Oracle row number over partition by: Oracle ROW_NUMBER Function by Practical Examples
Содержание
Оконные функции в SQL — что это и зачем они нужны
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
Примечание Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.

Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
SELECT athlete, event, ROW_NUMBER() OVER() AS row_number FROM Summer_Medals ORDER BY row_number ASC;
Каждая пара «спортсмен — вид спорта» получила номер, причём к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:
SELECT sport, ROW_NUMBER() OVER(ORDER BY sport ASC) AS Row_N FROM ( SELECT DISTINCT sport FROM Summer_Medals ) AS sports ORDER BY sport ASC;
PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
LAG
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы WITH Tennis_Gold AS ( SELECT Athlete, Gender, Year, Country FROM Summer_Medals WHERE Year >= 2004 AND Sport = 'Tennis' AND event = 'Singles' AND Medal = 'Gold')
-- Оконная функция разделяет по полу и берёт чемпиона из предыдущей строки SELECT Athlete as Champion, Gender, Year, LAG(Athlete) OVER (PARTITION BY gender ORDER BY Year ASC) AS Last_Champion FROM Tennis_Gold ORDER BY Gender ASC, Year ASC;
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин. Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
LEAD
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы WITH Tennis_Gold AS ( SELECT Athlete, Gender, Year, Country FROM Summer_Medals WHERE Year >= 2004 AND Sport = 'Tennis' AND event = 'Singles' AND Medal = 'Gold')
-- Оконная функция разделяет по полу и берёт чемпиона из следующей строки SELECT Athlete as Champion, Gender, Year, LEAD(Athlete) OVER (PARTITION BY gender ORDER BY Year ASC) AS Future_Champion FROM Tennis_Gold ORDER BY Gender ASC, Year ASC;
RANK
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Вот код:
-- Табличное выражение выбирает страны и считает годы
WITH countries AS (
SELECT
Country,
COUNT(DISTINCT year) AS participated
FROM
Summer_Medals
WHERE
Country in ('GBR', 'DEN', 'FRA', 'ITA','AUT')
GROUP BY
Country)
-- Разные оконные функции ранжируют страны
SELECT
Country,
participated,
ROW_NUMBER()
OVER(ORDER BY participated DESC) AS Row_Number,
RANK()
OVER(ORDER BY participated DESC) AS Rank_Number,
DENSE_RANK()
OVER(ORDER BY participated DESC) AS Dense_Rank
FROM countries
ORDER BY participated DESC;Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.
Адаптированный перевод статьи «Intro to Window Functions in SQL»
Функции ранжирования и нумерации в Transact-SQL — ROW_NUMBER, RANK, DENSE_RANK, NTILE | Info-Comp.ru
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.
В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же, как и функции ранжирования или их еще называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функциях, и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
Поэтому сегодня давайте поговорим именно об этих функциях, и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.
Содержание
- Ранжирующие функции в T-SQL
- Исходные данные для примеров
- ROW_NUMBER
- RANK
- DENSE_RANK
- NTILE
Ранжирующие функции в T-SQL
Ранжирующие функции — это функции, которые возвращают значение для каждой строки группы в результирующем наборе данных. На практике они могут быть использованы, например, для простой нумерации списка, составления рейтинга или постраничной выборки.
И для того чтобы лучше усвоить работу и применение этих функций, давайте рассмотрим все их по очереди, и параллельно будем сравнивать их друг с другом, т.е. таким образом, мы еще и узнаем в чем их отличие. Но для того чтобы начать рассматривать примеры, необходимо определится с исходными данными.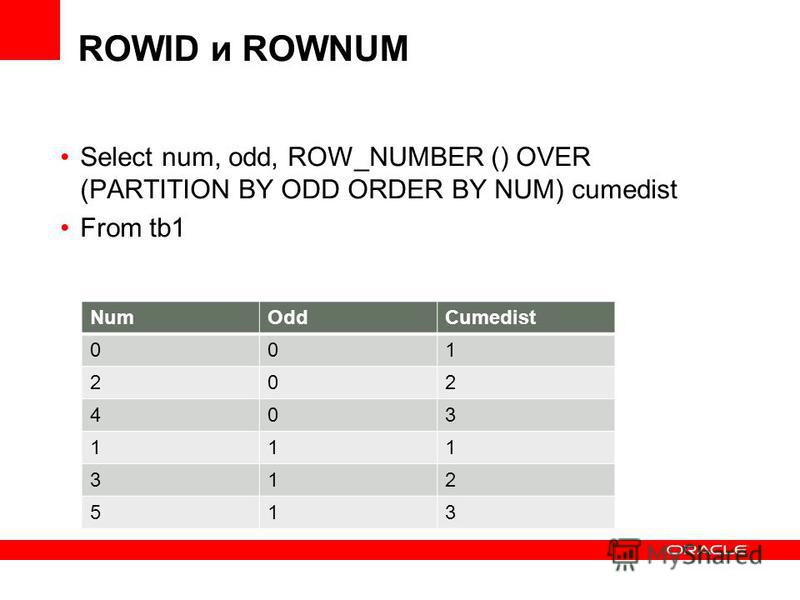
Заметка! Для комплексного изучения языка SQL рекомендую почитать мою книгу «SQL код». Данный книга рассчитана на изучение языка SQL как стандарта, т.е. на изучение тех возможностей SQL, которые доступны и точно будут работать во всех популярных системах управления базами данных (СУБД).
Исходные данные для примеров
Использовать мы будем MS SQL Server Express 2014, а запросы будем писать в Management Studio Express. В качестве тестовых данных будем использовать таблицу selling, которая будет содержать различные товары (телефоны, планшеты, ноутбуки, программы) с выдуманными ценами.
Наша тестовая таблица
CREATE TABLE [dbo].[selling](
[id] [int] IDENTITY(1,1) NOT NULL,
[NameProduct] [varchar](50) NOT NULL,
[price] [money] NOT NULL,
[category] [varchar](50) NOT NULL
) ON [PRIMARY]
GO
Заполним ее тестовыми данными, в итоге получим следующее (для выборки пишем простой запрос select)
Заметка! Функции TRIM, LTRIM и RTRIM в T-SQL – описание, отличия и примеры.

ROW_NUMBER
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.
Синтаксис
ROW_NUMBER () OVER ([PARTITION BY столбы группировки] ORDER BY столбец сортировки)
где, partition by — это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
Пример без группировки с сортировкой по цене
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER]
FROM selling
Пример с группировкой по категории и с сортировкой по цене
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART]
FROM selling
Как видите, здесь уже нумерация идет в каждой категории.
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
Пример без группировки с сортировкой по цене и отличие от row_number()
Текст запроса
SELECT NameProduct, price, category,
rank() over (order by price desc) [RANK],
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER]
FROM selling
Пример с группировкой по категории и с сортировкой по цене и отличие от row_number()
Текст запроса
SELECT NameProduct, price, category,
rank() over (partition by category order by price desc) [RANK],
ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART]
FROM selling
DENSE_RANK
DENSE_RANK — ранжирующая функция, которая возвращает ранг каждой строки, но в отличие от rank, в случае нахождения одинаковых значений, возвращает ранг без пропуска следующего.
Пример без группировки с сортировкой по цене и отличие от rank() и row_number()
Текст запроса
SELECT NameProduct, price, category,
rank() over (order by price desc) [RANK],
DENSE_RANK () over (order by price desc) [DENSE_RANK],
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER]
FROM selling
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример
Текст запроса
SELECT NameProduct, price, category,
NTILE(3)over (order by price desc) [NTILE]
FROM selling
В заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (order by price desc) as [ROW_NUMBER],
rank() over (order by price desc) [RANK],
DENSE_RANK () over (order by price desc) [DENSE_RANK],
NTILE(3)over (order by price desc) [NTILE]
FROM selling
Заметка! Для комплексного изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения и рассматриваются все конструкции языка SQL и T-SQL.
На этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
sql — ROW_NUMBER() over (Partition by….) для возврата определенной строки
Новое! Сохраняйте вопросы или ответы и организуйте свой любимый контент.
Узнать больше.
Мой запрос выглядит так:
с T1 как (
Выбирать
Dept_No,
Продукт не,
№ заказа,
Order_Type
Row_number() over (раздел по заказу Product_ID по Order_No desc) как «COUNT»
Из Orders_Table)
Выберите * из T1
где ("COUNT" = '1' и "Order_Type" <> 'Отмена')
или ("COUNT" = '2' AND "Order_Type" <> 'Отмена'
Итак, я пытаюсь получить самый последний заказ, который не был отменен. По сути, моя функция ROW_number() over (partition by…) помечает заказы в последовательном порядке, где 1 — самый последний заказ, а 2 — второй самый последний заказ. Проблема в том, что с этим запросом он извлекает как самый последний, так и второй самый последний заказ.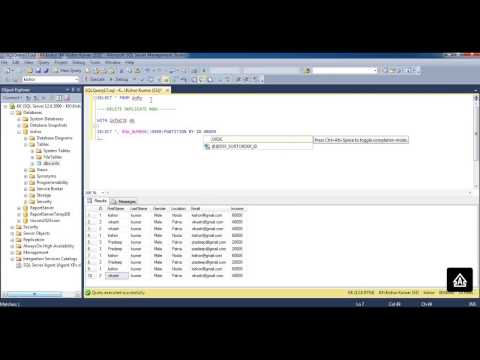 Я пытаюсь написать это туда, если это дает только одно или другое. Поэтому, если COUNT = 1 и order_type не отменен, покажите мне только эту запись. Если нет, то покажите мне 2-й.
Я пытаюсь написать это туда, если это дает только одно или другое. Поэтому, если COUNT = 1 и order_type не отменен, покажите мне только эту запись. Если нет, то покажите мне 2-й.
Заранее большое спасибо за помощь. Это делается в Toad для Oracle 9.5 с помощью вкладки SQL.
- sql
- оракул
- оконные функции
- номер строки
3
Но у вас есть или.
Если оба или удовлетворены, вы получите две строки.
с T1 как ( Выбирать Dept_No, Продукт не, № заказа, Order_Type Row_number() over (раздел по заказу Product_ID по Order_No desc) как «COUNT» Из Orders_Table где "Order_Type" <> "Отмена") Выберите * из T1 где "СЧЁТ" = "1"
Используйте выражение case, чтобы контролировать, какие строки получают результат от row_number(), здесь мы избегаем нумерации строк, которые были отменены:
WITH t1 AS (
ВЫБРАТЬ
Dept_No
, Продукт не
, № заказа
, Тип_Заказа
/* самый последний заказ, который не был отменен */
, случай, когда order_type <> 'Отмена'
затем ROW_NUMBER() OVER (PARTITION BY Product_ID
ORDER BY Order_No DESC)
конец AS is_recent
ИЗ Orders_Table
)
ВЫБРАТЬ
*
ОТ t1
ГДЕ is_recent = 1
Или, пожалуй, самый простой способ — просто исключить отмененные заказы, т. е.
е.
С т1 КАК (
ВЫБРАТЬ
Dept_No
, Продукт не
, № заказа
, Тип_Заказа
, ROW_NUMBER() OVER (РАЗДЕЛЕНИЕ ПО Product_ID
ORDER BY Order_No DESC)
КАК is_recent
ИЗ Orders_Table
ГДЕ order_type <> 'Отмена'
)
ВЫБРАТЬ
*
ОТ t1
ГДЕ is_recent = 1
Примечание: row_number() возвращает целое число, поэтому не сравнивайте этот столбец со строкой
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
sql — функция row_number() в оракуле
Задавать вопрос
Спросил
Изменено
3 года, 2 месяца назад
Просмотрено
2к раз
Новинка! Сохраняйте вопросы или ответы и организуйте свой любимый контент.
Узнать больше.
Я использую функцию ROW_NUMBER в оракуле и пытаюсь понять, как она будет вести себя, когда предложение section by и order by содержит те же данные, что и ранжирование (если есть повторяющиеся записи).
ниже пример набора данных
выберите * из теста
Результат
Дата создания зарплаты отдела HR 500 25 июля HR 200 25 июля HR 500 26 июля Счета 300 25 января Счета 300 26 января Счета 300 27 января
я запустил функцию row_number на основе вышеуказанного набора
выберите *, ROW_NUMBER() OVER (раздел по порядку отдела по зарплате) как row_number из теста
результат
Зарплата отдела Дата создания row_number HR 500 25 – 1 июля HR 200 25 – 1 июля HR 500 26 – 2 июля Счета 300 25-1 января Счета 300 26-2 января Счета 300 27-3 января
Как вы можете видеть вывод выше, я использую отдел как раздел и зарплату как порядок для row_number, это дало мне рейтинг 1,2,3.
Я пытаюсь понять, что для одних и тех же данных в разделе by и order by oracle назначает row_number на основе того, когда запись введена в систему, как в приведенном выше «Учетных записях» «300», он дал row_number 1 для запись, введенная раньше всех в системе «25 января»
есть где-нибудь, где четко указано, что если он выполняет разбиение и упорядочивание одних и тех же данных, то ранжирование будет выполняться на основе того, когда эти записи были введены в систему.
- sql
- оракул
- оконные функции
- номер строки
8
Я пытаюсь понять, что для одних и тех же данных в разделе by и order by oracle назначает row_number на основе того, когда запись введена в систему, как в приведенном выше «Учетные записи» «300»
Нет, это не так. Таблицы SQL представляют собой 90 115 неупорядоченных наборов из 90 116. Порядок отсутствует, если только он не указан явно путем ссылки на значения столбца.
Если вы сортируете по одинаковым значениям, порядок строк не гарантируется . Обратите внимание, что выполнение одного и того же запроса дважды может привести к разным результатам, если есть совпадения в порядке 90 121 по 90 122 ключам. Это возможно даже в рамках одного запроса. Это верно как для заказа на и для аналитических функций.
Если вам нужна гарантия, вам нужно включить уникальный столбец в качестве последнего ключа сортировки (ну, он не может быть последним, но фактически будет последним).