Sql cursor t: SQL Server Cursor Example
Содержание
НОУ ИНТУИТ | Лекция | Курсоры в Transact-SQL
< Урок 25 || Урок 26: 123456789 || Урок 27 >
Аннотация: Курсор – это особый временный объект SQL, предназначенный для использования в программах и хранимых процедурах. С его помощью можно в цикле пройти по результирующему набору строк запроса, по отдельности считывая и обрабатывая каждую его строку. В хранимых процедурах с помощью курсоров можно выполнять сложные вычисления, которые трудно выразить с помощью синтаксиса инструкции SELECT. Большой теоретический материал урока дополнен очень хорошими примерами. В частности, рассматривается применение функции CURSOR_STATUS, описание переменных @@CURSOR_ROWS и @@FETCH_STATUS, и многое другое.
Ключевые слова: FETCH, реляционные операции, представление, Transact-SQL, SQL, операции, курсор, объект, множества, server, API, activex data object, ADO, OLE DB, ODBC, синтаксис, DECLARE CURSOR, сеть, последовательный курсор, статический курсор, уникальный индекс, объявление курсора, условие членства, открытие курсора, динамический курсор, прокручиваемый курсор, data manipulation language, значение, SQL/92, предупреждающее сообщение, определение столбца, deallocation, освобождение курсора, analyzer, Типы данных столбцов, Prior
Вы научитесь:
intuit.ru/2010/edi»>объявлять курсор;
- открывать курсор;
- закрывать курсор;
- освобождать курсор;
- использовать простую команду FETCH;
- осуществлять выборку строки в переменные;
- осуществлять выборку строки по ее абсолютной позиции;
- осуществлять выборку строки по ее относительной позиции;
- выполнять позиционную модификацию;
- выполнять позиционное удаление;
- использовать глобальную переменную @@CURSOR_ROWS для определения количества строк во множестве курсора;
 ru/2010/edi»>использовать глобальную переменную @@FETCH_STATUS для определения результатов выполнения команды FETCH;
ru/2010/edi»>использовать глобальную переменную @@FETCH_STATUS для определения результатов выполнения команды FETCH;- использовать функцию CURSOR_STATUS для запроса статуса курсора.
Одним из характерных свойств реляционных баз данных является то, что действия выполняются над множествами строк. Множество может быть пустым, либо содержать только одну строку, но все равно оно считается множеством. Это необходимое и полезное свойство для реляционных операций, но оно порой может быть не слишком удобным для приложений.
Например, поскольку нет возможности указать на определенную строку во множестве, представление пользователю строк по одной за раз может вызвать затруднения. Даже несмотря на то, что предоставляемые Transact-SQL расширения к стандартному языку SQL позволяют реализовать гораздо большие возможности для программирования, тем не менее остаются операции, которые затруднительно, трудоемко или даже вообще невозможно выполнить на основе принципов работы с множествами.
Чтобы справиться с подобными ситуациями, в SQL предусмотрены курсоры. Курсор представляет собой объект, который указывает на определенную строку во множестве. В зависимости от сути созданного вами курсора, вы можете перемещать курсор внутри множества и модифицировать или удалять данные.
Понятие о курсорах
Microsoft SQL Server реально поддерживает два различных типа курсоров: курсоры Transact-SQL и курсоры API (курсоры программного интерфейса приложений). Курсоры API создаются внутри приложения, использующего объекты Microsoft ActiveX Data Objects (ADO), OLE DB, ODBC или DB-Library. Каждое из этих API поддерживает несколько отличающиеся функциональные возможности и использует различный синтаксис. Здесь мы не будем подробно обсуждать курсоры API; если вы планируете использовать их, обратитесь к соответствующей документации на API и языку программирования, который вы собираетесь применить.
Курсоры Transact-SQL создаются с помощью команды DECLARE CURSOR. Как объект курсора, так и множество строк, на которое он указывает, должны существовать на сервере. Подобные курсоры называются серверными курсорами. Если вы используете серверный курсор из приложения, соединенного с SQL Server через сеть, каждая операция с курсором требует двустороннего сетевого взаимодействия. Библиотеки API-курсоров, поддерживающие серверные курсоры, поддерживают также клиентский курсор, который существует в клиентской системе и кэширует строки, которые он обрабатывает на клиенте.
Множество строк, на которое указывает курсор, определяется с помощью команды SELECT. При создании курсора Transact-SQL на команду SELECT накладываются несколько ограничений:
- команда SELECT не может возвращать несколько результирующих множеств;
 ru/2010/edi»>команда SELECT не может содержать фразу INTO для создания новой таблицы;
ru/2010/edi»>команда SELECT не может содержать фразу INTO для создания новой таблицы;- команда SELECT не может содержать фразу COMPUTE или COMPUTE BY, используемые для агрегирования результатов. (Однако, она может содержать функции агрегирования, например, AVG.)
Характеристики курсоров
Transact-SQL поддерживает несколько различных типов курсоров. Выяснение различных характеристик каждого из курсоров является довольно утомительной задачей, но ее можно облегчить, если принять во внимание для каждого типа курсора три более или менее независимых характеристики: способность отражать изменения в исходных данных, способность осуществлять прокрутку во множестве строк, а также способность модифицировать множество строк.
Отражение изменений
Способность курсора отражать изменения в данных называется чувствительностью курсора. Предположим, что вы создали курсор для оператора:
Предположим, что вы создали курсор для оператора:
SELECT * FROM Oils WHERE Left(OilName, 1) = 'B'
База данных Aromatherapy вернет четыре строки, как показано на рис. 27.1. Если в процессе использования вами курсора кто-либо добавит значение Description для элемента Bergamot, либо добавит строку для элемента Bayberry, что произойдет с множеством строк, на которое указывает ваш курсор?
увеличить изображение
Рис.
27.1.
База данных Aromatherapy содержит четыре строки, начинающиеся с буквы В.
При создании вашего курсора могут быть независимо определены два вида чувствительности: изменения каких строк включаются во множество (членство множества) и отражение изменений в исходных строках.
Прокрутка
Второй характеристикой курсора является способность осуществления прокрутки как вперед, так и назад, либо только вперед. Здесь имеет место извечная для программирования дилемма: скорость против гибкости. Последовательные курсоры (forward-only) работают значительно быстрее, но имеют меньшую гибкость.
Здесь имеет место извечная для программирования дилемма: скорость против гибкости. Последовательные курсоры (forward-only) работают значительно быстрее, но имеют меньшую гибкость.
Обновление
Последней характеристикой, используемой для классификации курсоров, является возможность обновления строк курсором. Опять же, курсоры «только чтение» обычно более производительны, но имеют меньшую гибкость.
Дальше >>
< Урок 25 || Урок 26: 123456789 || Урок 27 >
sql server — курсор T-SQL в хранимой процедуре
спросил
Изменено
8 лет, 5 месяцев назад
Просмотрено
2к раз
Я использую хранимую процедуру и хочу использовать курсор для вставки новых данных (если данные существуют, я хочу их обновить)
Процедура ALTER [dbo].[conn] @ResellerID целое число, @GWResellerID целое число, @имя_пользователя varchar(50), @Пароль varchar(50), @URL varchar(100), @ServiceType целое число, @ServiceDesc varchar(50), бит @FeedFrom, @PublicKey varchar (макс.) КАК объявить курсор шлюза для выбирать * от reseller_profiles где main_reseller_ID = @ResellerID ОТКРЫТЫЙ шлюз ПОЛУЧИТЬ СЛЕДУЮЩИЙ ОТ шлюза В @ResellerID ПОКА @@FETCH_STATUS = 0 НАЧИНАТЬ ВСТАВЬТЕ В [dbo].tblGatewayConnection([ResellerID],[GWResellerID], [Имя пользователя], [Пароль], [URL], [ServiceType], [ServiceDesc],[feedFromMain], publicKey) ЗНАЧЕНИЯ (@ResellerID, @GWResellerID, @UserName, @Password, @URL, @ServiceType, @ServiceDesc, @FeedFrom, @PublicKey) ПОЛУЧИТЬ СЛЕДУЮЩИЙ ОТ шлюза В @ResellerID КОНЕЦ ЗАКРЫТЬ шлюз ОСВОБОЖДЕНИЕ шлюза
 [conn]
@ResellerID целое число,
@GWResellerID целое число,
@имя_пользователя varchar(50),
@Пароль varchar(50),
@URL varchar(100),
@ServiceType целое число,
@ServiceDesc varchar(50),
бит @FeedFrom,
@PublicKey varchar (макс.)
КАК
объявить курсор шлюза для
выбирать *
от reseller_profiles
где main_reseller_ID = @ResellerID
ОТКРЫТЫЙ шлюз
ПОЛУЧИТЬ СЛЕДУЮЩИЙ ОТ шлюза В @ResellerID
ПОКА @@FETCH_STATUS = 0
НАЧИНАТЬ
ВСТАВЬТЕ В [dbo].tblGatewayConnection([ResellerID],[GWResellerID], [Имя пользователя], [Пароль], [URL], [ServiceType], [ServiceDesc],[feedFromMain], publicKey)
ЗНАЧЕНИЯ (@ResellerID, @GWResellerID, @UserName, @Password, @URL, @ServiceType, @ServiceDesc, @FeedFrom, @PublicKey)
ПОЛУЧИТЬ СЛЕДУЮЩИЙ ОТ шлюза В @ResellerID
КОНЕЦ
ЗАКРЫТЬ шлюз
ОСВОБОЖДЕНИЕ шлюза
[conn]
@ResellerID целое число,
@GWResellerID целое число,
@имя_пользователя varchar(50),
@Пароль varchar(50),
@URL varchar(100),
@ServiceType целое число,
@ServiceDesc varchar(50),
бит @FeedFrom,
@PublicKey varchar (макс.)
КАК
объявить курсор шлюза для
выбирать *
от reseller_profiles
где main_reseller_ID = @ResellerID
ОТКРЫТЫЙ шлюз
ПОЛУЧИТЬ СЛЕДУЮЩИЙ ОТ шлюза В @ResellerID
ПОКА @@FETCH_STATUS = 0
НАЧИНАТЬ
ВСТАВЬТЕ В [dbo].tblGatewayConnection([ResellerID],[GWResellerID], [Имя пользователя], [Пароль], [URL], [ServiceType], [ServiceDesc],[feedFromMain], publicKey)
ЗНАЧЕНИЯ (@ResellerID, @GWResellerID, @UserName, @Password, @URL, @ServiceType, @ServiceDesc, @FeedFrom, @PublicKey)
ПОЛУЧИТЬ СЛЕДУЮЩИЙ ОТ шлюза В @ResellerID
КОНЕЦ
ЗАКРЫТЬ шлюз
ОСВОБОЖДЕНИЕ шлюза
Имя моей таблицы tblGatewayConnection имеет следующие столбцы:
resellerID gwResellerID имя пользователя пароль URL Тип Обслуживания serviceDesc FeedFromMain публичный ключ
Пока я вставляю данные с помощью хранимой процедуры, я получаю исключение
Cursorfetch: количество переменных, объявленных в списке INTO, должно совпадать с количеством выбранных столбцов.

Что я пропустил?
Будем признательны за любую помощь.
Спасибо.
- sql-сервер
- хранимые процедуры
- курсор
3
Зачем вообще курсор?!?!?!?!? Я не скажу вам, что не так с вашим курсором, потому что вместо того, чтобы фиксировать курсор, вы должны выучить , чтобы избежать его в первую очередь!
Серьезно — избегайте обработки RBAR ( строка за строкой ) всякий раз, когда вы можете, и здесь действительно совершенно бессмысленно использовать курсор — просто используйте этот красивый и чистый оператор на основе набора :
ALTER PROCEDURE [dbo].[conn] @ResellerID INT,
@GWResellerID INT,
@UserName VARCHAR(50),
@Пароль VARCHAR(50),
@URL VARCHAR(100),
@ServiceType INT,
@ServiceDesc VARCHAR(50),
@FeedFrom БИТ,
@PublicKey VARCHAR (макс. )
КАК
ВСТАВИТЬ В dbo.tblGatewayConnection
(ResellerID, GWResellerID, имя пользователя, пароль,
URL, ServiceType, ServiceDesc, feedFromMain,
открытый ключ)
ВЫБИРАТЬ
ResellerID, GWResellerID, имя пользователя, пароль,
URL, ServiceType, ServiceDesc, feedFromMain,
публичный ключ
ОТ
dbo.reseller_profiles
ГДЕ
main_reseller_ID = @ResellerID
 )
КАК
ВСТАВИТЬ В dbo.tblGatewayConnection
(ResellerID, GWResellerID, имя пользователя, пароль,
URL, ServiceType, ServiceDesc, feedFromMain,
открытый ключ)
ВЫБИРАТЬ
ResellerID, GWResellerID, имя пользователя, пароль,
URL, ServiceType, ServiceDesc, feedFromMain,
публичный ключ
ОТ
dbo.reseller_profiles
ГДЕ
main_reseller_ID = @ResellerID
)
КАК
ВСТАВИТЬ В dbo.tblGatewayConnection
(ResellerID, GWResellerID, имя пользователя, пароль,
URL, ServiceType, ServiceDesc, feedFromMain,
открытый ключ)
ВЫБИРАТЬ
ResellerID, GWResellerID, имя пользователя, пароль,
URL, ServiceType, ServiceDesc, feedFromMain,
публичный ключ
ОТ
dbo.reseller_profiles
ГДЕ
main_reseller_ID = @ResellerID
и готово!! Никакого беспорядочного курсора, никаких ненужных локальных переменных — просто INSERT... SELECT и вы добились того, что хотели!
Я не уверен, что сообщение об ошибке может быть более понятным:
Cursorfetch: количество переменных, объявленных в списке INTO, должно совпадать с количеством выбранных столбцов.
Вы выбираете все столбцы из reseller_profiles
объявляете курсор шлюза для
выбирать *
от reseller_profiles
где main_reseller_ID = @ResellerID
И пытаюсь поместить их в одну переменную:
FETCH NEXT FROM gateway INTO @ResellerID
Количество столбцов, которые вы выбираете в своем курсоре, должно соответствовать количеству переменных, в которые вы вставляете, поэтому вам нужно что-то вроде
объявить курсор шлюза для
выберите reseller_id
от reseller_profiles
где main_reseller_ID = @ResellerID
ОДНАКО вам не следует использовать для этого курсор, вы можете использовать то же самое, используя ВСТАВИТЬ . : . ВЫБРАТЬ
. ВЫБРАТЬ
ВСТАВИТЬ В [dbo].tblGatewayConnection
([ResellerID],[GWResellerID], [Имя пользователя], [Пароль], [URL],
[ServiceType], [ServiceDesc], [feedFromMain], publicKey
)
ВЫБЕРИТЕ Resellerid, @GWResellerID, @UserName, @Password,
@URL, @ServiceType, @ServiceDesc, @FeedFrom, @PublicKey
ОТ reseller_profiles
ГДЕ main_reseller_ID = @ResellerID;
Как уже было сказано, вы должны избегать курсоров любой ценой, если вам абсолютно необходимо использовать курсор, объявите самый легкий курсор, который вы можете. Например, в вашем случае вы двигались только вперед внутри курсора, только читали данные, не изменяя их, и только локально обращались к курсору, поэтому вы должны объявить курсор следующим образом:
DECLARE шлюз CURSOR LOCAL STATIC FAST_FORWARD
ДЛЯ
ВЫБИРАТЬ ...
ОТ ..
Хотя курсоры и в лучшие времена работают ужасно, их репутация ухудшается из-за ленивых объявлений.
Наконец, вам следует отвыкнуть от использования SELECT *
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Курсоры
SQL Server: практическое руководство
Время чтения: 9 минут
Возможно, вам понадобится использовать возможности курсора для выполнения какой-либо задачи в Microsoft SQL Server в какой-то момент вашей карьеры профессионала в области баз данных.
Курсоры – это инструмент, который мы используем при работе с большими объемами данных, когда вам необходимо выполнять итерации по этим данным для достижения какой-либо цели.
Курсоры — наиболее распространенное применение цикла WHILE в SQL Server. Не знаете, что такое цикл WHILE? Ознакомьтесь с полным руководством:
SQL Server WHILE Loop: структура принятия решений, которую вы должны знать
В этом руководстве мы обсудим пошаговое руководство о том, как написать курсор и как они могут нам помочь. Мы рассмотрим эти темы:
Что такое курсор и что он делает?
Шагов для создания и использования курсора:
Объявление курсора.
Открытие курсора .
«Выборка» данных для курсора
Перебор курсора.
Закрытие и освобождение курсора.

Начнем с основ:
Что такое курсор и что он делает?
Курсор позволит вам перебирать строки результирующего набора по одной за раз, чтобы выполнять работу над каждой строкой до тех пор, пока в результирующем наборе не останется строк.
Опять же, способ, которым мы «итерируемся» по результирующему набору, заключается в использовании цикла WHILE. Цикл WHILE — это сердце нашего курсора.
Если вы не знакомы с тем, что такое цикл WHILE, вам необходимо сначала просмотреть это руководство:
SQL Server WHILE Loop: структура принятия решений, которую вы должны знать
Мы используем курсор, когда нам нужно прокрутить результаты запроса сверху вниз, просматривая каждую строку и, возможно, выполняя какую-то работу с данными.
Существует несколько этапов создания, использования и закрытия курсора, поэтому лучший способ понять их — посмотреть на примере.
Шаги по созданию и использованию курсора
Итак, давайте подумаем о хорошем примере, когда нам может понадобиться использовать курсор.
Допустим, вы владелец небольшого предприятия по продаже деревянной мебели. Вы отслеживаете все свои заказы в таблице под названием Заказы . Вот как теперь выглядит таблица:
Давайте воспользуемся INNER JOIN, чтобы получить более значимые данные о продуктах:
Хорошо, круто. Таким образом, этот запрос показывает нам основные сведения о каждом заказе, который был размещен для нашего бизнеса. Мы видим:
- Номер заказа
- Идентификатор покупателя, купившего продукт
- Какой товар они купили
- Сколько указанного товара они купили
- Дата заказа
Отлично, так что, возможно, мы хотим получить список того, сколько всего каждого продукта было продано.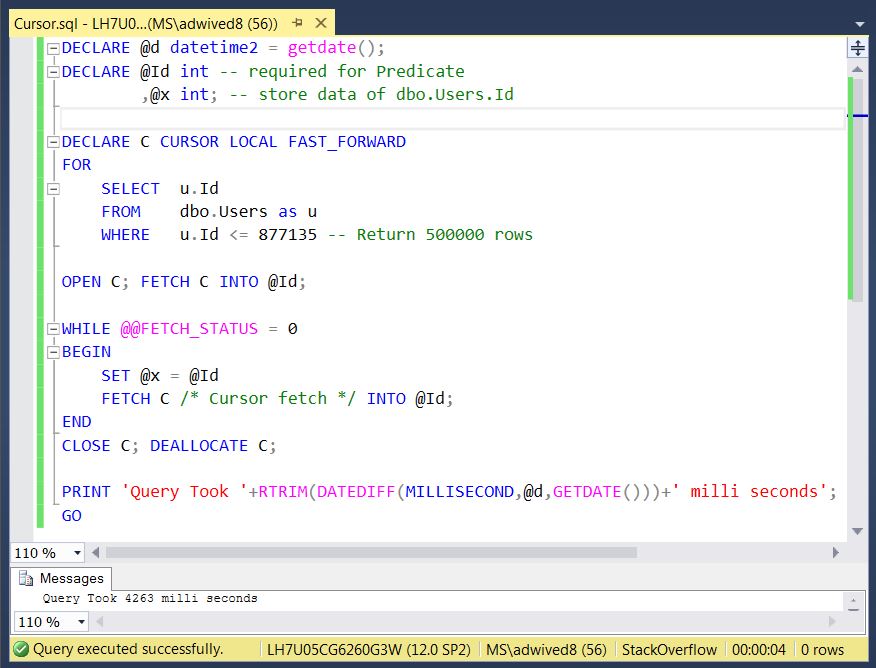 Это можно сделать с помощью простого запроса GROUP BY:
Это можно сделать с помощью простого запроса GROUP BY:
Итак, теперь мы видим, сколько всего каждого товара было продано.
Здесь мы могли бы использовать курсор:
Что, если бы мы захотели записать наши самые продаваемые товары в отдельную таблицу под названием « Бестселлеры »? Мы говорим, что наши «бестселлеры» — это продукты, которые мы продали более 9 раз.0043 3 оф.
В основном это означает, что мы смотрим на каждую строку в нашем запросе GROUP BY и видим, какое значение имеет продукт для столбца « Число проданных ». Если у товара номер « продано » больше, чем 3 , мы записываем его данные в таблицу BestSellers . В противном случае мы оставляем его вне таблицы.
Таблица BestSellers сейчас пуста:
Таким образом, мы установили, что в основном хотим повторить через каждую строку в нашем запросе GROUP BY, сверху вниз, и решить, нужно ли нам работать над строкой в этом наборе результатов.
Отличная задача для курсора!
И я знаю, это кажется пустой тратой времени для нашего небольшого набора результатов. Похоже, что именно « Small Bench » является нашим бестселлером. Но в SQL Server нам нужно думать БОЛЬШОЕ . Что, если вы работаете на Amazon и хотите попасть в список бестселлеров? С миллионами продуктов вам потребуется навсегда .
Итак, давайте подумаем, как использовать курсор для создания нашего списка бестселлеров:
1. Объявление курсора.
Первым шагом к использованию любого курсора в SQL Server является объявление курсора. Этот шаг состоит из двух частей, и они очень просты.
Во-первых, нам нужно дать этому итерационному процессу имя . Допустим, мы хотим назвать наш процесс INSERT_INTO_BEST_SELLERS . Синтаксис для объявления нашего курсора с этим именем следующий:
DECLARE INSERT_INTO_BEST_SELLERS CURSOR
Таким образом, вы просто используете ключевое слово DECLARE , за которым следует имя вашего курсора, за которым следует CURSOR ключевое слово.
Easy peasy
Вторая часть объявления курсора — это описание запроса, набор результатов которого вы хотите пройти. В нашем примере результирующий набор, который мы хотим пройти, следующий:
Это набор запросов/результатов, для которых будет использоваться курсор. Итак, мы включаем этот запрос как часть объявления, в основном так:
Вы просто используете ключевое слово FOR , за которым следует запрос, результаты которого вы хотите перебрать.
(Кроме того, не всем столбцам в вашем запросе нужны имена. Я назвал свой совокупный столбец «Количество проданных», но я мог бы не указывать этот псевдоним, если бы захотел.)
Хорошо, это было легко, верно?
2. Открытие курсора.
Этот шаг еще проще . Если мы официально готовы начать использовать наш курсор, нам нужно открыть его.
Синтаксис прост:
Вы используете ключевое слово OPEN , за которым следует имя вашего курсора. Так легко.
Так легко.
3. «Выборка» данных для курсора.
Хорошо, мы знали, что это не будет оставаться простым вечно, поэтому давайте поговорим о том, где все становится интереснее.
Давайте подумаем о наборе результатов нашего запроса. Вот оно:
Когда курсор перебирает этот набор результатов, он просматривает каждую строку по одной и выполняет работу с данными этой строки.
Начинается сверху, глядя на самый первый ряд. Чтобы « работал с данными этой строки », нам нужно записать данные этой строки в соответствующие переменные.
Первая строка содержит следующие данные:
ProdID = 1
ProdName = Большая скамья
Количество продано = 1
902 05 Нам нужно записать эти значения в переменные .
Таким образом, чтобы получить первую строку в результирующем наборе, а также записать ее значения в переменные, мы используем следующий синтаксис:
Таким образом, этот блок FETCH в основном запускает процесс . Все, что он говорит, это захватить следующую строку в наборе результатов (которая в то время будет просто первая строка ) и запишите значения столбца в переменные, которые мы будем использовать позже.
Все, что он говорит, это захватить следующую строку в наборе результатов (которая в то время будет просто первая строка ) и запишите значения столбца в переменные, которые мы будем использовать позже.
Вот что вам нужно сделать: Вам нужно объявить эти переменные.
Удобное место для объявления этих переменных вне курсора, например:
Итак, просто повторим, на этом этапе процесса наши переменные содержат данные для самой первой строки , которая будет:
@prodID = 1 900 44
@prodName = Большая скамья
@numberSold = 1
Мы будем использовать эти переменные в циклическом процессе нашего курсора (где мы « действительно работаем» ).
4. Перебор курсора.
Хорошо, вот мясо этого танга .
Вернемся к тому, что мы хотим сделать с помощью этого курсора. Мы хотим просмотреть каждую строку в нашем наборе результатов, и если значение « Количество проданных товаров » больше, чем 3 , мы запишем идентификатор и имя этого продукта в Бестселлеры стол.
Первый шаг к циклу по нашему результату, установленному для контура цикла WHILE . Вот как это выглядит сначала:
Нам нужно поговорить о @@FETCH_STATUS . Все, что спрашивается, это извлекла ли наша последняя операция FETCH что-то .
В этот момент в нашем курсоре мы сделали выборку для верхней строки набора результатов. Таким образом, если набор результатов содержит хотя бы одну строку, статус будет: « Что-то было успешно получено ».
Если « что-то было успешно извлечено », значение, возвращаемое @@FETCHED_STATUS, равно ноль .
Я знаю, это кажется бас назад . Обычно статус ноль является ложным. Но в случае @@FETCH_STATUS нам нужно ноль .
Это просто одна из тех вещей, которые нужно запомнить .
Содержимое цикла WHILE
Теперь нам нужно подумать о содержимом цикла WHILE. Я не собираюсь тратить слишком много времени на обсуждение содержания этого конкретного цикла WHILE, потому что ваш , вероятно, будет другим .
Я не собираюсь тратить слишком много времени на обсуждение содержания этого конкретного цикла WHILE, потому что ваш , вероятно, будет другим .
Просто знайте: В теле цикла WHILE вы выполняете свою работу, вероятно, используя некоторые или все переменные, являющиеся частью вашего курсора.
Вот тело нашего цикла WHILE:
Итак, первое, что мы делаем, это проверяем @numberSold значение для этой конкретной строки набора результатов, в которой мы находимся. Если он больше 3, мы знаем, что может потребоваться добавить в таблицу BestSellers .
Почему « может » это? Потому что мы не хотим вставлять детали этого продукта, если он уже находится в таблице BestSellers .
Мы используем переменную @prodID , чтобы узнать, есть ли этот продукт уже в таблице BestSellers . Мы используем наш удобный инструмент ЕСЛИ НЕ СУЩЕСТВУЕТ, чтобы увидеть, если что-то возвращается, когда мы запрашиваем таблицу в поисках этого конкретного идентификатора продукта.
(В ситуациях, когда я хочу знать, существуют ли вообще какие-либо строки, я предпочитаю использовать « SELECT 1 ». Не нужно извлекать данные столбца, если мне на самом деле не нужны данные столбца!)
Итак, если мы знаем, что @numberSold больше 3 , и товар еще не находится в таблице BestSellers , то мы, наконец, можем выполнить нашу INSERT, которая будет использовать @prodID и @prodName переменных.
Не забудьте переместить цикл WHILE вперед.
В цикле WHILE отсутствует кое-что очень важное.
Если вы помните наше руководство по циклу WHILE, мы говорили о том, как вам нужно убедиться, что вы перемещаете цикл вперед .
Помните, что нам нужен курсор, чтобы пройти все строк, возвращенных нашим запросом курсора. Способ, которым мы поддерживаем цикл, заключается в том, чтобы убедиться, что мы получить следующую строку в результирующем наборе.
Вот так:
Этот загружает наши переменные данными из следующей строки набора результатов из нашего запроса курсора.
Помните, что «запрос курсора» — это в основном запрос, идентифицируемый именем курсора, которое равно INSERT_INTO_BEST_SELLERS .
Эта прекрасная симфония продолжается для всех строк, возвращаемых нашим запросом курсора. Пока этот оператор FETCH продолжает возвращать строки, мы продолжаем входить в цикл WHILE и выполнять работу.
Как только мы обработаем окончательную строку набора результатов, что будет извлечено ?
Ответ: Абсолютно НИЧЕГО .
Итак, в этот момент @@FETCH_STATUS вернет что-то отличное от ноль , что делает наше условие ложным . Это приведет к выходу из цикла!
5. Закрытие и освобождение курсора.
К сожалению, когда мы выходим из цикла, курсор автоматически не закрывается. Нам нужно вручную закрыть и освободить курсор .
Нам нужно вручную закрыть и освободить курсор .
Поскольку нам пришлось вручную открывать курсор, не стоит удивляться, что нам также нужно вручную закрывать курсор.
Все просто:
Задача освобождения курсора может быть не такой очевидной.
За кулисами SQL Server создает структуру данных для удержания курсора и выполнения своей работы. Эта структура данных должна быть освобождена обратно в память, как только мы закончим использовать курсор.
Вам не нужно освобождать курсор, когда вы закончите с ним, но вы должны . Если вы не освободите курсор вручную, он будет освобожден естественным образом, когда выйдет из области действия .
Но, честно говоря, вы должны иметь привычку освобождать объекты, когда с ними покончено . Не следует слишком полагаться на процессы автоматической очистки. Вы можете попасть в беду, если будете слишком много брать на себя.
Так что сделайте себе одолжение и просто вручную освободите то, что вы создали:
Вот хорошая ссылка от Microsoft об освобождении курсоров: DEALLOCATE (Transact-SQL)
Вот отличный вопрос о переполнении стека о том, почему важно вручную освобождать курсоры: что произойдет, если вы забудете закрыть и освободить курсор?
Итак, теперь, когда наш курсор готов, мы можем быстро запустить его и увидеть, что он успешно вставляет только продукт Small Bench в нашу таблицу BestSellers :
Отлично!
Следующие шаги:
Оставьте комментарий , если этот урок был вам полезен!
Скорее всего, вы увидите и будете использовать курсоры в хранимых процедурах . Если вам нужно краткое изложение того, что такое хранимые процедуры и как они могут нам помочь, перейдите по этой ссылке:
Хранимые процедуры: Полное руководство для начинающих
Кроме того, есть очень полезная книга, которая знакомит вас со многими темами T-SQL, включая курсоры, которые вам следует взять в руки.