Pl pgsql учебник: PostgreSQL : Документация: 9.6: Глава 41. PL/pgSQL — процедурный язык SQL : Компания Postgres Professional
Содержание
PostgreSQL : Документация: 9.6: 41.2. Структура PL/pgSQL : Компания Postgres Professional
RU
EN
RU EN
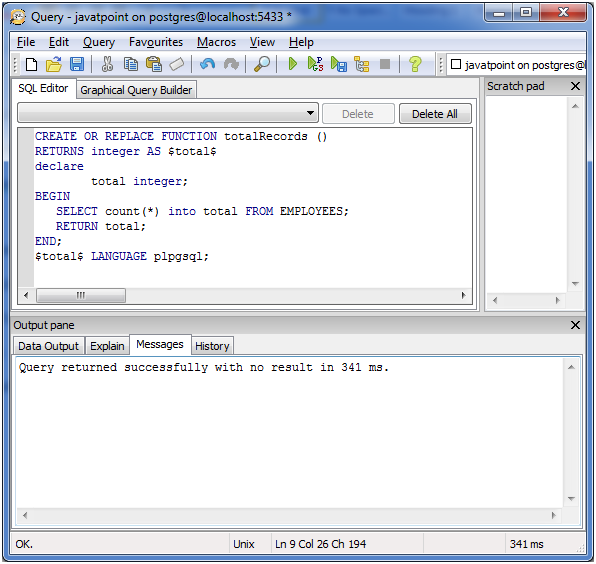
Функции, написанные на PL/pgSQL, определяются на сервере командами CREATE FUNCTION. Такая команда обычно выглядит, например, так:
CREATE FUNCTION somefunc(integer, text) RETURNS integer
AS 'тело функции'
LANGUAGE plpgsql; Если рассматривать CREATE FUNCTION, тело функции представляет собой просто текстовую строку. Часто для написания тела функции удобнее заключать эту строку в доллары (см. Подраздел 4.1.2.4), а не в обычные апострофы. Если не применять заключение в доллары, все апострофы или обратные косые черты в теле функции придётся экранировать, дублируя их. Почти во всех примерах в этой главе тело функций заключается в доллары.
PL/pgSQL это блочно-структурированный язык. Текст тела функции должен быть блоком. Структура блока:
[ <<метка>> ] [ DECLAREобъявления] BEGINоператорыEND [метка];
Каждое объявление и каждый оператор в блоке должны завершаться символом «;» (точка с запятой). Блок, вложенный в другой блок, должен иметь точку с запятой после
Блок, вложенный в другой блок, должен иметь точку с запятой после END, как показано выше. Однако финальный END, завершающий тело функции, не требует точки с запятой.
Подсказка
Распространённой ошибкой является добавление точки с запятой сразу после BEGIN. Это неправильно и приведёт к синтаксической ошибке.
Метка требуется только тогда, когда нужно идентифицировать блок в операторе EXIT, или дополнить имена переменных, объявленных в этом блоке. Если метка указана после END, то она должна совпадать с меткой в начале блока.
Ключевые слова не чувствительны к регистру символов. Как и в обычных SQL-командах, идентификаторы неявно преобразуются к нижнему регистру, если они не взяты в двойные кавычки.
Комментарии в PL/pgSQL коде работают так же, как и в обычном SQL. Двойное тире (--) начинает комментарий, который завершается в конце строки. Блочный комментарий начинается с /* и завершается */. Блочные комментарии могут быть вложенными.
Блочные комментарии могут быть вложенными.
Любой оператор в выполняемой секции блока может быть вложенным блоком. Вложенные блоки используются для логической группировки нескольких операторов или локализации области действия переменных для группы операторов. Во время выполнения вложенного блока переменные, объявленные в нём, скрывают переменные внешних блоков с такими же именами. Чтобы получить доступ к внешним переменным, нужно дополнить их имена меткой блока. Например:
CREATE FUNCTION somefunc() RETURNS integer AS $$
<< outerblock >>
DECLARE
quantity integer := 30;
BEGIN
RAISE NOTICE 'Сейчас quantity = %', quantity; -- Выводится 30
quantity := 50;
--
-- Вложенный блок
--
DECLARE
quantity integer := 80;
BEGIN
RAISE NOTICE 'Сейчас quantity = %', quantity; -- Выводится 80
RAISE NOTICE 'Во внешнем блоке quantity = %', outerblock.quantity; -- Выводится 50
END;
RAISE NOTICE 'Сейчас quantity = %', quantity; -- Выводится 50
RETURN quantity;
END;
$$ LANGUAGE plpgsql;Примечание
Существует скрытый «внешний блок», окружающий тело каждой функции на PL/pgSQL. Этот блок содержит объявления параметров функции (если они есть), а также некоторые специальные переменные, такие как
Этот блок содержит объявления параметров функции (если они есть), а также некоторые специальные переменные, такие как FOUND (см. Подраздел 41.5.5). Этот блок имеет метку, совпадающую с именем функции, таким образом, параметры и специальные переменные могут быть дополнены именем функции.
Важно не путать использование BEGIN/END для группировки операторов в PL/pgSQL с одноимёнными SQL-командами для управления транзакциями. BEGIN/END в PL/pgSQL служат только для группировки предложений; они не начинают и не заканчивают транзакции. Функции и триггерные процедуры всегда выполняются в рамках транзакции, начатой во внешнем запросе — они не могут начать или завершить эту транзакцию, так как у них внутри нет контекста для выполнения таких действий. Однако блок содержащий секцию EXCEPTION создаёт вложенную транзакцию, которая может быть отменена, не затрагивая внешней транзакции. Подробнее это описано в Подразделе 41. 6.6.
6.6.
8 книг по PostgreSQL для новичков и профессионалов
Тирекс
Самый зубастый автор
Подготовили подборку полезных книг для тех, кто только начал или собирается работать с PostgreSQL. Некоторые книги будут полезны и тем, кто уже знаком с этой СУБД, но желает углубить свои знания.
PostgreSQL — это объектно-реляционная система управления базами данных (СУБД), разработанная более 20 лет назад. Предназначена для создания и поддержки баз данных серверных приложений, в том числе ресурсоемких аналитических БД. Одной из особенностей этой СУБД является открытый исходный код, что обеспечило системе значительное развитие и большую популярность.
Мы подготовили подборку полезных книг для тех, кто только начал или собирается работать с PostgreSQL. Некоторые книги будут полезны и тем, кто уже знаком с этой СУБД, но желает углубить свои знания или научиться решать специальные задачи — например, разворачивать кластеры базы данных PostgreSQL в облаке. В подборку вошли актуальные руководства на русском и английском языках.
В подборку вошли актуальные руководства на русском и английском языках.
«Оптимизация запросов PostgreSQL»
Авторы: Г. Домбровская, Б. Новиков, А. Бейликова
Уровень: продолжающие
Цель пособия — научить администраторов баз данных, у которых нет достаточного опыта работы с PostgreSQL, решать распространенные проблемы с помощью этой СУБД.
В книге подробно описывается, что делать, когда не открывается страница приложения или система вылетает прямо перед совершением ключевых действий. Все представленные в книге сценарии протестированы авторами, которые долгое время работали с промышленными приложениями.
На примере работы с обширной базой данных виртуальной авиакомпании читатель научится:
- выполнять целевую оптимизацию в системах OLTP и OLAP,
- лучше понимать планы выполнения в системе PostgreSQL,
- выбирать индексы, улучшающие производительность запросов,
- оптимизировать процесс полного сканирования таблиц,
- выбирать наилучшую технику оптимизации для определенных запросов,
- безболезненно решать проблемы при работе с ORM-фреймворками.


Об авторах
→ Генриетта Домбровская — доктор физико-математических наук СПбГУ, специалист по науке о базах данных. В настоящее время заместитель директора по БД в Braviant Holdings (Чикаго, США). Это крупная компания, разрабатывающая системы машинного обучения. Домбровская также принимает активное участие в жизни сообщества Postgres и является одним из его лидеров.
→ Борис Новиков — профессор НИУ «Высшая школа экономики». Специализируется на системах управления информацией, потоковой обработки данных и аналитических приложениях. Имеет многолетний опыт работы с PostgreSQL.
→ Анна Бейликова — старший специалист по обработке данных в Zendesk. Это один из ведущих разработчиков программного обеспечения для крупного бизнеса. Также Бейликова является специалистом по работе с ETL-процессами (извлечение, преобразование и загрузка данных в корпоративных системах).
Где купить или скачать
Купить книгу можно на сайте издательства.
«Изучаем PostgreSQL 10»
Авторы: С. Джуба, А. Волков
Уровень: начинающие
Книга знакомит с основами PostgreSQL тех, кто в дальнейшем собирается работать с этой СУБД на профессиональном уровне. Как отмечают авторы, информации, содержащейся в руководстве, будет достаточно, чтобы ответить на все вопросы начинающего разработчика или администратора баз данных.
В книге подробно освещаются следующие темы:
- реляционные и объектно-реляционные БД с необходимыми алгебраическими операциями и моделированием данных,
- достоинства, архитектурные особенности и возможности PostgreSQL,
- основные блоки и функции Postgres, включая кодирование, иерархию объектов и компоненты баз данных (в качестве примера рассмотрена БД автомобильного сайта),
- дополнительные блоки и продвинутые функции Postgres: представления, выборки, извлечения, возвращение множеств, подзапросы, возможности группировки и агрегирования,
- основы серверного программирования на PL/pgSQL и динамическом SQL,
- технология обработки данных OLAP,
- транзакции, блокировки, основы безопасности, типы и структуры данных, каталоги,
- оптимизация производительности и тестирование,
- совместимость с серверными приложениями, написанными на Python, проблемы масштабируемости.

Об авторах
→ Джуба Салахалдин — сертифицированный разработчик ПО (сертификат MCSD), специалист по СУБД PostgreSQL, Greenplum и SQL Server, ETL-процессам обработки данных, разработке приложений OLAP и OLTP.
→ Андрей Волков — преподаватель SQL, специалист по системам финансовых и бухгалтерских данных и аналитики, основанных на Oracle. Работал финансовым аналитиком, архитектором хранилищ данных, занимался разработкой ETL-процессов. В настоящее время Волков занимает должность руководителя отдела разработки БД в телекоммуникационной компании.
Где купить или скачать
Файлы к книге можно скачать на сайте издательства. Там же есть информация по ее приобретению.
«Основы технологий баз данных: учебное пособие»
Автор: Б. Новиков, Е. Горшкова, Н. Графеева
Уровень: смешанный
Это объемное пособие было написано для студентов технических вузов, обучающихся программированию. Но оно будет так же полезно каждому практикующему разработчику и администратору баз данных PostgreSQL, желающему повысить свой профессиональный уровень или решить конкретную задачу.
Но оно будет так же полезно каждому практикующему разработчику и администратору баз данных PostgreSQL, желающему повысить свой профессиональный уровень или решить конкретную задачу.
Учебник разделен на две части. Первая предназначена для новичков в науке о базах данных. В этой части начинающие специалисты узнают об основах проектирования приложений, причем в качестве базовой СУБД для изучения используется PostgreSQL.
Вторая часть будет интересна тем, у кого уже есть опыт работы с СУБД. Разработчики и администраторы баз данных на Postgres познакомятся с возможностями языка SQL, выходящими за рамки базовых курсов, узнают о том, как создавать параллельные и распределенные системы БД на основе PostgreSQL. После каждой главы даются упражнения для закрепления материала.
Темы, которые будут интересны профессиональным разработчикам, включают:
- обеспечение согласованности работы СУБД и ее отказоустойчивости,
- возможности хранения коллекций и больших объектов,
- адаптивные методы оптимизации запросов, параметрическая, семантическая и многокритериальная оптимизация запросов,
- особенности управления транзакциями с описанием критериев корректности, диспетчеров и протоколов,
- вопросы обеспечения надежности БД, механизмы восстановления, описание разрушения носителя,
- дополнительные возможности, функции и процедуры PL/pgSQL и динамического SQL,
- механизмы расширения PostgreSQL, включая специальные модули, обертки и сторонние процедурные языки,
- модели, средства и обеспечение поддержки полнотекстового и нечеткого поиска,
- обеспечение безопасности данных, права и разграничение доступа, привилегии,
- администрирование, репликация БД, архитектура параллельных и распределенных БД, вопросы согласованности и выполнения запросов.

Об авторах
О Борисе Новикове мы уже рассказывали выше, поэтому несколько слов о соавторах.
→ Екатерина Горшкова — специалист по проектированию высоконагруженных приложений, анализу потоков данных, информационному поиску.
→ Наталья Графеева — занимается разработкой и проектированием крупных информационных систем, специалист в области систем БД, Big data и информационного поиска.
Где купить или скачать
Этот учебник бесплатный и доступен на официальном сайте Postgres Pro.
«PostgreSQL изнутри»
Автор: Е. Рогов
Уровень: продолжающие
Эта книга для «практикующих», то есть для администраторов баз данных и программистов, работающих с БД. Автор стремится избегать готовых рецептов (ведь на каждый случай их не напасешься), а старается дать читателю понимание механик работы PostgreSQL. Постигнув их, специалисты смогут самостоятельно находить решение в каждом конкретном случае.
Такой подход может замедлить решение конкретной задачи, однако принесет куда больше пользы в будущем. Рано или поздно перед программистом возникнут проблемы, решение которых уже не «нагуглишь».
В пяти частях книги подробно рассмотрены следующие темы:
- изоляция, работа с версиями, очистка внутри страниц и автоматическая очистка, перестроение структуры,
- буферный кеш Postgres, журнал и его режимы,
- различные виды блокировок (или замков) для решения проблемы одновременного обращения к файлам данных,
- запросы, статистика, различные методы доступа, сканирование, хеширование, сортировка, вложенные циклы,
- хеш-индексы для нахождения идентификаторов версий строк и виды хеш-индексов (GiST, SP-GiST, GIN, BRIN и другие).
Каждая глава богато иллюстрирована примерами кода, схемами и таблицами, так что даже у читателя, не знакомого с данной СУБД, но уже работавшего с другими, не должно возникнуть каких-либо проблем с усвоением материала.
Об авторе
Егор Рогов с 2015 года работает в Postgres Professional (компания-разработчик СУБД) и ведет там обучающие курсы для слушателей разного уровня. До этого работал руководителем проектов в нескольких компаниях, занимающихся разработкой приложений для баз данных.
Где купить или скачать
Скачать недавно вышедшую книгу можно прямо со страницы на официальном сайте компании, в которой работает автор.
Примените знания на практике в готовых кластерах баз данных.
«Postgres: первое знакомство»
Авторы: П. Лузанов, Е. Рогов, И. Лёвшин
Уровень: начинающие
Авторы скромно называют свою работу брошюрой, однако и ее объем, и содержание говорят о том, что это полноценный учебник по PostgreSQL для начинающих. При этом он всегда актуален, поскольку постоянно обновляется (с выходом каждой новой версии PostgreSQL).
Помимо общего описания СУБД, которое представлено в первой главе, читатель также узнает о следующем:
- новые возможности и «фишки» PostgreSQL 14, последней на данный момент версии программы,
- особенности установки СУБД в ОС Windows и Linux,
- подключение к серверу, написание SQL-запросов, использование транзакций,
- демобаза как возможность для углубления знаний SQL,
- использование Postgres в качестве БД для аналитических и веб-приложений,
- особенности серверных настроек при подключении 1C и других систем,
- pgAdmin — программа, которая может оказаться полезнее, чем многие думают,
- особенности формата JSON, возможность подключения доступа к внешним данным и включения полнотекстового поиска.

Также авторы дают подробную информацию о курсах по Postgres, рассказывают, как получить сертификат специалиста по этой СУБД и как не отставать от остальных в изучении предмета (список полезных книг и ресурсов прилагается).
Об авторах
→ Павел Лузанов — директор по образовательным программам компании Postgres Professional. Общее описание проводимых курсов можно найти в самой книге (раздел «Обучение и сертификация»), а вся актуальная информация здесь.
→ Игорь Лёвшин — программист, разработчик БД и автор блога. В нем он публикует ежемесячные отчеты с подробным описанием того, что случилось в мире Postgres, — от нюансов разработки до описания мероприятий в разных точках мира.
Где купить или скачать
Скачать книгу бесплатно можно здесь. А получить ее в бумажном варианте вы сможете, если примете участие в одном из мероприятий, организуемом разработчиками СУБД.
«PostgreSQL. Основы языка SQL»
Автор: Е. Моргунов
Моргунов
Уровень: начинающие
Пособие по изучению SQL с нуля, которое можно использовать для самостоятельного обучения. В первых трех главах автор в доступной форме рассказывает о базах данных, дает понимание реляционной модели. Затем идет описание языка SQL и подготовки к работе, после чего приводится подробное описание возможных операций с таблицами.
- В главе 4 изучаются типы данных в PostgreSQL (числовые, строковые, дата-временные, логические и другие).
- Глава 5 посвящена основам языка, в том числе описываются значения по умолчанию, механизмы работы с таблицами и модификация последних, схемы и представления.
- В главе 6 рассматриваются запросы и подзапросы, которые являются частями общих запросов.
- Седьмая глава рассказывает о различных способах изменения данных – вставке, обновлении и удалении строк в таблицах БД.
- Глава 8 — об индексах, частичных, уникальных и на основе выражений.
- Глава 9 рассказывает о важнейшем типе операций — транзакциях. Рассматриваются различные уровни изоляции, блокировки и даются примеры транзакций.
- Последняя глава посвящена описанию методов повышения производительности, что всегда актуально при работе с объемными базами данных. Вы узнаете о том, как управлять планировщиком, оптимизировать запросы, изучите методы формирования соединений и просмотра таблиц.
 Рассматриваются различные уровни изоляции, блокировки и даются примеры транзакций.
Рассматриваются различные уровни изоляции, блокировки и даются примеры транзакций.Каждая глава содержит немало полезных примеров, а в конце приводится список контрольных вопросов и заданий. Их рекомендуется выполнять для закрепления практических навыков, после чего можно переходить к экспериментам с тестовыми базами данных.
Об авторе
→ Евгений Моргунов — преподаватель СибГУ (Новосибирск), работал программистом еще с конца 1980-х годов, стоял у истоков разработки банковских приложений. При этом он является сторонником свободно распространяемого ПО — по крайней мере, в учебном процессе. Написал более 50 книг, имеет опыт работы с PostgreSQL более 17 лет.
Где купить или скачать
Еще одна бесплатная и при этом качественная работа, почитать или скачать которую можно все там же, на сайте Postgres Professional.
«Mastering PostgreSQL 13»/«PostgreSQL 13. Мастерство разработки»
Автор: Hans-Jürgen Schönig (Ханс-Юрген Шёниг)
Уровень: продолжающие
Эта книга написана специально для тех, кого не удовлетворяет базовая информация о PostgreSQL. Цель автора — углубить знания разработчиков и администраторов баз данных, подавая важные вещи в легкой для понимания форме.
- Глава 1 содержит обзор PostgreSQL и его функций. Также вы узнаете о новых вещах, доступных в PostgreSQL 13.
- В главе 2 — «Понимание транзакций и блокировок» — рассматривается один из наиболее важных аспектов любой системы баз данных. Правильная работа БД обычно невозможна без транзакций, и понимание транзакций и блокировок — ключ к обеспечению производительности системы.
- Глава 3 охватывает все, что нужно знать об индексах, которые очень важны для производительности базы данных. Если вы хотите получить хорошее взаимодействие базы данных с пользователем и высокую пропускную способность, уделите особое внимание этой главе.
- Глава 4 познакомит вас с некоторыми концепциями современного SQL. Вы узнаете об аналитических функциях и других важных элементах SQL.
- В главе 5 автор расскажет об управлении файлами журналов и особенностях мониторинга БД. Вы узнаете, как проверять свои серверы и извлекать информацию о времени выполнения процедуры в PostgreSQL.
- Глава 6 называется «Оптимизация запросов для повышения производительности». Здесь рассматривается настройка SQL, а также дается полезная информация об управлении памятью.
- В главе 7 представлены дополнительные темы, связанные с кодом на стороне сервера. Рассматриваются популярные серверные языки программирования и даются советы по совместимости с приложениями на этих языках.
- Информация в главе 8 поможет улучшить безопасность вашего сервера. Здесь представлено все необходимое для этого: от управления правами пользователей до шифрования данных.
- Глава 9 посвящена резервному копированию и восстановлению данных. Вы научитесь создавать резервные копии своих файлов, что позволит восстановить данные в случае отказа системы.
- Глава 10 «Понимание резервного копирования и репликации» посвящена проблеме избыточности. Вы научитесь асинхронной и синхронной репликации системы баз данных PostgreSQL. Все современные функции объясняются максимально доступно.
- Глава 11 описывает модули, которые расширяют функциональные возможности PostgreSQL. Вы узнаете о наиболее распространенных расширениях.
- В главе 12 автор предлагает системный подход к устранению проблем в PostgreSQL. Это позволит оперативно выявлять распространенные проблемы и подходить к ним во всеоружии.
- Последняя глава этой книги рассказывает о том, как безболезненно перейти с других БД на PostgreSQL. Здесь рассматриваются такие популярные базы данных, как MySQL, Oracle, MariaDB, SQLite, Db2 LUW и Microsoft SQL Server.


Об авторе
→ Ханс-Юрген Шёниг — генеральный директор компании Cybertec Schönig & Schönig GmbH, занимающейся поддержкой PostgreSQL и консалтинговыми услугами. До основания собственной фирмы в 2000 году он был разработчиком базы данных в частной компании, занимавшейся исследованием австрийского рынка труда. Там он выполнял интеллектуальный анализ данных и выстраивал модели прогнозирования. Ханс-Юрген также является автором еще нескольких книг по СУБД.
Там он выполнял интеллектуальный анализ данных и выстраивал модели прогнозирования. Ханс-Юрген также является автором еще нескольких книг по СУБД.
Где купить или скачать
Купить книгу в любом виде (бумажном, электронном) можно здесь. На данный момент заказать оригинальную бумажную версию из-за рубежа проблематично, однако эту же книгу, но по PostgreSQL 11, можно приобрести на сайте российского издательства. Она немного устарела, однако весь основной материал по-прежнему актуален и книга переведена на русский язык.
«Beginning PostgreSQL on the Cloud»/«Запуск PostgreSQL в облаке»
Авторы: Baji Shaik, Avinash Vallarapu (Баджи Шайк, Авинаш Валларапу)
Уровень: продолжающие
Прошли те времена, когда администраторам приходилось использовать собственные дата-центры для создания инфраструктуры БД. Теперь мы можем спокойно разворачивать базы данных PostgreSQL на облачных серверах, избегая проблем, связанных с управлением инфраструктурой, и лишних затрат. И авторы этой книги справедливо решили, что пришло время написать книгу, которая поможет специалистам, работающим с PostgreSQL, понять преимущества и ограничения известных облачных сервисов.
И авторы этой книги справедливо решили, что пришло время написать книгу, которая поможет специалистам, работающим с PostgreSQL, понять преимущества и ограничения известных облачных сервисов.
В книге содержится подробная информация об основных компаниях, предоставляющих услуги по развертыванию базы данных PostgreSQL в облаке. Книга начинается с введения в DBaaS и IaaS и краткого описания факторов, которые необходимо учитывать при развертывании баз данных.
Авторы подробно останавливаются на проблемах, с которыми вы можете столкнуться при развертывании баз данных в облаке. Рассматриваются конкретные шаги и процедуры, связанные с миграцией из локальной среды в облачную. Также в одной из глав подробно описывается архитектура PostgreSQL, что должно помочь понять большинство параметров для лучшей настройки вашей среды PostgreSQL.
Книга посвящена зарубежным провайдерам, однако эти знания будут полезны и в работе с готовыми кластерами баз данных в России.
Главное внимание уделяется помощи начинающим пользователям PostgreSQL в развертывании корпоративной базы данных.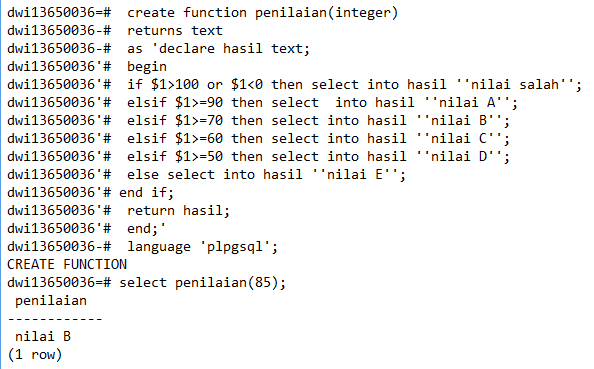 В книге рассматриваются основные аспекты этого процесса, такие как безопасность и уязвимости, шифрование, репликация, мониторинг и ряд других. Все эти темы обсуждаются с учетом особенностей каждого поставщика услуг облачных серверов.
В книге рассматриваются основные аспекты этого процесса, такие как безопасность и уязвимости, шифрование, репликация, мониторинг и ряд других. Все эти темы обсуждаются с учетом особенностей каждого поставщика услуг облачных серверов.
Об авторах
→ Баджи Шайк — администратор и разработчик баз данных, работает старшим консультантом по базам данных в OpenSCG (Хайдарабад, Индия). Он познакомился с СУБД в 2011 году и более 10 лет плотно работал с Oracle, PostgreSQL и Greenplum. Обладает обширными знаниями и опытом работы с базами данных SQL/NoSQL и за сравнительно короткий срок успел разработать множество оригинальных решений для баз данных, отвечающих жестким требованиям бизнеса. Баджи регулярно организует встречи представителей сообщества PostgreSQL и ведет собственный блог на Blogspot, где совершенно бескорыстно делится своими знаниями с сообществом. Он также является соавтором еще одной книги по данной СУБД, PostgreSQL Development Essentials.
→ Авинаш Валларапу работает архитектором баз данных в одной из материнских компаний PostgreSQL — OpenSCG. Он имеет 15-летний опыт работы с различными системами управления баз данных, такими как Oracle, PostgreSQL, MySQL, MariaDB и MongoDB, и является активным разработчиком приложений на Python. Он также является разработчиком инструмента pgPulse, который включает такие функции, как AWR и моментальные снимки в PostgreSQL 9 и выше. Авинаш выступал на ряде конференций и встреч по PostgreSQL, где делился опытом миграции с Oracle на PostgreSQL и развертывания PostgreSQL в облаке. Кроме того, он является экспертом по базам данных, активно участвует в различных соревнованиях и уже выиграл несколько хакатонов. Интерес Авинаша к упрощению сложных задач с помощью автоматизации делает его уникальным специалистом в сообществе.
Он имеет 15-летний опыт работы с различными системами управления баз данных, такими как Oracle, PostgreSQL, MySQL, MariaDB и MongoDB, и является активным разработчиком приложений на Python. Он также является разработчиком инструмента pgPulse, который включает такие функции, как AWR и моментальные снимки в PostgreSQL 9 и выше. Авинаш выступал на ряде конференций и встреч по PostgreSQL, где делился опытом миграции с Oracle на PostgreSQL и развертывания PostgreSQL в облаке. Кроме того, он является экспертом по базам данных, активно участвует в различных соревнованиях и уже выиграл несколько хакатонов. Интерес Авинаша к упрощению сложных задач с помощью автоматизации делает его уникальным специалистом в сообществе.
Где купить или скачать
Купить книгу в бумажном варианте проблематично из-за существующих ограничений, однако вы можете скачать электронную версию, предлагаемую на некоторых сайтах.
Автор: Роман Андреев
PostgreSQLБазы данных
Структура блока PL/pgSQL
Резюме : в этом руководстве вы узнаете о блочной структуре PL/pgSQL и о том, как написать и выполнить свой первый блок PL/pgSQL.
PL/pgSQL — это язык с блочной структурой, поэтому функции или хранимые процедуры PL/pgSQL организованы в блоки.
Ниже показан синтаксис полного блока в PL/pgSQL:
[ <
Рассмотрим структуру блока более подробно:
- Каждый блок состоит из двух разделов: объявления и тела. Раздел объявления необязателен, а раздел тела обязателен. Блок заканчивается точкой с запятой (
;) после ключевого словаEND. - Блок может иметь необязательную метку, расположенную в начале и в конце. Вы используете метку блока, когда хотите указать ее в
EXITоператора тела блока или когда вы хотите уточнить имена переменных, объявленных в блоке. - В разделе объявления вы объявляете все переменные, используемые в разделе тела. Каждый оператор в разделе объявлений завершается точкой с запятой (
;). - В разделе body вы размещаете код. Каждый оператор в разделе body также завершается точкой с запятой (;).

Пример блочной структуры PL/pgSQL
Следующий пример иллюстрирует очень простой блок. Это называется анонимным блоком.
сделать $$ <<первый_блок>> объявить целое число film_count := 0; начинать -- получить количество фильмов выберите количество (*) в число_фильмов из пленки; -- показать сообщение поднять уведомление 'Количество фильмов %', film_count; конец первого_блока $$; Язык кода: диалект PostgreSQL SQL и PL/pgSQL (pgsql)
ВНИМАНИЕ: Текущее значение счетчика равно 1 Язык кода: HTTP (http)
Чтобы выполнить блок из pgAdmin, нажмите кнопку «Выполнить», как показано на следующем рисунке:
Обратите внимание, что оператор DO не относится к блоку. Он используется для выполнения анонимного блока. PostgreSQL представил оператор DO , начиная с версии 9. 0.
0.
Анонимный блок должен быть заключен в одинарные кавычки, например:
'<> объявить целое число film_count := 0; начинать -- получить количество фильмов выберите количество (*) в число_фильмов из пленки; -- показать сообщение поднять уведомление ''Количество фильмов %'', film_count; конец первого_блока'; Язык кода: диалект PostgreSQL SQL и PL/pgSQL (pgsql)
Однако мы использовали синтаксис строковых констант в долларовых кавычках, чтобы сделать его более читабельным.
В разделе объявления мы объявили переменную film_count и установили ее значение равным нулю.
film_count целое число := 0; Язык кода: диалект PostgreSQL SQL и PL/pgSQL (pgsql)
Внутри раздела body мы использовали оператор select into с count() , чтобы получить количество фильмов из таблицы film и присвоить результат переменной film_count .
выберите количество (*) в число_фильмов из пленки; Язык кода: диалект PostgreSQL SQL и PL/pgSQL (pgsql)
После этого мы показали сообщение, используя уведомление о повышении :
уведомление о повышении 'Количество фильмов составляет %', film_count; Язык кода: диалект PostgreSQL SQL и PL/pgSQL (pgsql)
% — это заполнитель, который заменяется содержимым переменной film_count .
Обратите внимание, что метка first_block предназначена только для демонстрационных целей. В этом примере он ничего не делает.
Подблоки PL/pgSQL
PL/pgSQL позволяет размещать блок внутри тела другого блока.
Блок, вложенный в другой блок, называется подблоком. Блок, содержащий подблок, называется внешним блоком.
Следующий рисунок иллюстрирует внешний блок и подблок:
Как правило, вы делите большой блок на более мелкие и более логичные подблоки. Переменные в подблоке могут иметь те же имена, что и во внешнем блоке, хотя это и не рекомендуется.
Переменные в подблоке могут иметь те же имена, что и во внешнем блоке, хотя это и не рекомендуется.
Резюме
- PL/pgSQL — это язык с блочной структурой. Он организует программу в блоки.
- Блок состоит из двух частей: объявления и тела. Часть объявления необязательна, а часть тела обязательна.
- Блоки могут быть вложенными. Вложенный блок — это блок, помещенный внутрь тела другого блока.
Было ли это руководство полезным?
Пользовательские функции PostgreSQL — SQLServerCentral
Обзор
В этом руководстве мы узнаем о пользовательских функциях PostgreSQL. Затронутые темы будут такими: что такое функция, определяемая пользователем? Как создавать и использовать пользовательские функции с помощью запросов и графического интерфейса PgAdmin, их преимущества и некоторые примеры.
Что такое определяемая пользователем функция?
Пользовательская функция PostgreSQL — это группа произвольных операторов SQL, предназначенных для выполнения какой-либо задачи. Эти функции не являются стандартными и обычно создаются для обработки конкретных сценариев. Внутри функции можно выполнять операции выбора, вставки, обновления, удаления. Функцию PostgreSQL можно создать на любом языке, таком как SQL, C, PL/pgSQL, Python и т. д. не возможно.
Эти функции не являются стандартными и обычно создаются для обработки конкретных сценариев. Внутри функции можно выполнять операции выбора, вставки, обновления, удаления. Функцию PostgreSQL можно создать на любом языке, таком как SQL, C, PL/pgSQL, Python и т. д. не возможно.
Как создать пользовательскую функцию?
Функцию можно создать двумя способами: либо с помощью кода PostgreSQL, либо с помощью графического интерфейса PgAdmin. Давайте рассмотрим оба варианта.
Базовый синтаксис
В этом синтаксисе имя_функции вместе с количеством аргументов или списком параметров указывается после предложения CREATE OR REPLACE. Затем return_datatype объявляется после ключевого слова RETURN. return_datatype , по-видимому, является типом данных, возвращаемых функцией. Это может быть один из типов данных PostgreSQL, таких как символ, целое число, двойное число и т. д. Также возможно вернуть таблицу из функции PostgreSQL.
В этом синтаксисе имя_функции вместе с количеством аргументов или списком параметров указывается после предложения CREATE OR REPLACE.%E3%81%A7SQL%E3%81%AE%E7%B5%90%E6%9E%9C%E4%BB%B6%E6%95%B0%E3%82%92%E5%8F%96%E5%BE%97%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95-01.jpg) Затем return_datatype объявляется после ключевого слова RETURN. return_datatype , по-видимому, является типом данных, возвращаемых функцией. Это может быть один из типов данных PostgreSQL, таких как символ, целое число, двойное число и т. д. Также возможно вернуть таблицу из функции PostgreSQL.
Затем return_datatype объявляется после ключевого слова RETURN. return_datatype , по-видимому, является типом данных, возвращаемых функцией. Это может быть один из типов данных PostgreSQL, таких как символ, целое число, двойное число и т. д. Также возможно вернуть таблицу из функции PostgreSQL.
Далее после ключевого слова DECLARE объявляются переменные IN, OUT, используемые в функции. Затем в блоке BEGIN-END определяется function_body . function_body , по-видимому, содержит бизнес-логику функции. Далее после ключевого слова RETURN указывается имя_переменной , которое содержит возвращаемое значение из функции.
Наконец, после ключевого слова LANGUAGE указывается язык ( имя_языка ), на котором создана функция.
СОЗДАТЬ [ИЛИ ЗАМЕНИТЬ] ФУНКЦИЮ имя_функции (аргументы)
ВОЗВРАЩАЕТ return_datatype AS $variable_name$
ЗАЯВИТЬ
декларация;
[...]
НАЧИНАТЬ
<тело_функции>
[.. логика]
ВОЗВРАТ {имя_переменной | ценить }
КОНЕЦ;
LANGUAGE имя_языка; Запросы можно выполнять либо в оболочке PostgreSQL (PSQL), либо в инструменте запросов PgAdmin.
Пример
Здесь мы создаем функцию, которая возвращает текущую дату и время с сервера.
СОЗДАТЬ ФУНКЦИЮ getTimestamp() ВОЗВРАЩАЕТ временную метку КАК $$ НАЧИНАТЬ ВОЗВРАТ CURRENT_TIMESTAMP; КОНЕЦ; $$ ЯЗЫК PLPGSQL;
Список всех функций в схеме базы данных:
df.*
Давайте выполним вышеуказанную функцию:
PgAdmin GUI 9014 1
Создадим такую же функцию в программе PgAdmin .
Шаг 1-> Перейдите к серверам->База данных->Схема->Функция->Создать->Функция, как показано ниже:
Шаг 2 -> Укажите имя, владельца, схему, комментарий любой.
Шаг 3-> Укажите аргументы функции, тип возвращаемого значения и язык, как описано в предыдущем разделе.
Шаг 4 -> Укажите бизнес-логику на вкладке «Код»
Шаг 5 -> Затем укажите параметры на вкладке «Параметры» и сохраните для создания функции.
Примеры определяемых пользователем функций
Давайте теперь рассмотрим некоторые примеры функций, чтобы лучше понять концепцию.
Примечание : Для выполнения запросов можно использовать инструмент запросов PgAdmins или терминал Psql. В этом руководстве мы использовали инструмент запросов PgAdmin для этой цели. Оба этих редактора входят в состав последних версий PgAdmin.
Пример 1: Добавить 2 числа
Здесь была создана одна функция с именем addNumbers. Эта функция принимает 2 целочисленных параметра на вход и возвращает одно целое число на выходе.
СОЗДАТЬ ФУНКЦИЮ addNumbers(val1 integer, val2 integer) ВОЗВРАЩАЕТ целое число AS $$ НАЧИНАТЬ ВОЗВРАТ ЗНАЧ1 + ЗНАЧ2; КОНЕЦ; $$ ЯЗЫК PLPGSQL;
Вот функция, созданная в PgAdmin:
Функция отображается слева в разделе «Функции».
Давайте теперь выполним функцию, как показано ниже:
Пример 2: В этом примере мы увидим, как выполнить операцию условного выбора внутри функции
Эта функция используется для выполнения операции выбора на таблица под названием «Акции». Функция возвращает все те акции, цена которых меньше входного параметра ‘price_cap’. Переменная, объявленная в разделе declare, содержит выходное значение.
Функция возвращает все те акции, цена которых меньше входного параметра ‘price_cap’. Переменная, объявленная в разделе declare, содержит выходное значение.
создать функцию get_stocks(price_cap int) возвращает целое язык plpgsql как $$ объявить stock_count целое число; начинать выберите количество (*) в stock_count из публичного."Акции" где stock_price < price_cap; вернуть количество запасов; конец; $$;
Давайте создадим это в PgAdmin.
Давайте посмотрим на данные таблицы:
Теперь выполним функцию, чтобы проверить ее поведение: функция извлекла то же самое.
Пример 3: Возвращает таблицу.
Функция также может использоваться для возврата таблицы, если это необходимо. Мы будем использовать следующую таблицу, чтобы продемонстрировать эту функциональность.
Следующая функция возвращает все акции, цена которых меньше входной цены. Результат будет в виде таблицы.
СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ФУНКЦИЮ get_allStocks (price_cap int)
ТАБЛИЦА ВОЗВРАТА (
stock_serial_no целое число,
стоковый варчар,
price_of_stock
)
КАК $$
НАЧИНАТЬ
ВОЗВРАТ ЗАПРОСА ВЫБЕРИТЕ
stock_id,
имя_инвентаря,
цена_акции
ОТ
публичный.