Вставка в таблицу sql данных: MS SQL Server и T-SQL
Содержание
Копирование и вставка данных между базами данных в ArcGIS—ArcGIS Pro
Доступно с лицензией Standard или Advanced.
Вы можете копировать данные из базы данных и вставлять их в другую базу данных или многопользовательскую базу геоданных через ArcGIS Pro. Вы не можете копировать таблицы из или вставлять таблицы в облачные хранилища данных.
При перемещении данных из одного типа базы данных в другой, типы данных, используемые для атрибутов в вашей таблице, могут изменяться. Например, если вы копируете таблицу Microsoft SQL Server с полем UniqueIdentifier, то при ее вставке в базу данных PostgreSQL это поле будет типа Varchar.
ArcGIS не может вставлять типы данных или определения, которые она не поддерживает. Это означает, что таблица или класс пространственных объектов, вставленные в вашу целевую базу данных, будут содержать следующее:
- Типы данных, поддерживаемые в ArcGIS
Все столбцы, которые не совпадают с типом данных ArcGIS, не будут созданы в классе пространственных объектов целевой базы данных.

- Один пространственный столбец
Для классов пространственных объектов ArcGIS использует первый встретившийся пространственный столбец; второй столбец не будет создаваться в целевом классе пространственных объектов. Если вы хотите использовать второй пространственный столбец, то вам необходимо задать представление или слой запроса в таблице источника, которая содержит второй пространственный столбец. Если вы создаете представление, то вы можете скопировать его из исходной базы данных и вставить в целевую базу. Если вы задали слой запроса, то вы можете экспортировать данные из него в новый класс пространственных объектов целевой базы данных.
- Один тип геометрии
ArcGIS считывает тип геометрии (точки, линии, полигоны или мультиточки) первого объекта исходного класса. Только объекты, тип геометрии которых соответствует типу геометрии, заданному в первой строке, будут вставлены в класс пространственных объектов целевой базы данных. Если в вашем исходном классе пространственных объектов несколько типов геометрии, и вы собираетесь выбирать тип геометрии целевого класса объектов, создайте в исходном классе объектов слой запроса и задайте для него тип геометрии.
Затем выполните экспорт данных из слоя запроса в класс объектов целевой базы данных. Класс пространственных объектов целевой базы данных будет содержать только записи типа геометрии, которые вы определили для слоя запроса. - Одна настройка координат
ArcGIS считывает свойства координат (xy, xyz, xym, xyzm), хранящихся с первым объектом класса. У объектов класса, вставляемых в целевую базу данных, будут эти свойства координат. Например, если вы задали слой запроса, имеющий координаты x, y и z, но не имеющий координат m, то все записи, содержащие информацию о размере m в исходном классе пространственных объектов, не будут иметь ее и в целевом классе пространственных объектов. Аналогично, любая запись, которая имеет только координаты x,y в исходном классе пространственных объектов, будет иметь координаты x,y и z в целевом классе пространственных объектов (значение координаты z будет равно 0).
Чтобы убедиться в том, что вся информация о координатах хранится в целевом классе объектов, создайте в исходном классе объектов слой запроса и задайте его пространственные свойства, чтобы включить m- и z-значения.
Затем выполните экспорт данных из слоя запроса в класс объектов целевой базы данных. Все объекты созданного в целевой базе данных класса будут использовать настройки координат, заданные для слоя запроса. - Одна пространственная привязка
Если ваш исходный класс пространственных объектов имеет пространственную привязку, определяемую ArcGIS, то аналогичная пространственная привязка используется для класса пространственных объектов в целевой базе данных. Если пространственная привязка не определена для класса пространственных объектов, то ArcGIS будет использовать пространственную привязку из первой строки таблицы. Записи, не совпадающие с данной пространственной привязкой, не будут созданы в классе пространственных объектов целевой базы данных. И наоборот, если пространственная привязка не может быть определена для класса пространственных объектов или первой строки (например, при использовании пользовательской пространственной привязка), то пространственная привязка, используемая в целевом классе пространственных объектов, зависит от вашей СУБД.

 Затем выполните экспорт данных из слоя запроса в класс объектов целевой базы данных. Класс пространственных объектов целевой базы данных будет содержать только записи типа геометрии, которые вы определили для слоя запроса.
Затем выполните экспорт данных из слоя запроса в класс объектов целевой базы данных. Класс пространственных объектов целевой базы данных будет содержать только записи типа геометрии, которые вы определили для слоя запроса. Затем выполните экспорт данных из слоя запроса в класс объектов целевой базы данных. Все объекты созданного в целевой базе данных класса будут использовать настройки координат, заданные для слоя запроса.
Затем выполните экспорт данных из слоя запроса в класс объектов целевой базы данных. Все объекты созданного в целевой базе данных класса будут использовать настройки координат, заданные для слоя запроса.
Вы также не можете вставлять данные в облачные хранилища данных в ArcGIS.
Приведенные ниже шаги объясняют процедуру перемещения таблицы, класса пространственных объектов или вида между базами данных или из базы геоданных в базу данных с использованием операций копирования и вставки:
- Подключитесь к исходной и целевой базам данных.
- Если необходимо, подготовьте данные для перемещения.
- Чтобы переместить класс пространственных объектов, содержащий записи с различной размерностью, типами геометрии или пространственными привязками, перетащите таблицу на документ карты и измените результирующий слой запроса, выбрав одну размерность, тип геометрии или пространственную привязку. Для перемещения данных в целевую базу данных выполните экспорт слоя запроса. (Для слоя запроса операции копирования и вставки неприменимы.)
- Если класс пространственных объектов имеет несколько пространственных столбцов, создайте представление базы данных, которое включает только один из пространственных столбцов и выполните операции копирования и вставки представления.
- Чтобы переместить класс пространственных объектов, содержащий записи с различной размерностью, типами геометрии или пространственными привязками, перетащите таблицу на документ карты и измените результирующий слой запроса, выбрав одну размерность, тип геометрии или пространственную привязку.
- Щелкните правой кнопкой мыши на таблице, классе пространственных объектов или виде в исходной базе данных и выберите Копировать.
- Щелкните правой кнопкой мыши на целевой базе данных на панели Каталог и выберите Вставить.
Убедитесь, что вы подключаетесь к исходной базе данных как пользователь с правами доступа к данным в ней, и подключитесь к целевой базе данных как пользователь с правами, достаточными для создания таблиц.
 Для перемещения данных в целевую базу данных выполните экспорт слоя запроса. (Для слоя запроса операции копирования и вставки неприменимы.)
Для перемещения данных в целевую базу данных выполните экспорт слоя запроса. (Для слоя запроса операции копирования и вставки неприменимы.)Новая таблица или класс пространственных объектов создана в вашей целевой базе данных.
Отзыв по этому разделу?
Oracle: быстрая вставка данных в таблицу
Уменьшение времени пакетной (для olap/dwh) вставки данных:
Отличительная особенность olap: вставка одна, но очень большая.
1. Делаем таблицу не логируемой.
Что уменьшит затраты на вставку в redo log.
ALTER TABLE T NOLOGGING
* Может не сработать, если в базе включено FORCE_LOGGING = YES
2. Добавляем /*+ append */ в insert операцию
* Данные добавляются в конец таблицы, вместо попытки поиска пустых мест.
* Данные пишутся напрямую в data файлы, минуя буферный кэш.
Стоит заметить один нюанс при вставке с хинтом append из разных сессий в одну таблицу. Так делать нельзя, т.к. direct path вставка блокирует все остальные сессий к этой таблице: http://docs.oracle.com/cd/B19306_01/server.102/b14231/tables.htm#sthref2260 . Только одна сессия может одновременно осуществлять direct path вставку в одну таблицу. Т.к. чтобы обойти буферный кэш, сначала нужно скинуть все грязные данные из кэша на диск.
3. Отключаем constraint, trigger на таблице и явно вставляем значения в default колонки.
Замечу, что если надо ускорить вставку, то надо отключать FK на самой таблице, а если удаление, то FK на других таблицах, которые указывают на нашу.
4. Распараллеливаем запрос хинтом /*+ PARALLEL (8) */
Не забываем включать параллельность для DML, чтобы параллелился и insert, а не только select.
ALTER SESSION ENABLE PARALLEL DML;
5. Если распаралеллить вставку нельзя, к примеру из-за доступа по dblink.
Можно физически распаралелить вставку через несколько одновременных вставок кусками части данных из источника.
Сделать это можно через dbms_parallel.
Очень хорошо подходит для одновременного копирования нескольких таблиц или если таблица партиционирована.
При вставке в одну таблицу незабываем про ограничения хинта append из п.2
6. Удаляем index и foreign key с внешних таблиц.
Пришлось именно удалять, т.к.
* DISABLE можно делать только у функциональных индексов
* UNUSABLE можно сделать на всех индексах, но DML запросы все равно будут валиться на UNIQUE index
http://docs.oracle.com/cd/B13789_01/server.101/b10755/initparams197.htm
Ничего страшного в этом нет, восстановление индексов заняло 5 минут по 10 млн записей, что все равно лучше 4 часов вставки.
Удаляем все, включая Prmary Key. Но тут не забываем, что каскадно удалятся и все FK. Их надо будет потом восстановить, ну или PK придется пожертвовать и оставить.
ALTER TABLE T DROP CONSTRAINT PK CASCADE
7. Делаем кэшируемым Sequence.
Если в insert используется sequence, то делаем его кэшируемым.
С «CACHE 50000» мне удалось сократить время вставки 10 млн записей с 50 минут до 5. Это в 10 раз!
При кэширумом sequence последовательность заранее подготавливает числа и хранит в памяти, а это значит, что накладных расходов обмена становится меньше.
8. IOT таблица
Если на таблице один индекс, который покрывает большую часть столбцов, то ее можно конвертировать в IOT таблицу. Так мы уменьшаем число обслуживаемых объектов до 1. Что уменьшает число буферных чтений с 3 (2 чтения индекса + 1 чтения таблицы) при любых DML/select до 2 (2 чтения индекса).
Уменьшение времени распределенной/многопользовательской (oltp) вставки данных:
отличительной особенности вставок в oltp является то, что их очень много, каждая из них создает микроскопическую нагрузку, но все вместе могут создать большое кол-во событий ожиданий (busy wait).
Рассмотрим отдельно как обойти эти ожидания:
1. увеличение числа списка свободных блоков (free_list при создании таблицы)
+ уменьшение конкуренции за поиск свободных блоков за счет распараллеливания вставки
— раздувание таблицы, т.к. когда заканчивается free_list1, то он не будет использовать свободные блоки из free_list2, а выделит новые поверх HWM
— увеличивает фактор кластеризации индексов, т.к. данные физически раскидываются по разным местам таблицы, а не идут последовательно
2. сделать индекс реверсивным, если нет возможности отключить при вставке
+ уменьшение конкуренции за вставку данных в индекс, т.к. последовательные реверсивные данные будут использовать разные блоки индекса
— увеличение фактора кластеризации из-за разброса данных
— нельзя будет использовать range scan (сканирование по диапазону) индекса, т.к. в индексе уже не сами данные, а их инвертированные значения
Стоит заметить о факторе класетризации: чаще всего в oltp системе он не очень важен, т. к. доступ к данным идет по конкретному значению к одному конкретному блоку. Т.е. здесь нет скачков по разным блокам, как при сканировании по диапазону.
к. доступ к данным идет по конкретному значению к одному конкретному блоку. Т.е. здесь нет скачков по разным блокам, как при сканировании по диапазону.
3. использование хинта append_values
+ запись данных не будет использовать free_list, а будет просто писаться поверх HWM
— разрастание таблицы
4. секционирование таблицы, таким образом, чтобы параллельные вставки шли в физически разные секции таблицы.
Т.е. секционирование по первичному ключу или по дате не подходит, нужно по какомуто столбцу, которые присутствует во всех вставках ежедневно и имеет одинаковый разброс.
5. Выполнение вставки используя prepared statement
что позволит исключить парсинг SQL перед его выполнением.
6. Вставка строк блоками (executeBatch)
Что позволит снизить задержки на network lookup — время на установку соединения и передачу данных по сети.
7. 7п. из пакетной вставки — кэшируемый индекс
8. остальные способы из пакетной вставки, если они применимы в текущей ситуации
Если знаете еще способы ускорить insert — пишите в комментариях.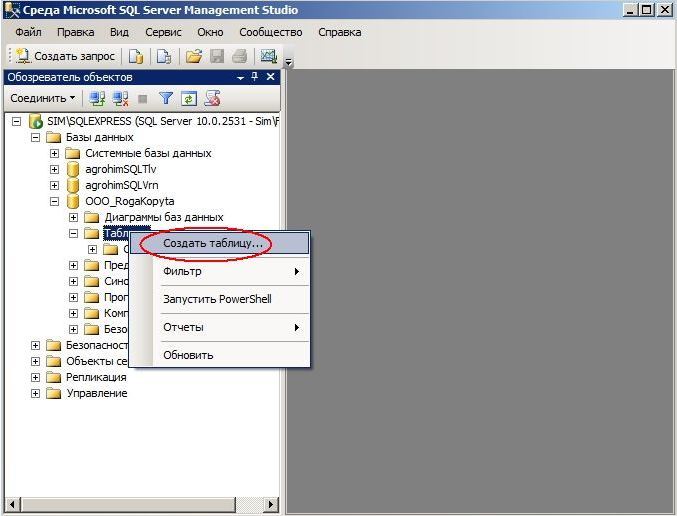
В продолжении: быстрая вставка данных в партиционированные таблицы http://blog.skahin.ru/2015/06/oracle.html
транзакция — сервер SQL — данные успешно вставлены в таблицу, но не возвращены в операторе Select
Запрос выбора SQL не возвращает записи, даже если операция вставки данных выполнена успешно.
У нас есть таблица [dbo].[Login] в нашей базе данных, куда данные вставляются с помощью следующей хранимой процедуры. Данные вставляются службой Windows, написанной на точечной сети. Он работал до прошлого месяца, и записи в таблице росли на несколько сотен тысяч. Недавно клиент пожаловался, что данные не отражаются в отчетах. Следовательно, мы исследовали и обнаружили, что в хранимой процедуре нет ошибки вставки, но когда мы выбираем таблицу, новые записи не возвращаются. Затем мы попытались установить для уровня изоляции SQL-транзакций значение Read un-Committed, после чего мы смогли увидеть недавно вставленные записи из таблицы. Мы проверили хранимую процедуру вставки, но не нашли ничего подозрительного.
СОЗДАТЬ ПРОЦЕДУРУ [dbo].[gp_Login_Insert]
(
@ID int OUTPUT, /*-- в качестве выходного параметра будет возвращено автоматически сгенерированное значение*/
@ReaderHardWareID целое число,
@CardID целое,
@EmpID целое,
@UEmpID varchar(50),
@Введите varchar(15),
@DateTime дата и время,
@CreatedByEmployeeId целое,
@CreatedDate дата и время,
@ModifiedByEmployeeId целое,
@ModifiedDate дата и время,
@version_ts метка времени
)
AS /* ** Добавить строку в таблицу входа */
если не существует (выберите 1 из входа, где EmpID=@EmpID и DateTime=@DateTime)
начинать
объявить @eventCount int
выберите @eventCount=count(*) из [логин]
где EmpID=@EmpID и [DateTime] между DATEADD(dd, 0, DATEDIFF(dd, 0, @DateTime)) и @DateTime
если(@eventCount<500)
Начинать
НАЧАТЬ СДЕЛКУ;
НАЧАТЬ ПОПРОБУЙТЕ
ВСТАВЬТЕ В [Войти]
( [ReaderHardWareID], [CardID], [EmpID], [UEmpID], [Type], [DateTime], [CreatedByEmployeeId], [CreatedDate], [ModifiedByEmployeeId], [ModifiedDate] )
ЦЕННОСТИ
( @ReaderHardWareID, @CardID, @EmpID, @UEmpID, @Type, @DateTime, @CreatedByEmployeeId, GETUTCDATE(), @ModifiedByEmployeeId, GETUTCDATE())
УСТАНОВИТЬ @ID = (ВЫБЕРИТЕ SCOPE_IDENTITY())
КОНЕЦ ПОПЫТКИ
НАЧАТЬ ЛОВИТЬ
ВЫБИРАТЬ
ОШИБКА_NUMBER()
ЕСЛИ @@TRANCOUNT > 0
ОТКАТ СДЕЛКИ;
КОНЦЕВОЙ ЗАХВАТ;
ЕСЛИ @@TRANCOUNT > 0
СОВЕРШИТЬ СДЕЛКУ;
Конец
КОНЕЦ
Выбрать Запрос к таблице возвращает следующие результаты:
выбрать уровень изоляции транзакции чтение незафиксированных выберите COUNT (*) из входа в систему, где CalFlag имеет значение null
возвращает 59341
выбрать уровень изоляции транзакции чтение зафиксировано выберите COUNT (*) из входа в систему, где CalFlag имеет значение null
возвращает 0
Ожидаемый результат: поскольку изоляция транзакций SQL Server по умолчанию имеет значение Read Committed, он должен возвращать правильное количество строк 59341 в режиме Read Committed. Но это не так.
Но это не так.
Версия сервера SQL: Microsoft SQL Server 2017 (окончательная первоначальная версия) — 14.0.1000.169 (X64) 22 августа > 2017 17:04:49 Copyright (C) Microsoft Corporation Express Edition 2017 (64-разрядная версия) > в Windows 10 Pro 10.0 (сборка 18362: )
Заранее спасибо,
Ujjal Sarmah
Как вставить данные в таблицу SQL с созданием новой таблицы SQL
Применимо к
Насос ApexSQL
Резюме
В этой статье объясняется, как вставлять данные в таблицу SQL с помощью Создать новую табличную функцию .
Описание
Наряду с базовой функциональностью для вставки данных в существующие таблицы SQL приложение имеет возможность использовать структуру из существующей таблицы SQL, создавать новую в базе данных SQL, а затем вставлять в нее нужные данные.
Чтобы начать процесс, первым шагом при запуске приложения является установка SQL Server , тип аутентификации и База данных SQL в окне Новый проект . В этом примере будет использоваться SQL Server 2019, тип аутентификации Windows и база данных AdventureWorks2018 :
В этом примере будет использоваться SQL Server 2019, тип аутентификации Windows и база данных AdventureWorks2018 :
При нажатии на кнопку «Далее» будет показана вкладка «Действие », которая является вторым шагом, который необходимо выполнить, чтобы иметь возможность вставлять данные в таблицу SQL. Здесь следует выбрать Режим импорта и нажать кнопку OK :
После выполнения этих начальных шагов база данных AdventureWorks2018 будет загружена в основную сетку с настройками по умолчанию:
Чтобы импортировать и вставить данные в таблицу SQL, которая будет создана позже, необходимо выполнить следующие шаги. Нажмите кнопку Manage на вкладке Home , и откроется окно Manage import :
Под этим окном нажмите кнопку, чтобы выбрать источник данных. Существует два варианта источников данных, База данных и Файл . В этом примере будет использоваться источник данных File :
Существует два варианта источников данных, База данных и Файл . В этом примере будет использоваться источник данных File :
Нажмите кнопку обзора и перейдите к файлу, который будет использоваться для вставки данных в таблицу SQL, выберите его и нажмите кнопку Открыть . В этом примере будет использоваться файл Excel dbo.NewListCustomers :
После этого вид вернется к предыдущему окну и, нажав Кнопка OK данные Excel будут показаны в окне Управление импортом . Для параметров Автоматически определять диапазон будет использоваться автоматический поиск всего диапазона данных в файле dbo.NewListCustomers.xlxs Excel , в этом примере данные в файле находятся в диапазоне от A1 до К51. Затем будет использоваться режим Импорт по строкам и для заголовка , Первая строка в диапазоне выбрано для включения имен столбцов при создании новой таблицы и вставке данных:
Когда исходные данные установлены, нажмите кнопку OK в правом нижнем углу окна Управление импортом , и представление вернется к основной сетке приложения. Следующим шагом для настройки и вставки данных в таблицу SQL является выбор таблицы SQL со структурой, которая будет использоваться в новой таблице SQL. В новой таблице SQL столбцы Идентификатор клиента, название компании, контактное лицо и Город будут использоваться. В этом примере структура с такой таблицей SQL уже существует в базе данных SQL с именем dbo.Customers , и эта таблица SQL используется в качестве шаблона для новой:
Следующим шагом для настройки и вставки данных в таблицу SQL является выбор таблицы SQL со структурой, которая будет использоваться в новой таблице SQL. В новой таблице SQL столбцы Идентификатор клиента, название компании, контактное лицо и Город будут использоваться. В этом примере структура с такой таблицей SQL уже существует в базе данных SQL с именем dbo.Customers , и эта таблица SQL используется в качестве шаблона для новой:
Щелкните панель Settings с правой стороны и в раскрывающемся меню Mapping выберите dbo.NewListCustomers.xlxs Файл Excel , который будет использоваться для импорта нового списка данных для новой таблицы SQL. Под Таблица Выберите «Создать новую опцию » и введите имя для новой таблицы, в данном случае таблица SQL будет названа DBO.NewCustomerList2020 и для режим импорта Оставьте опцию по умолчанию New и для :
Последним шагом перед началом процесса импорта является сопоставление столбцов в основной сетке, как уже упоминалось, в данном случае столбцов 9.