текст отсюда: OraDev.com — Optimizer hints и и переведенный translate.ru, впрочем понятнее от перевода он не стал… Но — когда ораклу переглючивает (?) — можно ему так сказать — какой индекс надо пользовать — ускоряется на порядки
HOWTO user hints. With hints one can influence the optimizer. The usage of hints (with exception of the RULE-hint) causes Oracle to use the Cost Based optimizer. The following syntax is used for hints:
HOWTO пользовательские намеки. С намеками можно влиять на optimizer. Использование намеков (за исключением НАМЕКА ПРАВИЛА) заставляет Оракулу использовать Стоимость Основанный optimizer. Следующий синтаксис используется для намеков:
select /*+ HINT */ name from emp where id =1;
Where HINT is replaced by the hint text. When the syntax of the hint text is incorrect, the hint text is ignored and will not be used.
Где НАМЕК заменен текстом намека. Когда синтаксис текста намека неправилен, текст намека игнорируется и не будет использоваться.
ALL_ROWS The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption).
Намек ALL_ROWS явно выбирает подход на основе стоимости оптимизировать блок утверждения(заявления) с целью лучшей производительности (то есть минимальное полное потребление ресурса).
FIRST_ROWS The FIRST_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best response time (minimum resource usage to return first row).
Намек FIRST_ROWS явно выбирает подход на основе стоимости оптимизировать блок утверждения(заявления) с целью лучшего времени ответа (минимальное использование ресурса, чтобы возвратить первый ряд).
CHOOSE The CHOOSE hint causes the optimizer to choose between the rule-based approach and the cost-based approach for a SQL statement based on the presence of statistics for the tables accessed by the statement
ВЫБИРАЮЩИЙСЯ намек заставляет optimizer выбирать между подходом на основе правила и подходом на основе стоимости для SQL утверждения(заявления), основанного на присутствии статистики для столов, к которым обращается утверждение(заявление)
RULE The RULE hint explicitly chooses rule-based optimization for a statement block. This hint also causes the optimizer to ignore any other hints specified for the statement block.
Намек ПРАВИЛА(ПРАВЛЕНИЯ) явно выбирает оптимизацию на основе правила для блока утверждения(заявления). Этот намек также заставляет optimizer игнорировать любые другие намеки, указанные для блока утверждения(заявления).
FULL The FULL hint explicitly chooses a full table scan for the specified table. The syntax of the FULL hint is FULL(table) where table specifies the name or alias of the table on which the full table scan is to be performed.
ПОЛНЫЙ намек явно выбирает полный просмотр стола для указанного стола. Синтаксис ПОЛНОГО намека ПОЛОН (против стола), где стол определяет название(имя) или псевдоним стола, на котором полный просмотр стола должен быть выполнен.
ROWID The ROWID hint explicitly chooses a table scan by ROWID for the specified table. The syntax of the ROWID hint is ROWID(table) where table specifies the name or alias of the table on which the table access by ROWID is to be performed.
Намек ROWID явно выбирает просмотр стола ROWID для указанного стола. Синтаксис намека ROWID ROWID (стол), где стол определяет название(имя) или псевдоним стола, на котором доступ стола ROWID должен быть выполнен.
CLUSTER The CLUSTER hint explicitly chooses a cluster scan to access the specified table. The syntax of the CLUSTER hint is CLUSTER(table) where table specifies the name or alias of the table to be accessed by a cluster scan.
Намек ГРУППЫ явно выбирает просмотр группы к доступу указанный стол. Синтаксис намека ГРУППЫ — ГРУППА (стол), где стол определяет название(имя) или псевдоним стола, который нужно обратить просмотром группы.
HASH The HASH hint explicitly chooses a hash scan to access the specified table. The syntax of the HASH hint is HASH(table) where table specifies the name or alias of the table to be accessed by a hash scan.
Намек МЕШАНИНЫ явно выбирает просмотр мешанины к доступу указанный стол. Синтаксис намека МЕШАНИНЫ — МЕШАНИНА (стол), где стол определяет название(имя) или псевдоним стола, который нужно обратить просмотром мешанины.
HASH_AJ The HASH_AJ hint transforms a NOT IN subquery into a hash anti-join to access the specified table. The syntax of the HASH_AJ hint is HASH_AJ(table) where table specifies the name or alias of the table to be accessed.
Намек HASH_AJ преобразовывает НЕ В подвопрос в мешанину, антиприсоединяются к доступу к указанному столу. Синтаксис намека HASH_AJ HASH_AJ (стол), где стол определяет название(имя) или псевдоним стола, который нужно обратить.
INDEX The INDEX hint explicitly chooses an index scan for the specified table. The syntax of the INDEX hint is INDEX(table index) where:table specifies the name or alias of the table associated with the index to be scanned and index specifies an index on which an index scan is to be performed. This hint may optionally specify one or more indexes:
Намек ИНДЕКСА явно выбирает просмотр индекса для указанного стола. Синтаксис намека ИНДЕКСА — ИНДЕКС (индекс стола) where:table определяет название(имя) или псевдоним стола, связанного с индексом, который будет просмотрен, и индекс определяет индекс, на котором просмотр индекса должен быть выполнен. Этот намек может произвольно определить один или более индексов:
INDEX_ASC The INDEX_ASC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in ascending order of their indexed values.
Намек INDEX_ASC явно выбирает просмотр индекса для указанного стола. Если утверждение(заявление) использует просмотр диапазона индекса, Оракул просматривает вхождения индекса в заказе(порядке) возрастания их индексированных ценностей.
INDEX_COMBINE If no indexes are given as arguments for the INDEX_COMBINE hint, the optimizer will use on the table whatever boolean combination of bitmap indexes has the best cost estimate. If certain indexes are given as arguments, the optimizer will try to use some boolean combination of those particular bitmap indexes. The syntax of INDEX_COMBINE is INDEX_COMBINE(table index)
Если никакие индексы не даются как аргументы(споры) за намек INDEX_COMBINE, optimizer будет использовать на столе имеет ли boolean комбинация bitmap индексов лучшую оценку(смету) стоимости. Если некоторые индексы даются как аргументы(споры), optimizer будет пробовать использовать некоторую boolean комбинацию тех специфических bitmap индексов. Синтаксис INDEX_COMBINE — INDEX_COMBINE (индекс стола)
INDEX_DESC The INDEX_DESC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, Oracle scans the index entries in descending order of their indexed values.
Намек INDEX_DESC явно выбирает просмотр индекса для указанного стола. Если утверждение(заявление) использует просмотр диапазона индекса, Оракул просматривает вхождения индекса в спускающемся заказе(порядке) их индексированных ценностей.
INDEX_FFS This hint causes a fast full index scan to be performed rather than a full table.
Этот намек заставляет быстрому полному просмотру индекса быть выполненным скорее чем полный стол.
MERGE_AJ The MERGE_AJ hint transforms a NOT IN subquery into a merge anti-join to access the specified table. The syntax of the MERGE_AJ hint is MERGE_AJ(table) where table specifies the name or alias of the table to be accessed.
Намек MERGE_AJ преобразовывает НЕ В подвопрос во сливающийся, антиприсоединяются к доступу к указанному столу. Синтаксис намека MERGE_AJ MERGE_AJ (стол), где стол определяет название(имя) или псевдоним стола, который нужно обратить.
AND_EQUAL The AND_EQUAL hint explicitly chooses an execution plan that uses an access path that merges the scans on several single-column indexes. The syntax of the AND_EQUAL hint is AND_EQUAL(table index index) where table specifies the name or alias of the table associated with the indexes to be merged. and index specifies an index on which an index scan is to be performed. You must specify at least two indexes. You cannot specify more than five.
Намек AND_EQUAL явно выбирает план выполнения, который использует дорожку доступа, которая сливает просмотры на нескольких индексах единственной колонки. Синтаксис намека AND_EQUAL — AND_EQUAL (индекс индекса стола) где стол определяет название(имя) или псевдоним стола, связанного с индексами, которые будут слиты. И индекс определяет индекс, на котором просмотр индекса должен быть выполнен. Вы должны определить по крайней мере два индекса. Вы не можете определить больше чем пять.
USE_CONCAT The USE_CONCAT hint forces combined OR conditions in the WHERE clause of a query to be transformed into a compound query using the UNION ALL set operator. Normally, this transformation occurs only if the cost of the query using the concatenations is cheaper than the cost without them.
Силы намека USE_CONCAT объединили(скомбинировали) ИЛИ условия(состояния) в ГДЕ пункт вопроса, который будет преобразован в составной вопрос, используя СОЮЗ ВЕСЬ оператор набора. Обычно, это преобразование происходит только, если стоимость вопроса, используя связи более дешевая чем стоимость без них.
ORDERED The ORDERED hint causes Oracle to join tables in the order in which they appear in the FROM clause. If you omit the ORDERED hint from a SQL statement performing a join , the optimizer chooses the order in which to join the tables. You may want to use the ORDERED hint to specify a join order if you know something about the number of rows selected from each table that the optimizer does not. Such information would allow you to choose an inner and outer table better than the optimizer could.
ЗАКАЗАННЫЙ намек заставляет Оракулу присоединяться к столам в заказе(порядке), в котором они появляются в ОТ пункта. Если Вы опускаете ЗАКАЗАННЫЙ намек от SQL утверждения(заявления), выполняющего присоединяющийся, optimizer выбирает заказ(порядок), чтобы присоединиться к столам. Вы можете хотеть использовать ЗАКАЗАННЫЙ намек, чтобы определить присоединенный заказ(порядок), если Вы знаете кое-что о номере(числе) рядов, отобранных из каждого стола, который optimizer не делает. Такая информация позволила бы Вам выбирать внутренний и внешний стол лучше, чем optimizer мог.
STAR The STAR hint forces the large table to be joined last using a nested loops join on the index. The optimizer will consider different permutations of the small tables.
Намек ЗВЕЗДЫ вынуждает большой стол быть соединенным к последнему(прошлому) использованию, вложенные петли присоединяются на индексе. Optimizer рассмотрит различные перестановки маленьких столов.
USE_NL The USE_NL hint causes Oracle to join each specified table to another row source with a nested loops join using the specified table as the inner table. The syntax of the USE_NL hint is USE_NL(table table) where table is the name or alias of a table to be used as the inner table of a nested loops join.
Намек USE_NL заставляет Оракулу присоединяться, каждый указанный стол к другому источнику ряда со вложенными петлями присоединяется к использованию указанного стола как внутренний стол. Синтаксис намека USE_NL — USE_NL (стол стола) где стол — название(имя) или псевдоним стола, который нужно использовать, поскольку внутренний стол вложенных петель присоединяется.
USE_MERGE The USE_MERGE hint causes Oracle to join each specified table with another row source with a sort-merge join. The syntax of the USE_MERGE hint is USER_MERGE(table table) where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a sort-merge join.
Намек USE_MERGE заставляет Оракулу присоединяться, каждый указанный стол с другим источником ряда со сливающимся видом присоединяется. Синтаксис намека USE_MERGE — USER_MERGE (стол стола) где стол — стол, который будет соединен к источнику ряда, следующему из соединения предыдущих столов в присоединенном заказе(порядке), используя сливающийся видом, присоединяются.
NO_MERGE The NO_MERGE hint causes Oracle not to merge mergeable views. This hint is most often used to reduce the number of possible permutations for a query and make optimization faster.
Намек NO_MERGE заставляет Оракулу не сливать представления(виды) mergeable. Этот намек наиболее часто используется, чтобы уменьшить номер(число) возможных перестановок для вопроса и делать оптимизацию быстрее.
USE_HASH The USE_HASH hint causes Oracle to join each specified table with another row source with a hash join. The syntax of the USE_HASH hint is USE_HASH(table table) where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a hash join.
Намек USE_HASH заставляет Оракулу присоединяться, каждый указанный стол с другим источником ряда с мешаниной присоединяется. Синтаксис намека USE_HASH — USE_HASH (стол стола) где стол — стол, который будет соединен к источнику ряда, следующему из соединения предыдущих столов в присоединенном заказе(порядке), используя мешанину, присоединяются.
PARALLEL The PARALLEL hint allows you to specify the desired number of concurrent query servers that can be used for the query. The syntax is PARALLEL(table number number). The PARALLEL hint must use the table alias if an alias is specified in the query. The PARALLEL hint can then take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table, the second value specifies how the table is to be split among the instances of a parallel server. Specifying DEFAULT or no value signifies the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism.
ПАРАЛЛЕЛЬНЫЙ намек позволяет Вам определять желательный номер(число) параллельной прислуги вопроса, которая может использоваться для вопроса. Синтаксис ПАРАЛЛЕЛЕН (номер(число) номера(числа) стола). ПАРАЛЛЕЛЬНЫЙ намек должен использовать псевдоним стола, если псевдоним определен в вопросе. ПАРАЛЛЕЛЬНЫЙ намек может тогда брать две ценности, отделенные запятыми после названия(имени) стола. Первая ценность определяет градус(степень) параллелизма для данного стола, вторая ценность определяет, как стол должен быть раздроблен среди случаев параллельной прислуги. Определение НЕПЛАТЕЖА или никакой ценности показывает, что координатор вопроса должен исследовать назначения параметров инициализации (описанный в более поздней секции) чтобы определить градус(степень) неплатежа параллелизма.
NOPARALLEL The NOPARALLEL hint allows you to disable parallel scanning of a table, even if the table was created with a PARALLEL clause.
Намек NOPARALLEL позволил бы Вам калечить параллельный просмотр стола, даже если стол был создан с ПАРАЛЛЕЛЬНЫМ пунктом.
CACHE The CACHE hint specifies that the blocks retrieved for the table in the hint are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables. In the following example, the CACHE hint overrides the table default caching specification.
Намек ТАЙНИКА определяет, что блоки, восстановленные для стола в намеке помещены максимум недавно используемый конец списка LRU в буферном тайнике, когда полный просмотр стола выполнен. Этот выбор полезен для маленьких столов поиска. В следующем примере, намек ТАЙНИКА отвергает стол, не выполняют обязательств caching спецификации.
NOCACHE The NOCACHE hint specifies that the blocks retrieved for this table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the normal behavior of blocks in the buffer cache.
Намек NOCACHE определяет, что блоки, восстановленные для этого стола помещены в наименее недавно используемый конец списка LRU в буферном тайнике, когда полный просмотр стола выполнен. Это — нормальное поведение блоков в буферном тайнике.
PUSH_SUBQ The PUSH_SUBQ hint causes nonmerged subqueries to be evaluated at the earliest possible place in the execution plan.
Причины намека PUSH_SUBQ неслили подвопросы, которые будут оценены в самом раннем возможном месте в плане выполнения.
BITMAP Usage: BITMAP(table_name index_name) Uses a bitmap index to access the table.
Использование: BITMAP (table_name index_name) Использует bitmap индекс к доступу стол.
Машинные переводчики (не словари) годны только для одного. Для генерации приколов.
А ещё есть чудная вещь dbms_profile 🙂 Желательно пользоваться через понимающую его тулзу.
From:ona_i_on 2002-11-26 04:21 am (UTC)
А чего сами английский не изучите? Это НЕ ТАК сложно. Не сложнее ораклов всяких, уж по крайней мере.
Но, вообще-то, это тех.текст. И перевести его, не зная ничего из терминологии, достаточно сложно. Не все смогут перевести.
From:(Anonymous) 2012-01-20 11:20 am (UTC)
Разработчик как-бэ намекает Ораклу, чтобы тот, цуко, использовал нужный индекс)
Организация хранения исторических данных в Oracle
Привет! Сегодня поговорим о разных способах организации хранения исторических данных в Oracle. Если вам известно более двух способов, то вы молодец и уже почти всё знаете, в чём вам и остаётся убедиться, просмотрев разделы статьи.
Под историческими данными будем понимать историю (лог) изменения данных в таблице.
Потребность логировать данные может возникнуть по разным причинам. Например,
И какие бы причины у вас ни были, можно выделить 4 основных подхода. Вообще, их больше, но мы рассмотрим наиболее применимые (с точки зрения адекватности).
Простой триггер DML
Подход, с которого начинают многие. Как его использовать для логирования, описано даже в 2 Day Developer’s Guide от Oracle.
Синтаксис
CREATE [OR REPLACE] TRIGGER
{BEFORE | AFTER}
{INSERT | DELETE | UPDATE | UPDATE OF }
ON
[FOR EACH ROW]
[WHEN (...)]
[DECLARE ... ]
BEGIN
[EXCEPTION ... ]
END ;
DML-триггер — это именованный PL/SQL-блок кода, который хранится в базе данных и вызывается по событию и по времени срабатывания. Событием запуска может быть вставка, удаление или обновление данных, также можно выбрать, когда будет вызываться триггер: до или после изменения.
Внутри триггера обязательно нужно указать код, который должен выполняться.
Достоинства
Недостатки
Если вас беспокоит первый недостаток простого DML-триггера, можно использовать его более оптимизированный вариант — составной DML-триггер.
Составной DML-триггер
Синтаксис
CREATE [ OR REPLACE ] TRIGGER
-- событие запуска
FOR {INSERT | DELETE | UPDATE |
UPDATE OF }
ON
[DECLARE ... ]
-- Выполняется один раз перед выполнением DML-выражения
BEFORE STATEMENT IS
BEGIN
;
END BEFORE STATEMENT;
-- Выполняется один раз для каждой строки перед самим действием
BEFORE EACH ROW IS
BEGIN
;
END EACH ROW;
-- Выполняется один раз для каждой строки после действия- :NEW, :OLD доступны
AFTER EACH ROW IS
BEGIN
;
END AFTER EACH ROW;
--Выполняется один раз для всего DML-выражения
AFTER STATEMENT IS
BEGIN
;
END AFTER STATEMENT;
END ;
При создании составного триггера нужно указать событие запуска (вставка, обновление или удаление записей), а также определить действия для каждой из четырех временных точек: перед и после выполнения команды DML, перед и после обработки каждой строки.
Достоинства
Недостатки
Как и в предыдущем варианте, нужно поддерживать таблицу логов и триггер при изменении структуры таблицы.
Слишком много логики в триггере.
Если перечисленные недостатки для вас являются весомыми (или у вас есть другие причины не использовать составной DML-триггер), можно использовать ручное логирование.
Ручное логирование
Этот подход более гибок. Итоговая производительность зависит от фантазии разработчика.
Так, можно сделать логирование, которое по скорости не обгоняет логирование через обычный триггер. Например, много раз вставлять в таблицу логов по одной строке. А можно реализовать логирование так, что оно обгонит по скорости составной триггер. Например, собирать данные пачками в коллекцию и вставлять в таблицу логов через команду forall.
Достоинства
Недостатки
Нужно поддерживать API и таблицу логов.
Merge-боль. Это когда вам нужно залогировать то, что происходит в merge, а нельзя (т.к. не поддерживается команда returning). И поэтому нужно развернуть merge до атомарных операций, таких как insert, update, delete. Но есть приятная новость — в 23-й версии для merge будет работать конманда returning, и merge уже не нужно будет разворачивать. Остаётся немного подождать.
Если есть причины не использовать перечисленные выше подходы, то можно использовать другой способ логирования — flashback archive. Это более современный метод, его рекомендуют некоторые широко известные в узких кругах специалисты, такие как К. Макдональд и Т. Кайт.
Flashback archive (архив ретроспективных данных)
Фоновый процесс Flashback Data Archiver Process (FBDA) позволяет отслеживать и сохранять транзакционные изменения в таблице в течение всего срока ее службы. После 11g Release 2 (11. 2.0.4) Flashback Archive доступен во всех редакциях бесплатно.
Перед коммитом транзакции на отслеживаемой таблице FBDA проверяет наличие новых сгенерированных UNDO-блоков, соответствующих этой таблице, и копирует информацию во внутренние секционированные таблицы.
Синтаксис
-- выдать права на создание архива
GRANT FLASHBACK ARCHIVE ADMINISTER TO ;
...
-- создать архив
CREATE FLASHBACK ARCHIVE [DEFAULT]
TABLESPACE
[QUOTA { M | G | T | P | E }]
[ [NO] OPTIMIZE DATA ]
RETENTION {YEAR | MONTH | DAY};
...
-- выдать права на использование архива
GRANT FLASHBACK ARCHIVE ON TO ;
...
-- включить архив для таблицы
ALTER TABLE FLASHBACK ARCHIVE ;
...
-- просмотр истории
SELECT
FROM
{ VERSIONS BETWEEN { SCN | TIMESTAMP }
{ expr | MINVALUE } AND { expr | MAXVALUE }
| VERSIONS PERIOD FOR valid_time_column BETWEEN
{ expr | MINVALUE } AND { expr | MAXVALUE }
| AS OF { SCN | TIMESTAMP } expr
| AS OF PERIOD FOR valid_time_column expr
}
Эта технология даёт возможность ничего не делать — Oracle всё сделает за вас (ну, почти всё).
Преимущества
Автоматические создание и очистка архивных таблиц.
Выгрузка истории.
Сжатие данных (платная опция OPTIMIZE DATA в Oracle Advanced Compression).
Oracle сам соберёт данные о пользователе и выполняемой программе из контекста.
Можно объединять логируемые таблицы в группы (и включать-выключать логирование на группах).
Недостатки
Ограничения на ddl-операции (см. General Guidelines for Oracle Flashback Technology). Например, если вам нужно сделать exchange partition, нужно «приостанавливать» логирование, а потом включать его обратно (иначе получим ошибку ORA-55610: Invalid DDL Statement On History-tracked Table).
Долгий поиск по логам при использовании сортировки. Но можно поэкспериментировать с оптимизацией и ускорить.
Скорость логирования
Можно посмотреть на скорость работы перечисленных методов относительно друг друга.
Произведём некоторые замеры времени вставки строк с использованием разных подходов к логированию. Замеры времени произведём через dbms_sql_monitor. Вставки будем делать пачками по 1000 и 100 000 строк.
Вставка 1000 строк
На вставке небольшого количества строк самым быстрым оказалось ручное логирование, составной триггер чуть медленнее. Эти два метода будут конкурировать в зависимости от реализации.
Еще медленнее flashback-архив, а обычный триггер оказался самым медленным. Стоит отметить, что все подходы отрабатывают в пределах четверти секунды.
Вставка 100 000
Увеличивая объем данных, мы замечаем большой разбег у методов. Медленнее всех оказался flashback archive, ручное логирование по-прежнему конкурирует с составным триггером.
Выводы и рекомендации
Нет одинаково хорошего решения для всех случаев.
Если не знаете, что выбрать, можно воспользоваться следующими рекомендациями.
Рекомендации по выбору способа логирования
Если у вас мало данных и мало изменений, то стоит обратить внимание на обычный триггер и flashback-архив.
Ручное логирование вы можете использовать везде, но нужно следить за вызовами.
Составной триггер лучше использовать, если в данных происходит много изменений, и вы по каким-то причинам не можете использовать ручное логирование.
В рубриках: Разное SQL, SQLServerPedia Syndication, Технические статьи — Теги: слияние, t-sql — Michael J. Swart @ 12:00 pm
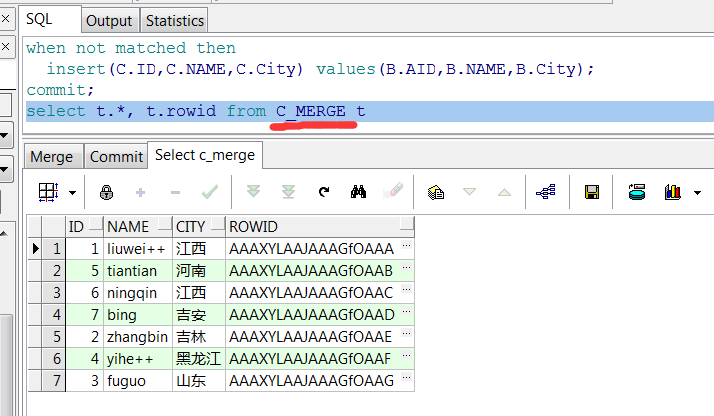
Итак, что у меня есть ниже является веб-формой. Он берет исходный запрос и целевую таблицу и выдает оператор слияния для стандартного варианта использования вставки/обновления. Сделал для себя, но может и вам пригодится. Я рассчитываю на то, что это реально сэкономит время (по крайней мере, для меня).
Некоторые полезные вещи
Эта веб-форма не публикуется ни на одном сервере. Это все javascript, который выполняется в вашем браузере. Это означает, что вам не нужно беспокоиться о том, что кто-то украдет ваш код, и I не нужно беспокоиться о том, что эта форма станет вирусной (ха-ха).
Фрагменты SQL (любого типа) не совсем обрабатывают здесь динамический список столбцов. Иначе сегодня вы бы читали другой пост.
Оператор MERGE гораздо более универсален, чем то, что я здесь показываю. Я просто рассматриваю наиболее распространенный вариант использования.
На что обратить внимание
Параллелизм. Если это важно для вас, не забудьте использовать соответствующие блокировки (обычно UPDLOCK) для целевой таблицы.
Убедитесь, что список столбцов исходного запроса совпадает со списком столбцов целевой таблицы.
Вам придется очистить сценарий, если в вашей целевой таблице есть столбцы, которые являются строками, идентификаторами, вычисляемыми и т. д….
Пользовательский ввод используется для генерации кода здесь. Так что мое паучье чутье SQL-инъекций начинает покалывать. Но в данном случае все в порядке, потому что я ничего не запускаю. Я просто показываю это. Вы тот, кто запускает этот материал, поэтому вы можете поручиться за любой сгенерированный код. Заботиться.
Форма
Уважаемый читатель RSS. К сожалению, веб-форма не выдержала путешествия по RSS-каналу. Почему бы вам не посетить этот пост на моем сайте, чтобы получить полный опыт MERGE.
Введите свои данные (или просто используйте образец здесь). Когда будете готовы, нажмите MERGE!
Исходный запрос выбирать * из Purchasing.ProductVendor_Staging
Целевая таблица Закупки.ProductVendor
Ключевые столбцы (один столбец в строке) Идантификационный номер продукта BusinessEntityID
Другие столбцы (один столбец в строке) Среднее время выполнения Стандартная цена LastReceiptCost LastReceiptDate MinOrderQty MaxOrderQty OnOrderQty UnitMeasureCode ModifiedDate
ctrl+c для копирования
Ваш запрос на слияние Ваш запрос появится здесь
— Комментарии (6)
RSS канал для комментариев к этому сообщению.
Извините, форма комментариев в настоящее время закрыта.
Powered by WordPress
Engine.execute() не выполняет автоматическую фиксацию при использовании синтаксиса обновлений слияния Oracle
Ответы Lightrun были разработаны, чтобы уменьшить постоянное поиск в Google, связанный с отладкой сторонних библиотек. Он собирает ссылки на все места, на которые вы могли бы обратить внимание, выискивая опасную ошибку.
И, если вы все еще застряли в конце, мы будем рады позвонить, чтобы узнать, как мы можем помочь.
См. исходную проблему GitHub
Описание проблемы
Опишите ошибку При использовании синтаксиса Oracle Merge Update транзакции не фиксируются автоматически при использовании engine.execute(). Пример синтаксиса Merge Update:
MERGE в Z_TEST2
используя (выберите Z_TEST1.descp, Z_TEST1.CHECKVAL из Z_TEST1) T1
ВКЛ (T1.DESCP = Z_TEST2.DESCP)
КОГДА СООТВЕТСТВУЕТ ТО
НАБОР ОБНОВЛЕНИЯ Z_TEST2. CHECKVAL = T1.CHECKVAL
Ожидаемое поведение Транзакция должна совершаться автоматически при использовании engine.execute()
Для воспроизведения Следующий скрипт на python продемонстрирует сбой проблемы с движком execute() и успешное завершение транзакции вручную.
импортировать панд как pd
из импорта sqlalchemy create_engine
двигатель = create_engine('oracle+cx_oracle://xxxxxx' )
защита check_commit():
df = pd.read_sql(" выберите CHECKVAL из Z_TEST2, где CHECKVAL='CHECK' ",con=engine)
если len(df) >= 1:
print('Выполнено успешно')
еще:
print('Транзакция не зафиксирована при выполнении обновления слиянием.')
## ПРОЦЕСС ##
engine.execute(" создать таблицу Z_TEST1 ( DESCP VARCHAR(20), CHECKVAL VARCHAR(20)) ")
engine.execute(" создать таблицу Z_TEST2 ( DESCP VARCHAR(20), CHECKVAL VARCHAR(20)) ")
engine.execute('ОБРЕЗАТЬ ТАБЛИЦУ Z_TEST1')
engine.execute('ОБРЕЗАТЬ ТАБЛИЦУ Z_TEST2')
engine. execute("вставить в значения Z_TEST1 ('Test1','CHECK')")
engine.execute("вставить в значения Z_TEST2 ('Test1',NULL)")
print('Выполняется обновление слиянием с использованием Execute')
merge_update_sql = '''Объединить в Z_TEST2
используя (выберите Z_TEST1.descp, Z_TEST1.CHECKVAL из Z_TEST1) T1
ВКЛ (T1.DESCP = Z_TEST2.DESCP)
КОГДА СООТВЕТСТВУЕТ ТО
НАБОР ОБНОВЛЕНИЯ Z_TEST2.CHECKVAL = T1.CHECKVAL
'''
engine.execute (merge_update_sql)
check_commit()
print('Выполняется обновление слияния с соединением/транзакцией')
с engine.connect() в качестве соединения:
транс = соединение.начало()
connection.execute (merge_update_sql)
транс.коммит()
check_commit()
engine.execute("УДАЛИТЬ ТАБЛИЦУ Z_TEST1 ОЧИСТИТЬ")
engine.execute("УДАЛИТЬ ТАБЛИЦУ Z_TEST2 ОЧИСТИТЬ")
Это распечатанный результат:
Запуск обновления слиянием с использованием Execute
Не удалось зафиксировать транзакцию при выполнении обновления слиянием.
Запуск Merge Update с соединением/транзакцией
Совершено успешно
Версии.
ОС: Windows 10
Python: 3.7.7
SQLAlchemy: 1.3.17
База данных: Oracle Database 11g Release 11.2.0.3.0 — 64-битная рабочая версия
DBAPI: cxOracle
Аналитика проблем
Состояние:
Создано 3 года назад
Реакций:1
Комментарии:5 (2 от сопровождающих)
Лучшие результаты из Интернета
как установить autocommit = 1 in sqlalchemy.engine.Connection
Функция «автоматическая фиксация» действует только в том случае, если в противном случае не было объявлено ни одной транзакции. Это означает, что эта функция обычно не используется с ……
Подробнее >
Требуется фиксация оператора слияния — Oracle Communities
Привет, команда, я использовал оператор слияния, Commit нужен или нет, и Rollback будет работать, подскажите?
Подробнее >
Работа с механизмами и соединениями — SQLAlchemy 2. 0 …
Метод execute() вызывается для выполнения оператора SQL, эта транзакция запускается автоматически, используя поведение, известное как автозапуск. Транзакция остается…
Читать дальше >
Понимание оператора SQL MERGE — SQLShack
Оператор MERGE в SQL является очень популярным предложением, которое может обрабатывать вставки, обновления и удаления в одной транзакции без…
Подробнее >
Команды — h3 Database Engine
UPDATE DELETE BACKUP CALL, EXECUTE IMMEDIATE EXPLAIN MERGE INTO … Нестандартный синтаксис, предназначенный только для совместимости, отмечен красным, не используйте его, если вам не нужно…
Читать далее >
Топ связанных сообщений в СМИ
Результатов не найдено
Топ связанных вопросов StackOverflow
Результатов не найдено и моментальные снимки для живого кода — без перезапусков или требуется повторное развертывание.
 The following syntax is used for hints:
The following syntax is used for hints:
 This hint also causes the optimizer to ignore any other hints specified for the statement block.
This hint also causes the optimizer to ignore any other hints specified for the statement block.
 Синтаксис намека МЕШАНИНЫ — МЕШАНИНА (стол), где стол определяет название(имя) или псевдоним стола, который нужно обратить просмотром мешанины.
Синтаксис намека МЕШАНИНЫ — МЕШАНИНА (стол), где стол определяет название(имя) или псевдоним стола, который нужно обратить просмотром мешанины. Синтаксис намека ИНДЕКСА — ИНДЕКС (индекс стола) where:table определяет название(имя) или псевдоним стола, связанного с индексом, который будет просмотрен, и индекс определяет индекс, на котором просмотр индекса должен быть выполнен. Этот намек может произвольно определить один или более индексов:
Синтаксис намека ИНДЕКСА — ИНДЕКС (индекс стола) where:table определяет название(имя) или псевдоним стола, связанного с индексом, который будет просмотрен, и индекс определяет индекс, на котором просмотр индекса должен быть выполнен. Этот намек может произвольно определить один или более индексов: If certain indexes are given as arguments, the optimizer will try to use some boolean combination of those particular bitmap indexes. The syntax of INDEX_COMBINE is INDEX_COMBINE(table index)
If certain indexes are given as arguments, the optimizer will try to use some boolean combination of those particular bitmap indexes. The syntax of INDEX_COMBINE is INDEX_COMBINE(table index)
 and index specifies an index on which an index scan is to be performed. You must specify at least two indexes. You cannot specify more than five.
and index specifies an index on which an index scan is to be performed. You must specify at least two indexes. You cannot specify more than five. Обычно, это преобразование происходит только, если стоимость вопроса, используя связи более дешевая чем стоимость без них.
Обычно, это преобразование происходит только, если стоимость вопроса, используя связи более дешевая чем стоимость без них. Такая информация позволила бы Вам выбирать внутренний и внешний стол лучше, чем optimizer мог.
Такая информация позволила бы Вам выбирать внутренний и внешний стол лучше, чем optimizer мог. Синтаксис намека USE_NL — USE_NL (стол стола) где стол — название(имя) или псевдоним стола, который нужно использовать, поскольку внутренний стол вложенных петель присоединяется.
Синтаксис намека USE_NL — USE_NL (стол стола) где стол — название(имя) или псевдоним стола, который нужно использовать, поскольку внутренний стол вложенных петель присоединяется. This hint is most often used to reduce the number of possible permutations for a query and make optimization faster.
This hint is most often used to reduce the number of possible permutations for a query and make optimization faster.
 ПАРАЛЛЕЛЬНЫЙ намек может тогда брать две ценности, отделенные запятыми после названия(имени) стола. Первая ценность определяет градус(степень) параллелизма для данного стола, вторая ценность определяет, как стол должен быть раздроблен среди случаев параллельной прислуги. Определение НЕПЛАТЕЖА или никакой ценности показывает, что координатор вопроса должен исследовать назначения параметров инициализации (описанный в более поздней секции) чтобы определить градус(степень) неплатежа параллелизма.
ПАРАЛЛЕЛЬНЫЙ намек может тогда брать две ценности, отделенные запятыми после названия(имени) стола. Первая ценность определяет градус(степень) параллелизма для данного стола, вторая ценность определяет, как стол должен быть раздроблен среди случаев параллельной прислуги. Определение НЕПЛАТЕЖА или никакой ценности показывает, что координатор вопроса должен исследовать назначения параметров инициализации (описанный в более поздней секции) чтобы определить градус(степень) неплатежа параллелизма. This option is useful for small lookup tables. In the following example, the CACHE hint overrides the table default caching specification.
This option is useful for small lookup tables. In the following example, the CACHE hint overrides the table default caching specification.
 Для генерации приколов.
Для генерации приколов.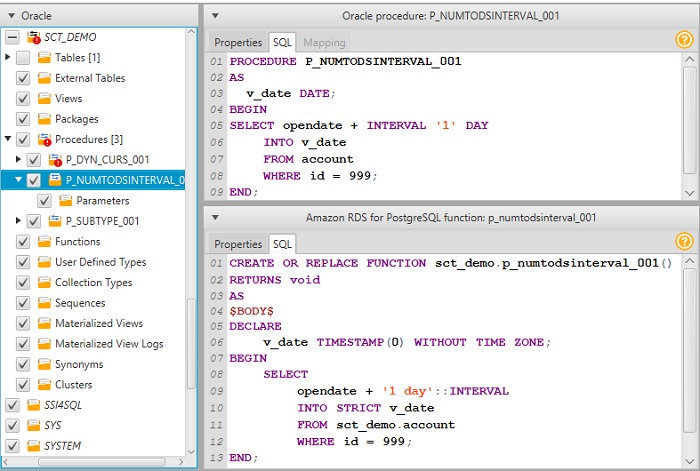 Если вам известно более двух способов, то вы молодец и уже почти всё знаете, в чём вам и остаётся убедиться, просмотрев разделы статьи.
Если вам известно более двух способов, то вы молодец и уже почти всё знаете, в чём вам и остаётся убедиться, просмотрев разделы статьи. 

 Это когда вам нужно залогировать то, что происходит в
Это когда вам нужно залогировать то, что происходит в  Это когда вам нужно залогировать то, что происходит в
Это когда вам нужно залогировать то, что происходит в  2.0.4) Flashback Archive доступен во всех редакциях бесплатно.
2.0.4) Flashback Archive доступен во всех редакциях бесплатно. 


 Это означает, что вам не нужно беспокоиться о том, что кто-то украдет ваш код, и I не нужно беспокоиться о том, что эта форма станет вирусной (ха-ха).
Это означает, что вам не нужно беспокоиться о том, что кто-то украдет ваш код, и I не нужно беспокоиться о том, что эта форма станет вирусной (ха-ха). Но в данном случае все в порядке, потому что я ничего не запускаю. Я просто показываю это. Вы тот, кто запускает этот материал, поэтому вы можете поручиться за любой сгенерированный код. Заботиться.
Но в данном случае все в порядке, потому что я ничего не запускаю. Я просто показываю это. Вы тот, кто запускает этот материал, поэтому вы можете поручиться за любой сгенерированный код. Заботиться.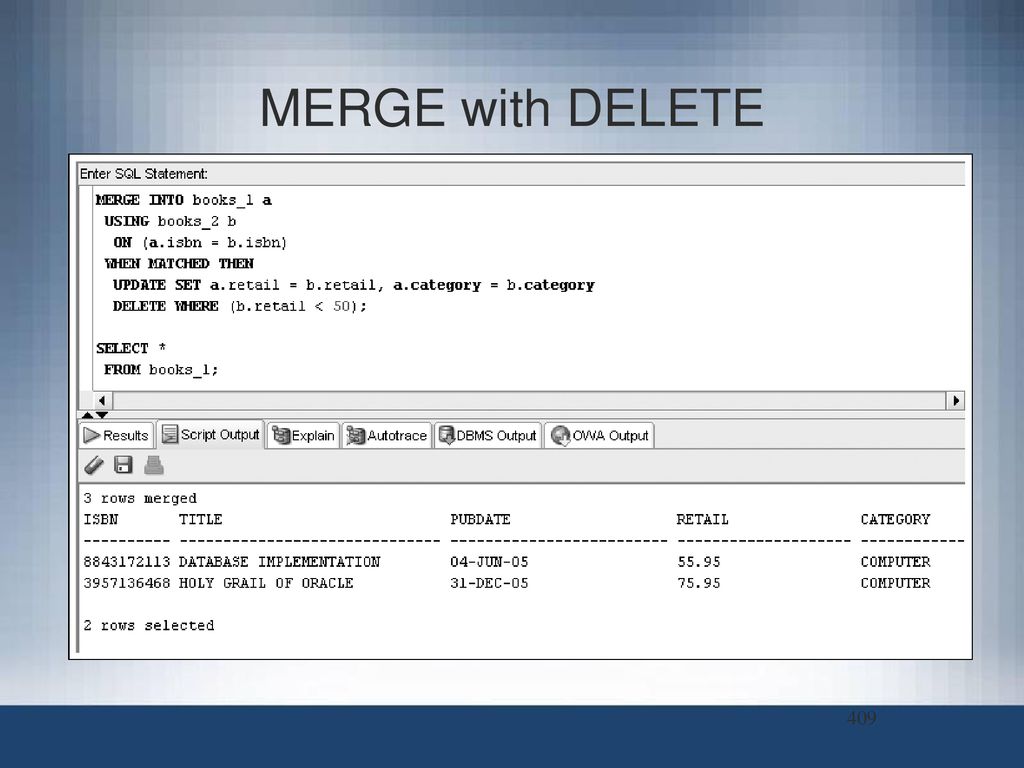
 CHECKVAL = T1.CHECKVAL
CHECKVAL = T1.CHECKVAL
 execute("вставить в значения Z_TEST1 ('Test1','CHECK')")
engine.execute("вставить в значения Z_TEST2 ('Test1',NULL)")
print('Выполняется обновление слиянием с использованием Execute')
merge_update_sql = '''Объединить в Z_TEST2
используя (выберите Z_TEST1.descp, Z_TEST1.CHECKVAL из Z_TEST1) T1
ВКЛ (T1.DESCP = Z_TEST2.DESCP)
КОГДА СООТВЕТСТВУЕТ ТО
НАБОР ОБНОВЛЕНИЯ Z_TEST2.CHECKVAL = T1.CHECKVAL
'''
engine.execute (merge_update_sql)
check_commit()
print('Выполняется обновление слияния с соединением/транзакцией')
с engine.connect() в качестве соединения:
транс = соединение.начало()
connection.execute (merge_update_sql)
транс.коммит()
check_commit()
engine.execute("УДАЛИТЬ ТАБЛИЦУ Z_TEST1 ОЧИСТИТЬ")
engine.execute("УДАЛИТЬ ТАБЛИЦУ Z_TEST2 ОЧИСТИТЬ")
execute("вставить в значения Z_TEST1 ('Test1','CHECK')")
engine.execute("вставить в значения Z_TEST2 ('Test1',NULL)")
print('Выполняется обновление слиянием с использованием Execute')
merge_update_sql = '''Объединить в Z_TEST2
используя (выберите Z_TEST1.descp, Z_TEST1.CHECKVAL из Z_TEST1) T1
ВКЛ (T1.DESCP = Z_TEST2.DESCP)
КОГДА СООТВЕТСТВУЕТ ТО
НАБОР ОБНОВЛЕНИЯ Z_TEST2.CHECKVAL = T1.CHECKVAL
'''
engine.execute (merge_update_sql)
check_commit()
print('Выполняется обновление слияния с соединением/транзакцией')
с engine.connect() в качестве соединения:
транс = соединение.начало()
connection.execute (merge_update_sql)
транс.коммит()
check_commit()
engine.execute("УДАЛИТЬ ТАБЛИЦУ Z_TEST1 ОЧИСТИТЬ")
engine.execute("УДАЛИТЬ ТАБЛИЦУ Z_TEST2 ОЧИСТИТЬ")
 Запуск Merge Update с соединением/транзакцией
Совершено успешно
Запуск Merge Update с соединением/транзакцией
Совершено успешно
 0 …
0 …