Ms sql оконные функции: Оконные функции SQL простым языком с примерами / Хабр
Содержание
Оконные функции в T-SQL (Ицик Бен-Ган)
3 199 ₽
2 339 ₽
+ до 350 бонусов
Купить
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на
сайте.
В наличии 2 шт
2
Цена на сайте может отличаться от цены в магазинах сети. Внешний вид книги может отличаться от изображения на
сайте.
В этой книге на конкретных примерах рассматриваются все типы оконных функций: агрегатные, ранжирующие, статистические, а также функции смещения и функции упорядоченного набора. Вы узнаете, как использовать оконные функции для повышения эффективности запросов, которые раньше писали с применением предикатов; освоить концепцию работы с окнами в SQL и строить запросы наиболее эффективным образом; умело использовать опции секционирования, упорядочивания и определения границ окна; оптимизировать оконные функции с использованием индексов и пакетного режима; применять оконные функции для решения распространенных бизнес-задач.
Издание предназначено для разработчиков, администраторов, специалистов в области бизнес-аналитики. Актуально для SQL Server 2019 и ниже, а также для Azure SQL Database.
Описание
Характеристики
В этой книге на конкретных примерах рассматриваются все типы оконных функций: агрегатные, ранжирующие, статистические, а также функции смещения и функции упорядоченного набора. Вы узнаете, как использовать оконные функции для повышения эффективности запросов, которые раньше писали с применением предикатов; освоить концепцию работы с окнами в SQL и строить запросы наиболее эффективным образом; умело использовать опции секционирования, упорядочивания и определения границ окна; оптимизировать оконные функции с использованием индексов и пакетного режима; применять оконные функции для решения распространенных бизнес-задач.
Издание предназначено для разработчиков, администраторов, специалистов в области бизнес-аналитики. Актуально для SQL Server 2019 и ниже, а также для Azure SQL Database.
ДМК Пресс
Как получить бонусы за отзыв о товаре
1
Сделайте заказ в интернет-магазине
2
Напишите развёрнутый отзыв от 300 символов только на то, что вы купили
3
Дождитесь, пока отзыв опубликуют.
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать
неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в
первой десятке.
Правила начисления бонусов
Если он окажется среди первых десяти, вы получите 30 бонусов на Карту Любимого Покупателя. Можно писать
неограниченное количество отзывов к разным покупкам – мы начислим бонусы за каждый, опубликованный в
первой десятке.
Правила начисления бонусов
По ту сторону анализа
Плюсы
Твёрдая обложка
Минусы
—
Книга «Оконные функции в T-SQL» есть в наличии в интернет-магазине «Читай-город» по привлекательной цене.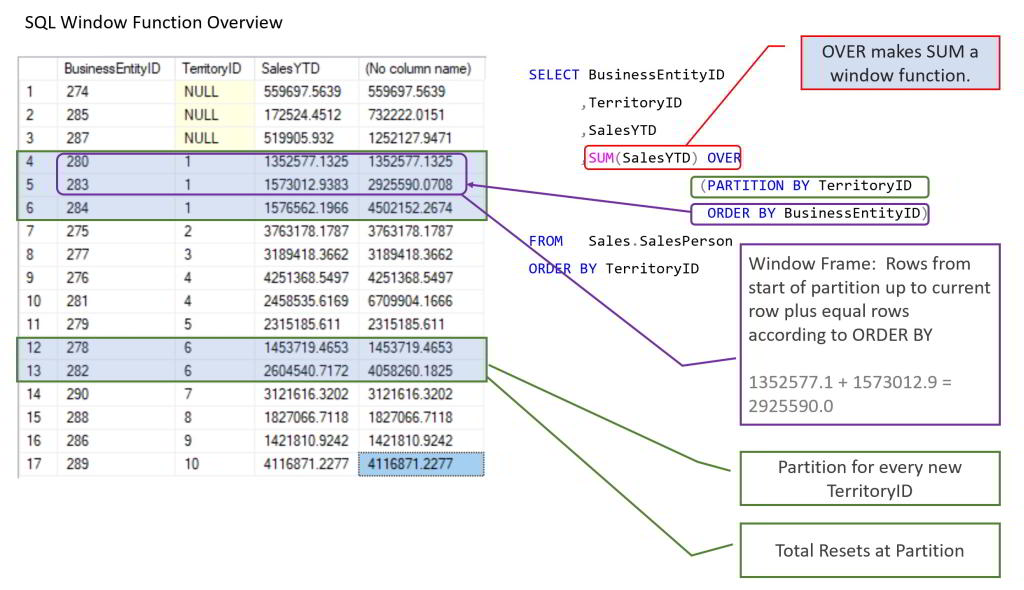
Если вы находитесь в Москве, Санкт-Петербурге, Нижнем Новгороде, Казани, Екатеринбурге, Ростове-на-Дону или любом
другом регионе России, вы можете оформить заказ на книгу
Ицик Бен-Ган
«Оконные функции в T-SQL» и выбрать удобный способ его получения: самовывоз, доставка курьером или отправка
почтой. Чтобы покупать книги вам было ещё приятнее, мы регулярно проводим акции и конкурсы.
sql server — Странная работа оконных функций min max в ms sql 2012 при обработке null
Вопрос задан
Изменён
7 лет 2 месяца назад
Просмотрен
167 раз
Странная работа оконных функций min, max в ms sql 2012 при обработке null–значений. 2 запроса
select max(q1) OVER(PARTITION BY q2 order by q1) from
(
select null as q1, 1 as q2, 0 as q3
union
select 11, 1, 1
union
select null, 1, 1
) a
select max(q1) OVER(PARTITION BY q2) from
(
select null as q1, 1 as q2, 0 as q3
union
select 11, 1, 1
union
select null, 1, 1
) a
Результат первого
- NULL
- NULL
- 11
Второго
- 11
- 11
- 11
Казалось бы причём тут в функциях min max order by. ..
..
Microsoft SQL Server 2012 — 11.0.5058.0 (X64)
May 14 2014 18:34:29
Copyright (c) Microsoft Corporation
Enterprise Edition: Core-based
Licensing (64-bit) on Windows NT 6.1 (Build 7601: Service Pack
1)
и
Microsoft SQL Server 2014 — 12.0.2000.8 (X64)
Feb 20 2014 20:04:26
Copyright (c) Microsoft Corporation
Enterprise Edition (64-bit) on
Windows NT 6.3 (Build 9600: )
- sql-server
- функции
1
Немного модифицируем ваш запрос:
select max(q1) OVER(PARTITION BY q2 order by q3),
min(q1) OVER(PARTITION BY q2 order by q3),
sum(q3) OVER(PARTITION BY q2 order by q3),
max(q1) OVER(PARTITION BY q2),
sum(q3) OVER(PARTITION BY q2)
from
(
select null as q1, 1 as q2, 0 as q3
union
select 12, 1, 1
union
select 11, 1, 2
) a
Результат:
NULL NULL 0 12 3 12 12 1 12 3 12 11 3 12 3
Видно, что у выражений без ORDER BY берется требуемое значение для всего окна, а для предложений с сортировкой — берется накопленное на данный момент значение в порядке сортировки.
Теперь открываем документацию, раздел «Общие примечания»:
Если предложение ORDER BY не указано, то для рамки окна используется весь раздел. Это относится только к тем функциям, которым не требуется предложение ORDER BY. Если предложение ROWS или RANGE не указаны, а указано предложение ORDER BY, то в качестве значения по умолчанию для рамки окна используется RANGE UNBOUNDED PRECEDING AND CURRENT ROW
Собственно в документации сказано именно то, что мы увидели в результате запроса. Если order by указан, то функции к которым это применимо, рассматривают окно он начала раздела заданного partition by до текущей строки.
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Как использовать функции окна в SQL Server
Все пользователи базы данных знают об обычных агрегатных функциях, которые работают со всей таблицей и используются с предложением GROUP BY. Но очень немногие используют оконные функции в SQL. Они работают с набором строк и возвращают одно агрегированное значение для каждой строки.
Но очень немногие используют оконные функции в SQL. Они работают с набором строк и возвращают одно агрегированное значение для каждой строки.
Основное преимущество использования оконных функций по сравнению с обычными агрегатными функциями заключается в следующем: оконные функции не группируют строки в одну выходную строку, строки сохраняют свои отдельные идентификаторы, и к каждой строке добавляется агрегированное значение.
Давайте посмотрим, как работают функции Window, а затем рассмотрим несколько примеров их использования на практике, чтобы убедиться, что все понятно, а также сравним SQL и выходные данные с функциями SUM().
Как всегда убедитесь, что у вас есть полная резервная копия, особенно если вы пробуете новые вещи с вашей базой данных.
Введение в функции окна
Оконные функции работают с набором строк и возвращают одно агрегированное значение для каждой строки. Термин Окно описывает набор строк в базе данных, с которыми будет работать функция.
Мы определяем Окно (набор строк, с которыми работают функции), используя предложение OVER(). Подробнее о предложении OVER() мы поговорим в статье ниже.
Типы оконных функций
- Агрегированные оконные функции
СУММ(), МАКС(), МИН(), СРЕДН(). СЧИТАТЬ() - Ранжирование оконных функций
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE() - Функции окна значений
LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()
Синтаксис
функция_окна ([ALL] выражение) OVER ([PARTITION BY partition_list] [ORDER BY order_list])
|
Аргументы
функция_окна
Укажите имя оконной функции
ВСЕ
ALL — необязательное ключевое слово. Когда вы включите ВСЕ, будут подсчитаны все значения, включая повторяющиеся. DISTINCT не поддерживается в оконных функциях.
выражение
Целевой столбец или выражение, с которым работают функции. Другими словами, имя столбца, для которого нам нужно агрегированное значение. Например, столбец, содержащий сумму заказа, чтобы мы могли видеть общее количество полученных заказов.
НАД
Задает предложения окна для агрегатных функций.
РАЗДЕЛ ПО partition_list
Определяет окно (набор строк, с которыми работает оконная функция) для оконных функций.
Нам нужно указать поле или список полей для раздела после предложения PARTITION BY. Несколько полей должны быть разделены запятой, как обычно. Если PARTITION BY не указан, группировка будет выполнена для всей таблицы, и значения будут агрегированы соответствующим образом.
ЗАКАЗАТЬ ПО order_list
Сортирует строки в каждом разделе. Если ORDER BY не указан, ORDER BY использует всю таблицу.
Примеры
Давайте создадим таблицу и вставим фиктивные записи для написания дальнейших запросов. Запустите код ниже.
Запустите код ниже.
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 13 14 15 16 17 18 90 003 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE TABLE [dbo].[Заказы] ( order_id INT, order_date DATE, customer_name VARCHAR(250), город VARCHAR(100), сумма_заказа ДЕНЬГИ )
ВСТАВИТЬ В [dbo].[Заказы] SELECT ‘1001’,’04/01 /2017», «Дэвид Смит», «Гилфорд ‘,10000 UNION ALL SELECT ‘1002’,’02.04.2017′,’David Jones’,’Arlington’,20000 UNION ALL SELECT ‘1003’,’ 03.04.2017′ ,’Джон Смит’,’Шалфорд’,5000 UNION ALL SELECT ‘1004’,’04/04/2017′,’Майкл Смит’,’GuildFord’,15000 UNION ALL SELECT ‘1005’,’05. UNION ALL SELECT ‘1006’,’06.04.2017′,’Paum Смит ‘,’GuildFord’,25000 UNION ALL SELECT ‘1007’,’10.04.2017′,’Andrew Smith’,’Arlington’,15000 UNION ALL SELECT ’10 08′,’04/ 11/2017′,’David Brown’,’Arlington’,2000 UNION ALL SELECT ‘1009’,’20/04/2017′,’Robert Smith’,’Shalford’,1000 UNION ALL ВЫБЕРИТЕ ‘1010’,’25.04.2017′,’Питер Смит’,’Гилфорд’,500
|
 04.2017′,’David Williams’,’Shalford’,7000
04.2017′,’David Williams’,’Shalford’,7000Агрегированные оконные функции
SUM()
Мы все знаем агрегатную функцию SUM(). Он делает сумму указанного поля для указанной группы (например, города, штата, страны и т. д.) или для всей таблицы, если группа не указана. Мы увидим, что будет на выходе обычной агрегатной функции SUM() и оконной агрегатной функции SUM().
Ниже приведен пример обычной агрегатной функции SUM(). Суммирует сумму заказа для каждого города.
Из набора результатов видно, что обычная агрегатная функция группирует несколько строк в одну выходную строку, из-за чего отдельные строки теряют свою идентичность.
ВЫБЕРИТЕ город, СУММА(сумма_заказа) общая_сумма_заказа ОТ [dbo].[Заказы] СГРУППИРОВАТЬ ПО городу
|
Этого не происходит с оконными агрегатными функциями. Строки сохраняют свою идентичность, а также отображают агрегированное значение для каждой строки. В приведенном ниже примере запрос делает то же самое, а именно агрегирует данные по каждому городу и показывает сумму общей суммы заказа для каждого из них. Однако теперь запрос вставляет еще один столбец для общей суммы заказа, чтобы каждая строка сохраняла свою идентичность. Столбец с пометкой grand_total является новым столбцом в приведенном ниже примере.
SELECT order_id, order_date, customer_name, city, order_amount ,SUM(order_amount) OVER(PARTITION BY city) as grand_total FROM [dbo].[Orders]
|
АВГ()
AVG или Average работают точно так же с функцией Window.
Следующий запрос даст вам среднюю сумму заказа для каждого города и за каждый месяц (хотя для простоты мы использовали данные только за один месяц).
Мы указываем более одного среднего значения, указав несколько полей в списке разделов.
Также стоит отметить, что вы можете использовать выражения в таких списках, как MONTH(order_date), как показано в запросе ниже. Как всегда, вы можете сделать эти выражения настолько сложными, насколько захотите, при условии правильного синтаксиса!
ВЫБЕРИТЕ идентификатор_заказа, дата_заказа, имя_клиента, город, сумма_заказа ,AVG(сумма_заказа) OVER(РАЗБИВКА ПО городам, МЕСЯЦ(дата_заказа)) как средняя_сумма_заказа ОТ [dbo].[Заказы]
|
На изображении выше мы ясно видим, что в среднем мы получили 12 333 заказа для города Арлингтон на апрель 2017 года.
Средняя сумма заказа = общая сумма заказа / общая сумма заказов
= (20 000 + 15 000 + 2 000) / 3
= 12 333
Вы также можете использовать комбинацию функций SUM() и COUNT() для вычисления среднего значения.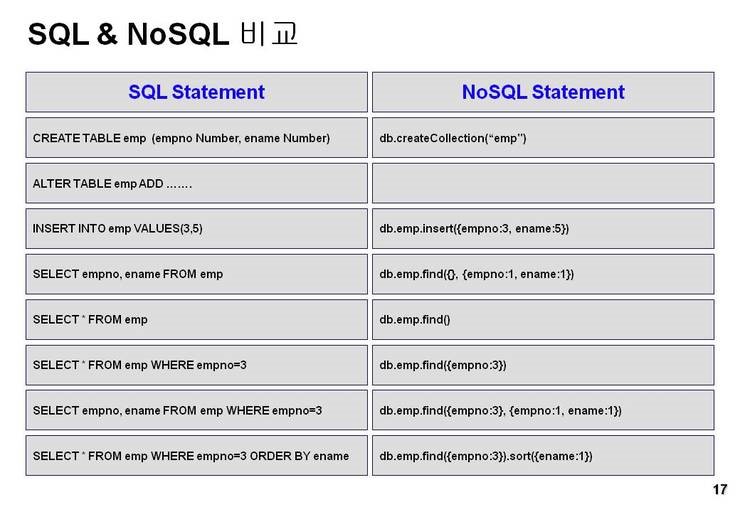
МИН()
Агрегатная функция MIN() найдет минимальное значение для указанной группы или для всей таблицы, если группа не указана.
Например, мы ищем наименьший заказ (минимальный заказ) для каждого города, мы бы использовали следующий запрос.
МАКС()
Точно так же, как функции MIN() дают вам минимальное значение, функция MAX() идентифицирует наибольшее значение указанного поля для указанной группы строк или для всей таблицы, если группа не указана.
найдем самый большой заказ (максимальную сумму заказа) для каждого города.
СЧЕТ()
Функция COUNT() будет подсчитывать записи/строки.
Обратите внимание, что DISTINCT не поддерживается с оконной функцией COUNT(), тогда как она поддерживается для обычной функции COUNT(). DISTINCT помогает вам найти различные значения указанного поля.
DISTINCT помогает вам найти различные значения указанного поля.
Например, если мы хотим узнать, сколько клиентов разместили заказ в апреле 2017 года, мы не можем напрямую подсчитать всех клиентов. Возможно, что один и тот же клиент разместил несколько заказов в одном и том же месяце.
COUNT(имя_клиента) даст вам неверный результат, так как будет подсчитываться дубликаты. Принимая во внимание, что COUNT(DISTINCT customer_name) даст вам правильный результат, поскольку он подсчитывает каждого уникального клиента только один раз.
Действительно для обычной функции COUNT():
ВЫБЕРИТЕ город,COUNT(DISTINCT имя_клиента) количество_клиентов ОТ [dbo].[Заказы] СГРУППИРОВАТЬ ПО городам
|
Недействительно для оконной функции COUNT():
SELECT order_id, order_date, customer_name, city, order_amount ,COUNT(DISTINCT customer_name) OVER(PARTITION BY city) as number_of_customers FROM [dbo]. 9 0002 |
 [Orders]
[Orders]Приведенный выше запрос с функцией Window даст вам ошибку ниже.
Теперь давайте найдем общий заказ, полученный для каждого города, используя оконную функцию COUNT().
SELECT order_id, order_date, customer_name, city, order_amount ,COUNT(order_id) OVER(PARTITION BY city) as total_orders FROM [dbo].[Orders]
|
Функции окна ранжирования
Точно так же, как агрегатные функции окна объединяют значение указанного поля, функции ранжирования ранжируют значения указанного поля и классифицируют их в соответствии с их рангом.
Наиболее распространенное использование функций RANKING — поиск лучших (N) записей на основе определенного значения. Например, Топ-10 самых высокооплачиваемых сотрудников, Топ-10 студентов, Топ-50 крупнейших заказов и т. д.
Поддерживаются следующие функции РЕЙТИНГА:
RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
Давайте обсудим их один за другим.
РАНГ()
Функция RANK() используется для присвоения каждой записи уникального ранга на основе указанного значения, например, оклада, суммы заказа и т. д.
Если две записи имеют одинаковое значение, функция RANK() присвоит обеим записям одинаковый ранг, пропуская следующий ранг. Это означает, что если есть два одинаковых значения в ранге 2, он присвоит одинаковый ранг 2 обеим записям, а затем пропустит ранг 3 и присвоит ранг 4 следующей записи.
Давайте ранжируем каждый заказ по сумме заказа.
ВЫБЕРИТЕ order_id,order_date,customer_name,city, RANK() OVER(ORDER BY order_amount DESC) [Rank] FROM [dbo].[Orders]
|
На изображении выше видно, что один и тот же ранг (3) назначается двум идентичным записям (каждая из которых имеет сумму заказа 15 000), а затем он пропускает следующий ранг (4) и присваивает ранг 5 следующей записи.
DENSE_RANK()
Функция DENSE_RANK() идентична функции RANK(), за исключением того, что она не пропускает ни одного ранга. Это означает, что если будут найдены две идентичные записи, DENSE_RANK() присвоит обеим записям одинаковый ранг, но не пропустит, а затем пропустит следующий ранг.
Давайте посмотрим, как это работает на практике.
SELECT order_id,order_date,customer_name,city, order_amount, DENSE_RANK() OVER(ORDER BY order_amount DESC) [Rank] FROM [dbo].[Orders]
|
Как вы можете ясно видеть выше, один и тот же ранг присваивается двум идентичным записям (каждая из которых имеет одинаковую сумму заказа), а затем следующий номер ранга присваивается следующей записи без пропуска значения ранга.
НОМЕР_СТРОКИ()
Название говорит само за себя. Эти функции присваивают каждой записи уникальный номер строки.
Номер строки будет сброшен для каждого раздела, если указано PARTITION BY. Давайте посмотрим, как ROW_NUMBER() работает без PARTITION BY, а затем с PARTITION BY.
ROW_ NUMBER() без РАЗДЕЛА ПО
ВЫБЕРИТЕ order_id,order_date,customer_name,city, order_amount, ROW_NUMBER() OVER(ORDER BY order_id) [row_number] FROM [dbo].[Orders]
|
ROW_NUMBER() с PARTITION BY
SELECT order_id,order_date,customer_name,city, order_amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY order_amount DESC) [row_number] FROM [dbo].[Orders] 9 0003
|
Обратите внимание, что мы сделали раздел по городу. Это означает, что номер строки сбрасывается для каждого города и снова начинается с 1. Однако порядок строк определяется суммой заказа, поэтому для любого заданного города наибольшая сумма заказа будет первой строкой, поэтому номер строки 1.
Однако порядок строк определяется суммой заказа, поэтому для любого заданного города наибольшая сумма заказа будет первой строкой, поэтому номер строки 1.
NTILE()
NTILE() — очень полезная оконная функция. Это поможет вам определить, к какому процентилю (или квартилю, или любому другому подразделению) относится данная строка.
Это означает, что если у вас есть 100 строк и вы хотите создать 4 квартили на основе указанного поля значений, вы можете легко сделать это и посмотреть, сколько строк попадает в каждый квартиль.
Давайте посмотрим пример. В приведенном ниже запросе мы указали, что хотим создать четыре квартили на основе суммы заказа. Затем мы хотим увидеть, сколько заказов попадает в каждый квартиль.
ВЫБЕРИТЕ order_id,order_date,customer_name,city, order_amount, NTILE(4) OVER(ORDER BY order_amount) [номер_строки] FROM [dbo].
|
 [Заказы]
[Заказы]NTILE создает тайлы на основе следующей формулы:
Количество строк в каждой плитке = количество строк в результирующем наборе / количество указанных плиток
Вот наш пример, у нас всего 10 строк и в запросе указано 4 плитки, поэтому количество строк в каждой плитке будет 2,5 (10/4). Поскольку количество строк должно быть целым числом, а не десятичным. Механизм SQL назначит 3 строки для первых двух групп и 2 строки для оставшихся двух групп.
Функции окна значений
Функции окна значений используются для поиска первого, последнего, предыдущего и следующего значений. Можно использовать следующие функции: LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE().
LAG() и LEAD()
Функции LEAD() и LAG() очень мощные, но их сложно объяснить.
Поскольку это вводная статья ниже, мы рассмотрим очень простой пример, чтобы проиллюстрировать, как их использовать.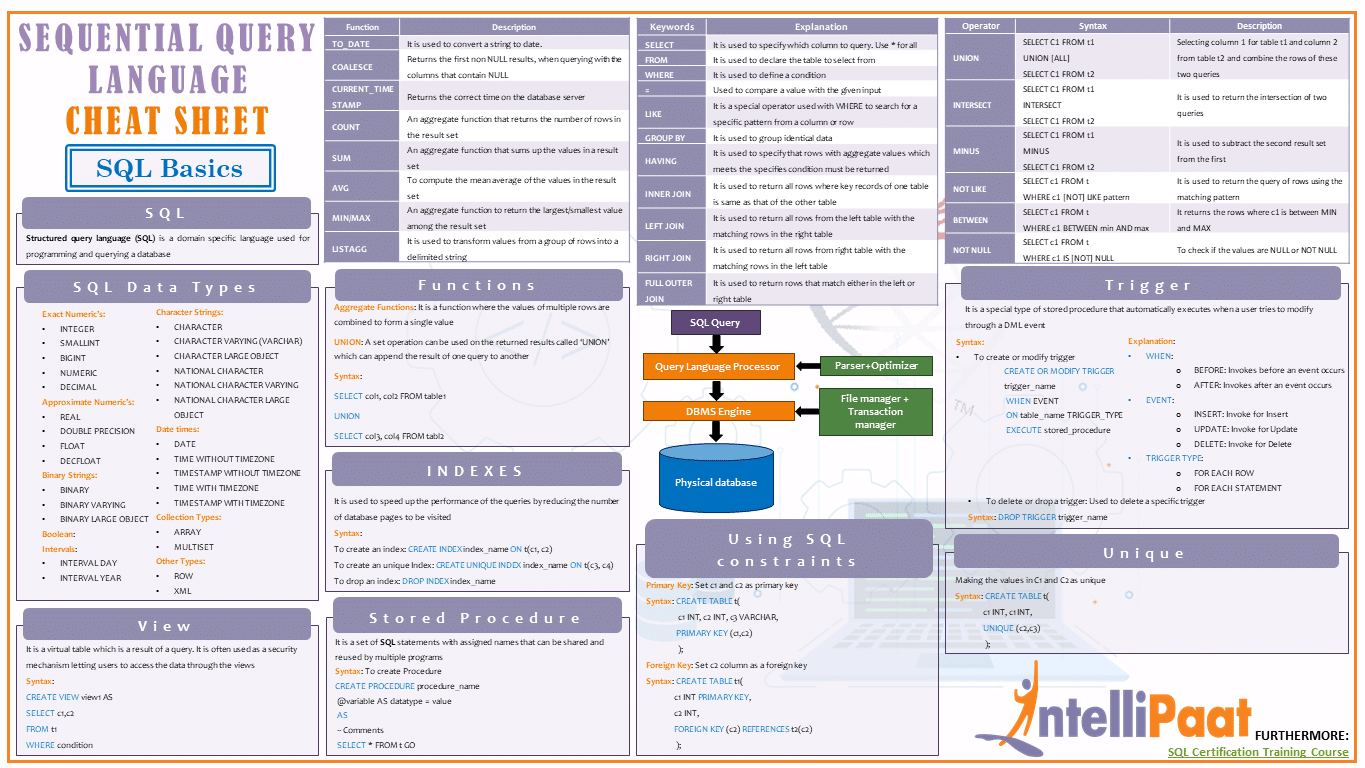
Функция LAG позволяет получить доступ к данным из предыдущей строки в том же наборе результатов без использования каких-либо соединений SQL. В приведенном ниже примере вы можете видеть, что с помощью функции LAG мы нашли дату предыдущего заказа.
Скрипт для поиска даты предыдущего заказа с помощью функции LAG():
1 2 3 4 5 6 |
ВЫБЕРИТЕ order_id,customer_name,city, order_amount,order_date, —в строке ниже 1 указывает на проверку предыдущей строки текущей строки |
Функция LEAD позволяет получить доступ к данным из следующей строки в том же наборе результатов без использования каких-либо соединений SQL. Вы можете видеть в примере ниже, используя функцию LEAD, мы нашли дату следующего заказа.
Скрипт для поиска даты следующего заказа с помощью функции LEAD():
1 2 3 4 5 6 |
SELECT order_id,customer_name,city, order_amount,order_date, —в нижней строке 1 означает проверку следующей строки текущей строки LEAD(order_date,1) OVER(ORDER BY order_date) next_order_date ОТ [dbo].
|
 [Заказы]
[Заказы]ПЕРВОЕ_ЗНАЧ() и ПОСЛЕДНЕЕ_ЗНАЧ()
Эти функции помогают определить первую и последнюю запись в разделе или во всей таблице, если PARTITION BY не указан.
Давайте найдем первый и последний порядок каждого города из нашего существующего набора данных. Примечание Предложение ORDER BY является обязательным для функций FIRST_VALUE() и LAST_VALUE().
1 2 3 4 5 6 |
SELECT order_id,order_date,customer_name,city, order_amount, FIRST_VALUE(order_date) OVER(PARTITION BY city ORDER BY city) first_order_date, LAST_VALUE(order_date) OVER(PART ПО ГОРОДУ ЗАКАЗ ПО городу) last_order_date ОТ [dbo].[Заказы]
|
На изображении выше мы ясно видим, что первый заказ получен 02 апреля 2017 г., а последний заказ получен 11 апреля 2017 г.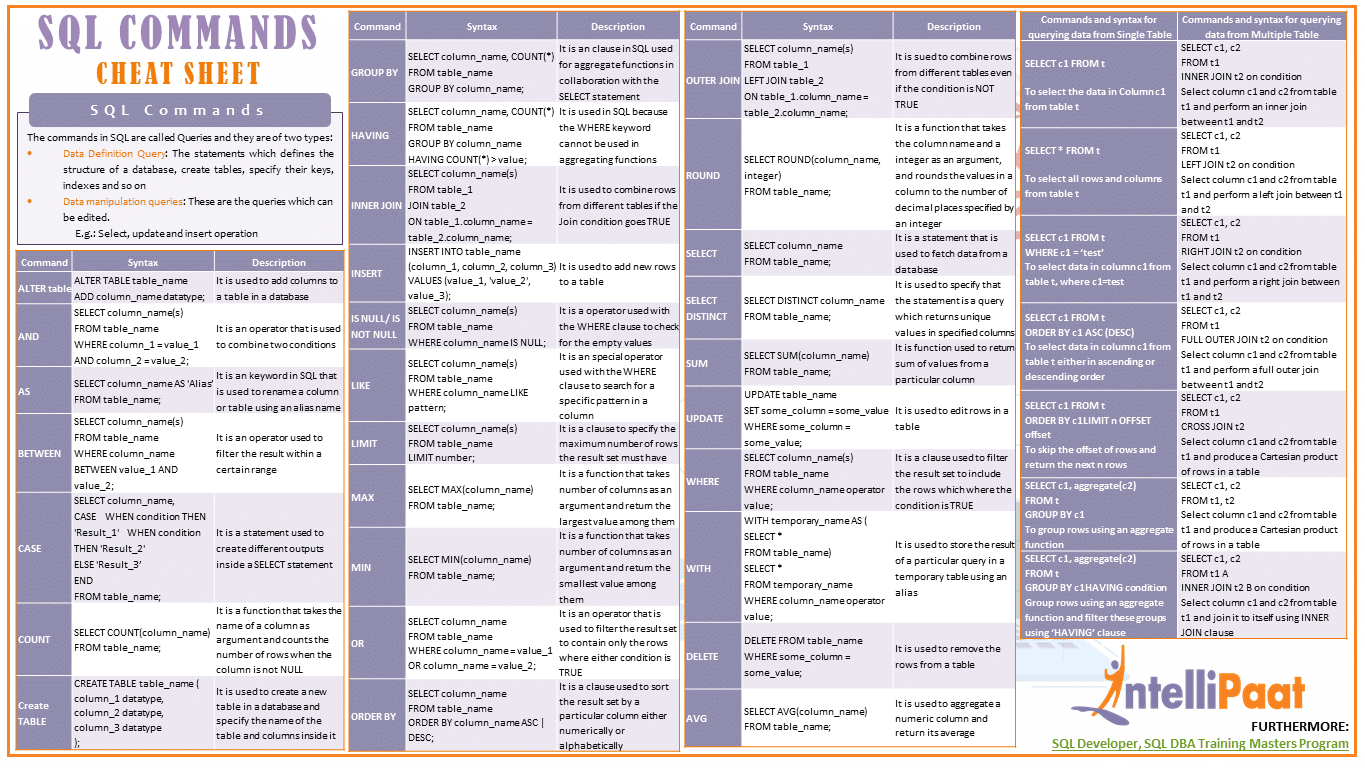 для города Арлингтон, и это работает так же для других городов.
для города Арлингтон, и это работает так же для других городов.
Полезные ссылки
- Типы и стратегии резервного копирования для баз данных SQL
- Статья TechNet о пункте OVER
- Статья MSDN о DENSE_RANK
Другие замечательные статьи Бена
| Как SQL Server выбирает жертву взаимоблокировки |
| Как использовать оконные функции |
- Автор
- Последние сообщения
Бен Ричардсон
Бен Ричардсон руководит Acuity Training, ведущим поставщиком услуг по обучению SQL в Великобритании. Он предлагает полный спектр обучения SQL, от вводных курсов до продвинутого обучения администрированию и работе с хранилищами данных. Подробнее см. здесь. Acuity имеет офисы в Лондоне и Гилфорде, графство Суррей. Он также иногда пишет в блоге Acuity
Просмотреть все сообщения Бена Ричардсона
Последние сообщения Бена Ричардсона (посмотреть все)
Функции окна SQL | Расширенный SQL
Начиная отсюда? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
Проверьте начало.
В этом уроке мы рассмотрим:
- Введение в оконные функции
- Основной синтаксис управления окнами
- Обычные подозреваемые: SUM, COUNT и AVG
- ROW_NUMBER()
- РАНГ() и DENSE_RANK()
- НТИЛЕ
- LAG и LEAD
- Определение псевдонима окна
- Расширенные методы работы с окнами
В этом уроке используются данные программы Capital Bikeshare в Вашингтоне, округ Колумбия, которая публикует подробные исторические данные о поездках на своем веб-сайте. Данные были загружены в феврале 2014 г., но ограничены данными, собранными в течение первого квартала 2012 г. Каждая строка представляет одну поездку. Большинство полей говорят сами за себя, за исключением rider_type : «Зарегистрированный» указывает на ежемесячное членство в программе совместного использования, «Повседневный» означает, что водитель купил 3-дневный проездной. 9Поля 0816 start_time и end_time были очищены от их исходных форм, чтобы соответствовать форматированию даты SQL — они хранятся в этой таблице как метки времени.
Введение в оконные функции
Документация PostgreSQL прекрасно знакомит с концепцией оконных функций:
Оконная функция выполняет вычисления для набора строк таблицы, которые так или иначе связаны с текущей строкой. Это сравнимо с типом вычислений, которые можно выполнить с помощью агрегатной функции. Но в отличие от обычных агрегатных функций использование оконной функции не приводит к группированию строк в одну строку вывода — строки сохраняют свои отдельные идентификаторы. За кулисами оконная функция может получить доступ не только к текущей строке результата запроса.
Наиболее практичным примером этого является промежуточный итог:
SELECT duration_seconds,
SUM(duration_seconds) OVER (ORDER BY start_time) AS running_total
ИЗ tutorial.dc_bikeshare_q1_2012
Вы можете видеть, что приведенный выше запрос создает агрегацию ( running_total ) без использования GROUP BY . Давайте разберем синтаксис и посмотрим, как он работает.
Давайте разберем синтаксис и посмотрим, как он работает.
Основной синтаксис работы с окнами
Первая часть вышеприведенной агрегации, SUM(duration_seconds) очень похоже на любую другую агрегацию. Добавление НАД определяет его как оконную функцию. Вы можете прочитать вышеприведенную агрегацию как «возьмите сумму duration_seconds по всему набору результатов, в порядке start_time ».
Если вы хотите сузить окно от всего набора данных до отдельных групп в наборе данных, вы можете использовать PARTITION BY для этого:
SELECT start_terminal,
длительность_секунд,
СУММ(длительность_секунд) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY start_time)
AS running_total
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
Приведенный выше запрос группирует и упорядочивает запрос по start_terminal . В каждом значении start_terminal оно упорядочено по start_time и промежуточной общей сумме по текущей строке и всем предыдущим строкам duration_seconds . Прокрутите вниз, пока значение
Прокрутите вниз, пока значение start_terminal не изменится, и вы заметите, что running_total начинается заново. Вот что происходит, когда вы группируете с помощью PARTITION BY . В случае, если вы все еще в тупике ORDER BY , он просто упорядочивает по назначенному столбцу (столбцам) так же, как предложение ORDER BY , за исключением того, что он рассматривает каждый раздел как отдельный. Он также создает промежуточную сумму — без ORDER BY каждое значение будет просто суммой всех значений duration_seconds в соответствующем start_terminal . Попробуйте выполнить приведенный выше запрос без ORDER BY , чтобы понять:
SELECT start_terminal,
длительность_секунд,
СУММ(длительность_секунд) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal) КАК start_terminal_total
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ПРИКАЗ и ЧАСТЬ определяют так называемое «окно» — упорядоченное подмножество данных, по которым выполняются вычисления.
Примечание. В одном запросе нельзя использовать оконные функции и стандартные агрегаты. В частности, вы не можете включать оконные функции в предложение GROUP BY .
Практическая задача
Напишите модификацию приведенного выше примера запроса, который показывает продолжительность каждой поездки в процентах от общего времени, накопленного пассажирами с каждого start_terminal.
Попробуйте См. ответ
Обычные подозреваемые: SUM, COUNT и AVG
При использовании оконных функций вы можете применять те же агрегаты, что и в обычных обстоятельствах — SUM , COUNT и AVG . Самый простой способ понять это — повторно запустить предыдущий пример с некоторыми дополнительными функциями. Сделать
ВЫБЕРИТЕ start_terminal,
длительность_секунд,
СУММ(длительность_секунд) БОЛЕЕ
(РАЗДЕЛ BY start_terminal) AS running_total,
COUNT(длительность_секунд) БОЛЕЕ
(РАЗДЕЛ ПО start_terminal) AS running_count,
СРЕДНЕЕ (длительность_секунд) БОЛЕЕ
(РАЗДЕЛ ПО start_terminal) AS running_avg
ИЗ tutorial. dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
 dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
В качестве альтернативы те же функции с ORDER BY :
SELECT start_terminal,
длительность_секунд,
СУММ(длительность_секунд) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY start_time)
AS running_total,
COUNT(длительность_секунд) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY start_time)
AS running_count,
СРЕДНЕЕ (длительность_секунд) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY start_time)
AS running_avg
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
Убедитесь, что вы подключили два предыдущих запроса к режиму и запустили их. Следующая практическая задача очень похожа на примеры, поэтому попробуйте изменить приведенный выше код, а не начинать с нуля.
Практическая задача
Напишите запрос, показывающий промежуточную сумму продолжительности поездок на велосипеде (аналогично последнему примеру), но сгруппированный по end_terminal , а продолжительность поездки отсортирована в порядке убывания.
ПопробуйтеСмотреть ответ
ROW_NUMBER()
ROW_NUMBER() делает именно то, на что похоже — отображает номер заданной строки. Он начинается с 1 и нумерует строки в соответствии с ORDER BY частью оператора окна. ROW_NUMBER() не требует указания переменной в круглых скобках:
SELECT start_terminal,
время начала,
длительность_секунд,
ROW_NUMBER() OVER (ЗАКАЗАТЬ ПО start_time)
AS row_number
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
Использование предложения PARTITION BY позволит вам снова начать считать 1 в каждом разделе. Следующий запрос снова запускает счет для каждого терминала:
SELECT start_terminal,
время начала,
длительность_секунд,
ROW_NUMBER() OVER (РАЗДЕЛ ПО start_terminal
ЗАКАЗАТЬ ПО start_time)
AS row_number
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
РАНГ() и DENSE_RANK()
RANK() немного отличается от ROW_NUMBER() . Например, если вы заказываете по
Например, если вы заказываете по start_time , может случиться так, что на некоторых терминалах есть поездки с двумя одинаковыми временами начала. В этом случае им присваивается одинаковый ранг, тогда как ROW_NUMBER() присваивает им разные номера. В следующем запросе вы видите 4-е и 5-е наблюдения для start_terminal 31000 — им обоим присваивается ранг 4, а следующий результат получает ранг 6:
ВЫБЕРИТЕ start_terminal,
длительность_секунд,
RANK() OVER (РАЗДЕЛ ПО start_terminal
ЗАКАЗАТЬ ПО start_time)
AS ранг
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
Вы также можете использовать DENSE_RANK() вместо RANK() в зависимости от вашего приложения. Представьте ситуацию, в которой три записи имеют одинаковое значение. Используя любую команду, все они получат одинаковый ранг. Для примера допустим, что это «2». Вот как две команды будут по-разному оценивать следующие результаты:
-
RANK()даст одинаковым строкам ранг 2, затем пропустит ранги 3 и 4, так что следующим результатом будет 5 -
DENSE_RANK()по-прежнему будет присваивать всем идентичным строкам ранг 2, но следующей строке будет присвоен ранг 3 — ни один ранг не будет пропущен.

Практическая задача
Напишите запрос, который показывает 5 самых длинных поездок от каждого начального терминала, упорядоченных по терминалам, и от самых длинных до самых коротких поездок в каждом терминале. Ограничение на поездки, совершенные до 8 января 2012 года.
Попробуйте См. ответ
NTILE
Вы можете использовать оконные функции, чтобы определить, в какой процентиль (или квартиль, или любое другое подразделение) попадает данная строка. Синтаксис: NTILE(*# сегментов*) . В этом случае ORDER BY определяет, какой столбец использовать для определения квартилей (или любого другого количества плиток, которое вы укажете). Например:
ВЫБЕРИТЕ start_terminal,
длительность_секунд,
НЕТ (4) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
Квартиль AS,
НЕТ (5) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
Квинтиль AS,
NTILE(100) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
AS процентиль
ИЗ tutorial. dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
 dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
Глядя на результаты запроса выше, вы можете видеть, что столбец процентиль вычисляется не так, как вы могли бы ожидать. Если бы у вас было только две записи и вы измеряли процентили, вы бы ожидали, что одна запись будет определять 1-й процентиль, а другая — 100-й процентиль. Используя функцию NTILE , вы фактически увидите одну запись в 1-м процентиле и одну во 2-м процентиле. Вы можете увидеть это в результатах для start_terminal 9.0817 31000 — столбец процентилей просто выглядит как числовое ранжирование. Если вы прокрутите вниз до start_terminal 31007, вы увидите, что он правильно вычисляет процентили, потому что для этого start_terminal существует более 100 записей. Если вы работаете с очень маленькими окнами, имейте это в виду и рассмотрите возможность использования квартилей или аналогичных небольших диапазонов.
Практическая задача
Напишите запрос, который показывает только продолжительность поездки и процентиль, в который попадает эта продолжительность (по всему набору данных, а не по терминалам).
Попробуйте. См. ответ
LAG и LEAD
Часто бывает полезно сравнить строки с предыдущими или последующими, особенно если вы получили данные в порядке, который имеет смысл. Вы можете использовать LAG или LEAD для создания столбцов, которые извлекают значения из других строк — все, что вам нужно сделать, это указать, из какого столбца извлекаться и сколько строк вы хотите извлечь. LAG вытягивает из предыдущих рядов и LEAD вытягивает из следующих рядов:
ВЫБЕРИТЕ start_terminal,
длительность_секунд,
ЗАДЕРЖКА(длительность_секунд, 1) ПРЕВЫШЕНО
(PARTITION BY start_terminal ORDER BY duration_seconds) AS отставание,
ОПЕРЕЖЕНИЕ(длительность_секунд, 1) ПРЕВЫШЕНИЕ
(PARTITION BY start_terminal ORDER BY duration_seconds) AS ведущий
ИЗ tutorial. dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
 dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
Это особенно полезно, если вы хотите вычислить разницу между строками:
SELECT start_terminal,
длительность_секунд,
duration_seconds -LAG(duration_seconds, 1) ПРЕВЫШЕНО
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
разница в качестве
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
Первая строка столбца разность пуста, так как нет предыдущей строки, из которой можно извлечь. Точно так же использование LEAD создаст нули в конце набора данных. Если вы хотите сделать результаты немного чище, вы можете обернуть их во внешний запрос, чтобы удалить пустые значения:
SELECT *
ОТ (
ВЫБЕРИТЕ start_terminal,
длительность_секунд,
duration_seconds -LAG(duration_seconds, 1) ПРЕВЫШЕНО
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
разница в качестве
ИЗ tutorial. dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
) суб
ГДЕ sub.difference НЕ NULL
 dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
) суб
ГДЕ sub.difference НЕ NULL
dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
) суб
ГДЕ sub.difference НЕ NULL
Определение псевдонима окна
Если вы планируете записать несколько оконных функций в один и тот же запрос, используя одно и то же окно, вы можете создать псевдоним. Возьмите приведенный выше пример NTILE :
SELECT start_terminal,
длительность_секунд,
НЕТ (4) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
Квартиль AS,
НЕТ (5) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
Квинтиль AS,
NTILE(100) БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО start_terminal ORDER BY duration_seconds)
AS процентиль
ИЗ tutorial.dc_bikeshare_q1_2012
ГДЕ start_time < '2012-01-08'
ORDER BY start_terminal, duration_seconds
Это можно переписать как:
SELECT start_terminal,
длительность_секунд,
NTILE(4) НАД ntile_window КАК квартиль,
NTILE(5) НАД ntile_window КАК квинтиль,
NTILE(100) БОЛЕЕ ntile_window КАК процентиль
ИЗ tutorial.