Sql запросов основы: Основные команды SQL, которые должен знать каждый программист
Содержание
Обработка запросов для таблиц, оптимизированных для памяти — SQL Server
-
Статья -
- Чтение занимает 12 мин
-
Применимо к: SQL Server (все поддерживаемые версии) Azure SQL Управляемый экземпляр SQL Azure базы данных
В SQL ServerIn-Memory OLTP вводятся оптимизированные для памяти таблицы и скомпилированные в собственном коде хранимые процедуры. В данной статье приводится обзор обработки запросов для таблиц, оптимизированных для памяти, и хранимых процедур, скомпилированных в собственном коде.
Документ поясняет процесс компиляции и выполнения запросов к таблицам, оптимизированным для памяти, включая:
канал обработки запросов в SQL Server для дисковых таблиц;
оптимизацию запросов, роль статистических данных в таблицах, оптимизированных для памяти, а также рекомендации по решению проблем, связанных с неоптимальными планами запросов;
Использование интерпретированного Transact-SQL для доступа к оптимизированным для памяти таблицам.

аспекты оптимизации запросов для доступа к таблицам, оптимизированным для памяти;
компиляция и обработка хранимых процедур, скомпилированных в собственном коде;
статистические данные, которые используются для оценки затрат оптимизатора;
способы исправления неоптимальных планов запросов;

Пример запроса
Следующий пример иллюстрирует концепции обработки запросов, рассматриваемые в данной статье.
Мы рассмотрим две таблицы, Customer и Order. Следующий скрипт Transact-SQL содержит определения для этих двух таблиц и связанных индексов в их (традиционной) форме на основе диска:
CREATE TABLE dbo.[Customer] ( CustomerID nchar (5) NOT NULL PRIMARY KEY, ContactName nvarchar (30) NOT NULL ) GO CREATE TABLE dbo.[Order] ( OrderID int NOT NULL PRIMARY KEY, CustomerID nchar (5) NOT NULL, OrderDate date NOT NULL ) GO CREATE INDEX IX_CustomerID ON dbo.[Order](CustomerID) GO CREATE INDEX IX_OrderDate ON dbo.
 [Order](OrderDate)
GO
[Order](OrderDate)
GO
Для конструирования планов запросов, показанных в данной статье, две таблицы были заполнены примерами данных из учебной базы данных Northwind, которую можно загрузить по следующий ссылке: Образцы баз данных Northwind и pubs для SQL Server 2000.
Рассмотрим следующий запрос, который выполняет соединение таблиц Customer и Order и возвращает идентификатор заказа и связанную с ним информацию о клиенте:
SELECT o.OrderID, c.* FROM dbo.[Customer] c INNER JOIN dbo.[Order] o ON c.CustomerID = o.CustomerID
Предполагаемый план выполнения в соответствии с отображением в SQL Server Management Studio следующий:
План запроса для соединения дисковых таблиц.
О данном плане запроса:
строки из таблицы Customer получены из кластеризованного индекса, который представляет собой основную структуру данных и содержит все данные таблицы;
данные из таблицы Order получены с помощью некластеризованного индекса в столбце CustomerID.
Этот индекс содержит столбец CustomerID, который используется для соединения, и столбец первичного ключа OrderID, который возвращается пользователю. Для возвращения дополнительных столбцов из таблицы Order потребуется поиск по кластеризованному индексу для таблицы Order.Логический оператор Inner Join реализован в форме физического оператора Merge Join. Остальные физические типы соединений — это Nested Loops и Hash Join. В операторе Merge Join используется то обстоятельство, что оба индекса отсортированы по столбцу соединения CustomerID.
 Этот индекс содержит столбец CustomerID, который используется для соединения, и столбец первичного ключа OrderID, который возвращается пользователю. Для возвращения дополнительных столбцов из таблицы Order потребуется поиск по кластеризованному индексу для таблицы Order.
Этот индекс содержит столбец CustomerID, который используется для соединения, и столбец первичного ключа OrderID, который возвращается пользователю. Для возвращения дополнительных столбцов из таблицы Order потребуется поиск по кластеризованному индексу для таблицы Order.Рассмотрим немного другую версию этого запроса, которая возвращает все столбцы из таблицы Order, а не только столбец OrderID:
SELECT o.*, c.* FROM dbo.[Customer] c INNER JOIN dbo.[Order] o ON c.CustomerID = o.CustomerID
Предполагаемый план выполнения для этого запроса:
план запроса для хэш-соединений дисковых таблиц.
В этом запросе строки из таблицы заказов получаются с помощью кластеризованного индекса. Физический оператор Hash Match теперь используется для Inner Join. Кластеризованный индекс в таблице Order не отсортирован по столбцу CustomerID, поэтому для Merge Join потребуется оператор сортировки, который повлияет на производительность запроса. Обратите внимание на относительную стоимость оператора Hash Match (75 %) по сравнению с затратами оператора Merge Join в предыдущем примере (46 %). Оптимизатором также рассматривался оператор Hash Match из предыдущего примера, но оказалось, что оператор Merge Join обеспечивает лучшую производительность.
SQL Server Обработка запросов для дисковых таблиц
На следующей диаграмме показан поток обработки запросов в SQL Server для нерегламентированных запросов:
Канал обработки запросов в SQL Server.
В этом сценарии:
Пользователь выполняет запрос.
Средство синтаксического анализа и алгебризер создают дерево запросов с логическими операторами на основе текста Transact-SQL, отправленного пользователем.
Оптимизатор создает оптимизированный план запроса, содержащий физические операторы (например, соединения вложенных циклов). После оптимизации план может храниться в кэше планов. Это действие пропускается, если кэш планов уже содержит план для этого запроса.
Подсистема выполнения запросов обрабатывает интерпретацию плана запроса.
Для каждого оператора поиска в индексе, просмотра индекса и просмотра таблицы подсистема выполнения запрашивает строки из соответствующего индекса и табличных структур у методов доступа.
Методы доступа получают строки из индекса и страниц данных в буферном пуле, и по мере необходимости загружают страницы из диска в буферный пул.

В первом примере запроса подсистема выполнения запрашивает у методов доступа строки в кластеризованном индексе таблицы Customer и в некластеризованном индексе таблицы Order. Чтобы получить запрашиваемые строки, методы доступа обходят индексные структуры сбалансированного дерева. В этом случае извлекаются все строки после полного просмотра индексов в соответствии с планом.
Чтобы получить запрашиваемые строки, методы доступа обходят индексные структуры сбалансированного дерева. В этом случае извлекаются все строки после полного просмотра индексов в соответствии с планом.
Примечание
В документации по SQL Server термин «сбалансированное дерево» обычно используется в отношении индексов. В индексах rowstore SQL Server реализует B+-дерево. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в руководстве по архитектуре и разработке индексов SQL Server.
Интерпретируемый доступ Transact-SQL к таблицам Memory-Optimized
Нерегламентированные пакеты и хранимые процедуры Transact-SQL также называются интерпретированными Transact-SQL. Термин «интерпретируемый» означает, что план запроса интерпретируется подсистемой выполнения запросов для каждого оператора в плане запроса. Подсистема выполнения считывает оператор и его параметры и выполняет операцию.
Интерпретируемый Transact-SQL можно использовать для доступа к оптимизированным для памяти таблицам и таблицам на диске. На следующем рисунке показана обработка запросов для интерпретированного доступа Transact-SQL к оптимизированным для памяти таблицам:
На следующем рисунке показана обработка запросов для интерпретированного доступа Transact-SQL к оптимизированным для памяти таблицам:
Конвейер обработки запросов для доступа к оптимизированным для памяти таблицам с помощью интерпретируемого кода Transact-SQL.
Как показано на рисунке, конвейер обработки запросов в основном остается неизменным:
средство синтаксического анализа и алгебризатор строят дерево запроса;
оптимизатор запросов создает план выполнения;
подсистема выполнения запроса интерпретирует план выполнения;
Основное отличие от традиционного конвейера обработки запросов (рис. 2) заключается в том, что строки для оптимизированной для памяти таблицы получаются из буферного пула при помощи методов доступа. Вместо этого строки извлекаются из структур данных в памяти с помощью подсистемы In-Memory OLTP. Из-за различий в структурах данных оптимизатор в некоторых случаях выбирает разные планы, как показано в следующем примере.
Следующий скрипт Transact-SQL содержит оптимизированные для памяти версии таблиц Order и Customer с использованием хэш-индексов:
CREATE TABLE dbo.[Customer] ( CustomerID nchar (5) NOT NULL PRIMARY KEY NONCLUSTERED, ContactName nvarchar (30) NOT NULL ) WITH (MEMORY_OPTIMIZED=ON) GO CREATE TABLE dbo.[Order] ( OrderID int NOT NULL PRIMARY KEY NONCLUSTERED, CustomerID nchar (5) NOT NULL INDEX IX_CustomerID HASH(CustomerID) WITH (BUCKET_COUNT=100000), OrderDate date NOT NULL INDEX IX_OrderDate HASH(OrderDate) WITH (BUCKET_COUNT=100000) ) WITH (MEMORY_OPTIMIZED=ON) GO
Тот же запрос, выполненный к таблицам, оптимизированным для памяти:
SELECT o.OrderID, c.* FROM dbo.[Customer] c INNER JOIN dbo.[Order] o ON c.CustomerID = o.CustomerID
Предполагаемый план:
План запроса для соединения таблиц, оптимизированных для памяти.
Изучите следующие отличия от плана для того же запроса к дисковым таблицам (рисунок 1):
Этот план для таблицы Customer содержит операцию просмотра таблицы, а не просмотра кластеризованного индекса.
Определение таблицы не содержит кластеризованный индекс.
Кластеризованные индексы для таблиц, оптимизированных для памяти, не поддерживаются. Вместо этого каждая оптимизированная для памяти таблица должна содержать по крайней мере один некластеризованный индекс, а все индексы для оптимизированных в памяти таблиц могут эффективно получать все столбцы таблицы без сохранения их в индексе или ссылки на кластеризованный индекс.
Этот план содержит оператор Hash Match , а не Merge Join. Индексы в таблицах Order и Customer представляют собой хэш-индексы и, следовательно, не упорядочены. Оператор Merge Join потребовал бы добавления операторов сортировки, которые вызвали бы снижение производительности запроса.
скомпилированные в собственном коде хранимые процедуры
Скомпилированные в собственном коде хранимые процедуры Transact-SQL — это хранимые процедуры Transact-SQL, которые компилируются в машинный код, а не интерпретируются обработчиком выполнения запросов.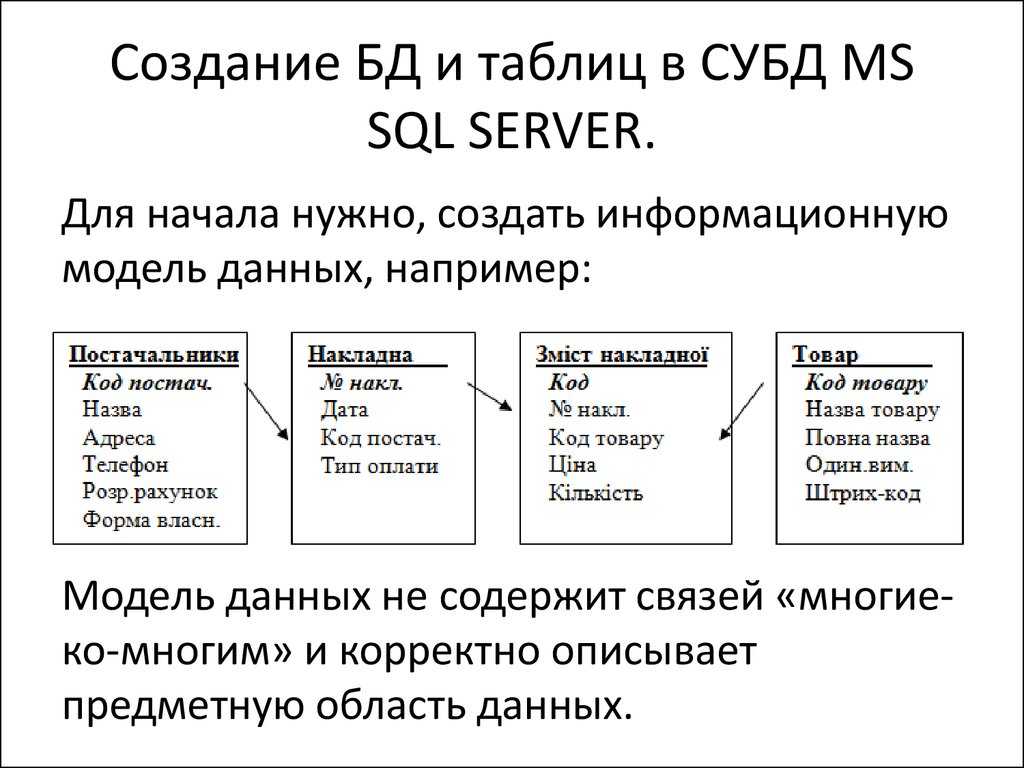 Следующий скрипт создает скомпилированную в собственном коде хранимую процедуру, которая выполняет пример запроса (из раздела «Пример запроса»).
Следующий скрипт создает скомпилированную в собственном коде хранимую процедуру, которая выполняет пример запроса (из раздела «Пример запроса»).
CREATE PROCEDURE usp_SampleJoin WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = 'english') SELECT o.OrderID, c.CustomerID, c.ContactName FROM dbo.[Order] o INNER JOIN dbo.[Customer] c ON c.CustomerID = o.CustomerID END
Скомпилированные в собственном коде хранимые процедуры компилируются при создании, а интерпретируемые хранимые процедуры компилируются в ходе первого выполнения. (Часть компиляции, особенно синтаксический анализ и алгебризация, происходит при создании. Однако для интерпретируемых хранимых процедур оптимизация планов запросов выполняется при первом выполнении.) Логика перекомпиляции аналогична. При первом выполнении процедуры после перезапуска сервера выполняется перекомпиляция скомпилированных в собственном коде хранимых процедур. Интерпретируемые хранимые процедуры повторно компилируются, если в кэше планов отсутствует план запроса. В следующей таблице объединены случаи компиляции и повторной компиляции для скомпилированных в собственном коде и интерпретируемых хранимых процедур.
Интерпретируемые хранимые процедуры повторно компилируются, если в кэше планов отсутствует план запроса. В следующей таблице объединены случаи компиляции и повторной компиляции для скомпилированных в собственном коде и интерпретируемых хранимых процедур.
| Тип компиляции | Скомпилированные в собственном коде | Доступ к оптимизированным для памяти таблицам с помощью интерпретируемого кода |
|---|---|---|
| Первичная компиляция | При создании. | При первом выполнении. |
| Автоматическая повторная компиляция | При первом выполнении процедуры после перезапуска базы данных или сервера. | При перезапуске сервера. Либо при вытеснении из кэша планов, обычно вследствие изменений схемы или статистических данных или нагрузки на память. |
| Повторная компиляция вручную | Используйте sp_recompile. | Используйте sp_recompile. Можно вручную удалить план из кэша при помощи инструкции DBCC FREEPROCCACHE. Можно также создать хранимую процедуру с параметром WITH RECOMPILE; такая хранимая процедура будет повторно компилироваться при каждом выполнении. Можно также создать хранимую процедуру с параметром WITH RECOMPILE; такая хранимая процедура будет повторно компилироваться при каждом выполнении. |
Компиляция и обработка запросов
На следующей диаграмме показан процесс компиляции для скомпилированных в собственном коде хранимых процедур:
Компиляция хранимых процедур в собственном коде.
Описание процесса
Пользователь выполняет инструкцию CREATE PROCEDURE в отношении SQL Server.
Средство синтаксического анализа и алгебризатор создают поток обработки для процедуры, а также деревья запросов для запросов Transact-SQL в хранимой процедуре.
Оптимизатор запросов создает оптимизированные планы выполнения запросов для всех запросов в данной хранимой процедуре.
Компилятор In-Memory OLTP принимает поток обработки с внедренными оптимизированными планами запросов и создает библиотеку DLL, которая содержит машинный код для выполнения хранимой процедуры.
Созданная библиотека DDL загружается в память.

Вызов хранимой процедуры, скомпилированной в собственном коде, транслируется в вызов функции из библиотеки DLL.
Выполнение хранимых процедур, скомпилированных в собственном коде.
Описание вызова хранимой процедуры, скомпилированной в собственном коде:
Пользователь выполняет инструкцию EXECusp_myproc .
Средство синтаксического анализа извлекает имя и параметры хранимой процедуры.
Если инструкция подготовлена, например, с помощью sp_prep_exec, анализатору не придется извлекать имя процедуры и параметры во время выполнения.
Среда выполнения In-Memory OLTP находит точки входа библиотеки DLL для хранимой процедуры.
Машинный код в DLL выполняется, и результаты возвращаются клиенту.
Пробное сохранение параметров
Интерпретированные хранимые процедуры Transact-SQL компилируются при первом выполнении, в отличие от скомпилированных в собственном коде хранимых процедур, которые компилируются во время создания.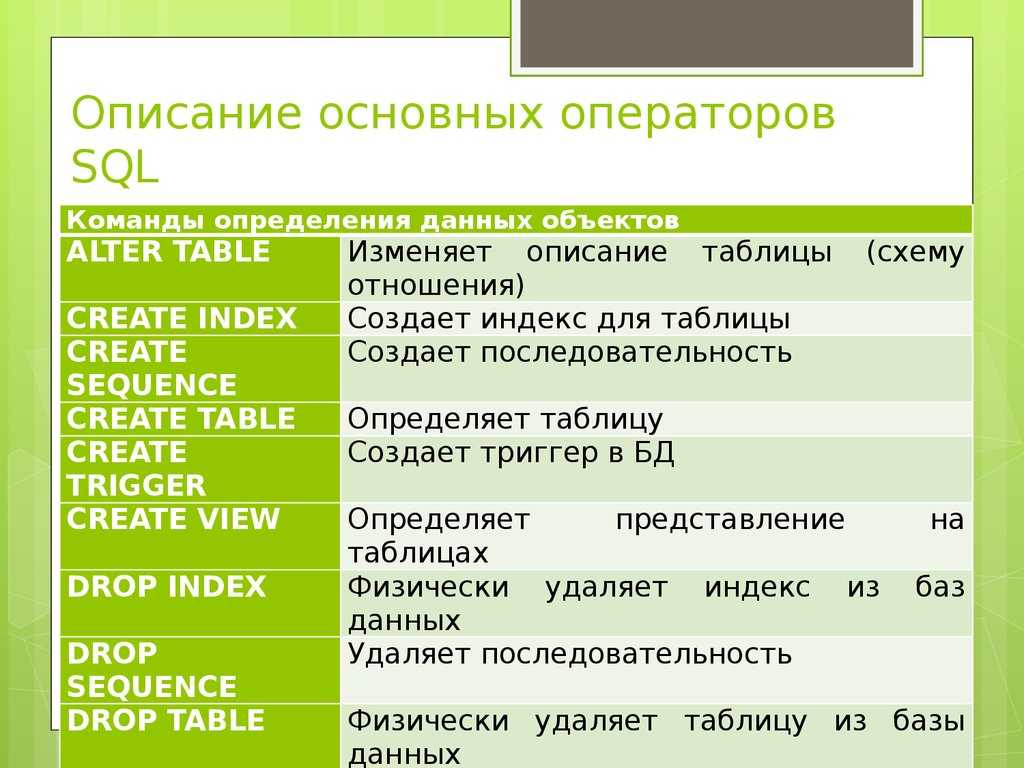 Если интерпретируемые хранимые процедуры компилируются при вызове, значения параметров, указанные для этого вызова, используются оптимизатором для создания плана выполнения. Такое использование параметров в процессе компиляции называется пробным сохранением параметров.
Если интерпретируемые хранимые процедуры компилируются при вызове, значения параметров, указанные для этого вызова, используются оптимизатором для создания плана выполнения. Такое использование параметров в процессе компиляции называется пробным сохранением параметров.
Пробное сохранение параметров не используется для компиляции хранимых процедур, скомпилированных в собственном коде. Предполагается, что у всех параметров хранимой процедуры значения UNKNOWN (неизвестны). Как и интерпретируемые хранимые процедуры, скомпилированные в собственном коде хранимые процедуры также поддерживают указание OPTIMIZE FOR . Дополнительные сведения см. в разделе Указания запросов (Transact-SQL).
Получение плана выполнения запроса для скомпилированных в собственном коде хранимых процедур
План выполнения запроса для скомпилированной в собственном коде хранимой процедуры можно получить с помощью предполагаемого плана выполнения в Management Studio или с помощью параметра SHOWPLAN_XML в Transact-SQL. Пример:
Пример:
SET SHOWPLAN_XML ON GO EXEC dbo.usp_myproc GO SET SHOWPLAN_XML OFF GO
План выполнения, созданный с помощью оптимизатора запросов, состоит из дерева с операторами запроса на узлах и конечных узлах дерева. Структура дерева определяет механизм взаимодействия (поток строк от одного оператора к другому) между операторами. В графическом представлении SQL Server Management Studioизображен поток справа налево. Например, план запроса в диаграмме 1 содержит два оператора просмотра индекса, которые передают строки оператору соединения слиянием. Оператор соединения слиянием merge join передает строки оператору выбора select. Наконец, оператор Select возвращает строки клиенту.
Операторы запросов в хранимых процедурах, скомпилированных в собственном коде
В следующей таблице перечислены операторы запросов, которые поддерживаются в хранимых процедурах, скомпилированных в собственном коде.
| Оператор | Пример запроса | Примечания |
|---|---|---|
| SELECT | SELECT OrderID FROM dbo. | |
| INSERT | INSERT dbo.Customer VALUES ('abc', 'def') | |
| UPDATE | UPDATE dbo.Customer SET ContactName='ghi' WHERE CustomerID='abc' | |
| DELETE | DELETE dbo.Customer WHERE CustomerID='abc' | |
| Compute Scalar | SELECT OrderID+1 FROM dbo.[Order] | Этот оператор используется как для встроенных функций, так и для преобразований типов. Не все функции и преобразования типов поддерживаются в хранимых процедурах, скомпилированных в собственном коде. |
| Соединение вложенными циклами | SELECT o.OrderID, c.CustomerID FROM dbo.[Order] o INNER JOIN dbo.[Customer] c | Nested Loops — единственный оператор соединения, который поддерживается в хранимых процедурах, скомпилированных в собственном коде. Все планы, содержащие соединения, будут использовать оператор вложенных циклов, даже если план для одного и того же запроса, выполняемого как интерпретируемый Transact-SQL, содержит хэш-соединение или соединение слиянием. |
| Сортировка | SELECT ContactName FROM dbo.Customer ORDER BY ContactName | |
| TOP | SELECT TOP 10 ContactName FROM dbo.Customer | |
| Оператор Top-sort | SELECT TOP 10 ContactName FROM dbo.Customer ORDER BY ContactName | Выражение TOP (количество возвращаемых строк) не может превышать 8000 строк. Если в запросе есть операторы объединения и агрегирования, то строк должно быть еще меньше. Соединения и агрегатные выражения обычно уменьшают количество строк для сортировки в сравнении с количеством строк в базовых таблицах. |
| Статистическое выражение потока | SELECT count(CustomerID) FROM dbo.Customer | Обратите внимание, что оператор Hash Match для статической обработки не поддерживается. Поэтому все агрегаты в скомпилированных в собственном коде хранимых процедурах используют оператор Stream Aggregate, даже если план для одного и того же запроса в интерпретируемом Transact-SQL использует оператор Hash Match. |
 [Order]
[Order]SQL Server ведет статистику значений в ключевых столбцах индекса, что позволяет оценить стоимость отдельных операций, таких как просмотр индекса и поиск в индексе. (SQL Server также создает статистику по ключевым столбцам вне индекса, если они создаются явно или если оптимизатор запросов создает их в ответ на запрос с предикатом.) Основной показатель в оценке стоимости — количество строк, обрабатываемых одним оператором. Обратите внимание, что для дисковых таблиц количество страниц, к которым обращается конкретный оператор, является существенным для оценки стоимости. Тем не менее, поскольку количество страниц не имеет значения для таблиц, оптимизированных для памяти (оно всегда равно нулю), мы сосредоточимся на количестве строк. Оценка начинается с операторов поиска в индексе и просмотра индекса в плане, а затем дополняется другими операторами, например, операторами соединения. Предполагаемое количество строк, которые будет обрабатывать оператор соединения, основано на оценке базовых операторов поиска и просмотра индекса. Для интерпретированного доступа Transact-SQL к оптимизированным для памяти таблицам можно просмотреть фактический план выполнения, чтобы увидеть разницу между предполагаемыми и фактическими числами строк для операторов в плане.
Для интерпретированного доступа Transact-SQL к оптимизированным для памяти таблицам можно просмотреть фактический план выполнения, чтобы увидеть разницу между предполагаемыми и фактическими числами строк для операторов в плане.
Например, на рисунке 1
- Оператор просмотра кластеризованного индекса в таблице Customer: предполагаемое количество — 91; реальное — 91;
- Просмотр некластеризованного индекса в CustomerID: предполагаемое 830, реальное 830.
- Оператор соединения слиянием: предполагаемое 815; реальное 830.
Оценки для оператора просмотра индекса являются точными. SQL Server поддерживает количество строк для дисковых таблиц. Оценки для всей таблицы и просмотра индекса всегда являются точными. Оценки для соединений также достаточно точные).
Если эти оценки изменяются, расчеты стоимости для различных вариантов плана также изменяются. Например, если один из участников соединения имеет предполагаемое количество строк 1 или всего несколько строк, использование соединений вложенными циклами является менее дорогостоящим. Обратите внимание на следующий запрос:
Обратите внимание на следующий запрос:
SELECT o.OrderID, c.* FROM dbo.[Customer] c INNER JOIN dbo.[Order] o ON c.CustomerID = o.CustomerID
После удаления всех строк, кроме одной строки в таблице Customer, создается следующий план запроса:
Относительно этого плана запроса:
- Оператор Hash Match был заменен на физический оператор соединения Nested Loops.
- Полный просмотр индекса в IX_CustomerID заменен поиском по индексу. В результате для полного просмотра индекса было просмотрено 5 строк вместо 830.
См. также:
Таблицы, оптимизированные для памяти
SQL
Язык запросов SQL — это язык, который позволяет общаться с реляционными базами данных. Иначе говоря, с помощью этого языка можно управлять базами данных: создавать и удалять базы данных, таблицы, записи. Также с помощью SQL можно делать выборки записей из таблиц базы данных и выводить их, к примеру, в окно браузера.
Этот язык используется в ПО MySQL, поэтому знать его надо обязательно.
Совершенно, очевидно, что работа с базой данных немыслима без языка запросов, коим является SQL. И в этой категории сайта Вы сможете познакомиться со всеми необходимыми командами. А после знакомства Вы сможете совершенно спокойно писать самые разнообразные запросы на SQL, и база данных станет для Вас не каким-то страшным словом, а таким же привычным и понятным, как термин «таблица умножения».
Полный курс по PHP и MySQL: http://srs.myrusakov.ru/php
Прочитав статьи по SQL, Вы узнаете:
1) SQL-запросы необходимые для управления пользователями.
2) SQL-запросы для создания и удаления баз данных.
3) SQL-запросы необходимые для работы с таблицами.
4) SQL-запросы на добавление записей в таблицу.
5) SQL-запросы для выборки записей из таблицы.
6) SQL-запросы необходимые для создания индекса.
7) SQL-запрос для выборки определённого числа записей.
8) SQL-запрос для сортировки результата выборки.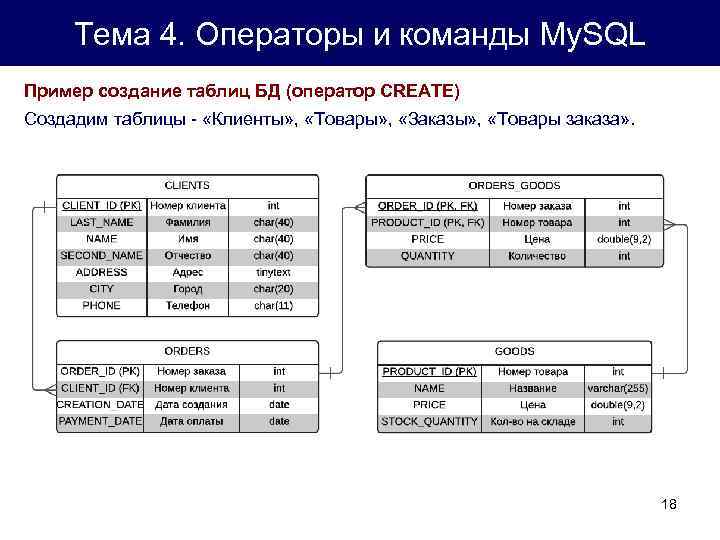
9) Об использовании конструкции WHERE в SQL.
10) О SQL-запросе на выборку записей сразу из нескольких таблиц.
11) Об решении одной из самых популярных причин неработоспособности SQL-запроса.
12) Как узнать количество записей в SQL-выборке.
13) Как сделать поиск по базе данных с сортировкой по релевантности.
14) Как увеличить значение поля на 1 через SQL.
15) Как сделать двойную сортировку в SQL-запросе.
16) Об использовании UNION в SQL-запросе.
17) О CONCAT в SQL-запросе.
18) Об использовании JOIN в SQL.
19) Как узнать размеры таблицы через SQL.
20) Как сделать сортировку сначала по одному полю, а затем по другому.
21) Как найти ошибку в SQL-запросе.
22) Как извлечь случайные записи из таблицы.
23) О GROUP BY в SQL-запросе.
24) О HAVING в SQL-запросе.
25) Оператор BETWEEN в SQL запросе.
26) Оператор IN в SQL запросе.
27) Функции MIN и MAX в SQL.
28) Как выбрать неповторяющиеся записи из базы данных на SQL.
29) Как узнать длину поля в SQL.
30) Как игнорировать вставку дублирующихся записей в SQL.
31) Как найти подстроку в строке на SQL.
32) Как заменить значение в строке на SQL.
33) Какие математические функции есть в SQL.
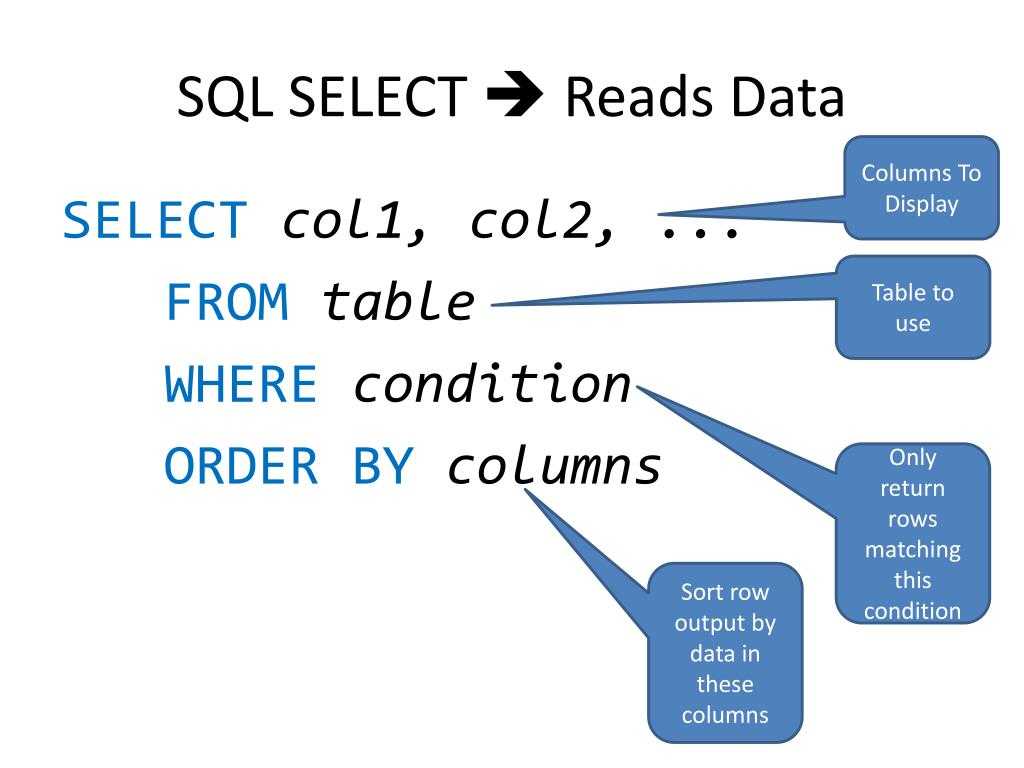
34) Оператор SELECT языка запросов SQL.
35) SQL запросы к базе данных. Часть #1.
36) SQL запросы к базе данных. Часть #2.
37) SQL запросы к базе данных. Часть #3.
38) SQL запросы к базе данных. Часть #4.
Все материалы по языку SQL
SQL Tuperial — Geeksforgeeks
Пропустить контент
Соглашение
- Напишите опыт интервью
Напишите статью
Relational Model (Relational Algebra, Tuple Calculus)
4
Relational Model (Relational Algebra, Tuple Calculus)
444444.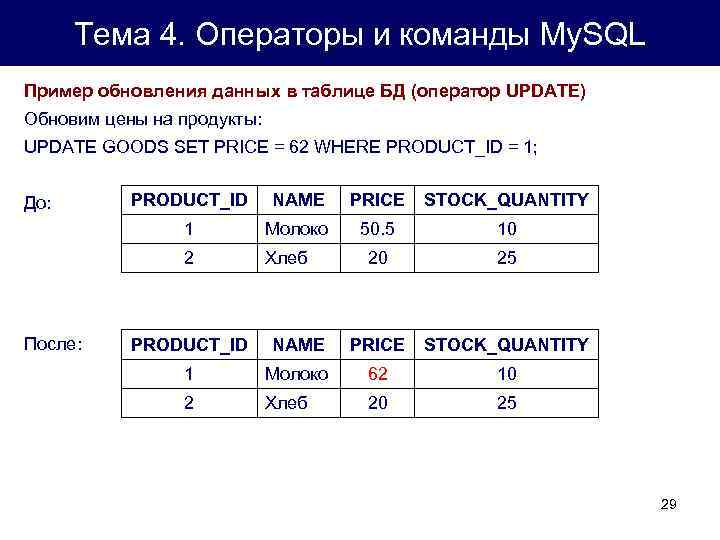 ограничения, нормальные формы)
ограничения, нормальные формы)
Транзакции и управление параллелизмом
Файловые структуры (последовательные файлы, индексирование, деревья B и B+)
Викторина по СУБД
Вопросы DBMS GATE
- Последнее обновление:
28 марта, 2022
S Tructured Q UERY
S TURCTURED Q UERY
S Q UERY
S Q UERY S Q UERY S Q UERY
S Q UERY
S Q 9. язык, который используется для создания, обслуживания и извлечения данных из реляционных баз данных, таких как MySQL, Oracle, SQL Server, PostGre и т. д. Последней стандартной версией SQL для ISO является SQL: 2019. .
.
Как следует из названия, он используется, когда у нас есть структурированные данные (в виде таблиц). Все базы данных, которые не являются реляционными (или не используют таблицы с фиксированной структурой для хранения данных) и, следовательно, не используют SQL, называются базами данных NoSQL. Примерами NoSQL являются MongoDB, DynamoDB, Cassandra и т. д.
Связанные курсы:
SQL или язык структурированных запросов — наиболее важный язык для изучения, чтобы получить работу в области анализа данных или наук о данных. К этому курсу может присоединиться любой, кто заинтересован в изучении SQL! Теперь выберите это SQL Foundation — курс для самостоятельного изучения из любой точки мира в любое время и изучение основ SQL с глубоким пониманием тем от отраслевых экспертов. Начните свое путешествие по SQL сегодня!
«Недавние статьи» на SQL
Тема:
- Основы
- Клаузы / Операторы
- Функции
- QUERIES
- SQL-INGEU0012 Разное
- Быстрые ссылки
Основы:
Предложения/операторы:
- SQL | Оператор WITH
- SQL | Со связями Статья
- SQL | Арифметические операторы
- SQL | Операторы подстановочных знаков
- SQL | Предложение Intersect & Except
- SQL | USING Статья
- SQL | Оператор MERGE
- Оператор MERGE в SQL Объяснение
- SQL | Команды DDL, DML, DCL и TCL
- SQL | СОЗДАТЬ ДОМЕН
- SQL | Оператор DESCRIBE
- SQL | Заявление о случае
- SQL | УНИКАЛЬНОЕ ограничение
- SQL | Создать расширение таблицы
- SQL | ИЗМЕНИТЬ (ПЕРЕИМЕНОВАТЬ)
- SQL | ALTER (ДОБАВИТЬ, УДАЛИТЬ, ИЗМЕНИТЬ)
- SQL | LIMIT Пункт
- SQL | Оператор INSERT IGNORE
- SQL | НРАВИТСЯ
- SQL | НЕКОТОРЫЕ
- SQL | OFFSET-FETCH Пункт
- SQL | За исключением пункта
- . Объединение агрегированных и неагрегированных значений в SQL с использованием пункта 9 Joins and Over.0013
- SQL | ВСЕ и ЛЮБЫЕ
- SQL | СУЩЕСТВУЕТ
- SQL | СГРУППИРОВАТЬ ПО
- SQL | Пункт Союза
- SQL | Псевдонимы
- SQL | ЗАКАЗАТЬ ПО
- SQL | SELECT TOP Пункт
- SQL | ОБНОВЛЕНИЕ Заявление
- SQL | Оператор DELETE
- SQL | Оператор INSERT INTO
- SQL | Операторы И и ИЛИ
- SQL | ГДЕ Пункт
- SQL | Отличительная статья
- SQL | ВЫБЕРИТЕ Запрос
- SQL | КАПЛЯ, ОБРЕЗНАЯ
- SQL | СОЗДАТЬ
- SQL | Соединение (декартово соединение и самосоединение)
- SQL | Альтернативный оператор котировок
- SQL | Оператор конкатенации
- SQL | МИНУС Оператор
- SQL | ОТДЕЛ
- SQL | НЕ Оператор
- SQL | МЕЖДУ И В Оператор
- SQL | Соединение (внутреннее, левое, правое и полное соединение)
- SQL | ПРОВЕРИТЬ Ограничение
 Объединение агрегированных и неагрегированных значений в SQL с использованием пункта 9 Joins and Over.0013
Объединение агрегированных и неагрегированных значений в SQL с использованием пункта 9 Joins and Over.0013Внедрение SQL:
Функции:
- SQL | Математические функции (КВАДРАТ, ПИ, КВАДРАТ, ОКРУГЛ, ПОТОЛОК И ПОЛ)
- SQL | Функция преобразования
- Общие функции SQL | NVL, NVL2, DECODE, COALESCE, NULLIF, LNNVL и NANVL
- SQL | Условные выражения
- SQL | Символьные функции с примерами
- SQL | Функции даты (Set-1)
- SQL | Функции даты (Set-2)
- SQL | СПИСОК
- SQL | Агрегатные функции
- SQL | Функции (агрегатные и скалярные функции)
- SQL | Функции даты
- SQL | НУЛЕВОЙ
- SQL | Числовые функции
- SQL | Строковые функции
- SQL | Advanced Functions
Queries:
PL/SQL:
MySQL:
SQL Server:
Misc:
- SQL using Python | Установите 1
- SQL с помощью Python и SQLite | Установить 2
- SQL с помощью Python | Набор 3 (обработка больших данных)
- Проверить наличие таблиц, представлений, триггеров и т. д. в Oracle
- Выполнение операций с базой данных в Java | SQL CREATE, INSERT, UPDATE, DELETE и SELECT
- Разница между простым и сложным представлением в SQL
- Разница между статическим и динамическим SQL
- Наличие предложения «Где»?
- Внутреннее соединение и внешнее соединение
- Разница между SQL и NoSQL
 д. в Oracle
д. в OracleБыстрые ссылки:
Улучшите свои навыки кодирования с помощью практики
Мы используем файлы cookie, чтобы обеспечить вам лучший опыт просмотра нашего веб-сайта. Используя наш сайт, вы
подтверждаете, что вы прочитали и поняли наши
Политика в отношении файлов cookie и
Политика конфиденциальности
Начните свое путешествие по программированию прямо сейчас!
Учебное пособие по SQL — javatpoint
следующий → Учебник SQL содержит базовые и расширенные понятия SQL. Наш учебник по SQL предназначен как для начинающих, так и для профессионалов. SQL (язык структурированных запросов) используется для выполнения операций с записями, хранящимися в базе данных, таких как обновление записей, вставка записей, удаление записей, создание и изменение таблиц базы данных, представлений и т. д. SQL — это не система баз данных, а язык запросов. Предположим, вы хотите выполнять запросы языка SQL к сохраненным данным в базе данных. В ваших системах требуется установить любую систему управления базами данных, например, Oracle, MySQL, MongoDB, PostgreSQL, SQL Server, DB2 и т. д. Что такое SQL?SQL — это краткая форма языка структурированных запросов, которая произносится как S-Q-L или иногда как See-Quell. Этот язык базы данных в основном предназначен для обслуживания данных в системах управления реляционными базами данных. Это специальный инструмент, используемый специалистами по данным для обработки структурированных данных (данных, которые хранятся в виде таблиц). Он также предназначен для потоковой обработки в RDSMS. Вы можете легко создавать базу данных и управлять ею, получать доступ и изменять строки и столбцы таблицы и т. д. Этот язык запросов стал стандартом ANSI в 1986 году и ISO в 1987 году. Если вы хотите получить работу в области науки о данных, то это самый важный язык запросов для изучения. Крупные предприятия, такие как Facebook, Instagram и LinkedIn, используют SQL для хранения данных в серверной части. Почему SQL?В настоящее время SQL широко используется в науке о данных и аналитике. Ниже приведены причины, объясняющие его широкое использование:
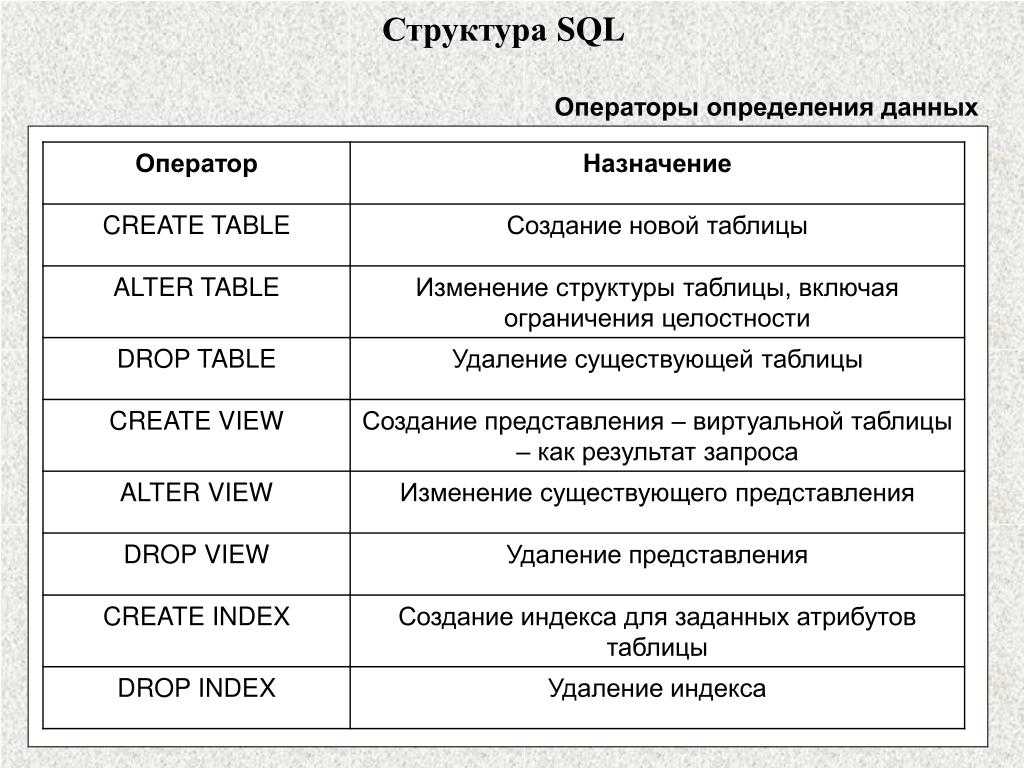
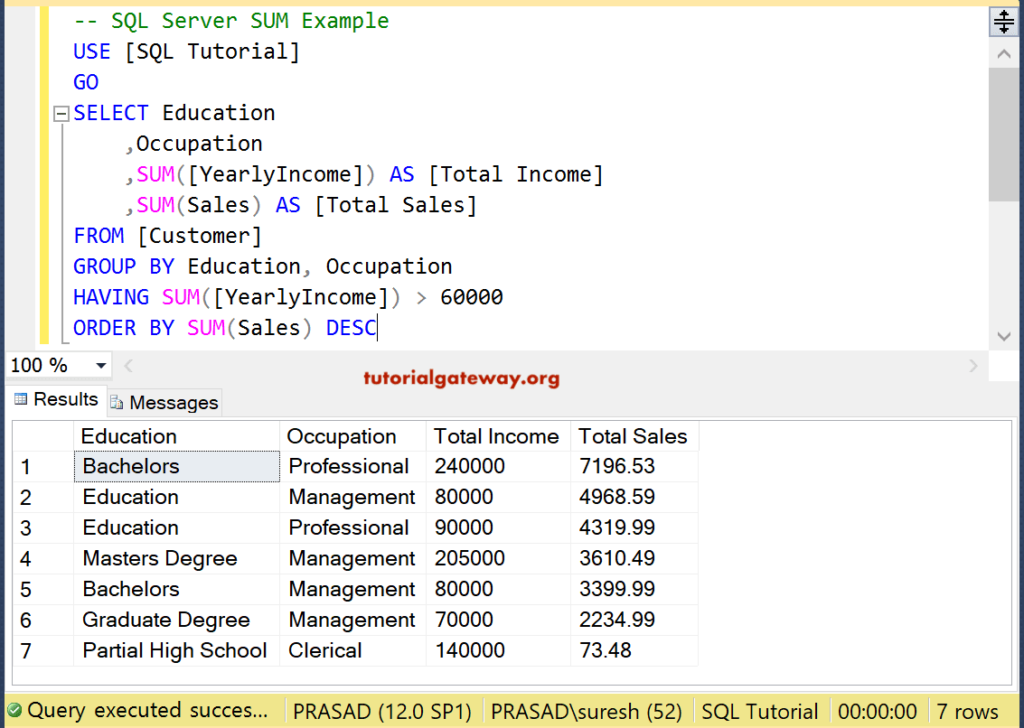
История SQL«Реляционная модель данных для больших общих банков данных» — статья, опубликованная великим ученым-компьютерщиком Э. Ф. Коддом в 1970 году. Исследователи IBM Рэймонд Бойс и Дональд Чемберлин первоначально разработали SEQUEL (язык структурированных английских запросов) после изучения статьи, предоставленной Э. Ф. Коддом. Они оба разработали SQL в исследовательской лаборатории корпорации IBM в Сан-Хосе в 1919 году.70. В конце 1970-х компания Relational Software Inc. разработала свой первый SQL, используя концепции Э. Ф. Кодда, Рэймонда Бойса и Дональда Чемберлина. Этот SQL был полностью основан на СУБД. Процесс SQLКогда мы выполняем команду SQL в любой системе управления реляционной базой данных, система автоматически находит наилучшую процедуру для выполнения нашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную команду. Язык структурированных запросов содержит в своем процессе следующие четыре компонента:
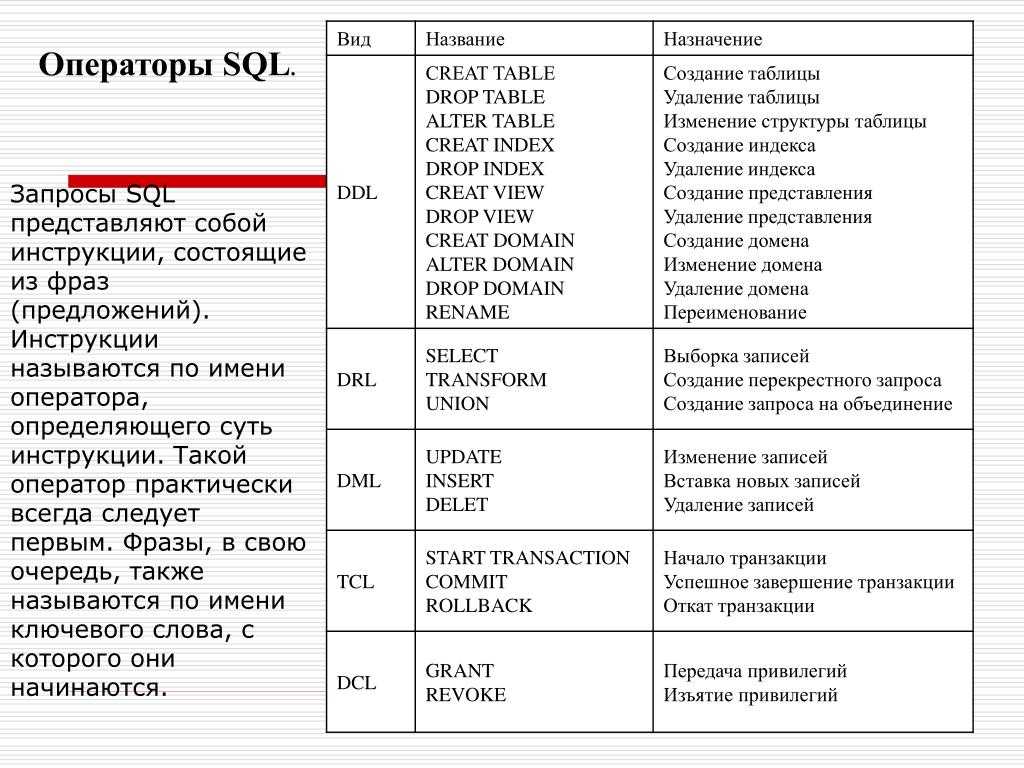
Классический механизм запросов позволяет специалистам по данным и пользователям выполнять запросы, отличные от SQL. Архитектура SQL показана на следующей диаграмме: Некоторые команды SQL Команды SQL помогают в создании базы данных и управлении ею.
Команда СОЗДАТЬЭта команда помогает создать новую базу данных, новую таблицу, табличное представление и другие объекты базы данных. Команда ОБНОВЛЕНИЯЭта команда помогает обновить или изменить сохраненные данные в базе данных. Команда УДАЛИТЬЭта команда помогает удалить или стереть сохраненные записи из таблиц базы данных. Он стирает один или несколько кортежей из таблиц базы данных. Команда ВЫБОРЭта команда помогает получить доступ к одной или нескольким строкам из одной или нескольких таблиц базы данных. Мы также можем использовать эту команду с предложением WHERE. Команда DROP Эта команда помогает удалить всю таблицу, табличное представление и другие объекты из базы данных. Команда ВСТАВИТЬЭта команда помогает вставлять данные или записи в таблицы базы данных. Мы можем легко вставлять записи как в одну, так и в несколько строк таблицы. SQL противбез SQL В следующей таблице описаны различия между SQL и NoSQL, которые необходимо понимать:
Преимущества SQLSQL предоставляет различные преимущества, которые делают его более популярным в области науки о данных. Это идеальный язык запросов, который позволяет специалистам по данным и пользователям общаться с базой данных. Ниже приведены лучшие преимущества языка структурированных запросов: . 1. Программирование не требуется SQL не требует большого количества строк кода для управления системами баз данных. Мы можем легко получить доступ к базе данных и поддерживать ее, используя простые синтаксические правила SQL. Эти простые правила делают SQL удобным для пользователя. 2. Высокоскоростная обработка запросов Быстрый и эффективный доступ к большому объему данных из базы данных с помощью запросов SQL. Операции вставки, удаления и обновления данных также выполняются за меньшее время. 3. Стандартизированный язык SQL соответствует давно установленным стандартам ISO и ANSI, которые предлагают единую платформу по всему миру для всех своих пользователей. 4. Мобильность Язык структурированных запросов можно легко использовать на настольных компьютерах, ноутбуках, планшетах и даже смартфонах. Его также можно использовать с другими приложениями в соответствии с требованиями пользователя. 5. Интерактивный язык Мы можем легко выучить и понять язык SQL. Мы также можем использовать этот язык для связи с базой данных, потому что это простой язык запросов. Этот язык также используется для получения ответов на сложные запросы за несколько секунд. |


 Relational Software Inc., известная сейчас как Oracle Corporation, представила Oracle V2 в июне 1979 года, которая является первой реализацией языка SQL. Эта версия Oracle V2 работает на компьютерах VAX.
Relational Software Inc., известная сейчас как Oracle Corporation, представила Oracle V2 в июне 1979 года, которая является первой реализацией языка SQL. Эта версия Oracle V2 работает на компьютерах VAX.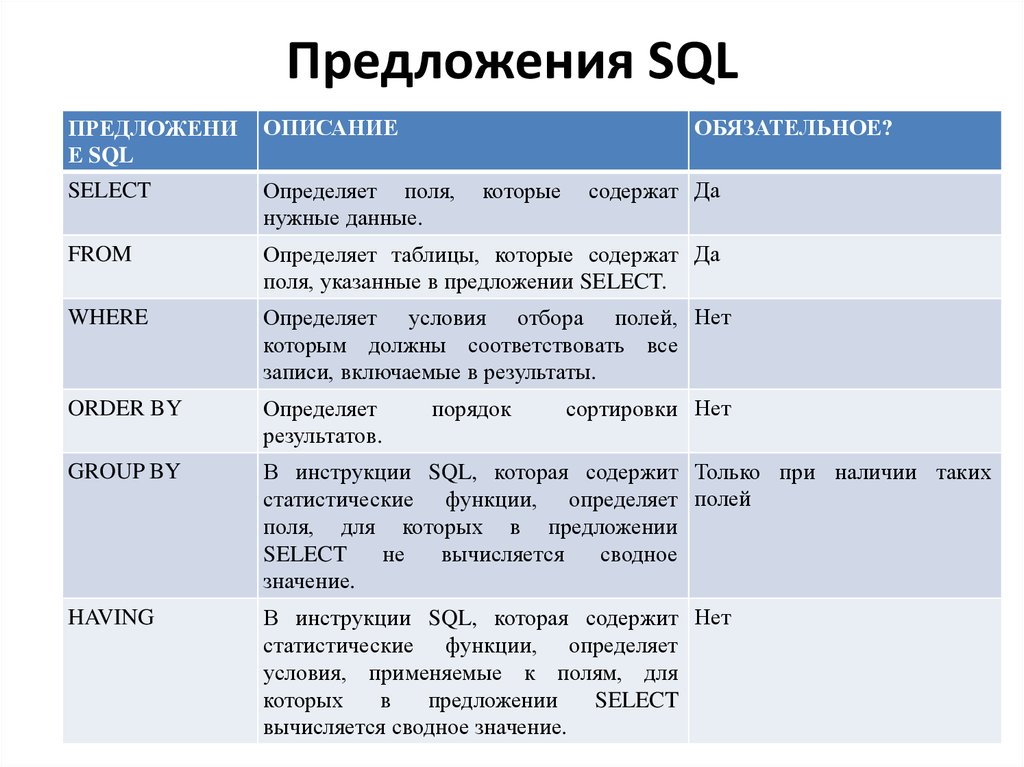 Наиболее часто используемые команды SQL перечислены ниже:
Наиболее часто используемые команды SQL перечислены ниже:
 Эти базы данных можно масштабировать по вертикали.
Эти базы данных можно масштабировать по вертикали. д. являются ведущими предприятиями, использующими этот язык запросов.
д. являются ведущими предприятиями, использующими этот язык запросов.