Ms sql примеры join: MS SQL Server и T-SQL
Содержание
JOIN без ON
← →
И. Павел ©
(2011-10-28 12:04)
[0]
Здравствуйте.
Насколько допутимой и рекомендуемой является в MS SQL SERVER конструкция:
FROM tab1 AS t1
LEFT JOIN tab2 AS t2 ON 1=1
LEFT JOIN tab3 AS t3 ON t3.id = …
Т.е. я просто хочу «умножить» две таблицы: t1 и t2. Можно перечислить их через запятую в предложении FROM, но такая конструкция считается устаревшей, да и придется тогда писать вложенный запрос внутри FROM — а это выглядит не так красиво. Но смущает то, что в JOIN обязательно должен быть блок ON, т.е. в синтаксисе не предусмотрено использовать JOIN вхолостую.
Заранее спасибо.
← →
han_malign
(2011-10-28 12:09)
[1]
> в синтаксисе не предусмотрено использовать JOIN вхолостую.
— предусмотрено — используются все поля с одинаковым именем(/форматом). ..
..
> «умножить» две таблицы: t1 и t2.
— CROSS JOIN
← →
vuk ©
(2011-10-28 12:11)
[2]
select
…
from
Table1 t1 cross join
Table2 t2
← →
И. Павел ©
(2011-10-28 12:23)
[3]
han_malign, vuk ©, большое спасибо!
← →
Омлет ©
(2011-10-28 12:41)
[4]
select * from Table1 t1, Table2 t2;
← →
И. Павел ©
(2011-10-28 12:57)
[5]
> [4] Омлет © (28.10.11 12:41)
Спасибо, это тоже вариант.
← →
Труп Васи Доброго ©
(2011-10-28 14:57)
[6]
> Спасибо, это тоже вариант.
Это не «вариант», только Омлет предложил именно умножение независимое от варианта SQL и СУБД
← →
Компромисс
(2011-10-28 17:11)
[7]
Почему CROSS, а не FULL?
← →
И. Павел ©
(2011-10-31 07:03)
[8]
> [7] Компромисс (28.10.11 17:11)
> Почему CROSS, а не FULL?
Насколько я понял из справки — full join возхвращает не только inner (что мне нужно) но и по одной записи от каждой таблицы, для которой не нашлось аналога в другой. Т.е. это смешение right+left join. Ну и еще для full join нужно указывать условие.
Вот цитата из википедии:
«FULL OUTER JOIN
К левой таблице присоединяются все записи из правой, соответствующие условию (по правилам inner join), плюс все не вошедшие записи из правой таблицы, поля левой таблицы заполняются значениями NULL и плюс все не вошедшие записи из левой таблицы, поля правой таблицы заполняются значениями NULL»
← →
Anatoly Podgoretsky ©
(2011-10-31 08:51)
[9]
> И.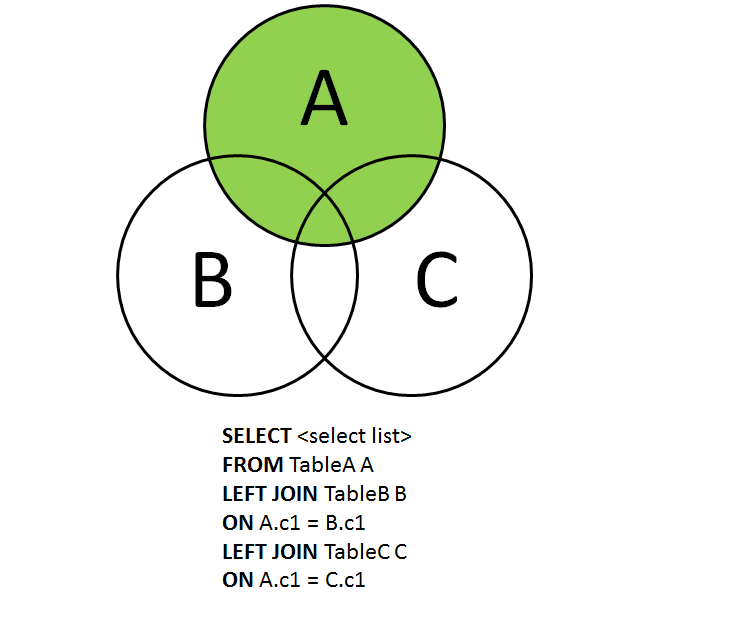 Павел (31.10.2011 07:03:08) [8]
Павел (31.10.2011 07:03:08) [8]
А вот из авторитетного источника
FULL OUTER JOIN, which includes all rows from both tables, regardless of
whether or not the other table has a matching value.
И вот оттуда же, но на русском
Логический оператор Full Outer Join возвращает каждую строку,
удовлетворяющую предикату объединения из первого (верхнего) входа и
объединенную с каждой строкой из второго (нижнего) входа. Он также
возвращает строки из:
a.. первого входа, не имеющего соответствий во втором входе;
b.. второго входа, не имеющего соответствий в первом входе.
Вход, не содержащий совпадающих значений, возвращается как значение NULL.
Full Outer Join является логическим оператором.
И никакого требования указания условия. Ты поосторожнее с этой дурипедией
Основы SQL – DML – SELECT – Часть II
В прошлый раз в этой серии статей я рассказал об операторе “SELECT” в самом простом его проявлении – запросы к одной таблице, без сложных фильтров. Теперь я расскажу о более интересной, но сложной теме – многотабличных запросах.
Теперь я расскажу о более интересной, но сложной теме – многотабличных запросах.
Также, в завершении статьи, я дам несколько полезных рекомендаций, предотвращающих превращение поддержки многотабличных запросов в постоянную головную боль.
Многотабличные запросы без JOIN
Хотя в более ранних версиях Microsoft SQL Server многотабличные запросы без “JOIN” были более распространены, теперь они используются все реже и реже. И это, с моей точки зрения, правильно. Использование “JOIN” приводит, как минимум, к более структурированному и читаемому коду (что мы увидим чуть позже), а на символах в исходном коде я никогда не экономил 🙂
Самый простой вариант многотабличного запроса – это двухтабличные запрос без условия соединения таблиц или декартово произведение таблиц. И это, пожалуй, единственный вариант, когда от отсутствия “JOIN” не страдает наглядность:
SELECT * FROM Persons, Phones
В данном случае, если взять количество строк в “Persons” равным N, а в “Phones” – равным M, то мы получим N*M строк, составленных из всевозможных комбинаций строк двух исходных таблиц. То есть, если вам пришлось бы произвести эту операцию вручную на листке бумаги, то пришлось бы нарисовать таблицу, у которой были бы все столбцы из “Persons”, а затем все столбцы из “Phones”. Затем потребовалось бы записать первую строку из “Persons” и добавить справа первую строку из “Phones”. Потом первую из “Persons” и вторую из “Phones” и так далее.
То есть, если вам пришлось бы произвести эту операцию вручную на листке бумаги, то пришлось бы нарисовать таблицу, у которой были бы все столбцы из “Persons”, а затем все столбцы из “Phones”. Затем потребовалось бы записать первую строку из “Persons” и добавить справа первую строку из “Phones”. Потом первую из “Persons” и вторую из “Phones” и так далее.
Конечно же, практической пользы от такого запроса немного. Скажу по секрету, в большинстве случаев, подобные “безусловные” запросы с декартовым произведением таблиц являются либо тестовыми, либо просто ошибочными (забыли добавить условие). На всякий случай уточню, что “в большинстве случаев” != “всегда”, вполне возможно, есть специфические приложения, где подобные запросы составляют значительную часть.
Теперь посмотрим на более осмысленный вариант предыдущего запроса – выведем все телефоны вместе с фамилиями и идентификаторами абонентов:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a, Phones t
WHERE a.PersonID = t.PersonID
 PersonID = t.PersonID
PersonID = t.PersonIDТакой запрос выведет M строк (все строки таблицы “Phones”), поскольку для одной строке таблицы “Persons” может соответствовать много строк таблицы “Phones”, но не наоборот. Также нужно отметить, что в результате мы получим только те строки таблицы “Persons”, для которых есть строки в таблице “Phones” (обратное условие обеспечивается внешним ключом, который мы создали ранее).
Обратите внимание – для таблиц используются псевдонимы (“a” и “t”), чтобы удобнее было указывать полное имя столбца. Полное имя столбца требуется указывать в тех случаях, когда в разных таблицах есть столбцы с одинаковыми названиями. В нашем случае это только “PersonID”, но для единообразия я добавил префиксы и для других столбцов. Помимо указания имен столбцов, псевдонимы имеет смысл задавать для более компактной записи запроса (в тех случаях, когда мы набираем его руками).
Для того, чтобы получить, в том числе, и те строки из “Persons”, идентификаторы которых отсутствуют в “Phones”, в ранних версиях Transact-SQL можно было использовать следующий синтаксис (в скрипте ниже также добавляется новая строка и меняется compatibility level, с учетом того, что запускаем скрипт на Microsoft SQL Server 2008):
IF NOT EXISTS(SELECT * FROM Persons
WHERE FirstName = 'Олег' AND LastName ='Аксенов')
INSERT Persons (FirstName, LastName) VALUES('Олег', 'Аксенов')
ALTER DATABASE FirstTest SET COMPATIBILITY_LEVEL = 80
GO
SELECT a.
FROM Persons a, Phones t
WHERE a.PersonID *= t.PersonID ALTER DATABASE FirstTest SET COMPATIBILITY_LEVEL = 100
 PersonID, a.LastName, t.Phone
PersonID, a.LastName, t.PhoneИменно такой синтаксис мне, в свое время, очень не нравился еще в MS SQL 6.5 из-за плохой наглядности (граничащей с отвратительной, когда таблиц становилось много и добавлялись дополнительные условия в WHERE). Спустя несколько лет я выпилил все подобные запросы, переписав их с помощью “JOIN”. К счастью, начиная с Microsoft SQL Server 2005 подобный синтаксис считается устаревшим и при его использовании возникает соответствующая ошибка.
И, в завершении разговора об устаревшем синтаксисе, добавлю, что никто не мешает добавить фильтрацию по каким-либо столбцам используемых таблиц:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a, Phones t
WHERE a.PersonID = t.PersonID AND t.Phone LIKE '101%'
Многотабличные запросы (JOIN)
После небольшого экскурса в историю пришло время разобраться с многотабличным запросами, использующими соединение таблиц (“JOIN”).
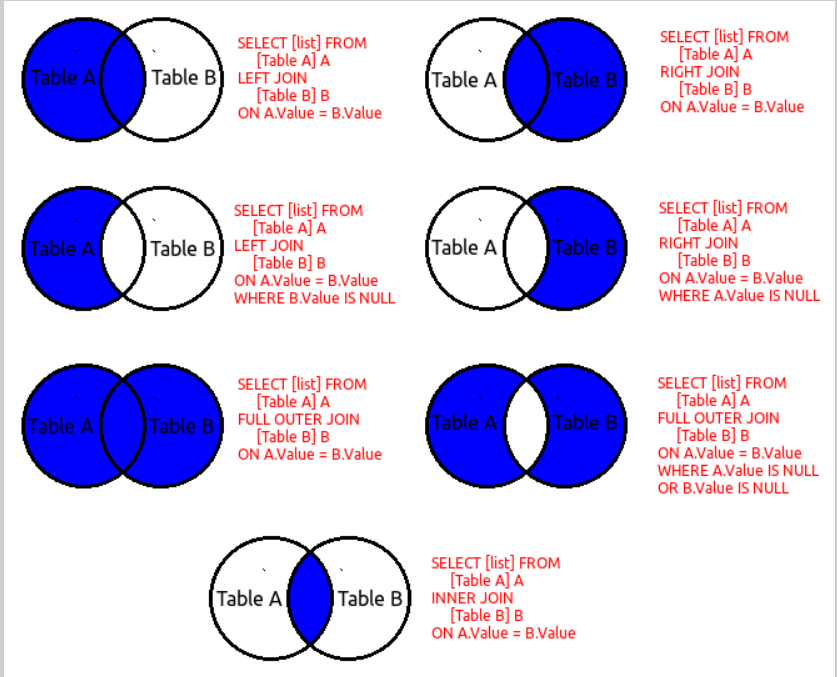
На мой взгляд, проще всего, для начала, посмотреть на аналоги запросов из предыдущей главы. Сразу отмечу, что префикс “INNER” (подразумевающий наличие соответствующих строк с обеих сторон соединения) используется в Transact-SQL по умолчанию и его можно не указывать.
Так мы получаем декартово произведение:
SELECT * FROM Persons CROSS JOIN Phones
Обратите внимание – использование “CROSS JOIN” предпочтительнее, чем использование обычного соединения с заведомо верным условием (например 1=1) хотя бы потому, что не оставляет сомнений в намерениях автора кода, в отличие от такого варианта:
SELECT * FROM Persons JOIN Phones ON 1=1
Вот все телефоны вместе с фамилиями и идентификаторами абонентов:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a JOIN Phones t ON a.PersonID = t.PersonID
А это запрос с учетом отсутствия телефона:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a LEFT JOIN Phones t ON a.
 PersonID = t.PersonID
PersonID = t.PersonIDНо основное преимущество заметно тогда, когда есть фильтры помимо условий соединения:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a JOIN Phones t ON a.PersonID = t.PersonID
WHERE t.Phone LIKE '101%'
В этом примере мы отчетливо видим, что соединение таблиц происходит по идентификатору и есть дополнительное условие для отбора только определенных номеров телефона.
Для того, чтобы предыдущий запрос вывел всех лиц, независимо от наличия телефона, можно воспользоваться “LEFT JOIN”. Только нужно учесть, что у нас есть фильтр в “WHERE” по необязательной в данном случае таблице “Phones”. Для того, чтобы он не отфильтровал результаты, убрав лиц без телефона, необходимо перенести условие в “LEFT JOIN”:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a LEFT JOIN Phones t ON a.PersonID = t.PersonID
AND t.Phone LIKE '101%'
Подробнее о синтаксисе
Теперь постараюсь не слишком формально и доступно рассказать о синтаксисе фразы “JOIN”.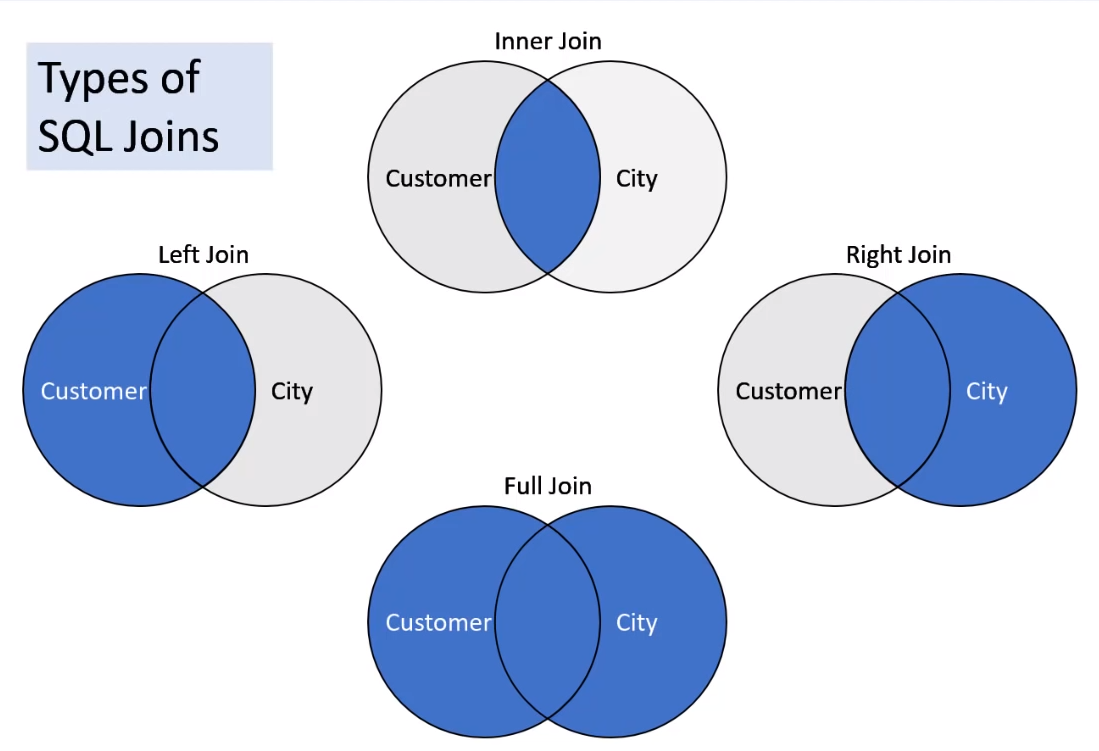 Более подробно ознакомиться с этим синтаксисом можно в статье MSDN о FROM.
Более подробно ознакомиться с этим синтаксисом можно в статье MSDN о FROM.
“CROSS JOIN” как вы знаете, позволяет получить декартово произведение. Можно только добавить, что можно аналогичным образом получить соединение трех и более таблиц, просто добавив еще один “CROSS JOIN”. Также можно “перемножить” таблицу саму на себя, если это требуется.
“INNER JOIN” подразумевает, что условие соединения (часть после “ON”) выполняется всегда (как если оно присутствовало бы в “WHERE”), поэтому, если нет соответствующих строк в одной из таблиц, то в результат не попадает и “одинокая” строка из другой таблицы.
Как я уже говорил ранее, слово “INNER” можно не указывать – вряд ли вы встретите разработчика использующего Transact-SQL, который не знает об этом и по этой причине не сразу поймет такой запрос. А если встретите – объясните ему ситуацию, пожалуйста 😉
“LEFT JOIN”, в отличие от “INNER JOIN”, позволяет выводить строки из таблицы слева если нет соответствующих строк справа. Если справа у нас родительская таблица, внешний ключ на которую (например, столбец с идентификатором) не позволяет хранить значения NULL, то использование “LEFT JOIN”, очевидно, не имеет смысла. Смысл есть, когда ссылка не может быть NULL или когда родительская таблица находится слева, а дочерняя – справа. Также есть менее распространенный вариант, когда соединение происходит не по внешним ключам.
Если справа у нас родительская таблица, внешний ключ на которую (например, столбец с идентификатором) не позволяет хранить значения NULL, то использование “LEFT JOIN”, очевидно, не имеет смысла. Смысл есть, когда ссылка не может быть NULL или когда родительская таблица находится слева, а дочерняя – справа. Также есть менее распространенный вариант, когда соединение происходит не по внешним ключам.
Обратите внимание – я сознательно не рассматриваю “RIGHT JOIN”, хотя он поддерживается Transact-SQL и аналогичен “LEFT JOIN”, только в этом случае выводятся строки из таблицы справа, если нет строк слева. Причина в том, что смешивание “RIGHT JOIN” и “LEFT JOIN” очень отрицательно сказывается на понимании запроса. И я рекомендую не только не использовать их в рамках одного запроса, но и вообще всегда использовать только один вариант. И лучше, чтобы вся ваша команда разделяла выбранный подход.
“FULL JOIN” я ранее не упоминал – он совмещает “LEFT” и “RIGHT”, то есть соответствующие строки могут отсутствовать и слева и справа. Используется не очень часто, но знать о нем полезно, чтобы не ломать голову над решением проблемы, которую он решит запросто.
Используется не очень часто, но знать о нем полезно, чтобы не ломать голову над решением проблемы, которую он решит запросто.
Подзапросы
Подзапросы, по крайней мере, в моем понимании этого слова, делятся на подзапросы внутри списка столбцов (select list) и подзапросы внутри списка таблиц (from).
Для демонстрации возможностей первого типа подзапросов, можно переделать последний запрос (возвращающий всех лиц и показывающий их телефоны, если они содержат “101”) следующим образом:
SELECT a.PersonID, a.LastName, (SELECT t.Phone
FROM Phones t WHERE a.PersonID = t.PersonID
AND t.Phone LIKE '101%') AS Phone
FROM Persons a
Если вы использовали скрипт для заполнения данных из предыдущих статей, у вас оба запроса выведут одинаковые результаты. Однако, внимательный читатель наверняка обратил внимание на то, что запросы не эквивалентны.
Этот запрос, в отличие от предыдущего, будет работать только тогда, когда подзапрос для каждой строки будет возвращать не более одной строки. В противном случае мы получим ошибку при выполнении запроса. Поэтому, в тех случаях, когда подзапрос может вернуть больше одной строки, но его необходимо использовать, к подзапросу добавляют ограничение “TOP 1”.
В противном случае мы получим ошибку при выполнении запроса. Поэтому, в тех случаях, когда подзапрос может вернуть больше одной строки, но его необходимо использовать, к подзапросу добавляют ограничение “TOP 1”.
Второй тип подзапросов позволяет представить результат подзапроса в виде некоей виртуальной таблицы, которую можно использовать во FROM. Правда, на такой подзапрос накладывается ряд ограничений, в частности, у всех столбцов должны быть уникальные названия. Напишем тот же запрос (на этот раз, эквивалентный исходному) с помощью подзапроса:
SELECT a.PersonID, a.LastName, t.Phone
FROM Persons a LEFT JOIN (
SELECT PersonID, Phone
FROM Phones WHERE Phone LIKE '101%') t
ON a.PersonID = t.PersonID
В данном случае назначение подзапроса не очень очевидно, однако подобные подзапросы очень упрощают жизнь, когда необходимо произвести несколько промежуточных вычислений, в частности – группировок. Пример такого запроса в следующей главе.
Пример нетривиального запроса
После всего, что я рассказал, захотелось привести пример, который демонстрировал бы большинство элементов оператора SELECT. Для разнообразия буду использовать системные таблицы, содержащие метаданные о таблицах и столбцах.
Для разнообразия буду использовать системные таблицы, содержащие метаданные о таблицах и столбцах.
Сформулируем задачу следующим образом – получить список первых 10 по количеству столбцов системных таблиц, с названием первого столбца и количества столбцов для каждой. Эту задачу решает (надо отметить, что, как это часто бывает с SQL, решение не единственное) следующий запрос:
SELECT TOP 10 o.name, c.name as firstColumn,
t.columnCount
FROM sys.objects o
JOIN (
SELECT c.object_id, MIN(c.column_id) AS column_id,
COUNT(*) AS columnCount
FROM sys.columns c
GROUP BY c.object_id
) t ON o.object_id = t.object_id
JOIN sys.columns c ON o.object_id = c.object_id
AND c.column_id = t.column_id
WHERE o.type = 'S'
ORDER BY columnCount DESC
Думаю, большая часть запроса для вас очевидна, поясню только смысл последнего JOIN. В подзапросе мы нашли минимальный идентификатор, но мы хотим вывести название столбца, и только ради этого мы присоединяем таблицу “sys.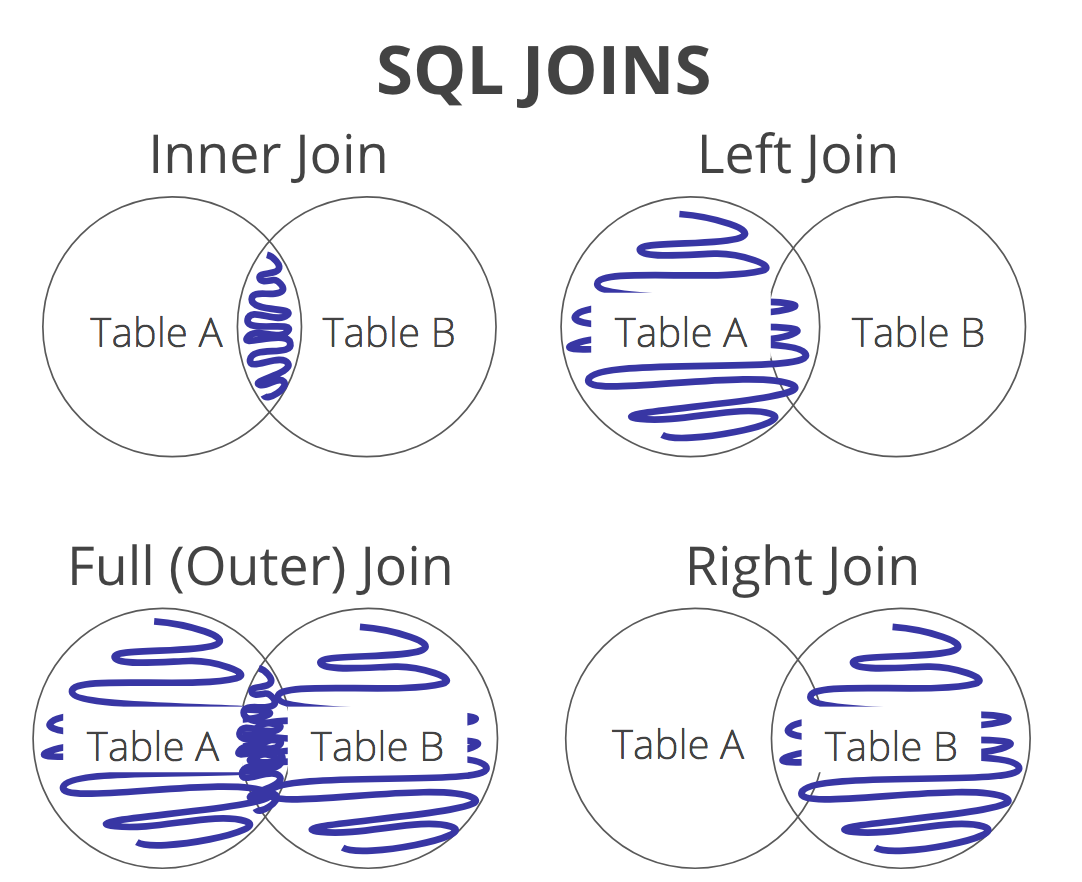 columns”, чтобы взять у нее, в итоге “firstColumn”.
columns”, чтобы взять у нее, в итоге “firstColumn”.
Кстати, не стоит рассчитывать на то, что приведенный здесь запрос сложный. Если вы будете активно работать с SQL напрямую, вероятно, вам понадобится реализовывать запросы на порядок более сложные. Если позволят обстоятельства и будет интерес у читателей, я сделаю серию статей с более сложными конструкциями SQL.
Рекомендации для многотабличных запросов
- Повторюсь, очень важно стараться использовать только один тип “OUTER JOIN”, в моем случае, это LEFT, просто потому что для меня (кстати, как и для моих коллег по работе) он выглядит более удобным и логичным.
- При чередовании INNER и LEFT JOIN во FROM иногда используются круглые скобки, однако я предпочитаю сначала написать все “INNER JOIN”, а потом все “LEFT JOIN”. Запрос получается, на мой взгляд, более читаемым и его проще дорабатывать. Только в том случае, когда это невозможно, я использую круглые скобки. Если же смешивать INNER и LEFT JOIN без скобок, в получившемся запросе часто бывает достаточно трудно разобраться.
- Если вам кажется, что в запросе используется слишком много таблиц и/или он возвращает слишком много лишних данных не бойтесь разбить его на несколько. Попытка сделать все “одним запросом” похвальна, но только тогда, когда это не ухудшает производительность.
- В продолжении предыдущего совета – не тащите много лишних данных из базы. Помните, вместо закачки тысячи ненужных строк есть альтернатива с paging/TOP; вместо получения десятков лишних столбцов из-за “*” есть альтернатива указать необходимые столбцы вручную и т.п. Не стоит, конечно, бросаться в крайности – если, скажем, одно и то же ФИО в результате JOIN’а дублируется десяток-другой раз, а получаем в результате сотню строк – это не страшно, скорее всего 🙂
Анонс
В следующей части рассказа об операторе “SELECT” я продолжу рассказ о многотабличных запросах прежде всего с точки зрения группировок данных.
Если у вас есть пожелания или новые темы – пишите в комментариях или на olegaxenow. reformal.ru. Постараюсь учесть.
reformal.ru. Постараюсь учесть.
SQL JOINS и Псевдонимы. Привет всем, в этом обзоре я… | от João Marçura
5 минут чтения
·
9 марта 2020 г.
Привет всем, в этом обзоре я покажу вам предложение JOIN.
С помощью объединений можно извлекать данные из двух или более таблиц на основе логических связей между таблицами. Соединения указывают, как SQL Server должен использовать данные из одной таблицы для выбора строк в другой таблице.
Различные типы соединений:
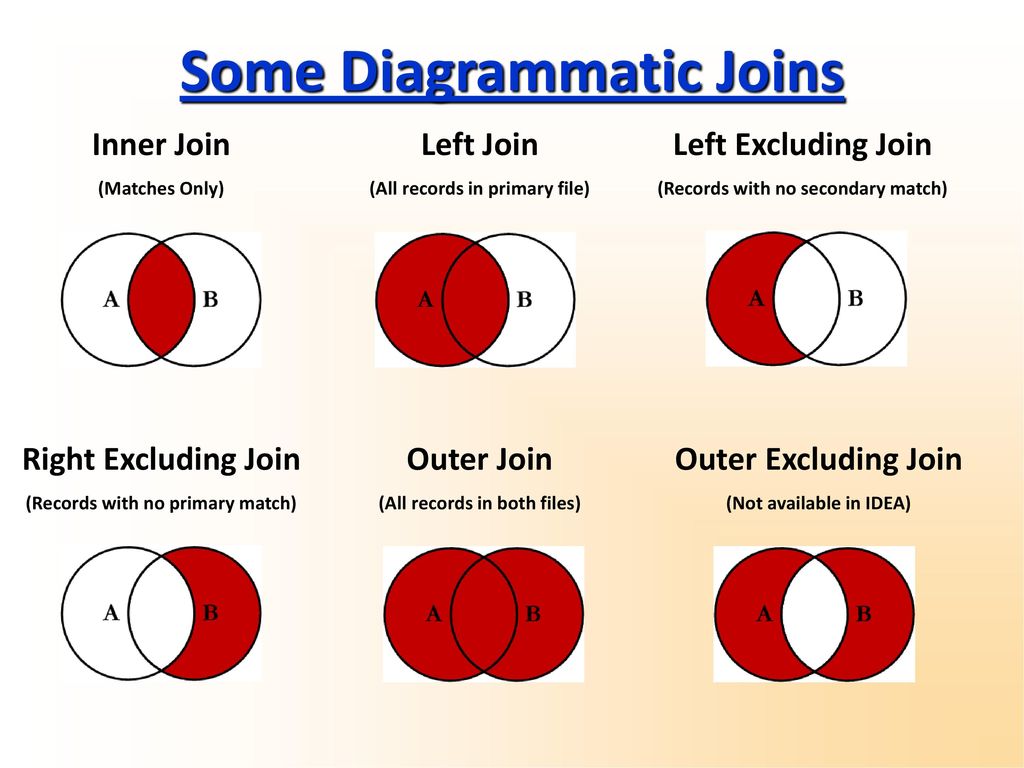
1. ВНУТРЕННЕЕ СОЕДИНЕНИЕ
2. ЛЕВОЕ СОЕДИНЕНИЕ
3. ПРАВОЕ СОЕДИНЕНИЕ 9 0016
4. ПОЛНОЕ СОЕДИНЕНИЕ
5. ДЕРКОВОЕ/ПОПЕРЕЧНОЕ СОЕДИНЕНИЕ
Прежде всего, нам нужны наши данные.
Я выберу 2 таблицы из GeeksforGeeks org, [Student] и [StudentCourse] таблиц.
Студент
Студент Курс
Псевдонимы SQL используются для присвоения таблице или столбцу в таблице временного имени.
Псевдоним существует только на время запроса и часто используется, чтобы сделать имена столбцов или таблиц более читабельными.
Далее мы дадим псевдонимы обеим таблицам [Student] и [StudentCourse].
Условие соединения определяет, как две таблицы связаны в запросе:
Указание столбца из каждой таблицы, который будет использоваться для соединения. Типичное условие соединения указывает внешний ключ из одной таблицы и связанный с ним ключ в другой таблице, в нашем примере я буду использовать « ROLL_NO » в качестве ключей в обеих таблицах.
Указание логического оператора (например, = или <>), который будет использоваться при сравнении значений из столбцов.
Результатом является таблица с объединенной информацией.
1. INNER JOIN
Inner Join
Только ключ совпадает между таблицами, строки, которые не совпадают, игнорируются.
Итак, мы присоединяемся к идентификатору курса из таблицы StudentCourse с name и age из таблицы Student, используя ROLL_NO в качестве ключа .
Пример:
SELECT StudentCourse.COURSE_ID, Student.NAME, Student.AGEFROM StudentINNER JOIN StudentCourseON Student.ROLL_NO = StudentCourse.ROLL_NO;
Использование псевдонимов
SELECT stdCrse.COURSE_ID, std.NAME, std.AGEFROM Student std --ALIASINNER JOIN StudentCourse stdCrse --ALIASON std.ROLL_NO = stdCrse.ROLL_NO;
Выход
Student INNER JOIN StudentCourse
2. LEFT JOIN
Это объединение возвращает все строк таблицы в левой части объединения и совпадающие строки для таблицы в правой части объединения. Строки, для которых нет соответствующей строки справа, набор результатов будет содержать null . LEFT JOIN также известен как LEFT OUTER JOIN .
LEFT JOIN также известен как LEFT OUTER JOIN .
Пример:
SELECT Student.NAME,StudentCourse.COURSE_IDFROM StudentLEFT JOIN StudentCourseON StudentCourse.ROLL_NO = Student.ROLL_NO;
Использование псевдонимов
SELECT std.NAME, stdCrse.COURSE_IDFROM Student stdLEFT JOIN StudentCourse stdCrseON stdCrse.ROLL_NO = std.ROLL_NO;
Вывод
Студент ЛЕВОЕ СОЕДИНЕНИЕ StudentCourse
3. ПРАВОЕ СОЕДИНЕНИЕ
ПРАВОЕ СОЕДИНЕНИЕ аналогично ЛЕВОМУ СОЕДИНЕНИЮ. Это объединение возвращает все строки таблицы с правой стороны объединения и совпадающие строки для таблицы с левой стороны объединения. Строки, для которых нет соответствующей строки слева, результирующий набор будет содержать ноль .
Пример:
SELECT Student.NAME,StudentCourse.COURSE_IDFROM StudentRIGHT JOIN StudentCourseON StudentCourse.ROLL_NO = Student.
 ROLL_NO;
ROLL_NO; Использование псевдонимов
SELECT std.NAME, stdCrse.COURSE_IDFROM Student stdRIGHT JOIN StudentCourse stdCrseON stdCrse.ROLL_NO = std.ROLL_NO;
Результат
Студент RIGHT JOIN StudentCourse
4. ПОЛНОЕ СОЕДИНЕНИЕ
ПОЛНОЕ СОЕДИНЕНИЕ создает результирующий набор, комбинируя результаты как левого, так и правого соединения. Набор результатов будет содержать все строки из обеих таблиц. Строки, для которых нет соответствия, результирующий набор будет содержать NULL
Пример:
SELECT Student.NAME,StudentCourse.COURSE_IDFROM StudentFULL JOIN StudentCourseON StudentCourse.ROLL_NO = Student.ROLL_NO;
Использование псевдонимов
SELECT std.NAME, stdCrse.COURSE_IDFROM Student stdFULL JOIN StudentCourse stdCrseON stdCrse.ROLL_NO = std.ROLL_NO;
Выходные данные
Студент ПОЛНОЕ СОЕДИНЕНИЕ StudentCourse
5. ДЕРКОВО/КРЕСТНОЕ СОЕДИНЕНИЕ
ДЕРКОВО/КРЕСТНОЕ СОЕДИНЕНИЕ
ДЕРКОВОЕ СОЕДИНЕНИЕ также известно как ПОПЕРЕЧНОЕ СОЕДИНЕНИЕ. В CARTESIAN JOIN есть соединение каждой строки одной таблицы с каждой строкой другой таблицы. Обычно это происходит, когда соответствующий столбец или условие WHERE не указаны.
При отсутствии условия WHERE CARTESIAN JOIN будет вести себя как CARTESIAN PRODUCT . т. е. количество строк в результирующем наборе является произведением количества строк в двух таблицах.
- В отсутствие условия WHERE CARTESIAN JOIN будет вести себя как CARTESIAN PRODUCT . т. е. количество строк в результирующем наборе является произведением количества строк в двух таблицах.
- При наличии условия WHERE это СОЕДИНЕНИЕ будет функционировать как ВНУТРЕННЕЕ СОЕДИНЕНИЕ.
- Вообще говоря, перекрестное соединение похоже на внутреннее соединение, где условие соединения всегда оценивается как True
Пример:
SELECT Student.
 NAME, Student.AGE, StudentCourse.COURSE_IDFROM StudentCROSS JOIN StudentCourse;
NAME, Student.AGE, StudentCourse.COURSE_IDFROM StudentCROSS JOIN StudentCourse; Использование псевдонимов
SELECT std.NAME, std.AGE, stdCrse.COURSE_IDFROM Student stdCROSS JOIN StudentCourse stdCrse;
Результат
Декартово произведение между Student и StudentCourse
https://www.w3schools.com/sql/sql_join.asp
https://www.geeksforgeeks.org/sql-join-set-1-inner-left-right-and-full-joins/
https://docs.microsoft.com/en-us/sql/relational-databases/performance/joins?view=sql-server-ver15
SQL | Соединение (декартово соединение и самосоединение) — GeeksforGeeks
SQL | JOIN (внутреннее, левое, правое и полное соединение) В этой статье мы обсудим два оставшихся соединения: рассмотрим…
www.geeksforgeeks.org
Объединение нескольких таблиц в SQL
Обзор
Мы используем объединение нескольких таблиц для объединения данных из более чем двух таблиц. Оператор соединения используется несколько раз для объединения нескольких таблиц в SQL, так как для каждой новой таблицы добавляется одно соединение. В SQL объединение нескольких таблиц означает, что вы можете присоединиться к nnn количеству таблиц, но для объединения nnn количества таблиц требуются соединения n-1n-1n-1, то есть для 333 таблиц требуется 222 соединения.
Оператор соединения используется несколько раз для объединения нескольких таблиц в SQL, так как для каждой новой таблицы добавляется одно соединение. В SQL объединение нескольких таблиц означает, что вы можете присоединиться к nnn количеству таблиц, но для объединения nnn количества таблиц требуются соединения n-1n-1n-1, то есть для 333 таблиц требуется 222 соединения.
Введение
Примечание. Прежде чем продолжить, убедитесь, что вы знакомы с SQL Joins. Вы можете обратиться к этой статье по темам Scaler для получения дополнительной информации.
Нам часто нужно получить данные из трех или более таблиц, чтобы получить значимую информацию. Этого можно добиться с помощью объединения нескольких таблиц. Данные могут быть получены с использованием различных типов соединений, таких как INNER JOIN, LEFT JOIN или обоих, в зависимости от различных требований.
Давайте узнаем, как их использовать. Предположим, что в нашей базе данных есть три таблицы Student, Branch и Address .
Таблица учащихся
Таблица учащихся содержит Stud_id в качестве первичного ключа, Name, Br_id в качестве внешнего ключа, относящегося к таблице Branch, Email и City_id в качестве внешнего ключа, относящегося к таблице Address.
| Stud_id | Имя | Br_id | City_id | |
|---|---|---|---|---|
| 1001 | Анкит | 101 | [email protected] | 1 |
| 1002 | Пранав 902 80 | 105 | [email protected] | 2 |
| 1003 | Радж | 102 | raj@bmail. ком | 2 |
| 1004 | Шьям | 112 | [email protected] | 4 |
| 1005 | Герцог | 11 2 | [email protected] | 2 |
| 1006 | Джон | 102 | [email protected] | 3 |
| 1007 | Аман | 101 | aman@bmail. com com | 4 |
| 1008 | Паван | 111 | [email protected] | 13 |
| 1009 | Вират | 112 | [email protected] | 12 |
Вы можете использовать приведенный ниже запрос для создания приведенной выше таблицы.
Запрос:
Таблица филиалов
Таблица филиалов содержит Br_id в качестве первичного ключа, Br_name, HOD и Contact.
| Br_id | Br_name | HOD | Контакт |
|---|---|---|---|
| 101 | CSE | SH Rao | 22345 |
| 102 | MECH | AP Sharma | 28210 |
| 103 | EXTC | ВК Редди | 34152 |
| 104 | ХЕМ | СК Мехта | 45612 |
| 105 | ИТ | ВЛ Шелке | 22521 |
| 106 | АИ | КХ Верма | 12332 |
| 107 | PROD | PG Kakde |
900 03
Вы можете использовать приведенный ниже запрос для создания приведенной выше таблицы.

Таблица адресов
Таблица адресов содержит city_id в качестве первичного ключа, City и Pincode.
| City_id | Город | PIN-код |
|---|---|---|
| 1 | Мумбаи | |
| 2 | Пуна | 450011 |
| 3 | Лакхнау | 553001 | 4 | Дели | 443221 |
| 5 | Калькутта | 213445 |
| Ченнаи | 345432 | |
| 7 | Нагпур | 323451 |
| 8 | Шри Нагар 9 0280 | 321321 |
Вы можете использовать приведенный ниже запрос для создания приведенной выше таблицы.
Соединение нескольких таблиц с помощью INNER JOIN
В SQL внутреннее соединение получает общие строки из всех таблиц, упомянутых в запросе. В нашем случае, если мы видим, что таблица Student и Branch имеет общий Br_id, а таблица Address and Student имеет общий city_id. Итак, чтобы получить данные, сначала нам нужно соединить две таблицы, а затем третью таблицу. Возьмем пример, чтобы было понятнее.
Итак, чтобы получить данные, сначала нам нужно соединить две таблицы, а затем третью таблицу. Возьмем пример, чтобы было понятнее.
Пример: Получите имена учащихся вместе с названиями их отделений, HOD, городом и PIN-кодом.
Запрос:
Вывод:
| Имя | Br_id | HOD | Город | PIN-код |
|---|---|---|---|---|
| 101 | С.Х. Рао | Мумбаи | 400121 | |
| Пранав | 105 | Пуна | 450011 | |
| Радж | 102 | AP Шарма | Пуна | 45001 1 |
| Джон | 102 | А.П. Шарма | Лакхнау | 553001 |
| Аман 902 80 | 101 | SH Рао | Дели | 443221 |
Объяснение:
Таким образом, чтобы получить данные из более чем двух таблиц, нам нужно использовать условие JOIN несколько раз. Первое соединение создает виртуальную таблицу, содержащую данные из первых двух таблиц, а затем к этой виртуальной таблице применяется второе условие JOIN. Здесь мы сначала INNER JOIN две таблицы, Branch и Student , используя Br_id, затем к выходным данным первых двух таблиц добавлено еще одно INNER JOIN с использованием city_id.
Первое соединение создает виртуальную таблицу, содержащую данные из первых двух таблиц, а затем к этой виртуальной таблице применяется второе условие JOIN. Здесь мы сначала INNER JOIN две таблицы, Branch и Student , используя Br_id, затем к выходным данным первых двух таблиц добавлено еще одно INNER JOIN с использованием city_id.
Примечание: Виртуальная таблица — это таблица, которая создается в памяти, когда мы объединяем три таблицы, результат объединения первых двух таблиц сохраняется в виртуальной таблице, а когда применяется второе соединение, он применяется к виртуальный стол.
Соединение нескольких таблиц с помощью левого соединения
Когда мы используем левое соединение для нескольких таблиц, оно будет включать все строки из левой таблицы, то есть таблицы, упомянутой в левой части соединения, и следующие левые соединения будут применяется к результату первого левого соединения.
Давайте рассмотрим пример, чтобы понять это.
Пример : Получить имена всех учеников, даже если они не присутствуют ни в одном городе и филиале.
Запрос:
Вывод:
| Имя | Город | Br_name |
|---|---|---|
| Анкит | Мумбаи | |
| Пранав | Пуна | IT |
| Радж | Пуна | МЕХ |
| Шьям | Дели | НОЛЬ |
| Герцог | Пуна | НУЛЬ |
| Джон | Лакхнау | МЕХ |
| Аман | Дел привет | CSE |
| Паван | NULL | NULL |
| Virat | NULL | NULL |
Объяснение:
В этом запросе первое левое соединение получает все строки с именами студентов из таблицы StudentStudentStudent вместе со всеми Br_name. Если имя не присутствует ни в одной ветке, поле Br_name, которое мы получаем для этого имени, равно NULL. В этой таблице другое левое соединение применяется к таблице AddressAddressAddress, которая сохраняет все Name и Br_name как есть и возвращает все строки из столбца city. Если Name и Br_name отсутствуют в каком-либо городе, поле City, которое мы получаем для этих Name и Br_name, имеет значение Null.
Если имя не присутствует ни в одной ветке, поле Br_name, которое мы получаем для этого имени, равно NULL. В этой таблице другое левое соединение применяется к таблице AddressAddressAddress, которая сохраняет все Name и Br_name как есть и возвращает все строки из столбца city. Если Name и Br_name отсутствуют в каком-либо городе, поле City, которое мы получаем для этих Name и Br_name, имеет значение Null.
Соединение нескольких таблиц с использованием обоих – INNER JOIN и LEFT JOIN
Комбинация внутреннего соединения и левого соединения может использоваться в SQL-запросе, где порядок соединения определяет результат запроса.
Давайте рассмотрим пример, чтобы понять это.
Пример: Получить все имена учеников, даже если они не представлены ни в одном филиале, исключая имя, которого нет ни в одном городе.
Запрос:
Вывод:
| Имя | Город | Br_name |
|---|---|---|
| Анкит | Мумбаи | |
| Пранав | Пуна | IT |
| Радж | Пуна | MECH |
| Шьям | Дели | НУЛЬ |
| Герцог | Пуна | НУЛЬ |
| Джон | Лакхнау | MECH |
| Аман | Дели | CSE |
Объяснение:
В этом запроса сначала возвращаются все имена из таблицы StudentStudentStudent и возвращается Br_name, даже если имя не имеет любое Br_name с помощью левого соединения. В этом результате применяется внутреннее соединение с таблицей AddressAddressAddress, которая исключает имя без города.
В этом результате применяется внутреннее соединение с таблицей AddressAddressAddress, которая исключает имя без города.
Использование отношения «родитель-потомок»
Родитель-потомок устанавливает отношение первичного ключа к внешнему ключу между двумя таблицами. Таблица имеет первичный ключ, указанный как родительский, а таблица с внешним ключом указана как дочерняя. Используя этот метод, вы можете просто объединить несколько таблиц в SQL.
Давайте возьмем тот же пример, что и для внутреннего соединения, и решим его с помощью метода отношений родитель-потомок.
Пример: Получите имена студентов вместе с названием их филиала, их HOD, городом и пин-кодом.
Запрос:
Вывод:
| Имя | Br_id | HOD | Город | PIN-код |
|---|---|---|---|---|
| 101 | SH Рао | Мумбаи | 400121 | |
| Пранав | 105 | В.
|