Установка postgresql 1c: Установка сервера 1С, Postgresql и терминального сервера для клиентских приложений 1С на ОС Fedora Linux / Хабр
Содержание
Postgresql для 1С — установка и настройка
1С программист » Программирование
PostgreSQL — достаточно современная и популярная СУБД в мире. Её не обошла и фирма 1С, выбрав в качестве одной из поддерживаемых для работы СУБД. Рассмотрим инструкцию по установке PostgreSQL и её первоначальной настройки для 1С 8.3 под ОС Windows.
Содержание
- Установка и настройка сервера 1С Предприятие
- Установка PostgreSQL
- Настройка PostgreSQL под 1С
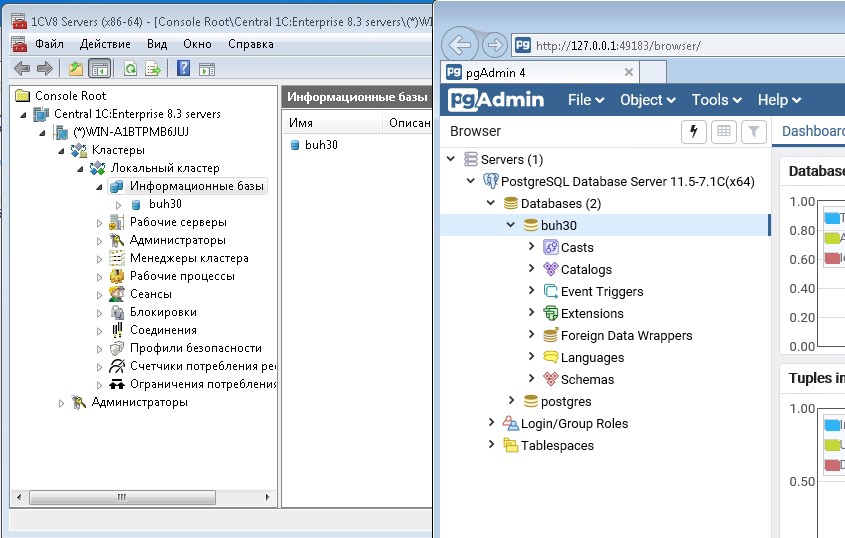
Установка и настройка сервера 1С Предприятие
Первым делом установим сервер 1C предприятия 8.3 (или 8.2). Для этого запустим файл setup.exe из архива. Установка мало чем отличается от обычной установки клиентского приложения, за исключением некоторых особенностей:
- Не забудьте выбрать в компонентах нужные пункты:
- Указать, от чьего имени будет запускаться приложение. Рекомендуется создавать нового пользователя «USR1Cv8». У этого пользователя должны быть установлены нужные права:
После установки части 1С можно приступить к работе с СУБД.
Установка PostgreSQL
Запустите файл postgresql‑9.1.2–1.1C(x64).msi, в папке windows выбрать подпапку 64 или 86, в зависимости от разрядности ОС. Можно оставить практически всё по умолчанию. Необходимо обратить внимание на следующие моменты:
Так же, как с 1С 8.3, СУБД устанавливается как сервис. Необходимо проверить права у используемого пользователя. Система по умолчанию создаст нового пользователя, от чего имени будет запускать службу:
Настройка кластера 1C. Здесь необходимо указать пароль для пользователя:
Для выполнения данного пункта должна быть запущена служба «Вторичный вход в систему» (secondary logon). Если он не запущен, его следует запустить в списке всех сервисов:
Настройка PostgreSQL под 1С
Опыт эксплуатации баз 1С на PostgreSQL показал, что наибольшей производительности и оптимальной работы 1С и PostgreSQL удалось добиться на linux, поэтому желательно использовать именно ее. Но вне зависимости от операционной системы, важно помнить, что настройки, указанные по умолчанию при установке PostgreSQL, предназначены только для запуска сервера СУБД. Ни о какой промышленной эксплуатации речи идти не может! Следующим шагом после запуска станет оптимизация PostgreSQL под 1С:
Ни о какой промышленной эксплуатации речи идти не может! Следующим шагом после запуска станет оптимизация PostgreSQL под 1С:
- Для начала отключаем Energy Saving (в противном случае могут непредсказуемо вырасти задержки ответов из БД) и запрещаем своппинг разделяемой памяти.
- Настраиваем основные параметры сервера СУБД (рекомендации по настройке описаны достаточно подробно, как на официальном сайте вендора, так и компанией 1С, поэтому остановимся только на самых важных).
- В типовых рекомендациях компании 1С предлагается отключать механизмы HyperThreading. Но тестирование Postgres-pro на серверах, с включенной SMT (simultaneous multi threading), показало другие результаты.
Установка параметра shared_buffers в RAM/4 является рекомендацией по умолчанию, но пример Sql Server говорит о том, что чем больше памяти ему выделяется, тем лучше его производительность (при отключенном сбросе страниц в файл подкачки). То есть, чем больше страниц данных располагаются в оперативной памяти, тем меньше обращений к диску. Возникает вопрос: почему такой маленький кэш? Ответ прост: если shared_buffers большой, то часть неиспользуемых страниц свопируется на диск. Но как отследить момент, когда сброс прекратится, и показатель параметра будет оптимальным? Для достижения и выхода на оптимальный показатель shared_buffers, его значение необходимо поднимать на продуктиве ежедневно (по возможности) с определенным шагом прироста и смотреть, в какой момент начнется сброс страниц на диск (увеличится своп).
Возникает вопрос: почему такой маленький кэш? Ответ прост: если shared_buffers большой, то часть неиспользуемых страниц свопируется на диск. Но как отследить момент, когда сброс прекратится, и показатель параметра будет оптимальным? Для достижения и выхода на оптимальный показатель shared_buffers, его значение необходимо поднимать на продуктиве ежедневно (по возможности) с определенным шагом прироста и смотреть, в какой момент начнется сброс страниц на диск (увеличится своп).
- Помимо этого, на «большой параметр» негативно влияет работа с множеством мелких страниц, которые по умолчанию имеют размер 8Кб. Работа с ними увеличивает накладные расходы. Что можно с этим сделать для оптимизации под 1С? В версии postgreSQL 9.4 появился параметр huge_pages, который можно включить, но только в Linux. По умолчанию включаются огромные страницы с размером по умолчанию 2048 kB. Дополнительно поддержку данных страниц необходимо включить в ОС. Таким образом, оптимизировав структуру хранения, можно выйти на больший показатель shared_buffers.

- work_mem = RAM/32..64 или 32MB..128MB Задает объем памяти для каждой сессии, который будет использоваться для внутренних операций сортировки, объединения и пр., прежде чем будут задействованы временные файлы. При превышении этого объема, сервер будет использовать временные файлы на диске, что может существенно снизить скорость обработки запросов. Данный параметр используется при выполнении операторов: ORDER BY, DISTINCT, соединения слиянием и пр.
- Посчитать дополнительно данный параметр можно следующим образом: (Общая память shared_buffers – память на другие программы) / число активных соединений. Это значение можно уменьшать, следя за количеством создаваемых временных файлов. Такую статистику по размеру и количеству временных файлов можно получить из системного представления pg_stat_database.
- effective_cache_size = RAM — shared_buffers основная задача этого параметра подсказать оптимизатору запроса, какой способ получения данных выбрать: полный просмотр или сканирование по индексу. Чем выше значение параметра, тем больше вероятность использования сканирования по индексу. При этом сервер не учитывает, что данные при выполнении запроса могут оставаться в памяти, и следующему запросу не надо их поднимать с диска.

 Чем выше значение параметра, тем больше вероятность использования сканирования по индексу. При этом сервер не учитывает, что данные при выполнении запроса могут оставаться в памяти, и следующему запросу не надо их поднимать с диска.
Чем выше значение параметра, тем больше вероятность использования сканирования по индексу. При этом сервер не учитывает, что данные при выполнении запроса могут оставаться в памяти, и следующему запросу не надо их поднимать с диска.window.yaContextCb.push(()=>{ Ya.Context.AdvManager.render({ renderTo: ‘yandex_rtb_R-A-589472-18’, blockId: ‘R-A-589472-18’ })})»+»ipt>»;
cachedBlocksArray[104027] = «window.yaContextCb.push(()=>{ Ya.Context.AdvManager.render({ renderTo: ‘yandex_rtb_R-A-589472-12’, blockId: ‘R-A-589472-12’ })})»+»ipt>»;
cachedBlocksArray[104028] = «window.yaContextCb.push(()=>{ Ya.Context.AdvManager.render({ renderTo: ‘yandex_rtb_R-A-589472-13’, blockId: ‘R-A-589472-13’ })})»+»ipt>»;
cachedBlocksArray[104031] = «window.yaContextCb.push(()=>{ Ya.Context.AdvManager.render({ renderTo: ‘yandex_rtb_R-A-589472-20’, blockId: ‘R-A-589472-20’ })})»+»ipt>»;
cachedBlocksArray[104026] = «window.yaContextCb.push(()=>{ Ya. Context.AdvManager.render({ renderTo: ‘yandex_rtb_R-A-589472-11’, blockId: ‘R-A-589472-11’ })})»+»ipt>»;
Context.AdvManager.render({ renderTo: ‘yandex_rtb_R-A-589472-11’, blockId: ‘R-A-589472-11’ })})»+»ipt>»;
Поделиться с друзьями
1С — настройка PostgreSQL 11.9 на сервере Windows Server 2019
Приветствую тебя, мой юный 1С-ник. Ты, как и я, не любишь 1С и стараешься как можно быстрее и качественнее отвязаться от задач, связанных с этим продуктом, чтобы больше никогда к ним не возвращаться? Настроил — и забыл, это наш подход!
1С тормозит. Корову можно кормить топовыми процессорами, SSD и немеряным количеством оперативки, но гепардом она всё равно не станет. Этому есть несколько причин:
- Транзакционная модель, от этого в финансах не уйти. Транзакция сидит на транзакции и транзакцией погоняет. Опять же, транзакции подразумевают блокировки, пока блокировка не будет снята, объект не станет доступным другим пользователям.
- Доступность среды разработки. Куча разработчиков сидят, что-то там программируют. Бесконечные циклы, утечки памяти, перерасход ресурсов, кривые руки и непонимание того, что они делают. Ладно бы это делалось централизованно, но сколько 1С серверов, столько и разработчиков. Одну и ту же задачу можно решить разными способами, зачастую решение задачи оказывается не самым оптимальным. В итоге мы слышим: «Это железо тормозит!» «Это база тормозит!»
- Временные таблицы. Весь 1С построен на временных таблицах. На каждый чих создаётся временная таблица, с которой проводятся операции, на них даже индексы строятся. И если БД не может правильно обрабатывать временные таблицы, то успеха не будет. Table Scan — не самая быстрая операция.
- Неправильные настройки сервера БД. Кривые настройки — такой же результат.
 Ладно бы это делалось централизованно, но сколько 1С серверов, столько и разработчиков. Одну и ту же задачу можно решить разными способами, зачастую решение задачи оказывается не самым оптимальным. В итоге мы слышим: «Это железо тормозит!» «Это база тормозит!»
Ладно бы это делалось централизованно, но сколько 1С серверов, столько и разработчиков. Одну и ту же задачу можно решить разными способами, зачастую решение задачи оказывается не самым оптимальным. В итоге мы слышим: «Это железо тормозит!» «Это база тормозит!»Сегодня будем настраивать PostgreSQL 11.9 на сервере Windows Server 2019.
Что лучше: MSSQL или PostgreSQL?
Сложно сказать. С одной стороны, крутые исследователи заявляют о том, что правильно настроенный PostgreSQL выигрывает у MSSQL:
https://infostart.ru/1c/articles/962876/
И тут я такой: «А если поднять у MSSQL tempdb в RAM диск?» И снова становится непонятно. Но понятно одно, MSSQL стоит денег, а PostgreSQL бесплатный.
Но понятно одно, MSSQL стоит денег, а PostgreSQL бесплатный.
Итак, тестовый стенд (или правильнее сказать, реальный?):
- Сервер, виртуальный, операционная система Windows Server 2019 Standard, триальная.
- CPU: 16 ядер
- ОЗУ: 64 ГБ
- Диск SSD, отдельный для БД.
- Размер базы: 50 Гб
- 1С 8.3 и PostgreSQL 11.9-1.1C вместе на одном сервере
- 50 аккаунтов пользователей 1С в настоящее время
По хорошему, мух следует отделять от котлет. И разносить 1С и БД на разные серверы. Однако, на практике, часто бывает иначе. Сервер имеется один, на нём размещают и базу и сервер 1С. И это не просто предположение, вчера привезли новый сервер и поставили задачу: установить Windows, MSSQL и 1С. Всё на одну машину. Но это немного другая история, не связанная с текущей.
Как разделить ресурсы между 1С и PostgreSQL?
Очень просто. 50 пользователей 1С работают в разное время, создают 3-4 рабочих процесса и забирают примерно 8-12 Гб ОЗУ. Оперативку я мысленно разделил так: 75% (48 Гб) отдаём PostgreSQL, 25% (16 Гб) отдаём 1С.
Оперативку я мысленно разделил так: 75% (48 Гб) отдаём PostgreSQL, 25% (16 Гб) отдаём 1С.
Следовательно, для настроек PostgreSQL я исхожу из цифр:
- CPU: 16 ядер
- ОЗУ: 48 ГБ
- Диск: SSD
- Количество пользователей 1С: 100 (с расчётом на будущее)
Далее RAM — это 48 Гб, которые выделены для PostgreSQL.
Полезные ссылки
https://pgtune.leopard.in.ua/
https://infostart.ru/public/554213/
http://www.gilev.ru/postgresql/
Настройка PostgreSQL 11.9
Основной файл настроек PostgreSQL — postgresql.conf. Приступим.
Сеть
max_connections = 100
Максимальное количество одновременных подключений к БД. Я просто установил в два раза больше, чем текущее количество 1С пользователей. К базе ещё подключается пользователь для мониторинга и администраторы. Если будет не хватать, то можно потом изменить параметры.
Память
shared_buffers = 12GB
Количество памяти, выделенное для кэша страниц. Рекомендуется от 1/8 до 1/4 RAM. Вычисляю: 48 Гб / 4 = 12 Гб.
Рекомендуется от 1/8 до 1/4 RAM. Вычисляю: 48 Гб / 4 = 12 Гб.
maintenance_work_mem = 2024MB
Лимит памяти для внутренних обслуживающих задач. Рекомендуется 1/4 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
effective_cache_size = 36GB
Кэш файловой системы. Планировщик исходя из этого параметра принимает решение об использовании больших индексов (IndexScan), и это хорошо. Рекомендуется RAM — shared_buffers. Вычисляю: 48 Гб — 12 Гб = 36 Гб.
work_mem = 2024MB
Лимит памяти для обработки одного запроса. При превышении этого объёма сервер начинает использовать временные файлы на диске. Рекомендуется от 1/32 до 1/16 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
temp_buffers = 2024MB
Буфер под временные объекты, например, для временных таблиц. Рекомендуется 1/20 RAM. Однако, при увеличении больше 2024MB служба PostgreSQL не запускается.
Процессор
max_worker_processes = 16
Максимальное число фоновых процессов.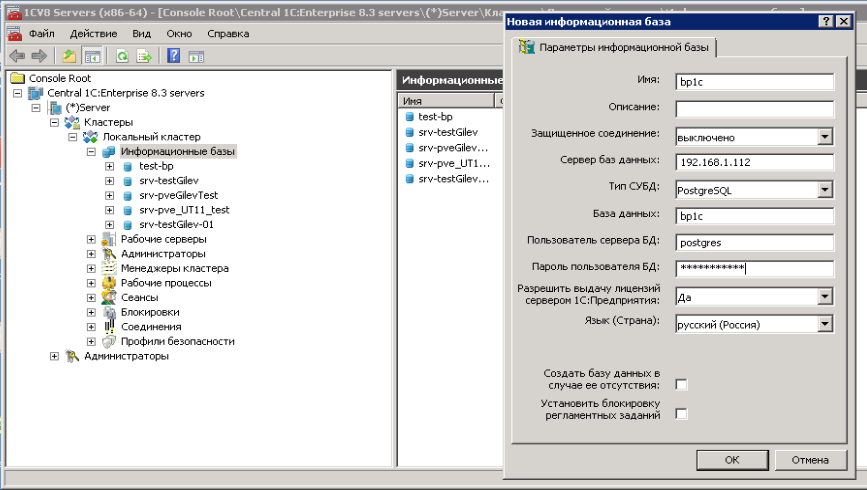 Зависит от количества выделенных для PostgreSQL ядер CPU. По калькулятору.
Зависит от количества выделенных для PostgreSQL ядер CPU. По калькулятору.
max_parallel_workers = 8
Задаёт максимальное число рабочих процессов, которое система сможет поддерживать для параллельных запросов. Рекомендуют равным max_worker_processes, однако в этом случае какой-то «толстый» запрос может сожрать все потоки и другим не достанется. Использую половину процессоров.
max_parallel_workers_per_gather = 8
Задаёт максимальное число рабочих процессов, которые могут запускаться одним узлом Gather илиGather Merge. Не более max_parallel_workers, задал по максимуму.
max_parallel_maintenance_workers = 4
Задаёт максимальное число рабочих процессов, которые могут запускаться одной служебной командой. По калькулятору.
max_files_per_process = 1000
Задаёт максимальное число файлов, которые могут быть одновременно открыты каждым процессом. Значение по умолчанию — 1000 файлов.
autovacuum_max_workers = 4
Задаёт максимальное число процессов автоочистки (не считая процесс, запускающий автоочистку), которые могут выполняться одновременно.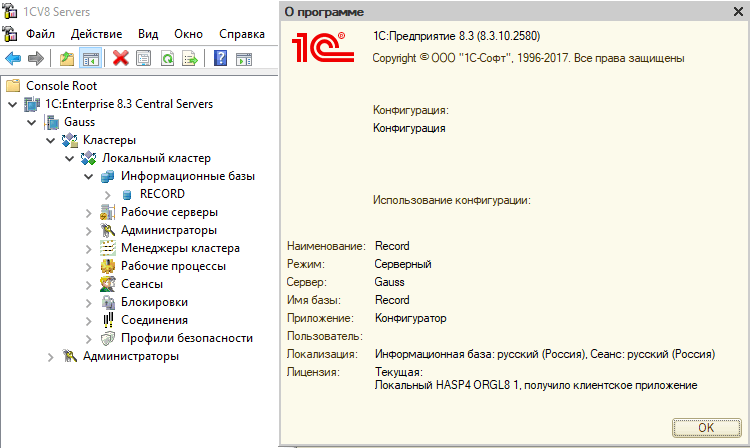 Чем больше запросов записи, тем больше процессов. Если база только для чтения, то достаточно одного процесса.
Чем больше запросов записи, тем больше процессов. Если база только для чтения, то достаточно одного процесса.
Диск
fsync = on
Если параметр fsync включён, то при выполнении операции COMMIT данные сразу переписываются из кэша операционной системы на диск, тем самым гарантируется целостность данных при возможном аппаратном сбое. При этом снижается производительность операций записи на диск, поскольку при этом не используются возможности отложенной записи данных операционной системы. Данный параметр можно отключать только при наличие аппаратного RAID контроллера с кэшем в режиме write-back и батарейкой для гарантированной записи данных при отключении питания.
#effective_io_concurrency = 2
Задаёт допустимое число параллельных операций ввода/вывода, которое говорит PostgreSQL о том, сколько операций ввода/вывода могут быть выполнены одновременно. Для магнитных носителей хорошим начальным значением этого параметра будет число отдельных дисков, составляющих массив RAID 0 или RAID 1, в котором размещена база данных.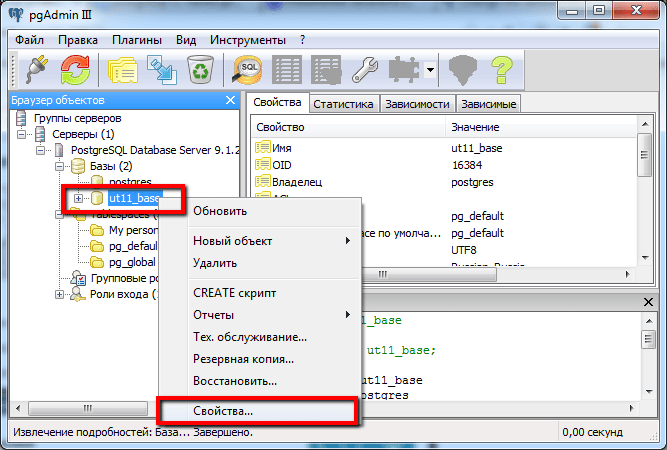 Для RAID 5 следует исключить один диск (как диск с чётностью). У меня один диск, поэтому у меня данный параметр закомментирован.
Для RAID 5 следует исключить один диск (как диск с чётностью). У меня один диск, поэтому у меня данный параметр закомментирован.
wal_sync_method = open_datasync
Метод, который используется для принудительной записи данных на диск. Возможные значения:
- open_datasync – запись данных методом open() с параметром O_DSYNC,
- fdatasync – вызов метода fdatasync() после каждого commit,
- fsync_writethrough – вызывать fsync() после каждого commit игнорирую паралельные процессы,
- fsync – вызов fsync() после каждого commit,
- open_sync – запись данных методом open() с параметром O_SYNC.
Выбор метода зависит от операционной системы под управлением, которой работает PostgreSQL. Для Windows рекомендуется open_datasync. Для Linux — fdatasync.
#checkpoint_segments = 32
В версии PostgreSQL 11.9 не используется, поэтому у меня данный параметр закомментирован. Данный параметр определяет количество сегментов (каждый по 16 МБ) лога транзакций между контрольными точками. В зависимости от объема данных установите этот параметр в диапазоне от 12 до 256 сегментов и, если в логе появляются предупреждения (warning) о том, что контрольные точки происходят слишком часто, постепенно увеличивайте его. Можно установить в 32 (если у вас PostgreSQL поддерживает этот параметр) и дальше смотреть предупреждения в логе.
В зависимости от объема данных установите этот параметр в диапазоне от 12 до 256 сегментов и, если в логе появляются предупреждения (warning) о том, что контрольные точки происходят слишком часто, постепенно увеличивайте его. Можно установить в 32 (если у вас PostgreSQL поддерживает этот параметр) и дальше смотреть предупреждения в логе.
checkpoint_completion_target = 0.9
Часть интервала контрольной точки. Рекомендуется максимальное значение 0.9.
wal_buffers = 16MB
PostgreSQL сначала пишет в буферы, а затем эти буферы сбрасываются в WAL файлы на диск. По молчанию 16MB.
min_wal_size = 4GB
Минимальный размер WAL файла. Установил чуть больше, чем предложил калькулятор.
max_wal_size = 16GB
Максимальный размер WAL файла. Рекомендуется от 2 * min_wal_size до 4 * min_wal_size.
autovacuum = on
Включение автоочистки.
bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0 bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем gwriter_lru_maxpages.
Параметры, управляющие интенсивностью записи фонового процесса записи.
synchronous_commit = off
Отключаем синхронизацию с диском в момент коммита. Есть риск потери последних нескольких транзакций, но гарантируется целостность базы данных. Значительно увеличивает производительность.
commit_delay = 1000
Пауза в микросекундах перед собственно выполнением сохранения WAL.
commit_siblings = 5
Минимальное число одновременно открытых транзакций, при котором будет добавляться задержка commit_delay.
Оптимизатор запросов
default_statistics_target = 300
Количество записей, просматриваемых при сборе статистики по таблицам. Рекомендуется для 1С от 1000 до 10000. Я поставил 300, если будут зависания, параметр можно увеличить.
from_collapse_limit = 20
Задаёт максимальное число элементов в списке FROM, до которого планировщик будет объединять вложенные запросы с внешним запросом. При меньших значениях сокращается время планирования, но план запроса может стать менее эффективным.
join_collapse_limit = 6
Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). Рекомендуется 1, но сложные запросы с большим количеством соединений и источников данных станут надолго зависать. Поэтому ставлю чуть меньше значения по умолчанию — 6.
seq_page_cost = 0.1
Задаёт приблизительную стоимость последовательного чтения одной страницы с диска. Для NVMe дисков рекомендуется 0.1. Для HDD 1.5 — 2.0. Для SSD 1.1 — 1.3. Можно посмотреть характеристики ваших дисков.
random_page_cost = 0.4
Задаёт приблизительную стоимость случайного чтения одной страницы с диска. Рекомендуется ставить чуть больше чем seq_page_cost.
cpu_operator_cost = 0.00025
Задаёт приблизительную стоимость обработки оператора или функции при выполнении запроса. Рекомендуется 0.00025.
online_analyze.table_type = 'temporary'
Типы таблиц, для которых выполняется немедленный анализ:
- all (все),
- persistent (постоянные),
- temporary (временные),
- none (никакие).
При возникновении проблем с производительностью выполнения регламентных операций можно включить сбор статистики для всех таблиц: all.
online_analyze.threshold = 50
Минимальное число изменений строк, после которого может начаться немедленный анализ.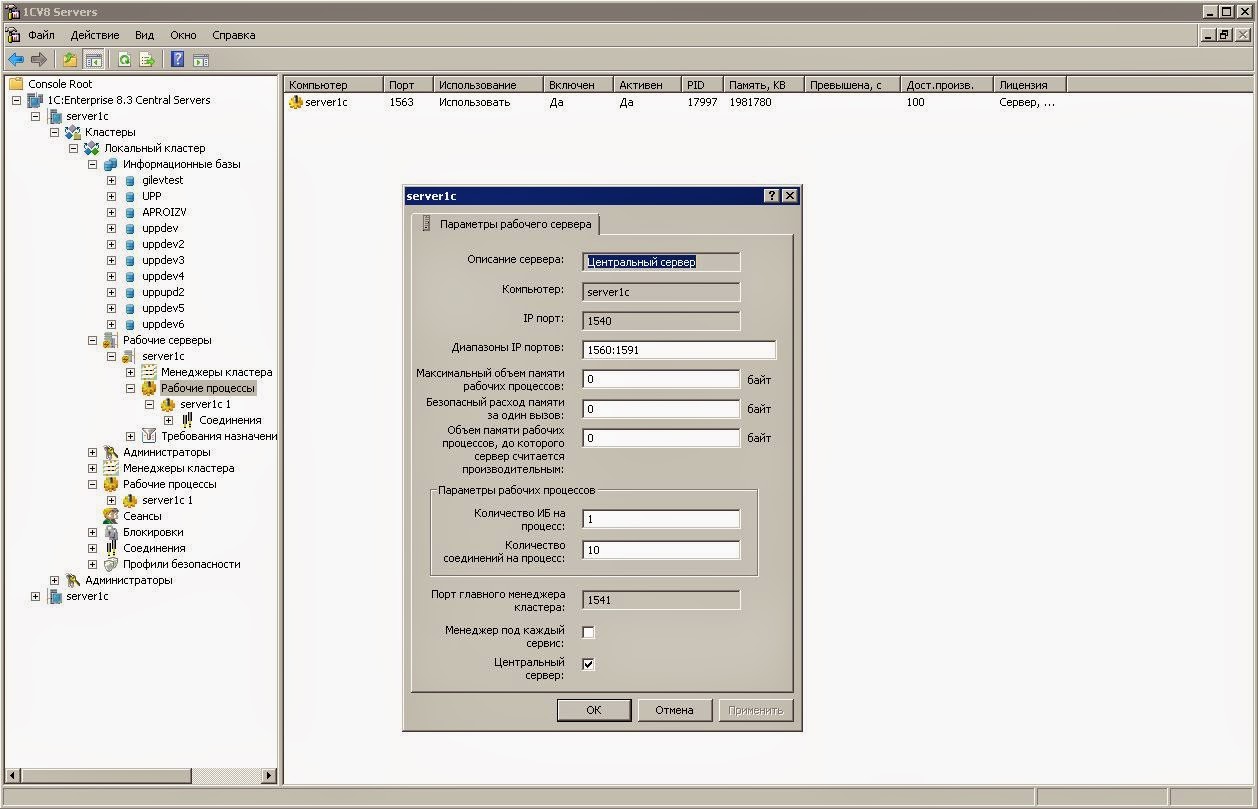
online_analyze.scale_factor = 0.1
Процент от размера таблицы, при котором начинается немедленный анализ.
online_analyze.min_interval = 10000
Минимальный интервал времени между вызовами ANALYZE для отдельной таблицы (в миллисекундах).
online_analyze.verbose = off
Отключаем подробные сообщения расширения online_analyze.
online_analyze.local_tracking = off
online_analyze использует для временных таблиц системную статистику по умолчанию.
plantuner.fix_empty_table = on
plantuner будет обнулять число страниц/кортежей в таблице, которая не содержит никаких блоков в файле.
enable_nestloop = off
Отключает использование планов соединения с вложенными циклами.
enable_mergejoin = off
Отключает использование планов соединения слиянием.
Сбор статистики
track_counts = on
Включает сбор статистики активности в базе данных. Этот параметр по умолчанию включён, так как собранная информация требуется автоочистке.
1С
standard_conforming_strings = off
Разрешить использовать символ «\» для экранирования.
escape_string_warning = off
Не выдавать предупреждение об использовании символа «\» для экранирования.
shared_preload_libraries = 'online_analyze, plantuner'
Библиотеки, которые будут загружаться при запуске сервера.
online_analyze.enable = on
Анализ статистики временных таблиц.
PostgreSQL
max_locks_per_transaction = 256
Этот параметр управляет средним числом блокировок объектов, выделяемым для каждой транзакции.
ssl = off
Шифрование. Если сеть защищена, то отключаем. Если 1С и PostgreSQL находятся на одном сервере — тем более отключаем.
Прошёл месяц
Сначала были какие-то ошибки в логах postgresql, но они были связаны с процессом разработки. Месяц — полёт нормальный.
Не удается установить postgres на Ubuntu (E: невозможно найти пакет postgresql)
спросил
Изменено
6 месяцев назад
Просмотрено
83k раз
Итак, у меня возникла проблема, когда по какой-то причине я не могу установить какой-либо пакет в своей системе Ubuntu.
я сейчас на Убунту 16.10 .
журналы установки терминала
Обновление:
Я ввел эти команды и получил это.
после обновления и apt-cache
Что мне теперь делать?
- postgresql
- Ubuntu
- Ubuntu-16.10
2
sudo apt-get установить wget ca-сертификаты wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-ключ добавить - sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/`lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list' sudo apt-получить обновление sudo apt-get установить postgresql postgresql-contrib
После установки сервера базы данных PostgreSQL по умолчанию создается пользователь «postgres» с ролью «postgres». Также создает системную учетную запись с тем же именем «postgres». Итак, чтобы подключиться к серверу Postgres, войдите в свою систему как пользователь postgres и подключитесь к базе данных.
судосу-постгрес psql
2
Сначала выполните
sudo apt-get update
При обновлении не должно быть ошибок. В этом случае у вас могут быть проблемы с брандмауэром или что-то, что мешает вам обновлять репозитории. Внимательно проверьте вывод.
Затем найдите правильное (точное!) имя пакета с помощью этой команды:
apt-cache search postgresql
В крайнем случае вы можете добавить внешний сторонний репозиторий, как описано в этом ответе. Просто не забудьте использовать имя вашего дистрибутива вместо «xenial».
1
Должно работать.
$ sudo apt-get установить postgresql postgresql-client
0
Если вы получаете (E: Не удалось найти пакет postgresql-12) во время миграции, вам может помочь следующий шаг:
sudo apt-get -y install bash-completion wget wget --quiet -O - https://www.
 postgresql.org/media/keys/ACCC4CF8.asc |
sudo apt-ключ добавить -
sudo apt-получить обновление
sudo apt-get -y установить postgresql-12 postgresql-client-12
sudo systemctl статус postgresql
postgresql.org/media/keys/ACCC4CF8.asc |
sudo apt-ключ добавить -
sudo apt-получить обновление
sudo apt-get -y установить postgresql-12 postgresql-client-12
sudo systemctl статус postgresql
ref: install postgres12 в ubuntu-18.04
У меня сработали следующие команды: sudo apt-get install wget ca-certificates
wget —quiet -O — https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add —
sudo sh -c ‘echo «deb http://apt.postgresql.org/pub/repos/apt/lsb_release -cs-pgdg main» >> /etc/apt/sources.list. d/pgdg.list’
sudo apt-get update
sudo apt install postgresql-11 libpq-dev
Зарегистрируйтесь или войдите
Зарегистрироваться через Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
установка postgresql: каталог данных initdb не пуст?
Я пытаюсь создать базу данных postgresql.
Когда я устанавливаю PostgreSQL, я дал эту команду:
sudo yum install postgresql postgresql-server
и более поздние версии я изменил файл конфигурации:
sudo vim /var/lib/pgsql/data/pg_hba.conf
и модифицированный как
локальный все все доверенные хост все все 127.0.0.1/32 доверие хост все все ::1/128 доверие хост все все 0.0.0.0/0 md5
Пока я пытаюсь запустить службу postgresql:
служба sudo postgresql initdb > Каталог данных не пуст! [НЕУСПЕШНЫЙ] sudo chkconfig postgresql на запуск службы sudo postgresql Запуск службы postgresql: [ ОК ]
Чем вызваны эти ошибки и как их исправить?
- postgresql
- установка
Initdb следует запускать только один раз. Он создаст каталог, в котором вы будете хранить файлы конфигурации и (обычно) фактическую базу данных. Вы, очевидно, уже сделали это; в противном случае не было бы файла pg_hba.conf для редактирования.
Так что просто не запускайте postgresql initdb снова, если только вы не выполняете полную переустановку.
3
Отсюда:
Если вы полностью стираете и переустанавливаете БД Postgres, при запуске initdb например:
service postgresql-9.2 initdb -E 'UTF8' --pgdata="/foo/bar/"
вы можете столкнуться с этой ошибкой службы:
Каталог данных не пуст! [НЕ ПРОЙДЕНО]
Чтобы исправить это (и это ядерный вариант — все данные базы данных стираются!)
В Amazon Linux (2014-x):
rm -rf /var/lib/pgsql9/data
В CentOS (6.x)
rm -rf /var/lib/pgsql/9.2/data
Теперь попробуйте еще раз ввести команду initdb , на этот раз она должна работать:
служба postgresql- 9.2 initdb
0
В системах на основе systemd, таких как RHEL/CentOS 7 и Fedora, процедура запуска initdb несколько отличается. Этого больше не делают скрипты инициализации (которых больше не существует), и новая процедура намного ближе к вышестоящим инструкциям.
Этого больше не делают скрипты инициализации (которых больше не существует), и новая процедура намного ближе к вышестоящим инструкциям.
Вы должны сначала su пользователю postgres , а затем запустить initdb или pg_ctl initdb . Нет необходимости указывать каталог данных, если вы используете сборку Red Hat, так как по умолчанию автоматически выбирается каталог данных по умолчанию /var/lib/pgsql .
Например:
# su - postgres $ pg_ctl initdb $ выход #
Конечно, вы делаете это только один раз, при первой установке, для настройки исходного каталога данных. Вы бы не делали этого снова, если бы не создавали совершенно новую установку или не восстанавливались после сбоя.
1
У меня была такая же проблема при использовании PostgreSQL 9.3 на CentOS 6.
Я удалил /var/lib/pgsql/9.3/data, затем повторно запустил команду
sudo service postgresql-9.
