Sql структура запроса: основные операторы, виды, синтаксис, написание, создание базы данных, примеры простых и сложных команд
Содержание
Структура SQL запроса на выборку данных
Простые, или так называемы прямые запросы, строить проще всего. Именно они максимально понятны, точки зрения логики. Как правило, такого рода запросы делаются с одной или нескольких, объединённых таблиц и имеют очень простую структуру.
Самым распространённым действием, при работе с таблицами баз данных является выборка интересующей пользователя информации. Такие процедуры проводиться с целью проанализировать определённого рода информацию. Начинается такая команда Служебным словом Select. Далее идёт перечень колонок, которые нужно выбрать, служебное слово From имя таблицы, с которой нужно сделать выборку данных. Различают две основные схемы запросов к базе данных:
- Простые
- Сложные или вложенные запросы.
Построение простых запросов баз данных
Простые, или так называемы прямые запросы, строить проще всего. Именно они максимально понятны, точки зрения логики. Как правило, такого рода запросы делаются с одной или нескольких, объединённых таблиц и имеют очень простую структуру. Для примера можно рассмотреть три таблицы, а именно: Counterfoil – условия оплаты, Person – сотрудники и таблица Depart – отделы. Из этих таблиц, скажем в первом случае необходимо просто выбрать всю имеющуюся в них информацию. Для этого нужно выполнить скрипт такого плана:
Как правило, такого рода запросы делаются с одной или нескольких, объединённых таблиц и имеют очень простую структуру. Для примера можно рассмотреть три таблицы, а именно: Counterfoil – условия оплаты, Person – сотрудники и таблица Depart – отделы. Из этих таблиц, скажем в первом случае необходимо просто выбрать всю имеющуюся в них информацию. Для этого нужно выполнить скрипт такого плана:
- Select * from Counterfoil
- Inner join Person on PE_ID = Cou_Person
- Order by PE_ID
Данный скрипт вернёт пользователю все данные из таблиц упорядоченный по сотрудникам. Это самая простая конструкция, которую, при необходимости можно усложнить условиями. Использование условий обозначается служебным словом Where, после которого можно указывать, те поля таблицы, к которым необходимо применить фильтры.
Структура сложных (вложенных) запросов баз данных
Простые запросы не всегда эффективны. Если в таблицах много полей и записей, то выборка может продолжаться от нескольких секунд, до нескольких минут, что не совсем целесообразно.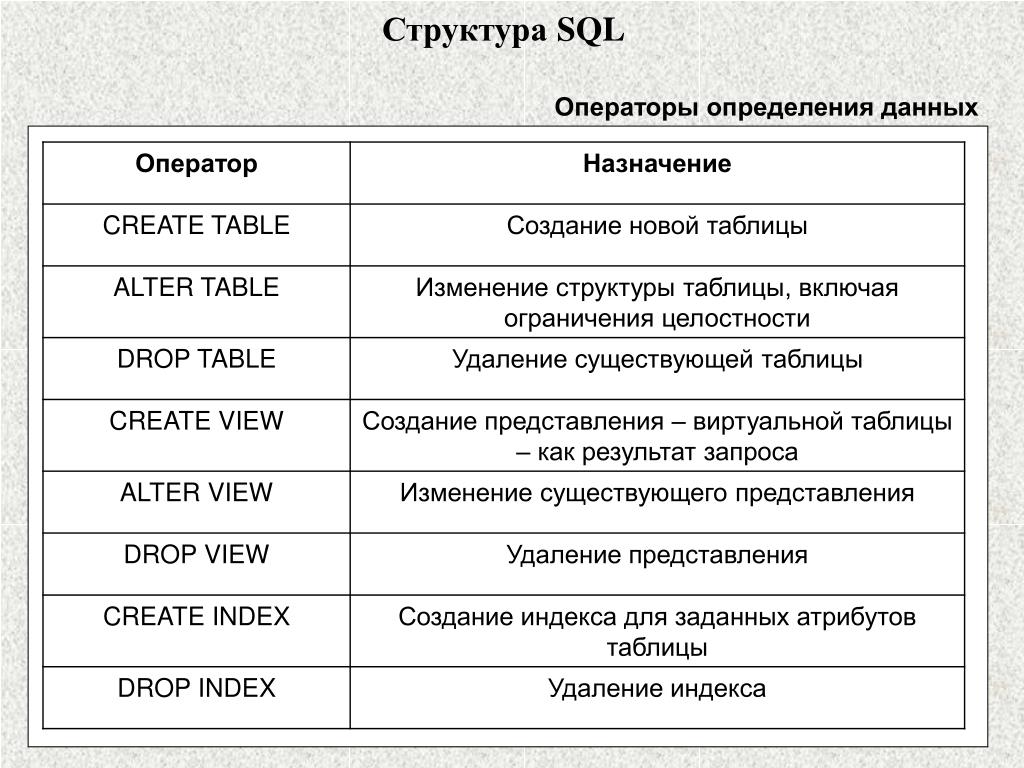 Задача любого программиста баз данных – это максимальная оптимизация работы запросов, не только для получения максимально корректной информации, но и ускорение времени их выполнения. Как раз для этих целей и существую так называемые вложенные запросы.
Задача любого программиста баз данных – это максимальная оптимизация работы запросов, не только для получения максимально корректной информации, но и ускорение времени их выполнения. Как раз для этих целей и существую так называемые вложенные запросы.
Как правило, в таких запросах идёт выборка не по всем полям, а только, по тем, которые необходимы. Можно рассмотреть такой пример. Необходимо вывести номер условия оплаты, сотрудника для которого производится оплата и отдел, где сотрудник работает. Для этого можно воспользоваться вложенным скриптом, который вернёт не все, а только нужные поля таблицы. Такой скрипт будет иметь следующий вид:
- Номер условия
- Наименование
- Код сотрудника
- Сотрудник
- Код отдела
В конце скрипта поставлен фильтр, который выведет информацию только о работающих, на данный момент, сотрудниках компании.
Скрипты на выборку данных с базы могут быть ещё сложнее, но общая структура запросов будет полностью похожа на выше описанные.
Автоматизация выполнения запросов в SQL с помощью Python
Время прочтения: 3 мин.
Основная идея работы скрипта – генерация запросов с учетом различных параметров и последовательное их выполнение для вставки данных в существующую таблицу или выгрузка данных в файл. Сама программа состоит из 3 частей:
- Соединение c базой данных;
- Определение варьируемых параметров;
- Выполнение запросов к базе (структура построения запросов позволяет выполнять запросы последовательно или параллельно, что позволяет управлять скоростью загрузки/выгрузки данных с сервера).
Соединение с БД определяется фабрикой, в которой содержатся параметры соединения с определенным сервером и определены ссылки на классы для работы с БД.
db = DatabaseFactory().build('*наименование сервера*')Сами объекты для работы с БД содержат 3 метода:
- collect – запускает запрос с помощью метода read_sql библиотеки pandas и возвращает DataFrame, содержащий результат выполненного запроса;
- execute – запускает запросы типа CREATE, UPDATE, DELETE\TRUNCATE\DROP;
- execute_many –используется в основном для загрузки данных внутрь БД.
 Сама загрузка производится с помощью BULK вставки.
Сама загрузка производится с помощью BULK вставки.
 Сама загрузка производится с помощью BULK вставки.
Сама загрузка производится с помощью BULK вставки.db.collect('select top 100 * from table')
db.execute('insert into table select * from another_table')
db. execute_many ('insert into from table (id, name, age) values (?,?,?)', [1,’Jhon’, 25])
Далее пользователь может задать параметры запроса с помощью метода add_var класса SqlContext. Данный метод принимает 4 параметра: наименование колонки, значения данной переменной, условие (=, <=, >=, between и т.п.) и разделитель (под разделителем понимаются команды AND и OR).
context = SqlContext()
context.add_var('col_name’, [1,2,3,4,5], separator='AND', condition='=')
context.add_var('col_name_1’, [[‘a’,’b’,’v’], [‘a1’,’b2’,’v3’],] , separator='AND', condition='in')
В случае определения нескольких параметров одновременно, в запросе они будут варьироваться по следующему правилу: сначала варьируются те параметры, которые были заданы в последнюю очередь. Если все вариации последнего параметра будут пройдены, то берутся следующее значения параметра выше и вновь перебираются все вариации последнего параметра. Так продолжается до тех пор, пока не переберутся все возможные комбинации заданных параметров.
Если все вариации последнего параметра будут пройдены, то берутся следующее значения параметра выше и вновь перебираются все вариации последнего параметра. Так продолжается до тех пор, пока не переберутся все возможные комбинации заданных параметров.
После того, как мы определили варьируемые параметры необходимо задать сам sql запрос. Для этого создаем объект SqlBuilder и вызываем метод custom_sql внутрь которого помещаем сам запрос:
builder = SqlBuilder()
builder.custom_sql('''
INSERT INTO insertable_table
SELECT
*
FROM table
WHERE 1=1
AND col1 in (1, 2,10,98,34)
AND col2 = 9
AND col3 between ‘20200101’ and ‘20200201’
''')
или можно воспользоваться встроенными в объект методами для генерации sql (select, insert_into, create_table и т.д.):
builder = SqlBuilder() builder.select([‘col1’, ‘col2’, ‘col3’]).from(‘table’)
Для запуска скрипта необходимо создать объект класса SqlGenerator, объекты SqlBuilder и SqlContext и с помощью цикла запустить обработку запроса (в качестве примера был взят вариант последовательного исполнения запроса):
generator = SqlGenerator(builder, context) for sql in tqdm(generator.
 generate()):
t = time.time()
db.execute(sql)
print('Итоговое время работы запроса: ' + str(time.time()-t))
generate()):
t = time.time()
db.execute(sql)
print('Итоговое время работы запроса: ' + str(time.time()-t))
В итоге данный скрипт позволяет значительно сократить трудозатраты и время на выполнение рутинных запросов, чем я неоднократно пользовался в своей работе.
Весь исходный код опубликован на github.
SQL 101 — Базовая структура запроса. Если вы хотите сменить карьеру на… | Надя Селас Новерсега
Надя Селас Новерсега
·
Подписаться
6 минут чтения
·
15 декабря 2021 г.
Если вы нацелены чтобы сменить профессию в IT, я бы посоветовал вам в первую очередь научиться это SQL (язык структурированных запросов), который является наиболее распространенным языком запросов СУБД (система управления реляционными базами данных). Даже если вы не занимаете инженерную должность, навыки работы с SQL будут очень полезны и для других должностей, таких как данные (конечно), QA, бизнес-аналитик или даже финансисты.
SQL — это язык запросов, используемый для управления и извлечения данных из реляционной базы данных. Существует 5 типов SQL-запросов:
- Язык определения данных (DDL) — используется для создания и изменения объектов базы данных (создание, удаление, изменение, усечение, комментарий, переименование)
- Язык манипулирования данными (DML) ) — используется для добавления, удаления и изменения данных в базе данных (вставка, обновление, удаление)
- Язык управления данными (DCL) — используется для управления доступом к данным, хранящимся в базе данных (предоставление, отзыв)
- Язык управления транзакциями (TCL) — используется для управления транзакциями (фиксация, откат, точка сохранения, установка транзакции)
- Язык запроса данных (DQL) ) — используется для выполнения запроса к данным (выбор)
В этой статье я более подробно расскажу о языке запросов данных (DQL), предполагая, что мы будем использовать SQL только для извлечения данных из базы данных.
Наиболее распространенная структура запроса —
ВЫБЕРИТЕ …
ИЗ …
ГДЕ …
СГРУППИРОВАТЬ ПО …
СКАЧАТЬ ПО …;
Иногда с добавлением ИМЕЮЩИЙ .
Теперь я объясню каждый пункт.
Под оператором выбора вы размещаете поля, которые хотите отобразить в своем запросе.
Допустим, у нас есть таблица «employee»:
Оператор select можно использовать следующим образом:
SELECT ID, employee_name
или
SELECT employee_name, age
или
SELECT * (если вы хотите показать все поле)
Или вы можете проявить творческий подход с помощью встроенной функции или позже, создать свою собственную функцию, например
SELECT max(age)
* потребуется агрегация объединяться с группой по утверждению. Будет объяснено позже в этой статье.
ОТ
Под ОТ вы пишете свой источник таблицы. Используя тот же пример, что и выше, наш запрос будет выглядеть так:
ВЫБЕРИТЕ ID, имя_сотрудника ОТ сотрудника
С добавлением предложения FROM наш запрос теперь достаточно завершен, чтобы получить некоторые результаты. Достаточно ли это практично в реальном случае? Иногда да, но в большинстве случаев данные, которые нам нужно получить, берутся не только из одной таблицы. Если мы хотим получить данные из более чем 1 таблицы, нам нужно присоединиться к этим таблицам.
Достаточно ли это практично в реальном случае? Иногда да, но в большинстве случаев данные, которые нам нужно получить, берутся не только из одной таблицы. Если мы хотим получить данные из более чем 1 таблицы, нам нужно присоединиться к этим таблицам.
Например, у нас есть 2 таблицы:
таблица «сотрудник»:
таблица «отдел»:
Если мы хотим получить данные, такие как имена сотрудников и названия отделов, мы не можем использовать ИЗ только с одним источником таблицы, поскольку имена сотрудников и названия отделов находятся в разных таблицах. SQL имеет 5 вариантов соединения для соединения таблиц:
- ЛЕВОЕ СОЕДИНЕНИЕ
- ПРАВОЕ СОЕДИНЕНИЕ
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ
- ПЕРЕКРЕСТНОЕ СОЕДИНЕНИЕ
Подробнее здесь
Для случая, описанного выше, мы будет использовать ЛЕВОЕ СОЕДИНЕНИЕ.
Чтобы использовать предложение соединения, в наших таблицах должно быть хотя бы одно связанное поле (кроме перекрестного соединения). Обратите внимание, что в нашем примере в обеих таблицах есть поле с именем 9.0051 dept_ID . Связь между двумя приведенными выше таблицами представляет собой поле
Обратите внимание, что в нашем примере в обеих таблицах есть поле с именем 9.0051 dept_ID . Связь между двумя приведенными выше таблицами представляет собой поле dept_ID .
Для получения данных об именах сотрудников и названиях отделов мы теперь можем использовать:
SELECT employee.employee_name, Department.nameFROM employeeLEFT JOIN Department on employee.dept_ID = Department.dept_ID
и вуаля, результат покажет
ГДЕ
Под , где пункт — это место, где мы помещаем фильтры или условия в наши данные. Фильтры могут быть по времени, имени, идентификатору, статусу или вообще всему, что у вас есть в полях (кроме агрегации, используйте вместо ). Вернемся к нашему примеру с таблицей «employee»
Если мы хотим получить данные о сотруднике старше 28 лет, мы можем использовать
SELECT *
FROM employee
WHERE age > 28
И результат покажет
В пределах где , вы можете проявить творческий подход, используя оператор if или case when, если это необходимо!
GROUP BY
GROUP BY является необязательным условием.
GROUP BY требуется, когда мы используем агрегацию в нашем операторе select (т.е.: MAX, MIN, SUM, COUNT) и мы хотим сгруппировать эти агрегации в пределах определенной границы.
Например, у нас есть таблица «employee_score»
Мы хотим узнать минимальный балл каждого человека.
Если мы воспользуемся запросом
SELECT MIN(score)
FROM employee_score
Результатом будет
Этот запрос извлечет минимальный балл из всех данных в этой таблице, потому что мы не указали группировку.
Теперь сравните с этим запросом.0049
Результатом будет
Данные будут сгруппированы на основе имени сотрудника, после чего будет получен минимальный балл по этим именам.
Для предложения group by можно использовать более 1 поля.
ORDER BY
ORDER BY используется для сортировки данных. Мы можем использовать более одного поля для сортировки данных.
Пример:
таблица «employee_score»
Для сортировки по имени сотрудника в алфавитном порядке и по баллу можно использовать
SELECT * FROM employee_score
ORDER BY employee_name, score
Мы также можем указать, как сортировать эти поля, написав ASC (по возрастанию) или DESC (по убыванию) после каждого имени поля в предложении ORDER BY .
HAVING
HAVING используется для размещения агрегированных фильтров или условий в наших данных, поскольку предложение WHERE не может принимать агрегирование.
Например, у нас есть таблица «employee_score»
Мы хотим исключить сотрудников с минимальным баллом менее 7.
Нам нужно сгруппировать сотрудников по именам, чтобы получить их минимальный балл, а затем исключить всех, у кого минимальный балл меньше 7.
В SQL мы можем написать:
ВЫБЕРИТЕ имя_сотрудника, МИН.(оценка) ИЗ_оценки_сотрудника
ГРУППИРОВАТЬ ПО имени_сотрудника
ИМЕЕТ min(оценка) < 7
Результатом нашего запроса будет
По мере роста потребности в данных вам может понадобиться проявите творческий подход, чтобы использовать эти пункты для получения необходимых данных. Для многих людей (включая меня) изучение чего-то нового может быть ошеломляющим, но если вы справитесь, я обещаю, что скоро все станет лучше! Помните, важнее понять концепцию, чем запомнить синтаксис!
Продолжайте практиковать свой вопрос, и вы быстро заговорите. Практика делает совершенным!
Практика делает совершенным!
Некоторые рекомендации для тренировки ваших навыков SQL:
- leetcode.com
- secret.knightlab.com
- любые игры sql!
P.S. Если у вас есть какие-либо вопросы или предложения, не стесняйтесь комментировать!
Структуры данных в SQL: полное руководство
Структуры данных обозначают различные способы хранения данных на компьютере и являются жизненно важной частью любой системы или проекта базы данных. Операции, которые вы можете выполнять с этими структурами данных, и инструкции, которые вы даете для их выполнения, называемые алгоритмами, часто имеют свои основные функции, адаптированные к дизайну структуры данных. Давайте посмотрим на важность структур данных и обсудим их использование в базах данных SQL.
Где используются структуры данных?
Помимо хранения созданных данных для сохранения данных, структуры данных также позволяют использовать службы и ресурсы Core OS. Например, выделение памяти, управление файловыми каталогами и планирование процессов можно выполнять с помощью связанных списков, деревьев и очередей соответственно.
Разработчики могут обмениваться пакетами через протоколы TCP/IP, организованные через структуры данных. Например, для бинарных деревьев поиска доступны эффективные методы упорядочивания и сортировки, а очереди с приоритетом позволяют программистам управлять элементами, соблюдая установленный приоритет.
Существует множество простых способов индексации и поиска данных в различных структурах данных. Структуры данных также играют важную роль в приложениях для работы с большими данными, которые обеспечивают высокую производительность и масштабируемость.
Как выбрать структуру данных
Различные характеристики могут помочь нам классифицировать структуры данных. Например, они могут быть линейными, как массив, в котором элементы данных появляются в заранее определенном порядке. В качестве альтернативы они могут быть нелинейными, как граф, в котором элементы неупорядочены.
В гомогенных структурах данных все элементы должны быть одного типа, а в гетерогенных структурах могут храниться данные разных типов. Кроме того, структуры данных могут быть либо статическими, с фиксированными размерами и ячейками памяти, либо динамическими, с размерами и ячейками памяти, которые вы можете изменить при необходимости.
Кроме того, структуры данных могут быть либо статическими, с фиксированными размерами и ячейками памяти, либо динамическими, с размерами и ячейками памяти, которые вы можете изменить при необходимости.
Нет однозначного ответа на вопрос, какую структуру данных следует использовать. В зависимости от вашего сценария использования каждая структура данных будет иметь свои плюсы и минусы. Поэтому крайне важно учитывать операции, которые вы будете выполнять с данными, принимая решение о том, какие из них использовать.
Например, несмотря на то, что к любому элементу массива легко получить доступ, используя его индекс, связанные списки лучше подходят для изменения размера элементов. С другой стороны, если вы выберете неподходящую структуру данных, время выполнения может увеличиться или ваш код может перестать отвечать на запросы.
Разработчики обычно учитывают пять факторов при выборе структур данных:
- Тип данных: тип информации, которую вы хотите сохранить
- Вариант использования: как вы будете использовать информацию
- Место: где хранятся данные
- Эффективность: лучший способ организации для легкого доступа
- Хранение: как оптимизировать резервирование хранилища
Структуры данных в системе управления базами данных SQL
SQL, или язык структурированных запросов, является одним из наиболее широко используемых языков программирования для управления и организации реляционных баз данных. База данных SQL состоит из таблиц со строками и столбцами. Разработчики используют SQL для чтения, обработки, доступа и анализа своих данных, чтобы получать ценную информацию и принимать обоснованные решения.
База данных SQL состоит из таблиц со строками и столбцами. Разработчики используют SQL для чтения, обработки, доступа и анализа своих данных, чтобы получать ценную информацию и принимать обоснованные решения.
Эти таблицы являются объектами базы данных, которые можно рассматривать как контейнеры. Вы можете реализовать такие структуры данных, как стеки, очереди и связанные списки (представленные в следующих разделах) на сервере SQL, сервере с базами данных SQL.
Стек
Вы можете реализовать стек на сервере SQL по нескольким причинам. Во-первых, стеки занимают память, что полезно при сбое интерфейса. Вы даже используете их для хранения контрольного журнала, чтобы вы могли исследовать журнал, когда что-то пойдет не так.
Стеки могут быть двух типов: LIFO и FIFO. Вы можете управлять стеком FIFO (First In First Out) с обоих концов, что означает, что вы можете добавлять или удалять элементы спереди и сзади. С другой стороны, вы можете управлять стеком LIFO (Last In First Out) только с одного конца, что означает, что вы можете хранить и извлекать элементы с одной и той же стороны.
Удаление элемента из стека называется извлечением, а добавление в него элемента — помещением в стек. Эти термины появляются часто, поэтому их полезно изучить.
Дерево
Деревья хранят предметы в иерархическом порядке. Каждый узел в дереве связан с дочерним узлом, родительским узлом или обоими. Каждый узел связан со значением ключа, и все они происходят от одного корневого узла.
Древовидная структура SQL полезна, когда данные, которые вы хотите сохранить в базе данных SQL, имеют несколько уровней. Они избавляют нас от необходимости выполнять несколько запросов для каждого узла, чтобы добраться до его дочернего узла. Они также помогают нам получить все данные, создавая структуру в коде.
Одним из распространенных подтипов деревьев являются бинарные деревья. Поисковые приложения и решатели выражений часто используют их. Каждый узел может иметь не более двух дочерних узлов в двоичном дереве.
Широкие таблицы
Широкие таблицы имеют "разреженный столбец" для оптимизированного хранения нулевых значений. Чтобы сделать таблицу широкой, все, что вам нужно сделать, это добавить набор столбцов к ее определению. В этих таблицах может быть до тридцати тысяч столбцов.
Чтобы сделать таблицу широкой, все, что вам нужно сделать, это добавить набор столбцов к ее определению. В этих таблицах может быть до тридцати тысяч столбцов.
Системные таблицы
Информацию об объектах и конфигурациях экземпляров сервера SQL можно хранить в системных таблицах, к которым затем можно получить доступ через системные представления. Системные таблицы доступны в базе данных master и имеют префикс «sys» в своих именах.
Многораздельные таблицы
Данные этих таблиц разделены по горизонтали на блоки, распределенные по одной или нескольким файловым группам в базе данных. Эта структура позволяет легко управлять большими таблицами, поскольку при необходимости можно получить доступ к небольшим фрагментам данных, сохраняя при этом целостность полных данных. По умолчанию на сервере SQL может быть до пятнадцати тысяч разделов.
Временные таблицы (созданы в системной базе данных "tempdb")
Если вам нужно поделиться какими-либо данными на короткий период, вы можете использовать временные таблицы. В SQL-сервере есть два вида временных таблиц: локальные и глобальные. Текущий пользователь может получить доступ только к локальным временным таблицам в рамках существующего подключения к базе данных. Если соединение закрыто, эти таблицы удаляются. Однако вы можете получить доступ к глобальным временным таблицам через любое подключение к базе данных, поскольку они видны любому пользователю, когда кто-то их создает. Глобальные временные таблицы удаляются только тогда, когда закрывается последнее соединение, использующее их.
В SQL-сервере есть два вида временных таблиц: локальные и глобальные. Текущий пользователь может получить доступ только к локальным временным таблицам в рамках существующего подключения к базе данных. Если соединение закрыто, эти таблицы удаляются. Однако вы можете получить доступ к глобальным временным таблицам через любое подключение к базе данных, поскольку они видны любому пользователю, когда кто-то их создает. Глобальные временные таблицы удаляются только тогда, когда закрывается последнее соединение, использующее их.
Хэш-таблица
Хэш-таблицы — это объекты, содержащие пары ключ-значение. Ключ действует как указатель значений и делает поиск значений очень быстрым и удобным. Генерация ключа происходит через хэш-функцию, выполняющую арифметические функции. Сгенерированные «хеш-значения» индексируют хеш-таблицу фиксированного размера.
Только ваше текущее подключение может получить доступ к созданной вами хеш-таблице. Человек, подключающийся к той же базе данных из другого соединения, не может получить к ней доступ.
Таблица кучи
Таблица кучи — это форма или организация данных без кластеризованного индекса, что означает, что строки данных хранятся случайным образом, а не по порядку. Страницы данных, на которых хранятся эти строки, также располагаются в случайном порядке. Когда вам нужно сохранить какие-либо новые данные, вы добавите их в первое доступное и доступное место. Если места для последних данных на какой-либо из страниц недостаточно, в таблице автоматически появятся дополнительные страницы, и вы будете вставлять информацию туда. Если вам нужно каким-либо образом упорядочить данные, вы можете использовать предложение ORDER BY оператора SELECT.
Граф
Граф на сервере SQL представляет собой набор таблиц с узлами и ребрами. Графики находятся в тренде, потому что запросы к высоко связанным данным могут значительно повысить производительность. Вы можете создать один график для каждой базы данных.
Существует несколько разновидностей графиков. Таблица узлов — это таблица, состоящая из узлов одного типа, а набор ребер сходного типа составляет таблицу ребер.
У вас могут быть как ориентированные, так и неориентированные структуры данных графа. Ориентированные графы имеют ребра, которые все указывают в направлении, которое показывает начальный и конечный узлы. Если нет направлений для указания начального и конечного узлов, у вас есть неориентированный граф, и вы можете двигаться в любом направлении. Эти графы также могут иметь узлы без ребер.
Разработчики используют графики для представления маршрутов и местоположений в картографической индустрии. Ребра обозначают маршруты, а узлы представляют местоположения. В современных системах социальных сетей каждый пользователь может считаться узлом. Края формируются, когда пользователи подключаются.
Например, таблица узлов Person будет содержать все узлы Person графа. Таблица ребер Friends будет содержать все ребра, соединяющие одного человека с другим. Краевые таблицы хранят Node ID узлов, где каждое ребро начинается и заканчивается. Кроме того, таблицы узлов содержат информацию об идентификаторе объекта
Кроме того, таблицы узлов содержат информацию об идентификаторе объекта , соответствующем каждому узлу.
Реализация стека FIFO
Теперь давайте посмотрим, как мы можем реализовать структуру данных стека в SQL Server. Следующий пример представляет собой стек FIFO для имитации номеров заказов в ресторане.
Во-первых, нам нужна таблица, которая будет нашим стеком. Мы назовем его OrderLog . Первый заказ в журнале заказов на одном конце кухонной линии будет также первым заказом на другом конце.
СОЗДАТЬ ТАБЛИЦУ [dbo].[OrdeLog] (
[OrderId] [int] NOT NULL,
[TableNumber] [char] (10) NOT NULL
)
ИДТИ
ИЗМЕНИТЬ ТАБЛИЦУ [dbo].[OrderLog] БЕЗ ПРОВЕРКИ ДОБАВИТЬ
ОГРАНИЧЕНИЕ [PK_OrderLog] ПЕРВИЧНЫЙ КЛЮЧ КЛАСТЕРИЗОВАН
(
[Номер заказа]
)
GO Создание структуры таблицы — это первый шаг.
Строки в таблице будут выглядеть примерно так:
OrderId TableNumber 1 А 2 Б 3 А 4 С 5 D
Пример заказов в OrderLog
Далее нам нужны две ключевые операции (push/pop) для структуры данных стека, которые мы реализуем как хранимые процедуры.
СОЗДАТЬ ПРОЦЕДУРУ dbo.FIFO_Push (@TableNumber CHAR (10)) КАК ОБЪЯВИТЬ @OrderId ЦЕЛОЕ ЧИСЛО ВЫБЕРИТЕ ТОП 1 @OrderId = OrderId ИЗ журнала заказов ЗАКАЗАТЬ ПО OrderId DESC ВСТАВИТЬ В OrderLog( OrderId, TableNumber ) VALUES( @OrderId + 1, @TableNumber ) SELECT * FROM OrderLog WHERE OrderId = @OrderId + 1 ИДТИ СОЗДАТЬ ПРОЦЕДУРУ dbo.FIFO_Pop КАК ОБЪЯВИТЬ @OrderId ЦЕЛОЕ ЧИСЛО ВЫБЕРИТЕ ТОП 1 @OrderId = OrderId ИЗ журнала заказов ЗАКАЗАТЬ ПО OrderId SELECT * FROM OrderLog WHERE @OrderId = идентификатор заказа УДАЛИТЬ ИЗ OrderLog, ГДЕ @OrderId = идентификатор заказа ВПЕРЕД
Если вы планируете использовать этот код в производственной среде, вы можете исключить операторы Select из каждой процедуры.
Поскольку у нас есть несколько образцов строк, теперь вы можете сталкивать и сталкивать по желанию.
Внедрение стека LIFO
Внедрение стека LIFO так же просто. Процедура push идентична приведенному выше коду. Единственное изменение заключается в добавлении DESC к строке, которая начинается с «SELECT TOP 1».