Рекурсивные sql запросы: Изучение SQL: рекурсивные запросы
Содержание
Настройка рекурсивных связей глубины с помощью sql:max-depth — SQL Server
-
Статья -
-
Применимо к:База данных SQL ServerAzure SQL
В реляционных базах данных участие таблицы в связи с самой собой называется рекурсивной связью. Например, таблица, в которой содержатся записи о сотрудниках и возможны связи «начальник-подчиненный», участвует в связи сама с собой. В этом случае таблица сотрудников выполняет роль начальника на одной стороне связи и та же таблица выполняет роль подчиненного на другой стороне.
Схемы сопоставления могут включать рекурсивные связи, в которых элемент и его предок относятся к одному типу.
Пример A
Рассмотрим следующую таблицу.
Emp (EmployeeID, FirstName, LastName, ReportsTo)
В этой таблице столбец ReportsTo содержит идентификатор служащего для менеджера.
Предположим, что нужно сформировать XML-иерархию служащих, на вершине которой находится менеджер, а служащие, подчиненные менеджеру, отображаются в соответствующей иерархии, как показано в следующем образце XML-фрагмента. В этом фрагменте показано рекурсивное дерево для сотрудника 1.
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3" LastName="Leverling">
<Emp FirstName="Margaret" EmployeeID="4" LastName="Peacock">
<Emp FirstName="Steven" EmployeeID="5" LastName="Devolio">
...
...
</root>
В этом фрагменте служащий 5 подчинен служащему 4, служащий 4 подчинен служащему 3, а служащие 3 и 2 подчинены служащему 1.
Чтобы получить этот результат, можно использовать следующую схему XSD и указать запрос XPath к ней. Схема описывает <элемент Emp> типа EmployeeType, состоящий из дочернего <элемента Emp> того же типа EmployeeType. Это рекурсивная связь (элемент и его предок относятся к одному типу). Кроме того, схема использует <sql:relationship> для описания отношений «родители-потомки» между руководителем и контролером. Обратите внимание, что в этом <sql:relationship> Emp является как родительской, так и дочерней таблицей.
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Поскольку связь рекурсивная, необходимо каким-то образом указать глубину рекурсии в схеме. В противном случае результатом будет бесконечная рекурсия (служащий, подчиненный служащему, подчиненному служащему, и т. д.). Заметка sql:max-depth позволяет указать, насколько глубоко будет проходить рекурсия. В этом примере, чтобы указать значение sql:max-depth, необходимо знать, насколько глубоко иерархия управления проходит в компании.
В противном случае результатом будет бесконечная рекурсия (служащий, подчиненный служащему, подчиненному служащему, и т. д.). Заметка sql:max-depth позволяет указать, насколько глубоко будет проходить рекурсия. В этом примере, чтобы указать значение sql:max-depth, необходимо знать, насколько глубоко иерархия управления проходит в компании.
Примечание
Схема задает заметку sql:limit-field , но не указывает заметку sql:limit-value . Это ограничивает верхний узел в результирующей иерархии только служащими, которые не подчиняются никому. (ReportsTo имеет значение NULL.) Это достигается при указании заметки sql:limit-field , а не при указании заметки sql:limit-value (по умолчанию — NULL). Если вы хотите, чтобы результирующий XML-код включал все возможные деревья отчетов (дерево отчетов для каждого сотрудника в таблице), удалите заметку sql:limit-field из схемы.
Примечание
В следующей процедуре используется база данных tempdb.
Проверка образца запроса XPath к схеме
Создайте образец таблицы с именем Emp в базе данных tempdb, на которую указывает виртуальный корневой каталог.
USE tempdb CREATE TABLE Emp ( EmployeeID int primary key, FirstName varchar(20), LastName varchar(20), ReportsTo int)Добавьте следующий образец данных:
INSERT INTO Emp values (1, 'Nancy', 'Devolio',NULL) INSERT INTO Emp values (2, 'Andrew', 'Fuller',1) INSERT INTO Emp values (3, 'Janet', 'Leverling',1) INSERT INTO Emp values (4, 'Margaret', 'Peacock',3) INSERT INTO Emp values (5, 'Steven', 'Devolio',4) INSERT INTO Emp values (6, 'Nancy', 'Buchanan',5) INSERT INTO Emp values (7, 'Michael', 'Suyama',6)
Скопируйте приведенный выше код схемы и вставьте его в текстовый файл. Сохраните файл под именем maxDepth.xml.
Скопируйте следующий шаблон и вставьте его в текстовый файл. Сохраните файл под именем maxDepthT.
 xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.
xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.<ROOT xmlns:sql="urn:schemas-microsoft-com:xml-sql"> <sql:xpath-query mapping-schema="maxDepth.xml"> /Emp </sql:xpath-query> </ROOT>Путь к каталогу схемы сопоставления (файл maxDepth.xml) задается относительно каталога, в котором сохранен шаблон. Можно также задать абсолютный путь, например:
mapping-schema="C:\MyDir\maxDepth.xml"
Создайте и запустите тестовый скрипт SQLXML 4.0 (Sqlxml4test.vbs), чтобы выполнить шаблон. Дополнительные сведения см. в статье Использование ADO для выполнения запросов SQLXML 4.0.
 xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.
xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.Результат:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3" LastName="Leverling">
<Emp FirstName="Margaret" EmployeeID="4" LastName="Peacock">
<Emp FirstName="Steven" EmployeeID="5" LastName="Devolio">
<Emp FirstName="Nancy" EmployeeID="6" LastName="Buchanan">
<Emp FirstName="Michael" EmployeeID="7" LastName="Suyama" />
</Emp>
</Emp>
</Emp>
</Emp>
</Emp>
</root>
Примечание
Чтобы получить иерархии разной глубины в результате, измените значение заметки sql:max-depth в схеме и выполняйте шаблон снова после каждого изменения.
В предыдущей схеме все <элементы Emp> имели точно одинаковый набор атрибутов (EmployeeID, FirstName и LastName). Следующая схема была немного изменена для возврата дополнительного атрибута ReportsTo для всех <элементов Emp> , которые передают отчеты руководителю.
Например, этот XML-фрагмент показывает подчиненных служащего 1:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2"
ReportsTo="1" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3"
ReportsTo="1" LastName="Leverling">
...
...
Ниже приведена измененная схема:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:documentation>
Customer-Order-Order Details Schema
Copyright 2000 Microsoft. All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
 All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
Заметка sql:max-depth
В схеме, состоящей из рекурсивных связей, глубина рекурсии должна быть явно указана в схеме. Это необходимо для успешной подготовки соответствующего запроса FOR XML EXPLICIT, который возвращает запрошенные результаты.
Это необходимо для успешной подготовки соответствующего запроса FOR XML EXPLICIT, который возвращает запрошенные результаты.
Используйте заметку sql:max-depth в схеме, чтобы указать глубину рекурсии в рекурсивной связи, описанной в схеме. Значение заметки sql:max-depth является положительным целым числом (от 1 до 50), которое указывает количество рекурсий: значение 1 останавливает рекурсию в элементе, для которого задана заметка sql:max-depth ; значение 2 останавливает рекурсию на следующем уровне от элемента, в котором указан параметр sql:max-depth ; и так далее.
Примечание
В базовой реализации запрос XPath, указанный в схеме сопоставления, преобразуется в select … ЗАПРОС FOR XML EXPLICIT. Для этого запроса необходимо указать конечную глубину рекурсии. Чем выше значение, указанное для параметра sql:max-depth, тем больше созданный запрос FOR XML EXPLICIT. Это может увеличить время выборки.
Примечание
Диаграммы обновления и массовая загрузка XML не учитывают заметку max-depth. Это означает, что рекурсивные обновления и вставки будут происходить независимо от значения, заданного для max-depth.
Задание sql:max-depth для сложных элементов
Заметку sql:max-depth можно указать в любом сложном элементе содержимого.
Рекурсивные элементы
Если параметр sql:max-depth указан как для родительского, так и для дочернего элемента в рекурсивной связи, то заметка sql:max-depth, указанная в родительском элементе, имеет приоритет. Например, в следующей схеме заметка sql:max-depth указывается для родительского и дочернего элементов employee. В этом случае приоритет имеет sql:max-depth=4, указанный в <родительском элементе Emp> (который играет роль супервизора). Значение sql:max-depth , указанное в дочернем <элементе Emp> (играющем роль контролируемого), игнорируется.
Пример Б
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo"
sql:max-depth="3" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="2" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Для проверки этой схемы выполните шаги, приведенные для образца А ранее в этом разделе.
Нерекурсивные элементы
Если заметка sql:max-depth указана в элементе схемы, который не вызывает рекурсии, она игнорируется. В следующей схеме <элемент Emp> состоит из дочернего <элемента Constant> , который, в свою очередь, имеет дочерний <элемент Emp> .
В этой схеме заметка sql:max-depth, указанная для <элемента Constant> , игнорируется, так как рекурсия между <родительским элементом Emp> и дочерним <элементом Constant> отсутствует. Но есть рекурсия между <предком Эмп> и ребенком <Эмп> . Схема указывает заметку sql:max-depth для обоих. Поэтому заметка sql:max-depth , указанная в предке (<Emp> в роли супервизора), имеет приоритет.
Пример В
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
child="Emp"
parent-key="EmployeeID"
child-key="ReportsTo"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
sql:relation="Emp"
type="EmpType"
sql:limit-field="ReportsTo"
sql:max-depth="1" />
<xsd:complexType name="EmpType" >
<xsd:sequence>
<xsd:element name="Constant"
sql:is-constant="1"
sql:max-depth="20" >
<xsd:complexType >
<xsd:sequence>
<xsd:element name="Emp"
sql:relation="Emp" type="EmpType"
sql:relationship="SupervisorSupervisee"
sql:max-depth="3" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
Для проверки этой схемы выполните шаги, приведенные для примера А ранее в этом разделе.
Сложные типы, наследуемые по ограничению
Если у вас есть наследование сложного типа по ограничению<>, элементы соответствующего базового сложного типа не могут указывать заметку sql:max-depth. В таких случаях заметку sql:max-depth можно добавить в элемент производного типа.
С другой стороны, если у вас есть сложный тип, производный от <расширения>, элементы соответствующего базового сложного типа могут указывать заметку sql:max-depth .
Например, следующая схема XSD создает ошибку, так как заметка sql:max-depth указана в базовом типе. Эта заметка не поддерживается для типа, наследуемого ограничением<> от другого типа. Чтобы устранить эту проблему, необходимо изменить схему и указать заметку sql:max-depth для элемента в производном типе.
Пример Г
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:msdata="urn:schemas-microsoft-com:mapping-schema">
<xsd:complexType name="CustomerBaseType">
<xsd:sequence>
<xsd:element name="CID" msdata:field="CustomerID" />
<xsd:element name="CompanyName"/>
<xsd:element name="Customers" msdata:max-depth="3">
<xsd:annotation>
<xsd:appinfo>
<msdata:relationship
parent="Customers"
parent-key="CustomerID"
child-key="CustomerID"
child="Customers" />
</xsd:appinfo>
</xsd:annotation>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="Customers" type="CustomerType"/>
<xsd:complexType name="CustomerType">
<xsd:complexContent>
<xsd:restriction base="CustomerBaseType">
<xsd:sequence>
<xsd:element name="CID"
type="xsd:string"/>
<xsd:element name="CompanyName"
type="xsd:string"
msdata:field="CName" />
<xsd:element name="Customers"
type="CustomerType" />
</xsd:sequence>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
</xsd:schema>
В схеме sql:max-depth указывается в сложном типе CustomerBaseType . Схема также указывает <элемент Customer> типа CustomerType, который является производным от CustomerBaseType. Запрос XPath, указанный в такой схеме, вызовет ошибку, так как sql:max-depth не поддерживается для элемента, определенного в базовом типе ограничения.
Схема также указывает <элемент Customer> типа CustomerType, который является производным от CustomerBaseType. Запрос XPath, указанный в такой схеме, вызовет ошибку, так как sql:max-depth не поддерживается для элемента, определенного в базовом типе ограничения.
Схемы с глубокой иерархией
Схема может иметь глубокую иерархию, в которой элемент содержит дочерний элемент, который в свою очередь содержит другой дочерний элемент, и т. д. Если заметка sql:max-depth , указанная в такой схеме, создает XML-документ, включающий иерархию из более чем 500 уровней (с элементом верхнего уровня на уровне 1, его дочерним элементом на уровне 2 и т. д.), возвращается ошибка.
НОУ ИНТУИТ | Лекция | Средства формулировки аналитических и рекурсивных запросов
< Лекция 9 || Лекция 6: 123456
Аннотация: В этой лекции мы завершаем обсуждение средств выборки данных языка SQL коротким описанием сравнительно недавно появившихся в языке SQL средств формулировки аналитических и рекурсивных запросов.
Ключевые слова: SQL, стандарт SQL:1999, аналитический запрос к базе данных, рекурсивный запрос, заработная плата, агрегатные функции, СУБД, Внешняя сортировка, агрегирование, динамическая, базы данных, OLTP, оперативная аналитическая обработка баз данных, OLAP, стандарт языка, разделы, раздел GROUP BY ROLLUP, раздел GROUP BY CUBE, агрегатная функция GROUPING, неопределенное значение, операторы SQL, частное решение, логическое программирование, Prolog, реляционная база данных, рекурсивный запрос с разделом WITH, выражение, линейная рекурсия, взаимная рекурсия, рекурсивное определение, расходы, основные средства, таблица, EMP, ORDER, определение столбца, контекст, обход дерева в ширину, обход дерева в глубину, цикл в ориентированном графе, Ориентированный граф, прямая рекурсия, виртуальная таблица, подзапрос, монотонная прогрессия, отрицание, INTERSECT, distinction, начальный источник рекурсии, рекурсивные вычисления, стратификация, семантика фиксированной точки, конструкция SEARCH, cycle, CAR, атомарность, UNION, шасси, частичный результат, потомок, раздел CYRCLE, значение выражения, тип символьной строки, Типы данных столбцов, рекурсивное представление, recursive
Введение
 intuit.ru/2010/edi»>Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
intuit.ru/2010/edi»>Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.В аналитических приложениях обычно требуются не детальные данные, непосредственно хранящиеся в базе данных, а некоторые их обобщения, агрегаты. Например, аналитика интересует не заработная плата конкретного человека в конкретное время, а изменение заработной платы некоторой категории людей в течение определенного промежутка времени. Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются «трудными» для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются «трудными» для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
В системах баз данных, специально спроектированных в расчете на аналитические приложения, проблему обычно решают за счет явного избыточного хранения агрегированных данных (т.е. результатов вызовов агрегатных функций). Конечно, для этого требуется динамическая корректировка хранимых агрегатных значений при изменении детальных данных, но для таких специализированных баз данных это не слишком обременительно, поскольку аналитические базы данных обновляются сравнительно редко.
 intuit.ru/2010/edi»>Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки ( OLAP ). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
intuit.ru/2010/edi»>Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки ( OLAP ). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.Разработчики стандарта языка SQL старались одновременно решить две задачи: сократить число запросов, требуемых в аналитических приложениях, и добиться снижения стоимости запросов с разделом GROUP BY, обеспечивающих требуемые суммарные данные. В этой лекции мы обсудим наиболее важные, с нашей точки зрения, конструкции языка SQL, облегчающие формулировку, выполнение и использование результатов аналитических запросов: разделы GROUP BY ROLLUP и GROUP BY CUBE и новую агрегатную функцию GROUPING , позволяющую правильно трактовать результаты аналитических запросов при наличии неопределенных значений.
Традиционно язык SQL никогда не обладал возможностью формулировки рекурсивных запросов, где под рекурсивным запросом (упрощенно говоря) мы понимаем запрос к таблице, которая сама каким-либо образом изменяется при выполнении этого запроса. Напомню, что это заложено в базовую семантику оператора SQL: до выполнения раздела WHERE результат раздела FROM должен быть полностью вычислен.
Однако разработчикам приложений часто приходится решать задачи, для которых недостаточно традиционных средств формулировки запросов языка SQL: например, нахождение маршрута движения между двумя заданными географическими точками, определения общего набора комплектующих для сбора некоторого агрегата и т.д. Компании-производители SQL-ориентированных СУБД пытались удовлетворять такие потребности за счет частных решений, обладающих ограниченными рекурсивными свойствами, но до появления стандарта SQL:1999 общие стандартизованные средства отсутствовали.
Следует отметить и некоторое давление на SQL-сообщество со стороны сообщества логических систем баз данных. На основе языка логического программирования Prolog был разработан язык реляционных баз данных Datalog, обеспечивающий все необходимые средства для обычной работы с базами данных наряду с развитыми возможностями рекурсивных запросов. Требовался адекватный ответ со стороны разработчиков стандарта SQL.
Компромиссное (не слишком красивое) решение для введения рекурсии в SQL было найдено на основе введения раздела WITH в выражение запроса. Только в этом разделе допускается как линейная, так и взаимная рекурсия между вводимыми порождаемыми таблицами. При этом только для линейной рекурсии обеспечиваются дополнительные возможности управления порядком вычисления рекурсивно определенной порождаемой таблицы и контроля отсутствия циклов. Следует заметить, что при чтении стандарта временами возникает впечатление, что его авторы сами не до конца еще осознали всех возможных последствий, к которым может привести использование введенных конструкций. Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Дальше >>
< Лекция 9 || Лекция 6: 123456
рекурсивных SQL-запросов с PostgreSQL | by Martin Heinz
Common Table Expression — менее известная функция SQL, позволяющая писать рекурсивные запросы. Давайте изучим это с помощью PostgreSQL!
Опубликовано в
·
Чтение: 6 мин.
·
16 марта 2020 г. 015 ВЫБЕРИТЕ , ОБНОВЛЕНИЕ (CRUD-операции), несколько JOIN s и WHERE , и на этом все. Но иногда вы будете сталкиваться с наборами данных и задачами, которые потребуют от вас использования гораздо более продвинутых функций SQL. Одним из них является CTE или общее табличное выражение и, более конкретно, Recursive CTE , которое мы можем использовать для выполнения рекурсивных запросов SQL. Давайте посмотрим, как это работает и что мы можем с этим сделать!
Давайте посмотрим, как это работает и что мы можем с этим сделать!
Во-первых, зачем вообще это нужно? Для чего нужны рекурсивные запросы? — В общем, рекурсивные запросы удобны при работе с самореферентными данными или графическими/древовидными структурами данных. Вот лишь несколько примеров таких вариантов использования:
Самореферентные данные:
- Менеджер -> Подчиненный (сотрудник) связь
- Категория -> Подкатегория -> Товар связь
- Графики — Карта полета (Путешествие на самолете)
- Любая система таксономии — книги, животные, генетика…
- Ссылки между статьями — например, в Википедии
- Раздел комментариев — например темы на Reddit
- Создать массив —
МАССИВ[значение_1, значение_2] - Объединить массив —
МАССИВ[значение_1, значение_2] || МАССИВ[значение_3] -
ВСЕфункция -"x" != ВСЕ(МАССИВ["a", "b", "c"])- сравнивает"x"для каждого значения в массиве, результат равенtrue, если все сравнения приводят кtrue
9 0043
Деревья:
Для любого из этих примеров вам потребуется построить временные таблицы или использовать курсоры чтобы получить полезные данные из таких наборов данных. Теперь, когда я, надеюсь, убедил вас в том, что рекурсивные запросы весьма полезны, давайте посмотрим, что они из себя представляют и как мы можем их использовать.
Рекурсивные запросы используют то, что называется CTE — Common Table expression , которое представляет собой предложение SQL WITH , чаще используемое для упрощения очень сложных запросов (подзапросов). Давайте посмотрим на пример этого:
Это очень простой пример, но вы, конечно, можете себе представить, как его можно использовать, чтобы сделать очень сложные запросы, содержащие несколько подзапросов, более читабельными.
Помимо приведенного выше синтаксиса, нам также потребуются некоторые данные, которые мы можем использовать для наших рекурсивных запросов. Для этого мы будем использовать Менеджер — подчиненная иерархия , использующая одну самоссылающуюся таблицу, определенную следующим образом:
Таблица сотрудников
Вот SQL для создания такой таблицы, включая некоторые данные для игры: запросы!
Повторять — человечно, повторять — божественно — Л. Питер Дойч
Начнем с формальной структуры рекурсивного SQL-запроса:
Это выглядит довольно просто, но мало что нам говорит, поэтому давайте см. удобочитаемый пример:
удобочитаемый пример:
И вывод этого запроса:
В этом примере наш нерекурсивный базовый случай — это просто SELECT 1 , а рекурсивная часть — SELECT n+1 FROM nums WHERE n+1 <= 10 . Эта часть создает рекурсию, ссылаясь на имя CTE ( nums ) и объединяя все результаты. В конце у нас есть предложение WHERE для завершения рекурсии, чтобы наш запрос не выполнялся бесконечно.
В предыдущем разделе был показан очень простой пример, который объясняет, как это работает, но не показывает, как рекурсивный CTE может нам помочь. Итак, давайте рассмотрим несколько примеров, используя данные иерархии Менеджер — Подчиненный сверху: по сути, это поддерево, начинающееся с какого-то конкретного сотрудника. В качестве базового случая здесь мы выбираем одного сотрудника (менеджера) по идентификатору, а также включаем уровень , чтобы указать, на сколько уровней вниз мы спустились в дереве. В рекурсивной части мы
В рекурсивной части мы ПРИСОЕДИНЯЙТЕ таблицу сотрудников к CTE ( менеджеров ), используя идентификаторы менеджеров. Опять же, мы включаем уровня , увеличивая уровень результатов предыдущего шага рекурсии. Вот результат:
Чтобы лучше представить, что там происходит, посмотрите на следующее дерево. Выделенная часть — это то, что возвращает запрос:
Другой практический пример с использованием тех же данных — вычисление степеней разделения между двумя сотрудниками :
Рекурсивный CTE очень похож на тот, что был в предыдущем примере. Для упрощения мы выбираем только ID и градусов (вместо уровня). Затем нам нужен запрос, который ищет и сообщает нам степени разделения для 2 сотрудников — для этого мы присоединяем таблицу сотрудников к нашей ранее созданной таблице rec , содержащей идентификаторы, и степеней , используя идентификаторы в соответствующих таблицах. В заключительной части
В заключительной части SELECT мы немного форматируем, чтобы получить более приятный результат, а в WHERE 9В пункте 0016 мы дополнительно указываем другого (второго) сотрудника, для которого мы хотим получить степени разделения. Вывод:
Опять же, играя с теми же данными, давайте выясним, какой может быть прогресс работы в гипотетической компании:
На этот раз мы запускаем рекурсию снизу вверх. Это достигается путем перестановки пункта ON по сравнению с предыдущими примерами. Чтобы создать читаемый вывод, мы используем функцию STRING_AGG , которая берет строки сверху SELECT и объединяет их, используя > в качестве разделителя. Вот что дает нам запрос:
Достаточно набора данных сотрудника , давайте посмотрим, что мы можем сделать с графами — графы как структура данных являются идеальным кандидатом для обхода с использованием рекурсии. Итак, давайте сначала определим простую таблицу и вставим некоторые данные, чтобы нам было с чем поиграть:
График
В качестве примера мы сделаем очевидную вещь — найдем пути в виде графика. Для этого нам понадобится PostgreSQL 9.0024 специальный —
Для этого нам понадобится PostgreSQL 9.0024 специальный — МАССИВ тип данных. Массивы не являются обычной функцией реляционных баз данных, но здесь они очень удобны для хранения путей. Если вы не знакомы с этим типом данных, то для понимания SQL вам понадобятся следующие вещи:
Хорошо, теперь для запроса:
Приведенный выше запрос сначала выбирает всех прямых соседей в нерекурсивном случай. Затем в рекурсивной части мы основываемся на базовом случае (и во время последующих итераций на предыдущих рекурсивных случаях) и добавляем доступное ребро к существующим путям и заменяем пункт назначения тем же ребром. Мы делаем это для каждой строки, где конец существующего пути (
Мы делаем это для каждой строки, где конец существующего пути ( dest ) совпадает с началом выбранного ребра и где новый пункт назначения еще не находится на пути (для предотвращения циклов). И это полный вывод:
Помимо полезных вещей выше, вы также можете использовать рекурсивную CTE с бесконечными потоками данных:
Рекурсивная таблица строится итеративно с каждым шагом, и каждый шаг создает конечное количество строк. , поэтому можно использовать LIMIT для получения первых n строк из бесконечного запроса!
В качестве небольшого бонуса я также хочу показать, что возможно (начиная с PostgreSQL 9.3) даже создавать рекурсивные представления:
Хотя это просто синтаксический сахар, он может облегчить вашу жизнь при работе с некоторыми рекурсивных запросов и данных.
Рекурсия — очень мощный инструмент, который может решить некоторые проблемы очень элегантным способом. Однако использование его с SQL не так распространено, поэтому, надеюсь, эта статья показала вам несколько способов его использования на случай, если вы столкнетесь с данными, которые можно обрабатывать только рекурсивно.
Рекурсия, однако, может сделать ваш код менее читаемым, поэтому используйте ее экономно, особенно с SQL, так как часто не так просто разобрать и понять даже без рекурсии.
Первоначально эта статья была опубликована по адресу martinheinz.dev
Рекурсивный запрос SQL Server с рекурсивным CTE (выражение общей таблицы)
Структура SQL Server Recursive Query впервые представлена с улучшением SQL Server 2005 Common Table Expression .
CTE (Common Table Expression) имеет широкую область применения в программировании T-SQL.
Но что делает CTE незаменимым при разработке SQL, так это его рекурсивный запрос особенности создания.
Рекурсивный запрос SQL Server состоит из трех разделов.
WITH RecursiveCTEQuery AS (
{Якорный запрос}
UNION ALL
{Запрос присоединен к RecursiveCTEQuery}
)
SELECT * FROM RecursiveCTEQuery
Код
Якорный запрос в рекурсивном CTE-запросе — это первый раздел.
Якорный запрос — это стартовая строка для рекурсии.
Например, в якорном запросе вы выбираете элемент верхнего уровня.
Или вы выбираете конкретную строку, используя предложение WHERE в якорном запросе.
Якорный запрос — это первая строка в первой рекурсии выражения CTE.
Вторая часть рекурсивного выражения CTE SQL — это оператор SELECT из целевой таблицы.
Обычно это та же таблица, которая используется в якоре SELECT.
Но на этот раз это INNER JOIN с рекурсивным CTE.
Условие INNER JOIN определяет, переходите ли вы к более высоким уровням или запрашиваете более низкие уровни.
Это выражение INNER JOIN устанавливает отношение родитель/потомок между строками в основной таблице sql.
Результирующие наборы внутренних разделов CTE объединяются в один возвращаемый набор с использованием выражения UNION ALL
Последний раздел — это инструкция SELECT, которая запрашивает само CTE.
Предположим, что компания, которую мы собираемся использовать в примерах рекурсивных запросов SQL Server, называется Adventure Works Cycle.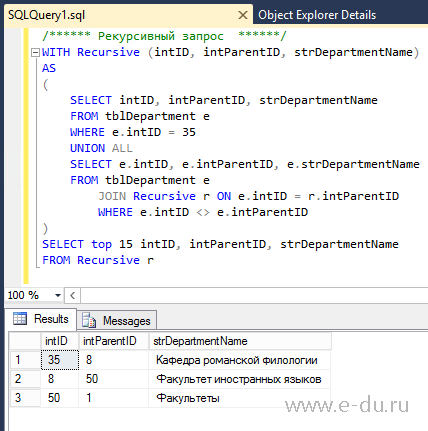
И предположим, что иерархическая организационная структура компании Adventure Works Cycle выглядит следующим образом.
Как обычно, на диаграмме есть родительские и дочерние организационные единицы, представляющие иерархическую структуру.
Это родительские/дочерние строки в нашей таблице базы данных, где мы скоро разработаем для хранения иерархической структуры компании.
Таблица OrganizationalStructures очень проста по дизайну.
Он имеет столбец со ссылкой на себя ParentUnitID, который ссылается на поле BusinessUnitID организационной единицы на один уровень выше.
Сразу после команды SQL CREATE TABLE образец данных для приведенной выше организационной схемы заполняется с помощью команды SQL INSERT INTO.
Мы будем использовать эту таблицу sql и данные в ней для примеров рекурсивных запросов SQL Server в этом руководстве по T-SQL.
Создание организационных структур таблицы (
BusinessUnitid Smallint Identity (1,1),
BusinessUnit varchar (100) не нулевой,
ParentUnitid Smallint
)
Вставка в значения организационных структур
(«Цикл приключенческих работ», NULL),
('Cupporting Care', 1), «
(«Сервис», 1),
(«Продажи и маркетинг», 1),
(«Поддержка клиентов», 2),
(«Поддержка OEM», 2),
(«Центральный регион», 3) ,
(«Восточный регион», 3),
(«Западный регион», 3),
(«OEM», 4),
(«Сбытовой маркетинг», 4),
(«Национальные счета», 4),
(«Продажи на местах», 4),
(«Маркетинг через национальные каналы», 11),
(«Маркетинг через розничные каналы», 11),
(«Центральный регион», 13),
(«Восточный регион», 13),
(«Западный регион», 13),
(«Велосипеды», 15),
(«Велозапчасти», 15)
Код
Давайте посмотрим, как выглядят данные нашего примера, используя команду SQL SELECT.
выберите * из организационных структур
Код
В этом учебном пособии по SQL с использованием рекурсивного CTE (Common Table Expression) программисты SQL вскоре смогут запрашивать иерархические данные SQL и возвращать список бизнес-единиц, связанных друг с другом с родительскими/дочерними свойствами
Следующее CTE-Common Table Expression является образцом рекурсивного запроса SQL Server .
Приведенный ниже рекурсивный запрос SQL возвращает список строк из OrganizationalStructures, для которых BusinessUnitID равен 1, и подэлементы этой строки привязки.
WITH Recursive_CTE AS (
SELECT
child.BusinessUnitID,
child.BusinessUnit,
CAST(child.ParentUnitID as SmallInt) ParentUnitID,
CAST(NULL as varchar(100)) ParentUnit
FROM OrganizationalStructures дочерний
WHERE BusinessUnitID = 1
UNION ALL
SELECT
child.BusinessUnitID,
child.BusinessUnit,
child. ParentUnitID,
ParentUnitID,
parent.BusinessUnit ParentUnit
FROM Recursive_CTE parent
INNER JOIN OrganizationalStructures дочерний ON child.ParentUnitID = parent .BusinessUnitID
)
SELECT * FROM Recursive_CTE
Код
Наш первый рекурсивный CTE-запрос SQL Server возвращает все записи в таблице, поскольку выбор привязки возвращает элемент верхнего уровня в иерархии организационной диаграммы.
Конечно, важно создавать повторно используемый код на SQL, как и на других языках программирования.
Разработчики TSQL могут сохранить приведенный выше рекурсивный запрос SQL Server в хранимой процедуре, внеся простые изменения в выражение CTE, чтобы сделать его параметрическим.
Мы можем изменить привязку SELECT во внутреннем выражении CTE, чтобы изменить рекурсивный запрос.
Как видно из следующего кода t-sql, запрос привязки возвращает строки с BusinessUnitID, равным значению параметра хранимой процедуры @BusinessUnitID.
Собственно, это все изменения, необходимые для создания параметрических рекурсивных запросов.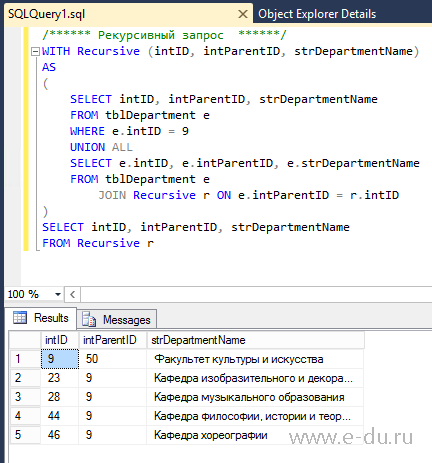
CREATE PROCEDURE sp_ListOrganizationalStructuresOf (
@BusinessUnitID smallint
)
AS
WITH Recursive_CTE AS (
SELECT
child.BusinessUnitID,
child.BusinessUnit,
CAST(child.ParentUnitID as SmallInt) ParentUnitID,
CAST(NULL as varchar(100)) ParentUnit
FROM OrganizationalStructures дочерний
WHERE BusinessUnitID = @BusinessUnitID
UNION ALL
SELECT
child.BusinessUnitID,
child.BusinessUnit,
child.ParentUnitID,
parent.BusinessUnit ParentUnit
FROM Recursive_CTE parent
INNER JOIN OrganizationalStructures дочерний ON child.ParentUnitID = parent.BusinessUnitID
)
SELECT * FROM Recursive_CTE 90 228 GO
EXEC sp_ListOrganizationalStructuresOf 11
Код
Сразу после создания хранимой процедуры я выполнил SP для возврата бизнес-единиц, определенных ниже Channel Marketing (прямой или косвенный комбинированный)
Давайте изменим приведенный выше рекурсивный запрос SQL Server, чтобы добавить некоторую подробную информацию об иерархии и придать некоторые визуальные эффекты следующим образом:
WITH Recursive_CTE AS (
SELECT
child. BusinessUnitID,
BusinessUnitID,
CAST(child.BusinessUnit as varchar(100)) BusinessUnit,
CAST(child.ParentUnitID as SmallInt) ParentUnitID,
CAST(NULL as varchar(1) 00)) Родительский блок,
CAST ('>> ' as varchar(100)) LVL,
CAST(child.BusinessUnitID as varchar(100)) Иерархия,
1 AS RecursionLevel
FROM OrganizationalStructures дочерний элемент
WHERE BusinessUnitID = 1
UNION ALL
SELECT
child.BusinessUnitID,
CAST(LVL + child.BusinessUnit as varchar (100)) AS BusinessUnit,
child.ParentUnitID,
parent.BusinessUnit ParentUnit,
CAST('>> ' + LVL as varchar(100)) AS LVL,
CAST(Hierarchy + ':' + CAST(child.BusinessUnitID as varchar(100)) as varchar(100)) Hierarchy,
RecursionLevel + 1 AS RecursionLevel
FROM Recursive_CTE parent
INNER JOIN OrganizationalStructures дочерний ON child.ParentUnitID = parent.BusinessUnitID
)
SELECT * FROM Recursive_CTE ORDER BY Hierarchy
Код
Вывод приведенного выше SQL-рекурсивного запроса CTE будет выглядеть следующим образом:
Я надеюсь, что разработчикам SQL так же, как и мне, понравится структура рекурсивных запросов SQL Server.