Sql openquery: Работа с удалёнными источниками данных (OPENQUERY, OPENROWSET, EXEC AT)
Содержание
MSSQL. OPENQUERY. Как linked_server := self ?
← →
12 ©
(2010-09-15 11:56)
[0]
Нужно быстро переделать хранимки, возвращающие tabl, чтоб можно было делать select из них.
т.е. есть
exec GetBLABLA1
вернет
с1 с2 с3
1 2 3
1 3 4
думаю, проще всего мне сделать
select * from OPENQUERY ( linked_server ,»exec GetBLABLA1″ )
загвоздка linked_server
надо что-то типа аналога self, ведь сам себе сервер по-идее должен быть linked, без явного указания. Или нет?
т.е. как то так хочу
select * from OPENQUERY ( self ,»exec GetBLABLA1″ )) T1
join
(select * from OPENQUERY ( self ,»exec GetBLABLA2″ ) T2
on T2.c1 = T1.c1
on T2.c2 = T1.c1
← →
12 ©
(2010-09-15 12:02)
[1]
> on T2.c2 = T1.c1
второй раз лишнее, разумеется
← →
Дмитрий Тимохов
(2010-09-15 12:38)
[2]
Что-то я не понял. Как получить результат процедуры в таблицу?
Как получить результат процедуры в таблицу?
Может так? (это пример)
create procedure a
as
begin
select 1
end
go
create table e (i int)
insert e exec a
select * from e
← →
Дмитрий Тимохов
(2010-09-15 12:38)
[3]
можно во временную таблицу
← →
12 ©
(2010-09-15 12:49)
[4]
нет
процедуры есть(22 шт). Их нельзя трогать.
Можно сделать копии, конечно, но это будет, наверное, неправильно
а OPENQUERY позволяет получить и так.
но sp_add_linked_server не каждый может запустить
вот и думаю: должен же сервер быть сам себе линкован или не должен?
← →
Ega23 ©
(2010-09-15 12:52)
[5]
> Может так? (это пример)
Так нельзя.
create table #xxx1 (c1 int, c2 int, c3 int)
insert into #xxx1 exec GetBLABLA1
create table #xxx2 (c1 int, c2 int, c3 int)
insert into #xxx2 exec GetBLABLA2
select T1.*, T2.*
from #xxx1 T1 join #xxx2 on T1.c2=T2.c1
drop table #xxx1
drop table #xxx2
Если данное безобразие в рамках ХП происходит, то временные таблицы дропнутся автоматом.
← →
Ega23 ©
(2010-09-15 12:53)
[6]
> а OPENQUERY позволяет получить и так.
Он медленный. Делай во временную таблицу, проверено.
← →
Дмитрий Тимохов
(2010-09-15 13:05)
[7]
> Ega23 © (15.09.10 12:52) [5]
>
>
> > Может так? (это пример)
>
>
> Так нельзя.
вообще не понятно о чем речь в вопросе.
я дал код, который работает.
вроде это автор и спрашивал — как работать в результатом процедуры как с таблицей.
← →
Ega23 ©
(2010-09-15 13:09)
[8]
> я дал код, который работает.
Дим, пардон, я не разглядел сразу.select * from e
мне показалось, что это select из хранимки.
← →
12 ©
(2010-09-15 13:30)
[9]
> я дал код, который работает.
> create procedure a
> as
> begin
> select 1
> end
> go
>
> create table e (i int)
> insert e exec a
> select * from e
да я понял, но не
наверное, я что то не так думаю, изначально..
← →
Дмитрий Тимохов
(2010-09-15 13:55)
[10]
> наверное, я что то не так думаю, изначально. .
.
видимо )
ты задачу лучше опиши
← →
12 ©
(2010-09-15 15:41)
[11]
да даже сказать не могу уже
спроектировано неверно, вероятнее всего, или надо автора из отпуска дождаться — пусть пояснит логику.
суть в том, что в oracle есть таблица, из нее надо достать distinct столбец, и пробежаться. И каждое значение подставить в sp на mssql
будет много таблиц в итоге.
их надо join и взять общую
или надо еще раз подумать 🙂
← →
Дмитрий Тимохов
(2010-09-15 15:46)
[12]
1. получаешь distinct значения во временную таблицу 1.
2. бежишь циклом (думаю, умеешь?)
3. для каждого значения из таблицы 1 выполняешь процедуру, результат во временную таблицу 2.
4. содержимое из 2 ДОБАВЛЯЕШЬ во временную таблицу 3.
5. очищаешь 2.
6. идешь на шаг 3.
результат — таблица 3
← →
12 ©
(2010-09-15 15:59)
[13]
да это понятно..
не нравится только. вот такое ощущение, что неправильно что-то
но спасибо, на крайняк так и сделаю
← →
Дмитрий Тимохов
(2010-09-15 16:01)
[14]
нормально это
от объемов, конечно, зависит.
← →
Ega23 ©
(2010-09-15 16:09)
[15]
> вот такое ощущение, что неправильно что-то
Решение как решение
Повышение производительности OPENQUERY с Oracle на SQL Server
В настоящее время я работаю над переносом базы данных с Oracle 11g на SQL Server 2019. Здесь речь идет о 10–12 ГБ примерно в 300 таблицах (поэтому их создание вручную недостижимо, как и создание 300 потоков данных в SSIS).
Идея заключалась в том, чтобы сделать это способом «ELT»: на первом этапе «реплицировать» содержимое исходной базы данных Oracle в промежуточную базу данных (имеющую простую модель восстановления и расположенную в экземпляре SQL Server) , а на втором этапе выполнить все необходимые преобразования для заполнения целевых таблиц (в целевой базе данных на том же экземпляре SQL Server). Этот вопрос касается только первого шага процесса.
Первая фаза «извлечение и загрузка один на один» проходит довольно хорошо. Прежде всего, я объявил сервер Oracle как связанный сервер (поставщик «OraOLEDB»). Затем я создал SP, который генерирует «на лету» все необходимые таблицы в промежуточной базе данных SQL Server (запрашивая метаданные Oracle и переводя их в соответствующий SQL Server DDL, включая первичные ключи, если они есть), запуская их без каких-либо ошибок.
Наконец, тот же SP генерирует все необходимые запросы для получения данных и запускает их. Все необходимые данные передаются по мере необходимости, но производительность совершенно нецелесообразна (миграция должна быть выполнена от начала до конца за одну ночь).
Все сгенерированные запросы имеют следующую простую форму (на самом деле, в большинстве запросов даже нет предложения WHERE):
INSERTWITH (TABLOCKX, HOLDLOCK) (<Список столбцов>) ОТ Openquery ([ ] , 'ВЫБЕРИТЕ <СписокКолонок> ОТ <Таблица Oracle> ГДЕ ') ЗАКАЗАТЬ ПО ;
Я ожидал, что такой объем будет передан, скажем, за 1 или 2 часа, но до такой производительности мне далеко. Сначала это заняло более 16 часов.
После прочтения документации я увеличил параметр FetchSize связанного сервера до 10 000, что сократило общую продолжительность почти до 9 часов, но это все еще слишком долго (я также пытался увеличить тот же параметр до 200 000, без дальнейшего повышения производительности).
Большинство ожиданий, которые я мог видеть во время процесса, были либо «OLEDB», либо «PREEMPTIVE_COM_GETDATA», что, по-видимому, указывает на то, что пункт назначения ожидает источник.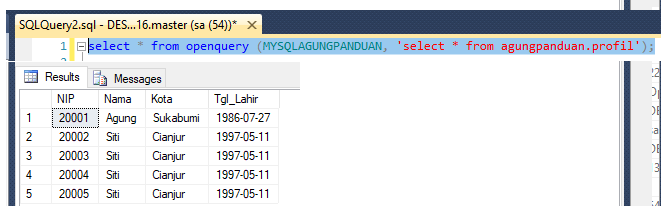 Обратите внимание, что в тестовой среде оба сервера находятся в одном и том же центре обработки данных, поэтому, вероятно, это не проблема сети (хотя при окончательной реальной миграции исходный сервер будет находиться за границей). Насколько я могу судить, я не видел никакого параллелизма в реальных планах выполнения, которые я мог бы перехватить.
Обратите внимание, что в тестовой среде оба сервера находятся в одном и том же центре обработки данных, поэтому, вероятно, это не проблема сети (хотя при окончательной реальной миграции исходный сервер будет находиться за границей). Насколько я могу судить, я не видел никакого параллелизма в реальных планах выполнения, которые я мог бы перехватить.
Если вам нужна какая-либо другая техническая информация, чтобы помочь мне, пожалуйста, не стесняйтесь спрашивать. (И, пожалуйста, простите любую английскую ошибку, так как это не мой родной язык).
Мой процесс ведет обширное журналирование, я мог бы рассказать вам о любой из сотен переданных таблиц, но, конечно, это во многом зависело бы от их объема (измеряется ли общая длина строки или количество строк). И, кстати, логирование не является причиной плохой производительности. Когда я прошу SP получить только первую строку всех необходимых таблиц (у меня есть параметр для этого), все это занимает меньше минуты.
Я зашел в свою таблицу журналов и взял для примера довольно типичную таблицу.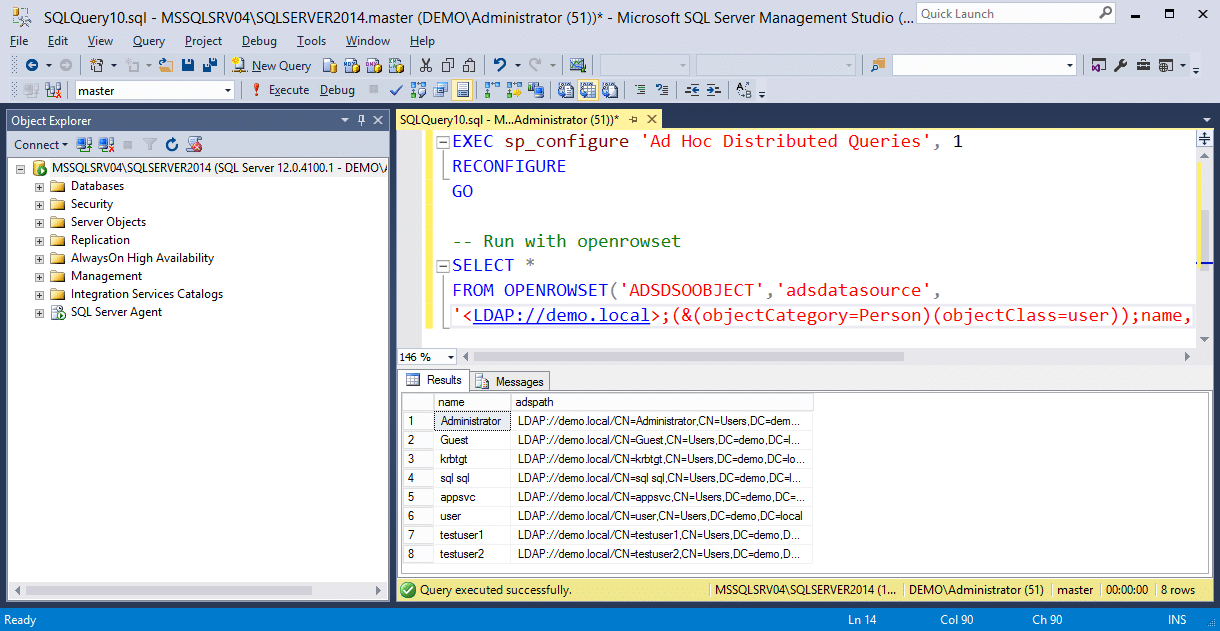 Он имеет 100 тыс. строк, весит около 25 МБ, а передача занимает около 45 секунд. Если я использую SQL Developer на целевом компьютере, чтобы извлечь CSV той же таблицы с исходного сервера, это займет всего около 9 секунд.
Он имеет 100 тыс. строк, весит около 25 МБ, а передача занимает около 45 секунд. Если я использую SQL Developer на целевом компьютере, чтобы извлечь CSV той же таблицы с исходного сервера, это займет всего около 9 секунд.
Я попытался вручную запустить в SSMS команды INSERT, сгенерированные моим SP, и обнаружил ту же (медленную) скорость. Я также попытался переформулировать их, используя синтаксис связанного сервера из четырех частей, без каких-либо различий. Но когда я пытаюсь экспортировать целевые таблицы в CSV в папке, используя функцию «Экспорт» SQL Developer, скорость, которую я могу получить, примерно в 4-5 раз выше.
План одного из моих элементарных запросов, возвращенный sp_WhoIsActive , можно найти здесь: https://www.brentozar.com/pastetheplan/?id=HJWj7Oqps
время (и время от времени указывает второстепенное ожидание 1-2 мс). Но другие столбцы кажутся мне более тревожными: во-первых, context_switches составляют более 740 000 000. Во-вторых,
Во-вторых, memory_info указывает, что у меня есть 7,3 ГБ доступной памяти, но на мой запрос было предоставлено только 10 КБ (и 3 КБ действительно используются), но я не уверен, что это актуально или может быть улучшено.
сервер sql — OPENQUERY в хранимой процедуре возвращает старые данные
Если я запускаю EXECUTE database.schema.procedure на SERVERB, хранимая процедура (нетривиальный SELECT без привязки к дате или времени) возвращает текущие данные.
Если я запускаю SELECT * FROM OPENQUERY(SERVERB, 'EXECUTE database.schema.procedure') на SERVERA, возвращаются данные 2-летней давности (строки, которые больше не существуют в запрашиваемой основной таблице).
SERVERA работает под управлением SQL Server 2012. SERVERB работал под управлением SQL Server 2012, когда хранимая процедура была создана и была обновлена на месте до SQL Server 2019.несколько месяцев спустя.
Естественно, с тех пор SERVERA несколько раз перезагружалась. Данные более поздние, чем дата создания хранимой процедуры, и намного старше, чем обновление SERVERB.
Данные более поздние, чем дата создания хранимой процедуры, и намного старше, чем обновление SERVERB.
Если я скопирую оператор SELECT из хранимой процедуры в оператор OPENROWSET() на SERVERA, будут возвращены текущие данные.
Где (и почему) SERVERA кэширует результаты двухлетней давности?
- SQL-сервер
Где (и почему) SERVERA кэширует результаты двухлетней давности?
Связанные серверы и OPENQUERY() не выполняют никакого кэширования.
При выполнении запроса SELECT * FROM OPENQUERY(SERVERB, 'EXECUTE database.schema.procedure') вы вызываете объект Linked Server с именем SERVERB , который существует на SERVERA . Тот факт, что он называется тем же именем, что и один из других ваших хост-серверов SQL, не означает, что он обязательно указывает на него.
Я бы рекомендовал запустить следующий код, чтобы проверить, где на самом деле разрешается этот объект Linked Server:
ВЫБОР
[имя] AS LinkedServerObjectName,
data_source AS ActualSourceServerName
ОТ sys. серверов
ГДЕ [имя] = 'СЕРВЕРБ';
серверов
ГДЕ [имя] = 'СЕРВЕРБ';
 серверов
ГДЕ [имя] = 'СЕРВЕРБ';
серверов
ГДЕ [имя] = 'СЕРВЕРБ';
Если возвращенное ActualSourceServerName равно SERVERB , то следующий вопрос: как узнать, что возвращаемым данным 2 года, а не то же самое, что возвращается при выполнении процедуры непосредственно на SERVERB ?
4
Решение моей проблемы было несколько неожиданным.
Хранимая процедура находится в схеме схемы на SERVERB и не добавляет префикс к таблицам в своем SELECT с именем схемы (они находятся в схеме dbo ).
Когда я выполняю хранимую процедуру непосредственно на SERVERB, используя мою учетную запись с привилегиями dbo, она читает dbo.Table1 и dbo.Table2 .
Когда я выполняю хранимую процедуру из SERVERA, используя OPENQUERY() и учетную запись, указанную на связанном сервере, который имеет общедоступный доступ к базе данных в вопросе, он читает схему .Таблица1 и схема . Таблица2 — копии таблиц, которые я сделал в 2021 году и про которые забыл.
Таблица2 — копии таблиц, которые я сделал в 2021 году и про которые забыл.
Я обнаружил это, войдя в SERVERB из SSMS, используя учетную запись, используемую связанным сервером.
Удаление скопированных таблиц решило проблему.
Кажется маловероятным, чтобы эта ситуация сохранялась в течение двух лет, и мои коллеги этого не заметили; Я думаю, более вероятно, что поведение изменилось с обновлением до SQL Server 2019.и это заняло несколько недель, чтобы быть замеченным.
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.