Over ms sql: Предложение OVER (Transact-SQL) — SQL Server
Содержание
T-SQL | Функции смещения
107
Работа с базами данных в .NET Framework — Оконные функции T-SQL — Функции смещения
Исходник базы данных
Оконные функции смещения делятся на две категории. Первая категория — функции, смещение которых указывается по отношению к текущей строке. Это LAG и LEAD. В функциях второй категории смещение указывается по отношению к началу или концу оконного кадра. Сюда относятся функции FIRST_VALUE, LAST_VALUE и NTH_VALUE. SQL Server 2012 поддерживает LAG, LEAD, FIRST_VALUE и LAST_VALUE и не поддерживает NTH_VALUE.
Функции первой категории (LAG и LEAD) поддерживают предложение секционирования, а также упорядочения окна. Ясно, что вторая часть вносит смысл в смещение. Функции из второй категории (FIRST_VALUE, LAST_VALUE и NTH_VALUE) помимо предложения секционирования и упорядочения окна поддерживают предложение оконного кадра.
Функции LAG и LEAD
Функции LAG и LEAD позволяют возвращать выражение значения из строки в секции окна, которая находится на заданном смещении перед (LAG) или после (LEAD) текущей строки. Смещение по умолчанию — «1», оно применяется, если смещение не указать.Например, следующий запрос возвращает текущую стоимость для каждого клиентского заказа, а также стоимости предыдущего и последующего заказов этого же клиента:
Смещение по умолчанию — «1», оно применяется, если смещение не указать.Например, следующий запрос возвращает текущую стоимость для каждого клиентского заказа, а также стоимости предыдущего и последующего заказов этого же клиента:
SELECT custid, orderdate, orderid, val,
LAG(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS prevval,
LEAD(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS nextval
FROM Sales.OrderValues;Так как мы явно не задали смещение, по умолчанию предполагается смещение в единицу. Так как данные в функции секционируются по custid, поиск строк выполняется только в рамках той же секции, содержащей данные одного клиента. Что касается упорядочения окон, то понятия «предыдущий» и «следующий» определяются упорядочением по orderdate и orderid в качестве дополнительного параметра. Заметьте, что в результатах запроса LAG возвращает NULL для первой строки оконной секции, потому что перед первой строкой других строк нет; аналогично LEAD возвращает NULL для последней строки.
Если нужно смещение, отличное от единицы, нужно указать его после входного выражения значения, как в этом запросе:
SELECT custid, orderdate, orderid,
LAG(val, 3) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS prev3val
FROM Sales.OrderValues;Как говорилось, LAG и LEAD по умолчанию возвращают NULL, если по заданному смещению нет строки. Если нужно возвращать другое значение, можно указать его в качестве третьего аргумента функции. Например, LAG(val, 3, 0.00) возвращает «0.00», если по смещению 3 перед текущей строкой строки вообще нет.
Для реализации подобного поведения в LAG и LEAD на версии SQL Server, предшествующей SQL Server 2012, можно применить следующий подход:
Напишите запрос, который возвращает номера строк с требуемыми параметрами секционирования и упорядочения, и создайте на его основе табличное выражение.
Соедините множественные табличные выражения так, чтобы они представляли текущую, предыдущую и следующую строки.

В предикате соединения сопоставьте столбцы секционирования различных экземпляров (текущего с предыдущим или последующим). Также в предикате соединения вычислите разницу между числом строк текущего и предыдущего или следующего экземпляра, а затем отфильтруйте на основе значения смещения, которое требуется в ваших вычислениях.

Вот запрос, реализующий этот подход и возвращающий для каждого заказа значения текущего, предыдущего и следующего заказа клиента:
WITH OrdersRN AS
(
SELECT custid, orderdate, orderid, val,
ROW_NUMBER() OVER(ORDER BY custid, orderdate, orderid) AS rn
FROM Sales.OrderValues
)
SELECT C.custid, C.orderdate, C.orderid, C.val,
P.val AS prevval,
N.val AS nextval
FROM OrdersRN AS C
LEFT OUTER JOIN OrdersRN AS P
ON C.custid = P.custid
AND C.rn = P.rn + 1
LEFT OUTER JOIN OrdersRN AS N
ON C.custid = N.custid
AND C. rn = N.rn - 1; rn = N.rn - 1;
rn = N.rn - 1;Ясно, что решить эту задачу можно также с помощью простых вложенных запросов.
Функции FIRST_VALUE, LAST_VALUE и NTH_VALUE
В предыдущем разделе я рассказал о функциях смещения LAG и LEAD, которые позволяют задавать смещение относительно текущей строки. Этот раздел посвящен функциям, которые позволяют определять смещение относительно начала или конца оконного кадра. Это функции FIRST_VALUE, LAST_VALUE и NTH_VALUE, причем последняя не реализована в SQL Server 2012.
Напомню, что LAG и LEAD поддерживают предложения секционирования и упорядочение, но не поддерживают предложение кадрирования окна. Это разумно, если смещение указывается относительно текущей строки. В функциях, в которых смещение указывается по отношению к началу или концу окна, кадрирование имеет смысл. Функции FIRST_VALUE и LAST_VALUE возвращают запрошенное выражение значения соответственно из первой и последней строки в кадре. Вот запрос, демонстрирующий, как возвращать с каждым заказом клиента текущее значение этого заказа, а также значения первого и последнего заказа:
SELECT custid, orderdate, orderid, val,
FIRST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS val_firstorder,
LAST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS val_lastorder
FROM Sales. OrderValues; OrderValues;
OrderValues;С технической точки зрения нам нужны значения из первой и последней строки секции. С FIRST_VALUE просто, потому что можно использовать кадрирование по умолчанию. Как вы помните, если поддерживается кадрирование и не указать предложение кадрирования окна, по умолчанию будет применяться RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Но с LAST_VALUE кадрирование по умолчанию бесполезно, потому что последней является текущая строка. Поэтому в этом примере используется явное определение кадра с UNBOUNDED FOLLOWING в качестве нижней границы кадра.
Обычно не возвращают первое или последнее значение вместе со всеми подробностями строк, как в предыдущем примере — в вычислениях обычно работают с одной цифрой и значением, возвращенным оконной функцией. В следующем примере запрос возвращает, вместе с каждым клиентским заказом, стоимость текущего заказа, а также разницу между ней и стоимостью первого и последнего заказа клиента:
SELECT custid, orderdate, orderid, val,
val - FIRST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS difffirst,
val - LAST_VALUE(val) OVER(PARTITION BY custid
ORDER BY orderdate, orderid
ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING) AS difflast
FROM Sales. OrderValues; OrderValues;
OrderValues;Как я говорил, стандартная функция NTH_VALUE не реализована в SQL Server 2012. Эта функция позволяет запрашивать выражение значения, которое находится на заданном смещении, выраженном в числе строк, от первой или последней строки в оконном кадре. Смещение задается во втором входном значении после выражения значения и ключевого слова FROM_FIRST или FROM_LAST, которое указывает, от какой строки отсчитывать смещение — от первой или последней. Например, следующее выражение возвращает значение из третьей строки, если считать от самой нижней в секции:
NTH_VALUE(val, 3) FROM LAST OVER(ROWS BETWEEN CURRENT ROW
AND UNBOUNDED FOLLOWING)Представим, что нам надо обеспечить функциональность, которую реализуют функции FIRST_VALUE, LAST_VALUE и NTH_VALUE, в версии, предшествующей SQL Server 2012. Для этого можно использовать такие конструкции, как обобщенные табличные выражения (CTE), функцию ROW_NUMBER и выражение CASE, группировку и соединение, следующим образом:
WITH OrdersRN AS
(
SELECT custid, val,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate, orderid) AS rna,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rnd
FROM Sales. OrderValues
),
Agg AS
(
SELECT custid,
MAX(CASE WHEN rna = 1 THEN val END) AS firstorderval,
MAX(CASE WHEN rnd = 1 THEN val END) AS lastorderval,
MAX(CASE WHEN rna = 3 THEN val END) AS thirdorderval
FROM OrdersRN
GROUP BY custid
)
SELECT O.custid, O.orderdate, O.orderid, O.val,
A.firstorderval, A.lastorderval, A.thirdorderval
FROM Sales.OrderValues AS O
JOIN Agg AS A
ON O.custid = A.custid
ORDER BY custid, orderdate, orderid; OrderValues
),
Agg AS
(
SELECT custid,
MAX(CASE WHEN rna = 1 THEN val END) AS firstorderval,
MAX(CASE WHEN rnd = 1 THEN val END) AS lastorderval,
MAX(CASE WHEN rna = 3 THEN val END) AS thirdorderval
FROM OrdersRN
GROUP BY custid
)
SELECT O.custid, O.orderdate, O.orderid, O.val,
A.firstorderval, A.lastorderval, A.thirdorderval
FROM Sales.OrderValues AS O
JOIN Agg AS A
ON O.custid = A.custid
ORDER BY custid, orderdate, orderid;
OrderValues
),
Agg AS
(
SELECT custid,
MAX(CASE WHEN rna = 1 THEN val END) AS firstorderval,
MAX(CASE WHEN rnd = 1 THEN val END) AS lastorderval,
MAX(CASE WHEN rna = 3 THEN val END) AS thirdorderval
FROM OrdersRN
GROUP BY custid
)
SELECT O.custid, O.orderdate, O.orderid, O.val,
A.firstorderval, A.lastorderval, A.thirdorderval
FROM Sales.OrderValues AS O
JOIN Agg AS A
ON O.custid = A.custid
ORDER BY custid, orderdate, orderid;В первом CTE по имени OrdersRN определяются номера строк как возрастающем, так и убывающем порядке для отметки позиций строк по отношению к первой и последней строке в секции. Во втором CTE по имени Agg используется выражение CASE для фильтрации только нужных номеров строк, группировки данных по элементу секционирования {custid) и применения агрегата к результату выражения CASE, чтобы вернуть запрошенное значение для каждой группы. Наконец во внешнем запросе результат группового запроса соединяется с исходной таблицей для сопоставления детализованной информации с агрегатами.
Полезные оконные функции SQL. Можно бесконечно долго «воротить нос»… | by Writes
Можно бесконечно долго «воротить нос» от использования SQL для Data Preparation, отдавая лавры змеиному языку, но нельзя не признавать факт, что чаще мы используем и еще долго будем использовать SQL для работы с данными, в том числе и очень объемными. Более того, считаем, что на текущий момент SQL окажется под рукой сотрудника с большей вероятностью, чем Python, и поможет быстро решить аналитическую задачку с приоритетом «-1».
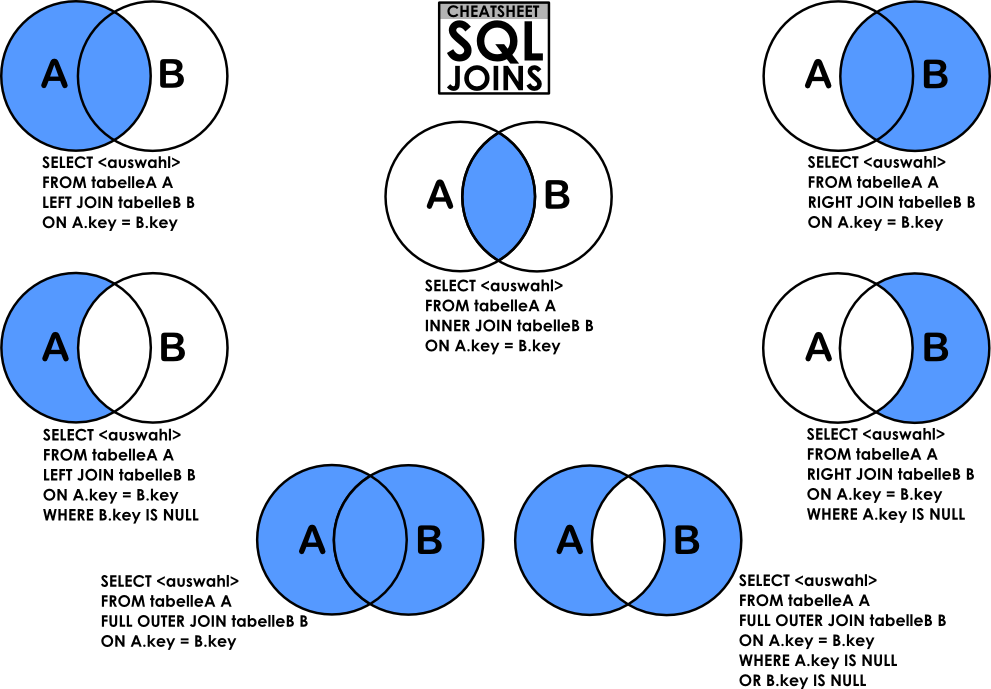
Предложение OVER помогает «открыть окно», т.е. определить строки, с которым будет работать та или иная функция.
Предложение partion BY не является обязательным, но дополняет OVER и показывает, как именно мы разделяем строки, к которым будет применена функция.
ORDER BY определит порядок обработки строк.
В одном select может быть больше одного OVER, эта прекрасная особенность упростит выполнение аналитической задачи в дальнейшем.
Итак, оконные функции делятся на:
- Агрегатные функции
- Ранжирующие функции
- Функции смещения
- Аналитические функции
Собственно, те же, что и обычные, только встроенные в конструкцию с OVER
SUM/ AVG / COUNT/ MIN/ MAX
Для наглядности работы данных функций воспользуемся базовым набором данных (T)
Задача:
Найти максимальную задолженность в каждом банке.
Для чего тут оконные функции? Можно же просто написать:
SELECT TB, max(OSZ) OSZ FROM T group by TB
В данном контексте, действительно, применение оконных функций нецелесообразно, но, когда речь заходит о задаче:
Собрать дэшборд, в котором содержится информация о максимальной задолженности в каждом банке, а также средний размер процентной ставки в каждом банке в зависимости от сегмента, плюс еще количество договоров всего всем банкам (в голове рисуются множественные джойны из подзапросов и как-то сразу тяжело на душе). Однако, как я говорил выше, в одном select можно использовать много OVER, а также еще один прекрасный факт: набор строк в окне, связывается с текущей строкой, а не с группой агрегированных. Таким образом:
Однако, как я говорил выше, в одном select можно использовать много OVER, а также еще один прекрасный факт: набор строк в окне, связывается с текущей строкой, а не с группой агрегированных. Таким образом:
SELECT TB, ID_CLIENT, ID_DOG, OSZ, PROCENT_RATE, RATING, SEGMENT , MAX(OSZ) OVER (PARTITION BY TB) ‘Максимальная задолженность в разбивке по банкам’ , AVG(PROCENT_RATE) OVER (PARTITION BY TB, SEGMENT) ‘Средняя процентная ставка в разрезе банка и сегмента’ , COUNT(ID_DOG) OVER () ‘Всего договоров во всех банках’ FROM T
На примере AVG(procent_RATE) OVER (partition BY TB, segment) подробнее:
- Мы применяем AVG — агрегатную функцию по подсчету среднего значения к столбцу procent_RATE.
- Затем предложением OVER определяем, что будем работать с некоторым набором строк. По умолчанию, если указать OVER() с пустыми строками, то этот набор строк равен всей таблице.
- Предложением partition BY выделяем разделы в наборе строк по заданному условию, в нашем случае, в разбивке на Территориальные банки и Сегмент.
- В итоге, к каждой строке базовой таблицы применится функция по подсчету среднего из набора строк, разбитых на разделы (по Территориальным Банкам и Сегменту).
Другой тип оконных функций, надо признать, мой любимый и был использован для решения многих задач. Функции ранжирования для каждой строки в разделе возвращают значение рангов или рейтингов. Все ведь любят рейтинги, правда…?
Базовый набор данных: банки, отделы и количество ревизий.
Сами ранжирующие функции:
ROW_number — нумерует строки в результирующем наборе.
RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается с пропуском.
DENSE_RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается без пропуска.
NTILE — помогает разделить результирующий набор на группы.
Для понимания написанного, проранжируем таблицу по убыванию количества ревизий:
SELECT * , ROW_NUMBER() OVER(ORDER BY count_revisions desc) , Rank() OVER(ORDER BY count_revisions desc) , DENSE_RANK() OVER(ORDER BY count_revisions desc) , NTILE(3) OVER(ORDER BY count_revisions desc) FROM Table_Rev
ROW_number — пронумеровал столбцы в порядке убывания количества ревизий.
RANK — проранжировал отделы во всех банках в порядке убывания количества ревизий, но как только встретились одинаковые значения (количество ревизий 95), функция присвоила им ранг 4, а следующее значение получило ранг 6.
DENSE_RANK — аналогично RANK, но как только встретились одинаковые значения, следующее значение получило ранг 5.
NTILE — функция помогла разбить таблицу на 3 группы (указал в аргументе). Так как в таблице 18 значений, в каждую группу попало по 6.
Задача:
Найти второй отдел во всех банках по количеству ревизий.
Можно, конечно, воспользоваться чем-то вроде:
SELECT MAX(count_revisions) ms FROM Table_Rev WHERE count_revisions!=(SELECT MAX(count_revisions) FROM Table_Rev)
Но если речь идет не про второй отдел, а про трети? .. уже сложнее. Действительно, никто не списывает со счетов offset, но в этой статье говорится об оконных функциях, так почему бы не написать так:
With T_R as ( SELECT * , DENSE_RANK() OVER(ORDER BY count_revisions desc) ds FROM Table_Rev ) SELECT * FROM T_R WHERE ds=3
Как и во всех других типах функций, здесь можно выделять разделы с помощью partitionby. Например, найти отдел в каждом банке, с меньшим количеством проведенных ревизий, для этого разделяем на секции по территориальным банкам, сортируем по возрастанию:
Например, найти отдел в каждом банке, с меньшим количеством проведенных ревизий, для этого разделяем на секции по территориальным банкам, сортируем по возрастанию:
With T_R as ( SELECT * , DENSE_RANK() OVER(PARTITION BY tb ORDER BY count_revisions) ds FROM Table_Rev ) SELECT tb,dep,count_revisions FROM T_R WHERE ds=1
Получаем:
Оконные функции смещения помогут нам, когда необходимо обратиться к строке в наборе данных из окна, относительно текущей строки с некоторым смещением. Проще говоря, узнать, какое значение (событие/ дата) идет после/до текущей строки. Похоже на отличную штуку в предобработке лога данных.
LAG — смещение назад.
LEAD — смещение вперед.
FIRST_VALUE — найти первое значение набора данных.
LAST_VALUE — найти последнее значение набора данных.
LAG и LEAD имеют следующие аргументы:
- Столбец, значение которого необходимо вернуть
- На сколько строк выполнить смешение (дефолт =1)
- Что вставить, если вернулся NULL
Как обычно, на практике проще:
Базовый набор данных, содержит id задачи, события внутри нее и их дату:
Применяя конструкцию:
SELECT * , LEAD (Event, 1, ‘end’) OVER (PARTITION BY ID_Task ORDER BY Date_Event) as Next_Event , LEAD (Date_Event, 1, ‘2099–01–01’) OVER(PARTITION BY ID_Task ORDER BY Date_Event) as Next_Date FROM Table_Task
Получаем набор данных, который хоть сейчас в graphviz (нет).
Аналитические оконные функции подходят под специфичные задачи и описывать их здесь я, пожалуй, не буду. Но, возможно, вы решите ознакомиться с ними самостоятельно, а значит будете более подготовлены к решению хитро закрученных задач.
Тем, кто слышит про данные функции впервые, надеюсь, статья окажется полезной, а, кто уже со всем этим знаком, простите, потраченное время никто не вернет.
sql server — Как проксировать соединения MSSQL через прокси-сервер TCP с кэшированными учетными данными Kerberos?
Мне нужно проксировать соединения MSSQL через прокси-сервер TCP, используя кэшированные учетные данные Kerberos. Идея состоит в том, чтобы пройти аутентификацию в базе данных с помощью kerberos, кэшировать учетную запись, а затем использовать эту учетную запись из заблокированной среды для подключения к базе данных через прокси-сервер.
Исходный и прокси-экземпляры — это машины Linux, работающие под управлением Centos 8.
В этом случае исходный/клиентский экземпляр не имеет подключения к контроллерам домена, используемым для проверки подлинности Kerberos, равно как и прокси-сервер. Прокси-сервер является чистым проходом к целевому серверу, который имеет подключение к контроллерам домена для выполнения обмена маркерами билета kerberos <--> и аутентификации.
Прокси-сервер является чистым проходом к целевому серверу, который имеет подключение к контроллерам домена для выполнения обмена маркерами билета kerberos <--> и аутентификации.
Вот как выглядит моя текущая среда:
Исходный прокси-приемник
+-+----+--+ +------------------------------+ +------- ----------+
| | TCP1 | HAProxy | TCP2 | |
| Клиент +--------------> front_end backend----------------->+ SQL Server |
| | | | | |
+---------+ +------------------------------+ +------- ----------+
Моя конфигурация прокси:
внешний интерфейс tcp-in-mssql привязать :5650 режим TCP use_backend mssql серверная часть MSSQL режим TCP сервер mssql.mydomain.com mssql.mydomain.com:5650 проверить
При тестировании я могу напрямую подключаться к SQL Server на экземпляре Dest из экземпляра Proxy как с помощью аутентификации на основе пароля, так и аутентификации Kerberos.
Примеры успешного подключения к SQL Server из экземпляра прокси:
$ env | grep KRB5 KRB5CCNAME=/tmp/krb5cc_12345 # <-- это действительный кэш билетов $ /opt/mssql-tools18/bin/sqlcmd -C -S mssql.
 mydomain.com,5650 -U мой пользователь
Пароль:
1> выйти
$ /opt/mssql-tools18/bin/sqlcmd -C -S mssql.mydomain.com,5650 -E
1> выйти
mydomain.com,5650 -U мой пользователь
Пароль:
1> выйти
$ /opt/mssql-tools18/bin/sqlcmd -C -S mssql.mydomain.com,5650 -E
1> выйти
При подключении через прокси с хоста прокси:
$ /opt/mssql-tools18/bin/sqlcmd -C -S localhost,5650 -U myuser Пароль: 1> выйти $ /opt/mssql-tools18/bin/sqlcmd -C -S локальный хост,5650 -E Sqlcmd: ошибка: драйвер Microsoft ODBC 18 для SQL Server: поставщик SSPI: сервер не найден в базе данных Kerberos. Sqlcmd: ошибка: драйвер Microsoft ODBC 18 для SQL Server: не удается создать контекст SSPI.
Думаю, это имеет смысл, если я использую localhost в параметре сервера sqlcmd .
Я получаю точно такие же результаты при замене localhost на прокси-хост в sqlcmd .
Я считаю, что моя единственная серьезная проблема здесь заключается в том, что я не могу установить соединение через прокси-сервер при установке переменных env socks_proxy или all_proxy , поэтому я могу использовать имя хоста SQL Server в параметре сервера sqlcmd .
Каждое из нижеперечисленных не проходит через прокси и идет напрямую к хосту в параметре сервера sqlcmd . То же самое происходит при использовании авторизации по паролю. Я знаю это, потому что не вижу подключений, зарегистрированных в журналах haproxy.
$ socks_proxy=socks5://localhost:5640 /opt/mssql-tools18/bin/sqlcmd -C -S mssql.mydomain.com,5650 -E 1> выйти $ socks_proxy=socks://localhost:5640 /opt/mssql-tools18/bin/sqlcmd -C -S mssql.mydomain.com,5650 -E 1> выйти $ all_proxy=socks5://localhost:5640 /opt/mssql-tools18/bin/sqlcmd -C -S mssql.mydomain.com,5650 -E 1> выйти $ all_proxy=socks://localhost:5640 /opt/mssql-tools18/bin/sqlcmd -C -S mssql.mydomain.com,5650 -E 1> выйти
Единственный способ, которым я могу использовать прокси, это использовать прокси в sqlcmd параметр сервера, который работает с аутентификацией по паролю, но не работает с аутентификацией Kerberos.
Я также пытался добавить ServerSPN=MSSQLSvc/mssql. в мои файлы  mydomain.com:5650
mydomain.com:5650 odbc.ini и odbcinst.ini .
В документе sqlcmd нет ничего, что бы принимало настройки прокси, поэтому я не знаю, что здесь делать. Я гибко отношусь к прокси, это не обязательно должен быть HAProxy, но HAProxy показался мне самым простым проходом через TCP-прокси, поэтому я использовал его через nginx.
sql — Деление на предложение «Over» в MSSQL работает, но деление на «Псевдоним» не работает
Я думаю, вы можете неправильно понять, где доступны столбцы с псевдонимом / на которые можно ссылаться по псевдониму, особенно потому, что вы сказали (парафраз ) «псевдоним, который я создал в строке 3 sql, недоступен в строке 4»:
Неправильно:
SELECT 1200 как games_won, 25 как лет_играл, --нельзя использовать эти псевдонимы ниже в том же блоке выбора, в котором они были объявлены games_won / years_played as games_won_per_year ...
Справа:
ВЫБОР 1200 как games_won, 25 как лет_играл, --может использовать значения, хотя 1200/25 как games_won_per_year
Справа:
ВЫБЕРИТЕ games_won/years_played as games_won_per_year --псевдоним из внутренней области доступен в этой внешней области.
 ИЗ
(
ВЫБРАТЬ
--эти псевдонимы становятся доступными только вне скобок
1200 как games_won,
25 как years_played
) Икс
ИЗ
(
ВЫБРАТЬ
--эти псевдонимы становятся доступными только вне скобок
1200 как games_won,
25 как years_played
) Икс
Вы не можете использовать псевдоним для столбца и снова использовать псевдоним в том же блоке выбора; вы можете использовать псевдоним только во внутреннем/подзапросе и использовать псевдоним во внешнем запросе. SQL , а не , как язык программирования, работающий построчно:
int gameswon = 1200; int отыграно = 25; int winsperyear = количество выигранных игр / количество сыгранных лет;
Здесь, в этом C#, вы можете видеть, что мы объявляем переменные (псевдонимы) в более ранних строках и используем их в более поздних строках, но это потому, что язык программирования работает построчно. Результаты выполнения более ранней строки доступны для более поздних строк. SQL так не работает; SQL работает со всеми разделами запроса одновременно. Ваши столбцы не получают эти псевдонимы, которые вы им дали, пока не завершится обработка всего блока выбора, поэтому вы не можете дать столбцу или вычислению псевдоним, а затем снова использовать этот псевдоним в том же блоке выбора. Единственный способ обойти это и создать псевдоним, который вы впоследствии будете использовать неоднократно, — это создать псевдоним в подзапросе.
Единственный способ обойти это и создать псевдоним, который вы впоследствии будете использовать неоднократно, — это создать псевдоним в подзапросе.
Вот еще пример:
ВЫБЕРИТЕ
fih.tot_amt / fih.amt_per_proj Распределение_суммы AS
ИЗ
(
ВЫБРАТЬ
CAST(f.total_net_amount_amount AS DECIMAL(18,8)) as tot_mt,
CAST(SUM(f.total_net_amount_amount) OVER (PARTITION BY p.project_key)) AS DECIMAL(18,8)) AS amt_per_proj
ИЗ
dbo.factinvoiceheader f
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
dbo.dimproject p
НА ...
) фих
Здесь вы можете видеть, что я вытащил нужные столбцы и присвоил им псевдонимы во внутреннем запросе, а затем использовал псевдонимы во внешнем запросе — это работает, потому что псевдонимы, декольированные во внутреннем блоке, становятся доступными для внешнего блока
Всегда помните, что SQL не построчно, как типичный язык программирования, а поблочно. Действительно, в большинстве языков программирования вещи, объявленные во внутренних блоках кода, недоступны во внешних блоках кода (если только они не являются какой-то глобализированной вещью, такой как javascript var), поэтому SQL отличается от того, к чему вы привыкли. Каждый раз, когда вы создаете блок инструкций в SQL, у вас есть возможность изменить псевдоним столбцов данных.
Каждый раз, когда вы создаете блок инструкций в SQL, у вас есть возможность изменить псевдоним столбцов данных.
Поскольку SQL основан на блоке за блоком, я делаю отступы в своих SQL-запросах по блокам, чтобы было легко увидеть, что обрабатывается вместе. Такие ключевые слова, как SELECT, FROM, WHERE, GROUP BY и ORDER BY, обозначают блоки и псевдонимы, которые могут быть созданы для столбцов в SELECT и для таблиц в FROM. В приведенном выше примере я применил псевдонимы не только к вычислениям и столбцам, но и к таблицам. Это значительно упрощает чтение запроса, когда он имеет отступы и псевдонимы — давайте своим именам таблиц псевдонимы, а не записывайте dbo.factinvoiceheader. перед каждым именем столбца
Вот несколько советов, как сделать ваши SQL-запросы более аккуратными и легкими для чтения и отладки:
- не размещайте их все в одной строке или на одном уровне отступа — делайте отступ в зависимости от того, насколько он глубокий или мелкий блок инструкций
- select, from, where, group by, order by и т.
