Ms sql select from insert: SQL INSERT INTO SELECT Statement
Содержание
Инструкция INSERT INTO в Transact-SQL – несколько способов добавления данных в таблицу | Info-Comp.ru
Всем привет! В данной статье речь пойдет о том, как можно добавлять данные в таблицу в Microsoft SQL Server, если Вы уже хоть немного знакомы с языком T-SQL, то наверно поняли, что сейчас мы будем разговаривать об инструкции INSERT, а также о том, как ее можно использовать для добавления данных в таблицу.
Начнем по традиции с небольшой теории.
Содержание
- Инструкция INSERT в T-SQL
- Исходные данные
- Пример 1 – Добавляем новую запись в таблицу с использованием конструктора табличных значений
- Пример 2 – Добавляем новые строки в таблицу с использованием запроса SELECT
- Пример 3 – Добавляем новые записи в таблицу с использованием хранимой процедуры
Инструкция INSERT в T-SQL
INSERT – это инструкция языка T-SQL, которая предназначена для добавления данных в таблицу, т.е. создания новых записей. Данную инструкцию можно использовать как для добавления одной строки в таблицу, так и для массовой вставки данных. Для выполнения инструкции INSERT требуется разрешение на вставку данных (INSERT) в целевую таблицу.
Данную инструкцию можно использовать как для добавления одной строки в таблицу, так и для массовой вставки данных. Для выполнения инструкции INSERT требуется разрешение на вставку данных (INSERT) в целевую таблицу.
Существует несколько способов использования инструкции INSERT в части данных, которые необходимо вставить:
- Перечисление конкретных значений для вставки;
- Указание набора данных в виде запроса SELECT;
- Указание набора данных в виде вызова процедуры, которая возвращает табличные данные.
Заметка! Начинающим рекомендую посмотреть мой видеокурс по T-SQL.
Упрощённый синтаксис
INSERT [INTO] [таблица] (список столбцов, …)
VALUES (список значений, …)
Или
SELECT запрос на выборку
Или
EXECUTE процедура
Где,
- INSERT INTO – это команда добавления данных в таблицу;
- Таблица – это имя целевой таблицы, в которую необходимо вставить новые записи;
- Список столбцов – это перечень имен столбцов таблицы, в которую будут вставлены данные, разделенные запятыми;
- VALUES – это конструктор табличных значений, с помощью которого мы указываем значения, которые будем вставлять в таблицу;
- Список значений – это значения, которые будут вставлены, разделенные запятыми.
 Они перечисляются в том порядке, в котором указаны столбцы в списке столбцов;
Они перечисляются в том порядке, в котором указаны столбцы в списке столбцов; - SELECT – это запрос на выборку данных для вставки в таблицу. Результирующий набор данных, который вернет запрос, должен соответствовать списку столбцов;
- EXECUTE – это вызов процедуры на получение данных для вставки в таблицу. Результирующий набор данных, который вернет хранимая процедура, должен соответствовать списку столбцов.
 Они перечисляются в том порядке, в котором указаны столбцы в списке столбцов;
Они перечисляются в том порядке, в котором указаны столбцы в списке столбцов;Вот примерно так и выглядит упрощённый синтаксис инструкции INSERT INTO, в большинстве случаев именно так Вы и будете добавлять новые записи в таблицы.
Список столбцов, в которые Вы будете вставлять данные, можно и не писать, в таком случае их порядок будет определен на основе фактического порядка столбцов в таблице. При этом необходимо помнить этот порядок, когда Вы будете указывать значения для вставки или писать запрос на выборку. Лично я Вам рекомендую все-таки указывать список столбцов, в которые Вы планируете добавлять данные.
Также следует помнить и то, что в списке столбцов и в списке значений, соответственно, должны присутствовать так называемые обязательные столбцы, это те, которые не могут содержать значение NULL. Если их не указать, и при этом у столбца отсутствует значение по умолчанию, будет ошибка.
Если их не указать, и при этом у столбца отсутствует значение по умолчанию, будет ошибка.
Еще хотелось бы отметить, что тип данных значений, которые Вы будете вставлять, должен соответствовать типу данных столбца, в который будет вставлено это значение, ну или, хотя бы, поддерживал неявное преобразование. Но я Вам советую контролировать тип данных (формат) значений, как в списке значений, так и в запросе SELECT.
Хватит теории, переходим к практике.
Исходные данные
Для того чтобы добавлять данные в таблицу, нам нужна соответственно сама таблица, давайте ее создадим, и уже в нее будем пробовать добавлять записи.
Примечание! Все примеры будут выполнены в Microsoft SQL Server 2016 Express.
CREATE TABLE TestTable(
[Id] [INT] IDENTITY(1,1) NOT NULL,
[ProductName] [VARCHAR](100) NOT NULL,
[Price] [Money] NOT NULL
)
Наша тестовая таблица, будет содержать перечень товаров с ценой.
Также в примерах мы будем использовать процедуру, которая возвращает табличное значение, для добавления данных в таблицу, поэтому давайте ее тоже создадим.
CREATE PROCEDURE TestProcedure
AS
BEGIN
SELECT ProductName, Price
FROM TestTable
END
Для примера она у нас будет возвращать данные из только что созданной таблицы TestTable.
Примечание!
Как Вы понимаете, чтение данного материала подразумевает наличные определенных знаний по языку T-SQL, поэтому если Вам что-то непонятно, рекомендую ознакомиться со следующими материалами:
- Справочник по Transact-SQL;
- Основы программирования на T-SQL;
- SQL код – самоучитель по SQL для начинающих программистов;
- Видеокурсы по T-SQL.
Пример 1 – Добавляем новую запись в таблицу с использованием конструктора табличных значений
Сначала давайте попробуем добавить одну запись и сразу посмотрим на результат, т. е. напишем запрос на выборку.
е. напишем запрос на выборку.
INSERT INTO TestTable(ProductName, Price)
VALUES ('Компьютер', 100)
GO
SELECT * FROM TestTable
Вы видите, что мы после названия таблицы перечислили через запятую имена столбцов, в которые мы будем добавлять данные, затем мы указали ключевое слово VALUES и в скобочках также, в том же порядке, через запятую написали значения, которые мы хотим вставить.
После инструкции INSERT я написал инструкцию SELECT и разделил их командой GO.
А теперь давайте представим, что нам нужно добавить несколько строк. Мы для этого напишем следующий запрос.
INSERT INTO TestTable(ProductName, Price)
VALUES ('Компьютер', 100),
('Клавиатура', 20),
('Монитор', 50)
GO
SELECT * FROM TestTable
В данном случае мы добавили три записи, т.е. три строки. После VALUES значения каждой новой строки указаны в скобочках, разделили мы их запятыми.
После VALUES значения каждой новой строки указаны в скобочках, разделили мы их запятыми.
Пример 2 – Добавляем новые строки в таблицу с использованием запроса SELECT
Очень часто возникает необходимость добавлять много данных в таблицу, например, на основе запроса на выборку, т.е. SELECT. Для этого вместо VALUES нам всего лишь нужно указать запрос.
INSERT INTO TestTable(ProductName, Price)
SELECT ProductName, Price
FROM TestTable
WHERE Id > 2
GO
SELECT * FROM TestTable
В данном примере мы написали запрос SELECT, который возвращает данные из таблицы TestTable, но не все, а только те, у которых идентификатор больше 2. А результат вставили все в ту же таблицу TestTable.
В качестве примера того, как можно добавлять записи в таблицу без указания списка столбцов, давайте напишем еще один запрос на вставку данных, который сделает равно то же самое что и запрос выше, только в нем не будет перечисления столбцов для вставки.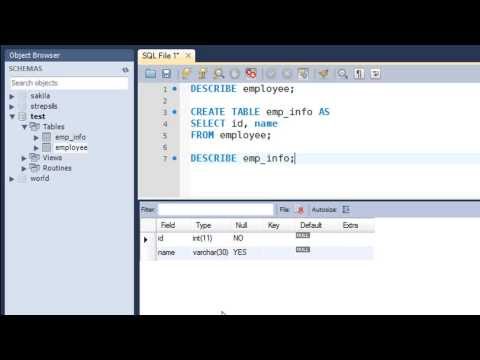
INSERT INTO TestTable
SELECT ProductName, Price
FROM TestTable
WHERE Id > 2
GO
SELECT * FROM TestTable
В данном случае мы уверены в том, что в таблице TestTable первый столбец это ProductName, а второй Price, поэтому мы можем позволить себе написать именно так. Но, снова повторюсь, на практике лучше указывать список столбцов.
Если Вы заметили, я во всех примерах не указывал столбец Id, а он у нас есть, ошибки не возникло, так как данный столбец со свойством IDENTITY, он автоматически генерирует идентификаторы, поэтому в такой столбец вставить данные просто не получится.
Пример 3 – Добавляем новые записи в таблицу с использованием хранимой процедуры
Сейчас давайте вставим в таблицу данные, которые нам вернёт хранимая процедура. Смысл здесь такой же, вместо VALUES и вместо запроса мы указываем вызов процедуры. Но как Вы понимаете, порядок и количество столбцов, возвращаемых процедурой, должен строго совпадать со списком столбцов для вставки (даже если список столбцов не указан).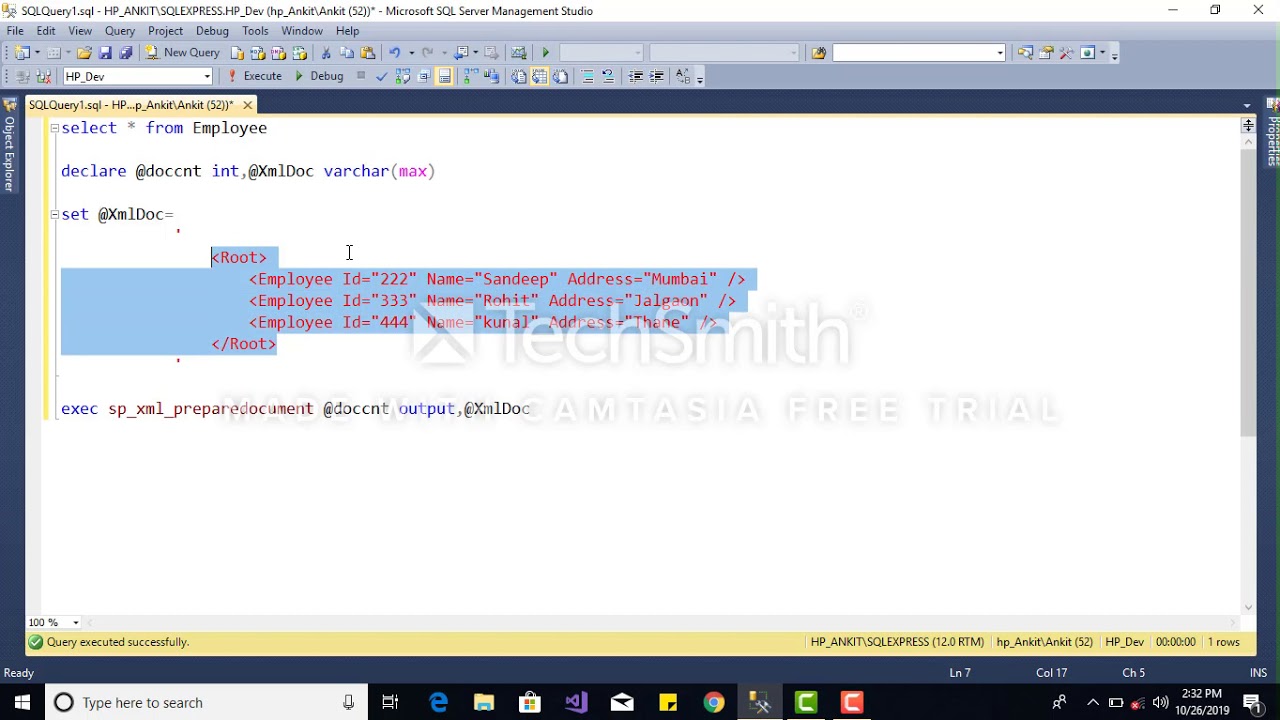
INSERT INTO TestTable(ProductName, Price)
EXEC TestProcedure
GO
SELECT * FROM TestTable
Надеюсь, данный материал помог Вам разобраться с инструкцией INSERT INTO, а у меня все, пока!
Оптимизация INSERT (Часть 1)
Введение
Недавно, мы проводили лабораторные испытания в Microsoft Enterprise Engineering Center, при которых использовалась большая рабочая нагрузка, характерная для OLTP систем. Целью этой лабораторной работы было определить, что случится при увеличении числа процессоров с 64 до 128, при обслуживании Microsoft SQL Server интенсивной рабочей нагрузки (примечание: эта конфигурация была ориентирована на релиз Microsoft SQL Server 2008 R2). Рабочая нагрузка представляла собой хорошо распараллеленные операции вставки, направляемые в несколько больших таблиц.
Рабочая нагрузка масштабировалась до 128 процессорных ядер, но в статистике ожиданий было очень много кратких блокировок PAGELATCH_UP и PAGELATCH_EX. Средняя продолжительность ожидания была десятки миллисекунд, и таких ожиданий было очень много. Такое их количество оказалось для нас неожиданностью, ожидалось, что продолжительность не будет превышать несколько миллисекунд.
Средняя продолжительность ожидания была десятки миллисекунд, и таких ожиданий было очень много. Такое их количество оказалось для нас неожиданностью, ожидалось, что продолжительность не будет превышать несколько миллисекунд.
В этой технической заметке вначале будет описано, как диагностировать подобную проблему и как для разрешения подобной проблемы использовать секционирование таблиц.
Диагностика проблемы
Когда в sys.dm_os_wait_stats наблюдается большое число PAGELATCH, с помощью sys.dm_os_waiting_tasks можно определить сессию и ресурс, который задача ожидает, например, с помощью этого сценария:
SELECT session_id, wait_type, resource_description
FROM sys.dm_os_waiting_tasks
WHERE wait_type LIKE ‘PAGELATCH%’
Пример результата:
В столбце resource_description указаны местоположения страниц, к которым ожидают доступ сессии, местоположение представлено в таком формате:
<database_id>:<file_id>:<page_id>
Опираясь на значения в столбце resource_description, можно составить довольно сложный сценарий, который предоставит выборку всех попавших в список ожидания страниц:
SELECT wt. session_id, wt.wait_type, wt.wait_duration_ms
session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
, CHARINDEX(‘:’, resource_description) AS file_index
, CHARINDEX(‘:’, resource_description
, CHARINDEX(‘:’, resource_description)) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE ‘PAGELATCH%’
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index, wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s. schema_id
schema_id
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms , s.name AS schema_name , o.name AS object_name , i.name AS index_name FROM sys.dm_os_buffer_descriptors bd JOIN ( SELECT * , CHARINDEX(‘:’, resource_description) AS file_index , CHARINDEX(‘:’, resource_description , CHARINDEX(‘:’, resource_description)) AS page_index , resource_description AS rd FROM sys.dm_os_waiting_tasks wt WHERE wait_type LIKE ‘PAGELATCH%’ ) AS wt ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index) AND bd.file_id = SUBSTRING(wt.rd, wt.file_index, wt.page_index) AND bd.page_id = SUBSTRING(wt.rd, wt.page_index, LEN(wt.rd)) JOIN sys. JOIN sys.partitions p ON au.container_id = p.partition_id JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id JOIN sys.objects o ON i.object_id = o.object_id JOIN sys.schemas s ON o.schema_id = s.schema_id |
 allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
allocation_units au ON bd.allocation_unit_id = au.allocation_unit_idСценарий показал, что ожидаемые страницы относятся к кластеризованному индексу, определённому первичным ключом таблицы с представленной ниже структурой:
CREATE TABLE HeavyInsert (
ID INT PRIMARY KEY CLUSTERED
, col1 VARCHAR(50)
) ON [PRIMARY]
|
| CREATE TABLE HeavyInsert ( ID INT PRIMARY KEY CLUSTERED , col1 VARCHAR(50) ) ON [PRIMARY] |
Что происходит, почему возникает очередь ожиданий к страницам данных индекса — всё это будет рассмотрено в этой технической заметке.
Основная информация
Чтобы определить, что происходит с нашей большой OLTP-нагрузкой, важно понимать, как SQL Server выполняет вставку в индекс новой строки.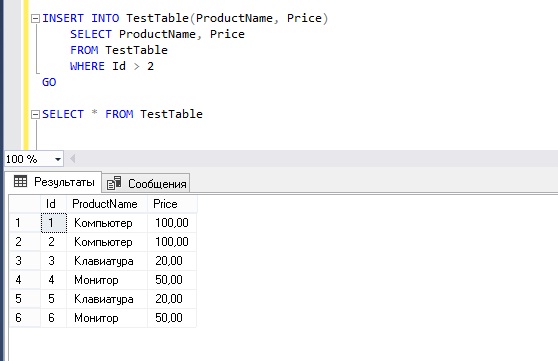 При необходимости вставки в индекс новой строки, SQL Server будет следовать следующему алгоритму внесения изменений:
При необходимости вставки в индекс новой строки, SQL Server будет следовать следующему алгоритму внесения изменений:
- В журнале транзакций создаётся запись о том, что строка изменилась.
- Осуществляется поиск в В-дереве местонахождения той страницы, куда должна будет попасть новая запись.
- Осуществляется наложение на эту страницу краткой блокировки PAGELATCH_EX, которая призвана воспрепятствовать изменениям из других потоков.
- Осуществляется добавление строки на страницу и, если это необходимо, осуществляется пометка этой страницы как «грязной».
- Осуществляется снятие краткой блокировки со страницы.
В итоге, страница должна будет быть сброшена на диск процессом контрольной точкой или отложенной записи.
Если же все вставки строк направлены на ту же самую страницу, можно наблюдать рост очереди к этой странице. Даже притом, что краткая блокировка весьма непродолжительна, она может стать причиной конкуренции при высоком параллелизме рабочей нагрузки. У нашего клиента, первый и единственный столбец в индексе являлся монотонно возрастающим ключом. Из-за этого, каждая новая вставка шла на ту же самую страницу в конце В-дерева, пока эта страница не была заполнена. Рабочие нагрузки, которые используют в качестве первичного ключа IDENTITY или другие столбцы с последовательно увеличивающимися значениями, также могут столкнуться с подобной проблемой, если распараллеливание достаточно высоко.
У нашего клиента, первый и единственный столбец в индексе являлся монотонно возрастающим ключом. Из-за этого, каждая новая вставка шла на ту же самую страницу в конце В-дерева, пока эта страница не была заполнена. Рабочие нагрузки, которые используют в качестве первичного ключа IDENTITY или другие столбцы с последовательно увеличивающимися значениями, также могут столкнуться с подобной проблемой, если распараллеливание достаточно высоко.
Решение
Всегда, когда несколько потоков получают синхронный доступ к одному и тому же ресурсу, может проявиться описанная выше проблема. Стандартное решение состоит в том, чтобы создать больше ресурсов конкурентного доступа. В нашем случае, таким конкурентным ресурсом является последняя страница В-дерева.
Одним из способов снизить конкуренцию за одну страницу состоит в том, чтобы выбрать в качестве первого столбца индекса другой, не увеличивающийся монотонно столбец. Однако, для нашего клиента это потребовало бы внесения изменений на прикладном уровне в клиентских системах. Мы должны были найти другое решение, которое могло бы ограничиться только изменениями в базе данных.
Мы должны были найти другое решение, которое могло бы ограничиться только изменениями в базе данных.
Помните, что местом конкуренции является одна страница в В-дерева, и конкуренция была бы меньше, если бы было возможно использовать для этого несколько В-деревьев, и в то же время работать только с одной таблицей. К счастью, такая возможность есть, это: Секционированные таблицы и индексы. Таблица может быть секционирована таким способом, чтобы новые строки размещались в нескольких секциях.
Сначала нужно создать функцию и схему секционирования:
CREATE PARTITION FUNCTION pf_hash (INT) AS RANGE LEFT FOR VALUES (0,1,2)
CREATE PARTITION SCHEME ps_hash AS PARTITION pf_hash ALL TO ([PRIMARY])
|
| CREATE PARTITION FUNCTION pf_hash (INT) AS RANGE LEFT FOR VALUES (0,1,2) CREATE PARTITION SCHEME ps_hash AS PARTITION pf_hash ALL TO ([PRIMARY]) |
Представленный выше пример использует четыре секции. Число необходимых секций зависит от числа активных процессов, выполняющих операции INSERT в описанную выше таблицу. Есть некоторая сложность в секционировании таблицы с помощью хэш-столбца, например, в том что всякий раз, когда происходит выборка строк из таблицы, будут затронуты все секции. Это означает, что придётся обращаться более чем к одному В-дереву, т.е. не будет отброшенных оптимизатором за ненадобностью ненужных секций. Будет дополнительная нагрузка на процессоры и некоторое увеличение времени ожиданий процессоров, что побуждает минимизировать число планируемых секций (их должно быть минимальное количество, при котором не наблюдается PAGELATCH). В рассматриваемом нами случае, в системе нашего клиента имелось достаточно много резерва в утилизации процессоров, так что было вполне возможно допустить небольшую потерю времени для инструкций SELECT, и при этом увеличить до необходимых объёмов норму инструкций INSERT.
Число необходимых секций зависит от числа активных процессов, выполняющих операции INSERT в описанную выше таблицу. Есть некоторая сложность в секционировании таблицы с помощью хэш-столбца, например, в том что всякий раз, когда происходит выборка строк из таблицы, будут затронуты все секции. Это означает, что придётся обращаться более чем к одному В-дереву, т.е. не будет отброшенных оптимизатором за ненадобностью ненужных секций. Будет дополнительная нагрузка на процессоры и некоторое увеличение времени ожиданий процессоров, что побуждает минимизировать число планируемых секций (их должно быть минимальное количество, при котором не наблюдается PAGELATCH). В рассматриваемом нами случае, в системе нашего клиента имелось достаточно много резерва в утилизации процессоров, так что было вполне возможно допустить небольшую потерю времени для инструкций SELECT, и при этом увеличить до необходимых объёмов норму инструкций INSERT.
Ещё одной сложностью является то, что нужен дополнительный столбец, по которому будет выполняться секционирование, т. е. на основании значения которого будут распределяться вставки по четырем секциям. Такого столбца изначально в сценарии Microsoft Enterprise Engineering Center не было. Однако, его достаточно просто было создать. Для этого использовался тот факта, что столбец ID монотонно увеличивается с приращением равным единице, и здесь легко применима довольно простая хеш-функция:
е. на основании значения которого будут распределяться вставки по четырем секциям. Такого столбца изначально в сценарии Microsoft Enterprise Engineering Center не было. Однако, его достаточно просто было создать. Для этого использовался тот факта, что столбец ID монотонно увеличивается с приращением равным единице, и здесь легко применима довольно простая хеш-функция:
CREATE TABLE HeavyInsert_Hash(
ID INT NOT NULL
, col1 VARCHAR(50)
, HashID AS CAST(ABS(ID % 4) AS TINYINT) PERSISTED NOT NULL)
|
| CREATE TABLE HeavyInsert_Hash( ID INT NOT NULL , col1 VARCHAR(50) , HashID AS CAST(ABS(ID % 4) AS TINYINT) PERSISTED NOT NULL) |
С помощью столбца HashID, вставки в четыре секции будут выполняться циклически.
Создаём кластеризованный индекс следующим образом:
CREATE UNIQUE CLUSTERED INDEX CIX_Hash
ON HeavyInsert_Hash (ID, HashID) ON ps_hash(HashID)
|
| CREATE UNIQUE CLUSTERED INDEX CIX_Hash ON HeavyInsert_Hash (ID, HashID) ON ps_hash(HashID) |
Используя новую схему таблицы с секционированием вместо первоначального варианта таблицы, мы сумели избавиться от очередей PAGELATCH и повысить скорость вставки.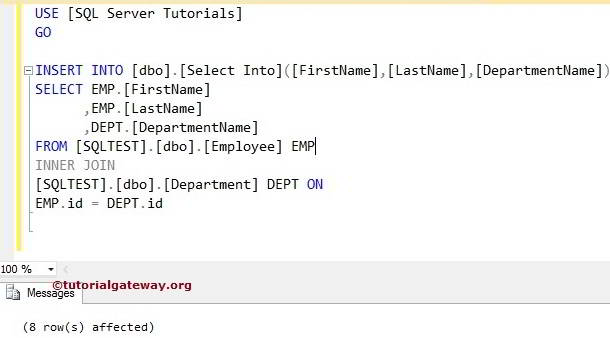 Этого удалось достичь за счёт балансировки вставки между несколькими секциями и высокого параллелизма. Вставка происходит в несколько страниц, и каждая страница размещается в своей собственной структуре В-дерева. Для нашего клиента удалось повысить производительность вставки на 15 процентов, и справится с большой очередью PAGELATCH к горячей странице индекса одной таблицы. Но при этом удалось также оставить достаточно большой резерв циклов процессоров, что оставило возможность сделать аналогичную оптимизацию для другой таблицы, тоже с высокой нормой вставки.
Этого удалось достичь за счёт балансировки вставки между несколькими секциями и высокого параллелизма. Вставка происходит в несколько страниц, и каждая страница размещается в своей собственной структуре В-дерева. Для нашего клиента удалось повысить производительность вставки на 15 процентов, и справится с большой очередью PAGELATCH к горячей странице индекса одной таблицы. Но при этом удалось также оставить достаточно большой резерв циклов процессоров, что оставило возможность сделать аналогичную оптимизацию для другой таблицы, тоже с высокой нормой вставки.
Строго говоря, суть этой уловки в оптимизации логической схемы первичного ключа таблицы. Однако, потому что ключ просто стал длиннее на величину хеш-функции относительно изначального ключа, дубликатов для столбца ID удалось избежать. Уникальные индексы по единственному столбцу таблицы зачастую становятся причиной проблем с очередями PAGELATCH. Но даже если эту проблему удастся устранить, у таблицы может оказаться другой, некластеризованный индекс, который будет подвержен той же самой проблеме. Как правило, проблема наблюдается для уникальных ключей на единственном столбце, где каждая вставка попадает на одну и ту же страницу. Если и у других таблиц индексы подвержены проблеме с PAGELATCH, можно применить эту же уловку с секционированием к индексам таких таблиц, используя такой же ключ с хэшем в качестве первичного ключа.
Как правило, проблема наблюдается для уникальных ключей на единственном столбце, где каждая вставка попадает на одну и ту же страницу. Если и у других таблиц индексы подвержены проблеме с PAGELATCH, можно применить эту же уловку с секционированием к индексам таких таблиц, используя такой же ключ с хэшем в качестве первичного ключа.
Не всегда возможно внести изменения в приложение, особенно, если оно является плодом усилий третьих фирм. Но если изменение запросов возможно, становится доступной их оптимизация за счёт добавления к ним условий фильтрации по предикатам первичного ключа.
Пример: Чтобы отбросить ненужные секции, можно внести следующие изменения в сценарий:
SELECT * FROM HeavyInsert_Hash
WHERE ID = 42
|
| SELECT * FROM HeavyInsert_Hash WHERE ID = 42 |
Который после изменений будет выглядеть так:
SELECT * FROM HeavyInsert_Hash
WHERE ID = 42 AND HashID = 42 % 4
|
| SELECT * FROM HeavyInsert_Hash WHERE ID = 42 AND HashID = 42 % 4 |
Исключение оптимизатором ненужных секций по значению хэша не будет вам ничего стоить, если только не считать большой платой за это увеличение на один байт каждой строки кластеризованного индекса.
Запись опубликована в рубрике Полезно и интересно с метками performance. Добавьте в закладки постоянную ссылку.
INSERT INTO SELECT * для SQL Server, невозможно, я прав?
спросил
Изменено
8 лет, 4 месяца назад
Просмотрено
23 тысячи раз
Использование SQL Server 2008 R2
По-видимому, можно сделать
INSERT INTO Table1 SELECT * FROM Table1, где Id=1234
см.: W3Schools
Но в SQL Server это не работает. Правильно ли я думаю, что SQL Server не поддерживает приведенный выше оператор INSERT и должен конкретно указывать столбцы.
Спасибо.
РЕДАКТИРОВАТЬ
Итак, неполный SQL выше, теперь исправлен
- sql-server
- sql-server-2008
1
Вы пропустили имя таблицы, которую хотите вставить в
вставить в таблицу_назначения выберите * из исходной_таблицы
Конечно, это работает только для таблиц с одинаковыми столбцами. Если вы хотите вставить только определенные столбцы, вам также нужно указать их
Если вы хотите вставить только определенные столбцы, вам также нужно указать их
вставить в целевую_таблицу (столбец1, столбец2) выберите col7, col3 из исходной_таблицы
4
Если вы просто пытаетесь скопировать строку из таблицы с первичным ключом (столбец IDENTITY), вы не можете использовать следующий синтаксис:
INSERT INTO Table1 SELECT * FROM Table1, где Id=1234
Это приведет к нарушению уникальных значений первичного ключа, поскольку будет предпринята попытка вставить дубликат IDENTITY.
Вместо этого выберите все столбцы, кроме IDENTITY, предполагая, что с этой схемой:
Table1 ------ ИДЕНТИФИКАТОР Кол1 Кол2 Кол3
Вы сделаете это, и IDENTITY автоматически увеличится для вас:
INSERT INTO Table1 (Col1, Col2, Col3) ВЫБЕРИТЕ Кол1, Кол2, Кол3 ИЗ Таблицы1 ГДЕ идентификатор = 1234
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
ВСТАВИТЬ В таблицу SQL Server с помощью команды SELECT
Автор: Джереми Кадлек
Обзор
В некоторых из наших предыдущих примеров мы использовали оператор SELECT для проверки результатов ранее выполненных операторов INSERT. Как вы знаете, команда INSERT добавляет записи в таблицу, а оператор SELECT извлекает данные из одной или нескольких таблиц. Знаете ли вы, что вы можете использовать оператор SELECT с командой INSERT для заполнения таблицы? Давайте рассмотрим три примера.
Как вы знаете, команда INSERT добавляет записи в таблицу, а оператор SELECT извлекает данные из одной или нескольких таблиц. Знаете ли вы, что вы можете использовать оператор SELECT с командой INSERT для заполнения таблицы? Давайте рассмотрим три примера.
Пояснение
В первом примере команда INSERT используется со статическими значениями из команды SELECT, как показано ниже:
ВСТАВИТЬ В [dbo].[Заказчик] ([Имя] ,[Фамилия] ,[Номер телефона] ,[Адрес электронной почты] ,[Приоритет] ,[Дата создания]) ВЫБЕРИТЕ «Карон» , 'Акула' ,'333-333-3333' ,'[электронная почта защищена]' ,1 ,'2011-09-15';
Во втором примере команда INSERT используется с многочисленными статическими значениями с отдельными командами SELECT и UNION, что приводит к вставке трех записей, как показано ниже:
ВСТАВИТЬ В [dbo].[Заказчик] ([Имя] ,[Фамилия] ,[Номер телефона] ,[Адрес электронной почты] ,[Приоритет] ,[Дата создания]) ВЫБЕРИТЕ «Кэти», «QueenCrab», «444-333-3333», «[электронная почта защищена]», 1, «2011-09-15» СОЮЗ ВСЕХ ВЫБЕРИТЕ «Джессика», «TastyTuna», «555-333-3333», «[электронная почта защищена]», 1, «2011-09-15» СОЮЗ ВСЕХ ВЫБЕРИТЕ «Шарон», «WellDoneSteak», «666-333-3333», «[электронная почта защищена]», 1, «2011-09-15»
В третьем примере команда INSERT используется с командой SELECT для доступа к данным из архивной таблицы для заполнения таблицы dbo.