Объединение строк sql: + (объединение строк) (Transact-SQL) — SQL Server
Содержание
+ (объединение строк) (Transact-SQL) — SQL Server
-
Статья -
-
Применимо к: SQL Server Azure SQL DatabaseУправляемый экземпляр SQL AzureAzure Synapse Analytics AnalyticsPlatform System (PDW)Конечная точка SQL в хранилище Microsoft Fabricв Microsoft Fabric
Оператор в строковом выражении, объединяющий две или более символьных или двоичных строки, два или более столбцов или несколько строк и имен столбцов в одно выражение (строковый оператор). Например, SELECT 'book'+'case'; возвращает bookcase.
Соглашения о синтаксисе Transact-SQL
Синтаксис
expression + expression
Примечание
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
в статье Документация по предыдущим версиям.
Аргументы
expression
Любое действительное выражение любого типа данных в категории символьных и двоичных данных, за исключением типов данных image, ntext и text. Оба выражения должны иметь одинаковый тип данных, или одно из выражений должно допускать неявное преобразование к типу данных другого выражения.
При сцеплении двоичных строк с любыми символами между двоичными строками необходимо использовать явное преобразование в символьные данные. В следующем примере показано, когда CONVERT или CAST должны использоваться с двоичной конкатенацией и когда CONVERT или CAST не нужно использовать.
DECLARE @mybin1 VARBINARY(5), @mybin2 VARBINARY(5) SET @mybin1 = 0xFF SET @mybin2 = 0xA5 -- No CONVERT or CAST function is required because this example -- concatenates two binary strings. SELECT @mybin1 + @mybin2 -- A CONVERT or CAST function is required because this example -- concatenates two binary strings plus a space.SELECT CONVERT(VARCHAR(5), @mybin1) + ' ' + CONVERT(VARCHAR(5), @mybin2) -- Here is the same conversion using CAST. SELECT CAST(@mybin1 AS VARCHAR(5)) + ' ' + CAST(@mybin2 AS VARCHAR(5))
 SELECT CONVERT(VARCHAR(5), @mybin1) + ' '
+ CONVERT(VARCHAR(5), @mybin2)
-- Here is the same conversion using CAST.
SELECT CAST(@mybin1 AS VARCHAR(5)) + ' '
+ CAST(@mybin2 AS VARCHAR(5))
SELECT CONVERT(VARCHAR(5), @mybin1) + ' '
+ CONVERT(VARCHAR(5), @mybin2)
-- Here is the same conversion using CAST.
SELECT CAST(@mybin1 AS VARCHAR(5)) + ' '
+ CAST(@mybin2 AS VARCHAR(5))
Типы результата
Возвращает тип данных аргумента с самым высоким приоритетом. Дополнительные сведения см. в статье Приоритет типов данных (Transact-SQL).
При работе с пустыми строками нулевой длины оператор + (объединение строк) ведет себя иначе, чем при работе со значениями NULL или с неизвестными значениями. Символьная строка символа нулевой длины может быть указана в виде двух одинарных кавычек без каких-либо символов между ними. Двоичная строка нулевой длины может быть указана как 0x без указания каких-либо байтовых значений в шестнадцатеричной константе. При сцеплении строки нулевой длины всегда сцепляются две указанные строки. При работе со строками со значением NULL результат объединения зависит от настроек сеанса. При присоединении нулевого значения к известному значению результатом будет неизвестное значение, объединение строк с нулевым значением также дает нулевое значение, как и в арифметических действиях с нулевыми значениями. Однако можно изменить данное поведение, поменяв значение
Однако можно изменить данное поведение, поменяв значение CONCAT_NULL_YIELDS_NULL для текущего сеанса. Дополнительные сведения см. в статье SET CONCAT_NULL_YIELDS_NULL (Transact-SQL).
Если результат объединения строк превышает предел в 8 000 байт, то он усекается. Однако усечения не произойдет, если хотя бы одна из сцепляемых строк принадлежит к типу больших значений.
Примеры
A. Использование объединения строк
В следующем примере создается единственный столбец с заголовком Name из нескольких символьных столбцов, где за фамилией лица следуют запятая, один пробел и имя того же лица. Результирующий набор сортируется в алфавитном порядке по возрастанию, сначала по фамилии, а затем по имени.
-- Uses AdventureWorks SELECT (LastName + ', ' + FirstName) AS Name FROM Person.Person ORDER BY LastName ASC, FirstName ASC;
Б. Объединение числовых типов данных и дат
В приведенном ниже примере функция CONVERT используется для объединения типов данных numeric и date.
-- Uses AdventureWorks SELECT 'The order is due on ' + CONVERT(VARCHAR(12), DueDate, 101) FROM Sales.SalesOrderHeader WHERE SalesOrderID = 50001; GO
Результирующий набор:
------------------------------------------------ The order is due on 04/23/2007 (1 row(s) affected)
В. Использование объединения нескольких строк
Следующий пример сцепляет несколько строк в одну длинную строку для отображения фамилии и первой буквы инициалов вице-президентов в Компания Adventure Works Cycles. После фамилии ставится запятая, а после первой буквы инициалов — точка.
-- Uses AdventureWorks
SELECT (LastName + ',' + SPACE(1) + SUBSTRING(FirstName, 1, 1) + '.') AS Name, e.JobTitle
FROM Person.Person AS p
JOIN HumanResources.Employee AS e
ON p.BusinessEntityID = e.BusinessEntityID
WHERE e.JobTitle LIKE 'Vice%'
ORDER BY LastName ASC;
GO
Результирующий набор:
Name Title ------------- ---------------` Duffy, T.
 Vice President of Engineering
Hamilton, J. Vice President of Production
Welcker, B. Vice President of Sales
(3 row(s) affected)
Vice President of Engineering
Hamilton, J. Vice President of Production
Welcker, B. Vice President of Sales
(3 row(s) affected)
Г. Использование больших строк при объединении
В приведенном ниже примере выполняется объединение нескольких строк в одну длинную строку, а затем предпринимается попытка вычислить длину итоговой строки. Итоговая длина результирующего набора равна 16 000, так как вычисление выражения начинается слева: @x + @z + @y => (@x + @z) + @y. В этом случае результат (@x + @z) усекается до 8000 байтов, а затем в результирующий набор добавляется значение @y, после чего длина итоговой строки становится равна 16 000. Так как @y — это строка типа с большим значением, усечения не происходит.
DECLARE @x VARCHAR(8000) = REPLICATE('x', 8000)
DECLARE @y VARCHAR(max) = REPLICATE('y', 8000)
DECLARE @z VARCHAR(8000) = REPLICATE('z',8000)
SET @y = @x + @z + @y
-- The result of following select is 16000
SELECT LEN(@y) AS y
GO
Результирующий набор:
y ------- 16000 (1 row(s) affected)
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
Д.
 Использование объединения нескольких строк
Использование объединения нескольких строк
В приведенном ниже примере несколько строк сцепляются в одну длинную строку для отображения фамилий и инициалов имен вице-президентов из образца базы данных. После фамилии ставится запятая, а после первой буквы инициалов — точка.
-- Uses AdventureWorks SELECT (LastName + ', ' + SUBSTRING(FirstName, 1, 1) + '.') AS Name, Title FROM DimEmployee WHERE Title LIKE '%Vice Pres%' ORDER BY LastName ASC;
Результирующий набор:
Name Title ------------- --------------- Duffy, T. Vice President of Engineering Hamilton, J. Vice President of Production Welcker, B. Vice President of Sales
См. также:
+= (присваивание объединения строк) (Transact-SQL)
ALTER DATABASE (Transact-SQL)
Функции CAST и CONVERT (Transact-SQL)
Преобразование типов данных (ядро СУБД)
Типы данных (Transact-SQL)
Выражения (Transact-SQL)
Встроенные функции (Transact-SQL)
Операторы (Transact-SQL)
SELECT (Transact-SQL)
Инструкции SET (Transact-SQL)
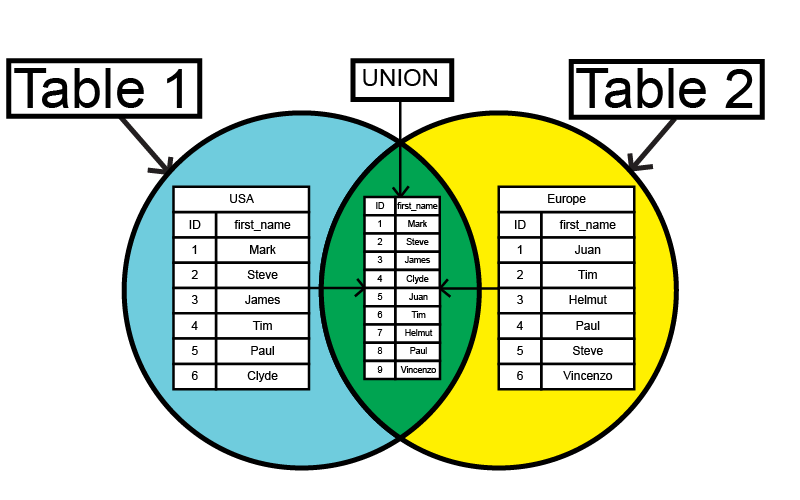
Объединение таблиц с помощью операторов Join и Keep
Объединение — операция объединения двух таблиц в одну. Записи результирующей таблицы представляют собой комбинации записей в исходных таблицах. При этом две такие записи, составляющие одну комбинацию в результирующей таблице, как правило, имеют общее значение одного или нескольких общих полей. Такое объединение называется естественным. В программе Qlik Sense объединение может выполняться в скрипте, создавая логическую таблицу.
Записи результирующей таблицы представляют собой комбинации записей в исходных таблицах. При этом две такие записи, составляющие одну комбинацию в результирующей таблице, как правило, имеют общее значение одного или нескольких общих полей. Такое объединение называется естественным. В программе Qlik Sense объединение может выполняться в скрипте, создавая логическую таблицу.
Таблицы, которые находятся в скрипте, можно объединять. Логика Qlik Sense будет распознавать не отдельные таблицы, а результаты объединения, которые будут представлены в одной внутренней таблице. В некоторых случаях это требуется, однако существуют недостатки:
- Загруженные таблицы часто становятся больше, и программа Qlik Sense работает медленнее.
- Некоторая информация может быть потеряна: частота (количество записей) в исходной таблице может быть больше недоступна.
Функция Keep, которая позволяет уменьшить одну или обе таблицы до пересечения данных таблиц перед сохранением таблиц в программу Qlik Sense, предназначена для уменьшения количества случаев, когда необходимо использовать явные объединения.
Примечание к информацииВ данном руководстве термин «объединение» обычно используется для объединений, выполненных до создания внутренних таблиц. Однако ассоциация, выполненная после создания внутренних таблиц, по сути, также является объединением.
Объединения внутри оператора SQL SELECT
При использовании некоторых драйверов ODBC можно выполнять объединение внутри оператора SELECT. Это практически эквивалентно созданию объединения с помощью префикса Join.
Однако большинство драйверов ODBC не позволяют сделать полное внешнее объединение (двунаправленное). Они позволяют сделать только левостороннее или правостороннее внешнее объединение. Левостороннее (правостороннее) внешнее объединение включает только сочетания, в которых в левой (правой) таблице существует ключ объединения. Полное внешнее объединение включает все сочетания. Программа Qlik Sense автоматически создает полное внешнее объединение.
Более того, создание объединений в операторах SELECT значительно сложнее, чем создание объединений в программе Qlik Sense.
Пример:
SELECT DISTINCTROW
[Order Details].ProductID, [Order Details].
UnitPrice, Orders.OrderID, Orders.OrderDate, Orders.CustomerID
FROM Orders
RIGHT JOIN [Order Details] ON Orders.OrderID = [Order Details].OrderID;
Этот оператор SELECT позволяет объединить таблицу, содержащую заказы несуществующей компании, и таблицу, содержащую сведения о заказах. Это правостороннее внешнее объединение, то есть будут включены все записи OrderDetails и записи со значением OrderID, которое отсутствует в таблице Orders. Однако заказы, содержащиеся в таблице Orders, но не содержащиеся в OrderDetails, не будут включены.
Join
Самым простым способом создания объединения является использование префикса Join в скрипте, который позволяет объединять внутреннюю таблицу с другой именованной таблицей или последней созданной таблицей. Объединение будет внешним и позволит создать все возможные сочетания значений из двух таблиц.
Объединение будет внешним и позволит создать все возможные сочетания значений из двух таблиц.
Пример:
LOAD a, b, c from table1.csv;
join LOAD a, d from table2.csv;
Результирующая внутренняя таблица имеет поля a, b, c и d. Количество записей различается в зависимости от значений полей этих двух таблиц.
Примечание к информацииИмена объединяемых полей должны совпадать. Количество объединяемых полей может быть любым. Обычно в таблицах должно быть одно или несколько общих полей. При отсутствии общих полей будет рассматриваться декартово произведение таблиц. В принципе все поля могут быть общими, однако обычно в этом нет смысла. Пока имя ранее загруженной таблицы не будет указано в операторе Join, префиксом Join будет использоваться последняя созданная таблица. Поэтому порядок двух операторов не является произвольным.
 WebHelpOnly»>Для получения дополнительной информации см. Join.
WebHelpOnly»>Для получения дополнительной информации см. Join.Keep
Явный префикс Join в скрипте загрузки данных выполняет полное объединение двух таблиц. В результате получается одна таблица. Во многих случаях такие объединения приводят к созданию очень больших таблиц. Одной из основных функций программы Qlik Sense является способность к связыванию таблиц вместо их объединения, что позволяет сократить использование памяти, повысить скорость обработки и гибкость. Функция keep предназначена для сокращения числа случаев необходимого использования явных объединений.
Префикс Keep между двумя операторами LOAD или SELECT приводит к уменьшению одной или обеих таблиц до пересечения их данных перед сохранением таблиц в программе Qlik Sense. Перед префиксом Keep следует задать одно из ключевых слов: Inner, Left или Right. Выборка записей из таблицы осуществляется так же, как и при соответствующем объединении. Однако две таблицы не объединяются и сохраняются в программе Qlik Sense в виде двух отдельных именованных таблиц.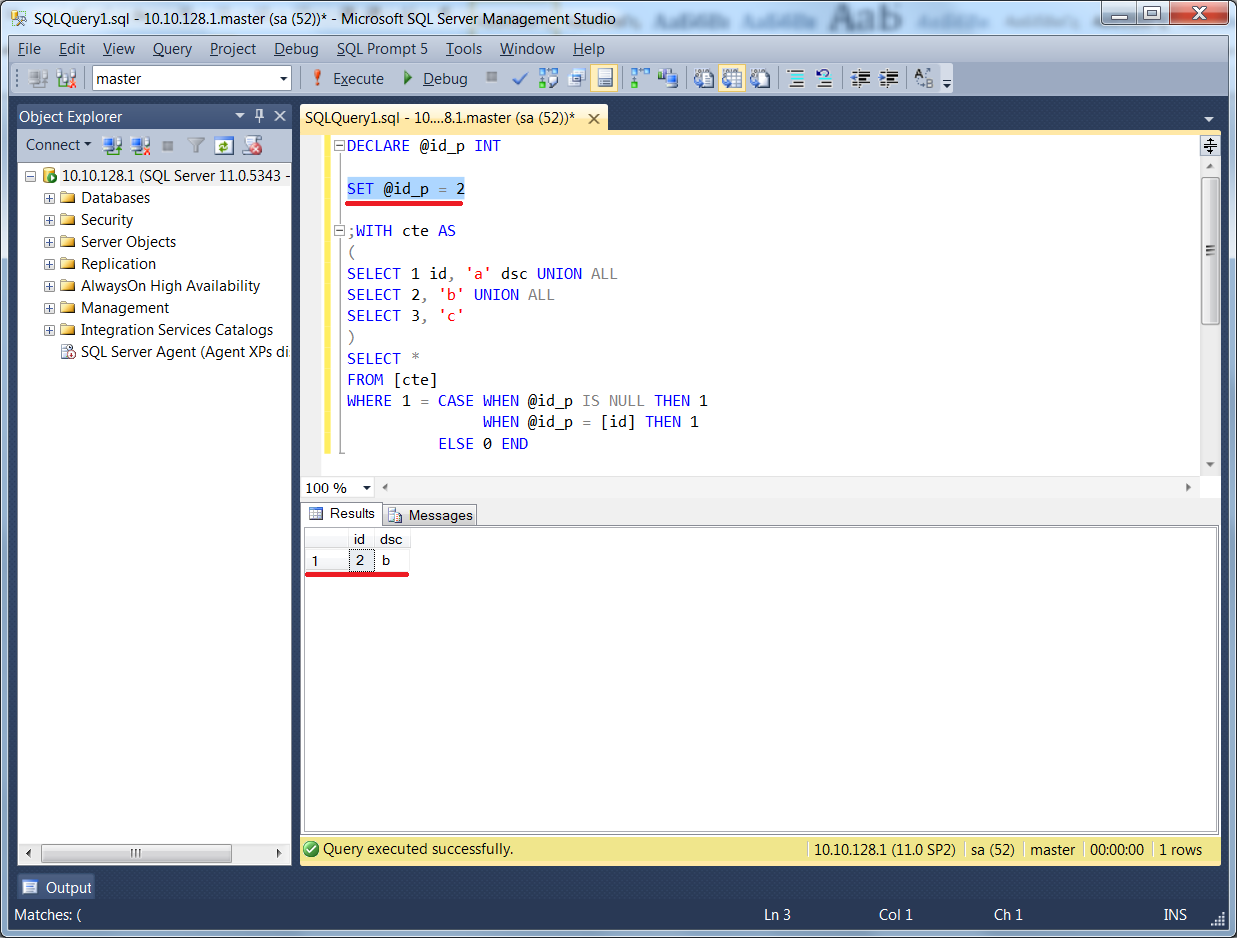
Для получения дополнительной информации см. Keep.
Inner
Перед префиксами Join и Keep в скрипте загрузки данных можно использовать префикс Inner.
При использовании этого префикса перед префиксом Join объединение двух таблиц будет внутренним. Полученная таблица содержит только сочетания из двух таблиц, включающие полный набор данных с обеих сторон.
Если этот префикс используется перед Keep, он указывает, что две таблицы следует уменьшить до области взаимного пересечения, прежде чем они смогут быть сохранены в программе Qlik Sense.
Пример:
В этих таблицах используются исходные таблицы Table1 и Table2:
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
 NotToTranslate»/>
NotToTranslate»/>Inner Join
Сначала выполняется Inner Join в отношении таблиц, в результате чего образуется таблица VTable, содержащая только одну строку, только одну запись, существующую в обеих таблицах, с данными из обеих таблиц.
VTable:
SELECT * from Table1;
inner join SELECT * from Table2;
| A | B | C |
|---|---|---|
| 1 | aa | xx |
Inner Keep
Если вместо этого выполняется Inner Keep, таблиц все равно будет две. Две таблицы связаны посредством общего поля A.
Две таблицы связаны посредством общего поля A.
VTab1:
SELECT * from Table1;
VTab2:
inner keep SELECT * from Table2;
| A | B |
|---|---|
| 1 | aa |
| A | C |
|---|---|
| 1 | xx |
 WebHelpOnly»>Для получения дополнительной информации см. Inner.
WebHelpOnly»>Для получения дополнительной информации см. Inner.Left
Перед префиксами Join и Keep в скрипте загрузки данных можно использовать префикс left.
При использовании этого префикса перед префиксом Join объединение двух таблиц будет левосторонним. Полученная таблица содержит только сочетания из двух таблиц, включающие полный набор данных из первой таблицы.
Если этот префикс используется перед префиксом Keep, он указывает, что вторую таблицу следует уменьшить до области взаимного пересечения с первой таблицей перед сохранением в программе Qlik Sense.
Пример:
В этих таблицах используются исходные таблицы Table1 и Table2:
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
 NotToTranslate»/>
NotToTranslate»/>Сначала выполняется Left Join в отношении таблиц, в результате чего образуется таблица VTable, содержащая все строки из таблицы Table1, совмещенные с полями из совпадающих строк в таблице Table2.
VTable:
SELECT * from Table1;
left join SELECT * from Table2;
| A | B | C |
|---|---|---|
| 1 | aa | xx |
| 2 | cc | — |
| 3 | ee | — |
 NotToTranslate»/>
NotToTranslate»/>Если вместо этого выполняется Left Keep, таблиц все равно будет две. Две таблицы связаны посредством общего поля A.
VTab1:
SELECT * from Table1;
VTab2:
left keep SELECT * from Table2;
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
 NotToTranslate»/>
NotToTranslate»/>| A | C |
|---|---|
| 1 | xx |
Для получения дополнительной информации см. Left.
Right
Перед префиксами Join и Keep в скрипте загрузки данных можно использовать префикс right.
При использовании этого префикса перед префиксом Join объединение двух таблиц будет правосторонним. Полученная таблица содержит только сочетания из двух таблиц, включающие полный набор данных из второй таблицы.
Если этот префикс используется перед префиксом Keep, он указывает, что первую таблицу следует уменьшить до области взаимного пересечения со второй таблицей перед сохранением в программе Qlik Sense.
Пример:
В этих таблицах используются исходные таблицы Table1 и Table2:
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
 NotToTranslate»/>
NotToTranslate»/>Сначала выполняется Right Join в отношении таблиц, в результате чего образуется таблица VTable, содержащая все строки из таблицы Table2, совмещенные с полями из совпадающих строк в таблице Table1.
VTable:
SELECT * from Table1;
right join SELECT * from Table2;
| A | B | C |
|---|---|---|
| 1 | aa | xx |
| 4 | — | yy |
 NotToTranslate»/>
NotToTranslate»/>Если вместо этого выполняется Right Keep, таблиц все равно будет две. Две таблицы связаны посредством общего поля A.
VTab1:
SELECT * from Table1;
VTab2:
right keep SELECT * from Table2;
| A | B |
|---|---|
| 1 | aa |
 NotToTranslate»/>
NotToTranslate»/>| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
Для получения дополнительной информации см. Right.
SQL Server CONCATENATE Операции с функциями SQL Plus (+) и SQL CONCAT
В этой статье рассматриваются операции SQL Server Concatenate с использованием оператора SQL Plus (+) и функции SQL CONCAT.
Введение
Мы используем различные типы данных в SQL Server для правильного определения данных в конкретном столбце. У нас могут быть требования для объединения данных из нескольких столбцов в строку. Например, в таблице «Сотрудники» у нас могут быть имя, отчество и фамилия сотрудника в разных столбцах.
На следующем снимке экрана у нас есть 10 лучших записей из таблицы сотрудников, чье среднее имя НЕ NULL (я объясню причину этого, когда мы будем двигаться дальше в этой статье).
SELECT TOP (10) [Имя], [Отчество], [Фамилия] ОТ [AdventureWorks2017].[ Person].[Person] , где отчество НЕ НУЛЕВОЕ |
Обзор оператора SQL Plus
Обычно мы используем оператор SQL Plus (+) для выполнения операции SQL Server Concatenate с несколькими полями вместе. Мы также можем указать пробел между этими столбцами.
Синтаксис оператора SQL Plus(+)
строка1 + строка2 + …….строкаn
Примеры оператора SQL Plus(+)
Посмотрите на следующий запрос. В этом запросе мы используем оператор SQL Plus(+) и пробел между одинарными кавычками в качестве разделителя между этими полями.
1 2 3 4 5 6 | SELECT TOP 10 Имя, Отчество, Фамилия, Имя + ‘ ‘ + Отчество + ‘ ‘ + Фамилия КАК Полное Имя ОТ [AdventureWorks2017].[Person].[Person] ГДЕ Отчество НЕ НУЛЕВОЙ; |
В выходных данных SQL Server Concatenate с использованием оператора SQL Plus (+) мы объединяем данные из этих полей (имя, отчество и фамилия) в виде нового столбца FullName.
У нас есть недостаток в данных SQL Server Concatenate с оператором SQL Plus (+). Посмотрите на следующий пример.
SELECT TOP 10 Имя, Отчество, Фамилия, Имя + ‘ ‘ + Отчество + ‘ ‘ + Фамилия AS Полное имя ОТ [AdventureWorks2017].[Person].[Person] |
В этом примере мы видим, что если у нас есть какое-либо значение NULL , присутствующее в любых полях, мы получаем вывод объединенной строки как NULL с оператором SQL Plus (+).
Мы можем использовать функцию SQL ISNULL с оператором +, чтобы заменить значения NULL пробелом или любым конкретным значением. Выполните следующий запрос, и мы по-прежнему можем использовать оператор SQL Plus (+) для объединения строк.
SELECT TOP 10 Имя, Отчество, Фамилия, ISNULL (Имя, ») + ‘ ‘ + ISNULL(отчество, ») + ‘ ‘ + ISNULL(фамилия, ») КАК полное имя ОТ [AdventureWorks2017]. |
 [Человек].[Человек];
[Человек].[Человек];Давайте рассмотрим еще один пример значений SQL Server Concatenate со строковыми и числовыми значениями. В следующем запросе мы хотим объединить первое, среднее, полное имя вместе с номером NationalID.
1 2 3 4 5 6 7 8 | SELECT стр.[Название], стр.[Имя], стр.[Отчество], стр. [Фамилия], стр. Имя + ‘ ‘ + p.Отчество + ‘ ‘ + p .LastName + ‘NationalIDNumber is:’ + e.NationalIDNumber AS EmpDetail FROM [HumanResources].[Employee] e INNER JOIN [Person].[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID] ГДЕ p.Middlename НЕ NULL; |
Предположим, нам нужна одинарная кавычка и в SQL Server Concatenate. В SQL Server, когда мы объединяем строки с помощью оператора SQL Plus (+), он объединяет значения в одинарных кавычках. В следующем запросе мы видим, что указали две одинарные кавычки, чтобы отобразить одинарную кавычку на выходе.
В следующем запросе мы видим, что указали две одинарные кавычки, чтобы отобразить одинарную кавычку на выходе.
SELECT ‘Давайте» + ‘изучите SQL Server со статьями о SQLShack’; |
Если есть какое-либо несоответствие или неправильное использование одинарной кавычки, вы получите следующее сообщение об ошибке.
Сообщение 102, уровень 15, состояние 1, строка 4
Неправильный синтаксис рядом с «+».
Сообщение 319, уровень 15, состояние 1, строка 4
Неправильный синтаксис рядом с ключевым словом «с». Если этот оператор является обычным табличным выражением,
предложение xmlnamespaces или предложение контекста отслеживания изменений, предыдущий оператор должен заканчиваться точкой с запятой.
Сообщение 105, уровень 15, состояние 1, строка 4
Незакрытые кавычки после строки символов ‘;
‘.
Если мы хотим напечатать больше одинарных кавычек, нам нужно определить в строке в следующем формате две одинарные кавычки.
Ожидаемый результат : «Давайте изучим SQL Server со статьями о SQLShack»
Мы можем изменить SQL-запрос следующим образом.
SELECT »’Давайте» + ‘ изучить SQL Server со статьями о SQLShack»’; |
- Примечание : не следует путать одинарные кавычки с двойными кавычками. SQL Server обрабатывает двойные кавычки как символ.
В следующем запросе мы использовали двойную кавычку в сочетании с одинарной кавычкой.
SELECT ‘»»Давайте»s’ + ‘изучите SQL Server со статьями о SQLShack»’; |
Мы можем выполнить операцию конкатенации SQL Server, используя оператор SQL Plus (+); однако это становится сложным, если вам нужно использовать несколько одинарных кавычек. Также трудно отлаживать код, так как вам также нужно смотреть на все комбинации одинарных кавычек.
ФУНКЦИЯ СЦЕПЛЕНИЯ SQL
Начиная с SQL Server 2012, у нас есть новая функция для объединения строк в SQL Server.
Синтаксис функции SQL CONCAT
СЦЕП (строка1, строка2….строкаN)
Нам требуется, чтобы по крайней мере два значения были объединены вместе и указаны в функции SQL CONCAT.
Примеры
Давайте рассмотрим SQL CONCAT на примере. Следующий запрос объединяет строку и выдает результат в виде одной строки. Мы указали несколько одинарных кавычек между каждым словом, чтобы печатать пробел между каждым словом.
SELECT CONCAT(‘Мой’,’ ‘, ‘Имя’,’ ‘, ‘есть’,’ ‘, ‘Ражендра’,’ ‘, ‘Гупта’) КАК введение |
Мы также можем использовать системные функции для объединения строк с помощью функции SQL CONCAT.
SELECT CONCAT(‘функция SQL ISNULL опубликована’,’ ‘,GETDATE()-2) AS SingleString |
Мы также используем функцию Getdate() для получения указанной даты в объединенной строке.
В предыдущем разделе мы рассмотрели, что если мы хотим объединить строку с помощью оператора +, и любая из строк имеет значение NULL, и мы получим вывод как NULL. Мы используем функцию SQL ISNULL для замены значений NULL в строке. Нам нужно использовать SQL ISNULL с каждым столбцом, содержащим значения NULL. Если у нас есть большое количество столбцов, которые могут иметь значения NULL, писать такой код становится сложно.
Давайте еще раз рассмотрим это с помощью функции SQL CONCAT. Нам нужно только сразу указать функцию SQL CONCAT и указать все строковые столбцы. Мы получаем вывод в виде объединенной строки.
SELECT TOP 10 Имя, Отчество, Фамилия, CONCAT(FirstName, ‘ ‘,Отчество,’ ‘,Фамилия) AS Полное имя FROM [AdventureWorks2017].[Person].[Person]; |
- Примечание: Если все строки, переданные в SQL-функции CONCAT, имеют значение NULL, мы также получаем NULL на выходе этой функции.

SQL CONCAT и преобразование типов данных
Функция SQL CONCAT неявно преобразует аргументы в строковые типы перед конкатенацией. Мы также можем использовать функцию SQL CONVERT без преобразования соответствующего типа данных.
Если мы объединяем строку с помощью оператора плюс (+), нам нужно использовать функцию SQL CONVERT для преобразования типов данных. Давайте рассмотрим это на следующем примере.
В следующем запросе мы хотим объединить две строки. В этом примере тип данных первой строки — текст, а другой тип данных — дата.
Объявить @Text Varchar(100)=’Microsoft SQL Server 2019 Community Technology Preview 2.5 запущен’ Объявить @date date=’201 |
Выполните этот запрос, и мы получим следующий вывод.
Сообщение 402, уровень 16, состояние 1, строка 3
Типы данных varchar и date несовместимы в операторе добавления.
Нам нужно использовать функцию SQL CONVERT в соответствии со следующим запросом, и она возвращает вывод без сообщения об ошибке.
Объявить @Text Varchar(100)=’Microsoft SQL Server 2019 Community Technology Preview 2.5 запущен’ Объявить @date date=’201 |
Нам не нужно использовать функцию SQL CONVERT для преобразования типа данных в функцию SQL CONCAT. Он автоматически выполняет преобразование на основе типа входных данных.
Объявить @Text Varchar(100)=’Microsoft SQL Server 2019 Community Technology Preview 2.5 запущен’ Объявить @date date=’201 |
В следующей таблице мы видим это преобразование типов данных для входных и выходных типов данных в функции SQL CONCAT.
Тип входных данных | Тип выходных данных |
SQL CLR | NVARCHAR(МАКС) |
NVARCHAR(МАКС) | NVARCHAR(МАКС) |
NVARCHAR(<=4000 символов) | NVARCHAR(<=4000 символов) |
VARBINARY(МАКС) | NVARCHAR(МАКС) |
Все остальные типы данных | VARCHAR(<=8000) *если тип данных любого параметра - NVARCHAR, выходное значение будет NVARCHAR(MAX) |
Заключение
В этой статье мы рассмотрели полезные функции SQL для объединения нескольких значений с помощью оператора SQL Plus(+) и функции SQL CONCAT. Если у вас есть комментарии или вопросы, не стесняйтесь оставлять их в комментариях ниже.
- Автор
- Последние сообщения
Раджендра Гупта
Привет! Я Раджендра Гупта, специалист по базам данных и архитектор, помогаю организациям быстро и эффективно внедрять решения Microsoft SQL Server, Azure, Couchbase, AWS, устранять связанные проблемы и настраивать производительность с более чем 14-летним опытом.
Я автор книги «DP-300 Administering Relational Database on Microsoft Azure». Я опубликовал более 650 технических статей о MSSQLTips, SQLShack, Quest, CodingSight и MultipleNines.
Я создатель одной из крупнейших бесплатных онлайн-коллекций статей по одной теме, включая его серию из 50 статей о группах доступности SQL Server Always On.
Основываясь на моем вкладе в сообщество SQL Server, я был признан престижным Лучшим автором года непрерывно в 2019, 2020 и 2021 годах (2-е место) в SQLShack и наградой чемпионов MSSQLTIPS в 2020 году.
Личный блог: https://www.dbblogger.com
Меня всегда интересуют новые задачи, поэтому, если вам нужна консультационная помощь, свяжитесь со мной по адресу [email protected]
Просмотреть все сообщения Раджендры Гупты
Последние сообщения Раджендры Гупты (посмотреть все)
Эффективное использование конкатенации SQL Server
Автор: Sherlee Dizon |
Комментарии (17) | Похожие: 1 | 2 | 3 | 4 | 5 | 6 | Подробнее > Функции Система
Проблема
В этой статье я хотел бы поделиться некоторыми советами по эффективному использованию конкатенации.
для разработки приложений. Здесь я хотел бы отметить некоторые вещи, которые мы
необходимо учитывать и учитывать при объединении значений или полей в наших запросах или
хранимые процедуры.
Ознакомьтесь с этим советом, чтобы узнать больше.
Решение
Конкатенация строк — это добавление одной строки в конец другой строки.
Язык SQL позволяет нам объединять строки, но синтаксис зависит от
какую систему баз данных мы используем. Конкатенацию можно использовать для соединения строк из
различные источники, включая значения столбцов, литеральные строки, вывод из определенных пользователем
функции, скалярные подзапросы и т. д. Давайте рассмотрим, как объединять строки.
Как SQL Server объединяет строки?
Начиная с версии SQL Server 2008 R2 и ниже «+» (знак плюс) — это оператор
используется в строковом выражении, которое объединяет две или более символьных или двоичных строк,
столбцы или комбинацию строк и имен столбцов в одно выражение или в
другой столбец.
Из версий SQL Server 2008, 2008 R2 и 2012 «+=» (добавить знак равенства) является еще одним
оператор конкатенации строк, который можно использовать для конкатенации двух строк и
устанавливает строку в результат операции. Этот оператор нельзя использовать без
переменная, в противном случае выполнение запроса завершается ошибкой.
Теперь SQL Server 2012 и более поздние версии предоставляют нам CONCAT(), новую функцию для конкатенации. Он возвращается
строка, являющаяся результатом объединения двух или более строковых значений. Новый
функция неявно преобразует все аргументы в строковые типы, а затем объединяет
входы. Требуется как минимум два входных значения, иначе конкатенация завершится неудачно.
Рекомендации по проектированию базы данных SQL Server
Один из принципов проектирования реляционной базы данных заключается в том, что поля
таблицы данных должны отражать одну характеристику предмета таблицы, которая
означает, что они не должны содержать конкатенированные строки. Например, для отображения
Например, для отображения
физический адрес определенного сотрудника, данные могут включать подразделение здания
номер, название здания, название улицы, название города, название провинции, почтовый индекс и страна
название, например, «Блок 2307 ABC Tower Salcedo St. Makati City, 1402, Филиппины», который
объединяет 7 полей.
Однако таблица данных сотрудников не должна использовать одно поле для хранения объединенных данных.
нить; скорее, объединение 7 полей должно произойти при запуске
отчет или приложение. Причина таких принципов в том, что без них
ввод и обновление больших объемов данных становится подверженным ошибкам и трудоемким.
Отдельный ввод города, почтового индекса и страны позволяет проверить ввод данных.
(например, обнаружение неверного почтового индекса). Затем эти отдельные элементы можно использовать для
сортировка или индексация записей, например, все с «Макати» в качестве названия города.
Использование конкатенации строк в SQL Server
Конкатенация может предоставить результат в более читаемом формате, сохраняя при этом
данные в отдельных столбцах для большей гибкости. Ниже приведены некоторые варианты использования строки
Ниже приведены некоторые варианты использования строки
конкатенация в SQL Server:
- Для объединения строк из разных источников, включая значения столбцов, литералы
строки, вывод из определяемых пользователем функций или скалярных подзапросов. - Для создания файла с разделителями-запятыми (файл .csv) или текстового файла (файл .txt).
- Для объединения значений нескольких столбцов в один столбец, который можно разделить
запятой, одиночным пробелом или другим разделителем. - Для объединения числовых типов данных, дат и типов данных varchar в один столбец
или любая комбинация. - Когда нам нужно объединить несколько строковых значений в одну длинную строку, где
добавляется запятая, точка или специальный символ. - Чтобы объединить несколько строк в одну строку или столбец.
Рекомендации по использованию конкатенации строк в запросе
1. Знайте, где будет использоваться набор результатов запроса.
- Если в отчете требуется объединение, это должно быть
время выполнения отчета. - Когда требуется объединение для отображения списка данных на веб-странице
или в приложении (форма Windows), он должен быть создан в коде позади
или в классе. - Если набор результатов запроса будет использоваться для создания отчетов с помощью
Инструмент лучше всего выполнять конкатенацию строк с помощью инструмента создания отчетов. - Если набор результатов запроса будет использоваться для отображения списка данных для веб-сайта
страницу или конкретное приложение, объединяя значения столбцов или выражения
из нескольких строк обычно лучше всего делать на клиентской стороне приложения.
язык. Однако вы можете сделать это, используя различные подходы в Transact SQL,
но лучше избегать таких методов для долгосрочных решений.

2. Знайте, кто будет использовать или кому понадобится набор результатов запроса.
- Если пользователь, который будет использовать набор результатов запроса, не знаком с
инструмент или любой язык приложения, как правило, лучше всего выполнить конкатенацию
или форматирование данных для них.

3. Определите размер соединяемых строк.
- Мы должны определить максимальное количество символов в строке, которую мы собираемся объединить.
Существует ограничение на объединение строк с определенными типами данных.
4. Знайте, насколько велики данные, которые вам нужно запрашивать и отображать.
- Вы должны сопоставить стоимость возвращаемых дополнительных данных со стоимостью обработки
данные. Также имейте в виду последствия обслуживания как в SQL Server,
и во внешнем приложении.
5. Знайте, могут ли нужные вам данные быть нулевым значением.
- Всегда проверять нулевые значения при объединении нескольких полей или значений
в вашем запросе, чтобы предотвратить неправильный вывод, особенно если вы еще не используете
MSSQL 2012. Сделайте ваш запрос максимально гибким, потому что мы можем никогда не узнать
когда наш клиент или пользователь изменит свои требования к отчету.
Пример использования конкатенации SQL в нескольких платформах баз данных
Конкатенация зависит от типа и версии базы данных. Посмотрите эти примеры
Посмотрите эти примеры
чтобы увидеть код в действии.
База данных: Microsoft Access
Microsoft Access использует оператор «+» плюс для выполнения конкатенации. Пример
ниже добавляет значение в столбце FirstName с пробелом, т.е. ‘ ‘ и
затем добавляет значение из столбца LastName. Полученной строке присваивается
Псевдоним FullName, чтобы мы могли легко идентифицировать его в нашем наборе результатов.
ВЫБЕРИТЕ Имя + ' ' + Фамилия как полное имя ОТ сотрудников
База данных: Oracle
Oracle использует функцию CONCAT(string1, string2) или || оператор. Оракул
Функция CONCAT может принимать только две строки, поэтому приведенный выше пример был бы невозможен.
поскольку есть три строки, которые нужно соединить (FirstName, ‘ ‘ и LastName). Достигать
это в Oracle нам нужно было бы использовать || оператор, который эквивалентен +
оператор конкатенации строк в SQL Server и Access.
ВЫБЕРИТЕ Имя || ' ' || Фамилия как полное имя ОТ сотрудников
База данных: MySQL
MySQL использует функцию CONCAT(string1, string2, string3. ..). Пример выше
..). Пример выше
будет выглядеть следующим образом в MySQL.
SELECT CONCAT(FirstName, ' ', LastName) As FullName FROM Employees
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
символов
В этом примере я объединю 2 столбца, оба из которых используют строковые символы.
с типом данных nvarchar в один столбец.
ИСПОЛЬЗОВАТЬ AdventureWorks; SELECT GroupName + '-' + Name as AdventureWorksDept ОТ [Отдела кадров].[Отдел] ЗАКАЗАТЬ ПО GroupName
Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
символы и цифры
При объединении чисел нам нужно преобразовать их в строку. Мы можем использовать CAST()
или функцию CONVERT() для этого. В этом примере я посчитаю сумму всех
часы отпуска и отпуска по болезни для каждого производственного отдела, а затем объединить строку
к общему количеству часов.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ [Название], «Общее количество часов отпуска:» + CONVERT (varchar (5), SUM ([VacationHours])) AS VacationHours, 'Общее количество часов отпуска по болезни: ' + CONVERT (varchar (5), SUM ([SickLeaveHours])) AS SickLeaveHour ОТ [AdventureWorks].
 [Человеческие ресурсы].[Сотрудник]
ГДЕ НАЗВАНИЕ КАК «Производство%»
СГРУППИРОВАТЬ ПО [Название]
ЗАКАЗАТЬ ПО СУММЕ ([Отпускные часы]), СУММЕ ([Отпускные часы по болезни])
[Человеческие ресурсы].[Сотрудник]
ГДЕ НАЗВАНИЕ КАК «Производство%»
СГРУППИРОВАТЬ ПО [Название]
ЗАКАЗАТЬ ПО СУММЕ ([Отпускные часы]), СУММЕ ([Отпускные часы по болезни])
Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
числа и даты
Так же, как и при объединении чисел, нам также нужно преобразовать даты в строку.
Мы также можем использовать функцию CAST() или CONVERT().
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ empDeptHist.[StartDate],HRDept.[Name] как DeptName, CONVERT(varchar(5),COUNT(empDeptHist.[EmployeeID])) AS EmpCount, CONVERT(varchar(5),COUNT(empDeptHist.[EmployeeID])) + ' ' + CONVERT(varchar(12), empDeptHist.[StartDate], 101) as ConcatenatedNumberDate FROM [HumanResources].[EmployeeDepartmentHistory] empDeptHist LEFT OUTER JOIN [HumanResources].[Department] HRDept ON empDeptHist.[DepartmentID] = HRDept.[DepartmentID] ГДЕ HRDept.[Имя] = 'Продажи' СГРУППИРОВАТЬ ПО empDeptHist.
 [StartDate],HRDept.[Name]
[StartDate],HRDept.[Name]
Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
символы и даты
Вот самый простой способ соединить строку и дату.
SELECT 'Сегодня:' + ПРОБЕЛ (5) + CONVERT (varchar (12), GETDATE(), 101) AS CurrentDate
Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
с несколькими значениями
Теперь попробуем объединить разные типы данных в один столбец.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ empDeptHist.[StartDate],HRDept.[Name] как DeptName, CONVERT(varchar(5),COUNT(empDeptHist.[EmployeeID])) AS EmpCount, HRDept.[Name] + ' with ' + CONVERT(varchar(5),COUNT(empDeptHist.[EmployeeID])) + ' сотрудник нанят для ' + CONVERT(varchar(12), empDeptHist.[StartDate], 101) as ConcatenatedValues FROM [HumanResources].[EmployeeDepartmentHistory] empDeptHist LEFT OUTER JOIN [HumanResources].
 [Department] HRDept
ON empDeptHist.[DepartmentID] = HRDept.[DepartmentID]
ГДЕ HRDept. [Имя] как «Доставка%»
СГРУППИРОВАТЬ ПО empDeptHist.[StartDate],HRDept.[Name]
[Department] HRDept
ON empDeptHist.[DepartmentID] = HRDept.[DepartmentID]
ГДЕ HRDept. [Имя] как «Доставка%»
СГРУППИРОВАТЬ ПО empDeptHist.[StartDate],HRDept.[Name] Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
со значениями NULL
В этом примере я покажу, как обрабатывать значения NULL НЕПРЯМО и ЯВНО.
Мы можем явно обрабатывать нулевые значения, используя
ISNULL() или
ОБЪЕДИНЕНИЕ()
функция.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ ПЕРВЫЕ 10 [Название],[Имя],[Отчество],[Фамилия],[Суффикс] ,[Название]+' '+[Имя]+' '+[Отчество]+' '+[Фамилия]+' '+[Суффикс] as HandlingNULLНеявно ,ISNULL([Название],'') + ' ' + ISNULL([Имя],'') + ' ' + ISNULL([Отчество],'') + ' ' + ISNULL([LastName],'') + ' ' + ISNULL([Suffix],'') as HandlingNULLявно ,COALESCE([Title],'') + ' ' + COALESCE([FirstName],'') + ' ' + COALESCE([отчество],'') + ' ' + COALESCE([LastName],'') + ' ' + COALESCE([Suffix],'') as UsingCoalesce ОТ [AdventureWorks].
 [Лицо].[Контактное лицо]
ГДЕ [Название] = 'Мистер'
[Лицо].[Контактное лицо]
ГДЕ [Название] = 'Мистер' Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
GUID
В этом примере я попытаюсь объединить rowguid с уникальным идентификатором.
тип данных.
ИСПОЛЬЗОВАТЬ AdventureWorks; SELECT TOP 10 [FirstName], [LastName], [rowguid], len([rowguid]) как char_count ,CAST([rowguid] as varchar(36)) + '==> ' + [LastName] + ', '+ [FirstName] as ConcatenatedValue ОТ [AdventureWorks].[Лицо].[Контактное лицо]
Вот набор результатов.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
строки значений в один столбец
В этом примере я покажу, как объединить список отделов определенного
группа, разделенная запятой, только в один столбец.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ [DepartmentID],[Имя],[Имя группы] ОТ [AdventureWorks].[Отдел кадров].[Отдел] ГДЕ [Имя группы] = «Исполнительный директор и администрация» ОБЪЯВИТЬ @GroupDept VARCHAR(8000) SELECT @GroupDept = COALESCE(@GroupDept + ', ', '') + Имя ОТ [AdventureWorks].
 [Отдел кадров].[Отдел]
ГДЕ [Имя группы] = «Исполнительный директор и администрация»
ВЫБЕРИТЕ 'Главный исполнительный директор и отдел группы администраторов: ' + @GroupDept + '.' AS GroupDeptList
[Отдел кадров].[Отдел]
ГДЕ [Имя группы] = «Исполнительный директор и администрация»
ВЫБЕРИТЕ 'Главный исполнительный директор и отдел группы администраторов: ' + @GroupDept + '.' AS GroupDeptList
Вот набор результатов. Чтобы проверить правильность объединенных значений, я включил
список названий отделов для выбранного имени группы.
База данных: SQL Server использует синтаксис «+» (знак плюс) — объединение
строки с FOR XML PATH
В этом примере я буду суммировать данные в группы или список значений двумя способами.
с помощью коррелированного подзапроса или с помощью CROSS APPLY.
ИСПОЛЬЗОВАТЬ AdventureWorks;
-- Использование коррелированного подзапроса
ВЫБЕРИТЕ G.GroupName,
STUFF((SELECT ', ' + DN.Name
ОТ HumanResources.Department AS DN
ГДЕ DN.GroupName = G.GroupName
ЗАКАЗАТЬ ПО G.GroupName
FOR XML PATH('') ), 1, 1, '') AS dept_list
ОТ HumanResources.Department AS G
СГРУППИРОВАТЬ ПО Имя группы
-- Использование ПЕРЕКРЕСТНОГО ПРИМЕНЕНИЯ
ВЫБЕРИТЕ G. GroupName, STUFF (P.dept_list, 1, 1, '') AS dept_list
ОТ HumanResources.Department AS G
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ (ВЫБРАТЬ ', ' + DN.Name
ОТ HumanResources.Department AS DN
ГДЕ DN.GroupName = G.GroupName
ЗАКАЗАТЬ ПО G.GroupName
FOR XML PATH('') ) AS P (dept_list)
СГРУППИРОВАТЬ ПО GroupName,P.dept_list
 GroupName, STUFF (P.dept_list, 1, 1, '') AS dept_list
ОТ HumanResources.Department AS G
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ (ВЫБРАТЬ ', ' + DN.Name
ОТ HumanResources.Department AS DN
ГДЕ DN.GroupName = G.GroupName
ЗАКАЗАТЬ ПО G.GroupName
FOR XML PATH('') ) AS P (dept_list)
СГРУППИРОВАТЬ ПО GroupName,P.dept_list
GroupName, STUFF (P.dept_list, 1, 1, '') AS dept_list
ОТ HumanResources.Department AS G
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ (ВЫБРАТЬ ', ' + DN.Name
ОТ HumanResources.Department AS DN
ГДЕ DN.GroupName = G.GroupName
ЗАКАЗАТЬ ПО G.GroupName
FOR XML PATH('') ) AS P (dept_list)
СГРУППИРОВАТЬ ПО GroupName,P.dept_list
Вот набор результатов. Этот подход можно использовать в некоторых целях отчетности для
суммировать нормализованные таблицы в группы или список значений. Есть также некоторые отчеты
и инструменты на стороне клиента, которые поддерживают это напрямую. Этот метод часто называют
Метод черного ящика XML. Предложение PATH используется с входной строкой, указывающей
имя элемента оболочки, который будет создан. Когда используется предложение PATH
с пустой строкой он используется в качестве ввода, что приводит к пропуску элемента-оболочки
поколение.
Вот запрос для проверки правильности данных.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ имя группы, имя из HumanResources.
 Department
ЗАКАЗАТЬ ПО GroupName
Department
ЗАКАЗАТЬ ПО GroupName
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
символов
В этом примере я буду конкатенировать 2 столбца, которые оба являются типами данных nvarchar
в один столбец, но на этот раз с помощью новой функции CONCAT в SQL Server 2012.
ИСПОЛЬЗОВАТЬ AdventureWorks; SELECT CONCAT([GroupName], '-', [Name]) as AdventureWorksDept2012 ОТ [Отдела кадров].[Отдел] ЗАКАЗАТЬ ПО [Имя группы]
Вот набор результатов.
Имейте в виду, что хотя сейчас мы используем Microsoft SQL Server 2012, мы
может по-прежнему использовать предыдущий синтаксис «+» (знак плюс). Он будет производить
такие же результаты. Не о чем беспокоиться, если вам придется использовать или перенести
предыдущая хранимая процедура, созданная с использованием предыдущего синтаксиса.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
символы и цифры
ИСПОЛЬЗОВАТЬ AdventureWorks;
SELECT [Title], CONCAT('Общее количество часов отпуска: ', SUM([VacationHours])) AS VacationHours
,CONCAT('Общее количество часов отпуска по болезни: ', SUM([SickLeaveHours])) AS SickLeaveHour
ОТ [AdventureWorks]. [Человеческие ресурсы].[Сотрудник]
ГДЕ НАЗВАНИЕ КАК «Производство%»
СГРУППИРОВАТЬ ПО [Название]
ЗАКАЗАТЬ ПО СУММЕ ([Отпускные часы]), СУММЕ ([Отпускные часы по болезни])
 [Человеческие ресурсы].[Сотрудник]
ГДЕ НАЗВАНИЕ КАК «Производство%»
СГРУППИРОВАТЬ ПО [Название]
ЗАКАЗАТЬ ПО СУММЕ ([Отпускные часы]), СУММЕ ([Отпускные часы по болезни])
[Человеческие ресурсы].[Сотрудник]
ГДЕ НАЗВАНИЕ КАК «Производство%»
СГРУППИРОВАТЬ ПО [Название]
ЗАКАЗАТЬ ПО СУММЕ ([Отпускные часы]), СУММЕ ([Отпускные часы по болезни])
Вот набор результатов.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
числа и даты
Вот как легко объединять числа и даты в SQL Server 2012. Для
в этом примере я пытаюсь объединить общее количество нанятых сотрудников по отделам
исходя из даты их начала.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ empDeptHist.[StartDate],HRDept.[Name] как DeptName, CONVERT(varchar(5),COUNT(empDeptHist.[EmployeeID])) AS EmpCount, CONCAT(COUNT(empDeptHist.[EmployeeID]) , ' ', CONVERT(varchar(12), empDeptHist.[StartDate], 101)) as ConcatenatedNumberDate FROM [HumanResources].[EmployeeDepartmentHistory] empDeptHist LEFT OUTER JOIN [HumanResources].[Department] HRDept ON empDeptHist.[DepartmentID] = HRDept.[DepartmentID] ГДЕ HRDept.
 [Имя] = 'Продажи'
СГРУППИРОВАТЬ ПО empDeptHist.[StartDate],HRDept.[Name]
[Имя] = 'Продажи'
СГРУППИРОВАТЬ ПО empDeptHist.[StartDate],HRDept.[Name]
Вот набор результатов.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
символы и даты
В этом примере я буду объединять строку с текущей датой и отображать
это в один столбец.
SELECT CONCAT('Сегодня:', ПРОБЕЛ(5), CONVERT(varchar(12), GETDATE(), 101)) AS CurrentDate
Вот набор результатов.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
несколько типов данных
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ empDeptHist.[StartDate],HRDept.[Name] как DeptName, CONVERT(varchar(5),COUNT(empDeptHist.[EmployeeID])) AS EmpCount, CONCAT(HRDept.[Name] , ' with ', COUNT(empDeptHist.[EmployeeID]) , ' сотрудник нанят для ', CONVERT(varchar(12), empDeptHist.[StartDate], 101)) as ConcatenatedValues FROM [HumanResources].[EmployeeDepartmentHistory] empDeptHist LEFT OUTER JOIN [HumanResources].
 [Department] HRDept
ON empDeptHist.[DepartmentID] = HRDept.[DepartmentID]
ГДЕ HRDept. [Имя] как «Доставка%»
СГРУППИРОВАТЬ ПО empDeptHist.[StartDate],HRDept.[Name]
[Department] HRDept
ON empDeptHist.[DepartmentID] = HRDept.[DepartmentID]
ГДЕ HRDept. [Имя] как «Доставка%»
СГРУППИРОВАТЬ ПО empDeptHist.[StartDate],HRDept.[Name] Вот набор результатов.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
Значения NULL
В этом примере я покажу, что плюсик «+» все еще работает в 2012 году и как
она отличается от новой функции CONCAT().
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ ПЕРВЫЕ 10 [Название],[Имя],[Отчество],[Фамилия],[Суффикс] ,[Название]+' '+[Имя]+' '+[Отчество]+' '+[Фамилия]+' '+[Суффикс] as HandlingNULLНеявно ,ISNULL([Название],'') + ' ' + ISNULL([Имя],'') + ' ' + ISNULL([Отчество],'') + ' ' + ISNULL([LastName],'') + ' ' + ISNULL([Suffix],'') as HandlingNULLявно ,COALESCE([Title],'') + ' ' + COALESCE([FirstName],'') + ' ' + COALESCE([отчество],'') + ' ' + COALESCE([Фамилия],'') + ' ' + COALESCE([Суффикс],'') as UsingCoalesce ,CONCAT([Название] , ' ' + [Имя] , ' ' , [Отчество] , ' ' , [Фамилия] , ' ' , [Суффикс]) as UsingCONCAT ОТ [AdventureWorks].
 [Лицо].[Контактное лицо]
ГДЕ [Название] = 'Мистер'
[Лицо].[Контактное лицо]
ГДЕ [Название] = 'Мистер'
Вот набор результатов. Из приведенного ниже набора результатов обратите внимание, что функция CONCAT
неявно преобразует все аргументы в строковые типы, а затем объединяет входные данные.
Для функции CONCAT требуется как минимум два входных значения, иначе конкатенация
терпит неудачу.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
ГИДЫ
В этом примере я попытаюсь объединить rowguid с уникальным идентификатором.
тип данных, использующий новую функцию и предыдущий синтаксис для конкатенации.
способны увидеть их различие.
ИСПОЛЬЗОВАТЬ AdventureWorks; SELECT TOP 10 [FirstName], [LastName], [rowguid], len([rowguid]) как char_count ,CAST([rowguid] as varchar(36)) + '==> ' + [LastName] + ', '+ [FirstName] as ConcatenatedValue ,CONCAT([rowguid] , '==> ' , [LastName] , ', '+ [FirstName]) as UsingCONCAT ОТ [AdventureWorks].[Лицо].[Контактное лицо]
Вот набор результатов.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
ряды значений в один столбец
В этом примере я покажу, как объединить список отделов определенного
группа, разделенная запятой, только в один столбец.
ИСПОЛЬЗОВАТЬ AdventureWorks;
ВЫБЕРИТЕ [DepartmentID],[Имя],[Имя группы]
ОТ [AdventureWorks].[Отдел кадров].[Отдел]
ГДЕ [Имя группы] = «Исполнительный директор и администрация»
ОБЪЯВИТЬ @GroupDept VARCHAR(8000)
SELECT @GroupDept = CONCAT(@GroupDept,', ', Name )
ОТ [AdventureWorks].[Отдел кадров].[Отдел]
ГДЕ [Имя группы] = «Исполнительный директор и администрация»
SELECT CONCAT('Главный исполнительный директор и отделы административной группы ', @GroupDept , '.') AS GroupDeptList Вот набор результатов. Чтобы проверить правильность объединенных значений, я включил
список названий отделов для выбранного имени группы.
База данных: SQL Server 2012 и более поздние версии с использованием функции CONCAT() — объединение
строки с FOR XML PATH
В этом примере я буду суммировать данные в группы или список значений двумя способами.
с помощью коррелированного подзапроса или с помощью CROSS APPLY.
ИСПОЛЬЗОВАТЬ AdventureWorks;
-- Использование коррелированного подзапроса
ВЫБЕРИТЕ G.GroupName,
STUFF((SELECT CONCAT(', ' , DN.Name)
ОТ HumanResources.Department AS DN
ГДЕ DN.GroupName = G.GroupName
ЗАКАЗАТЬ ПО G.GroupName
FOR XML PATH('') ), 1, 1, '') AS dept_list
ОТ HumanResources.Department AS G
СГРУППИРОВАТЬ ПО Имя группы
-- Использование ПЕРЕКРЕСТНОГО ПРИМЕНЕНИЯ
ВЫБЕРИТЕ G.GroupName, STUFF (P.dept_list, 1, 1, '') AS dept_list_UsingCROSS_APPLY
ОТ HumanResources.Department AS G
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ (ВЫБЕРИТЕ CONCAT(', ' , DN.Name)
ОТ HumanResources.Department AS DN
ГДЕ DN.GroupName = G.GroupName
ЗАКАЗАТЬ ПО G.GroupName
FOR XML PATH('') ) AS P (dept_list)
СГРУППИРОВАТЬ ПО GroupName,P.dept_list
Вот набор результатов. Этот подход можно использовать в некоторых целях отчетности для
суммировать нормализованные таблицы в группы или список значений. Есть также некоторые отчеты
Есть также некоторые отчеты
и инструменты на стороне клиента, которые поддерживают это напрямую. Этот метод часто называют
Метод черного ящика XML. Предложение PATH используется с входной строкой, указывающей
имя элемента оболочки, который будет создан. Когда предложение PATH с пустым
строка используется в качестве входных данных, что приводит к пропуску генерации элемента-оболочки.
Вот запрос для проверки данных.
ИСПОЛЬЗОВАТЬ AdventureWorks; ВЫБЕРИТЕ имя группы, имя ОТ HumanResources.Department ЗАКАЗАТЬ ПО GroupName
Заключение
Недостаточно знать, как объединять строки или значения. Мы также должны
знать, где и когда его использовать. Также всегда принимайте во внимание конечного пользователя
кто будет использовать вывод. Различные аспекты программирования должны быть тщательно
Считается, что предпочтение отдается одному методу, а не другому, в зависимости от ситуации. Всегда
проверьте и запомните ограничения каждого подхода. Один из самых логичных вариантов
будет наличие встроенного оператора с необязательными настраиваемыми параметрами
который может выполнять конкатенацию значений в зависимости от типа данных.