Sql индексы: Все, что необходимо знать про индексы MS SQL OTUS
Содержание
Индексы — SQL Server | Microsoft Learn
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 3 мин
-
Применимо к: SQL Server (все поддерживаемые версии) Azure SQL базы данных Управляемый экземпляр SQL Azure
Доступные типы индексов
В следующей таблице перечислены типы индексов, доступные в SQL Server, и приведены ссылки на дополнительные сведения.
| Тип индекса | Описание | Дополнительные сведения |
|---|---|---|
| Хэш | При использовании хэш-индекса доступ к данным осуществляется через хэш-таблицу в памяти. Хэш-индексы используют фиксированный размер памяти, который зависит от числа контейнеров. | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по проектированию хэш-индексов |
| Некластеризованный индекс, оптимизированный для памяти | Для оптимизированных для памяти некластеризованных индексов потребление памяти является функцией от количества строк и размера ключевых столбцов индекса | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по проектированию некластеризованных индексов, оптимизированных для памяти |
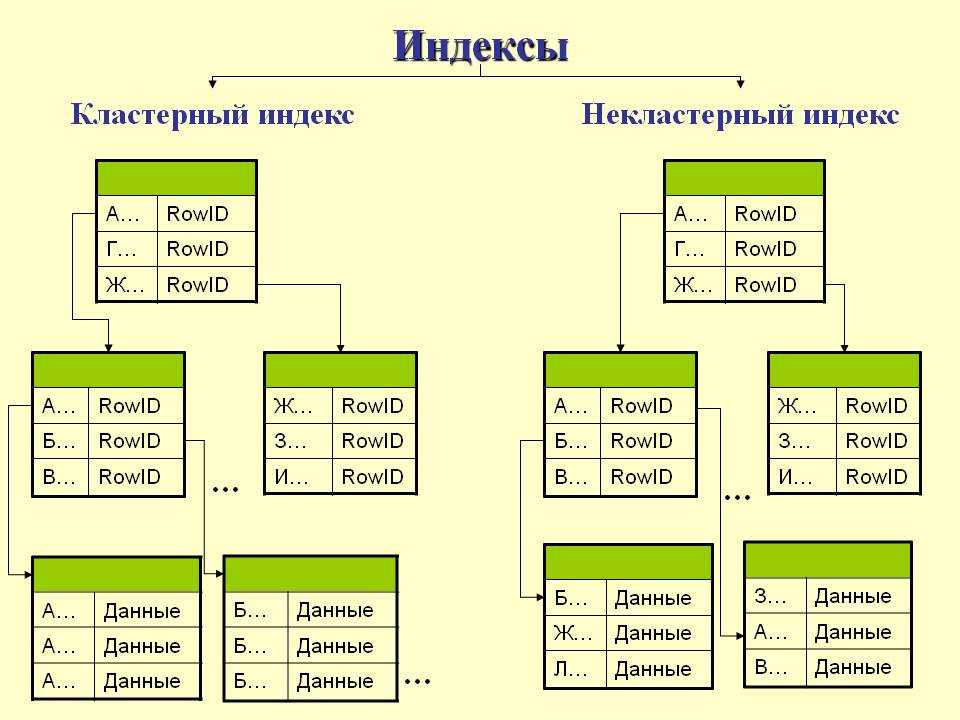
| Кластеризованный | Кластеризованный индекс сортирует и хранит строки данных таблицы или представления в порядке, определяемом ключом кластеризованного индекса.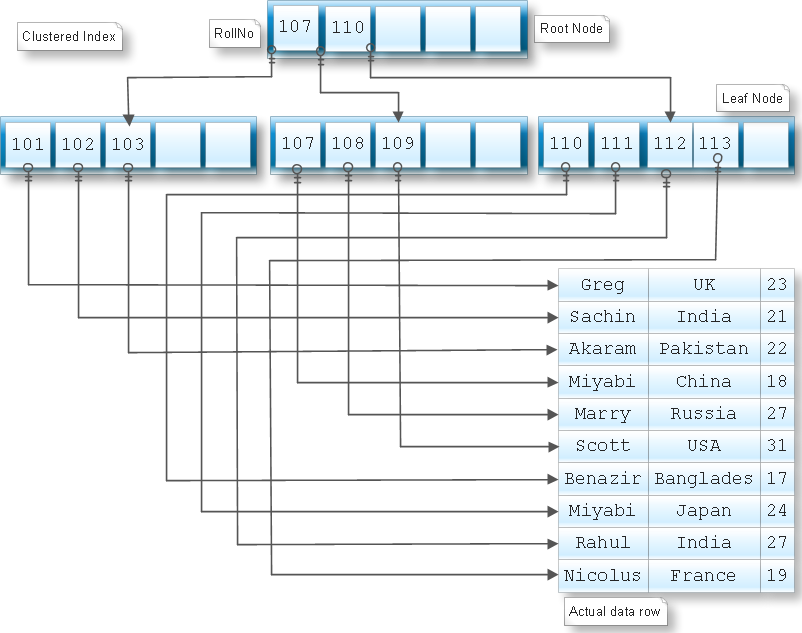 Кластеризованный индекс реализуется в виде сбалансированного дерева, которое поддерживает быстрое получение строк по значениям ключа кластеризованного индекса. Кластеризованный индекс реализуется в виде сбалансированного дерева, которое поддерживает быстрое получение строк по значениям ключа кластеризованного индекса. | Описание кластеризованных и некластеризованных индексов Создание кластеризованных индексов Правила проектирования кластеризованного индекса |
| Некластеризованный | Некластеризованный индекс можно определить в таблице или представлении вместе с кластеризованным индексом или в куче. Каждая строка некластеризованного индекса содержит некластеризованное ключевое значение и указатель на строку. Этот указатель определяет строку данных кластеризованного индекса или кучи, содержащую ключевое значение. Строки в индексе хранятся в порядке, определяемом значениями ключа индекса, но до создания кластеризованного индекса в таблице нет никакой гарантии того, что строки данных будут расположены в каком-либо определенном порядке. | Описание кластеризованных и некластеризованных индексов Создание некластеризованных индексов Рекомендации по созданию некластеризованных индексов |
| Уникальная идентификация | Уникальный индекс обеспечивает отсутствие повторяющихся значений ключа индекса, что, в свою очередь, приводит к тому, что каждая строка в таблице или представлении является в каком-то смысле уникальной. Как кластеризованные, так и некластеризованные индексы могут быть уникальными. | Создание уникальных индексов Правила по созданию уникальных индексов |
| columnstore | Индекс columnstore в памяти хранит данные и управляет данными с использованием основанного на столбцах хранилища данных и обработки запросов. Индексы Columnstore подходят для рабочих нагрузок хранилища данных, которые выполняют в основном массовую загрузку и запросы только для чтения. Используйте индекс columnstore для повышения производительности запросов максимум в 10 раз относительно традиционного хранилища, основанного на строках, и повышения эффективности сжатия данных до 7 раз относительно несжатых данных. | Руководство по индексам columnstore Рекомендации по проектированию индексов columnstore |
| Индекс с включенными столбцами | Некластеризованный индекс, дополнительно содержащий кроме ключевых столбцов еще и неключевые.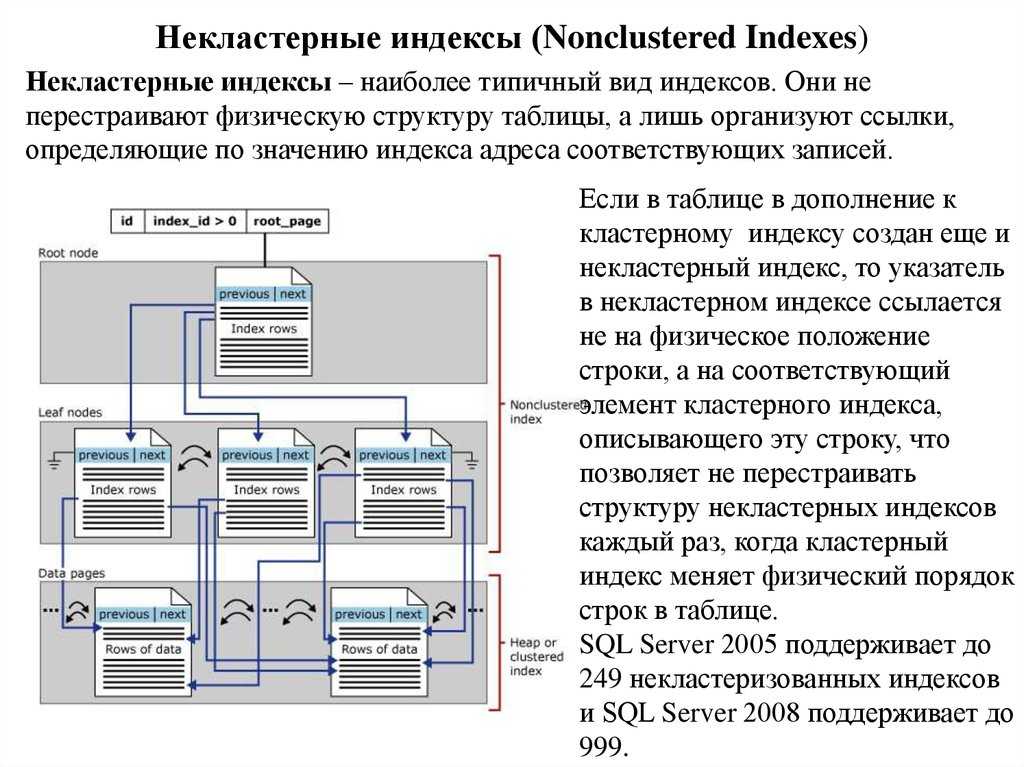 | Создание индексов с включенными столбцами |
| Индекс на вычисляемых столбцах | Индекс на столбце, являющемся производным от одного или нескольких других столбцов или нескольких детерминированных источников. | Индексы вычисляемых столбцов |
| Filtered | Оптимизированный некластеризованный индекс, в особенности подходящий для покрытия запросов из хорошо определенного подмножества данных. Он использует предикат фильтра для индексирования части строк в таблице. Хорошо спроектированный отфильтрованный индекс позволяет повысить производительность запросов, снизить затраты на обслуживание и хранение индексов по сравнению с полнотабличными индексами. | Создание отфильтрованных индексов Рекомендации по проектированию отфильтрованных индексов |
| пространственный индекс | Пространственный индекс обеспечивает возможность более эффективного использования определенных операций с пространственными объектами (пространственными данными) в столбце типа данных geometry . Пространственные индексы снижают количество объектов, к которым должны применяться пространственные операции, требующие больших затрат. Пространственные индексы снижают количество объектов, к которым должны применяться пространственные операции, требующие больших затрат. | Общие сведения о пространственных индексах |
| XML | Вырезанное материализованное представление больших двоичных XML-объектов в столбце с типом данных xml. | XML-индексы (SQL Server) |
| Полнотекстовый | Особый тип функционального индекса на основе токенов, который создается и обслуживается подсистемой Microsoft Full-Text для SQL Server. Он обеспечивает эффективную поддержку сложных операций поиска слов в символьных строковых данных. | Заполнение полнотекстовых индексов |
Примечание
В документации по SQL Server термин «сбалансированное дерево» обычно используется в отношении индексов. В индексах rowstore SQL Server реализует B+-дерево. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в руководстве по архитектуре и разработке индексов SQL Server.
См. также
Руководство по проектированию индексов SQL Server
Параметр SORT_IN_TEMPDB для индексов
Отключение индексов и ограничений
Включение индексов и ограничений
Переименование индексов
Установка параметров индекса
Требования к месту на диске для DDL-операций индекса
Реорганизация и перестроение индексов
Указание коэффициента заполнения для индекса
Руководство по архитектуре страниц и экстентов
Описание кластеризованных и некластеризованных индексов
Пространственные индексы и ST_Geometry—Справка | ArcGIS Desktop
- Oracle
- PostgreSQL
- SQLite
- IBM DB2 и Informix
Пространственные индексы используются с ST_Geometry и работают по-разному в зависимости от типа СУБД. ST_Geometry в Oracle и DB2 использует индекс пространственной сетки. Модуль IBM Informix Spatial DataBlade и реализация ST_Geometry в PostgreSQL и SQLite используют индекс R-tree для индексации пространственных данных. В SQLite индекс R-tree – это виртуальная таблица.
В SQLite индекс R-tree – это виртуальная таблица.
Вы можете создать пространственный индекс следующими способами:
- Чтобы создать индексы пространственной сетки, щелкните Добавить (Add) на закладке Индексы (Indexes) в окне Свойства класса пространственных объектов (Feature Class Properties) в ArcCatalog. См. Установка пространственных индексов.
- Использовать SQL. См. Создание пространственных индексов для таблиц со столбцом ST_Geometry с помощью SQL.
Помните, что когда вы выполняете запросы пространственных отношений к таблицам, содержащим столбцы ST_Geometry, они используют пространственный индекс для ускорения работы только при применении определенных функций пространственных отношений. Они указаны в разделе Когда используются пространственные индексы?.
Oracle
Классы пространственных объектов, созданные с помощью ST_Geometry с пространственным индексом, создают дополнительную таблицу в базе данных Oracle. Таблица пространственного индекса называется S<n>_IDX$, где <n> – это значение индекса геометрии таблицы. Значение может быть получено с помощью запроса к таблице SDE.ST_GEOMETRY_COLUMNS. Таблица пространственного индекса создается как Oracle Indexed Organized Table (IOT). Пространственный индекс атрибута ST_Geometry выглядит как A<n>_IX1, при просмотре из Enterprise Manager. Значение <n> соответствует LAYER_ID, хранящемуся в таблице LAYERS.
Значение может быть получено с помощью запроса к таблице SDE.ST_GEOMETRY_COLUMNS. Таблица пространственного индекса создается как Oracle Indexed Organized Table (IOT). Пространственный индекс атрибута ST_Geometry выглядит как A<n>_IX1, при просмотре из Enterprise Manager. Значение <n> соответствует LAYER_ID, хранящемуся в таблице LAYERS.
Два дополнительных индекса создаются в таблице S<n>_IDX$: S<n>$_IX1 и S<n>$_IX2. Можно задать способ хранения этих индексов в СУБД с помощью параметра S_STORAGE в ключевом слове конфигурации DBTUNE при создании класса объектов.
Если вы создаете разделяемую бизнес-таблицу, содержащую столбец ST_Geometry, желательно также использовать разделяемый пространственный индекс. Существуют два типа метода разделения: глобальный и локальный. По умолчанию в разделяемой бизнес-таблице создаются глобальные разделяемые индексы. Чтобы создать локальный индекс, необходимо добавить ключевое слово LOCAL в конце выражения CREATE INDEX.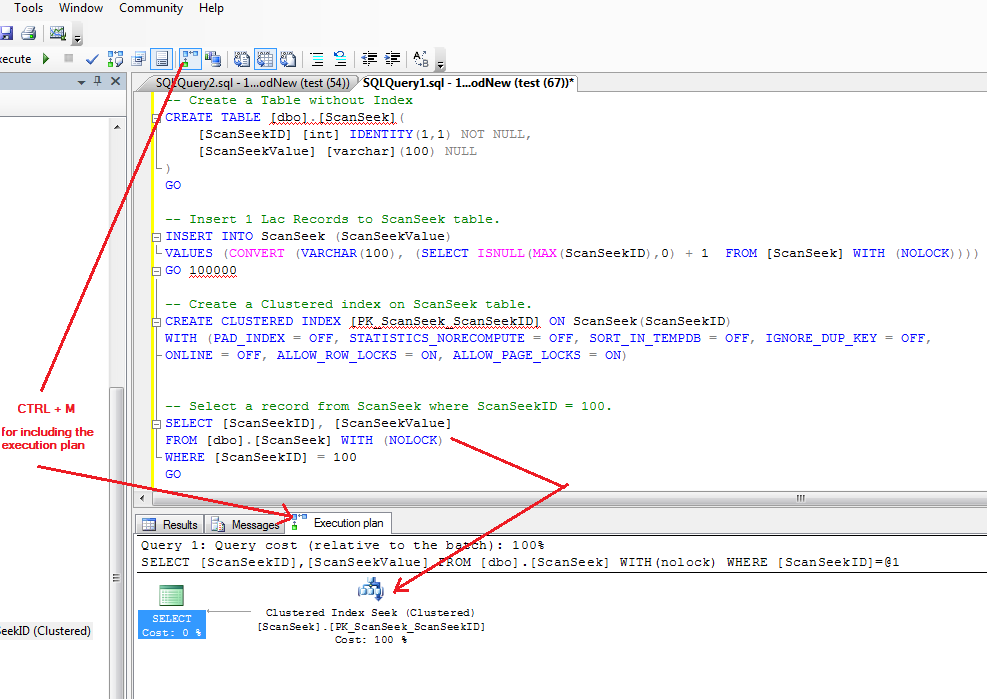 Чтобы разрешить ArcGIS добавить LOCAL в конце выражения CREATE INDEX, задайте параметру ST_INDEX_PARTITION_LOCAL значение TRUE под ключевым словом DEFAULTS.
Чтобы разрешить ArcGIS добавить LOCAL в конце выражения CREATE INDEX, задайте параметру ST_INDEX_PARTITION_LOCAL значение TRUE под ключевым словом DEFAULTS.
PostgreSQL
В PostgreSQL индекс R-tree является встроенным с помощью инфраструктуры модуля Generalized Search Tree, GiST. Более подробная информация об индексировании GiST находится в документации PostgreSQL.
SQLite
Пространственный индекс в SQLite – это набора таблиц, использующийся в качестве индекса R-tree.
IBM DB2 и Informix
Для получения более полной информации о пространственных индексах в DB2 и Informix, обратитесь к документации IBM.
Связанные разделы
индексов — SQL Server | Microsoft Узнайте
Редактировать
Твиттер
Фейсбук
Электронное письмо
- Статья
- 3 минуты на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
База данных SQL Azure
Управляемый экземпляр Azure SQL
Доступные типы индексов
В следующей таблице перечислены типы индексов, доступных в SQL Server, и приведены ссылки на дополнительную информацию.
| Тип указателя | Описание | Дополнительная информация |
|---|---|---|
| Хэш | При использовании хеш-индекса доступ к данным осуществляется через хэш-таблицу в памяти. Хэш-индексы потребляют фиксированный объем памяти, который зависит от количества сегментов. | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Руководство по проектированию хэш-индекса |
| оптимизированный для памяти Некластеризованный | Для оптимизированных для памяти некластеризованных индексов потребление памяти зависит от количества строк и размера ключевых столбцов индекса | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по разработке некластеризованных индексов, оптимизированных для памяти |
| Кластерный | Кластеризованный индекс сортирует и сохраняет строки данных таблицы или представления в порядке, основанном на ключе кластеризованного индекса. Кластеризованный индекс реализован в виде структуры индекса B-дерева, которая поддерживает быстрое извлечение строк на основе их значений ключа кластеризованного индекса. Кластеризованный индекс реализован в виде структуры индекса B-дерева, которая поддерживает быстрое извлечение строк на основе их значений ключа кластеризованного индекса. | Описание кластеризованных и некластеризованных индексов Создание кластеризованных индексов Руководство по проектированию кластеризованных индексов |
| Некластерный | Некластеризованный индекс можно определить для таблицы или представления с кластеризованным индексом или для кучи. Каждая строка индекса в некластеризованном индексе содержит значение некластеризованного ключа и указатель строки. Этот локатор указывает на строку данных в кластеризованном индексе или куче, имеющую значение ключа. Строки в индексе хранятся в порядке значений ключа индекса, но не гарантируется, что строки данных будут располагаться в каком-либо определенном порядке, если для таблицы не создан кластеризованный индекс. | Описание кластеризованных и некластеризованных индексов Создание некластеризованных индексов Рекомендации по проектированию некластеризованных индексов |
| Уникальный | Уникальный индекс гарантирует, что ключ индекса не содержит повторяющихся значений, поэтому каждая строка в таблице или представлении в некотором роде уникальна.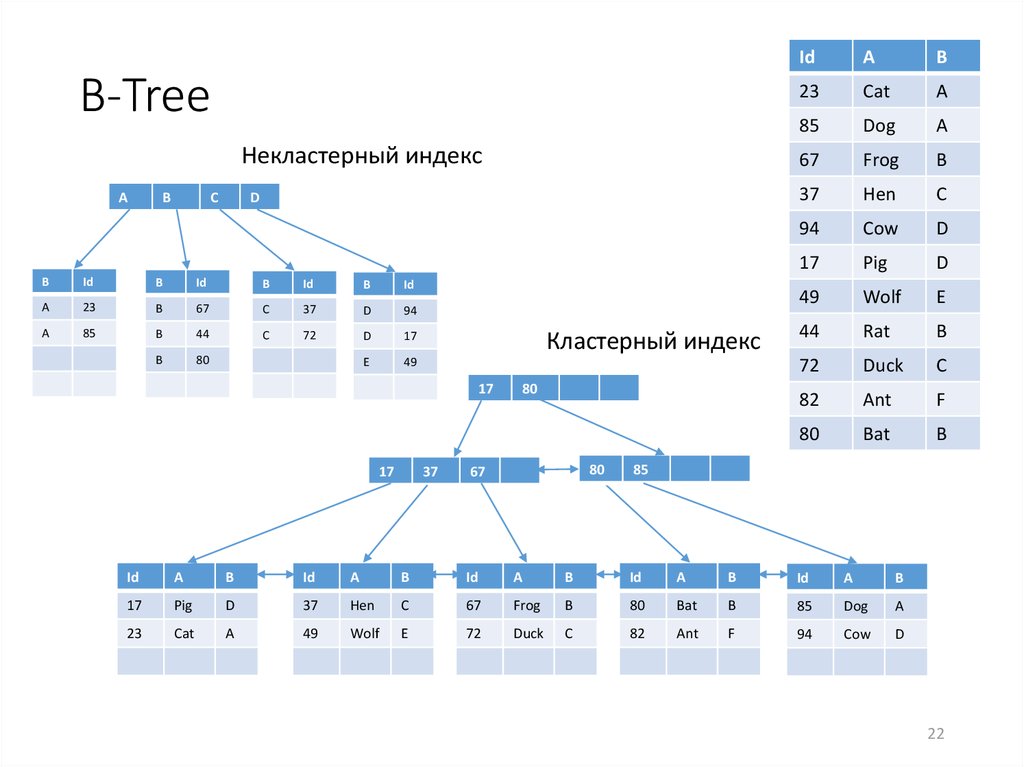 Уникальность может быть свойством как кластеризованных, так и некластеризованных индексов. | Создание уникальных индексов Рекомендации по проектированию уникальных индексов |
| Колонный магазин | Индекс columnstore в памяти хранит данные и управляет ими, используя хранилище данных на основе столбцов и обработку запросов на основе столбцов. Индексы Columnstore хорошо подходят для рабочих нагрузок хранилища данных, которые в основном выполняют массовые загрузки и запросы только для чтения. Используйте индекс columnstore, чтобы получить до 10-кратного увеличения производительности запросов в раз по сравнению с традиционным хранилищем, ориентированным на строки, и до 7-кратного сжатия данных в раз по сравнению с размером несжатых данных. | Руководство по индексам Columnstore Руководство по проектированию индексов Columnstore |
| Указатель с включенными столбцами | Некластеризованный индекс, расширенный за счет включения неключевых столбцов в дополнение к ключевым столбцам. | Создание индексов с включенными столбцами |
| Индекс вычисляемых столбцов | Индекс столбца, полученный из значения одного или нескольких других столбцов или определенных детерминированных входных данных. | Индексы в вычисляемых столбцах |
| Фильтрованный | Оптимизированный некластеризованный индекс, особенно подходящий для покрытия запросов, которые выбираются из четко определенного подмножества данных. Он использует предикат фильтра для индексации части строк в таблице. Хорошо спроектированный отфильтрованный индекс может повысить производительность запросов, снизить затраты на обслуживание индекса и уменьшить затраты на хранение индекса по сравнению с полнотабличными индексами. | Создание отфильтрованных индексов Рекомендации по проектированию отфильтрованных индексов |
| Пространственный | Пространственный индекс позволяет более эффективно выполнять определенные операции над пространственными объектами ( пространственные данные ) в столбце типа данных геометрия . Пространственный индекс уменьшает количество объектов, к которым необходимо применять относительно дорогостоящие пространственные операции. Пространственный индекс уменьшает количество объектов, к которым необходимо применять относительно дорогостоящие пространственные операции. | Обзор пространственных индексов |
| XML | Измельченное и сохраненное представление больших двоичных объектов XML (BLOB) в xml столбец типа данных. | XML-индексы (SQL Server) |
| Полный текст | Специальный тип функционального индекса на основе токенов, который создается и поддерживается полнотекстовым механизмом Microsoft для SQL Server. Он обеспечивает эффективную поддержку сложного поиска слов в данных символьных строк. | Заполнение полнотекстовых индексов |
Примечание
В документации SQL Server термин B-дерево обычно используется в отношении индексов. В индексах rowstore SQL Server реализует дерево B+. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в Руководстве по архитектуре и дизайну индекса SQL Server.
в Руководстве по архитектуре и дизайну индекса SQL Server.
Связанное содержимое
Руководство по проектированию индексов SQL Server
Параметр SORT_IN_TEMPDB для индексов
Отключить индексы и ограничения
Включить индексы и ограничения
Переименовать индексы
Задать параметры индекса для индекса
Руководство по архитектуре страниц и экстентов
Описание кластеризованных и некластеризованных индексов
Обратная связь
Отправить и просмотреть отзыв для
Этот продукт
Эта страница
Просмотреть все отзывы о странице
6 важных типов индексов в SQL Server
Введение
Индекс называется структурой на сервере SQL, хранящейся или поддерживаемой в структуре памяти или на диске, связанной с таблицей или представлениями, которая используется главным образом для распознавания определенный набор или строка таблицы или представления.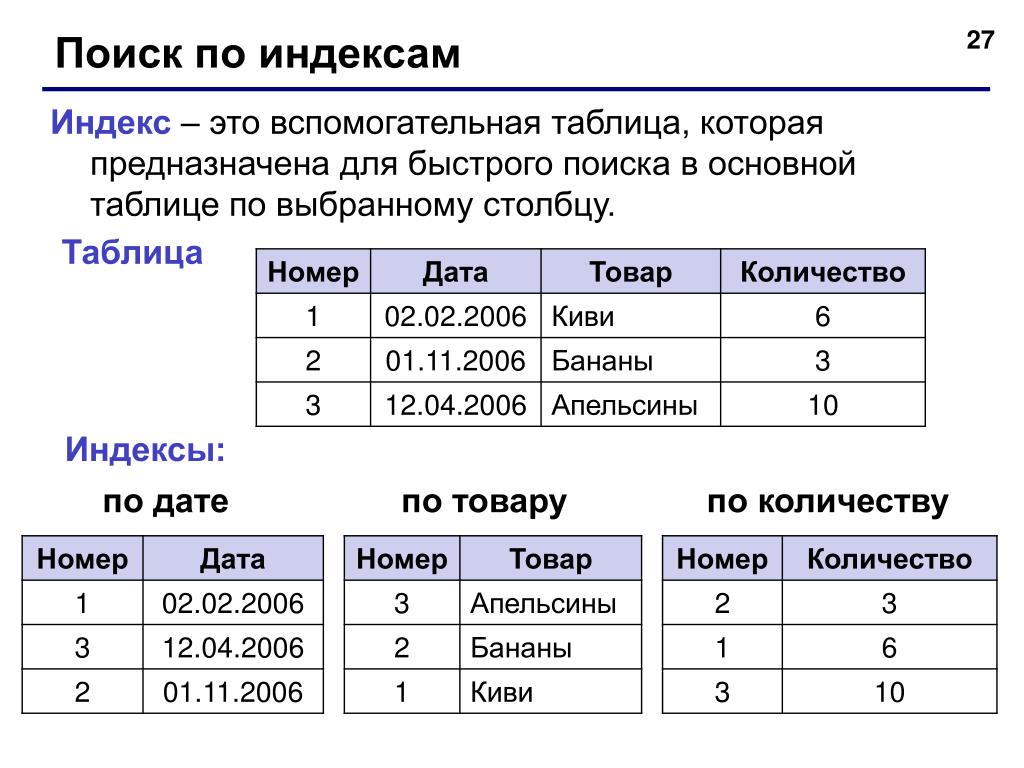 Индексы в SQL — это отдельные таблицы поиска, которые используются поисковиком набора данных в Интернете для ускорения восстановления общей информации.
Индексы в SQL — это отдельные таблицы поиска, которые используются поисковиком набора данных в Интернете для ускорения восстановления общей информации.
Использование индекса в SQL для быстрого обнаружения данных в таблице набора данных без просмотра каждой ее строки. В индексе SQL очень важно иметь дополнительное хранилище, чтобы создать дубликат набора данных. Таблицы на сервере SQL содержатся внутри держателей элементов базы данных, которые называются схемами. Схема также выступает в качестве предела безопасности, где вы можете ограничить авторизацию клиента набора данных на определенном уровне схемы, как это было. Чтобы узнать, какие существуют типы индексов в SQL Server, прочитайте эту статью, чтобы изучить их и лучше понять.
Различные типы индексов в SQL Server
В SQL Server существуют различные типы индексов:
- Кластеризованный индекс
- Некластерный индекс
- Индекс хранилища столбцов
- Отфильтрованный индекс
- Хэш-индекс
- Уникальный индекс
1.
 Кластерный индекс
Кластерный индекс
Кластерный индекс хранит и сортирует строки данных в представлении или таблице в зависимости от их центральных значений. В каждой таблице может быть только один кластеризованный индекс, так как это может дать клиенту возможность хранить данные в одиночном запросе. Кластеризованный индекс хранит данные упорядоченным образом, и таким образом, в какой бы точке данные ни содержались в таблице упорядоченным образом, подразумевается, что они организованы с помощью кластеризованного индекса.
В тот момент, когда таблица содержит кластеризацию на сервере SQL, она называется кластеризованной таблицей. Кластерный индекс рекомендуется использовать, когда в любом наборе данных требуется корректировка гигантской информации. Если данные, помещенные в таблицу или набор данных, не организованы в нисходящем или восходящем запросе, в этот момент таблица данных называется кучей.
2.
Некластеризованный индекс
Представляет собой структуру, изолированную от строк данных. Эти типы индексов в SQL-сервере охватывают некластеризованные значения ключей, и каждая пара значений имеет указатель на строку данных, которая имеет жизненно важное значение.
Эти типы индексов в SQL-сервере охватывают некластеризованные значения ключей, и каждая пара значений имеет указатель на строку данных, которая имеет жизненно важное значение.
В некластеризованном индексе клиент, несомненно, может добавить неключевой элемент на конечный уровень, поскольку он обходит точки отсечения ключа текущего индекса и выполняет полностью покрытые записанные вопросы. Некластеризованный указатель сделан для улучшения общего представления большей части часто задаваемых вопросов, которые не охвачены сгруппированными вещами.
Кластеризованный и некластеризованный индекс в SQL Server заключается в том, что некластеризованный индекс хранит данные в одной области, а индексы — в другой области, тогда как кластеризованный индекс — это своего рода индекс, который сортирует строки данных в таблице по их ключевые значения.
3.
Индекс хранилища столбцов
Индекс хранилища столбцов — это один из типов индексов в SQL Server, который имеет стандартный тип индекса в отношении хранения и проверки огромных таблиц истинности хранилища данных. Это индекс SQL, который был предназначен для развития в представлении запросов в случае заданий с большими объемами данных.
Это индекс SQL, который был предназначен для развития в представлении запросов в случае заданий с большими объемами данных.
Индекс хранилища столбцов позволяет помещать информацию в небольшие показы, что помогает ускорить работу. Использование этого индекса учитывает, что клиент может получить ввод-вывод с многократно более высоким выполнением запроса по сравнению с обычной емкостью, организованной по столбцам. Для проверки индекс Columnstore дает значительную степень, чтобы иметь преимущество над другими записями в SQL. Индексы хранения столбцов из той же области имеют сравнительные качества, что увеличивает общую скорость сжатия данных.
4.
Отфильтрованный индекс
Отфильтрованный индекс — это один из типов индексов на сервере SQL, который создается, когда в столбце есть всего несколько подходящих номеров для вопросов по подмножеству значений. Если, когда таблица содержит разнородные строки данных, в SQL составляется отдельный список хотя бы для одного вида данных.
5.
Хэш-индекс
Хэш-индекс — это один из типов индексов в SQL-сервере, который содержит указатель или массив из N сегментов и строку в каждом слоте или сегменте. Он использует хэш-функцию F (K, N), где N — несколько сегментов, а K — критическое значение. Емкость определяет ключ, относящийся к корзине хеш-индекса. Каждое ведро хэш-индекса состоит из восьми байтов, которые используются для хранения адреса памяти подключенного набора основных разделов.
6.
Уникальный индекс
Уникальный индекс на сервере SQL подтверждает и гарантирует, что ключ индекса не содержит каких-либо копий, и в соответствии с этим дает клиентам возможность проверять, что каждая строка в таблице является исключительной в в любом случае.
Уникальный индекс в SQL чрезвычайно используется, когда клиенту нужно иметь исключительную характеристику каждой информации. Это позволяет людям гарантировать респектабельность данных каждого охарактеризованного раздела таблицы в наборе данных. Этот индекс также дает дополнительные данные о таблице данных, которые полезны для опроса энхансеров.
Этот индекс также дает дополнительные данные о таблице данных, которые полезны для опроса энхансеров.
Типы страниц в SQL Server
- Страницы данных
- Массовое изменение карты
- страниц текста/изображений
- Страница Свободное место
- Карта размещения индексов
- Вторичная глобальная карта распределения
- Дифференциальная измененная карта
- Карта глобального распределения
Типы базы данных на сервере SQL
- tempdb
- msdb
- Мастер
- Модель
Заключение
Для создания индекса в операторе SQL используется для создания файлов в таблицах. Индексы используются для более быстрого восстановления информации из набора данных, чем что-либо еще. Клиенты не могут видеть списки, они просто используются для ускорения запросов/поисков.
Индекс — это ключ, работающий хотя бы с одного столбца в информационной базе, который ускоряет получение строк из представления или таблицы.