Писать sql запросы как: Урок 1. Первые SQL запросы
Чистый SQL код — Статьи : Персональный сайт Михаила Флёнова
05 Июля 2021
Базы данных
SQL тоже нужно писать красиво, чтобы этот код проще было впоследствии поддерживать. Если запрос состоит из выбора данных из одной таблицы, то можно и забить на чистоту, и оставить все как есть, но когда мы работаем над большим приложением, где много простых запросов или над одним запросом, но большим, очень важно написать код так, чтобы его проще было потом сопровождать.
Мне достаточно часто приходилось работать с большими по размеру запросами, в основном это были какие-то финансовые отчеты, но были и онлайн запросы, которые выполнялись регулярно.
Если запрос состоит из одного select из одной таблицы, то его можно записать как попало. Следующий запрос особо оформлять и не нужно, он легко читается:
select * from person
Печалька в том, что такие запросы в реальной жизни очень редко нужны.
Для начала нужно сказать, что выбирать все колонки с помощью звездочки можно ради тестов или когда вам действительно нужны все колонки, что бывает очень редко. В реальности рекомендуется или лучше все же приучать себя выбирать только колонки, которые вам действительно нужны и при этом указывать их в порядке, который вам необходим. В этом случае вы будете защищены от возможной смены структуры базы данных. Я конечно не рекомендую менять структуру, но сталкивался с таким уже много раз. Правда бывают и. случаи, когда наоборот, вы добавили колонку в запрос, а ее реально удалили и тут уже звездочка наоборот может спасти.
В реальности рекомендуется или лучше все же приучать себя выбирать только колонки, которые вам действительно нужны и при этом указывать их в порядке, который вам необходим. В этом случае вы будете защищены от возможной смены структуры базы данных. Я конечно не рекомендую менять структуру, но сталкивался с таким уже много раз. Правда бывают и. случаи, когда наоборот, вы добавили колонку в запрос, а ее реально удалили и тут уже звездочка наоборот может спасти.
Перечисление колонок помогает в системах, где больше одного сервера приложений и нужен максимальный аптайм. Чтобы этого достигнуть желательно делать обновление базы данных не ломающим приложение, то есть вы должны иметь возможность добавить новые колонки и таблицы, но при этом старый код должен продолжать работать, а для этого нужно соблюдать два основных правила: не удалять колонки и не изменять на несовместимый тип.
Если вы будете выбирать в своих запросах только нужные колонки, то после наложения скриптов обновления код не увидит того, чего не должен видеть, для этого нужно будет обновить еще и код.
Надеюсь, я вас убедил, что не стоит использовать звездочку, а значит наш запрос должен выглядеть так:
select personid, teamid, firstname, lastname, positionid from person
Вот тут уже все не так все гладко читается. Если команды SQL написать большими буквами, что очень часто делают, то текст уже становиться чуть лучше:
SELECT personid, teamid, firstname, lastname, positionid FROM person
Это еще не все, можно разделить на строки, каждую секцию написать в своей строке:
SELECT personid, teamid, firstname, lastname, positionid FROM person
Тут даже если написать все маленькими буквами все тоже будет в принципе читаемым:
select personid, teamid, firstname, lastname, positionid from person
Да, это читаемо, но все же на мой вкус все писать большими буквами лучше.
Если код хранить в тексте программы, а текст программы находиться в GIT, то могут возникнуть проблемы со слиянием кода. Если два программиста изменят запрос и каждый из них добавит по одной колонке, то точно возникнет конфликт. Если вы используете ORM, то разрулить конфликт будет относительно просто, а если обращение идет через низкоуровневые функции и индексы колонок, то гореть вам в аду.
Если вы используете ORM, то разрулить конфликт будет относительно просто, а если обращение идет через низкоуровневые функции и индексы колонок, то гореть вам в аду.
Если писать колонки в отдельной строке то можно снизить вероятность конфликтов:
SELECT personid,
teamid,
firstname,
lastname,
positionid
FROM person
Теперь конфликт возникнет только если два программиста добавят колонку в одно и то же место, к сожалению, это чаще всего и происходит, потому что программисты обычно добавляют колонки в конец запроса.
С другой стороны, такой вариант записи SQL удобная еще и тем, что проще убирать временно ненужные колонки. Можно удалить целую строку или поставить комментарии:
SELECT personid,
teamid,
-- firstname,
lastname,
positionid
FROM person
Теперь я отключил колонку firstname и это сделать было очень просто. В оформленном таким образом запросе проще сортировать колонки, если забыть про последнюю.
В оформленном таким образом запросе проще сортировать колонки, если забыть про последнюю.
SELECT personid,
firstname,
lastname,
teamid,
positionid
FROM person
Недостаток – перемещать удобно любую колонку, кроме последней. С конфликтами тоже была проблема с последней колонкой, причем чтобы добавить новую колонку программисты будут не только добавлять еще одну строку, но еще и трогать последнюю строку с колонками, туда придется добавить запятую после positioned. Эта запятая может стать проблемой, потому что она как раз усложняет слияние.
Запятую лучше писать вначале:
SELECT personid
, firstname
, lastname
, teamid
, positionid
FROM person
Теперь можно закомментировать любую колонку, кроме первой, а это первичный ключ и его редко отключают в запросе. И добавлять новую строку проще – просто добавляем в конец и добавляем одну единственную строку, а значит конфликты разрешать проще.
Да, для огромных запросов, которые возвращают более 20 колонок, такой запрос начинает занимать очень много места в файле и приходиться очень много скролить в коде. Скролить тоже плохо. И вот мы встаем перед выбором – что лучше? Зависит от ситуации и личных предпочтений, я же все же рекомендовал бы писать имена колонки каждую в своей строке.
Усложняем жизнь, добавляем объединение таблиц:
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on p.positionid = psn.positionid
Некоторые явно предпочитают писать INNER JOIN, чтобы указать, что перед нами именно INNER объединение. Я за счет лени не пишу лишние пять букв, а сокращаю все до JOIN, потому что привык, что именно это поведение по умолчанию. Тут у меня проблем с чтением нет.
Чуть другое дело, если что-то касается – где писать дополнительные фильтры. Например, следующие два запроса будут абсолютно идентичны:
Например, следующие два запроса будут абсолютно идентичны:
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on p.positionid = psn.positionid and psn.Name = 'Coach'
И
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on p.positionid = psn.positionid
WHERE psn.Name = 'Coach'
И даже этот запрос
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on 1=1
WHERE p.positionid = psn.positionid
AND psn.Name = 'Coach'
Вот реально все равно, где вы напишите проверку на Name = ‘Coach’, потому что в случае с INNER JOIN она не повлияет на результат и с точки зрения производительности я не видел разницы, потому что оптимизаторы обычно не смотрят, где вы пишите фильтры. Но проверка Name = ‘Coach’ логически не относится к объединению двух таблиц и поэтому не должна быть в JOIN, она должна быть в секции WHERE, потому что просто логически принадлежит этой секции.
Но проверка Name = ‘Coach’ логически не относится к объединению двух таблиц и поэтому не должна быть в JOIN, она должна быть в секции WHERE, потому что просто логически принадлежит этой секции.
Логическое расположение важно, и оно в будущем вам будет говорить, где искать определенный код. Например, если вы видите, что связь между двумя таблицами не работает, значит нужно идти, и проверять JOIN и что написано после ON. Если результат не совсем верный и отображаются только тренера, то скорей всего нужно смотреть на фильтры, а значит это секция WHERE. В реальной жизни бывает всякое, но по умолчанию именно логика поиска проблемы должна быть именно такой.
Посмотрим на секцию WHERE в последнем запросе:
WHERE p.positionid = psn.positionid AND psn.Name = 'Coach'
Обратите внимание, что каждый фильтр находиться в отдельной строке. Каждый AND должен быть отдельно. В одну строку можно помещать две проверки, только если они объединены с помощью OR, это удобно, чтобы не забыть поставить скобки:
WHERE p.positionid = psn.positionid AND (psn.Name = 'Coach' OR psn.Name like 'P%')
 positionid = psn.positionid
AND (psn.Name = 'Coach' OR psn.Name like 'P%')
positionid = psn.positionid
AND (psn.Name = 'Coach' OR psn.Name like 'P%')
Если две проверки в одной строке, это всегда должно быть сигналом, что они должны работать как одно целое и там есть скобки.
Секция WHERE одно из самых важных мест, где нужно правильно расставлять отступы. Не стесняйтесь ставить пробелы, чтобы текст запроса рос вправо. Если в каждой строке только одна проверка, то это норм, вы не заметите проблем. Слишком сильно вправо он не должен убежать.
В одном из видео Строим таблицу чемпионата на SQL — Проще некуда и в этой текстовой версии Практика — ищем победителей я написал запрос, в котором мы искали победителей чемпионата по какому-то командному спорту. Запрос получился вот такой:
select team, sum(points)
from (
select
case
when hometeamgoals > guestteamgoals then hometeamid
when hometeamgoals < guestteamgoals then guestteamid
end team,
3 as points
from game
where hometeamgoals != guestteamgoals
union all
select hometeamid, 1 as points
from game
where hometeamgoals = guestteamgoals
union all
select guestteamid, 1 as points
from game
where hometeamgoals = guestteamgoals
) p
group by team
order by 2 desc
Если вы не видели того видео или видели его очень давно, то понять и разобрать подобный запрос будет достаточно сложно.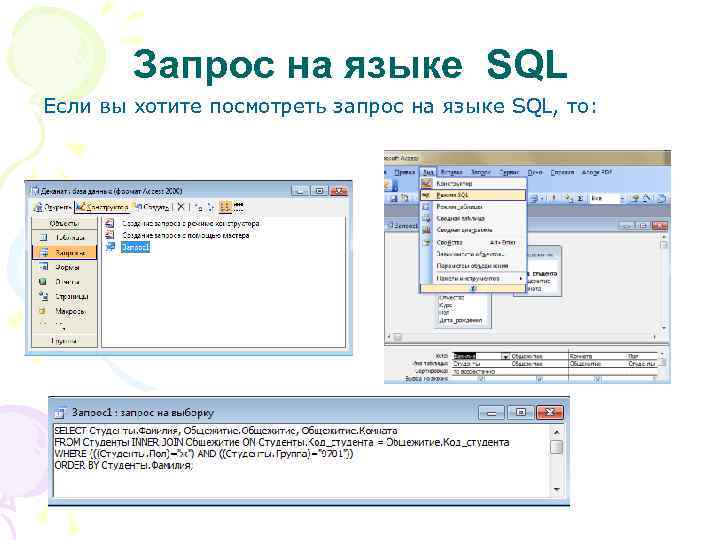 В секции FROM находиться три запроса и каждый из них выполняет что-то, а чтобы понять, что они делают, приходиться читать каждый из них и вдумываться.
В секции FROM находиться три запроса и каждый из них выполняет что-то, а чтобы понять, что они делают, приходиться читать каждый из них и вдумываться.
Можно было бы использовать комментарии, но я противник таких вещей. Если нужен комментарий, то код скорей всего плохой и читать его поддерживать будет сложно. Комментарии – это что-то, что должно быть в коде только в самом крайнем случае.
Запрос выше должен был бы выглядеть следующим образом:
select team, sum(points)
from (
select * from winners3points
union all
select * from hometies1point
union all
select * from guestties1point
) p
group by team
order by 2 desc
Вот такой запрос читать на много проще – здесь объединяются три выборки winners3points, hometies1point и guestties1point. По имени уже понятно, что это делает, а как. . . Вот тут есть два варианта, можно взять код, который был на этом месте и вынести в представления. Но я создаю представления только если код будет использоваться в нескольких местах. Если у вас нагруженная система с требованием обновления онлайн, то представления могут привести к проблемам и с ними нужно быть осторожнее.
Если у вас нагруженная система с требованием обновления онлайн, то представления могут привести к проблемам и с ними нужно быть осторожнее.
Если какой-то код только разово, то можно использовать CTE (в MySQL поддерживается с 8-й версии):
with
winners3points as (
select
case
when hometeamgoals > guestteamgoals then hometeamid
when hometeamgoals < guestteamgoals then guestteamid
end team,
3 as points
from game
where hometeamgoals != guestteamgoals
),
hometies1point as (
select hometeamid, 1 as points
from game
where hometeamgoals = guestteamgoals
),
guestties1point as (
select guestteamid, 1 as points
from game
where hometeamgoals = guestteamgoals
)
select team, sum(points)
from (
select * from winners3points
union all
select * from hometies1point
union all
select * from guestties1point
) p
group by team
order by 2 desc
CTE практически то же самое, что и псевдонимы для SQL запросов. Глядя на имена псевдонимов, мы без проблем можем понять, что делает запрос без дополнительных комментариев, а если мы хотим понять, как работает один из псевдонимов, мы можем взглянуть на него.
Глядя на имена псевдонимов, мы без проблем можем понять, что делает запрос без дополнительных комментариев, а если мы хотим понять, как работает один из псевдонимов, мы можем взглянуть на него.
CTE может помочь даже с точки зрения производительности. Из личного опыта – разбиение запросов на небольшие составляющие позволяет базе данных проще понять, что от него требуется.

Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Почему стоит начать изучать SQL
31 октября, 2022 12:19 пп
32 views
| Комментариев нет
General | Amber
| Комментировать запись
SQL или язык структурированных запросов, поначалу может показаться сложным и пугающим. Этот язык в основном применяется для определения, обработки и запроса данных, которые хранятся в реляционных базах данных — это такие БД, в которых данные хорошо организованы и структурированы, чтобы соответствовать четко определенным строкам и столбцам.
Этот язык в основном применяется для определения, обработки и запроса данных, которые хранятся в реляционных базах данных — это такие БД, в которых данные хорошо организованы и структурированы, чтобы соответствовать четко определенным строкам и столбцам.
Читайте также: Введение в реляционные базы данных
С момента появления SQL в 70-х годах его популярность выросла, а области применения значительно расширились. Сейчас SQL – это проверенный и распространенный способ запроса и обработки данных в разных отраслях, и это осуществляется с помощью популярных утилит. Скорее всего, вы столкнетесь с SQL на работе, если вы администратор или архитектор базы данных, инженер-программист, аналитик данных. Но даже если вашей профессии нет в списке и вы не используете SQL напрямую, разобраться с тем, как он работает, все равно полезно.
В этой статье мы расскажем, почему стоит изучать SQL, а также где и как вы сможете применить эти знания.
SQL и реляционные базы данных
Если вы работаете с любой реляционной базой данных – MySQL, PostgreSQL, Microsoft SQL, Oracle SQL или тд. , вы обязательно используете операторы SQL. Этот язык задействуют для определения, обработки и запроса данных в БД такого типа. Это основной способ взаимодействия с механизмом БД.
, вы обязательно используете операторы SQL. Этот язык задействуют для определения, обработки и запроса данных в БД такого типа. Это основной способ взаимодействия с механизмом БД.
Сегодня многие системы баз данных работают с простыми инструментами графического интерфейса, однако SQL не устаревает от этого. Простые задачи можно быстро решить и без SQL, но более сложная обработка данных потребует применения SQL для построения запросов.
С помощью SQL можно запрашивать нужные данные и делать это эффективно, если вы знаете сильные стороны механизма БД.
Понимая SQL, вы сможете быстро освоить практически любую современную реляционную систему баз данных. И ваши знания не будут ограничены программным обеспечением.
Применение SQL в других областях
Благодаря своей популярности SQL нашел свое применение в других СУБД и инструментах анализа данных.
SQL и его аналоги поддерживаются во многих системах и механизмах анализа данных, утилитах бизнес-аналитики и инструментах интеллектуального анализа данных, включая нереляционные и аналитические (OLAP) базы данных, а также для работы с большими данными.
Если вы столкнетесь с любым программным обеспечением для анализа больших массивов данных, то, скорее всего, вы сможете применить свои знания SQL. У вас также будет возможность применить аналогичный подход с разными базами данных, это сделает работу доступной и универсальной для разных источников данных. Как видите, в результате знание SQL является основополагающим, оно часто необходимо специалистам по анализу данных.
SQL входит в первую десятку самых популярных языков программирования согласно TIOBE Programming Community index (индекс популярности языков программирования).
SQL помогает общаться с людьми о данных
Обсуждение данных часто может быть сложной задачей, поскольку люди могут немного неправильно понимать друг друга. Чтобы избежать неоднозначностей в общении с коллегами, полезно знать основы SQL.
Даже если вы не будете писать SQL запросы, ваши знания пригодятся для того, чтобы точно выразить свои требования и ожидания. Вы также сможете точно определить проблемы в полученных данных и дадите понятную и действенную обратную связь аналитикам, которые подготовили данные для вас.
Получается, что SQL – это универсальный язык, который понимают все, кто работает с данными. Даже если вы не столкнетесь с SQL напрямую, знание концепций SQL поможет вам наладить коммуникацию.
На SQL создают лучшие базы данных
При создании любой базы данных важно учитывать, какие данные будут храниться в ней, как к ним будет осуществляться доступ и как их будут обрабатывать в будущем. Можно создавать базы данных, основываясь исключительно на хорошем знании проектирования БД, но переход от теории к практике может быть сложным и подкинуть сюрпризы.
Получить любые данные из базы можно с помощью SQL-запроса, написанным аналитиком данных или созданным с помощью программного обеспечения. Понимая модели использования и умея переводить их в разные SQL-запросы, вы будете заранее знать, как SQL будет обращаться к основной базе для получения данных, и что должен будет сделать механизм БД, чтобы ответить на такой запрос.
Также эти знания можно применить для разработки баз данных, соответствующих поставленной цели. Принимая во внимание варианты использования, которые должна поддерживать база данных, вы можете выбрать структуру, которая позволяет выполнять необходимые запросы проще и эффективнее.
Принимая во внимание варианты использования, которые должна поддерживать база данных, вы можете выбрать структуру, которая позволяет выполнять необходимые запросы проще и эффективнее.
Вы сможете продуманно структурировать таблицы, а также использовать типы данных, отношения внешних ключей и индексы для облегчения доступа к данным. По сути, вы научитесь проектировать базы данных, более подходящие для ваших целей.
SQL помогает разрабатывать приложения
Современные платформы разработки программного обеспечения и популярные веб-фреймворки – Laravel, Symfony, Django или Ruby on Rails, – часто используют уровни абстракции данных, например объектно-реляционные преобразователи. Это нужно, чтобы скрыть сложность доступа к данным от разработчика. При работе с такими платформами вы не будете взаимодействовать с SQL напрямую. Простой и понятный синтаксис, типичный для фреймворка, сделает так, что все будет “просто работать”, а нужные данные станут доступными.
Но сколько бы сокращений и упрощений не предоставляли фреймворки, основной механизм базы данных будет запрашиваться с помощью SQL-запроса, который создан на основе ваших данных.
Понимание принципов работы SQL поможет вам задействовать возможности фреймворка, чтобы сделать запросы более быстрыми и эффективными.
Вы также сможете легко решить любую проблему, связанную с запросом данных и их обработкой. Механизмы БД часто выдают ошибки из-за неудачно выполненного SQL-запроса, но это затрудняет отслеживание проблемы. Понимая ошибки базы данных, вы можете точно определить проблему.
И последнее, но не менее важное: вы будете знакомы с угрозами безопасности, которые возникают в результате неправильных SQL-запросов (например, внедрение SQL-кода).
Зная SQL, вы будете полностью контролировать процесс доступа к данным и неважно, используете ли вы SQL напрямую или будете работать с программными абстракциями и инструментами ORM в рамках фреймворков.
SQL легко выучить
Понимание и применение языка структурированных запросов на практике имеет много плюсов, но самое главное – это его доступность для начинающих, так как он четко описывает свои действия. В его синтаксисе для названия операций, фильтров и других модификаторов используются в основном обычные английские слова. SQL-запросы часто можно прочитать как английские предложения и быстро понять, о чем идет речь, даже не имея опыта программирования.
В его синтаксисе для названия операций, фильтров и других модификаторов используются в основном обычные английские слова. SQL-запросы часто можно прочитать как английские предложения и быстро понять, о чем идет речь, даже не имея опыта программирования.
Существуют более сложные и комплексные аспекты языка, которые могут показаться запутанными и потребовать значительных усилий. Но основы SQL можно понять и изучить на базовом уровне. Вы можете начать с самых основных понятий SQL и пополнять свои знания всякий раз, когда вам нужно ИЗВЛЕЧЬ некоторые данные способом, которым вы раньше пользовались. С SQL легко экспериментировать, что делает его безопасным и надежным.
Изучив SQL, вы получите много преимуществ, узнаете новые методы получения и анализа данных из различных источников. А также сможете стать специалистом в области анализа данных и открыть новые возможности для карьерного роста в различных областях.
Заключение
Благодаря своей гибкости, простоте использования и популярности в разных областях, SQL является распространенным языком запросов и обработки данных. Его изучение принесет много плюсов, даже если ваша основная работа не связана с базами данных или созданием программного обеспечения напрямую.
Его изучение принесет много плюсов, даже если ваша основная работа не связана с базами данных или созданием программного обеспечения напрямую.
Tags: SQL
Операторы LIKE и BETWEEN в SQL — Учебник по SQL
LIKE и BETWEEN в SQL
Операторы LIKE и BETWEEN в SQL используются для сравнения значений в базе данных. В этом учебном разделе мы обсудим:
- Оператор LIKE в SQL
- Оператор МЕЖДУ в SQL
Смотреть это Операторы Like и Between в SQL
Оператор LIKE в SQL
Оператор LIKE в SQL используется для извлечения записей, в которых присутствует определенный шаблон. В предложении WHERE оператор LIKE используется для поиска определенного шаблона в столбце. В SQL он имеет два подстановочных знака, например:
- Символ процента (%): Это замена нуля, одного или нескольких символов.
- Символ подчеркивания (_): Это замена одного символа.

Получите 100%-й подъем!
Осваивайте самые востребованные навыки прямо сейчас!
Заинтересованы в изучении SQL? Запишитесь на наш курс обучения SQL прямо сейчас!
Вот примеры того, как мы используем оператор LIKE с подстановочным знаком 9.0005
| Как оператор | Описание |
| ГДЕ EmployeeName LIKE ‘e%’ | Находит значения, начинающиеся с «e» |
| ГДЕ Имя Сотрудника КАК ‘%e’ | Находит значения, оканчивающиеся на «е» |
| ГДЕ EmployeeName LIKE ‘%en%’ | Находит значения, которые имеют «en» в любой позиции |
| ГДЕ EmployeeName LIKE ‘_e%’ | Находит значения, которые содержат «е» только во второй позиции |
| ГДЕ EmployeeName LIKE ‘e__%’ | Находит значения, начинающиеся с «e» и имеющие длину не менее 3 символов |
| ГДЕ EmployeeName LIKE ‘e%0’ | Находит значения, начинающиеся с «е» и заканчивающиеся на «0» |
Синтаксис SQL Like
SELECT column_list ОТ имя_таблицы ГДЕ столбец_N НРАВИТСЯ ‘_xxxxx%’;
где SELECT, FROM, WHERE и LIKE — ключевые слова, список_столбцов — список столбцов, имя_таблицы — имя таблицы, N_столбца — имя столбца, а также шаблон, за которым следует точка с запятой.
Давайте рассмотрим пример, чтобы лучше понять это, представьте, что мы хотим извлечь имя человека из таблицы сотрудников ниже.
Демонстрационная база данных
| e_id | e_name | е_зарплата | e_age | e_gender | e_dept |
| 1 | Джон | 30000 | 25 | мужской | операции |
| 2 | юлия | 540000 | 27 | женский | операции |
| 3 | Анна | 125000 | 27 | женский | аналитика |
| 4 | боб | 50000 | 24 | мужской | поддержка |
| 5 | макс. | 540000 | 29 | мужской | операции |
Выполним несколько операций с запросом LIKE в SQL. Извлеките все записи, где имя сотрудника начинается с буквы «J»
Выберите * из сотрудника, где e_name LIKE 'j%';
После написания запроса нажмите кнопку «Выполнить», чтобы проверить наличие ошибок. После выполнения SQL-запроса появляется сообщение типа «Команды успешно выполнены». Как мы видим в результате, у нас получилось всего две строки, в которых имена начинаются с буквы «j».
После выполнения SQL-запроса появляется сообщение типа «Команды успешно выполнены». Как мы видим в результате, у нас получилось всего две строки, в которых имена начинаются с буквы «j».
Теперь давайте возьмем еще один пример, в котором мы извлекаем все записи из базы данных, в которых возраст сотрудника находится в двадцатых годах.
Выберите * из сотрудника, где e_age LIKE '2_';
Смена карьеры
Хотите пройти сертификацию по SQL! Учитесь у нашего эксперта по SQL и добейтесь успеха в своей карьере благодаря сертификации Intellipaat по Microsoft SQL.
Еще раз, после написания запроса, вы должны нажать на кнопку выполнения, чтобы проверить наличие ошибок. Если ошибок не обнаружено, выводится информация обо всех сотрудниках, возраст которых находится в диапазоне от 20 до 29 лет., будет отображаться как есть.
Оператор BETWEEN в SQL
Оператор BETWEEN в SQL используется для выбора значений в заданном диапазоне. Например, чтобы извлечь только те записи, в которых возраст человека составляет от 20 до 25 лет, мы должны использовать запрос BETWEEN в SQL.
Например, чтобы извлечь только те записи, в которых возраст человека составляет от 20 до 25 лет, мы должны использовать запрос BETWEEN в SQL.
SQL между синтаксисом
SELECT column_list ОТ имя_таблицы Где column_N МЕЖДУ val1 И val2;
где SELECT, FROM, WHERE, BETWEEN и AND — ключевые слова, список_столбцов — список столбцов, имя_таблицы — имя таблицы, N_столбца — имя столбца, знач.1 — минимальное значение диапазона, а знач.2 — максимальное значение диапазона, за которым следует точка с запятой. Давайте теперь отобразим сотрудников в возрасте от 25 до 35 лет из приведенной выше таблицы сотрудников.
Выберите * От сотрудника, где e_age ОТ 25 ДО 35;
Посетите наше сообщество SQL, чтобы получить ответы на все ваши вопросы!
После написания запроса нажмите кнопку «Выполнить», чтобы проверить наличие ошибок. После выполнения запроса появится таблица.
Давайте отобразим зарплаты сотрудников от 60 000 до 120 000 долларов из таблицы сотрудников.
Выберите * От сотрудника, где e_salary ОТ 60000 ДО 1200000;
После написания запроса нажмите кнопку «Выполнить», чтобы проверить наличие ошибок. После выполнения запроса появится таблица.
На этом мы подошли к концу этого учебного раздела. Теперь вы готовы приступить к использованию LIKE в SQL и BETWEEN в SQL для сравнения значений в вашей базе данных.
Курсы, которые могут вам понравиться
Ознакомьтесь с вопросами для интервью по SQL, чтобы получить преимущество в своей карьере!
Расписание курсов
Использование оператора SQL LIKE для запроса данных на основе шаблонов
Резюме : в этом руководстве мы покажем вам, как использовать оператор SQL LIKE для запроса данных на основе шаблонов.
Знакомство с оператором SQL LIKE
Оператор LIKE позволяет искать строку текста на основе заданного шаблона. Вы можете использовать оператор LIKE в предложении WHERE любой допустимой инструкции SQL, такой как SELECT, UPDATE или DELETE.
SQL предоставляет два подстановочных знака, которые позволяют создавать шаблоны. Эти два подстановочных знака представляют собой процент (%) и символ подчеркивания (_).
- Подстановочный знак в процентах (%) соответствует последовательности любых символов, включая пробел.
- Подстановочный знак ( _ ) соответствует любому одиночному символу.
Синтаксис оператора LIKE при использовании с оператором SELECT следующий:
SELECT
столбец1, столбец2
ОТ
стол
ГДЕ
столбец НРАВИТСЯ шаблон; Тип данных столбца в предложении WHERE должен быть буквенно-цифровым, например, char , varchar и т. д., чтобы можно было использовать оператор LIKE .
Примеры операторов SQL LIKE
Давайте рассмотрим несколько примеров использования оператора LIKE .
Оператор SQL LIKE с подстановочным знаком процента (%) примеры
Предположим, вы хотите найти сотрудника, фамилия которого начинается с буквы 9. 0280 D , вы можете использовать следующий запрос.
0280 D , вы можете использовать следующий запрос.
ВЫБЕРИТЕ
фамилия Имя
ОТ
сотрудники
ГДЕ
lastname LIKE 'D%' Язык кода: JavaScript (javascript) Шаблон «D%» соответствует любой строке, которая начинается с символа «D» и сопровождается любыми символами.
Чтобы найти сотрудников, чье имя заканчивается на «т», вы можете выполнить следующий запрос:
ВЫБЕРИТЕ
фамилия Имя
ОТ
сотрудники
ГДЕ
имя НРАВИТСЯ '%t' Язык кода: JavaScript (javascript) Шаблон «%t» соответствует любой строке, которая заканчивается символом «t».
Вы можете поместить подстановочный знак «%» в начале и в конце строки, чтобы соответствовать любой строке, содержащей строку в подстановочных знаках. Например, чтобы найти сотрудников, чья фамилия содержит строку
Например, чтобы найти сотрудников, чья фамилия содержит строку 'll ‘, вы можете использовать следующий запрос:
SELECT
фамилия Имя
ОТ
сотрудники
ГДЕ
фамилия НРАВИТСЯ '%ll%' Язык кода: JavaScript (javascript) Пример комбинации двух подстановочных знаков
Вы можете комбинировать два подстановочных знака «%» и «_» для создания шаблона. Например, вы можете найти сотрудника, чья фамилия начинается с любого одиночного символа, за которым следует символ a и заканчивается любыми символами, с помощью следующего запроса:
SELECT
фамилия Имя
ОТ
сотрудники
ГДЕ
фамилия LIKE '_a%' Язык кода: JavaScript (javascript) Оператор SQL LIKE с оператором NOT
Вы можете комбинировать оператор LIKE с оператором NOT , чтобы найти любую строку, которая не соответствует указанному шаблону. Предположим, вы хотите найти сотрудников, чье имя не начинается с буквы «D», вы можете выполнить следующий запрос:
Предположим, вы хотите найти сотрудников, чье имя не начинается с буквы «D», вы можете выполнить следующий запрос:
ВЫБЕРИТЕ
фамилия Имя
ОТ
сотрудники
ГДЕ
фамилия NOT LIKE 'D%' Язык кода: JavaScript (javascript) Экранирование подстановочных знаков
В случае, если шаблон, который вы хотите сопоставить, содержит подстановочные знаки, например, 5% или _10. Чтобы использовать этот шаблон, вам нужно экранировать подстановочные знаки в шаблоне.
В разных продуктах баз данных используются разные способы экранирования подстановочных знаков ( %, _ ) в шаблоне. Наиболее распространенными способами экранирования подстановочных знаков являются использование символа обратной косой черты (\) или предложения ESCAPE.
В следующем примере показано, как экранировать подстановочный знак с помощью символа обратной косой черты (\):
столбец LIKE '%\_10%' Язык кода: JavaScript (javascript) Предложение ESCAPE позволяет указать управляющий символ по вашему выбору, а не обратную косую черту.