Sql строки: MS SQL Server и T-SQL
Содержание
5 cпособов осуществить агрегацию строк в MS SQL / Хабр
Иногда возникает необходимость осуществить агрегацию строк в SQL запросе, то есть, по такому набору данных:
| GroupId | Item |
|---|---|
| 1 | AAA |
| 2 | IS |
| 5 | OMG |
| 2 | WHAT |
| 2 | THE |
| 1 | This |
получить примерно такой:
| GroupId | ItemList |
|---|---|
| 1 | AAA,This |
| 2 | IS,WHAT,THE |
| 5 | OMG |
MySQL, например, для таких целей обладает встроенной функцией GROUP_CONCAT():
SELECT GroupId, GROUP_CONCAT(Item SEPARATOR ",") AS ItemList FROM Items
В MS SQL Server’e такой функции нету, поэтому приходится извращаться. Перед тем, как приступить, сделаем скрипт для создания тестовой таблицы:
Перед тем, как приступить, сделаем скрипт для создания тестовой таблицы:
CREATE TABLE Items(GroupId INT, Item NVARCHAR(10)) INSERT INTO Items(GroupId, Item) SELECT 1 AS GroupId, 'AAA' AS Item UNION ALL SELECT 2, 'IS' UNION ALL SELECT 5, 'OMG' UNION ALL SELECT 2, 'WHAT' UNION ALL SELECT 2, 'THE' UNION ALL SELECT 1, 'This'
Итак, начнем.
Самый тупой прямолинейный способ — создать временную таблицу и собирать в нее промежуточные результаты агрегации, пробегая по таблице Items курсором. Этот способ очень медленно работает и код его страшен. Любуйтесь:
DECLARE @Aggregated TABLE (GroupId INT, ItemList NVARCHAR(100))
DECLARE ItemsCursor CURSOR READ_ONLY
FOR SELECT GroupId, Item
FROM Items
DECLARE @CurrentGroupId INT
DECLARE @CurrentItem NVARCHAR(10)
DECLARE @CurrentItemList NVARCHAR(100)
OPEN ItemsCursor
FETCH NEXT FROM ItemsCursor
INTO @CurrentGroupId, @CurrentItem
WHILE @@FETCH_STATUS = 0
BEGIN
SET @CurrentItemList = (SELECT ItemList
FROM @Aggregated
WHERE GroupId = @CurrentGroupId)
IF @CurrentItemList IS NULL
INSERT INTO @Aggregated(GroupId, ItemList)
VALUES(@CurrentGroupId, @CurrentItem)
ELSE
UPDATE @Aggregated
SET ItemList = ItemList + ',' + @CurrentItem
WHERE GroupId = @CurrentGroupId
FETCH NEXT FROM ItemsCursor
INTO @CurrentGroupId, @CurrentItem
END
CLOSE ItemsCursor
DEALLOCATE ItemsCursor
SELECT GroupId, ItemList
FROM @Aggregated
Есть более красивый способ, не использующий временных таблиц. Он основан на трюке SELECT var = var + ‘,’ + col FROM smwhere. Да, так можно и это работает:
Он основан на трюке SELECT var = var + ‘,’ + col FROM smwhere. Да, так можно и это работает:
CREATE FUNCTION ConcatItems(@GroupId INT)
RETURNS NVARCHAR(100)
AS
BEGIN
DECLARE @ItemList varchar(8000)
SET @ItemList = ''
SELECT @ItemList = @ItemList + ',' + Item
FROM Items
WHERE GroupId = @GroupId
RETURN SUBSTRING(@ItemList, 2, 100)
END
GO
SELECT GroupId, dbo.ConcatItems(GroupId) ItemList
FROM Items
GROUP BY GroupId
Немного лучше, но все же костылевато. В случае, когда нам известно, что максимальное количество агрегируемых строк ограничего, можно использовать следующий способ (этот запрос основан на предположении, что не существует группы с более чем четырьмя элементами в ней):
SELECT GroupId,
CASE Item2 WHEN '' THEN Item1
ELSE CASE Item3 WHEN '' THEN Item1 + ',' + Item2
ELSE CASE Item4 WHEN '' THEN Item1 + ',' + Item2 + ',' + Item3
ELSE Item1 + ',' + Item2 + ',' + Item3 + ',' + Item4
END END END AS ItemList
FROM (
SELECT GroupId,
MAX(CASE ItemNo WHEN 1 THEN Item ELSE '' END) AS Item1,
MAX(CASE ItemNo WHEN 2 THEN Item ELSE '' END) AS Item2,
MAX(CASE ItemNo WHEN 3 THEN Item ELSE '' END) AS Item3,
MAX(CASE ItemNo WHEN 4 THEN Item ELSE '' END) AS Item4
FROM (
SELECT GroupId,
Item,
ROW_NUMBER() OVER (PARTITION BY GroupId ORDER BY Item) ItemNo
FROM Items
) AS OrderedItems
GROUP BY GroupId
) AS AlmostAggregated
Да, много кода. Но зато ни одного лишнего объекта в БД — просто один чистый селект. Это иногда важно.
Но зато ни одного лишнего объекта в БД — просто один чистый селект. Это иногда важно.
Тем не менее, существует способ обойти и ограничение на размер группы, оставшись при этом в рамках одного запроса. Мы будем собирать все элементы группы в XML-поле, которое затем сконвертим к строковому типу и заменим теги между элементами на запятые:
SELECT GroupId,
REPLACE(SUBSTRING(ItemListWithTags, 4, LEN(ItemListWithTags)-7),
'<a>',
',') AS ItemList
FROM (
SELECT GroupId,
CAST(XmlItemList AS NVARCHAR(200)) ItemListWithTags
FROM (
SELECT GroupId,
(SELECT Item AS A
FROM Items ii
WHERE ii.GroupId = GroupIds.GroupId
FOR XML PATH('')) AS XmlItemList
FROM (SELECT DISTINCT GroupId FROM Items) AS GroupIds
) AS subq1
) AS subq2
В общем, работает не очень шустро, зато всегда. И, конечно, нужен SQL Server не ниже 2000.
И, конечно, нужен SQL Server не ниже 2000.
Да, еще есть способ агрегировать строки через CLR Aggregate Functions, но это вообще мрачный ужас, ибо вусмерть медленно и несообразно сложности задачи. Если возникнет достаточный спрос на такую статью, напишу её позже.
Жду с нетерпением комментариев и критики. И ещё: если кто-нибудь знает, как можно сделать такую подсветку кода, как я сделал у себя дома — подскажите. Я, кроме как вставить скриншоты, другого способа пока не вижу.
SQL Строки и выражения в запросе SELECT
Предположим, нам необходимо выполнить простые числовые операции с данными для представления их в более удобном виде. SQL позволяет вносить скалярные выражения и константы в выбранные поля. Эти выражения могут дополнять или заменять поля в предложениях SELECT и могут содержать множество выбранных полей. 1. Например, можно представить комиссионные продавцов в виде процентов, а не десятичных чисел:
SELECT snum, sname, city, comm * 100 FROM Salespeople;
Последний столбец в данном примере не имеет имени, так как является вычисляемым. Вычисляемые (выходные) столбцы – это столбцы, которые создаются с помощью запроса в тех случаях, когда в предложении SELECT используются агрегатные функции, константы или выражения, а не извлекаются непосредственно из таблицы. Поскольку имена столбцов являются атрибутами таблицы, столбцы, не переходящие из таблицы в выходные данные, не имеют имен. Почти во всех ситуациях выходные столбцы отличаются от столбцов, извлекаемых из таблицы тем, что они не поименованы. Константы, а также текст, можно включать в предложение запроса SELECT. Однако, буквенные константы, в отличие от числовых, нельзя использовать в выражениях. В SELECT-предложение можно включить 1+2, но не «А»+ «В», поскольку «А» и «В» здесь просто буквы, а не переменные или символы, используемые для обозначения чего-либо отличного от них самих. Тем не менее, возможность вставить текст в выходные данные запроса вполне реальна. 2. Например, можно пометить комиссионные продавцов, выраженные в процентах, символом «процент» (%), что позволяет представить их в выходных данных в виде символов и комментариев:
Вычисляемые (выходные) столбцы – это столбцы, которые создаются с помощью запроса в тех случаях, когда в предложении SELECT используются агрегатные функции, константы или выражения, а не извлекаются непосредственно из таблицы. Поскольку имена столбцов являются атрибутами таблицы, столбцы, не переходящие из таблицы в выходные данные, не имеют имен. Почти во всех ситуациях выходные столбцы отличаются от столбцов, извлекаемых из таблицы тем, что они не поименованы. Константы, а также текст, можно включать в предложение запроса SELECT. Однако, буквенные константы, в отличие от числовых, нельзя использовать в выражениях. В SELECT-предложение можно включить 1+2, но не «А»+ «В», поскольку «А» и «В» здесь просто буквы, а не переменные или символы, используемые для обозначения чего-либо отличного от них самих. Тем не менее, возможность вставить текст в выходные данные запроса вполне реальна. 2. Например, можно пометить комиссионные продавцов, выраженные в процентах, символом «процент» (%), что позволяет представить их в выходных данных в виде символов и комментариев:
SELECT snum, sname, city, ‘%’, comm * 100 FROM Salespeople;
Результат выполнения запроса:
| snum | sname | city | ||
|---|---|---|---|---|
| 1001 | Peel | London | % | 12 |
| 1002 | Monika | New York | % | 15 |
| 1004 | Rifkin | London | % | 11 |
3. Можно пометить выходные данные, включив в них некоторый комментарий. Однако нужно помнить, что один и тот же комментарий будет печататься не один раз для всей таблицы, а в каждой строке выходных данных. Например, генерируются выходные данные для отчета, в котором фиксируется количество заказов на каждый день:
Можно пометить выходные данные, включив в них некоторый комментарий. Однако нужно помнить, что один и тот же комментарий будет печататься не один раз для всей таблицы, а в каждой строке выходных данных. Например, генерируются выходные данные для отчета, в котором фиксируется количество заказов на каждый день:
SELECT odate, ‘поступило’, COUNT (DISTINCT onum), ‘заказов’ FROM Orders GROUP BY odate;
Результат выполнения запроса:
| оdate | |||
|---|---|---|---|
| 10/03/05 | поступило | 5 | заказов |
| 11/03/05 | поступило | 1 | заказов |
| 12/03/05 | поступило | 12 | заказов |
Выходные данные запроса также можно изменить путем объединения столбцов. Метод, применяемый для слияния выходных данных двух столбцов в единое целое, называется конкатенацией и обозначается символами || :
Метод, применяемый для слияния выходных данных двух столбцов в единое целое, называется конкатенацией и обозначается символами || :
SELECT odate || ‘поступило’ || COUNT (DISTINCT onum) || ‘заказов’ FROM Orders GROUP BY odate;
4. Любому столбцу при выдаче оператора SELECT можно присвоить любое, более информативное имя, не нарушая правил по длине, установленных в описании типа данных столбца. Такое имя называется псевдонимом. Псевдонимы указываются двумя способами: после описания столбца через пробел или при помощи ключевого слова AS, отмечающего псевдоним более четко:
SELECT snum, sname, city, comm * 100 AS commis FROM Salespeople;
Работа со строками | SQL Tutorial Documentation on data.world
Concepts/Intermediate/
Введение в работу со строками.
SQL имеет несколько встроенных функций для управления строковыми данными в полях.
Некоторые из наиболее распространенных: CONCAT , LEFT , LOWER , UPPER ,
ПОДСТРОКА , STRING_SPLIT и ДЛИНА .
Полный список строковых функций см. в справочном разделе.
СЦЕПЛЕНИЕ
CONCAT принимает два или более строковых значения и объединяет их в одно значение.
Эти значения можно задать в запросе или выбрать из таблицы. в
В следующем примере запрос объединяет имя менеджера, разделяющий пробел
(значение, указанное в запросе) и имя продавца:
SELECT CONCAT(manager, ", ", sales_agent) ОТ sales_teams
siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
Результирующая таблица выглядит так:
| конкат |
|---|
| Дастин Бринкманн, Анна Снеллинг |
| Дастин Бринкманн, Сесили Лэмпкин |
| Мелвин Марксен, Мей-Мей Джонс |
| Кара Лош, Вайолет Маклелланд |
| Кара Лош, Corliss Cosme |
| Кара Лош, Рози Пападопулос |
| Кара Лош, Гаррет Киндер |
| Кара Лош, Уилберн Фаррен |
| Кара Лош, Элизабет Андерсон |
| Рокко Нойберт, Даниэль Хаммак |
| Рокко Нойберт, Кэсси Кресс |
Для удобства SQL также поддерживает объединение строк с помощью конкатенации
оператор || . Используя оператор конкатенации, предыдущий запрос может быть
Используя оператор конкатенации, предыдущий запрос может быть
написано так:
Менеджер SELECT || "," || агент по продажам ОТ продаж_команд
siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
ЛЕВЫЙ
Строковая функция LEFT возвращает указанное количество
крайние левые символы от значения. Если бы мы хотели использовать однобуквенный идентификатор
для каждого из региональных офисов агентов по продажам мы могли бы запустить такой запрос
это:
ВЫБЕРИТЕ агента по продажам,
СЛЕВА(региональный_офис, 1)
ОТ продаж_команд siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
и мы получим обратно:
| агент по продажам | осталось |
|---|---|
| Анна Снеллинг | С |
| Сесили Лэмпкин | С |
| Мей-Мей Джонс | С |
| Вайолет Маклеланд | Е |
| Корлисс Косме | Е |
| Рози Пападопулос | Е |
| Гаррет Киндер | Е |
| Уилберн Фаррен | Е |
| Элизабет Андерсон | Е |
| Дэниел Хамак | Е |
| Кэсси Кресс | Е |
| Донн Кантрелл | Е |
| Верси Хиллебранд | С |
НИЖНИЙ
LOWER — полезная строковая функция для очистки представления данных в виде
он преобразует все символы значения в нижний регистр. Например, мы могли бы
Например, мы могли бы
измените все названия продуктов на нижний регистр в следующем запросе:
ВЫБЕРИТЕ МЕНЬШЕ(продукт) ИЗ продуктов
siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
| нижний |
|---|
| gtx базовый |
| gtx про |
| мг специальный |
| мг расширенный |
| gtx плюс про |
| gtx плюс базовый |
| ГТК 500 |
| мг моно |
| альфа |
ВЕРХНИЙ
Аналогично НИЖНЯЯ , ВЕРХНЯЯ возвращает все символы в строке как верхние
кейс. Если бы нам понадобился список сотрудников, написанный заглавными буквами, мы могли бы запустить
запрос:
ВЫБЕРИТЕ ЗАГЛАВНУЮ (продажный_агент) ОТ sales_teams
siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
| верхний |
|---|
| АННА СНЕЛЛИНГ |
| СЕСИЛИ ЛАМПКИН |
| МЕЙ-МЭЙ ДЖОНС |
| ВИОЛЕТ МАКЛЕЛЛАНД |
| КОРЛИСС КОСМЭ |
| РОЗИ ПАПАДОПУЛОС |
| ЧЕРДАЧНЫЙ КИНДЕР |
| УИЛБЕРН ФАРРЕН |
| ЭЛИЗАБЕТ АНДЕРСОН |
ПОДСТРОКА
SUBSTRING — это функция, которая используется для возврата
часть строки в зависимости от ее положения в строке. Например, если мы
Например, если мы
просматривали данные только для линейки продуктов GTX, и мы хотели удалить
Префикс GTX из результатов нашего запроса мы могли бы использовать следующий запрос:
ВЫБРАТЬ ПОДСТРОКУ(продукт, 5),
цена для продажи
ИЗ продуктов
ГДЕ продукт НРАВИТСЯ "GTX%" siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
, и возвращаемые результаты будут выглядеть так:
.
| подстрока | цена_продажи |
|---|---|
| Базовый | 550 |
| Про | 4 821 |
| Плюс Про | 5 482 |
| Плюс Базовый | 1 096 |
Функция SUBSTRING требует два аргумента и может принимать
третий. Первый аргумент — это строка, которую нужно найти, и ее можно указать
либо в виде строки, либо в виде столбца. Вторым аргументом является размещение в
Вторым аргументом является размещение в
строка первого возвращаемого символа. Третий (необязательный) аргумент
количество возвращаемых символов. Если третий аргумент опущен,
запрос возвращает всю строку от первого возвращенного символа до конца
строка.
ДЛИНА
Функция LENGTH возвращает количество символов в
строка. Может показаться странным хотеть знать, но это полезно, когда
вы хотите удалить символы из начала строки, оставив
заданное количество символов с конца. В нашем наборе данных нет
особенно хорошая строка, где эта операция имела бы смысл, но как
например, мы могли бы запустить запрос, чтобы вернуть только последние пять букв каждой продажи
имя агента, и оно будет выглядеть так:
ВЫБЕРИТЕ агента по продажам,
ПОДСТРОКА(агент_продаж, ДЛИНА(агент_продаж) -5)
ОТ sales_teams siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
| агент по продажам | подстрока |
|---|---|
| Анна Снеллинг | эллинг |
| Сесили Лэмпкин | усилитель |
| Мей-Мей Джонс | Джонс |
| Вайолет Маклеланд | Элланд |
| Корлисс Косме | Косме |
| Рози Пападопулос | пулос |
| Гаррет Киндер | Киндер |
| Уилберн Фаррен | Фаррен |
| Элизабет Андерсон | Дерсон |
| Дэниел Хамак | аммак |
| Кэсси Кресс | Кресс-салат |
| Донн Кантрелл | нтрелл |
STRING_SPLIT
STRING_SPLIT — это функция, которая используется для разделения строки на несколько
строки, основанные на некотором разделителе. В отличие от других функций,
В отличие от других функций, STRING_SPLIT
возвращает несколько строк для каждой введенной строки. Например, если вы искали
чтобы получить имена и фамилии ваших агентов по продажам в одном столбце, вы
могли бы разделить их имена, используя символ пробела в качестве разделителя:
ВЫБЕРИТЕ агента по продажам,
STRING_SPLIT(торговый_агент, " ")
ОТ sales_teams siyeh/sql-crm-example-data
Выполнить запрос
Скопировать код
| агент по продажам | подстрока |
|---|---|
| Анна Снеллинг | Анна |
| Анна Снеллинг | Снеллинг |
| Сесили Лэмпкин | Сесили |
| Сесили Лэмпкин | Лампкин |
| Мей-Мей Джонс | Мэй-Мэй |
| Мей-Мей Джонс | Джонс |
Функция STRING_SPLIT требует два аргумента.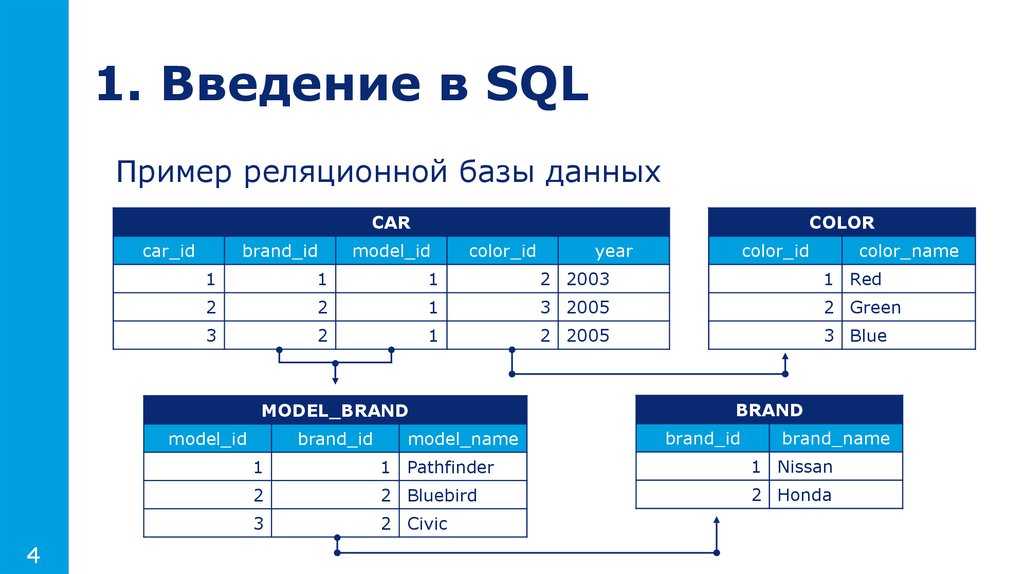 Первый аргумент – это
Первый аргумент – это
строка, которая будет разделена, и она может быть указана либо как строка, либо как столбец.
Второй аргумент — это символ-разделитель, используемый для разделения строки.
Далее: работа с датами
Введение в работу с датами.
Строковые типы данных в SQL Server
В sql строковые типы данных используются для хранения любых данных в таблице. В строковых типах данных у нас есть возможность разрешить пользователям хранить либо фиксированную длину символов, либо данные большой длины в зависимости от их требований.
В SQL у нас есть другой тип строковых типов данных, это
- Типы данных символьных строк
- Типы данных строки символов Unicode
Типы данных символьной строки SQL
В sql типы данных символьной строки содержат другой тип символьных типов данных, это
- char тип данных
- тип данных varchar
SQL Char DataType
В sql тип данных char используется для хранения символов фиксированной длины. Предположим, если мы объявим char(50) , тогда он выделит память для 50 символов для хранения 50 символов данных. В случае, если мы вставим только 10 символов строки, то будет использовано только 10 символов памяти, а оставшиеся 40 символов памяти будут потрачены впустую.
Предположим, если мы объявим char(50) , тогда он выделит память для 50 символов для хранения 50 символов данных. В случае, если мы вставим только 10 символов строки, то будет использовано только 10 символов памяти, а оставшиеся 40 символов памяти будут потрачены впустую.
SQL Varchar DataType
В sql varchar означает переменные символы и используется для хранения символов, отличных от Юникода. Он будет выделять память на основе вставленных числовых символов. Предположим, если мы объявим varchar(50), , то он будет выделять память 0 символов во время объявления. Теперь, если мы вставим только 10 символов строки, то она выделит память только для 10 символов.
Дополнительные сведения о типах данных символьных строк в SQL Server см. в следующей таблице.