Union join sql: Difference between JOIN and UNION in SQL
Содержание
Разница между JOIN и UNION в SQL
- 2019
JOIN и UNION — это предложения в SQL, используемые для объединения данных двух или более отношений. Но способ, которым они объединяют данные и формат полученного результата, отличается. Предложение JOIN
Котлеты из фарша с …
Please enable JavaScript
Котлеты из фарша с грибами, удивительные вкусные котлеты!😋
объединяет атрибуты двух отношений для формирования результирующих кортежей, тогда как предложение UNION объединяет результат двух запросов. Давайте обсудим разницу между JOIN и UNION с помощью сравнительной таблицы, показанной ниже.
Сравнительная таблица
| Основа для сравнения | ПРИСОЕДИНИТЬСЯ | UNION |
|---|---|---|
| основной | JOIN объединяет атрибуты кортежей, присутствующих в двух разных отношениях, которые имеют общие поля или атрибуты. | UNION объединяет кортежи отношений, которые присутствуют в запросе. |
| Состояние | JOIN применяется, когда два вовлеченных отношения имеют хотя бы один общий атрибут. | UNION применяется, когда число столбцов, присутствующих в запросе, одинаково и соответствующие атрибуты имеют одинаковый домен. |
| Типы | ВНУТРЕННЯЯ, ПОЛНАЯ (НАРУЖНАЯ), ЛЕВАЯ РЕГИСТРАЦИЯ, ПРАВАЯ СОЕДИНЕНИЕ | СОЮЗ и СОЮЗ ВСЕХ. |
| эффект | Длина результирующих кортежей больше по сравнению с длиной кортежей вовлеченных отношений. | Количество результирующих кортежей больше по сравнению с количеством кортежей, присутствующих в каждом отношении, участвующем в запросе. |
| схема |
Определение JOIN
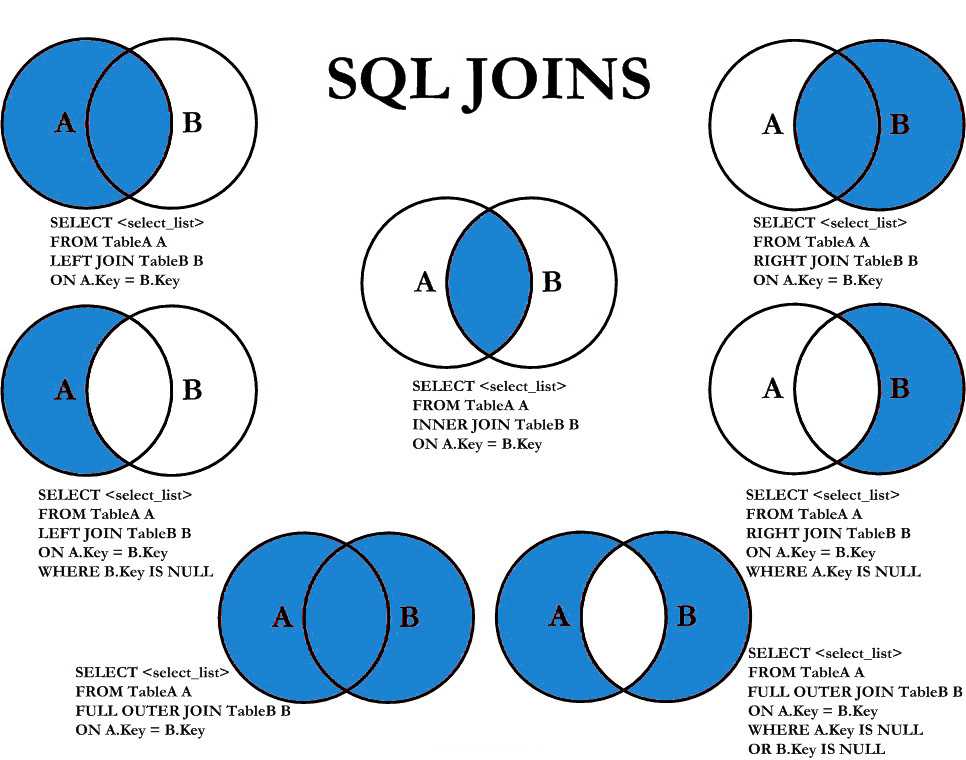
Предложение JOIN в SQL объединяет кортежи из двух отношений или таблиц, что приводит к увеличению размера кортежа. Результирующий кортеж содержит атрибуты из обоих отношений.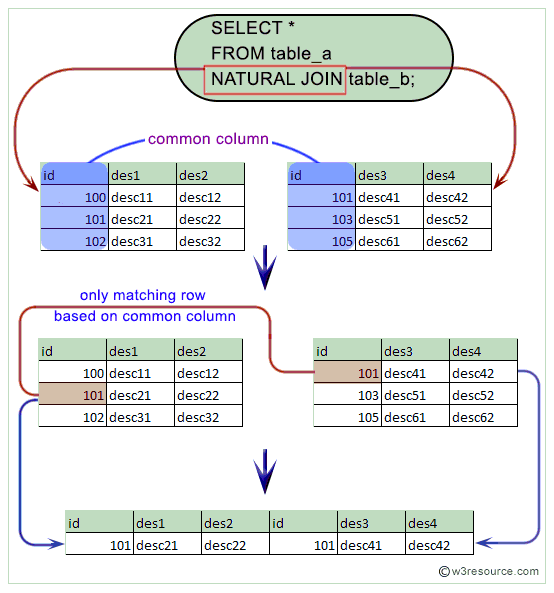 Атрибуты объединяются на основе общих атрибутов между ними. Различные типы JOIN в SQL: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN.
Атрибуты объединяются на основе общих атрибутов между ними. Различные типы JOIN в SQL: INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL OUTER JOIN.
INNER JOIN объединяет кортежи из обеих таблиц, если между ними существует общий атрибут. LEFT JOIN приводит ко всем кортежам левой таблицы и соответствующим кортежу из правой таблицы. RIGHT JOIN приводит ко всем кортежам из правой таблицы и соответствует только кортежу из левой таблицы. FULL OUTER JOIN приводит ко всем кортежам из обеих таблиц, хотя они имеют совпадающие атрибуты или нет.
ВНУТРЕННЕЕ СОЕДИНЕНИЕ — то же самое, что СОЕДИНЕНИЕ. Вы также можете удалить ключевое слово INNER и просто использовать JOIN для выполнения INNER JOIN.
Определение СОЮЗА
UNION — это операция над множествами в SQL. UNON объединяет результат двух запросов. Результат UNION включает в себя кортежи обоих отношений, присутствующих в запросе. Условия, которые должны быть выполнены для объединения двух отношений:
- Два отношения должны иметь одинаковое количество атрибутов.

- Домены соответствующего атрибута должны быть одинаковыми.
Существует два типа UNION: UNION и UNION ALL . Результат, полученный с помощью UNION, не содержит дубликатов. С другой стороны, результат, полученный с помощью UNION ALL, сохраняет дубликат.
- Основное различие между JOIN и UNION состоит в том, что JOIN объединяет кортежи из двух отношений, а результирующие кортежи включают атрибуты из обоих отношений. С другой стороны, UNION объединяет результат двух запросов SELECT.
- Предложение JOIN применимо только тогда, когда два участвующих отношения имеют хотя бы один общий атрибут в обоих. С другой стороны, UNION применяется, когда два отношения имеют одинаковое количество атрибутов и домены соответствующих атрибутов одинаковы.
- Существует четыре типа РЕАГИРОВАНИЯ ВНУТРЕННЕГО РЕШЕНИЯ, ЛЕВОГО СОЕДИНЕНИЯ, ПРЯМОГО СОЕДИНЕНИЯ, ПОЛНОГО НАРУЖНОГО СОЕДИНЕНИЯ. Но есть два типа UNION, UNION и UNION ALL.
- В JOIN результирующий кортеж имеет больший размер, поскольку включает атрибуты обоих отношений. С другой стороны, в UNION число кортежей увеличивается, в результате чего в них входит кортеж из обоих отношений, присутствующих в запросе.
 С другой стороны, в UNION число кортежей увеличивается, в результате чего в них входит кортеж из обоих отношений, присутствующих в запросе.
С другой стороны, в UNION число кортежей увеличивается, в результате чего в них входит кортеж из обоих отношений, присутствующих в запросе.Заключение:
Обе операции объединения данных используются в разных ситуациях. JOIN используется, когда мы хотим объединить атрибуты двух отношений, имеющих хотя бы один общий атрибут. UNION используется, когда мы хотим объединить кортежи двух отношений, которые присутствуют в запросе.
SQL операторы JOIN, UNION, INTERSECT и EXCEPT
Содержание
- Естественное соединение
- Декартово произведение (перекрестное соединение)
- Внешнее соединение
- Тета-соединение
- Самосоединение
- Полусоединение
- Оператор UNION
Соединение таблиц в запросе SELECT выполняется с помощью оператора JOIN.
Возможно также выполнить соединение и без оператора JOIN с помощью инструкции WHERE используя столбцы соединения, но этот синтаксис считается неявным и устаревшим.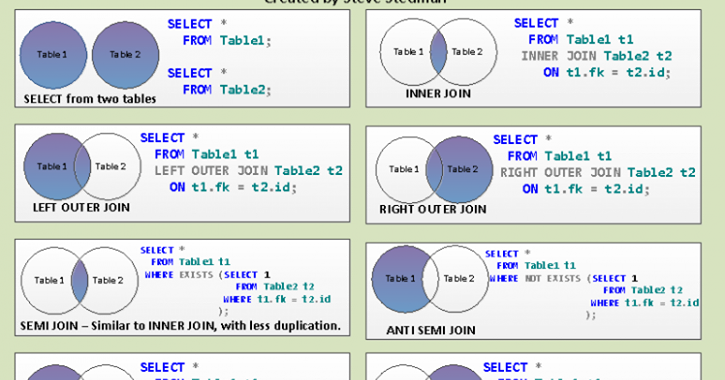
Выделяют следующие виды соединения, каждому из которых соответствует своя форма оператора JOIN:
- CROSS JOIN — перекрестное или декартово соединение
- [INNER] JOIN — естественное или внутреннее соединение
- LEFT [OUTER] JOIN — левое внешнее соединение
- RIGHT [OUTER] JOIN — правое внешнее соединение
- FULL [OUTER] JOIN — полное внешнее соединение
Существует также тета-соединение, самосоединение и полусоединение.
Естественное соединение
Естественное соединение — внутреннее соединение или соединение по эквивалентности.
Transact-SQL
SELECT employee.*, department.*
FROM employee INNER JOIN department
ON employee.dept_no = department.dept_no;
SELECT employee.*, department.* FROM employee INNER JOIN department ON employee. |
 dept_no = department.dept_no;
dept_no = department.dept_no;Здесь предложение FROM определяет соединяемые таблицы и в нем явно указывается тип соединения — INNER JOIN. Предложение ON является частью предложения FROM и указывает соединяемые столбцы. Выражение employee.dept_no = department.dept_no определяет условие соединения.
Эквивалентный запрос с применением неявного синтаксиса:
Transact-SQL
SELECT employee.*, department.*
FROM employee, department
WHERE employee.dept_no = department.dept_no;
SELECT employee.*, department.* FROM employee, department WHERE employee.dept_no = department.dept_no; |
Соединяемые столбцы должны иметь идентичную семантику, т.е. оба столбца должны иметь одинаковое логическое значение. Соединяемые столбцы не обязательно должны иметь одинаковое имя (или даже одинаковый тип данных), хотя часто так и бывает.
Соединяются только строки имеющие одинаковое значение в соединяемых столбцах.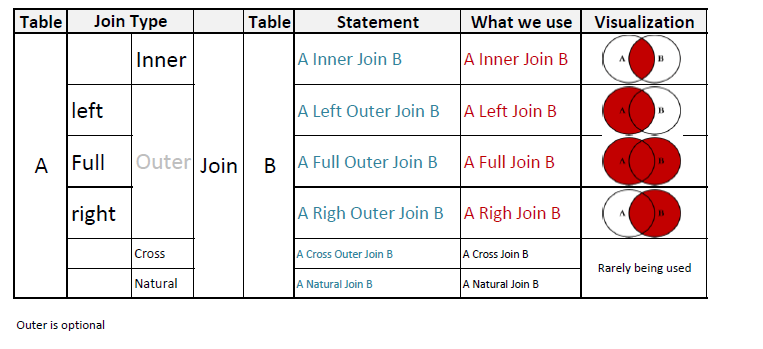 Строки, не имеющие таких одинаковых значений в результирующий набор вообще не попадут.
Строки, не имеющие таких одинаковых значений в результирующий набор вообще не попадут.
В инструкции SELECT объединить можно до 64 таблиц (ограничение MS SQL), при этом один оператор JOIN соединяет только две таблицы:
Transact-SQL
SELECT emp_fname, emp_lname
FROM works_on
JOIN employee ON works_on.emp_no=employee.emp_no
JOIN department ON employee.dept_no=department.dept_no
SELECT emp_fname, emp_lname FROM works_on JOIN employee ON works_on.emp_no=employee.emp_no JOIN department ON employee.dept_no=department.dept_no |
Декартово произведение (перекрестное соединение)
Декартово произведение (перекрестное соединение) соединяет каждую строку первой таблицы с каждой строкой второй. Результатом декартово произведения первой таблицы с n строками и второй таблицы с m строками будет таблица с n × m строками.
Transact-SQL
SELECT employee. *, department.*
*, department.*
FROM employee CROSS JOIN department;
SELECT employee.*, department.* FROM employee CROSS JOIN department; |
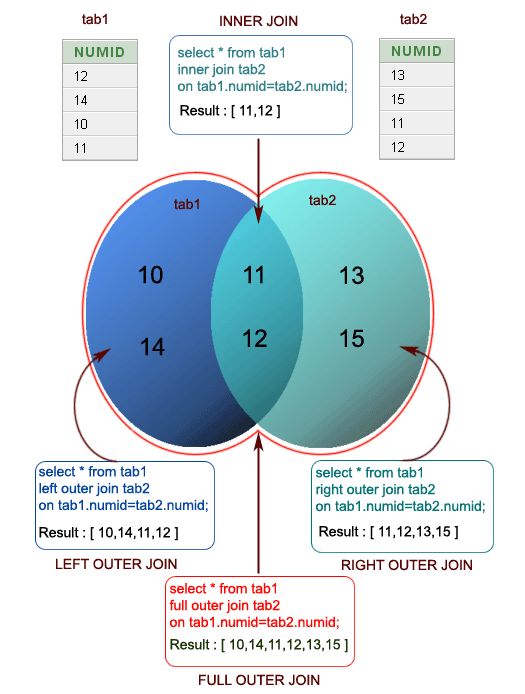
Внешнее соединение
Внешнее соединение позволяет в отличие от внутреннего извлечь не только строки с одинаковыми значениями соединяемых столбцов, но и строки без совпадений из одной или обеих таблиц.
Выделяют три вида внешних соединений:
- левое внешнее соединение — в результирующий набор попадают все строки из таблицы с левой стороны оператора сравнения (независимо от того имеются ли совпадающие строки с правой стороны), а из таблицы с правой стороны — только строки с совпадающими значениями столбцов. При этом если для строки из левой таблицы нет соответствий в правой таблице, значениям строки в правой таблице будут присвоены NULL
Transact-SQL
SELECT employee_enh.*, department.location
FROM employee_enh LEFT OUTER JOIN department
ON domicile = location;SELECT employee_enh.
*, department.locationFROM employee_enh LEFT OUTER JOIN department
ON domicile = location;
- правое внешнее соединение — аналогично левому внешнему соединению, но таблицы меняются местами
Transact-SQL
SELECT employee_enh.domicile, department.*
FROM employee_enh RIGHT OUTER JOIN department
ON domicile =location;SELECT employee_enh.domicile, department.*
FROM employee_enh RIGHT OUTER JOIN department
ON domicile =location;
- полное внешнее соединение — композиция левого и правого внешнего соединения: результирующий набор состоит из всех строк обеих таблиц. Если для строки одной из таблиц нет соответствующей строки в другой таблице, всем ячейкам строки второй таблицы присваивается значение NULL.
 *, department.location
*, department.locationТета-соединение
Условие сравнения столбцов соединения не обязательно должно быть равенством, но может быть любым другим сравнением.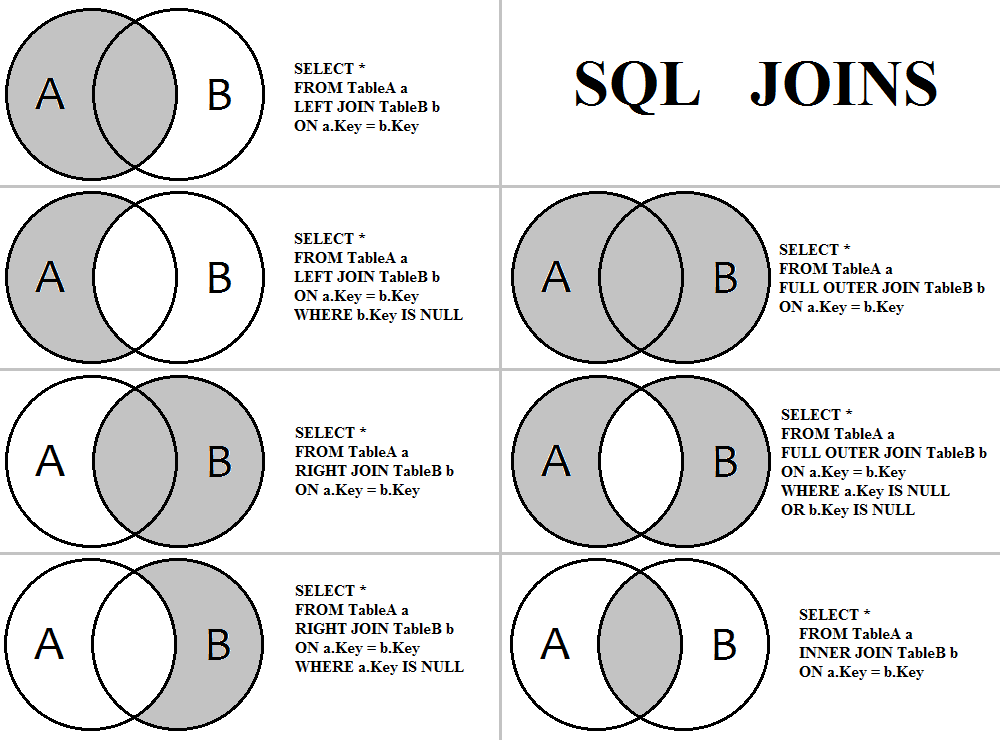 Соединение, в котором используется общее условие сравнения столбцов соединения, называется тета-соединением:
Соединение, в котором используется общее условие сравнения столбцов соединения, называется тета-соединением:
Transact-SQL
SELECT emp_fname, emp_lname, domicile, location
FROM employee_enh JOIN department
ON domicile < location;
SELECT emp_fname, emp_lname, domicile, location FROM employee_enh JOIN department ON domicile < location; |
Самосоединение
Самосоединение — это естественное соединение таблицы с самой собой. При этом один столбец таблицы сравнивается сам с собой. Сравнивание столбца с самим собой означает, что в предложении FROM инструкции SELECT имя таблицы употребляется дважды. Поэтому необходимо иметь возможность ссылаться на имя одной и той же таблицы дважды. Это можно осуществить, используя, по крайней мере, один псевдоним. То же самое относится и к именам столбцов в условии соединения в инструкции SELECT. Для того чтобы различить столбцы с одинаковыми именами, необходимо использовать уточненные имена.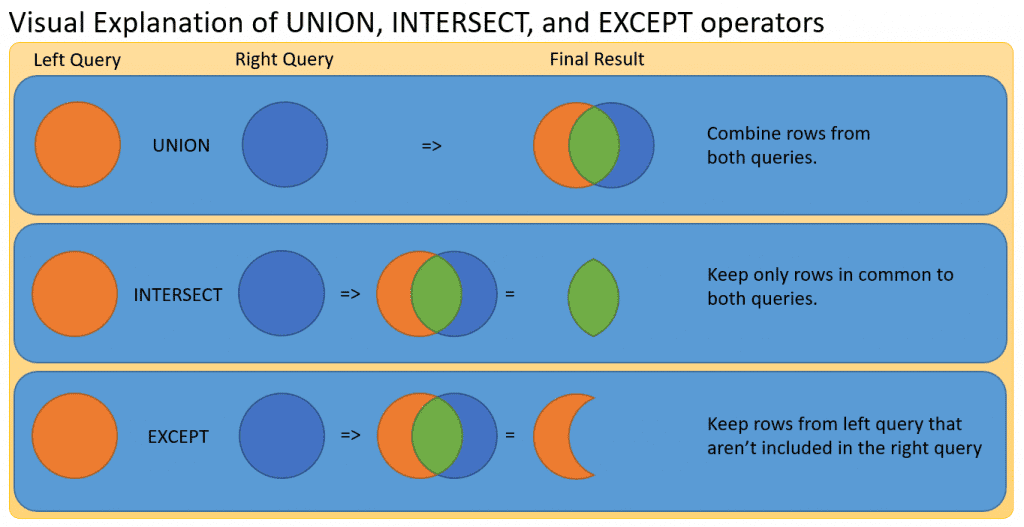
Полусоединение
Полусоединение похоже на естественное соединение, но возвращает только набор всех строк из одной таблицы, для которой в другой таблице есть одно или несколько совпадений.
Оператор UNION
Оператор UNION объединяет результаты двух или более запросов в один результирующий набор, в который входят все строки, принадлежащие всем запросам в объединении:
Transact-SQL
select_1 UNION [ALL] select_2 {[UNION [ALL] select_3]}…
select_1 UNION [ALL] select_2 {[UNION [ALL] select_3]}… |
Параметры select_1, select_2, … представляют собой инструкции SELECT, которые создают объединение. Если используется параметр ALL, отображаются все строки, включая дубликаты. По умолчанию дубликаты удаляются.
Объединять с помощью инструкции UNION можно только совместимые таблицы. Под совместимыми таблицами имеется в виду, что оба списка столбцов выборки должны содержать одинаковое число столбцов, а соответствующие столбцы должны иметь совместимые типы данных.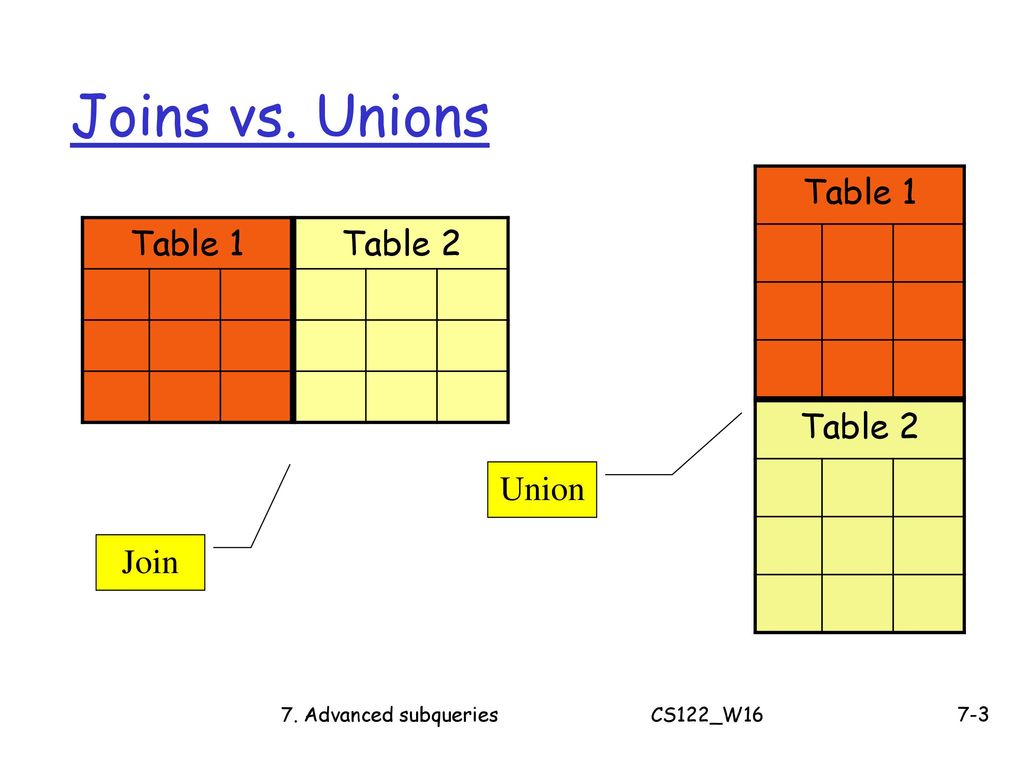 Результат объединения можно упорядочить, только используя предложение ORDER BY в последней инструкции SELECT. Предложения GROUP BY и HAVING можно применять с отдельными инструкциями SELECT, но не в самом объединении.
Результат объединения можно упорядочить, только используя предложение ORDER BY в последней инструкции SELECT. Предложения GROUP BY и HAVING можно применять с отдельными инструкциями SELECT, но не в самом объединении.
Два других оператора для работы с наборами:
- INTERSECT — пересечение — набор строк, которые принадлежат к обеим таблицам
- EXCEPT — разность двух таблиц — все значения, которые принадлежат к первой таблице и не присутствуют во второй
Как использовать объединение SQL
Соединения SQL чрезвычайно полезны. В отличие от других типов соединения SQL, соединение union не пытается сопоставить строку из левой исходной таблицы с какими-либо строками в правой исходной таблице. Он создает новую виртуальную таблицу, содержащую SQL-объединение всех столбцов в обеих исходных таблицах. В виртуальной таблице результатов столбцы, полученные из левой исходной таблицы, содержат все строки, которые были в левой исходной таблице.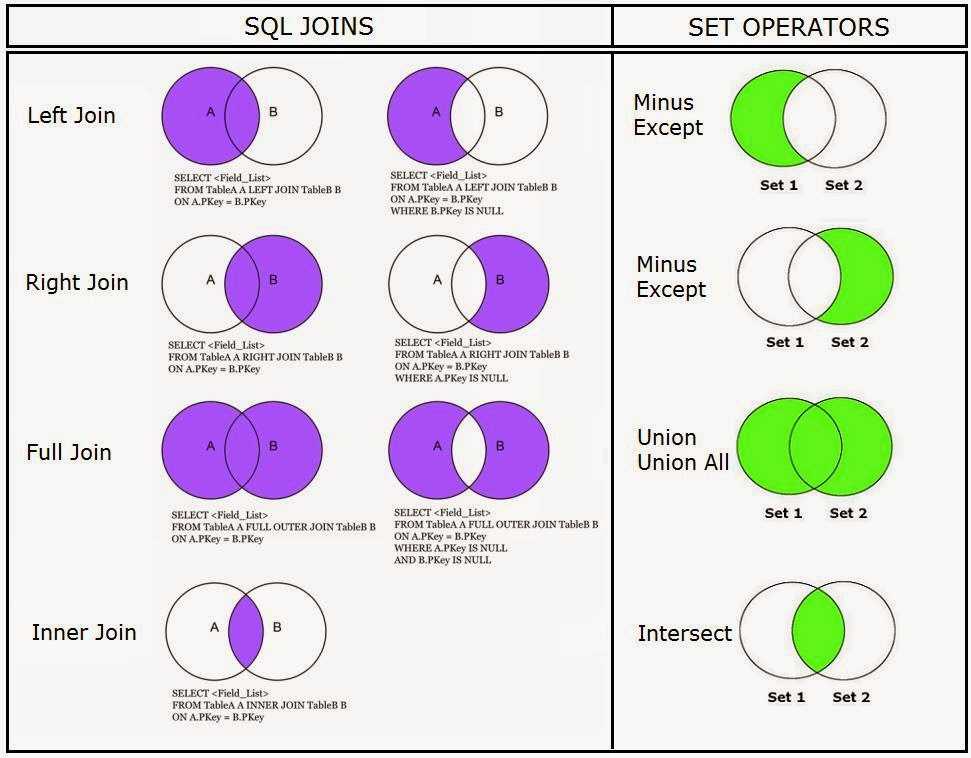 Для этих строк все столбцы, полученные из правой исходной таблицы, имеют нулевое значение.
Для этих строк все столбцы, полученные из правой исходной таблицы, имеют нулевое значение.
Аналогично, столбцы, полученные из правой исходной таблицы, содержат все строки, которые были в правой исходной таблице. Для этих строк все столбцы, полученные из левой исходной таблицы, имеют нулевое значение. Таким образом, таблица, полученная в результате объединения, содержит все столбцы обеих исходных таблиц, а количество содержащихся в ней строк равно сумме количества строк в двух исходных таблицах.
В большинстве случаев результат SQL-объединения сам по себе бесполезен; он создает таблицу результатов с большим количеством нулей. Но вы можете получить полезную информацию от объединения, когда используете его в сочетании с COALESCE выражение. Посмотрите на пример.
Предположим, вы работаете в компании, которая проектирует и производит экспериментальные ракеты. У вас в работе несколько проектов. У вас также есть несколько инженеров-конструкторов, обладающих навыками в нескольких областях.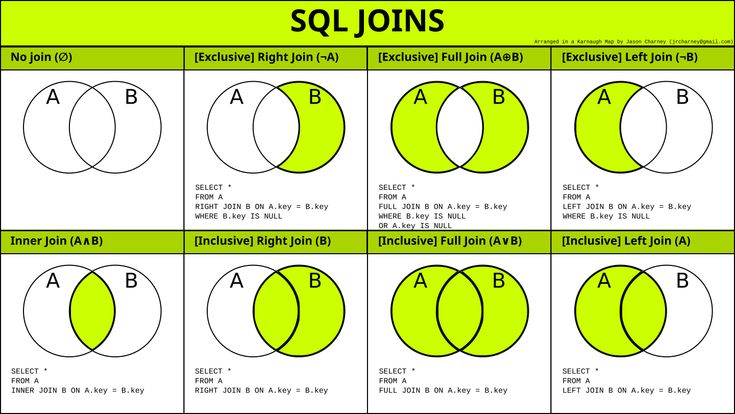 Как руководитель вы хотите знать, какие сотрудники, обладающие какими навыками, над какими проектами работали. В настоящее время эти данные разбросаны по таблицам EMPLOYEE, PROJECTS и SKILLS.
Как руководитель вы хотите знать, какие сотрудники, обладающие какими навыками, над какими проектами работали. В настоящее время эти данные разбросаны по таблицам EMPLOYEE, PROJECTS и SKILLS.
Таблица EMPLOYEE содержит данные о сотрудниках, и EMPLOYEE.EmpID — его первичный ключ. В таблице PROJECTS есть строка для каждого проекта, над которым работал сотрудник. PROJECTS.EmpID — это внешний ключ, ссылающийся на таблицу EMPLOYEE. Таблица SKILLS показывает опыт каждого сотрудника. SKILLS.EmpID — это внешний ключ, ссылающийся на таблицу EMPLOYEE.
Таблица EMPLOYEE содержит по одной строке для каждого сотрудника; таблица PROJECTS и таблица SKILLS содержат ноль или более строк.
В следующих таблицах приведены примерные данные.
| EmpID | Имя |
| 1 | Фергюсон |
| 2 | Фрост |
| 3 | Тойон |
| Имя проекта | EmpID |
| Структура X-63 | 1 |
| Структура X-64 | 1 |
| Х-63 Руководство | 2 |
| Х-64 Руководство | 2 |
| X-63 Телеметрия | 3 |
| X-64 Телеметрия | 3 |
| Навык | EmpID |
| Механический дизайн | 1 |
| Аэродинамическая нагрузка | 1 |
| Аналоговый дизайн | 2 |
| Конструкция гироскопа | 2 |
| Цифровой дизайн | 3 |
| Дизайн RF/F | 3 |
Из таблиц видно, что Фергюсон работал над конструкцией X-63 и X-64 и имеет опыт в области механического проектирования и аэродинамических нагрузок.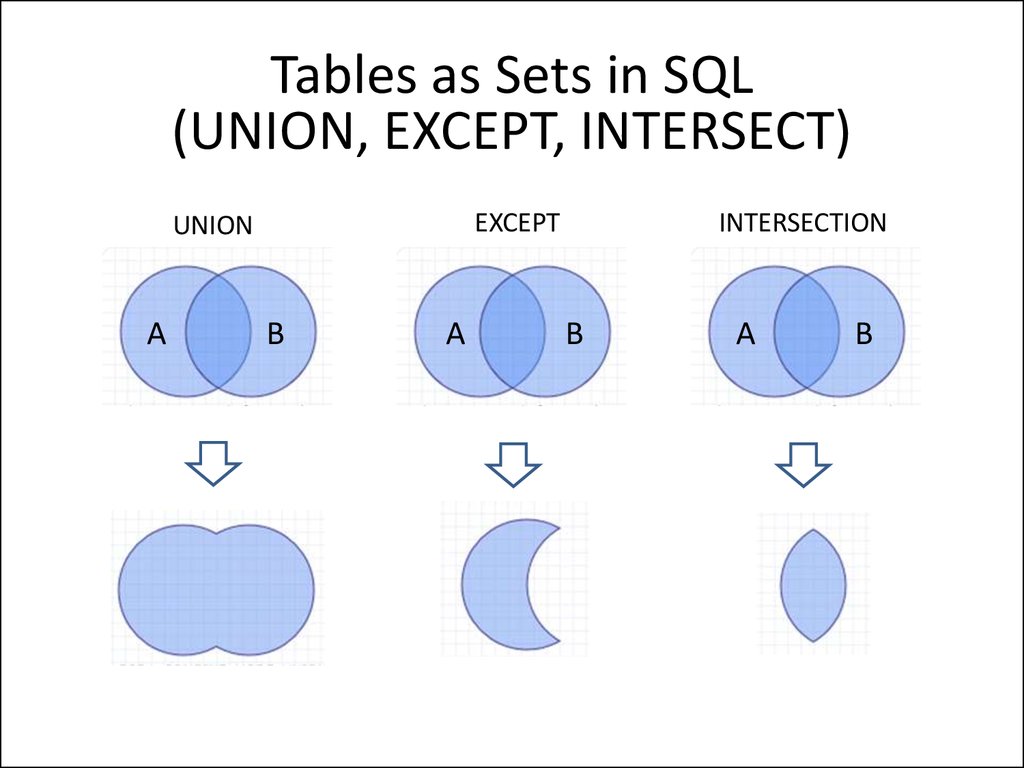
Теперь предположим, что вы как менеджер хотите видеть всю информацию обо всех сотрудниках. Вы решили применить эквивалентное соединение к таблицам EMPLOYEE, PROJECTS и SKILLS:
ВЫБОР * ОТ СОТРУДНИКА E, ПРОЕКТЫ P, НАВЫКИ S ГДЕ E.EmpID = P.EmpID И E.EmpID = S.EmpID ;
Эту же операцию можно выразить как внутреннее соединение, используя следующий синтаксис:
Обе формулировки дают одинаковый результат.
| E.EmpID | Имя | P.EmpID | ИмяПроекта | S.EmpID | Навык |
| 1 | Фергюсон | 1 | Структура Х-63 | 1 | Механический дизайн |
| 1 | Фергюсон | 1 | Структура Х-63 | 1 | Аэродинамическая нагрузка |
| 1 | Фергюсон | 1 | Структура Х-64 | 1 | Механический дизайн |
| 1 | Фергюсон | 1 | Структура Х-64 | 1 | Аэродинамическая нагрузка |
| 2 | Фрост | 2 | Х-63 Руководство | 2 | Аналоговый дизайн |
| 2 | Фрост | 2 | Х-63 Руководство | 2 | Конструкция гироскопа |
| 2 | Фрост | 2 | Х-64 Руководство | 2 | Аналоговый дизайн |
| 2 | Фрост | 2 | Х-64 Руководство | 2 | Конструкция гироскопа |
| 3 | Тойон | 3 | X-63 Телеметрия | 3 | Цифровой дизайн |
| 3 | Тойон | 3 | X-63 Телеметрия | 3 | Дизайн R/F |
| 3 | Тойон | 3 | X-64 Телеметрия | 3 | Цифровой дизайн |
| 3 | Тойон | 3 | X-64 Телеметрия | 3 | Дизайн R/F |
Такое расположение данных не особенно информативно.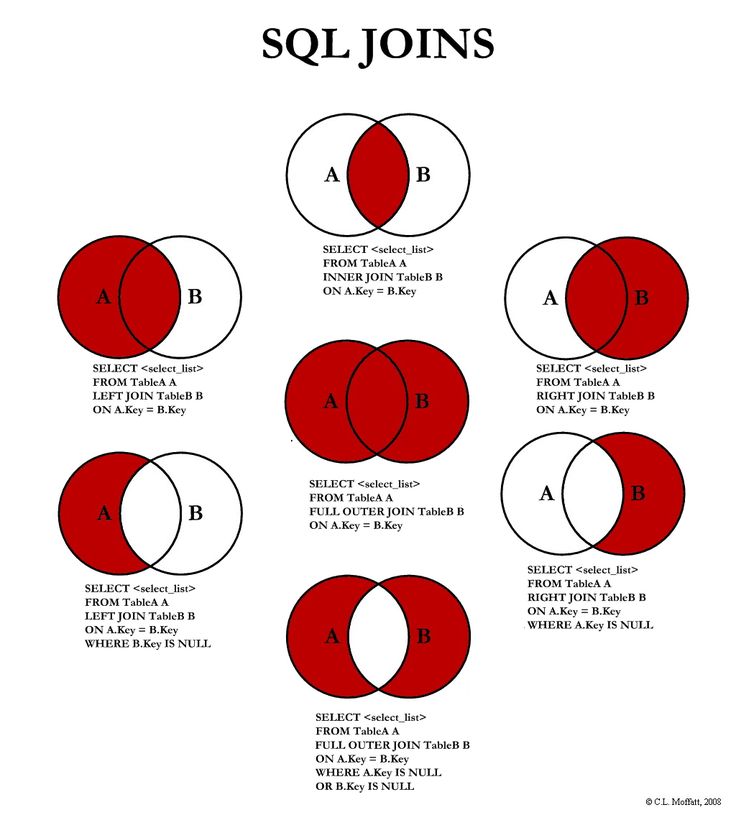 Идентификационные номера сотрудников появляются три раза, а проекты и навыки дублируются для каждого сотрудника. Итог: внутренние соединения SQL не очень подходят для ответа на этот тип вопросов. Здесь вы можете использовать SQL union join вместе с некоторыми стратегически выбранными
Идентификационные номера сотрудников появляются три раза, а проекты и навыки дублируются для каждого сотрудника. Итог: внутренние соединения SQL не очень подходят для ответа на этот тип вопросов. Здесь вы можете использовать SQL union join вместе с некоторыми стратегически выбранными SELECT , чтобы получить более подходящий результат. Вы начинаете с базового объединения SQL:
Обратите внимание, что объединение не имеет условия ON . Он не фильтрует данные, поэтому предложение ON не требуется. Этот оператор дает результат, показанный в следующей таблице.
| E.EmpID | Имя | P.EmpID | ИмяПроекта | S.EmpID | Навык |
| 1 | Фергюсон | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | 1 | Структура Х-63 | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | 1 | Структура Х-64 | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 1 | Механический дизайн |
| НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 1 | Аэродинамическая нагрузка |
| 2 | Фрост | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | 2 | Х-63 Руководство | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | 2 | Х-64 Наведение | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 2 | Аналоговый дизайн |
| НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 2 | Конструкция гироскопа |
| 3 | Тойон | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЕ | 3 | X-63 Телеметрия | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | 3 | X-64 Телеметрия | НУЛЕВОЙ | НУЛЕВОЙ |
| НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 3 | Цифровой дизайн |
| НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | НУЛЕВОЙ | 3 | Дизайн R/F |
Каждая таблица была расширена вправо или влево с помощью нулей, и эти строки с нулевым расширением были объединены.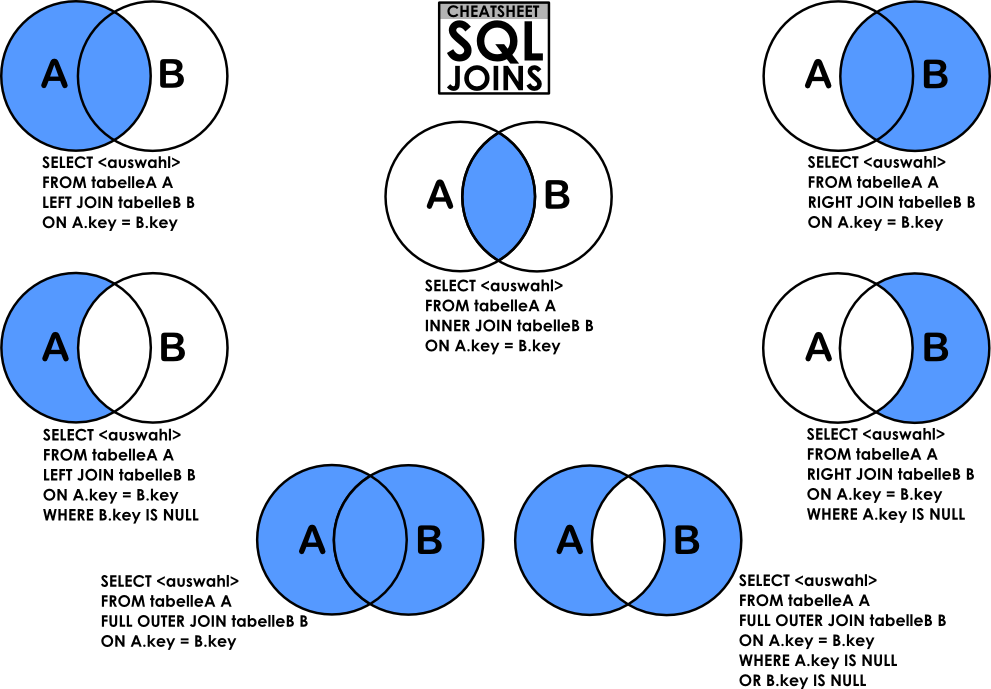 Порядок строк произвольный и зависит от реализации. Теперь вы можете массировать данные, чтобы привести их в более полезную форму.
Порядок строк произвольный и зависит от реализации. Теперь вы можете массировать данные, чтобы привести их в более полезную форму.
Обратите внимание, что в таблице есть три столбца идентификаторов, два из которых пусты в любой строке. Вы можете улучшить отображение, объединив столбцы ID. Выражение COALESCE принимает значение первого ненулевого значения в списке значений. В данном случае он принимает значение единственного ненулевого значения в списке столбцов:
ВЫБЕРИТЕ ОБЪЕДИНЕНИЕ (E.EmpID, P.EmpID, S.EmpID) КАК ИДЕНТИФИКАТОР, E.Name, P.ProjectName, S.Skill ОТ СОТРУДНИКА E СОЮЗ ПРИСОЕДИНЯЙТЕСЬ К ПРОЕКТАМ P СОЮЗ ПРИСОЕДИНЯЙТЕСЬ К НАВЫКАМ S ЗАКАЗАТЬ ПО ID ;
Предложение FROM такое же, как и в предыдущем примере, но теперь три столбца EMP_ID объединены в один столбец с именем ID . Вы также упорядочиваете результат по ID . В следующей таблице показан результат.
| ID | Имя | ИмяПроекта | Навык |
| 1 | Фергюсон | Структура Х-63 | НУЛЕВОЙ |
| 1 | Фергюсон | Структура Х-64 | НУЛЕВОЙ |
| 1 | Фергюсон | НУЛЕВОЙ | Механический дизайн |
| 1 | Фергюсон | НУЛЕВОЙ | Аэродинамическая нагрузка |
| 2 | Фрост | Х-63 Руководство | НУЛЕВОЙ |
| 2 | Фрост | Х-64 Руководство | НУЛЕВОЙ |
| 2 | Фрост | НУЛЕВОЙ | Аналоговый дизайн |
| 2 | Фрост | НУЛЕВОЙ | Конструкция гироскопа |
| 3 | Тойон | X-63 Телеметрия | НУЛЕВОЙ |
| 3 | Тойон | X-64 Телеметрия | НУЛЕВОЙ |
| 3 | Тойон | НУЛЕВОЙ | Цифровой дизайн |
| 3 | Тойон | НУЛЕВОЙ | Дизайн R/F |
Каждая строка в этом результате содержит данные о проекте или навыке, но не о том и другом.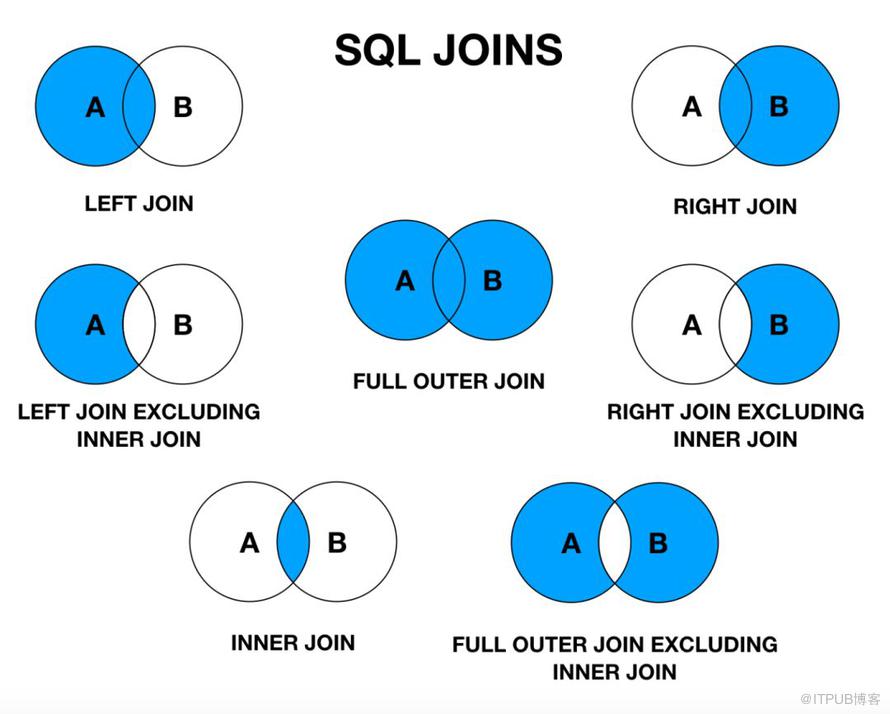 Когда вы читаете результат, вы сначала должны определить, какой тип информации находится в каждой строке (проект или навык). Если
Когда вы читаете результат, вы сначала должны определить, какой тип информации находится в каждой строке (проект или навык). Если ProjectName 9Столбец 0008 имеет ненулевое значение, в строке указан проект, над которым работал сотрудник. Если столбец Skill не равен нулю, в строке указывается один из навыков сотрудника.
Вы можете сделать результат более ясным, добавив еще одно COALESCE к оператору SELECT следующим образом:
ВЫБЕРИТЕ ОБЪЕДИНЕНИЕ (E.EmpID, P.EmpID, S.EmpID) КАК ИДЕНТИФИКАТОР,
E.Name, COALESCE (P.Type, S.Type) AS Type,
P.ProjectName, S.Skill
ОТ СОТРУДНИКА E
UNION JOIN (ВЫБРАТЬ «Проект» КАК Тип, P.*
ИЗ ПРОЕКТОВ) П
UNION JOIN (ВЫБЕРИТЕ «Skill» AS Type, S.*
ОТ НАВЫКОВ) С
ЗАКАЗАТЬ ПО ID, Тип ; В этом объединении таблица PROJECTS в предыдущем примере заменяется вложенным и SELECT , который добавляет столбец с именем P.Type с постоянным значением «Проект» к столбцам, поступающим из таблицы PROJECTS.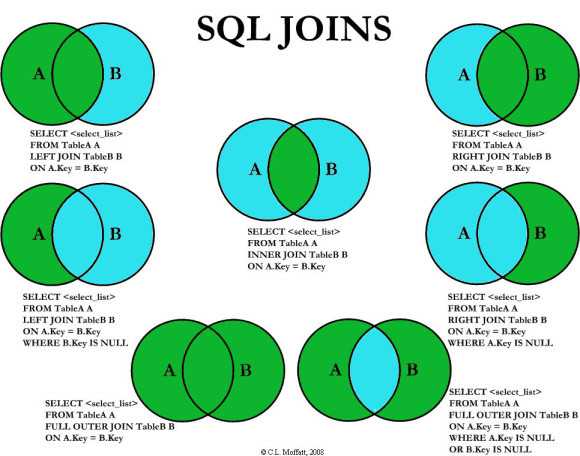 Точно так же таблица SKILLS заменяется вложенным
Точно так же таблица SKILLS заменяется вложенным SELECT , который добавляет столбец с именем S.Type с постоянным значением «Skill» к столбцам, поступающим из таблицы SKILLS. В каждой строке P.Type имеет значение null или 9.0007 "Проект" S.Type либо нулевой, либо "Навык" .
Внешний список SELECT указывает COALESCE из этих двух столбцов Type в один столбец с именем Type . Затем вы указываете Введите в предложении ORDER BY , которое сортирует строки с одинаковым идентификатором в порядке, в котором все проекты располагаются первыми, а затем все навыки. Результат показан в следующей таблице.
| ID | Имя | Тип | ИмяПроекта | Навык |
| 1 | Фергюсон | Проект | Структура Х-63 | НУЛЕВОЙ |
| 1 | Фергюсон | Проект | Структура Х-64 | НУЛЕВОЙ |
| 1 | Фергюсон | Навык | НУЛЕВОЙ | Механический дизайн |
| 1 | Фергюсон | Навык | НУЛЕВОЙ | Аэродинамическая нагрузка |
| 2 | Фрост | Проект | Х-63 Руководство | НУЛЕВОЙ |
| 2 | Фрост | Проект | Х-64 Руководство | НУЛЕВОЙ |
| 2 | Фрост | Навык | НУЛЕВОЙ | Аналоговый дизайн |
| 2 | Фрост | Навык | НУЛЕВОЙ | Конструкция гироскопа |
| 3 | Тойон | Проект | X-63 Телеметрия | НУЛЕВОЙ |
| 3 | Тойон | Проект | X-64 Телеметрия | НУЛЕВОЙ |
| 3 | Тойон | Навык | НУЛЕВОЙ | Цифровой дизайн |
| 3 | Тойон | Навык | НУЛЕВОЙ | Дизайн R/F |
Таблица результатов теперь представляет собой очень удобочитаемый отчет об опыте проекта и наборах навыков всех сотрудников в таблице EMPLOYEE.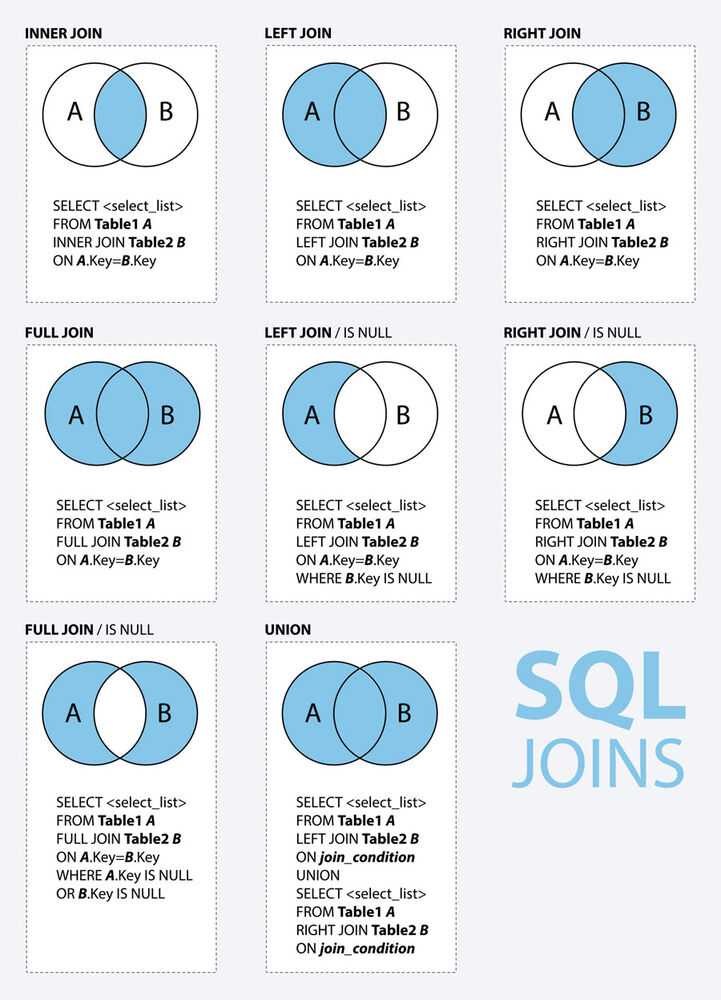
Учитывая количество доступных операций SQL JOIN , связывание данных из разных таблиц не должно быть проблемой, независимо от структуры таблиц. Вы можете быть уверены, что если в вашей базе данных существуют необработанные данные, SQL сможет извлечь их и отобразить в осмысленной форме.
сервер sql — SQL UNION и MERGE
У меня есть несколько операторов выбора, включающих множество таблиц и соединений. Все операторы select имеют одинаковые заголовки. Я пытаюсь объединить все это в один набор результатов. Итак, какой подход лучше SQL UNION или MERGE ?
Я знаю, что UNION это A+B. Итак, если столбец имеет значение NULL в таблице A и имеет значение в таблице B, тогда UNION даст мне две строки, верно? Итак, если я хочу объединить все строки в одну строку на основе идентификатора, должен ли я использовать MERGE? У меня есть возможность сделать это в SQL или SSIS.
ВЫБЕРИТЕ ID, ИМЯ, VitalName как VitalName ИЗ ТАБЛИЦЫ A СОЮЗ ВЫБЕРИТЕ ID, ИМЯ, VitalReadings как VitalName ИЗ ТАБЛИЦЫ B
Таблица A
+----+------+-----------+ | ID | Имя | VitalName | +----+------+-----------+ | 1 | ААА | частота сердечных сокращений | | 2 | | Систолический | | 3 | | диастолический | +----+------+-----------+
Таблица B
+----+------+---------------+ | ID | Имя | Жизненно важные чтения | +----+------+----------------+ | 1 | ААА | частота сердечных сокращений | | 2 | ВВВ | Систолический | +----+------+----------------+
Ожидаемый результат
+----+------+---------------+ | ID | Имя | VitalName | +----+------+----------------+ | 1 | ААА | частота сердечных сокращений | | 2 | ВВВ | Систолический | | 3 | | диастолический | +----+------+----------------+
- sql
- sql-сервер
- слияние
- объединение
3
UNION и MERGE совершенно разные концепции и оба не решают вашу проблему.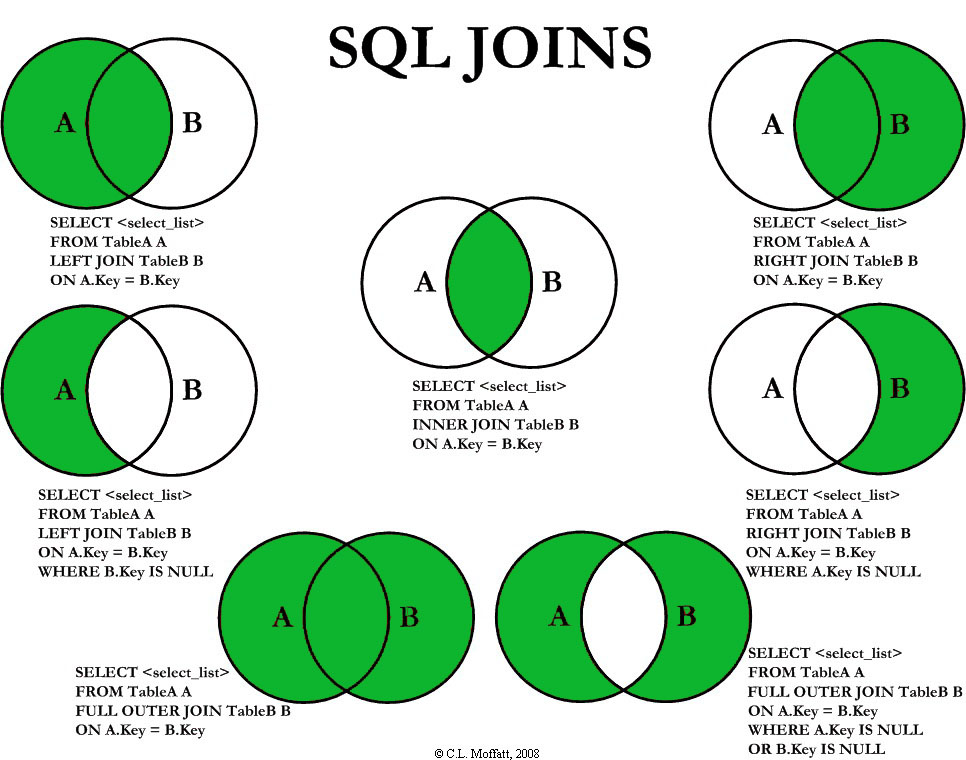 Но можно использовать
Но можно использовать FULL JOIN для этого.
DECLARE @TableA TABLE (ID INT, Name VARCHAR(10), VitalName VARCHAR(10))
ВСТАВИТЬ В @TableA ЗНАЧЕНИЯ
(1, «ААА», «ЧСС»),
(2, NULL, «Систолическое»),
(3, NULL, «Диастолическое»)
DECLARE @TableB TABLE (ID INT, Name VARCHAR(10), VitalReadings VARCHAR(10))
ВСТАВЬТЕ В ЗНАЧЕНИЯ @TableB
(1, «ААА», «ЧСС»),
(2, «ВВВ», «Систолическое»)
ВЫБРАТЬ
ПОМОГАТЬ,
COALESCE(A.Name, B.Name) Имя,
COALESCE(A.VitalName, B.VitalReadings) VitalName
ОТ
@Таблица А
ПОЛНОЕ СОЕДИНЕНИЕ @TableB B ON A.ID = B.ID
Результат:
ID Имя VitalName ----------- ---------- ---------- 1 пульс ААА 2 BBB систолическое 3 НУЛЕВОЕ диастолическое
GROUP BY результат UNION . Используйте MAX() , чтобы вернуть ИМЯ:
выберите ID, MAX(NAME), VitalName
от
(
ВЫБЕРИТЕ ID, ИМЯ, VitalName как VitalName ИЗ ТАБЛИЦЫ A
СОЮЗ ВСЕХ
ВЫБЕРИТЕ ID, ИМЯ, VitalReadings как VitalName ИЗ ТАБЛИЦЫ B
) дт
группировать по ID, VitalName
Используйте объединение, а затем выберите отдельные, чтобы удалить дубликаты.