Вставка в таблицу sql данных: MS SQL Server и T-SQL
Добавление, изменение и удаление данных. (Урок 6)
← Удаление записей из базы данных SQL
Объединение наборов записей в SQL Server →
Рубрика: Учебные материалы
Метки: SQL
Основы Transact SQL: Добавление, изменение и удаление данных в таблицах
Запросы, рассмотренные ранее, были направлены на то, чтобы получить данные, содержащиеся в существующих таблицах базы данных. Главным ключевым словом таких запросов на выборку данных является SELECT.
Запросы на выборку данных всегда возвращают виртуальную таблицу, которая отсутствует в базе данных и создается временно лишь для того, чтобы представить выбранные данные пользователю. При создании и дальнейшем сопровождении базы данных обычно возникает задача добавления новых и удаления ненужных записей, а также изменения содержимого ячеек таблицы. В SQL для этого предусмотрены операторы INSERT (вставить), DELETE (удалить) и UPDATE (изменить). Запросы, начинающиеся с этих ключевых слов, не возвращают данные в виде виртуальной таблицы, а изменяют содержимое уже существующих таблиц базы данных. Запросы на модификацию (добавление, удаление и изменение) данных могут содержать вложенные запросы на выборку данных из той же самой таблицы или из других таблиц, однако сами не могут быть вложены в другие запросы. Таким образом, операторы INSERT, DELETE и UPDATE в SQL-выражении могут находиться только в самом начале.
Запросы, начинающиеся с этих ключевых слов, не возвращают данные в виде виртуальной таблицы, а изменяют содержимое уже существующих таблиц базы данных. Запросы на модификацию (добавление, удаление и изменение) данных могут содержать вложенные запросы на выборку данных из той же самой таблицы или из других таблиц, однако сами не могут быть вложены в другие запросы. Таким образом, операторы INSERT, DELETE и UPDATE в SQL-выражении могут находиться только в самом начале.
Добавление новых записей
Для вставки записей в таблицу используется оператор INSERT, который имеет несколько форм:
- INSERT INTO имяТаблицы VALUES (списокЗначений)
вставляет запись в указанную таблицу и заполняет эту запись значениями из списка, указанного за ключевым словом VALUES. При этом первое в списке значение вводится в первый столбец таблицы, второе значение — во второй столбец и т. д. Порядок столбцов задается при создании таблицы. Данная форма оператора INSERT не очень надежна, поскольку нетрудно ошибиться в порядке вводимых значений. Более надежной и гибкой является следующая форма.
д. Порядок столбцов задается при создании таблицы. Данная форма оператора INSERT не очень надежна, поскольку нетрудно ошибиться в порядке вводимых значений. Более надежной и гибкой является следующая форма.
- INSERT INTO имяТаблицы (списокСтолбцов) VALUES (списокЗначений)
вставляет запись в указанную таблицу и вводит в заданные столбцы значения из указанного списка. При этом в первый столбец из списокСтолбцов вводится первое значение из списокЗначений, во второй столбец — второе значение и т. д. Порядок имен столбцов в списке может отличаться от их порядка, заданного при создании таблицы. Столбцы, которые не указаны в списке, заполняются значением NULL. Рекомендуется использовать именно данную форму оператора INSERT. Следующий запрос добавляет новую запись в справочник городов.
INSERT INTO City(CityName)
VALUES(‘Калуга’)
Обратите внимание, что столбец IdCity не задается, поскольку он является счетчиком и заполняется СУБД автоматически.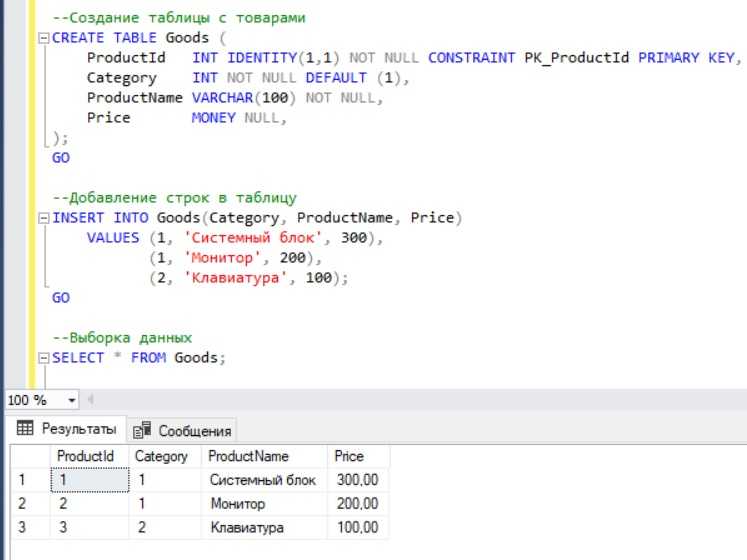
- INSERT INTO имяТаблицы (списокСтолбцов) SELECT …
вставляет в указанную таблицу записи, возвращаемые запросом на выборку. На практике нередко требуется загрузить в одну таблицу данные из другой таблицы. Например, следующий запрос вставляет в таблицу City сразу два города, возвращаемых запросом с объединением.
INSERT INTO City(CityName)
SELECT ‘Уфа’
UNION
SELECT ‘Волгоград’
- Начало работы с Microsoft SQL Server 2005 (Урок 1)
- Создание таблиц в SQL Server 2005 (Урок 2)
- Создание ограничений в SQL Server 2005(Урок 3)
- Основы Transact SQL: Простые выборки данных (Урок 4, часть 1)
- Основы Transact SQL: Простые выборки данных (Урок 4, часть 2)
- Фильтрация данных SQL Server
- Агрегатные функции SQL
- Запросы SQL с группировкой строк
- Основы Transact SQL: Сложные (многотабличные запросы)(Урок 5, часть 1)
- Основы Transact SQL: Сложные (многотабличные запросы)(Урок 5, часть 2)
- Внутреннее и внешнее соединение при помощи оператора JOIN
- Объединение наборов записей в SQL Server
- Основы Transact SQL: Добавление, изменение и удаление данных.
 (Урок 6)
(Урок 6)- Удаление записей из базы данных SQL
- Microsoft Sql Server 2005. Представления (Урок 7)
- SQL Server 2005. Программирование на T-SQL (Урок 8)
- Microsoft SQL Server 2005. Хранимые процедуры (Урок 9)
 (Урок 6)
(Урок 6)Oracle: быстрая вставка данных в таблицу
Уменьшение времени пакетной (для olap/dwh) вставки данных:
Отличительная особенность olap: вставка одна, но очень большая.
1. Делаем таблицу не логируемой.
Что уменьшит затраты на вставку в redo log.
ALTER TABLE T NOLOGGING
* Может не сработать, если в базе включено FORCE_LOGGING = YES
2. Добавляем /*+ append */ в insert операцию
* Данные добавляются в конец таблицы, вместо попытки поиска пустых мест.
* Данные пишутся напрямую в data файлы, минуя буферный кэш.
Стоит заметить один нюанс при вставке с хинтом append из разных сессий в одну таблицу. Так делать нельзя, т.к. direct path вставка блокирует все остальные сессий к этой таблице: http://docs.oracle.com/cd/B19306_01/server.102/b14231/tables.htm#sthref2260 . Только одна сессия может одновременно осуществлять direct path вставку в одну таблицу. Т.к. чтобы обойти буферный кэш, сначала нужно скинуть все грязные данные из кэша на диск.
Так делать нельзя, т.к. direct path вставка блокирует все остальные сессий к этой таблице: http://docs.oracle.com/cd/B19306_01/server.102/b14231/tables.htm#sthref2260 . Только одна сессия может одновременно осуществлять direct path вставку в одну таблицу. Т.к. чтобы обойти буферный кэш, сначала нужно скинуть все грязные данные из кэша на диск.
3. Отключаем constraint, trigger на таблице и явно вставляем значения в default колонки.
Замечу, что если надо ускорить вставку, то надо отключать FK на самой таблице, а если удаление, то FK на других таблицах, которые указывают на нашу.
4. Распараллеливаем запрос хинтом /*+ PARALLEL (8) */
Не забываем включать параллельность для DML, чтобы параллелился и insert, а не только select.
ALTER SESSION ENABLE PARALLEL DML;
5. Если распаралеллить вставку нельзя, к примеру из-за доступа по dblink.
Можно физически распаралелить вставку через несколько одновременных вставок кусками части данных из источника.
Сделать это можно через dbms_parallel.
Очень хорошо подходит для одновременного копирования нескольких таблиц или если таблица партиционирована.
При вставке в одну таблицу незабываем про ограничения хинта append из п.2
6. Удаляем index и foreign key с внешних таблиц.
Пришлось именно удалять, т.к.
* DISABLE можно делать только у функциональных индексов
* UNUSABLE можно сделать на всех индексах, но DML запросы все равно будут валиться на UNIQUE index
http://docs.oracle.com/cd/B13789_01/server.101/b10755/initparams197.htm
Ничего страшного в этом нет, восстановление индексов заняло 5 минут по 10 млн записей, что все равно лучше 4 часов вставки.
Удаляем все, включая Prmary Key. Но тут не забываем, что каскадно удалятся и все FK. Их надо будет потом восстановить, ну или PK придется пожертвовать и оставить.
ALTER TABLE T DROP CONSTRAINT PK CASCADE
7. Делаем кэшируемым Sequence.
Если в insert используется sequence, то делаем его кэшируемым.
С «CACHE 50000» мне удалось сократить время вставки 10 млн записей с 50 минут до 5. Это в 10 раз!
При кэширумом sequence последовательность заранее подготавливает числа и хранит в памяти, а это значит, что накладных расходов обмена становится меньше.
8. IOT таблица
Если на таблице один индекс, который покрывает большую часть столбцов, то ее можно конвертировать в IOT таблицу. Так мы уменьшаем число обслуживаемых объектов до 1. Что уменьшает число буферных чтений с 3 (2 чтения индекса + 1 чтения таблицы) при любых DML/select до 2 (2 чтения индекса).
Уменьшение времени распределенной/многопользовательской (oltp) вставки данных:
отличительной особенности вставок в oltp является то, что их очень много, каждая из них создает микроскопическую нагрузку, но все вместе могут создать большое кол-во событий ожиданий (busy wait).
Рассмотрим отдельно как обойти эти ожидания:
1. увеличение числа списка свободных блоков (free_list при создании таблицы)
+ уменьшение конкуренции за поиск свободных блоков за счет распараллеливания вставки
— раздувание таблицы, т.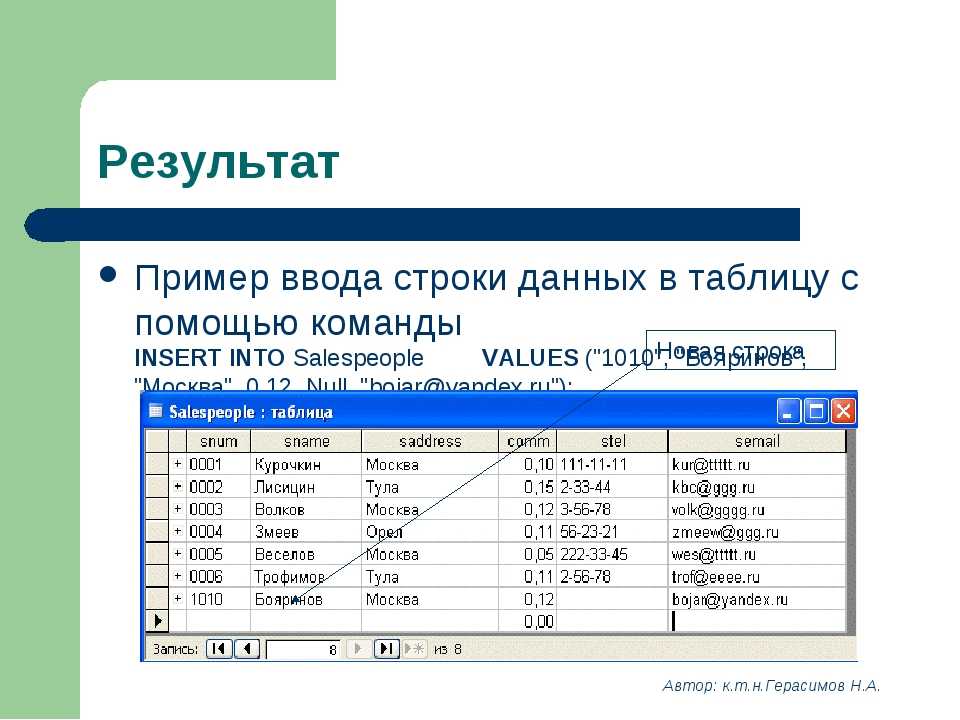 к. когда заканчивается free_list1, то он не будет использовать свободные блоки из free_list2, а выделит новые поверх HWM
к. когда заканчивается free_list1, то он не будет использовать свободные блоки из free_list2, а выделит новые поверх HWM
— увеличивает фактор кластеризации индексов, т.к. данные физически раскидываются по разным местам таблицы, а не идут последовательно
2. сделать индекс реверсивным, если нет возможности отключить при вставке
+ уменьшение конкуренции за вставку данных в индекс, т.к. последовательные реверсивные данные будут использовать разные блоки индекса
— увеличение фактора кластеризации из-за разброса данных
— нельзя будет использовать range scan (сканирование по диапазону) индекса, т.к. в индексе уже не сами данные, а их инвертированные значения
Стоит заметить о факторе класетризации: чаще всего в oltp системе он не очень важен, т.к. доступ к данным идет по конкретному значению к одному конкретному блоку. Т.е. здесь нет скачков по разным блокам, как при сканировании по диапазону.
3. использование хинта append_values
+ запись данных не будет использовать free_list, а будет просто писаться поверх HWM
— разрастание таблицы
4. секционирование таблицы, таким образом, чтобы параллельные вставки шли в физически разные секции таблицы.
секционирование таблицы, таким образом, чтобы параллельные вставки шли в физически разные секции таблицы.
Т.е. секционирование по первичному ключу или по дате не подходит, нужно по какомуто столбцу, которые присутствует во всех вставках ежедневно и имеет одинаковый разброс.
5. Выполнение вставки используя prepared statement
что позволит исключить парсинг SQL перед его выполнением.
6. Вставка строк блоками (executeBatch)
Что позволит снизить задержки на network lookup — время на установку соединения и передачу данных по сети.
7. 7п. из пакетной вставки — кэшируемый индекс
8. остальные способы из пакетной вставки, если они применимы в текущей ситуации
Если знаете еще способы ускорить insert — пишите в комментариях.
В продолжении: быстрая вставка данных в партиционированные таблицы http://blog.skahin.ru/2015/06/oracle.html
mysql — SQL: INSERT INTO table(…) VALUES (…) с данными, полученными из других таблиц
Задавать вопрос
спросил
Изменено
2 года, 8 месяцев назад
Просмотрено
392 раза
Спасибо, что прошли мимо.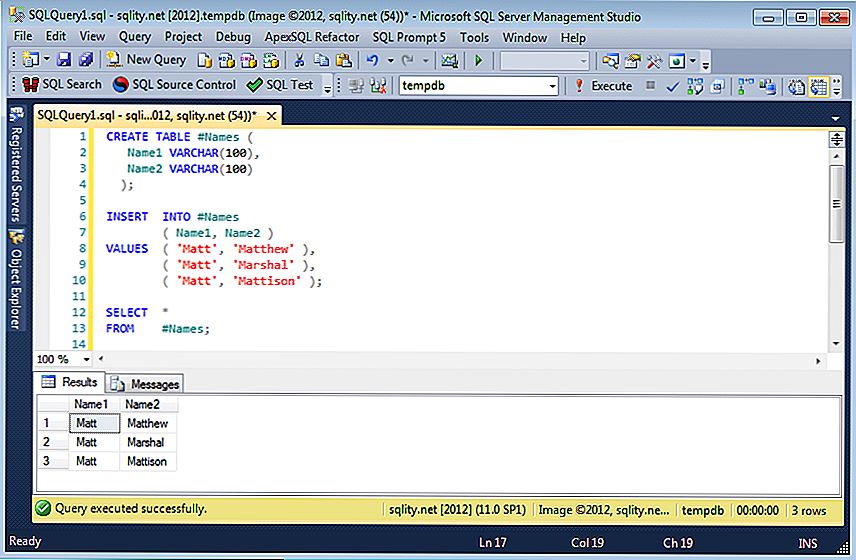 Я знаю базовый синтаксис SQL и не могу найти способ выполнить эту задачу.
Я знаю базовый синтаксис SQL и не могу найти способ выполнить эту задачу.
Мне нужно создать хранимую процедуру, которая вставляет данные из одной таблицы в другую, а также извлекает данные из многих других. Предположим, у меня есть эти таблицы со столбцами:
пользователей- имя (varchar)
- sub_id (целое число)
- dub_id (целое число)
tmp_users- имя (varchar)
- под_имя (varchar)
- dub_name (varchar)
субтитры- идентификатор (целое число)
- имя (varchar)
дабы- идентификатор (целое число)
- имя (varchar)
В псевдокоде я должен сделать что-то вроде этого:
ВСТАВИТЬ В пользователей (имя, sub_id, dub_id)
ВСЕ СТРОКИ ИЗ ЗНАЧЕНИЙ tmp_users (
имя = tmp_users.имя,
sub_id = ВЫБЕРИТЕ идентификатор ИЗ подпрограмм, ГДЕ tmp_users. sub_name = подпрограммы.имя,
dub_id = ВЫБЕРИТЕ идентификатор ИЗ дубляжей, ГДЕ tmp_users.dub_name = dubs.name,
)
 sub_name = подпрограммы.имя,
dub_id = ВЫБЕРИТЕ идентификатор ИЗ дубляжей, ГДЕ tmp_users.dub_name = dubs.name,
)
sub_name = подпрограммы.имя,
dub_id = ВЫБЕРИТЕ идентификатор ИЗ дубляжей, ГДЕ tmp_users.dub_name = dubs.name,
)
В формулировке мне нужно вставить в пользователей все строки из tmp_users , чтобы сохранить col tmp_users.name , но получить афферентные id всех других таблиц на основе столбца *_name . Как мне подойти к этой задаче?
- mysql
- sql
- база данных
- sql-insert
1
Кажется, вы ищете INSERT ... SELECT синтаксис:
INSERT INTO пользователей (имя, sub_id, dub_id)
ВЫБРАТЬ
ты.имя,
с.ид,
делал
ОТ tmp_users ту
LEFT JOIN subs ON s.name = tu.sub_name
LEFT JOIN dubs d ON d.name = tu.dub_name
Это приносит все строки из tmp_users , а затем пытается восстановить соответствующие sub_id и dub_id . Для каждой строки, возвращаемой
Для каждой строки, возвращаемой select , запись вставляется в пользователей . Преимущество этого синтаксиса в том, что вы можете запустить сначала выберите запрос независимо, чтобы увидеть, что будет вставлено.
0
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Создание и вставка данных во временную таблицу в SQL Server
Временная таблица или временная таблица — это таблица, созданная пользователем, которая существует с единственной целью хранения подмножества данных из одной или нескольких физических таблиц. Временные таблицы можно использовать для хранения больших объемов данных, которые в противном случае потребовали бы многочисленных запросов для многократной фильтрации этих данных. Временные таблицы существуют только до тех пор, пока соединение, создавшее их, активно или пока они не будут вручную удалены пользователем или процедурой и не будут находиться в пределах
Временные таблицы можно использовать для хранения больших объемов данных, которые в противном случае потребовали бы многочисленных запросов для многократной фильтрации этих данных. Временные таблицы существуют только до тех пор, пока соединение, создавшее их, активно или пока они не будут вручную удалены пользователем или процедурой и не будут находиться в пределах tempdb системная база данных.
Также стоит отметить, что стандартная временная таблица, о которой я в первую очередь буду говорить в этом посте, доступна только для того соединения, которое ее создало. Однако вы также можете создавать глобальные временные таблицы, доступные для любого подключения. Я кратко расскажу об этой концепции в конце статьи.
Шаги, описанные ниже, помогут вам создать физическую таблицу для хранения некоторых данных, а затем создать временную таблицу, которая затем будет заполнена данными из физической таблицы.
Первый шаг — создать физическую таблицу базы данных и заполнить ее данными. Сценарий, описанный ниже, создаст таблицу с именем
Сценарий, описанный ниже, создаст таблицу с именем employee . Таблица будет содержать столбец идентификатора сотрудника, который будет автоматически увеличиваться и действовать как PRIMARY KEY . В таблице также будут указаны фамилия, имя, дата приема на работу и должность.
СОЗДАТЬ ТАБЛИЦУ сотрудника ( emp_id INT IDENTITY PRIMARY KEY, last_name VARCHAR(30) НЕ NULL, first_name VARCHAR(30) НЕ NULL, найм_дата ДАТАВРЕМЯ НЕ NULL, job_title VARCHAR(50) НЕ NULL )
Следующим шагом является заполнение недавно созданной таблицы сотрудников некоторыми данными, которые мы можем использовать. В следующем сценарии для этого используется вызов функции INSERT INTO .
ВСТАВИТЬ В сотрудника ЦЕННОСТИ («Смит», «Джеймс», «01.03.2016», «Штатный бухгалтер»), («Уильямс», «Роберта», «7 февраля 2004 г.», «Старший инженер-программист») («Вайнберг», «Джефф», «02.01.2007», «Менеджер по персоналу») («Франклин», «Виктория», «02.
 07.2010», «Операционный менеджер»),
(«Армстронг», «Уильямс», «14.11.2012», «Администратор базы данных»),
(«Кромли», «Эрик», «9/9/2009», «Менеджер по подбору персонала»)
(«Ричардсон», «Джон», «11.02.2007», «Служба безопасности»)
(«Хортон», «Мишель», «12.06.2009», «Бухгалтерский учет»),
(«Вашингтон», «Марк», «19 августа 2014 г.», «Технический специалист службы поддержки»)
07.2010», «Операционный менеджер»),
(«Армстронг», «Уильямс», «14.11.2012», «Администратор базы данных»),
(«Кромли», «Эрик», «9/9/2009», «Менеджер по подбору персонала»)
(«Ричардсон», «Джон», «11.02.2007», «Служба безопасности»)
(«Хортон», «Мишель», «12.06.2009», «Бухгалтерский учет»),
(«Вашингтон», «Марк», «19 августа 2014 г.», «Технический специалист службы поддержки»)
Теперь, когда физическая таблица создана и заполнена, вы можете легко запросить ее.
ВЫБЕРИТЕ * ОТ сотрудника
На следующем снимке экрана показаны выходные данные.
Существует два способа создания и заполнения временной таблицы.
Первый и, возможно, самый простой способ сделать это — SELECT данные INTO временная таблица. Это по существу создает временную таблицу на лету. В приведенном ниже примере будет создана временная таблица и вставлены last_name , first_name , Hire_date и job_title всех сотрудников в физической таблице employee с наймом , который больше 01.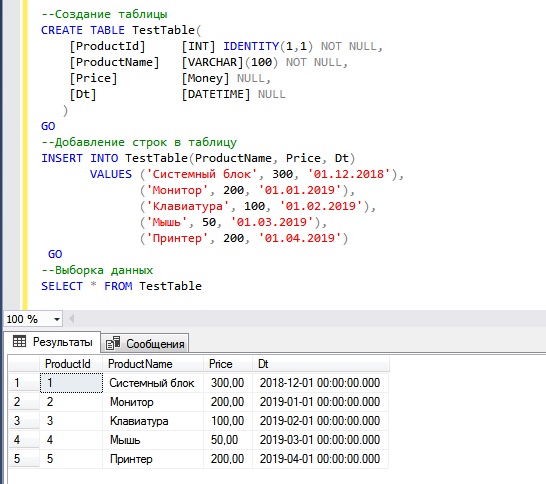 01.2010. .
01.2010. .
ВЫБЕРИТЕ фамилию, имя, дату найма, должность_название INTO #tmp_employees ОТ dbo.employee ГДЕ найм_дата > '01.01.2010'
Вы можете запрашивать временную таблицу так же, как и любую физическую таблицу.
ВЫБЕРИТЕ * из #tmp_employees
Вывод должен выглядеть следующим образом:
Как обсуждалось ранее, есть два способа удалить временную таблицу. Первый — закрыть соединение с базой данных, которая создала временную таблицу. Другой — выполнить следующую команду.
УДАЛИТЬ ТАБЛИЦУ #tmp_employees
Этот метод более полезен в большинстве практических приложений, так как вы можете использовать команду drop вместе с проверкой при создании временных таблиц в хранимых процедурах, чтобы проверить, существует ли временная таблица или нет, и удалить ее перед запуском процедуры. Пример такой логики можно увидеть ниже.
ЕСЛИ OBJECT_ID('tempdb..#tmp_employees') НЕ NULL
УДАЛИТЬ ТАБЛИЦУ #tmp_employees
Второй метод создания и заполнения временной таблицы включает в себя сначала создание временной таблицы, а затем использование команды INSERT INTO для заполнения временной таблицы.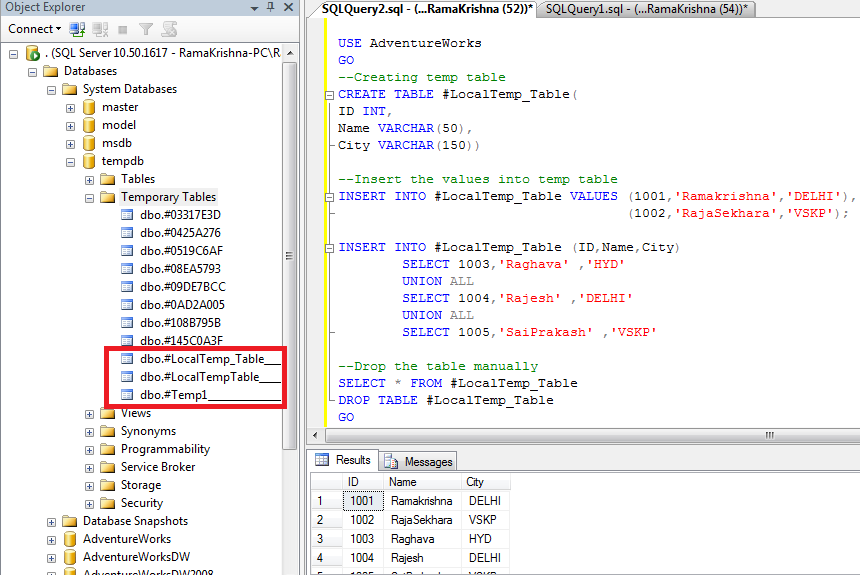 Эти шаги аналогичны шагам, используемым для создания и заполнения физической таблицы выше.
Эти шаги аналогичны шагам, используемым для создания и заполнения физической таблицы выше.
В следующем скрипте вы заметите, что при создании временной таблицы вам нужно будет назначить тип данных для каждого создаваемого вами столбца. Лучшей практикой является соответствие типу данных физической таблицы или таблиц, из которых будут извлекаться данные. Это предотвратит возникновение потенциальных ошибок усечения при заполнении временной таблицы.
СОЗДАТЬ ТАБЛИЦУ #tmp_employees ( фамилия VARCHAR(30), имя VARCHAR(30), наем_дата ДАТАВРЕМЯ, job_title VARCHAR(50) ) ВСТАВИТЬ В #tmp_employees ВЫБЕРИТЕ фамилию, Имя, Дата приема на работу, название работы ОТ dbo.employee ГДЕ наем_дата < '1/1/2010'
После создания таблицы сценарий использует команду INSERT INTO для заполнения #tmp_employees last_name , first_name , Hire_date и job_title всех сотрудников из физической таблицы сотрудников , у которых найм_дата меньше, чем 01. 01.2010.
01.2010.
Опять же, вы можете запросить данные, используя тот же оператор выбора, что и выше.
Как упоминалось ранее, эти типы временных таблиц доступны только для соединения, которое их создало. Чтобы создать глобально доступную временную таблицу, все, что вам нужно сделать, это добавить двойную решетку перед именем таблицы. Срок действия глобальных временных таблиц также истекает, когда создавший их пользователь или процедура перестает быть активными. Однако любой пользователь базы данных может получить доступ к глобальной временной таблице, пока она существует.
Используя ту же логику, что и в первом примере, следующий сценарий создает глобальную временную таблицу.
ВЫБЕРИТЕ фамилию, имя, дату найма, должность_название INTO ##tmp_employees ОТ dbo.employee ГДЕ найм_дата > '01.01.2010'
Как и обычные временные и физические таблицы, к глобальной временной таблице можно обращаться таким же образом.
ВЫБЕРИТЕ * ОТ ##tmp_employees
Независимо от того, являетесь ли вы новичком в SQL или плохо знакомы с концепцией временных таблиц, я надеюсь, что описанные выше шаги дали ценную информацию о том, как создавать временные таблицы и управлять ими в SQL Server.