Sql запросы select: SELECT SQL примеры и синтаксис SQL запроса SELECT
Содержание
Что такое SQL и как работает SELECT — Кирилл Гуськов product практик на vc.ru
Кому и зачем?
31
просмотров
Представьте себе, что
- вам нужно написать (или прочитать — мало ли кто его уже написал, но надо же разобраться как это работает) запрос к таблице или базе данных.
- Вы никогда этого не делали (сами), но задача кажется не настолько сложной и достаточно важной чтобы воспользоваться случаем и наконец
- разобраться что же это за SELECT такой, про который так много и часто слышно со всех сторон.
Что и кто?
SQL — это язык (стандарт) структурированных запросов. Запросов, очевидно, к базе данных, точнее, к её таблицам. Да, речь идёт о реляционных базах данных, состоящих из таблиц (отношений — relation). Под таблицей понимается множество записей (строк, рядов — row) одинаковой структуры, то есть состоящих из определённого набора полей (элементов столбцов — column).
Наверное самый популярный (известный широкой аудитории) запрос — это SELECT, возвращающий содержимое таблицы (в том числе, виртуальной — составленной из других таблиц и результатов других запросов) полностью (то самое, ставшее мемом SELECT * FROM a_table;) или частично (здесь всё сложнее, в том числе и с мемами). Логика его работы проста и изящна, а возможностей уточнения (структуры) запроса достаточно для того чтобы анализировать данные и представлять результаты в удобном виде.
Где и с чем?
Существует множество источников, подробно излагающих структуру и синтаксис SELECT, поэтому ограничимся общими наблюдениями и рассуждениями о логике обработки данных.
Для начала традиционно определимся с дефинициями (определениями), а точнее с сущностями, о которых хотим порассуждать, или которые понадобятся для рассуждений.
- Исходные данные (таблица — одна или несколько). Напомним, что таблица — это набор записей (строк) одинаковой структуры. Исходные данные, как правило, где-то хранятся, например, в базе данных.

- Виртуальная таблица, в отличие от той, что представляет собой исходные данные — временная сущность, возникающая в результате обработки исходных данных.
- Виртуальной таблицей, например, является результат выполнения SELECT, и данные, поступающие запросу на вход. Кстати, попытайтесь себе представить размер и структуру виртуальной таблицы из следующего примера (SELECT * FROM a_table, una_tabla;), если кома (запятая) эквивалентна CROSS JOIN, который в свою очередь суть декартово произведение.Так что, если вы перфекционист, не забывайте старину Декарта и не злоупотребляйте запятыми.
- Агрегатом назовём результат агрегации (агрегирования) данных таблицы (исходной или виртуальной), то есть виртуальную таблицу, полученную путём объединения или группировки её записей (всех, или некоторых, или даже по группам).
- Агрегат можно получить в результате выполнения запроса SELECT, использующего агрегатные функции и/или модификатор GROUP BY. В случае группировки, агрегатом уместно называть как всю совокупность полученных записей так и (если это требуется) каждую из записей
- Модификатором назовём условие выбора записей таблицы, поступающей на вход SELECT или способ их обработки (например, вышеупомянутый GROUP BY).

 В случае группировки, агрегатом уместно называть как всю совокупность полученных записей так и (если это требуется) каждую из записей
В случае группировки, агрегатом уместно называть как всю совокупность полученных записей так и (если это требуется) каждую из записейКак?
Как же работает SELECT? Принцип очень простой — на вход поступает таблица (напомним: множество записей (строк) одинаковой структуры), некоторые строки которой могут быть исключены из рассмотрения или сгруппированы с помощью модификаторов (например, WHERE, GROUP BY, HAVING). На выход отправляется таблица, структура строк которой (содержимое полей — столбцов) явно описана между SELECT и FROM. Это могут быть все (*) или некоторые (явно указанные) столбцы входной таблицы, а также (явно описанные) выражения или агрегаты, вычисленные на основе этих столбцов.
Почему?
В чём же мощь (и причина популярности) этого (такого простого на первый взгляд) инструмента? Рискнём предположить, что помимо простой логики (см. предыдущий раздел), мощь SELECT обеспечивается широкими возможностями объединения и группировки (в том числе, с применением агрегирования) данных. За объединение “отвечает” JOIN, а за всё остальное (помимо GROUP BY и более продвинутых модификаторов) — агрегатные (в том числе, оконные) функции.
предыдущий раздел), мощь SELECT обеспечивается широкими возможностями объединения и группировки (в том числе, с применением агрегирования) данных. За объединение “отвечает” JOIN, а за всё остальное (помимо GROUP BY и более продвинутых модификаторов) — агрегатные (в том числе, оконные) функции.
Оставим подробности для отдельных эссе, приведя лишь несколько примеров:
- C помощью JOIN можно, например, обогащать исходную таблицу данными из другой, например, из таблицы-справочника.
- По простому (например): таблицу объектов, привязанных к субъектам (по идентификатору субъекта) можно обогатить данными из справочника субъектов. А если таблица объектов используется только для привязки к субъектам, а подробная информация об объектах хранится в справочнике объектов (IMHO, это правильный (высокий) стиль), то можно добавить в JOIN и побольше информации о каждом объекте.
- С помощью агрегатных оконных функций можно сегментировать и кластеризовать данные, заодно вычисляя необходимые метрики, характеризующие сегменты.
- Ту же таблицу объектов из предыдущего абзаца можно сгруппировать по принадлежности к субъекту, которых в свою очередь можно сегментировать по какому-то из их параметров (мало ли характеристик субъекта может содержаться в справочнике). Да и объекты внутри группы по субъектам можно кластеризовать по какой-нибудь ещё характеристике самого объекта.

Опрос:
Захотелось ли вам научиться писать SQL запросы?
— Да! Я и не думал, что это так увлекательно!
— Да, но не раньше, чем выйдет обещанное продолжение про JOIN и агрегатные функции.
— Читать и понимать — скорее да, писать самому — наверное нет.
— Нет. Всё сложно и ничего не понятно. Ещё и Декарта вспомнили!
SQL-запросы. Нужно ли перечислять конкретные поля в SELECT?
-
Категория:
Код -
– Автор:
Игорь (Администратор)
В рамках данной статьи про SQL-запросы, я расскажу вам про то, нужно ли перечислять конкретные поля в SELECT, а так же какие при этом могут быть нюансы.
Базы данных предоставляют массу полезных возможностей, для облегчения процесса написания sql-запросов. Однако, периодически их бездумное применение может весьма заметно сказываться на производительности и возникновении ошибок. Это же касается и оператора SELECT с возможностью получить все поля выборки, только указав символ * (звездочка).
Конечно, когда речь идет о выборке небольшой таблицы с парой десятков строк и простейшими столбцами, то нет никакой необходимости перечислять поля в запросе. А уж если поля такой таблицы генерируются по мере необходимости, то звездочка сильно упрощает процесс получения данных, ведь нет никакой необходимости на серверной стороне заниматься рутинной задачей получения информации о колонках таблицы и составления динамического запроса.
Однако, всегда существуют ситуации, где необдуманное применение выборки всех полей может если не привести к ошибкам, то сказаться на производительности. И далее я приведу пару примеров в порядке — вначале простой и предугадываемый, затем более сложный.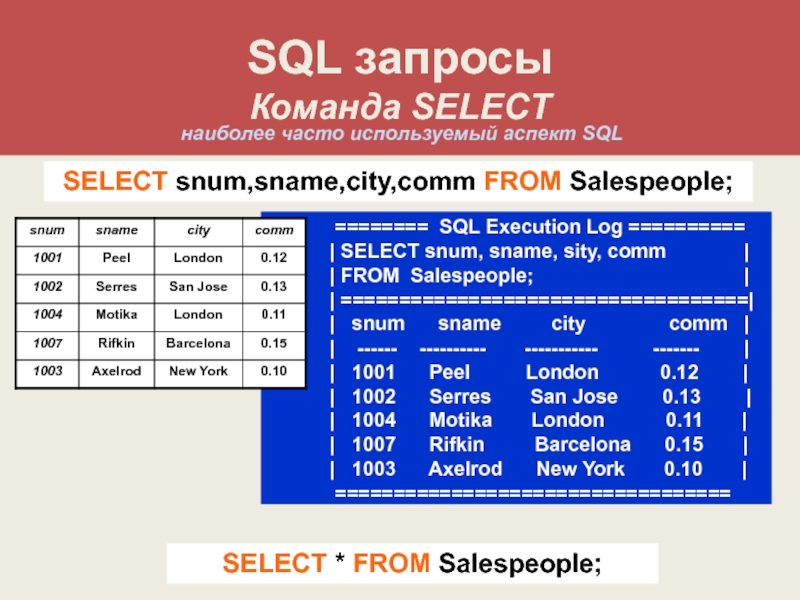
Но, прежде, чем рассказывать, введем небольшую вводную. Представьте, что у вас есть две таблицы. Например, продукты и категории. Считаем, что продукт может быть только в одной категории. Вот так выглядят эти две таблицы.
Таблица продуктов:
| product_id | cat_id | name | desc |
|---|---|---|---|
| 1 | 1 | Продукт 1 | Длинное описание |
| … | … | … | Длинное описание |
| N | X | Продукт Z | Длинное описание |
Таблица категорий:
| cat_id | name | desc |
|---|---|---|
| 1 | Категория 1 | Длинное описание |
| … | … | Длинное описание |
| Z | Категория Z | Длинное описание |
Вполне себе стандартные таблицы. А теперь, попробуем рассмотреть разные запросы для получения данных.
А теперь, попробуем рассмотреть разные запросы для получения данных.
Первая ситуация. SQL-запрос для получения полных данных по каждому продукту. Если в такой ситуации вы не будете перечислять поля, а используете в SELECT звездочку, то в зависимости о БД и серверного кода, вы можете столкнуться с рядом проблем. Вот запрос.
-- Получим все поля сразу select * from `product` p join `cat` c on cat.cat_id = p.cat_id
Если вы запустите этот SELECT в админке БД, то никаких ошибок не появится и вы получите все товары с их категориями. Однако, если же вы попытаетесь использовать классы с динамическим присваиванием имен полей, например, в PHP, то возникнут проблемы. Дело в том, что колонки «name» и «desc» повторяются у таблиц. Это означает, что в результате при получении данных значения полей в том же PHP будут заменяться. К примеру, вместо описаний продуктов вы получите описания категорий.
Примечание: Стоит знать, что в зависимости от драйверов и типа БД, данный запрос может интерпретироваться по разному и так же результаты могут быть разными, но в большинстве своем они все будут приводить к ошибкам.
Если же вы перечислите поля и используете возможность указания названия полей в результатах SELECT, то с такой ошибкой вы не столкнетесь:
-- Получим нужные поля select p.product_id, p.name, p.desc, c.cat_id, c.name as cat_name, c.desc as cat_desc from `product` p join `cat` c on cat.cat_id = p.cat_id
Как видите, такой select запрос уже не приведет к проблемам на серверной стороне.
Примечание: Стоит понимать, что несмотря на то, что пример простой, в больших БД со сложной структурой такая мелочь может привести к существенным ошибкам.
Вторая ситуация. SQL-запросы для получения значений справочников. Каждый знаком с выпадающими списками. Чаще всего они используются в админках сайтов и, порой, во всяких формах обратной связи. Представим себе как раз ситуацию с некой формой, где вам нужно указывать отдельно товар и отдельно категорию. Чаще всего в такой ситуации используют два следующих запроса:
-- Получим все поля продукта select * from `product` -- Получим все поля категории select * from `cat`
Несмотря на то, что выглядят эти SQL-запросы вполне логичными, их применение может серьезно сказываться на производительности. И вот почему это происходит.
И вот почему это происходит.
Когда у вас десяток строк в каждой таблице и сайт посещает сотня другая человек в день, то каких-то проблем не будет. Однако, если записей хотя бы 1000 и поля с описаниями заполнены хорошими объемными статьями в среднем по 3000 символов, то при большой посещаемости вы можете получать тормоза, несмотря на то, что задача элементарна.
Дело в том, что используя оператор * (звездочка) в SELECT, вы говорите БД, чтобы она вытаскивала не только нужные вам данные (идентификатор и название), но и все описания. А это значит, что каждый запрос потребует дополнительного возвращать по 3 Мб данных (1000 * 3000). Т.е. для отображения формы вам нужно дополнительно формировать 6 Мб данных. Что же будет, если хотя бы сотня пользователей откроет вашу страничку? Правильно, вначале БД придется передавать веб-серверу, а затем веб-серверу придется передавать браузерам пользователей 600 Мб!!!! ненужных данных.
Примечание: Конечно, стоит знать, что БД предусматривают кэш запросов, ровно как и некоторые классы серверных приложений, однако на производительности это все равно сказывается.
Решается же эта проблема легко и элементарно:
-- Получим нужные поля продукта select `product_id`, `name` from `product` -- Получим нужные поля категории select `cat_id`, `name` from `cat`
Вроде бы указали всего пару полей, но в такой ситуации, БД уже не будет передавать эти 6 Мб лишних данных и пользователи не будут наблюдать тормоза на сайте.
Как видите, используя возможности SQL-запросов, того же SELECT и * (звездочки), всегда стоит задумываться о здравом смысле.
☕ Понравился обзор? Поделитесь с друзьями!
- SQL-запросы. SELECT, JOIN, WHERE и математика
- PHP — массивы и несколько хитростей
Добавить комментарий / отзыв
Оператор SQL SELECT, часть IV. В этой статье мы узнаем о SQL… | Мрунали Патил
Чтение: 4 мин.
·
20 мая 2020 г.
В этой статье мы узнаем об операторе SQL SELECT. Итак, давайте начнем…
- Язык структурированных запросов (SQL) — это язык запросов, с помощью которого мы можем общаться с базой данных.
- Он может определять структуру данных, изменять данные в базе данных, а также задавать ограничения безопасности.
- SQL состоит из нескольких частей: —

I. Язык определения данных (DDL)
II. Язык управления данными (DML)
I. Язык определения данных (DDL): —
SQL DDL предоставляет команды для определения структур таблиц, удаления таблиц и изменения структур таблиц. Сюда входят такие запросы, как создание таблицы, удаление таблицы, изменение таблицы и т. д.
II. Язык манипулирования данными (DML): —
SQL DML предоставляет возможность запрашивать информацию из базы данных и вставлять кортежи, удалять кортежи и изменять кортежи в базе данных. Он включает такие запросы, как вставка, обновление, удаление и извлечение данных из таблиц базы данных.
SELECT — это оператор DML в SQL.
Синтаксис оператора SELECT: —
SELECT ColumnName(s) FROM TableName
Здесь оператор select выбирает столбцы, указанные вместо столбца(ов) из таблицы, указанной в Имя таблицы и отображение результат.
Пример: —
Оператор SELECT для отображения всех записей: —
- Для извлечения всех данных и отображения всех записей из таблицы используется символ «*». Символ «*» указывает на все.
Синтаксис: —
SELECT * FROM TableName
Выводит все столбцы и кортежи из указанного TableName.
Пример: —
Оператор SELECT с предложением WHERE: —
- Оператор SELECT также помогает получить определенные данные из таблицы. Для этого используется предложение WHERE. Он указывает условие, из которого мы хотим получить данные из таблицы.
Синтаксис: —
SELECT * FROM TableName
WHERE Condition
Пример: —
Оператор SELECT с числовым и строковым значением: — 9 0061
Есть два способа получить данные из таблицы с помощью предложения where. Это: —
Это: —
- Числовой: —
Если вам нужны данные из таблицы, то вы даете условие. При задании условия просто дает условный оператор и условие в виде номеров формы, таких как идентификатор, зарплата и т. д., используя это нам нужны ваши запрошенные записи.
Пример: —
2. Строка: —
Хотя нам нужны данные из таблицы, и мы задаем условие в виде строкового значения, затем поместите эту условную строку в одинарные кавычки (») .
Пример: —
ВЫБЕРИТЕ определенные столбцы с псевдонимом: —
Пример: —
- В приведенном выше примере выходная таблица как имя столбца, указанное в запросе выбора.
- Но иногда это не понимают.
- Итак, для этого мы даем новое имя столбца тому же столбцу.
- Это называется алиас. Псевдоним используется с ключевым словом «AS».
Пример:-
Оператор подстановочной карты:-
- Оператор подстановочной карты используется для получения строки соответствия шаблону.
- Используется с оператором LIKE для поиска соответствующей строки.
- Для оператора подстановочных знаков синтаксис : —

SELECT * FROM TableName
WHERE ColumnName LIKE ‘PatternMatchingString’
- Пример 1: —
- Пример 2:-
- Inner Join помогает отображать только совпадающие записи из обеих таблиц.
- Левое объединение выбирает все записи из левой таблицы и только совпадающие записи из правой таблицы и отображает.
- Правое объединение выбирает все записи из правой таблицы и только совпадающие записи из левой таблицы и отображает.
9 0021
Выбрать с внутренним соединением:-
Синтаксис: —
ВЫБЕРИТЕ имя(я) столбца(я) ИЗ Таблицы1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Таблица2 ON Table1.ColumnName=Table2.ColumnName;
Пример:-
Выбор с левым объединением:-
Синтаксис: —
ВЫБЕРИТЕ имя(я) столбца ИЗ Таблицы1
LEFT JOIN Table2 ON Table1.
 ColumnName=Table2.ColumnName;
ColumnName=Table2.ColumnName;Пример:-
Выбрать с правым соединением:-
Синтаксис:-
ВЫБЕРИТЕ имя(я) столбца(я) ИЗ Таблицы1
ПРАВОЕ СОЕДИНЕНИЕ Таблица2 ON Table1.ColumnName=Table2.ColumnName;
Пример: —
Для получения дополнительной информации об операторе SQL-запроса необходимо посмотреть это видео: —
Если вы не читали мои предыдущие статьи, то ниже приведены ссылки, прочитайте их и, если вам так кажется полезно, затем поделитесь с тем, кому это может понадобиться.
SQL Server для начинающих, часть I
В этой статье мы узнаем о SQL-сервере.
medium.com
SQL Server для начинающих, часть II
В предыдущей статье мы узнали об установке SQL Server 2019 и SSMS.
 Также мы узнали о базе данных и таблицах…
Также мы узнали о базе данных и таблицах…
medium.com
SQL Server для начинающих, часть III
Здесь мы узнаем о ключе-кандидате, уникальном ключе и первичном ключе. Также видим разницу между уникальным ключом и…
medium.com
sql server — объединить два запроса SELECT с разными предложениями WHERE
спросил
Изменено
2 года, 4 месяца назад
Просмотрено
264 тыс. раз
У меня есть одна таблица услуг. Мне нужно объединить два запроса SELECT. Оба имеют разные предложения where. Например
ВЫБОР U_REGN как «Регион», COUNT(callID) как «OpenServices», SUM(СЛУЧАЙ, КОГДА описание LIKE '%DFC%' THEN 1 ELSE 0 END) 'DFC' ОТ ОСКЛ ГДЕ ([статус] = - 3) ГРУППА ПО U_REGN СОРТИРОВАТЬ ПО Описание OpenServices
Это дает мне результат
Регион | OpenServices | ДФК Карачи | 14 | 4 Лахор | 13 | 3 Исламабад | 10 | 4
У меня есть другой запрос
ВЫБЕРИТЕ U_REGN как «Регион», COUNT(callID) как «Закрыто вчера» ОТ ОСКЛ ГДЕ DATEDIFF(день, closeDate, GETDATE()) = 1 ГРУППА ПО U_REGN СОРТИРОВАТЬ ПО Описание «Закрыто вчера»
Это дает мне результат
Регион | ЗакрытыеУслуги Карачи | 8 Лахор | 7 Исламабад | 4
Мне нужно объединить оба результата и показать ClosedServices рядом со столбцом DFC.
- sql-сервер
2
Обработайте наборы результатов двух текущих запросов как таблицы и соедините их:
выберите
FirstSet.Region,
Фёрстсет.OpenServices,
Первый набор.DFC,
SecondSet.ClosedYesterday
от
(
ВЫБЕРИТЕ U_REGN как «Регион», COUNT (callID) как «OpenServices»,
SUM(СЛУЧАЙ, КОГДА описание LIKE '%DFC%' THEN 1 ELSE 0 END) 'DFC'
ОТ ОСКЛ
ГДЕ ([статус] = - 3)
СГРУППИРОВАТЬ ПО U_REGN
--ORDER BY 'OpenServices' описание
) как первый набор
внутреннее соединение
(
ВЫБЕРИТЕ U_REGN как «Регион»,
COUNT(callID) как «Закрыто вчера»
ОТ ОСКЛ
ГДЕ DATEDIFF (день, closeDate, GETDATE()) = 1
СГРУППИРОВАТЬ ПО U_REGN
--ORDER BY 'ClosedYesterday' desc
) как второй набор
на FirstSet.Region = SecondSet.Region
заказ по FirstSet.Region
Не самая красивая часть SQL, которую я когда-либо писал, но, надеюсь, вы увидите, как она работает, и поймете, как ее поддерживать.
Я подозреваю, что более производительным запросом будет одиночный SELECT из OSCL, сгруппированный U_REGN, с каждым из ваших трех счетчиков в виде отдельных операторов SUM(CASE .