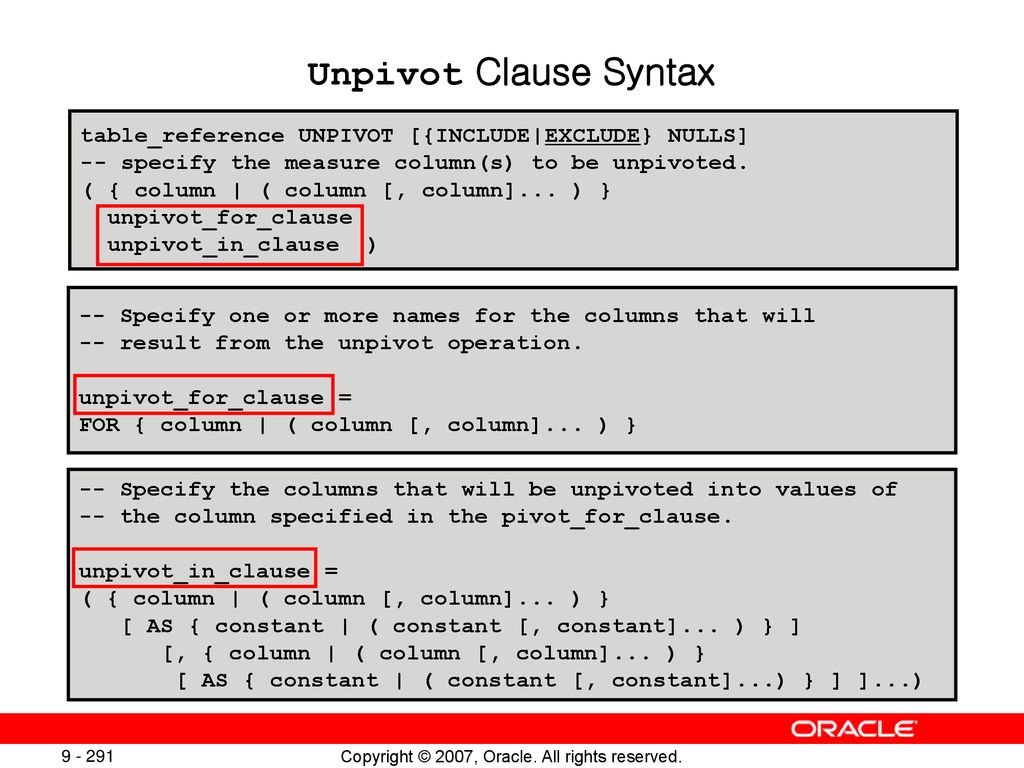
Пример unpivot sql: UNPIVOT | SQL | SQL-tutorial.ru
Содержание
Аналитические функции SQL в хранилищах данных
Главная / Курсы / Oracle / Разработка Oracle Database / Oracle Database 12c: Аналитические функции SQL в хранилищах данных
Oracle Database 12c: Analytic SQL for Data Warehousing
Курс научит вас как интерпретировать концепцию иерархических запросов, созданию иерархически-структурированных отчетов, форматированию иерархических данных и исключению отдельных частей из структуры иерархии. Вы также научитесь использовать регулярные выражения и подвыражения для поиска, сопоставления и замены строк.
Целевая аудитория
- Разработчики приложений
- Аналитики хранилищ данных
- Разработчики хранилищ данных
- Администраторы баз данных
- Проектировщики баз данных
- Инженеры поддержки
Приобретаемые знания и навыки
По окончании курса слушатели изучат:
- Использование SQL с операторами агрегации, SQL с аналитическими функциями и построения отчетов.

- Группировка и агрегация данных посредством операторов ROLLUP и CUBE, функции GROUPING, составных столбцов и комбинированных группировок.
- Анализ данных и построение отчётов с применением функций ранжирования, функций LAG/LEAD и предложений PIVOT и UNPIVOT.
- Выполнения расширенного сопоставления по шаблонам.
- Использование регулярные выражения для поиска, сопоставления и замены строк.

Программа курса
Модуль 1: Введение
- Тематика курса, расписание курса и учётные записи курса
- Описание схем и дополнений, используемых в курсе
- Обзор среды SQL*Plus
- Обзор SQL Developer
- Обзор аналитического SQL
- Документация по Oracle Database SQL и хранилищам данных
Модуль 2: Группировка и агрегация данных с использованием SQL
- Генерация отчётов посредством группировки связанных данных
- Обзор групповых функций
- Обзор предложений GROUP BY и HAVING
- Использование операторов ROLLUP и CUBE
- Использование функции GROUPING
- Работа с операторами GROUPING SET и составными столбцами
- Использование комбинированных группировок с примерами
Модуль 3. Иерархические выборки
Иерархические выборки
- Использование иерархических запросов
- Примерные данные из таблицы EMPLOYEES
- Структура в виде натурального дерева
- Иерархические запросы: синтаксис
- Обход дерева: указание начальной позиции
- Обход дерева: задание направления обхода
- Использование предложения WITH
- Пример иерархического запроса: использование предложения CONNECT BY
Модуль 4. Работа с регулярными выражениями
- Введение в регулярные выражения
- Использование функций регулярных выражений и условий в SQL и PL/SQL
- Введение в метасимволы
- Использование метасимволов с регулярными выражениями
- Функции регулярных выражений и условия: синтаксис
- Выполнение простого поиска с помощью условия REGEXP_LIKE
- Нахождение паттернов с использованием функции REGEXP_INSTR
- Извлечение подстрок с использованием функции REGEXP_SUBSTR
Модуль 5: Анализ данных и построение отчётов с использованием SQL
- Обзор функций SQL для анализа и построения отчётов
- Использование аналитических функций
- Использование функций ранжирования
- Использование функций построения отчётов
Модуль 6: Выполнение операций свёртывания и развёртывания
- Выполнение операций свёртывания
- Использование предложений PIVOT и UNPIVOT
- Свёртывание по колонке QUARTER: концептуальный пример
- Выполнение операции развёртывания
- Использование предложения UNPIVOT на колонках в операции развёртывания
- Создание новой таблицы-свёртки: пример
Модуль 7. Сопоставление по шаблону с использованием SQL
Сопоставление по шаблону с использованием SQL
- Операции обнаружения строк, соответствующих шаблону
- Обработка пустых результатов поиска или несоответствующих шаблону строк
- Исключение частей шаблона из результатов вывода
- Учёт всех возможных перестановок шаблонов
- Правила и ограничения при сопоставлении по шаблону
- Примеры сопоставления по шаблону
Модуль 8: Моделирование данных с использованием SQL
- Использование предложения MODEL
- Демонстрация ссылок на отдельную ячейку и диапазон ячеек
- Использование функции CV
- Использование конструкции FOR в операторе IN (список), последовательности значений и подзапросах
- Использование аналитических функций в предложении SQL MODEL
- Отличие отсутствующих ячеек от значения NULL
- Использование опций UPDATE, UPSERT и UPSERT ALL
- Референсные модели
Предварительные требования
- Концептуальный опыт проектирования хранилищ данных
- Хорошее понимание реляционных технологий
- Практический опыт реализации хранилищ данных
- Использование Java – для разработчиков баз данных и на PL/SQL
Документы об окончании курса
- Сертификат Учебного центра Noventiq
- Cертификат об обучении установленного образца
Оставить отзыв
Информация о курсе
924 BYN
с учетом НДС 20%
Вендор: Oracle
Код курса: 12cASQL
Продолжительность: 2 дня / 16 ак. часов
часов
Направление: Разработка Oracle Database
Экзамен :
Ближайшие курсы
Oracle Database 19c: SQL Tuning for Developers
19cTSQL
24-28 июля
Администрирование Oracle Database 12c
12cDBA
7-11 августа
Развертывание и администрирование PT Application Firewall
ПТ23
19-20 июля
Основы ITIL 4
ITIL 4
26-28 июля
Управление ИТ персоналом
ITHRM
24-25 июля
Все предложения
Ваше имя*
Email*

facebook.com/NoventiqEducationBelarus»>Учебный центр Noventiq Belarus
Производительность конструкции UNPIVOT и ее аналогов
За время моей работы, на должности DBA, я сталкивался с широким кругом задач. Одни задачи требовали монотонной работы, другие сводились к чистому креативу.
Самые креативные задачи, которые я могу сейчас вспомнить, так или иначе, затрагивали вопросы оптимизации запросов.
Оптимизация – это, в первую очередь, поиск оптимального плана запроса. Однако, что делать в ситуации, когда стандартная конструкция языка выдает план, который очень далек от оптимального?
Именно с такой проблемой я столкнулся, когда я применял конструкцию UNPIVOT для преобразования столбцов в строки.
Выход был один – необходимо было найти для UNPIVOT более эффективную альтернативу…
Чтобы задача не казалось абстрактной, предположим, что в нашем распоряжении таблица, содержащая информацию о количестве медалей среди пользователей.
IF OBJECT_ID('dbo. UserBadges', 'U') IS NOT NULL
DROP TABLE dbo.UserBadges
CREATE TABLE dbo.UserBadges
(
UserID INT
, Gold SMALLINT NOT NULL
, Silver SMALLINT NOT NULL
, Bronze SMALLINT NOT NULL
, CONSTRAINT PK_UserBadges PRIMARY KEY (UserID)
)
INSERT INTO dbo.UserBadges (UserID, Gold, Silver, Bronze)
VALUES
(1, 5, 3, 1),
(2, 0, 8, 1),
(3, 2, 4, 11)
 UserBadges', 'U') IS NOT NULL
DROP TABLE dbo.UserBadges
CREATE TABLE dbo.UserBadges
(
UserID INT
, Gold SMALLINT NOT NULL
, Silver SMALLINT NOT NULL
, Bronze SMALLINT NOT NULL
, CONSTRAINT PK_UserBadges PRIMARY KEY (UserID)
)
INSERT INTO dbo.UserBadges (UserID, Gold, Silver, Bronze)
VALUES
(1, 5, 3, 1),
(2, 0, 8, 1),
(3, 2, 4, 11)
UserBadges', 'U') IS NOT NULL
DROP TABLE dbo.UserBadges
CREATE TABLE dbo.UserBadges
(
UserID INT
, Gold SMALLINT NOT NULL
, Silver SMALLINT NOT NULL
, Bronze SMALLINT NOT NULL
, CONSTRAINT PK_UserBadges PRIMARY KEY (UserID)
)
INSERT INTO dbo.UserBadges (UserID, Gold, Silver, Bronze)
VALUES
(1, 5, 3, 1),
(2, 0, 8, 1),
(3, 2, 4, 11)
Взяв за основу эту таблицу, приведем различные методы преобразования столбцов в строки, а также планы их выполнения.
Чтобы не было лишних вопросов, в душе я небольшой перфекционист, поэтому максимальное удобство, при работе с планами выполнения, я получаю в dbForge Studio for SQL Server. По этой причине, все скриншоты планов сделаны именно при помощи данного инструмента, а не в SSMS.
Перейдём от слов к делу…
1. UNION ALL
В свое время, SQL Server 2000 не предоставлял эффективного способа преобразовывать столбцы в строки. Вследствие чего широко практиковалась практика многократной выборки из одной и той же таблицы, но с разным набором столбцов, объединенных через конструкцию UNION ALL:
SELECT UserID, BadgeCount = Gold, BadgeType = 'Gold' FROM dbo.
 UserBadges
UNION ALL
SELECT UserID, Silver, 'Silver'
FROM dbo.UserBadges
UNION ALL
SELECT UserID, Bronze, 'Bronze'
FROM dbo.UserBadges
UserBadges
UNION ALL
SELECT UserID, Silver, 'Silver'
FROM dbo.UserBadges
UNION ALL
SELECT UserID, Bronze, 'Bronze'
FROM dbo.UserBadges
Огромным минус этого подхода — повторные чтения данных, которые существенно снижали эффективность при выполнения такого запроса.
Если взглянуть на план выполнения, то в этом можно легко убедится:
2. UNPIVOT
С релизом SQL Server 2005, стало возможным использовать новую конструкцию языка T-SQL – UNPIVOT.
Применяя UNPIVOT предыдущий запрос можно упростить до:
SELECT UserID, BadgeCount, BadgeType
FROM dbo.UserBadges
UNPIVOT (
BadgeCount FOR BadgeType IN (Gold, Silver, Bronze)
) unpvt
При выполнении мы получим следующий план:
3. VALUES
Начиная с SQL Server 2008 стало возможным использовать конструкцию VALUES не только для создания многострочных INSERT запросов, но и внутри блока FROM.
Применяя конструкцию VALUES, запрос выше можно переписать так:
SELECT p.
 UserID, t.*
FROM dbo.UserBadges p
CROSS APPLY (
VALUES
(Gold, 'Gold')
, (Silver, 'Silver')
, (Bronze, 'Bronze')
) t(BadgeCount, BadgeType)
UserID, t.*
FROM dbo.UserBadges p
CROSS APPLY (
VALUES
(Gold, 'Gold')
, (Silver, 'Silver')
, (Bronze, 'Bronze')
) t(BadgeCount, BadgeType)
При этом, по-сравнению с UNPIVOT, план выполнения немного упростится:
4. Dynamic SQL
Применяя динамический SQL, есть возможность создать «универсальный» запрос для любой таблицы. Главное условие при этом — столбцы, которые не входят в состав первичного ключа, должны иметь совместимые между собой типы данных.
Узнать список таких столбцов можно следующим запросом:
SELECT c.name
FROM sys.columns c WITH(NOLOCK)
LEFT JOIN (
SELECT i.[object_id], i.column_id
FROM sys.index_columns i WITH(NOLOCK)
WHERE i.index_id = 1
) i ON c.[object_id] = i.[object_id] AND c.column_id = i.column_id
WHERE c.[object_id] = OBJECT_ID('dbo.UserBadges', 'U')
AND i.[object_id] IS NULL
Если посмотреть на план запроса, можно заметить, что соединение с sys.index_columns является достаточно затратной:
Чтобы избавится от этого соединения можно воспользоваться функцией INDEX_COL. В результате итоговый вариант запроса примет следующий вид:
В результате итоговый вариант запроса примет следующий вид:
DECLARE @table_name SYSNAME
SELECT @table_name = 'dbo.UserBadges'
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = '
SELECT *
FROM ' + @table_name + '
UNPIVOT (
value FOR code IN (
' + STUFF((
SELECT ', [' + c.name + ']'
FROM sys.columns c WITH(NOLOCK)
WHERE c.[object_id] = OBJECT_ID(@table_name)
AND INDEX_COL(@table_name, 1, c.column_id) IS NULL
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + '
)
) unpiv'
PRINT @SQL
EXEC sys.sp_executesql @SQL
При выполнении будет сформирован запрос в соответствии с шаблоном:
SELECT * FROM <table_name> UNPIVOT ( value FOR code IN (<unpivot_column>) ) unpiv
Даже если брать во внимание оптимизации, которые мы проделали, стоит отметить, что данный способ более медленный.
поскольку, для автоматического формирования запроса UNPIVOT, дополнительно используется выборка из системных представлений и конкатенация строк через XML:
5.
 XML
XML
Более элегантно реализовать динамический UNPIVOT возможно, если использовать следующий трюк с XML:
SELECT
p.UserID
, BadgeCount = t.c.value('.', 'INT')
, BadgeType = t.c.value('local-name(.)', 'VARCHAR(10)')
FROM (
SELECT
UserID
, [XML] = (
SELECT Gold, Silver, Bronze
FOR XML RAW('t'), TYPE
)
FROM dbo.UserBadges
) p
CROSS APPLY p.[XML].nodes('t/@*') t(c)
В котором для каждой строки формируется XML вида:
<t Column1="Value1" Column2="Value2" Column3="Value3" ... />
После чего парсится имя каждого атрибута и его значения.
В большинстве случаев, при использовании XML получается более медленный план выполнения – это расплата за универсальность.
Теперь сравним полученные примеры:
Кардинальной разницы в скорости выполнения между UNPIVOT и VALUES не наблюдается. Это утверждение верно, если речь идет о простом преобразовании столбцов в строки.
Усложним задачу и рассмотрим другой вариант, где по каждому пользователю необходимо узнать тип медалей, которых у него больше всего.
Попробуем решить задачу применяя конструкцию UNPIVOT:
SELECT
UserID
, GameType = (
SELECT TOP 1 BadgeType
FROM dbo.UserBadges b2
UNPIVOT (
BadgeCount FOR BadgeType IN (Gold, Silver, Bronze)
) unpvt
WHERE UserID = b.UserID
ORDER BY BadgeCount DESC
)
FROM dbo.UserBadges b
На плане выполнения видно, что проблема наблюдается в повторном чтении данных и сортировке, которая необходима для упорядочивания данных:
Избавится от повторного чтения достаточно легко, если вспомнить, что в подзапросе допускается использовать столбцы из внешнего блока:
SELECT UserID , GameType = ( SELECT TOP 1 BadgeType FROM (SELECT t = 1) t UNPIVOT ( BadgeCount FOR BadgeType IN (Gold, Silver, Bronze) ) unpvt ORDER BY BadgeCount DESC ) FROM dbo.
 UserBadges
UserBadges
Повторные чтения ушли, но операция сортировки никуда не делась:
Посмотрим как ведет себя конструкция VALUES в данной задаче:
SELECT
UserID
, GameType = (
SELECT TOP 1 BadgeType
FROM (
VALUES
(Gold, 'Gold')
, (Silver, 'Silver')
, (Bronze, 'Bronze')
) t (BadgeCount, BadgeType)
ORDER BY BadgeCount DESC
)
FROM dbo.UserBadges
План ожидаемо упростился, но сортировка по-прежнему присутствует в плане:
Попробуем обойти сортировку используя аггрегирующую функцию:
SELECT
UserID
, BadgeType = (
SELECT TOP 1 BadgeType
FROM (
VALUES
(Gold, 'Gold')
, (Silver, 'Silver')
, (Bronze, 'Bronze')
) t (BadgeCount, BadgeType)
WHERE BadgeCount = (
SELECT MAX(Value)
FROM (
VALUES (Gold), (Silver), (Bronze)
) t(Value)
)
)
FROM dbo. UserBadges
 UserBadges
UserBadges
Мы избавились от сортировки:
Небольшие итоги:
В ситуации, когда необходимо произвести простое преобразование столбцов в строки, то наиболее предпочтительно использовать конструкции UNPIVOT или VALUES.
Если после преобразования, полученные данные планируется использовать в операциях агрегирования или сортировки, то более предпочтительно использовать именно конструкцию VALUES, которая, в большинстве случае, позволяет получать более эффективные планы выполнения.
Если число столбцов в таблицы переменчиво, рекомендуется использовать XML, который в отличии от динамического SQL, можно использовать внутри табличных функций.
P.S.
Чтобы адаптировать, часть примеров под особенности SQL Server 2005, конструкцию с применением VALUES:
SELECT * FROM ( VALUES (1, 'a'), (2, 'b') ) t(id, value)
необходимо заменить на комбинацию SELECT UNION ALL SELECT:
SELECT id = 1, value = 'a' UNION ALL SELECT 2, 'b'
Автор: AlanDenton
Источник
Как использовать оператор PIVOT/UNPIVOT для создания отчета о представлении в SQL
PIVOT — это оператор отношения, который позволяет разработчикам баз данных преобразовывать результаты запроса из строк в столбцы. Между тем, UNPIVOT будет использоваться для поворота данных из столбцов в строки. Другими словами, вы можете преобразовать табличное выражение в другую таблицу, используя UNPIVOT/UNPIVOT. И пользователи будут назначать имена столбцов для новой таблицы. Предварительным условием, которое позволяет пользователям чередовать данные из столбцов в строки или наоборот, является то, что данные должны быть агрегированы на основе функций агрегирования (СЧЁТ, СУММ и т. д.).
Между тем, UNPIVOT будет использоваться для поворота данных из столбцов в строки. Другими словами, вы можете преобразовать табличное выражение в другую таблицу, используя UNPIVOT/UNPIVOT. И пользователи будут назначать имена столбцов для новой таблицы. Предварительным условием, которое позволяет пользователям чередовать данные из столбцов в строки или наоборот, является то, что данные должны быть агрегированы на основе функций агрегирования (СЧЁТ, СУММ и т. д.).
PIVOT и UNPIVOT — это важные функции, помогающие изменить способ отображения данных в базе данных, чтобы пользователям было легче их анализировать. Более того, разработчикам не нужно использовать сложные операторы внутри запроса. Давайте углубимся, чтобы узнать, как мы можем применить оператор поворота и как он работает.
Как использовать оператор PIVOT
- Синтаксис оператора PIVOT
Скопировать код
Скопировано
Используйте другой браузер
SELECT <Необязательный несводный столбец>,
[Сводная колонка 1] AS <имя колонки 1>,
[Сводная колонка 2] AS <имя колонки 2>,
. ..
[Сводной столбец n] AS <имя столбца n>
ОТ
(<таблица, представление или хранимая процедура, даже запрос Select>)
AS <псевдоним исходного запроса>
ВРАЩАТЬСЯ
(
<функция агрегирования>(<агрегируемый столбец>)
ДЛЯ
[<столбец, содержащий значения, которые станут заголовками столбцов>]
IN ( [Сводная колонка 1], [Сводная колонка 2],
... [Сводная колонка n])
) AS <псевдоним для сводной таблицы>
<необязательное предложение ORDER BY>;
 ..
[Сводной столбец n] AS <имя столбца n>
ОТ
(<таблица, представление или хранимая процедура, даже запрос Select>)
AS <псевдоним исходного запроса>
ВРАЩАТЬСЯ
(
<функция агрегирования>(<агрегируемый столбец>)
ДЛЯ
[<столбец, содержащий значения, которые станут заголовками столбцов>]
IN ( [Сводная колонка 1], [Сводная колонка 2],
... [Сводная колонка n])
) AS <псевдоним для сводной таблицы>
<необязательное предложение ORDER BY>;
..
[Сводной столбец n] AS <имя столбца n>
ОТ
(<таблица, представление или хранимая процедура, даже запрос Select>)
AS <псевдоним исходного запроса>
ВРАЩАТЬСЯ
(
<функция агрегирования>(<агрегируемый столбец>)
ДЛЯ
[<столбец, содержащий значения, которые станут заголовками столбцов>]
IN ( [Сводная колонка 1], [Сводная колонка 2],
... [Сводная колонка n])
) AS <псевдоним для сводной таблицы>
<необязательное предложение ORDER BY>;
- Простой пример
Давайте сначала создадим некоторые образцы данных:
Скопировать код
Скопировано
Используйте другой браузер
DECLARE @Candidate TABLE( Идентификатор INT IDENTITY (1,1), Страна НВАРЧАР(250), Плавающая оценка) INSERT INTO @Candidate(Country, Score) VALUES('Америка', 7) INSERT INTO @Candidate(Country, Score) VALUES('Канада', NULL) ВСТАВЬТЕ В @Candidate(Страна, Оценка) VALUES('Вьетнам', 9) INSERT INTO @Candidate(Country, Score) VALUES('Таиланд', 9) ВСТАВЬТЕ В @Candidate(Страна, Оценка) VALUES('Вьетнам', 6) INSERT INTO @Candidate(Country, Score) VALUES('Америка', 8)Затем примените PIVOT с запросом на подсчет кандидатов по странам.
Скопировать код
Скопировано
Используйте другой браузерВЫБЕРИТЕ [Америка], [Канада], [Вьетнам], [Таиланд] ОТ ( ВЫБЕРИТЕ страну ИЗ @Candidate ) КАК источник PIVOT (COUNT(Country) FOR Country IN ([Америка], [Канада], [Вьетнам], [Таиланд])) AS pvtКогда мы смотрим на следующие результаты, мы видим, что столбец [Страна] уже сгруппирован и превращен в заголовки. В то же время данные строки были агрегированы COUNT.
Простой пример — сводной запрос
Давайте рассмотрим более сложный пример, чтобы увидеть возможности PIVOT.
Использование оператора GROUP BY для группировки строк данных в агрегированном отчете недостаточно для адекватного определения параметров этого отчета. Учитывая, что для того, чтобы отчет был полным и подробным, мы можем использовать оператор PIVOT для статистики и синтеза данных наиболее интуитивно понятным образом.
Например, мы можем составить отчет, в котором будет указано, сколько кандидатов в системе из одной и той же страны. И каждый кандидат должен претендовать на эти вакансии («Разработчик», «Дизайнер»).
Теперь нам понадобятся две таблицы, которые связаны с таблицей Candidate. Тем не менее, чтобы было ясно, эти таблицы не будут включать отношения FK.
Скопировать код
Скопировано
Используйте другой браузерDECLARE @Job TABLE (Id INT, JobName NVARCHAR(255)) ВСТАВИТЬ В @Job (Id, JobName) ЗНАЧЕНИЯ (1, "Разработчик") ВСТАВИТЬ В @Job (Id, JobName) ЦЕННОСТИ (2, «Дизайнер») ВСТАВИТЬ В @Job (Id, JobName) ЦЕННОСТИ (3, «Журналист») DECLARE @Shortlist TABLE (Id INT, JobId INT, CandidateId INT, STAGE NVARCHAR(255)) ВСТАВЬТЕ В @Shortlist (Id, JobId, CandidateId, STAGE) ЗНАЧЕНИЯ (1, 1, 1, «Применяется») ВСТАВЬТЕ В @Shortlist (Id, JobId, CandidateId, STAGE) ЗНАЧЕНИЯ (2, 1, 2, «Применяется») ВСТАВЬТЕ В @Shortlist (Id, JobId, CandidateId, STAGE) ЦЕННОСТИ (3, 2, 3, «Интервью») ВСТАВЬТЕ В @Shortlist (Id, JobId, CandidateId, STAGE) ЦЕННОСТИ (4, 3, 4, «Интервью») ВСТАВЬТЕ В @Shortlist (Id, JobId, CandidateId, STAGE) ЗНАЧЕНИЯ (5, 1, 5, 'Hỉred') ВСТАВЬТЕ В @Shortlist (Id, JobId, CandidateId, STAGE) ЗНАЧЕНИЯ (6, 2, 6, «Отклонить»)Когда все данные будут готовы, мы будем следовать синтаксису, чтобы сделать запрос.
Исходный запрос:
Скопировать код
Скопировано
Используйте другой браузерВЫБЕРИТЕ c.Id КАК CandidateId, c.Country, j.Id КАК JobId, j.JobName FROM @Candidate c ПРИСОЕДИНЯЙТЕСЬ к @Shortlist s ON s.CandidateId = c.Id ПРИСОЕДИНЯЙТЕСЬ к @Job j ON s.JobId = j.Id ГДЕ j.JobName IN («Разработчик», «Дизайнер»)Сводной запрос:
Скопировать код
Скопировано
Используйте другой браузерSELECT JobName, [Америка], [Канада], [Вьетнам], [Таиланд] ОТ ( ВЫБЕРИТЕ c.Id КАК CandidateId, c.Country, j.Id КАК JobId, j.JobName FROM @Candidate c ПРИСОЕДИНЯЙТЕСЬ к @Shortlist s ON s.CandidateId = c.Id ПРИСОЕДИНЯЙТЕСЬ к @Job j ON s.JobId = j.Id ГДЕ j.JobName IN («Разработчик», «Дизайнер») ) КАК источник PIVOT (COUNT(CandidateId) FOR Country IN ([Америка], [Канада], [Вьетнам], [Таиланд])) AS pvtВыполните запросы, и результат будет выглядеть следующим образом:
Расширенный пример — исходный запрос
Расширенный пример — сводной запрос 9 0003
Оператор PIVOT выполнит оператор, аналогичный GROUP BY для поля данных [Страна] с помощью агрегированной функции COUNT().
Важное примечание. При использовании агрегатных функций с PIVOT наличие нулевых значений в столбце значений не учитывается при вычислении агрегата.
Как использовать оператор UNPIVOT


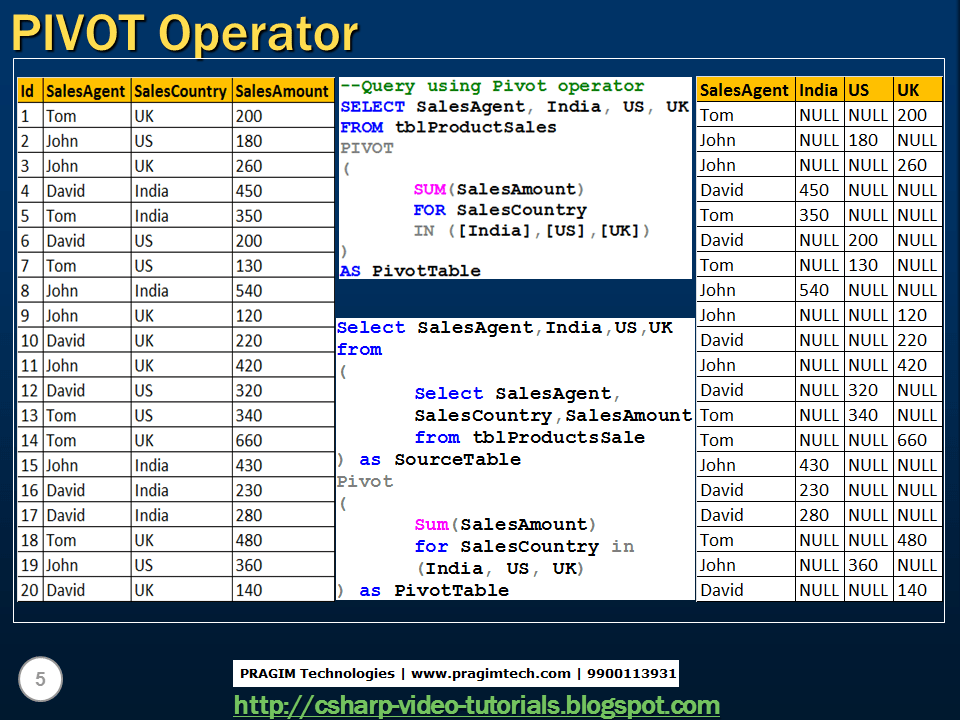 Сгруппированные значения [Страна] будут чередоваться из строк в столбцы для каждого значения, указанного в предложении сводки. Значение поля [CandidateId] служит столбцами данных; во время выполнения эти данные строки будут сгруппированы с помощью функции агрегации, а затем распределены для каждого сводного столбца.
Сгруппированные значения [Страна] будут чередоваться из строк в столбцы для каждого значения, указанного в предложении сводки. Значение поля [CandidateId] служит столбцами данных; во время выполнения эти данные строки будут сгруппированы с помощью функции агрегации, а затем распределены для каждого сводного столбца.- Синтаксис оператора UNPIVOT
Скопировать код
Скопировано
Используйте другой браузер
ВЫБЕРИТЕ [Столбец 1], [Столбец 2] ОТ ( ВЫБЕРИТЕ [Столбец 1], [Столбец 2], <> ИЗ [Сводная таблица] ) UNPIVOT ( < > FOR < > IN ( > )) <Необязательные предложения WHERE> <Необязательные предложения ORDER BY>
- <
> : Вот имя столбца, в котором объединены все данные значений из столбцов в списке столбцов. - <
> : Это имя столбца, который объединил все столбцы в списке столбцов в качестве данных значений. - <
> : Имена столбцов в исходной таблице будут объединены в один сводной столбец. Имена столбцов будут извлечены в name_column, а значения столбцов будут заполнены до 9.0014 <<значение_столбца>> .

Пример UNPIVOT
UNPIVOT — это оператор, который можно использовать для возврата результата PIVOT к исходному. Однако результат UNPIVOT не будет полностью таким же, как предыдущий, мы можем использовать небольшую хитрость, чтобы решить эту проблему. В некоторых особых случаях, возможно, это не сработает.
Предположим, у нас есть таблица, в которой хранятся данные, аналогичные результату после выполнения PIVOT:
UNPIVOT — Исходный
Теперь мы будем использовать оператор UNPIVOT для перехода от столбцов к строкам данных. Это означает, что заголовок для ([Америка], [Канада]) будет возвращен к строке данных столбца «Страна». Перед этим нам нужно настроить данные для этого запроса:
Это означает, что заголовок для ([Америка], [Канада]) будет возвращен к строке данных столбца «Страна». Перед этим нам нужно настроить данные для этого запроса:
Скопировать код
Скопировано
Используйте другой браузер
DECLARE @Pivoted Table (ID INT, Score FLOAT, Америка INT, Канада INT, Вьетнам INT, Таиланд INT) INSERT INTO @Pivoted (Id, Score, [Америка], [Канада], [Вьетнам], [Таиланд]) ВЫБЕРИТЕ идентификатор, счет, [Америка], [Канада], [Вьетнам], [Таиланд] ОТ ( ВЫБЕРИТЕ идентификатор, страну, идентификатор как [IdToCount], оценка от @Candidate ) КАК источник PIVOT (COUNT([IdToCount]) FOR Country IN ([Америка], [Канада], [Вьетнам], [Таиланд])) AS pvtЗапрос UNPIVOT
Скопировать код
Скопировано
Используйте другой браузерВЫБЕРИТЕ Идентификатор, Оценка, Страна ОТ ( ВЫБЕРИТЕ Id, Оценка, Америка, Канада, Вьетнам, Таиланд ОТ @Pivoted ) АС ООО UNPIVOT (Всего ДЛЯ страны IN (Америка, Канада, Вьетнам, Таиланд)) AS unpvtВот результат запроса:
Результат разворота
Поля [ID] и [Score] будут сохранены как в исходном запросе.
Что касается данных, которые мы определяем, данные строки с [всего] = 0 не нужны. Таким образом, мы можем исключить эти данные, чтобы получить окончательный результат, добавив предложение Where в запрос выше.
... ГДЕ Всего > 0
Вот конечный результат:
Окончательный результат Unpivot
Заключение
90 002 Создание отчета — неотъемлемая часть современных приложений, требующих высокой точности результатов вывода, а также производительности запросов ( путем оптимизации операторов запроса). Помимо использования операторов GROUP BY, UNION или CROSS APPLY, применение реляционного оператора PIVOT/UNPIVOT также является хорошим выбором для создания простого запроса и даже для повышения производительности запроса.
Ссылки
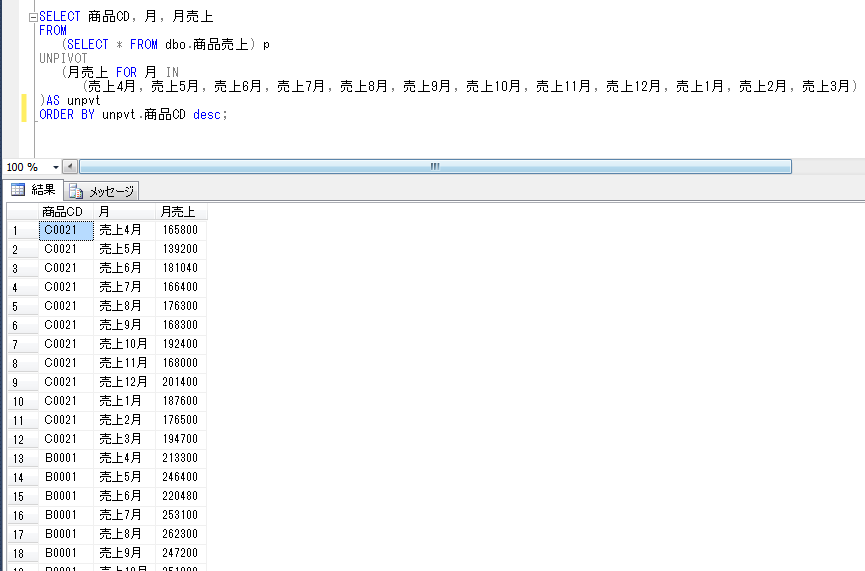 Такие поля, как [Америка], [Вьетнам], [Канада] и [Таиланд], будут определены в операторе IN PIVOT, а [Всего] от имени агрегированных данных теперь станут новыми данными поля.
Такие поля, как [Америка], [Вьетнам], [Канада] и [Таиланд], будут определены в операторе IN PIVOT, а [Всего] от имени агрегированных данных теперь станут новыми данными поля.- Использование PIVOT и UNPIVOT — SQL Server | Документы Microsoft, docs. microsoft.com, 2022.
- UNPIVOT — документация по Snowflake, docs.snowflake.com.
 microsoft.com, 2022.
microsoft.com, 2022.T-SQL Pivot и UnPivot — javatpoint
следующий → Pivot и Unpivot в Transact SQL являются реляционными операторами. Они трансформируют один стол в другой, чтобы получить четкое представление о столе. Оператор Pivot преобразует данные строки в данные столбца . Реляционный оператор Unpivot работает противоположно оператору Pivot. Он преобразует данные на основе столбцов в данные на основе строк и данные на основе строк в данные на основе столбцов. 1. Шарнир: SELECT (Имена столбцов)/Запись имен столбцов 2.
SELECT (имена столбцов)/имя столбца Пример 1-Здесь мы создаем таблицу с именем « javatpoint » и значениями: Название курса, Категория курса, Цена и Значения . Создать таблицу javatpoint Вставить в значения Javatpoint(‘C’, ‘ПРОГРАММИРОВАНИЕ’, 5000) ВЫБЕРИТЕ * ИЗ Javatpoint На выходе мы получаем:
Теперь, применяя оператор PIVOT к этим данным: ВЫБЕРИТЕ Название курса, ПРОГРАММИРОВАНИЕ, ПОДГОТОВКА К ИНТЕРВЬЮ После использования оператора Pivot мы получаем следующий результат:
Пример 2- Теперь мы используем ту же таблицу « Javatpoint », созданную в приведенном выше примере, и применяем оператор Unpivot к нашей сводной таблице. |
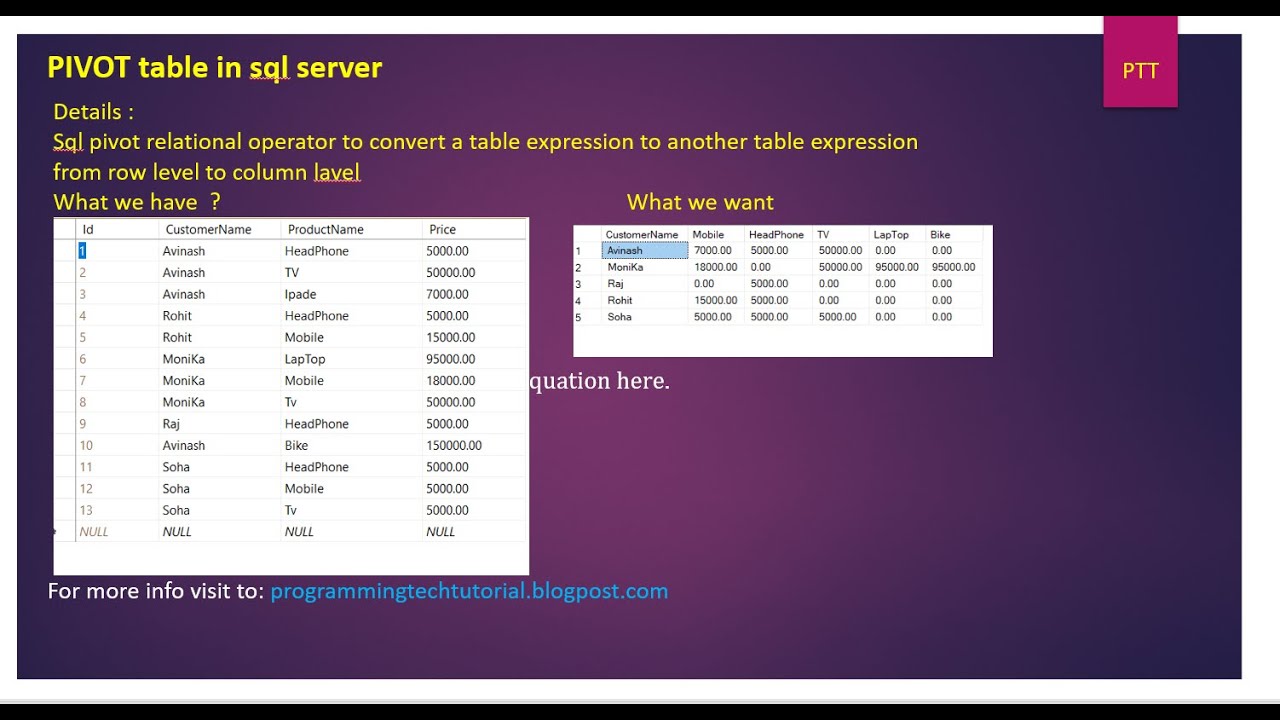 UnPivot:
UnPivot: