Sql unpivot: UNPIVOT | SQL | SQL-tutorial.ru
Содержание
UNPIVOT данных с использованием CROSS JOIN
Зачастую мы получаем данные в предагрегированном виде, когда каждая отдельная колонка является посчитанной метрикой. По аналогии мы получаем подобный результат, когда строим сводную таблицу в Excel и используем некоторое количество фактов для агрегации. Но что делать, если нам нужно произвести обратную операцию — Unpivot?
Как поступить, если в датасете понадобилось трансформировать данные в реляционный вид? В Tableau есть фича Unpivot, которая сделает всё сама: если датасет построен из файла, достаточно выделить нужные колонки и нажать на кнопку «Pivot». А в некоторых диалектах SQL, например, в Transact, уже есть встроенные функции, которые тоже делают это сами.
Но в случае, если датасет построен на Custom SQL Query из базы данных, у которой в арсенале отсутствуют встроенные функции для трансформации в сводную и обратно, необходим какой-то другой подход, и Tableau порекомендует для такой таблицы:
| ID | a | b | c |
| 1 | a1 | b1 | c1 |
| 2 | a2 | b2 | c2 |
Воспользоваться таким стандартным универсальным, но не очень эффективным решением:
select id, ‘a’ AS col, a AS value from yourtable union all select id, ‘b’ AS col, b AS value from yourtable union all select id, ‘c’ AS col, c AS value from yourtable
И в результате получить таблицу вида:
| id | col | value |
| 1 | a | a1 |
| 2 | a | a2 |
| 1 | b | b1 |
| 2 | b | b2 |
| 1 | c | c1 |
| 2 | c | c2 |
Порой, когда мы работаем с физической таблицей и нам надо быстро получить результаты для двух-трех колонок, действительно, подобное решение можно быстро применить, не задумываясь. Однако в случае, когда вместо таблицы содержится, например, сложный подзапрос с несколькими джойнами и нужно сделать Pivot для 5+ колонок, подзапрос вызовется целых 5+ раз, согласитесь, не очень действенно считать одно и тоже неоднократно. Вместо этого можно воспользоваться рецептом с CROSS JOIN, найденным на просторах Stack Overflow:
Однако в случае, когда вместо таблицы содержится, например, сложный подзапрос с несколькими джойнами и нужно сделать Pivot для 5+ колонок, подзапрос вызовется целых 5+ раз, согласитесь, не очень действенно считать одно и тоже неоднократно. Вместо этого можно воспользоваться рецептом с CROSS JOIN, найденным на просторах Stack Overflow:
select t.id,
c.col,
case c.col
when 'a' then a
when 'b' then b
when 'c' then c
end as data
from yourtable t
cross join
(
select 'a' as col
union all select 'b'
union all select 'c'
) cРазберём запрос подробнее. CROSS JOIN — перекрёстное соединение, декартово произведение, или, проще говоря, произведение всех строк со всеми. За ненадобностью в синтаксисе CROSS JOIN отсутствует ON — мы объединяем не по какому-то конкретному полю две таблицы, а сразу по всем существующим строкам.
Сначала мы формируем таблицу со всеми колонками, предназначенными для преобразования в строки. В нашем случае это колонки a, b и c: поэтому мы сделали таблицу c, в которой будет колонка col со значениями a, b и c:
В нашем случае это колонки a, b и c: поэтому мы сделали таблицу c, в которой будет колонка col со значениями a, b и c:
(
select 'a' as col
union all select 'b'
union all select 'c'
) cВыглядит она так:
| col |
| a |
| b |
| c |
Затем таблицы yourtable и c объединятся перекрестным соединением, а после мы возьмём поля id, col и в зависимости от того, как называется ячейка в col, подставим соответствующие данные в поле data.
select t.id,
c.col,
case c.col
when 'a' then a
when 'b' then b
when 'c' then c
end as value
from yourtable t
cross join
(
select 'a' as col
union all select 'b'
union all select 'c'
) cВ итоге получим ту же самую искомую таблицу, с которой уже можно удобно работать любым аналитическим инструментом:
| id | col | value |
| 1 | a | a1 |
| 2 | a | a2 |
| 1 | b | b1 |
| 2 | b | b2 |
| 1 | c | c1 |
| 2 | c | c2 |
PIVOT и UNPIVOT в SQL Server
Вернуться к: Учебное пособие по SQL Server для начинающих и профессионалов
В этой статье я собираюсь обсудить Как реализовать PIVOT и UNPIVOT в SQL Server с примерами. Пожалуйста, прочтите нашу предыдущую статью, в которой мы подробно обсуждали Change Data Capture . PIVOT и UNPIVOT — это два оператора в SQL Server, которые в основном используются для создания многомерных отчетов. Оператор PIVOT используется, когда вы хотите преобразовать данные по строкам в данные по столбцам, а оператор UNPIVOT используется, когда вы хотите преобразовать данные по столбцам в данные по строкам. Прежде чем реализовать поворот и разворот, давайте сначала разберемся, что именно означает поворот.
Пожалуйста, прочтите нашу предыдущую статью, в которой мы подробно обсуждали Change Data Capture . PIVOT и UNPIVOT — это два оператора в SQL Server, которые в основном используются для создания многомерных отчетов. Оператор PIVOT используется, когда вы хотите преобразовать данные по строкам в данные по столбцам, а оператор UNPIVOT используется, когда вы хотите преобразовать данные по столбцам в данные по строкам. Прежде чем реализовать поворот и разворот, давайте сначала разберемся, что именно означает поворот.
Что такое оператор сводки в SQL Server?
Чтобы понять это, мы будем использовать следующую таблицу Customers . Как видите, следующая таблица Customers имеет три столбца ( CustomerName, ProductName и Amount ). В следующей таблице указано, какой клиент принес какие продукты. Некоторые клиенты купили и ноутбуки, и настольные компьютеры, в то время как некоторые клиенты купили либо ноутбук, либо настольный компьютер. Опять несколько клиентов, они купили продукт несколько раз.
Опять несколько клиентов, они купили продукт несколько раз.
Выполните приведенный ниже сценарий SQL, чтобы создать и заполнить таблицу «Клиенты» необходимыми данными.
СОЗДАТЬ ТАБЛИЦУ Клиенты
(
Имя клиента VARCHAR(50),
Название продуктаVARCHAR(50),
Сумма INT
)
ИДТИ
ВСТАВИТЬ В Customers VALUES('Джеймс', 'Ноутбук', 30000)
INSERT INTO Customers VALUES('James', 'Desktop', 25000)
INSERT INTO Customers VALUES('David', 'Laptop', 25000)
INSERT INTO Customers VALUES('Smith', 'Desktop', 30000)
INSERT INTO Customers VALUES('Pam', 'Laptop', 45000)
INSERT INTO Customers VALUES('Pam', 'Laptop', 30000)
INSERT INTO Customers VALUES('John', 'Desktop', 30000)
INSERT INTO Customers VALUES('John', 'Desktop', 30000)
ВСТАВИТЬ В Customers VALUES('Джон', 'Ноутбук', 30000)
Давайте представим приведенные выше данные клиента под другим углом. Например, мы хотим узнать, сколько клиентов купили ноутбуки и сколько клиентов купили настольные компьютеры, как показано на рисунке ниже.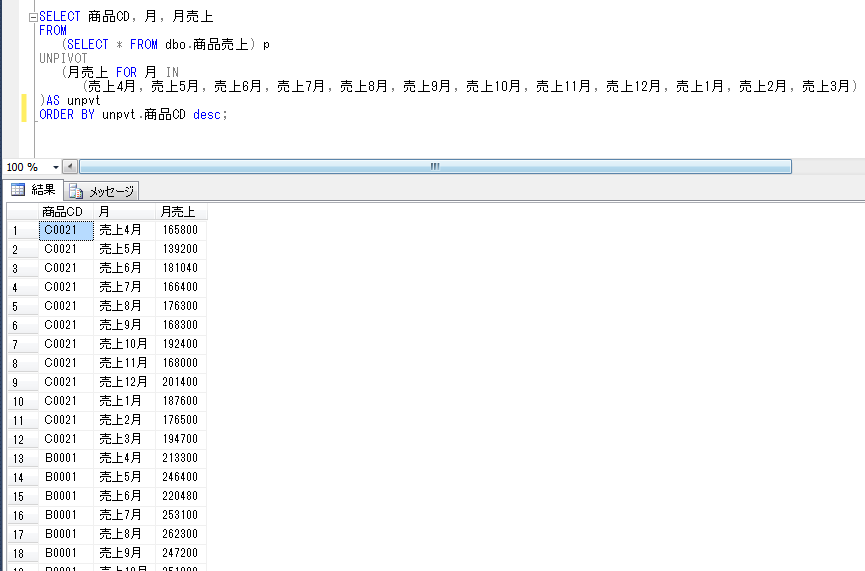 Здесь, на самом деле, мы должны изменить представление строковых данных на столбцовые.
Здесь, на самом деле, мы должны изменить представление строковых данных на столбцовые.
Итак, по сути, мы хотим преобразовать данные по строкам в данные по столбцам. Теперь вопрос в том, как мы можем реализовать это в SQL Server? SQL Server предоставляет одну встроенную функцию под названием Pivot, которую мы можем использовать для преобразования данных по строкам в данные по столбцам.
Как реализовать PIVOT в SQL Server?
Давайте разберемся, как реализовать оператор PIVOT в SQL Server. Чтобы понять Pivot, взгляните на следующее изображение. Как вы можете видеть на изображении ниже, мы разделили сводной код на три части.
Раздел 1:
Раздел 1 содержит оператор выбора, и этот оператор выбора имеет имя столбца, который мы хотим отобразить. В выходных данных нам нужны CustomerName, Laptop и Desktop, поэтому оператор select содержит эти три столбца. Первый столбец (Имя клиента) не является основным, а остальные столбцы являются сводными (ноутбук и настольный компьютер).
Раздел 2:
Этот раздел фактически получает фактические данные, необходимые для сводного отчета. В нашем примере фактические данные — это не что иное, как данные таблицы Customers. Следовательно, как видите, здесь мы используем оператор select для получения данных из таблицы Customers.
Раздел 3:
Это раздел, в котором находится ваша сводная функция. Сначала в функции нам нужно использовать агрегатный метод, такой как SUM, Count и т. д. Здесь мы используем агрегатный метод SUM, и этому методу мы передаем поле Amount, поскольку мы выполняем суммирование в столбце Amount. В предложении For нам нужно передать имя столбца, которое содержит значения, которые будут заголовком столбца. В нашем случае это столбец ProductName. В В предложении нам нужно указать имена сводных столбцов. В нашем примере это ноутбук и настольный компьютер.
Пример: оператор PIVOT
Давайте выполним следующий код и увидим ожидаемый результат.
-- Раздел 1: определение имен столбцов
ВЫБЕРИТЕ имя клиента,
Ноутбук,
Рабочий стол
ОТ
-- Раздел 2: Получите фактические данные
(
ВЫБЕРИТЕ имя клиента,
Наименование товара,
Количество
ОТ клиентов
) КАК сводные данные
-- Section3: Функция Pivot
ВРАЩАТЬСЯ
(
Сумма (сумма) FOR ProductName
IN (ноутбук, рабочий стол)
) КАК сводная таблица
Ниже приведен синтаксис оператора Pivot.
UNPIVOT в SQL Server:
Оператор UNPIVOT выполняет операцию, прямо противоположную операции PIVOT. То есть оператор UNPIVOT превращает СТОЛБЦЫ в СТРОКИ. Давайте разберемся в этом на примере. Мы собираемся использовать следующую таблицу ProductSales, чтобы понять эту концепцию.
Используйте приведенный ниже сценарий SQL, чтобы создать и заполнить таблицу ProductSales необходимыми данными.
Создать таблицу ProductSales
(
Имя Агента VARCHAR(50),
Индия,
США,
Великобритания
)
Идти
ВСТАВЬТЕ В ЗНАЧЕНИЯ ProductSales ("Smith", 9160, 5220, 3360)
ВСТАВЬТЕ В ЗНАЧЕНИЯ ProductSales («Дэвид», 9770, 5440, 8800)
ВСТАВИТЬ В ЗНАЧЕНИЯ ProductSales («Джеймс», 9870, 5480, 8900)
Идти
Давайте визуализируем приведенные выше данные о продажах продуктов с другой точки зрения. Например, мы хотим указать сумму продаж по счетчику для каждого агента, как показано ниже. Здесь, на самом деле, мы должны изменить перспективу столбцовых данных на строковые.
Например, мы хотим указать сумму продаж по счетчику для каждого агента, как показано ниже. Здесь, на самом деле, мы должны изменить перспективу столбцовых данных на строковые.
Здесь нам нужно преобразовать данные по столбцам в данные по строкам. Теперь вопрос в том, как мы можем сделать это в SQL Server? SQL Server предоставляет еще одну встроенную функцию под названием UNPIVOT, которую мы можем использовать для преобразования данных по столбцам в данные по строкам.
Как реализовать UNPIVOT в SQL Server?
Давайте разберемся, как использовать оператор UNPIVOT в SQL Server. Чтобы понять, как использовать UNPIVOT; пожалуйста, взгляните на следующую диаграмму. Как вы можете видеть на изображении ниже, как и в PIVOT, здесь мы также разделили код UNPIVOT на три части.
Раздел 1:
Раздел 1 содержит оператор выбора, и этот оператор выбора имеет имя столбца, которое мы хотим отобразить в сводном отчете. В выходных данных нам нужны AgentName, Country и SalesAmount, поэтому оператор select содержит эти три столбца. Первый столбец (AgentName) — это обычный столбец, а остальные — несводные столбцы (Country и SalesAmount).
В выходных данных нам нужны AgentName, Country и SalesAmount, поэтому оператор select содержит эти три столбца. Первый столбец (AgentName) — это обычный столбец, а остальные — несводные столбцы (Country и SalesAmount).
Раздел 2:
В этот раздел поступают фактические данные из фактической таблицы, необходимые для несводного отчета. В нашем примере фактические данные — это не что иное, как данные таблицы ProductSales. Следовательно, как видите, здесь мы используем оператор select для получения данных из таблицы ProductSales.
Раздел 3:
В этом разделе работает наша функция UNPIVOT. Поскольку нам нужна сумма продаж по стране, мы используем здесь опцию SalesAmount For Country . Поскольку нам нужны значения столбца India, US, UK в качестве заголовка столбца, поэтому здесь мы передаем эти значения столбца в предложение IN.
Пример: оператор UNPIVOT
Пожалуйста, выполните следующий сценарий SQL и посмотрите результат.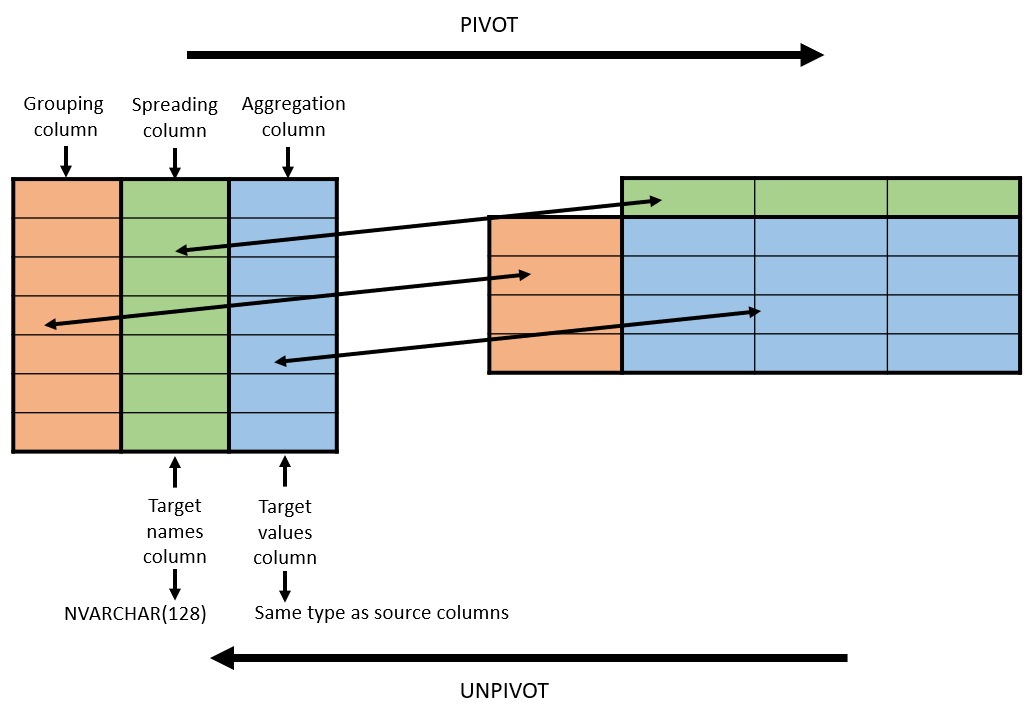
ВЫБЕРИТЕ AgentName, Country, SalesAmount
ОТ
(
ВЫБЕРИТЕ имя агента,
Индия,
НАС,
Великобритания
ОТ ProductSales) AS ActualData
UNPIVOT
(
Объем продаж
ДЛЯ страны В (Индия, США, Великобритания)
) КАК UnpivotData
На сегодня все. В следующей статье я собираюсь обсудить Как перевернуть сводную таблицу в SQL Server с примерами. Здесь, в этой статье, я пытаюсь объяснить , как реализовать PIVOT и UNPIVOT в SQL Server. Я надеюсь, вам понравится эта статья Как реализовать PIVOT и UNPIVOT в SQL Server и вы поймете необходимость и использование PIVOT и UNPIVOT в SQL Server.
Как повернуть и развернуть фрейм данных Spark
Распространить любовь
Функция Spark pivot() используется для поворота/поворота данных из одного столбца DataFrame/Dataset в несколько столбцов (преобразование строки в столбец) и используется разворот преобразовать его обратно (преобразовать столбцы в строки).
В этой статье я объясню, как использовать функцию Pivot() SQL для переноса одной или нескольких строк в столбцы.
Pivot() — это агрегация, в которой значения одного из столбцов группировки перенесены в отдельные столбцы с отдельными данными.
- Pivot Spark DataFrame
- Pivot Повышение производительности в Spark 2.0
- Unpivot Spark DataFrame
- Pivot или Transpose без агрегирования
Давайте создадим DataFrame для работы .
val data = Seq(("Банан",1000,"США"), ("Морковь",1500,"США"), ("Фасоль",1600,"США"),
(«Апельсин», 2000 г., «США»), («Апельсин», 2000 г., «США»), («Банан», 400, «Китай»),
(«Морковь», 1200, «Китай»), («Фасоль», 1500, «Китай»), («Апельсин», 4000, «Китай»),
(«Банан», 2000 г., «Канада»), («Морковь», 2000 г., «Канада»), («Бобы», 2000 г., «Мексика»))
импортировать spark.sqlContext.implicits._
val df = data.toDF («Продукт», «Количество», «Страна»)
df.show ()
DataFrame ‘df’ состоит из 3 столбцов Product, Amount и Country, как показано ниже.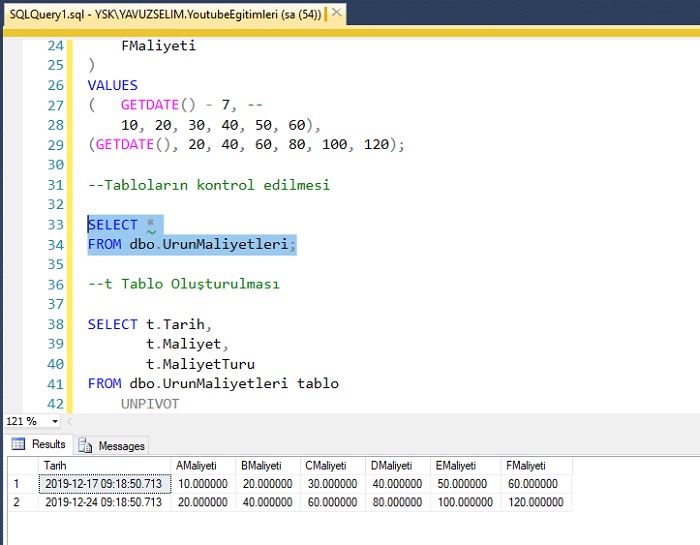
+-------+------+-------+ |Продукт|Сумма|Страна| +-------+------+-------+ | Банан| 1000| США| |Морковь| 1500| США| | Фасоль| 1600| США| | Оранжевый| 2000 | США| | Оранжевый| 2000 | США| | Банан| 400| Китай| |Морковь| 1200| Китай| | Фасоль| 1500| Китай| | Оранжевый| 4000| Китай| | Банан| 2000 | Канада| |Морковь| 2000 | Канада| | Фасоль| 2000 | Мексика| +-------+-----+-------+
PySpark Tutorial For Beginners (Spa…
Включите JavaScript
Учебное пособие по PySpark для начинающих (Spark с Python)
Pivot Spark DataFrame
Spark SQL предоставляет функцию pivot() для ротации данных из одного столбца в несколько столбцов (перенос строки в столбец). Это агрегация, в которой значения одного из столбцов группировки перенесены в отдельные столбцы с отдельными данными. Из приведенного выше DataFrame, чтобы получить общую сумму, экспортированную в каждую страну, для каждого продукта будет выполняться группировка по продуктам, поворот по странам и сумма сумм.
val pivotDF = df.groupBy("Продукт").pivot("Страна").sum("Сумма")
pivotDF.show() Это перенесет страны из строк DataFrame в столбцы и выдаст результат ниже. Там, где данные отсутствуют, по умолчанию они представляются нулевыми.
+-------+------+-----+------+----+ |Продукт|Канада|Китай|Мексика| США| +-------+------+-----+------+----+ | Оранжевый| ноль | 4000| ноль|4000| | Фасоль| ноль | 1500| 2000|1600| | Банан| 2000 | 400| ноль|1000| |Морковь| 2000 | 1200| ноль|1500|
Повышение производительности Pivot в Spark 2.0
Производительность Spark 2.0 и более поздних версий была улучшена в Pivot, однако, если вы используете более раннюю версию; обратите внимание, что поворот — очень дорогая операция, поэтому рекомендуется предоставлять данные столбца (если они известны) в качестве аргумента для работы, как показано ниже.
val countrys = Seq("США","Китай","Канада","Мексика")
val pivotDF = df.groupBy("Продукт").pivot("Страна", страны). sum("Сумма")
PivotDF.show ()
sum("Сумма")
PivotDF.show ()
 sum("Сумма")
PivotDF.show ()
sum("Сумма")
PivotDF.show ()
Другой подход заключается в двухэтапной агрегации. Spark 2.0 использует эту реализацию для повышения производительности Spark-13749.
val pivotDF = df.groupBy("Продукт","Страна")
.сумма("Сумма")
.groupBy("Продукт")
.pivot("Страна")
.sum("сумма(сумма)")
PivotDF.show ()
Два приведенных выше примера возвращают тот же результат, но с большей производительностью.
Unpivot Spark DataFrame
Unpivot — это обратная операция, которую мы можем выполнить, превратив значения столбцов в значения строк. В Spark SQL нет функции unpivot, поэтому будет использоваться функция stack() . Ниже код преобразует страны столбца в строку.
// развернуть
val unPivotDF = pivotDF.select($"Продукт",
expr("stack(3, 'Канада', Канада, 'Китай', Китай, 'Мексика', Мексика) как (Страна, Итого)"))
.where("Итого не равно нулю")
unPivotDF.show() Преобразует сводную колонку «страна» в строки.