Php curl парсер: Работа с библиотекой CURL в PHP
Содержание
что нужно знать новичкам OTUS
Серверная разработка требует от программиста определенного спектра знаний и навыков. Весьма полезным покажется парсер. Главное разобраться, каким образом его реализовать на PHP.
Статья расскажет о том, что такое парсинг, для чего он нужен и как функционирует. В ней будут приведены наглядные примеры, которые пригодятся для любого URL при веб-разработке.
Parsing – это…
Парсер – программное обеспечение, которое осуществляет анализ входных текстовых сведений. После этого занимается извлечением необходимой информации, на основе которых будет производиться результат в заранее заданном формате.
На PHP parser работает так:
- скрипт создает запрос по URL;
- осуществляется получение ответа от сервера в виде HTML или ином текстовом формате;
- сведения анализируются;
- из электронных материалов URL извлекаются (парсятся) нужные элементы;
- формируется и выводится результат.
Итог можно записывать в файлы и базы данных, а также непосредственно выводить на дисплей устройства.
Для чего необходим
При изучении парсеров в PHP стоит выяснить, для чего они вообще нужны. Подобное программное обеспечение:
- Автоматизируют информацию в пределах URL.
- Собирают и обрабатывают большие объемы данных.
- Сравнивают содержимое страниц с заданными параметрами. Пример – поисковые системы.
- Помогают организовывать спам-рассылку.
А еще парсером на PHP можно наполнять собственные веб-ресурсы «чужим» контентом. Подобные проекты стараются блокировать, но это не всегда выходит быстро.
Parser избавляет от перепечатывания информации однотипного характера. Пример – наполнение интернет-магазина тем или иным товаром.
Основа функционирования
Если мы парсим текст, не стоит думать, что парсер будет его читать. Соответствующее ПО:
- получает набор команд и инструкций от разработчика;
- считывает слова;
- сравнивает то, что обнаружено в Сети согласно заданным принципам.
Далее происходит непосредственная обработка. То, как робот ведет себя с информацией командной строки, носит название регулярного выражения. В русском языке также встречается в виде понятий «маски» и «шаблоны».
То, как робот ведет себя с информацией командной строки, носит название регулярного выражения. В русском языке также встречается в виде понятий «маски» и «шаблоны».
Для того, чтобы парсер воспринимал регулярные выражения, он должен быть составлен на языке, который поддерживает оные при использовании строк. PHP – один из вариантов, который пользуется спросом.
Регулярные выражения для URL прописываются через синтаксис Unix. Он уже устарел и редко применяется на практике при разработке софта. Но за счет свойств обратной совместимости по сей день Юникс задействован программистами и системными администраторами.
За счет Unix можно регулировать активность parsing. В зависимости от соответствующего значения будет меняться длина строки, копируемой с веб-страницы. Сверхжадный парсинг может считывать весь контент, а также HTML-кодификацию и внешние таблицы CSS.
Почему PHP
PHP – язык программирования, который используется для работы с веб-контентом. Позволяет создавать разнообразный софт: от бизнес-аналитики до игр. Его функции позволяют контактировать с парсерами максимально комфортно:
Его функции позволяют контактировать с парсерами максимально комфортно:
- Наличие библиотеки libcurl. Она отвечает за подключение скрипта ко всем видам серверов (даже при работе с http протоколами).
- Поддержка регулярных выражений. За их счет парсер осуществляет обработку информации.
- Наличие библиотеки DOM, используемой для работы с XML-расширяемым языком разметки текста. Он пригодится при выводе результатов обработки информации.
- Высокая совместимость с HTML.
При запуске URL сайта и внедрения парсера PHP станет настоящим спасением. Это не слишком сложный, но очень мощный язык.
Parse URL – особенности
Parse_url – функция, которая разбирает URL, а затем осуществляет возврат его компонентов. Применяется в PHP 4, 5, 7.
Стоит запомнить ее следующие особенности:
- mixed parse_url (string $url [int $component = -1]) – функция, которая разбирает URL и возвращает ассоциативный массив со всеми компонентами соответствующего адрес в Сети;
- не позволяет проверять корректность URL;
- разбивает адрес на части.

Parse_url старается разобрать частичные URL предельно корректно.
О параметрах
У рассматриваемой функции есть несколько параметров. Первый – URL.. Это – адрес для разбора. Символы, которые воспринимаются парсером как недопустимые, будут заменяться на подчеркивание.
Component – возможность считывания конкретного элемента адреса в виде строчки. Исключение – php_url_port. Этот вариант предусматривает возврат значения int.
Возвращаемые значения
Если URLs значительно некорректные, парсер может вернуть значение False. Когда component опускается, функция будет возвращать ассоциативный массив. В нем расположен хотя бы один элемент.
В массиве ассоциативного характера (array) могут встречаться такие ключи:
- scheme – пример: http;
- port;
- host;
- pass;
- user;
- query – после знака вопроса;
- fragment – после знака «решетка».
При определении component функция parse_url() вернет строчку или число вместо массива. Когда запрошенный элемент отсутствует в URL, «операция» возвращает значение null (пусто, ничего).
Когда запрошенный элемент отсутствует в URL, «операция» возвращает значение null (пусто, ничего).
Наглядные примеры – CURL и phpQuery
Если нужно осуществить парсинг сайта, можно использовать для этого библиотеку CURL. Второй вариант – phpQuery, который представлен аналогом jQuery для PHP. Каждый подход имеет собственные преимущества.
Предварительная подготовка
Парсинг на сайте (ru) может быть проведен при помощи функции file_get_content. Помогает получить содержимое необходимой разработчику странички:
В качестве параметра используется желаемый адрес. Аналогичная функция помогает добавлять заголовки через потоковый контекст:
Для запуска соответствующего метода опция allow_url_fopen в php.ini должна быть активирована.
Второй вариант получения содержимого – через сокеты (pfsockopen). Но лучше использовать библиотеку php CURL.
CURL и парсинг
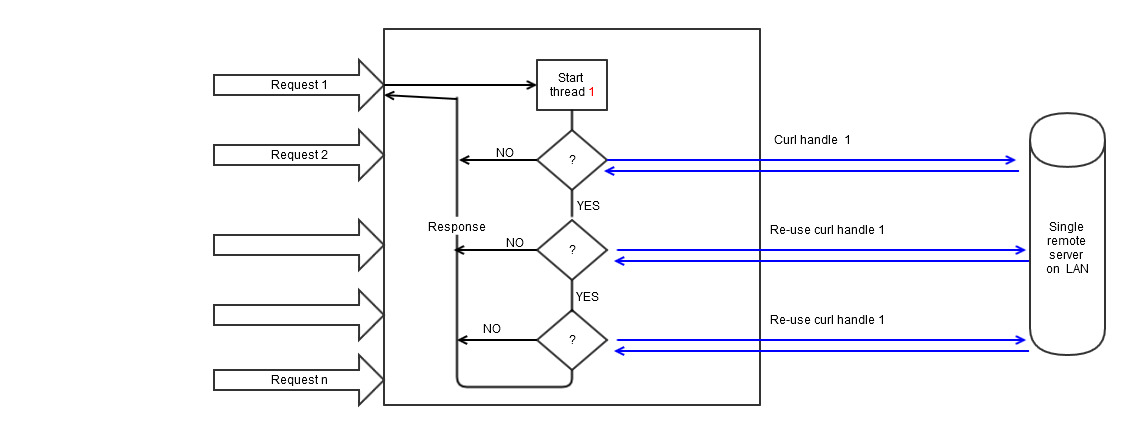
Теперь настало время запуска парсинга. Первый подход – с помощью CURL. Действовать предстоит следующим образом:
- Сначала требуется получить http страницы без параметров.
- Получение http странички с get-параметрами.
- Получение веб-ресурса по протоколам https.
- Извлечение http, которая будет загружаться непосредственно через редиректы (следование 302).
- Нужно сформировать POST-запрос и отправить его. Делаются подобные операции через CURL.
- Требуется активировать куки в запросе.
- В запросе GZIP активировать функцию сжатия. Требуется, когда тело ответа – это непонятный набор текста.
- Вывод заголовков ответов от сервера. Помогает при отладке. Пример – когда сервер не присылает правильное тело ответа или вовсе не дает его.
При парсинге огромную роль играют следующие параметры:
Первый будет всегда в «приложении». Остальные добавляются по мере необходимости. Параметр curlopt_header отвечает за поиск проблем. С ним наладить функционирование парсера php curl не составит никакого труда.
PhpQuery – принцип работы
Второй вариант применения парсинга – через phpQuery. Помогает тогда, когда страничка получена через CURL или иным методом.
Помогает тогда, когда страничка получена через CURL или иным методом.
Код выше наглядно показывает, как создать парсер на php через phpQuery. Он выступает полноценным аналогом iQuery. Все функции соответствующей «возможности» прописаны в сопутствующей документации. По этой ссылке можно обнаружить селекторы и методы. А здесь – еще несколько кодов парсеров.
Быстрее освоиться в parsers, а также таких понятиях как print_r, echo, curl и других помогут специализированные дистанционные курсы. В срок от пары месяцев до года удастся освоить программирование «с нуля».
Как использовать cURL для веб-скрапинг
В этой статье вы узнаете:
- Что такое cURL?
- Как использовать cURL?
- Почему cURL так популярен?
- Использование cURL через прокси
- Как изменить User-Agent
- Веб-скрейпинг с помощью cURL
Что такое cURL?
cURL (также curl) — это инструмент командной строки, который можно использовать для передачи данных по сетевым протоколам. Имя cURL расшифровывается как «URL-адрес клиента». Эта команда использует синтаксис URL для передачи данных на серверы и с них. Curl работает на «libcurl» – бесплатной и простой в использовании библиотеке для передачи URL-адресов.
Имя cURL расшифровывается как «URL-адрес клиента». Эта команда использует синтаксис URL для передачи данных на серверы и с них. Curl работает на «libcurl» – бесплатной и простой в использовании библиотеке для передачи URL-адресов.
Почему выгодно использовать curl?
Универсальность этой команды означает, что вы можете использовать curl по-разному, в том числе для:
- Аутентификации пользователя
- HTTP-сообщения
- SSL-соединения
- Поддержки прокси
- FTP-загрузки
Простейший вариант использования curl –загрузка и выгрузка целых сайтов с использованием одного из поддерживаемых протоколов.
Curl протоколы
Curl имеет длинный список поддерживаемых протоколов. Если вы не укажите конкретный протокол, по умолчанию будет использован HTTP. Список поддерживаемых протоколов:
Установка curl
Команда curl установлена по умолчанию в дистрибутивах Linux.
Как проверить, установлен ли у вас curl?
1.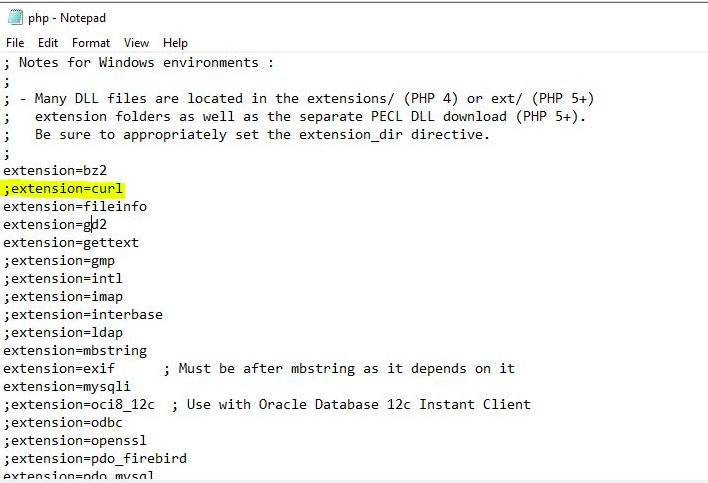 Откройте консоль Linux
Откройте консоль Linux
2. Введите ‘curl’ и нажмите ‘Ввод’.
3. Если у вас уже установлен curl, вы увидите следующее сообщение:
4. Если у вас еще не установлен curl, вы увидите: ‘Команда не найдена’. Можете обратиться к своему дистрибутиву и установить его (подробнее об этом ниже).
Как использовать cURL
Синтаксис команды Curl довольно прост:
Например, если вы хотите загрузить веб-страницу: webpage.com, просто выполните команду:
Затем команда выдаст вам исходный код страницы в окне терминала. Имейте в виду, если вы не укажете протокол, curl по умолчанию будет использовать HTTP. Посмотрите пример – как определить конкретные протоколы:
Если вы забудете добавить ://, curl догадается, какой протокол вы хотите использовать.
Мы кратко рассказали о базовом использовании команды. Вы можете самостоятельно найти список опций на сайте документации curl. Опции – это возможные действия, которые можно выполнить с URL. Когда вы выбираете вариант, он указывает curl, какое действие выполнить для указанного URL. URL сообщает cURL, где он должен выполнить это действие. Затем cURL позволяет вам перечислить один или несколько URL-адресов.
URL сообщает cURL, где он должен выполнить это действие. Затем cURL позволяет вам перечислить один или несколько URL-адресов.
Чтобы загрузить несколько URL, добавьте к каждому префикс -0, за которым следует пробел. Вы можете сделать это в одной строке или написать отдельную строку для каждого URL. Также можете загрузить часть URL, перечислив страницы. Например:
Сохранение загрузки
Вы можете сохранить содержимое URL в файл с помощью curl двумя способами:
1. Метод -o: Позволяет добавить имя файла, в котором будет сохранен URL. Этот вариант имеет следующую структуру:
2. -O method: Здесь вам не нужно добавлять имя файла, так как эта опция позволяет сохранить файл под именем URL. Чтобы использовать вариант, просто добавьте к URL-адресу префикс -O.
Возобновление загрузки
Может случиться так, что загрузка остановится на середине. В этом случае перепишите команду, добавив в начале параметр -C :
Почему curl так популярен?
Curl — это инструмент, созданный для сложных операций. У него есть альтернативы, например, «wget» или «Kurly», которые хороши для более простых задач.
У него есть альтернативы, например, «wget» или «Kurly», которые хороши для более простых задач.
Curl – фаворит среди разработчиков, потому что доступен практически для каждой платформы. В некоторых установлен по умолчанию. Это означает, что какие бы программы/задания вы ни запускали, команды curl должны работать.
Кроме того, есть вероятность, что, если вашей ОС меньше десяти лет, у вас будет установлен curl. Вы также можете изучить документы в браузере и проверить документацию по curl. Если используете последнюю версию Windows, вероятно, у вас уже установлен curl. Если нет, прочтите эту статью на Stack Overflow, чтобы узнать больше.
Использование cURL через прокси
Некоторые люди предпочитают использовать cURL в сочетании с прокси. Преимущества в этом случае следующие:
- Повышение способности успешно управлять запросами данных из разных геолокаций.
- Экспоненциальный рост числа заданий по работе с данными, которые можно выполнять одновременно.

Для достижения этой цели вы можете использовать возможности ‘-x’ и ‘(- – proxy)’, встроенные в cURL. Вот пример командной строки, которую вы можете использовать для интеграции используемого вами прокси с cURL:
$ curl -x 026.930.77.2:6666 http://linux.com/
В приведенном выше фрагменте кода – ‘6666’ – это номер порта, а ‘026.930.77.2’ – это IP-адрес.
Полезно знать: cUrl совместим с большинством распространенных типов прокси, включая HTTP, HTTPS и SOCKS.
Как изменить User-Agent
User-Agents (пользовательский агент) – это характеристики, которые позволяют сайтам идентифицировать устройство, которое запрашивает информацию. Целевой сайт может потребовать определенные критерии, прежде чем вернуть данные. Это может относиться к типу устройства, ОС или браузеру. В этом сценарии компании, собирающие данные, захотят подражать идеальному «кандидату» своего целевого сайта.
Для примера предположим, что сайт, на который вы нацелились, «предпочитает», чтобы пользователи использовали браузер Chrome. Чтобы получить нужный набор данных с помощью cURL, необходимо эмулировать эту «черту браузера» так:
Чтобы получить нужный набор данных с помощью cURL, необходимо эмулировать эту «черту браузера» так:
curl -A “Goggle/9.0 (X11; Linux x86_64; rv:60.0) Gecko/20100101 Chrome/103.0.5060.71” https://getfedora.org/.
Веб-скрапинг с помощью cURL
Совет для профессионалов: обязательно соблюдайте правила сайта и не пытайтесь получить доступ к защищенному паролем контенту, который по большей части является незаконным или не одобряется.
Вы можете использовать curl для автоматизации повторяющегося процесса скрапинга, чтобы избежать утомительных задач. Для этого понадобится PHP. Вот пример, который мы нашли на GitHub:
При использовании curl для сканирования веб-страницы есть три опции:
- – curl_init($url) -> Инициализирует сеанс
- – curl_exec() -> Выполняет
- – curl_close() -> Закрывает
Другие параметры, которые вы должны использовать:
- Curlopt_url -> Устанавливает URL-адрес, который вы хотите очистить.
- Curlopt_returntransfer -> Призывает curl сохранить очищенную страницу как переменную. (Это позволяет получить именно то, что вы хотели извлечь со страницы.)
Устали от ручного парсинга веб-страниц?
Компания Bright Data разработала полностью автоматизированное решение без кода, которое позволяет получить доступ ко всем сайтам и конкретным точкам данных в один клик.
Попробовать бесплатно
Преобразование команд curl в Ansible
Преобразование команд curl в Python, JavaScript и т. д.
Преобразование curl в Python, JavaScript и т. д.
Команда curl
Примеры:
ПОЛУЧАТЬ
—
ПОЧТА
—
JSON
—
Базовая аутентификация
—
Файлы
—
Форма
Язык:
AnsibleC#ClojureColdFusion MLDartElixirGoHARHTTPHTTPieJava + java.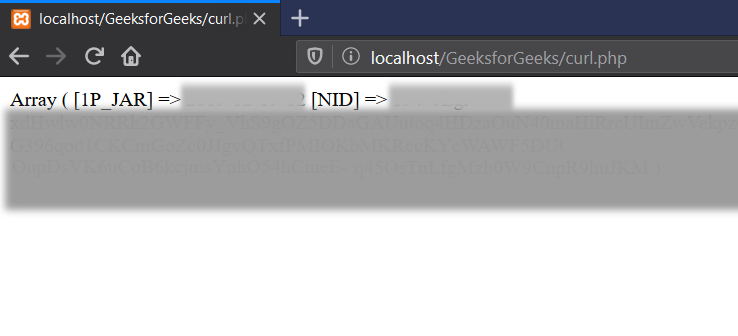 net.httpJava + AsyncHttpClientJava + OkHttpJavaScript + fetchJavaScript + jQueryJavaScript + XHRJSONKotlinMATLABNode.js + AxiosNode.js + GotNode.js + node-fetchNode.js + requestNode + httpObjective-COCamlPHP + cURLPHP + GuzzlePowerShell + Invoke-RestMethodPowerShell + Invoke-WebRequestPython + RequestsPython + http.clientRRubyRustSwiftWget
net.httpJava + AsyncHttpClientJava + OkHttpJavaScript + fetchJavaScript + jQueryJavaScript + XHRJSONKotlinMATLABNode.js + AxiosNode.js + GotNode.js + node-fetchNode.js + requestNode + httpObjective-COCamlPHP + cURLPHP + GuzzlePowerShell + Invoke-RestMethodPowerShell + Invoke-WebRequestPython + RequestsPython + http.clientRRubyRustSwiftWget
- Ансибль
С
- С#
- CFML
- Кложур
- Дартс
- Эликсир
- Идти
- ХАР
- HTTP
- HTTPie
- Джава
- JavaScript
- JSON
- Котлин
- МАТЛАБ
- Node. js
- Цель-C
- OCaml
- PHP
- PowerShell
- Питон
- р
- Рубин
- Ржавчина
- Быстрый
- Wget
 js
js -
имя: 'http://example.com'
ури:
URL-адрес: 'http://example.com'
метод: ПОЛУЧИТЬ
регистрация: результат
Копировать в буфер обмена
curl из Google Chrome
- Откройте вкладку «Сеть» в DevTools
- Щелкните правой кнопкой мыши (или щелкните, удерживая нажатой клавишу Ctrl) запрос
- Нажмите «Копировать» → «Копировать как cURL» «Копировать как cURL ( bash )»
- Вставьте его в поле команды curl над
Это также работает в Safari и Firefox.
Предупреждение : скопированная команда может содержать файлы cookie или другие конфиденциальные данные. Будьте осторожны, если вы делитесь командой с другими людьми, отправка кому-либо файла cookie для веб-сайта аналогична отправке им вашего пароля.
curl из Safari
- Откройте вкладку «Сеть» в инструментах разработчика
- Щелчок правой кнопкой мыши (или щелчок с нажатой клавишей Ctrl или щелчок двумя пальцами) запроса
- Нажмите «Копировать как cURL» в раскрывающемся меню
- Вставьте его в поле команды curl над
Это также работает в Chrome и Firefox.
Предупреждение : скопированная команда может содержать файлы cookie или другие конфиденциальные данные. Будьте осторожны, если вы делитесь командой с другими людьми, отправка кому-либо файла cookie для веб-сайта аналогична отправке им вашего пароля.
curl из Firefox
- Откройте вкладку «Сетевой монитор» в инструментах разработчика
- Щелкните правой кнопкой мыши (или щелкните, удерживая нажатой клавишу Ctrl) запрос
- Нажмите «Копировать» → «Копировать как cURL»
- Вставьте его в поле команды curl над
Это также работает в Chrome и Safari.
Предупреждение : скопированная команда может содержать файлы cookie или другие конфиденциальные данные. Будьте осторожны, если вы делитесь командой с другими людьми, отправка кому-либо файла cookie для веб-сайта аналогична отправке им вашего пароля.
Конфиденциальность
Мы , а не передаем или записываем команды curl, которые вы вводите, или то, во что они преобразуются.
Это статический веб-сайт (размещенный на страницах GitHub), и преобразование происходит полностью в вашем браузере с использованием JavaScript.
Существует также расширение VS Code и инструмент командной строки, который вы можете установить из npm с помощью
npm install -g curlconverter
Аналогичные инструменты
- Почтальон, Бессонница и Лапа
- завивка на ходу
- curl-to-PHP
- завиток к рубину
- http-переводчик (на Python и JS)
- curl’s —libcurl (на C)
- развернуть (на Python)
- hrbrmstr/curlconverter (в R)
- завиток в elisp
- HAR-закручивание
- curlify (Питон для завивки)
- Баш3py
Поддержите нас
GitHub сопоставляет все вклады в этот проект на GitHub Sponsors.
Внести свой вклад сейчас
Нашли проблему?
Пожалуйста, сообщайте об ошибках
на Гитхабе.
PHP: rfc:curl-url-api
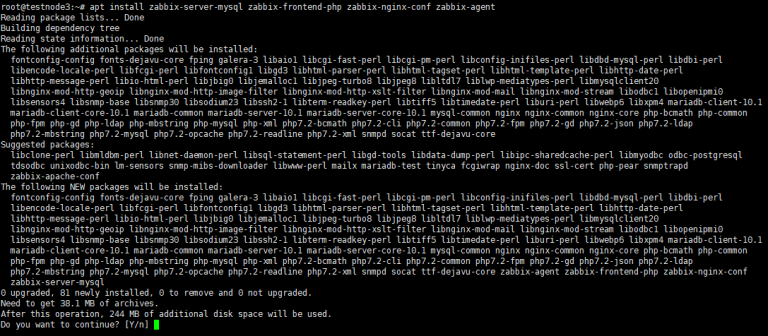
Введение
Начиная с версии 7.62.0 libcurl, 1 в библиотеке появился совершенно новый URL-адрес API 2, который можно использовать для анализа и генерации URL-адресов с помощью собственного анализатора libcurl. Одна из целей этого API предназначен для устранения проблемной уязвимой области для приложений, где библиотека парсера URL будет верить в одно, а libcurl — в другое. Это могло и иногда приводило к проблемам с безопасностью. 3
Предложение
Очевидно, что существует множество различных способов реализации этого API в пользовательской среде, и недавние обсуждения показали, что пока нет единого мнения о том, как это должно быть сделано. Фактическое состояние ext/curl lib таково, что все существующие функции являются тонкой оболочкой над libcurl. Предлагается добавить новый Curl Url API , сохраняя его согласованность с другими функциями curl_. Эта реализация представляет собой простую привязку функций libcurl один к одному. Базовый дескриптор CURLU будет отображаться как непрозрачный объект
Предлагается добавить новый Curl Url API , сохраняя его согласованность с другими функциями curl_. Эта реализация представляет собой простую привязку функций libcurl один к одному. Базовый дескриптор CURLU будет отображаться как непрозрачный объект CurlUrl .
Реализации добавят 3 новые функции curl_url(), curl_url_set() и curl_url_get() , которые будут использоваться для управления объектом/дескриптором CurlUrl .
Все константы CURLUPART_* и CURLU_* будут отображаться как глобальные константы с тем же именем в пользовательской области.
Также будет доступна одна новая опция Curl: CURLOPT_CURLU . Curl будет использовать данный объект и не будет изменять его содержимое.
Эти классы и функции будут существовать только в том случае, если версия libcurl, установленная в системе, больше или равна 7.62. Если версия старше, их не будет.
const CURLUPART_FRAGMENT = НЕИЗВЕСТНО;
const CURLUPART_HOST = НЕИЗВЕСТНО;
const CURLUPART_OPTIONS = НЕИЗВЕСТНО;
const CURLUPART_PASSWORD = НЕИЗВЕСТНО;
константа CURLUPART_PATH = НЕИЗВЕСТНО;
константа CURLUPART_PORT = НЕИЗВЕСТНО;
const CURLUPART_QUERY = НЕИЗВЕСТНО;
const CURLUPART_SCHEME = НЕИЗВЕСТНО;
const CURLUPART_URL = НЕИЗВЕСТНО;
константа CURLUPART_USER = НЕИЗВЕСТНО;
const CURLU_APPENDQUERY = НЕИЗВЕСТНО;
const CURLU_DEFAULT_PORT = НЕИЗВЕСТНО;
const CURLU_DEFAULT_SCHEME = НЕИЗВЕСТНО;
const CURLU_DISALLOW_USER = НЕИЗВЕСТНО;
const CURLU_GUESS_SCHEME = НЕИЗВЕСТНО;
const CURLU_NO_DEFAULT_PORT = НЕИЗВЕСТНО;
const CURLU_NON_SUPPORT_SCHEME = НЕИЗВЕСТНО;
const CURLU_PATH_AS_IS = НЕИЗВЕСТНО;
const CURLU_URLDECODE = НЕИЗВЕСТНО;
const CURLU_URLENCODE = НЕИЗВЕСТНО;
/* libcurl >= 7.65.0 */
const CURLUPART_ZONEID = НЕИЗВЕСТНО;
/* libcurl >= 7.67.0 */
const CURLU_NO_AUTHORITY = НЕИЗВЕСТНО;
/* libcurl >= 7.78.0 */
const CURLU_ALLOW_SPACE = НЕИЗВЕСТНО;
функция curl_url(?string $url = null): CurlUrl {}
функция curl_url_set(CurlUrl $url, int $part, ?string $content, int $flags = 0): void {}
функция curl_url_get(CurlUrl $url, int $part, int $flags = 0): ?string {}
конечный класс CurlUrl {
общедоступная функция __clone() {}
} curl_url(?string $url = null)
Создайте новый объект CurlUrl. Если установлено
Если установлено $url , объект будет инициализирован с использованием этого URL , в противном случае все части будут установлены на null
Все ошибки libcurl станут CurlUrlException .
curl_url_set(CurlUrl $url, int $part, ?string $content, int $flags = 0): void
Обновите отдельные части URL . Аргумент $part идентифицирует конкретный Часть URL для установки или изменения ( CURLUPART_* ). Установка для части значения null эффективно удалит содержимое этой части из объекта CurlUrl .
Аргумент $flags представляет собой битовую маску с индивидуальными функциями.
Все ошибки libcurl станут CurlUrlException .
| Поддерживаемые флаги | Описание |
|---|---|
CURLU_NON_SUPPORT_SCHEME | Если установлено, позволяет этой функции устанавливать неподдерживаемую схему. |
CURLU_URLENCODE | Если установлено, URL кодирует часть. |
CURLU_DEFAULT_SCHEME | Если установлено, позволяет установить URL-адрес без схемы, и в этом случае схема будет установлена по умолчанию: HTTPS. Переопределяет параметр CURLU_GUESS_SCHEME , если установлены оба. |
CURLU_GUESS_SCHEME | Если установлено, позволяет установить URL-адрес без схемы, вместо этого он «угадывает», какая схема была предназначена, на основе имени хоста. Если имя самого внешнего субдомена соответствует DICT, FTP , IMAP, LDAP, POP3 или SMTP, то будет использоваться эта схема; в противном случае он выбирает HTTP. Конфликтует с параметром CURLU_DEFAULT_SCHEME , который имеет приоритет, если установлены оба. |
CURLU_NO_AUTHORITY | Если установлено, проверка прав доступа пропускается. RFC позволяет отдельным схемам опускать часть хоста (обычно это единственная обязательная часть полномочий), но libcurl не может знать, разрешено ли это для пользовательских схем. Указание флага разрешает пустые разделы полномочий, аналогично тому, как обрабатывается файловая схема. |
CURLU_PATH_AS_IS | Если установлено, заставляет libcurl пропускать нормализацию пути. Это процедура, в которой curl удаляет последовательности точка-слэш, точка-точка и т. д. |
CURLU_ALLOW_SPACE | Если установлено, парсер URL допускает пробел ( ASCII 32), где это возможно. Синтаксис URL обычно не допускает пробелов нигде, но они должны быть закодированы как %20 или ‘+’.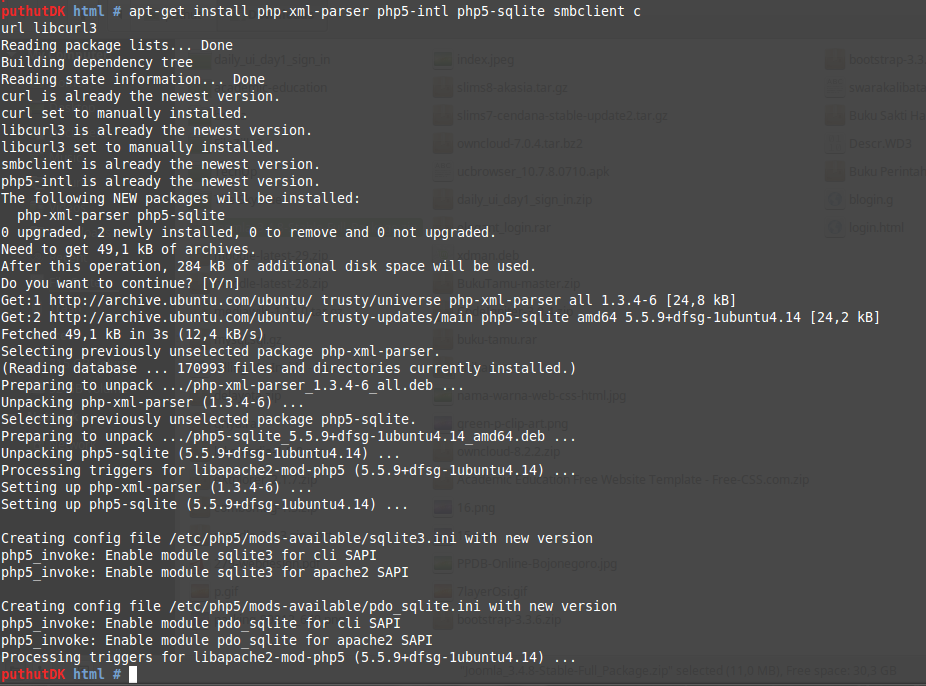 Когда пробелы разрешены, они все равно не разрешены в схеме. Когда пространство используется и разрешено в URL-адресе , он будет сохранен как есть, если также не установлен Когда пробелы разрешены, они все равно не разрешены в схеме. Когда пространство используется и разрешено в URL-адресе , он будет сохранен как есть, если также не установлен CURLU_URLENCODE . |
curl_url_get(CurlUrl $url, int $part, int $flags = 0):? строка
Эта функция позволяет пользователю извлекать отдельные фрагменты из объекта $url . Если конкретная часть не установлена, эта функция вернет null , все остальные ошибки libcurl станут CurlUrlException .
Аргумент $part идентифицирует конкретную часть URL для извлечения.
Аргумент $flags представляет собой битовую маску с индивидуальными функциями.
| Поддерживаемые флаги | Описание |
|---|---|
CURLU_DEFAULT_PORT | Если для объекта не сохранен порт, эта опция заставит функцию вернуть порт по умолчанию для используемой схемы. |
CURLU_DEFAULT_SCHEME | Если для объекта не сохранена схема, эта опция заставит функцию возвращать схему по умолчанию вместо нуля. |
CURLU_NO_DEFAULT_PORT | Указывает функции не возвращать номер порта, если он совпадает с портом по умолчанию для схемы. |
CURLU_URLDECODE | Если установлено, функция будет кодировать часть имени хоста. Если не задано (по умолчанию), libcurl возвращает URL-адрес с «сырым» именем хоста, чтобы имена IDN отображались как есть. Имена хостов IDN обычно используют не- ASCII байтов, которые в противном случае будут закодированы в процентах. Обратите внимание, что даже если не запрашивается кодировка URL-адреса , «%» (байт 37) будет закодирован как URL-адрес , чтобы убедиться, что имя хоста остается действительным. |
CURLU_URLENCODE | Если установлено, функция будет декодировать часть имени хоста. Если в декодированной строке есть какие-либо значения байтов меньше 32, операция get вместо этого вернет ошибку. |
Курлурлексцептион
Класс CurlUrlException представляет собой ошибку, вызванную libcurl. Константы, представленные в этом классе, — это все коды, которые может вернуть CurlUrlException::getCode() . Эти коды внутренне сопоставляются с кодами ошибок CURLUE_*, которые может вызвать libcurl. Эти константы могут различаться в зависимости от версии libcurl ext/curl, с которой был скомпилирован.
Если ext/curl был скомпилирован с libcurl > 7.80, то CurlUrlException::getMessage() вернет удобное для пользователя сообщение с описанием проблемы. (Пример: искаженный ввод в функцию URL ).
/* libcurl >= 7.62.0 */
конечный класс CurlUrlException расширяет исключение
{
общедоступная константа BAD_PORT_NUMBER = НЕИЗВЕСТНО;
общедоступная константа MALFORMED_INPUT = UNKNOWN;
общедоступная константа OUT_OF_MEMORY = НЕИЗВЕСТНО;
общедоступная константа UNSUPPORTED_SCHEME = UNKNOWN;
общедоступная константа URL_DECODING_FAILED = НЕИЗВЕСТНО;
общедоступная константа USER_NOT_ALLOWED = UNKNOWN;
/* libcurl >= 7. 81.0 */
общедоступная константа BAD_FILE_URL = НЕИЗВЕСТНО;
общедоступная константа BAD_FRAGMENT = UNKNOWN;
общедоступная константа BAD_HOSTNAME = UNKNOWN;
общедоступная константа BAD_IPV6 = НЕИЗВЕСТНО;
общедоступная константа BAD_LOGIN = UNKNOWN;
общедоступная константа BAD_PASSWORD = UNKNOWN;
общедоступная константа BAD_PATH = НЕИЗВЕСТНО;
общедоступная константа BAD_QUERY = UNKNOWN;
общедоступная константа BAD_SCHEME = UNKNOWN;
общедоступная константа BAD_SLASHES = UNKNOWN;
общедоступная константа BAD_USER = НЕИЗВЕСТНО;
}  81.0 */
общедоступная константа BAD_FILE_URL = НЕИЗВЕСТНО;
общедоступная константа BAD_FRAGMENT = UNKNOWN;
общедоступная константа BAD_HOSTNAME = UNKNOWN;
общедоступная константа BAD_IPV6 = НЕИЗВЕСТНО;
общедоступная константа BAD_LOGIN = UNKNOWN;
общедоступная константа BAD_PASSWORD = UNKNOWN;
общедоступная константа BAD_PATH = НЕИЗВЕСТНО;
общедоступная константа BAD_QUERY = UNKNOWN;
общедоступная константа BAD_SCHEME = UNKNOWN;
общедоступная константа BAD_SLASHES = UNKNOWN;
общедоступная константа BAD_USER = НЕИЗВЕСТНО;
}
81.0 */
общедоступная константа BAD_FILE_URL = НЕИЗВЕСТНО;
общедоступная константа BAD_FRAGMENT = UNKNOWN;
общедоступная константа BAD_HOSTNAME = UNKNOWN;
общедоступная константа BAD_IPV6 = НЕИЗВЕСТНО;
общедоступная константа BAD_LOGIN = UNKNOWN;
общедоступная константа BAD_PASSWORD = UNKNOWN;
общедоступная константа BAD_PATH = НЕИЗВЕСТНО;
общедоступная константа BAD_QUERY = UNKNOWN;
общедоступная константа BAD_SCHEME = UNKNOWN;
общедоступная константа BAD_SLASHES = UNKNOWN;
общедоступная константа BAD_USER = НЕИЗВЕСТНО;
} Почему не объектно-ориентированный API?
С очень короткой задержкой, которую мы имеем до заморозки функций 8.2. Безопаснее поддерживать единообразие всего расширения curl API и не торопиться с новым проектом объектно-ориентированного программирования, с которым, очевидно, никто не согласен, поскольку все обсуждения показали, что мы даже не близки к достижению консенсуса.