Rank oracle: RANK ФУНКЦИЯ — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Содержание
Oracle — Функции RANK() и DENSE_RANK() (Или учимся выбирать необходимые значения внутри множественной выборки)
Oracle — Функции RANK() и DENSE_RANK() (Или учимся выбирать необходимые значения внутри множественной выборки)
Осваиваем Oracle и PL/SQL
Начнем с функции RANK(). С объяснения для чего она и в каких случаях она нам может пригодиться.
Функция RANK() — это очень полезная функция, она позволяет нам пронумеровать набор по некоторому группирующему значению внутри всего выбранного набора данных. Проще всего показать это на примере. Для этого создадим небольшую таблицу:
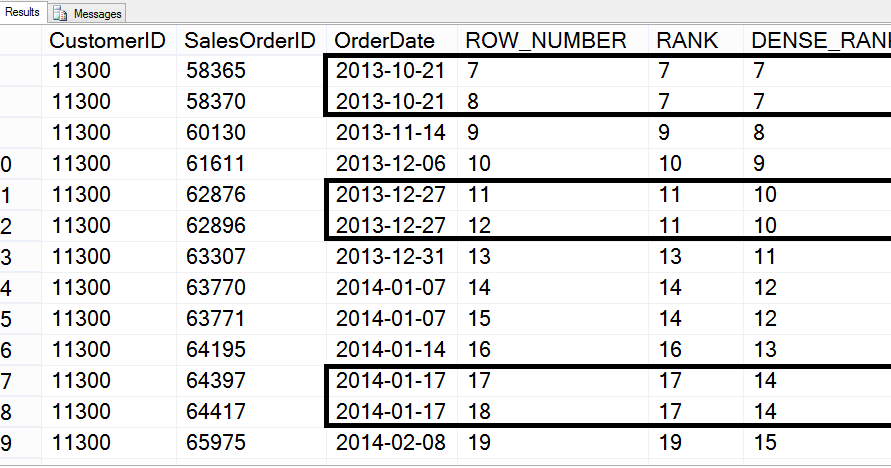
ID PERSON DT SM 1 Роман 01.10.2016 11:51:31 545.3 2 Роман 01.10.2016 11:51:31 445.2 3 Роман 01.10.2016 11:51:31 145.3 4 Кирил 01.05.2016 16:51:31 99.5 5 Алена 01.07.2016 12:51:31 445.3 6 Роман 01.12.2016 16:51:31 876.1 7 Кирил 01.06.2016 16:51:31 237.22 8 Алена 01.12.2016 16:51:31 145.3 9 Алена 01.02.2016 14:51:31 534.7 10 Роман 01.03.2016 16:51:31 165.3 11 Кирил 01.04.2016 16:51:31 345.2
 12.2016 16:51:31 145.3
9 Алена 01.02.2016 14:51:31 534.7
10 Роман 01.03.2016 16:51:31 165.3
11 Кирил 01.04.2016 16:51:31 345.2
12.2016 16:51:31 145.3
9 Алена 01.02.2016 14:51:31 534.7
10 Роман 01.03.2016 16:51:31 165.3
11 Кирил 01.04.2016 16:51:31 345.2Пусть в этой таблице будет содержать некоторые выставленные счета разным пользователям PERSON на разные суммы SM в разное время DT.
А теперь предположим что мы хотим получить по каждому пользователю максимально выставленный ему счет за всё время.
Именно такого рода задачи позволяет очень легко решать функция RANK().
Для того, чтобы добиться желаемого результата, нам необходимо сгруппировать пользователей с зарплатой по убыванию, вот так:
select * from T_PAYS t order by t.PERSON, t.SM desc
Получим:
ID PERSON DT SM 9 Алена 01.02.2016 14:51:31 534.7 --Максимальное значение для Алены 5 Алена 01.07.2016 12:51:31 445.3 8 Алена 01.12.2016 16:51:31 145.3 11 Кирил 01.
 04.2016 16:51:31 345.2 --Максимальное значение для Кирила
7 Кирил 01.06.2016 16:51:31 237.22
4 Кирил 01.05.2016 16:51:31 99.5
6 Роман 01.12.2016 16:51:31 876.1 --Максимальное значение для Романа
1 Роман 01.10.2016 11:51:31 545.3
2 Роман 01.10.2016 11:51:31 445.2
10 Роман 01.03.2016 16:51:31 165.3
3 Роман 01.10.2016 11:51:31 145.3
04.2016 16:51:31 345.2 --Максимальное значение для Кирила
7 Кирил 01.06.2016 16:51:31 237.22
4 Кирил 01.05.2016 16:51:31 99.5
6 Роман 01.12.2016 16:51:31 876.1 --Максимальное значение для Романа
1 Роман 01.10.2016 11:51:31 545.3
2 Роман 01.10.2016 11:51:31 445.2
10 Роман 01.03.2016 16:51:31 165.3
3 Роман 01.10.2016 11:51:31 145.3Теперь, всё что нам надо это только взять по порядку первую запись для каждого пользователя, в ней и будет максимальное значение. Вот для этого нам и понадобится функция RANK().
Для этого перепишем наш запрос вот так:
select t.*, rank() over(partition by t.PERSON order by t.sm desc) rnk from T_PAYS t
Получим:
ID PERSON DT SM RNK 9 Алена 01.02.2016 14:51:31 534.7 1 5 Алена 01.07.2016 12:51:31 445.3 2 8 Алена 01.12.2016 16:51:31 145.3 3 11 Кирил 01.04.2016 16:51:31 345.2 1 7 Кирил 01.06.2016 16:51:31 237.22 2 4 Кирил 01.
 05.2016 16:51:31 99.5 3
6 Роман 01.12.2016 16:51:31 876.1 1
1 Роман 01.10.2016 11:51:31 545.3 2
2 Роман 01.10.2016 11:51:31 445.2 3
10 Роман 01.03.2016 16:51:31 165.3 4
3 Роман 01.10.2016 11:51:31 145.3 5
05.2016 16:51:31 99.5 3
6 Роман 01.12.2016 16:51:31 876.1 1
1 Роман 01.10.2016 11:51:31 545.3 2
2 Роман 01.10.2016 11:51:31 445.2 3
10 Роман 01.03.2016 16:51:31 165.3 4
3 Роман 01.10.2016 11:51:31 145.3 5Теперь мы получили дополнительный столбец который нумерует значения по сумме (SM) внутри группировок по каждому человеку (PERSON).
Теперь всё что нам остается, это выбрать из полученного набора те записи в которых значение нового поля RNK = 1.
select * from ( select t.*, rank() over(partition by t.PERSON order by t.sm desc) rnk from T_PAYS t ) where rnk=1
Получаем искомый набор максимальных счетов по каждому пользователю:
ID PERSON DT SM RNK 9 Алена 01.02.2016 14:51:31 534.7 1 11 Кирил 01.04.2016 16:51:31 345.2 1 6 Роман 01.12.2016 16:51:31 876.1 1
Теперь попробуем объяснить для чего же нам функция DENSE_RANK(). По сути эти функции делают одно и то же, за очень маленьким исключением, это исключение продемонстрируем на примере. Для этого изменим исходный набор так, чтобы в нем было много одинаковых значений суммы счета (SM). Вот таким образом:
По сути эти функции делают одно и то же, за очень маленьким исключением, это исключение продемонстрируем на примере. Для этого изменим исходный набор так, чтобы в нем было много одинаковых значений суммы счета (SM). Вот таким образом:
ID PERSON DT SM 9 Алена 01.02.2016 14:51:31 534.7 5 Алена 01.07.2016 12:51:31 445.3 8 Алена 01.12.2016 16:51:31 145.3 11 Кирил 01.04.2016 16:51:31 345.2 7 Кирил 01.06.2016 16:51:31 237.22 4 Кирил 01.05.2016 16:51:31 237.22 6 Роман 01.12.2016 16:51:31 876.1 2 Роман 01.10.2016 11:51:31 545.3 1 Роман 01.10.2016 11:51:31 545.3 10 Роман 01.03.2016 16:51:31 145.3 3 Роман 01.10.2016 11:51:31 145.3
Теперь выполним ужа знакомый нам скрипт, добавив ещё один столбец который будет нумеровать нам группировки, но только с функцией DENSE_RANK():
select t.*, rank() over(partition by t.PERSON order by t.sm desc) rnk , dense_rank() over(partition by t.PERSON order by t.
 sm desc) dense_rnk
from T_PAYS t
sm desc) dense_rnk
from T_PAYS t Получим результат:
ID PERSON DT SM RNK DENSE_RNK 9 Алена 01.02.2016 14:51:31 534.7 1 1 5 Алена 01.07.2016 12:51:31 445.3 2 2 8 Алена 01.12.2016 16:51:31 145.3 3 3 11 Кирил 01.04.2016 16:51:31 345.2 1 1 7 Кирил 01.06.2016 16:51:31 237.22 2 2 4 Кирил 01.05.2016 16:51:31 237.22 2 2 6 Роман 01.12.2016 16:51:31 876.1 1 1 2 Роман 01.10.2016 11:51:31 545.3 2 2 1 Роман 01.10.2016 11:51:31 545.3 2 2 10 Роман 01.03.2016 16:51:31 145.3 4 3 3 Роман 01.10.2016 11:51:31 145.3 4 3
Теперь мы можем заметить разницу на персоне Романа, здесь видно, что функция RANK() для следующей группы одинаковых значений поля SM присваивает порядковый номер записи внутри группировки, тогда как функция DENSE_RANK() присваивает просто следующий порядковый номер. Это различие нам может пригодиться при решении такой задачи, при которой необходимо выбрать не первую запись, а скажем 3 или 4, и здесь условие применения той или иной функции может варьироваться в зависимости от того, что мы хотим получить. Если мы хотим получить 3-е уникальное значение то правильнее будет использовать DENSE_RANK(), при помощи RANK() мы в данном случае можем получить порядковый номер строки искомого значения.
Если мы хотим получить 3-е уникальное значение то правильнее будет использовать DENSE_RANK(), при помощи RANK() мы в данном случае можем получить порядковый номер строки искомого значения.
Вот и всё.
Oracle
RANK()
DENSE_RANK()
группировка
выбор первых
PL/SQL
программирование
SQL
Лоран Функции ранжирования Семейство ранжирующих функций использует ORDER BY в Выберите ENAME HIREDATE ROW_NUMBER возвращает номер строки в указанном RANK и DENSE_RANK являются детерминированными. Выберите ЭНАМЯ Row_number всегда возвращает различные числа для для ROW_NUMBER, DENSE_RANK и RANK имеют разные ВЫБЕРИТЕ ОТДЕЛ Примечание. По умолчанию LEAD и LAG возвращают предыдущий и ВЫБЕРИТЕ ЭНАМЯ Значения последних трех строк возвращаются.
|
 LAG возвращает предыдущую строку, а LEAD возвращает следующую строку.
LAG возвращает предыдущую строку, а LEAD возвращает следующую строку. И RANK, и DENSE_RANK возвращают повторяющиеся числа для
И RANK, и DENSE_RANK возвращают повторяющиеся числа для Аналитическая функция не может
Аналитическая функция не может
Oracle SQL, как фильтровать множество по рангу?
спросил
Изменено
9 лет, 6 месяцев назад
Просмотрено
22к раз
Прямо сейчас я борюсь со следующим SQL-запросом:
http://sqlfiddle.com/#!4/736a7/12
select uc.* от usercredential uc пользователи внутреннего соединения u on u.userid = uc.userid учетные данные внутреннего соединения c на c.credentialid = uc.credentialid внутреннее соединение healthsystemcredential hsc на hsc.
 credentialid = c.credentialid
уровень доступа внутреннего соединения ac на hsc.hscredentialid в (
-- Пытаетесь понять, как здесь фильтровать?
выберите 1 из двойных
)
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равно null) или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate))
credentialid = c.credentialid
уровень доступа внутреннего соединения ac на hsc.hscredentialid в (
-- Пытаетесь понять, как здесь фильтровать?
выберите 1 из двойных
)
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равно null) или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate))
В основном я пытаюсь получить UserCredential, который является Many To One с Credential. Учетные данные — это один ко многим с HealthSystemCredential.
HealthSystemCredential имеет внешний ключ AccessLevel, однако этот столбец AccessLevel в HealthSystemCredential фактически является самым низким допустимым уровнем доступа. Записи AccessLevel имеют ранг типа от 1 (самый низкий) до 4 (самый высокий).
Пример: HealthSystemCredential с записью AccessLevel, которая имеет Type Rank 2, должна извлекаться, когда я фильтрую свой запрос по AccessLevels с Types 2, 3 или 4.
Проблема в том, что я не могу понять, как это сделать в одном запросе. Есть ли способ получить столбец DENSE_RANK в подзапросе AccessLevels, применить мой фильтр в подзапросе и каким-то образом соединить его с таблицей, чтобы получить все применимые HealthSystemCredentials, которые я хочу?
Есть ли способ получить столбец DENSE_RANK в подзапросе AccessLevels, применить мой фильтр в подзапросе и каким-то образом соединить его с таблицей, чтобы получить все применимые HealthSystemCredentials, которые я хочу?
- оракул
0
Есть несколько функций ранжирования, которые вы можете использовать. Вы можете прочитать аналитические функции в документации Oracle. В вашем случае RANK() и DENSE_RANK() будут работать, если я вас понял:
select *
из
( выберите уч.*,
DENSE_RANK() OVER (РАЗДЕЛ ПО ac.HEALTHSYSTEMID
ЗАКАЗАТЬ ПО ac.ACCESSLEVELTYPE ASC)
как пьяный
от usercredential uc
внутреннее соединение пользователей u
на u.userid = uc.userid
учетные данные внутреннего соединения c
на c.credentialid = uc.credentialid
внутреннее соединение HealthSystemcredential hsc
на hsc. credentialid = c.credentialid
уровень доступа внутреннего соединения ac
на hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
)
) тмп
где напиток = 1 ;
 credentialid = c.credentialid
уровень доступа внутреннего соединения ac
на hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
)
) тмп
где напиток = 1 ;
credentialid = c.credentialid
уровень доступа внутреннего соединения ac
на hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
)
) тмп
где напиток = 1 ;
Условие для drnk = 1 (самый низкий ранг типа) будет применяться, конечно, после других условий во внутреннем , где применяется . Если вы хотите сначала отфильтровать по самому низкому рангу типа (это может дать вам меньше строк в конечном результате), вы можете сгруппировать по производной таблице, а затем присоединиться:
select uc.*
от usercredential uc
внутреннее соединение пользователей u
на u.userid = uc.userid
учетные данные внутреннего соединения c
на c.credentialid = uc.credentialid
внутреннее соединение HealthSystemcredential hsc
на hsc.credentialid = c. credentialid
внутреннее соединение ( SELECT HEALTHSYSTEMID,
MIN(ACCESSLEVELTYPE) AS ACCESSLEVELTYPE
ОТ уровня доступа
ГРУППА ПО ЗДОРОВЬЮ СИСТЕМИД
) переменный ток
на hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
) ;
 credentialid
внутреннее соединение ( SELECT HEALTHSYSTEMID,
MIN(ACCESSLEVELTYPE) AS ACCESSLEVELTYPE
ОТ уровня доступа
ГРУППА ПО ЗДОРОВЬЮ СИСТЕМИД
) переменный ток
на hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
) ;
credentialid
внутреннее соединение ( SELECT HEALTHSYSTEMID,
MIN(ACCESSLEVELTYPE) AS ACCESSLEVELTYPE
ОТ уровня доступа
ГРУППА ПО ЗДОРОВЬЮ СИСТЕМИД
) переменный ток
на hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
) ;
или используйте подзапрос в пункте ON . Это ближе к вашей попытке, но довольно сложно. SQL-Server имеет CROSS APPLY , что упрощает запись такого типа соединений:
select uc.*
от usercredential uc
внутреннее соединение пользователей u
на u.userid = uc.userid
учетные данные внутреннего соединения c
на c.credentialid = uc.credentialid
внутреннее соединение HealthSystemcredential hsc
на hsc.credentialid = c.credentialid
уровень доступа внутреннего соединения ac
на ac. HEALTHSYSTEMID = hsc.HEALTHSYSTEMID
и ac.ACCESSLEVELTYPE =
( ВЫБРАТЬ MIN(aci.ACCESSLEVELTYPE) КАК ACCESSLEVELTYPE
ОТ уровня доступа aci
ГДЕ aci.HEALTHSYSTEMID = hsc.HEALTHSYSTEMID
)
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
) ;
 HEALTHSYSTEMID = hsc.HEALTHSYSTEMID
и ac.ACCESSLEVELTYPE =
( ВЫБРАТЬ MIN(aci.ACCESSLEVELTYPE) КАК ACCESSLEVELTYPE
ОТ уровня доступа aci
ГДЕ aci.HEALTHSYSTEMID = hsc.HEALTHSYSTEMID
)
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
) ;
HEALTHSYSTEMID = hsc.HEALTHSYSTEMID
и ac.ACCESSLEVELTYPE =
( ВЫБРАТЬ MIN(aci.ACCESSLEVELTYPE) КАК ACCESSLEVELTYPE
ОТ уровня доступа aci
ГДЕ aci.HEALTHSYSTEMID = hsc.HEALTHSYSTEMID
)
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равен нулю)
или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate)
) ;
Пробовал в SQL-Fiddle. Вы можете протестировать данные в таблицах, чтобы увидеть, какие из них соответствуют вашим требованиям и должны ли соединения быть в hsc.HEALTHSYSTEMID = ac.HEALTHSYSTEMID или в каком-либо другом столбце.
Я чувствую, что у ypercube был хороший ответ, который объяснил DENSE_RANK и как это можно использовать в отношении моего запроса, поэтому я решил принять его ответ, но я хочу опубликовать дополнительный ответ с подробным описанием того, что я в итоге сделал.
В конечном итоге я думаю, что смог выполнить это без использования аналитической функции. Вот запрос, который я придумал ниже:
Вот запрос, который я придумал ниже:
с минимальным типом доступа как (
выберите ac_.accessleveltype в качестве типа доступа из vs.accesslevel ac_
где ac_.accesslevelid = 3
)
выберите ук.*
от vs.usercredential uc
внутреннее соединение против пользователей u на u.userid = uc.userid
внутреннее соединение против credential c на c.credentialid = uc.credentialid
внутреннее соединение vs.healthsystemcredential hsc на hsc.credentialid = c.credentialid
где c.fulfillmentmethod = 'Прикрепить'
и c.display = 1
и uc.auditstatus <> 0
и ((uc.auditstatus равно null) или (uc.auditstatus = 1 и uc.lastmodified > uc.auditdate))
и uc.lastmodified > TO_DATE('01-APR-2013','DD-MON-YYYY')
и существует (выберите null
from vs.accesslevel ac
где ac.healthsystemid = hsc.healthsystemid
и hsc.accesslevelid = ac.accesslevelid
и ac.accessleveltype <= (выберите тип доступа из минимального типа уровня доступа)
)
и hsc.healthsystemid = 3
Обратите внимание, что у меня есть примеры значений для моих фильтров по умолчанию, это должно было продемонстрировать, что запрос действительно возвращает и отфильтровывает данные, которые я ожидал.