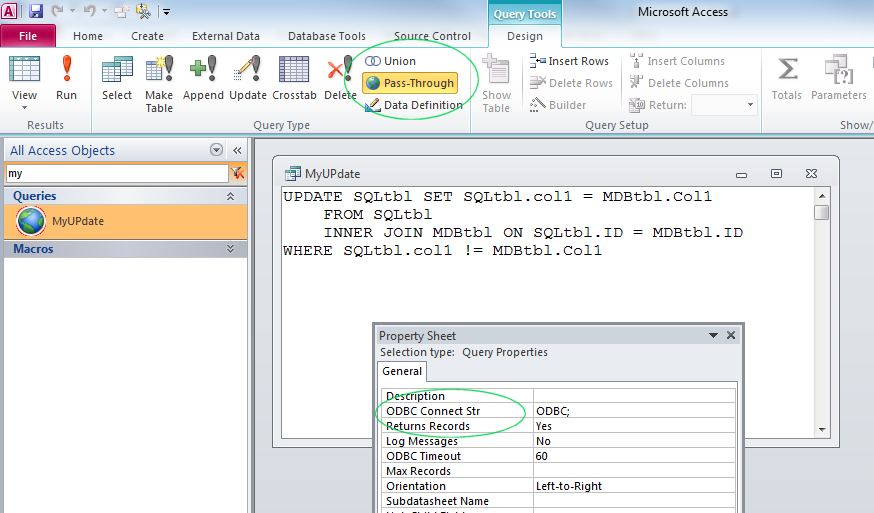
Sql insert несколько строк: примеры вставки строк в таблицу БД MySQL
Содержание
Как вывести по N строк из каждой группы?
Моисеенко С.И. (23-05-2009)
Такой вопрос возникает, например, когда на сайте требуется вывести по 3 самых свежих анонса в каждой новостной группе, или рекламу 5 самых популярных товаров в каждой категории.
Чтобы решить эту задачу, нужно выполнить разбиение всего набора строк на группы, произвести сортировку по требуемому критерию (по дате или количеству продаж) в пределах каждой группы и последовательно выбрать требуемое количество строк, начиная с первой строки в каждой группе.
Подобную задачу можно решать процедурно, используя временные таблицы и/или курсоры. Здесь же я хочу предложить два решения в стиле тех задач, которые мы решаем на сайте, т.е. одним запросом SELECT. Первое решение — «классическое», которое должно работать на большинстве СУБД; второе решение использует новые конструкции, которые появились в стандарте SQL:1999 и поддерживаются еще не так широко.
Рассмотрим следующую задачу:
Вывести из таблицы Product по три модели с наименьшими номерами из каждой группы, характеризуемой типом продукции.
Т.е. требует получить 3 компьютера, 3 ноутбука и 3 принтера, номера которых меньше номеров остальных моделей в своей группе. Поскольку номер модели является уникальным в таблице Product, то тут не возникает проблем с дубликатами. Заметим, что проблема дубликатов не является принципиальной, однако потребует уточнения формулировки.
«Классическое» решение
Это решение опирается на алгоритм нумерации строк, возвращаемых запросом. Т.е. мы нумеруем строки, а потом выбираем те их них, которые имеют номера, меньшие заданного числа. Следуя упомянутому алгоритму, запрос, который нумерует упорядоченный по возрастанию номера модели весь набор строк в таблице, можно записать так:
SELECT Pr1.model, COUNT(*) num FROM Product Pr1 JOIN Product Pr2 ON Pr1.model >= Pr2.model GROUP BY Pr1.model
Только для решения нашей задачи нужно пронумеровать не весь набор, а каждую группу в отдельности. Этого легко добиться, если в условие соединения таблиц добавить условие совпадения типов продукции, а также добавить группировку по типу:
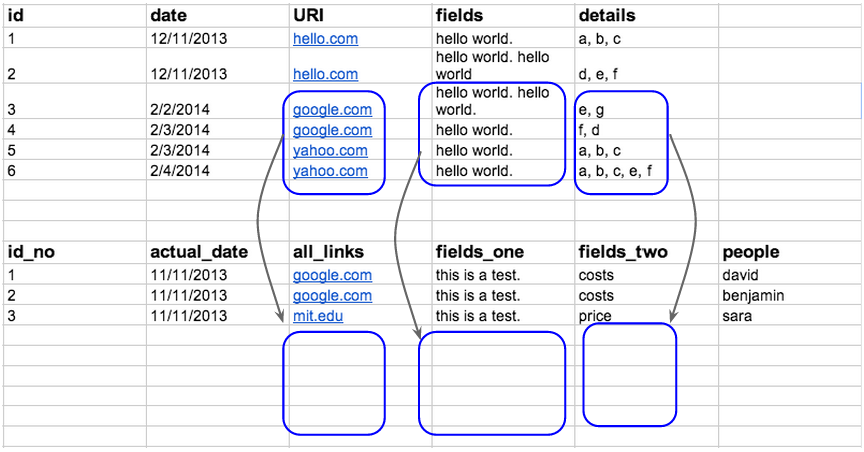
SELECT Pr1.model, Pr1.type, COUNT(*) num FROM Product Pr1 JOIN Product Pr2 ON Pr1.type = Pr2.type AND Pr1.model >= Pr2.model GROUP BY Pr1.type, Pr1.model HAVING COUNT (*) <= 3 ORDER BY type, model
 model, Pr1.type, COUNT(*) num
FROM Product Pr1 JOIN Product Pr2
ON Pr1.type = Pr2.type AND Pr1.model >= Pr2.model
GROUP BY Pr1.type, Pr1.model
HAVING COUNT (*) <= 3
ORDER BY type, model
model, Pr1.type, COUNT(*) num
FROM Product Pr1 JOIN Product Pr2
ON Pr1.type = Pr2.type AND Pr1.model >= Pr2.model
GROUP BY Pr1.type, Pr1.model
HAVING COUNT (*) <= 3
ORDER BY type, model
Предложение
HAVING COUNT (*) < = 3
в соответствии с условием задачи ограничивает тремя количество строк в каждой группе. Фактически мы уже решили задачу. Осталось лишь добавить производителя (maker), что также можно сделать разными способами. Например, еще раз соединить по номеру модели приведенный выше запрос с таблицей Product, или использовать коррелирующий подзапрос в предложении SELECT. В учебных целях приведу оба подхода.
1. Соединение
SELECT maker, X.model, X.type
FROM product JOIN (
SELECT Pr1.model, Pr1.type
FROM Product Pr1 JOIN Product Pr2
ON Pr1.type = Pr2.type AND Pr1.model >= Pr2.model
GROUP BY Pr1.type, Pr1.model
HAVING COUNT (*) <= 3
) X on X.model = product.model
ORDER BY type,model
Здесь мы исключили лишний столбец num, который использовался в демонстрационных целях, поскольку нам не требуется выводить номер строки.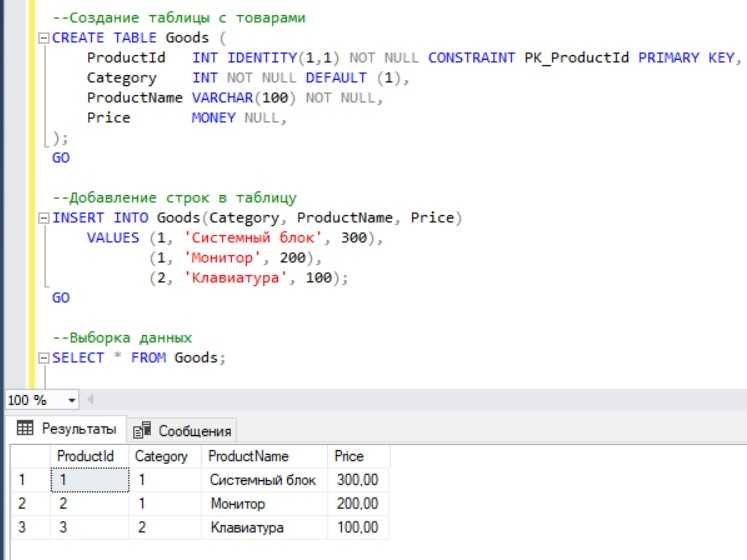
2. Подзапрос в предложении SELECT
SELECT (SELECT maker FROM Product WHERE Product.model = Pr1.model) maker, Pr1.model, Pr1.type FROM product Pr1 JOIN product Pr2 ON Pr1.type = Pr2.type AND Pr1.model >= Pr2.model GROUP BY Pr1.type, Pr1.model HAVING COUNT (*) <= 3 ORDER BY type,model
Использование подзапроса в предложении SELECT допускается, если он возвращает всего одно значение для каждой строки основного запроса. Это условие у нас выполняется, т.к. мы выбираем производителя модели, которая передается из основного запроса и является уникальной (первичный ключ в таблице Product).
Решение на основе ранжирующих функций
Ранжирующие функции — ROW_NUMBER, RANK, DENSE_RANK и NTILE появились в составе SQL Server, начиная с версии 2005. Их появление в языке SQL было вызвано потребностью выполнять упорядоченные вычисления. Собственно, наше упражнение как раз и относится к этому классу задач. И теперь у нас есть возможность оценить данное приобретение.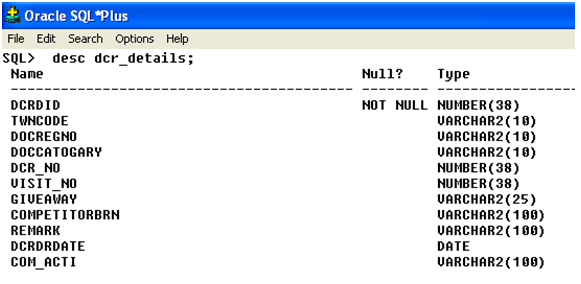 :
:
Для решения нашей задачи воспользуемся функцией RANK. Эта функция позволяет разбить все строки, возвращаемые запросом, на группы и вычислить ранг каждой строки в группе в соответствии заданной сортировкой. Поскольку мы будем сортировать по уникальному номеру модели, то ранг фактически будет совпадать с номером строки в группе. Итак, решение
SELECT maker, model, type FROM ( SELECT maker, model, type, RANK() OVER(PARTITION BY type ORDER BY model) num FROM Product ) X WHERE num <= 3
Собственно, все делается в подзапросе. Внешний запрос служит лишь для того, чтобы ограничить выборку тремя моделями по каждой группе. Говоря другими словами, мы оставляем только те строки, у которых ранг не превышает трех.
Экономно, не так ли. Однако давайте разберем более детально конструкцию
RANK() OVER(PARTITION BY type ORDER BY model)
Предложение PARTITION BY type формирует группы; в одну группу у нас попадают строки, имеющий один и тот же тип продукции (одно и то же значение в столбце type).
Предложение ORDER BY model задает сортировку строк в группе (по возрастанию номера модели).
Наконец, RANK() присваивает ранг каждой строке в группе на основе заданной сортировки, т.е. первая строка в группе получает ранг 1, следующая, если она имеет отличный номер модели, ранг 2 и т.д. Как я уже сказал, поскольку номер модели уникальный, то каждая строка в группе будет иметь отличный ранг. В противном случае, строки с одинаковым номером модели имели бы одинаковый ранг.
Подробное описание функций ранжирования выходит за рамки данной статьи, но, возможно, я напишу нечто подобное для Учебника по SQL.
Dzone.com
Цикл WHILE для выбора данных за период в T-SQL — Разработка на vc.ru
Зачастую в нашей работе возникает потребность получить набор данных за определенный период. Сделать это можно несколькими способами. В этой статье рассмотрим применение цикла WHILE для задачи поиска расходных операций за несколько месяцев по перечню счетов и сравним его с запросом, в котором весь период будет указан в блоке WHERE.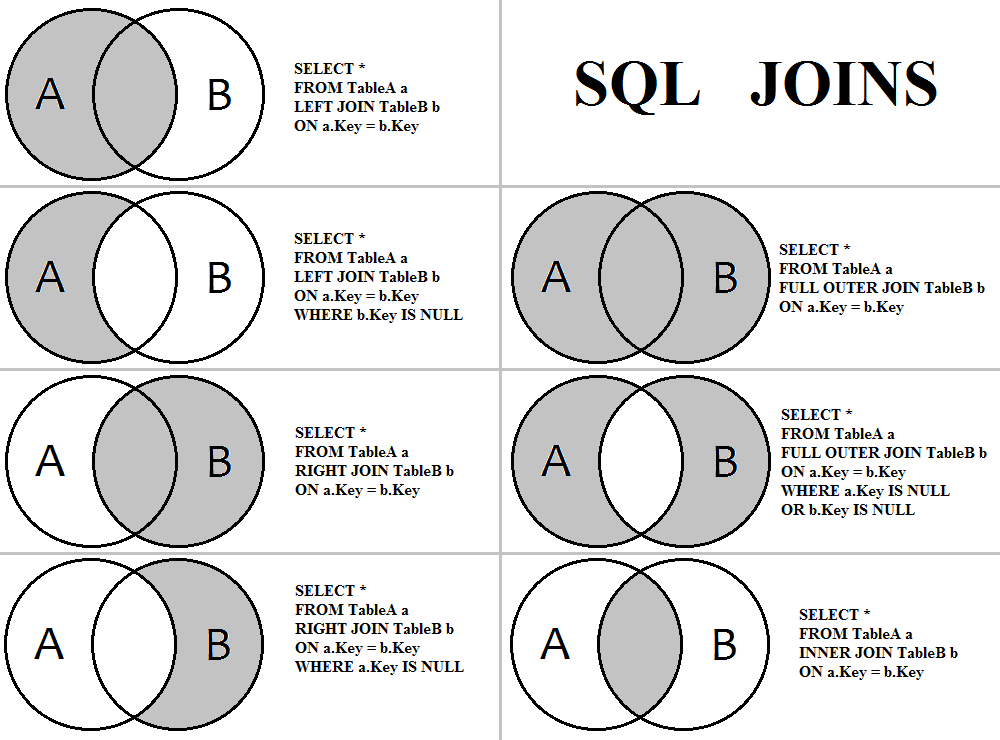
6252
просмотров
Зачастую в нашей работе возникает потребность получить набор данных за определенный период. Сделать это можно несколькими способами. В этой статье рассмотрим применение цикла WHILE для задачи поиска расходных операций за несколько месяцев по перечню счетов и сравним его с запросом, в котором весь период будет указан в блоке WHERE.
Для начала разберем синтаксис конструкции WHILE. Выглядит он следующим образом:
WHILE [логическое условие]
BEGIN
[инструкция]
END
В блоке Условие находится выражение, возвращающее значение TRUE или FALSE, в блоке Инструкций будет находиться наш запрос на выбор необходимого набора данных. Блок инструкций необходимо «ограничить» словами управления BEGIN и END.
Теперь рассмотрим на примере применение цикла WHILE и сравним его с простым запросом. Для начала создадим таблицы для перечня счетов (1000 счетов с движением средств), результатов простого запроса и результатов цикла WHILE.
CREATE TABLE [TB44_SANDBOX].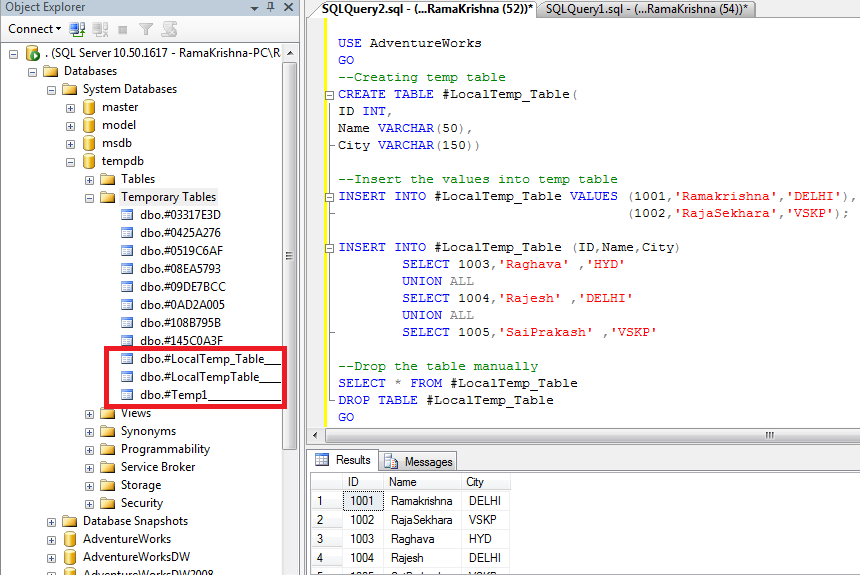 [mis].[depohist_test_accounts]
[mis].[depohist_test_accounts]
(
[account_nbr] nvarchar(255)
) ON [PRIMARY] WITH (DATA_COMPRESSION = PAGE)
GO
CREATE TABLE [TB44_SANDBOX].[mis].[depohist_test_query]
(
[DEPOHIST_ID_MAJOR] bigint
,[DEPOHIST_ID_MINOR] bigint
,[DEPOHIST_ID_MEGA] bigint
,[DEPOSIT_ID_MAJOR] bigint
,[DEPOSIT_ID_MINOR] bigint
,[DEPOSIT_ID_MEGA] bigint
,[PERSON_ID_MAJOR] bigint
,[PERSON_ID_MINOR] bigint
,[PERSON_ID_MEGA] bigint
) ON [PRIMARY] WITH (DATA_COMPRESSION = PAGE)
GO
CREATE TABLE [TB44_SANDBOX].[mis].[depohist_test_while]
(
[DEPOHIST_ID_MAJOR] bigint
,[DEPOHIST_ID_MINOR] bigint
,[DEPOHIST_ID_MEGA] bigint
,[DEPOSIT_ID_MAJOR] bigint
,[DEPOSIT_ID_MINOR] bigint
,[DEPOSIT_ID_MEGA] bigint
,[PERSON_ID_MAJOR] bigint
,[PERSON_ID_MINOR] bigint
,[PERSON_ID_MEGA] bigint
) ON [PRIMARY] WITH (DATA_COMPRESSION = PAGE)
GO
Информация об операциях в нашем случае хранится в [backoffice_STG].[deposit].[VW_depohist], где созданы индексы на номер счета ([deposit_printableno]) и дату операции ([depohist_OpDay]). Далее напишем запрос на выборку и вставку данных с указанием всего периода в блоке WHERE.
Далее напишем запрос на выборку и вставку данных с указанием всего периода в блоке WHERE.
INSERT INTO [TB44_SANDBOX].[mis].[depohist_test_query]
SELECT
[dh].[DEPOHIST_ID_MAJOR]
,[dh].[DEPOHIST_ID_MINOR]
,[dh].[DEPOHIST_ID_MEGA]
,[dh].[DEPOSIT_ID_MAJOR]
,[dh].[DEPOSIT_ID_MINOR]
,[dh].[DEPOSIT_ID_MEGA]
,[dh].[PERSON_ID_MAJOR]
,[dh].[PERSON_ID_MINOR]
,[dh].[PERSON_ID_MEGA]
FROM
[BACKOFFICE_STG].[DEPOSIT].[VW_DEPOHIST] AS [dh] WITH(NOLOCK)
INNER JOIN [TB44_SANDBOX].[mis].[depohist_test_accounts] AS [t] WITH(NOLOCK)
ON [dh].[DEPOSIT_PRINTABLENO] = [t].[account_nbr]
WHERE
[dh].[DEPOHIST_OpCash] < 0
AND [dh].[DEPOHIST_OpDay] >= ‘2020-01-01’
AND [dh].[DEPOHIST_OpDay] < ‘2020-03-01’
Данный запрос выполнялся около полутора минут и вставил в таблицу 1606 строк.
Теперь напишем запрос с использованием цикла WHILE.
DECLARE @startdate date = ‘2020-01-01’
DECLARE @enddate date = ‘2020-03-01’
WHILE @startdate < @enddate
BEGIN
INSERT INTO [TB44_SANDBOX]. [mis].[depohist_test_while]
[mis].[depohist_test_while]
SELECT
[dh].[DEPOHIST_ID_MAJOR]
,[dh].[DEPOHIST_ID_MINOR]
,[dh].[DEPOHIST_ID_MEGA]
,[dh].[DEPOSIT_ID_MAJOR]
,[dh].[DEPOSIT_ID_MINOR]
,[dh].[DEPOSIT_ID_MEGA]
,[dh].[PERSON_ID_MAJOR]
,[dh].[PERSON_ID_MINOR]
,[dh].[PERSON_ID_MEGA]
FROM
[BACKOFFICE_STG].[DEPOSIT].[VW_DEPOHIST] AS [dh] WITH(NOLOCK)
INNER JOIN [TB44_SANDBOX].[mis].[depohist_test_accounts] AS [t] WITH(NOLOCK)
ON [dh].[DEPOSIT_PRINTABLENO] = [t].[account_nbr]
WHERE
[dh].[DEPOHIST_OpCash] < 0
AND [dh].[DEPOHIST_OpDay] = @startdate
SET @startdate = DATEADD(DAY, 1, @startdate)
END
В начале определяем две переменные, в которых будет находится необходимый период. Далее логическое условие выполнения цикла – дата начала периода строго меньше даты окончания периода. В теле цикла между словами управления BEGIN и END наш запрос на выборку и вставку данных. Обратите внимание, что вместо периода для столбца [dh].[depohist_OpDay] мы указываем конкретное значение, которое содержит переменная @startdate. После запроса мы присваиваем нашей переменной новое значение в +1 день от текущего значения с помощью функции dateadd(), чтобы перейти на следующий шаг выполнения цикла.
После запроса мы присваиваем нашей переменной новое значение в +1 день от текущего значения с помощью функции dateadd(), чтобы перейти на следующий шаг выполнения цикла.
Таким образом наш цикл будет выполняться пока значение переменной @startdate не станет равным значению @enddate, и на каждом шаге цикла будет выполняться запрос на выборку данных за конкретную дату.
Теперь запустим этот запрос и сравним его результаты с предыдущим.
На вкладке «Сообщения» будет несколько строк, которые соответствуют выполненному запросу на каждом шаге цикла. Запрос с использованием цикла выполнялся 35 секунд и вставил в таблицу те же 1606 строк.
Данный способ позволяет быстрее получить необходимые данные, так как при каждом выполнении будет использоваться индекс на дату, и, если в результате выполнения запроса случится какая-либо ошибка, сохранить результат ранее отработанных шагов цикла.
Вставка нескольких строк в таблицу SQL с использованием Excel в качестве шаблона
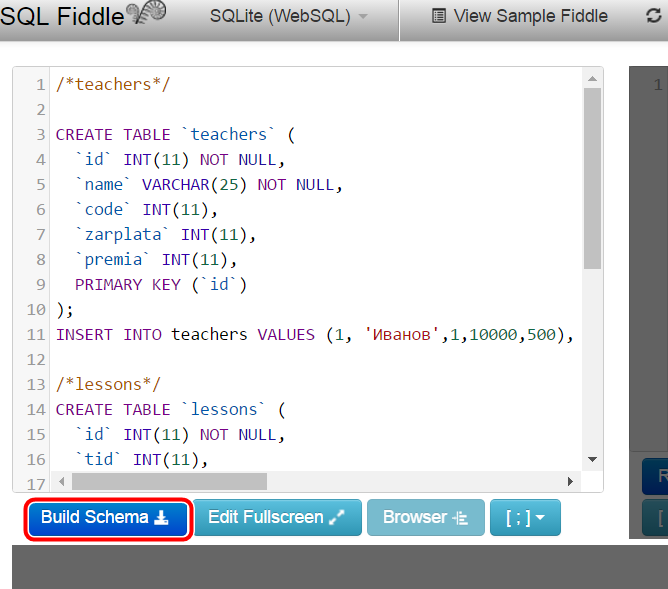
Надеюсь, вы следовали предыдущему руководству, где мы проверили Создали несколько новых таблиц базы данных, используя Excel в качестве шаблона.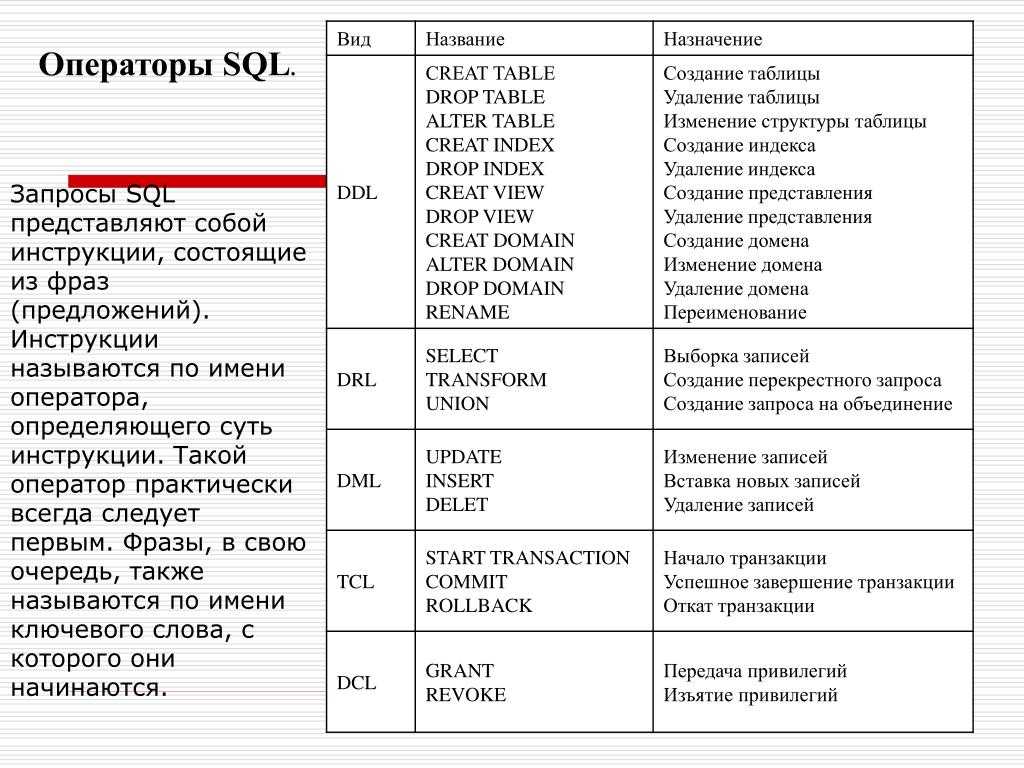
Давайте заполним эти таблицы значимыми данными. Хорошо, это может быть не самый значимый набор данных, поскольку я только что создал эти данные с помощью Mockaroo.com. (Отличный сайт для создания образцов данных «на лету».)
В этом упражнении используйте данные из трех таблиц Excel для заполнения таблиц в Microsoft SQL Server.
Мы предоставили образцы данных, чтобы вам было проще следовать моим шаблонам или полностью украсть их и создавать собственные плавные SQL-запросы.
Вот образцы наших столов.
Экспертная таблица – Хранит идентификатор, имя и день рождения наших экспертов
Таблица технологий Эксперты владеют
Давайте заполним нашу первую таблицу, используя вкладку «Вставка заявления 1» из примера рабочего листа. Вот наш шаблон.
Строка зеленого цвета предназначена только для маркировки.
Чтобы увидеть, что происходит, переключитесь на представление формулы, сочетание клавиш (CTRL + `).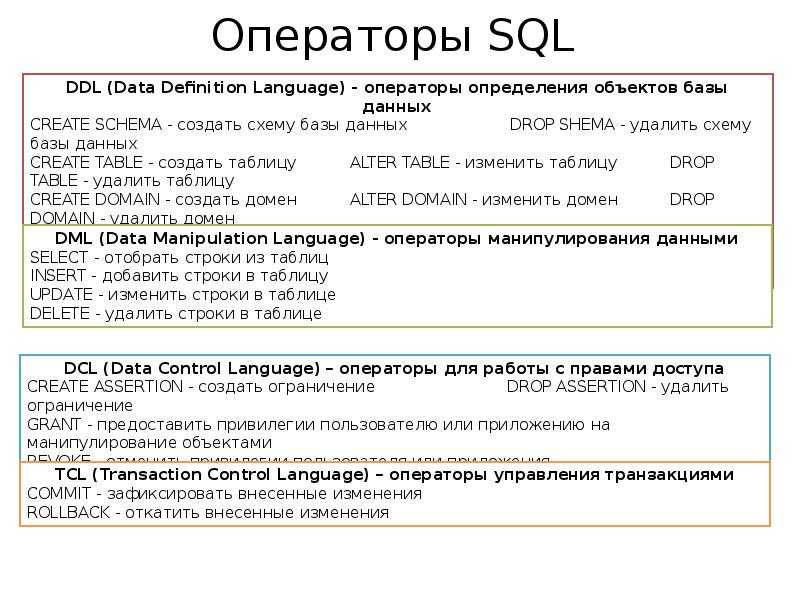
Преимущество использования Excel для форматирования заключается в том, что вам нужно настроить только один столбец данных, а затем вы можете перетащить формулу в конец набора данных.
Форматирование строки 5, строки 6 и ниже различается, поскольку строка 5 содержит заголовки, а шестая и ниже содержит импортированную информацию.
Вторая половина таблицы вставки
Обратите внимание, что эти поля метаданных также имеют разный формат.
Столбец N готов к вырезанию и вставке в Microsoft SQL Server.
Прежде чем вырезать и вставлять, вы заслуживаете объяснения того, что только что произошло.
Для лучшего понимания следуйте примерам данных.
Наша первая вкладка, вкладка «исходные данные», — это то, что мы хотим загрузить. Вкладка «Вставить выписку 1» выполняет следующие задачи:
- Вызывает значения ячеек из Исходных данных — Сначала, используя кавычки и символы &, мы форматируем каждый фрагмент данных, готовый к загрузке.
- Форматирование их как строки для нашей загрузки SQL — Затем мы используем формулу Concat, чтобы соединить все вместе.
Наш полезный друг, метаданные
Как упоминалось ранее, три столбца являются метаданными:
- Изменено — отслеживает последнего человека, редактировавшего столбец
- Timestamp — отслеживает дату последнего редактирования столбца
- Rowversion — это поле используется несколькими способами. Сохраняйте повторяющиеся строки и полагайтесь на последнюю версию строки, чтобы указать самую новую запись, или замените старые строки, и пусть версия строки сигнализирует, сколько раз эта строка была изменена.
Теперь разместите этот сценарий в MSSQL и запустите эту присоску.
Сценарии формулируемых выражений вставки Excel в Microsoft SQL
После успешного выполнения запроса в окне сообщения отображается 20 обновленных строк.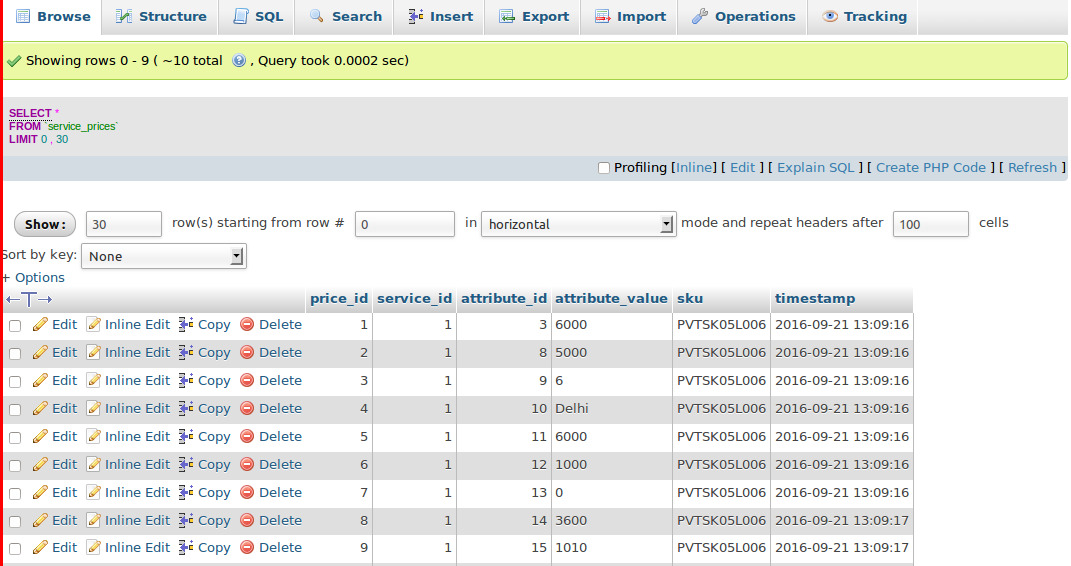
Поскольку первые сценарии отработаны, попробуйте тот же процесс с двумя другими сценариями вставки.
Таблица 2 Загружено.
Таблица 3 Загружено.
Проверьте свою работу
Пришло время перепроверить наши результаты.
Используйте сценарии ниже, чтобы проверить первые три результата из каждой таблицы, потому что мы не хотим просматривать каждую строку!
В этих сценариях используются подзапросы, что более интересно для дальнейшего обсуждения.
– Получить первые 3 записи для каждой из вновь созданных таблиц ГДЕ Exp_TECH_ID IN (ВЫБЕРИТЕ ТОП 3 Exp_TECH_ID ИЗ testExpert.dbo.experttech)
ВЫБЕРИТЕ * ИЗ testExpert.dbo.technology
ГДЕ Technology_ID В (ВЫБЕРИТЕ ТОП 3 Technology_ID ИЗ testExpert.dbo.technology)
Мы только что выполнили вставку нескольких строк в SQL с использованием шаблона Excel.
Продолжайте и начинайте осторожно вставлять записи в некоторые таблицы.
Можно вставлять операторы по одному.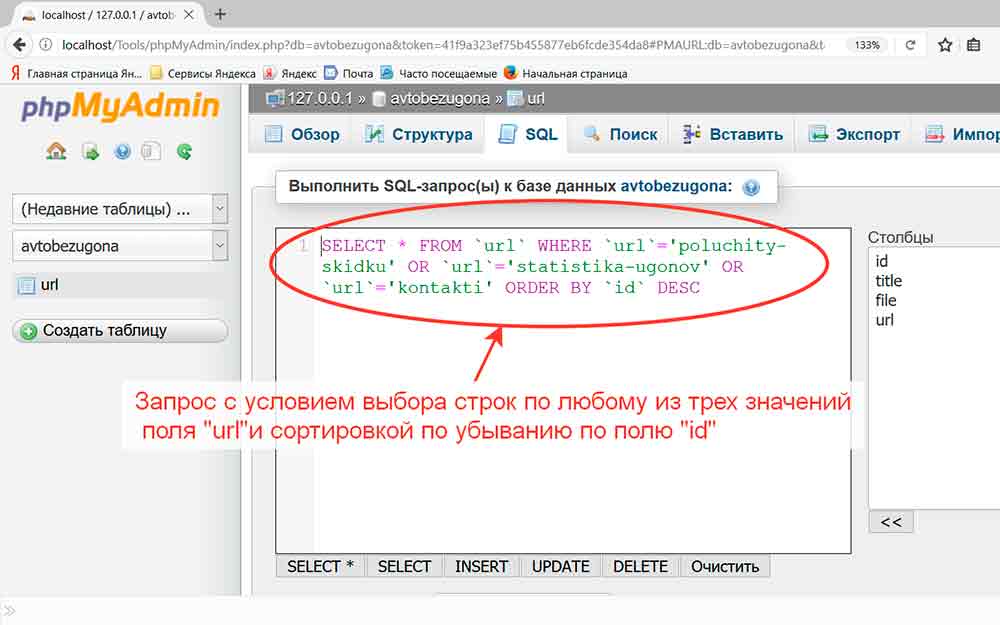 Особенно, если вы хотите играть очень безопасно. Обсудим в следующий раз.
Особенно, если вы хотите играть очень безопасно. Обсудим в следующий раз.
Вставка нескольких строк в таблицу SQL Server
Информационный бюллетень сообщества за апрель 2023 г.
Добро пожаловать в наш Информационный бюллетень сообщества за апрель 2023 г., где мы будем освещать последние новости, выпуски, предстоящие события и отличную работу наших участников в Biz. Сообщества приложений. Вы можете подписаться на новости и объявления и быть в курсе последних новостей из нашей постоянно растущей сети участников, которые быстро обнаруживают, что «Сообщество больше внутри».
ПОСЛЕДНИЕ НОВОСТИ
Мероприятие по запуску бизнес-приложений Microsoft — по запросу
Зарегистрируйтесь ниже, чтобы подробно ознакомиться с последними обновлениями Microsoft #PowerPlatform и #Dynamics365. Узнайте о новых функциях, возможностях и передовых методах подключения данных для обеспечения исключительного качества обслуживания клиентов, совместной работы с использованием аналитики на основе ИИ и повышения производительности с помощью автоматизации. Среди приглашенных докладчиков — Чарльз Ламанна, Эмили Хе, Георг Гланчниг, Джули Штраус, Джефф Комсток, Лори Ламкин, Майк Мортон, Рэй Смит и Уолтер Сан.
Среди приглашенных докладчиков — Чарльз Ламанна, Эмили Хе, Георг Гланчниг, Джули Штраус, Джефф Комсток, Лори Ламкин, Майк Мортон, Рэй Смит и Уолтер Сан.
Смотреть сейчас: мероприятие по запуску бизнес-приложений
Соединения с силовой платформой — Эпизод девятый
Сегодня в 12:00 по тихоокеанскому стандартному времени состоится премьера девятого эпизода #PowerPlatform Connections, когда Дэвид Уорнер II и Хьюго Бернье беседуют с главным менеджером программы Весой Ювонен, а также замечательные работы Троя Тейлора, Гиты Сивасайлам, Майкла Мегеля, Натали Лендерс, Ритеша Ранджана Чуби, Клэя Везенера. , Тристан ДЕХОВ, Дайан Тейлор и Кэт Шнайдер.
Нажмите на ссылку ниже, чтобы подписаться и получать уведомления, с Дэвидом и Хьюго LIVE в чате YouTube с 12:00 по тихоокеанскому времени. И не забудьте использовать хэштег #PowerPlatformConnects в социальных сетях, чтобы ваша работа была представлена на шоу!
Приложение за день — Бесплатный семинар
Ищете способ создать решение для быстрого удовлетворения потребностей вашего бизнеса? Зарегистрируйтесь ниже, чтобы принять участие в БЕСПЛАТНОМ семинаре «Приложение за день», чтобы узнать, как создавать собственные бизнес-приложения без написания кода!
Семинары Microsoft Power Platform за один день
ПРЕДСТОЯЩИЕ СОБЫТИЯ
Направления Азия
Узнайте больше о конференции Directions 4 Partners Asia 2023, которая пройдет в Бангкоке 27–28 апреля 2023 года с участием ключевых спикеров Майка Мортона, Янника Баусагера и Дмитрия Чадаева.
Это мероприятие предназначено для партнеров Dynamics, ориентированных на малый и средний бизнес, и их сотрудников, чтобы получить знания о продуктах Business Central, Power Platform и #DynamicsSales, а также вдохновиться и мотивироваться передовым опытом, экспертными знаниями и инновационными идеями.
Если вы хотите встретиться с отраслевыми экспертами, получить преимущество на рынке малого и среднего бизнеса и получить новые знания о #MicrosoftDynamics Business Central, нажмите на ссылку ниже, чтобы купить билет сегодня!
Нажмите здесь, чтобы зарегистрироваться
Иберийский технический саммит
Приходите посмотреть на Иберийский технологический саммит, который пройдет в отеле Real Marina Hotel & Spa в Ольяне, Португалия, с 28 по 30 апреля 2023 года.
Иберийский технологический саммит является первым в своем роде с четкой целью — пересечь границы полуострова и помочь сообществу профессионалов, рабочих и предприятий стать сильнее вместе.
Поздравляем Кайлу Блумфилд, Адама Б., Ану Инес Уррутиа де Соуза и всю команду за организацию этого замечательного мероприятия.