Ms sql over: Предложение OVER (Transact-SQL) — SQL Server
Содержание
Оконные функции в T-SQL – инструкция OVER | Info-Comp.ru
В языке Transact-SQL существует очень полезный и мощный инструмент для формирования различных аналитических отчетов – это инструкция OVER, которая работает совместно с так называемыми «оконными функциями», именно об этом мы сегодня с Вами и поговорим.
Содержание
- Инструкция OVER в Transact-SQL
- Упрощенный синтаксис инструкции OVER
- Оконные функции в Transact-SQL
- Исходные данные для примеров
- Агрегатные оконные функции
- Ранжирующие оконные функции
- Оконные функции смещения
- Аналитические оконные функции
Инструкция OVER в Transact-SQL
OVER – это инструкция T-SQL, которая определяет окно для применения оконной функции. «Окно» в Microsoft SQL Server – это контекст, в котором работает функция с определённым набором строк, относящихся к текущей строке.
Оконная функция – это функция, которая соответственно работает с окном, т. е. набором строк, и возвращает значение на основе неких вычислений.
е. набором строк, и возвращает значение на основе неких вычислений.
Как я уже отметил, оконные функции используют в аналитических отчетах, например, для вычисления каких-то статистических значений (суммы, скользящие средние, промежуточные итоги и так далее) для каждой строки результирующего набора данных.
Честно скажу это очень удобный и полезный функционал Microsoft SQL Server. Впервые поддержка оконных функций появилась в версии Microsoft SQL Server 2005, в которой была реализованы базовая функциональность. В Microsoft SQL Server 2012 функционал оконных функций был расширен, и теперь он с лёгкостью решает много задач, которые до этого решались написанием дополнительного, в некоторых случаях, сложного, непонятного кода (вложенные запросы и т.д.).
Упрощенный синтаксис инструкции OVER
Оконная функция (столбец для вычислений) OVER (
[PARTITION BY столбец для группировки]
[ORDER BY столбец для сортировки]
[ROWS или RANGE выражение для ограничения строк в пределах группы]
)
В выражении для ограничения строк в группе можно использовать следующие ключевые слова:
- ROWS – ограничивает строки;
- RANGE — логически ограничивает строки за счет указания диапазона значений в отношении к значению текущей строки;
- UNBOUNDED PRECEDING — указывает, что окно начинается с первой строки группы.
 Данная инструкция используется только как начальная точка окна;
Данная инструкция используется только как начальная точка окна; - UNBOUNDED FOLLOWING – с помощью данной инструкции можно указать, что окно заканчивается на последней строке группы, соответственно, она может быть указана только как конечная точка окна;
- CURRENT ROW – инструкция указывает, что окно начинается или заканчивается на текущей строке, она может быть задана как начальная или как конечная точка;
- BETWEEN «граница окна» AND «граница окна» — указывает нижнюю и верхнюю границу окна, при этом верхняя граница не может быть меньше нижней границы;
- «Значение» PRECEDING – определяет число строк перед текущей строкой. Эта инструкция не допускается в предложении RANGE;
- «Значение» FOLLOWING — определяет число строк после текущей строки. Если FOLLOWING используется как начальная точка окна, то конечная точка должна быть также указана с помощью FOLLOWING. Эта инструкция не допускается в предложении RANGE.
 Данная инструкция используется только как начальная точка окна;
Данная инструкция используется только как начальная точка окна;Примечание! Чтобы указать выражение для дополнительного ограничения строк (ROWS или RANGE) в окне должна быть указана инструкция ORDER BY.

А сейчас давайте рассмотрим оконные функции, которые существуют в Transact-SQL.
Заметка! Функции TRIM, LTRIM и RTRIM в T-SQL – описание, отличия и примеры.
Оконные функции в Transact-SQL
В T-SQL оконные функции можно подразделить на следующие группы:
- Агрегатные функции;
- Ранжирующие функции;
- Функции смещения;
- Аналитические функции.
В одной инструкции SELECT с одним предложением FROM можно использовать несколько оконных функций. Если инструкция PARTITION BY не указана, функция будет обрабатывать все строки результирующего набора. Некоторые функции не поддерживают инструкцию ORDER BY, ROWS или RANGE.
Исходные данные для примеров
Перед тем как перейти к рассмотрению использования оконных функций, давайте сначала создадим тестовые данные, для того чтобы выполнять примеры.
В качестве сервера у меня будет выступать Microsoft SQL Server 2016 Express.
Допустим, у нас будет таблица TestTable, которая содержит список товаров с некоторыми характеристиками.
--Создание таблицы
CREATE TABLE TestTable(
[ProductId] [INT] IDENTITY(1,1) NOT NULL,
[CategoryId] [INT] NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [Money] NULL
)
GO
--Вставляем в таблицу данные
INSERT INTO TestTable
VALUES (1, 'Клавиатура', 100),
(1, 'Мышь', 50),
(1, 'Системный блок', 200),
(1, 'Монитор', 250),
(2, 'Телефон', 300),
(2, 'Планшет', 500)
SELECT * FROM TestTable
Агрегатные оконные функции
Агрегатные функции – это функции, которые выполняют на наборе данных вычисления и возвращают итоговое значение. Агрегатные функции, я думаю, всем известны — это, например:
Агрегатные функции, я думаю, всем известны — это, например:
- SUM – возвращает сумму значений в столбце;
- AVG — определяет среднее значение в столбце;
- MAX — определяет максимальное значение в столбце;
- MIN — определяет минимальное значение в столбце;
- COUNT — вычисляет количество значений в столбце (значения NULL не учитываются). Если написать COUNT(*), то будут учитываться все записи, т.е. все строки. Возвращает тип данных INT;
- COUNT_BIG – работает также как COUNT, только возвращает тип данных BIGINT.
Обычно агрегатные функции используются в сочетании с инструкцией GROUP BY, которая группирует строки, но их также можно использовать и без GROUP BY, например, с использованием инструкции OVER, и в данном случае они будут вычислять значения в определённом окне (наборе данных) для каждой текущей строки. Это очень удобно, если Вам необходимо получить какую-нибудь величину по отношению к общей сумме, например.
Пример использования агрегатных оконных функций с инструкцией OVER.
В этом примере продемонстрировано простое применение некоторых агрегатных оконных функций.
SELECT ProductId, ProductName, CategoryId, Price,
SUM(Price) OVER (PARTITION BY CategoryId) AS [SUM],
AVG(Price) OVER (PARTITION BY CategoryId) AS [AVG],
COUNT(Price) OVER (PARTITION BY CategoryId) AS [COUNT],
MIN(Price) OVER (PARTITION BY CategoryId) AS [MIN],
MAX(Price) OVER (PARTITION BY CategoryId) AS [MAX]
FROM TestTable
Как видите, у нас вывелись все строки, включая столбцы с агрегированными данными, сгруппированными по категории.
Ранжирующие оконные функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в группе. Например, их можно использовать для того, чтобы пронумеровать строки по группам или выставить ранг и составить рейтинг.
В Microsoft SQL Server существуют следующие ранжирующие функции:
- ROW_NUMBER – функция возвращает номер строки, используется для нумерации строк в секции результирующего набора;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
- NTILE – это функция, которая возвращает результирующий набор, разделённый на группы по определенному столбцу.
Пример использования ранжирующих оконных функций с инструкцией OVER.
В данном примере мы пронумеруем строки в каждой категории, при этом используем сортировку по столбцу ProductId, а также выставим ранг каждому товару в категории на основе его цены.
SELECT ProductId, ProductName, CategoryId, Price,
ROW_NUMBER() OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [ROW_NUMBER],
RANK() OVER (PARTITION BY CategoryId ORDER BY Price) AS [RANK]
FROM TestTable
ORDER BY ProductId
Более детально про ранжирующие функции мы говорили в материале – Функции ранжирования и нумерации в Transact-SQL.
Оконные функции смещения
Функции смещения – это функции, которые позволяют перемещаться и, соответственно, обращаться к разным строкам в наборе данных (окне) относительно текущей строки или просто обращаться к значениям в начале или в конце окна. Эти функции появились в Microsoft SQL Server 2012.
К функциям смещения в T-SQL относятся:
- LEAD – функция обращается к данным из следующей строки набора данных. Ее можно использовать, например, для того чтобы сравнить текущее значение строки со следующим. Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- LAG – функция обращается к данным из предыдущей строки набора данных. В данном случае функцию можно использовать для того, чтобы сравнить текущее значение строки с предыдущим. Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
- FIRST_VALUE — функция возвращает первое значение из набора данных, в качестве параметра принимает столбец, значение которого необходимо вернуть;
- LAST_VALUE — функция возвращает последнее значение из набора данных, в качестве параметра принимает столбец, значение которого необходимо вернуть.
 Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
Имеет три параметра: столбец, значение которого необходимо вернуть (обязательный параметр), количество строк для смещения (по умолчанию 1), значение, которое необходимо вернуть если после смещения возвращается значение NULL;
Пример использования оконных функций смещения в T-SQL.
В этом примере сначала мы вернем следующее и предыдущее значение идентификатора товара в категории. Затем с помощью FIRST_VALUE и LAST_VALUE получим первое и последнее значение идентификатора товара в категории, при этом в качестве примера я покажу, как используется синтаксис дополнительного ограничения строк. А потом, используя необязательные параметры функций LEAD и LAG, мы сместимся уже на 2 строки относительно текущей, при этом, если после смещения функцией LAG такой строки не окажется, нам вернется 0, так как мы укажем третий необязательный параметр со значением 0.
SELECT ProductId, ProductName, CategoryId, Price,
LEAD(ProductId) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LEAD],
LAG(ProductId) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LAG],
FIRST_VALUE(ProductId) OVER (PARTITION BY CategoryId
ORDER BY ProductId
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS [FIRST_VALUE],
LAST_VALUE (ProductId) OVER (PARTITION BY CategoryId
ORDER BY ProductId
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
) AS [LAST_VALUE],
LEAD(ProductId, 2) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LEAD_2],
LAG(ProductId, 2, 0) OVER (PARTITION BY CategoryId ORDER BY ProductId) AS [LAG_2]
FROM TestTable
ORDER BY ProductId
Аналитические оконные функции
Здесь я перечислю так называемые функции распределения, которые возвращают информацию о распределении данных. Эти функции очень специфичны и в основном используются для статистического анализа, к ним относятся:
Эти функции очень специфичны и в основном используются для статистического анализа, к ним относятся:
- CUME_DIST — вычисляет и возвращает интегральное распределение значений в наборе данных. Иными словами, она определяет относительное положение значения в наборе;
- PERCENT_RANK — вычисляет и возвращает относительный ранг строки в наборе данных;
- PERCENTILE_CONT — вычисляет процентиль на основе постоянного распределения значения столбца. В качестве параметра принимает процентиль, который необходимо вычислить;
- PERCENTILE_DISC — вычисляет определенный процентиль для отсортированных значений в наборе данных. В качестве параметра принимает процентиль, который необходимо вычислить.
У функций PERCENTILE_CONT и PERCENTILE_DISC синтаксис немного отличается, столбец, по которому сортировать данные, указывается с помощью ключевого слова WITHIN GROUP.
Пример использования аналитических оконных функций в T-SQL.
SELECT ProductId, ProductName, CategoryId, Price,
CUME_DIST() OVER (PARTITION BY CategoryId ORDER BY Price) AS [CUME_DIST],
PERCENT_RANK() OVER (PARTITION BY CategoryId ORDER BY Price) AS [PERCENT_RANK],
PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY ProductId) OVER(PARTITION BY CategoryId) AS [PERCENTILE_DISC],
PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY ProductId) OVER(PARTITION BY CategoryId) AS [PERCENTILE_CONT]
FROM TestTable
Оконные функции языка T-SQL мы рассмотрели, некоторые из них, как я уже говорил, очень полезны и значительно упрощают написание SQL запросов, всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL, у меня на этом все, пока!
Заметка! Все возможности языка SQL и T-SQL очень подробно рассматриваются в моих видеокурсах по T-SQL, с помощью которых Вы «с нуля» научитесь работать с SQL и программировать на T-SQL в Microsoft SQL Server.

Оконные функции T-SQL
1012
Работа с базами данных в .NET Framework — Оконные функции T-SQL
Оконными функциями (window functions) называются функции, которые применяются к наборам строк и определяются посредством предложения OVER. В основном они используются для аналитических задач, позволяя вычислять нарастающие итоги и скользящие средние, а также выполнять многие другие вычисления. Эти функции основаны на глубоком принципе языка SQL (обоих стандартов — ISO и ANSI) — принципе работы с окнами (windowing). Основа этого принципа — возможность выполнять различные вычисления с набором, или окном, строк и возвращать одно значение. Оконные функции позволяют решать многие задачи, связанные с запросом данных, позволяя выражать вычисления в рамках наборов намного проще, интуитивно понятнее и эффективнее.
В истории поддержки стандарта оконных функций в Microsoft SQL Server есть две ключевые точки:
Отсутствует поддержка некоторой стандартной функциональности, но с улучшениями в SQL Server 2012, поддержку оконных функций можно считать достаточно обширной. В этом небольшом руководстве я расскажу как о реализации этой функциональности в SQL Server, так и о стандартной функциональности, которая в этом сервере отсутствует. Каждый раз, упоминая новую функциональность, я буду указывать, поддерживается ли она в SQL Server, а также в какой версии появилась эта поддержка.
В этом небольшом руководстве я расскажу как о реализации этой функциональности в SQL Server, так и о стандартной функциональности, которая в этом сервере отсутствует. Каждый раз, упоминая новую функциональность, я буду указывать, поддерживается ли она в SQL Server, а также в какой версии появилась эта поддержка.
С момента появления поддержки оконных функций в SQL Server 2005 я обнаружил, что все чаще использую эти функции для совершенствования своих решений. Я методично заменяю старые решения, в которых применяются классические, традиционные конструкции языка, более новыми оконными функциями. А результаты обычно удается получить проще и более эффективно. Это настолько удобно, что в большинстве своих решений, требующих запроса данных, я теперь использую оконные функции.
Также стандартные SQL-системы и реляционные системы управления базами данных (РСУБД) все больше движутся в сторону аналитических решений, и оконные функции являются важной частью этой тенденции. Поэтому мне кажется, что оконным функциям принадлежит будущее в области запроса данных средствами SQL Server, а время, затраченное на их изучение, не пропадет зря.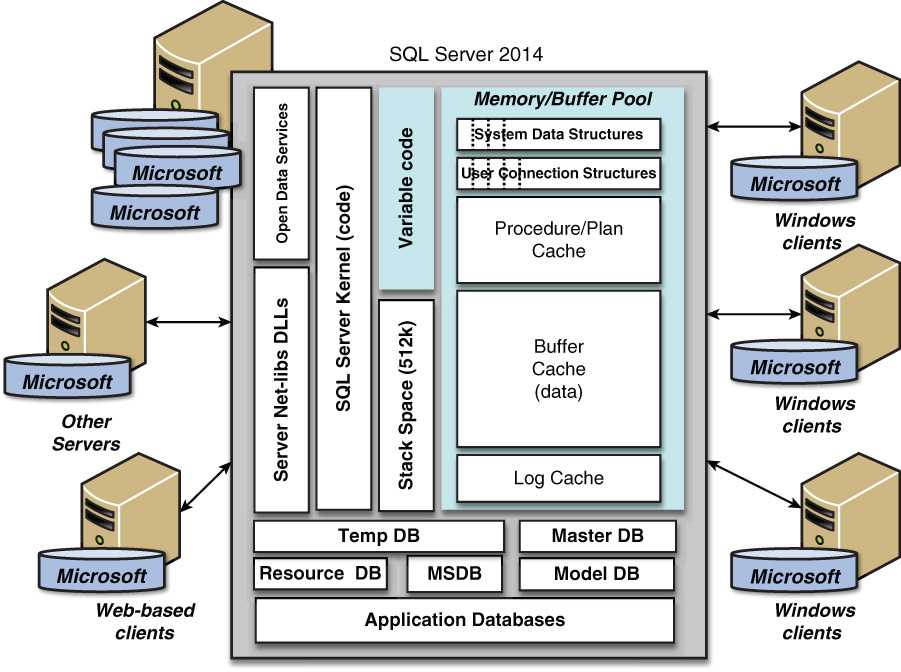
В этом руководстве подробно рассказывается об оконных функциях, их оптимизации и о решениях для получения данных на их основе.
-
1. Окна в SQL Server
- Основы оконных функций
- Обзор решений с использованием оконных функций
- Структура оконных функций
- Запросы
- Агрегатные функции
- Вложенные операторы в агрегатных функциях
- Функции ранжирования
- Аналитические функции
- Функции смещения
-
2. Сортировка и оптимизация
- Функции гипотетического набора
- Функции обратного распределения и смещения
- Конкатенация строк
- Индексирование
- Оптимизация функций ранжирования
- Использование APPLY
- Оптимизация функций агрегирования и смещения
- Оптимизация аналитических функций
-
3.
Решения с использованием оконных функций- Вспомогательные виртуальные таблицы чисел
- Последовательности значений даты и времени
- Последовательности ключей
- Разбиение на страницы
- Удаление повторений
- Сведение данных
- Выбор первых n элементов в группе
- Моды
- Вычисление нарастающих итогов
- Максимальное количество параллельных интервалов
- Упаковка интервалов
- Пробелы и диапазоны
- Медианы
- Условные агрегаты
- Сортировка иерархий
 Решения с использованием оконных функций
Решения с использованием оконных функций
sql server — Предложение SQL OVER() — когда и почему оно полезно?
Итак, простыми словами:
Предложение Over может использоваться для выбора не агрегированных значений вместе с агрегированными.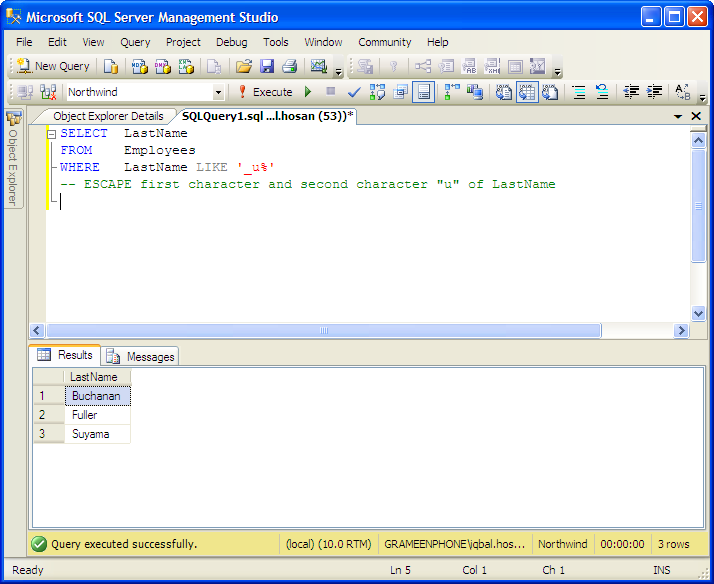
Раздел BY , ORDER BY внутри и ROWS или RANGE являются частью предложения OVER() by . Раздел
используется для разделения данных, а затем выполнения этих оконных, агрегированных функций, и если у нас нет раздела, то весь набор результатов рассматривается как один раздел.
Предложение OVER можно использовать с функциями ранжирования (Rank, Row_Number, Dense_Rank..), агрегатными функциями, такими как (AVG, Max, Min, SUM… и т. д.), и аналитическими функциями, такими как (First_Value, Last_Value и некоторыми другими).
Рассмотрим основной синтаксис предложения OVER
OVER (
[ ]
[ <предложение ORDER BY> ]
[ <предложение ROW или RANGE> ]
)
РАЗДЕЛ НА:
Он используется для разделения данных и выполнения операций над группами с одинаковыми данными.
ЗАКАЗАТЬ ПО:
Он используется для определения логического порядка данных в разделах. Когда мы не указываем раздел, весь набор результатов рассматривается как один раздел
:
Это можно использовать, чтобы указать, какие строки должны учитываться в разделе при выполнении операции.
Возьмем пример:
Вот мой набор данных:
Id Имя Пол Зарплата ------------------------- --------------------------------------- ----------- ---------- ----------- 1 Марка Мужчина 5000 2 Джон Мале 4500 3 Паван Мужской 5000 Женщина в 4 часа 5500 5 Сара Женщина 4000 6 Арадхья Женский 3500 7 Том Мале 5500 8 Мария Женский 5000 9Бен Мале 6500 10 Джоди Женский 7000 11 Том Мале 5500 12 Рон Мале 5000
Итак, позвольте мне выполнить различные сценарии и посмотреть, как это влияет на данные, и я перейду от сложного синтаксиса к простому. сотрудники
Идентификатор Имя Пол Зарплата sum_sal
————————- ————————————— ———— ———- ———— ————
6 Арадхья Женский 3500 3500
5 Сара Женщина 4000 7500
2 Джон Мале 4500 12000
3 Паван Мужской 5000 32000
1 марка Мужской 5000 32000
8 Мария Женский 5000 32000
12 Рон Мале 5000 32000
11 Том Мале 5500 48500
7 Том Мужской 5500 48500
4 Па, Женский 5500 48500
9Бен Мале 6500 55000
10 Джоди Женский 7000 62000
Просто обратите внимание на часть sum_sal. Здесь я использую заказ по зарплате и использую «ДИАПАЗОН МЕЖДУ НЕОГРАНИЧЕННЫМ ПРЕДЫДУЩИМ И ТЕКУЩИМ РЯДОМ» .
Здесь я использую заказ по зарплате и использую «ДИАПАЗОН МЕЖДУ НЕОГРАНИЧЕННЫМ ПРЕДЫДУЩИМ И ТЕКУЩИМ РЯДОМ» .
В этом случае мы не используем раздел, поэтому все данные будут рассматриваться как один раздел, и мы заказываем по зарплате.
И главное здесь UNBOUNDED PRECEDING AND CURRENT ROW . Это означает, что когда мы вычисляем сумму, от начальной строки до текущей строки для каждой строки.
Но если мы видим строки с зарплатой 5000 и name=»Pavan», в идеале должно быть 17000, а для зарплаты=5000 и name=Mark должно быть 22000. Но так как мы используем RANGE и в этом случае, если это находит любые похожие элементы, затем рассматривает их как одну и ту же логическую группу, выполняет над ними операцию и присваивает значение каждому элементу в этой группе. Вот почему у нас одинаковое значение зарплаты = 5000. Двигатель поднялся до зарплаты = 5000 и имени = Рон и подсчитал сумму, а затем присвоил ее всем зарплатам = 5000.
Выберите *,SUM(salary) Over(порядок по зарплате ROWS IN BOUNDED PRECEDING AND CURRENT ROW) как sum_sal от сотрудников Идентификатор Имя Пол Зарплата sum_sal ------------------------- --------------------------------------- ----------- ---------- ----------- ----------- 6 Арадхья Женский 3500 3500 5 Сара Женщина 4000 7500 2 Джон Мале 4500 12000 3 Паван Мужской 5000 17000 1 марка Мужской 5000 22000 8 Мария Женский 5000 27000 12 Рон Мале 5000 32000 11 Том Мале 5500 37500 7 Том Мужской 5500 43000 4 Па, Женский 5500 48500 9Бен Мале 6500 55000 10 Джоди Женский 7000 62000
Итак, с СТРОКАМИ МЕЖДУ НЕОГРАНИЧЕННОЙ ПРЕДЫДУЩЕЙ И ТЕКУЩЕЙ СТРОКАМИ Разница заключается в том, что элементы с одинаковым значением вместо группировки их вместе. Он вычисляет СУММУ от начальной строки к текущей строке и не обрабатывает элементы с одинаковым значением по-разному, как ДИАПАЗОН
Он вычисляет СУММУ от начальной строки к текущей строке и не обрабатывает элементы с одинаковым значением по-разному, как ДИАПАЗОН
Выберите *,СУММ(зарплата) Сверх(упорядочить по зарплате) как sum_sal от сотрудников Идентификатор Имя Пол Зарплата sum_sal ------------------------- --------------------------------------- ----------- ---------- ----------- ----------- 6 Арадхья Женский 3500 3500 5 Сара Женщина 4000 7500 2 Джон Мале 4500 12000 3 Паван Мужской 5000 32000 1 марка Мужской 5000 32000 8 Мария Женский 5000 32000 12 Рон Мале 5000 32000 11 Том Мале 5500 48500 7 Том Мужской 5500 48500 4 Па, Женский 5500 48500 9Бен Мале 6500 55000 10 Джоди Женский 7000 62000
Эти результаты такие же, как
Выберите *, СУММА (зарплата) Больше (порядок по зарплате ДИАПАЗОН МЕЖДУ НЕОГРАНИЧЕННОЙ ПРЕДЫДУЩЕЙ И ТЕКУЩЕЙ СТРОКАМИ) как sum_sal от сотрудников
Это потому, что Over(порядок по зарплате) — это просто сокращение от Over(порядок по зарплате ДИАПАЗОН МЕЖДУ НЕОГРАНИЧЕННЫМ ПРЕДЫДУЩИМ И ТЕКУЩИМ РЯДОМ)
Таким образом, везде, где мы просто указываем Order by без ROWS или RANGE , по умолчанию используется RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW .
Примечание. Это применимо только к функциям, которые фактически принимают RANGE/ROW. Например, ROW_NUMBER и несколько других не принимают RANGE/ROW, и в этом случае это не входит в картину.
До сих пор мы видели, что предложение Over с порядком принимает Range/ROWS и синтаксис выглядит примерно так ДИАПАЗОН МЕЖДУ НЕОГРАНИЧЕННЫМ ПРЕДЫДУЩИМ И ТЕКУЩИМ РЯДОМ
И он фактически вычисляет текущую строку из первой строки. Но что, если он хочет вычислить значения для всего раздела данных и иметь их для каждого столбца (то есть от 1-й строки до последней строки). Вот запрос для этого
Выберите *, сумма (зарплата) Больше (упорядочение по зарплате РЯДЫ МЕЖДУ НЕОГРАНИЧЕННЫМИ ПРЕДЫДУЩИМИ И НЕОГРАНИЧЕННЫМИ СЛЕДУЮЩИМИ) как sum_sal от сотрудников Идентификатор Имя Пол Зарплата sum_sal ------------------------- --------------------------------------- ----------- ---------- ----------- ----------- 1 марка Мужской 5000 62000 2 Джон Мале 4500 62000 3 Паван Мужской 5000 62000 4 Па, Женский 5500 62000 5 Сара Женщина 4000 62000 6 Арадхья Женский 3500 62000 7 Том Мужской 5500 62000 8 Мария Женский 5000 62000 9Бен Мале 6500 62000 10 Джоди Женский 7000 62000 11 Том Мале 5500 62000 12 Рон Мале 5000 62000
Вместо CURRENT ROW я указываю UNBOUNDED FOLLOWING , что дает указание движку вычислять до последней записи раздела для каждой строки.
Теперь поговорим о том, что такое OVER() с пустыми фигурными скобками?
Это просто короткий путь для Over(порядок по зарплате РЯДЫ МЕЖДУ НЕОГРАНИЧЕННЫМИ ПРЕДЫДУЩИМИ И НЕОГРАНИЧЕННЫМИ СЛЕДУЮЩИМИ)
Здесь мы косвенно указываем, что весь мой набор результатов следует рассматривать как один раздел, а затем выполнять вычисления от первой записи до последняя запись каждого раздела.
Выберите *,Sum(salary) Over() как sum_sal от сотрудников Идентификатор Имя Пол Зарплата sum_sal ------------------------- --------------------------------------- ----------- ---------- ----------- ----------- 1 марка Мужской 5000 62000 2 Джон Мале 4500 62000 3 Паван Мужской 5000 62000 4 Па, Женский 5500 62000 5 Сара Женщина 4000 62000 6 Арадхья Женский 3500 62000 7 Том Мужской 5500 62000 8 Мария Женский 5000 62000 9Бен Мале 6500 62000 10 Джоди Женский 7000 62000 11 Том Мале 5500 62000 12 Рон Мале 5000 62000
Я создал видео об этом, и если вам интересно, вы можете посмотреть его.
https://www.youtube.com/watch?v=CvVenuVUqto&t=1177s
Спасибо,
Паван Кумар Арьясомаяджулу
HTTP://xyzcoder.github.io
sql — Получить верхнюю 1 строку каждой группы
Проверка отличного и правильного ответа Клинта сверху:
Интересна производительность между двумя приведенными ниже запросами. 52% — это верхний. И 48% — второй. Повышение производительности на 4% при использовании DISTINCT вместо ORDER BY. Но ORDER BY имеет преимущество в сортировке по нескольким столбцам.
ЕСЛИ (OBJECT_ID('tempdb..#DocumentStatusLogs') НЕ NULL) BEGIN DROP TABLE #DocumentStatusLogs END
CREATE TABLE #DocumentStatusLogs (
[ID] int NOT NULL,
[ID документа] int NOT NULL,
[Статус] varchar(20),
[дата создания] дата и время
)
ВСТАВЬТЕ В #DocumentStatusLogs([ID], [ID документа], [Статус], [Дата создания]) ЗНАЧЕНИЯ (2, 1, 'S1', '7/29/2011 1:00:00')
ВСТАВЬТЕ В #DocumentStatusLogs([ID], [DocumentID], [Status], [DateCreated]) VALUES (3, 1, 'S2', '30.07.2011 2:00:00')
ВСТАВЬТЕ В #DocumentStatusLogs([ID], [DocumentID], [Status], [DateCreated]) VALUES (6, 1, 'S1', '02. 08.2011 3:00:00')
ВСТАВИТЬ В #DocumentStatusLogs([ID], [DocumentID], [Status], [DateCreated]) VALUES (1, 2, 'S1', '28.07.2011 4:00:00')
ВСТАВИТЬ В #DocumentStatusLogs([ID], [DocumentID], [Status], [DateCreated]) VALUES (4, 2, 'S2', '30.07.2011 5:00:00')
ВСТАВИТЬ В #DocumentStatusLogs([ID], [DocumentID], [Status], [DateCreated]) VALUES (5, 2, 'S3', '01.08.2011 6:00:00')
ВСТАВИТЬ В #DocumentStatusLogs([ID], [DocumentID], [Status], [DateCreated]) VALUES (6, 3, 'S1', '02.08.2011 7:00:00')
Вариант 1:
ВЫБОР
[Экстент1].[ID],
[Extent1].[ID документа],
[Экстент1].[Статус],
[Экстент1].[Дата Создания]
ОТ #DocumentStatusLogs AS [Extent1]
НАРУЖНОЕ ПРИМЕНЕНИЕ (
ВЫБЕРИТЕ ТОП 1
[Экстент2].[ID],
[Extent2].[ID документа],
[Экстент2].[Статус],
[Экстент2].[Дата Создания]
ОТ #DocumentStatusLogs AS [Extent2]
ГДЕ [Extent1].[ID документа] = [Extent2].[ID документа]
ORDER BY [Extent2].[DateCreated] DESC, [Extent2]. [ID] DESC
) КАК [Проект2]
ГДЕ ([Project2].[ID] IS NULL OR [Project2].[ID] = [Extent1].[ID])
 [ID] DESC
) КАК [Проект2]
ГДЕ ([Project2].[ID] IS NULL OR [Project2].[ID] = [Extent1].[ID])
[ID] DESC
) КАК [Проект2]
ГДЕ ([Project2].[ID] IS NULL OR [Project2].[ID] = [Extent1].[ID])
Вариант 2:
ВЫБОР
[Limit1].[ID документа] AS [ID],
[Limit1].[ID документа] AS [ID документа],
[Ограничение1].[Статус] AS [Статус],
[Limit1].[DateCreated] AS [DateCreated]
ИЗ (
SELECT DISTINCT [Extent1].[ID документа] AS [ID документа] FROM #DocumentStatusLogs AS [Extent1]
) КАК [Отличительно1]
НАРУЖНОЕ ПРИМЕНЕНИЕ (
SELECT TOP (1) [Project2].[ID] AS [ID], [Project2].[DocumentID] AS [DocumentID], [Project2].[Status] AS [Status], [Project2].[DateCreated] AS [ Дата создания]
ИЗ (
ВЫБРАТЬ
[Extent2].[ID] AS [ID],
[Extent2].[ID документа] AS [ID документа],
[Extent2].[Статус] AS [Статус],
[Extent2].[DateCreated] AS [DateCreated]
ОТ #DocumentStatusLogs AS [Extent2]
ГДЕ [Distinct1].[ID документа] = [Extent2].[ID документа]
) КАК [Проект2]
ЗАКАЗАТЬ ПО [Проект2]. [ID] DESC
) КАК [Предел1]
 [ID] DESC
) КАК [Предел1]
[ID] DESC
) КАК [Предел1]
В Microsoft SQL Server Management Studio: после выделения и запуска первого блока выделите вариант 1 и вариант 2, щелкните правой кнопкой мыши -> [Отобразить предполагаемый план выполнения]. Затем запустите все это, чтобы увидеть результаты.
Вариант 1 Результаты:
ID DocumentID Status DateCreated 6 1 С1 02.08.11 3:00 5 2 С3 01.08.11 6:00 6 3 С1 02.08.11 7:00
Вариант 2 Результаты:
ID DocumentID Status DateCreated 6 1 С1 02.08.11 3:00 5 2 С3 01.08.11 6:00 6 3 С1 02.08.11 7:00
Примечание:
Обычно я использую APPLY, когда хочу, чтобы соединение было 1-к-(1 из многих).
Я использую JOIN, если хочу, чтобы соединение было 1-ко-многим или многие-ко-многим.
Я избегаю CTE с ROW_NUMBER(), если только мне не нужно сделать что-то сложное, и меня устраивает снижение производительности окон.
Я также избегаю подзапросов EXISTS / IN в предложениях WHERE или ON, так как это приводило к ужасным планам выполнения.