Ms sql create index: CREATE INDEX (Transact-SQL) — SQL Server
Содержание
SQL Server: как отслеживать ход выполнения команды CREATE INDEX?
спросил
Изменено
9 месяцев назад
Просмотрено
62к раз
SQL Server 2014, Std Ed
Я читал, что процент_завершения в dm_exec_requests не работает для CREATE INDEX, и на практике процент_завершения остается равным 0. Так что это не помогает.
В настоящее время я использую описанный ниже метод, который, по крайней мере, показывает мне движение (что создание индекса не заблокировано). Но я понятия не имею, прошёл ли я через процесс 10% или 99%.
Попробовал метод описанный здесь:
https://dba.stackexchange.com/a/102545/6229
но он показывает явно неправильное время завершения EST (в основном он показывает «сейчас» для более чем 60-минутного процесса, на который у меня уходит 10 минут)
Как я могу получить подсказку?
ВЫБЕРИТЕ процент_завершения, расчетное_время_завершения, чтение, запись, логическое_чтение, размер_текста, * ИЗ sys.dm_exec_requests AS r КУДА r.session_id <> @@SPID И r.session_id = 58
 dm_exec_requests AS r
КУДА
r.session_id <> @@SPID
И r.session_id = 58
dm_exec_requests AS r
КУДА
r.session_id <> @@SPID
И r.session_id = 58
- sql-сервер
- индекс
- sql-сервер-2014
- индекс-обслуживание
0
Я думаю, что следующий запрос, по крайней мере, поможет вам приблизиться. Он использует динамическое административное представление, которое было представлено в SQL Server 2014: sys.dm_exec_query_profiles (и спасибо Мартину Смиту за то, что представил его мне через этот связанный ответ DBA.StackExchange: ход выполнения оператора SELECT INTO :-).
Обратите внимание:
!! Вам нужно будет добавить
УСТАНОВИТЬ ПРОФИЛЬ СТАТИСТИКИ ВКЛ;илиВКЛЮЧИТЬ СТАТИСТИКУ XML;в пакете запросов, который выполняетCREATE INDEX(и поместил перед операторомCREATE INDEX, если это не было очевидно), иначе в этом DMV не появятся строки для этого SPID /session_id!!Оператор
INиспользуется для фильтрации индексной вставкиTotalRows, что исказит расчеты, поскольку в этой строке никогда не отображаются обработанные строки.Отображаемое здесь количество строк (т. е.
TotalRows) в два раза превышает количество строк в таблице из-за того, что операция состоит из двух шагов, каждый из которых работает со всеми строками: первый — это «Сканирование таблицы» или «Сканирование кластеризованного индекса». «, а второе — «Сортировка». Вы увидите «Сканирование таблицы» при создании кластеризованного индекса или создании некластеризованного индекса в куче. Вы увидите «Сканирование кластеризованного индекса» при создании некластеризованного индекса в кластеризованном индексе.Этот запрос не работает при создании фильтрованных индексов. По какой-то причине отфильтрованные индексы а) не имеют шага «Сортировка» и б) полеrow_countникогда не увеличивается с 0.
Не уверен, что я тестировал раньше, но мои тесты теперь показывают, что отфильтрованные индексы захвачено этим запросом. Сладкий. Хотя просто имейте в виду, что количество строк может быть отключено (я посмотрю, смогу ли я это исправить когда-нибудь).При создании кластеризованного индекса в куче, на которой уже есть некластеризованные индексы, необходимо перестроить некластеризованные индексы (чтобы заменить RID — RowID — на ключ(и) кластеризованного индекса), и каждый некластеризованный индекс перестроение будет отдельной операцией и, следовательно, не будет отражаться в статистике, возвращаемой этим запросом во время создания кластеризованного индекса.
Этот запрос был протестирован на:
- Создание:
- Некластеризованные индексы в куче
- a Кластеризованный индекс (некластеризованных индексов не существует)
- Некластеризованные индексы в кластеризованном индексе/таблице
- Кластеризованный индекс, когда некластеризованные индексы уже существуют
- Уникальные некластеризованные индексы в кластеризованном индексе/таблице
- Перестроение (таблица с кластеризованным индексом и одним некластеризованным индексом; проверено на SQL Server 2014, 2016, 2017 и 2019). ) с помощью:
-
ALTER TABLE [имя_схемы].[имя_таблицы] REBUILD;(только Кластерный индекс отображается при использовании этого метода ) -
ALTER INDEX ALL ON [имя_схемы].[имя_таблицы] REBUILD; -
ALTER INDEX [имя_индекса] ON [имя_схемы].[имя_таблицы] REBUILD;
-
- Создание:
 ) с помощью:
) с помощью: DECLARE @SPID INT = 51;
;С агг. как
(
SELECT SUM(qp.[row_count]) AS [RowsProcessed],
SUM(qp.[estimate_row_count]) AS [TotalRows],
MAX(qp.last_active_time) - MIN(qp.first_active_time) AS [ElapsedMS],
MAX(IIF(qp.[close_time] = 0 И qp.[first_row_time] > 0,
[физическое_имя_оператора],
N'<Переход>')) AS [CurrentStep]
ИЗ sys.dm_exec_query_profiles qp
ГДЕ qp.[physical_operator_name] IN (N'Table Scan', N'Clustered Index Scan',
N'Индексное сканирование', N'Сортировка')
И qp.[session_id] = @SPID
), комп АС
(
ВЫБРАТЬ *,
([TotalRows] - [RowsProcessed]) AS [RowsLeft],
([ElapsedMS] / 1000,0) КАК [ElapsedSeconds]
ОТ агг
)
ВЫБЕРИТЕ [Текущий шаг],
[Всего строк],
[Обработано строк],
[Ряды слева],
ПРЕОБРАЗОВАТЬ(ДЕСЯТИЧНОЕ(5, 2),
(([Обработано строк] * 1,0) / [Всего строк]) * 100) AS [PercentComplete],
[Истекшие секунды],
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]) AS [EstimatedSecondsLeft],
ДАТАДОБАВИТЬ(ВТОРАЯ,
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]),
GETDATE()) AS [EstimatedCompletionTime]
ИЗ комп;
Пример вывода:
Процент строк с истекшим сроком действия Расчетный Расчетный CurrentStep TotalRows Processed RowsLeft Complete Seconds SecondsLeft CompletionTime ----------- --------- --------- -------- -------- ----- -- ----------- -------------- Сгруппировано 11248640 4786937 6461703 42,56 4,89400 6,606223 23 мая 2016 г.
 Индексное сканирование 14:32:40.547
Индексное сканирование 14:32:40.547
2
Я думаю, мы можем удалить переменную @SPID со ссылкой на sys.dm_exec_requests:
;WITH agg AS
(
SELECT SUM(qp.[row_count]) AS [RowsProcessed],
SUM(qp.[estimate_row_count]) AS [TotalRows],
MAX(qp.last_active_time) - MIN(qp.first_active_time) AS [ElapsedMS],
MAX(IIF(qp.[close_time] = 0 И qp.[first_row_time] > 0,
[физическое_имя_оператора],
N'<Переход>')) AS [CurrentStep]
ИЗ sys.dm_exec_query_profiles qp
ГДЕ qp.[physical_operator_name] IN (N'Table Scan', N'Clustered Index Scan',
N'Индексное сканирование', N'Сортировка')
И qp.[session_id] IN (ВЫБЕРИТЕ session_id из sys.dm_exec_requests, где команда IN («СОЗДАТЬ ИНДЕКС», «ИЗМЕНИТЬ ИНДЕКС», «ИЗМЕНИТЬ ТАБЛИЦУ»))
), комп АС
(
ВЫБРАТЬ *,
([TotalRows] - [RowsProcessed]) AS [RowsLeft],
([ElapsedMS] / 1000,0) КАК [ElapsedSeconds]
ОТ агг
)
ВЫБЕРИТЕ [Текущий шаг],
[Всего строк],
[Обработано строк],
[Ряды слева],
ПРЕОБРАЗОВАТЬ(ДЕСЯТИЧНОЕ(5, 2),
(([Обработано строк] * 1,0) / [Всего строк]) * 100) AS [PercentComplete],
[Истекшие секунды],
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]) AS [EstimatedSecondsLeft],
ДАТАДОБАВИТЬ(ВТОРАЯ,
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]),
GETDATE()) AS [EstimatedCompletionTime]
ИЗ комп;
Поскольку эта тема все еще актуальна, я подумал, что стоит отметить, что использование новых возобновляемых операций с индексами в SQL Server 2019 и Azure SQL DB (в режиме совместимости 150) обеспечивает эту функциональность. В представлении каталога sys.index_resumable_operations есть столбец процент_завершения, который показывает ход выполнения.
В представлении каталога sys.index_resumable_operations есть столбец процент_завершения, который показывает ход выполнения.
Помимо возможности отслеживать создание и перестроение индекса, возобновляемые операции с индексами также помогают разбивать операцию на небольшие фрагменты, которые фиксируются по мере выполнения операции. Это помогает сохранить небольшой размер журнала транзакций, а также может помочь с такими вещами, как группы доступности, поскольку операция может быть реплицирована на любые вторичные серверы. Благодаря возобновляемым операциям с индексами вы можете возобновить создание или перестроение индекса на новом первичном сервере после отработки отказа без потери прогресса, а поскольку транзакции фиксируются в процессе, у вас не будет проблем с резервным копированием синхронизации во время длительных операций с индексами. .
2
В дополнение к Брюсу Пратту: давайте сгруппируем по session_id, чтобы мы могли видеть прогресс для нескольких команд Create Index, работающих параллельно.
;С агг.
(
ВЫБЕРИТЕ qp.session_id, SUM(qp.[row_count]) AS [RowsProcessed],
SUM(qp.[estimate_row_count]) AS [TotalRows],
MAX(qp.last_active_time) - MIN(qp.first_active_time) AS [ElapsedMS],
MAX(IIF(qp.[close_time] = 0 И qp.[first_row_time] > 0,
[физическое_имя_оператора],
N'<Переход>')) AS [CurrentStep]
ИЗ sys.dm_exec_query_profiles qp
ГДЕ qp.[physical_operator_name] IN (N'Table Scan', N'Clustered Index Scan',
N'Индексное сканирование', N'Сортировка')
И qp.[session_id] IN (ВЫБЕРИТЕ session_id из sys.dm_exec_requests, где команда IN («СОЗДАТЬ ИНДЕКС», «ИЗМЕНИТЬ ИНДЕКС», «ИЗМЕНИТЬ ТАБЛИЦУ»))
группа по qp.session_id
), комп АС
(
ВЫБРАТЬ *,
([TotalRows] - [RowsProcessed]) AS [RowsLeft],
([ElapsedMS] / 1000,0) КАК [ElapsedSeconds]
ОТ агг
)
ВЫБЕРИТЕ идентификатор_сеанса,
[Текущий шаг],
[Всего строк],
[Обработано строк],
[Ряды слева],
ПРЕОБРАЗОВАТЬ(ДЕСЯТИЧНОЕ(5, 2),
(([Обработано строк] * 1,0) / [Всего строк]) * 100) AS [PercentComplete],
[Истекшие секунды],
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]) AS [EstimatedSecondsLeft],
ДАТАДОБАВИТЬ(ВТОРАЯ,
(([ElapsedSeconds] / [RowsProcessed]) * [RowsLeft]),
GETDATE()) AS [EstimatedCompletionTime]
ИЗ комп;
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
Как это работает и когда использовать
Переводы
中文 对索引Include子句的深入分析
Некоторые базы данных, а именно Microsoft SQL Server, IBM Db2, а также PostgreSQL, начиная с версии 11, предлагают предложение include в операторе create index . Введение этой функции в PostgreSQL стало поводом для давно назревшего объяснения пункта include .
Прежде чем вдаваться в подробности, давайте начнем с краткого обзора того, как работают (некластеризованные) индексы B-дерева и что такое всемогущее сканирование только индексов.
Contents:
- Recap: B-tree Indexes
- Recap: Index-Only Scan
- The
IncludeClause - Filtering on
IncludeColumns - Unique Indexes with
IncludeClause - Compatibility
- PostgreSQL: без фильтрации перед проверкой видимости
Резюме: индексы B-tree
Чтобы понять предложение include , вы должны сначала понять, что использование индекса затрагивает до трех уровней структур данных:
Первые две структуры вместе образуют индекс, поэтому их можно объединить в один элемент, т. е. «индекс B-дерева». Я предпочитаю держать их отдельно, поскольку они служат разным потребностям и по-разному влияют на производительность. Более того, объяснение пункта
е. «индекс B-дерева». Я предпочитаю держать их отдельно, поскольку они служат разным потребностям и по-разному влияют на производительность. Более того, объяснение пункта включает положение требует проведения этого различия.
TABLE DATA…TABLE DATA…KEYKEYKEYKEYTableIndexDoublelinked list
В общем случае программное обеспечение базы данных начинает обход B-дерева, чтобы найти первую совпадающую запись на уровне конечного узла (1). Затем он следует по двусвязному списку, пока не найдет все совпадающие записи (2), и, наконец, извлекает каждую из этих совпадающих записей из таблицы (3). На самом деле последние два шага можно чередовать, но это не имеет значения для понимания общей концепции.
TABLE DATA…TABLE DATA…KEYKEYKEYKEY❶ ❷ ❸ TableIndexDoublelinked list
Следующие формулы дают приблизительное представление о том, сколько операций чтения требуется для каждого из этих шагов. Сумма этих трех компонентов представляет собой общую трудоемкость доступа к индексу. list: <строки, прочитанные из индекса> / 100
list: <строки, прочитанные из индекса> / 100
Таблица: <строки, прочитанные из таблицы> 1
При загрузке нескольких строк B-дерево вносит наибольший вклад в общую работу. Как только вам нужно получить всего несколько строк из таблицы, этот шаг выходит на первый план. В любом случае — мало или много строк — двусвязный список обычно является второстепенным фактором, потому что он хранит строки с похожими значениями рядом друг с другом, так что одна операция чтения может получить 100 или даже больше строк. Формула отражает это соответствующим делителем2
Примечание
Если вы думаете: «Вот почему у нас есть кластеризованные индексы», прочитайте мою статью: « Необоснованные значения по умолчанию: первичный ключ как ключ кластеризации ».
Самая общая идея оптимизации заключается в том, чтобы делать меньше работы для достижения той же цели. Когда дело доходит до доступа к индексу, это означает, что программное обеспечение базы данных пропускает доступ к структуре данных, если ему не нужны данные из нее3. Анатомия индекса SQL ”Объяснение производительности SQL.
Анатомия индекса SQL ”Объяснение производительности SQL.
Резюме: сканирование только индекса
Сканирование только индекса делает именно это: оно пропускает доступ к таблице, если требуемые данные доступны в двусвязном списке индекса.
Рассмотрим следующий индекс и запрос, которые я позаимствовал из « Сканирование только индекса: обход таблицы
Доступ ».
СОЗДАТЬ ИНДЕКС idx
по продажам
(subsubscribe_id, eur_value) ВЫБЕРИТЕ СУММУ (eur_value) ОТ продаж ГДЕ филиал_идентификатор = ?
На первый взгляд может возникнуть вопрос, почему столбец eur_value вообще присутствует в определении индекса — он не упоминается в предложении where .
Индексы B-дерева помогают многим предложениям
Распространено заблуждение, что индексы помогают только предложению where .
Индексы B-дерева также могут помочь упорядочить по , сгруппировать по , выбрать и другие пункты. Это просто часть B-дерева индекса, а не двусвязный список, который не может использоваться другими предложениями.
Это просто часть B-дерева индекса, а не двусвязный список, который не может использоваться другими предложениями.
Важным моментом в этом примере является то, что индекс B-дерева содержит все необходимые столбцы — программному обеспечению базы данных не требуется доступ к самой таблице. Это то, что мы называем сканированием только индекса .
TABLE DATA…TABLE DATA…KEYKEYKEYKEY❶ ❷ TableIndexDoublelinked list
При применении приведенных выше формул выигрыш в производительности очень мал, если только несколько строк удовлетворяют условию where . С другой стороны, если предложение where принимает много строк, например. миллионов, количество операций чтения существенно сокращается в 100 раз.
Примечание
Нередко сканирование только индекса повышает производительность на один или два порядка.
В приведенном выше примере используется тот факт, что двусвязный список — конечные узлы B-дерева — содержит столбец eur_value . Хотя другие узлы B-дерева также хранят этот столбец, этот запрос не использует информацию в этих узлах.
Хотя другие узлы B-дерева также хранят этот столбец, этот запрос не использует информацию в этих узлах.
Предложение
Include
Предложение include позволяет нам различать столбцы, которые мы хотели бы иметь во всем индексе (ключевые столбцы), и столбцы, которые нам нужны только в конечных узлах ( включает столбца). Это означает, что он позволяет нам удалять столбцы из нелистовых узлов, если они нам там не нужны.
«Покрывающий индекс»
Термин «покрывающий индекс» иногда используется в контексте сканирования только индекса или включает пункты . Поскольку этот термин часто используется в другом значении, я обычно его избегаю.
Важно то, может ли данный индекс поддерживать данный запрос посредством сканирования только индекса. Независимо от того, имеет ли этот индекс include 9Предложение 0044 или содержит все столбцы таблицы не имеет значения.
Используя предложение include , мы можем уточнить индекс для этого запроса:
CREATE INDEX idx
ПО продажам (subtribute_id)
INCLUDE ( eur_value ) Запрос может по-прежнему использовать этот индекс для сканирования только по индексу, таким образом обеспечивая практически ту же производительность.
KEYKEYKEYKEYINCLUDEINCLUDEINCLUDEINCLUDEKEYKEYKEYKEYKEYKEYKEYKEYKEYKEYKEYTABLE DATA...TABLE DATA...TableIndexDoublelinked list
Помимо очевидных отличий в картинке, есть и более тонкая разница: порядок записей конечных узлов не учитывает включая столбца. Индекс упорядочен исключительно по ключевым столбцам.4 Это имеет два следствия: включают столбцы , которые нельзя использовать для предотвращения сортировки и они не учитываются для обеспечения уникальности (см. ниже).
Ограничения длины
Максимальная длина элемента указателя ограничена. Это означает, что вы не всегда можете поместить все столбцы, которые хотите, в индекс.
Некоторые продукты, в частности SQL Server, налагают более жесткие ограничения на ключевую часть индекса, как и на общую длину записи индекса с , включая столбца.5 В таких системах вы можете вернуться к предложению , включая , если вы не можете поместить все необходимые столбцы в ключ индекса. Несмотря на то, что эти столбцы нельзя использовать в качестве предикатов доступа, они по-прежнему позволяют проверять условия для этих столбцов без доступа к таблице.
Несмотря на то, что эти столбцы нельзя использовать в качестве предикатов доступа, они по-прежнему позволяют проверять условия для этих столбцов без доступа к таблице.
По сравнению с исходным определением индекса новое определение с номером 9Предложение 0043 include имеет некоторые преимущества:
В дереве может быть меньше уровней (<~40%)
Поскольку узлы дерева над двусвязным списком не содержат столбцов
include, база данных может хранить больше ветвей в каждом блоке, чтобы в дереве было меньше уровней.Индекс немного меньше (<~3%)
Поскольку неконечные узлы дерева не содержат
, включаютстолбца, общий размер этого индекса немного меньше. Однако на уровне конечных узлов индекса в любом случае требуется больше всего места, поэтому потенциальная экономия на оставшихся узлах очень мала.Он документирует свое назначение
Это, безусловно, самое недооцененное преимущество предложения
include: причина, по которой столбец находится в индексе, документирована в самом определении индекса.
Позвольте мне подробнее остановиться на последнем пункте.
При расширении существующего индекса очень важно точно знать, почему индекс в настоящее время определен именно так, как он определен. Свобода, которую вы имеете при изменении индекса без нарушения каких-либо других запросов, является прямым результатом этих знаний.
Следующий запрос демонстрирует это:
SELECT * ОТ продаж ГДЕ филиал_идентификатор = ? ЗАКАЗ ПО TS DESC FETCH FIRST 1 ROW ONLY
Как и прежде, для данной дочерней компании этот запрос извлекает самую последнюю запись о продажах ( ts для отметки времени).
Для оптимизации этого запроса было бы здорово иметь индекс, начинающийся с ключевых столбцов (subsidiary_id, ts) . С помощью этого индекса программное обеспечение базы данных может напрямую перейти к последней записи для этой дочерней компании и сразу же вернуть ее. Нет необходимости читать и сортировать все записи для этой дочерней компании, потому что двусвязный список сортируется в соответствии с ключом индекса, т. е. последняя запись для любой данной дочерней компании должна иметь наибольшие
е. последняя запись для любой данной дочерней компании должна иметь наибольшие Значение ts для этой дочерней компании. При таком подходе запрос выполняется так же быстро, как и поиск первичного ключа. Дополнительные сведения об этом методе см. в разделах « Порядок индексации по » и « Запрос первых N строк ».
От своего имени
Я зарабатываю на жизнь обучением SQL, настройкой и консультированием SQL, а также своей книгой «Объяснение производительности SQL». Узнайте больше на https://winand.at/.
Перед добавлением нового индекса для этого запроса мы должны проверить, существует ли существующий индекс, который можно изменить (расширить) для поддержки этого трюка. Как правило, это хорошая практика, поскольку расширение существующего индекса оказывает меньшее влияние на накладные расходы на обслуживание, чем добавление нового индекса. Однако при изменении существующего индекса нам нужно убедиться, что мы не делаем этот индекс менее полезным для других запросов.
Если мы посмотрим на исходное определение индекса, мы столкнемся с проблемой:
CREATE INDEX idx
по продажам
(subsubscriber_id, eur_value) Чтобы этот индекс поддерживал предложение order by приведенного выше запроса, нам нужно вставить столбец ts между двумя существующими столбцами:
CREATE INDEX idx
по продажам
(subsubscriber_id , ts , eur_value) Однако это может сделать этот индекс менее полезным для запросов, которым требуется eur_value столбец во второй позиции, например. если это было в , где или закажите по пункту . Изменение этого индекса сопряжено со значительным риском: сломать другие запросы, если мы не знаем, что таких запросов нет. Если мы не знаем, часто лучше оставить индекс как есть и создать другой для нового запроса.
Картина полностью изменится, если мы посмотрим на индекс с предложением include .
СОЗДАТЬ ИНДЕКС idx
ПО продажам (subtribute_id)
ВКЛЮЧИТЬ (евро_значение) Поскольку столбец eur_value находится в предложении include , он не находится в нелистовых узлах и, следовательно, не полезен для навигации по дереву или для упорядочивания. Добавление нового столбца в конец ключевой части относительно безопасно.
Добавление нового столбца в конец ключевой части относительно безопасно.
СОЗДАТЬ ИНДЕКС idx
ПО продажам (substory_id , ts )
INCLUDE ( eur_value ) Несмотря на то, что все еще существует небольшой риск негативных последствий для других запросов, обычно стоит пойти на этот риск6.0043 включите пункт , если это все, что вам нужно. Столбцы, которые только что были добавлены для включения сканирования только индекса, являются первыми кандидатами на это.
Фильтрация по столбцам
Include
До сих пор мы фокусировались на том, как предложение include может включить сканирование только индекса. Давайте также рассмотрим другой случай, когда полезно иметь дополнительный столбец в индексе.
ВЫБЕРИТЕ * ОТ продаж ГДЕ филиал_идентификатор = ? И отмечает LIKE '%search term%'
Я сделал поисковый запрос буквальным значением, чтобы показать начальные и конечные подстановочные знаки — конечно, вы должны использовать в своем коде параметр связывания.
Теперь давайте подумаем о правильном индексе для этого запроса. Очевидно, что subtribute_id должен быть на первой позиции. Если взять предыдущий индекс сверху, то он уже удовлетворяет этому требованию:
CREATE INDEX idx
ПО продажам (substory_id , ts )
INCLUDE ( eur_value ) Программное обеспечение базы данных может использовать этот индекс с помощью трехэтапной процедуры, как описано в начале: (1) оно будет использовать B-дерево, чтобы найти первую запись индекса для данной дочерней компании; (2) он будет следовать двусвязному списку, чтобы найти все продажи для этой дочерней компании; (3) он извлечет все связанные продажи из таблицы, удалив те, для которых как шаблон в столбце notes не соответствует и возвращает остальные строки.
Проблема заключается в последнем шаге этой процедуры: доступ к таблице загружает строки, не зная, попадут ли они в окончательный результат. Довольно часто доступ к таблице вносит наибольший вклад в общие усилия по выполнению запроса. Загрузка данных, которые даже не выбраны, — это огромная производительность, нет-нет.
Загрузка данных, которые даже не выбраны, — это огромная производительность, нет-нет.
Важно
Избегайте загрузки данных, которые не влияют на результат запроса.
Проблема с этим конкретным запросом заключается в том, что он использует встроенный шаблон , подобный . Обычные индексы B-tree не поддерживают поиск таких шаблонов. Однако индексы B-tree по-прежнему поддерживают фильтрацию для таких шаблонов. Обратите внимание на выделение: поиск против фильтрация .
Другими словами, если столбец notes присутствует в двусвязном списке, программное обеспечение базы данных может применить шаблон как перед выборкой этой строки из таблицы (не PostgreSQL, см. ниже). Это предотвращает доступ к таблице, если вроде шаблона не совпадает. Если в таблице больше столбцов, по-прежнему существует доступ к таблице для выборки этих столбцов для строк, которые удовлетворяют предложению where — из-за select * .
СОЗДАТЬ ИНДЕКС idx
ПО продажам (subtribute_id, ts)
INCLUDE ( eur_value , notes ) Если в таблице больше столбцов, индекс не включает сканирование только индекса. Тем не менее, он может приблизить производительность к сканированию только индекса, если часть строк, соответствующих , как и , очень низкий. В обратном случае — если все строки соответствуют шаблону — производительность немного хуже из-за увеличения размера индекса. Однако безубыточности легко достичь: для общего повышения производительности часто бывает достаточно, чтобы фильтр , например , удалял небольшой процент строк. Ваш пробег будет варьироваться в зависимости от размера задействованных столбцов.
Уникальные индексы с
Включить Пункт
И последнее, но не менее важное: это совершенно другой аспект включает предложение : уникальные индексы с предложением включают учитывают уникальность только ключевых столбцов.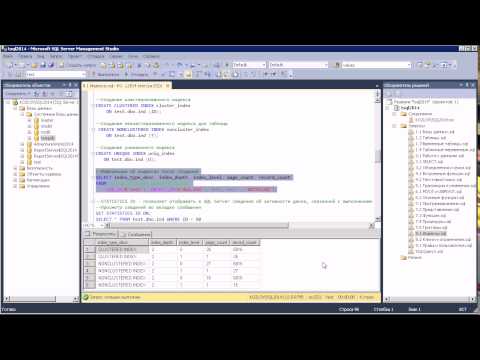
Это позволяет нам создавать уникальные индексы с дополнительными столбцами в листовых узлах, например. для индексного сканирования.
СОЗДАТЬ УНИКАЛЬНЫЙ ИНДЕКС …
ВКЛ … ( идентификатор )
INCLUDE (полезная нагрузка) Этот индекс защищает от повторяющихся значений в столбце id 7, но поддерживает сканирование только индекса для следующего запроса.
ВЫБРАТЬ полезную нагрузку ИЗ … ГДЕ идентификатор = ?
Обратите внимание, что условие include не является обязательным для такого поведения: базам данных, которые делают правильное различие между уникальными ограничениями и уникальными индексами , просто нужен индекс с уникальными ключевыми столбцами в качестве крайних левых столбцов — дополнительные столбцы отлично.
Для базы данных Oracle соответствующий синтаксис таков:
CREATE INDEX …
ON… (id, payload) ALTER TABLE… ADD UNIQUE (id)
ИСПОЛЬЗОВАНИЕ ИНДЕКСА … Совместимость
Db2 (LUW)MariaDBMySQLOracle DBaPostgreSQLSQL ServerSQLiteindex … includeunique index … includeFiltering on include
- Использовать
уникальный (…) с использованием индекса …с индексом, имеющим больше столбцов База данных PostgreSQL имеет ограничение на применение фильтров на уровне индекса. Короче говоря, он этого не делает, за исключением нескольких случаев. Хуже того, некоторые из этих случаев работают только тогда, когда соответствующие данные хранятся в ключевой части индекса, а не в 9-й части.0043 включают пункт . Это означает, что перемещение столбцов в предложение includeможет негативно сказаться на производительности, даже если вышеописанная логика по-прежнему применяется.Долгая история начинается с того факта, что PostgreSQL сохраняет старые версии строк в таблице до тех пор, пока они не станут невидимыми для всех транзакций, а процесс очистки не удалит их в какой-то более поздний момент времени. Чтобы узнать, видна ли версия строки (для данной транзакции) или нет, каждая таблица имеет два дополнительных атрибута, которые указывают, когда версия строки была создана и удалена:
xminиxmax. Строка видна, только если текущая транзакция попадает в диапазонxmin/xmax.8К сожалению, значения
xmin/xmaxне сохраняются в индексах. просматривая запись индекса, он не может сказать, видна ли эта запись для текущей транзакции. Это может быть удаленная запись или запись, которая еще не была зафиксирована. Канонический способ узнать это — заглянуть в таблицу и проверить xmin/xmaxзначения.Следствием этого является то, что в PostgreSQL нет такого понятия, как сканирование только индекса. Независимо от того, сколько столбцов вы поместите в индекс, PostgreSQL всегда будет проверять видимость, которая недоступна в индексе.
Тем не менее, в PostgreSQL есть операция
Index Only Scan, но для этого по-прежнему необходимо проверять видимость каждой версии строки, обращаясь к данным вне индекса. Вместо того, чтобы идти к столу,Только сканирование индексасначала проверяет так называемую карту видимости. Эта карта видимости очень плотная, поэтому количество операций чтения (надеюсь) меньше, чем выборкаxmin/xmaxиз таблицы. Однако карта видимости не всегда дает однозначный ответ: карта видимости либо утверждает, что строка известна как видимая, либо что видимость неизвестна. В последнем случае Index Only Scanпо-прежнему должен получитьxmin/xmaxиз таблицы (показана как «выборка кучи» в, поясните, анализируйте).После этого небольшого отступления от наглядности мы можем вернуться к фильтрации на уровне индекса.
SQL допускает произвольные сложные выражения в предложении
where. Эти выражения также могут вызывать ошибки времени выполнения, такие как «деление на ноль». Если бы PostgreSQL оценивал такое выражение перед подтверждением видимости соответствующей записи, даже невидимые строки могли бы вызвать такие ошибки. Чтобы предотвратить это, PostgreSQL обычно проверяет видимость до для оценки таких выражений.Из этого общего правила есть одно исключение. Поскольку видимость не может быть проверена во время поиска по индексу , операторы, которые можно использовать для поиска по индексу , всегда должны быть безопасными.
Это операторы, которые определены в соответствующем классе операторов. Если простой фильтр сравнения использует операцию из такого класса операторов, PostgreSQL может применить этот фильтр перед проверкой видимости, поскольку знает, что эти операторы безопасны для использования. Суть в том, что только ключевых столбцов имеют связанный с ними класс оператора. Столбцы в включают в себя пункт, но фильтры на их основе не применяются до подтверждения их видимости. Это мое понимание из темы в списке рассылки хакеров PostgreSQL.Для демонстрации возьмите предыдущий индекс и запрос:
CREATE INDEX idx ПО продажам (subtribute_id, ts) ВКЛЮЧИТЬ (евро_значение , примечания )ВЫБРАТЬ * ОТ продаж ГДЕ филиал_идентификатор = ? И примечания LIKE '%search term%'
План выполнения — отредактированный для краткости — может выглядеть так:
ПЛАН ЗАПРОСА ------------------------------------------------------------- Сканирование индекса с использованием idx по продажам (фактические строки = 16) Условие индекса: (subsidiary_id = 1) Фильтр: (примечания ~~ '%search term%') Строки, удаленные фильтром: 240 Буферы: shared hit=54Фильтр
какпоказан вFilter, а не вIndex Cond. Это означает, что он был применен на уровне таблицы. Кроме того, количество общих обращений довольно велико для выборки 16 строк.В
Bitmap Index/Heap Scanявление становится более очевидным.ПЛАН ЗАПРОСА -------------------------------------------------------------- Сканирование растровой кучи при продажах (фактические строки = 16) Перепроверьте состояние: (idsubsidiary_id= 1) Фильтр: (примечания ~~ '%search term%') Строки, удаленные фильтром: 240 Блоки кучи: точно = 52 Буферы: общий хит=54 -> Сканирование растрового индекса на idx (фактические строки = 256 ) Условие индекса: (subsidiary_id = 1) Буферы: общий хит=2Сканирование растрового индекса
как. Вместо этого он возвращает 256 строк — намного больше, чем 16, которые удовлетворяют предложению, где.Обратите внимание, что это не особенность
включаетстолбец в данном случае . Перемещение столбцов includeв ключ индекса дает тот же результат.СОЗДАТЬ ИНДЕКС idx ПО продажам (substory_id, ts , eur_value, notes )ПЛАН ЗАПРОСА -------------------------------------------------------------- Сканирование растровой кучи при продажах (фактические строки = 16) Перепроверьте состояние: (subsidiary_id = 1) Фильтр: (примечания ~~ '%поисковое слово%') Строки, удаленные фильтром: 240 Блоки кучи: точно = 52 Буферы: общий хит=54 -> Сканирование растрового индекса на idx (фактические строки = 256 ) Условие индекса: (subsidiary_id = 1) Буферы: shared hit=2Это связано с тем, что оператор
, как и, не является частью класса операторов, поэтому он не считается безопасным.Если вы используете операцию из класса операторов, т.е. равны, план выполнения меняется.
ВЫБЕРИТЕ * ОТ продаж ГДЕ филиал_идентификатор = ? И notes = 'search term'
Сканирование растрового индекса
whereи передает только оставшиеся 16 строк на сканирование кучи растрового изображения
 Короче говоря, он этого не делает, за исключением нескольких случаев. Хуже того, некоторые из этих случаев работают только тогда, когда соответствующие данные хранятся в ключевой части индекса, а не в 9-й части.0043 включают пункт . Это означает, что перемещение столбцов в предложение
Короче говоря, он этого не делает, за исключением нескольких случаев. Хуже того, некоторые из этих случаев работают только тогда, когда соответствующие данные хранятся в ключевой части индекса, а не в 9-й части.0043 включают пункт . Это означает, что перемещение столбцов в предложение  просматривая запись индекса, он не может сказать, видна ли эта запись для текущей транзакции. Это может быть удаленная запись или запись, которая еще не была зафиксирована. Канонический способ узнать это — заглянуть в таблицу и проверить
просматривая запись индекса, он не может сказать, видна ли эта запись для текущей транзакции. Это может быть удаленная запись или запись, которая еще не была зафиксирована. Канонический способ узнать это — заглянуть в таблицу и проверить  Однако карта видимости не всегда дает однозначный ответ: карта видимости либо утверждает, что строка известна как видимая, либо что видимость неизвестна. В последнем случае
Однако карта видимости не всегда дает однозначный ответ: карта видимости либо утверждает, что строка известна как видимая, либо что видимость неизвестна. В последнем случае  Это операторы, которые определены в соответствующем классе операторов. Если простой фильтр сравнения использует операцию из такого класса операторов, PostgreSQL может применить этот фильтр перед проверкой видимости, поскольку знает, что эти операторы безопасны для использования. Суть в том, что только ключевых столбцов имеют связанный с ними класс оператора. Столбцы в
Это операторы, которые определены в соответствующем классе операторов. Если простой фильтр сравнения использует операцию из такого класса операторов, PostgreSQL может применить этот фильтр перед проверкой видимости, поскольку знает, что эти операторы безопасны для использования. Суть в том, что только ключевых столбцов имеют связанный с ними класс оператора. Столбцы в  Это означает, что он был применен на уровне таблицы. Кроме того, количество общих обращений довольно велико для выборки 16 строк.
Это означает, что он был применен на уровне таблицы. Кроме того, количество общих обращений довольно велико для выборки 16 строк.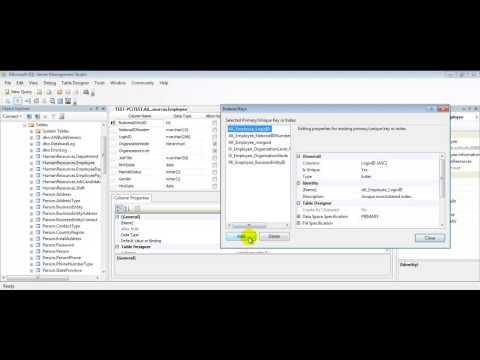 Перемещение столбцов
Перемещение столбцов