Merge oracle delete: BASE — MERGE Statement Enhancements in Oracle Database 10g
Содержание
Условная вставка, обновление или удаление в SQL
Apache DerbyBigQueryDb2 (LUW)h3MariaDBMySQLOracle DBPostgreSQLSQL ServerSQLite20072009201120132015201720192021⊘ 3.5.7 — 3.41.0⚠ 2008R2 — 2022a✓ 15+⊘ 8,3 — 14⚠ 11gR1 — 21cabc⊘ 5,0 — 8,0,33⊘ 5,1 — 900 02
SQL слияние выполняет вставка , обновление и удаление операций на основе когда…тогда правил. Это полезно для синхронизации содержимого таблицы с более новыми данными. Вместо запуска , удаления , и , , обновления, , и , и , вставки , одна инструкция , слияние, позаботится обо всем… ну, почти обо всем. К сожалению, существует сценарий, при котором стандартный SQL слияние не распространяется, так что в итоге вам могут понадобиться два оператора. Начнем с самого начала…
Начнем с самого начала…
Содержание:
- Базовый синтаксис
-
Когда ... ТогдаПравила -
Когда ... ИУсловия - Нелогичные ошибки
- Область действия
-
Несоответствие по источнику: Удаление Дополнительные строки - Документы JSON как источник
- Связанные
- Дополнительная совместимость
- Нормативные ссылки
Базовый синтаксис
Каждый оператор слияния должен предоставлять целевую таблицу (предложение в ), источник ( с использованием предложения ) и условие соединения ( в предложении ).
ОБЪЕДИНЕНИЕ
INTO <цель> [[AS] <имя новой цели>]
USING <источник> [[AS] <новое имя источника>]
ON <условие соединения>
Хотя целью обычно является имя таблицы1, источником может быть все, что возвращает таблицу, даже подзапросы или табличные функции, такие как json_table . Источник и цель могут быть переименованы так же, как в предложении
Источник и цель могут быть переименованы так же, как в предложении из . аналогичная функциональность, предоставляемая эта система
Когда … Тогда Правила
За базовым синтаксисом следует правило , когда…тогда . Точнее, к 9.0013 когда [не] совпало…тогда… правил. Каждое правило применяется либо в том случае, если для одной исходной строки предложение на идентифицирует соответствующие строки в целевом объекте ( при совпадении с ), либо нет ( при несоответствии ). Если в целевом объекте есть соответствующие строки, независимо от их количества, их можно обновить или удалить. В противном случае, если в целевом объекте нет соответствующих строк, нет , можно выполнить вставку .
Apache DerbyBigQueryDb2 (LUW)h3Oracle DBabPostgreSQLSQL Server, когда нет совпадения, вставить, когда соответствует, затем обновить, когда соответствует, затем удалить
- Невозможно обновить столбцы, используемые в разделе
на - Не путать с
, затем обновить … удалить [где]
Следующий пример демонстрирует типичный вариант использования слияния : синхронизация содержимого таблицы с более новой информацией, полученной из внешней системы. В данном примере внешняя система представляет собой внешний интерфейс интернет-магазина, предоставляющий пользователю список пожеланий. База данных хранит содержимое всех списков пожеланий в
В данном примере внешняя система представляет собой внешний интерфейс интернет-магазина, предоставляющий пользователю список пожеланий. База данных хранит содержимое всех списков пожеланий в списки пожеланий таблица ( user_id , product_id , qty ).2 Когда пользователь редактирует список пожеланий, внешний интерфейс предоставляет отредактированный список пожеланий для слияния 90 014, который идентифицирует и выполняет необходимые операции. На данный момент мы предполагаем, что внешний интерфейс помещает отредактированный список желаний в таблицу my_wish_list ( product_id , qty ). Позже мы непосредственно обработаем документ JSON.
ОБЪЕДИНЕНИЕ
INTO списки желаний
ИСПОЛЬЗУЯ my_wish_list
ПО желаний_lists.user_id = ?
И списки желаний.product_id = my_wish_list.product_id
ЕСЛИ НЕ СООТВЕТСТВУЕТ, ВСТАВЬТЕ (user_id, product_id, qty)
ЗНАЧЕНИЯ ( ?, product_id, количество)
КОГДА СООТВЕТСТВУЕТ, ТО ОБНОВЛЯЕТ НАБОР qty = my_wish_list. qty
qty
 qty
qty
Оператор слияния называет целевую таблицу желаний_списков и исходную таблицу my_wish_list . Предложение на принимает во внимание только те строки в целевой таблице, которые принадлежат конкретному пользователю, тогда как значение user_id предоставляется через параметр привязки ( ? ). Кроме того, предложение на использует product_id для назначения оставшихся строк таблицы желаний строкам в my_wish_list .
Например, если в my_wish_list есть строка для определенного продукта X, предложение на фактически проверяет целевую таблицу на наличие соответствующих строк. Если в списках желаний нет строки, для которой user_id и product_id имеют правильные значения, применяется правило , когда не соответствует , и соответствующая строка вставляется. Это происходит, если пользователь добавил новый товар в список желаний. В противном случае, если в целевой таблице есть соответствующая строка, применяется условие
Это происходит, если пользователь добавил новый товар в список желаний. В противном случае, если в целевой таблице есть соответствующая строка, применяется условие при совпадении и обновляется столбец qty совпадающей строки (строк).3 Это происходит, если у пользователя уже был этот продукт в списке пожеланий.
Команды после ключевого слова , затем в основном следуют синтаксису, известному от их автономных родственников, хотя и в сокращенном виде. Во-первых, команды , а затем не указывают цель — предложение слияния в устанавливает цель для всех операций. Причем команды выполняются в контексте одной исходной строки и соответствующих целевых строк. Поэтому обновить и удалить не принимают где предложение✓✗ — они в любом случае знают, над какими строками работать. Наконец, 9Синтаксис 0013 вставки ограничен однострочным предложением значений . Вы не можете использовать вставку … выберите , а также вы не можете использовать предложение значений , которое создает более одной строки.
Обратите внимание, что стандартное слияние SQL управляется исходной таблицей. Каждая строка в исходном коде проверяется на соответствие правилам when…then . Строки в целевом объекте, не имеющие соответствующей исходной строки, игнорируются. В примере результат предложения на никогда не равен 9.0025 true для других пользователей, поэтому команда merge не повлияет на эти строки. Это нормально для нашего варианта использования, когда мы хотим обновить список желаний только одного конкретного пользователя. С другой стороны, если этот конкретный пользователь удаляет продукт из списка, мы также должны удалить соответствующую запись из таблицы желаний_списков . В этом и заключается идея синхронизации. К сожалению, стандартный SQL не имеет изящного синтаксиса для обработки дополнительных строк в целевом объекте. Мы рассмотрим это снова позже.
Прежде чем мы продолжим с более сложным синтаксисом, следует отметить еще одну фундаментальную вещь. Оператор слияния
Оператор слияния изменяет каждую целевую строку не более одного раза.4 Если одна целевая строка имеет несколько соответствующих исходных строк, оператор слияния вызывает ошибку✓✗ и прерывается.5 Это предотвращает неблагоприятную ситуацию, когда порядок, в котором исходные строки обрабатываются влияет на эффект слияния . Посмотрите на приведенный выше пример и спросите себя: что произойдет, если my_wish_list содержит несколько записей для одного продукта?6 Если значения qty не совпадают, то порядок выполнения имеет большое значение.
Когда … И Условия
Условия when не ограничиваются [не] совпавшими ключевыми словами. После и можно поставить дополнительное, сколь угодно сложное условие. Это позволяет нам добавить еще одно правило при совпадении , которое удаляет строку, если кол-во это 0 .
… ПРИ СООТВЕТСТВИИ И my_wish_list.
 qty = 0 ЗАТЕМ УДАЛИТЬ
WHEN MATCHED THEN UPDATE SET qty = my_wish_list.qty
qty = 0 ЗАТЕМ УДАЛИТЬ
WHEN MATCHED THEN UPDATE SET qty = my_wish_list.qty Из-за дополнительного условия первое правило при совпадении применяется только в том случае, если qty установлено равным нулю. В этом случае соответствующая целевая строка удаляется. Оставшиеся строки « соответствуют » вызывают обновление , как и раньше. Это обновление также может быть ограничено дополнительным условием: wish_lists.qty <> my_wish_list.qty . Это предотвращает обновление , если количество не изменилось. Это семантически чище, особенно если задействованы триггеры или сбор данных об изменениях (CDC), и в целом может привести к значительному повышению производительности в некоторых системах.
В случае нескольких , когда выполняются условия , действует только первое из них — очень похоже на то, как работает случай . Поэтому порядок правил имеет значение. 7 Исходные строки, которые не удовлетворяют ни одному из
7 Исходные строки, которые не удовлетворяют ни одному из , когда условие не вызывает никаких действий.
Apache DerbyBigQueryDb2 (LUW)h3Oracle DBaPostgreSQLSQL Server… сопоставлено и… затем несколько … затем обновить несколько … затем вставить
- Альтернатива:
, гдепункт. См. «Значимые расширения ».
Обратите внимание, что существуют системы, которые принимают условия и , но по-прежнему ограничены одним правилом для каждого случая , совпадающего с /, не совпадающего с .
Нелогичные ошибки
Иногда слияние вызывает путаницу, выдавая неожиданные сообщения об ошибках. Это происходит из-за того, что стандартное слияние SQL сначала идентифицирует все изменения, которые необходимо сделать, а затем, на втором этапе, применяет эти изменения. Другими словами, все условия , когда оцениваются до внесения каких-либо изменений. В последнем примере это означает, что строки, удаленные новым правилом, не активируют никакое правило , если не соответствует правилу , даже если оно появляется позже в команда слияния . К тому времени, когда
К тому времени, когда вставит , обновит или удалит , все решения уже будут приняты. быть вставленным. Между тем, прежде чем слияние фактически вставит строку, другая транзакция вставит строку с теми же значениями первичного ключа и зафиксирует транзакцию. Когда слияние в конечном итоге выполняет операции, вставка завершается ошибкой с нарушением ограничения. Это может стать неожиданностью, потому что правило , если оно не соответствует, затем вставить , не должно применяться, если строка существует. Merge сначала решает, что делать, а потом делает. За это время ситуация могла измениться. Ограничения и изоляция транзакций сохраняются, даже если они вызывают неожиданные ошибки.
Упомянутые ниже операторы upsert, предоставляемые некоторыми системами, могут вести себя в таких сценариях менее неожиданно.
Scoping
Я уже объяснил некоторые синтаксические различия, которые применяются к вставка , обновление и удаление при использовании в слияние по сравнению с их автономными родственниками. Однако есть более тонкий аспект, который следует учитывать: автономные операторы
Однако есть более тонкий аспект, который следует учитывать: автономные операторы вставка , обновление и удаление имеют только одну таблицу в области действия, но внутри слияние они имеют в области видимости две таблицы. В следующем примере выделены четыре места, где неясно, какой столбец таблицы x используется, если обе таблицы имеют этот столбец.
ОБЪЕДИНЕНИЕ
В цель
ИСПОЛЬЗОВАНИЕ источника
ВКЛ х = х ⓵
ПРИ СООТВЕТСТВИИ И x > 0 ⓶ ЗАТЕМ ОБНОВЛЕНИЕ НАБОР x = x + 1 ⓷
ЕСЛИ НЕ СООТВЕТСТВУЕТ, ТОГДА ВСТАВЬТЕ (x) ЗНАЧЕНИЯ (x) ⓸ Конечно, мы можем устранить эти неоднозначности, уточнив столбец с соответствующим именем таблицы, например. source.x , но мы также ожидаем, что система сообщит о неясностях, если они есть, и не сообщит о них, если их нет. Оказывается, эти вполне разумные ожидания не всегда оправдываются.
Apache Derbyb⚡dBigQuerybDb2 (LUW)b⚡ch3b⚡dOracle DBaab⚡c⚡dPostgreSQLSQL Serverbисходный и целевой объект видимы в on ⓵сообщает о неоднозначности в on ⓵исходный и целевой объект отображается в и ⓶сообщает о неоднозначности в и ⓶исходный и целевой объект отображается в наборе ⓷сообщает о неоднозначности в наборе ⓷неправильная двусмысленность в значениях ⓸
- См. « Известные расширения »
- Целевое имя также отображается с левой стороны, что не распространяется на стандартный синтаксис SQL BNF:
набор обновлений. <имя_столбца> = … - ⚡Ошибки не возникло: определяемое реализацией разрешение неоднозначных имен столбцов
- Имена столбцов, которые существуют в обеих таблицах, могут вызывать ошибки, даже если в области действия должен находиться только источник — в этих квалификациях систем решает проблему, но это не стандарт SQL
 « Известные расширения »
« Известные расширения » Особенно беспокоит то, что некоторые системы не сообщают о двусмысленности, помеченной как ⓷ . В конце концов, имеет большое значение, увеличивает ли обновление значение, хранящееся в данный момент в цели ( x = target.x + 1 ) или задает для него значение x = source.x + 1 . Это две совершенно не связанные вещи, и некоторые системы просто выбирают одну по своему усмотрению.
Не соответствует источнику : Удаление лишних строк
Стандартный SQL не имеет синтаксиса для обработки строк в целевом объекте, которым нет соответствующей строки в источнике, но это просто стандартный SQL. На самом деле есть системы, которые предлагают такой синтаксис — помимо того, что написано в стандарте.10
На самом деле есть системы, которые предлагают такой синтаксис — помимо того, что написано в стандарте.10
Для демонстрации продолжим пример со списком желаний. Заявление о слиянии также должно охватывать случай, когда элемент, который ранее был в списке пожеланий, удаляется. Таким образом, строку в списках желаний следует удалить, если в источнике нет соответствующей записи. Нестандартный синтаксис для этого — , если не соответствует источнику .
…
ЕСЛИ НЕ СООТВЕТСТВУЕТ, ВСТАВЬТЕ (user_id, product_id, qty)
ЗНАЧЕНИЯ ( ?, product_id, количество)
ЕСЛИ НЕ СООТВЕТСТВУЕТ ПО ИСТОЧНИКУ ЗАТЕМ УДАЛИТЬ
… Новое правило применяется к тем целевым строкам, которым нет соответствующей исходной строки. Предложение , затем удаляет их. Все они. То есть в дополнение к элементам списка пожеланий, которые удалил конкретный пользователь, также удаляются все элементы списка пожеланий из всех других пользователей ! Посмотрите на предложение на : условие на user_id предназначалось для ограничения влияния оператора слияния на одного конкретного пользователя. Это работает, если только исходные строки могут инициировать действия. С
Это работает, если только исходные строки могут инициировать действия. С , если не соответствует источнику , отдельные целевые строки также могут инициировать действия. Поскольку элементы других пользователей никогда не имеют соответствующей исходной строки, все они удаляются. Требование не затрагивать других пользователей было преступно игнорировано.
К счастью, это требование можно добавить прямо в условие when .
КОГДА НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ И user_id = ? ЗАТЕМ УДАЛИТЬ
Из-за и правило применяется только к записям соответствующего пользователя.
Apache DerbyBigQueryDb2 (LUW)h3Oracle DBPostgreSQLSQL Server… когда не соответствует источнику… когда не соответствует цели
условие , когда не соответствует без какого-либо квалификатора на .
Стандартные SQL слияние также могут выполнять свою работу, поскольку в качестве источника можно использовать произвольно сложные подзапросы. Это позволяет вам добавлять дополнительные строки, которые необходимо удалить, к источнику, используя
Это позволяет вам добавлять дополнительные строки, которые необходимо удалить, к источнику, используя полное внешнее соединение или объединение . С точки зрения слияния эти строки будут «сопоставленными» строками, поэтому при совпадении они могут активировать правило , а затем удалить правило . Однако этот подход теряет почти всю красоту одного оператора слияния . Использование отдельного оператора для удаления может быть лучшим вариантом. Я оставлю это в качестве упражнения для читателей и в заключение покажу лучший пример того, что вы можете сделать в исходном коде merge .
Документы JSON как источник
Вам может быть интересно, и не без оснований, какой смысл в примере со списком пожеланий, если внешний интерфейс должен сначала вставить в таблицу my_with_list ?11 В конце концов, это может быть проще выполнить требуемые операторы delete , update и insert , в частности, если они сгенерированы инструментом ORM. Цель этого примера — продемонстрировать, как сочетание различных функций SQL открывает интересные возможности.
Цель этого примера — продемонстрировать, как сочетание различных функций SQL открывает интересные возможности.
На самом деле веб-интерфейс будет предоставлять отредактированное содержимое списка пожеланий в виде документа JSON, например:
[
{"product_id":42 ,"кол-во":1}
,{"product_id":123,"кол-во":2}
] Теперь функция json_table может легко преобразовать такой документ JSON в табличную форму, подходящую в качестве источника слияния . Просто поместите его в , используя пункт .
…
ИСПОЛЬЗОВАНИЕ JSON_TABLE( ?
, '$[*]'
СТОЛБЦЫ ( product_id INT PATH '$.product_id'
, кол-во INT PATH '$.кол-во'
)
) Мой список пожеланий
… Если вызывающая сторона предоставляет документ JSON в качестве значения параметра привязки ( ? ), SQL позаботится обо всем остальном.
Пока мы говорим о возможности компоновки, давайте добавим краткое рассмотрение похожего, но существенно отличающегося варианта использования: размещение заказа. Этот вариант использования похож, поскольку он будет использовать аналогичный документ JSON. Тем не менее, есть три причины, по которым он также существенно отличается: (1) заказанные продукты просто нужно вставить — это не случай
Этот вариант использования похож, поскольку он будет использовать аналогичный документ JSON. Тем не менее, есть три причины, по которым он также существенно отличается: (1) заказанные продукты просто нужно вставить — это не случай слияние ; (2) Необходимо заполнить вторую таблицу — таблицу для самого заказа, а не для заказанных продуктов. Таким образом, нам нужны два оператора вставки для разных целей.12 Опять же, слияние здесь не поможет, но полезна функция SQL T495, «Объединенное изменение и извлечение данных». Он позволяет встраивать вставить , обновить , удалить и объединить операторов через подзапросы в выбрать операторов. Таким образом, вы можете произвольно комбинировать их в одном операторе SQL, который выполняет все операции с базой данных, необходимые для размещения заказа. Это что-то для другой статьи.
А пока нам нужно завершить список из трех существенных различий между обновлением списка желаний и размещением заказа: (3) Табличное (реляционное) хранение заказов и заказанных товаров, безусловно, полезно для дальнейшей обработки. Это не обязательно относится к списку желаний. Мы также можем сохранить список пожеланий в формате JSON как есть. В случае, если содержимое списков пожеланий когда-либо потребуется проанализировать, соответствующие функции SQL (например,
Это не обязательно относится к списку желаний. Мы также можем сохранить список пожеланий в формате JSON как есть. В случае, если содержимое списков пожеланий когда-либо потребуется проанализировать, соответствующие функции SQL (например, json_table ) все еще могут получить доступ к содержимому документа JSON. Ведь SQL делает , а не определяют, как вы храните данные; на самом деле верно как раз обратное: SQL поддерживает различные подходы.13 Мы можем — фактически мы должны — выбрать наилучший подход для каждого варианта использования.
Apache DerbyBigQueryDb2 (LUW)ah3bMariaDBMySQLOracle DBPostgreSQLSQL ServerSQLiteКомбинированные операторы изменения и извлечения данных, изменяющие данные, с
- Без
merge• Только если оператор верхнего уровняselect:вставка 90 134 в … выбрать …финал из (удалить из …) - Без
merge
Об авторе
Маркус Винанд рассказывает о SQL и показывает, как его поддерживают различные системы, на сайте modern-sql. com. Ранее он использовал use-the-index-luke.com, который до сих пор активно поддерживается. Маркуса можно нанять в качестве тренера, спикера и консультанта через winand.at.
com. Ранее он использовал use-the-index-luke.com, который до сих пор активно поддерживается. Маркуса можно нанять в качестве тренера, спикера и консультанта через winand.at.
вставить … при конфликте сделать …(PostgreSQL, SQLite)вставить … при дублировании ключа …(MariaDB, MySQL)вставка … журнал ошибок …(Oracle DB)обновление … из(BigQuery, PostgreSQL, SQL Server, SQLite)9 0004
T495, «Комбинированное изменение данных и извлечение» (DB2 (LUW))
Операторы изменения данных в
с(PostgreSQL)
Дополнительная совместимость
Известные расширения
Apache Derby BigQueryDb2 (LUW)h3Oracle DBaPostgreSQLSQL Server… сопоставлено, затем ничего не делать… сопоставлено затем … где …… если не соответствует источнику … когда не соответствует цели
- ⚡Определенное реализацией разрешение неоднозначных имен столбцов
Коды ошибок (SQLSTATE)
Apache DerbyBigQueryaDb2 (LUW)bh3aOracle DBaPostgreSQLSQL ServeraНарушение кардинальности: 21000
- Неверный SQLSTATE класс (не 21)
- Правильный класс SQLSTATE 21, но подкласс не 000
Варианты синтаксиса
Если вы заботитесь о максимальной совместимости, имейте в виду, что не все продукты поддерживают все варианты синтаксиса.
Apache DerbyaBigQueryDb2 (LUW)h3Oracle DBPostgreSQLSQL Server… в
- Только если не переименовывать целевую таблицу
Нормативные ссылки
Оператор слияния определен в ISO/IEC 9075-2:2016 как дополнительные функции F312, «оператор MERGE», F313, «расширенный оператор MERGE» и F314, «оператор MERGE с веткой DELETE».
Слияние и вставка, обновление и удаление
Я часто вижу, что когда люди узнают об операторе MERGE, они часто его используют, и я понимаю, что оператор MERGE легко читается и весьма практичен, поскольку вам нужен только один оператор для написания вставки, обновления и удаления заявления. Оператор MERGE, как описано в документации.
Оператор слияния в документах: https://docs. microsoft.com/en-us/sql/t-sql/statements/merge-transact-sql?view=sql-server-ver15
microsoft.com/en-us/sql/t-sql/statements/merge-transact-sql?view=sql-server-ver15
MERGE
[ ВЕРХ ( выражение ) [ ПРОЦЕНТ ] ]
[ INTO ] [ WITH ( ) ] [ [ AS ] table_alias ]
ИСПОЛЬЗОВАНИЕ
ON <условие_поиска_слияния>
[ ПРИ СОВПАДАНИИ [ И <условие_поиска> ]
ТОГДА ] [ ...n ]
[ ЕСЛИ НЕ СООТВЕТСТВУЕТ [ ПО ЦЕЛИ ] [ И <условие_поиска в пункте> ]
ТОГДА ]
[ ЕСЛИ НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ [ И <условию_поиска> ]
ТОГДА ] [ ...n ]
[ ]
[ ВАРИАНТ ( [ ,...n ] ) ]
;
Но хотя хорошо иметь один оператор для обработки всего, если мы посмотрим на совет по производительности в документах:
«Условное поведение, описанное для оператора MERGE, лучше всего работает, когда две таблицы имеют сложную смесь совпадающих характеристик. . Например, вставка строки, если она не существует, или обновление строки, если она соответствует. При простом обновлении одной таблицы на основе строк другой таблицы улучшите производительность и масштабируемость с помощью базовых операторов INSERT, UPDATE и DELETE. Например: «
При простом обновлении одной таблицы на основе строк другой таблицы улучшите производительность и масштабируемость с помощью базовых операторов INSERT, UPDATE и DELETE. Например: «
Именно для этого я часто вижу операторы слияния, простые операторы обновления и вставки. Давайте попробуем это на очень маленьком столе. Я скопирую некоторые данные из базы данных AdventureWorks и создам таблицу обновлений с помощью этого скрипта:
DROP TABLE IF EXISTS PersonCopy
УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ
SELECT ROW_NUMBER() OVER (ORDER BY LastName) EmpId, FirstName, LastName, E.JobTitle
INTO PersonCopy
FROM Person.Person P INNER JOIN HumanResources.Employee E On P.BusinessEntityID = E.BusinessEntityID
ВЫБЕРИТЕ EmpId, Имя, Фамилия, Должность
INTO PersonCopyUpdate
ОТ PersonCopy, ГДЕ Имя = «Майкл» И 1% 2 = 1
ОБНОВЛЕНИЕ
SET Имя = 'Джек',
Фамилия = 'Воробей'
ВСТАВЬТЕ В ЗНАЧЕНИЯ PersonCopyUpdate ( 999, «Супер», «Человек», «Герой»), (666, «The», «Дьявол», «Плохой парень»)
ИДТИ
СОЗДАТЬ УНИКАЛЬНЫЙ КЛАСТЕРНЫЙ ИНДЕКС idx_PersonCopy ON PersonCopy (EmpId)
СОЗДАТЬ УНИКАЛЬНЫЙ КЛАСТЕРНЫЙ ИНДЕКС idx_PersonCopyUpdate ON PersonCopyUpdate (EmpId)
Я создам EmpId на основе простой функции ROW_NUMBER(), этот идентификатор используется для сопоставления, затем я скопирую некоторые строки в таблицу PersonCopyUpdate, внеся некоторые изменения и добавив 2 новые строки.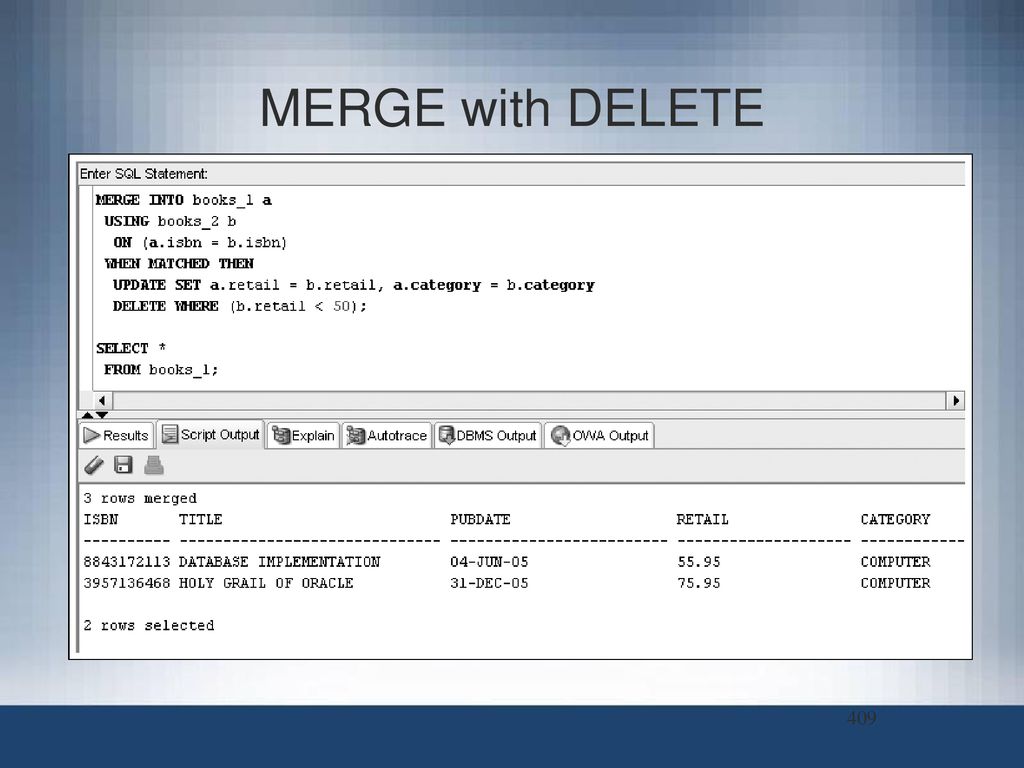 Наконец, я создам Clustered уникальный индекс для обеих таблиц.
Наконец, я создам Clustered уникальный индекс для обеих таблиц.
А теперь простой тест в операторе MERGE. Я буду использовать PersonCopy в качестве цели и PersonCopyUpdate в качестве источника, затем я буду использовать EmpId в качестве соответствующего столбца. Затем, при совпадении, я обновлю Имя и Фамилию из PersonCopyUpdate. Если не совпадают, вставьте и, когда целевые строки не существуют в исходной таблице, затем удалите, это выглядит так:
MERGE PersonCopy AS TARGET
ИСПОЛЬЗОВАНИЕ (ВЫБЕРИТЕ EmpId, Имя, Фамилию, Должность ИЗ PersonCopyUpdate) В КАЧЕСТВЕ ИСТОЧНИКА
ВКЛ (ЦЕЛЬ.EmpId = ИСТОЧНИК.EmpId )
КОГДА СООТВЕТСТВУЕТ
THEN UPDATE SET FirstName = SOURCE.FirstName,
Фамилия = ИСТОЧНИК.Фамилия
КОГДА НЕ СООТВЕТСТВУЕТ
THEN INSERT (EmpId, FirstName, LastName, Jobtitle) VALUES(SOURCE.EmpId, SOURCE.FirstName, SOURCE.LastName, SOURCE.Jobtitle)
ЕСЛИ НЕ СООТВЕТСТВУЕТ ИСТОЧНИКУ
ЗАТЕМ УДАЛИТЬ
При выполнении оператора я должен получить 10 x Джека Воробья, одного супермена и одного Дьявола:
И статистика выглядит так:
Теперь давайте напишем обновление, вставим и удалим оператор, чтобы сделать то же самое:
--Обновить соответствующие строки ОБНОВЛЕНИЕ П SET Имя = S.
 FirstName,
Фамилия = S.LastName
FROM PersonCopy P INNER JOIN PersonCopyUpdate S ON P.EmpId = S.EmpId
-- Вставить новые строки
ВСТАВИТЬ В PersonCopy
ВЫБЕРИТЕ EmpId,
Имя,
Фамилия,
Должность
ОТ PersonCopyUpdate S
ГДЕ НЕ СУЩЕСТВУЕТ(
ВЫБЕРИТЕ НУЛЬ
ОТ PersonCopy P
ГДЕ P.EmpId = S.EmpId
)
--Удалить строки
УДАЛИТЬ р
ОТ PersonCopy P
ГДЕ НЕ СУЩЕСТВУЕТ(
ВЫБЕРИТЕ НУЛЬ
ОТ PersonCopyUpdate S
ГДЕ S.EmpId = P.EmpId
FirstName,
Фамилия = S.LastName
FROM PersonCopy P INNER JOIN PersonCopyUpdate S ON P.EmpId = S.EmpId
-- Вставить новые строки
ВСТАВИТЬ В PersonCopy
ВЫБЕРИТЕ EmpId,
Имя,
Фамилия,
Должность
ОТ PersonCopyUpdate S
ГДЕ НЕ СУЩЕСТВУЕТ(
ВЫБЕРИТЕ НУЛЬ
ОТ PersonCopy P
ГДЕ P.EmpId = S.EmpId
)
--Удалить строки
УДАЛИТЬ р
ОТ PersonCopy P
ГДЕ НЕ СУЩЕСТВУЕТ(
ВЫБЕРИТЕ НУЛЬ
ОТ PersonCopyUpdate S
ГДЕ S.EmpId = P.EmpId
)
И снова у нас должно получиться 10 х Джек Воробей, один Супермен и один Дьявол:
И посмотрите на статистику: (Я показываю только суммарные итоги. Я использовал фантастический сайт http://statisticsparser .com/)
Хорошо, время меньше, чем было с оператором MERGE (на этом сервере больше ничего не работает, чтобы мешать измерениям времени)
Хорошо, давайте сделаем его намного больше, давайте поместим много больше данных в таблицы:
СОЗДАТЬ ТАБЛИЦУ PersonCopy( EmpId INT IDENTITY(1,1), Имя ИМЯ, Фамилия ИМЯ, ДолжностьNVARCHAR(75) ) ИДТИ ВСТАВИТЬ В PersonCopy (Имя, Фамилия, Должность) ВЫБЕРИТЕ Имя, Фамилию, E.
 JobTitle
FROM Person.Person P INNER JOIN HumanResources.Employee E On P.BusinessEntityID = E.BusinessEntityID
JobTitle
FROM Person.Person P INNER JOIN HumanResources.Employee E On P.BusinessEntityID = E.BusinessEntityID
ГО 5000
Затем возьмите 100 лучших в PersonCopyUpdate:
SELECT TOP 100 EmpId ,FirstName, LastName, JobTitle INTO PersonCopyUpdate
FROM PersonCopy WHERE FirstName = 'Michael' AND 1 % 2 = 1
Теперь давайте запустим тот же тест, что и раньше, он должен закончиться 102 строками:
И на этот раз статистика
Теперь для обновления, операторы вставки и удаления (выполнить в указанном порядке), в итоге должно получиться 102 строки, как и ожидалось. и с этой статистикой:
Обратите внимание, что время составляет 35 секунд, где слияние было 39 секунд, но посмотрите на логические чтения, они составляют 203 008 для PersonCopy с помощью Insert, update Delete (итого) и 4 516 795 для PersonCopy в операторе MERGE .
Но что, если я изменю порядок вставки, обновления и удаления и начну с удаления? У меня такой вариант, когда ведомости пишу отдельно, вот статистика:
И теперь мы сократили время до 28 секунд, что почти на 11 секунд быстрее, чем оператор слияния.