PostgreSQL. Postgresql php авторизация
Оптимизация Apache + PHP + PostgreSQL
После ввода в строй динамического веб-сервера на базе apach + php + postgresql (да и на базе других систем тоже, если честно), вебмастер часто обнаруживает, что производительность системы начинает с большей или меньшей активностью стремиться к нулю, порой его достигая при наплывах посетителей. Стандартными действиями вебмастера при этом являются лихорадочное чтение документации, поиск в Интернете всяческих полезных советов, общение в форумах и прочие телодвижения, типичные для "компьютерного аврала". При этом очень часто находятся какие-то обрывки информации, ответы из серии "у меня заработало, почему у тебя не работает не знаю", противоречивые советы и ссылки на мегабайтные исходники, разбор которых грозит затянуться на несколько лет...
Поэтому ниже предпринята попытка в компактном виде изложить те вещи, которые наиболее значительно влияют на производительность сервера. Нельзя сказать, что этот список является полным и законченным, но он может послужить неплохой пищей для размышлений. А если у вас есть какие-то свои наработки и "идеи по поводу" - пишите автору, он постарается учесть их в следующей редакции этой статьи...
Настройка php
Настройка php, по большому счету, сводится к включению persistent connections и, соответственно, использованию pg_pconnect() вместо pg_connect() в скриптах. Для этого в файле php.ini надо указать pgsql.allow_persistent = on В некоторых форумах встречалась рекомендация установить еще и pgsql.auto_reset_persistent = on для определения "битых" соединений, но то ли "битые соединения" встречаются очень редко, то ли они проявляются как-то незаметно... Словом, этого можно и не делать. Ограничений по количеству соединений в php можно не устанавливать, оставивpgsql.max_persistent = -1pgsql.max_links = -1
Эффект от перехода на постоянные соединения очень заметен, особенно на посещаемых сайтах. Загрузка сразу падает процентов на двадцать-тридцать, а то и больше! Только не пугайтесь обнаруживая в top'е кучу postres'ов в состоянии sbwait...
Настройка postgresql
Настройка postgresql осуществляется с помощью редактирования файла postgresql.conf и последующего перезапуска постмастера. Несмотря на то, что некоторые параметры можно менять "на лету", практика показала, что полный перезапуск позволяет намного точнее и быстрее отследить влияние тех или иных изменений конфигурации на поведение системы в целом, так что имеет смысл использовать именно этот метод.
Настройка shared_buffers в postgres'е очень важна. Чем больше памяти ему выделено, тем больше данных он сможет использовать не обращаясь к диску. Но если памяти выделить слишком много, то другим процессам ее может не хватить и они будут использовать файл подкачки. Поэтому с настройкой этого параметра придется поэкспериментировать - помимо всего прочего, очень многое зависит от конкретики вашего сайта, в частности от того, насколько часто запрашиваются одни и те же данные. В качестве стартовой точки можно попробовать выделить postgres'у 40% памяти, если он работает на одной машине с веб-сервером, и 70%, если это выделенный сервер баз данных. Только не забудьте, что до того, как указывать количество памяти в файле postgresql.conf, вам надо настроить операционную систему, чтобы она разрешила эту память забрать, иначе postgresql просто не запустится, написав в лог, что не удалось получить требуемую память. О том как настроить выделение необходимой памяти в разных ОС подробно написано в документации postgresql. Эта память выделяется один раз при старте сервера.
Следующий полезный параметр - sort_mem. Эта память используется для сортировки полученных наборов данных, и большое ее количество полезно, если ваши запросы часто используют select ... order by... Но с этим параметром надо быть очень осторожным - мало того, что указанное вами количество памяти выделяется каждому процессу, так оно еще и может выделяться несколько раз для сложных запросов! Так что с этим параметром тоже стоит "поиграть" - попробуйте изменять его значения в диапазоне, скажем, от 1 Мб до 128 Кб. Причем иногда результаты бывают парадоксальными - уменьшение памяти ведет к повышению производительности, по всей видимости, из-за создания множества маленьких временных файлов, которые операционная система успешно кеширует в свободной памяти.
Если задачи, выполняющиеся на сервере не являются критичными и возможная потеря нескольких записей при аварии вас не пугает, то стоит также отменить принудительную запись на диск результатов каждой транзакции. Делается это указанием fsync = false. При этом результаты ваших изменений будут хранится в памяти и записываться на диск целыми блоками, что позволит достаточно заметно увеличить производительность. Но, как было отмечено выше, если вдруг сервер "упадет", то результаты нескольких последних обновлений могут быть утеряны.
Очень сильно влияет на скорость работы грамотное индексирование таблиц. Про индексы можно писать (и уже написано) много, но основной принцип - индексировать надо те поля, которые используется для выборки данных (проверяются в where). Составные индексы (в которых используется несколько полей) работают, если отбор происходит с условием and, если используется or, то надо создавать несколько отдельных индексов.
Однако для маленьких таблиц (скажем, до 500 строк) перебор почти всегда оказывается быстрее, чем использование индексов. Тут можно применить маленькую хитрость: в postgresql.conf указать enable_seqscan = false (это запретит перебор для тех таблиц, у которых есть индексы) и удалить все индексы в маленьких таблицах (индексы, автоматически создаваемые для первичных ключей, можно удалить, используя drop constraint).
Неплохой выигрыш в производительности может дать и оптимизация самих sql запросов, особенно тех, которые используются чаще всего. Для того, чтобы их вычислить можно в скриптах перенумеровать все запросы и перед каждым вызовом pg_query() записывать в лог (или в таблицу) номер запроса. А потом просто проанализировать лог... Для того, чтобы посмотреть как будет выполняться запрос можно (нужно!) использовать команду explain. Учтите, что в некоторых случаях даже простое изменение порядка следования условий выборки в секции where может изменить план выполнения запроса!
В некоторых случаях может помочь и использование представлений (views). Дело в том, что при выдаче "обычного" sql запроса сервер его анализирует, создает план выполнения и потом выполняет. А если используется представление, то анализ и составление плана производится только при его создании. Если запросы выполняются часто, то сэкономленное время работы процессора может оказаться весьма заметным. Не говоря уже о том, что запросы в скриптах станут намного короче и нагляднее...
Практически во всех руководствах (и в документации postgresql) можно встретить рекомендации регулярно запускать vacuum analyze, для сжатия таблиц. Рекомендация правильная и полезная, но недостаточная. Практика показала, что без более-менее регулярных запусков vacuum full analyze производительность системы постепенно падает, причем чем дальше, тем больше. Разница между vacuum и vacuum full заключается в том, что full физически переписывает на диске всю таблицу таким образом, чтобы в ней не оставалось "дырок" от удаленных или обновленных записей. Но его недостаток в том, что во время работы таблица полностью блокируется, что может привести к проблемам на популярном сервере - начнет скапливаться очередь запросов, ожидающих доступа к базе, каждый запрос требует памяти, память кончается, начинается запись в swap, из-за отсутствия памяти сам vacuum тоже начинает использовать swap и все начинает работать очень-очень медленно.
Тут можно использовать следующий трюк - во время работы vacuum'а перенаправлять посетителей на страничку с пояснениями, что идет профилактика и сервер восстановит свою работу через несколько минут. При использовании веб-сервера apache это легко делается с помощью mod_rewrite: ваш оптимизирующий скрипт при запуске создает, а при окончании работы удаляет файл /home/site/optimizer.pid, а в apache включается mod_rewrite и указываетсяrewritecond /home/site/optimizer.pid -frewriterule .* /optimization_message.html
Для того чтобы уменьшить время, в течение которого посетители не могут добраться до вашего сайта, можно перенаправлять посетителей только в то время, когда оптимизируются большие и частоиспользуемые таблицы, а остальные "чистить" паралльно с работой сайта. Если данные в базе обновляются очень часто, то можно, скажем, каждый час запускать vacuum analyze, а раз в сутки - vacuum full analyze. Как правило, "время недоступности" сервера при таком подходе можно сократить до одной-двух минут даже на очень больших сайтах.
Кроме того, надо учесть, что vacuum не оптимизирует индексы, поэтому после отработки vacuum full analyze стоит запускать еще и reindex.
Разумеется, очень большое влияние на производительность оказывает и структура вашей базы данных, но эта область очень сильно зависит от конкретной задачи и в этой статье затрагиваться не будет.
Настройка apache
Конфигурационный файл apache, как правило, находится в /usr/local/apache/conf/httpd.conf, а заставить сервер его перечитать можно с помощью проргаммы /usr/local/apache/bin/apachectl.
Основной целью дальнейших рекомендаций является определение и ограничение количества "апачей", выполняющихся в каждый момент времени (предполагается, что сам сервер у вас уже настроен и работоспособен). Дело в том, что (условно) на каждого посетителя сайта "тратится" процесс apache, и каждый такой процесс расходует память и процессорное время. Поэтому если у вас будет слишком много запущенных серверов, то оперативной памяти не хватит, а использование swap'а сильно замедляет работу сайта. С другой стороны, если запущенных серверов мало, то при заходе пользователя будет тратиться время на создание нового процесса, что опять же приводит к задержкам и расходу процессорного времени.
Из вышесказанного ясно, что с одной стороны желательно всегда иметь некоторый запас запущенных серверов для обслуживания посетителей, а с другой - надо убивать лишние сервера, чтобы не занимать слишком уж много памяти. Понятно, что конкретные цифры зависят от посещаемости вашего сайта и доступных ресурсов, поэтому приводимые ниже цифры стоит использовать только как основу, корректируя их по необходимости.
Максимальное количество "апачей", которые могут быть запущены одновременно определяется параметром maxclients. Это число должно чуть-чуть превышать максимальное количество посетителей, которые могут в какой-то момент времени оказаться у вас на сайте. В то же время, если желающих к вам попасть много, а ресурсов сервера для их обслуживания не хватает, то излишне высокое число запущенных серверов только затормозит всю работу. Поэтому желательно установить какое-то разумное ограничение, скажем 150 или 200.
Время, в течение которого сервер ждет откликов от клиента определяется параметром timeout. Обрывы связи иногда случаются и если браузер посетителя обратился к вашему серверу, не получил ответа и послал повторный запрос (скажем, пользователь нажал reload), то у вас запустятся два "апача", причем один из них будет просто висеть и в течение указанного времени ждать, когда посетитель подтвердит свое желание посмотреть страничку. По умолчанию этот параметр установлен в 300 секунд, но значительно более эффективным оказалось понизить его до 30.
Включение поддержки keepalive может заметно облегчить жизнь. Дело в том, что в "обычном" режиме для передачи каждого файла клиенту требуется установить соединение, и если у вас на страничке, например, есть 10 картинок, то придется устанавливать и разрывать 10 соединений для их передачи. А в режиме keepalive сервер после передачи файла соединение не разрывает и последующие запросы от этого клиента обрабатывает, используя уже установленное соединение. Таким образом экономится время на установку и разрыв соединений, причем для популярных сайтов эта разница может быть очень заметна!
Для keepalive соединений, точно также как и для обычных, надо установить timeout с помощью параметра keepalivetimeout. Так как сервер, установивший соединение с клиентом, недоступен для других клиентов пока соединение не будет разорвано, слишком большое значение может привести к куче серверов, ничего не делающих и просто ждущих не захочет ли их клиент скачать еще что-нибудь. Причем в это же время толпа новых посетителей может обнаружить, что ваш сайт не отвечает, так как достигнуто максимальное число разрешенных "апачей"... Наиболее практичным значением параметра keepalivetimeout является что-то между десятью и двадцатью секундами.
Как известно, долгое использование какой-то программы может привести к "утечкам памяти" или каких-то других ресурсов. Чтобы избежать таких проблем есть два параметра: maxkeepaliverequests и maxrequestsperchild. Первый параметр отвечает за принудительное "убиение" процесса после обработки указанного числа keepalive запросов, а второй - после указанного числа "обычных" запросов. В принципе, на абсолютном большинстве систем утечек памяти быть не должно и эти параметры можно сделать достаточно большими - по несколько тысяч. Но на всякий случай последите за поведением сервера - не исключено, что "утечки" обнаружатся в какой-то из библиотек, которые вы используете. Удобнее всего двигаться "снизу вверх" - сначала установить значения небольшими, скажем, 100 и 50, а потом их увеличивать, наблюдая за поведением сервера.
Ну и еще три параметра, регулирующие количество запущенных процессов: startservers, minspareservers и maxspareservers. Первый, при старте сервера запускает указанное число "апачей". Второй определяет минимальное число бездельничающих в ожидании нового клиента серверов, а третий - их максимальное число. В качестве первого шага можно поробовать, скажем, 25, 2 и 10, а дальше посмотреть на загруженность сайта...
Проверка результатов
Наиболее простым методом быстро оценить влияние сделанных вами изменений в настройках является команда top. В верхней части окна при ее работе выводится полезная статистическая информация, примерно такая:
last pid: 40772; load averages: 0.52, 0.50, 0.50 up 23+17:53:40 09:51:01233 processes: 1 running, 231 sleeping, 1 zombiecpu states: 21.2% user, 0.0% nice, 6.4% system, 0.4% interrupt, 72.0% idlemem: 367m active, 239m inact, 123m wired, 48m cache, 112m buf, 107m freeswap: 1024m total, 13m used, 1011m free, 1% inuseВ первую очередь, надо обращать внимание на load averages - чем выше числа, тем хуже. В идеале, в нормальном состоянии они не должны превышать единицы. Следующее, к чему стоит присмотреться - это использование файла подкачки. Справа от строки swap могут появляться сообщения о записи в swap-файл (page out) или о чтении из него (page in). Чем чаще такие сообщения появляются - тем хуже. Дисковые операции уж очень медленные... Ну и, конечно, надо следить за количеством свободной памяти и загрузкой процессора. Впрочем, если вы сумеете добиться ситуации, когда swap-файл не будет использоваться, то, скорее всего, все остальное быстро придет в норму...
Статьи по теме
-
Описание: Определяет правила для механизма преобразований Синтаксис: RewriteRule ШаблонПодстановка Значение по умолчанию: None К...
2012-10-29
-
1. Почему русский Apache. Сегодня в русском Internet существует проблема различных кодировок. Не все пользователи могут воспользоваться, напри...
2011-02-10
-
Установка языка серверных сценариев PHP. PHP представляет собой язык программирования, используемый на стороне web-сервера для динамическ...
2011-02-10
-
По материалам статей: Stricty (http://www.opennet.ru/base/sec/ssl_freebsd.txt.html) Alexch (http://www.opennet.ru/base/net/apache_mod_ssl.txt.html) Недавно на OpenNET были опубликованы две статьи...
2011-02-10
-
Каждому из нас хочется побыть "большим братом" и последить за своими посетителями. Это можно делать по-разному: поставить счетчик, наприм...
2011-02-10
-
Несмотря, на то, что данные в публикуемой статье немного устарели, мы нашли полезным разместить ее на нашем сайте. Статья представляет об...
2011-02-08
-
Разработка сайтов в связке Apache + PHP + XML + MySQL требует от себя установки вышеперечисленного софта. Но не всегда для этого надо ставить Linux. Де...
2011-02-08
-
Все чаще обнаруживается, что некоторые начинающие сайтостроители, увлеченные скриптованием (на perl/cgi, php и т.д.) не знают, что такое chmod и ка...
2011-02-08
-
Русский Apache Самый распространенный Web-сервер в мире - это Apache. По данным компании Netcraft (http://www.netcraft.com/Survey/) общее число Web-узлов, работающих...
2011-02-08
-
Где найти и скачать Perl В настоящее время варианты PERL (так называемые "порты" (ports) ) существуют для многих разных машин и операционных сис...
2011-02-08
-
Здесь описывается установка Perl 5.6.1.635 - учитывайте, что установка более новых версий может несколько отличаться от описываемой. Вам нео...
2011-02-04
-
Директивы Apache для контроля доступа Контроль по IPЕсли вам нужно просто разрешить или блокировать доступ к какой-либо части сайта или вс...
2011-02-04
-
Обзор В ходе данной инструкции мы подробно рассмотрим установку веб сервера Apache, PHP, Tomcat (для поддержки JSP) и их привязку для совместной ...
2011-02-04
-
Поставим PHP 5.1.2. Где его достать? Здрасте, естественно на PHP.net. Выбираем самое близкое к себе зеркало и качаем себе ZIP. Пока качает сделаем ...
2011-02-04
-
Как правило, для того, чтобы установить и настроить сервер Apache, а также подключить к работе PHP, базы данных MySQL и Perl, необходимо, во-первых ...
2011-02-04
lred.ru
PostgreSQL : Документация: 9.6: 20.3. Методы аутентификации : Компания Postgres Professional
20.3. Методы аутентификации
Следующие подразделы содержат более детальную информацию о методах аутентификации.
20.3.1. Аутентификация trust
Когда указан способ аутентификации trust, PostgreSQL предполагает, что любой подключающийся к серверу авторизован для доступа к базе данных вне зависимости от указанного имени пользователя базы данных (даже если это имя суперпользователя). Конечно, ограничения, прописанные в столбцах база и пользователь, продолжают работать. Этот метод должен применяться только в том случае, когда на уровне операционной системы обеспечена адекватная защита от подключений к серверу.
Аутентификация trust очень удобна для локальных подключений на однопользовательской рабочей станции. Но сам по себе этот метод обычно не подходит для машин с несколькими пользователями. Однако вы можете использовать trust даже на многопользовательской машине, если ограничите доступ к файлу Unix-сокета сервера на уровне файловой системы. Для этого установите конфигурационные параметры unix_socket_permissions (и, возможно, unix_socket_group) как описано в Разделе 19.3. Либо вы можете установить конфигурационный параметр unix_socket_directories, чтобы разместить файл сокета в должным образом защищённом каталоге.
Установка разрешений на уровне файловой системы помогает только в случае подключений через Unix-сокеты. На локальные подключения по TCP/IP ограничения файловой системы не влияют. Поэтому, если вы хотите использовать разрешения файловой системы для обеспечения локальной безопасности, уберите строку host ... 127.0.0.1 ... из pg_hba.conf или смените метод аутентификации.
Метод аутентификации trust для подключений по TCP/IP допустим только в случае, если вы доверяете каждому пользователю компьютера, получившему разрешение на подключение к серверу строками файла pg_hba.conf, указывающими метод trust. Не стоит использовать trust для любых подключений по TCP/IP, отличных от localhost (127.0.0.1).
20.3.2. Аутентификация password
Методы аутентификации с помощью пароля — md5 и password. Эти методы действуют похожим образом; отличие состоит только в том, как передаётся пароль по каналу связи, а именно: в виде хеша MD5, или открытым текстом, соответственно.
Если вас беспокоит возможность перехвата трафика, предпочтительнее использовать метод md5. Простого метода password следует избегать всегда, если возможно. Однако, md5 не может быть использован с параметром db_user_namespace. Если подключение зашифровано по SSL, тогда password тоже может быть использован без опасений (хотя аутентификация через SSL сертификат будет наилучшим выбором для тех, кто зависит от использования SSL).
База данных паролей PostgreSQL отделена от паролей пользователей операционной системы. Пароль для каждого пользователя базы данных хранится в системном каталоге pg_authid. Работать с паролями можно через команды SQL CREATE USER и ALTER ROLE, например, CREATE USER foo WITH PASSWORD 'secret'. Если для пользователя не было установлено пароля, пароль сохраняется как null, и аутентификация через пароль для данного пользователя будет невозможна.
20.3.3. Аутентификация GSSAPI
GSSAPI является протоколом отраслевого стандарта для безопасной авторизации, определённым в RFC 2743. PostgreSQL поддерживает GSSAPI с Kerberos аутентификацией с соответствии с RFC 1964. GSSAPI обеспечивает автоматическую аутентификацию (single sign-on), для систем, которые её поддерживают. Сама по себе аутентификация безопасна, но данные, отсылаемые в ходе подключения к базе данных, не защищены, если не используется SSL.
Поддержка GSSAPI должна быть включена при сборке PostgreSQL; за дополнительными сведениями обратитесь к Главе 16.
При работе с Kerberos GSSAPI использует стандартные учётные записи в формате servicename/hostname@realm. Сервер PostgreSQL примет любого принципала, включённого в используемый сервером файл таблицы ключей, но необходимо проявить осторожность в указании корректных деталей принципала в ходе соединения с клиентом, применяющим параметр подключения krbsrvname. (См. также Подраздел 32.1.2.) Значение имени сервиса по умолчанию postgres может быть изменено во время сборки с помощью ./configure --with-krb-srvnam=whatever. В большинстве сред изменять данный параметр не требуется. Однако некоторые реализации Kerberos могут потребовать иного имени сервиса, например, Microsoft Active Directory требует, чтобы имя сервиса было набрано заглавными буквами (POSTGRES).
hostname здесь — это полное доменное имя компьютера, где работает сервер. Областью субъекта-службы является предпочитаемая область данного компьютера.
Принципалы клиентов могут быть сопоставлены с различными именами пользователей баз данных PostgreSQL в pg_ident.conf. Например, принципалу pgusername@realm может быть сопоставлено просто pgusername. Так же возможно использовать в качестве имени роли в PostgreSQL полное имя принципала username@realm без какого-либо сопоставления.
PostgreSQL также поддерживает возможность убирать область из имени принципала. Эта возможность оставлена для обратной совместимости и использовать её крайне нежелательно, так как при этом оказывается невозможно различить разных пользователей, имеющих одинаковые имена, но приходящих из разных областей. Чтобы включить её, установите для include_realm значение 0. В простых конфигурациях с одной областью исключение области в сочетании с параметром krb_realm (который позволяет ограничить область пользователя одним значением, заданным в krb_realm parameter) будет безопасным, но менее гибким вариантом по сравнению с явным описанием сопоставлений в pg_ident.conf.
Убедитесь, что файл ключей вашего сервера доступен для чтения (и желательно недоступен для записи) учётной записи сервера PostgreSQL. (См. также Раздел 18.1.) Расположение этого файла ключей указывается параметром krb_server_keyfile. По умолчанию это /usr/local/pgsql/etc/krb5.keytab (каталог может быть другим, в зависимости от значения sysconfdir при сборке). Из соображений безопасности рекомендуется использовать отдельный файл keytab для сервера PostgreSQL, а не открывать доступ к общесистемному файлу.
Файл таблицы ключей генерируется программным обеспечением Kerberos; подробнее это описано в документации Kerberos. Следующий пример для MIT-совместимых реализаций Kerberos 5:
kadmin% ank -randkey postgres/server.my.domain.org kadmin% ktadd -k krb5.keytab postgres/server.my.domain.orgПри подключении к базе данных убедитесь, что у вас есть разрешение на сопоставление принципала с именем пользователя базы данных. Например, для имени пользователя базы данных fred, принципал fred@EXAMPLE.COM сможет подключиться. Чтобы дать разрешение на подключение принципалу fred/users.example.com@EXAMPLE.COM, используйте файл сопоставления имён пользователей, как описано в Разделе 20.2.
Для метода GSSAPI доступны следующие параметры конфигурации:
include_realmКогда этот параметр равен 0, из принципала аутентифицированного пользователя убирается область, и оставшееся имя проходит сопоставление имён (см. Раздел 20.2). Этот вариант не рекомендуется и поддерживается в основном для обратной совместимости, так как он небезопасен в окружениях с несколькими областями, если только дополнительно не задаётся krb_realm. Более предпочтительный вариант — оставить значение include_realm по умолчанию (1) и задать в pg_ident.conf явное сопоставление для преобразования имён принципалов в имена пользователей PostgreSQL.
mapРазрешает сопоставление имён пользователей системы и пользователей баз данных. За подробностями обратитесь к Разделу 20.2. Для принципала GSSAPI/Kerberos, такого как username@EXAMPLE.COM (или более редкого username/hostbased@EXAMPLE.COM), именем пользователя в сопоставлении будет username@EXAMPLE.COM (или username/hostbased@EXAMPLE.COM, соответственно), если include_realm не равно 0; в противном случае именем системного пользователя в сопоставлении будет username (или username/hostbased).
krb_realmУстанавливает область, с которой будут сверяться имена принципалов пользователей. Если этот параметр задан, подключаться смогут только пользователи из этой области. Если не задан, подключаться смогут пользователи из любой области, в зависимости от установленного сопоставления имён пользователей.
20.3.4. Аутентификация SSPI
SSPI — технология Windows для защищённой аутентификации с единственным входом. PostgreSQL использует SSPI в режиме negotiate, который применяет Kerberos, когда это возможно, и автоматически возвращается к NTLM в других случаях. Аутентификация SSPI работает только, когда и сервер, и клиент работают на платформе Windows, или, на не-Windows платформах, если доступен GSSAPI.
Если используется аутентификация Kerberos, SSPI работает так же, как GSSAPI; подробнее об этом рассказывается в Подразделе 20.3.3.
Для SSPI доступны следующие параметры конфигурации:
include_realmКогда этот параметр равен 0, из принципала аутентифицированного пользователя убирается область, и оставшееся имя проходит сопоставление имён (см. Раздел 20.2). Этот вариант не рекомендуется и поддерживается в основном для обратной совместимости, так как он небезопасен в окружениях с несколькими областями, если только дополнительно не задаётся krb_realm. Более предпочтительный вариант — оставить значение include_realm по умолчанию (1) и задать в pg_ident.conf явное сопоставление для преобразования имён принципалов в имена пользователей PostgreSQL.
compat_realmЕсли равен 1, для параметра include_realm применяется имя домена, совместимое с SAM (также известное как имя NetBIOS). Это вариант по умолчанию. Если он равен 0, для имени принципала Kerberos применяется действительное имя области.
Этот параметр можно отключить, только если ваш сервер работает под именем доменного пользователя (в том числе, виртуального пользователя службы на компьютере, включённом в домен) и все клиенты, проходящие проверку подлинности через SSPI, также используют доменные учётные записи; в противном случае аутентификация не будет выполнена.
upn_usernameЕсли этот параметр включён вместе с compat_realm, для аутентификации применяется имя Kerberos UPN. Если он отключён (по умолчанию), применяется SAM-совместимое имя пользователя. По умолчанию у новых учётных записей эти два имени совпадают.
Заметьте, что libpq использует имя, совместимое с SAM, если имя не задано явно. Если вы применяете libpq или драйвер на его базе, этот параметр следует оставить отключённым, либо явно задавать имя пользователя в строке подключения.
mapПозволяет сопоставить пользователей системы с пользователями баз данных. За подробностями обратитесь к Разделу 20.2. Для принципала SSPI/Kerberos, такого как username@EXAMPLE.COM (или более редкого username/hostbased@EXAMPLE.COM), именем пользователя в сопоставлении будет username@EXAMPLE.COM (или username/hostbased@EXAMPLE.COM, соответственно), если include_realm не равно 0; в противном случае именем системного пользователя в сопоставлении будет username (или username/hostbased).
krb_realmУстанавливает область, с которой будут сверяться имена принципалов пользователей. Если этот параметр задан, подключаться смогут только пользователи из этой области. Если не задан, подключаться смогут пользователи из любой области, в зависимости от установленного сопоставления имён пользователей.
20.3.5. Аутентификация Ident
Метод аутентификации ident работает, получая имя пользователя операционной системы клиента от сервера Ident и используя его в качестве разрешённого имени пользователя базы данных (с возможным сопоставлением имён пользователя). Способ доступен только для подключений по TCP/IP.
Примечание
Когда для локального подключения (не TCP/IP) указан ident, вместо него используется метод аутентификации peer (см. Подраздел 20.3.6).
Для метода ident доступны следующие параметры конфигурации:
mapПозволяет сопоставить имена пользователей системы и базы данных. За подробностями обратитесь к Разделу 20.2.
Протокол «Identification» (Ident) описан в RFC 1413. Практически каждая Unix-подобная операционная система поставляется с сервером Ident, по умолчанию слушающим TCP-порт 113. Базовая функция этого сервера — отвечать на вопросы, вроде «Какой пользователь инициировал подключение, которое идет через твой порт X и подключается к моему порту Y?». Поскольку после установления физического подключения PostgreSQL знает и X, и Y, он может опрашивать сервер Ident на компьютере клиента и теоретически может определять пользователя операционной системы при каждом подключении.
Недостатком этой процедуры является то, что она зависит от интеграции с клиентом: если клиентская машина не вызывает доверия или скомпрометирована, злоумышленник может запустить любую программу на порту 113 и вернуть любое имя пользователя на свой выбор. Поэтому этот метод аутентификации подходит только для закрытых сетей, где каждая клиентская машина находится под жёстким контролем и где администраторы операционных систем и баз данных работают в тесном контакте. Другими словами, вы должны доверять машине, на которой работает сервер Ident. Помните предупреждение:
Протокол Ident не предназначен для использования как протокол авторизации и контроля доступа. | ||
| --RFC 1413 | ||
У некоторых серверов Ident есть нестандартная возможность, позволяющая зашифровать возвращаемое имя пользователя, используя ключ, который известен только администратору исходного компьютера. Эту возможность нельзя использовать с PostgreSQL, поскольку PostgreSQL не сможет расшифровать возвращаемую строку и получить фактическое имя пользователя.
20.3.6. Аутентификация peer
Метод аутентификации peer работает, получая имя пользователя операционной системы клиента из ядра и используя его в качестве разрешённого имени пользователя базы данных (с возможностью сопоставления имён пользователя). Этот метод поддерживается только для локальных подключений.
Для метода peer доступны следующие параметры конфигурации:
mapПозволяет сопоставить имена пользователей системы и базы данных. За подробностями обратитесь к Разделу 20.2.
Аутентификация peer доступна только на операционных системах, поддерживающих функцию getpeereid(), параметр сокета SO_PEERCRED или сходные механизмы. В настоящее время это Linux, большая часть разновидностей BSD, включая OS X, и Solaris.
20.3.7. Аутентификация LDAP
Данный метод аутентификации работает сходным с методом password образом, за исключением того, что он использует LDAP как метод подтверждения пароля. LDAP используется только для подтверждения пары "имя пользователя/пароль". Поэтому пользователь должен уже существовать в базе данных до того, как для аутентификации будет использован LDAP.
Аутентификация LDAP может работать в двух режимах. Первый режим называется простое связывание. В ходе аутентификации сервер связывается с характерным именем, составленным следующим образом: prefix username suffix. Обычно, параметр prefix используется для указания cn= или DOMAIN\ в среде Active Directory. suffix используется для указания оставшейся части DN или в среде, отличной от Active Directory.
Во втором режиме, который мы называем поиск+связывание, сервер сначала связывается с каталогом LDAP с предопределённым именем пользователя и паролем, указанным в ldapbinddn и ldapbindpasswd, и выполняет поиск пользователя, пытающегося подключиться к базе данных. Если имя пользователя и пароль не определены, сервер пытается связаться с каталогом анонимно. Поиск выполняется в поддереве ldapbasedn, при этом проверятся точное соответствие имени пользователя атрибуту ldapsearchattribute. Как только при поиске находится пользователь, сервер отключается и заново связывается с каталогом уже как этот пользователь, с паролем, переданным клиентом, чтобы удостовериться, что учётная запись корректна. Этот же режим используется в схемах LDAP-аутентификации в другом программном обеспечении, например, в pam_ldap и mod_authnz_ldap в Apache. Данный вариант даёт больше гибкости в выборе расположения объектов пользователей, но при этом требует дважды подключаться к серверу LDAP.
Следующие параметры конфигурации доступны при аутентификации в обоих режимах:
ldapserverИмена и IP-адреса LDAP-серверов для связи. Можно указать несколько серверов, разделяя их пробелами.
ldapportНомер порта для связи с LDAP-сервером. Если порт не указан, используется установленный по умолчанию порт библиотеки LDAP.
ldaptlsРавен 1 для установки соединения между PostgreSQL и LDAP-сервером с использованием TLS-шифрования. Имейте в виду, что так шифруется только обмен данными с LDAP-сервером, а клиентское подключение остаётся незашифрованным, если только не применяется SSL.
Следующие параметры конфигурации доступны только при аутентификации в режиме простого связывания:
ldapprefixЭта строка подставляется перед именем пользователя во время формирования DN для связывания при аутентификации в режиме простого связывания.
ldapsuffixЭта строка размещается после имени пользователя во время формирования DN для связывания, при аутентификации в режиме простого связывания.
Следующие параметры конфигурации доступны только при аутентификации поиск+связывание:
ldapbasednКорневая папка DN для начала поиска пользователя при аутентификации в режиме поиск+связывание.
ldapbinddnDN пользователя для связи с каталогом при выполнении поиска в ходе аутентификации в режиме поиск+связывание.
ldapbindpasswdПароль пользователя для связывания с каталогом при выполнении поиска в ходе аутентификации в режиме поиск+связывание.
ldapsearchattributeАтрибут для соотнесения с именем пользователя в ходе аутентификации поиск+связывание. Если атрибут не указан, будет использован атрибут uid.
ldapurlАдрес RFC 4516 LDAP. Это альтернативный путь для написания некоторых функций LDAP в более компактной и стандартной форме. Формат записи таков:
ldap://host[:port]/basedn[?[attribute][?[scope]]]scope должен быть представлен или base, или one, или sub, обычно последним. Используется один атрибут, некоторые компоненты стандартных LDAP-адресов, такие, как фильтры и расширения, не поддерживаются.
Для неанонимного связывания ldapbinddn и ldapbindpasswd должны быть указаны как раздельные параметры.
Для применения зашифрованных LDAP-подключений, в дополнение к параметру ldapurl необходимо использовать параметр ldaptls. URL-схема ldaps (прямое SSL-подключение) не поддерживается.
В настоящее время URL-адреса LDAP поддерживаются только с OpenLDAP, не в Windows.
Нельзя путать параметры конфигурации для режима простого связывания с параметрами для режима поиск+связывание, это ошибка.
Это пример конфигурации LDAP для простого связывания:
host ... ldap ldapserver=ldap.example.net ldapprefix="cn=" ldapsuffix=", dc=example, dc=net"Когда запрашивается подключение к серверу базы данных в качестве пользователя базы данных someuser, PostgreSQL пытается связ
postgrespro.ru
PostgreSQL | Руководство по PHP
Примечания
Замечание:
Не все функции могут поддерживаться в собранном модуле. Это зависит от версии вашей libpq (клиентская библиотека PostgreSQL) и как libpq была собрана. Если расширение PostgreSQL для PHP отсутствует, то это значит, что версия вашей libpq не поддерживается.
Замечание:
Большинство функций PostgreSQL принимают connection в качестве первого необязательного параметра. Если параметр отсутствует, то используется последнее открытое соединение. Если же такого не существует, то функция возвращает FALSE.
Замечание:
PostgreSQL автоматически переводит все идентификаторы (такие, как имена таблиц/столбцов) в нижний регистр во время создания объекта и выполнения запроса. Для того, чтобы заставить использовать идентификаторы в обоих или только в верхнем регистрах, вы должны экранировать идентификатор с помощью двойные кавычки ("").
Замечание:
В PostgreSQL нет специальных команд для получения информации о схеме БД (к примеру, всех таблиц выбранной базы данных). Но вместо этого в версиях PostgreSQL 7.4 и выше существует стандартная схема, которая называется information_schema. Она содержит системные представления (view) со всей необходимой информацией в легкодоступной форме. Для дополнительной информации см. » документацию PostgreSQL
Содержание
- pg_affected_rows — Возвращает количество затронутых запросом записей (кортежей)
- pg_cancel_query — Остановка асинхронного запроса.
- pg_client_encoding — Получение кодировки клиента.
- pg_close — Закрывает соединение с базой данных PostgreSQL
- pg_connect_poll — Poll the status of an in-progress asynchronous PostgreSQL connection attempt.
- pg_connect — Открывает соединение с базой данных PostgreSQL
- pg_connection_busy — Проверяет, занято ли соединение в данный момент.
- pg_connection_reset — Сброс подключение (переподключение)
- pg_connection_status — Определяет состояние подключения
- pg_consume_input — Reads input on the connection
- pg_convert — Преобразует значения ассоциативного массива в приемлемые для использования в SQL запросах
- pg_copy_from — Вставляет записи из массива в таблицу
- pg_copy_to — Копирует данные из таблицы в массив
- pg_dbname — Определяет имя базы данных
- pg_delete — Удаляет записи
- pg_end_copy — Синхронизирует с бэкендом PostgreSQL
- pg_escape_bytea — Экранирует спецсимволы в строке для вставки в поле типа bytea
- pg_escape_identifier — Escape a identifier for insertion into a text field
- pg_escape_literal — Escape a literal for insertion into a text field
- pg_escape_string — Экранирование спецсимволов в строке запроса
- pg_execute — Запускает выполнение ранее подготовленного параметризованного запроса и ждет результат
- pg_fetch_all_columns — Выбирает все записи из одной колонки результата запроса и помещает их в массив
- pg_fetch_all — Выбирает все данные из результата запроса и помещает их в массив
- pg_fetch_array — Возвращает строку результата в виде массива
- pg_fetch_assoc — Выбирает строку результата запроса и помещает данные в ассоциативный массив
- pg_fetch_object — Выбирает строку результата запроса и возвращает данные в виде объекта
- pg_fetch_result — Возвращает запись из результата запроса
- pg_fetch_row — Выбирает строку результата запроса и помещает данные в массив
- pg_field_is_null — Проверка поля на значение SQL NULL
- pg_field_name — Возвращает наименование поля
- pg_field_num — Возвращает порядковый номер именованного поля
- pg_field_prtlen — Возвращает количество печатаемых символов
- pg_field_size — Возвращает размер поля
- pg_field_table — Возвращает наименование или идентификатор таблицы, содержащей заданное поле
- pg_field_type_oid — Возвращает идентификатор типа заданного поля
- pg_field_type — Возвращает имя типа заданного поля
- pg_flush — Flush outbound query data on the connection
- pg_free_result — Очистка результата запроса и освобождение памяти
- pg_get_notify — Получение SQL NOTIFY сообщения
- pg_get_pid — Получает ID процесса сервера БД
- pg_get_result — Получение результата асинхронного запроса
- pg_host — Возвращает имя хоста, соответствующего подключению
- pg_insert — Заносит данные из массива в таблицу базы данных
- pg_last_error — Получает сообщение о последней произошедшей ошибке на соединении с базой данных
- pg_last_notice — Возвращает последнее уведомление от сервера PostgreSQL
- pg_last_oid — Возвращает OID последней добавленной в базу строки
- pg_lo_close — Закрывает большой объект
- pg_lo_create — Создает большой объект
- pg_lo_export — Вывод большого объекта в файл
- pg_lo_import — Импорт большого объекта из файла
- pg_lo_open — Открывает большой объект базы данных
- pg_lo_read_all — Читает содержимое большого объекта и посылает напрямую в броузер
- pg_lo_read — Читает данные большого объекта
- pg_lo_seek — Перемещает внутренний указатель большого объекта
- pg_lo_tell — Возвращает текущее положение внутреннего указателя большого объекта
- pg_lo_truncate — Truncates a large object
- pg_lo_unlink — Удаление большого объекта
- pg_lo_write — Записывает данные в большой объект
- pg_meta_data — Получение метаданных таблицы
- pg_num_fields — Возвращает количество полей в выборке
- pg_num_rows — Возвращает количество строк в выборке
- pg_options — Получение параметров соединения с сервером баз данных
- pg_parameter_status — Просмотр текущих значений параметров сервера
- pg_pconnect — Открывает постоянное соединение с сервером PostgreSQL
- pg_ping — Проверка соединения с базой данных
- pg_port — Возвращает номер порта, соответствующий заданному соединению
- pg_prepare — Посылает запрос на создание параметризованного SQL выражения и ждет его завершения
- pg_put_line — Передает на PostgreSQL сервер строку с завершающим нулем
- pg_query_params — Посылает параметризованный запрос на сервер, параметры передаются отдельно от текста SQL запроса
- pg_query — Выполняет запрос
- pg_result_error_field — Возвращает конкретное поле из отчета об ошибках
- pg_result_error — Возвращает сообщение об ошибке, связанной с запросом результата
- pg_result_seek — Смещает указатель на строку выборки в ресурсе результата запроса
- pg_result_status — Возвращает состояние результата запроса
- pg_select — Выбирает записи из базы данных
- pg_send_execute — Запускает предварительно подготовленный SQL запрос и передает ему параметры; не ожидает возвращаемого результата
- pg_send_prepare — Посылает запрос на создание параметризованного SQL выражения; не ожидает его завершения
- pg_send_query_params — Посылает параметризованный запрос на сервер, не ожидает возвращаемого результата
- pg_send_query — Отправляет асинхронный запрос
- pg_set_client_encoding — Устанавливает клиентскую кодировку
- pg_set_error_verbosity — Определяет объем текста сообщений, возвращаемых функциями pg_last_error и pg_result_error
- pg_socket — Get a read only handle to the socket underlying a PostgreSQL connection
- pg_trace — Включает трассировку подключения PostgreSQL
- pg_transaction_status — Возвращает текущее состояние транзакции на сервере
- pg_tty — Возвращает имя терминала TTY, связанное с соединением
- pg_unescape_bytea — Убирает экранирование двоичных данных типа bytea
- pg_untrace — Отключает трассировку соединения с PostgreSQL
- pg_update — Обновление данных в таблице
- pg_version — Возвращает массив, содержащий версии клиента, протокола клиент-серверного взаимодействия и сервера (если доступно)
Вернуться к: PostgreSQL
php.ru
- Устройства для сопряжения компьютера со средой передачи информации
- Интернет скорость проверить мтс

- Windows 10 руководство пользователя на русском
- Почему не запускается программа на компьютере

- Телеграмм установка на телефон

- Не открывается мой компьютер windows 10
- Для чего нужна термопаста в компьютере

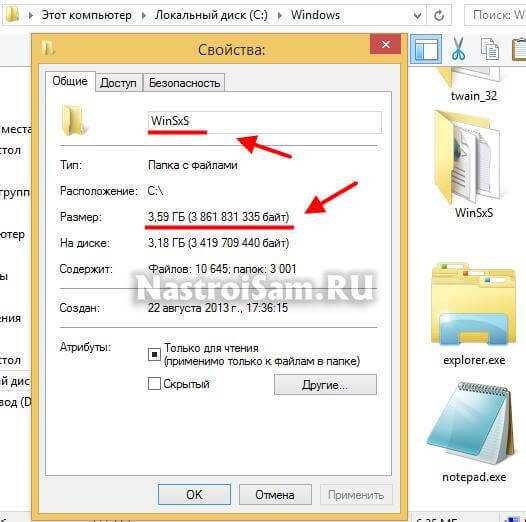
- Чистка папки winsxs в windows 7
- Debian для новичков
- Веб камеры нет в диспетчере устройств

- Как открыть гугл диск на компьютер
