Pivot pl sql: PIVOT оператор — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Содержание
ФОРС. Интернет-журнал, № 2
ФОРС. Интернет-журнал, № 2
Аруп Нанда,
Член-директор коллегии Oracle ACE
Источник:
сайт корпорации Oracle, серия статей «Oracle Database 11g:
The Top New Features for DBAs and Developers» («Oracle Database 11g: Новые возможности для администраторов и
разработчиков»), статья 16
http://www.oracle.com/technetwork/articles/sql/11g-pivot-097235.html
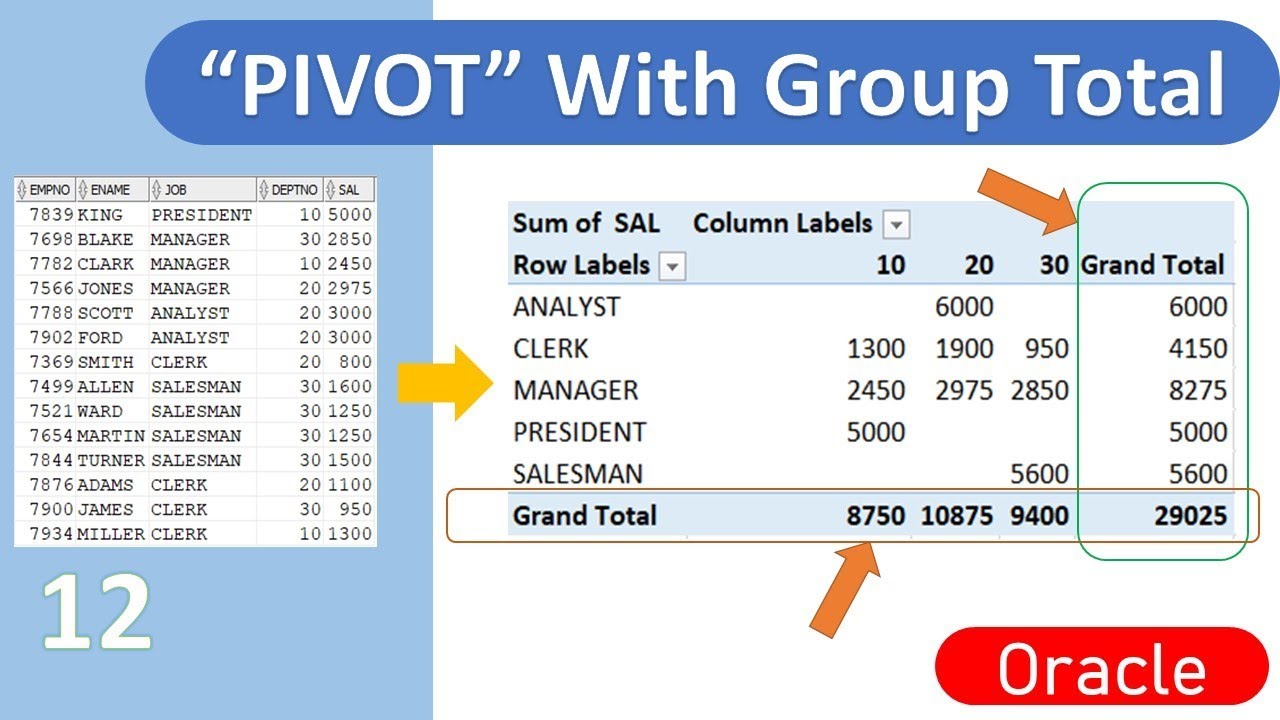
Представление информации в виде сводного кросс-табличного отчета, полученного из любой реляционной таблицы с использованием простого
SQL-запроса, и сохранение данных из кросс-развернутой таблицы в реляционной таблице.
Поворот(Pivot)
Как известно, реляционные таблицы обычно представляются в матричном виде, то есть, они состоят из пар — столбец-значение.
Рассмотрим, например, таблицу CUSTOMERS.
SQL> desc customers Name Null? Type ---------------------- ----- --------------------------- CUST_ID NUMBER(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)
Когда из этой таблицы делается выборка:
select cust_id, state_code, times_purchased from customers order by cust_id;
выход таков
CUST_ID STATE_CODE TIMES_PURCHASED ------- ---------- --------------- 1 CT 1 2 NY 10 3 NJ 2 4 NY 4 ...
и так далее ...
Заметим, что данные представлены в виде строк значений: для каждого клиента строка называет его домашний штат и количество
заказов, сделанных им в магазине. Всякий раз, когда клиент делает следующий
Всякий раз, когда клиент делает следующий
заказ, столбец times_purchased обновляется.
Теперь рассмотрим случай, когда надо получить отчет о частоте заказов по каждому штату, то есть, сколько клиентов в
конкретном штате сделали один, два, три заказа и т.д. На стандартном языке SQL
это могло бы выглядеть следующем образом:
select state_code, times_purchased, count(1) cnt from customers group by state_code, times_purchased;
с таким вот результатом:
ST TIMES_PURCHASED CNT -- --------------- ---------- CT 0 90 CT 1 165 CT 2 179 CT 3 173 CT 4 173 CT 5 152 ...
и так далее ...
Это та информация, которая вам нужна, только ее несколько
неудобно читать.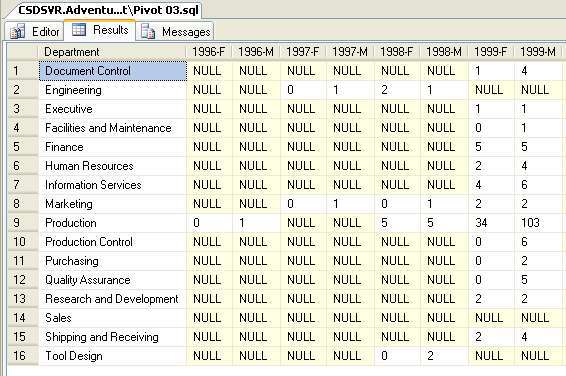 Лучше было бы представить эти же самые данные в виде
Лучше было бы представить эти же самые данные в виде
кросс-табличного отчета, в котором следовало бы вертикально расположить
частоту покупок, а коды штатов — горизонтально, как в сводной таблице:
Times_purchased
CT NY NJ ...
и так далее ...
1 0 1 0 ...
2 23 119 37 ...
3 17 45 1 ...
...
и так далее. ...
До Oracle Database11
вы сделали бы это посредством некоей сортировки функции декодирования для каждого значения и
записали бы каждое неповторяющееся значение отдельным столбцом. Однако, такой
способ неочевиден.
К счастью, сейчас имеется отличная новая возможность – PIVOT
(ПОВОРОТ) для представления любого запроса в кросс-табличном формате, используя новый
оператор, соответственно названный pivot
.
Теперь, когда в запросе написано:
select * from (
select times_purchased, state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
order by times_purchased
/
результат будет таким
TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO'
--------------- ---------- ------- ------ ---- ------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
... и так далее ...
Это показывает возможности оператора pivot. Коды штатов
(state_codes) показываются в строке
заголовка, а не в столбце.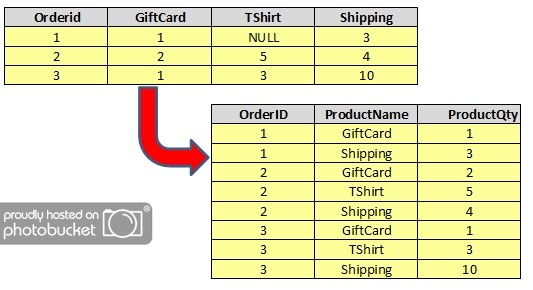 Иллюстративно обычный табулированный формат
Иллюстративно обычный табулированный формат
выглядит так:
Рис. 1. Обычное табулированное представление.
В кросс-табличном отчете вы хотите переместить столбец
«Times Purchased» в строку заголовка,
как показано на рис. 2. Столбец становится строкой, как если бы столбец был
повернут на 90 градусов против часовой стрелки, чтобы стать строкой заголовка.
Это фигуративное вращение (figurative rotation) должно иметь поворотную точку
(pivot point), и в нашем случае точкой поворота служит выражение
count(stat_code).
Рис.2. Транспонированное представление
Это выражение должно быть задано в синтаксисе запроса:
...
pivot
(
count(state_code)
for state_code in ('NY','CT','NJ','FL','MO')
)
...
Вторая строка «for state_code . ..,» ограничивает
..,» ограничивает
запрос только указанными значениями. Эта строка необходима, поэтому, к
сожалению, нужно заранее знать возможные значения. Это ограничение смягчается в
XML-формате запроса, описанном далее в этой статье.
Обратите внимание на строку заголовка в отчете:
TIMES_PURCHASED 'NY' 'CT' 'NJ' 'FL' 'MO' --------------- --------- ---------- ---------- -------- ----------
Заголовки столбцов являются значениями из самой таблицы: это коды штатов. Сокращения могут говорить сами за себя, но допустим,
вы хотите вывести названия штатов вместо сокращений, («Connecticut
» вместо «CT»). В таком случае нужно немного скорректировать
запрос в фразе FOR, как показано ниже:
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot
(
count(state_code)
for state_code in ('NY' as "New York",'CT' "Connecticut",'NJ' "New Jersey",'FL' "Florida",'MO' as "Missouri")
)
order by 1
/
Puchase Frequency New York Connecticut New Jersey Florida Missouri
----------------- ---------- ----------- ---------- ------- ----------
0 16601 90 0 0 0
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
. ..
..
и так далее ...
 ..
..
Фразой FOR можно указывать алиасы для значений, которые
станут заголовками столбцов.
Разворот (Unpivot)
Если для материи существует антиматерия, то и для транспонирования (
pivot) должно существовать обратное транспонирование
(«unpivot«), не так ли?
Действительно, существует естественная необходимость в обратной к
pivot операции, так сказать, в обратном
транспонировании. Предположим, что есть сводная таблица, которая отображает
кросс-табличный отчет следующим образом:
| Purchase Frequency | New York | Connecticut | New Jersey | Florida | Missouri |
| 0 | 12 | 11 | 1 | 0 | 0 |
| 1 | 900 | 14 | 22 | 98 | 78 |
| 2 | 866 | 78 | 13 | 3 | 9 |
. .. .. | . |
Теперь надо загрузить данные в реляционную таблицу CUSTOMERS:
SQL> desc customers Name Null? Type --------------------- -------- --------------------- CUST_ID NUMBER(10) CUST_NAME VARCHAR2(20) STATE_CODE VARCHAR2(2) TIMES_PURCHASED NUMBER(3)
Данные из сводной таблицы должны быть переведены
в реляционный формат и после этого сохранены. Конечно, вы могли бы написать
сложный скрипт для SQL*Loader или SQL-скрипт, использующий функцию DECODE
для загрузки данных в таблицу CUSTOMERS. Или же можно воспользоваться обратным повороту (pivot) действием — UNPIVOT
– и разбить столбцы, чтобы они стали строками, как это возможно сделать в Oracle Database 11g.
Это проще продемонстрировать на примере. Создадим для начала кросс-таблицу, используя оператор
pivot:
1 create table cust_matrix
2 as
3 select * from (
4 select times_purchased as "Puchase Frequency", state_code
5 from customers t
6 )
7 pivot
8 (
9 count(state_code)
10 for state_code in ('NY' as "New York",'CT' "Conn",'NJ' "New Jersey",'FL' "Florida",
'MO' as "Missouri")
11 )
12* order by 1
Проверим, как данные сохранены в таблице:
SQL> select * from cust_matrix
2 /
Puchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ------- ---------- ------- ---------
1 33048 165 0 0 0
2 33151 179 0 0 0
3 32978 173 0 0 0
4 33109 173 0 1 0
. . и так далее. ...
 . и так далее. ...
. и так далее. ...
В сводной таблице данные сохраняются следующим
образом: каждый штат — это столбец в таблице («New York», «Conn» и так далее).
SQL> desc cust_matrix Name Null? Type -------------------------- -------- --------------------------- Puchase Frequency NUMBER(3) New York NUMBER Conn NUMBER New Jersey NUMBER Florida NUMBER Missouri NUMBER
Вам необходимо разбить таблицу так, чтобы строки содержали только сокращения штатов и число заказов в этом штате. Это можно
сделать с помощью оператора unpivot, как показано ниже:
select *
from cust_matrix
unpivot
(
state_counts
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
)
order by "Puchase Frequency", state_code
/
Выход таков:
Puchase Frequency STATE_CODE STATE_COUNTS
----------------- ---------- ------------
1 Conn 165
1 Florida 0
1 Missouri 0
1 New Jersey 0
1 New York 33048
2 Conn 179
2 Florida 0
2 Missouri 0
. ..
и так далее ...
 ..
и так далее ...
..
и так далее ...
Отметим, что каждое имя столбца стало значением
в столбце STATE_CODE. Как Oracle узнал, что
state_column — заголовок столбца? Он узнал это из следующего выражения в запросе:
for state_code in ("New York","Conn","New Jersey","Florida","Missouri")
Здесь вы определили, что значения «New York», «Conn» и т.д. — это
значения нового столбца, называемого state_code, который вы хотите свернуть
обратно (unpivoted). Посмотрим на фрагмент исходных данных:
Purchase Frequency New York Conn New Jersey Florida Missouri
----------------- ---------- ---------- ---------- ---------- ---------
1 33048 165 0 0 0
Коль скоро имя столбца "New York» неожиданно стало
значением в строке, где показать значение 33048, к какому столбцу его отнести?
Ответ на этот вопрос находится в приведенном выше запросе прямо в выражении
for в операторе unpivot.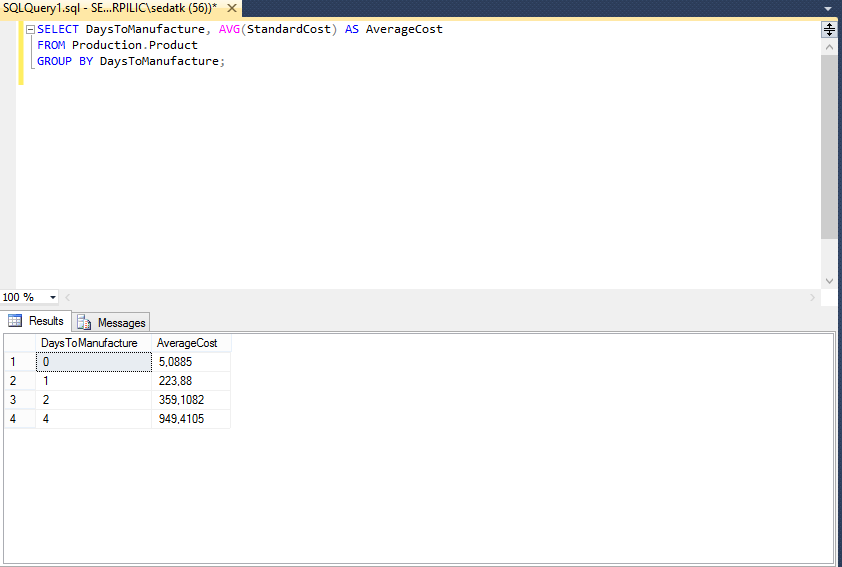 Как вы определите
Как вы определите
state_counts, таким и будет имя вновь создаваемого столбца в результирующем выводе.
Действие unpivot можно рассматривать как противоположное действию pivot, но не надо полагать, что одно из них может
обратить то, что сделает другое. Например, в предыдущем примере вы создали таблицу CUST_MATRIX, использовав оператор pivot над таблицей
CUSTOMERS. Затем был применен оператор unpivot к таблице CUST_MATRIX, но вы не получили в точности исходную таблицу CUSTOMERS.
Вместо этого кросс-табличный отчет показал другой способ загрузки в реляционную таблицу. Таким образом, unpivot не отменяет действия,
сделанные pivot, факт который нужно самым тщательным образом учитывать прежде, чем удалять (dropping) исходную таблицу после создания повернутой
(pivoted) таблицы.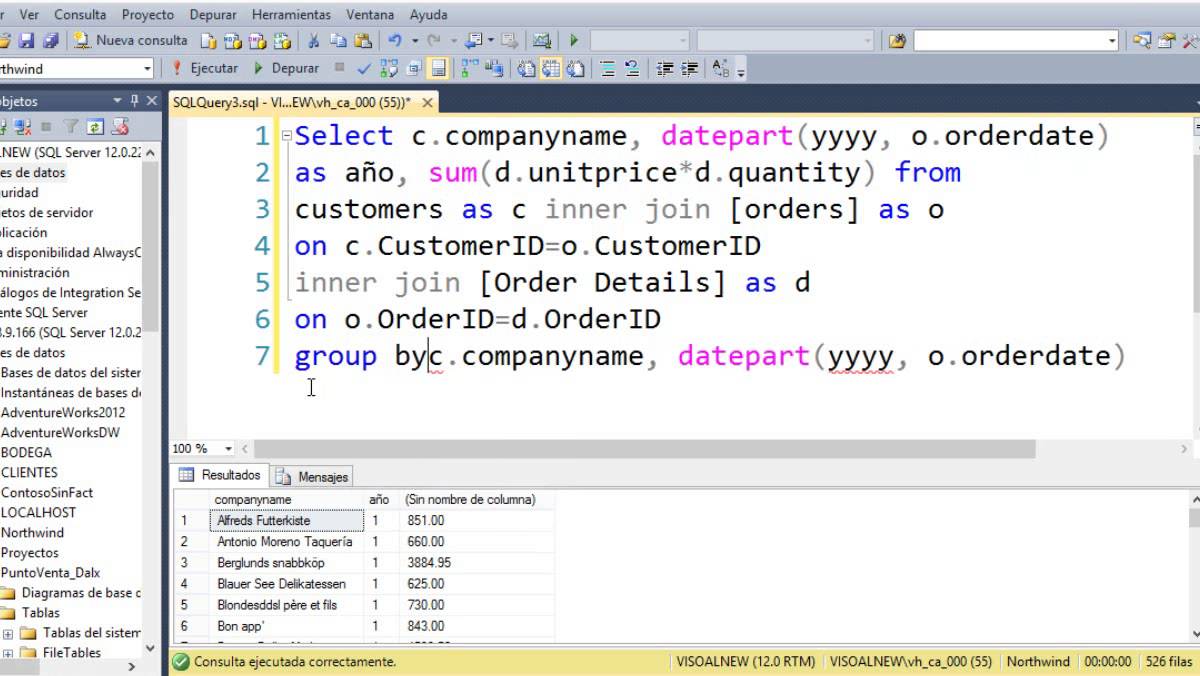
Некоторые очень интересные случаи использования unpivot, подобно рассмотренному
ранее примеру, выходят за грани обычной обработки данных. Член-директор Oracle ACE
Лукас Джеллема (Lucas Jellema) из компании Amis Technologies в заметке «Flexible
Row Generator with Oracle 11g Unpivot Operator» показал, как генерировать строки специфичных данных для тестирования [От
редакции FORS Magazine: перевод этой заметки приводится ниже в качестве приложения к данной статье]. В данной статье я
буду использовать незначительно измененную форму его кода для генерации гласных английского алфавита:
select value
from
(
(
select
'a' v1,
'e' v2,
'i' v3,
'o' v4,
'u' v5
from dual
)
unpivot
(
value
for value_type in
(v1,v2,v3,v4,v5)
)
)
/
Выход таков:
V
-
a
e
i
o
u
Эта модель может быть расширена для создания генератора строк любого типа. Скажем спасибо Лукасу, показавшему нам этот
Скажем спасибо Лукасу, показавшему нам этот
остроумный прием.
XML Type
В предыдущем примере нужно было определить правильные коды штатов
state_codes:
for state_code in ('NY','CT','NJ','FL','MO')
Это требование предполагает, что вы знаете, какие значения присутствуют в столбце
state_column. А как построить запрос, если не известно,
какие значения допустимы?
К счастью, существует другая форма операции pivot
— XML, которая позволяет создавать повернутый отчет в XML-формате, когда можно определить специальный
оператор ANY, вместо литеральных значений. Вот пример:
select * from (
select times_purchased as "Purchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (any)
)
order by 1
/
Результат выводится как CLOB, поэтому прежде чем выполнять запрос, надо удостовериться, что параметр
LONGSIZE устанавливает достаточное значение.
SQL> set long 99999
Существуют два четких различия (помечены жирным
шрифтом) этого запроса по сравнению с исходной операцией
pivot. Во-первых, вы пишете
pivot xml
вместо просто pivot. Это создает вывод в
формате XML. Во-вторых, выражение for
содержит for state_code in (any)
вместо длинного списка значений. XML позволяет использовать
ключевое слово ANY, и вам не нужно вводить значения
strong>state_code. Вот выход:
Purchase Frequency STATE_CODE_XML
------------------ --------------------------------------------------
1 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">165</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33048</colu
mn></item></PivotSet>
2 <PivotSet><item><column name = "STATE_CODE">CT</co
lumn><column name = "COUNT(STATE_CODE)">179</colum
n></item><item><column name = "STATE_CODE">NY</col
umn><column name = "COUNT(STATE_CODE)">33151</colu
mn></item></PivotSet>
. .. и так далее .. и так далее
.. и так далее
Как можно видеть, тип столбца STATE_CODE_XML — действительно
XMLTYPE, а <PivotSet> — корневой элемент (root element). Каждое значение
представлено парами элементов «имя–значение». Вы можете использовать этот выход
в любом XML-парсере для создания более наглядного выхода.
В дополнение к выражению ANY можно написать
подзапрос. Предположим, существует список предпочтительных штатов, и вы хотите
выбрать строки только для них. Вы сохранили коды предпочитаемых штатов в новой
таблице, названной preferred_states:
SQL> create table preferred_states
2 (
3 state_code varchar2(2)
4 )
5 /
Table created.
SQL> insert into preferred_states values ('FL')
2> /
1 row created.
SQL> commit;
Commit complete.
Теперь операция pivot выглядит следующим образом:
select * from (
select times_purchased as "Puchase Frequency", state_code
from customers t
)
pivot xml
(
count(state_code)
for state_code in (select state_code from preferred_states)
)
order by 1
/
В подзапросе фразы for может быть все, что вы
захотите. Например, если надо выбрать все записи, без ограничительных условий
Например, если надо выбрать все записи, без ограничительных условий
на предпочтительные штаты, во фразе for можно использовать
следующую конструкцию:
for state_code in (select distinct state_code from customers)
Подзапрос должен возвращать неповторяющиеся значения, иначе запрос будет ошибочным.
Именно поэтому в запросе был использован оператор DISTINCT
.
Заключение
Оператор Pivot добавляет очень важную и полезную
функциональность в язык SQL. Вместо создания замысловатого непрозрачного кода с большим
количеством функций-декодеров (decode functions), можно использовать
функцию pivot для создания кросс-табличного представления любой реляционной таблицы.
Точно так же можно преобразовать кросс-табличное представление в обычную реляционную таблицу, используя операцию
unpivot. Выход pivot может быть как
Выход pivot может быть как
текстовым, так и в XML-формате. В последнем случае не нужно определять область значений, к которым применяется этот
оператор.
=======*******=======
За более подробной информацией об операторах
pivot и unpivot следует обратиться к
документу
Oracle Database 11g SQL Language Reference
=======*******=======
Приложение
Лукас Джеллема
(Flexible Row Generator with Oracle 11g Unpivot Operator, by Lucas Jellema)
Источник: сайт AMIS Technology (http://technology.amis.nl/),
http://technology.amis.nl/2007/10/05/flexible-row-generator-with-oracle-11g-unpivot-operator/»>
Генератор
строк — очень полезный механизм для многих (полу-) продвинутых SQL-запросов. В
В
предыдущих статьях мы обсудили различные методы генерации строк.
Тому примерами являются оператор CUBE, табличные функции (Table Functions)
и фраза «Connect By Level < #» количества подходящих записей, не говоря уже о старом добром UNION ALL
с многократным «select from dual». Эти приемы разнятся по гибкости и компактности. CUBE
и Connect By обеспечивают легкую генерацию большого количества строк как с незначительным, так и
сложным управлением значениями в таких строках, в то время как UNION ALL сложен и громоздок, даже при том, что он
предоставляет большие возможности управления точными значениями.
Оператор Unpivot в Oracle11g предоставляет нам новый способ
сгенерировать строки с великолепными возможностями управления над значениями в
строках и более компактный и изящный синтаксис, чем альтернатива UNION ALL.
Давайте рассмотрим простой пример.
Предположим, что нам нужен набор строк с определенными значениями, возможно, для использования в качестве встроенного представления
внутри нашего сложного запроса или в качестве автономного представления. В этом примере я взял шесть довольно бесполезных величин, но он излагает концепцию,
что значение имеет.
Единственным select-предложением выборки из DUAL, а не шестью запросами из DUAL, которые по
UNION ALL [соединяются] вместе, мы выбираем шесть требуемых значений, как из индивидуальных столбцов – от a
до f. Оператор UNPIVOT, который мы затем применяем к этому результату, берет единственную строку с шестью столбцами и превращает ее в шесть строк с двумя
столбцами, один из которых содержит имя исходного столбца исходной строки, а другой — значение в том исходном столбце:
select * from ( ( select ‘value1′ a , ‘value27′ b , ‘value534′ c , ‘value912′ d , ‘value1005′ e , ‘value2165′ f from dual ) unpivot > ( value for value_type in ( a,b,c,d,e, f) ) ) /
Результат этого запроса таков:
:
V VALUE - ——— A value1 B value27 C value534 D value912 E value1005 F value2165 6 rows selected.

Замечание:
в ситуациях, где требуется прямая генерация большого количества строк, прием strong>«CONNECT BY» все
еще будет превалирующим. Например, чтобы сгенерировать алфавит, следует использовать предложение типа:
1 select chr(rownum+64) letter 2 from (select level 3 from dual 4 connect 5 by level<27 6* )
Однако, чтобы сгенерировать поднабор, скажем, все гласные из алфавита, подход с применением оператора strong>UNPIVOT
может оказаться полезным.
select vowel from ( ( select ‘a’ v1 , ‘e’ v2 , ‘i’ v3 , ‘o’ v4 , ‘u’ v5 from dual ) unpivot ( vowel for dummy in ( v1,v2,v3,v4,v5) ) ) /
MySQL, MariaDB, SQLite, PostgreSQL, Oracle, …
Сводка данных — довольно распространенная проблема, которая бывает разных видов. По сути, требование состоит в переносе данных из нескольких строк в столбцы одной строки.
По сути, требование состоит в переносе данных из нескольких строк в столбцы одной строки.
Это требование особенно распространено в контексте отчетности. Поэтому следующее объяснение основано на запросе, сообщающем о ежемесячных доходах:
ВЫБЕРИТЕ ВЫДЕРЖКУ (ГОД ОТ даты_фактуры) год
, ВЫДЕРЖАТЬ(МЕСЯЦ ОТ даты_фактуры) месяц
, СУММ(доход) доход
ИЗ счетов-фактур
СГРУППИРОВАТЬ ПО ВЫДЕРЖКЕ(ГОД ОТ invoice_date)
, ВЫДЕРЖКА(МЕСЯЦ ОТ даты_фактуры) Запрос возвращает результат в чисто вертикальной форме — одно значение в строке. Довольно часто данные требуются в другом виде: например, всего одна строка за год и отдельный столбец за каждый месяц. Другими словами, строки года должны быть превращены в столбцы.
Первым шагом в реализации этого требования является удаление месяца из группы с помощью и выбора предложений для получения одной строки за год:
SELECT EXTRACT(YEAR FROM invoice_date) year
, SUM(доход) total_revenue
ИЗ счетов-фактур
СГРУППИРОВАТЬ ПО ВЫДЕРЖКЕ(ГОД С_даты_фактуры) Очевидно, что результат больше не обеспечивает разбивку по месяцам, тем не менее, этот шаг необходим для сведения результата к одной строке за год.
Следующим шагом является определение двенадцати столбцов, в каждом из которых суммируются доходы только за один месяц. Например, чтобы получить выручку за январь, выражение сумма(доход) должно учитывать только счета-фактуры за январь. Это легко сделать с помощью фильтра :
sum(revenue) FILTER (WHERE EXTRACT(MONTH FROM invoice_date) = 1)
Предложение filter ограничивает агрегированные строки теми, которые удовлетворяют условию в скобках. В этом примере только счета за январь. Таким же образом можно получить доходы других месяцев.
Чтобы сделать запрос более грамотным, выражение Extract можно переместить в центральное расположение. Это может быть сгенерированный столбец или представление, чтобы другие запросы могли повторно использовать эти выражения. Для этого примера достаточно централизовать извлечь выражение из запроса — либо с помощью предложения with , либо в виде встроенного представления:
SELECT year
, СУММА(доход) ФИЛЬТР (ГДЕ месяц = 1 ) jan_revenue
, СУММ(доход) ФИЛЬТР (ГДЕ месяц = 2 ) feb_revenue
. ..
, СУММ(доход) ФИЛЬТР (ГДЕ месяц = 12 ) dec_revenue
ОТ (ВЫБЕРИТЕ счета.*
, ВЫДЕРЖКА (ГОД ОТ даты_фактуры) год
, ВЫДЕРЖКА(МЕСЯЦ ОТ даты_фактуры) месяц
ИЗ счетов-фактур
) счета
GROUP BY year  ..
, СУММ(доход) ФИЛЬТР (ГДЕ месяц = 12 ) dec_revenue
ОТ (ВЫБЕРИТЕ счета.*
, ВЫДЕРЖКА (ГОД ОТ даты_фактуры) год
, ВЫДЕРЖКА(МЕСЯЦ ОТ даты_фактуры) месяц
ИЗ счетов-фактур
) счета
GROUP BY year
..
, СУММ(доход) ФИЛЬТР (ГДЕ месяц = 12 ) dec_revenue
ОТ (ВЫБЕРИТЕ счета.*
, ВЫДЕРЖКА (ГОД ОТ даты_фактуры) год
, ВЫДЕРЖКА(МЕСЯЦ ОТ даты_фактуры) месяц
ИЗ счетов-фактур
) счета
GROUP BY year Соответствующие альтернативы
Несмотря на то, что предложение filter было введено в SQL:2003, сегодня оно почти не поддерживается. К счастью, это не большая проблема, потому что case можно использовать для той же цели. Хитрость заключается в сопоставлении значений, которые , а не , удовлетворяющих критериям фильтра, в нейтральные значения, которые не изменяют результат агрегирования. Null — очень хороший выбор для этого, потому что он не меняет результат 9.0059 любая агрегатная функция — даже не avg . Кроме того, else null является предложением по умолчанию для выражений case без явного предложения else — в любом случае достаточно пропустить предложение else .
ВЫБЕРИТЕ год
, СУММА(СЛУЧАЙ, КОГДА месяц = 1 , ТОГДА доход КОНЕЦ) jan_revenue
, СУММА(СЛУЧАЙ, КОГДА месяц = 2 , ТОГДА доход КОНЕЦ) feb_revenue
...
, СУММА (СЛУЧАЙ, КОГДА месяцев = 12 THEN доход КОНЕЦ) dec_revenue
ОТ (ВЫБЕРИТЕ счета.*
, ВЫДЕРЖКА (ГОД ОТ даты_фактуры) год
, ВЫДЕРЖКА (МЕСЯЦ ОТ даты_фактуры) месяц
ИЗ счетов-фактур
) счета
ГРУППА ПО году Выражение СЛУЧАЙ, КОГДА месяц = 1, ТОГДА доход КОНЕЦ , оценивается как доход для счетов-фактур за январь. Для других счетов подразумеваемый иначе null возвращает значение null , которое не меняет результат сумма . См. также « Null в Агрегатных функциях (количество, сумма,…) » и «Альтернативы, соответствующие filter ».
Особый случай EAV
Самая большая проблема с проблемой поворота состоит в том, чтобы распознать ее, когда вы с ней столкнетесь.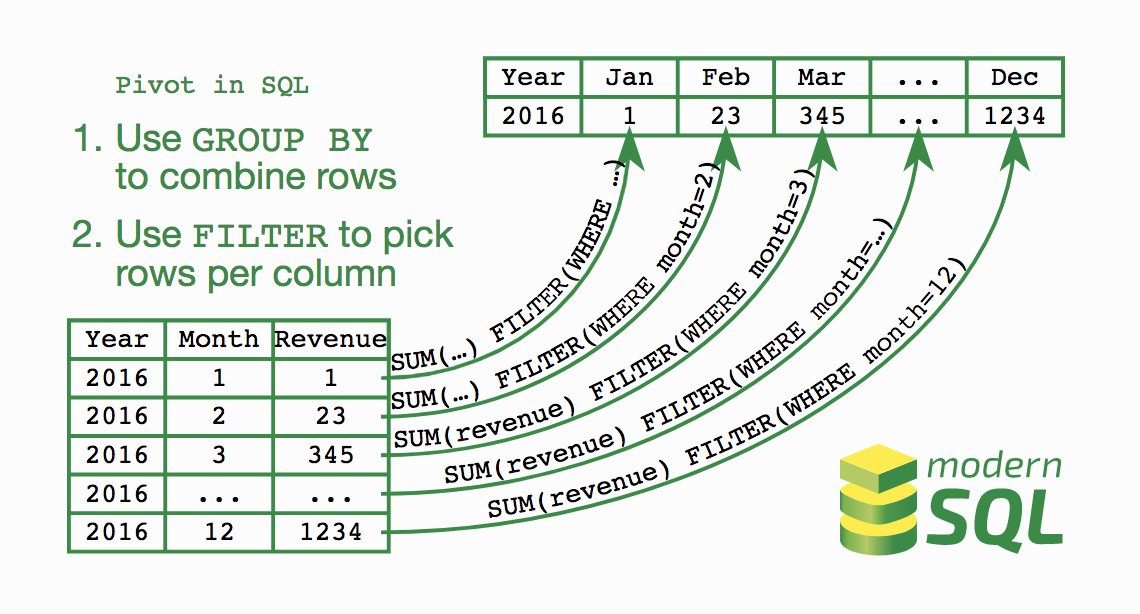 Это особенно верно при работе с так называемой моделью сущность-атрибут-значение (EAV): она не похожа на проблему разворота, но, тем не менее, может быть решена точно так же.
Это особенно верно при работе с так называемой моделью сущность-атрибут-значение (EAV): она не похожа на проблему разворота, но, тем не менее, может быть решена точно так же.
Модель EAV доводит нормализацию до предела и больше не использует столбцы традиционным способом. Вместо этого каждое отдельное значение хранится в отдельной строке. Помимо значения, в строке также есть столбец, указывающий, какой атрибут представляет значение, и третий столбец, указывающий, к какому объекту принадлежат значения. В конечном счете, таблица с тремя столбцами может содержать любые данные без необходимости изменять определение таблицы. Таким образом, модель EAV часто используется для хранения динамических атрибутов.
Модель EAV не лишена недостатков: например, почти невозможно использовать ограничения для проверки данных. Однако самая загадочная проблема с моделью EAV заключается в том, что преобразование в нотацию с одним столбцом на атрибут почти всегда выполняется с использованием соединений — довольно часто одно внешнее соединение на атрибут. Это не только громоздко, но и приводит к очень низкой производительности — настоящий анти-шаблон.
Это не только громоздко, но и приводит к очень низкой производительности — настоящий анти-шаблон.
Однако превращение строк в столбцы — это проблема сводки в чистом виде. Таким образом, эти шаги следует выполнить еще раз: (1) используйте сгруппируйте по , чтобы сократить количество строк до одной строки на объект, (2) используйте фильтр или случай , чтобы выбрать правильный атрибут для каждого столбца.
ВЫБЕРИТЕ ИД_отправки
, MAX(CASE WHEN attribute='name' THEN value END) имя
, MAX(CASE WHEN attribute='email' THEN value END) адрес электронной почты
, MAX(CASE WHEN attribute='website' THEN value END) веб-сайт
ОТ form_submissions
GROUP BY submit_id Обратите внимание на использование функции max : требуется свести строки группы (все атрибуты) к одному значению. Это чисто синтаксическое требование, которое применимо независимо от фактического количества сгруппированных строк.
Чтобы получить исходное значение для каждого атрибута — даже если мы должны использовать агрегатную функцию — соответствующая логика фильтра ( case или filter ) не должна возвращать более одного значения not- null . В приведенном выше примере крайне важно, чтобы каждый из именованных атрибутов (
В приведенном выше примере крайне важно, чтобы каждый из именованных атрибутов ( имя , электронная почта , веб-сайт ) существовал только один раз для submit_id . Если дубликаты существуют, запрос возвращает только один из них.
Необходимое условие, заключающееся в том, что каждый атрибут не должен появляться более одного раза, лучше всего обеспечивается ограничением уникальности.0 В качестве альтернативы запрос может подсчитывать агрегированные строки, используя count(*) и соответствующие выражения case (или предложения filter ). Результаты можно проверить в приложении — если они выбраны в качестве дополнительных столбцов — или в предложении , имеющем : , имеющем фильтр count(*) (...) <= 1 .
Если предварительное условие выполнено и агрегирование всегда выполняется для одного значения not- null , каждая агрегатная функция просто возвращает входное значение.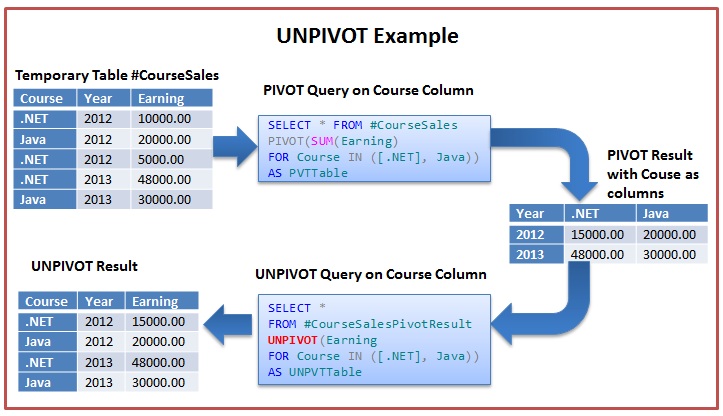 Однако
Однако min и max имеют то преимущество, что они также работают для символьных строк ( char , varchar и т. д.).
Ограничения
SQL является статически типизированным языком: запрос должен заранее перечислять столбцы результатов. Чтобы свести таблицу с неизвестными или динамическими атрибутами, можно использовать мультимножества или типы документов (XML, JSON) для представления хранилища ключей и значений в одном столбце. См. соответствующие альтернативы listagg : типы документов.
Совместимость
BigQueryDb2 (LUW)MariaDBMySQLaOracle DBPostgreSQLSQL ServerSQLitefilter casecase
- Расширение
filter_plugin(стороннее) переписываетfilterвcaseс использованием регулярных выражений 0011 unpivot (SQL Server, Oracle)SQL Server поддерживает сводку
Пунктыиunpivotначиная с версии 2005 (документация). Они также доступны в базе данных Oracle, начиная с версии 11 g (документация).9Предложение 0011 модели
(Oracle)
Собственное предложение
модели, представленное в версии Oracle 10 g , также можно использовать для решения задачи поворота (документация).кросс-таблицатабличная функция (PostgreSQL)База данных PostgreSQL поставляется с набором
кросс-таблицытабличных функций для сводных данных (документация).Oracle Dynamic SQL Pivoting — кража Антона Грома — AMIS, блог, управляемый данными
0 0
Время считывания: 7 минут 38 секунд
У меня есть коллега, у которого гениальный ход. Он может создавать вещи на SQL и PL/SQL, которые мне очень трудно понять, не говоря уже о том, что я мог бы придумать сам. Его зовут Антон, и в последнее время он занимается Pivoting в SQL. Процесс переворачивания результата запроса с ног на голову, чтобы представить его по-другому.
Превращение набора значений в одном из столбцов в заголовки столбцов для всего запроса.Как получить следующий результат запроса:
и превратив его в следующую структуру:
Антон недавно написал короткую, несколько загадочную статью о Pivoting SQL Queries в этом блоге; см.: https://technology.amis.nl/blog/?p=1197. В этой статье Антон представил подход к повороту, который не требует от нас жесткого кодирования всех значений, которые мы хотим видеть в заголовках столбцов (например, значения для JOB в приведенном выше примере). Однако ТИП ОБЪЕКТА, который он использует в этой статье, содержит сам запрос жесткого кода. Это было уже неплохо, но он пошел туда, куда не ходил человек, и создал реализацию, полностью динамическую. Мы просто передаем запрос, который мы хотим повернуть, и функция, созданная Антоном, обязывает.
В этой статье я покажу несколько примеров того, что мы можем сделать с этим удивительным драгоценным камнем, а также сделаю сам код доступным для скачивания.
Однако, и это последний раз, когда я трублю в его трубу, это не мой кодекс. Я хорошо пишу многословные статьи, а Антон подделывает какой-то источник.Первый результат запроса в статье был создан с использованием довольно простого запроса:
select deptno , работа , ср(сал) сал_ср из эмп группа от отдела , работа /
Второй сводной результат был создан с использованием того же запроса, однако на этот раз он был передан в виде строки в сводную функцию, о которой я расскажу позже:
select * из таблицы(свод('выбрать отделно , работа , ср(сал) сал_ср из эмп группа от отдела , работа ') )Мы уже видели ошеломляющий результат этого звонка. Чтобы доказать, что это действительно работает, я могу добавить две строки в нашу таблицу EMP:
вставить в emp (эмпно, имя, работа, отдел, сал) ценности ( 1111, 'АНТОН', 'ВОЛШЕБНИК', 10, 1991) / вставить в эмп (эмпно, имя, работа, отдел, сал) ценности ( 1112, 'ТОБИАС', 'ПРОДАВЕЦ', 40, 1100) /
Теперь, если мы повторно запустим последний запрос, результатом будет:
Итак, мы взяли новые записи и извлекли новое значение JOB (WIZARD), которое было добавлено в качестве нового столбца в результат нашего запроса.
Примечание: иногда новые значения столбца не так легко подбираются. В таких случаях нам приходится немного схитрить, побуждая CBO переоценить наш запрос (или, похоже, мы не совсем поняли, что это такое). Если мы добавим пробел где-нибудь в строке запроса или внесем другое изменение, будут выбраны новые значения столбца.Создание матрицы расстояний
Ваша средняя дорожная карта будет иметь фигуру в виде сетки, матрицу расстояний, в которой перечислены города и расстояния между ними. Используя функцию Pivot Антона, оказывается довольно просто создать такую матрицу расстояний. Давайте рассмотрим гипотетический пример (расстояния ни в коем случае не правильные, но это не главное) для основных городов Нидерландов:
Западная часть Нидерландов называется Де Рандстад. Здесь проживает почти половина населения и сосредоточена большая часть экономической деятельности. Карта для этого куска (синий на карте, потому что он ниже уровня моря) нашей страны:
Теперь мы хотим построить небольшую матрицу расстояний для четырех основных городов Де Рандстада.
Мы создаем небольшую структуру базы данных для сведений о городе и связи:Для облегчения доступа к нашим данным мы создаем служебное представление:
создаем или заменяем представление city_connections как выберите from_city.name from_city , to_city.name to_city , соед.расстояние расстояние из городов from_city , соединения конн. , города to_city где conn.from_id = from_city.id и conn.to_id = to_city.id союз выберите from_city.name from_city , to_city.name to_city , соед.расстояние расстояние из городов from_city , соединения конн. , города to_city где conn.to_id = from_city.id и conn.from_id = to_city.id /
Простой запрос к этому представлению дает следующие результаты:
ОТ_ГОРОДА ДО_ГОРОДА РАССТОЯНИЕ --------------------------- ------------------ АМСТЕРДАМ РОТТЕРДАМ 22 АМСТЕРДАМ ГААГА 25 АМСТЕРДАМ УТРЕХТ 25 РОТТЕРДАМ АМСТЕРДАМ 22 РОТТЕРДАМ ГААГА 35 РОТТЕРДАМ УТРЕХТ 15 ГААГА АМСТЕРДАМ 25 ГААГА РОТТЕРДАМ 35 ГААГА УТРЕХТ 45 УТРЕХТ АМСТЕРДАМ 25 УТРЕХТ РОТТЕРДАМ 15 УТРЕХТ ГААГА 45
Сводной запрос, который нам нужен, следующий:
select * from table( pivot( 'select * from city_connections' ) ) /
и его результаты
Конечно, мы чувствуем необходимость еще раз доказать пудинг, добавив пятый город в стране — Ньювегейн (ну, это не совсем пятый город, но именно там мы (AMIS) расположены как компания:
вставить в города ( id, name) значения ( 5, 'NIEUWEGEIN') / вставить в соединения ( from_id , to_id , Distance ) значения ( 5, 2, 5) /
Обратите внимание только на одно соединение между Утрехтом и Ньювегейном.
На карте это выглядит так:Теперь наш сводной запрос плавно расширится, чтобы включить Ньювегейн?
Так и есть! (Конечно, я знал, что иначе я бы не стал поднимать эту тему).
Использование этой волшебной функции поворота
Возможно, вы поняли, как мы используем эту функцию поворота. На самом деле это довольно просто: мы передаем ему varchar2, который содержит запрос. Запрос должен запрашивать как минимум три столбца. Допускается больше. Столбцы могут иметь любой тип данных — NUMBER, VARCHAR2, DATE, INTERVAL, TIMESTAMP и т. д. Хотя не уверен насчет BLOB — вероятно, не очень хорошая идея.
Последний столбец в запросе, который вы вводите в сводную функцию, появляется в ячейках матрицы. В предпоследнем столбце представлены значения для столбцов в матрице. Остальные столбцы (все) используются как метки строк.
Итак, еще один пример: мы хотели бы видеть, какие роли имеют права на какие таблицы. В нашей схеме есть таблицы CAREER, CITIES, DEPT, EMP и POINTS.
Мы предоставили права доступа различным ролям, и мы хотели бы получить обзор. Мы знаем, что такая информация доступна в представлении словаря данных USER_TAB_PRIVS. В этом представлении есть полезные для нас столбцы GRANTEE и TABLE_NAME. Нам нужны роли в строках нашей матрицы и таблицы в столбцах. Таким образом, запрос, который мы предлагаем для поворота, должен выбрать три столбца, из которых роль — первый, имя_таблицы — второй, а третий должен быть тем, что мы хотим отобразить в ячейках:выбрать * из таблицы(свод( 'выбрать роль получателя , имя_таблицы , '' * '' от user_tab_privs ') ) /Примечание: в этом случае мы просто отмечаем ячейку, если роль имеет (любую) привилегию на таблицу. Мы могли бы улучшить это, чтобы показать всю палитру CRUD (для привилегий CREATE, RETRIEVE, UPDATE и DELETE).
Как это работает
Я действительно не мог вам сказать.
Ну, я могу рассказать вам некоторые из них. Но я тоже пытаюсь разобраться в этом.Функция pivot определяется следующим образом:
создать или заменить поворот функции ( p_stmt в varchar2 , p_fmt в varchar2 := 'верхний (@p@)' , фиктивное число := 0 ) вернуть любой набор данных, переданный с помощью PivotImpl; /
Суть поворота явно не в функции, а в типе PivotImpl, который она использует. Функция определена как конвейерная, выдающая записи одну за другой, а не целым набором, и возвращает AnyDataSet. Из-за этого возвращаемого типа мы можем рассматривать эту функцию как табличную функцию, которую мы можем использовать с оператором TABLE в предложении FROM: select * from TABLE(TABLE_FUN()).
Функция конвейерной таблицы реализована с помощью интерфейса, требует, чтобы пользователь предоставил тип, который реализует предопределенный интерфейс Oracle, состоящий из операций запуска, выборки и закрытия. Подробнее см.: Глава 13 – Конвейерные табличные функции в Oracle Data Cartridge Guide.
Интерфейсный подход требует, чтобы пользователь предоставил тип, который реализует предопределенный интерфейс Oracle, состоящий из операций запуска, выборки и закрытия. Тип связывается с табличной функцией при создании табличной функции. Во время выполнения запроса
метод fetchвызывается многократно для итеративного извлечения результатов. При интерфейсном подходе методы типа реализации, связанные с табличной функцией, могут быть реализованы на любом из поддерживаемых внутренних или внешних языков (включая PL/SQL, C/C++ и Java).Ресурсы
Загрузите исходники для этой статьи: AntonsPivoting.zip. Подключившись как SCOTT, сначала запустите pivotFun.sql, а затем либо pivot.sql, либо pivot_distances.sql.
Также ознакомьтесь с обсуждением этой статьи на AskTom (сентябрь 2012 г.): http://asktom.oracle.com/pls/apex/f?p=100:11:0::::P11_QUESTION_ID:4843682300346852395#5394721000346803830.
Руководство разработчика Oracle® Data Cartridge 10g Выпуск 1 (10.
 Они также доступны в базе данных Oracle, начиная с версии 11 g (документация).
Они также доступны в базе данных Oracle, начиная с версии 11 g (документация). Превращение набора значений в одном из столбцов в заголовки столбцов для всего запроса.
Превращение набора значений в одном из столбцов в заголовки столбцов для всего запроса. Однако, и это последний раз, когда я трублю в его трубу, это не мой кодекс. Я хорошо пишу многословные статьи, а Антон подделывает какой-то источник.
Однако, и это последний раз, когда я трублю в его трубу, это не мой кодекс. Я хорошо пишу многословные статьи, а Антон подделывает какой-то источник. Примечание: иногда новые значения столбца не так легко подбираются. В таких случаях нам приходится немного схитрить, побуждая CBO переоценить наш запрос (или, похоже, мы не совсем поняли, что это такое). Если мы добавим пробел где-нибудь в строке запроса или внесем другое изменение, будут выбраны новые значения столбца.
Примечание: иногда новые значения столбца не так легко подбираются. В таких случаях нам приходится немного схитрить, побуждая CBO переоценить наш запрос (или, похоже, мы не совсем поняли, что это такое). Если мы добавим пробел где-нибудь в строке запроса или внесем другое изменение, будут выбраны новые значения столбца. Мы создаем небольшую структуру базы данных для сведений о городе и связи:
Мы создаем небольшую структуру базы данных для сведений о городе и связи: На карте это выглядит так:
На карте это выглядит так: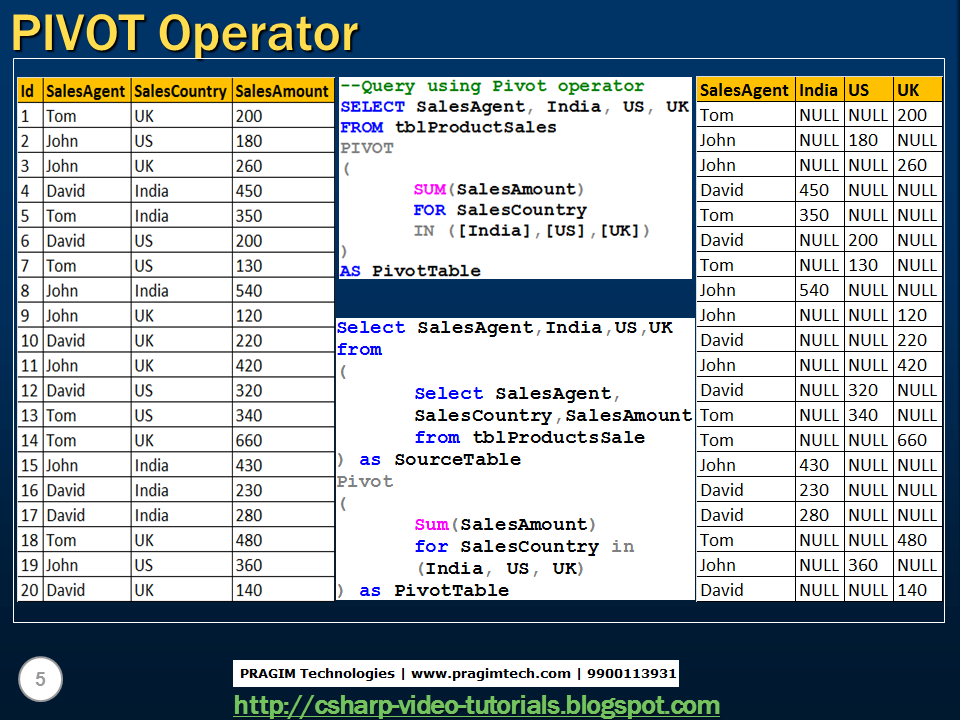 Мы предоставили права доступа различным ролям, и мы хотели бы получить обзор. Мы знаем, что такая информация доступна в представлении словаря данных USER_TAB_PRIVS. В этом представлении есть полезные для нас столбцы GRANTEE и TABLE_NAME. Нам нужны роли в строках нашей матрицы и таблицы в столбцах. Таким образом, запрос, который мы предлагаем для поворота, должен выбрать три столбца, из которых роль — первый, имя_таблицы — второй, а третий должен быть тем, что мы хотим отобразить в ячейках:
Мы предоставили права доступа различным ролям, и мы хотели бы получить обзор. Мы знаем, что такая информация доступна в представлении словаря данных USER_TAB_PRIVS. В этом представлении есть полезные для нас столбцы GRANTEE и TABLE_NAME. Нам нужны роли в строках нашей матрицы и таблицы в столбцах. Таким образом, запрос, который мы предлагаем для поворота, должен выбрать три столбца, из которых роль — первый, имя_таблицы — второй, а третий должен быть тем, что мы хотим отобразить в ячейках: Ну, я могу рассказать вам некоторые из них. Но я тоже пытаюсь разобраться в этом.
Ну, я могу рассказать вам некоторые из них. Но я тоже пытаюсь разобраться в этом.
