeeks = NULLIF([user_seeks], 0)
, TotalScans = NULLIF([user_scans], 0)
, TotalLookups = NULLIF([user_lookups], 0)
, LastUsage = (
SELECT MAX(dt)
FROM (
VALUES ([last_user_seek])
, ([last_user_scan])
, ([last_user_lookup])
, ([last_user_update])
) t(dt)
)
FROM sys. dm_db_index_usage_stats WITH(NOLOCK)
WHERE [database_id] = @DBID
) u ON i.ObjectID = u.ObjectID
AND i.IndexID = u.IndexID
LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID
AND lob.IndexID = i.IndexID
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id]
AND i.PartitionNumber = dds.[destination_id]
JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id]
WHERE o.[type] IN ('V', 'U')
AND (
f.Fragmentation >= @Fragmentation
OR
i.PagesCount > @PreDescribeSize
OR
i.IndexType IN (5, 6)
) DataCompression
, f.Fragmentation
, IndexStats = STATS_DATE(i.ObjectID, i.IndexID)
, IsLobLegacy = ISNULL(lob.IsLobLegacy, 0)
, IsLob = ISNULL(lob.IsLob, 0)
, IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT)
, IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT)
, FileGroupName = fg.[name]
, i.IsUnique
, i.IsPK
, i.FillFactorValue
, i.IsFiltered
, a.IndexColumns
, a.IncludedColumns
FROM #Indexes i
JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID
JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id]
LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID
AND a.IndexID = i.IndexID
LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID
LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID
AND f.IndexID = i.IndexID
AND f.PartitionNumber = i.PartitionNumber
LEFT JOIN (
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, TotalWrites = NULLIF([user_updates], 0)
, TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0)
, TotalSeeks = NULLIF([user_seeks], 0)
, TotalScans = NULLIF([user_scans], 0)
, TotalLookups = NULLIF([user_lookups], 0)
, LastUsage = (
SELECT MAX(dt)
FROM (
VALUES ([last_user_seek])
, ([last_user_scan])
, ([last_user_lookup])
, ([last_user_update])
) t(dt)
)
FROM sys.
DataCompression
, f.Fragmentation
, IndexStats = STATS_DATE(i.ObjectID, i.IndexID)
, IsLobLegacy = ISNULL(lob.IsLobLegacy, 0)
, IsLob = ISNULL(lob.IsLob, 0)
, IsSparse = CAST(CASE WHEN p.ObjectID IS NULL THEN 0 ELSE 1 END AS BIT)
, IsPartitioned = CAST(CASE WHEN dds.[data_space_id] IS NOT NULL THEN 1 ELSE 0 END AS BIT)
, FileGroupName = fg.[name]
, i.IsUnique
, i.IsPK
, i.FillFactorValue
, i.IsFiltered
, a.IndexColumns
, a.IncludedColumns
FROM #Indexes i
JOIN sys.objects o WITH(NOLOCK) ON o.[object_id] = i.ObjectID
JOIN sys.schemas s WITH(NOLOCK) ON s.[schema_id] = o.[schema_id]
LEFT JOIN #AggColumns a ON a.ObjectID = i.ObjectID
AND a.IndexID = i.IndexID
LEFT JOIN #Sparse p ON p.ObjectID = i.ObjectID
LEFT JOIN #Fragmentation f ON f.ObjectID = i.ObjectID
AND f.IndexID = i.IndexID
AND f.PartitionNumber = i.PartitionNumber
LEFT JOIN (
SELECT ObjectID = [object_id]
, IndexID = [index_id]
, TotalWrites = NULLIF([user_updates], 0)
, TotalReads = NULLIF([user_seeks] + [user_scans] + [user_lookups], 0)
, TotalSeeks = NULLIF([user_seeks], 0)
, TotalScans = NULLIF([user_scans], 0)
, TotalLookups = NULLIF([user_lookups], 0)
, LastUsage = (
SELECT MAX(dt)
FROM (
VALUES ([last_user_seek])
, ([last_user_scan])
, ([last_user_lookup])
, ([last_user_update])
) t(dt)
)
FROM sys. dm_db_index_usage_stats WITH(NOLOCK)
WHERE [database_id] = @DBID
) u ON i.ObjectID = u.ObjectID
AND i.IndexID = u.IndexID
LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID
AND lob.IndexID = i.IndexID
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id]
AND i.PartitionNumber = dds.[destination_id]
JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id]
WHERE o.[type] IN ('V', 'U')
AND (
f.Fragmentation >= @Fragmentation
OR
i.PagesCount > @PreDescribeSize
OR
i.IndexType IN (5, 6)
)
dm_db_index_usage_stats WITH(NOLOCK)
WHERE [database_id] = @DBID
) u ON i.ObjectID = u.ObjectID
AND i.IndexID = u.IndexID
LEFT JOIN #Lob lob ON lob.ObjectID = i.ObjectID
AND lob.IndexID = i.IndexID
LEFT JOIN sys.destination_data_spaces dds WITH(NOLOCK) ON i.DataSpaceID = dds.[partition_scheme_id]
AND i.PartitionNumber = dds.[destination_id]
JOIN sys.filegroups fg WITH(NOLOCK) ON ISNULL(dds.[data_space_id], i.DataSpaceID) = fg.[data_space_id]
WHERE o.[type] IN ('V', 'U')
AND (
f.Fragmentation >= @Fragmentation
OR
i.PagesCount > @PreDescribeSize
OR
i.IndexType IN (5, 6)
)
После этого точечными запросами определяем уровень фрагментации для больших индексов.
EXEC sp_executesql N'
DECLARE @DBID INT = DB_ID()
SELECT [avg_fragmentation_in_percent]
FROM sys.dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'')
WHERE [index_level] = 0
AND [alloc_unit_type_desc] = ''IN_ROW_DATA'''
, N'@ObjectID int,@IndexID int,@PartitionNumber int'
, @ObjectId = 1044198770, @IndexId = 1, @PartitionNumber = 1
EXEC sp_executesql N'
DECLARE @DBID INT = DB_ID()
SELECT [avg_fragmentation_in_percent]
FROM sys. dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'')
WHERE [index_level] = 0
AND [alloc_unit_type_desc] = ''IN_ROW_DATA'''
, N'@ObjectID int,@IndexID int,@PartitionNumber int'
, @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1 dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'')
WHERE [index_level] = 0
AND [alloc_unit_type_desc] = ''IN_ROW_DATA'''
, N'@ObjectID int,@IndexID int,@PartitionNumber int'
, @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1
dm_db_index_physical_stats(@DBID, @ObjectID, @IndexID, @PartitionNumber, ''LIMITED'')
WHERE [index_level] = 0
AND [alloc_unit_type_desc] = ''IN_ROW_DATA'''
, N'@ObjectID int,@IndexID int,@PartitionNumber int'
, @ObjectId = 1552724584, @IndexId = 0, @PartitionNumber = 1
За счет такого подхода при генерации запросов получилось решить проблемы с производительностью сканирования, которые встречались в приложениях конкурентов. На этом можно было бы закончить, но в процессе разработки постепенно появлялись новые идеи, которые позволяли расширять область применения своего продукта.
Вначале была реализована поддержка работы с WAIT_AT_LOW_PRIORITY, потом стало возможным использовать DATA_COMPRESSION и FILL_FACTOR при ребилде индексов.
Приложение по чуть-чуть обрастало незапланированным ранее функционалом вроде обслуживания колумнсторов:
SELECT *
FROM (
SELECT IndexID = [index_id]
, PartitionNumber = [partition_number]
, PagesCount = SUM([size_in_bytes]) / 8192
, UnusedPagesCount = ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0) / 8192
, Fragmentation = CAST(ISNULL(SUM(CASE WHEN [state] = 1 THEN [size_in_bytes] END), 0)
* 100. / SUM([size_in_bytes]) AS FLOAT)
FROM sys.fn_column_store_row_groups(@ObjectID)
GROUP BY [index_id]
, [partition_number]
) t
WHERE Fragmentation >= @Fragmentation
AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize / SUM([size_in_bytes]) AS FLOAT)
FROM sys.fn_column_store_row_groups(@ObjectID)
GROUP BY [index_id]
, [partition_number]
) t
WHERE Fragmentation >= @Fragmentation
AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize
/ SUM([size_in_bytes]) AS FLOAT)
FROM sys.fn_column_store_row_groups(@ObjectID)
GROUP BY [index_id]
, [partition_number]
) t
WHERE Fragmentation >= @Fragmentation
AND PagesCount BETWEEN @MinIndexSize AND @MaxIndexSize
Или возможности создавать некластерные индексы на основе информации из dm_db_missing_index:
SELECT ObjectID = d.[object_id]
, UserImpact = gs.[avg_user_impact]
, TotalReads = gs.[user_seeks] + gs.[user_scans]
, TotalSeeks = gs.[user_seeks]
, TotalScans = gs.[user_scans]
, LastUsage = ISNULL(gs.[last_user_scan], gs.[last_user_seek])
, IndexColumns =
CASE
WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NOT NULL
THEN d.[equality_columns] + ', ' + d.[inequality_columns]
WHEN d.[equality_columns] IS NOT NULL AND d.[inequality_columns] IS NULL
THEN d.[equality_columns]
ELSE d. [inequality_columns]
END
, IncludedColumns = d.[included_columns]
FROM sys.dm_db_missing_index_groups g WITH(NOLOCK)
JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle]
JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle]
WHERE d.[database_id] = DB_ID()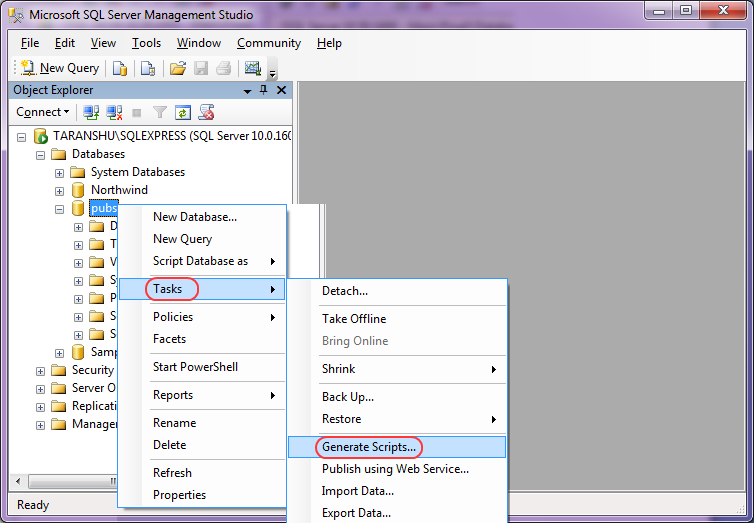 [inequality_columns]
END
, IncludedColumns = d.[included_columns]
FROM sys.dm_db_missing_index_groups g WITH(NOLOCK)
JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle]
JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle]
WHERE d.[database_id] = DB_ID()
[inequality_columns]
END
, IncludedColumns = d.[included_columns]
FROM sys.dm_db_missing_index_groups g WITH(NOLOCK)
JOIN sys.dm_db_missing_index_group_stats gs WITH(NOLOCK) ON gs.[group_handle] = g.[index_group_handle]
JOIN sys.dm_db_missing_index_details d WITH(NOLOCK) ON g.[index_handle] = d.[index_handle]
WHERE d.[database_id] = DB_ID()Итоги
После шести месяцев активной фазы разработки радует, что на этом планы не заканчиваются, поскольку хочется и дальше развивать этот продукт. На очереди планируется добавить функционал по поиску дублирующих или неиспользуемых индексов, а также реализовать полноценную поддержку по обслуживанию статистики в рамках SQL Server.
Исходя из того, что на рынке сейчас много платных решений, хочется верить, что за счет бесплатного позиционирования, более оптимизированного дескрайба метаданных и наличия разного рода полезных мелочей для кого-то этот продукт точно станет полезным в повседневных задачах.
Актуальную версию приложения можно скачать на GitHub. Исходники лежат там же.
Исходники лежат там же.
Microsoft SQL Server — передачи
| С источником данных Microsoft SQL Server Remote Desktop Manager использует мощь Microsoft SQL Server для сохранения и управления записями. |
Поддерживаемый Microsoft SQL Server:
- 2019 для Windows и Linux (все выпуски)
- 2017 г. для Windows и Linux (все выпуски)
- 2016 Пакет обновления 2
- 2014 Пакет обновления 3
- 2012 Пакет обновления 4
Также поддерживаются следующие функции:
- Всегда в группе доступности
- Кластеризация
- Доставка бревен
- Зеркальное отображение базы данных
Основные моменты
- Поддерживает управление пользователями с превосходной моделью безопасности.
- Поддерживает автономный режим, когда сервер или сеть недоступны.
- Поддерживает полные журналы входа и вложения.
- Поддерживает Vault для организации тысяч записей.

Для предотвращения возможной потери данных необходимо реализовать правильную стратегию резервного копирования базы данных. Пожалуйста, обратитесь к теме Резервные копии.
В зависимости от модели восстановления базовой базы данных может потребоваться регулярное выполнение некоторых операций обслуживания для поддержания работоспособности базы данных. Пожалуйста, обратитесь к модели восстановления.
Использование входа в базу данных или встроенной безопасности по своей сути менее безопасно, поскольку это означает, что конечный пользователь может напрямую подключиться к базе данных с помощью любого доступного инструмента. У нас есть безопасность на уровне таблиц и столбцов, но организации, заботящиеся о безопасности, сочтут это неприемлемым. Рекомендуется использовать нашу пользовательскую модель входа.
Конфигурация
Дополнительные сведения о настройке см. в разделе Настройка SQL Server.
Настройки
Общий
Microsoft SQL Server — вкладка «Общие»
ОПЦИЯ | ОПИСАНИЕ |
|---|---|
| Имя | Введите имя источника данных. |
| Хозяин | Введите имя хоста или IP-адрес сервера. |
| Режим входа | Укажите используемый режим аутентификации. Выберите между:
|
Имя пользователя | Введите имя пользователя для доступа к базе данных SQL Azure. |
| Пароль | Введите пароль для доступа к базе данных SQL Azure. |
| Всегда спрашивать пароль | Запрашивать пароль, когда пользователь подключается к источнику данных. |
| Разрешить изменение имени пользователя | Разрешить редактирование имени пользователя при подключении к источнику данных. (Только при включенном параметре Всегда спрашивать пароль) |
| База данных | Введите имя базы данных SQL Azure. |
| Два фактора | Включите многофакторную аутентификацию. |
| Тестовый сервер | Протестируйте соединение с сервером, чтобы убедиться, что предоставлена верная информация. |
| Тестовая база данных | Протестируйте соединение с базой данных, чтобы убедиться, что предоставлена верная информация. |
Настройки
Microsoft SQL Server — вкладка «Параметры»
ОПЦИЯ | ОПИСАНИЕ |
|---|---|
| Корневой фильтр | Введите имя папки корневого уровня, чтобы отобразить только записи, содержащиеся в этой папке. |
| Онлайн-метод пинга | Укажите предпочтительный метод пинга онлайн. Выберите между:
|
Автоматический переход в автономный режим | Используйте источник данных в автономном режиме, когда метод проверки связи не отвечает. |
| Отключить блокировку | Отключите возможность блокировки источника данных напрямую. Вы по-прежнему можете заблокировать приложение, но вам не будет предложено ввести пароль источника данных, если этот параметр отключен. |
Хранилище пользователя
Microsoft SQL Server — вкладка User Vault
ОПЦИЯ | ОПИСАНИЕ |
|---|---|
| Тип | Выберите тип пользовательского хранилища для использования. Выберите между:
|

Обновление
Microsoft SQL Server — вкладка «Обновление»
| ВАРИАНТ | ОПИСАНИЕ |
|---|---|
| Тестовый сервер | Протестируйте соединение с сервером, чтобы убедиться, что предоставлена верная информация. |
| Создать базу данных | Создайте базу данных на сервере SQL. |
| Обновление базы данных | Обновите базу данных на сервере SQL. |
| Тестовая база данных | Протестируйте соединение с базой данных, чтобы убедиться, что предоставлена верная информация. |
| Схема электронной почты для поддержки | Отправьте свою схему в нашу службу поддержки. |
VPN
Перед подключением к Microsoft SQL Server откройте VPN для доступа к своим данным.
Microsoft SQL Server — вкладка VPN
Расширенный
Microsoft SQL Server — вкладка «Дополнительно»
ОПЦИЯ | ОПИСАНИЕ |
|---|---|
| Режим кэширования | Определяет, как записи будут перезагружаться в источнике данных. Дополнительные сведения см. в разделе Кэширование. |
| Время соединения вышло | Установите задержку тайм-аута соединения. |
| Время ожидания команды | Установите задержку тайм-аута команды. |
| Автоматическое обновление | Установите интервал автоматического обновления. |
| Запрашивать автономный режим при запуске | Попросите использовать источник данных в автономном режиме, когда пользователь подключается к источнику данных. |
| Разрешить бета-обновление базы данных | Разрешить бета-обновление базы данных (при использовании бета-версии Remote Desktop Manager). |
| Управление кешем | Управление кэшем источника данных. На больших источниках данных кэширование является обязательным и значительно повысит производительность. Дополнительные сведения см. в разделе «Управление кэшем». |
| Больше настроек | Измените значения строки подключения напрямую. |
Переход на MSSQL — документация WSO2 API Manager 4.1.0
По умолчанию WSO2 API Manager использует встроенную базу данных h3 в качестве базы данных для хранения данных управления пользователями и реестра. Ниже приведены шаги, которые необходимо выполнить, чтобы использовать MSSQL для этой цели.
Настройка MSSQL
В следующих разделах описано, как настроить Microsoft SQL Server для замены базы данных h3 по умолчанию в вашем продукте WSO2:
- Настройка базы данных и пользователей
- Настройка драйверов
- Выполнение сценариев БД в базе данных MSSQL
Настройка базы данных и пользователей
Выполните следующие действия, чтобы настроить базу данных Microsoft SQL и пользователей.
Включить TCP/IP
- В меню «Пуск» щелкните Программы и запустите Microsoft SQL Server 2017.
- Щелкните Средства настройки , а затем щелкните Диспетчер конфигурации SQL Server .
- Включить TCP/IP и отключите Named Pipes от протоколов вашего сервера Microsoft SQL.
- Дважды щелкните TCP/IP , чтобы открыть окно свойств TCP/IP, и установите Listen All на
Yesна вкладке Protocol . На вкладке IP-адрес отключите Динамические порты TCP , оставив это поле пустым, и укажите действительный порт TCP, чтобы сервер Microsoft SQL прослушивал этот порт.
Аналогичным образом включите TCP/IP из Конфигурация собственного клиента SQL и отключите Именованные каналы .
Также проверьте, правильно ли установлен порт 1433.- Перезапустите сервер Microsoft SQL.
 Также проверьте, правильно ли установлен порт 1433.
Также проверьте, правильно ли установлен порт 1433.Создать базу данных и пользователя
- Откройте Microsoft SQL Management Studio, чтобы создать базу данных и пользователя.
- Нажмите Новая база данных в меню База данных и укажите все параметры для создания новой базы данных.
- Нажмите New Login в меню Logins и укажите все необходимые параметры.
Предоставление разрешений
Назначьте вновь созданным пользователям необходимые права и разрешения для входа в систему и создания таблиц, а также для вставки, индексирования, выбора, обновления и удаления данных в таблицах во вновь созданной базе данных. Это минимальный набор разрешений SQL Server.
Настройка драйверов
Разархивируйте пакет WSO2 API Manager. Назовем это
Загрузите tar-архив драйвера Microsoft SQL JDBC и распакуйте его.
Скопируйте файл JAR, соответствующий вашей версии JRE, в каталог
/repository/components/lib/

Совет
Обязательно используйте версию соединителя, поддерживаемую используемой версией MSSQL. Если вы столкнулись с проблемами из-за несовместимости версий, выполните следующие действия:
- Выключите сервер и удалите все существующие коннекторы из каталогов
/repository/components/lib /repository/components/dropins - Скопируйте файл JAR только в расположение
/repository/components/lib dropinsпри запуске сервера.
Выполнение сценариев базы данных для создания таблиц в базе данных MSSQL
Установите инструмент запросов командной строки mssql-cli для SQL Server.
$ pip установить mssql-cli
Чтобы создать таблицы в базе данных реестра и диспетчера пользователей (
WSO2_SHARED_DB), выполните соответствующий сценарий, как показано ниже.$ mssql-cli -U sharedadmin -P sharedadmin -d shared_db -i
/dbscripts/mssql.sql; Чтобы создать таблицы в базе данных APIM (
WSO2AM_DB), выполните соответствующий сценарий, как показано ниже.$ mssql-cli -U sharedadmin -P sharedadmin -d apim_db -i
/dbscripts/apimgt/mssql.sql;

Примечание
Поскольку база данных WSO2_MB_STORE не является общей и не содержит данных, которые необходимо перенести, рекомендуется использовать h3 по умолчанию для WSO2_MB_STORE_DB даже в рабочей среде.
Устранение неполадок
Если вы столкнулись со следующей ошибкой при использовании базы данных h3 по умолчанию в качестве базы данных хранилища МБ, следуйте инструкциям в этом разделе. Обратите внимание, что эта ошибка возникает только в том случае, если база данных хранилища МБ повреждена.
ОШИБКА ApplicationRegistry org.wso2.andes.kernel.AndesException: Ошибка подключения к базе данных с поиском jndi: WSO2MBStoreDB.
 имя пользователя источника данных: wso2carbon. Сообщение об ошибке SQL: общая ошибка: java.lang.ArrayIndexOutOfBoundsException
имя пользователя источника данных: wso2carbon. Сообщение об ошибке SQL: общая ошибка: java.lang.ArrayIndexOutOfBoundsException Замените базу данных хранилища МБ на базу данных хранилища МБ h3 по умолчанию из нового дистрибутива WSO2 API-M.
Перезапустите сервер.
Изменение базы данных на MSSQL
- Создание подключения к источнику данных для MSSQL
Создание подключения к источнику данных для MSSQL
Источник данных используется для установления соединения с базой данных. По умолчанию источники данных SHARED_DB и AM_DB настроены в файле deployment.toml для подключения к базам данных h3 по умолчанию.
После настройки базы данных MSSQL для замены базы данных h3 по умолчанию измените настройки по умолчанию для SHARED_DB и источник данных AM_DB или настройте новый источник данных, чтобы он указывал на новую базу данных, как описано ниже.
Примечание
Если вы настраиваете API-M в распределенной установке , внесите изменения во все компоненты WSO2 API-M.
Выполните следующие действия, чтобы изменить тип источника данных по умолчанию.
Откройте файл конфигурации
/repository/conf/deployment.toml [database.shared_db]и[database.apim_db]элементы конфигурации.Вам просто нужно обновить URL-адрес, указывающий на вашу базу данных MSSQL, имя пользователя и пароль, необходимые для доступа к базе данных, сведения о драйвере MSSQL и проверочный запрос для проверки соединения, как показано ниже.
Элемент Описание тип Используемый тип базы данных адрес URL базы данных. Порт по умолчанию для MSSQL — 1433 .
имя пользователя и пароль Имя и пароль пользователя базы данных DriverClassName Имя класса драйвера базы данных проверка запроса SQL-запрос, который будет использоваться для проверки подключений из этого пула перед возвратом их вызывающей стороне. Пример конфигурации показан ниже:
Формат
тип = "mssql" url = "jdbc:sqlserver://localhost:1433;databaseName=
;SendStringParametersAsUnicode=false" имя пользователя = "<ИМЯ_ПОЛЬЗОВАТЕЛЯ>" password = "<ПАРОЛЬ>" Пример
[database.shared_db] тип = "mssql" url = "jdbc:sqlserver://localhost:1433;databaseName=shared_db;SendStringParametersAsUnicode=false" имя пользователя = "общийадмин" пароль = "общийадмин" [база данных.apim_db] тип = "mssql" url = "jdbc:sqlserver://localhost:1433;databaseName=apim_db;SendStringParametersAsUnicode=false" имя пользователя = "apimadmin" пароль = "апиадмин"
Предупреждение
Задайте для параметра
SendStringParametersAsUnicodeзначение false, чтобы обойти ограничение драйвера клиента Microsoft SQL. Без этого параметра драйвер базы данных ошибочно преобразует данныеVARCHARвNVARCHARи снизит производительность базы данных.Вы можете обновить приведенные ниже элементы конфигурации для подключения к базе данных.
Элемент Описание максАктив Максимальное количество активных подключений, которые могут быть выделены одновременно из этого пула. Введите любое отрицательное значение, чтобы обозначить неограниченное количество активных подключений. максимальное ожидание Максимальное количество миллисекунд, в течение которого пул будет ожидать (при отсутствии доступных подключений) соединения, которое будет возвращено, прежде чем сгенерировать исключение. Вы можете ввести ноль или отрицательное значение, чтобы ждать бесконечно. мин. простоя Минимальное количество активных подключений, которые могут простаивать в пуле без создания дополнительных, или введите ноль, чтобы не создавать ни одного. testOnBorrow Указание того, будут ли объекты проверяться перед заимствованием из пула. Если объект не проходит проверку, он будет удален из пула, и будет предпринята еще одна попытка заимствования другого. интервал проверки Указание избегать избыточной проверки и запускать проверку не более чем с этой частотой (время в миллисекундах). Если соединение должно пройти проверку, но уже было проверено ранее в течение этого интервала, оно не будет проверяться снова. defaultAutoCommit Это свойство имеет номер , а не , применимое к базе данных Carbon в продуктах WSO2, поскольку автоматическая фиксация обычно обрабатывается на уровне кода, т. е. вместо этого элемента свойства будет действовать конфигурация автоматической фиксации по умолчанию, указанная для драйвера СУБД. Как правило, автоматическая фиксация включена для драйверов СУБД по умолчанию. Если включена автоматическая фиксация, каждый оператор SQL будет зафиксирован в базе данных как отдельная транзакция, а не несколько операторов как одна транзакция.коммитонвозврат Если defaultAutoCommit =false, вы можете установитьcommitOnReturn =true, чтобы пул мог завершить транзакцию, вызвав фиксацию соединения, когда оно возвращается в пул. Однако еслиrollbackOnReturn = true, то этот атрибут игнорируется. Значение по умолчанию неверно.откат при возврате Если defaultAutoCommit = false, тогда вы можете установитьrollbackOnReturn =true, чтобы пул мог завершить транзакцию, вызвав откат соединения, когда оно возвращается в пул. Значение по умолчанию неверно.Пример конфигурации показан ниже:
Формат
тип = "mssql"
url = "jdbc:sqlserver://localhost:1433;databaseName=;SendStringParametersAsUnicode=false"
имя пользователя = "<ИМЯ_ПОЛЬЗОВАТЕЛЯ>"
пароль = "<ПАРОЛЬ>"
pool_options.


 Если включена автоматическая фиксация, каждый оператор SQL будет зафиксирован в базе данных как отдельная транзакция, а не несколько операторов как одна транзакция.
Если включена автоматическая фиксация, каждый оператор SQL будет зафиксирован в базе данных как отдельная транзакция, а не несколько операторов как одна транзакция.