Оператор join: SQL: оператор JOIN. Основные типы объединения
Содержание
Объединение таблиц с помощью операторов Join и Keep
Объединение — операция объединения двух таблиц в одну. Записи результирующей таблицы представляют собой комбинации записей в исходных таблицах. При этом две такие записи, составляющие одну комбинацию в результирующей таблице, как правило, имеют общее значение одного или нескольких общих полей. Такое объединение называется естественным. В программе Qlik Sense объединение может выполняться в скрипте, создавая логическую таблицу.
Таблицы, которые находятся в скрипте, можно объединять. Логика Qlik Sense будет распознавать не отдельные таблицы, а результаты объединения, которые будут представлены в одной внутренней таблице. В некоторых случаях это требуется, однако существуют недостатки:
- Загруженные таблицы часто становятся больше, и программа Qlik Sense работает медленнее.
- Некоторая информация может быть потеряна: частота (количество записей) в исходной таблице может быть больше недоступна.


Функция Keep, которая позволяет уменьшить одну или обе таблицы до пересечения данных таблиц перед сохранением таблиц в программу Qlik Sense, предназначена для уменьшения количества случаев, когда необходимо использовать явные объединения.
Примечание к информацииВ данном руководстве термин «объединение» обычно используется для объединений, выполненных до создания внутренних таблиц. Однако ассоциация, выполненная после создания внутренних таблиц, по сути, также является объединением.
Объединения внутри оператора SQL SELECT
При использовании некоторых драйверов ODBC можно выполнять объединение внутри оператора SELECT. Это практически эквивалентно созданию объединения с помощью префикса Join.
Однако большинство драйверов ODBC не позволяют сделать полное внешнее объединение (двунаправленное). Они позволяют сделать только левостороннее или правостороннее внешнее объединение. Левостороннее (правостороннее) внешнее объединение включает только сочетания, в которых в левой (правой) таблице существует ключ объединения.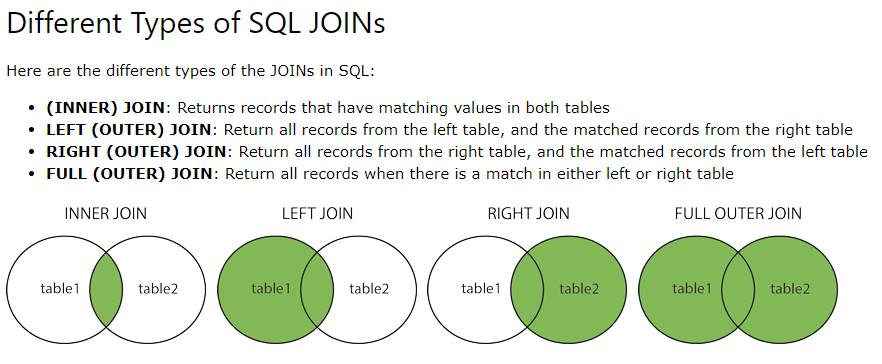 Полное внешнее объединение включает все сочетания. Программа Qlik Sense автоматически создает полное внешнее объединение.
Полное внешнее объединение включает все сочетания. Программа Qlik Sense автоматически создает полное внешнее объединение.
Более того, создание объединений в операторах SELECT значительно сложнее, чем создание объединений в программе Qlik Sense.
Пример:
SELECT DISTINCTROW
[Order Details].ProductID, [Order Details].
UnitPrice, Orders.OrderID, Orders.OrderDate, Orders.CustomerID
FROM Orders
RIGHT JOIN [Order Details] ON Orders.OrderID = [Order Details].OrderID;
Этот оператор SELECT позволяет объединить таблицу, содержащую заказы несуществующей компании, и таблицу, содержащую сведения о заказах. Это правостороннее внешнее объединение, то есть будут включены все записи OrderDetails и записи со значением OrderID, которое отсутствует в таблице Orders. Однако заказы, содержащиеся в таблице Orders, но не содержащиеся в OrderDetails, не будут включены.
Однако заказы, содержащиеся в таблице Orders, но не содержащиеся в OrderDetails, не будут включены.
Join
Самым простым способом создания объединения является использование префикса Join в скрипте, который позволяет объединять внутреннюю таблицу с другой именованной таблицей или последней созданной таблицей. Объединение будет внешним и позволит создать все возможные сочетания значений из двух таблиц.
Пример:
LOAD a, b, c from table1.csv;
join LOAD a, d from table2.csv;
Результирующая внутренняя таблица имеет поля a, b, c и d. Количество записей различается в зависимости от значений полей этих двух таблиц.
Примечание к информацииИмена объединяемых полей должны совпадать. Количество объединяемых полей может быть любым. Обычно в таблицах должно быть одно или несколько общих полей. При отсутствии общих полей будет рассматриваться декартово произведение таблиц. В принципе все поля могут быть общими, однако обычно в этом нет смысла. Пока имя ранее загруженной таблицы не будет указано в операторе Join, префиксом Join будет использоваться последняя созданная таблица. Поэтому порядок двух операторов не является произвольным.
При отсутствии общих полей будет рассматриваться декартово произведение таблиц. В принципе все поля могут быть общими, однако обычно в этом нет смысла. Пока имя ранее загруженной таблицы не будет указано в операторе Join, префиксом Join будет использоваться последняя созданная таблица. Поэтому порядок двух операторов не является произвольным.
Для получения дополнительной информации см. Join.
Keep
Явный префикс Join в скрипте загрузки данных выполняет полное объединение двух таблиц. В результате получается одна таблица. Во многих случаях такие объединения приводят к созданию очень больших таблиц. Одной из основных функций программы Qlik Sense является способность к связыванию таблиц вместо их объединения, что позволяет сократить использование памяти, повысить скорость обработки и гибкость. Функция keep предназначена для сокращения числа случаев необходимого использования явных объединений.
Префикс Keep между двумя операторами LOAD или SELECT приводит к уменьшению одной или обеих таблиц до пересечения их данных перед сохранением таблиц в программе Qlik Sense. Перед префиксом Keep следует задать одно из ключевых слов: Inner, Left или Right. Выборка записей из таблицы осуществляется так же, как и при соответствующем объединении. Однако две таблицы не объединяются и сохраняются в программе Qlik Sense в виде двух отдельных именованных таблиц.
Для получения дополнительной информации см. Keep.
Inner
Перед префиксами Join и Keep в скрипте загрузки данных можно использовать префикс Inner.
При использовании этого префикса перед префиксом Join объединение двух таблиц будет внутренним. Полученная таблица содержит только сочетания из двух таблиц, включающие полный набор данных с обеих сторон.
Если этот префикс используется перед Keep, он указывает, что две таблицы следует уменьшить до области взаимного пересечения, прежде чем они смогут быть сохранены в программе Qlik Sense.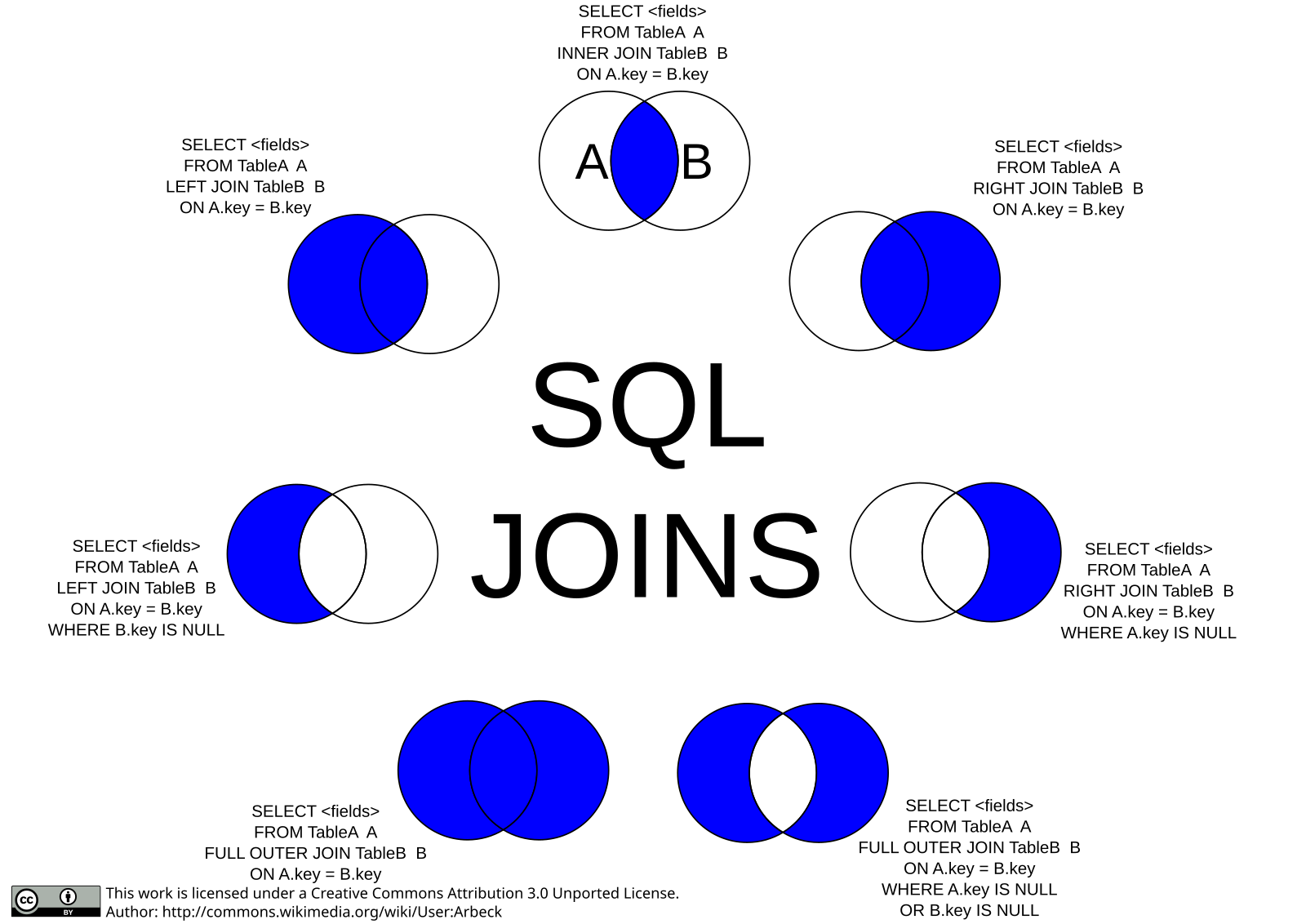
Пример:
В этих таблицах используются исходные таблицы Table1 и Table2:
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
Inner Join
Сначала выполняется Inner Join в отношении таблиц, в результате чего образуется таблица VTable, содержащая только одну строку, только одну запись, существующую в обеих таблицах, с данными из обеих таблиц.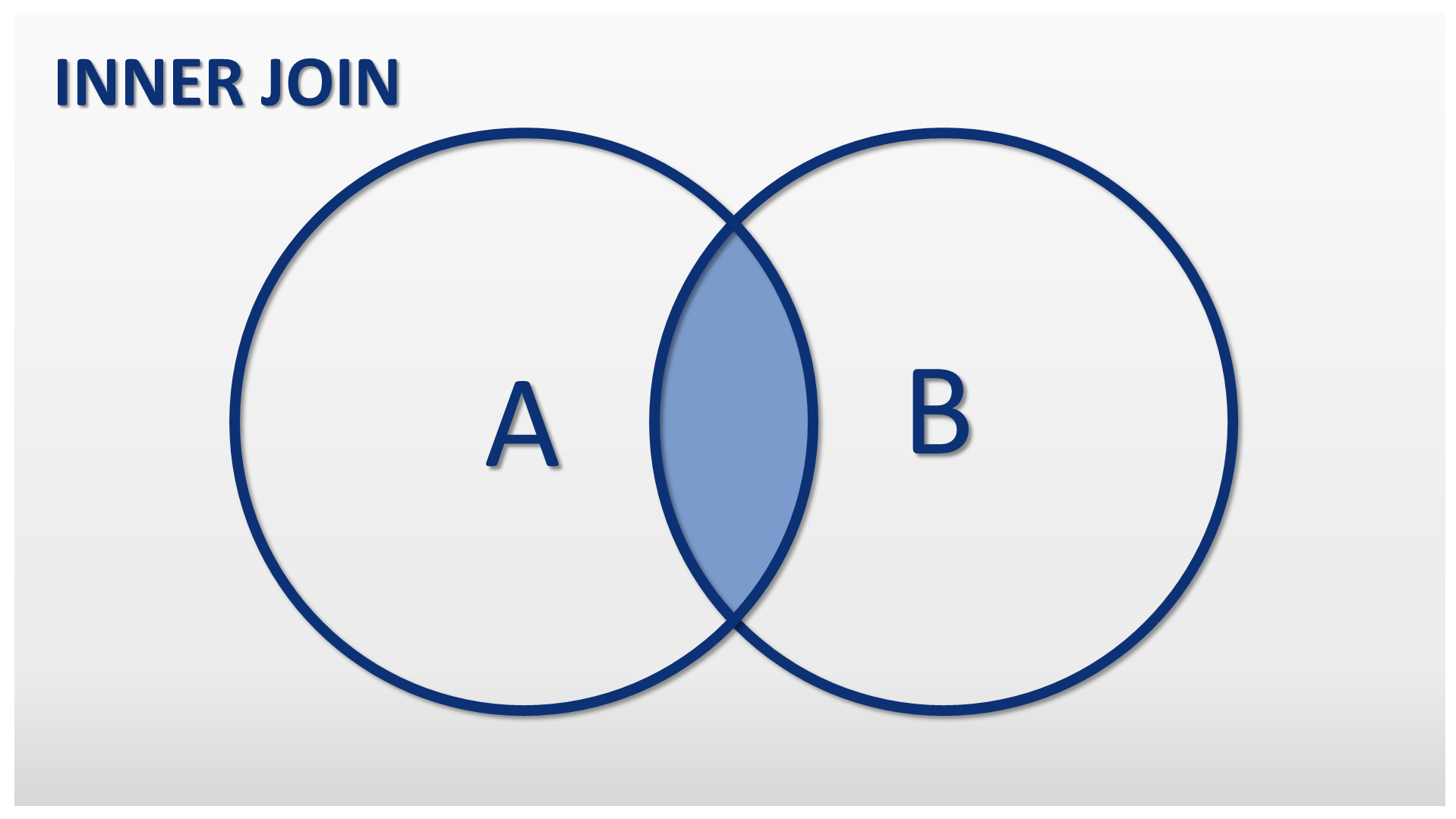
VTable:
SELECT * from Table1;
inner join SELECT * from Table2;
| A | B | C |
|---|---|---|
| 1 | aa | xx |
Inner Keep
Если вместо этого выполняется Inner Keep, таблиц все равно будет две. Две таблицы связаны посредством общего поля A.
VTab1:
SELECT * from Table1;
VTab2:
 NotToTranslate»>inner keep SELECT * from Table2;
NotToTranslate»>inner keep SELECT * from Table2;| A | B |
|---|---|
| 1 | aa |
| A | C |
|---|---|
| 1 | xx |
Для получения дополнительной информации см. Inner.
Left
Перед префиксами Join и Keep в скрипте загрузки данных можно использовать префикс left.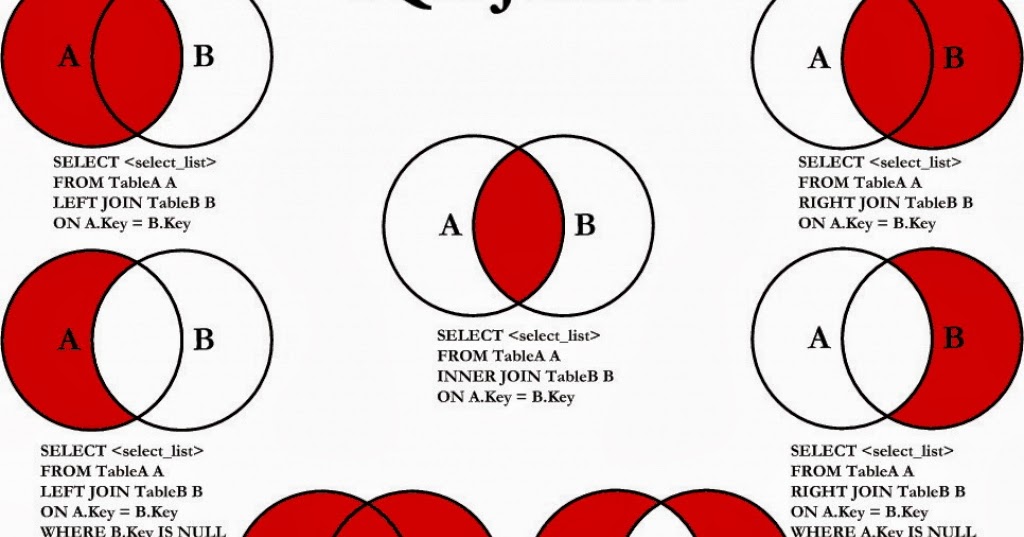
При использовании этого префикса перед префиксом Join объединение двух таблиц будет левосторонним. Полученная таблица содержит только сочетания из двух таблиц, включающие полный набор данных из первой таблицы.
Если этот префикс используется перед префиксом Keep, он указывает, что вторую таблицу следует уменьшить до области взаимного пересечения с первой таблицей перед сохранением в программе Qlik Sense.
Пример:
В этих таблицах используются исходные таблицы Table1 и Table2:
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
 NotToTranslate»/>
NotToTranslate»/>Сначала выполняется Left Join в отношении таблиц, в результате чего образуется таблица VTable, содержащая все строки из таблицы Table1, совмещенные с полями из совпадающих строк в таблице Table2.
VTable:
SELECT * from Table1;
left join SELECT * from Table2;
| A | B | C |
|---|---|---|
| 1 | aa | xx |
| 2 | cc | — |
| 3 | ee | — |
 NotToTranslate»/>
NotToTranslate»/>Если вместо этого выполняется Left Keep, таблиц все равно будет две. Две таблицы связаны посредством общего поля A.
VTab1:
SELECT * from Table1;
VTab2:
left keep SELECT * from Table2;
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
 NotToTranslate»/>
NotToTranslate»/>| A | C |
|---|---|
| 1 | xx |
Для получения дополнительной информации см. Left.
Right
Перед префиксами Join и Keep в скрипте загрузки данных можно использовать префикс right.
При использовании этого префикса перед префиксом Join объединение двух таблиц будет правосторонним. Полученная таблица содержит только сочетания из двух таблиц, включающие полный набор данных из второй таблицы.
Если этот префикс используется перед префиксом Keep, он указывает, что первую таблицу следует уменьшить до области взаимного пересечения со второй таблицей перед сохранением в программе Qlik Sense.
Пример:
В этих таблицах используются исходные таблицы Table1 и Table2:
| A | B |
|---|---|
| 1 | aa |
| 2 | cc |
| 3 | ee |
| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
 NotToTranslate»/>
NotToTranslate»/>Сначала выполняется Right Join в отношении таблиц, в результате чего образуется таблица VTable, содержащая все строки из таблицы Table2, совмещенные с полями из совпадающих строк в таблице Table1.
VTable:
SELECT * from Table1;
right join SELECT * from Table2;
| A | B | C |
|---|---|---|
| 1 | aa | xx |
| 4 | — | yy |
 NotToTranslate»/>
NotToTranslate»/>Если вместо этого выполняется Right Keep, таблиц все равно будет две. Две таблицы связаны посредством общего поля A.
VTab1:
SELECT * from Table1;
VTab2:
right keep SELECT * from Table2;
| A | B |
|---|---|
| 1 | aa |
 NotToTranslate»/>
NotToTranslate»/>| A | C |
|---|---|
| 1 | xx |
| 4 | yy |
Для получения дополнительной информации см. Right.
Курс SQL & Hibernate — Лекция: Оператор OUTER JOIN
Причины появления OUTER JOIN
Кстати, помнишь, мы объединяли наши таблицы и у нас пропали задачи по уборке офиса, так как самой уборщицы еще не было?
Если выполнить такой запрос:
SELECT * FROM task
То мы получим такой результат:
| id | emploee_id | name | deadline |
|---|---|---|---|
| 1 | 1 | Исправить багу на фронтенде | 2022-06-01 |
| 2 | 2 | Исправить багу на бэкенде | 2022-06-15 |
| 3 | 5 | Купить кофе | 2022-07-01 |
| 4 | 5 | Купить кофе | 2022-08-01 |
| 5 | 5 | Купит кофе | 2022-09-01 |
| 6 | (NULL) | Убрать офис | (NULL) |
| 7 | 4 | Наслаждаться жизнью | (NULL) |
| 8 | 6 | Наслаждаться жизнью | (NULL) |
Задача “Убрать офис” пропадает, если мы попробуем объединить таблицу task с таблицей employee по employee_id.
Чтобы решить эту проблему, в оператор JOIN добавили различные модификаторы, которые позволяют сохранить такие потерянные строки без пары в другой таблице.
Напомню классический вид оператора JOIN:
таблица1 JOIN таблица2 ON условие
Мы можем сказать SQL-серверу, чтобы все данные из левой таблицы (таблица1) обязательно присутствовали в объединенной таблице. Даже если для них нет пары в правой таблице. Для этого всего лишь нужно написать:
таблица1 LEFT JOIN таблица2 ON условие
Если же ты хочешь, чтобы в объединенной таблице обязательно были все строки из правой таблицы, то нужно написать:
таблица1 RIGHT JOIN таблица2 ON условие
Давай напишем запрос, который объединит все задачи и сотрудников, чтобы при этом задачи без исполнителя не терялись. Для этого нужно написать запрос:
SELECT * FROM employee e RIGHT JOIN task t ON e.id = t.emploee_id
И результат такого запроса:
| id | name | occupation | salary | age | join_date | id | emploee_id | name |
|---|---|---|---|---|---|---|---|---|
| 1 | Иванов Иван | Программист | 100000 | 25 | 2012-06-30 | 1 | 1 | Исправить багу на фронтенде |
| 2 | Петров Петр | Программист | 80000 | 23 | 2013-08-12 | 2 | 2 | Исправить багу на бэкенде |
| 4 | Рабинович Мойша | Директор | 200000 | 35 | 2015-05-12 | 7 | 4 | Наслаждаться жизнью |
| 5 | Кириенко Анастасия | Офис-менеджер | 40000 | 25 | 2015-10-10 | 3 | 5 | Купить кофе |
| 5 | Кириенко Анастасия | Офис-менеджер | 40000 | 25 | 2015-10-10 | 4 | 5 | Купить кофе |
| 5 | Кириенко Анастасия | Офис-менеджер | 40000 | 25 | 2015-10-10 | 5 | 5 | Купить кофе |
| 6 | Васька | кот | 1000 | 3 | 2018-11-11 | 8 | 6 | Наслаждаться жизнью |
| (NULL) | (NULL) | (NULL) | (NULL) | (NULL) | (NULL) | 6 | (NULL) | Убрать офис |
В нашу таблицу добавилась еще одна строка, и что интересно в ней очень много значений NULL. Все данные, которые брались из таблицы employee отображаются в виде NULL, так как для задачи “Убрать офис” не нашлось исполнителя из таблицы employee.
Все данные, которые брались из таблицы employee отображаются в виде NULL, так как для задачи “Убрать офис” не нашлось исполнителя из таблицы employee.
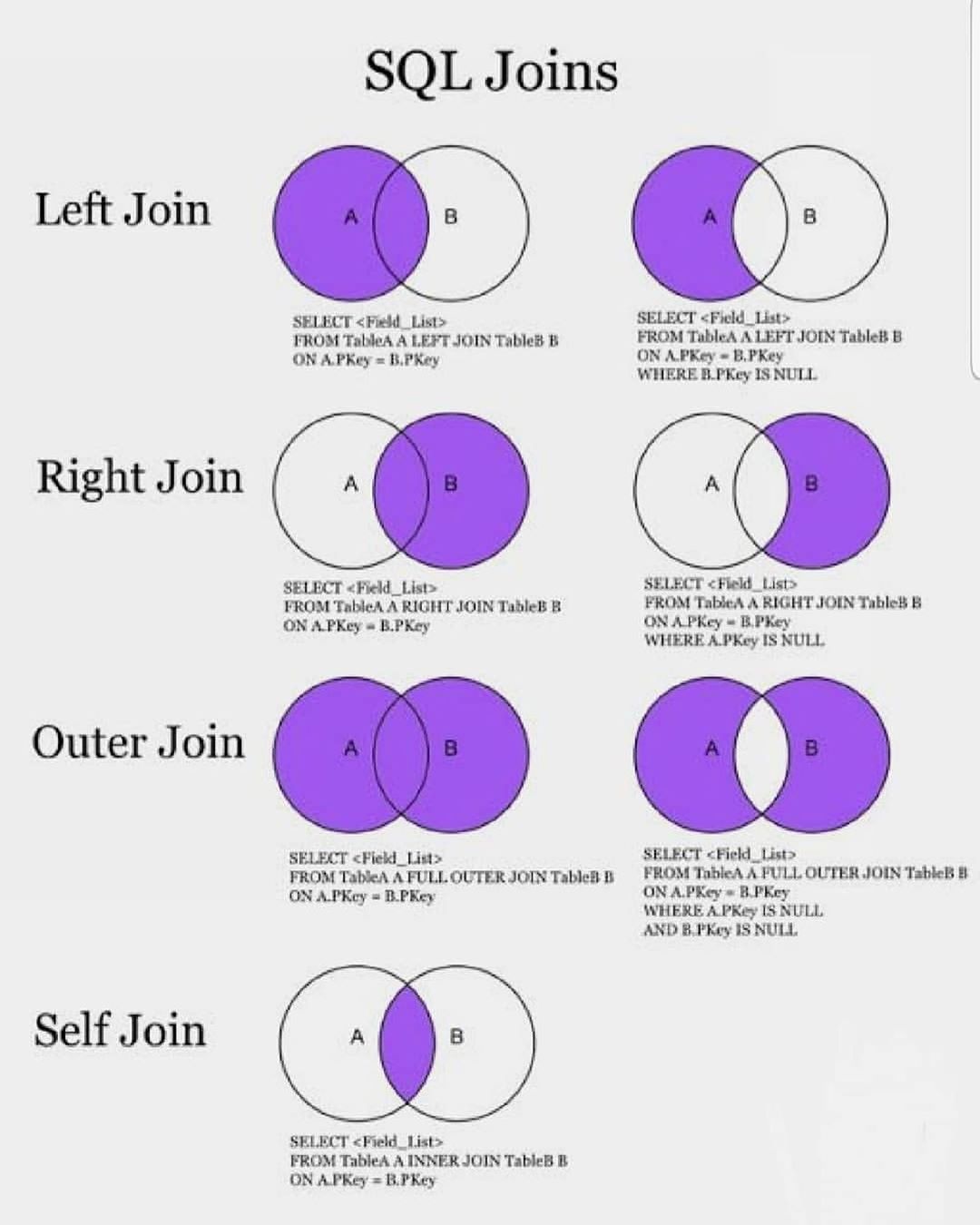
Типы JOIN-ов
Всего существует 4 типа JOIN-ов. Они представлены в таблице ниже:
| Краткая запись | Длинная запись | Пояснение | |
|---|---|---|---|
| 1 | JOIN | INNER JOIN | Только записи, которые есть в таблицах А и Б |
| 2 | LEFT JOIN | LEFT OUTER JOIN | Все строки без пары из таблицы А должны быть |
| 3 | RIGHT JOIN | RIGHT OUTER JOIN | Все строки без пары из таблицы Б должны быть |
| 4 | OUTER JOIN | FULL OUTER JOIN | Все строки баз пар из таблиц А и Б должны быть |
Для простоты, если мы представим таблицы в виде множеств, то JOIN можно будет отображать в виде картинки:
Под пересечением множеств подразумевается, что для одной таблицы есть соответствующая запись из другой таблицы, на которую она ссылается.
Вопрос с собеседования
Иногда программистов-новичков на собеседовании валят очень простым вопросом. С учетом наших таблиц его можно сформулировать так:
“Напишите запрос, которые отобразит список всех сотрудников, для которых нет задач”.
Сначала попробуем немного перефразировать этот вопрос:
“Напишите запрос, которые отобразит список всех сотрудников из таблицы employee, для которых нет задач в таблице task”.
Нам нужно получить вот это множество:
Можно решить эту задачу многими способами, но я начну с самых простых:
Во-первых, ты можешь объединить наши таблицы с помощью LEFT JOIN, а потом с помощью WHERE исключить все строки, для которых недостающие данные были дополнены NULL-ами.
SELECT * FROM employee e LEFT JOIN task t ON e.id = t.emploee_id WHERE t.id IS NULL
И результат такого запроса:
| id | name | occupation | salary | age | join_date | id | emploee_id | name |
|---|---|---|---|---|---|---|---|---|
| 3 | Иванов Сергей | Тестировщик | 40000 | 30 | 2014-01-01 | (NULL) | (NULL) | (NULL) |
Единственный минус такого решения, что тут в таблице строки содержат NULL, а нам по условию нужно отобразить список сотрудников.
Для этого нужно или перечислить в SELECT требуемые колонки таблицы employee, или если нужно отобразить их все, то можно написать такую конструкцию:
SELECT e.* FROM employee e, task t
Полный запрос будет выглядеть так:
SELECT e.* FROM employee e RIGHT JOIN task t ON e.id = t.emploee_id WHERE t.id IS NULL
результат такого запроса:
| id | name | occupation | salary | age | join_date |
|---|---|---|---|---|---|
| 3 | Иванов Сергей | Тестировщик | 40000 | 30 | 2014-01-01 |
Остальные способы остаются вам для домашнего задания. Не хочу лишать вас удовольствия найти их самостоятельно.
Использование оператора соединения
Содержимое
- Введение
- Характеристики:
Вкладка «Общие» - Свойства: Параметры присоединения
Вкладка - Свойства: на основе ценности
Вкладка «Настройки» - Свойства: на основе кортежей
Вкладка «Настройки» - Свойства: настройки вывода
Вкладка - Свойства: вкладка «Параллелизм»
- Пример
1: Соединение на основе ценности - Пример
2: Соединение на основе кортежей - Похожие темы
В этом разделе объясняется, как работает оператор Join, и действия, которые вы можете выполнять с его помощью.
Просмотр свойств.
Введение
Оператор Join объединяет кортежи из двух входных потоков, которые соответствуют условию проверки.
(предикат) и, возможно, находятся в пределах указанного расстояния в своих полях заказа.
Оператор соединения предполагает, что каждый входной поток правильно упорядочен. Он сравнивает
упорядоченные кортежи из первого входного потока в упорядоченные кортежи из второго входного потока
поток, в пределах ограничения расстояния. Результаты объединений
выпускается в одном выходном потоке.
Используйте оператор Join для объединения потоков, имеющих некоторую связь между данными в
оба потока. Например, если было два фида с одним и тем же капиталом,
оператор может сравнить цену акций за период времени и выдать кортеж, если
цена в одном или обоих потоках соответствовала определенным критериям, таким как
указанный порог или если один из них превысил значение.
В оставшейся части этого раздела описываются действия, которые вы можете выполнять на каждой вкладке
Присоединиться к просмотру свойств оператора.
Примечание
На нескольких вкладках оператора соединения, описанных в этом разделе, используются выражения
которые ссылаются на поля во входных потоках. Когда важно указать, какой
входной поток, в котором находится поле, вы можете уточнять имена полей, используя
условный ввод1. имя поля и
вход2. имя-поля . ввод1. Префикс относится к данным, поступающим на «верхний» порт (#1),
в то время как input2. Префикс относится к данным, поступающим на
«нижний» порт (#2). Примеры: input1.SKU и
ввод2.SKU .
Характеристики:
Вкладка «Общие»
Имя: используйте это поле, чтобы указать или изменить
имя компонента, которое должно быть уникальным в приложении. Имя должно содержать только
Имя должно содержать только
алфавитные символы, цифры и знаки подчеркивания, а не дефисы или другие специальные символы.
персонажи. Первый символ должен быть буквенным или символом подчеркивания.
Включить порт вывода ошибок: установите этот флажок, чтобы добавить
Порт ошибки к этому компоненту. На холсте EventFlow порт ошибок отображается как
красный выходной порт, всегда последний порт для компонента. См. Использование портов ошибок и потоков ошибок для
узнать о портах ошибок.
Описание: При желании введите текст для краткого описания
назначение и функции компонента. На холсте EventFlow вы можете увидеть
описание, нажав Ctrl пока
отображается всплывающая подсказка компонента.
Свойства: вкладка «Параметры присоединения»
На вкладке «Настройки присоединения» укажите, как будет выполняться сопряжение входных данных (путем
значения или кортежи), когда удалять любые кортежи, время ожидания которых истекло, и предикат
(тестовое условие), при котором должно произойти соединение.
- Присоединиться через
Соединения на основе значений полезны, когда важно иметь StreamBase.
вернуть полный ответ, а не приблизительный ответ. Присоединение
values означает, что значения кортежей в одном входном потоке будут
по сравнению со значениями кортежей в другом входном потоке.Соединения на основе кортежей полезны, когда нет необходимости (или невозможно)
иметь полный ответ (например, при обработке неопределенных или
неограниченные потоки). Соединения на основе кортежей генерируют приблизительные решения для
запросы на соединение (как в операторах SQL). Кортежи в одном входном потоке
будут сравниваться с кортежами в другом входном потоке, независимо от
ценить.
- Тайм-аут кортежа
Прошедшее время, по истечении которого кортежи должны быть удалены из буфера соединения.
- Предикат
Укажите выражение, которое будет оцениваться как
правда
илиложь. Когда true, условие соединения
удовлетворяется, и оператор Join выдает выходные данные, указанные в
Вкладка «Параметры вывода».Примечание
Ваш выбор
Присоединиться квариантам вызывает следующее
вкладку в представлении «Свойства объединения» с названием «Настройки на основе значений» или «На основе кортежей».
Настройки.
 Кортежи в одном входном потоке
Кортежи в одном входном потоке
Свойства: вкладка «Параметры на основе значений»
Вкладка «Параметры на основе значений» доступна только в том случае, если на вкладке «Параметры объединения» выбран параметр «Объединить по значениям». Используйте эту вкладку для выбора
поля, которые вы хотите заказать, и диапазон значений, за пределами которого эти два поля не могут
отличаются:
В полях заказа укажите поля, в которых
данные от каждого из двух входных портов будут упорядочены.В диапазоне соединения укажите диапазон значений, которые могут содержать поля упорядочивания:
В обоих случаях разница выражается как значение относительно порядка
поле в первом потоке.Диапазон соединения действует как окно: поле с наивысшим порядком в буфере устанавливает верхнюю границу диапазона соединения.
диапазон. Если приходит новый кортеж, который выше, диапазон соответственно сбрасывается:
любые значения ниже этого диапазона удаляются из буфера и будут исключены
из любых объединений.

В следующем примере диапазон соединения равен 120: значение Time_C может быть на 60 меньше.
чем значение в Time_R, и на 60 больше:
Примечание
Поскольку оператор Join чувствителен к порядку, результаты непредсказуемы, если кортежи
приходят не по порядку относительно полей заказа.
Свойства: вкладка «Настройки на основе кортежей»
Вкладка «Настройки на основе кортежей» доступна только в том случае, если вы выбрали «Присоединиться по кортежам» на вкладке «Настройки присоединения». Когда вы присоединяетесь кортежами,
кортежи на одном входном порту сравниваются с кортежами на другом входном порту, независимо
ценности.
Используйте эту вкладку, чтобы указать размеры окна для первого и второго портов. Окно
size указывает, сколько кортежей одного входного порта сравнивается с каждым поступающим
кортеж на другом входном порту. Как правило, чем больше размер окна, тем
ближе приблизительный результат запроса будет к «полному ответу».
Примечание
Только соединения на основе кортежей имеют размеры окна, и эти окна увеличиваются на 1.
Свойства: вкладка «Параметры вывода»
Вкладка «Параметры вывода» позволяет указать имена полей и выражения,
Оператор присоединения должен отпустить. Освобождение происходит, когда предикат в настройке соединения
вкладка оценивается как правда .
Укажите поля вывода, используя один из двух параметров вывода:
Выберите все поля ввода, чтобы автоматически
передать все входные поля в выходной поток.По умолчанию этот параметр добавляет префиксы к именам полей ввода, как показано ниже.
на следующем экране:Префиксы являются необязательными и редактируемыми.
Их цель состоит в том, чтобы избежать имени
конфликты в полях вывода, которые могут возникнуть в результате объединения повторяющихся имен полей
во входных портах. Однако, если вы измените или удалите префиксы и
оператору не удается выполнить проверку типов, рассмотрите возможность восстановления префиксов.Выберите явно заданные поля, чтобы указать
поля вывода вручную.Если выбрана явная опция, выходные данные
Таблица полей изначально пуста. Добавьте строку для каждого поля вывода, которое вы
хотите, указав имя выходного поля и его
Выражение. В качестве альтернативы используйте Pass All
Кнопка для загрузки любого или всех полей ввода в таблицу.На следующем экране показана таблица полей вывода.
который был отредактирован вручную с использованием явной опции.
 Их цель состоит в том, чтобы избежать имени
Их цель состоит в том, чтобы избежать имени
Свойства: вкладка «Параллелизм»
Используйте вкладку Concurrency, чтобы указать параллельные регионы для этого экземпляра этого
компонент, или параметры множественности, или и то, и другое. Настройки вкладки «Параллелизм»
описано в параллелизме
Параметры и стили отправки описаны в разделе Стили отправки.
Осторожность
Параметры параллелизма подходят не для каждого приложения, и их использование
settings требует тщательного анализа вашего приложения. Подробнее см.
Подробнее см.
Порядок исполнения и
Параллелизм, который включает важные рекомендации по использованию параллелизма.
параметры.
Пример 1:
Соединение на основе значения
В этом примере отслеживается выполнение установленного образца приложения Join.
со СтримБейс. Приложение объединяет сделки из двух каналов, ReutersIn и
КомстокИн. Схема входного потока содержит следующие поля: символ акции,
его цена и временная метка.
Соединение происходит, когда кортеж на одном порту совпадает с кортежем на другом порту. Чтобы соответствовать,
два кортежа должны иметь одинаковые символы акций, а разница в цене должна быть
больше или равно 1, используя следующее выражение
Symbol_R == Symbol_C && abs(PricePS_R - PricePS_C) >= 1.
 0
0
В дополнение к выражению ценовой разницы устанавливается ограничение расстояния, так что
совпадающие пары должны иметь временные метки в пределах 60 секунд друг от друга. Выходные кортежи
содержат разницу в цене между совпадающими кортежами, цена за акцию от
каждый, и значение времени из кортежа Reuters.
На каждом шаге этого примера показано, как новый кортеж помещается в очередь оператора Join, и
любые выпущенные выходные кортежи. Содержимое двух буферов операторов
отображается после поступления каждого кортежа и после освобождения любых кортежей.
Кортеж входит в оператор Join на входном порту ReutersIn (здесь сокращено до
R) и хранится в буфере:Кортеж входит в порт ComstockIn (сокращенно C).
Значение его первого
поле (B) соответствует символу в первом кортеже, но разница в цене (в
второе поле) меньше единицы. Таким образом, присоединение ничего не освобождает.
оператор:Кортеж на порту R совпадает с другим портом и имеет разницу в цене.
равно 1. Условия для операции соединения выполнены, и оператор соединения
выдает выходной кортеж:В очередь ставится кортеж, содержащий новый символ акции (A).
Потому что это не
соответствуют любым существующим кортежам, вывод не производится:Кортеж поступает на порт C, символ которого совпадает с двумя кортежами из другого порта.
порт. В обоих случаях разница в цене больше 1. В результате два
выпускаются кортежи — по одному на каждое совпадение:Новый кортеж соответствует символу одного существующего кортежа на другом входном порту,
с разницей в цене 2. Следовательно, оператор Join выдает еще один кортеж:Последний кортеж, помещенный в очередь на входном порту C, соответствует двум кортежам на порте R.
Однако новый кортеж вызывает диапазон значений времени в соответствующих кортежах
превышать указанный диапазон соединения в 60 секунд. Новый кортеж продвигает
верхней границы диапазона до 100, а другие совпадающие кортежи теперь ниже
присоединиться к диапазону. В результате совпадающие кортежи на другом порту удаляются из
буфер, и вывод не производится:
 Значение его первого
Значение его первого Потому что это не
Потому что это не Следовательно, оператор Join выдает еще один кортеж:
Следовательно, оператор Join выдает еще один кортеж: Пример 2:
Соединение на основе кортежей
В этом примере отслеживается выполнение операции соединения на основе кортежа. Приложение
Приложение
достаточно просто, чтобы ясно проиллюстрировать основную идею объединения на основе кортежей. Каждый вход
port содержит всего два поля: символ акции и цену. Пары операторов Join
кортежи, которые совпадают в обоих полях. Размеры окна установлены на 3 для первого ввода.
порт и 2 для второго входного порта. Когда происходит соединение, выходной кортеж включает
совпадающий символ и значения цены.
На каждом шаге этого примера показано, как новый кортеж ставится в очередь оператору соединения.
содержимое двух окон отображается после поступления каждого кортежа и после любых кортежей
выпущены. Можно сказать, что окна «движутся» по потоку данных: обратите внимание, что
когда количество прибывающих кортежей превышает выделенный размер окна, самый старый
кортежи удаляются из окна.
Для начала четыре кортежа ставятся в очередь.
Кортежи, входящие в первый входной порт,
буферизуются в первом окне оператора Join, а вводимые во втором
port хранятся во втором окне. Вывод пока не происходит, потому что ни один из
кортежи, входящие в первый порт, соответствуют любым кортежам из второго порта:Далее кортеж поступает во второй входной порт и соответствует кортежу в первом
буфер. Поэтому происходит соединение, и оператор выпускает соответствующий кортеж. В
Кроме того, обратите внимание, что когда окно заполнено и поступает новый кортеж,
окно перемещается по потоку кортежей: самый старый кортеж в окне (B,
60), смывается из окна.Теперь шестой кортеж, входящий в первый входной порт, заполняет первый входной порт.
окно. Обратите внимание, что никаких выходных данных не происходит: вспомните, что соответствующий кортеж, который был
сохраненное ранее в другом окне, было удалено на предыдущем шаге.Наконец, другой кортеж, входящий в первый входной порт, вызывает его окно.
продвигаться вперед и сбрасывать самый старый кортеж. Между тем, новый кортеж соответствует еще одному.
хранится во втором окне, поэтому оператор Join освобождает кортеж.
 Кортежи, входящие в первый входной порт,
Кортежи, входящие в первый входной порт, Поэтому происходит соединение, и оператор выпускает соответствующий кортеж. В
Поэтому происходит соединение, и оператор выпускает соответствующий кортеж. В
Похожие темы
Образец оператора присоединения
Выражение StreamBase
Языковые функции9
SQL и оператор JOIN — SQLServerCentral
Первое, что мы научимся делать с SQL, — писать оператор SELECT для получения данных из одной таблицы.
Такое утверждение кажется простым и очень близким к языку, на котором мы говорим.Но реальные запросы часто намного сложнее, чем простые операторы SELECT.
Во-первых, обычно нужные нам данные разбиваются на несколько разных таблиц. Это естественное следствие нормализации данных, которая является важным свойством любой хорошо спроектированной модели базы данных. И SQL дает вам возможность объединить эти данные.
Раньше администраторы баз данных и разработчики помещали все необходимые таблицы и/или представления в предложение FROM, а затем использовали предложение WHERE, чтобы определить, как записи из каждой таблицы будут объединяться с другими записями. (Чтобы сделать этот текст немного более читабельным, с этого момента я буду упрощать и говорить «таблица» вместо «таблица и/или представление»).
Но у нас уже давно нет стандарта для объединения этих данных. И делается это с помощью оператора JOIN (ANSI-SQL 92). К сожалению, есть некоторые подробности об операторах JOIN, которые остаются неясными для многих людей.
Ниже я покажу различные синтаксисы соединений, поддерживаемые T-SQL (то есть SQL SERVER 2008). Я обрисую в общих чертах несколько концепций, которые, по моему мнению, не следует забывать каждый раз, когда мы объединяем данные из двух или более таблиц.
Приступая к работе: 1 таблица, без объединения
Если у вас есть только один объект для запроса, синтаксис будет довольно простым, и соединение не будет использоваться. Оператор будет старым добрым « SELECT fields FROM object » плюс любое другое необязательное предложение, которое вы, возможно, захотите использовать (например, WHERE, GROUP BY, HAVING или ORDER BY).
Одна вещь, о которой конечные пользователи не знают, это то, что мы, администраторы баз данных, обычно скрываем множество сложных объединений в одном красивом и удобном представлении. Это делается по нескольким причинам, начиная от безопасности данных и заканчивая производительностью базы данных. Например, администраторы баз данных могут предоставлять конечным пользователям разрешения на доступ к одному представлению вместо нескольких рабочих таблиц, что, очевидно, повышает безопасность данных.
Или, учитывая производительность, администраторы баз данных могут создать представление, используя правильные параметры для объединения записей из нескольких таблиц, правильно используя индексы базы данных и тем самым повышая производительность запросов.В целом, соединения могут быть в базе данных, даже если конечные пользователи их не видят.
Логика объединения таблиц
Много лет назад, когда я начал работать с SQL, я узнал, что существует несколько типов соединений. Но мне потребовалось некоторое время, чтобы понять, что именно я делал, когда собирал эти таблицы вместе. Возможно, из-за того, что люди так боятся математики, редко говорят, что вся идея объединения таблиц связана с теорией множеств. Несмотря на причудливое название, концепция настолько проста, что нас учат этому в начальной школе.
Рисунок на Рисунке 1 очень похож на рисунки из книг моих детей из первого класса. Идея состоит в том, чтобы найти соответствующие объекты в разных наборах. Ну, это именно то, что мы делаем с SQL JOIN!
Рисунок 1 : Объединение объектов из разных наборов
Как только вы поймете аналогию, все начнет обретать смысл.
Учтите, что 2 набора в Рисунок 1 — это таблицы, а числа, которые мы видим, — это ключи, которые мы будем использовать для соединения таблиц. Таким образом, в каждом наборе вместо представления всех записей мы видим только ключевые поля из каждой таблицы. Результирующий набор этой комбинации будет определяться типом соединения, которое мы рассматриваем, и это тема, которую я сейчас покажу. Чтобы проиллюстрировать наши примеры, представьте, что у нас есть 2 таблицы, показанные ниже:
Таблица1
ключ1 поле1 поле2 ключ 2 ключ3 3 Эрик 8 1 6 9 0142
4 Джон 3 4 4 6 Марк 3 7 1 7 Peter 6 8 5 8 Harry 0 9 2 Table2
key2 field1 field2 поле3 1 Нью-Йорк A N 2 Сан-Паулу B N 4 Париж C Y 5 Лондон C Y 6 Рим C Y 9 Мадрид Скрипт для создания и заполнить эти таблицы доступны в виде одного прикрепленного файла ( SQLServerCentral. com_JOIN.sql ) в разделе ресурсов ниже.Вы заметите, что этот скрипт не полностью реализует ссылочную целостность. Я намеренно оставил таблицы без внешних ключей, чтобы лучше объяснить функциональность различных типов соединений. Но я сделал это только в дидактических целях. Внешние ключи чрезвычайно полезны для обеспечения согласованности данных, и их нельзя исключать ни из одной реальной базы данных.
Что ж, теперь мы готовы к работе. Давайте проверим типы соединений, которые мы можем использовать в T-SQL, соответствующий синтаксис и результирующий набор, который генерирует каждое из них.
Внутреннее соединение
Это наиболее распространенное соединение, которое мы используем в SQL. Возвращает пересечение двух наборов. Или, с точки зрения таблиц, он приносит только записи из обеих таблиц, которые соответствуют заданным критериям.
На рис. 2 показана диаграмма Венна, иллюстрирующая внутреннее соединение двух таблиц. Результатом операции является область красного цвета.
Рисунок 2 : Представление ВНУТРЕННЕГО СОЕДИНЕНИЯ
Теперь проверьте синтаксис, чтобы объединить данные из Table1 и Table2 с использованием INNER JOIN.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как город
ИЗ Table1 t1
INNER JOIN Table2 t2 ON t1.key2 = t2.key2;Результатом этого оператора будет:
key1 Name T1Key 901 40 T2Key
Город 3 Эрик 1 1 Нью-Йорк 4 Джон 4 4 Париж 8 Гарри 9 9 Мадрид Обратите внимание, что возвращаются только данные из записей, которые имеют одинаковое значение для key2 как в Table1 , так и в Table2 .
В отличие от ВНУТРЕННЕГО СОЕДИНЕНИЯ существует также ВНЕШНЕЕ СОЕДИНЕНИЕ. Существует 3 типа ВНЕШНИХ СОЕДИНЕНИЙ: полное, левое и правое. Ниже мы подробно рассмотрим каждый из них.
ПОЛНОЕ СОЕДИНЕНИЕ
Это также известно как ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ (зарезервированное слово OUTER является необязательным). FULL JOIN работают как объединение двух наборов. Теперь у нас есть Рисунок 3 Диаграмма Венна, иллюстрирующая ПОЛНОЕ СОЕДИНЕНИЕ двух таблиц. Результатом операции снова является область красного цвета.
Рисунок 3 : Представление FULL JOIN
Синтаксис почти такой же, как мы видели раньше.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как город
FROM Table1 t1
FULL JOIN Table2 t2 ON t1.key2 = t2.key2 ;Результатом этого оператора будет:
key1 Name T1Key 901 40 T2Key
Город 3 Эрик 1 1 Нью-Йорк 4 Джон 4 4 Париж 6 Марка 7 нулевой нулевой 9043 9
7 Питер 8 ноль ноль 8 Гарри 9 9 Мадрид нулевой нулевой нулевой 2 Сан-Паулу нулевой нулевой нулевой 5 Лондон нулевой нулевой нулевой 6 Рим null null null 0 Bangalore FULL JOIN возвращает все записи из Table1 и Table2 , без дублирования данных.
ЛЕВОЕ СОЕДИНЕНИЕ
Также известное как ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ, это частный случай ПОЛНОГО СОЕДИНЕНИЯ. Он приносит все запрошенные данные из таблицы, которая появляется слева от оператора JOIN, плюс данные из правой таблицы, которая пересекается с первой. Ниже у нас есть диаграмма Венна, иллюстрирующая ЛЕВОЕ СОЕДИНЕНИЕ двух таблиц на рис. 4.
Рис. 4: Представление ЛЕВОГО СОЕДИНЕНИЯ
См. приведенный ниже синтаксис.
ВЫБЕРИТЕ t1.key1, t1.field1 как Имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как Город
ИЗ Table1 t1
LEFT JOIN Table2 t2 ON t1.key2 = t2.key2 ;Результатом этого оператора будет:
key1 Name T1Key 901 40 T2Key
Город 3 Эрик 1 1 Нью-Йорк 4 9 0141 Джон 4 4 Париж 6 Марк 7 null null 7 Peter 8 null null 9014 0 8 Гарри 9 9 Мадрид Третья и четвертая записи ( key1 равно 6 и 7) показывают значения NULL в последних полях, поскольку из второй таблицы нет никакой информации.
Это означает, что у нас есть значение в поле key2 в Table1 без соответствующего значения в Table2 . Мы могли бы избежать этой «несогласованности данных», если бы у нас был внешний ключ в поле key2 в Table1 .ПРАВОЕ СОЕДИНЕНИЕ
Также известное как ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ, это еще один частный случай ПОЛНОГО СОЕДИНЕНИЯ. Он приносит все запрошенные данные из таблицы, которая появляется справа от оператора JOIN, плюс данные из левой таблицы, которая пересекается с правой. Диаграмма Венна для ПРАВОГО СОЕДИНЕНИЯ двух таблиц показана на рис. 5.
Рисунок 5: Представление RIGHT JOIN
Как видите, синтаксис очень похож.
ВЫБЕРИТЕ t1.key1, t1.field1 в качестве имени, t1.key2 в качестве T1Key,
t2.key2 в качестве T2Key, t2.field1 в качестве города
FROM Table1 t1
RIGHT JOIN Table2 t2 ON t1.key2 = t2.key2 ;Результатом этого оператора будет:
key1 Name T1Key 901 40 T2Key
Город null null null 0 Бангалор 3 Эрик 1 1 Нью-Йорк null null null 2 Сан-Паулу 4 Джон 4 4 Париж 9014 1 нулевой нулевой null 5 London null null null 6 Rome 9014 2
8 Гарри 9 9 Мадрид Обратите внимание на записи с key1 равным 6 и 7 больше не появляются в наборе результатов.
Это потому, что у них нет соответствующей записи в правой таблице. Есть 4 записи со значениями NULL в первых полях, потому что они недоступны в левой таблице.ПОПЕРЕЧНОЕ СОЕДИНЕНИЕ
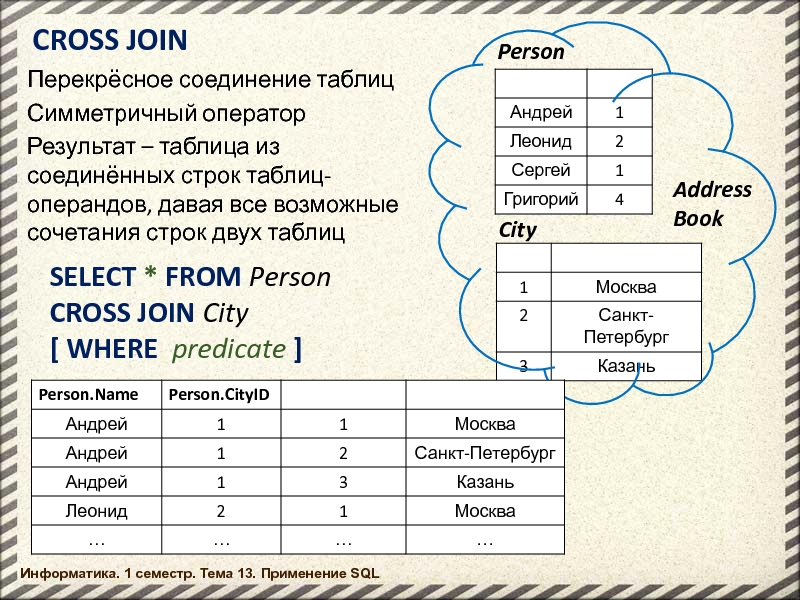
ПОПЕРЕЧНОЕ СОЕДИНЕНИЕ на самом деле является декартовым произведением. Использование CROSS JOIN создает точно такой же результат вызова двух таблиц (разделенных запятой) без какого-либо соединения. Это означает, что мы получим огромный набор результатов, где каждая запись Table1 будет дублироваться для каждой записи в Table2 . Если Table1 имеет N1 записей, а Table2 имеет N2 записей, на выходе будет N1 умножить на N2 записей.
Я не думаю, что есть какой-либо способ представить этот результат на диаграмме Венна. Я предполагаю, что это будет трехмерное изображение. Если это действительно так, диаграмма будет скорее запутанной, чем пояснительной.
Синтаксис для CROSS JOIN будет следующим:
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.
key2 как T1Key,
t2.key2 как T2Key, t2.field1 как город
FROM Table1 t1
CROSS JOIN Table2 t2 ;Так как Table1 имеет 5 записей, а Table2 имеет еще 7, вывод для этого запроса будет иметь 35 записей (5 x 7).
Проверьте прикрепленный файл (SQLServerCentral.com_JOIN_CrossJoin.rpt). Честно говоря, я не помню в этот момент ни одной реальной ситуации, в которой мне нужно было бы сгенерировать декартово произведение двух таблиц. Но всякий раз, когда вам нужно, CROSS JOIN всегда рядом.
Кроме того, вам следует побеспокоиться о производительности. Скажем, вы случайно запустили на своем рабочем сервере запрос с CROSS JOIN для двух таблиц с 1 миллионом записей. Это, безусловно, то, что даст вам головную боль. Вероятно, ваш сервер начнет показывать проблемы с производительностью, так как ваш запрос может выполняться в течение некоторого времени, потребляя значительное количество ресурсов сервера.
SELF JOIN
Оператор JOIN может использоваться для объединения любой пары таблиц, включая объединение таблицы с самой собой. Это «самосоединение». Самостоятельные соединения могут использовать любой оператор JOIN.
Например, посмотрите на этот классический пример возврата начальника сотрудника (на основе Table1 ). В этом примере мы считаем, что значение в field2 на самом деле является кодовым номером босса, поэтому связано с key1 .
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.field2, зеркало.field1 как Босс FROM Table1 t1
LEFT JOIN Зеркало таблицы 1 ON t1.field2 = зеркало.key1;А это результат этого запроса.
ключ1 Имя поле2 Босс 3 9014 1 Эрик 8 Гарри 4 Джон 3 Эрик 9 0140 6 Марк 3 Эрик 7 Питер 6 Гарри 8 Гарри 0 null В этом примере последняя запись показывает, что у Гарри нет начальника, или, другими словами, он является №1 в иерархии компании.
Исключая пересечение множеств
Проверяя предыдущие диаграммы Венна, которые я только что показал выше, можно прийти к простому вопросу: а что, если мне нужно получить все записи из Table1 кроме тех, которые совпадают с записями в Table2 . Ну, это довольно полезно в повседневном бизнесе, но очевидно, что для этого нам не нужен специальный оператор JOIN.
Посмотрите на приведенные выше наборы результатов, и вы увидите, что вам нужно всего лишь добавить предложение WHERE в оператор SQL для поиска записей, имеющих значение NULL для ключа Table2 . Итак, набор результатов, который мы ищем, — это красная область, показанная на диаграмме Венна ниже (рис. 6).
Рисунок 6: Несовпадающие записи из Table1 .
Мы можем написать LEFT JOIN для этого запроса, например:
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как город
FROM Table1 t1
LEFT JOIN Table2 t2 ON t1. key2 = t2.key2
ГДЕ t2.key2 IS NULL;И, наконец, результирующий набор будет:
ключ1 Имя T1Key 90 140 T2Key
Город 6 Знак 7 нулевой нулевой 7 Peter 8 null null Когда мы делаем такой запрос, мы должны обратить внимание на то, какое поле мы выбираем для предложения WHERE. Мы должны использовать поле, которое не допускает значений NULL. В противном случае результирующий набор может включать нежелательные записи. Поэтому я предложил использовать ключ второй таблицы. Точнее, его первичный ключ. Поскольку первичные ключи не принимают значения NULL, они гарантируют, что наш результирующий набор будет именно тем, что нам нужно.
Несколько слов о планах выполнения
Эти комментарии подводят нас к важному выводу. Обычно мы не останавливаемся на этом, но замечаем, что план выполнения SQL-запросов будет сначала вычислять набор результатов для предложения FROM и оператора JOIN (если есть), а затем будет выполняться предложение WHERE.
Это так же верно для SQL Server, как и для любой другой СУБД.
Базовое понимание того, как работает SQL, важно для любого администратора баз данных или разработчика. Это поможет вам добиться цели. Быстрым и надежным способом. Если вам это интересно, просто взгляните на план выполнения запроса выше, показанный на рис. 7.9.0005
Рисунок 7: План выполнения запроса с использованием LEFT JOIN
Соединения и индексы
Еще раз взгляните на план выполнения этого запроса. Обратите внимание, что он использовал кластеризованные индексы обеих таблиц. Использование индексов — лучший способ ускорить выполнение вашего запроса.
Но вы должны обратить внимание на некоторые детали.Когда мы пишем наши запросы, мы ожидаем, что оптимизатор запросов SQL Server будет использовать индексы таблиц для повышения производительности ваших запросов. Мы также можем помочь оптимизатору запросов выбрать проиндексированные поля, которые будут частью вашего запроса.
Например, при использовании оператора JOIN идеальный подход состоит в том, чтобы основывать условие соединения на индексированных полях. Снова проверяя Execution Plan, мы замечаем, что использовался кластеризованный индекс Table2 . Этот индекс был автоматически создан на основе key2 при создании этой таблицы, поскольку key2 является первичным ключом этой таблицы.
С другой стороны, Table1 не имеет индекса в поле key2 . Из-за этого оптимизатор запросов пытался быть достаточно умным и повышать производительность запросов 9.0043 key2 с использованием единственного доступного индекса. Это был кластеризованный индекс таблицы, основанный на key1 , первичный ключ на Table1 .
Вы видите, что оптимизатор запросов действительно умный инструмент. Но вы бы очень помогли, создав новый индекс (некластеризованный) на key2 .Вспомнив немного о ссылочной целостности, вы видите, что key2 должен быть внешним ключом в Table1 , потому что он связан с другим полем в другой таблице (которое равно Таблица2.ключ2 ).
Лично я считаю, что внешние ключи должны существовать во всех реальных моделях баз данных. Также рекомендуется создавать некластеризованные индексы для всех внешних ключей. Вы всегда будете выполнять множество запросов, а также использовать оператор JOIN на основе ваших первичных и внешних ключей.
(ВАЖНО: SQL Server автоматически создаст кластеризованный индекс для первичных ключей. Но по умолчанию он ничего не делает с внешними ключами. Поэтому убедитесь, что у вас есть правильные настройки в вашей базе данных).
Неравные сравнения
Когда мы пишем операторы SQL, используя оператор JOIN, мы обычно сравниваем, если одно поле в одной таблице равно другому полю в другой таблице.
Но это не обязательный синтаксис. Мы могли бы использовать любой логический оператор, например, отличный от (<>), больше чем (>), меньше чем (<) и так далее.Хотя эта причудливая штука может создать у вас впечатление, что SQL обладает такой мощью, мне кажется, что это больше похоже на косметическую функцию. Рассмотрим этот пример. См. Таблицу 1 выше, где у нас есть 5 записей. Теперь давайте рассмотрим следующий оператор SQL.
ВЫБЕРИТЕ t1.key1, t1.field1 как имя, t1.key2 как T1Key,
t2.key2 как T2Key, t2.field1 как город
FROM Table1 t1
INNER JOIN Table2 t2 ON t1.key2 <= t2.key2
WHERE t1 .key1 = 3;Обратите внимание, что здесь используется внутреннее соединение, и мы специально выбираем одну запись из Table1 , ту, где key1 равно 3. Единственная проблема заключается в том, что есть 6 записей и Table2 , которые удовлетворяют условию соединения . Взгляните на вывод этого запроса.
ключ1 Имя T1Key T2Key 901 41 Город 3 Эрик 1 1 Нью-Йорк 9 0140 3 Эрик 1 2 Сан-Паулу 3 Эрик 1 901 40 4
Париж 3 Эрик 1 5 Лондон 3 Эрик 1 6 Рим 3 Эрик 1 9 Мадрид Проблема с неравными соединениями заключается в том, что они обычно дублируют записи.
И это не то, что вам нужно на регулярной основе. В любом случае, теперь вы знаете, что можете это сделать.Множественные JOIN
SQL JOIN всегда связаны с объединением пары таблиц и поиском связанных объектов, которые подчиняются заданному правилу (обычно, но не ограничиваясь, равными значениями). Мы можем присоединиться к нескольким таблицам. Например, чтобы объединить 3 таблицы, вам понадобится 2 соединения. И для каждой новой таблицы потребуется новое соединение. Если вы используете соединение на каждом шаге, чтобы объединить N таблиц, вы будете использовать соединения N-1.
Важным моментом является то, что SQL позволяет использовать различные типы соединений в одном операторе.
Но администраторы баз данных и разработчики должны быть осторожны при объединении слишком большого количества таблиц. Несколько раз я видел ситуации, когда запросы требовали 10, 20 таблиц или даже больше. Из соображений производительности не рекомендуется выполнять один запрос для объединения всех данных.
Оптимизатор запросов будет работать лучше, если вы разобьете свой запрос на несколько более мелких и простых запросов.Теперь представим, что у нас есть третья таблица с именем Таблица3 , показанная ниже.
Таблица3
ключ3 поле1 1 Инженер 901 41 2 Хирург 3 DBA 4 Юрист 9014 1 5 Учитель 6 Актер Теперь давайте напишем заявление, чтобы указать имя работника, город, в котором он живет, и его профессию. Это потребует от нас присоединиться ко всем 3 таблицам. Просто помните, что соединения записываются парами.
Итак, сначала мы присоединимся к Таблица 1 до Таблица 2 . И тогда мы соединим Table1 и Table3 . Полученный скрипт показан ниже.ВЫБЕРИТЕ t1.key1, t1.field1 как сотрудника,
t2.key2, t2.field1 как город,
t3.key3, t3.field1 как профессию
ИЗ таблицы 1 t1
INNER JOIN Table2 t2 ON t1.key2 = t2.key2
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Таблица3 t3 ON t1.key3 = t3.key3;Поскольку мы используем только ВНУТРЕННИЕ СОЕДИНЕНИЯ, у нас будут только записи, соответствующие комбинации 3 таблиц. См. вывод ниже.
ключ1 Имя ключ2 Город 90 140 key3
Профессия 3 Эрик 1 Нью-Йорк 901 40 6
Актер 4 Джон 4 Париж 4 Адвокат 9 0439
6 Гарри 9 Мадрид 2 Хирург Помимо операторов SELECT
Использование операторов JOIN не ограничивается операторами SELECT.
 Такое утверждение кажется простым и очень близким к языку, на котором мы говорим.
Такое утверждение кажется простым и очень близким к языку, на котором мы говорим.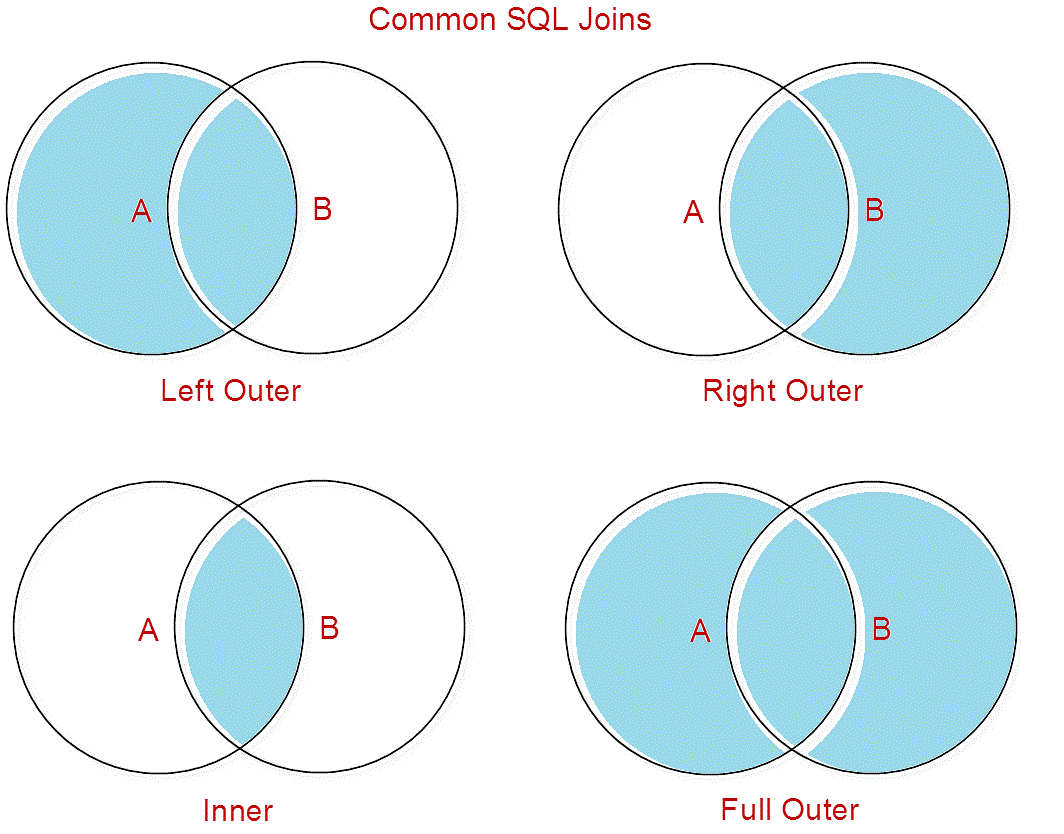
 Или, учитывая производительность, администраторы баз данных могут создать представление, используя правильные параметры для объединения записей из нескольких таблиц, правильно используя индексы базы данных и тем самым повышая производительность запросов.
Или, учитывая производительность, администраторы баз данных могут создать представление, используя правильные параметры для объединения записей из нескольких таблиц, правильно используя индексы базы данных и тем самым повышая производительность запросов.
 com_JOIN.sql ) в разделе ресурсов ниже.
com_JOIN.sql ) в разделе ресурсов ниже.


 Это означает, что у нас есть значение в поле key2 в Table1 без соответствующего значения в Table2 . Мы могли бы избежать этой «несогласованности данных», если бы у нас был внешний ключ в поле key2 в Table1 .
Это означает, что у нас есть значение в поле key2 в Table1 без соответствующего значения в Table2 . Мы могли бы избежать этой «несогласованности данных», если бы у нас был внешний ключ в поле key2 в Table1 .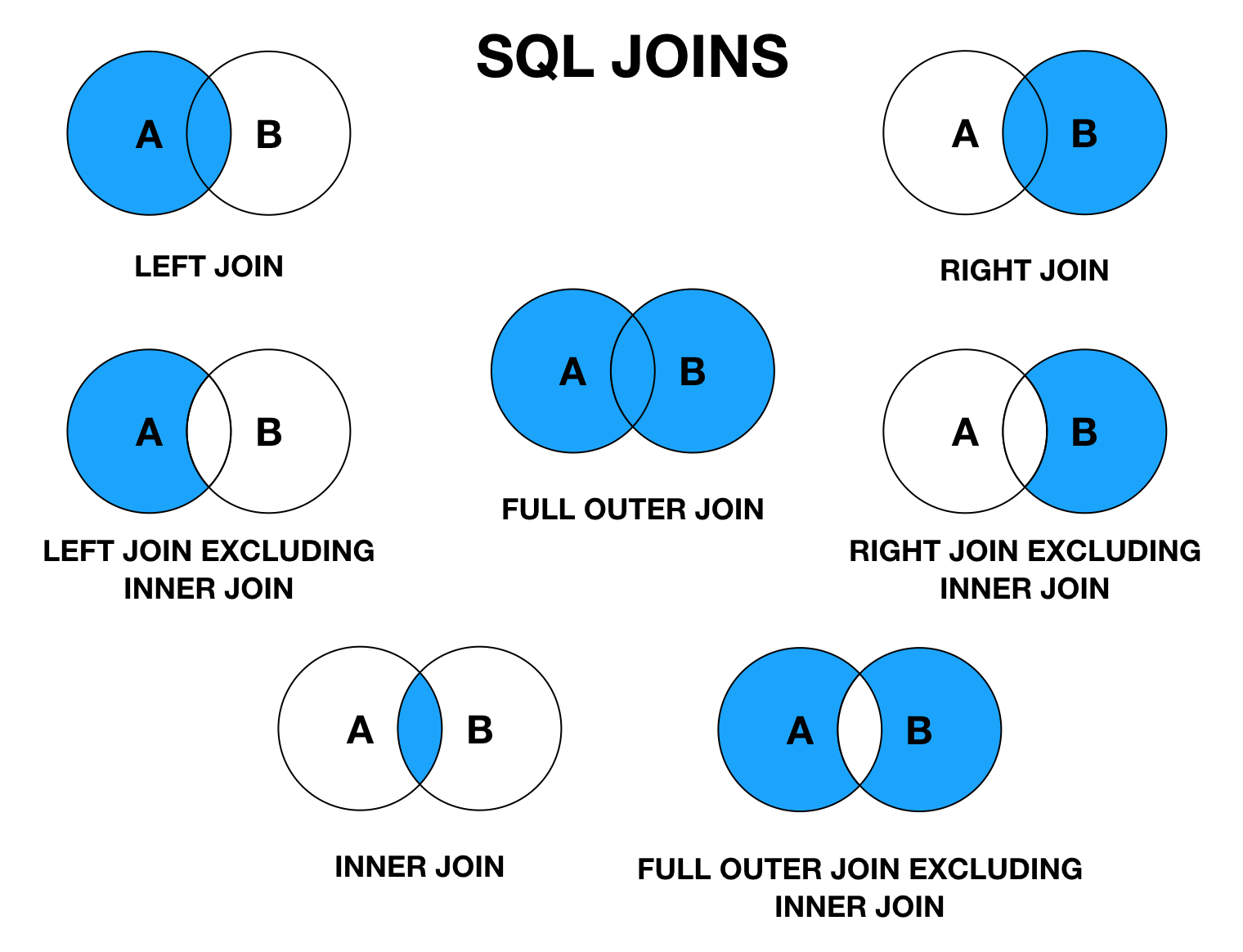 Это потому, что у них нет соответствующей записи в правой таблице. Есть 4 записи со значениями NULL в первых полях, потому что они недоступны в левой таблице.
Это потому, что у них нет соответствующей записи в правой таблице. Есть 4 записи со значениями NULL в первых полях, потому что они недоступны в левой таблице. key2 как T1Key,
key2 как T1Key, 

 key2 = t2.key2
key2 = t2.key2 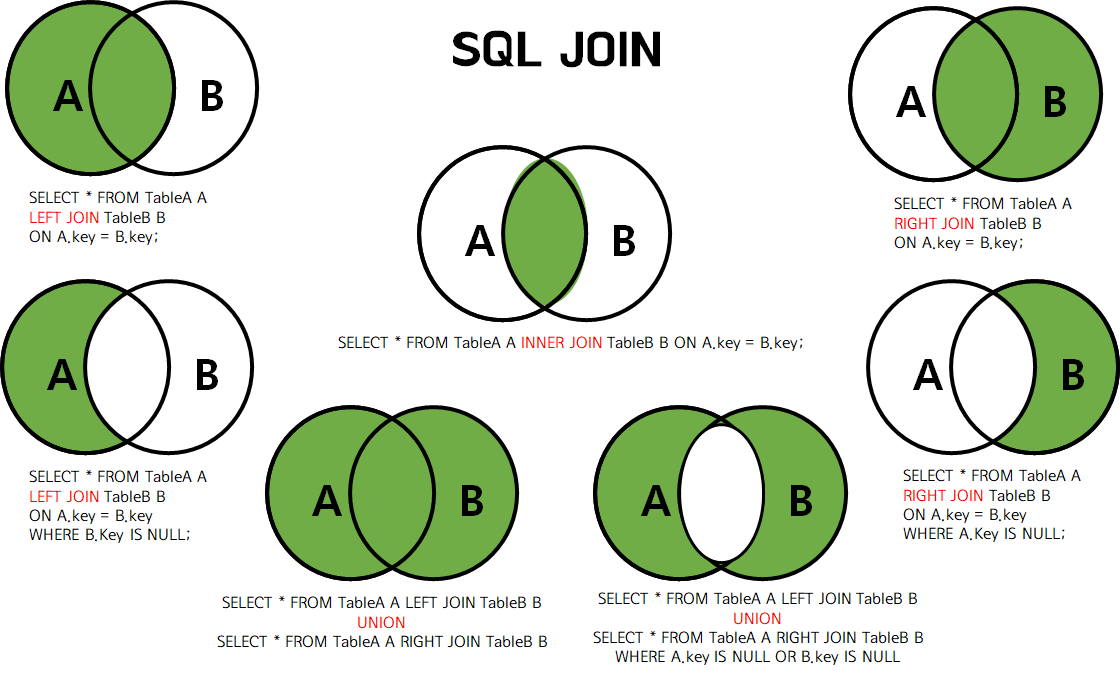
 Но вы должны обратить внимание на некоторые детали.
Но вы должны обратить внимание на некоторые детали. Вы видите, что оптимизатор запросов действительно умный инструмент. Но вы бы очень помогли, создав новый индекс (некластеризованный) на key2 .
Вы видите, что оптимизатор запросов действительно умный инструмент. Но вы бы очень помогли, создав новый индекс (некластеризованный) на key2 .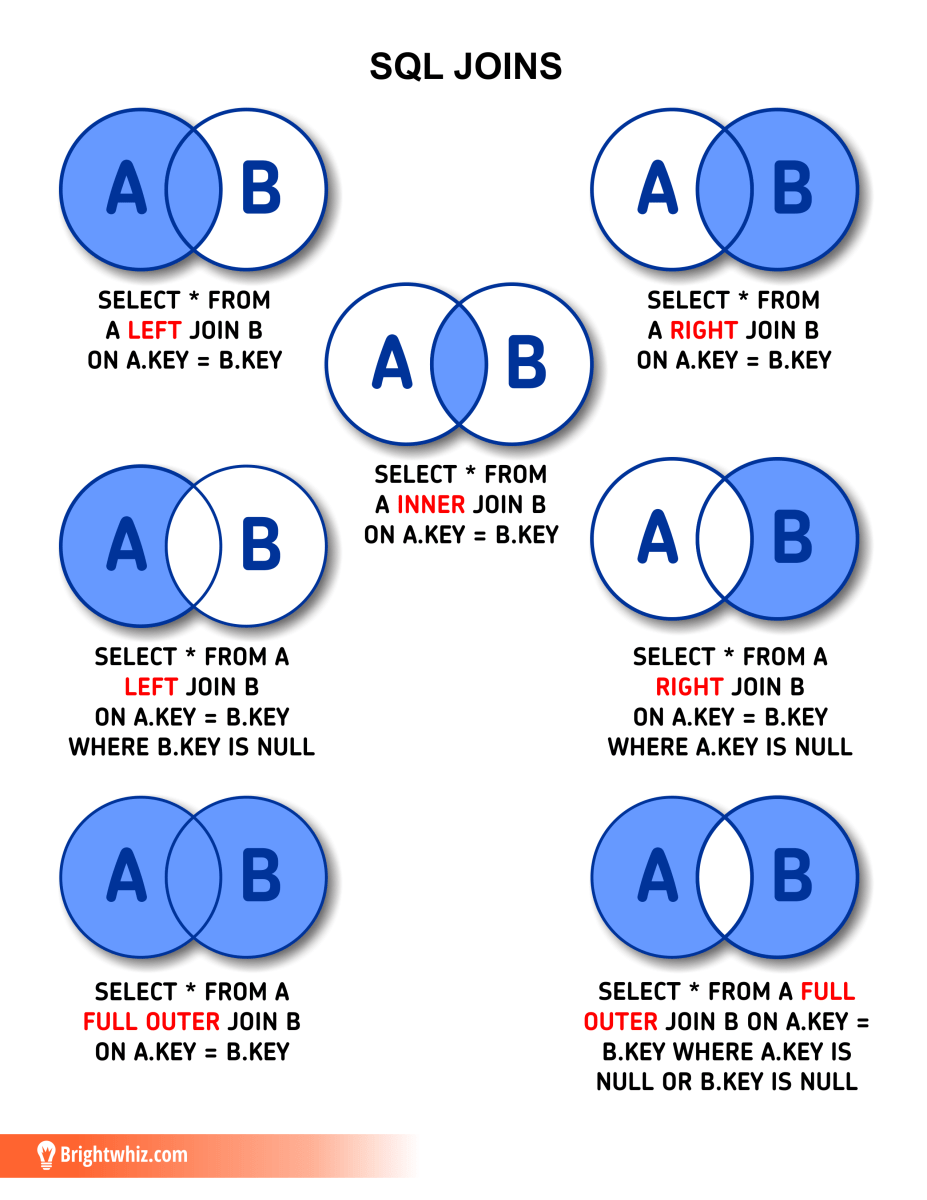 Но это не обязательный синтаксис. Мы могли бы использовать любой логический оператор, например, отличный от (<>), больше чем (>), меньше чем (<) и так далее.
Но это не обязательный синтаксис. Мы могли бы использовать любой логический оператор, например, отличный от (<>), больше чем (>), меньше чем (<) и так далее.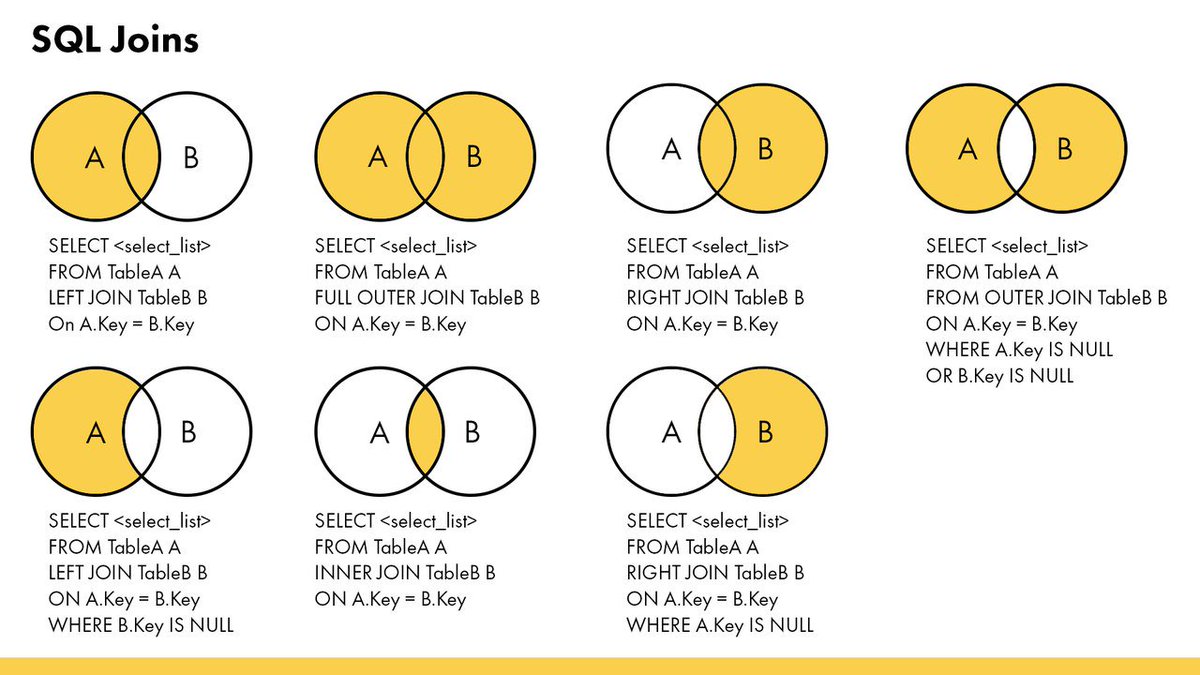 И это не то, что вам нужно на регулярной основе. В любом случае, теперь вы знаете, что можете это сделать.
И это не то, что вам нужно на регулярной основе. В любом случае, теперь вы знаете, что можете это сделать. Оптимизатор запросов будет работать лучше, если вы разобьете свой запрос на несколько более мелких и простых запросов.
Оптимизатор запросов будет работать лучше, если вы разобьете свой запрос на несколько более мелких и простых запросов.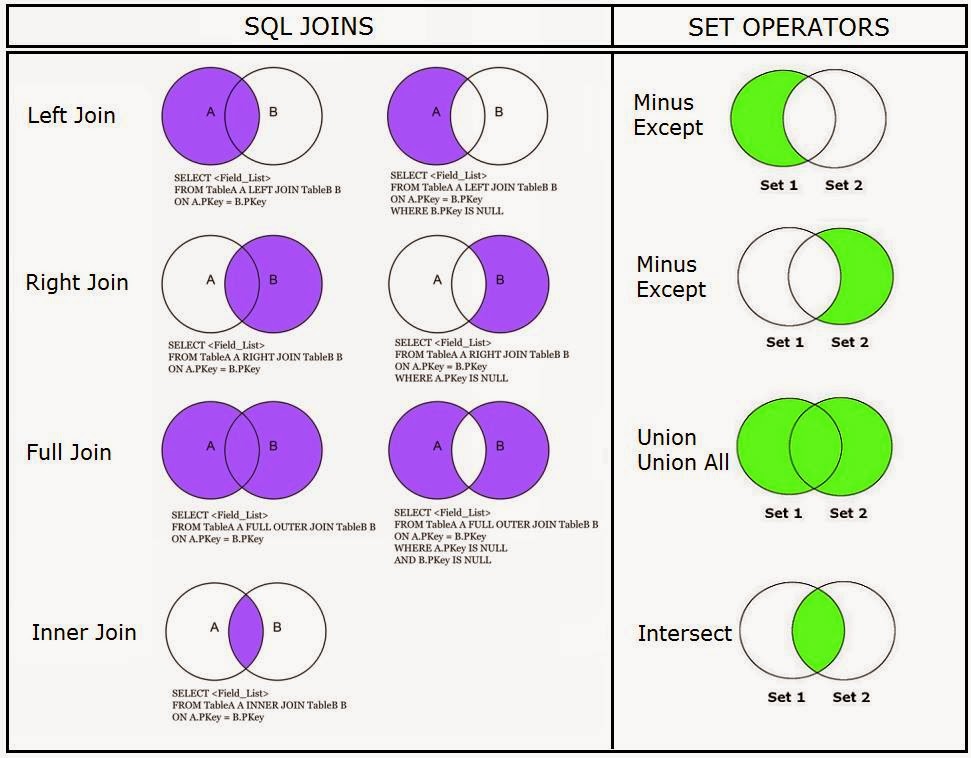 Итак, сначала мы присоединимся к Таблица 1 до Таблица 2 . И тогда мы соединим Table1 и Table3 . Полученный скрипт показан ниже.
Итак, сначала мы присоединимся к Таблица 1 до Таблица 2 . И тогда мы соединим Table1 и Table3 . Полученный скрипт показан ниже.