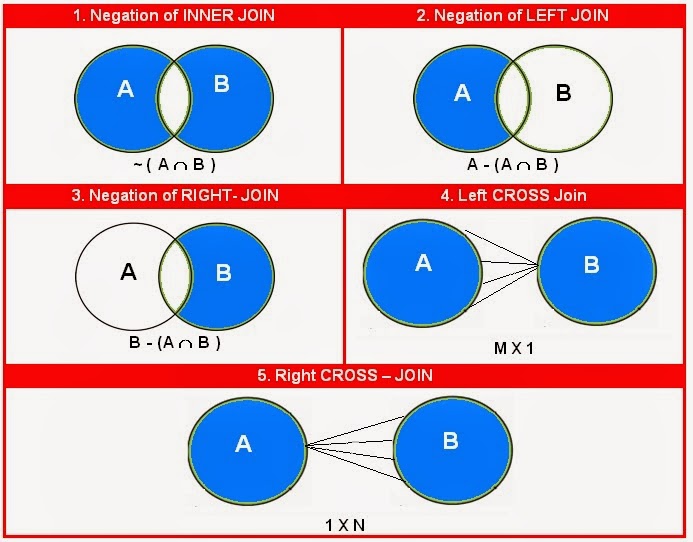
Sql cross apply описание: CROSS APPLY | SQL | SQL-tutorial.ru
Содержание
8 первоклассных инструкций SQL на каждый день | by Jenny V | NOP::Nuances of Programming
Предлагаем вашему вниманию 8 инструкций SQL для экономии рабочего времени. Одни из них базовые, другие немного посложнее, но все из них вам пригодятся. Поэтому начнем без лишних разговоров.
С помощью этого простого запроса мы получаем список строк с одинаковым значением, указанным в поле column_name. Кроме того, мы видим, сколько раз они повторяются.
select column_name, count(column_name)
from table
group by column_name
having count (column_name) > 1;
Хотя эту информацию можно получить с помощью клиента базы данных, сделаем это посредством инструкции SQL.
select TABLE_NAME, count(*)
from all_indexes
where owner = 'OWNER_NAME' or table_owner = 'TABLE_OWNER'
group by TABLE_NAME
order by TABLE_NAME;
Это предложение, кажущееся сложным, но таким не являющееся, демонстрирует типы предложений, выполнение которых занимает у движка базы данных особенно много времени. Поэтому нам пригодится умение выявлять инструкции SQL, требующие оптимизации.
Поэтому нам пригодится умение выявлять инструкции SQL, требующие оптимизации.
select
st.TEXT AS QueryName,
wt.execution_count AS ExecutionCount,
wt.total_worker_time/1000000 AS TotalCpuTimeInSeconds,
wt.total_worker_time/wt.execution_count/1000 AS AverageCpuTimeInMs],
qp.query_plan,
DB_NAME(st.dbid) AS [Database Name]
from
(select top 10
qs.execution_count,
qs.total_worker_time
from sys.dm_exec_query_stats qs
order by qs.total_worker_time desc) wtcross apply sys.dm_exec_sql_text(plan_handle) st
cross apply sys.dm_exec_query_plan(plan_handle) qp
order by wt.total_worker_time desc;
Как правило, со временем число индексов в базе данных увеличивается.
Сколько раз вы проверяли, действительны ли они? Индексы занимают место на диске и немалое, особенно в больших таблицах. Поэтому всегда лучше проверить, какие из них используются, а потом решить, удалять их или нет.
Для этой цели сначала необходимо включить мониторинг индексов:
ALTER INDEX INDEX_NAME MONITORING USAGE;
Для отключения этой опции достаточно выполнить следующую инструкцию:
ALTER INDEX INDEX_NAME NOMONITORING USAGE;
Теперь можно проводить мониторинг данных, обратившись к v$object_usage view:
select *
from
v$object_usage view
- Поле
START_MONITORINGотмечает время начала мониторинга.
- Поле
MONITORINGпоказывает, подвергается индекс проверке или нет. - Поле
USEDсловом “YES” указывает на применение индекса с момента активации мониторинга.
Перед удалением индекса, который, по вашему мнению, бездействует, рекомендуется продолжить работу мониторинга на определенное время. Это нужно для того, чтобы выявить возможные batch-процессы, которые задействуют этот индекс и выполняются нечасто.
При любой возможности выбирайте count(1) вместо count(*). Оператор count(*) принимает в расчет все столбцы таблицы для выполнения вычислений, тогда как count(1) учитывает только первый столбец.
Обратите внимание, что результат остается неизменным, будь то count (*) или count (1).
При использовании count(1) движок базы данных задействует меньше ресурсов и работает быстрее. В случае небольших таблиц эта разница будет незаметна, но если дело касается больших из них, то данный фактор существенно отразится на производительности запросов.
--BETTER
select
count(1) from big_table;--WORSE
select
count(*) from big_table;
Вы можете воспользоваться классом case when, аналогичным оператору if-then-else в других языках программирования, для написания условных выражений в запросах.
select column1, column2,
case when price >= 100 then '1'
when price between 90 and 99 then '2'
else 'Other case' end price_type
from table
Этот тип выражения позволяет определять временный именованный набор результатов, доступный в памяти в области выполнения инструкций, таких как SELECT, INSERT, UPDATE, DELETE и MERGE.
Данное выражение также применяется в инструкции CREATE VIEW как часть определяющей ее инструкции SELECT.
Главным образом ОТВ позволяют замещать подзапросы и табличные переменные.
В случае подзапросов ОТВ не обеспечивают преимущества в производительности, но зато способствует написанию более организованного и чистого кода, что улучшает его читаемость.
В случае табличных переменных ОТВ повышают производительность запроса, поэтому всегда будут предпочтительным вариантом.
--WORSE
select *
from other_table
where
name in (select name
from table
where
condition1 < 1000 and ... )--BETTER
with CTE_NAME as (
select name
from table
where condition1 < 1000 and ...
)select *
from other_table
where name in (SELECT name from CTE_NAME)
Этот небольшой пример не раскрывает всего потенциала ОТВ, но дает представление о том, как будет выглядеть код мегасложных и больших подзапросов.
Выражение OVER позволяет получать агрегированную информацию без GROUP BY и связанных с ним сложностей. Например, можно извлечь набор строк и вместе с ними получить агрегированные данные.
OVER предоставляет весь набор результатов для агрегации, но вы можете разделить его на части с помощью выражения PARTITION BY.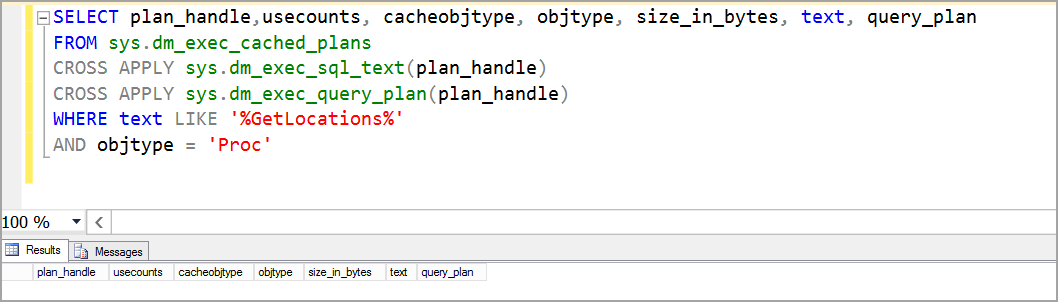
--OVER
select
SUM(column1) OVER () AS sum1,
column2
from table1--OVER PARTITION
select
SUM(column1) OVER (PARTITION BY client ) AS sum1,
column2
from table1
В данном примере разделение происходит по клиенту, и каждое “окно” одного клиента будет рассматриваться отдельно от других “окон”.
Мы рассмотрели небольшой перечень инструкций SQL, которые экономят время или помогают в повседневной работе.
Одни из них применяются в SQL Server, а другие — в Oracle. Но в целом вы можете подобрать их эквивалент для любого другого движка базы данных.
Читайте также:
- Как выполнять выражения и процедуры PL/SQL в Python
- SQL или NoSQL: как правильно выбрать базу данных?
- Руководство по SQL: команда MySQL INSERT в подробностях
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Kesk -*-: 8 Super-useful SQL Snippets You’ll Want to Have on Hand
Методы в Teradata SQL, о которых, возможно, вы не знали — Разработка на vc.
 ru
ru
В этой статье хотелось бы рассмотреть примеры методов, которые доступны в Teradata SQL, но отсутствует T-SQL или реализованы в менее удобном виде.
3641
просмотров
Загрузим тестовую таблицу c необходимой для проверки информацией о картах клиента, для демонстрации некоторых возможностей Teradata SQL:
В Teradata удобно реализована возможность разбиения столбца по разделителю. Для этого используется метод strtok ([столбец], [разделитель], [порядковый номер возвращаемого токена]). Благодаря нему можно создать столбец на основе уже существующего.
Разделим в нашей таблице столбец fullname по разделителю , ’:
select
a.num_account
,a.num_card
,a.issue_date
,strtok( a.fullname,’,’,1) as surname
,strtok( a.fullname,’,’,2) as firstname
,strtok( a.fullname,’,’,3) as middlename
from accounts a
В T-SQL присутствует похожий метод string_split, который работает несколько иным образом. Он принимает на вход символьную строку и разбивает ее на подстроки по заданному разделителю, которые формируют значения унарной таблицы.
Для одной строки из столбца fullname — это будет выглядеть так:
Что заставляет производить дополнительные манипуляции (к примеру, cross apply и последующий pivot), чтобы привести в вид, аналогичный применению метода strtok.
Перейдем к следующему методу qualify, условное предложение которое вычисляется после отработки оператора Select. Это означает, что в нем можно напрямую обращаться к оконным функциям. Рассмотрим пример, когда из нашей таблицы нам нужно вывести информацию по последней выпущенной карте клиента в рамках одного счета с использованием ранжирования.
select
a.num_account
,a.num_card
,a.issue_date
,strtok( a.fullname,’,’,1) as surname
,strtok( a.fullname,’,’,2) as firstname
,strtok( a.fullname,’,’,3) as middlename
from accounts a
qualify 1 = dense_rank() over(partition by num_account order by issue_date desc)
Результат выполнения запроса будет выглядеть так:
Также qualify позволяет ссылаться на псевдонимы столбцов, определённых в списке Select. Это позволяет переписать предыдущий запрос и результат будет идентичен.
Это позволяет переписать предыдущий запрос и результат будет идентичен.
select
a.num_account
,a.num_card
,a.issue_date
,strtok( a.fullname,’,’,1) as surname
,strtok( a.fullname,’,’,2) as firstname
,strtok( a.fullname,’,’,3) as middlename
,dense_rank() over(partition by num_account order by issue_date desc) as rnk
from accounts a
qualify rnk=1
Знание нюансов работы каждой СУБД позволяет пользователю не теряться в подборе своего решения и останавливать свой выбор на наиболее эффективном и подходящем в данной ситуации. Иногда это просто добавляет вариативности, так как не бывает единственного правильного решения задачи. Исходя из этого можно сделать вывод, который заключается в том, что не нужно останавливаться на изучении какого-то одного продукта, вариативность всегда будет хорошим подспорьем в решении задач.
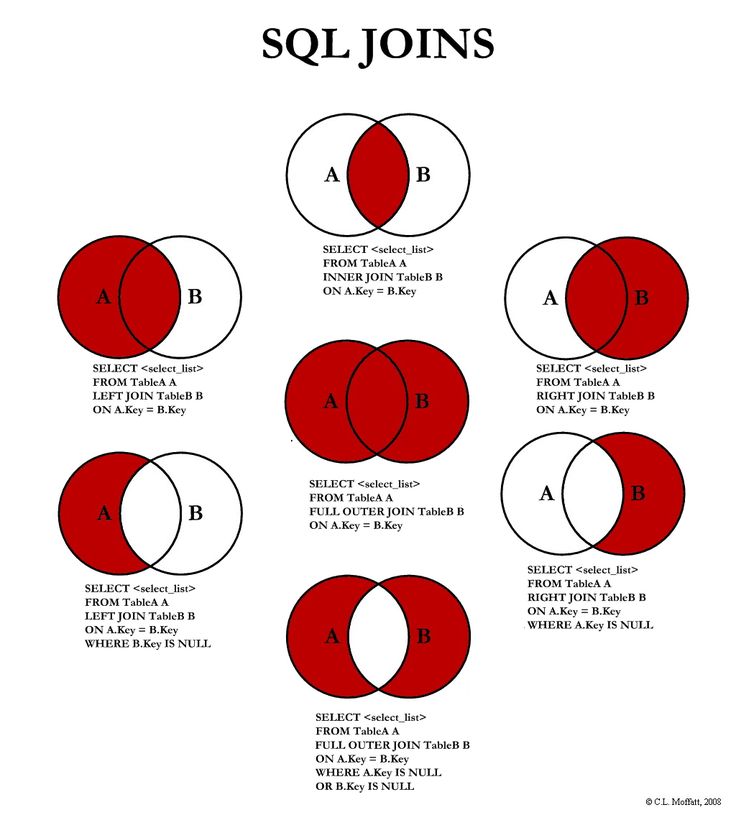
SQL Server — Оператор SQL CROSS APPLY
Автор: mandy.doward
Теги:
SQL Server, SQL, SELECT, CROSS APPLY 0 Комментарии
Использование CROSS APPLY в операторах SQL SELECT
Я беру В этой статье через следующее:
- ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ
- НАРУЖНОЕ ПРИМЕНЕНИЕ
- ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ с пользовательскими табличными функциями
Когда следует использовать оператор CROSS APPLY
Оператор CROSS APPLY ведет себя аналогично коррелированному подзапросу, но позволяет использовать операторы ORDER BY внутри подзапроса.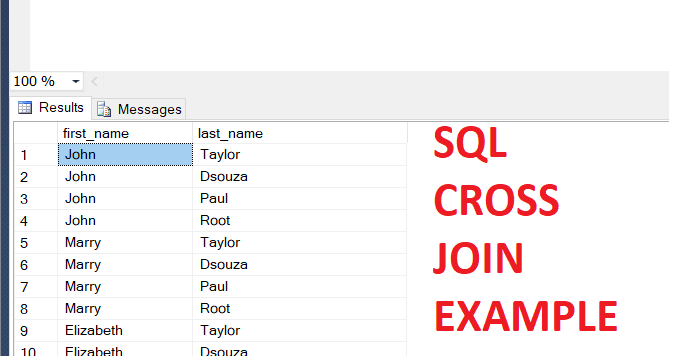 Это очень полезно, когда мы хотим извлечь верхнюю запись из подзапроса для использования во внешнем подзапросе.
Это очень полезно, когда мы хотим извлечь верхнюю запись из подзапроса для использования во внешнем подзапросе.
CROSS APPLY также используется, когда мы хотим передать значения в определяемую пользователем табличную функцию.
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ
В следующем примере создается список заказов вместе с количеством дней между заказом и следующим заказом, размещенным тем же клиентом.
ИСПОЛЬЗОВАНИЕ Северный ветер
ИДТИ
ВЫБЕРИТЕ o1.OrderID, o1.OrderDate, ca.OrderID AS NextOrder,
ca.OrderDate AS NextOrderDate, CustomerID,
DATEDIFF(DAY, o1.OrderDate,ca.OrderDate) DaysToNextOrder
ОТ Заказы AS o1
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ
(SELECT TOP 1 o.OrderDate, o.OrderID
ОТ заказов КАК o
ГДЕ o.customerID = o1.customerID
И o.OrderID > o1.OrderID
ЗАКАЗАТЬ ПО OrderID) AS ca
ЗАКАЗ ПО CustomerID, o1.OrderID
CROSS APPLY позволяет нам присоединять записи заказов ( Orders AS o1 ) к подзапросу (производная таблица с именем ca ), но мы также можем использовать ORDER BY в подзапросе для сортировки записей заказов в подзапросе. в порядке возрастания даты заказа, чтобы мы могли определить первый заказ (ТОП 1) после даты заказа текущей записи.
в порядке возрастания даты заказа, чтобы мы могли определить первый заказ (ТОП 1) после даты заказа текущей записи.
OUTER APPLY
Оператор OUTER APPLY ведет себя как OUTER JOIN.
В следующем примере будут сохранены все заказы из внешнего запроса (Orders AS o1), даже если нет последующих заказов. Предыдущая версия будет отображать только те заказы, которые имеют последующие заказы.
-- Количество дней между заказами – включить заказы, в которых больше нет заказов. ИСПОЛЬЗОВАНИЕ Северный ветер ИДТИ ВЫБЕРИТЕ o1.OrderID, o1.OrderDate, ca.OrderID AS NextOrder, ca.OrderDate AS NextOrderDate, CustomerID, DATEDIFF(DAY, o1.OrderDate,ca.OrderDate) DaysToNextOrder ОТ Заказы AS o1 НАРУЖНОЕ ПРИМЕНИТЬ (SELECT TOP 1 o.OrderDate, o.OrderID ОТ заказов КАК o ГДЕ o.customerID = o1.customerID И o.OrderID > o1.OrderID ЗАКАЗАТЬ ПО OrderID) AS ca ЗАКАЗ ПО CustomerID, o1.OrderID
CROSS APPLY и функции с табличным значением
Функции с табличным значением возвращают набор записей в качестве выходных данных.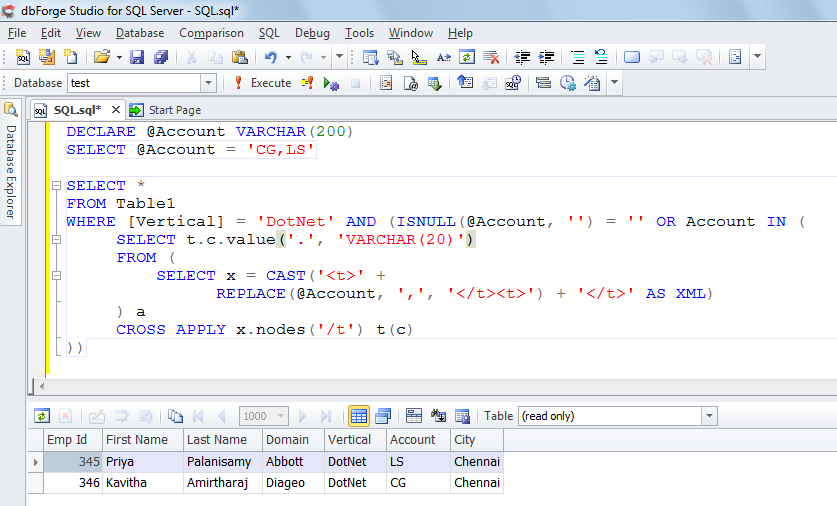 Если мы просто хотим просмотреть все записи, возвращенные для данного входного значения, мы можем вызвать определяемую пользователем функцию следующим образом:
Если мы просто хотим просмотреть все записи, возвращенные для данного входного значения, мы можем вызвать определяемую пользователем функцию следующим образом:
USE AdventureWorks2014 ИДТИ ВЫБИРАТЬ * ОТ [dbo].[ufnGetContactInformation] (5454)
Если, однако, мы хотим передать значение в функцию для каждой записи в другой таблице, нам нужно соединить пользовательскую функцию и таблицу. Для этого требуется оператор CROSS APPLY, поскольку мы не можем использовать INNER JOIN с предложением ON — значение соединения должно быть передано в функцию.
См. следующий пример.
ИСПОЛЬЗОВАТЬ AdventureWorks2014 ИДТИ ВЫБЕРИТЕ AccountNumber, ci.* ОТ Продажи.Клиент ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ [dbo].[ufnGetContactInformation] (PersonID) AS ci
Чтобы включить все записи клиентов, даже те, которые не имеют связанной контактной информации (например, магазины), используйте ВНЕШНЕЕ ПРИМЕНЕНИЕ:
ИСПОЛЬЗУЙТЕ AdventureWorks2014 ИДТИ ВЫБЕРИТЕ AccountNumber, ci.
 *
ОТ Продажи.Клиент
ВНЕШНЕЕ ПРИМЕНЕНИЕ [dbo].[ufnGetContactInformation] (PersonID) AS ci
*
ОТ Продажи.Клиент
ВНЕШНЕЕ ПРИМЕНЕНИЕ [dbo].[ufnGetContactInformation] (PersonID) AS ci
Если вы хотите узнать больше об операторах SQL Server SELECT, напишите нам по адресу [email protected] с вашими вопросами или почему бы не взглянуть на наши учебные курсы по запросам к базе данных SQL Server:
Запросы к базе данных SQL Server
Дополнительные запросы к базе данных SQL Server
Поделиться этой публикацией
Вероятно, лучшее введение в JOIN, CROSS APPLY, UNION, CROSS JOINS и многое другое в SQL Server | Никола Симболи
В этом рассказе мы начнем с нуля, чтобы понять, как мы можем объединять две или более таблиц в SQL Server. Мы будем использовать SQL Server 2019, но почти каждый запрос, описанный ниже, может быть выполнен в более старых версиях SQL Server или даже в других базах данных SQL, таких как Oracle или MySQL, с очень небольшими изменениями.
Прежде чем начать, важно знать, что структуру, данные и все запросы в этой статье можно найти на этой странице db<>fiddle . Вы найдете это очень полезным, так как они могут быть как редактируемыми, так и исполняемыми, поэтому не стесняйтесь экспериментировать со всем, что приходит вам в голову.
Вы найдете это очень полезным, так как они могут быть как редактируемыми, так и исполняемыми, поэтому не стесняйтесь экспериментировать со всем, что приходит вам в голову.
Мы будем использовать следующие таблицы и примеры данных для всех запросов. Представьте, что вы просматриваете (очень упрощенную версию) хранилище данных службы проката электронных скутеров, такой как Bird, Lime, Dott.
У нас есть следующие таблицы:
- Таблица [dbo].[Trip] : таблица транзакций со всеми поездками. Он имеет одну строку на поездку или, другими словами, одна строка генерируется каждый раз, когда пользователь разблокирует самокат, использует его для поездок на работу и снова блокирует.
- Таблица [dbo].[Пользователь] : таблица измерений пользователей.
- Таблица [dbo].[Скутер] : таблица размеров скутеров.
- Таблица [dbo].[RepairedScooter] : это таблица, содержащая список самокатов, которые хотя бы один раз прошли ремонтную палату.

Вы можете просмотреть код для создания и заполнения данных из db<>fiddle, а также просмотреть предварительный просмотр.
Мы можем использовать CROSS JOIN (или декартово соединение) в разных ситуациях, но, вероятно, чаще всего его используют, когда вы хотите ВЫБРАТЬ все комбинации двух или более полей из одной или нескольких таблиц.
В следующем примере вы можете использовать CROSS JOIN для выполнения SELECT для каждой комбинации самокатов и пользователей. Например, это может быть полезно, если вы хотите создать первую таблицу для анализа того, арендуют ли пользователи одни и те же самокаты более одного раза или нет.
— Запрос A001
ВЫБЕРИТЕ РАЗЛИЧНЫЕ A.[ID],A.[Имя пользователя],B.[ID],B.[Бренд],B.[Модель]
FROM [User] A,[Scooter] B
ORDER BY A.[ID],B.[ID]
СОЕДИНЕНИЕ используется, когда вы хотите добавить в таблицу (таблица A) один или несколько столбцов из другой таблицы (таблица B). Это, вероятно, самая важная конструкция для освоения, если вы хотите работать с базой данных на основе SQL.
Это, вероятно, самая важная конструкция для освоения, если вы хотите работать с базой данных на основе SQL.
Введение в синтаксис
Перед тем, как разобраться в различных типах соединений, давайте кратко рассмотрим синтаксис, который следует использовать, когда мы хотим выполнить СОЕДИНЕНИЕ между таблицами.
Следующий запрос представляет собой базовое СОЕДИНЕНИЕ между таблицей [Trip] (с псевдонимом «A») и таблицей [Scooter] (с псевдонимом «B»). Тип соединения — INNER JOIN, мы поймем, что это значит, позже в этом разделе статьи. Условия соединения перечислены после предложения ON. Здесь есть одно простое равенство между столбцами, но их может быть больше одного (в этом случае вы должны использовать операторы И, ИЛИ, НЕ) или что-то более сложное, например, МЕЖДУ или НРАВИТСЯ. В условиях JOIN вы также можете найти функции, применяемые к столбцам (например, LEFT), но это введение, поэтому мы не найдем ни одного из этих случаев.
— Запрос B001
ВЫБЕРИТЕ A.
FROM [Trip] A
INNER JOIN [Scooter ] B
ON A.[ID_Scooter]=B.[ID]
 [ID],A.[DateTimeStart],A.[TripDuration],B.[Brand],B.[Model]
[ID],A.[DateTimeStart],A.[TripDuration],B.[Brand],B.[Model] Мы использовали в запросе некоторые псевдонимы, но мы могли бы также повторить полное имя таблицы и получить тот же результат.
— Запрос B003
ВЫБЕРИТЕ [Поездка].[ID],[Поездка].[ДатаВремяНачала],[Поездка].[Продолжительность поездки],[Скутер].[Марка],[Скутер].[Модель]
ОТ [Поездка]
INNER JOIN [Scooter]
ON [Trip].[ID_Scooter]=[Scooter].[ID]
Не обязательно (но рекомендуется) указывать имя или псевдоним таблицы, если имя столбца существует только в одном из столы. Кроме того, этот запрос дает те же результаты, что и два других.
— Запрос B002
ВЫБЕРИТЕ A.[ID],[DateTimeStart],[TripDuration],[Brand],[Model]
FROM [Trip] A
INNER JOIN [Scooter] B
ON [ID_Scooter]= B.[ID]
Конечно, вы можете расширить все эти правила с помощью JOIN трех или более таблиц, ограничений на этот способ нет.
— Запрос B004
ВЫБЕРИТЕ A.[ID],A.[DateTimeStart],A.[DurationDuration],B.[Бренд],B.[Модель],C.*
ИЗ [Trip] A
INNER JOIN [Scooter] B
ON A.[ID_Scooter]=B.[ID]
INNER JOIN [User] C
ON A.[ID_User]=C.[ID]
Наконец, вы можете найти JOIN предложения с другим синтаксисом (например, если вы используете пакет SAP Business Objects), похожим на предложение CROSS JOIN. Это также допустимый синтаксис, известный как ANSI-92, но в этой статье мы его не используем, так что не стесняйтесь найти множество статей о нем в Интернете.
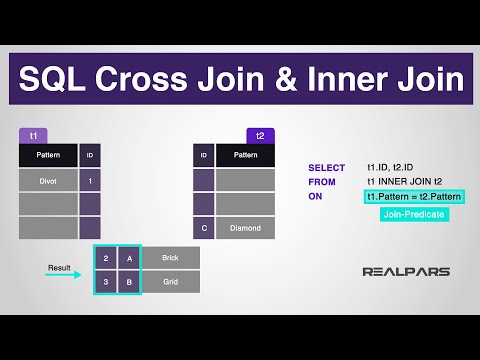
FULL OUTER JOIN
Результаты FULL OUTER JOIN будут включать по крайней мере одну строку из таблицы A и по крайней мере одну строку из таблицы B, даже если условия JOIN не выполняются, в этом случае строка значений NULL придет из строки, которая не соответствует.
См. следующий пример, поясняющий эту концепцию.
— Запрос C001
SELECT *
FROM [Trip] A
FULL OUTER JOIN [User] B
ON A.
 [ID_User]=B.[ID]
[ID_User]=B.[ID]ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
ЛЕВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ похоже на ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ, но асимметрично. Это означает, что в результатах будет хотя бы одна строка из таблицы слева (таблица A в следующем примере), но строки таблицы справа (таблица B в примере), которые не удовлетворяют правилам JOIN, не будет показано.
— Запрос D001
SELECT *
FROM [Trip] A
LEFT JOIN [User] B
ON A.[ID_User]=B.[ID]
Обратите внимание, что мы можем использовать LEFT OUTER JOIN построить, чтобы найти строки таблицы слева (таблица A), которые не имеют строки соответствия в таблице справа (таблица B) на основе правил JOIN. Это очень полезное приложение, которое можно использовать, просто добавив предложение WHERE в запрос, как в следующем примере.
— Запрос D002
ВЫБЕРИТЕ A.*
ИЗ [Поездка] A
LEFT JOIN [User] B
ON A.
ГДЕ B.[ID] IS NULL
 [ID_User]=B.[ID]
[ID_User]=B.[ID] ПРАВОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
Как вы, вероятно, ожидаете, все соображения, которые мы сделали для ЛЕВОГО ВНЕШНЕГО СОЕДИНЕНИЯ, могут быть симметрично использованы в ПРАВОМ ВНЕШНЕМ СОЕДИНЕНИИ.
Не стесняйтесь взглянуть на следующие два примера, чтобы подтвердить или опровергнуть ваши ожидания относительно RIGHT OUTER JOIN после понимания LEFT OUTER JOIN в разделе выше.
— Запрос E001
ВЫБОР *
ИЗ [Поездка] A
ПРАВОЕ СОЕДИНЕНИЕ [Пользователь] B
ON A.[ID_User]=B.[ID]
2 — 0 SELECT E03 100807 — 0 0Query Б. *
FROM [Trip] A
RIGHT JOIN [User] B
ON A.[ID_User]=B.[ID]
WHERE A.[ID] IS NULL
INNER JOIN
Концептуально INNER JOIN является комбинация LEFT и RIGHT OUTER JOIN, поэтому в результатах этого JOIN будут только строки, соответствующие правилам JOIN.
— Запрос F001
SELECT *
FROM [Trip] A
INNER JOIN [User] B
ON A. [ID_User]=B.[ID]
[ID_User]=B.[ID]
ANTI JOIN
отобразит только строки таблицы слева (таблица A) и строки таблицы справа (таблица B), которые не соответствуют правилам JOIN.
— Запрос G001
ВЫБОР *
ИЗ [Поездка] A
ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ [Пользователь] B
ON A.[ID_User]=B.[ID]
ГДЕ A.[ID] IS NULL OR B.[ ID] НУЛЬ
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ похоже на ВНУТРЕННЕЕ СОЕДИНЕНИЕ, но оно используется, когда вы хотите указать более сложные правила о количестве или порядке в СОЕДИНЕНИИ. Наиболее распространенное практическое использование CROSS APPLY, вероятно, когда вы хотите сделать JOIN между двумя (или более) таблицами, но вы хотите, чтобы каждая строка таблицы A вычисляла одну и только одну строку таблицы B. В следующем примере в более подробно, каждый пользователь (таблица A) будет соответствовать своей самой продолжительной поездке (таблица B). Обратите внимание, что пользователи, которые не совершили ни одной поездки, не будут включены в результаты, так как мы уже говорили, что CROSS APPLY в чем-то похож на INNER JOIN.
— Запрос H001
ВЫБЕРИТЕ A.*,B.[TripDuration],B.[ID]
FROM [User] A
CROSS APPLY (
SELECT TOP 1 *
FROM [TripDuration] C
WHERE C.[ ID_User]=A.[ID]
ORDER BY C.[TripDuration] DESC
) B
OUTER APPLY
Конструкция OUTER APPLY очень близка к CROSS APPLY, которую мы только что обсуждали. Основное отличие состоит в том, что OUTER APPLY будет включать в результаты также строки из таблицы A, которые не соответствуют правилам соответствия, определенным в предложении WHERE.
Следующий пример аналогичен тому, который мы сделали в разделе ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ, но, как вы можете легко заметить, в результаты включаются и пользователи, у которых не было поездок.
— Запрос I001
ВЫБЕРИТЕ A.*,B.[TripDuration],B.[ID]
FROM [User] A
OUTER APPLY (
SELECT TOP 1 *
FROM [TripDuration] C
WHERE C.[ ID_User]=A.[ID]
ORDER BY C.[TripDuration] DESC
) B
Использование условий WHERE в JOINS
Прежде чем двигаться дальше, важно понять, как используется предложение WHERE при использовании ПРИСОЕДИНИТЬСЯ.
Мы рассмотрим четыре примера с четырьмя совершенно разными результатами, которые, я надеюсь, помогут понять, как правильно писать правила JOIN и WHERE.
В запросе L001 можно увидеть важный факт о СОЕДИНЕНИИ, так как база данных, в первую очередь, сделает СОЕДИНЕНИЕ между таблицами, основываясь на правилах СОЕДИНЕНИЯ, и только после этого будет фильтровать с помощью предложения WHERE. Таким образом, результаты будут включать только строки, ГДЕ B.[Имя пользователя]=’Бренда’.
— Запрос L001
SELECT *
FROM [Trip] A
LEFT JOIN [User] B
ON A.[ID_User]=B.[ID]
WHERE B.[Username]=’Brenda’
Еще один важный факт о JOIN заключается в том, что вы можете указать некоторые правила фильтрации внутри правил JOIN. Это хорошая идея, если вы считаете, что правила JOIN применяются перед предложением WHERE, поэтому вы ограничите количество строк, которые база данных должна извлечь перед фильтрами.
Другая сторона медали заключается в том, что вы должны знать и всегда обращать внимание на то, что в LEFT OUT JOIN будут учитываться только правила фильтрации, примененные к правой таблице (таблица B).
— Запрос L002
ВЫБЕРИТЕ *
ИЗ [Поездка] A
LEFT JOIN [User] B
ON A.[ID_User]=B.[ID] AND B.[Username]=’Brenda’
— Запрос L003
SELECT *
FROM [Trip] A
LEFT JOIN [User] B
ON A.[ID_User]=B.[ID]
WHERE A.[ID_Scooter]=’SR001′
As мы уже говорили в примере с запросом L002, что в LEFT OUT JOIN будут учитываться только правила фильтрации, примененные к правой таблице (таблица B). В этом примере видно, что правило фильтрации A.[ID_Scooter]=’SR001’ игнорируется, и в результатах извлекаются все самокаты. Пожалуйста, выделите немного времени, чтобы понять разницу между результатами запросов L003 и L004.
— Запрос L004
SELECT *
FROM [Trip] A
LEFT JOIN [User] B
ON A.[ID_User]=B.[ID] AND A.[ID_Scooter]=’SR001′
5 После объединения столбцов из разных таблиц вы, вероятно, спросите, можно ли объединять строки из разных таблиц.
 Ответ определенно да, но вы должны освоить различные конструкции.
Ответ определенно да, но вы должны освоить различные конструкции.
UNION и UNION ALL
Первое важное предположение об объединении строк из разных таблиц заключается в том, что имена и тип столбцов должны быть одинаковыми. Например, если вы попытаетесь объединить таблицы Scooter и RepairedScooter с помощью UNION ALL, вы получите сообщение об ошибке, поскольку они имеют разные столбцы.
— Запрос M001
SELECT *
FROM [Scooter]
UNION ALL
SELECT *
FROM [RepairedScooter]
Сообщение 205 Уровень 16 Состояние 1 Строка 2 Все запросы должны быть объединены оператором EXPTERS или INTERS с использованием UNION, INTERS одинаковое количество выражений в своих целевых списках.
Без изменения структуры таблиц вы можете легко объединить две таблицы, выбрав только те столбцы, которые существуют в обеих из них.
— Запрос M002
ВЫБЕРИТЕ [ID],[Марка],[Модель],[Год производства]
ИЗ [Скутер]
ОБЪЕДИНЕНИЕ ВСЕХ
ВЫБЕРИТЕ [ID],[Марка],[Модель],[Год производства]
ИЗ [RepairedScooter]
Разница между UNION и UNION ALL заключается в том, что первый включает в результаты только значения DISTINCT, и по этой причине он немного медленнее, чем другой.
— Запрос M003
ВЫБЕРИТЕ [ID],[Бренд],[Модель],[Год выпуска]
ИЗ [Скутер]
UNION
ВЫБЕРИТЕ [ID],[Бренд],[Модель],[Год выпуска]
FROM [RepairedScooter]
EXCEPT
Мы можем использовать EXCEPT, если хотим извлечь строки, которые есть в первой таблице, но не во второй таблице.
— Запрос N001
ВЫБЕРИТЕ [ID],[Бренд],[Модель],[Год выпуска]
ИЗ [Скутер]
КРОМЕ
ВЫБЕРИТЕ [ID],[Бренд],[Модель],[Год выпуска]
ИЗ [RepairedScooter]
INTERSECT
Мы можем использовать INTERSECT, если хотим извлечь строки как из первой, так и из второй таблицы.
— Запрос O001
ВЫБЕРИТЕ [ID],[Бренд],[Модель],[Год производства]
ИЗ [Скутер]
INTERSECT
ВЫБЕРИТЕ [ID],[Бренд],[Модель],[Год производства]
ИЗ [RepairedScooter]
Мы видели много конструкций, и я надеюсь, что эта история помогла вам лучше понять разницу между ними. На рисунке ниже вы можете найти блок-схему, которая может оказаться полезной на первых шагах при объединении данных из разных источников в SQL Server.