Server sql join: Joins (SQL Server) — SQL Server
Содержание
Объединение таблиц с разных серверов
спросил
Изменено
3 года, 1 месяц назад
Просмотрено
132к раз
Все предложения как соединить таблицы от по-разному серверов в хранимой процедуре?
- sql-сервер
- sql-сервер-2000
0
Без подробностей трудно привести прямые примеры, но вот основная идея:
Во-первых, вне хранимой процедуры хост-сервер (сервер, на котором будет храниться хранимая процедура) должен знать о втором сервере , включая (возможно) информацию для входа.
На главном сервере запустите хранимую процедуру sp_addlinkedserver. Это нужно сделать только один раз:
exec sp_addlinkedserver @server='(ваш второй сервер)';
Если вам необходимо предоставить информацию для входа на этот второй сервер (например, процесс не может войти в систему с теми же учетными данными, которые используются при первоначальном подключении к базе данных), сделайте это с хранимой процедурой sp_addlinkedsrvlogin:
exec sp_addlinkedsrvlogin @rmtsrvname='(ваш второй сервер)', @useself=ложь, @rmtuser='ваше имя пользователя', @rmtpassword='вашпароль';
Затем в вашей хранимой процедуре вы можете указать таблицы на втором сервере:
SELECT table1.* ИЗ таблицы1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ [второй сервер].[база данных].[схема].[таблица] AS table2 ON table1.joinfield = таблица2.joinfield
 *
ИЗ таблицы1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [второй сервер].[база данных].[схема].[таблица] AS table2 ON
table1.joinfield = таблица2.joinfield
*
ИЗ таблицы1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [второй сервер].[база данных].[схема].[таблица] AS table2 ON
table1.joinfield = таблица2.joinfield
1
1. Проверьте, есть ли у вас связанные серверы, используя exec sp_helpserver
2. Если ваш сервер не возвращен, значит, он не Связанный , что означает, что вам нужно его добавить. В противном случае перейдите к шагу 3.
Для Sql Server 2008 R2 перейдите к Серверный объект > Связанные серверы > Добавить новый связанный сервер
Или
exec sp_addlinkedserver @server='ServerName';
3. Подключитесь к вторичному серверу вот так…
exec sp_addlinkedsrvlogin @rmtsrvname='ИмяСервера' , @useself=false , @rmtuser='пользователь' , @rmtpassword='Пароль';
4. Теперь вы можете объединить таблицы для двух разных серверов.
ВЫБОР
СРВ1.*
ОТ
DB1.имя_базы_данных.dbo.имя_таблицы SRV1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ DB2.имя_базы_данных.dbo.имя_таблицы SRV2
НА SRV1.columnId = SRV2.columnId
ИДТИ
0
Перед объединением таблиц необходимо связать два сервера. Как только они будут связаны, вы можете просто использовать приведенный ниже запрос и заменить имена серверов, баз данных и таблиц.
Не забудьте выполнить приведенный ниже sql в DB2:
EXEC sp_addlinkedserver DB1 ИДТИ -- приведенный ниже оператор подключает учетную запись sa DB2 к DB1. EXEC sp_addlinkedsrvlogin @rmtsrvname = 'DB1', @useself = 'false', @locallogin = 'sa', @rmtuser = 'sa', @rmtpassword = 'DB1 sa pwd' ИДТИ ВЫБЕРИТЕ столбцы ИЗ DB1.database_name.dbo.table_name a ВНУТРЕННЕЕ СОЕДИНЕНИЕ DB2.имя_базы_данных.dbo.имя_таблицы b ON a.columnId = b.columnId ИДТИ
Связывание серверов — http://msdn.microsoft.com/en-us/library/ms188279.aspx
Вы можете написать запрос, как показано ниже, для присоединения к другому серверу в SQL Server
SELECT table_1.
 *
ИЗ [База данных_1].[dbo].[Таблица_1] таблица_1
INNER JOIN [IP_OF_SERVER_2].[Database_2].[dbo].[Table_2] table_2 ON table_1.tablekey COLLATE DATABASE_DEFAULT = table_2.tablekey COLLATE DATABASE_DEFAULT
*
ИЗ [База данных_1].[dbo].[Таблица_1] таблица_1
INNER JOIN [IP_OF_SERVER_2].[Database_2].[dbo].[Table_2] table_2 ON table_1.tablekey COLLATE DATABASE_DEFAULT = table_2.tablekey COLLATE DATABASE_DEFAULT
p/s: COLLATE DATABASE_DEFAULT для кодирования,
Предотвратить ошибку ниже
Не удается разрешить конфликт сортировки между «Vietnamese_CI_AS» и «SQL_Latin1_General_CP1_CI_AS» в операции «равно».
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.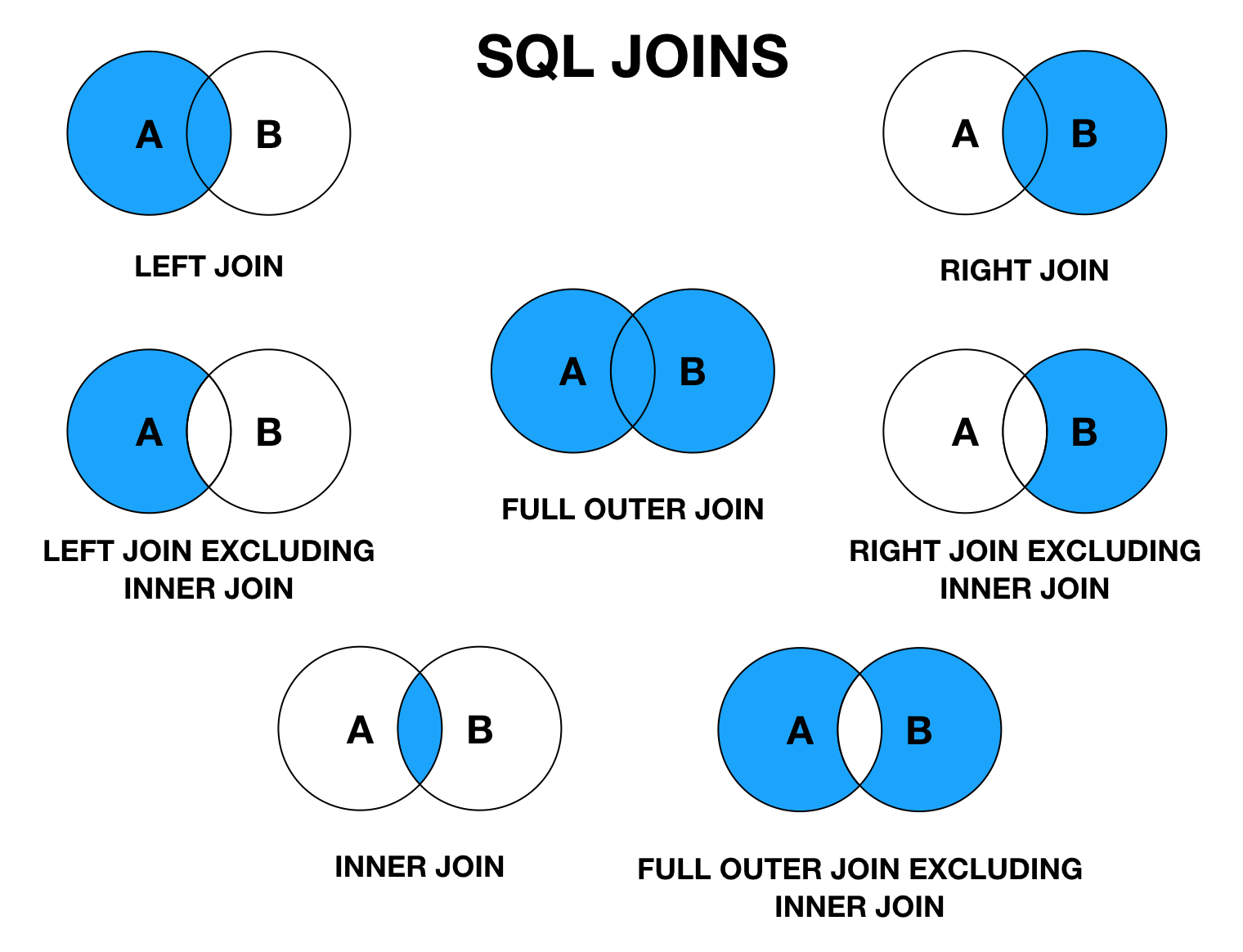
Введение в логические соединения SQL Server
Синтаксис JOIN является дополнительной частью оператора FROM и используется для указания того, как возвращать данные из разных таблиц (или представлений). Как правило, когда мы думаем о соединении таблиц вместе, мы думаем о возвращении данных из двух таблиц с соответствием на равенство (INNER JOIN) между источниками. Однако ключевое слово JOIN также имеет параметры для возврата всех данных из одной таблицы и только соответствующих записей из другой таблицы (ВНЕШНЕЕ СОЕДИНЕНИЕ). В этом руководстве рассказывается, когда и зачем использовать определенные типы соединений, а также о некоторых распространенных ошибках, с которыми сталкиваются разработчики при написании операторов SQL Server JOIN. Многие из приведенных ниже примеров используют базу данных AdventureWorks.
В этом руководстве есть несколько замечаний. Во-первых, несмотря на то, что для изменения данных (INSERT/UPDATE/DELETE) возможно СОЕДИНИТЬ несколько таблиц, для простоты я буду придерживаться операторов SELECT. Во-вторых, я сосредоточусь на использовании таблиц и представлений в качестве источников. Хотя вы можете использовать оператор APPLY для выполнения тех же функций, что и операторы JOIN, включающие пользовательские функции с табличным значением, я оставлю это объяснение для другого учебника по SQL.
Во-вторых, я сосредоточусь на использовании таблиц и представлений в качестве источников. Хотя вы можете использовать оператор APPLY для выполнения тех же функций, что и операторы JOIN, включающие пользовательские функции с табличным значением, я оставлю это объяснение для другого учебника по SQL.
Наконец, стоит упомянуть, что хотя SQL Server позволяет вам писать очень сложные операторы JOIN, включающие множество таблиц, это не значит, что вы должны это делать. Как я покажу позже, чем сложнее оператор SQL, тем больше шансов, что оптимизатор запросов не создаст хороший план выполнения. На протяжении многих лет я помогал очень многим клиентам повысить производительность своих установок SQL Server, упростив операторы JOIN. Чем проще, тем лучше, когда дело доходит до JOIN.
Общий синтаксис
Общий синтаксис оператора JOIN в SQL Server:
INNER JOIN
Оператор T-SQL INNER JOIN возвращает строки из двух источников, в которых входные данные совпадают. Ключевое слово INNER является необязательным; если вы его опускаете и используете только JOIN, используется INNER JOIN.
Ключевое слово INNER является необязательным; если вы его опускаете и используете только JOIN, используется INNER JOIN.
Обратите внимание, что T-SQL является интерпретируемым языком. Синтаксис описывает для SQL Server, какие результаты вы хотите вернуть, но не сообщает SQL Server, КАК возвращать данные. Оптимизатор запросов должен определить наилучший порядок JOIN. Таким образом, порядок, в котором вы пишете свои ВНУТРЕННИЕ СОЕДИНЕНИЯ, обычно не имеет значения, поскольку SQL Server перепишет их по мере необходимости. Есть редкие случаи, когда это не соответствует действительности, но, опять же, эта тема имеет достаточно достоинств, чтобы стать отдельным руководством по SQL Server.
В следующем примере возвращаются совпадающие строки из таблицы Sales.SalesOrderHeader и таблицы Sales.SalesOrderDetail, где значения в столбце SalesOrderID между двумя таблицами совпадают:
Обратите внимание, что в примере используются псевдонимы таблиц для сокращения объема T-SQL. необходимо для ссылок на таблицы.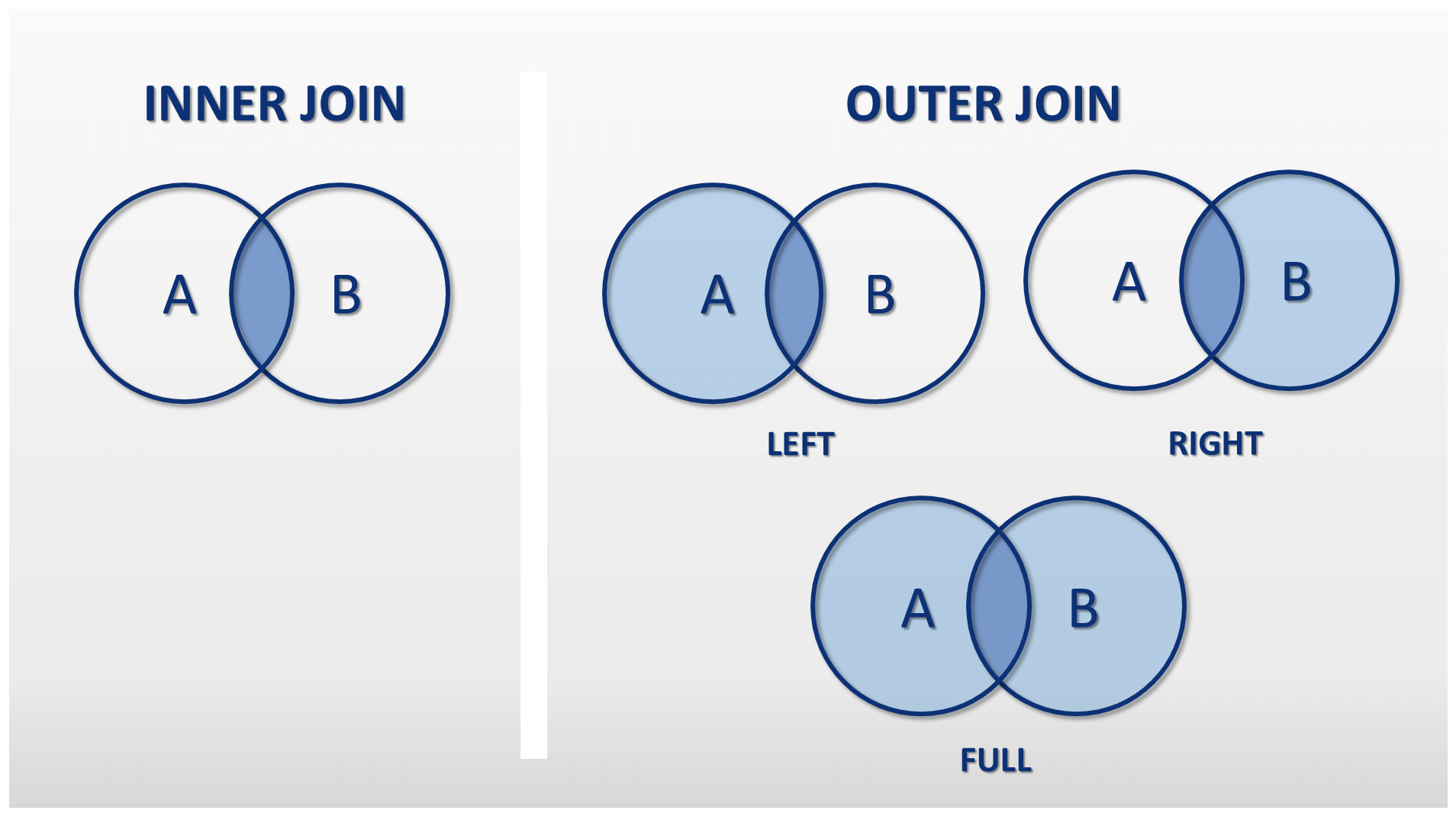 Поскольку между таблицами есть общий столбец (SalesOrderID), код должен уточнять, на какую таблицу ссылается оператор JOIN. При объединении таблиц в предложении FROM должно быть хотя бы одно сравнение столбцов, но при необходимости могут быть добавлены дополнительные столбцы для объединения.
Поскольку между таблицами есть общий столбец (SalesOrderID), код должен уточнять, на какую таблицу ссылается оператор JOIN. При объединении таблиц в предложении FROM должно быть хотя бы одно сравнение столбцов, но при необходимости могут быть добавлены дополнительные столбцы для объединения.
Ниже приведен пример «старого» стиля INNER JOIN, в котором предложение JOIN опущено, а условия соединения указаны в предложении WHERE.
Хотя это несколько устаревшая практика, она по-прежнему работает и выполняется так же, как СОЕДИНЕНИЕ, записанное как ВНУТРЕННЕЕ СОЕДИНЕНИЕ. Вы должны быть осторожны при использовании синтаксиса INNER JOIN, так как он вызовет ошибку, если вы не включите оператор сравнения как часть предложения JOIN. С приведенным выше синтаксисом старого стиля вы можете легко забыть включить критерии JOIN в предложение WHERE, что приведет к декартовому произведению (CROSS JOIN).
За годы консультирования чрезмерно сложные операторы SQL стали одной из самых серьезных проблем с производительностью, с которыми я сталкивался. По мере увеличения количества ВНУТРЕННИХ СОЕДИНЕНИЙ возможности порядка соединения резко увеличиваются, что дает оптимизатору запросов гораздо больше путей соединения для оценки. SQL Server может одновременно объединять только два входа (независимо от количества таблиц в операторе JOIN), поэтому определение наилучшего порядка объединения таблиц может быть дорогостоящим процессом. У оптимизатора есть хитрый способ справиться с такими ситуациями, чтобы обеспечить своевременное выполнение запроса: он устанавливает ограничение по времени на то, сколько оптимизации он фактически проведет. Как только он достигнет предела, он выполнит лучший план, который он представил до сих пор.
По мере увеличения количества ВНУТРЕННИХ СОЕДИНЕНИЙ возможности порядка соединения резко увеличиваются, что дает оптимизатору запросов гораздо больше путей соединения для оценки. SQL Server может одновременно объединять только два входа (независимо от количества таблиц в операторе JOIN), поэтому определение наилучшего порядка объединения таблиц может быть дорогостоящим процессом. У оптимизатора есть хитрый способ справиться с такими ситуациями, чтобы обеспечить своевременное выполнение запроса: он устанавливает ограничение по времени на то, сколько оптимизации он фактически проведет. Как только он достигнет предела, он выполнит лучший план, который он представил до сих пор.
Рассмотрим следующий запрос, который включает шесть таблиц, объединенных ВНУТРЕННИМ СОЕДИНЕНИЕМ:
Когда я выполняю запрос и просматриваю план выполнения, я вижу, что план имеет значение «Причина досрочного завершения оптимизации оператора» «Время истекло». ‘
Это означает, что на этапе оптимизации запроса было так много вариантов плана, что лимит времени для оптимизации был достигнут, и в качестве плана выполнения был выбран «лучший» план из изученных альтернатив плана.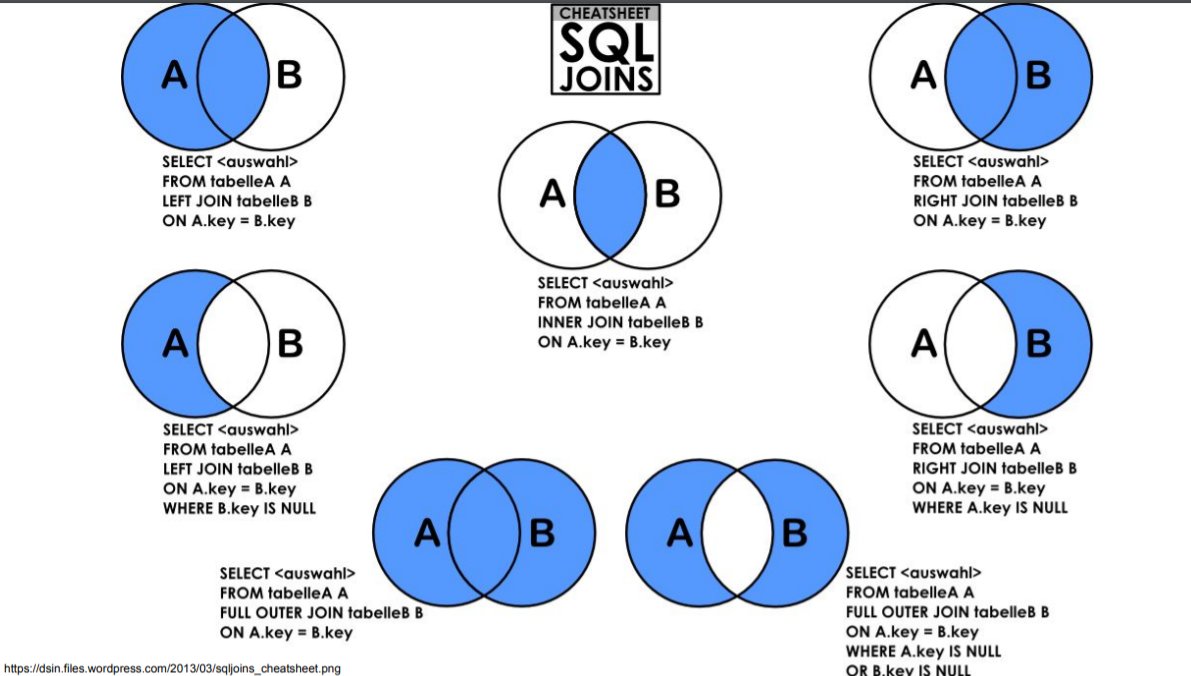 Это случается довольно часто. Если у вас есть сложные операторы T-SQL и вы не получаете желаемого плана выполнения, возможно, пришло время реорганизовать эти операторы T-SQL, чтобы они включали меньше объединений или разбивали их на отдельные операторы.
Это случается довольно часто. Если у вас есть сложные операторы T-SQL и вы не получаете желаемого плана выполнения, возможно, пришло время реорганизовать эти операторы T-SQL, чтобы они включали меньше объединений или разбивали их на отдельные операторы.
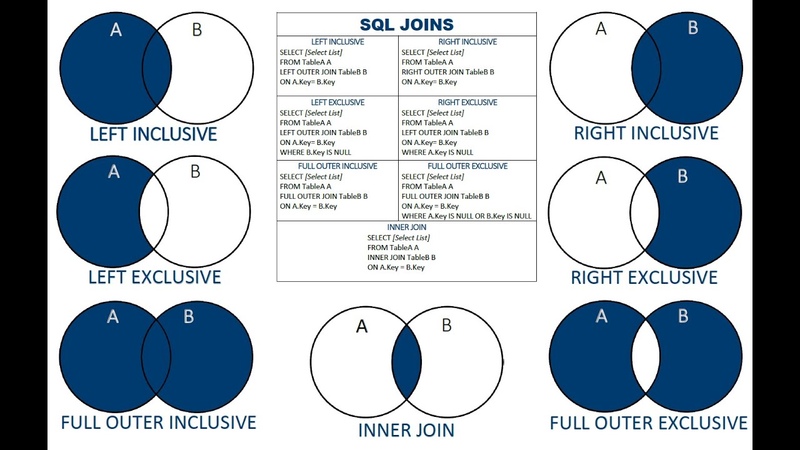
ВНЕШНЕЕ СОЕДИНЕНИЕ
ВНЕШНЕЕ СОЕДИНЕНИЕ T-SQL — это когда одна таблица сохраняется, а другая возвращает строки, если значения совпадают с сохраненной таблицей. Под «сохраненными» я подразумеваю, что все строки из этой таблицы могут быть возвращены в запросе, в то время как ВНЕШНЯЯ таблица будет возвращать строки только в том случае, если в сохраненной таблице есть совпадение.
Есть два типичных ВНЕШНИХ СОЕДИНЕНИЯ:
- ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
- ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Существует также ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ, которое сочетает в себе функции ЛЕВОГО и ПРАВОГО ВНЕШНЕГО СОЕДИНЕНИЯ. Обратите внимание, что ключевое слово OUTER является необязательным для соединений OUTER — использование LEFT JOIN такое же, как и LEFT OUTER JOIN для целей синтаксиса.
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ — это место, где левая таблица (первая указанная таблица) сохраняется, в то время как таблица на другой стороне СОЕДИНЕНИЯ возвращает значения, если есть совпадение, и в противном случае возвращает значения NULL, если совпадений нет. Это один из тех случаев, когда важно то, КАК вы пишете оператор SQL.
Рассмотрим следующий пример создания двух временных таблиц, в которых будут храниться разные числовые значения:
Следующий запрос возвращает все значения из #Numbers1 и только те значения из #Numbers2, которые совпадают:
Обратите внимание, что таблица #Numbers1 находится СЛЕВА от оператора JOIN, поэтому она сохраняется. Если в таблице #Numbers2 совпадений нет, возвращается значение NULL.
Одним из полезных аспектов использования OUTER JOIN является то, что он позволяет легко возвращать значения из одной таблицы, если в другой таблице нет совпадения. Для этого просто добавьте критерий в предложение WHERE для поиска значений NULL в таблице OUTER. Вот пример:
Вот пример:
Многие разработчики делают одну логическую ошибку, добавляя предикат к таблице OUTER в предложении WHERE. Когда вы пытаетесь отфильтровать строки в таблице OUTER в предложении WHERE, это фактически превращает JOIN во INNER JOIN, поскольку значения NULL отфильтровываются из-за порядка операций T-SQL. Ниже приведен пример неправильной фильтрации строк в таблице OUTER:
Если в запросе необходимо сначала применить критерии к таблице OUTER в запросе, вам нужно будет применить фильтр в операторе JOIN. Приведенный ниже запрос имеет тот же фильтр, что и выше, но вместо этого в операторе JOIN:
Этот подход отфильтровывает эти записи в таблице #Numbers2, пока выполняется оператор OUTER JOIN. Это дает больше значений NULL, возвращаемых из таблицы #Numbers2, при сохранении всех записей из таблицы #Numbers1.
ПРАВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
Во всех смыслах и целях ПРАВОЕ СОЕДИНЕНИЕ такое же, как и ЛЕВОЕ СОЕДИНЕНИЕ, с сохранением правой таблицы и единственным отличием в порядке написания инструкции.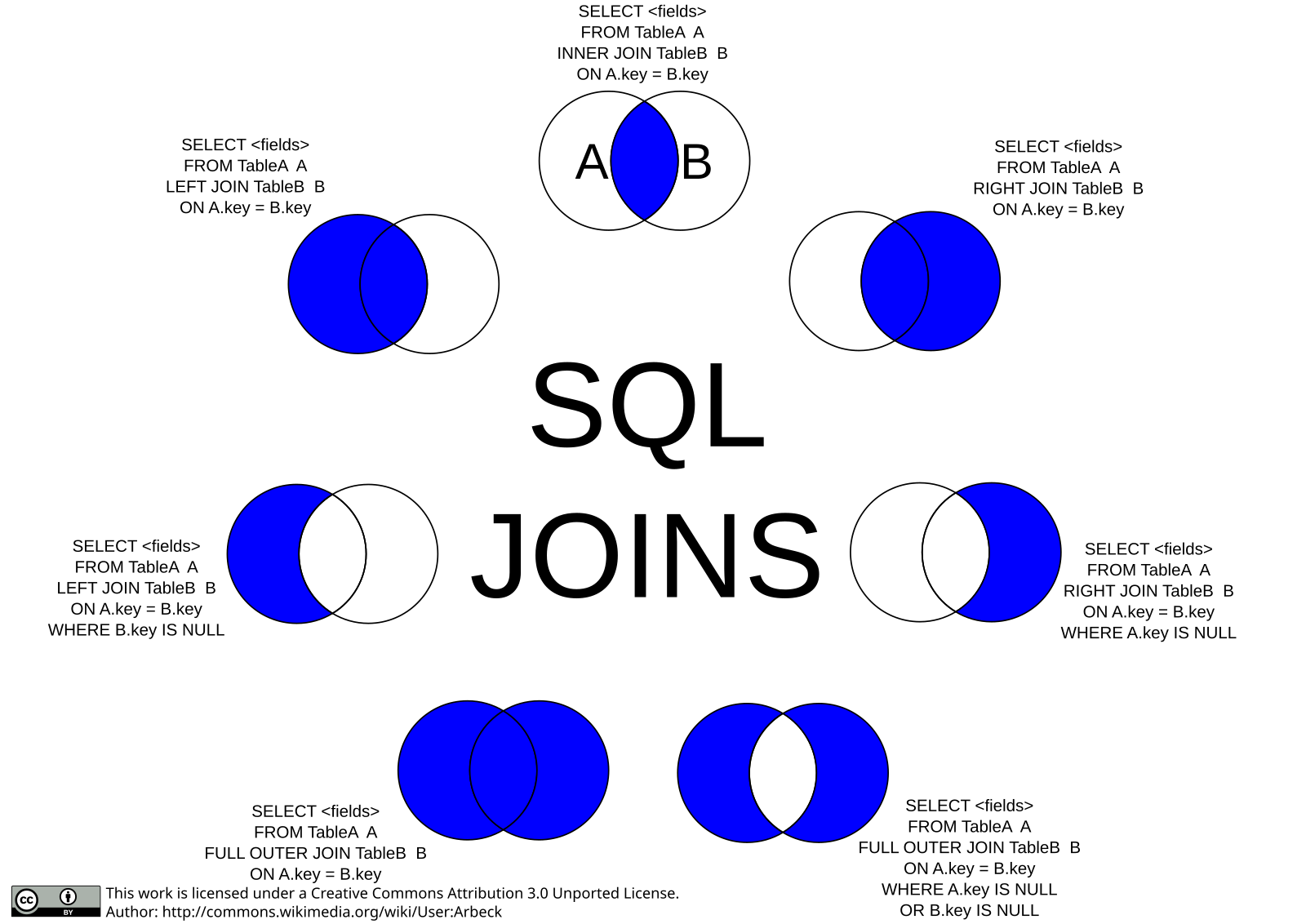 Приведенный ниже запрос идентичен первому примеру LEFT OUTER JOIN, но вместо этого написан как RIGHT OUTER JOIN. Единственная разница между ними заключается в порядке таблицы в предложении FROM.
Приведенный ниже запрос идентичен первому примеру LEFT OUTER JOIN, но вместо этого написан как RIGHT OUTER JOIN. Единственная разница между ними заключается в порядке таблицы в предложении FROM.
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ T-SQL сочетает в себе функциональные возможности ЛЕВОГО и ПРАВОГО ВНЕШНИХ СОЕДИНЕНИЙ. Используйте этот тип JOIN, если вы хотите вернуть (сохранить) строки из обеих таблиц. При отсутствии соответствия между двумя таблицами возвращаются значения NULL. Следующий запрос возвращает строки из таблицы #Numbers1 и #Numbers2:
При совпадении между таблицами будут возвращены оба значения. Если совпадения нет, возвращается значение из таблицы, в которой оно существует, а из другой таблицы возвращается значение NULL.
CROSS JOIN
CROSS JOIN T-SQL умножает все строки между таблицами в объединении для создания декартова произведения. Этот тип JOIN обычно подходит только для быстрого создания тестовых данных или получения таблицы с одной строкой и объединения ее со всеми строками во второй таблице. Обратите внимание, что между таблицами, перечисленными в приведенном ниже примере, нет критериев сравнения. В приведенном ниже примере запроса T-SQL используются таблицы spt_values в базе данных master и оконная функция ROW_NUMBER для быстрого создания 10 000 монотонно возрастающих значений.
Обратите внимание, что между таблицами, перечисленными в приведенном ниже примере, нет критериев сравнения. В приведенном ниже примере запроса T-SQL используются таблицы spt_values в базе данных master и оконная функция ROW_NUMBER для быстрого создания 10 000 монотонно возрастающих значений.
Когда использовать объединения в SQL
Соединение связанных таблиц является фундаментальной операцией в мире реляционных баз данных, и понимание того, когда использовать различные типы объединения, является важным навыком для любого разработчика баз данных. Используйте INNER JOIN, если вы хотите вернуть только те строки, в которых есть совпадения между таблицами. Используйте LEFT или RIGHT OUTER JOIN, если вы хотите сохранить одну таблицу и возвращать только те строки из таблицы OUTER, если есть совпадение. Используйте FULL OUTER JOIN, если вы хотите объединить функциональные возможности LEFT и RIGHT OUTER JOIN для возврата значений из обеих таблиц. Вы можете прочитать этот пост в блоге, чтобы глубже погрузиться в ключевые различия между типами CROSS JOIN и INNER JOIN.
Будьте внимательны при построении предложений JOIN и не усложняйте их. Включение слишком большого количества таблиц в JOIN, скорее всего, приведет к снижению производительности из-за сложности, связанной с тем, что оптимизатор запросов создает хороший план выполнения.
SolarWinds ® SQL Sentry создан для более эффективного мониторинга активности процессора запросов путем анализа того, что обрабатывается, сколько времени это занимает и какие ресурсы используются. С помощью функции Top SQL используйте встроенный инструмент анализа запросов Plan Explorer для сбора и анализа планов запросов, используемых для выполнения, и статистики, используемой для создания планов запросов для более обоснованной оптимизации и настройки. Вы можете скачать SQL Sentry со встроенным инструментом Plan Explorer бесплатно в течение 14 дней.
Пол С. Рэндал — генеральный директор SQLskills.com, которым он управляет вместе со своей женой Кимберли Л. Трипп. И Пол, и Кимберли являются широко известными и уважаемыми экспертами в мире SQL Server, и оба являются давними MVP SQL Server.