Sql оконные функции: Оконные функции SQL простым языком с примерами / Хабр
Содержание
Оконные функции SQL
Нет более обманчивого раздела SQL, чем «оконные функции». Когда слышишь эти слова, думаешь «наверно, просто придумали какие-то дополнительные функции». А вот и нет! «Оконные функции» — это отдельный язык, встроенный в обычный SQL. И он сложнее, чем все, что вы знали о «селектах», вместе взятое.
Если вкратце — оконные функции помогают делать классные аналитические отчеты без участия «экселя». Хотите посчитать процент продаж по месяцам от общих продаж за год? Оконные функции. Разделить маркетинговые каналы на эффективные и неэффективные? Оконные функции. Выбрать топ-10 клиентов по каждому сегменту? Тоже они.
Я прочитал несколько десятков статей «для начинающих», которые объясняли, что такое оконные функции. Все они страдали от одной из двух проблем:
- Все понятно, но описано 10% возможностей «окошек».
- Написано так сложно, что если бы я уже не знал предмет обсуждения — ничего бы не понял.
Если не разобраться в запросах с «окошками», выглядят они как-то так
Я решил исправить ситуацию и подготовил интерактивный курс об оконных функциях SQL.
О курсе
Это понятное и наглядное введение в оконные функции. Понятное, потому что я умею доходчиво писать о сложных темах. Наглядное — потому что подготовил сотню картинок и пятьдесят упражнений, которые помогут глубоко понять «окошки».
Оконные функции — реально сложная тема. Поэтому курс не пытается объять необъятное, и объясняет их шаг за шагом. А еще на курсе много практики — потому что только с ней абстрактные знания превратятся в навыки.
Пошаговое изложение и иллюстрации облегчают непростой материал. Пятьдесят шесть интерактивных упражнений помогут освоить оконные функции на практике.
Курс можно использовать с любой из следующих СУБД:
- MySQL 8.0.2+ (MariaDB 10.2+)
- PostgreSQL 11+
- SQLite 3.28+
- MS SQL 2012+
- Oracle 11g+
Записаться на курс
Чему вы научитесь
Зачем нужны оконные функции
Часть 1. Окна и функции
- Ранжирование
- Смещение
- Агрегация
- Скользящие агрегаты
- Статистика
Часть 2.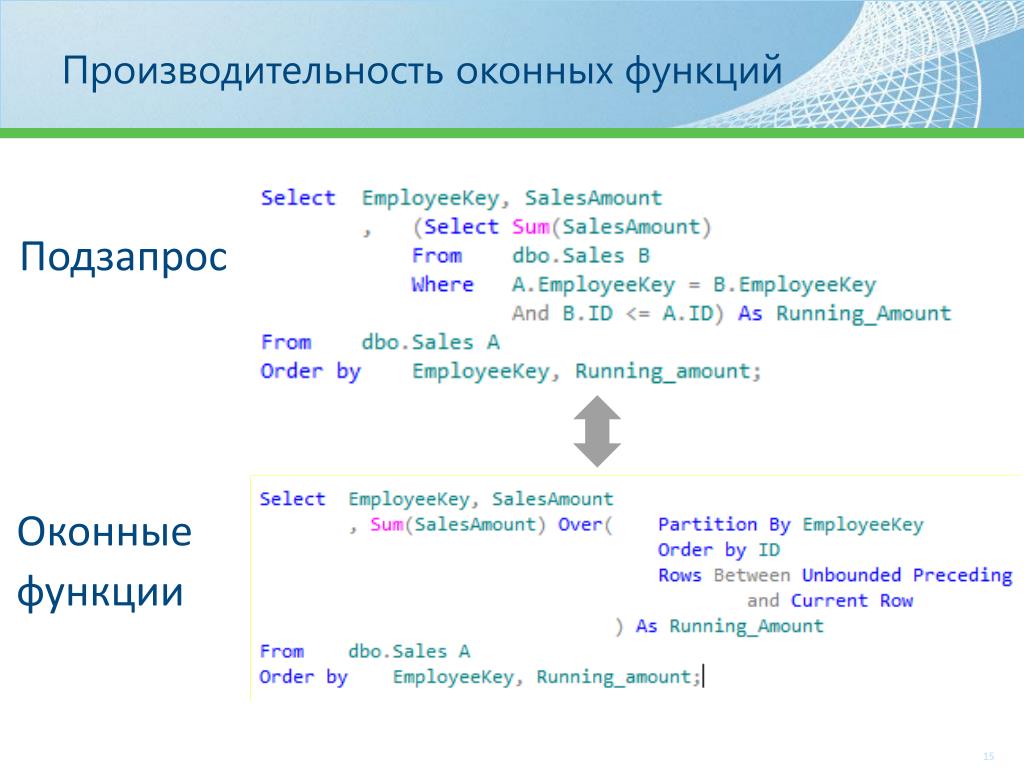 Фреймы
Фреймы
- ROWS и GROUPS
- RANGE
- EXCLUDE
- FILTER
Часть 3. Практика
- Финансы
- Кластеризация
- Очистка данных
Каждая глава подробно раскрывает одну темуПодробное содержание
Введение
О курсе
Зачем нужны оконные функции
Песочница
Часть 1. Окна и функции
Ранжирование
- Оконная функция
- Сортировка окна и сортировка результатов
- Однозначность сортировки
- Несколько окон
- Секции окна
- Группы
- Функции ранжирования
Смещение
- Сравнение с соседями
- Сравнение с границами
- Окно, секция, фрейм
- Сравнение с границами, окончание
- Функции смещения
Агрегация
- Агрегат по секции
- Фильтрация и порядок выполнения
- Описание окна
- Функции агрегации
Скользящие агрегаты
- Скользящее среднее
- Фрейм
- Сумма нарастающим итогом
- Фрейм по умолчанию
- Функции для скользящих агрегатов
Статистика
- Кумулятивное распределение
- Относительный ранг
- Сводные значения
- Процентили в SQL
- Процентиль как оконная функция
- Статистические функции
Резюме
Часть 2. Фреймы
Фреймы
ROWS и GROUPS
- ROWS-фреймы
- GROUPS-фреймы
RANGE
- RANGE-фреймы
- Особенности диапазонов
- Границы фрейма
- Фрейм по умолчанию
- Частые вопросы о фреймах
EXCLUDE
- Исключение строк
- Виды исключений
FILTER
- Фильтрация строк
- CASE как альтернатива FILTER
Резюме
Часть 3. Практика
Финансы
- Сначала агрегация, затем окна
- Сначала окна, затем отсев
- Агрегация и null
- Выручка по тарифу gold
- Выручка по тарифам за 1 квартал
- Скользящее среднее по тарифу platinum
- Сравнение с декабрем
- Вклад тарифов
- Высокая, средняя и низкая выручка
- 2020 vs 2019
- Рейтинг месяцев по продажам
Кластеризация
- Идентифицируем острова
- Острова с дублями
- Острова на датах
- Кластеры значений
- Кластеры на датах
Очистка данных
- Дубли
- Пропуски
- Предыдущее непустое значение
- Выбросы
Финал
Курс начинается с основ «окошек» (часть 1), погружается в нюансы фреймов (часть 2) и заканчивает довольно продвинутыми приемами (часть 3).
Первые четыре урока (без задач) доступны по ссылкам в оглавлении выше.
Об авторе
Я Антон Жиянов, Python/Golang разработчик и энтузиаст SQLite. Работаю над опенсорсом, веду курсы и блог.
В 2021 я запустил курс по оконным функциям SQL. Сейчас у него больше 1000 выпускников и 340 отзывов со средним рейтингом 5 звезд.
Записаться на курс
Подписывайтесь на канал, чтобы не пропустить новые заметки 🚀
ABAP Blog | Оконные функции в ABAP
Начиная с версии ABAP 7.54 в ABAP SQL появились так называемые оконные выражения. Оконные выражения — SQL выражения определяемые с помощью дополнения OVER в запросе, позволяют определить окна, как подмножества итогового результата запроса и выполнять над ним оконные функции.
Оконные функции можно сравнить с агрегатными функциями, но, в отличие от обычной агрегатной функции, при использовании оконной функции несколько строк не группируются в одну, а продолжают существовать отдельно. При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле.
При этом результаты работы оконных функций просто добавляются к результирующей выборке как еще одно поле.
Оконные функции являются частью стандарта SQL и даже если версия языка не позволит вам использовать их непосредственно в ABAP, всегда можно воспользоваться Native SQL (Так, по одной из задач, применение оконной функции внутри AMDP позволило ускорить работу запроса в десятки раз).
Далее на небольших примерах рассмотрим основные оконные функции и то, как с ними работать.
Синтаксис
Описание синтаксиса тут и далее взято из последней доступной версии ABAP — 7.55
Общий синтаксис оконного выражения выглядит следующим образом:
1 2 3 4 5 6 7 8 9 10 11 | … win_func OVER( [PARTITION sql_exp1, sql_exp2 …] [ORDER BY col1 [ASCENDING|DESCENDING], col2 [ASCENDING|DESCENDING] [ROWS BETWEEN {UNBOUNDED PRECEDING} |{CURRENT ROW} |{(n) PRECEDING} |{(n) FOLLOWING} AND {UNBOUNDED FOLLOWING} |{CURRENT ROW} |{(n) PRECEDING} |{(n) FOLLOWING}]] ) . |
 ..
..Оконное выражение состоит из оконной функции, за которой следует дополнение OVER, в круглых скобках которого определяется окно в общем наборе результатов (или подмножество), для которого отрабатывает оконная функция. Внутри окна опционально можно указать:
- PARTITION BY sql_exp1, sql_exp2 … Определяет перечень столбцов для группировки. Можно использовать все SQL выражения доступные в ABAP SQL за исключением оконных и агрегатных функций. Если оставить данный раздел пустым, будет обработан весь набор данных запроса.
- ORDER BY. Определяет как порядок сортировки, так и ограничения над набором данных в окне. Является обязательным для некоторых оконных функций ранжирования/смещения.
Если оконное выражение используется как поле выбора в запросе с группировкой GROUP BY, окна вычисляются над объединённым набором результатов, а результаты агрегатных функций этого запроса могут быть аргументами оконной функции.
Как и с общими табличными выражениями, они поддерживаются не на всех СУБД, проверку можно выполнить через класс CL_ABAP_DBFEATURES:
1 2 3 4 5 6 7 8 | IF cl_abap_dbfeatures=>use_features( EXPORTING requested_features = VALUE #( ( cl_abap_dbfeatures=>windowing ) ) ). … ELSE. … ENDIF. |
Win_func определяет оконную функцию:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | … AVG( col [AS dtype] ) | MEDIAN( sql_exp ) | MAX( sql_exp ) | MIN( sql_exp ) | SUM( sql_exp ) | STDDEV( sql_exp ) | VAR( sql_exp ) | CORR( sql_exp1,sql_exp2 ) | CORR_SPEARMAN( sql_exp,sql_exp2 ) | COUNT( sql_exp ) | COUNT( * ) | COUNT(*) | ROW_NUMBER( ) | RANK( ) | DENSE_RANK( ) | NTILE( n ) | LEAD|LAG( sql_exp1[, diff[, sql_exp2]] ) | FIRST_VALUE|LAST_VALUE( col ) . |
 ..
..Оконные функции могут быть трёх видов:
- Агрегатные: AVG, MIN, MAX, SUM и др.,
- Функции ранжирования: ROW_NUMBER, RANK и др.,
- Функции смещения или функции значений (value functions): LEAD, LAG и др,
- Аналитические функции: PERCENT_RANK, CUME_DIST и др., пока не представлены в ABAP.
Данные для тестирования
В качестве тестовых данных будем рассматривать стандартную таблицу SFLIGHT и следующий набор данных:
Агрегатные функции
В следующем примере посчитаем максимальную сумму оплаты PAYMENTSUM в разрезе авиакомпаний и рейсов:
1 2 3 4 5 6 7 | SELECT DISTINCT carrid, connid, MAX( paymentsum ) OVER( PARTITION BY carrid, connid ) AS max_sum FROM sflight ORDER BY carrid, connid INTO TABLE @DATA(lt_sflight). |

Результат:
Тут следует еще раз обратить внимание на то, что оконные функции не занимаются группировкой набора данных основного запроса, а формируют значение поля max_sum для каждой строки и чтобы взять только уникальные значения, мы задействовали в основном запросе DISTINCT.
В противном случае получили мы максимальную сумму по всем строкам основного запроса:
При выполнении оконной функции с помощью дополнения PARTITION BY мы определили группу, в рамках которой формируются окна, в рамках каждого из окна идёт расчёт максимального значения.
Аналогичным образом мы можем посчитать суммы по всем рейсам:
1 2 3 4 5 6 7 8 9 | SELECT DISTINCT carrid, connid, sum( paymentsum ) OVER( PARTITION BY carrid, connid ) AS total_sum FROM sflight ORDER BY carrid, connid INTO TABLE @DATA(lt_sflight). |

Результат:
Используя агрегатные оконные функции, без указания ORDER BY подсчёт идёт один раз для всего окна (в функциях ранжирования выполняется расчёт для каждой строки, несмотря на пустой ORDER BY). Однако, если указать ORDER BY подсчёт в каждой строке будет осуществляться c учётом сортировки по каждой уникальной записи. Таким образом мы можем рассчитывать например какой-нибудь нарастающий итог.
Исходный набор данных по авиакомпании AZ:
Выполним по этой авиакомпании следующий запрос:
1 2 3 4 5 6 7 8 9 10 | SELECT carrid, fldate, sum( paymentsum ) OVER( PARTITION BY carrid ORDER BY carrid, fldate ) AS balance FROM sflight WHERE carrid = ‘AZ’ ORDER BY carrid, fldate INTO TABLE @DATA(lt_sflight). |

В данном примере мы сделали окно по авиакомпании, где для каждой новой даты рассчитали баланс по сумме — PAYMENTSUM, т.е. для каждой строки с уникальной датой посчитали итог от начала окна до текущей в обработке строки. Получили нарастающий итог по каждой дате.
Кстати, оконные функции можно использовать сразу по несколько штук и они не мешают выполнению друг друга:
1 2 3 4 5 6 7 8 9 10 11 | SELECT DISTINCT carrid, fldate, sum( paymentsum ) OVER( PARTITION BY carrid ORDER BY carrid, fldate ) AS balance, sum( paymentsum ) OVER( PARTITION BY carrid ) AS total FROM sflight ORDER BY carrid, fldate INTO TABLE @DATA(lt_sflight). |
В результате получим:
Ранжирующие функции
Ранжирующие функции – это функции, которые ранжируют значение для каждой строки в окне. Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
Например, их можно использовать для того, чтобы присвоить порядковый номер строке или составить рейтинг.
- ROW_NUMBER – функция возвращает номер строки и используется для нумерации;
- RANK — функция возвращает ранг каждой строки. В данном случае значения уже анализируются и, в случае нахождения одинаковых, возвращает одинаковый ранг с пропуском следующего значения;
- DENSE_RANK — функция возвращает ранг каждой строки. Но в отличие от функции RANK, она для одинаковых значений возвращает ранг, не пропуская следующий;
В качестве самой простой задачи, мы можем выбрать все уникальные коды авиакомпаний и пронумеровать их по порядку:
1 2 3 4 5 6 | SELECT carrid, ROW_NUMBER( ) OVER( ORDER BY carrid ) AS row_number FROM sflight GROUP BY carrid ORDER BY row_number INTO TABLE @DATA(lt_sflight). |

Результат:
Порядок нумерации может быть изменён как внутри окна, так и относительно результата оконной функции:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | SELECT carrid, ROW_NUMBER( ) OVER( ORDER BY carrid DESCENDING ) AS row_number FROM sflight GROUP BY carrid ORDER BY carrid INTO TABLE @DATA(lt_sflight).
» Тоже самое что и:
* SELECT carrid, * ROW_NUMBER( ) OVER( ORDER BY carrid ) AS row_number * FROM sflight * GROUP BY carrid * ORDER BY row_number DESCENDING * INTO TABLE @DATA(lt_sflight). |
Усложним пример, добавив в оконную функцию ограничение по коду авиакомпании:
1 2 3 4 5 6 7 8 9 | SELECT carrid, connid, ROW_NUMBER( ) OVER( PARTITION BY carrid ) AS row_number FROM sflight GROUP BY carrid, connid ORDER BY carrid, row_number INTO TABLE @DATA(lt_sflight). |

Результат:
В данном примере мы добавили ограничение окна на поле CARRID, таким образом оконная функция подсчёта строк работает уже над тремя подмножествами запроса по трём имеющимся авиакомпаниям, где для каждой авиакомпании ведёт нумерацию рейсов.
Результат работы оконной функции невозможно отфильтровать в запросе с помощью WHERE, потому что оконные функции выполняются после всей фильтрации и группировки, т.е. с тем, что получилось. Соответственно нельзя добавить в WHERE row_number = 2 и выбрать только вторые строки. Но можно воспользоваться общими табличными выражениями:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | WITH +window_result AS ( SELECT carrid, connid, ROW_NUMBER( ) OVER( PARTITION BY carrid ORDER BY carrid, connid ) AS row_number FROM sflight GROUP BY carrid, connid ORDER BY carrid, connid ) SELECT * FROM +window_result WHERE row_number = 2 INTO TABLE @DATA(lt_sflight). |

В результате получим только строку где row_number = 2.
Прочие ранжирующие функции можно рассмотреть на примере:
1 2 3 4 5 6 7 8 9 10 11 12 | SELECT carrid, fldate, ROW_NUMBER( ) OVER( PARTITION BY carrid ORDER BY fldate ) AS row_number, RANK( ) OVER( PARTITION BY carrid ORDER BY fldate ) AS rank, DENSE_RANK( ) OVER( PARTITION BY carrid ORDER BY fldate ) AS dense_rank FROM sflight ORDER BY carrid, fldate INTO TABLE @DATA(lt_sflight). |
row_number — в рамках каждой авиакомпании выставляет номер строки, rank — выставляет ранг строки (для повторяющихся fldate он одинаковый) с увеличением счётчика, dense_rank — аналогичен rank( ) но без увеличения счётчика.
Функции смещения (функции значений)
Функции смещения – это функции, которые позволяют перемещаться и обращаться к разным строкам в окне, относительно текущей строки, а также обращаться к значениям в начале или в конце окна.
- LEAD – функция обращается к данным из следующей строки набора данных. Ее можно использовать, например, для того чтобы сравнить текущее значение строки со следующим.
- LAG – функция обращается к данным из предыдущей строки набора данных. В данном случае функцию можно использовать для того, чтобы сравнить текущее значение строки с предыдущим.
Рассмотрим простой пример:
1 2 3 4 5 6 7 8 9 10 | SELECT carrid, fldate, LAG( fldate ) OVER( PARTITION BY carrid ORDER BY fldate ) AS lag_date, LEAD( fldate, 2 ) OVER( PARTITION BY carrid ORDER BY fldate ) AS lead_date FROM sflight ORDER BY carrid, fldate INTO TABLE @DATA(lt_sflight). |
В результате получим:
Как видно из примера, для строк с функцией LAG предыдущая строка для первых строк в окне недоступна, значение будет NULL, по при преобразовании к ABAP типу вернётся начальное значение для даты.
Для функции LEAD мы использовали дополнение, указывающее на число строк, которые необходимо пропустить после текущей для получения значения (по умолчанию 1). Соответственно для двух последних строк в каждом окне значение даты определить не удалось.
Ограничения строк
Начиная с версии ABAP 7.55 появилась дополнительная возможность ограничивать строки обрабатываемые в рамках окна, задавая так называемый фрейм (или рамку). Фрейм определяется относительно текущей строки окна, что позволяет ему перемещаться одновременно с расчётом строк внутри окна. Каждый фрейм имеет начальную и конечную границу, существует три варианта определения границ фрейма:
- {UNBOUNDED PRECEDING}/{UNBOUNDED FOLLOWING}
- UNBOUNDED PRECEDING начальная граница фрейма определяется начальной строкой окна.


- UNBOUNDED FOLLOWING определяет конечную границу фрейма, как последнюю строку окна.
- CURRENT ROW может определять как конечную, так и начальную границу фрейма (в зависимости от комбинации другими ключевыми словами). .
- {(n) PRECEDING}/{(n) FOLLOWING}
- (n) PRECEDING может использоваться для определения начала и конца фрейма. Определяет что фрейм начинается или заканчивается до N строк относительно текущей строки.
- (n) FOLLOWING может использоваться для определения начала и конца фрейма. Определяет что фрейм начинается или заканчивается после N строк относительно текущей строки.
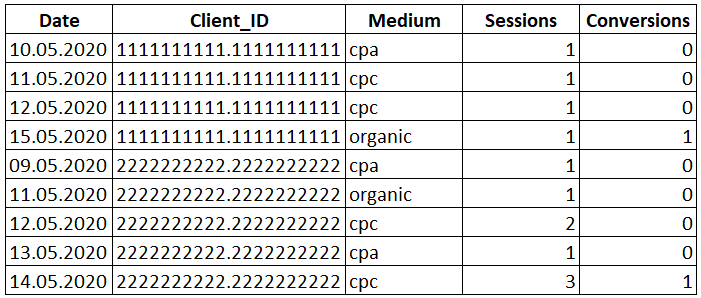
Т.к. версии 7.55 под рукой у меня нет (Docker образ ABAP Platform 2020 еще в работе :)), рассмотрим пример из сети:
SELECT Date, Medium, Conversions, SUM(Conversions) OVER( PARTITION BY Date ORDER BY Conversions ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING ) AS ‘Sum’ FROM Orders. |

Границы фрейма определены от текущей строки до следующей за ней.
В данном случае сумма рассчитывается по текущей и следующей ячейке в окне. А последняя строка в окне имеет то же значение, что и столбец «Conversions», потому что больше не с чем складывать. Комбинируя ключевые слова, вы можете подогнать диапазон работы оконной функции под вашу специфическую задачу.
Благодаря таким ограничениям можно легко находить скользящие средние значения, определяя сколько следующих строк фрейма следует учитывать в агрегатной функции AVG.
В стандарте SQL кроме выражения ROWS есть так же дополнение RANGE которое пока не представлено в ABAP. Предложение RANGE предназначено также для ограничения набора строк. В отличие от ROWS, оно работает не с физическими строками, а с диапазоном строк в предложении ORDER BY. Это означает, что одинаковые по рангу строки в контексте предложения ORDER BY будут считаться как одна текущая строка для функции CURRENT ROW. Более подробно можете ознакомиться в этом материале.
Более подробно можете ознакомиться в этом материале.
Топ-5 самых популярных оконных функций и способы их использования
Команда данных в Mode любит SQL. Мы программируем его, пишем об этом и даем возможность людям использовать его по всему миру. Итак, в этом ключе мы подумали, что было бы забавно использовать немного SQL для анализа SQL! Тем не менее, мы не верим в анализ ради анализа, поэтому мы провели небольшое исследование, чтобы помочь нашим читателям лучше понять один из самых мощных инструментов SQL — оконные функции.
Что такое оконная функция?
Мы собираемся позаимствовать определение PostgreSQL:
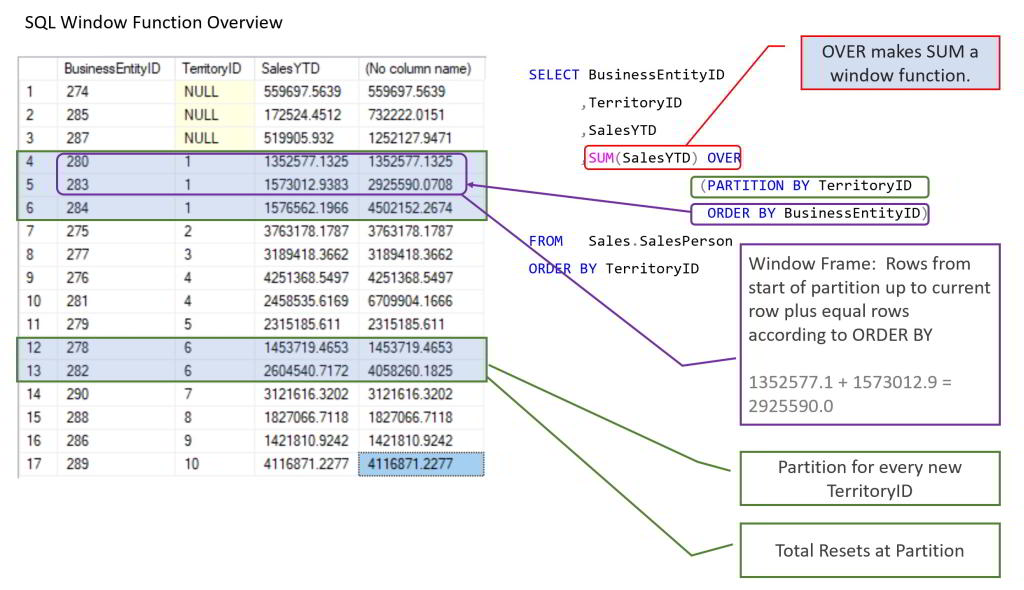
«Оконная функция выполняет вычисление в наборе строк таблицы, которые так или иначе связаны с текущей строкой. Это сравнимо с типом вычисления, которое можно выполнить с помощью агрегата Но в отличие от обычных агрегатных функций использование оконной функции не приводит к группированию строк в одну строку вывода — строки сохраняют свои отдельные идентификаторы. За кулисами оконная функция может получить доступ не только к текущей строке результата запроса».
За кулисами оконная функция может получить доступ не только к текущей строке результата запроса».
Тем, кто не знаком с концепцией оконных функций, я рекомендую перед тем, как двигаться дальше, ознакомиться с руководством по режиму на эту тему.
Итак, нам было любопытно понять, какие оконные функции используются чаще всего, поэтому мы встроили окно (каламбур вместо ) в использование нашими клиентами этих типов вычислений.
Мы создали набор данных всех запросов, созданных с 1 января 2019 года, и использовали магию регулярных выражений для извлечения оконных функций. Затем мы подсчитали использование каждой оконной функции в нашем наборе данных и определили наиболее часто используемые.
На приведенной ниже диаграмме показан процент использования всех оконных функций, приходящийся на пять наиболее часто используемых оконных функций.
Учитывая, что это наиболее часто используемые оконные функции, мы подумали, что будет полезно предоставить примеры их использования — как для новичков в SQL, так и для таких пользователей SQL, как я, которые иногда забывают немного синтаксиса.
1. Sum
Одним из наиболее распространенных случаев использования оконной функции SUM является вычисление текущей суммы. Давайте рассмотрим пример:
SELECT o.occurred_at,
SUM(o.gloss_qty) OVER(ORDER BY o.occurred_at) как running_gloss_orders
ОТ demo.orders o
Чтобы разобрать здесь синтаксис, SUM(o.gloss_qty) определяет агрегацию — мы возьмем сумму gloss_qty . Далее, предложение OVER(ORDER BY o.occurred_at) сообщает вашему движку SQL, что он должен идти построчно и брать сумму каждой записи gloss_qty в порядке произошел_в до строки, которую он сейчас просматривает. .
Мы также можем создавать отдельные текущие суммы для разных групп в нашем наборе данных, добавляя PARTITION BY как показано ниже:
SELECT o.occurred_at,
о.account_id,
SUM(o.gloss_qty) OVER(PARTITION BY o.account_id
ORDER BY o.occurred_at) как running_gloss_orders
ОТ demo. orders o
 orders o
orders o
2. Номер строки
Ах, номер строки. Это моя любимая оконная функция. Обычно я использую ROW_NUMBER , когда хочу вернуть самую последнюю запись таблицы, с которой работаю. ROW_NUMBER просто возвращает номер данной строки, начиная с 1, которая является первой записью, как определено ЗАКАЗАТЬ . Здесь не нужно указывать переменную в скобках!
С
order_ranks как (
ВЫБЕРИТЕ идентификатор,
о.account_id,
o.gloss_qty,
о.gloss_amt_usd,
ROW_NUMBER() OVER(РАЗДЕЛ ПО o.account_id
ORDER BY o.occurred_at DESC) как acct_order_rank
ОТ demo.orders o
)
ВЫБИРАТЬ *
ОТ order_ranks
ГДЕ acct_order_rank = 1
Обратите внимание на DESC в ORDER BY — это указывает механизму SQL упорядочивать строки по произошло_в в порядке убывания (т. е. последняя запись первой). Приведенный выше запрос возвращает самую последнюю запись в таблице заказов для каждой учетной записи. Этот запрос также использует CTE (если это иностранная концепция, прочитайте наш последний пост о них).
Этот запрос также использует CTE (если это иностранная концепция, прочитайте наш последний пост о них).
3. Dense Rank
DENSE_RANK работает аналогично ROW_NUMBER , но отличается тем, как он обрабатывает случаи, когда две строки для поля, указанного в вашем ORDER BY , имеют одинаковых значений . DENSE_RANK назначит строкам с одинаковыми значениями ORDER_BY одинаковый номер, тогда как ROW_NUMBER создаст различные значения.
ВЫБЕРИТЕ идентификатор,
о.account_id,
DATE_TRUNC('день',o.occurred_at) как наступил_день,
o.gloss_qty,
о.gloss_amt_usd,
DENSE_RANK() OVER(РАЗДЕЛ ПО o.account_id
ЗАКАЗАТЬ ПО DATE_TRUNC('день',o.occurred_at)) в плотном_ранге
ОТ demo.orders o
Вы можете видеть в результатах ниже, что 2-я и 3-я строки имеют одинаковые плотное_ранг значение 2. Да, и вы заметите, что оконная функция выше использует значение, полученное из другой функции SQL DATE_TRUNC — вложение функций SQL внутри оконной функции является честной игрой.
4. Отставание
Функция LAG является любимой среди любителей временных рядов. Эта функция позволяет сравнивать строку с любой из предшествующих ей строк. Так, например, если вы хотите узнать, как один заказ gloss_qty сравнивается с предыдущими заказами, используйте эту функцию.
ВЫБЕРИТЕ идентификатор,
o.occurred_at,
o.gloss_qty,
LAG(gloss_qty,1) OVER(ORDER BY o.occurred_at) as order_lag_1,
LAG(gloss_qty,2) OVER(ORDER BY o.occurred_at) as order_lag_2,
LAG(gloss_qty,3) OVER(ORDER BY o.occurred_at) as order_lag_3
ОТ demo.orders o
Имейте в виду, что первые n строк ваших данных будут NULL (где n — указанное вами количество «задержек»). Вы можете увидеть это в результатах нашего запроса:
5. Max
И, наконец, мы можем завершить этот список MAX . MAX работает так же, как SUM , поэтому я собираюсь оживить пример более сложным синтаксисом. Допустим, я хочу посмотреть, как текущий заказ соотносится с наибольшим количеством заказа среди предыдущих 5 заказов на
Допустим, я хочу посмотреть, как текущий заказ соотносится с наибольшим количеством заказа среди предыдущих 5 заказов на gloss_qty . Мы можем сделать это, добавив дополнительный синтаксис в наше предложение ORDER BY .
ВЫБЕРИТЕ идентификатор,
o.occurred_at,
o.gloss_qty,
MAX(gloss_qty) OVER(ЗАКАЗ ПО o.occurred_at
РЯДЫ МЕЖДУ 5 ПРЕДШЕСТВУЮЩИМИ И 1 ПРЕДЫДУЩИМИ) as max_order
ОТ demo.orders o
После того, как мы указываем поле для сортировки, мы добавляем определение размера нашего окна: РЯД МЕЖДУ 5 ПРЕДЫДУЩИМИ И 1 ПРЕДЫДУЩЕЙ . Этот пункт, по сути, говорит: «Оглянитесь на предыдущие 5 заказов (не включая текущий заказ) и возьмите максимальное значение».
Этот синтаксис является гибким и может определять любое окно в вашем наборе данных. Синтаксис обычно выглядит так:
ORDER BY [order_var] ROWS BETWEEN window_start AND window_end
где window_start и window_end принимают одно из следующих значений:
-
UNBOUNDED PRECEDING(т. е. все строки перед текущей строкой) -
[ЗНАЧЕНИЕ] ПРЕДШЕСТВУЮЩИЙ(где [ЗНАЧЕНИЕ] = количество строк после текущей строки для рассмотрения) -
ТЕКУЩАЯ РЯДКА -
[ЗНАЧЕНИЕ] ПОСЛЕ(где [ЗНАЧЕНИЕ] = количество строк перед текущей строкой для рассмотрения) -
UNBOUNDED FOLLOWING(т. е. все строки после текущей строки)
 е. все строки перед текущей строкой)
е. все строки перед текущей строкой)Оконные функции — невероятно мощные инструменты, обеспечивающие быстрый и гибкий анализ в контексте редактора SQL. Теперь найдите свою любимую оконную функцию и проанализируйте!
Оконные функции в Python и SQL
Для аналитика или специалиста по данным становится все более полезным иметь глубокое понимание нескольких аналитических языков программирования. Растет число людей, использующих SQL и Python в гибридной манере для анализа данных. Но диалог об использовании этих двух языков имеет тенденцию изображать их как взаимодополняющие, но функционально обособленные.
В этом диалоге не рассматривается значительный средний уровень общей функциональности между SQL и Python, особенно после появления таких библиотек, как pandas. Наша цель в этой серии — отвлечь наше мышление от размышлений о них с точки зрения того, чем они отличаются, и больше с точки зрения того, чем они похожи. Мы сделаем это, связав общие аналитические операции в двух языках.
Изучение этой золотой середины может помочь нам лучше понять возможности обоих языков. Когда мы поймем, как пересекаются языки, мы сможем принимать более разумные решения о том, что и когда использовать.
Имея в виду эту идею, давайте рассмотрим инструмент, который большинство из нас, вероятно, использует в повседневной жизни: оконные функции.
Из окна в окно
Функции окна — чрезвычайно распространенные операции в мире отчетов и аналитики. Документация PostgreSQL прекрасно знакомит с концепцией оконных функций:
.
Оконная функция выполняет вычисления для набора строк таблицы, которые так или иначе связаны с текущей строкой.
 Это сравнимо с типом вычислений, которые можно выполнить с помощью агрегатной функции. Но в отличие от обычных агрегатных функций использование оконной функции не приводит к группированию строк в одну строку вывода — строки сохраняют свои отдельные идентификаторы. За кулисами оконная функция может получить доступ не только к текущей строке результата запроса.
Это сравнимо с типом вычислений, которые можно выполнить с помощью агрегатной функции. Но в отличие от обычных агрегатных функций использование оконной функции не приводит к группированию строк в одну строку вывода — строки сохраняют свои отдельные идентификаторы. За кулисами оконная функция может получить доступ не только к текущей строке результата запроса.На практике оконные функции часто выглядят как вычисление скользящего среднего из необработанных данных временного ряда. При отображении рядом с временными рядами аналитики могут использовать скользящее среднее, чтобы подчеркнуть тенденцию:
Оконные функции в SQL
Оконная функция SQL будет знакома любому, кто немного знаком с SQL. По своей сути оконная функция SQL состоит из пяти основных компонентов:
- Выполняемая функция (например,
sum(),avg(),count()и т. д.) - Предложение
вместосразу после имени функции и аргументов. Этот пункт указывает, что применяемая функция является функцией окна и должна быть вычислена по соответствующему набору строк. - Раздел
на списокв предложенииover(), который делит обрабатываемые строки на группы или разделы, которые имеют одинаковые значения в разделена 9Список 0028. Для каждой строки оконная функция вычисляется для строк, которые попадают в тот же раздел, что и текущая строка. - Список
order byв предложенииover(), указывающий порядок, в котором должны обрабатываться строки. - Предложение рамки окна в предложении
over(), указывающее подмножество раздела, над которым нужно работать. Это может быть тот же размер, что и раздел, или меньше.
 Этот пункт указывает, что применяемая функция является функцией окна и должна быть вычислена по соответствующему набору строк.
Этот пункт указывает, что применяемая функция является функцией окна и должна быть вычислена по соответствующему набору строк.В совокупности этот расчет будет выглядеть следующим образом:
sum() over (раздел по порядку по строкам между 13 предыдущей и текущей строкой) как псевдоним
Этот оператор эквивалентен фразе «взять сумму столбца 1 для каждого отдельного значения в столбце 2, но ограничить эту сумму значениями в текущей строке и предыдущих 13 строк после упорядочения по столбцу 3».
В большинстве аналитических хранилищ данных на основе SQL существуют специализированные функции помимо обычных подозреваемых, которые можно использовать в оконных функциях. Примеры этого включают такие функции, как lag() и lead() , которые позволяют читать данные из предыдущей или следующей строки в разделе соответственно. Другой пример — row_number() , который возвращает текущий номер строки результата запроса по окну.
Чтобы предоставить практический пример того, как можно применять оконные функции SQL, ознакомьтесь с этим примером отчета, в котором мы анализируем данные о поездках на велосипедах в Сан-Франциско. Оконные функции рассчитывают такие показатели, как 14-дневное скользящее среднее, промежуточный итог, разница по неделям и процентное увеличение количества поездок по неделям. Поездки — запрос SQL Window точно показывает, как мы это делаем: сначала мы агрегируем количество поездок в день в CTE с именем input :
с вводом как (
выбирать
считать(1) поездками,
date_trunc('день',start_date) как дата
из modeanalytics. sf_bike_share_trip
сгруппировать по 2
)
 sf_bike_share_trip
сгруппировать по 2
)
sf_bike_share_trip
сгруппировать по 2
)
Выходные данные этого CTE будут содержать общее количество поездок, начатых за день. Мы применим нашу оконную функцию к этому выводу. Поскольку мы хотим вычислить скользящее *среднее *поездок, мы начнем с написания функции, которую хотим выполнить:
выбрать дата, поездки, avg(поездки) как функция из ввода
В своей текущей форме SQL считает, что вы пытаетесь выполнить обычную агрегацию avg() для столбца trips . Однако мы хотим специально выполнить функцию окна . Чтобы сообщить SQL, что эта функция должна применяться как функция окна , нам нужно следовать нашей функции avg() с предложением over :
select дата, поездки, avg(поездки) по () as window_function из ввода
На данный момент мы сказали SQL рассматривать эту функцию avg() как оконную функцию. Теперь мы можем приступить к уточнению нашей оконной функции в соответствии с нашими конкретными потребностями. Поскольку мы хотим рассчитать 14-дневную скользящую среднюю , а каждая строка представляет один день, мы хотим ограничить количество обрабатываемых строк текущей строкой и предыдущими 13:
Поскольку мы хотим рассчитать 14-дневную скользящую среднюю , а каждая строка представляет один день, мы хотим ограничить количество обрабатываемых строк текущей строкой и предыдущими 13:
выберите дата, поездки, avg(trips) over (упорядочить строки по дате между 13 предыдущей и текущей строкой) как mvg_avg из ввода
Вот и все. Теперь мы рассчитали нашу 14-дневную скользящую среднюю с помощью SQL. На данный момент у нас есть все необходимое для начала создания визуализаций. В качестве примера мы создали диаграмму для визуализации 14-дневных скользящих средних поездок поверх ежедневных данных. Эта визуализация дает нам гораздо лучшее непосредственное понимание основных тенденций в этих данных.
В пример отчета мы включили несколько других распространенных оконных операций, чтобы продемонстрировать дополнительные возможности работы с окнами.
Но что, если вместо этого мы захотим использовать Python? Как будут отличаться детали реализации?
Оконные функции в Python
Несмотря на то, что семантически они совершенно разные, оконные функции в pandas имеют довольно много общего с точки зрения функциональности с SQL.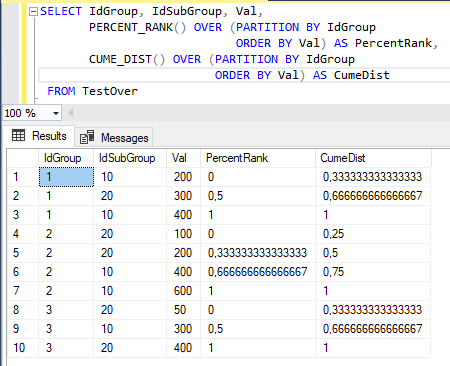
Панды реализуют оконные функции в основном с помощью операторов , скользящих и , расширяющих . При вызове серии pandas или Dataframe они возвращают Rolling 9.0028 или Expanding Объект, который позволяет группировать по скользящему или расширяющемуся окну соответственно.
В качестве примера мы собираемся использовать выходные данные запроса Trips — Python Window в качестве входных данных для нашего фрейма данных ( df ) в нашей записной книжке Python.
Обратите внимание, что в этом кадре данных нет оконных функций, вычисляемых с помощью SQL. Это просто часть CTE ранее использовавшегося запроса Trips — SQL Window .
В нашей записной книжке Python мы собираемся создать новый столбец mvg_avg в нашем кадре данных, который представляет собой эквивалент 14-дневной скользящей средней, которую мы ранее рассчитали с помощью SQL. Чтобы сделать это с помощью pandas, мы сначала выбираем столбец, к которому мы хотим применить нашу оконную функцию ( trips ) из нашего Dataframe в качестве объекта Series, используя df. . trips
trips
Затем мы вызываем оператор Rolling для серии, извлеченной с помощью df.trips , чтобы создать новый объект Rolling. Этот объект Rolling ведет себя аналогично объекту GroupBy, за исключением того, что вместо включения группировки по определенным значениям он включает группировку на основе скользящего окна, определенного пользователем. roll() метод принимает дополнительные аргументы от пользователя, такие как:
-
окно: размер движущегося окна -
win_type: тип применяемого окна. -
min_periods: требуемый порог ненулевых точек данных (по умолчанию нет данных) -
center: устанавливать ли метки в центре (по умолчанию False)
В нашем примере мы хотим рассчитать 14-дневную скользящую среднюю нашего дневного ряда, используя 9-дневную скользящую среднюю.0027 roll() , поэтому мы укажем значение 14 для окна :
df.
 trips.rolling(window=14)
trips.rolling(window=14)
Что также может быть сокращенно записано как:
df.trips.rolling(14)
Теперь, когда мы создали наш объект Rolling с 14-дневным окном, мы можем вызывать любые доступные методы и свойства, включая такие методы, как mean() , count() и median () , среди прочего. Поскольку наша цель — рассчитать 14-дневный мувинг Average , мы вызовем метод mean() для нашего объекта Rolling:
df.trips.rolling(14).mean()
Затем мы можем назначить нашу 14-дневную скользящую среднюю новому столбцу в нашем существующем фрейме данных:
df["mvg_avg"] = df.trips.rolling(14).mean()
И все! Мы рассчитали и сохранили нашу 14-дневную скользящую среднюю в нашем Dataframe. Сравните эту операцию с ее эквивалентом в SQL:
avg(trips) over (упорядочить строки по дате между 13 предыдущей и текущей строкой) как mvg_avg
Метод pandas . позволяет пользователям дополнительно настраивать свои методы агрегирования, позволяя пользователям указывать такие вещи, как настраиваемый вес значений в окне, используя различные типы окон. Например, мы можем рассчитать 14-дневную скользящую среднюю, используя треугольное окно, указав аргумент ключевого слова  rolling()
rolling() win_type в нашем методе .rolling() :
df["mvg_avg_triang"] = df.trips.rolling(window =14, win_type='треугольник').среднее()
После того, как пользователи преодолеют нюансы применения оконных функций к сериям и фреймам данных в пандах, они, как правило, оценят краткость и широкие возможности настройки, которые он предоставляет. В следующих фрагментах показаны дополнительные примеры эквивалентных оконных функций между SQL и pandas. Он также демонстрирует некоторый синтаксический сахар, предлагаемый pandas для очень распространенных оконных операций, включая промежуточные итоги, различия строк и процентные изменения между строками.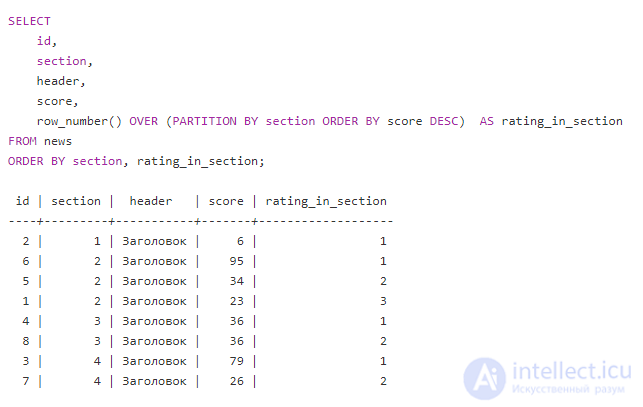
Итого
В SQL:
сумма (поездки) больше (упорядочение по строкам даты без ограничений предшествующих) как running_total_trips
В Python
df["running_total_trips"] = df.trips.cumsum()
Недельное изменение в процентах
В SQL:
(поездки - отставание(поездки,7) от (по дате))/отставание(поездки,7) от (по дате)::decimal(18 ,2) как wow_percent_change
В Python:
df["wow_percent_change"] = df.trips.pct_change(7)
Недельная разница
В SQL:
поездок - отставание (поездки, 7) по (порядок по дате) как wow_difference
В Python:
df["wow_difference"] = df.trips.diff(7)
Размытие линии
Никакое фиксированное правило не может определить, какой язык должен использоваться для какой функции. У всех будут разные потребности. Например, некоторые из наших пользователей начали переносить такие операции, как оконные функции, в записную книжку Python, чтобы разгрузить работу из своего хранилища данных.