Рекурсивный запрос sql: Изучение SQL: рекурсивные запросы
Содержание
рекурсия — ms sql задача по рекурсии
Поскольку опыта нет, рассмотрим рекурсивные выражения и затем применим их на практике.
Рекурсия имеет свойство хранить в себе память любых предыдущих значений. Зависит от реализации. Как правило это предыдущие значения. В нашем примере также будем использовать корневое значение. Какое значение? Интересует зарплата.
Рекурсия в SQL CTE
Рекурсивное выражение состоит из двух частей: корневая (ancor member expression) и рекурсивная (recursive member expression)
В корневой части составляется обыкновенный запрос на выборку и задается общая структура полей в выражении:
SELECT
e.Salary
, e.ID
, e.ManagerID
, 0 AS Stack
FROM employees e
В рекурсивной части — запрос который будет добавляться к предыдущей (пока что корневой) записи с помощью оператора UNION :
UNION ALL
-- recursive member expression
SELECT e. Salary
, e.ID
, e.ManagerID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
Salary
, e.ID
, e.ManagerID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
 Salary
, e.ID
, e.ManagerID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
Salary
, e.ID
, e.ManagerID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
Если собрать из этих двух частей выражение:
; WITH __cte AS
(
-- ancor member expression
SELECT e.Salary
, e.ID
, e.ManagerID
, 0 AS Stack
FROM employees e
UNION ALL
-- recursive member expression
SELECT e.Salary
, e.ID
, e.ManagerID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
)
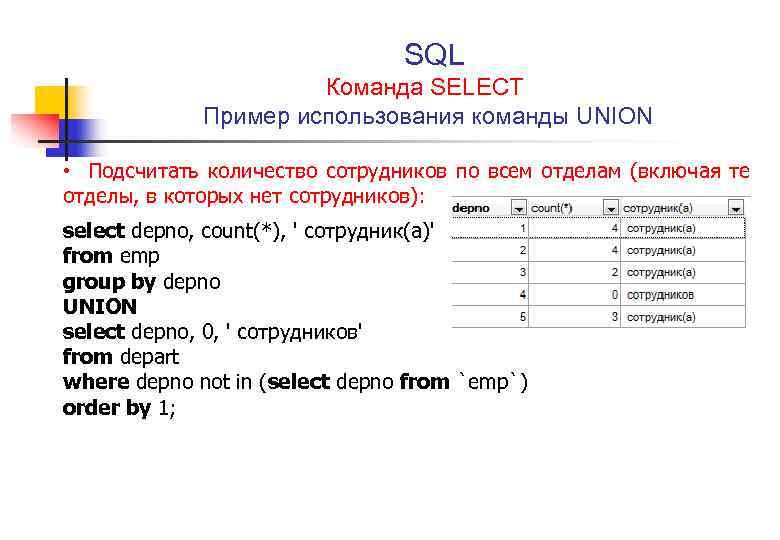
SELECT c.ID, c.Salary, c.Stack
from __cte c
order by id, Stack
и запустить его — будет получена выборка по всему персоналу с обходом их подчиненных:
Как можно заметить, здесь уже участвует «предыдущее» значение Stack.
Применение рекурсии
Для начала, я позволил себе расширить входные данные, чтоб покрыть больше случаев:
В корневую часть запроса добавил проекцию на зарплату, разницу и айди с которым идет сравнение (для трассировки):
-- ancor member expression
SELECT e.Salary
, e.ID
, e.ManagerID
-- порядок полей очень важен
, e.Salary AS RootSalary
, 0 AS RootSalaryDiff
, e.ID AS RootID
, 0 AS Stack
FROM employees e
А в рекурсивной части — некоторые из значений изменяю, что делает их как бы «предыдущими» или назовем лучше рекурсивными, а другую часть значений оставил без изменений, сделав их корневыми :
UNION ALL
-- recursive member expression
SELECT e.Salary
, e. ID
, e.ManagerID
-- порядок полей очень важен
, c.RootSalary AS RootSalary
, c.RootSalary - e.Salary AS RootSalaryDiff
, c.RootID AS RootID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
 ID
, e.ManagerID
-- порядок полей очень важен
, c.RootSalary AS RootSalary
, c.RootSalary - e.Salary AS RootSalaryDiff
, c.RootID AS RootID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
ID
, e.ManagerID
-- порядок полей очень важен
, c.RootSalary AS RootSalary
, c.RootSalary - e.Salary AS RootSalaryDiff
, c.RootID AS RootID
, c.Stack + 1 AS Stack
FROM employees e
JOIN __cte c
ON c.Id = e.ManagerID
Эти две части работают согласно принципам рекурсии и логике работы оператора FROM — в выражении выполняется вычитание «корневой» зарплаты с текущей (это всё что нас интересует в задаче), а оператор FROM сделает полный обход записей табличного выражения. Грубо говоря пройдется по всем сотрудникам.
Перебор данного табличного выражения осуществляется следующим образом:
SELECT c.ID AS ID , c.Salary AS Salary , c.RootID AS RootID -- , c.RootSalary AS RootSalary , c.
 RootSalaryDiff AS RootSalaryDiff
-- , c.Stack AS Stack
from __cte c
where c.RootSalaryDiff < 0
order by id, RootID
RootSalaryDiff AS RootSalaryDiff
-- , c.Stack AS Stack
from __cte c
where c.RootSalaryDiff < 0
order by id, RootID
Как и сказано выше — делается обход по записям сотрудников, при необходимости — выполняется объединение (рекурсия), а результат фильтруется по разнице зарплаты — она должна быть меньше нуля. То есть это индикатор что интересующий нас кадр получает на Х денег больше чем конкретный его начальник прямой или косвенный (RootID).
Результат выборки:
Трассируем. Для краткости «Сотрудник» обозначим С:
С1 получает 100 уе в его прямом подчинении С2, С4 которые получают 200 и 150 уе соответственно. Выборка говорит - С2 и С4 получают на 100 и 50 больше уе соответственно. косвенно ему подчиняются С3, С5 и С6, с окладами 150, 50 и 175 соответственно. Выборка - С3, С6 на 50 и 75 соответственно С3 получает 150 уе и у него только в прямом подчинении С5 и С6, с окладами 50 и 175. Выборка - С6 получает на 25 больше.
Постановка задачи удовлетворена
И полный код — бери запускай (на базе my_dev под SQL Server): https://pastebin. com/gt1vzHyt
com/gt1vzHyt
Настройка рекурсивных связей глубины с помощью sql:max-depth — SQL Server
-
Статья -
- Чтение занимает 7 мин
-
Применимо к: SQL Server (все поддерживаемые версии) Azure SQL базе данных
В реляционных базах данных участие таблицы в связи с самой собой называется рекурсивной связью. Например, таблица, в которой содержатся записи о сотрудниках и возможны связи «начальник-подчиненный», участвует в связи сама с собой. В этом случае таблица сотрудников выполняет роль начальника на одной стороне связи и та же таблица выполняет роль подчиненного на другой стороне.
Схемы сопоставления могут включать рекурсивные связи, в которых элемент и его предок относятся к одному типу.
Пример A
Рассмотрим следующую таблицу.
Emp (EmployeeID, FirstName, LastName, ReportsTo)
В этой таблице столбец ReportsTo содержит идентификатор служащего для менеджера.
Предположим, что нужно сформировать XML-иерархию служащих, на вершине которой находится менеджер, а служащие, подчиненные менеджеру, отображаются в соответствующей иерархии, как показано в следующем образце XML-фрагмента. Этот фрагмент показывает рекурсивное дерево для сотрудника 1.
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3" LastName="Leverling">
<Emp FirstName="Margaret" EmployeeID="4" LastName="Peacock">
<Emp FirstName="Steven" EmployeeID="5" LastName="Devolio">
...
...
</root>
В этом фрагменте служащий 5 подчинен служащему 4, служащий 4 подчинен служащему 3, а служащие 3 и 2 подчинены служащему 1.
Чтобы получить этот результат, можно использовать следующую схему XSD и указать запрос XPath к ней. Схема описывает <элемент Emp> типа EmployeeType, состоящий из <дочернего элемента Emp> того же типа EmployeeType. Это рекурсивная связь (элемент и его предок относятся к одному типу). Кроме того, схема использует <sql:relationship> для описания связи «родители-потомки» между руководителем и контролестом. Обратите внимание, что в этом <sql:relationship> Emp является родительской и дочерней таблицей.
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Поскольку связь рекурсивная, необходимо каким-то образом указать глубину рекурсии в схеме. В противном случае результатом будет бесконечная рекурсия (служащий, подчиненный служащему, подчиненному служащему, и т. д.). Заметка sql:max-depth позволяет указать глубину рекурсии. В этом конкретном примере, чтобы указать значение для sql:max-depth, необходимо знать, насколько глубоко иерархия управления идет в компании.
В противном случае результатом будет бесконечная рекурсия (служащий, подчиненный служащему, подчиненному служащему, и т. д.). Заметка sql:max-depth позволяет указать глубину рекурсии. В этом конкретном примере, чтобы указать значение для sql:max-depth, необходимо знать, насколько глубоко иерархия управления идет в компании.
Примечание
Схема задает заметку sql:limit-field , но не указывает заметку sql:limit-value . Это ограничивает верхний узел в результирующей иерархии только служащими, которые не подчиняются никому. (ReportsTo имеет значение NULL.) Указание sql:limit-field и не указание заметки sql:limit-value (по умолчанию равно NULL) выполняет это. Если вы хотите, чтобы полученный XML-код включал все возможные деревья отчетов (дерево отчетов для каждого сотрудника в таблице), удалите заметку sql:limit-field из схемы.
Примечание
В следующей процедуре используется база данных tempdb.
Проверка образца запроса XPath к схеме
Создайте образец таблицы с именем Emp в базе данных tempdb, на которую указывает виртуальный корневой каталог.
USE tempdb CREATE TABLE Emp ( EmployeeID int primary key, FirstName varchar(20), LastName varchar(20), ReportsTo int)Добавьте следующий образец данных:
INSERT INTO Emp values (1, 'Nancy', 'Devolio',NULL) INSERT INTO Emp values (2, 'Andrew', 'Fuller',1) INSERT INTO Emp values (3, 'Janet', 'Leverling',1) INSERT INTO Emp values (4, 'Margaret', 'Peacock',3) INSERT INTO Emp values (5, 'Steven', 'Devolio',4) INSERT INTO Emp values (6, 'Nancy', 'Buchanan',5) INSERT INTO Emp values (7, 'Michael', 'Suyama',6)
Скопируйте приведенный выше код схемы и вставьте его в текстовый файл. Сохраните файл под именем maxDepth.xml.
Скопируйте следующий шаблон и вставьте его в текстовый файл. Сохраните файл под именем maxDepthT.
xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.<ROOT xmlns:sql="urn:schemas-microsoft-com:xml-sql"> <sql:xpath-query mapping-schema="maxDepth.xml"> /Emp </sql:xpath-query> </ROOT>Путь к каталогу схемы сопоставления (файл maxDepth.xml) задается относительно каталога, в котором сохранен шаблон. Можно также задать абсолютный путь, например:
mapping-schema="C:\MyDir\maxDepth.xml"
Создайте и запустите тестовый скрипт SQLXML 4.0 (Sqlxml4test.vbs), чтобы выполнить шаблон. Дополнительные сведения см. в разделе «Использование ADO для выполнения запросов SQLXML 4.0».
 xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.
xml в том же каталоге, где был сохранен файл maxDepth.xml. Запрос в шаблоне возвращает всех сотрудников в таблице Emp.Результат:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3" LastName="Leverling">
<Emp FirstName="Margaret" EmployeeID="4" LastName="Peacock">
<Emp FirstName="Steven" EmployeeID="5" LastName="Devolio">
<Emp FirstName="Nancy" EmployeeID="6" LastName="Buchanan">
<Emp FirstName="Michael" EmployeeID="7" LastName="Suyama" />
</Emp>
</Emp>
</Emp>
</Emp>
</Emp>
</root>
Примечание
Чтобы создать различные глубины иерархий в результате, измените значение заметки sql:max-depth в схеме и снова выполните шаблон после каждого изменения.
В предыдущей схеме все <элементы Emp> имели точно одинаковый набор атрибутов (EmployeeID, FirstName и LastName). Следующая схема была немного изменена, чтобы вернуть дополнительный атрибут ReportsTo для всех <элементов Emp> , которые сообщают руководителю.
Например, этот XML-фрагмент показывает подчиненных служащего 1:
<?xml version="1.0" encoding="utf-8" ?>
<root>
<Emp FirstName="Nancy" EmployeeID="1" LastName="Devolio">
<Emp FirstName="Andrew" EmployeeID="2"
ReportsTo="1" LastName="Fuller" />
<Emp FirstName="Janet" EmployeeID="3"
ReportsTo="1" LastName="Leverling">
...
...
Ниже приведена измененная схема:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:documentation>
Customer-Order-Order Details Schema
Copyright 2000 Microsoft. All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
 All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
All rights reserved.
</xsd:documentation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo" />
<xsd:complexType name="EmpType">
<xsd:sequence>
<xsd:element name="Emp"
type="EmpType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="6"/>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
<xsd:attribute name="ReportsTo" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
Заметка sql:max-depth
В схеме, состоящей из рекурсивных связей, глубина рекурсии должна быть явно указана в схеме. Это необходимо для успешной подготовки соответствующего запроса FOR XML EXPLICIT, который возвращает запрошенные результаты.
Это необходимо для успешной подготовки соответствующего запроса FOR XML EXPLICIT, который возвращает запрошенные результаты.
Используйте заметку sql:max-depth в схеме, чтобы указать глубину рекурсии в рекурсивной связи, описанной в схеме. Значение заметки sql:max-depth является положительным целым числом (от 1 до 50), которое указывает количество рекурсий: значение 1 останавливает рекурсию в элементе, для которого указана заметка sql:max-depth ; значение 2 останавливает рекурсию на следующем уровне от элемента, в котором указана sql:max-depth ; и так далее.
Примечание
В базовой реализации запрос XPath, указанный для схемы сопоставления, преобразуется в select … ЗАПРОС FOR XML EXPLICIT. Для этого запроса необходимо указать конечную глубину рекурсии. Чем выше значение, указанное для sql:max-depth, тем больше созданный запрос FOR XML EXPLICIT. Это может увеличить время выборки.
Примечание
Диаграммы обновления и массовая загрузка XML не учитывают заметку max-depth. Это означает, что рекурсивные обновления и вставки будут происходить независимо от значения, заданного для max-depth.
Это означает, что рекурсивные обновления и вставки будут происходить независимо от значения, заданного для max-depth.
Задание sql:max-depth для сложных элементов
Заметку sql:max-depth можно указать для любого сложного элемента содержимого.
Рекурсивные элементы
Если для родительского элемента и дочернего элемента в рекурсивной связи указана функция sql:max-depth, указанная в родительском элементе, имеет приоритет. Например, в следующей схеме заметка sql:max-depth указывается как для родительских, так и для дочерних элементов сотрудников. В этом случае sql:max-depth=4, указанный в родительском элементе <Emp> (играя роль руководителя), имеет приоритет. Значение sql:max-depth , указанное в дочернем <элементе Emp> (играя роль защищенного элемента), игнорируется.
Пример Б
<xsd:schema xmlns:xsd="http://www.
 w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo"
sql:max-depth="3" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="2" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
parent-key="EmployeeID"
child="Emp"
child-key="ReportsTo" />
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:limit-field="ReportsTo"
sql:max-depth="3" />
<xsd:complexType name="EmployeeType">
<xsd:sequence>
<xsd:element name="Emp" type="EmployeeType"
sql:relation="Emp"
sql:key-fields="EmployeeID"
sql:relationship="SupervisorSupervisee"
sql:max-depth="2" />
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:ID" />
<xsd:attribute name="FirstName" type="xsd:string"/>
<xsd:attribute name="LastName" type="xsd:string"/>
</xsd:complexType>
</xsd:schema>
Для проверки этой схемы выполните шаги, приведенные для образца А ранее в этом разделе.
Нерекурсивные элементы
Если заметка sql:max-depth указана для элемента в схеме, которая не вызывает рекурсии, она игнорируется. В следующей схеме <элемент Emp> состоит из дочернего <элемента Constant> , который, в свою очередь, имеет дочерний <элемент Emp> .
В этой схеме заметка sql:max-depth , указанная в элементе <Constant> , игнорируется, так как между родительским элементом <Emp> и дочерним элементом <Constant> нет рекурсии. Но между предком Emp> и потомком Emp существует рекурсия<.>< Схема задает заметку sql:max-depth для обоих типов. Поэтому приоритет имеет аннотация sql:max-depth , указанная на предке (<Emp> в роли руководителя).
Пример В
<xsd:schema xmlns:xsd="http://www.
 w3.org/2001/XMLSchema"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
child="Emp"
parent-key="EmployeeID"
child-key="ReportsTo"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
sql:relation="Emp"
type="EmpType"
sql:limit-field="ReportsTo"
sql:max-depth="1" />
<xsd:complexType name="EmpType" >
<xsd:sequence>
<xsd:element name="Constant"
sql:is-constant="1"
sql:max-depth="20" >
<xsd:complexType >
<xsd:sequence>
<xsd:element name="Emp"
sql:relation="Emp" type="EmpType"
sql:relationship="SupervisorSupervisee"
sql:max-depth="3" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
w3.org/2001/XMLSchema"
xmlns:sql="urn:schemas-microsoft-com:mapping-schema">
<xsd:annotation>
<xsd:appinfo>
<sql:relationship name="SupervisorSupervisee"
parent="Emp"
child="Emp"
parent-key="EmployeeID"
child-key="ReportsTo"/>
</xsd:appinfo>
</xsd:annotation>
<xsd:element name="Emp"
sql:relation="Emp"
type="EmpType"
sql:limit-field="ReportsTo"
sql:max-depth="1" />
<xsd:complexType name="EmpType" >
<xsd:sequence>
<xsd:element name="Constant"
sql:is-constant="1"
sql:max-depth="20" >
<xsd:complexType >
<xsd:sequence>
<xsd:element name="Emp"
sql:relation="Emp" type="EmpType"
sql:relationship="SupervisorSupervisee"
sql:max-depth="3" />
</xsd:sequence>
</xsd:complexType>
</xsd:element>
</xsd:sequence>
<xsd:attribute name="EmployeeID" type="xsd:int" />
</xsd:complexType>
</xsd:schema>
Для проверки этой схемы выполните шаги, приведенные для примера А ранее в этом разделе.
Сложные типы, наследуемые по ограничению
Если у вас есть сложное наследование по ограничению<>, элементы соответствующего базового сложного типа не могут указать заметку sql:max-depth. В таких случаях заметку sql:max-depth можно добавить в элемент производного типа.
С другой стороны, при наличии сложного наследования по <расширению> элементы соответствующего базового сложного типа могут указать заметку sql:max-depth .
Например, следующая схема XSD создает ошибку, так как заметка sql:max-depth указана в базовом типе. Эта заметка не поддерживается для типа, производного от <ограничений> другого типа. Чтобы устранить эту проблему, необходимо изменить схему и указать заметку sql:max-depth для элемента в производном типе.
Пример Г
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:dt="urn:schemas-microsoft-com:datatypes"
xmlns:msdata="urn:schemas-microsoft-com:mapping-schema">
<xsd:complexType name="CustomerBaseType">
<xsd:sequence>
<xsd:element name="CID" msdata:field="CustomerID" />
<xsd:element name="CompanyName"/>
<xsd:element name="Customers" msdata:max-depth="3">
<xsd:annotation>
<xsd:appinfo>
<msdata:relationship
parent="Customers"
parent-key="CustomerID"
child-key="CustomerID"
child="Customers" />
</xsd:appinfo>
</xsd:annotation>
</xsd:element>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="Customers" type="CustomerType"/>
<xsd:complexType name="CustomerType">
<xsd:complexContent>
<xsd:restriction base="CustomerBaseType">
<xsd:sequence>
<xsd:element name="CID"
type="xsd:string"/>
<xsd:element name="CompanyName"
type="xsd:string"
msdata:field="CName" />
<xsd:element name="Customers"
type="CustomerType" />
</xsd:sequence>
</xsd:restriction>
</xsd:complexContent>
</xsd:complexType>
</xsd:schema>
В схеме sql :max-depth указывается в сложном типе CustomerBaseType . Схема также указывает <элемент Customer> типа CustomerType, производный от CustomerBaseType. Запрос XPath, указанный в такой схеме, приведет к ошибке, так как sql:max-depth не поддерживается для элемента, определенного в базовом типе ограничения.
Схема также указывает <элемент Customer> типа CustomerType, производный от CustomerBaseType. Запрос XPath, указанный в такой схеме, приведет к ошибке, так как sql:max-depth не поддерживается для элемента, определенного в базовом типе ограничения.
Схемы с глубокой иерархией
Схема может иметь глубокую иерархию, в которой элемент содержит дочерний элемент, который в свою очередь содержит другой дочерний элемент, и т. д. Если заметка sql:max-depth , указанная в такой схеме, создает XML-документ, содержащий иерархию более 500 уровней (с элементом верхнего уровня на уровне 1, его дочерним элементом на уровне 2 и т. д.), возвращается ошибка.
Рекурсивное выражение SQL с визуальным объяснением
Рекурсия в SQL? Но почему? О, этому есть много применений. В SQL принято хранить иерархические данные, а рекурсивные запросы — удобный способ извлечения информации из таких графов. Некоторые распространенные примеры иерархических данных, с которыми вы можете столкнуться, включают организационную структуру, структуру меню приложения, набор задач с подзадачами в проекте, ссылки между веб-страницами и разбивку модуля оборудования на части и подчасти.
Что такое рекурсивное выражение общей таблицы SQL (CTE)?
Рекурсивное выражение общей таблицы SQL (CTE) — это запрос, который постоянно ссылается на предыдущий результат, пока не вернет пустой результат. Его лучше всего использовать как удобный способ извлечения информации из иерархических данных. Это достигается с помощью CTE, который в SQL известен как оператор with. Это позволяет вам назвать результат и позже ссылаться на него в других запросах.
Этот пост не будет вдаваться в подробности этих многочисленных вариантов использования, а будет рассматривать два гипотетических примера, разработанных, чтобы помочь вам понять концепцию — простейший возможный случай рекурсии чисел и запроса данных из генеалогического дерева.
Рекурсивный SQL: что это значит и как это работает?
Давайте подумаем о запросах как о функции в том смысле, что функция принимает входные данные и производит выходные данные. Запросы оперируют отношениями или, можно сказать, таблицами. Мы будем обозначать их как
Мы будем обозначать их как Rn . Запрос принимает три отношения — R1 , R2 и R3 — и выдает результат R . Достаточно просто.
Визуальное представление того, как рекурсивный запрос работает в SQL. | Изображение: Денис Лукичев
Пример SQL: ВЫБЕРИТЕ ИЗ R1, R2, R3, ГДЕ .
Запрос может принимать что-то и ничего не производить:
Визуальное представление запроса, который принимает что-то и ничего не производит. | Изображение: Денис Лукичев
Пример SQL: SELECT FROM R1 WHERE 1 = 2
Он может ничего не брать и что-то производить:
Визуальное представление запроса, который ничего не берет и что-то производит. | Изображение: Денис Лукичев
Пример SQL: SELECT 1 .
Или он ничего не может взять и ничего не произвести.
Визуальное представление запроса, ничего не принимающего и ничего не производящего. | Изображение: Денис Лукичев
SELECT 1 WHERE 1 = 2
Подробнее о блок-диаграммах DataUnderstanding
На жаргоне SQL это называется общим табличным выражением (CTE).
 Это позволяет вам назвать результат и позже ссылаться на него в других запросах.
Это позволяет вам назвать результат и позже ссылаться на него в других запросах.
Именование результата и ссылка на него в других запросах
Вот пример.
С R AS (ВЫБРАТЬ 1 КАК n) ВЫБЕРИТЕ n + 1 ИЗ R
Запрос (ВЫБРАТЬ 1 КАК n) теперь имеет имя R . Мы ссылаемся на это имя в SELECT n + 1 FROM R . R — это таблица с одной строкой и одним столбцом, содержащая номер один. Результатом всего выражения является число два.
Рекурсивная версия инструкции WITH ссылается на себя при вычислении выходных данных.
Использование рекурсивного общего табличного выражения. | Скриншот: Денис Лукичев
Чтобы рекурсия работала, нам нужно с чего-то начать и решить, когда рекурсия должна остановиться. Для этого рекурсивный оператор with обычно имеет следующую форму:
Рекурсивный оператор with в SQL. | Изображение: Денис Лукичев
Важно отметить, что базовый запрос не включает R , однако рекурсивный запрос ссылается на R . На первый взгляд кажется, что это бесконечный цикл. Чтобы вычислить
На первый взгляд кажется, что это бесконечный цикл. Чтобы вычислить R , нам нужно вычислить R . Но есть одна загвоздка. R не ссылается на себя, а просто ссылается на предыдущий результат. И когда предыдущий результат — пустая таблица, рекурсия останавливается. Это может помочь думать об этом как об итерации, а не о рекурсии.
Вот что происходит. Базовый запрос выполняется первым, принимая все необходимое для вычисления результата R0. Второй рекурсивный запрос выполняется, принимая на вход R0 — это R ссылается на R0 в рекурсивном запросе при первом выполнении. Рекурсивный запрос выдает результат R1 , и это то, на что R будет ссылаться при следующем вызове, и так далее, пока рекурсивный запрос не вернет пустой результат. В этот момент все промежуточные результаты объединяются.
Блок-схема алгоритма выполнения рекурсивного запроса. | Изображение: Денис ЛукичевПоследовательность выполнения рекурсивного запроса. | Изображение: Денис Лукичев
| Изображение: Денис Лукичев
Примеры рекурсивного SQL
Если это слишком абстрактно, давайте рассмотрим пару конкретных примеров.
Пример 1. Считаем до трех
Первый пример, который мы рассмотрим, — это счет до трех.
Запуск рекурсивного оператора с оператором для выполнения подсчета до трех команд. | Скриншот: Денис Лукичев
Базовый запрос возвращает число 1 , рекурсивный запрос берет его под именем countUp и выдает число 2 , которое является входом для следующего рекурсивного вызова. Когда рекурсивный запрос возвращает пустую таблицу n >= 3 , результаты вызовов складываются вместе.
Иллюстрация результатов вызова, сложенных вместе. | Изображение: Денис Лукичев
Однако на таких подсчетах далеко не уедешь. Есть предел рекурсии. По умолчанию он равен 100, но его можно расширить с помощью параметра MAXRECURSION (зависит от сервера Microsoft SQL). На практике, однако, было бы плохой идеей увеличить предел рекурсии. Графики могут иметь циклы, а ограниченная глубина рекурсии может быть хорошим защитным механизмом для предотвращения плохого поведения запроса:
Графики могут иметь циклы, а ограниченная глубина рекурсии может быть хорошим защитным механизмом для предотвращения плохого поведения запроса: ОПЦИЯ (MAXRECURSION 200) .
Подробнее о руководстве SQLA по разрешению расхождений данных в SQL
Пример 2. Поиск предков
Давайте рассмотрим другой пример, поиск предков человека.
Использование рекурсии для поиска предков человека. | Изображение: Денис Лукичев Рекурсивная общая таблица для поиска предков человека. | Скриншот: Денис Лукичев
Базовый запрос находит родителя Фрэнка, Мэри, а затем рекурсивный запрос берет этот результат под Имя предка и находит родителей Мэри, которых зовут Дейв и Ева. Этот процесс продолжается до тех пор, пока мы не сможем найти больше родителей.
Иллюстрация результатов рекурсии по поиску предков человека. | Изображение: Денис Лукичев Таблица данных, которая включает год рождения, чтобы найти родителей человека. | Изображение: Денис Лукичев
Этот запрос обхода дерева может быть основой, на основе которой вы дополняете запрос некоторой другой интересующей вас информацией. Например, имея в таблице год рождения, мы можем вычислить, сколько лет было родителю, когда родился ребенок. Наш следующий запрос может сделать именно это, наряду с отображением родословных. Для этого он обходит дерево сверху вниз.
Например, имея в таблице год рождения, мы можем вычислить, сколько лет было родителю, когда родился ребенок. Наш следующий запрос может сделать именно это, наряду с отображением родословных. Для этого он обходит дерево сверху вниз. parentAge равно нулю в первой строке, потому что по имеющимся у нас данным мы не знаем, когда родилась Алиса.
Запуск рекурсии для нахождения года рождения человека и его предков. | Скриншот: Денис Лукичев. Таблица, представляющая результаты рекурсии для нахождения года рождения и предков человека. | Изображение: Денис Лукичев
Вывод: рекурсивный запрос ссылается на результат нашего базового запроса или предыдущий вызов рекурсивного запроса. Цепочка останавливается, когда рекурсивный запрос возвращает пустую таблицу.
Введение в рекурсивный SQL
Крейг С. Маллинз
Маллинз
Если вы программист SQL, изучение методов рекурсивного SQL может повысить вашу производительность. Рекурсивный запрос — это запрос, который ссылается сам на себя. Я думаю, что лучший способ быстро понять концепцию рекурсии — это подумать о зеркале, которое отражается в другом зеркале, и когда вы смотрите в него, вы видите бесконечные отражения себя. Это рекурсия в действии.
Различные продукты СУБД реализуют рекурсивный SQL по-разному. Рекурсия реализована в стандарте SQL-99 с использованием общих табличных выражений (CTE). DB2, Microsoft SQL Server, Oracle и PostgreSQL поддерживают рекурсивные запросы с использованием CTE. Обратите внимание, что Oracle также предлагает альтернативный синтаксис с использованием конструкции CONNECT BY, который мы здесь обсуждать не будем.
CTE можно рассматривать как именованную временную таблицу в операторе SQL, которая сохраняется на время выполнения этого оператора.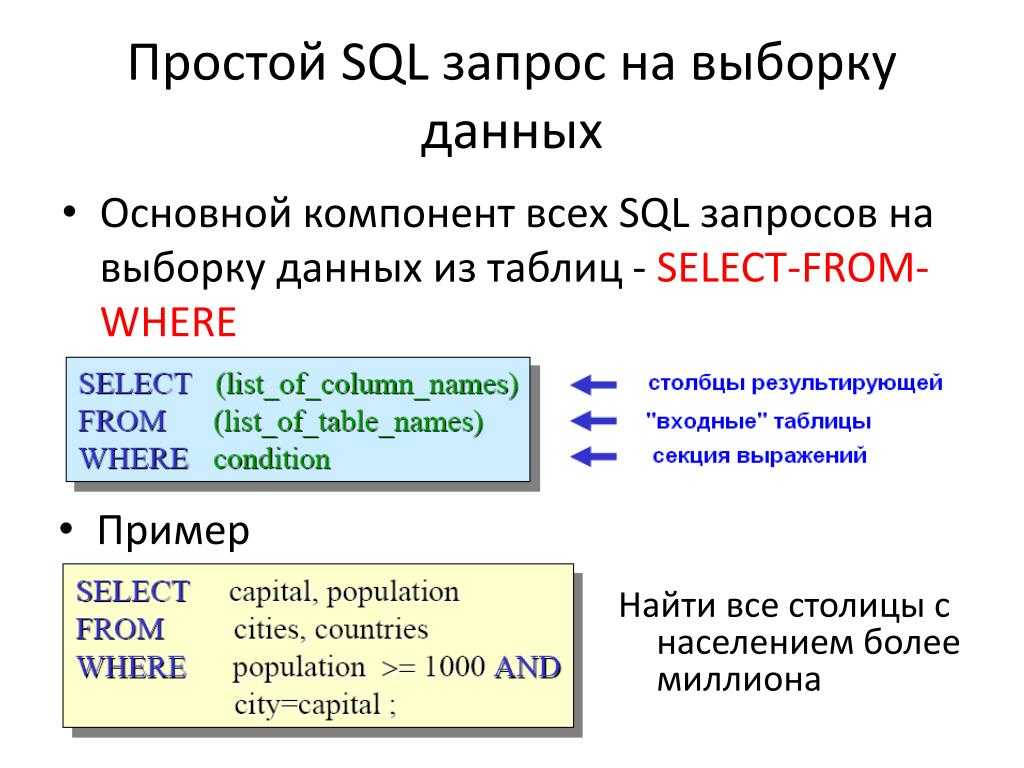 В одном операторе SQL может быть много CTE, но каждое из них должно иметь уникальное имя. CTE определяется в начале запроса с использованием предложения WITH.
В одном операторе SQL может быть много CTE, но каждое из них должно иметь уникальное имя. CTE определяется в начале запроса с использованием предложения WITH.
Теперь, прежде чем мы углубимся в рекурсию, давайте сначала рассмотрим некоторые данные, которые выиграют от рекурсивного чтения. На рис. 1 показана иерархическая организационная схема.
Рис. 1. Пример иерархии .
Таблица, содержащая эти данные, можно настроить следующим образом:
Создание таблицы org_chart
(MGR_ID Smallint,
EMP_ID Smallint,
EMP_NAME char (20))
;
Конечно, это простая реализация, и для производственной иерархии, вероятно, потребуется гораздо больше столбцов. Но простота этой таблицы подойдет для наших целей изучения рекурсии. Чтобы сделать данные в этой таблице, соответствуют нашей диаграмме, мы загрузили таблицу следующим образом:
MGR_ID EMP_ID EMP_NAME
-1 1 Big Boss
1 2 Lackey
1 3 Lil Boss
1 4 Bootlicker
2 5 Grunt
3 6 Lead Lead
6 7 Low Man
6 8 Scrub
MGR_ID для наиболее максимальной row, в данном случае используется –1. Теперь, когда мы загрузили данные, мы можем написать запрос для обхода иерархии с использованием рекурсивного SQL. Предположим, нам нужно отчитаться по всей организационной структуре под LIL BOSS. Следующий рекурсивный SQL с использованием CTE сделает свое дело:
Теперь, когда мы загрузили данные, мы можем написать запрос для обхода иерархии с использованием рекурсивного SQL. Предположим, нам нужно отчитаться по всей организационной структуре под LIL BOSS. Следующий рекурсивный SQL с использованием CTE сделает свое дело:
с expl (mgr_id, emp_id, emp_name) как
(
Select root.mgr_id, root.emp_id, root.emp_name
из org_chart root
, где root.mgr_id = 3
All
2
2
2
2
Выберите child.mgr_id, child.emp_id, child.emp_name
от expl parent, org_chart Child
, где parent.emp_id = child.mgr_id
)
SELECT DISTINCT MGR_ID, EMP_ID, EMP_NAME
FROM EXPL
ORDER BY MGR_ID, EMP_ID;
Результаты выполнения этого запроса будут:
MGR_ID EMP_ID EMP_NAME
1 3 LIL BOSS
3 6 Ведущие команды
6 7 Low Man
9 8 Scrub
Давайте разбили этот комплекс вниз в его составные части, помогающие понять, что происходит.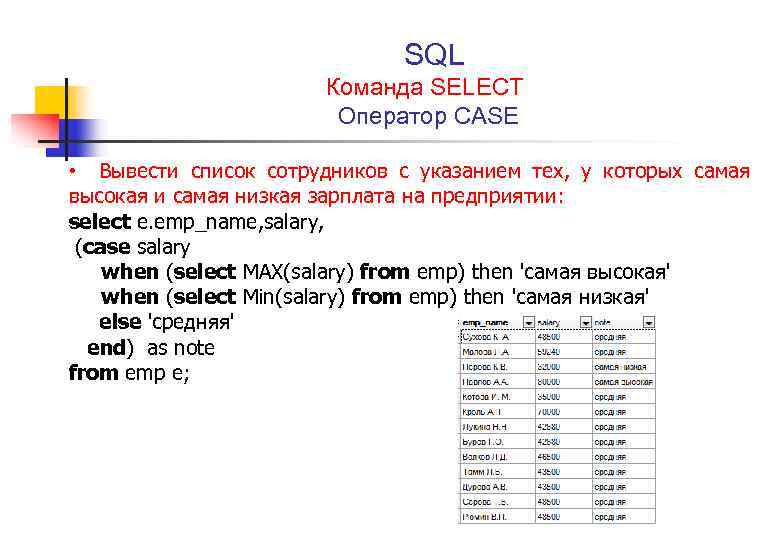 Во-первых, рекурсивный запрос реализуется с использованием предложения WITH (с использованием CTE). CTE называется EXPL. Первый SELECT запускает насос для инициализации «корня» поиска. В нашем случае начать с EMP_ID 3, то есть LIL BOSS.
Во-первых, рекурсивный запрос реализуется с использованием предложения WITH (с использованием CTE). CTE называется EXPL. Первый SELECT запускает насос для инициализации «корня» поиска. В нашем случае начать с EMP_ID 3, то есть LIL BOSS.
Следующий SELECT представляет собой внутреннее соединение, объединяющее CTE с таблицей, на которой основано CTE. Вот где в дело вступает рекурсия. Часть определения CTE ссылается сама на себя. Наконец, мы ВЫБИРАЕМ из CTE. Подобные запросы могут быть написаны, чтобы полностью разрушить иерархию, чтобы получить всех потомков любого заданного узла.
Рекурсивный SQL может быть очень элегантным и эффективным. Однако из-за сложности понимания рекурсии разработчиками ее иногда считают «слишком неэффективной для частого использования». Но если у вас есть деловая потребность в обходе или взрыве иерархий в вашей базе данных, рекурсивный SQL, вероятно, будет вашим наиболее эффективным вариантом. Что еще ты собираешься делать? Вы можете создавать предварительно разнесенные таблицы, но это требует денормализации и большой предварительной обработки, которая не будет эффективной.