Откуда берется информация в интернете: Откуда берется Интернет | Интернет
Содержание
Откуда берется интернет? Google и Facebook тянут кабели по дну океанов
- Майкл Уинроу
- Корреспондент Би-би-си по вопросам бизнеса и технологий
Подпишитесь на нашу рассылку ”Контекст”: она поможет вам разобраться в событиях.
Автор фото, Orange Marine
Подпись к фото,
Кабель из французского городка Сент-Илер-де-Рец тянется по дну до самой Америки
То, что вы можете выложить фото в «Фейсбук» или видео на YouTube и их мгновенно увидят люди в любой точке земного шара, поражает воображение, но для этого требуется огромная невидимая работа, в том числе на дне океана, говорит Алан Молдин, директор по исследованиям консалтинговой компании TeleGeography.
Мы обычно не задумываемся о том, что доступ к интернету целиком зависит от тысячемильных кабелей, пересекающих океаны. 98% глобального трафика проходит через них.
Некоторые кабели связывают соседние страны, как 131-километровый CeltixConnect между Ирландией и Соединенным Королевством. Другие, как Азиатско-Американский Gateway, тянутся на 20 тысяч километров и связывают континенты.
Данные идут через оптические волокна толщиной в человеческий волос. Кабель представляет собой пучок таких волокон, помещенных в защитную оболочку.
По словам Даниэля Соузы, управляющего директора по производству в американской компании SubCom, занимающейся подводными телекоммуникациями, одна из трудностей состоит в том, что кабельные системы должны изготавливаться и испытываться как одно целое.
- Google прокладывает свой собственный подводный кабель в Европу
- Почему российский шпионский корабль «Янтарь» тревожит Запад
- Могут ли российские подлодки оставить мир без интернета?
Тестирование проводится на берегу перед погрузкой кабеля на корабль и занимает около двух недель, говорит глава компании Orange Marine Дидье Диллар.
Orange Marine владеет шестью специальными судами, одно из которых, «Рене Декарт», способно уложить шесть тысяч километров кабеля.
Раньше основными заказчиками этих сложных и дорогостоящих проектов были телекоммуникационные компании. Теперь в них начали серьезно вкладываться гиганты хайтека.
По данным TeleGeography, основные мировые производители интернет-контента — Google, Facebook, Amazon and Microsoft — за последние пять лет инвестировали в прокладку подводных кабелей более полутора миллиардов долларов.
Автор фото, Orange Marine
Подпись к фото,
Судно «Рене Декарт» может нести на борту до 6 тыс. километров кабеля
Пропустить Подкаст и продолжить чтение.
Подкаст
Что это было?
Мы быстро, просто и понятно объясняем, что случилось, почему это важно и что будет дальше.
эпизоды
Конец истории Подкаст
Google делает ставку на собственные кабели. Кабель «Кюри» связал Чили с Соединенными Штатами, а построенный в партнерстве с SubCom «Дюнан» — Америку и Францию через прибрежную станцию компании Orange Marine в Сент-Илер-де-Рец.
Кабель «Кюри» связал Чили с Соединенными Штатами, а построенный в партнерстве с SubCom «Дюнан» — Америку и Францию через прибрежную станцию компании Orange Marine в Сент-Илер-де-Рец.
Скоро вступят в строй еще два кабеля: «Эквиано» пойдет из Португалии вдоль западных берегов Африки в ЮАР, а «Грейс Хоппер» свяжет США, Британию и Испанию.
Повышение надежности доступа к интернету, на который мы полагаемся в жизни, и его распространение на ранее неохваченные территории — две основные причины для капиталовложений.
Это также инвестиция в «облачные» сервисы Google. В этой области конкуренция особенно сильна, что побудило наблюдателей говорить об «облачной войне» между интернет-гигантами за доминирование в ней.
«Облачные» технологии превратились в огромный бизнес по мере того, как компании стали переносить свои хранилища цифровых данных в такие сервисы, как Amazon AWS и Azure от Microsoft.
А есть ли в контроле над этими важнейшими коммуникационными линиями отрицательные моменты?
Алан Молдин говорит, что кабели могут быть частными, но ни у кого нет исключительного права пользоваться ими: «Пользователи многочисленны, и все используют одну и ту же инфраструктуру».
Google не торгует доступом к своим кабелям напрямую, но выделение части емкости телекоммуникационным компаниям — распространенная практика.
Например, Orange Marine предоставляет своим клиентам доступ к кабелю «Дюнан», взамен позволяя Google использовать ее станцию в Сент-Илер-де-Рец.
Алан Молдин сравнивает подземные кабели с автострадой: Google и Facebook — это фуры, но по ней ездят и легковые машины, доставляя данные своим клиентам.
Автор фото, Orange Marine
Подпись к фото,
Прокладку кабелей оплачивают Google и Facebook, но пользоваться ими смогут и другие компании
Разговоры о том, что спутники со временем вытеснят подводные кабели, идут десятилетиями. Компания OneWeb со штаб-квартирой в Лондоне недавно запустила шестую партию своих спутников. SpaceX Илона Маска инвестирует в технологии спутниковой связи в рамках ее проекта Starlink.
Однако сравнивать эти два вида связи нельзя. Спутники наиболее эффективны в отдаленных местах Земли, куда физически трудно или невыгодно проложить кабели. Но кабели незаменимы для передачи больших массивов данных.
Но кабели незаменимы для передачи больших массивов данных.
«Основная работа по обмену большими объемами данных между хранилищами по всему миру будет выполняться подводными кабелями», — уверен Алан Молдин.
Опора на океанские кабели имеет геополитический аспект.
В марте этого года Facebook отказался от прокладки кабеля из Калифорнии в Гонконг, предположительно по настоянию американских чиновников в сфере национальной безопасности.
Британский Королевский ВМФ объявил о начале постройки специального корабля-наблюдателя для защиты критически важных кабелей от диверсий со стороны подводных лодок недружественных государств.
Как вообще Интернет приходит в ЦОД / Хабр
Пользователь VDS-хостинга задал нам вопрос о том, откуда берётся Интернет. И тут мы поняли, что это тот самый детский вопрос, на который не так-то просто нормально ответить.
Думаю, что 99 % людей ответят: берёт и приходит, а потом задумаются. Это настолько естественно и очевидно, что обычно просто не обсуждается. Ну там, знаете, оптика, она приходит в домик, в домике стоит коробка, а из коробки идёт медь. Вот примерно так оно и работает.
Ну там, знаете, оптика, она приходит в домик, в домике стоит коробка, а из коробки идёт медь. Вот примерно так оно и работает.
В теории всё так и есть, но на практике это выглядит немного иначе. И есть нюансы. Давайте покажу, откуда к нам приходит Интернет и в чём. А заодно поговорим про то, где фильтруется трафик и как это устроено в хостинге.
Для нас всё начинается вот с этой ракеты в Королёве:
Источник
Это памятник «Восток-2М» (8А292М), стоящий в Королёве примерно на том месте, где вообще был разработан «Восток». Перед ним находится люк, где одна трасса оптики разделяется на три к M9, или MSK-IX — московской международной телефонной станции № 9, где когда-то появился самый крупный узел обмена трафика. Сейчас это главное место, откуда Интернет поставляется в Москву. Из-за некоторых особенностей нашей территории бомбоубежища именно в этом люке под ракетой находится уязвимое место оптики, где все три канала идут вместе, и их легко перерубить экскаватором на протяжении примерно 120 метров. В других местах до и после ракеты такого нет.
В других местах до и после ракеты такого нет.
Соответственно один луч идёт через наш ЦОД в Ивантеевку, поворачивает в Щёлково и заканчивается на M9-IX. Второй подземный ввод идёт через Ярославское шоссе, третий ввод — дополнительный, он скачет по столбам от коллектора до ЦОДа в одну сторону и до местного провайдера в другую, а провайдер уже врезается в кольцо оптики по городу и тоже попадает в девятку.
Мы сейчас говорим про наш первый ЦОД в Москве в бомбоубежище завода. Вот тут есть больше деталей про него. Трассы попадают в наш ЦОД тремя разными путями по территории завода и заходят в здание, под которым находится уже само убежище, с разных сторон. Вот первый ввод:
Он, кстати, продолжается дальше в советской старой грузовой лифтовой шахте (сейчас она не используется) и примерно вот так попадает уже на территорию дата-центра:
Вот ещё ввод — как раз от местного провайдера:
Это прямая тёмная оптика, никаких оптических уплотнителей (DWDM) у нас нет. Если нам понадобится больше ёмкости, то провайдеры просто выделят нам больше волокон, и мощности кольца хватит на это: там ещё много свободных пучков.
Если нам понадобится больше ёмкости, то провайдеры просто выделят нам больше волокон, и мощности кольца хватит на это: там ещё много свободных пучков.
Далее все эти оптические линки приходят в коммутационное ядро, состоящее из коммутаторов Джунипер. Выводы из ядра уже соединяются с коммутаторами стоек, где стоят серверы, на которых хостятся ваши виртуальные машины.
Фальшпол, видно крадущийся кабель
То есть до коммутационного ядра приходит оптический кабель на 32 жилы тёмной оптики, большую часть из которых составляет резерв на расширение (потому что всё равно этот кабель кидать один раз, и стоимость кабеля даже близко не имеет значения на фоне стоимости прокладки и контракта на связь). В коммутационном ядре происходит магия, которая дальше разливает Интернет уже по локальной оптике до коммутаторов стоек. Каждый сервер имеет два аплинка: от своего коммутатора и от одного из соседних на случай выхода из строя своего. Коммутаторы стоек добавляют немного магии коммутации и ещё превращают оптический кабель в медный, уже втыкающийся в LAN-порты серверов.
Ещё один порт связывает наш служебный хаб для инженерного интерфейса с сервером. То есть итого в сервер заходят два «жирных» соединения для большого Интернета и один поменьше для инженерного доступа, чтобы не катать тележку с консолью. Среди прочего — чтобы не катать её из Москвы в Новосибирск, но это уже речь идёт про другие ЦОДы.
Коммутаторы ядра у нас все одинаковые. Меняются они обычно пачкой по мере схода с поддержки, устаревают медленнее серверных линеек железа. Лотки и соединения внутри ЦОДа выглядят так:
Некоторые коммутаторы стоек принимают оптику, некоторые — нет: к ним ещё нужен отдельный переходник.
Всё это работает просто для того, чтобы пакеты из Интернета приходили на ваш сервер, попадали куда нужно и, соответственно, отправлялись обратно в Интернет как надо. Фильтрация трафика и прочие хитрые защиты происходят в коммутационном ядре. То есть в него приходит сырой трафик. Создаётся software-defined-петля, которая гонит трафик не на коммутатор стойки, а на другую часть ядра, которая занимается фильтрацией по правилам (файрволл) или вычисляет сигнатуры DDoS-атаки (анти-DDoS). Дальше создаётся очищенный поток, который уже дальше пускается в маршрутизаторы стойки и по потребителям. Для более хитрых защит, требующих статистического анализа трафика, может создаваться дополнительная петля через специальные устройства, подключённые к ядру. Для некоторых ответственных госзаказчиков ещё нужны отечественные файрволлы, эти устройства устанавливаются на стойке на выходе из сервера. Однажды спецслужбы ловили у нас владельца биржи наркотиков, они принесли кучу бумажек, решений суда и свою железку типа файрволла, которую поставили в разрыв между сервером и коммутатором стойки. Также можно подключать центры очистки трафика для туннелирования потока через них, чтобы очистка происходила не на нашей точке, а к нам уже приезжал очищенный трафик: это имеет смысл при направленных атаках, начинающихся с DDoS-уровня в несколько сотен гигабит в секунду. У нас пока такой потребности не было.
Дальше создаётся очищенный поток, который уже дальше пускается в маршрутизаторы стойки и по потребителям. Для более хитрых защит, требующих статистического анализа трафика, может создаваться дополнительная петля через специальные устройства, подключённые к ядру. Для некоторых ответственных госзаказчиков ещё нужны отечественные файрволлы, эти устройства устанавливаются на стойке на выходе из сервера. Однажды спецслужбы ловили у нас владельца биржи наркотиков, они принесли кучу бумажек, решений суда и свою железку типа файрволла, которую поставили в разрыв между сервером и коммутатором стойки. Также можно подключать центры очистки трафика для туннелирования потока через них, чтобы очистка происходила не на нашей точке, а к нам уже приезжал очищенный трафик: это имеет смысл при направленных атаках, начинающихся с DDoS-уровня в несколько сотен гигабит в секунду. У нас пока такой потребности не было.
Вот примерно так приходит Интернет в ЦОД. Если у вас есть вопросы любой сложности, то задавайте их. Как выяснилось, детские вопросы могут на некоторое время поставить в тупик.
Как выяснилось, детские вопросы могут на некоторое время поставить в тупик.
Как работает интернет?
Несмотря на то, что Интернет еще молодая технология, сейчас трудно представить жизнь без него. С каждым годом инженеры создают все больше устройств для интеграции с Интернетом. Эта сеть сетей пересекает земной шар и простирается даже в космос. Но что заставляет это работать?
Чтобы понять Интернет, полезно посмотреть на него как на систему, состоящую из двух основных компонентов. Первым из этих компонентов является аппаратное обеспечение . Это включает в себя все, от кабелей, которые передают терабиты информации каждую секунду, до компьютера, сидящего перед вами.
Реклама
Другие типы оборудования, поддерживающего Интернет, включают маршрутизаторы, серверы, вышки сотовой связи, спутники, радиоприемники, смартфоны и другие устройства. Все эти устройства вместе создают сеть сетей. Интернет — это податливая система: он мало меняется по мере того, как элементы присоединяются к сетям по всему миру и покидают их. Некоторые из этих элементов могут оставаться довольно статичными и составлять основу Интернета. Другие более периферийны.
Некоторые из этих элементов могут оставаться довольно статичными и составлять основу Интернета. Другие более периферийны.
Эти элементы являются соединениями. Некоторые из них являются конечными точками — компьютер, смартфон или другое устройство, которое вы используете для чтения, может считаться одной из них. Мы называем эти конечные точки клиентов . Машины, на которых хранится информация, которую мы ищем в Интернете, — это серверов . Другими элементами являются узлов , которые служат точкой соединения на маршруте движения. А еще есть линии передачи, которые могут быть физическими, как в случае кабелей и оптоволокна, или они могут быть беспроводными сигналами со спутников, сотовых телефонов или вышек 4G, или радио.
Все это оборудование не создало бы сеть без второго компонента Интернета: протоколов. Протоколы — это наборы правил, которым машины следуют для выполнения задач. Без общего набора протоколов, которым должны следовать все машины, подключенные к Интернету, связь между устройствами невозможна.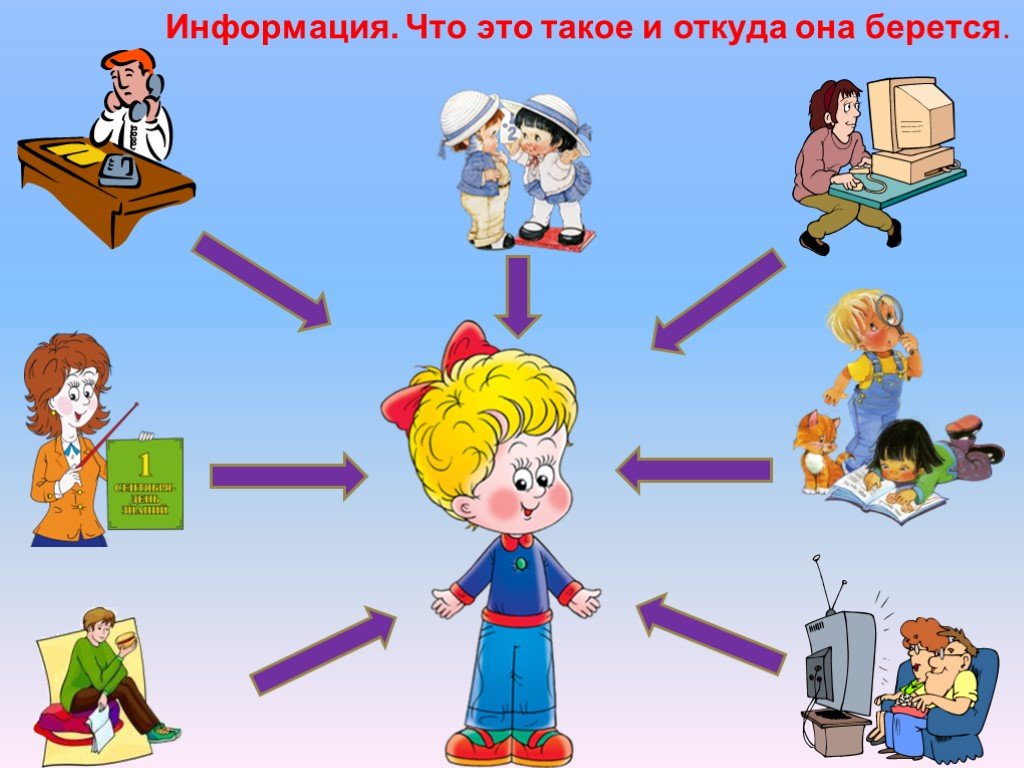 Различные машины не смогут понимать друг друга или даже посылать осмысленную информацию. Протоколы обеспечивают как метод, так и общий язык для машин, используемых для передачи данных.
Различные машины не смогут понимать друг друга или даже посылать осмысленную информацию. Протоколы обеспечивают как метод, так и общий язык для машин, используемых для передачи данных.
На следующей странице мы более подробно рассмотрим протоколы и то, как информация передается через Интернет.
Реклама
Содержание
- Дело протоколов
- Пакет, пакет, у кого пакет?
Дело протоколов
Вы, наверное, слышали о нескольких протоколах в Интернете. Например, протокол передачи гипертекста — это то, что мы используем для просмотра веб-сайтов через браузер — это то, что обозначает http перед любым веб-адресом. Если вы когда-либо использовали FTP-сервер, вы полагались на протокол передачи файлов. Подобные и десятки других протоколов создают основу, в рамках которой должны работать все устройства, чтобы быть частью Интернета.
Двумя наиболее важными протоколами являются протокол управления передачей (TCP) и Интернет-протокол (IP) . Мы часто объединяем их вместе — в большинстве дискуссий об интернет-протоколах вы увидите их в списке как TCP/IP.
Реклама
Что делают эти протоколы? На самом базовом уровне эти протоколы устанавливают правила прохождения информации через Интернет. Без этих правил вам потребовались бы прямые подключения к другим компьютерам для доступа к хранящейся на них информации. Вам также потребуется, чтобы ваш компьютер и целевой компьютер понимали общий язык.
Вы, наверное, слышали об IP-адресах. Эти адреса соответствуют интернет-протоколу. Каждое устройство, подключенное к Интернету, имеет IP-адрес . Вот как одна машина может найти другую через огромную сеть.
Сегодня большинство из нас использует IPv4, основанный на 32-битной системе адресации. В этой системе есть одна большая проблема: у нас заканчиваются адреса. Вот почему Инженерная рабочая группа Интернета (IETF) еще в 1991 году решила, что необходимо разработать новую версию IP, чтобы создать достаточное количество адресов для удовлетворения спроса. Результатом стала IPv6, 128-битная система адресации. Этого количества адресов достаточно для удовлетворения растущего спроса на доступ в Интернет в обозримом будущем [источник: Opus One].
Результатом стала IPv6, 128-битная система адресации. Этого количества адресов достаточно для удовлетворения растущего спроса на доступ в Интернет в обозримом будущем [источник: Opus One].
Когда вы хотите отправить сообщение или получить информацию с другого компьютера, протоколы TCP/IP делают передачу возможной. Ваш запрос отправляется по сети, затрагивая серверов доменных имен (DNS) по пути, чтобы найти целевой сервер. DNS направляет запрос в правильном направлении. Как только целевой сервер получает запрос, он может отправить ответ обратно на ваш компьютер. Данные могут пройти совершенно другой путь, чтобы вернуться к вам. Этот гибкий подход к передаче данных является частью того, что делает Интернет таким мощным инструментом.
Давайте подробнее рассмотрим, как информация распространяется через Интернет.
Реклама
Пакет, пакет, у кого пакет?
Чтобы получить эту статью, ваш компьютер должен был подключиться к веб-серверу, содержащему файл статьи. Мы будем использовать это как пример того, как данные перемещаются по Интернету.
Мы будем использовать это как пример того, как данные перемещаются по Интернету.
Сначала вы открываете веб-браузер и подключаетесь к нашему веб-сайту. Когда вы делаете это, ваш компьютер отправляет электронный запрос через интернет-соединение на ваш Интернет-провайдер (ISP) . Интернет-провайдер направляет запрос на сервер, расположенный выше по цепочке в Интернете. В конце концов, запрос попадет на сервер доменных имен (DNS).
Реклама
Этот сервер будет искать совпадение с введенным вами доменным именем (например, www.howstuffworks.com). Если он найдет совпадение, он направит ваш запрос на соответствующий IP-адрес сервера. Если он не найдет совпадения, он отправит запрос дальше по цепочке на сервер, у которого есть больше информации.
В конечном итоге запрос придет на наш веб-сервер. Наш сервер ответит, отправив запрошенный файл серией пакетов. Пакеты — это части файла размером от 1000 до 1500 байт. Пакеты имеют заголовки и нижние колонтитулы, которые сообщают компьютерам, что находится в пакете и как информация соответствует другим пакетам для создания всего файла. Каждый пакет возвращается вверх по сети и вниз к вашему компьютеру. Пакеты не обязательно идут по одному и тому же пути — обычно они идут по пути наименьшего сопротивления.
Каждый пакет возвращается вверх по сети и вниз к вашему компьютеру. Пакеты не обязательно идут по одному и тому же пути — обычно они идут по пути наименьшего сопротивления.
Это важная функция. Поскольку пакеты могут проходить по нескольким путям, чтобы добраться до пункта назначения, информация может проходить через перегруженные области Интернета. На самом деле, пока сохраняются некоторые соединения, целые разделы Интернета могут отключаться, а информация по-прежнему может перемещаться из одного раздела в другой, хотя это может занять больше времени, чем обычно.
Когда пакеты попадают к вам, ваше устройство упорядочивает их по правилам протоколов. Это похоже на сборку пазла. Конечным результатом является то, что вы видите эту статью.
Это относится и к другим типам файлов. Когда вы отправляете электронное письмо, оно разбивается на пакеты перед масштабированием через Интернет. Телефонные звонки через Интернет также преобразуют разговоры в пакеты с использованием протокола передачи голоса по Интернету (VoIP). Мы можем поблагодарить пионеров сетевых технологий, таких как Винтон Серф и Роберт Кан, за эти протоколы — их ранняя работа помогла создать масштабируемую и надежную систему.
Мы можем поблагодарить пионеров сетевых технологий, таких как Винтон Серф и Роберт Кан, за эти протоколы — их ранняя работа помогла создать масштабируемую и надежную систему.
Вот как работает Интернет. Присмотревшись к различным устройствам и протоколам, вы заметите, что картина гораздо сложнее, чем представленный нами обзор. Это увлекательная тема — узнайте больше, перейдя по ссылкам на следующей странице.
Реклама
Как работает Интернет Часто задаваемые вопросы
Что такое Интернет?
Интернет состоит из компьютерных сетей, которые позволяют пользователям получать доступ к информации с других компьютеров (при условии, что у них есть на это разрешение). Интернет часто использует различные протоколы, такие как TCP/IP, чтобы сделать это общение возможным.
Каковы основные возможности Интернета?
Одной из главных особенностей Интернета является доступность. Любой, у кого есть доступ к компьютеру и широкополосному соединению, может получить доступ к Интернету без ограничений. Интернет также оказывается недорогим и совместимым с большинством платформ.
Интернет также оказывается недорогим и совместимым с большинством платформ.
Как данные перемещаются через Интернет?
Данные разбиты на пакеты. Эти пакеты проходят через провайдера. Интернет-провайдер направляет запрос на сервер, расположенный выше по цепочке в Интернете. В конце концов, запрос попадет на сервер доменных имен (DNS). Этот сервер будет искать совпадение с введенным вами доменным именем (например, www.howstuffworks.com). Если он найдет совпадение, он направит ваш запрос на соответствующий IP-адрес сервера. Пакеты имеют заголовки и нижние колонтитулы, которые сообщают компьютерам, что находится в пакете и как информация соответствует другим пакетам для создания всего файла. Каждый пакет возвращается вверх по сети и вниз к вашему компьютеру.
Сколько данных находится в Интернете?
Исследования PwC показали, что к 2019 году Интернет достиг около 4,4 ZB (зеттабайт) данных (зеттабайт равен 1 073 741 824 терабайт). Большая часть этих данных хранится в сервисных компаниях, таких как Amazon, Microsoft, Facebook и Google.
Большая часть этих данных хранится в сервисных компаниях, таких как Amazon, Microsoft, Facebook и Google.
Много дополнительной информации
Похожие статьи HowStuffWorks
Другие полезные ссылки
- Музей компьютерной истории
- DARPA
- Живой Интернет
Источники
- Музей компьютерной истории «Пионер компьютеров Роберт Кан с Эдом Фейгенбаумом». YouTube. 9 января 2007 г. (23 апреля 2010 г.) http://www.youtube.com/watch?v=t3uTKs9XZyk
- Дайджест Конгресса. «История Интернета: от ARPANET к широкополосному доступу». Февраль 2007 г. стр. 35–37, 64.
- Хаубен, Ронда. «От ARPANET к Интернету». Колумбийский университет. 23 июня 1998 г. (26 апреля 2010 г.) http://www.columbia.edu/~rh220/other/tcpdigest_paper.txt
- Институт информационных наук. «Протокол Интернета.» Сентябрь 1981 г. (26 апреля 2010 г.
 ) http://www.ietf.org/rfc/rfc791.txt
) http://www.ietf.org/rfc/rfc791.txt - Opus One. «Что такое IPv6?» (27 апреля 2010 г.) http://www.opus1.com/ipv6/whatisipv6.html
- Проект THINK. «Техническая история ARPANET». Техасский университет в Остине. (26 апреля 2010 г.) http://userweb.cs.utexas.edu/users/chris/nph/ARPANET/ScottR/arpanet/index.htm
 ) http://www.ietf.org/rfc/rfc791.txt
) http://www.ietf.org/rfc/rfc791.txtПроцитировать это!
Пожалуйста, скопируйте/вставьте следующий текст, чтобы правильно цитировать эту статью HowStuffWorks.com:
Джонатан Стрикленд
«Как работает Интернет?»
7 мая 2010 г.
HowStuffWorks.com.
29 июня 2023 г.
Цитата
Краткая история Интернета
Прочтите об истории Интернета, начиная с его зарождения в 1950-х годах и заканчивая взрывом популярности Всемирной паутины в конце 19 века.90-е и «пузырь доткомов».
Истоки интернета
Истоки Интернета уходят корнями в США 1950-х годов. Холодная война была в разгаре, и между Северной Америкой и Советским Союзом существовала огромная напряженность. Обе сверхдержавы обладали смертоносным ядерным оружием, и люди жили в страхе перед внезапными атаками с большого расстояния. США поняли, что им нужна система связи, на которую не могла бы повлиять советская ядерная атака.
Обе сверхдержавы обладали смертоносным ядерным оружием, и люди жили в страхе перед внезапными атаками с большого расстояния. США поняли, что им нужна система связи, на которую не могла бы повлиять советская ядерная атака.
В то время компьютеры были большими и дорогими машинами, которые использовались исключительно военными учеными и сотрудниками университетов.
Компьютер Elliott/NRDC 401 MkI, 1953 г. Elliott-NRDC 401 был одним из первых электронных компьютеров, разработанных британской электротехнической компанией Elliott Brothers в 1952 году, когда машины этого типа могли достигать 4 метров в длину и весить более тонны.
Групповая коллекция Музея науки
Больше информации
о компьютере Elliott/NRDC 401 MkI, c.1953. Elliott-NRDC 401 был одним из первых электронных компьютеров, разработанных британской электротехнической компанией Elliott Brothers в 1952 году, когда машины этого типа могли достигать 4 метров в длину и весить более тонны.
Эти машины были мощными, но их было мало, и исследователи все больше разочаровывались: им требовался доступ к технологии, но для ее использования приходилось преодолевать большие расстояния.
Чтобы решить эту проблему, исследователи запустили «разделение времени». Это означало, что пользователи могли одновременно получать доступ к мейнфрейму через ряд терминалов, хотя по отдельности они имели в своем распоряжении лишь часть фактической мощности компьютера.
Сложность использования таких систем побудила ученых, инженеров и организации исследовать возможность создания крупномасштабной компьютерной сети.
Кто изобрел интернет?
Интернет не изобретал никто. Когда впервые были разработаны сетевые технологии, ряд ученых и инженеров объединили свои исследования для создания сети ARPANET. Позже творения других изобретателей проложили путь к Интернету в том виде, в каком мы его знаем сегодня.
• ПОЛ БАРАН (1926–2011)
Инженер, чья работа пересекалась с исследованиями ARPA. В 1959 году он присоединился к американскому аналитическому центру RAND Corporation, и его попросили исследовать, как ВВС США могут сохранить контроль над своим флотом, если когда-либо произойдет ядерная атака. В 1964 году Баран предложил сеть связи без центрального командного пункта. Если бы одна точка была уничтожена, все выжившие точки по-прежнему могли бы общаться друг с другом. Он назвал это распределенной сетью.
В 1959 году он присоединился к американскому аналитическому центру RAND Corporation, и его попросили исследовать, как ВВС США могут сохранить контроль над своим флотом, если когда-либо произойдет ядерная атака. В 1964 году Баран предложил сеть связи без центрального командного пункта. Если бы одна точка была уничтожена, все выжившие точки по-прежнему могли бы общаться друг с другом. Он назвал это распределенной сетью.
• ЛОУРЕНС РОБЕРТС (1937–2018)
Главный научный сотрудник ARPA, ответственный за разработку компьютерных сетей. Идея Пола Бэрана понравилась Робертсу, и он начал работать над созданием распределенной сети.
• ЛЕОНАРД КЛЕЙНРОК (1934–)
Американский ученый, работавший над созданием распределенной сети вместе с Лоуренсом Робертсом.
• ДОНАЛД ДЭВИС (1924–2000)
Британский ученый, одновременно с Робертсом и Клейнроком разрабатывавший аналогичную технологию в Национальной физической лаборатории в Миддлсексе.
• БОБ КАН (1938–) И ВИНТ СЕРФ (1943–)
Американские ученые-компьютерщики, разработавшие TCP/IP, набор протоколов, управляющих перемещением данных по сети. Это помогло ARPANET превратиться в Интернет, который мы используем сегодня. Винту Серфу приписывают первое письменное использование слова «интернет».
Это помогло ARPANET превратиться в Интернет, который мы используем сегодня. Винту Серфу приписывают первое письменное использование слова «интернет».
Когда меня просят объяснить мою роль в создании Интернета, я обычно использую пример города. Я помогал строить дороги — инфраструктуру, которая доставляет вещи из пункта А в пункт Б.
— Винт Серф, 2007
• ПОЛ МОКАПЕТРИС (1948–) И ДЖОН ПОСТЕЛ (1943–1998)
Изобретатели DNS, «телефонной книги Интернета».
• ТИМ БЕРНЕРС-ЛИ (1955–)
Создатель Всемирной паутины, разработавший многие принципы, которые мы используем до сих пор, такие как HTML, HTTP, URL-адреса и веб-браузеры.
Не было «Эврика!» момент. Это не было похоже на легендарное яблоко, упавшее на голову Ньютона, чтобы продемонстрировать концепцию гравитации. Изобретение Всемирной паутины повлекло за собой растущее осознание того, что есть сила в том, чтобы упорядочивать идеи без ограничений, как в сети.
— Тим Бернерс-Ли, Weaving the Web , 1999
 И это осознание пришло ко мне именно благодаря такому процессу. Сеть возникла как ответ на открытый вызов, благодаря смешению влияний, идей и реализаций со многих сторон.
И это осознание пришло ко мне именно благодаря такому процессу. Сеть возникла как ответ на открытый вызов, благодаря смешению влияний, идей и реализаций со многих сторон.• МАРК АНДРЕССЕН (1971–)
Изобретатель Mosaic, первого широко используемого веб-браузера.
Первое использование компьютерной сети
В 1965 году Лоуренс Робертс впервые заставил два отдельных компьютера в разных местах «разговаривать» друг с другом. В этом экспериментальном канале использовалась телефонная линия с модемом с акустической связью, а цифровые данные передавались с помощью пакетов.
Когда была разработана первая сеть с коммутацией пакетов, Леонард Клейнрок был первым, кто использовал ее для отправки сообщения. Он использовал компьютер в Калифорнийском университете в Лос-Анджелесе, чтобы отправить сообщение на компьютер в Стэнфорде. Клейнрок попытался ввести «логин», но система дала сбой после того, как на мониторе Стэнфорда появились буквы «L» и «O».
Вторая попытка оказалась успешной, и два сайта обменялись дополнительными сообщениями. ARPANET родилась.
Жизнь и смерть ARPANET
В 1958 году президент Дуайт Д. Эйзенхауэр создал Агентство перспективных исследовательских проектов (ARPA), объединив лучшие научные умы страны. Их цель состояла в том, чтобы помочь американским военным технологиям опережать своих врагов и предотвратить повторение сюрпризов, таких как запуск спутника 1. Среди проектов ARPA была проверка возможности создания крупномасштабной компьютерной сети.
Лоуренс Робертс отвечал за разработку компьютерных сетей в ARPA, работая с ученым Леонардом Клейнроком. Робертс был первым, кто соединил два компьютера. Когда в 19 г. была разработана первая сеть с коммутацией пакетов69, Kleinrock успешно использовал его для отправки сообщений на другой сайт, и так родилась сеть ARPA или ARPANET.
Как только сеть ARPANET была запущена, она быстро расширилась. К 1973 году к сети присоединились 30 академических, военных и исследовательских институтов, соединив такие места, как Гавайи, Норвегию и Великобританию.
По мере роста сети ARPANET необходимо было ввести набор правил для обработки пакетов данных. В 1974 году ученые-компьютерщики Боб Кан и Винт Серф изобрели новый метод, называемый протоколом управления передачей, широко известный как TCP/IP, который, по сути, позволял компьютерам говорить на одном языке.
После введения TCP/IP ARPANET быстро превратилась в глобальную взаимосвязанную сеть сетей, или «Интернет».
Сеть ARPANET была выведена из эксплуатации в 1990 году.
Что такое коммутация пакетов?
«Коммутация пакетов» — это метод разделения и отправки данных. Компьютерный файл эффективно разбивается на тысячи небольших сегментов, называемых «пакетами» (каждый обычно составляет около 1500 байт), которые распределяются по сети, а затем переупорядочиваются обратно в один файл в месте назначения. Метод коммутации пакетов очень надежен и позволяет безопасно передавать данные даже по поврежденным сетям; он также очень эффективно использует полосу пропускания и не нуждается в единой выделенной линии, как при телефонном звонке.
Первая в мире компьютерная сеть с коммутацией пакетов была создана в 1969 году. Компьютеры в четырех американских университетах были соединены между собой с помощью отдельных мини-компьютеров, известных как «процессоры интерфейсных сообщений» или «IMP». IMP выступали в качестве шлюзов для пакетов и с тех пор превратились в то, что мы сейчас называем «маршрутизаторами».
Коммутация пакетов — это основа, на которой до сих пор работает Интернет.
Что такое TCP/IP?
TCP/IP расшифровывается как Протокол управления передачей/Интернет-протокол. Этот термин используется для описания набора протоколов, управляющих перемещением данных по сети.
После создания ARPANET к сети стало присоединяться больше сетей компьютеров, и возникла потребность в согласованном наборе правил для обработки данных. В 1974 году два американских ученых-компьютерщика, Боб Кан и Винт Серф, предложили новый метод, предусматривающий отправку пакетов данных в цифровом конверте или «датаграмме». Адрес в дейтаграмме может быть прочитан любым компьютером, но только конечная хост-машина может открыть конверт и прочитать сообщение внутри.
Адрес в дейтаграмме может быть прочитан любым компьютером, но только конечная хост-машина может открыть конверт и прочитать сообщение внутри.
Кан и Серф назвали этот метод протоколом управления передачей (TCP). TCP позволил компьютерам говорить на одном языке и помог ARPANET превратиться в глобальную взаимосвязанную сеть сетей, пример «межсетевого взаимодействия» — для краткости Интернет.
IP означает Интернет-протокол и в сочетании с TCP помогает интернет-трафику найти свое назначение. Каждому устройству, подключенному к Интернету, присваивается уникальный IP-адрес. Известный как IP-адрес, этот номер можно использовать для определения местоположения любого подключенного к Интернету устройства в мире.
Что такое DNS?
DNS означает систему доменных имен. Это интернет-эквивалент телефонной книги, который преобразует трудно запоминаемые IP-адреса в простые имена.
В начале 1980-х годов более дешевая технология и появление настольных компьютеров способствовали быстрому развитию локальных вычислительных сетей (ЛВС). Увеличение количества компьютеров в сети усложнило отслеживание всех различных IP-адресов.
Увеличение количества компьютеров в сети усложнило отслеживание всех различных IP-адресов.
Эта проблема была решена введением системы доменных имен (DNS) в 1983 году. DNS была изобретена Полом Мокапетрисом и Джоном Постелом из Университета Южной Калифорнии. Это было одно из нововведений, проложивших путь к всемирной паутине.
Начало электронной почты
Электронная почта была быстрым, но непреднамеренным следствием роста ARPANET. По мере роста популярности и масштабов сети пользователи быстро осознали потенциал сети как инструмента для отправки сообщений между различными компьютерами ARPANET.
Рэй Томлинсон, американский программист, отвечает за электронную почту, какой мы ее знаем сегодня. Он представил идею о том, что адресат сообщения должен указываться с помощью символа @, который впервые использовался для различения имени отдельного пользователя и имени его компьютера (т. е. пользователь@компьютер). Когда DNS был представлен, он был расширен до user@host. domain.
domain.
Первые пользователи электронной почты отправляли личные сообщения и составляли списки рассылки по определенным темам. Одним из первых больших списков рассылки был «SF-LOVERS» для любителей научной фантастики.
Развитие электронной почты показало, как изменилась сеть. Вместо того, чтобы получить доступ к дорогостоящим вычислительным мощностям, он стал местом для общения, сплетен и друзей.
Первые домашние компьютеры
Начиная с 1970-х годов индустрия домашних компьютеров росла экспоненциально. Использование домашних компьютеров не обязательно было обусловлено потребностями пользователей или функциональностью компьютера; ранние машины на самом деле могли делать относительно немного. Обращение к потребителю заключалось в том, чтобы стать частью «Информационной революции». В компьютеры была встроена риторика будущего и обучения, но в большинстве случаев это означало обучение программированию, чтобы люди действительно могли заставить технологию что-то делать, например, играть в игры.
Персональный компьютер Apple I, 1976–79 гг.
Групповая коллекция Музея науки
Персональный компьютер Tandy Radio Shack TRS 80 I, 1978–80 гг.
Групповая коллекция Музея науки
Персональный компьютер Commodore PET 2001-8-BS, 1977 г.
Групповая коллекция Музея науки
Компьютерный монитор Apple II, 1980–1990 гг.
Групповая коллекция Музея науки
Микрокомпьютер Sinclair ZX 81, 1981–85 гг.
Групповая коллекция Музея науки
Портативный компьютер Osborne 1, 1981 г.
Групповая коллекция Музея науки
Персональный компьютер IBM 5150, 1983 г.
Групповая коллекция Музея науки
Микрокомпьютерная система BBC, 1981 г.
Групповая коллекция Музея науки
Микрокомпьютер Commodore 64, 1982–85 гг.
Групповая коллекция Музея науки
Микрокомпьютер Sinclair ZX Spectrum, 1982–85 гг.
Групповая коллекция Музея науки
Персональный компьютер Apple Macintosh, 1984 г.
Групповая коллекция Музея науки
Персональный текстовый процессор Amstrad с монитором, принтером, документацией и программным обеспечением, 1988
Групповая коллекция Музея науки
Рост Интернета, 1985–1995 гг.
Изобретение DNS, повсеместное использование TCP/IP и популярность электронной почты вызвали всплеск активности в Интернете. В период с 1986 по 1987 год сеть выросла с 2000 узлов до 30 000. Теперь люди использовали Интернет для отправки сообщений друг другу, чтения новостей и обмена файлами. Однако для подключения к системе и ее эффективного использования по-прежнему требовались передовые знания в области вычислений, и до сих пор не было соглашения о том, как форматируются документы в сети.
Однако для подключения к системе и ее эффективного использования по-прежнему требовались передовые знания в области вычислений, и до сих пор не было соглашения о том, как форматируются документы в сети.
Интернет должен быть проще в использовании. Ответ на эту проблему появился в 1989 году, когда британский ученый-компьютерщик по имени Тим Бернерс-Ли представил предложение своему работодателю, CERN, международной лаборатории по исследованию частиц в Женеве, Швейцария. Бернерс-Ли предложил новый способ структурирования и связывания всей информации, доступной в компьютерной сети ЦЕРН, который сделал ее доступной и быстрой. Его концепция «информационной сети» в конечном итоге стала всемирной паутиной.
Запуск браузера Mosaic в 1993 году открыл Интернет для новой аудитории, не являющейся учеными, и люди начали открывать для себя, насколько легко создавать свои собственные веб-страницы в формате HTML. Следовательно, количество веб-сайтов выросло со 130 в 1993 г. до более чем 100 000 в начале 1996 г. 10 миллионов пользователей по всему миру.
10 миллионов пользователей по всему миру.
Чем Всемирная паутина отличается от Интернета?
Термины «всемирная паутина» и «интернет» часто путают. Интернет — это сетевая инфраструктура, которая соединяет устройства друг с другом, а Всемирная паутина — это способ доступа к информации через Интернет.
Тим Бернерс-Ли впервые предложил идею «информационной сети» в 1989 году. Она основывалась на «гиперссылках» для соединения документов. Написанная на языке гипертекстовой разметки (HTML), гиперссылка может указывать на любую другую HTML-страницу или файл, который находится в Интернете.
В 1990 году Бернерс-Ли разработал протокол передачи гипертекста (HTTP) и разработал систему универсального идентификатора ресурса (URI). HTTP — это язык, который компьютеры используют для передачи HTML-документов через Интернет, а URI, также известный как URL-адрес, предоставляет уникальный адрес, по которому можно легко найти страницы.
Бернерс-Ли также создал программу, которая могла представлять HTML-документы в удобном для чтения формате. Он назвал этот «браузер» «WorldWideWeb».
Он назвал этот «браузер» «WorldWideWeb».
6 августа 1991 года код для создания дополнительных веб-страниц и программное обеспечение для их просмотра были размещены в свободном доступе в Интернете. Компьютерные энтузиасты по всему миру начали создавать свои собственные веб-сайты. Видение Бернерса-Ли свободного, глобального и общего информационного пространства начало обретать форму.
Сеть мечтает об общем информационном пространстве, в котором мы общаемся, обмениваясь информацией. Важна его универсальность: тот факт, что гипертекстовая ссылка может указывать на что угодно, будь то личное, локальное или глобальное, будь то черновик или тщательно отполированный текст.
Тим Бернерс-Ли (1998)
Внедрение веб-браузеров
Тим Бернерс-Ли был первым, кто создал программу, которая могла представлять HTML-документы в удобном для чтения формате. Он назвал этот «браузер» «WorldWideWeb». Однако это исходное приложение имело ограниченное применение, поскольку его можно было использовать только на продвинутых компьютерах NeXT. Упрощенная версия, которая могла работать на любом компьютере, была создана Николой Пеллоу, студенткой-математиком, работавшей вместе с Бернерсом-Ли в ЦЕРНе.
Он назвал этот «браузер» «WorldWideWeb». Однако это исходное приложение имело ограниченное применение, поскольку его можно было использовать только на продвинутых компьютерах NeXT. Упрощенная версия, которая могла работать на любом компьютере, была создана Николой Пеллоу, студенткой-математиком, работавшей вместе с Бернерсом-Ли в ЦЕРНе.
В 1993 году Марк Андриссен, американский студент из Иллинойса, запустил новый браузер под названием Mosaic. Созданный в Национальном центре суперкомпьютерных приложений (NCSA), Mosaic было легко загрузить и установить, он работал на многих разных компьютерах и обеспечивал простой доступ к World Wide Web по принципу «укажи и щелкни». Mosaic также был первым браузером, который отображал изображения рядом с текстом, а не в отдельном окне.
Простота Mosaic открыла Интернет для новой аудитории и вызвала всплеск активности в Интернете: количество веб-сайтов выросло со 130 в 19с 93 до более чем 100 000 в начале 1996 года.
В 1994 году Андрисен вместе с предпринимателем Джимом Кларком основал компанию Netscape Communications. Они привели компанию к созданию Netscape Navigator, широко используемого интернет-браузера, который в то время был быстрее и совершеннее, чем любой из конкурентов. К 1995 году у Navigator было около 10 миллионов пользователей по всему миру.
Они привели компанию к созданию Netscape Navigator, широко используемого интернет-браузера, который в то время был быстрее и совершеннее, чем любой из конкурентов. К 1995 году у Navigator было около 10 миллионов пользователей по всему миру.
Ранняя электронная коммерция и «пузырь доткомов»
Огромный ажиотаж вокруг Интернета привел к массовому буму обмена новыми технологиями между 1998 и 2000. Это стало известно как «пузырь доткомов».
Утверждалось, что мировая промышленность переживает «новую экономическую парадигму», подобной которой еще никогда не было. Инвесторы на фондовом рынке начали верить в шумиху и бросились в бешеную активность. Считалось, что Интернет играет центральную роль в экономическом росте, а цены на акции подразумевают, что новые онлайн-компании несут в себе семена для расширения. Это, в свою очередь, привело к лихорадочному уровню инвестиций и нереалистичным ожиданиям относительно нормы прибыли.
Мы вступили в период устойчивого роста, который может в конечном итоге удваивать мировую экономику каждые десять лет и приносить все большее процветание — в буквальном смысле — миллиардам людей на планете.
