Sql иерархические запросы: Иерархические (рекурсивные) запросы / Хабр
Содержание
Иерархические запросы — SQL для Oracle
Без рубрики
sql oracle
·
24.07.2021
·
Рубрика: Иерархическое извлечение
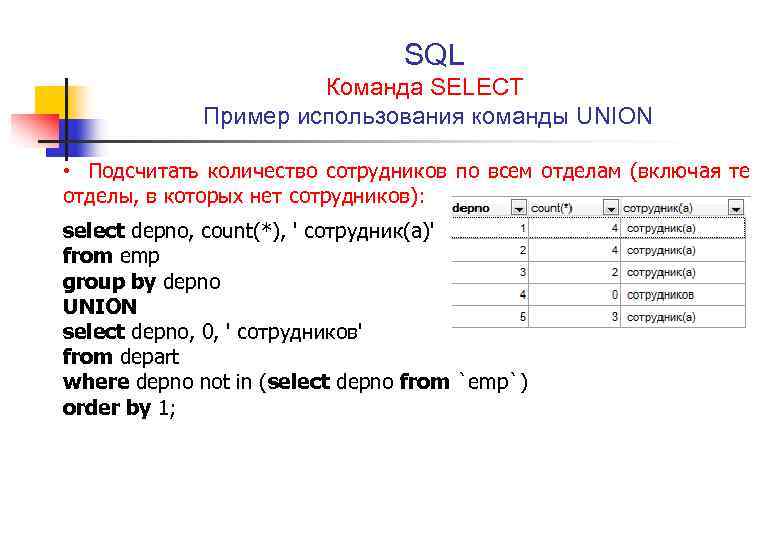
Иерархические запросы можно определить по наличию предложений CONNECT BY и START WITH.
Ключевые слова и предложения
Элементы синтаксиса:
SELECTСтандартное предложениеSELECTLEVELДля каждой строки, возвращаемой иерархическим запросом, псевдостолбецLEVELвозвращает 1 для корневой строки, 2 для дочернего объекта корня и т. д.FROMтаблица Задает таблицу, представление или снимок, содержащие столбцы.Можно выбирать данные только из одной таблицы.
WHEREОграничивает строки, возвращаемые запросом, не влияя на другие строки иерархииусловие Сравнение с выражениями
START WITHЗадает корневые строки иерархии (точку начала). Это предложение обязательно для настоящего иерархического запроса.
Это предложение обязательно для настоящего иерархического запроса.CONNECT BYЗадает столбцы, в которых существует отношение между родитель- скими и дочерними строкамиPRIOR. Это предложение обязательно для иерархического запроса.
 Это предложение обязательно для настоящего иерархического запроса.
Это предложение обязательно для настоящего иерархического запроса.Далее: Управление средой SQL Developer
Написать
Post Views: 12
Похожие записи
Без рубрики
sql oracle
·
25.04.2023
·
Используя предложение WITH, можно определить блок запроса до его применения в запросе. Предложение WITH (формально называется subquery_factoring_clause) позволяет многократно использовать один и тот же блок запроса в инструкции SELECT, когда она встречается более одного раза в сложном запросе. Это особенно… Читать далее
Без рубрики
mikl
·
22.04.2023
·
Оператор WITH в SQL — это чрезвычайно полезный инструмент для создания временных таблиц и использования их внутри других запросов.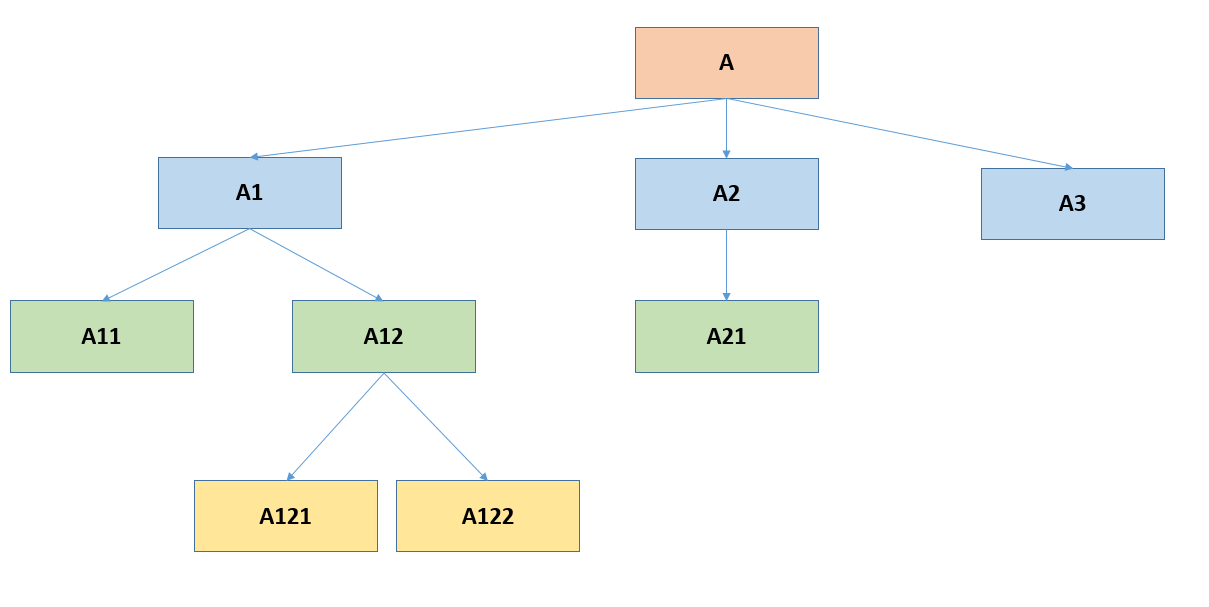 Это позволяет упростить код и улучшить производительность запросов. Оператор WITH (также известный как Common Table Expression) используется для создания временных таблиц,… Читать далее
Это позволяет упростить код и улучшить производительность запросов. Оператор WITH (также известный как Common Table Expression) используется для создания временных таблиц,… Читать далее
Без рубрики
sql oracle
·
15.04.2022
·
Внешняя таблица не описывает никаких данных, которые хранятся в базе данных. Внешняя таблица не описывает порядок хранения данных во внешнем источнике. Вместо этого она описывает, как уровень внешней таблицы должен представлять данные для сервера. За преобразования, которые требуется выполнять над… Читать далее
Без рубрики
sql oracle
·
15.04.2022
·
Позволяет восстанавливать таблицы до состояния на заданный момент времени с помощью одной инструкции. Восстанавливает табличные данные вместе со связанными индексами и ограничениями. Позволяет возвращать таблицу и ее содержимое в состояние, существовавшее на определенный момент времени, или к изменению системы, определенному.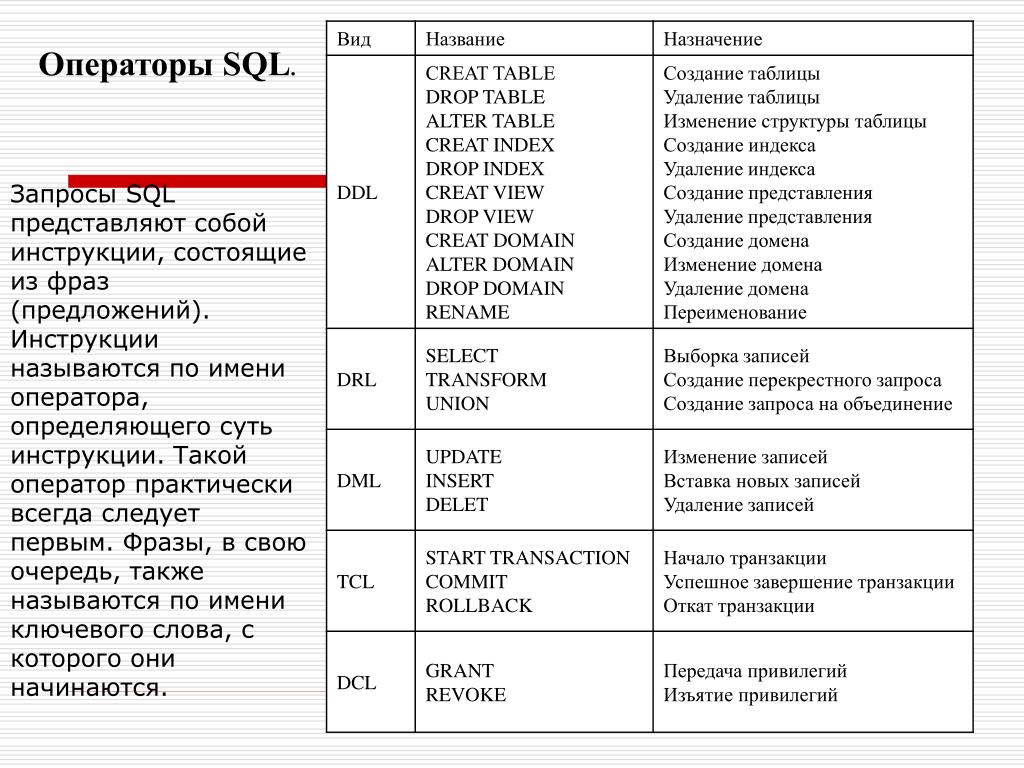 .. Читать далее
.. Читать далее
Без рубрики
sql oracle
·
04.04.2022
·
Внешние таблицы создаются с помощью предложения ORGANIZATION EXTERNAL инструкции CREATE TABLE. В действительности таблица не создается. Точнее, создаются метаданные в словаре данных, который можно использовать для доступа к внешним данным. Предложение ORGANIZATION применяется для указания порядка, в котором сохраняются строки… Читать далее
Без рубрики
sql oracle
·
04.04.2022
·
В базе данных Oracle имеется функция для удаления таблиц. При удалении таблицы база данных не сразу освобождает пространство, занимаемое таблицей. Точнее, база данных переименовывает таблицу и помещает ее в корзину, где таблица позже может быть восстановлена с помощью инструкции FLASHBACK… Читать далее
Без рубрики
sql oracle
·
18. 03.2022
03.2022
·
Рассмотрим, как создаются внешние таблицы посредством драйвера доступа ORACLE_LOADER. Предположим, что существует текстовый файл, в котором имеются записи в следующем формате: 10,jones,11-Dec-1934 20,smith,12-Jun-1972 Записи разделяются символом новой строки, и все поля заканчиваются запятой ( , ). Имя файла: /emp_dir/emp.dat…. Читать далее
Без рубрики
sql oracle
·
18.03.2022
·
Используя драйвер доступа ORACLE_DATAPUMP, можно выполнять с внешними таблицами операции выгрузки и повторной загрузки. Примечание. В контексте внешних таблиц загрузка данных обозначает операцию чтения данных из внешней таблицы и их загрузку в таблицу базы данных. Под выгрузкой данных понимается чтение… Читать далее
Без рубрики
sql oracle
·
12.02.2022
·
Можно настроить много аспектов интерфейса и среды SQL Developer, изменяя предпочтения SQL Developer согласно Вашим потребностям. Чтобы изменить предпочтения SQL Developer, выберите Tools, а затем Preferences. Настройте интерфейс SQL Developer и среду. В меню Tools выберите Preferences. Предпочтения группируется в… Читать далее
Чтобы изменить предпочтения SQL Developer, выберите Tools, а затем Preferences. Настройте интерфейс SQL Developer и среду. В меню Tools выберите Preferences. Предпочтения группируется в… Читать далее
Без рубрики
sql oracle
·
12.02.2022
·
В этой рубрике было рассмотрено использование SQL Developer, чтобы выполнять следующие задачи: Просматривать, создавать и редактировать объекты базы данных Выполнять SQL-операторы и сценарии на Рабочем листе SQL Создавать и сохранять пользовательские отчеты SQL Developer является бесплатным графическим инструментом, позволяющим упростить… Читать далее
Иерархические структуры и деревья в SQL | Мир ПК
Программисту, работающему с приложениями баз данных, на практике часто приходится сталкиваться с древовидными структурами
. Примеры могут быть найдены в совершенно разных предметных областях: классификация товаров, контрагентов, комплектация изделия, иерархия должностей, административно-территориальное деление, генеалогическое древо, наконец, просто дерево перебора вариантов или дерево классов.
В общем случае все сводится к моделированию многоуровневой связи «главный—подчиненный», «предок—потомок», «общий—конкретный». Говоря более строгим математическим языком, мы моделируем граф без циклов.
Углубляться в теорию графов в рамках статьи мы не будем, ограничившись минимальными пояснениями по ходу изложения, и рассмотрим наиболее часто встречающиеся варианты реализации древовидных структур в базах данных. В качестве примера используем Microsoft SQL Server 2005, но, познакомившись с общими принципами, вы сможете без затруднений перенести реализацию на любую другую СУБД, с которой придется работать.
Список смежности
Это интуитивно понятный способ организации дерева: замыкаем связь таблицы на саму себя (рефлексивная связь), рис. 1.
Как известно из теории, граф можно представить в виде матрицы, где на пересечении i-й строки и j-го столбца стоит 1, если между узлами (вершинами) графа с номерами i и j есть связь (ребро, дуга), или 0 в противном случае. Такая абстракция называется матрицей смежности.
Такая абстракция называется матрицей смежности.
Матрица смежности может быть также представлена в виде списка (множества) пар с номерами (идентификаторами, кодами) вершин по принципу: есть пара — есть связь, нет пары — нет связи.
Корневые вершины отличаются от других пар пустой (NULL) ссылкой на предка, в приведенном примере это поле «Код вышестоящей территории».
Для выполнения часто используемых выборок требуется поддержка рекурсивных запросов. Если СУБД не умеет выполнять такие запросы, то выборки придется строить с использованием других механизмов, например временных таблиц или хранимых процедур и функций. Рассмотрим примеры запросов.
Выборка поддерева по заданному узлу (здесь и далее по тексту используем синтаксис MS SQL Server 2005):
WITH Поддерево ([Код территории], [Код вышестоящей территории], Наименование, Уровень) AS
(
SELECT [Код территории], [Код вышестоящей территории], Наименование, 1
FROM Территории
WHERE [Код вышестоящей территории] = 40288000 — корень поддерева или IS NULL для корня целого дерева
UNION ALL
SELECT Территории. [Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
[Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
FROM Территории
INNER JOIN Поддерево ON Территории.[Код вышестоящей территории] = Поддерево.[Код территории]
WHERE Территории.[Код вышестоящей территории] IS NOT NULL
)
SELECT [Код территории], [Код вышестоящей территории], Наименование, Уровень
FROM Поддерево
Выборка всех предков (путь к узлу от корня):
WITH Поддерево ([Код территории], [Код вышестоящей территории], Наименование, Уровень) AS
(
SELECT [Код территории], [Код вышестоящей территории], Наименование, 1
FROM Территории
WHERE [Код территории] = 40288000 — узел
UNION ALL
SELECT Территории.[Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
FROM Территории
INNER JOIN Поддерево ON Территории.[Код территории] = Поддерево.[Код вышестоящей территории]
)
SELECT [Код территории], [Код вышестоящей территории], Наименование, (SELECT MAX(Уровень) FROM Поддерево) — Уровень
FROM Поддерево
Проверка, входит ли узел в поддерево, определяемое своим корнем (например, входит ли данный товар в группу одного из верхних уровней, «Кисточка» в «Инструменты для ремонта»):
WITH Поддерево ([Код территории], [Код вышестоящей территории], Наименование, Уровень) AS
(
SELECT [Код территории], [Код вышестоящей территории], Наименование, 1
FROM Территории
WHERE [Код территории] = 40288000 — узел, проверяемый на вхождение
UNION ALL
SELECT Территории. [Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
[Код территории], Территории.[Код вышестоящей территории], Территории.Наименование, Уровень + 1
FROM Территории
INNER JOIN Поддерево ON Территории.[Код территории] = Поддерево.[Код вышестоящей территории]
)
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM Поддерево
WHERE [Код территории] = 40260000 /* корень поддерева */)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END
Подмножества
Сразу оговорюсь: к способу, продвигаемому Джо Селко (Joe Celko) и по недоразумению называемому nested sets (вложенные множества), эта схема никакого отношения не имеет. Поэтому, чтобы избежать путаницы, я даже изменил информативное название «вложенные множества» на более простое.
В этой схеме дерево представляется вложенными подмножествами: корневой уровень включает в себя все подмножества — узлы первого уровня, а они, в свою очередь, включают в себя все узлы второго уровня и т. д. Иерархия территорий может выглядеть так, как показано на рис. 2.
д. Иерархия территорий может выглядеть так, как показано на рис. 2.
В реляционном же виде схема представлена на рис. 3.
Но за излишества надо платить. Целостность данных будет поддерживаться триггерами, которые перезаписывают список и уровни предков данного узла при его изменении. Для операции удаления достаточно декларативной ссылочной целостности (каскадное удаление), если ваша СУБД его поддерживает.
Если за образец принять список смежности, который не содержит никакой избыточности, то для метода подмножеств на каждый уровень потребуется столько дополнительных записей в таблице подмножеств, сколько элементов находится на данном уровне дерева, умноженном на номер уровня (вершину считаем первым уровнем). Количество записей растет в арифметической прогрессии.
Однако стоит взглянуть на примеры все тех же типовых запросов, как становятся очевидными преимущества, полученные от избыточности хранения: запросы стали короткими и быстрыми.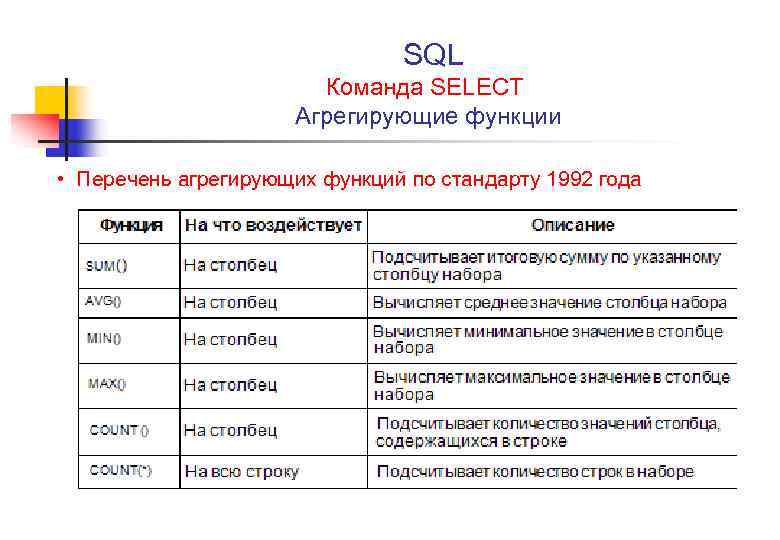
Выборка поддерева по заданному узлу:
SELECT [Код подмножества], Уровень
FROM Подмножества
WHERE [Код множества] = 123 — корень поддерева
ORDER BY Уровень
Выборка всех предков (путь к узлу от корня):
SELECT [Код множества], Уровень
FROM Подмножества
WHERE [Код подмножества] = 345 — узел
ORDER BY Уровень
Проверка вхождения узла в поддерево:
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM Подмножества
WHERE [Код подмножества] = 345 /* узел */
AND [Код множества] = 211 /* корень поддерева */)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END
Маршрут обхода
Как известно из уже упомянутой теории графов, для обхода дерева существует три способа: можно проходить узлы в префиксном, инфиксном или суффиксном порядке. Префиксный порядок обхода дерева рекурсивно определяется так: сначала корень дерева, потом узлы левого поддерева в префиксном порядке, наконец, узлы правого поддерева в префиксном порядке. Сложно? Взгляните на рис. 4, и все станет предельно ясно.
Сложно? Взгляните на рис. 4, и все станет предельно ясно.
Хранение маршрута обхода дерева в префиксном порядке и есть тот самый способ, который его уважаемый автор Джо Селко (или его интерпретаторы), видимо, по недоразумению продвигает под названием «вложенные множества» (nested sets). По недоразумению, потому что из рис. 4 ясно, что о множествах здесь речи не идет. Однако эта неувязка с названиями нисколько не уменьшает практической ценности метода.
Квадратик на рисунке обозначает узел, цифра в левом его углу является порядковым номером этапа маршрута при входе в узел, а цифра справа — при выходе, т.е. когда тем же способом пройдены все потомки. Как нетрудно заметить, номера потомков всегда располагаются в интервале между соответствующими номерами предка, сколь угодно дальнего. Храня порядок обхода дерева (рис. 5), этим замечательным свойством можно воспользоваться в типовых запросах, избежав рекурсии.
Очевидная сложность — пересчет порядка обхода при добавлении новых или перемещении имеющихся узлов (удаление можно игнорировать). В триггере придется реализовать последовательный порядок обхода с оптимизацией. Но, например, если добавляется элемент самого нижнего уровня, то все равно придется пересчитать все, что «выше» или «правее», а это может быть сравнимо с пересчетом маршрута по всему дереву.
В триггере придется реализовать последовательный порядок обхода с оптимизацией. Но, например, если добавляется элемент самого нижнего уровня, то все равно придется пересчитать все, что «выше» или «правее», а это может быть сравнимо с пересчетом маршрута по всему дереву.
Типовые запросы в методе маршрута обхода также лаконичные и быстрые.
Выборка поддерева по заданному узлу:
SELECT T1.*
FROM [Территории 3] as T1, [Территории 3] as T2
WHERE T1.Вход BETWEEN T2.Вход AND T2.Выход
AND T2.[Код территории] = 123 — корень поддерева
ORDER BY T1.Вход
Выборка всех предков симметрична предыдущему запросу относительно BETWEEN:
SELECT T1.*
FROM [Территории 3] as T1, [Территории 3] as T2
WHERE T2.Вход BETWEEN T1.Вход AND T1.Выход
AND T2.[Код территории] = 345 — узел
ORDER BY T1.Вход
Проверка вхождения узла в поддерево:
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM [Территории 3] as T1, [Территории 3] as T2
WHERE T1. [Код территории] = 456 /* узел */
[Код территории] = 456 /* узел */
AND T2.[Код территории] = 123 /* корень поддерева */
AND T1.Вход BETWEEN T2.Вход AND T2.Выход)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END
Оптимизация: хранение номеров с «дырками»
Давным-давно, в эпоху распространенности языка Бейсик (не путать с Visual Basic), строки программы последовательно нумеровались. Делалось это для того, чтобы, во-первых, интерпретатору было легче обрабатывать текст программы, а во-вторых, чтобы работали многочисленные операторы безусловного перехода (GOTO, если кто забыл) на строку с таким-то номером. Существовало и ограничение, согласно которому на каждой строке мог находиться только один оператор.
Поскольку программа во время своей жизни подвергалась изменениям, то в нее добавлялись новые операторы. Опытные программисты сразу нумеровали строки не 1, 2, 3, а 10, 20, 30. Это позволяло вставить в текст новую строку без полной перенумерации всех последующих.
Думаю, идею вы уже поняли: надо нумеровать входы и выходы из узлов с некоторым интервалом, например 100 или 1000, что в значительной степени зависит от предварительных оценок количества хранимых узлов дерева.
Материализованные пути
Суть метода заключается в хранении пути от вершины до данного узла в явном виде и в качестве ключа. Например, ранее приведенная на рисунке иерархия территорий могла бы выглядеть так:
Как видите, очень напоминает нумерацию частей, разделов и глав в книге.
Данный метод является наиболее наглядным с точки зрения кодификации элементов: каждый узел получает интуитивно понятное значение, сам код и его части несут смысловую нагрузку. Подобные свойства важны в классификациях, предназначенных для широкого использования, например в стандартизованных справочниках территорий (ОКАТО), отраслей экономики (ОКВЭД, NAICS), медицинских диагнозов (МКБ — международный классификатор болезней) и во многих других областях.
Сложнее ситуация с запросами. Они лаконичны, но не всегда эффективны, так как могут требовать поиска по подстроке.
Они лаконичны, но не всегда эффективны, так как могут требовать поиска по подстроке.
Выборка поддерева по заданному узлу:
SELECT *
FROM [Территории 4]
WHERE Путь LIKE ‘1.2%’ — корень поддерева
ORDER BY Путь
Выборка всех предков:
SELECT *
FROM [Территории 4]
WHERE ‘1.2.1’ /* узел */ LIKE Путь + ‘%’
ORDER BY Путь
или
SELECT T1.*
FROM [Территории 4] T1, [Территории 4] T2
WHERE T2.Путь LIKE T1.Путь + ‘%’
AND T2.Наименование like ‘МО Рыбацкое’
Проверка вхождения узла в поддерево:
SELECT result =
CASE
WHEN EXISTS(
SELECT 1 FROM [Территории 4] as T1, [Территории 4] as T2
WHERE T1.Наименование = ‘МО Рыбацкое’ /* узел */
AND T2.Наименование = ‘Невский район’ /* корень поддерева */
AND T1.Путь LIKE T2.Путь + ‘%’)
THEN ‘Узел входит в поддерево’
ELSE ‘Узел НЕ входит в поддерево’
END
Оптимизация
Зная заранее максимальное количество уровней и максимальное число прямых потомков, можно обойтись без разделителей, используя числовые коды с фиксированной разбивкой на группы разрядов.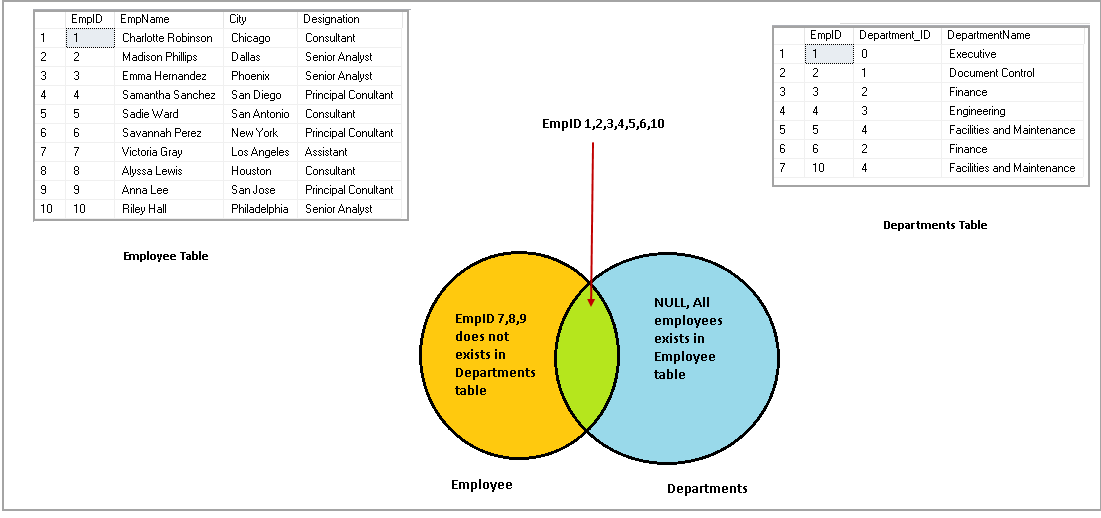 Пустые лидирующие разряды заполняются нулями.
Пустые лидирующие разряды заполняются нулями.
Подобная система используется во многих межсистемных классификаторах, например относящихся к государственному стандарту ОКАТО (Общероссийский классификатор объектов административно-территориального деления) или NAICS (North American Industry Classification System — Североамериканская система классификации отраслей экономики).
Итоги
Пришла пора подвести черту под нашим небольшим обзором. Если собрать достоинства и недостатки в одну общую таблицу, то мы получим более полную картину.
Следует помнить, что нет «плохих» или «хороших» методов: вы делаете оценки и выбор, исходя из условий конкретной задачи.
Нам хотелось показать вам основные принципы, используя которые вы сможете не только сделать обоснованный рациональный выбор одного из известных методов, но и создать свой, оптимизированный вариант. В конце концов, инженер тем и отличается от рабочего на сборке, что может и должен уметь находить оптимальные средства для решения задачи, а не слепо копировать чужие инструкции и шаблоны.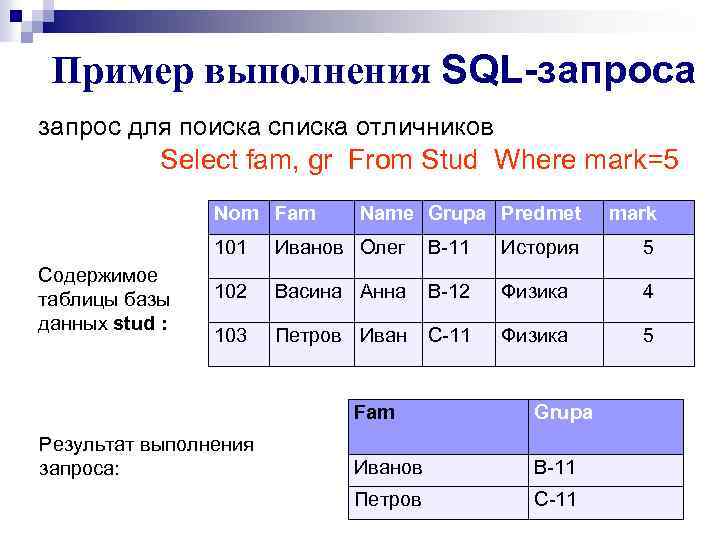
Рекомендуемая литература и ресурсы
- Joe Celko. Trees in SQL. Some answers to some common questions about SQL trees and hierarchies. http://www.intelligententerprise.com/001020/celko.jhtml?_requestid=1266295
- Vadim Tropashko. Trees in SQL: Nested Sets and Materialized Path. http://www.dbazine.com/oracle/or-articles/ tropashko4
- Джо Селко. Стиль программирования Джо Селко на SQL. Пер. с англ. СПб.: Питер, 2006.
ОБ АВТОРЕ
Сергей Тарасов — инженер, e-mail: [email protected].
Преимущества и недостатки рассмотренных методов
Пошаговое руководство по созданию иерархических запросов SQL
1. Введение
Иерархический запрос — это тип запроса SQL, который обычно используется для получения значимых результатов из иерархических данных. Иерархические данные определяются как набор элементов данных, связанных друг с другом иерархическими отношениями. Иерархические отношения существуют, когда один элемент данных является родителем другого элемента. Реальные примеры иерархических данных, которые обычно хранятся в базах данных, включают следующее:
Иерархические отношения существуют, когда один элемент данных является родителем другого элемента. Реальные примеры иерархических данных, которые обычно хранятся в базах данных, включают следующее:
- Иерархия сотрудников (отношения между сотрудником и менеджером)
- Организационная иерархия
- График ссылок между веб-страницами
- Подключенный граф социальных сетей
- Набор задач в проекте
- Файловая система
Если ваша база данных не является иерархической базой данных, такой как IBM Information Management System (IMS), вам потребуется написать иерархический SQL для извлечения реляционных данных в иерархическом формате, который устанавливает отношения родитель-потомок между объектами для лучшего понимания конечным пользователем.
Существует три типа иерархических синтаксисов SQL-запросов, которые можно использовать в различных коммерческих базах данных:
- CONNECT BY: широко доступен в базе данных Oracle SQL
- Common Table Expression (CTE): обычно используется с Microsoft SQL Server
- АНСИ SQL
.
Теперь давайте рассмотрим особенности и примеры для каждого из типов.
2. CONNECT BY
Этот метод поддерживается Oracle, EnterpriseDB (PostgreSQL), CUBRID, IBM Informix и DB2. Стандартный синтаксис для запроса CONNECT BY подобен приведенному ниже. Как видите, SELECT, FROM и CONNECT BY — единственные обязательные предложения в операторе.
SELECT select_list
FROM table_expression
[ ГДЕ … ] [ НАЧАТЬ С начальным_выражением ] CONNECT BY [NOCYCLE] {PRIOR child_expr = parent_expr | parent_expr = PRIOR child_expr }
[ ORDER SIBLINGS BY column1 [ ASC | DESC ] [ столбец2 [ ASC | DESC ] ] …
[GROUP BY … ] [ HAVING … ]
Следует отметить несколько важных моментов, касающихся синтаксиса:
- START WITH указывает корневую или родительскую строку (строки) иерархии.
- CONNECT BY определяет связь между родительскими и дочерними строками иерархии.
- Параметр NOCYCLE указывает базе данных возвращать строки из запроса, даже если в данных существует циклическая связь (CONNECT BY LOOP). Вы можете использовать этот параметр вместе с псевдостолбцом CONNECT_BY_ISCYCLE, чтобы увидеть, какие строки содержат цикл.
- В иерархическом запросе одно выражение в условии должно быть дополнено оператором PRIOR, чтобы ссылаться на родительскую строку. Например,
 Вы можете использовать этот параметр вместе с псевдостолбцом CONNECT_BY_ISCYCLE, чтобы увидеть, какие строки содержат цикл.
Вы можете использовать этот параметр вместе с псевдостолбцом CONNECT_BY_ISCYCLE, чтобы увидеть, какие строки содержат цикл. … ПРЕДЫДУЩЕЕ выражение = выражение
или
… выражение = ПРЕДЫДУЩЕЕ выражение
2.1 CONNECT BY Working Mechanism
База данных оценивает иерархические запросы в следующем порядке:
- Соединение, если оно присутствует, оценивается первым, независимо от того, указано ли соединение в предложении FROM или с предикатами предложения WHERE
- Условие CONNECT BY оценивается
- Оцениваются все оставшиеся предикаты предложения WHERE
Затем ядро базы данных использует информацию из этих оценок для формирования иерархии, используя следующие шаги (см. документацию Oracle 10g):
- Выбирает корневую строку (строки) иерархии, то есть те строки, которые удовлетворяют условию НАЧАТЬ С.
- Выбирает дочерние строки каждой корневой строки. Каждая дочерняя строка должна удовлетворять условию CONNECT BY относительно одной из корневых строк.
- Выбирает последующие поколения дочерних строк. Механизм базы данных сначала выбирает дочерние элементы строк, возвращенных на шаге 2, затем дочерние элементы этих дочерних элементов и так далее. База данных всегда выбирает потомков, оценивая условие CONNECT BY относительно текущей родительской строки.
- Если запрос содержит предложение WHERE без объединения, то база данных удаляет из иерархии все строки, которые не удовлетворяют условию предложения WHERE. База данных оценивает это условие для каждой строки отдельно, а не удаляет все дочерние элементы строки, которая не удовлетворяет условию.
- База данных возвращает строки в порядке, показанном на рисунке 1 ниже. На диаграмме дети появляются ниже своих родителей.
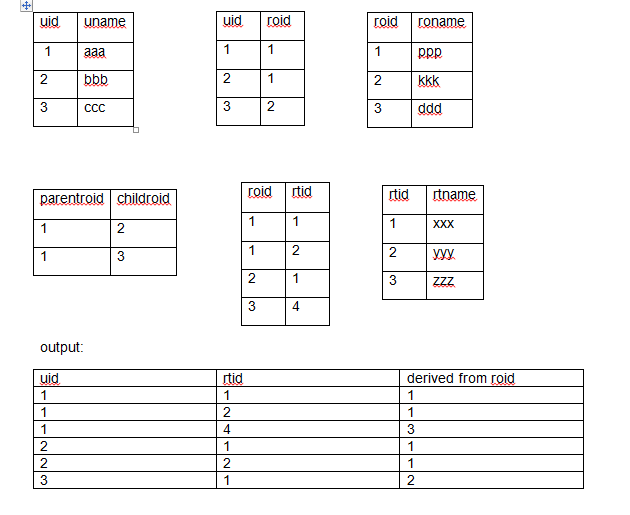
Рисунок 1. Иерархический порядок возврата строк запроса (из документации Oracle 10g)
Формат иерархического запроса CONNECT BY содержит операторы (особенно в Oracle), псевдостолбцы и функции для извлечения и представления иерархических данных в удобном для пользователя формате. :
:
- УРОВЕНЬ: The положение в иерархии текущей строки по отношению к корневому узлу.
- CONNECT_BY_ROOT: возвращает корневые узлы, связанные с текущей строкой.
- SYS_CONNECT_BY_PATH: возвращает навигационную цепочку с разделителями от корня до текущей строки.
- CONNECT_BY_ISLEAF: указывает, является ли текущая строка конечным узлом.
- ORDER SIBLINGS BY: Применяет порядок к одноуровневым элементам без изменения базовой иерархической структуры данных, возвращаемых запросом.
2.2 CONNECT BY & LEVEL Пример
Чтобы найти потомков родительской строки, база данных оценивает выражение PRIOR условия CONNECT BY для родительской строки и другое выражение для каждой строки в таблице. Строки, для которых условие истинно, являются дочерними элементами родителя. Условие CONNECT BY может содержать другие условия для дальнейшей фильтрации строк, выбранных запросом, однако оно не может содержать подзапрос.
Для примеров мы будем использовать знакомую иерархическую структуру данных «сотрудник-менеджер» из таблицы EMP. Вот пример иерархического SQL-запроса с CONNECT BY и LEVEL в его самой простой форме.
Вот пример иерархического SQL-запроса с CONNECT BY и LEVEL в его самой простой форме.
ВЫБЕРИТЕ EMPNO, ENAME, MGR, УРОВЕНЬ
ИЗ EMP
ПОДКЛЮЧИТЬСЯ ПО MGR = ПРЕДВАРИТЕЛЬНЫЙ EMPNO
ЗАКАЗАТЬ СЕСТРОВ ПО MGR;
Как вы заметили, здесь нет предложения START WITH; в результате мы не получаем хорошо организованных, значимых данных для эффективной отчетности. Итак, давайте введем START WITH в запрос и посмотрим на результаты.
2.3 START WITH Пример
Используйте предложение START WITH, чтобы указать корневую строку для иерархии, и предложение ORDER BY, используя ключевое слово SIBLINGS, чтобы сохранить порядок в иерархии. В иерархическом запросе используйте ORDER (или GROUP BY) SIBLINGS BY, чтобы отсортировать строки элементов одного и того же родителя; это сохранит иерархический порядок результатов CONNECT BY.
ВЫБЕРИТЕ EMPNO, ENAME, MGR, УРОВЕНЬ
ИЗ EMP
НАЧАТЬ С MGR IS NULL
ПОДКЛЮЧИТЬСЯ ПО MGR = ПРЕДЫДУЩИЙ EMPNO
ЗАКАЗАТЬ СЕСТРОВ ПО MGR;
2.
 4 NOCYCLE Пример
4 NOCYCLE Пример
Иерархический набор данных может быть циклическим, что создаст проблему при запросе данных. Однако предложение NOCYCLE с CONNECT BY предписывает базе данных не проходить циклические иерархии данных. В этом случае функция CONNECT_BY_ISCYCLE показывает запись, отвечающую за цикл. Обратите внимание, что CONNECT_BY_ISCYCLE можно использовать, только если указано предложение NOCYCLE.
ВЫБЕРИТЕ EMPNO, ENAME, MGR, LEVEL, CONNECT_BY_ISCYCLE AS Cycle
FROM EMP
START WITH MGR IS NULL ПО МГР;
2.5 CONNECT_BY_ROOT Пример
Это предложение возвращает корневые узлы, связанные с текущей строкой. В следующем примере возвращается имя каждого сотрудника в отделе 20, каждого менеджера выше этого сотрудника в иерархии, количество уровней между менеджером и сотрудником и путь между ними:
Если вам нужно рассчитать общую заработную плату для каждого менеджера и всех его/ее подчиненных, используйте предложение CONNECT_BY_ROOT. Вот простой пример для сотрудников отдела 20 из таблицы EMP:
Вот простой пример для сотрудников отдела 20 из таблицы EMP:
2.6 Пример дополнительного иерархического запроса
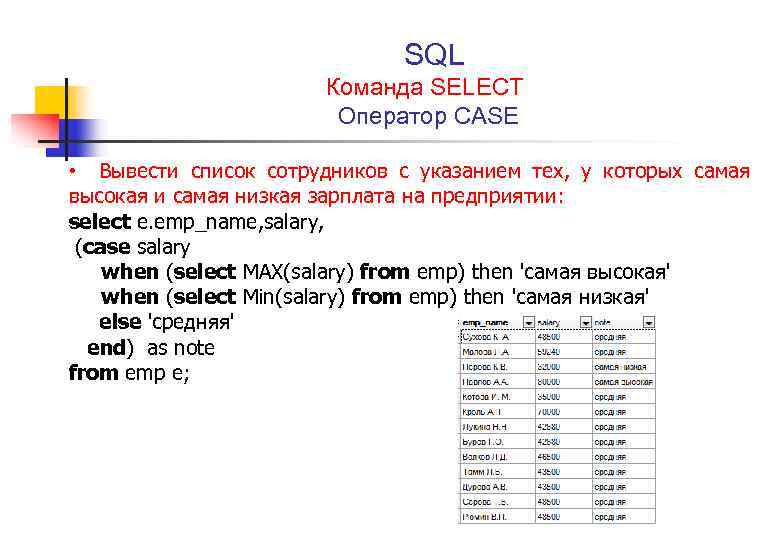
Если вам нужно добавить вкладки для визуального представления иерархических данных, вы можете использовать функции заполнения, как показано в примере ниже. Значения в поле TREE имеют отступы, чтобы визуально показать иерархию отчетов (связь) сотрудников. Кроме того, PATH предоставляет связь между сотрудниками в формате с разделителями.
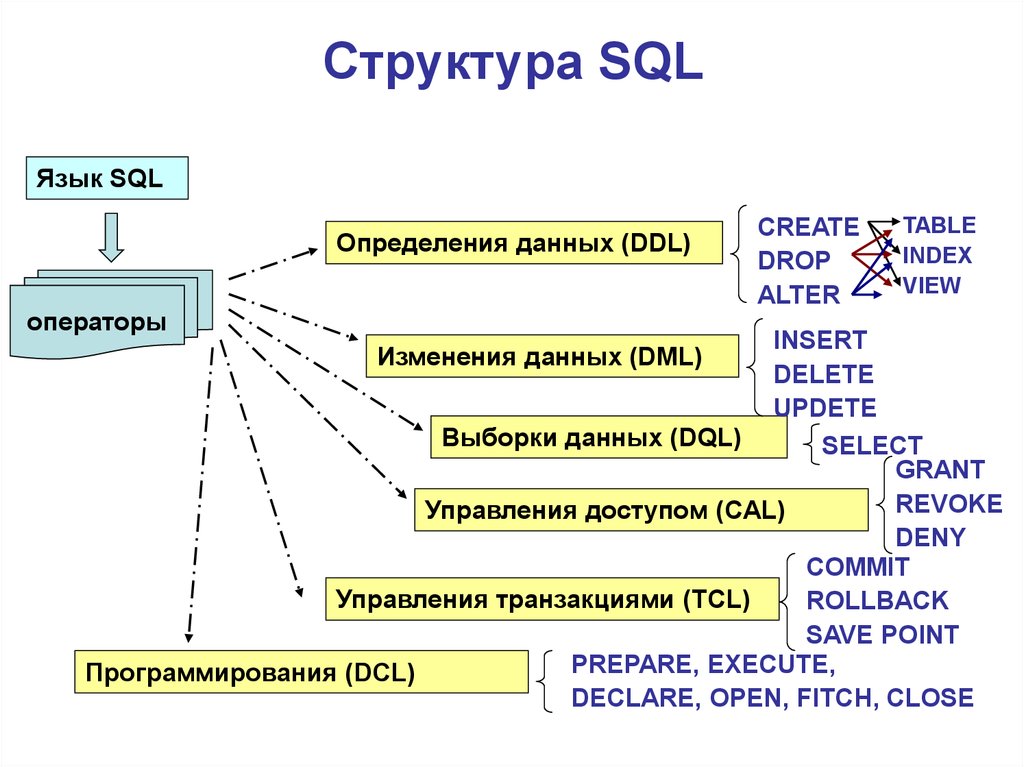
3. Common Table Expression (CTE)
CTE можно рассматривать как временный набор результатов, и он похож на производную таблицу или таблицу подзапросов тем, что не хранится как объект и существует только на время выполнения запроса. . Однако CTE более эффективен, чем производная таблица, поскольку она может ссылаться на себя или даже ссылаться несколько раз в одном запросе.
Синтаксис CTE поддерживается базами данных Teradata, DB2, Firebird, Microsoft SQL Server, Oracle, PostgreSQL, SQLite, HyperSQL, h3. КТР называется « рекурсивный подзапрос с факторингом ” в базе данных Oracle.
КТР называется « рекурсивный подзапрос с факторингом ” в базе данных Oracle.
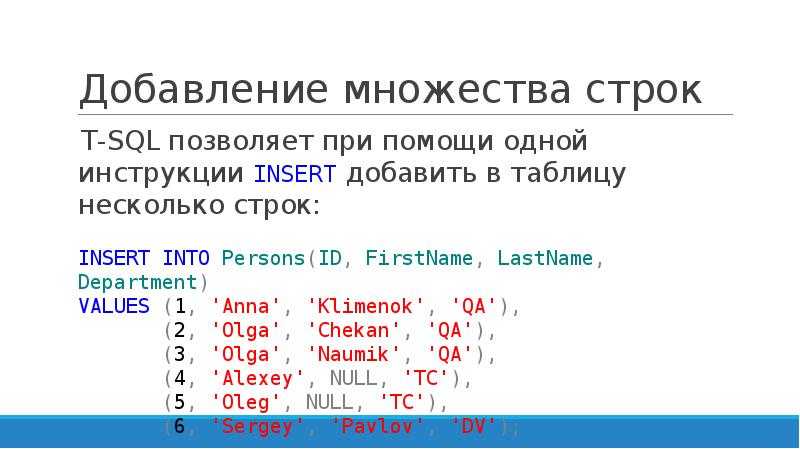
3.1 Построение рекурсивного CTE
Рекурсивное CTE должно состоять из четырех элементов для правильной работы:
- Якорный запрос — выполняется один раз, и результаты задают рекурсивный запрос
- Рекурсивный запрос — выполняется несколько раз и является критерием для остальных результатов
- UNION ALL — оператор для связывания Anchor и Recursive запросов вместе
- INNER JOIN — оператор для привязки рекурсивного запроса к результатам CTE
Ниже приведен полный запрос CTE, который создает иерархические данные из таблицы EMP. Давайте идентифицируем каждый из четырех вышеперечисленных элементов запроса CTE.
с Ourcte (Empno, Ename, Mgr, Emplevel)
AS (Select Empno, Ename, Mgr, 1 Emplovel — Unitial Subquery
из EMP
, где Mgr — NULL
Union All
Select E.Empno, E.Ename, E .MGR, CTE.EMPLEVEL + 1 – рекурсивный подзапрос
ИЗ EMP E
ВНУТРЕННЕЕ СОЕДИНЕНИЕ OURCTE CTE ON E. MGR = CTE.EMPNO
MGR = CTE.EMPNO
, ГДЕ E.MGR НЕ НУЛЕВОЕ)
ВЫБЕРИТЕ *
ИЗ OURCTE
ЗАКАЗАТЬ ПО EMPLEVEL;
3.1.1 Якорный запрос
Сотрудники, у которых нет менеджера (MGR IS NULL), например, генеральный директор компании, являются сотрудниками высшего уровня организации. (Генеральный директор, скорее всего, подчиняется председателю совета директоров, если только он или она не занимает совместные должности, но давайте пока не будем об этом беспокоиться). Эта группа представляет сотрудников уровня 1. Запрос Anchor идентифицирует этих сотрудников и передает эти данные в следующий рекурсивный запрос.
ВЫБЕРИТЕ EMPNO, ENAME, MGR – Начальный подзапрос
ИЗ EMP
ГДЕ MGR НУЛЬ;
3.1.2 Рекурсивный запрос
Задача рекурсивного запроса состоит в том, чтобы найти всех сотрудников уровня 2 или ниже, для которых определен менеджер (MGR НЕ NULL). Приведенный ниже запрос является нашим рекурсивным запросом, который в конечном итоге будет иметь INNER JOIN для рекурсивной ссылки на результаты запроса Anchor.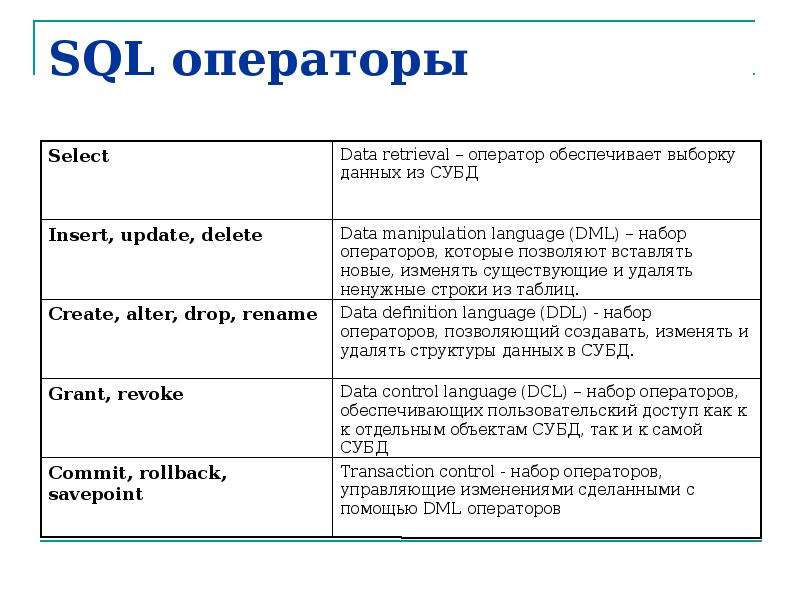
SELECT E.EMPNO, E.ENAME, E.MGR – рекурсивный подзапрос
ИЗ EMP E
, ГДЕ E.MGR НЕ НУЛЬ;
3.1.3 СОЕДИНЕНИЕ ВСЕ 9 0061
Мы можем преобразовать якорные и рекурсивные запросы, поместив между ними оператор UNION ALL, заключив их в круглые скобки и добавив объявление WITH OURCTE AS с псевдонимами столбцов и, наконец, добавив SELECT * FROM OURCTE после закрывающих скобок.
С OURCTE (EMPNO, ENAME, MGR)
AS (ВЫБРАТЬ EMPNO, ENAME, MGR – начальный подзапрос
FROM EMP
WHERE MGR IS NULL
UNION ALL – Объединение всех объединенных запросов Anchor и Recursive
SELECT E.EMPNO, E.ENAME, E.MGR – Recursive Subquery
FROM EMP E
WHERE E.MGR НЕ NULL)
SELECT *
ОТ OURCTE;
Как видите, результаты запроса CTE точно такие же, как объединенные результаты якорных и рекурсивных запросов выше.
Запрос Anchor внутри CTE представляет всех на уровне 1, а рекурсивный запрос представляет всех на уровне 2 и выше. Чтобы визуализировать каждый уровень в наборе результатов, вам нужно будет добавить поле выражения к каждому запросу, как показано ниже:
Чтобы визуализировать каждый уровень в наборе результатов, вам нужно будет добавить поле выражения к каждому запросу, как показано ниже:
WITH OURCTE (EMPNO, ENAME, MGR, EMPLEVEL)
AS (SELECT EMPNO, ENAME, MGR, ‘1’ EMPLEVEL – выражение для уровня дорожки
FROM Emp
WHERE MGR IS NULL
UNION ALL
SELECT E.EMPNO, E .ENAME, E.MGR, ‘2 или выше’ EMPLEVEL – Выражение для отслеживания уровня (здесь просто заполнитель)
FROM EMP E
– INNER JOIN OURCTE CTE ON E.MGR = CTE.EMPNO
ГДЕ E.MGR НЕ NULL )
SELECT *
FROM OURCTE
ORDER BY EMPLEVEL;
3.1.4 ВНУТРЕННЕЕ СОЕДИНЕНИЕ
Как видите, мне пришлось поместить жестко заданное значение для поля EMPLEVEL в секции Recursive запроса выше. Это произошло потому, что я не присоединил рекурсивный раздел запроса к нашему рекурсивному CTE. Теперь, чтобы заставить весь иерархический запрос работать с фактическим иерархическим уровнем назначенных записей, нам нужно выполнить ВНУТРЕННЕЕ СОЕДИНЕНИЕ, как в приведенном ниже запросе. Обратите внимание на разницу в значении поля EMPLEVEL. Это полный иерархический запрос в формате CTE. Обратите внимание, что ORDER BY здесь необязателен.
Обратите внимание на разницу в значении поля EMPLEVEL. Это полный иерархический запрос в формате CTE. Обратите внимание, что ORDER BY здесь необязателен.
WITH OURCTE (EMPNO, ENAME, MGR, EMPLEVEL)
AS (SELECT EMPNO, ENAME, MGR, 1 EMPLEVEL – Initial Subquery
FROM Emp
WHERE MGR IS NULL
UNION ALL
SELECT E.EMPNO, E.ENAME, E .MGR, CTE.EMPLEVEL + 1 – рекурсивный подзапрос
FROM EMP E
INNER JOIN OURCTE CTE ON E.MGR = CTE.EMPNO –Inner Join
, ГДЕ E.MGR НЕ NULL)
SELECT *
FROM OURCTE
ORDER BY EMPLEV ЭЛЬ ;
Если вам нужно отобразить имя менеджера рядом с идентификатором менеджера, обратитесь к следующему запросу:
ВЫБЕРИТЕ CTE.EMPNO, CTE.ENAME, CTE.MGR, E.ENAME «ИМЯ MGR», CTE.EMPLEVEL
ИЗ (
С OURCTE (EMPNO, ENAME, MGR, EMPLEVEL)
AS (ВЫБЕРИТЕ EMPNO, ENAME, MGR , 1 EMPLEVEL – исходный подзапрос
FROM Emp
WHERE MGR IS NULL
UNION ALL
SELECT E.EMPNO, E.ENAME, E.MGR, CTE.EMPLEVEL + 1 – рекурсивный подзапрос
FROM EMP E
INNER JOIN OURCTE CTE ON Е . MGR = CTE.EMPNO
MGR = CTE.EMPNO
, ГДЕ E.MGR НЕ НУЛЕВОЕ)
SELECT *
FROM OURCTE
ЗАКАЗАТЬ ПО EMPLEVEL) CTE
LEFT OUTER JOIN EMP E ON CTE.MGR = E.EMPNO
ЗАКАЗАТЬ CTE.EMPLEVEL,E.ENAME;
4. ANSI SQL
CONNECT_BY и Common Table Expression (CTE) — два наиболее широко используемых метода построения иерархических результатов из реляционных данных. Однако функции CONNECT_BY, которые обсуждались выше, в основном доступны для базы данных Oracle SQL, и не все они совместимы с ANSI SQL. С другой стороны, хотя синтаксис CTE соответствует стандарту ANSI SQL 99, он не очень гибкий и не полностью совместим со всеми базами данных, такими как HP Vertica. В результате вам может потребоваться получить иерархические результаты из реляционных структур данных с использованием ANSI SQL в системах баз данных, которые не полностью поддерживают синтаксис CONNECT_BY и CTE.
Существует довольно простой способ сделать это с помощью SQL LEFT OUTER JOIN. В этом методе мы сглаживаем иерархические данные, которые имеют отношение родитель-потомок.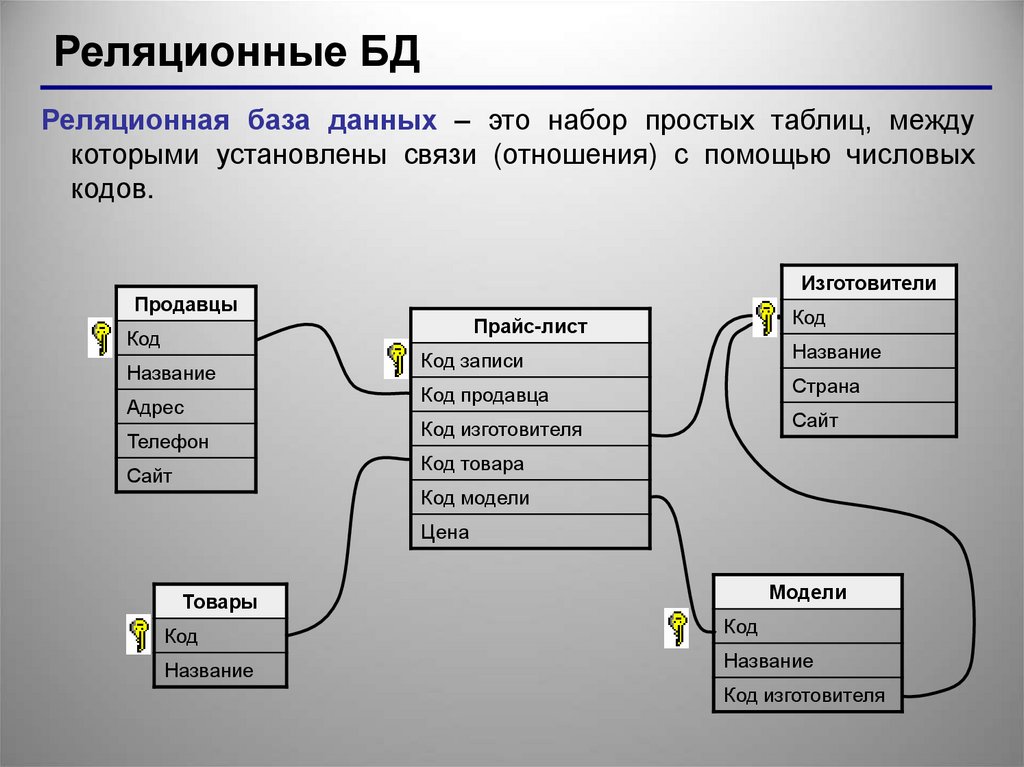 Результатом этого запроса является обширный и редко заполняемый набор данных с дополнительными столбцами для хранения идентификаторов узлов и значений на разных уровнях иерархии. Количество дополнительных столбцов с непустыми значениями напрямую связано с глубиной иерархии.
Результатом этого запроса является обширный и редко заполняемый набор данных с дополнительными столбцами для хранения идентификаторов узлов и значений на разных уровнях иерархии. Количество дополнительных столбцов с непустыми значениями напрямую связано с глубиной иерархии.
Еще раз, мы будем использовать таблицу EMP для построения иерархического запроса ANSI SQL для создания плоского набора данных с помощью предложения LEFT OUTER JOIN. Это простейшая форма запроса, однако разработанный здесь принцип может быть применен к источнику(ам) данных с несколькими встроенными в них иерархиями. С учетом сказанного, вот шаги, которые выполняются для разработки иерархического запроса ниже:
1. Определите корень иерархии. В случае таблицы EMP запись с MGR IS NULL представляет собой корень иерархии данных менеджер-сотрудник. Это уровень 1 или самый верхний узел всей иерархии. Давайте назначим псевдоним T1 этому встроенному набору результатов.
2. Затем рекурсивно перемещайтесь на один уровень вниз, используя LEFT OUTER JOIN, в котором левое внешнее соединение T1 с таблицей EMP (T2) в полях EMPNO и MGR соответственно. Этот запрос возвращает сотрудников, которые подчиняются сотруднику(ам) уровня 1. Теперь у нас есть список сотрудников уровня 2 вместе с сотрудниками уровня 1. Обратите внимание, что каждая новая рекурсия добавляет в результирующий набор дополнительные столбцы, делая его более плоским и разреженным. Присвоим этому результирующему набору псевдоним T2.
Этот запрос возвращает сотрудников, которые подчиняются сотруднику(ам) уровня 1. Теперь у нас есть список сотрудников уровня 2 вместе с сотрудниками уровня 1. Обратите внимание, что каждая новая рекурсия добавляет в результирующий набор дополнительные столбцы, делая его более плоским и разреженным. Присвоим этому результирующему набору псевдоним T2.
3. Продолжайте повторять шаг 2, пока мы не найдем уровень со всеми пустыми значениями полей. Это когда мы знаем, что уровней больше нет; мы прошли даже на один уровень ниже самого глубокого листа иерархии. В нашем примере последним является уровень 4, поскольку все поля уровня 5 пусты.
4. В этот момент вы будете думать: «Как я узнаю, где остановиться и/или сколько уровней мне нужно определить в моем запросе, чтобы убедиться, что мой запрос не сломается, если появятся новые узлы?» добавлены в иерархию?». В большинстве случаев практического использования глубина иерархии будет определена или находится в определенных пределах.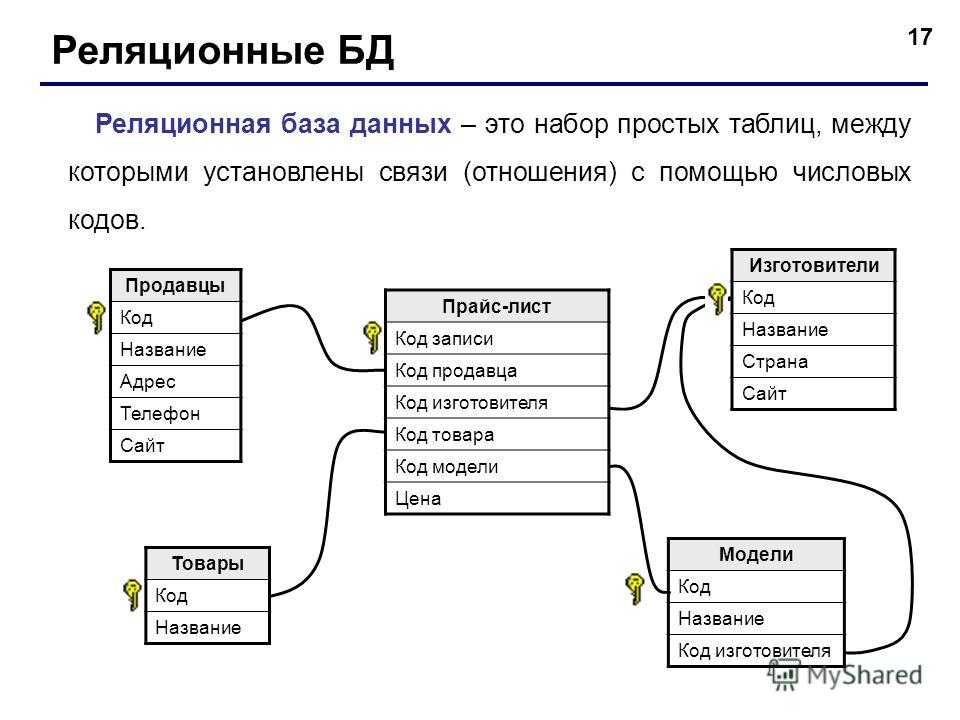 Однако в определенных ситуациях, таких как организационные изменения или слияния и поглощения, иерархия может измениться. Поэтому рекомендуется определить несколько дополнительных уровней, хотя это добавит в набор результатов больше столбцов с пустыми значениями. Но дополнительные поля не изменят конечный результат, поскольку они пусты и, следовательно, не изменяют эффективную длину ветви дерева иерархии.
Однако в определенных ситуациях, таких как организационные изменения или слияния и поглощения, иерархия может измениться. Поэтому рекомендуется определить несколько дополнительных уровней, хотя это добавит в набор результатов больше столбцов с пустыми значениями. Но дополнительные поля не изменят конечный результат, поскольку они пусты и, следовательно, не изменяют эффективную длину ветви дерева иерархии.
Ниже приведен наш запрос и набор результатов. Как видите, уровень 5 добавлен для избыточности, но это не меняет окончательный результат запроса в реальном смысле.
5. Заключение
Каждый из этих иерархических форматов запросов имеет свое место и варианты использования. Если вы используете базу данных Oracle версии 10g или более поздней, вам следует использовать метод CONNECT BY, поскольку иерархические функции SQL Oracle просты в использовании, зрелы и универсальны. Однако если вы используете базу данных (например, Microsoft SQL Server), которая не поддерживает метод CONNECT BY, вам необходимо использовать синтаксис CTE для построения иерархического набора результатов.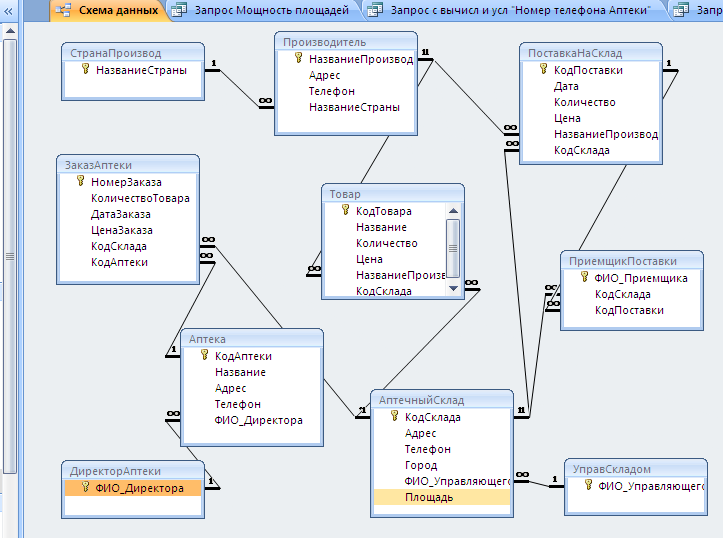 Наконец, если вы работаете с одной из платформ Big Data SQL, такой как HP Vertica, вам может потребоваться использовать ANSI SQL для получения иерархических данных в линейном формате (например, Excel) из реляционных данных. В Clarity Solution Group наши аналитики данных решают эту и многие другие сложные задачи в нашей повседневной работе. Узнайте больше о службах данных и аналитики Clarity.
Наконец, если вы работаете с одной из платформ Big Data SQL, такой как HP Vertica, вам может потребоваться использовать ANSI SQL для получения иерархических данных в линейном формате (например, Excel) из реляционных данных. В Clarity Solution Group наши аналитики данных решают эту и многие другие сложные задачи в нашей повседневной работе. Узнайте больше о службах данных и аналитики Clarity.
Первоначально эта статья была опубликована в блоге Clarity Solution Group по адресу http://clarity-us.com/guide-sql-hierarchical-queries/
Иерархические запросы в Oracle SQL
Советы Oracle от Лорана Шнайдера |
Лоран
Шнайдер считается одним из лучших экспертов по Oracle SQL.
он является автором книги «Advanced SQL Programming» издательства Rampant TechPress. Следующее
это отрывок из книги.
Иерархические запросы
Иерархия строится на отношениях родитель-потомок внутри
ту же таблицу или представление. Иерархический запрос — одна из самых первых возможностей
Oracle Database и была представлена более двадцати лет назад!
В традиционном запросе Oracle ищет хорошее выполнение
planand извлекает строки одну за другой, в произвольном порядке.
В иерархии строки организованы в виде дерева:
Рисунок 6.1:
Иерархия
Дерево
В таблице известных сотрудников (EMP) король является
президент. Ниже президента у каждого менеджера есть свой отдел. в
бухгалтерии, у Кларка есть один клерк, Миллер. Отдел продаж
под контролем Блейка. У Блейка четыре продавца — Аллен, Уорд, Мартин и
Тернер — и один клерк, Джеймс. Джонс возглавляет исследовательский отдел. Аналитик
У Форда есть клерк по имени Смит, а у аналитика Скотта также есть клерк по имени Адамс.
Большинство компаний имеют очень иерархическую структуру.
иерархию можно проходить снизу вверх; например, чтобы получить верхнюю иерархию
сотрудника или сверху вниз, чтобы обнаружить всех сотрудников под одним менеджером.
Одной из наиболее распространенных проблем в иерархиях является цикличность.
То есть, если топ-менеджер сам себе начальник, Oracle обнаружит петлю и
вернуть ошибку. Эта проблема частично исправлена в 10g новым механизмом, который устанавливает
флаг и прекращает обработку ветки-нарушителя.
До версии 9i доступные поля находились либо на текущей
строке или в родительской строке. В 10g поля в верхней части иерархии
также доступны, что позволяет анализировать и агрегировать по всему
иерархия. Еще одно дополнение в 10g — это флаг для нижней части иерархии,
называются листовыми рядами.
ПОДКЛЮЧИТЬСЯ, ДО и НАЧАТЬ С
Есть два обязательных ключевых слова для построения иерархии,
ПОДКЛЮЧАЙТЕСЬ ПО и ПРЕД. Иерархия строится, когда одна строка является родительской для другой строки.
START WITH определяет первого предка.
ВЫБЕРИТЕ
ENAME
FROM
EMP
ПОДКЛЮЧИТЬ
ПРЕДЫДУЩИЙ EMPNO = MGR
НАЧАТЬ С
ENAME = ‘JONES’;
ENAME
———-
ДЖОНС
СКОТТ
АДАМС
ФОРД
СМИТ
Джонс и его сотрудники возвращены. Адамс — сотрудник
Скотта, а Скотт — сотрудник Джонса, поэтому Адамс также вернулся.
УРОВЕНЬ
Уровень псевдостолбца возвращает глубину иерархии.
Первый уровень — корень:
ВЫБЕРИТЕ
ENAME
FROM
EMP
ГДЕ
УРОВЕНЬ=2 ;
ENAME
———
SCOTT
FORD
Возвращаются только непосредственные сотрудники Jones. Джонс
первый предок и имеет уровень 1. Адамс и Смит на один уровень ниже
прямых сотрудников и относятся к третьему уровню, начатому Джонсом.
Дерево отображается с дочерними элементами с отступом под их
родителей, используя отступы с количеством пробелов, пропорциональным LEVEL.
SELECT
CONCAT
(
LPAD
(
‘ ‘ ,
LEVEL*3-3
), 90 039 ENAME
) ENAME
FROM
EMP
СОЕДИНИТЬ ПО
ПРЕДЫДУЩИЙ EMPNO = MGR
НАЧАТЬ С
MGR IS NULL;
ENAME
——————
KING
JONES
SCOTT
ADAMS
FORD
SMITH
BLAKE 90 039 АЛЛЕН
ОТДЕЛЕНИЕ
МАРТИН
ТЕРНЕР
ДЖЕЙМС
КЛАРК
МИЛЛЕР
Начиная с топ-менеджера, имена сотрудников
дополняются пробелами в соответствии с их уровнем.