Sql группировка: Оператор SQL GROUP BY: синтаксис, примеры
Группирование строк в результатах запроса — Visual Database Tools
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
-
Применимо к:SQL Server
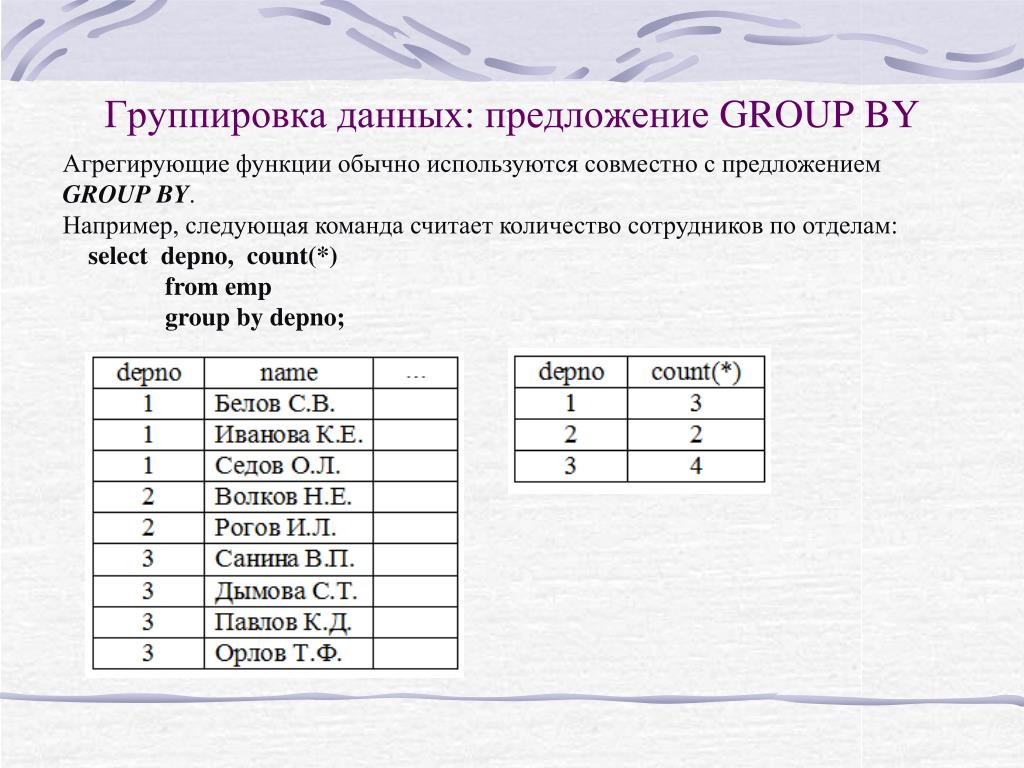
Если нужно создать подытог или отобразить другие сводные сведения о подмножествах таблицы, создайте группы, используя статистический запрос. Каждая такая группа обобщает данные всех строк таблицы, имеющих одно и то же значение.
Каждая такая группа обобщает данные всех строк таблицы, имеющих одно и то же значение.
Например, нужно узнать среднюю стоимость книг, данные о которых хранятся в таблице titles , и разделить результаты в соответствии с идентификаторами издателей. Для этого следует сгруппировать запрос на основе идентификатора издателя (например pub_id). Сведения, выведенные таким запросом, могли бы выглядеть следующим образом:
Группируя данные, можно отобразить только сводные или сгруппированные данные, подобные следующим.
Значения сгруппированных столбцов (столбцов, указанных в предложении GROUP BY). В приведенном выше примере столбец
pub_idявляется сгруппированным.Значения, созданные агрегатными функциями, такими как SUM( ) и AVG( ). В приведенном выше примере второй столбец создается путем применения функции AVG( ) к столбцу
price.
Отобразить значения отдельных строк нельзя. Например, если группируются данные только по идентификаторам издателей, нельзя отобразить в запросе еще и отдельные названия книг. Таким образом, если столбцы добавляются в вывод запроса, конструктор запросов и представлений автоматически добавляет их в предложение GROUP BY инструкции на панели SQL. Если нужно, чтобы столбец содержал статистические данные, можете определить для него агрегатную функцию.
Таким образом, если столбцы добавляются в вывод запроса, конструктор запросов и представлений автоматически добавляет их в предложение GROUP BY инструкции на панели SQL. Если нужно, чтобы столбец содержал статистические данные, можете определить для него агрегатную функцию.
Если данные группируются по нескольким столбцам, каждая группа в запросе отображает статистические значения всех столбцов группировки.
Например, следующий запрос таблицы titles группирует данные по идентификаторам издателей (pub_id) и типам книг (type). Результаты запроса упорядочиваются по идентификаторам издателей и представляют сводные данные о каждом типе книг, издаваемых издателем:
SELECT pub_id, type, SUM(price) Total_price FROM titles GROUP BY pub_id, type
Итоговый вывод мог бы выглядеть следующим образом:
Группирование строк
Инициируйте запрос, добавив таблицы, сводную информацию о которых нужно получить, на панель диаграмм.

Щелкните правой кнопкой мыши фон панели диаграммы и выберите из контекстного меню пункт Добавить Group By . Конструктор запросов и представлений добавляет столбец Группировать в сетку на панели критериев.
Добавьте столбец или столбцы, которые нужно сгруппировать, на панель критериев. Если нужно, чтобы столбец был отображен в выводе запроса, не забудьте убедиться в том, что для вывода выбран столбец Вывод .
Конструктор запросов и представлений добавит в инструкцию, отображаемую на панели SQL, предложение GROUP BY. Например, инструкция SQL может иметь такой вид:
SELECT pub_id FROM titles GROUP BY pub_id
Добавьте на панель критериев столбец или столбцы, статистическую информацию о которых нужно получить. Убедитесь, что столбец помечен для вывода.
В ячейке Группировать для столбца, статистическую информацию о котором нужно получить, выберите подходящую агрегатную функцию.
Конструктор запросов и представлений автоматически назначает суммируемому столбцу псевдоним, Псевдоним, созданный автоматически, можно заменить более содержательным псевдонимом. Дополнительные сведения см. в статье о создании псевдонимов столбцов.
Соответствующая инструкция могла бы выглядеть на панели SQL следующим образом:
SELECT pub_id, SUM(price) AS Totalprice FROM titles GROUP BY pub_id


Сортировка и группировка результатов запроса
Группировка (GROUP) | Основы реляционных баз данных
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
С агрегатными функциями связано множество разных задач. Например, они помогают вывести общее число топиков для каждого пользователя. Так это может выглядеть:
SELECT COUNT(*) FROM topics WHERE user_id = 3; SELECT COUNT(*) FROM topics WHERE user_id = 4; -- .
 ..
..
При этом здесь мы сталкиваемся с одной сложностью — невозможно выполнить данную задачу за один запрос, используя только функции. Нам придется делать выборку для каждой категории индивидуально, а это долго и неудобно. Если пользователей тысячи, то такое решение вопроса неприемлемо в принципе.
Подобные задачи возникают настолько часто, что для них существует специальная форма GROUP BY. В этом уроке мы изучим, как работает эта функция.
GROUP BY
Эта функция группирует строки по определенному признаку и выполняет подсчеты внутри каждой группы независимо от других групп:
SELECT user_id, COUNT(*) FROM topics GROUP BY user_id;
user_id | count
---------+-------
71 | 1
80 | 1
84 | 3
92 | 1
60 | 1
97 | 2
98 | 1
44 | 1
40 | 1
43 | 1
В запросе выше мы создали группы записей по значению поля user_id. Эти данные можно представить себе как набор виртуальных таблиц, каждая из которых содержит все записи по одному пользователю. Подсчет количества идет по каждому пользователю независимо от других. К результатам такой выборки можно применять сортировку и лимитирование:
Подсчет количества идет по каждому пользователю независимо от других. К результатам такой выборки можно применять сортировку и лимитирование:
SELECT user_id, COUNT(*) FROM topics GROUP BY user_id ORDER BY count DESC LIMIT 3;
user_id | count
---------+-------
84 | 3
97 | 2
57 | 2
С помощью сортировки мы можем обращаться не только к полям самой таблицы, но и к вычисленному значению. По умолчанию имя этого виртуального поля совпадает с именем функции, но его можно изменить с помощью механизма псевдонимов:
SELECT user_id, COUNT(*) AS topics_count FROM topics GROUP BY user_id ORDER BY topics_count DESC LIMIT 3;
Псевдонимы создаются не только для агрегатных значений, но и для любых имен в запросе. Переименовываются даже существующие поля. Общая структура имени выглядит так: <expression> AS <name>.
У псевдонимов есть одно удобное свойство. Если определить их в одном месте, они становятся доступны в других частях SQL-запроса:
SELECT first_name AS name FROM users ORDER BY name;
Теперь попытаемся выполнить следующий запрос:
SELECT user_id, created_at, COUNT(*) AS topics_count FROM topics GROUP BY user_id;
Запрос завершится с ошибкой:
ERROR: column "topics.
 created_at" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: SELECT user_id, created_at, COUNT(*) AS topics_count FROM topics G...
created_at" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: SELECT user_id, created_at, COUNT(*) AS topics_count FROM topics G...
Чтобы лучше понять работу GROUP BY, разберемся, почему запрос выше не сработает.
Дело в том, что группировка обращается к записям в таблице и создает из них независимые группы записей, по которым проводится анализ.
Группа записей — не то же самое, что одна запись. Мы не можем просто взять и указать имя любого поля — база данных сама не выберет какое-то значение из этой группы. Такое поведение создает неоднозначность и не несет в себе смысла.
СУБД отслеживает такие ошибки и просит выполнить одно из двух действий:
Действие 1 — указать поле created_at в выражении GROUP BY. Тогда значение поля для каждой записи из группы будет одинаковым — в этом и суть группировки. Значит, СУБД однозначно определит, что нужно добавить в результат:
SELECT user_id, created_at, COUNT(*) AS topics_count
FROM topics
GROUP BY user_id, created_at;
user_id | created_at | topics_count
---------+-------------------------+--------------
40 | 2018-12-05 18:40:05. 603 | 1
67 | 2018-12-06 05:23:40.65 | 1
 603 | 1
67 | 2018-12-06 05:23:40.65 | 1
603 | 1
67 | 2018-12-06 05:23:40.65 | 1
Такой запрос выполнит группировку сначала по user_id, а затем по дате создания. Даты создания у всех топиков почти наверняка уникальны, поэтому вся таблица разобьется на группы по одному элементу. Смысла в таком запросе не очень много, гораздо полезнее сделать то же самое с разбивкой по дням или месяцам. Тогда можно будет увидеть, сколько топиков создает конкретный пользователь каждый день:
-- В этом запросе используется функция EXTRACT,
-- которая извлекает значения из даты: например, номер дня или месяца
SELECT user_id, EXTRACT(day from created_at) AS day, COUNT(*) AS topics_count
FROM topics
GROUP BY user_id, day
ORDER BY user_id;
user_id | day | topics_count
--------+-----+--------------
1 | 5 | 1
1 | 6 | 1
4 | 6 | 1
6 | 5 | 1
7 | 6 | 2
8 | 5 | 1
9 | 6 | 1
Действие 2 — использовать created_at внутри агрегатной функции. В таком случае мы получим результат на основе анализа всех значений в рамках группы. Например, добавление вызова
В таком случае мы получим результат на основе анализа всех значений в рамках группы. Например, добавление вызова MAX(created_at) посчитает дату последнего добавленного топика для каждой группы:
SELECT user_id, MAX(created_at), COUNT(*) AS topics_count
FROM topics
GROUP BY user_id;
user_id | max | topics_count
--------+-------------------------+--------------
40 | 2018-12-05 18:40:05.603 | 1
67 | 2018-12-06 05:23:40.65 | 1
49 | 2018-12-06 14:55:08.99 | 1
43 | 2018-12-06 00:20:11.835 | 1
HAVING
Иногда встречаются более сложные ситуации, в которых нужно проводить анализ только по некоторым группам. Предположим, что мы хотим выбрать всех пользователей, у которых количество топиков больше одного. Эта задача сводится к поиску групп, в которых более одной записи.
Подобный запрос невозможно сделать через WHERE, потому что эти условия применяются к записям исходной выборки, еще до создания самих групп.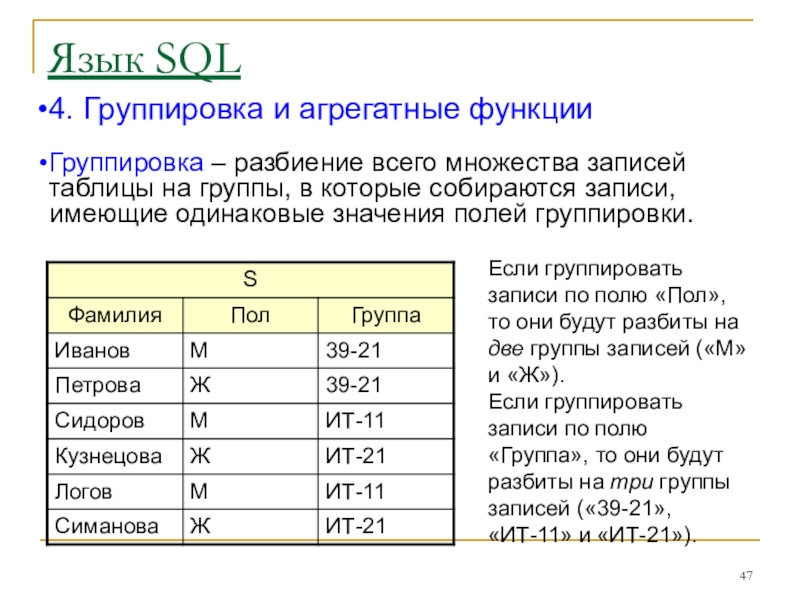
В этой задаче понадобится дополнение к GROUP BY, которое называется HAVING:
SELECT user_id, COUNT(*) FROM topics
GROUP BY user_id
HAVING COUNT(*) > 1;
user_id | count
---------+-------
84 | 3
97 | 2
57 | 2
30 | 2
83 | 2
7 | 2
38 | 2
1 | 2
(8 rows)
Подчеркнем, что HAVING нужен для отбора групп по какому-то агрегатному признаку — например, количеству записей в группе. Если вам надо посмотреть значение конкретного поля, используйте именно WHERE.
Группировка — это мощный, но в то же время сложный инструмент, который помогает анализировать данные в таблицах. Не заморачивайтесь над тем, чтобы выучить группировку от и до прямо сейчас. Опытные разработчики пользуются ей не каждый день и сами постоянно подсматривают в документацию.
Важно понимать спектр задач, для которых группировка подходит, а остальное — дело техники и умения читать документацию. Это общее правило, характерное и для многих других аспектов баз данных.
Это общее правило, характерное и для многих других аспектов баз данных.
ГРУППИРОВКА (Transact-SQL) — SQL Server
Редактировать
Твиттер
Фейсбук
Электронная почта
- Статья
Применяется к: SQL Server База данных SQL Azure Azure SQL Управляемый экземпляр Azure Synapse Analytics Конечная точка SQL в Microsoft Fabric Warehouse в Microsoft Fabric
Указывает, является ли указанное выражение столбца в списке GROUP BY агрегированным или нет. GROUPING возвращает 1 для агрегирования или 0 для отсутствия агрегирования в результирующем наборе. GROUPING можно использовать только в предложениях SELECT